
An Enhanced Replica Selection Approach Based on Distance Constraint in ICN

Abstract
1. Introduction
- (1)
- We propose an enhanced replica selection approach called ERS to realize efficient content retrieval in the ICN scenario. ERS leverages a distance-constrained-based name resolution system to discover all nearby cached replicas, and the most appropriate replica is chosen according to a local node state table that maintains the state of replica nodes within a limited domain.
- (2)
- We innovatively introduce path congestion degree as one of the main factors to select an appropriate replica. The detailed method to maintain the information of these factors and update the node state table is designed. Meanwhile, a refresh mechanism to avoid information expire is also adopted.
- (3)
- We conduct sufficient simulation experiments to measure the performance of our approach. We compare our approach with several state-of-the-art methods, and the results show that our approach has better performance in terms of average content download delay and performs effectively in server and link load balance. Finally, we analyze the overhead of ERS and further prove the availability of the proposed approach.
2. Related Work
2.1. Content Discovery Mechanisms
2.2. Replica Selection Strategies
3. ERS Design
3.1. Motivation
3.2. Overview of ERS
| Algorithm 1: The Operation Process of ERS |
| Input: Output: 1: initialization: , 2: 3: if then 4: 5: else 6: 7: ifthen 8: 9: end if 10: end if 11: return |
3.3. Content Discovery Mechanism Based on Distance Constraint
3.4. Replica Selection Strategy Based on Node State Table
4. Usage of Node State Table
4.1. Calculation of Node State Values
4.2. Update of Node State Table
| Algorithm 2: Update of NST |
| Input: Output: Parameters: 1: if is a content request then 2: for in if do 3: 4: 5: update using Equation (6) with and 6: end for 7: else if is a content response then 8: for in if do 9: 10: 11: 12: 13: 14: using the hops field in 15: update using Equation (6) with and 16: end for 17: end if 18: return |
5. Performance Evaluation
5.1. Experimental Setup
5.2. Performance Comparison
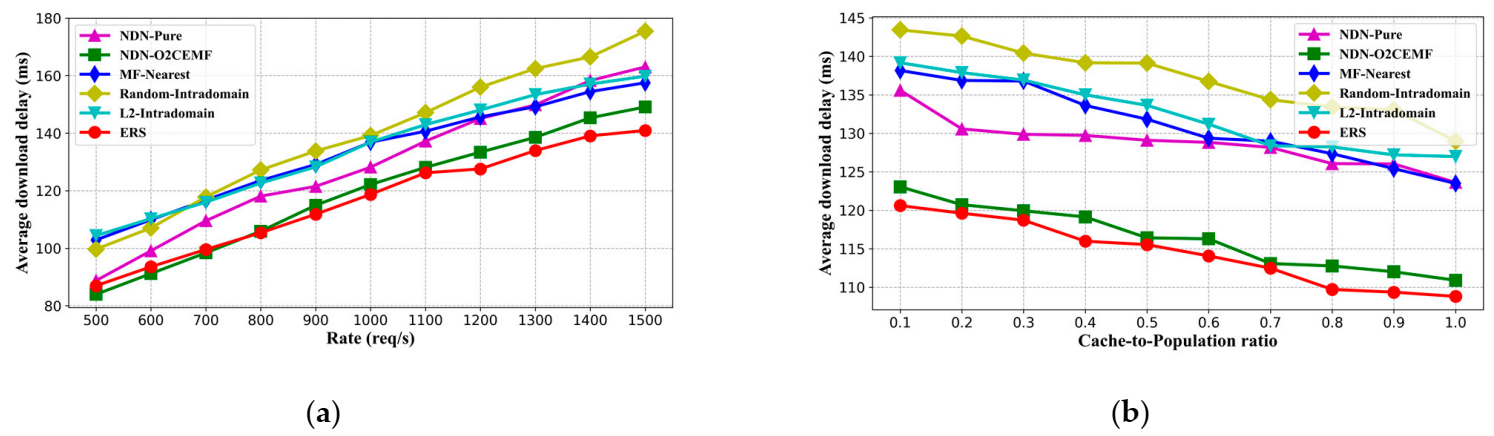
5.2.1. Average Content Download Delay
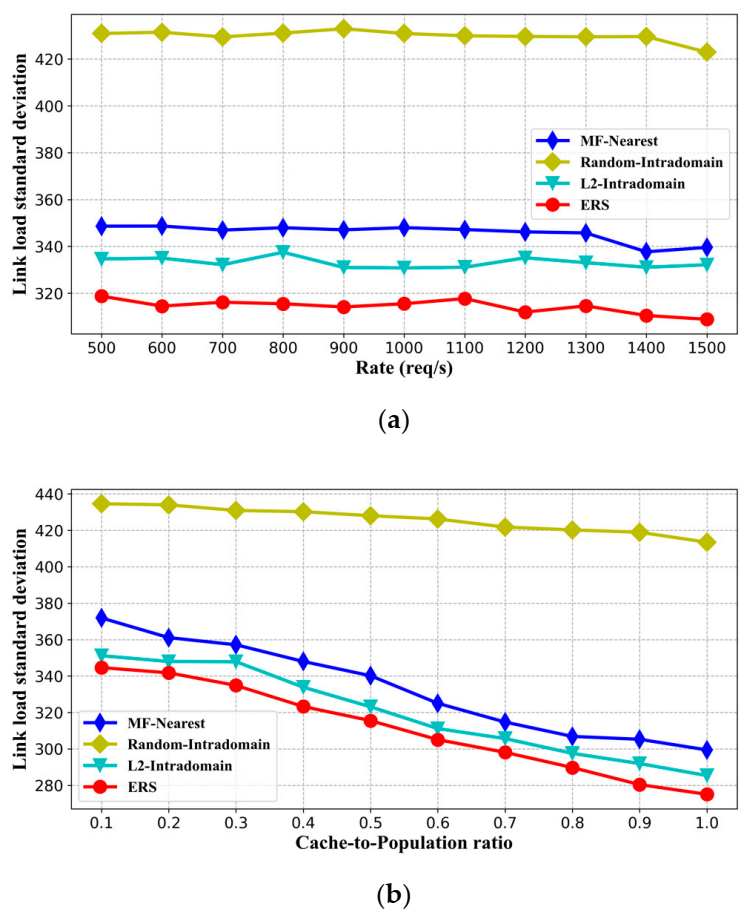
5.2.2. Standard Deviation of Replica Node Load
5.2.3. Standard Deviation of Link Load
5.2.4. Real-World Dataset
5.3. Delay Range of ENRS Domain
5.4. Overhead Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Fu, T.; Li, Y.; Lin, T.; Tan, H.; Tang, H.; Ci, S. An effective congestion control scheme in content-centric networking. In Proceedings of the 2012 IEEE International Conference on Parallel and Distributed Computing, Applications and Technologies, Beijing, China, 14–16 December 2012; pp. 245–248. [Google Scholar]
- Lee, M.; Song, J.; Cho, K.; Pack, S.; Kwon, T.; Kangasharju, J.; Choi, Y. Content discovery for information-centric networking. Comput. Netw. 2015, 83, 1–14. [Google Scholar] [CrossRef]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.F.; Briggs, N.H.; Braynard, R.L. Networking named content. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies, Rome, Italy, 1–4 December 2009; pp. 1–12. [Google Scholar]
- Passarella, A. A survey on content-centric technologies for the current Internet: CDN and P2P solutions. Comput. Commun. 2012, 35, 1–32. [Google Scholar] [CrossRef]
- Ioannou, A.; Weber, S. A Survey of Caching Policies and Forwarding Mechanisms in Information-Centric Networking. IEEE Commun. Surv. Tutor. 2016, 18, 2847–2886. [Google Scholar] [CrossRef]
- Saur, S.; Centenaro, M. Radio access protocols with multi-user detection for URLLC in 5G. In Proceedings of the 23rd European Wireless Conference, Dresden, Germany, 15 May 2017; pp. 1–6. [Google Scholar]
- Schulz, P.; Matthe, M.; Klessig, H.; Simsek, M.; Fettweis, G.; Ansari, J.; Ashraf, S.A.; Almeroth, B.; Voigt, J.; Riedel, I.; et al. Latency Critical IoT Applications in 5G: Perspective on the Design of Radio Interface and Network Architecture. IEEE Commun. Mag. 2017, 55, 70–78. [Google Scholar] [CrossRef]
- Parvez, I.; Rahmati, A.; Guvenc, I.; Sarwat, A.I.; Dai, H. A survey on low latency towards 5G: RAN, core network and caching solutions. IEEE Commun. Surv. Tutor. 2018, 20, 3098–3130. [Google Scholar] [CrossRef]
- Xylomenos, G.; Ververidis, C.N.; Siris, V.A.; Fotiou, N.; Tsilopoulos, C.; Vasilakos, X.; Katsaros, K.V.; Polyzos, G.C. A survey of information-centric networking research. IEEE Commun. Surv. Tutor. 2014, 16, 1024–1049. [Google Scholar] [CrossRef]
- Liao, Y.; Sheng, Y.; Wang, J. A Brief Survey on Information Centric Networking Proof of Concepts for IMT-2020 and Emerging Networks. J. Netw. New Media 2018, 7, 54–63. [Google Scholar]
- Proof-of-Concept for Data Service Using Information Centric Networking in IMT-2020. Available online: https://www.itu.int/itu-t/recommendations/rec.aspx?rec=13655 (accessed on 20 May 2020).
- Zhang, H.; Xie, R.; Zhu, S.; Huang, T.; Liu, Y. DENA: An Intelligent Content Discovery System Used in Named Data Networking. IEEE Access 2016, 4, 9093–9107. [Google Scholar] [CrossRef]
- Rossini, G.; Rossi, D. Coupling caching and forwarding: Benefits, analysis, and implementation. In Proceedings of the 1st International Conference on Information-Centric Networking, Paris, France, 24–26 September 2014; pp. 127–136. [Google Scholar]
- Bastos, I.V.; Moraes, I.M. A diversity-based search-and-routing approach for named-data networking. Comput. Netw. 2019, 157, 11–23. [Google Scholar] [CrossRef]
- Hu, X.; Zheng, S.; Zhang, G.; Zhao, L.; Cheng, G.; Gong, J.; Li, R. An on-demand off-path cache exploration based multipath forwarding strategy. Comput. Netw. 2020, 166, 1–15. [Google Scholar] [CrossRef]
- Chiocchetti, R.; Perino, D.; Lucent, A.; Labs, B.; Rossi, D.; Rossini, G. INFORM adynamic INterest FORwarding Mechanism for Information Centric Networking. In Proceedings of the 3rd ACM SIGCOMM Workshop on Information-Centric Networking, Hong Kong, China, 12 August 2013; pp. 9–14. [Google Scholar]
- Raychaudhuri, D.; Nagaraja, K.; Venkataramani, A. MobilityFirst: A robust and trustworthy mobility-centric architecture for the future internet. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2012, 16, 2–13. [Google Scholar] [CrossRef]
- Boutaba, R.; Ahmed, R.; Mathieu, B.; Bari, M.; Chowdhury, S. A survey of naming and routing in information-centric networks. IEEE Commun. Mag. 2012, 50, 44–53. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, Y.; Raychaudhuri, D. Edge caching and nearest replica routing in information-centric networking. In Proceedings of the 37th IEEE Sarnoff Symposium, Newark, NJ, USA, 19–21 September 2016; pp. 181–186. [Google Scholar] [CrossRef]
- Badov, M.; Seetharam, A.; Kurose, J.; Firoiu, V.; Nanda, S. Congestion-aware caching and search in information-centric networks. In Proceedings of the 1st International Conference on Information-Centric Networking, Paris, France, 24–26 September 2014; pp. 37–46. [Google Scholar]
- Dong, L.; Wang, G. A Hybrid Approach for Name Resolution and Producer Selection in Information Centric Network. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 5745–5780. [Google Scholar]
- Koponen, T.; Chawla, M.; Chun, B.-G.; Ermolinskiy, A.; Kim, K.H.; Shenker, S.; Stoica, I. A data-oriented (and beyond) network architecture. In Proceedings of the ACM SIGCOMM Computer Communication Review, Kyoto, Japan, 27 August 2007; pp. 181–192. [Google Scholar] [CrossRef]
- Fotiou, N.; Nikander, P.; Trossen, D.; Polyzos, G.C. Developing information networking further: From PSIRP to PURSUIT. In Proceedings of the International Conference on Broadband Communications, Networks and Systems, Athens, Greece, 25–27 October 2010; pp. 11–13. [Google Scholar]
- Dannewitz, C.; Kutscher, D.; Ohlman, B.; Farrell, S.; Ahlgren, B.; Karl, H. Network of Information (NetInf)—An information-centric networking architecture. Comput. Commun. 2013, 36, 721–735. [Google Scholar] [CrossRef]
- Liao, Y.; Sheng, Y.; Wang, J. A deterministic latency name resolution framework using network partitioning for 5G-ICN integration. Int. J. Innov. Comput. Inf. Control 2019, 15, 1865–1880. [Google Scholar]
- Potys, R.A.; Ali, N.M.; Marsh, I.; Osmani, F. NetInf TP: A receiver-driven protocol for ICN data transport. In Proceedings of the 2015 IEEE 23rd International Symposium on Quality of Service (IWQoS), Portland, OR, USA, 15–16 June 2015; pp. 267–272. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, H.; Zhou, X.; Fang, L.; Wang, J. Understanding and improvement of the selection of replica servers in key-value stores. Inf. Syst. 2019, 83, 218–228. [Google Scholar] [CrossRef]
- Bogdanov, K.; Péon-Quiŕos, M.; Maguire, G.Q.; Kostíc, D. The nearest replica can be farther than you think. In Proceedings of the 6th ACM Symposium on Cloud Computing, Kohala Coast, HI, USA, 27–29 August 2015; pp. 16–29. [Google Scholar]
- Suresh, L.; Canini, M.; Schmid, S.; Feldmann, A. C3: Cutting tail latency in cloud data stores via adaptive replica selection. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation, Oakland, CA, USA, 4–6 May 2015; pp. 513–527. [Google Scholar]
- Xue, M.; Shen, J.; Guo, X. Two phase enhancing replica selection in cloud storage system. In Proceedings of the 35th Chinese Control Conference, Chengdu, China, 27–29 July 2016; pp. 5255–5260. [Google Scholar]
- Rahman, R.M.; Alhajj, R.; Barker, K. Replica selection strategies in data grid. J. Parallel Distrib. Comput. 2008, 68, 1561–1574. [Google Scholar] [CrossRef]
- Li, C.; Tang, J.; Luo, Y. Scalable replica selection based on node service capability for improving data access performance in edge computing environment. J. Supercomput. 2019, 75, 7209–7243. [Google Scholar] [CrossRef]
- Ding, L.; Wang, J.L.; Sheng, Y.Q.; Wang, L.F. A Split Architecture Approach to Terabyte-Scale Caching in a Protocol-Oblivious Forwarding Switch. IEEE Trans. Netw. Serv. Manag. 2017, 14, 1171–1184. [Google Scholar] [CrossRef]
- Wakil, K.; Nazif, H.; Panahi, S.; Abnoosian, K.; Sheikhi, S. Method for replica selection in the Internet of Things using a hybrid optimisation algorithm. IET Commun. 2019, 13, 2820–2826. [Google Scholar] [CrossRef]
- Rossi, D.; Testa, C.; Valenti, S.; Muscariello, L. LEDBAT: The new BitTorrent congestion control protocol. In Proceedings of the 19th International Conference on Computer Communications and Networks, Zurich, Switzerland, 2–5 August 2010; pp. 1–6. [Google Scholar]
- Nguyen, D.; Sugiyama, K.; Tagami, A. Congestion price for cache management in information-centric networking. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops, Hong Kong, China, 26 April 2015; pp. 287–292. [Google Scholar]
- D’Ambrosio, M.; Dannewitz, C.; Karl, H.; Vercellone, V. MDHT: A hierarchical name resolution service for information-centric networks. In Proceedings of the ACM SIGCOMM Workshop on Information-Centric Networking, Toronto, ON, Canada, 19 August 2011; pp. 7–12. [Google Scholar]
- Saino, L.; Psaras, I.; Pavlou, G. Hash-routing schemes for information centric networking. In Proceedings of the 3rd ACM SIGCOMM Workshop on Information-Centric Networking, Hong Kong, China, 12 August 2013; pp. 27–32. [Google Scholar]
- Kong, L.; Zhu, J.; Dai, R.; Sadat, M.N. Impact of Distributed Caching on Video Streaming Quality in Information Centric Networks. In Proceedings of the 2017 IEEE International Symposium on Multimedia, Taichung, Taiwan, 11–13 December 2017; pp. 399–402. [Google Scholar]
- Huang, L.; Guan, Y.; Zhang, X.; Guo, Z. On-path collaborative in-network caching for information-centric networks. In Proceedings of the 2017 IEEE Conference on Computer Communications Workshops, Atlanta, GA, USA, 1–4 May 2017; pp. 175–180. [Google Scholar]
- Zeng, L.; Ni, H.; Han, R. An incrementally deployable IP-compatible information-centric networking hierarchical cache system. Appl. Sci. 2020, 10, 6228. [Google Scholar] [CrossRef]
- Eum, S.; Nakauchi, K.; Murata, M.; Shoji, Y.; Nishinaga, N. CATT: Potential Based Routing with Content Caching for ICN. In Proceedings of the 2nd Edition of the ICN Workshop on Information-Centric Networking, Helsinki, Finland, 17 August 2012; pp. 49–54. [Google Scholar]
- Gettys, J.; Nichols, K. Bufferbloat: Dark buffers in the internet. Commun. ACM 2012, 55, 57–65. [Google Scholar] [CrossRef]
- Rani, P.V.; Ravi, N.; Shalinie, S.M.; Pariventhan, P.; Rajkumar, K. Fuzzy Based Congestion-Aware Secure (FuCaS) Route Selection in ICN. In Proceedings of the 9th International Conference on Computing, Communication and Networking Technologies, Bengaluru, India, 10–12 July 2018; pp. 1–7. [Google Scholar]
- Albalawi, A.A.; Garcia-Luna-Aceves, J.J. A Delay-Based Congestion-Control Protocol for Information-Centric Networks. In Proceedings of the 2019 International Conference on Computing, Networking and Communications, Honolulu, HI, USA, 18–21 February 2019; pp. 809–815. [Google Scholar]
- Brakmo, L.S.; Peterson, L.L. TCP Vegas: End to End Congestion Avoidance on a Global Internet. IEEE J. Sel. Areas Commun. 1995, 13, 1465–1480. [Google Scholar] [CrossRef]
- Wei, D.X.; Jin, C.; Low, S.H.; Hegde, S. FAST TCP: Motivation, architecture, algorithms, performance. IEEE/ACM Trans. Netw. 2006, 14, 1246–1259. [Google Scholar] [CrossRef]
- Ma, P.; Wang, J.; You, J. An Improved Maximum Flow Routing Algorithm for Multi-homing in Information-Centric Networking. In Proceedings of the 28th International Conference on Computer Communication and Networks, Valencia, Spain, 29 July–1 August 2019; pp. 1–8. [Google Scholar]
- Saino, L.; Psaras, I.; Pavlou, G. Icarus: A Caching simulator for Information Centric Networking (ICN). In Proceedings of the Seventh International Conference on Simulation Tools and Techniques SIMUTools, Lisbon, Portugal, 17–19 March 2014; pp. 66–75. [Google Scholar] [CrossRef]
- Detti, A.S.; Salsano, M.; Cancellieri, N.A.; Detti, S.; Salsano, M.; Cancellieri, N.; Blefari-Melazzi, N.; Pomposini, M. Transport-layer issues in information centric networks. In Proceedings of the 2nd Edition of the ICN Workshop on Information-Centric Networking, Helsinki, Finland, 17 August 2012; pp. 19–24. [Google Scholar]
- Wang, L.; Bayhan, S.; Kangasharju, J. Optimal chunking and partial caching in information-centric networks. Comput. Commun. 2015, 61, 48–57. [Google Scholar] [CrossRef]
- Data Aware Networking (Information Centric Networking)—Requirements and Capabilities. Available online: https://www.itu.int/ITU-T/recommendations/rec.aspx?rec=13253 (accessed on 17 January 2021).
- Spring, N.; Mahajan, R.; Wetherall, D. Measuring ISP Network Topologies with Rocketfuel. In Proceedings of the ACM SIGCOMM, Pittsburgh, PE, USA, 19–23 August 2002; pp. 133–145. [Google Scholar]
- Michael, Z.; Kyoungwon, S.; Gu, Y.; Kurose, J. Watch global, cache local: YouTube network traffic at a campus network: Measurements and implications. Multimed. Comput. Netw. 2008, 6818, 681805–681813. [Google Scholar]
- Azimdoost, B.; Westphal, C.; Sadjadpour, H.R. Resolution-Based Content Discovery in Network of Caches: Is the Control Traffic an Issue? IEEE Trans. Commun. 2017, 65, 2943–2955. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Replica Selection Approach | Scenario | Content Discovery Mechanism | Replica Selection Strategy |
|---|---|---|---|
| NDN [3] | ICN (Information-Centric Networking) | Name-based routing, without name resolution | Utilize the nearest on-path replicas towards the content source |
| DENA [12] | ICN | Name-based routing, without name resolution | Using announcement table to utilize the nearest off-path replicas |
| SCAN [2] | ICN | Name-based routing, without name resolution | Intermediate routers send probe packets to explore the nearest off-path replicas |
| O2CEMF [15] | ICN | Name-based routing, without name resolution | Each network node explores nearby off-path replicas when users begin to request data |
| MF (MobilityFirst) [17] | ICN | Standalone name resolution, global name resolution | Global nearest replicas without considering link congestion or replica node overload |
| Random [27] | key-value stores | _ | Randomly select replica, good balance among replica nodes, but may select a farther one |
| L2 [28] | key-value stores | _ | First select replicas with the least number of outstanding requests, then select by the least response time |
| ERS (enhanced replica selection) proposed in this paper | ICN | Hybrid name resolution ofenhanced name resolution system and global name resolution system | Replicas a selected based on the distance constraint and replica node state |
| Symbol | Meaning | Symbol | Meaning |
|---|---|---|---|
| the size of a content | the bandwidth of a sender | ||
| the link delay of link l between two network nodes | the number of flows in a selected replica node when a request arrives | ||
| the bandwidth of router q | the number of flows in router q |
| C | |||
|---|---|---|---|
| Importance | Definition | |
|---|---|---|
| Equal | 1 | |
| Moderate | 3 | |
| Strong | 5 | |
| Very Strong | 7 | |
| Extreme | 9 | |
| Inner | between above neighboring | 2/4/6/8 |
| Parameter | Description |
|---|---|
| Topology | TISCALI |
| Catalog | 104 contents with Zipf distribution |
| Traffic workload | Stationary |
| Zipf skewness | alpha = 0.9 |
| Size of the content | Uniformed, C = 2 MB |
| Delay range of ENRS domain | 15 ms |
| Cache strategy | LCE |
| Cache replacement | LRU |
| Request number | |
| Requests | 1000 req/s with a Poisson distribution |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Ni, H.; Zhu, X. An Enhanced Replica Selection Approach Based on Distance Constraint in ICN. Electronics 2021, 10, 490. https://doi.org/10.3390/electronics10040490
Song Y, Ni H, Zhu X. An Enhanced Replica Selection Approach Based on Distance Constraint in ICN. Electronics. 2021; 10(4):490. https://doi.org/10.3390/electronics10040490
Chicago/Turabian StyleSong, Yaqin, Hong Ni, and Xiaoyong Zhu. 2021. "An Enhanced Replica Selection Approach Based on Distance Constraint in ICN" Electronics 10, no. 4: 490. https://doi.org/10.3390/electronics10040490
APA StyleSong, Y., Ni, H., & Zhu, X. (2021). An Enhanced Replica Selection Approach Based on Distance Constraint in ICN. Electronics, 10(4), 490. https://doi.org/10.3390/electronics10040490