
Deep Learning-Based Content Caching in the Fog Access Points




Abstract
1. Introduction
1.1. Related Works
1.2. Contribution and Organization
- An optimization problem to minimize content access delay in the future time is introduced.
- DLCC strategy is proposed.
- Open access real-life large dataset, such as MovieLens dataset [30] is analyzed and formatted using different data pre-processing techniques for the proper use for supervised DL-based approach.
- 2D CNN model is trained using 1D dataset to obtain the most popular future data.
- The most popular data are then stored in the cache memory of the F-APs.
- The performance is shown in terms of mean square error (MSE), DL-accuracy, cache hit ratio, and overall system delay.
2. System Model
2.1. Delay Formulation
3. DL-based Caching Policy
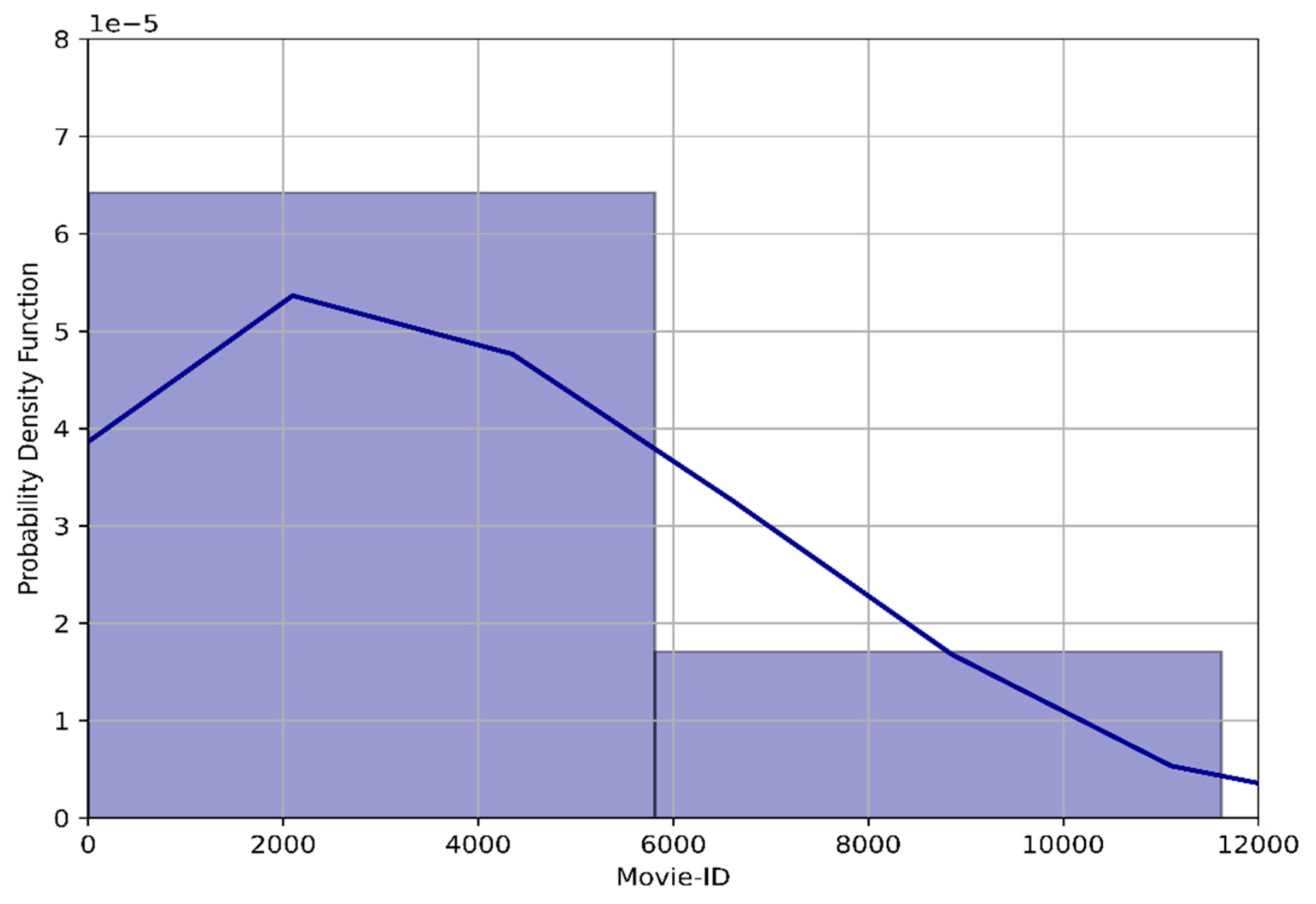
3.1. Dataset
3.2. Data Pre-Processing
3.3. DLCC Model
3.3.1. Problem Statement
3.3.2. Model Implementation
| Algorithm 1: Training process for DLCC model. |
 |
3.4. Cache Decision
| Algorithm 2: Cache content decision process. |
 |
4. Performance Analysis
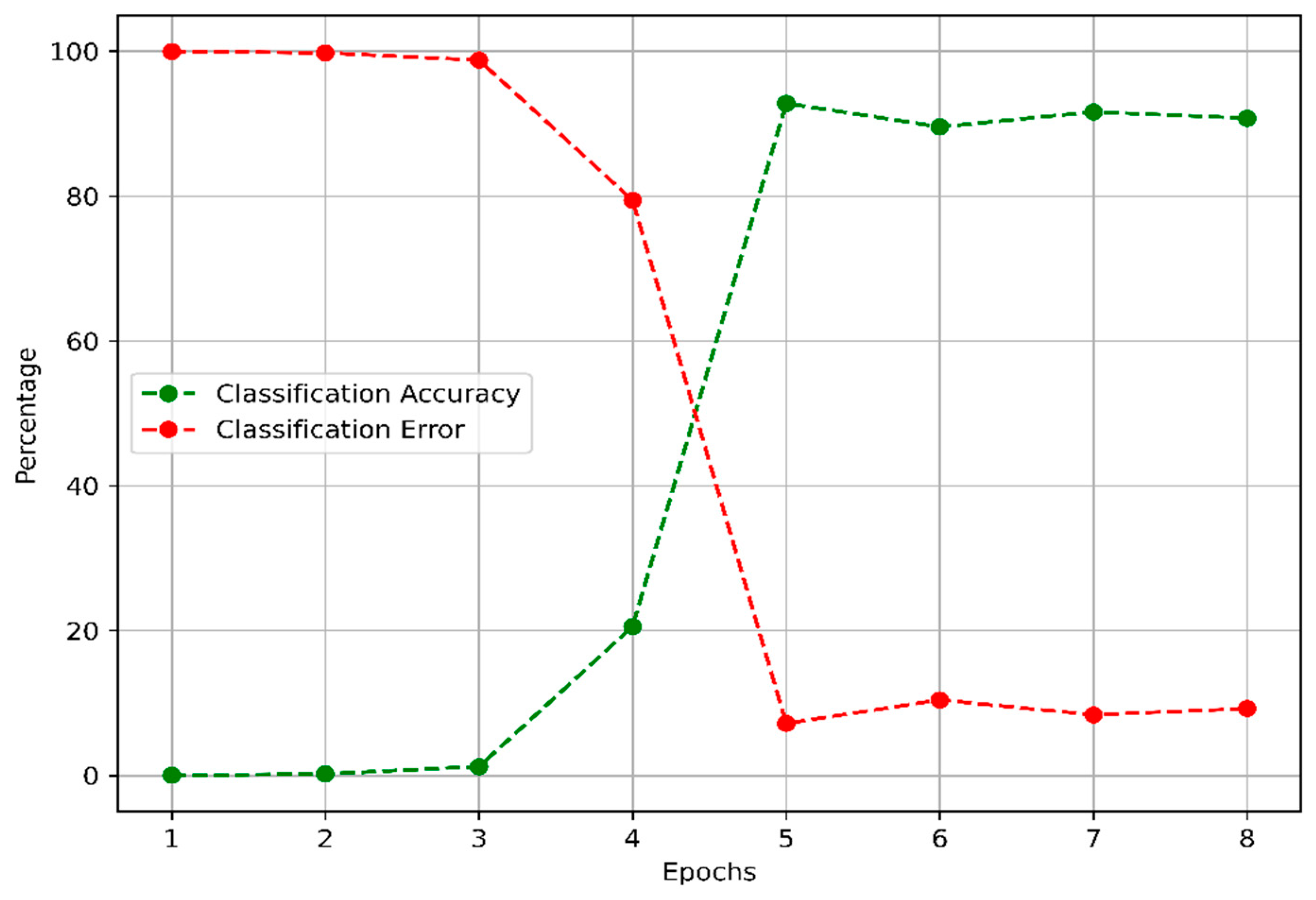
4.1. Model KPI
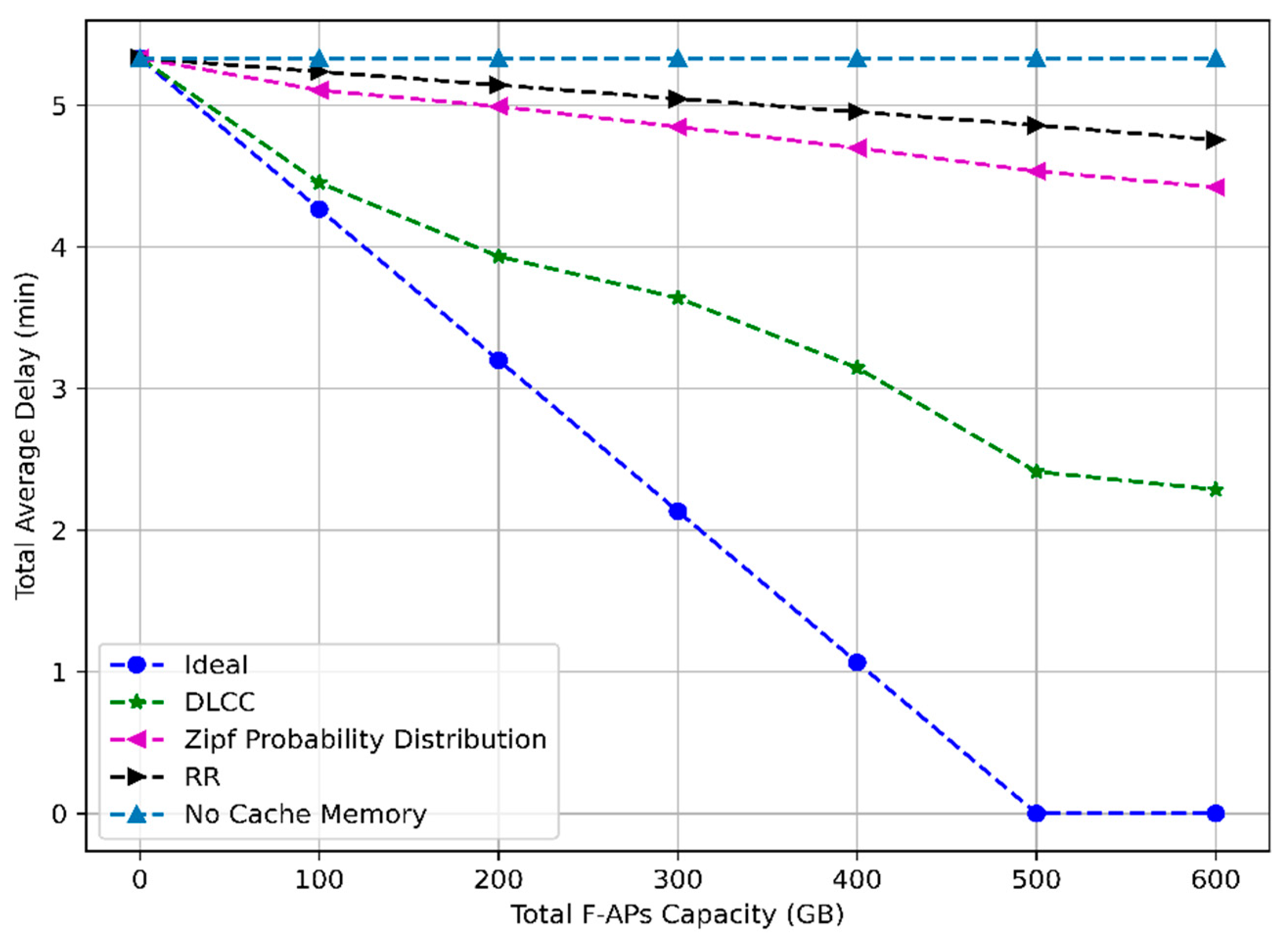
4.2. System KPI
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cisco. White Paper. Internet of Things at a Glance. Available online: https://www.cisco.com/c/dam/en_us/solutions/trends/iot/docs/iot-aag.pdf (accessed on 1 January 2021).
- Anawar, M.; Wang, S.; Azam Zia, M.; Jadoon, A.; Akram, U.; Raza, S. Fog Computing: An Overview of Big IoT Data Analytics. Wireless Commun. Mobile Comput. 2018, 2018, 1–22. [Google Scholar] [CrossRef]
- Peng, M.; Yan, S.; Zhang, K.; Wang, C. Fog Computing based Radio Access Networks: Issues and Challenges. IEEE Netw. 2015, 30, 46–53. [Google Scholar] [CrossRef]
- Bhandari, S.; Kim, H.; Ranjan, N.; Zhao, H.P.; Khan, P. Optimal Cache Resource Allocation Based on Deep Neural Networks for Fog Radio Access Networks. J. Internet Technol. 2020, 21, 967–975. [Google Scholar]
- Zeydan, E.; Bastug, E.; Bennis, M.; Kader, M.A.; Karatepe, I.A.; Er, A.S.; Debbah, M. Big data caching for networking: Moving from cloud to edge. IEEE Commun. Mag. 2016, 54, 36–42. [Google Scholar] [CrossRef]
- Jiang, Y.; Huang, W.; Bennis, M.; Zheng, F.-C. Decentralized asynchronous coded caching design and performance analysis in fog radio access networks. IEEE Trans. Mobile Comput. 2020, 19, 540–551. [Google Scholar] [CrossRef]
- Jiang, Y.; Hu, Y.; Bennis, M.; Zheng, F.-C.; You, X. A mean field game-based distributed edge caching in fog radio access networks. IEEE Trans. Commun. 2020, 68, 1567–1580. [Google Scholar] [CrossRef]
- Blasco, P.; Gündüz, D. Learning-based optimization of cache content in a small cell base station. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 1897–1903. [Google Scholar]
- Yang, P.; Zhang, N.; Zhang, S.; Yu, L.; Zhang, J.; Shen, X. Content popularity prediction towards location-aware mobile edge caching. IEEE Trans. Multimedia 2019, 21, 915–929. [Google Scholar] [CrossRef]
- Zhang, S.; He, P.; Suto, K.; Yang, P.; Zhao, L.; Shen, X. Cooperative edge caching in user-centric clustered mobile networks. IEEE Trans. Mobile Comput. 2018, 17, 1791–1805. [Google Scholar] [CrossRef]
- Deng, T.; You, L.; Fan, P.; Yuan, D. Device caching for network offloading: Delay minimization with presence of user mobility. IEEE Wireless Commun. Lett. 2018, 7, 558–561. [Google Scholar] [CrossRef]
- Xu, M.; David, J.; Kim, S. The Fourth Industrial Revolution: Opportunities and Challenges. Inter J. Financ. Res. 2018, 9, 1–90. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Schmidhuber, J. Deep learning in neural network: An overview. arXiv 2014, arXiv:1404.7828. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, J.; Liang, Z.; Peng, L.; Cai, J. Content Popularity Prediction and Caching for ICN: A Deep Learning Approach With SDN. IEEE Access 2018, 6, 5075–5089. [Google Scholar] [CrossRef]
- Poularakis, K.; Iosifidis, G.; Tassiulas, L. Approximation algorithms for mobile data caching in small cell networks. IEEE Trans. Wireless Commun. 2014, 62, 3665–3677. [Google Scholar] [CrossRef]
- Golrezaei, N.; Molisch, A.F.; Dimakis, A.G.; Caire, G. Femtocaching and device-to-device collaboration: A new architecture for wireless video distribution. IEEE Commun. Mag. 2013, 51, 142–149. [Google Scholar] [CrossRef]
- Tandon, R.; Simeone, O. Cloud-aided wireless networks with edge caching: Fundamental latency trade-offs in fog radio access networks. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 2029–2033. [Google Scholar]
- Din, I.U.; Hassan, S.; Khan, M.K.; Guizani, M.; Ghazali, O.; Habbal, A. Caching in Information-Centric Networking: Strategies, Challenges, and Future Research Directions. IEEE Commun. Surv. Tutor. 2018, 20, 1443–1474. [Google Scholar] [CrossRef]
- Wang, X.; Leng, S.; Yang, K. Social-aware edge caching in fog radio access networks. IEEE Access 2017, 5, 8492–8501. [Google Scholar] [CrossRef]
- Hung, S.; Hsu, H.; Lien, S.; Chen, K. Architecture Harmonization between Cloud Radio Access Networks and Fog Networks. IEEE Access 2015, 3, 3019–3034. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Sun, Y.; Peng, M.; Zhou, Y.; Huang, Y.; Mao, S. Application of machine learning in wireless networks: Key techniques and open issues. IEEE Commun. Surv. Tutor. 2019, 21, 3072–3108. [Google Scholar] [CrossRef]
- Ranjan, N.; Bhandari, S.; Zhao, H.P.; Kim, H.; Khan, P. City-Wide Traffic Congestion Prediction Based on CNN, LSTM and Transpose CNN. IEEE Access 2020, 8, 81606–81620. [Google Scholar] [CrossRef]
- Bastug, E.; Bennis, M.; Debbah, M. Living on the edge: The role of proactive caching in 5g wireless networks. IEEE Commun. Mag. 2014, 52, 82–89. [Google Scholar] [CrossRef]
- Hou, T.; Feng, G.; Qin, S.; Jiang, W. Proactive Content Caching by Exploiting Transfer Learning for Mobile Edge Computing. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Ale, L.; Zhang, N.; Wu, H.; Chen, D.; Han, T. Online proactive caching in mobile edge computing using bidirectional deep recurrent neural network. J. IEEE Internet Things 2019, 6, 5520–5530. [Google Scholar] [CrossRef]
- Tsai, K.C.; Wang, L.; Han, Z. Mobile social media networks caching with convolutional neural network. In Proceedings of the 2018 IEEE Wireless Communications Network Conference Workshops (WCNCW), Barcelona, Spain, 15–18 April 2018; pp. 83–88. [Google Scholar]
- Thar, K.; Tran, N.H.; Oo, T.Z.; Hong, C.S. DeepMEC: Mobile Edge Caching Using Deep Learning. IEEE Access 2018, 6, 78260–78275. [Google Scholar] [CrossRef]
- GroupLens. Available online: https://grouplens.org/datasets/movielens/ (accessed on 5 January 2021).
- Hancock, J.; Khoshgoftaar, T. Survey on categorical data for neural networks. J. Big Data 2020, 7, 28. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. A Math. Phys. Eng. Sci. 2016, 374. [Google Scholar] [CrossRef] [PubMed]
- Loffe, S. Szegedy, Christian. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Wu, H.; Gu, X. Towards dropout training for convolutional neural networks. Neural Netw. 2015, 71, 1–10. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Visa, S.; Ramsay, B.; Ralescu, A.; Knaap, E. Confusion Matrix-based Feature Selection. In Proceedings of the 2011 CEUR Workshop, Heraklion, Crete, Greece, 30 May 2011; pp. 120–127. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Input Size | Output Size | Filter Size |
|---|---|---|---|
| Conv2D_1 | 9019 7, 1 | 9019 7, 32 | 3 3, 32 |
| Max_Pooling_1 | 9019 7, 32 | 4509 3, 32 | ____________ |
| Dropout_1 | 4509 3, 32 | 4509 3, 32 | ____________ |
| Batch_Normalization_1 | 4509 3, 32 | 4509 3, 32 | ____________ |
| Conv2D_2 | 4509 3, 32 | 4509 3, 16 | 3 3, 16 |
| Max_Pooling_2 | 4509 3, 16 | 2254 1, 16 | ____________ |
| Dropout_2 | 2254 1, 16 | 2254 1, 16 | ____________ |
| Batch_Normalization_2 | 2254 1, 16 | 2254 1, 16 | ____________ |
| Conv2D_3 | 2254 1, 16 | 2254 1, 8 | 3 3, 8 |
| Dropout_3 | 2254 1, 8 | 2254 1, 8 | ____________ |
| Flatten_1 | 2254 1, 8 | 18,032 | ____________ |
| Batch_Normalization_3 | 18,032 | 18,032 | ____________ |
| FCNN_1 | 18,032 | 9019 | ____________ |
| Model | Description | Filter Configuration | Validation Loss (MSE) | Computational Time (min) |
|---|---|---|---|---|
| DLCC_1_1 | 1 2D-CNN and 1 FCNN | 32 | N/A | N/A |
| DLCC_2_1 | 2 2D-CNN and 1 FCNN | 32_16 | 0.2785 | 23.75 |
| DLCC_3_1 | 3 2D-CNN and 1 FCNN | 32_16_8 | 0.0452 | 13.35 |
| DLCC_4_1 | 4 2D-CNN and 1 FCNN | 32_16_8_4 | 0.0596 | 7.98 |
| Model | Filter Configuration | Validation Loss (MSE) | Computational Time (min) |
|---|---|---|---|
| DLCC_3_1 | 64_32_16 | 0.0729 | 26.3 |
| DLCC_3_1 | 32_16_8 | 0.0452 | 13.35 |
| DLCC_3_1 | 16_8_4 | 0.0741 | 7.28 |
| Parameters | Values |
|---|---|
| Training Size | (1461, 9019, 7, 1) |
| Validation Size | (304, 9019, 7, 1) |
| Testing Size | (21, 9019, 7, 1) |
| Training Period | January 2015– December 2018 |
| Validation Period | January 2019–October 2019 |
| Testing Period | November 2019 |
| Number of 2D CNN Layers | 3 |
| Number of FCNN Layer | 1 |
| Number of Features | 7 |
| Number of Label | 1 |
| Output Activation Function | ReLU |
| Batch Size | 8 |
| Learning Rate | 0.001 |
| Epoch | 1–8 |
| Model Type | Validation Loss (MSE) |
|---|---|
| DLCC (Proposed) | 0.045 |
| 1D CNN [29] | 0.066 |
| 1D LSTM [29] | 0.056 |
| 1D CRNN [29] | 0.059 |
| Range (Predicted Values) | Classification (Hard-Decision) |
|---|---|
| 0–0.5 | 0 |
| 0.5–1 | 1 |
| 1–1.5 | 1 |
| 1.5–2 | 2 |
| 2–2.5 | 2 |
| 2.5–3 | 3 |
| Predicted Values | |||||
|---|---|---|---|---|---|
| Actual Values | Class | 0 | 1 | 2 | 3 |
| 0 | 5.713 | 2.433 | 2.230 | 0.676 | |
| 1 | 2.676 | 50.926 | 49.227 | 1.984 | |
| 2 | 0.572 | 22.858 | 300.249 | 401.784 | |
| 3 | 0.369 | 1.781 | 161.292 | 8014.230 | |
| Parameters | Values |
|---|---|
| Number of F-APs () | 50 |
| Number of UEs () | 400 |
| Number of movie files in the pool () | 9019 |
| Size of each movie ) | 1 (GB) |
| Fronthaul link capacity () | 10 Gbps @ 10 km+ |
| Total cache memory () | 0–600 (GB) |
| Distance between F-AP and central cloud | 10 km |
| Parameter | DLCC | LECC [26] |
|---|---|---|
| Number of F-APs | 50 | 4 |
| Total content items | 9019 GB | 500 GB |
| Total F-APs Capacity | 600 GB | 400 GB |
| Total F-APs capacity normalized by the total content items | 0.066 | 0.8 |
| Cache hit ratio | 57% | 55% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhandari, S.; Ranjan, N.; Khan, P.; Kim, H.; Hong, Y.-S. Deep Learning-Based Content Caching in the Fog Access Points. Electronics 2021, 10, 512. https://doi.org/10.3390/electronics10040512
Bhandari S, Ranjan N, Khan P, Kim H, Hong Y-S. Deep Learning-Based Content Caching in the Fog Access Points. Electronics. 2021; 10(4):512. https://doi.org/10.3390/electronics10040512
Chicago/Turabian StyleBhandari, Sovit, Navin Ranjan, Pervez Khan, Hoon Kim, and Youn-Sik Hong. 2021. "Deep Learning-Based Content Caching in the Fog Access Points" Electronics 10, no. 4: 512. https://doi.org/10.3390/electronics10040512
APA StyleBhandari, S., Ranjan, N., Khan, P., Kim, H., & Hong, Y.-S. (2021). Deep Learning-Based Content Caching in the Fog Access Points. Electronics, 10(4), 512. https://doi.org/10.3390/electronics10040512