
Pothole Detection Using Image Enhancement GAN and Object Detection Network


Abstract
:1. Introduction
1.1. Problem Description and Motivation
1.2. Contributions
2. Related Works
2.1. Pothole Object Detection
2.2. Super-Resolution Techniques
2.3. Super-Resolution Based Object Detectors
3. Materials and Methods
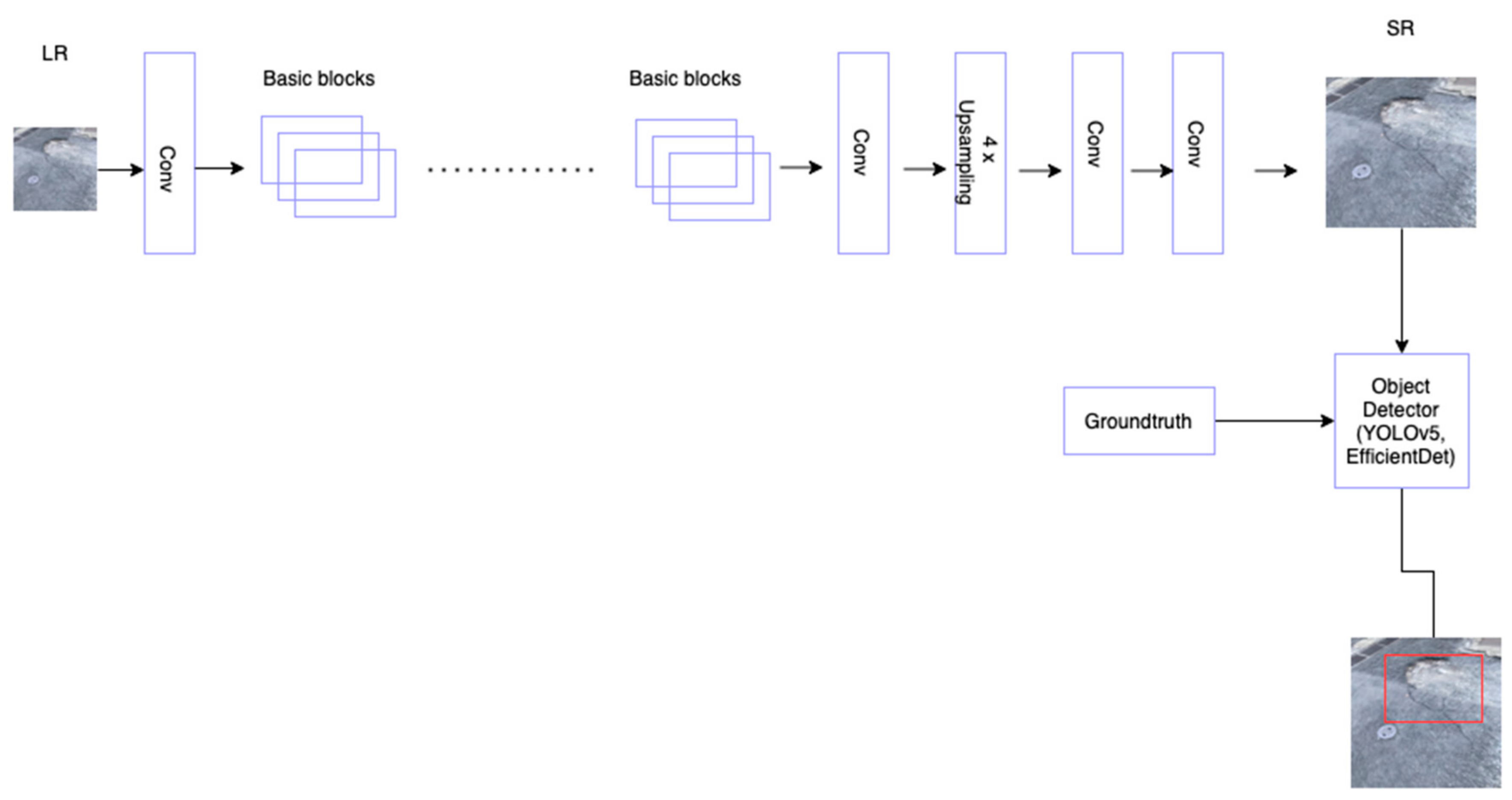
3.1. Super-Resolution with ESRGAN
3.1.1. Relativistic Discriminator
3.1.2. Perceptual Loss
3.2. Object Detection
3.2.1. You Only Look Once (YOLOv5)
3.2.2. EfficientDet
3.3. Training
4. Experiments
4.1. Datasets
- CCSAD—Guzmán et al. [7] presented a dataset named challenging sequences for autonomous driving (CCSAD), which consists of captured video at 20 fps using two Basler Scout scA1300-32fm firewire greyscale cameras from a moving vehicle on the street of Mexico. The dataset presents instances of potholes on the road surface amongst other objects. The entire dataset is divided into four segments, colonial town streets, urban streets, avenues and small roads, and tunnel networks. It is a very large dataset of about 500 GB consisting of calibrated and rectified pairs of sterol images, videos, and meta-data for each of the segments. The image resolution of the dataset is 1096 × 822.
- Japan—The Japan dataset has been widely used in road damage detection competitions and some research work. It contains about 163 k images of roads with dimensions of 600 × 600 collected across Japan. Different categories of road damages are presented in the dataset, including cracks and potholes; however, few instances of potholes are presented in the dataset. We have selected from the few available images with instances of potholes contained in them.
- Sunny—This dataset presents several images of pothole instances, mostly small-sized and at a distance. The image resolution is 3680 × 2760 captured with a GoPro camera mounted on the vehicle.
- PNW—The dataset [6] is a YouTube video recorded on a Pacific Northwest highway during the winter season. The dataset presents a realistic pothole detection problem with roads that have been dilapidated by melting snow and rainwater. The vehicle from which the video is recorded has a typical speed range of 45 km/h to 90 km/h. Images of dimension 1280 × 720 were extracted from the video frames.
4.2. Evaluation Metrics for Detection
5. Results
5.1. Detection with SR and LR Images
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dewangan, D.K.; Sahu, S.P. PotNet: Pothole Detection for Autonomous Vehicle System using Convolutional Neural Network. Electron. Lett. 2020, 57, 53–56. [Google Scholar] [CrossRef]
- Kavith, R.; Nivetha, S. Pothole and Object Detection for an Autonomous Vehicle Using YOLO. In Proceedings of the 5th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 6–8 May 2021; pp. 1585–1589. [Google Scholar] [CrossRef]
- Patra, S.; Middya, A.I.; Roy, S. PotSpot: Participatory Sensing Based Monitoring System for Pothole Detection using Deep Learning. Multimed. Tools Appl. 2021, 80, 25171–25195. [Google Scholar] [CrossRef]
- Salcedo, E.; Jaber, M.; Requena Carrión, J. A Novel Road Maintenance Prioritisation System Based on Computer Vision and Crowdsourced Reporting. J. Sens. Actuator Netw. 2022, 11, 15. [Google Scholar] [CrossRef]
- Junqing, Z.; Jingtao, Z.; Tao, M.; Xiaoming, H.; Weiguang, Z.; Yang, Z. Pavement Distress Detection using Convolutional Neural Networks with Images captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- PNW Dataset. Available online: www.youtube.com/watch?v=BQo87tGRM74 (accessed on 23 January 2022).
- Guzmán, R.; Hayet, J.; Klette, R. Towards Ubiquitous Autonomous Driving: The CCSAD Dataset. In Computer Analysis of Images and Patterns: 14th International Conference, CAIP 2011, Seville, Spain, August 29–31 2011, Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. arXiv 2014, arXiv:1409.0575. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Yang, L.; Peng, S.; Nickolas, W.; Yi, S. A survey and Performance Evaluation of Deep Learning Methods for Small Object Detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Bashir, S.M.A.; Wang, Y. Small Object Detection in Remote Sensing Images with Residual Feature Aggregation-Based Super-Resolution and Object Detector Network. Remote Sens. 2021, 13, 1854. [Google Scholar] [CrossRef]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Task-Driven Super Resolution: Object Detection in Low-Resolution Images. In Neural Information Processing. 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, December 8–12 2021, Proceedings, Part VI; Mantoro, T., Lee, M., Ayu, M.A., Wong, K.W., Hidayanto, A.N., Eds.; Springer: Cham, Switzerland, 2021; p. 1516. [Google Scholar] [CrossRef]
- Luo, Y.; Cao, X.; Zhang, J.; Cao, X.; Guo, J.; Shen, H.; Wang, T.; Feng, Q. CE-FPN: Enhancing Channel Information for Object detection. arXiv 2022, arXiv:2103.10643. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Computer Vision—ECCV 2018 Workshops: Munich, Germany, September 8–14, 2018, Proceedings, Part III; Springer: Berlin/Heidelberg, Germany, 2019; pp. 63–79. [Google Scholar] [CrossRef] [Green Version]
- Rabbi, J.; Ray, N.; Schubert, M.; Chowdhury, S.; Chao, D. Small-object Detection in Remote Sensing Images with End-to-end Edge-enhanced GAN and Object Detector Network. Remote Sens. 2020, 12, 1432. [Google Scholar] [CrossRef]
- Kamal, K.; Mathavan, S.; Zafar, T.; Moazzam, I.; Ali, A.; Ahmad, S.U.; Rahman, M. Performance Assessment of Kinect as a Sensor for Pothole Imaging and Metrology. Int. J. Pavement Eng. 2016, 19, 565–576. [Google Scholar] [CrossRef]
- Li, S.; Yuan, C.; Liu, D.; Cai, H. Integrated Processing of Image and GPR Data for Automated Pothole Detection. J. Comput. Civ. Eng. 2016, 30, 04016015. [Google Scholar] [CrossRef]
- Sha, A.; Tong, Z.; Gao, J. Recognition and measurement of pavement disasters based on convolutional neural networks. China J. Highw. Transp. 2018, 31, 1–10. [Google Scholar]
- Chen, H.; Yao, M.; Gu, Q. Pothole detection using Location-aware Convolutional Neural Networks. Int. J. Mach. Learn. Cybern. 2020, 11, 899–911. [Google Scholar] [CrossRef]
- Silva, L.A.; Sanchez San Blas, H.; Peral García, D.; Sales Mendes, A.; Villarubia González, G. An Architectural Multi-Agent System for a Pavement Monitoring System with Pothole Recognition in UAV Images. Sensors 2020, 20, 6205. [Google Scholar] [CrossRef]
- Jinchao, G.; Xu, Y.; Ling, D.; Xiaoyun, C.; Vincent, C.S.; Lee, C.J. Automated Pixel-level Pavement Distress Detection based on Stereo Vision and Deep Learning. Autom. Constr. 2021, 129, 103788. [Google Scholar] [CrossRef]
- Fan, R.; Wang, H.; Wang, Y.; Liu, M.; Pitas, I. Graph Attention Layer Evolves Semantic Segmentation for Road Pothole Detection: A Benchmark and Algorithms. IEEE Trans. Image Process. 2021, 30, 8144–8154. [Google Scholar] [CrossRef]
- Gao, M.; Wang, X.; Zhu, S.; Guan, P. Detection and Segmentation of Cement Concrete Pavement Pothole Based on Image Processing Technology. Math. Probl. Eng. 2020, 2020, 1360832. [Google Scholar] [CrossRef]
- Wang, P.; Hu, Y.; Dai, Y.; Tian, M. Asphalt Pavement Pothole Detection and Segmentation Based on Wavelet Energy Field. Math. Probl. Eng. 2017, 2017, 1604130. [Google Scholar] [CrossRef] [Green Version]
- Koch, C.; Brilakis, I. Pothole Detection in Asphalt Pavement Images. Adv. Eng. Inf. 2011, 25, 507–515. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–27 July 2017; pp. 136–144. [Google Scholar] [CrossRef] [Green Version]
- Shermeyer, J.; Van Etten, A. The Effects of Super-resolution on Object Detection Performance in Satellite Imagery. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Wei, Z.; Liu, Y. Deep Intelligent Neural Network for Medical Geographic Small-target Intelligent Satellite Image Super-resolution. J. Imaging Sci. Technol. 2021, 65, art00008. [Google Scholar] [CrossRef]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-ESRGAN: Training Real-World Blind Super-Resolution With Pure Synthetic Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 1905–1914. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Zhang, K.; Liang, J.; Van Gool, L.; Timofte, R. Designing a Practical Degradation Model for Deep Blind Image Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Tan, M. Closed-loop matters: Dual Regression Networks for Single Image Super-resolution. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 18–20 June 2020; pp. 5406–5415. [Google Scholar] [CrossRef]
- Mei, Y.; Fan, Y.; Zhou, Y. Image Super-Resolution With Non-Local Sparse Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 3517–3526. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for Small Object Detection. In Proceedings of the 9th International Conference on Advances in Computing and Information Technology, Sydney, Australia, 21–22 December 2019; pp. 119–133. [Google Scholar] [CrossRef]
- Park, D.; Ramanan, D.; Fowlkes, C. Multiresolution Models for Object Detection. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 241–254. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Chang, L.; Chen, Y.-T.; Wang, J.-H.; Chang, Y.-L. Modified Yolov3 for Ship Detection with Visible and Infrared Images. Electronics 2022, 11, 739. [Google Scholar] [CrossRef]
- Lv, N.; Xiao, J.; Qiao, Y. Object Detection Algorithm for Surface Defects Based on a Novel YOLOv3 Model. Processes 2022, 10, 701. [Google Scholar] [CrossRef]
- Courtrai, L.; Pham, M.T.; Lefèvre, S. Small Object Detection in Remote Sensing Images based on Super-resolution with Auxiliary Generative Adversarial Networks. Remote Sens. 2020, 12, 3152. [Google Scholar] [CrossRef]
- Hui, Z.; Li, J.; Gao, X.; Wang, X. Progressive Perception-oriented Network for Single Image Super-resolution. Inf. Sci. 2021, 546, 769–786. [Google Scholar] [CrossRef]
- Ferdous, S.N.; Mostofa, M.; Nasrabadi, N. Super Resolution-assisted Deep Aerial Vehicle Detection. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, Baltimore, MD, USA, 15–17 May 2019; p. 1100617. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-Enhanced GAN for Remote Sensing Image Superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Wang, Y.; Bashir, S.M.A.; Khan, M.; Ullah, Q.; Wang, R.; Song, Y.; Guo, Z.; Niu, Y. Remote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art. Expert Syst. Appl. 2022, 197, 116793. [Google Scholar] [CrossRef]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017. [Google Scholar]
- Jolicoeur-Martineau, A. The Relativistic Discriminator: A Key Element missing from Standard Gan. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-time Style Transfer and Super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; TaoXie; Fang, J.; imyhxy; Michael, K.; et al. ultralytics/yolov5: v6.1-TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference (v6.1). Zenodo 2022. [Google Scholar] [CrossRef]
- Wang, C.; Liao, H.Y.; Yeh, I.H. CSPNET: A New Backbone that can Enhance Learning Capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar]
- Shu, L.; Lu, Q.; Haifang, Q.; Jianping, S.; Jiaya, J. Path Aggregation Network for Instance Segmentation. arXiv 2018, arXiv:1803.01534. [Google Scholar]
- Tsung-Yi, L.; Piotr, D.; Ross, G.; Kaiming, H.; Bharath, H.; Serge, B. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Dhiman, A.; Klette, R. Pothole Detection Using Computer Vision and Learning. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3536–3550. [Google Scholar] [CrossRef]
- Darapaneni, A.; Reddy, N.S.; Urkude, A.; Paduri, A.R.; Satpute, A.A.; Yogi, A.; Natesan, D.K.; Surve, S.; Srivastava, U. Pothole Detection Using Advanced Neural Networks. In Proceedings of the IEEE 12th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 27–30 October 2021; pp. 0567–0572. [Google Scholar] [CrossRef]
- Kortmann, F.; Talits, K.; Fassmeyer, P.; Warnecke, A.; Meier, N.; Heger, J.; Drews, P.; Funk, B. Detecting various Road Damage Types in Global Countries Utilizing Faster R-cnn. In Proceedings of the IEEE International Conference on Big Data, Atlanta, GA, USA, 10–13 December 2020; pp. 5563–5571. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Image Resolution | Test Results (mAP at IoU = 0.5:0.95) | Test Results (mAP at IoU = 0.5) | Test Results (Recall) | Test Results (Precision) |
|---|---|---|---|---|---|
| ESRGAN + EfficientDet | LR | 10.6% | 20% | 30% | 53% |
| ESRGAN + YOLOv5 | LR | 12% | 30% | 41% | 60% |
| ESRGAN + EfficientDet | SR | 26% | 39% | 66.77% | 100% |
| ESRGAN + YOLOv5 | SR | 32% | 46% | 70% | 97.60% |
| Method | Mean Precision (%) | Mean Recall (%) |
|---|---|---|
| ESRGAN + EfficientDet | 100 | 71.5 |
| ESRGAN + YOLOv5 | 100 | 72.2 |
| LM1 | 89.9 | 92.8 |
| Method | Mean Precision (%) | Mean Recall (%) |
|---|---|---|
| ESRGAN + EfficientDet | 100 | 63 |
| ESRGAN + YOLOv5 | 92.5 | 86.1 |
| LM1 | 88.6 | 85.05 |
| Dataset | ESRGAN + YOLOv5 | ESRGAN + EfficientDet | ||
|---|---|---|---|---|
| Mean Precision (%) | Mean Recall (%) | Mean Precision (%) | Mean Recall (%) | |
| CCSAD | 100 | 72.2 | 100 | 71.5 |
| Sunny | 100 | 57 | 60 | 34 |
| PNW | 92.5 | 86.1 | 100 | 63 |
| Japan | 86.3 | 61.58 | 81.25 | 65.8 |
| Author | Method | Mean Precision (%) | Mean Recall (%) |
|---|---|---|---|
| Darapaneni et al. [58] | YOLOv3 | 60 | 50 |
| Darapaneni et al. [58] | YOLOv4 | 90 | 11 |
| Darapaneni et al. [58] | YOLOv5 | 40 | 40 |
| Kortmann et al. [59] | FRCNN | 68.56 | 54.02 |
| Our method | ESRGAN + EfficientDet | 81.25 | 65.85 |
| Our method | ESRGAN + YOLOv5 | 86.3 | 61.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salaudeen, H.; Çelebi, E. Pothole Detection Using Image Enhancement GAN and Object Detection Network. Electronics 2022, 11, 1882. https://doi.org/10.3390/electronics11121882
Salaudeen H, Çelebi E. Pothole Detection Using Image Enhancement GAN and Object Detection Network. Electronics. 2022; 11(12):1882. https://doi.org/10.3390/electronics11121882
Chicago/Turabian StyleSalaudeen, Habeeb, and Erbuğ Çelebi. 2022. "Pothole Detection Using Image Enhancement GAN and Object Detection Network" Electronics 11, no. 12: 1882. https://doi.org/10.3390/electronics11121882
APA StyleSalaudeen, H., & Çelebi, E. (2022). Pothole Detection Using Image Enhancement GAN and Object Detection Network. Electronics, 11(12), 1882. https://doi.org/10.3390/electronics11121882