
State Management for Cloud-Native Applications †



Abstract
1. Introduction
1.1. Contributions
- An architecture design for the state layer of cloud computing systems (e.g., stateless NFV systems) that store the externalized data of virtualized applications (e.g., NFs).
- A replica controller module that determines the optimal replication factor for each state, one by one, in order to keep the state access traffic and the read latency low.
- A state placement algorithm, which can handle a large number of states and their readable copies, and maximize reliability and read performance by adapting the location to their state access pattern.
- A comprehensive evaluation of the proposed state layer compares the performance results to naive solutions.
1.2. Terminology
1.3. Similarity to Content Delivery Networks
1.4. Organization of the Paper
2. Our Proposed Design for the State Layer
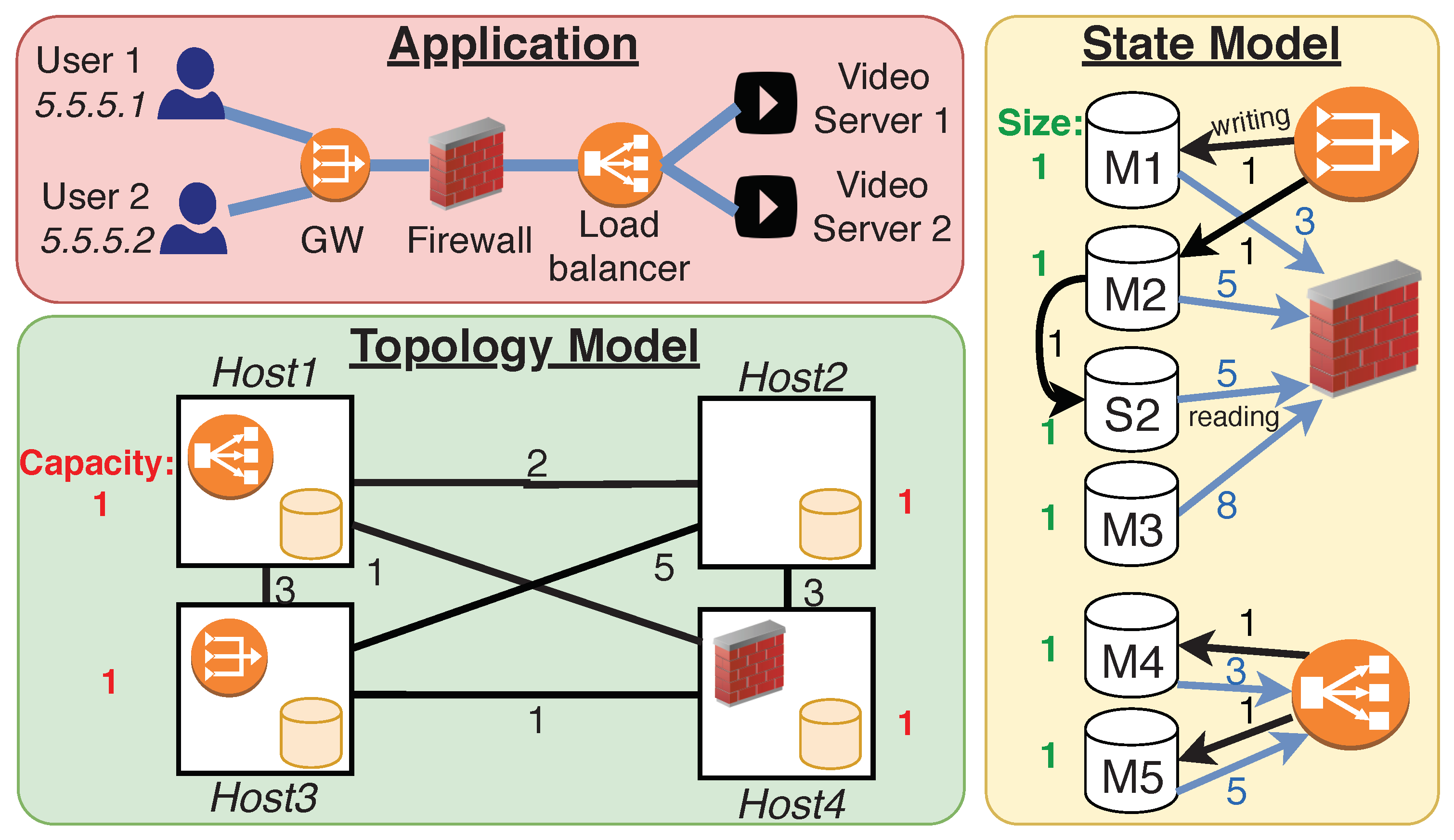
2.1. State Layer Interface and State Access Descriptor
- One or multiple state data (with keys and values), which need to be saved in the state layer;
- The size of a state data in memory;
- Replication factor (a minimum number of slaves is optionally defined by policy);
- *
- NF instances accessing the state data (a state can belong to a single NF instance, or can be shared);
- *
- Type of access, that is, reads, writes, or both; and
- *
- Ease of access, number of accesses per second.
2.2. Replication Module
2.3. Infrastructure Monitor
- The list of hosts in the data center cluster;
- The memory capacities of these hosts;
- The measured network delays between the host pairs; and
- The hosts of already deployed NF instances.
2.4. Placement Module
2.5. Migration Module
2.6. Access Pattern Monitor
3. A Use-Case for Stateless Design
4. Optimal Number of Slave Instances
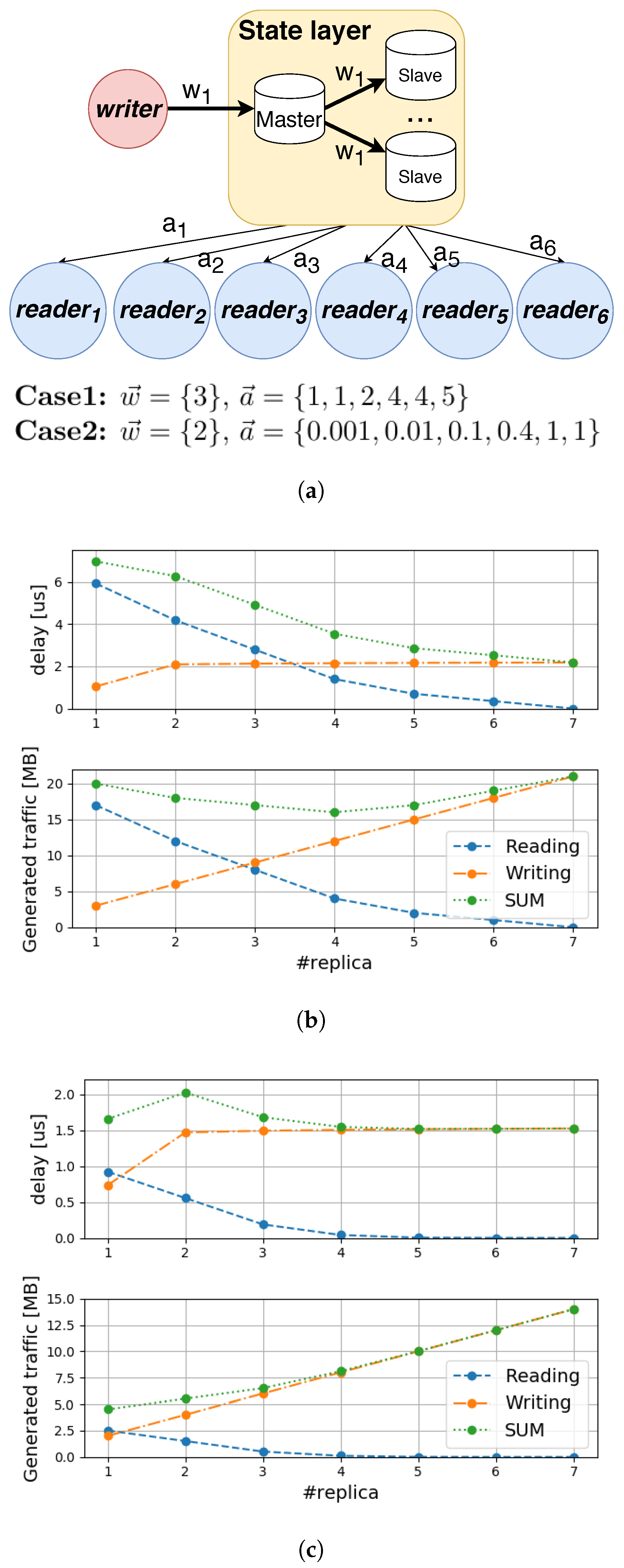
4.1. Network Traffic Depending on Replication Factor
- The key and value of the state s;
- Its size, ;
- The set of its writer NFs , consisting of elements ;
- How frequently NFs write state s in a second, that is, a writing rate vector , where for example, means that the NF2 in writes the state times per second;
- The set of its reader NFs consisting of elements ;
- How frequently NFs read state s in a second, that is, a reading rate vector . Without the loss of generality, let be sorted in increasing order, that is, where .
4.2. Network Delay Depending on Replication Factor
4.3. Maximum Access Rate Depending on the Slave Count
4.4. Proposed Model for Determining the Replication Factor
5. The Complexity of the State Placement Problem and Our Heuristic Solution
5.1. Problem Formulation
5.2. Proof of Complexity
5.3. Proposed Heuristic Placement Algorithm
| Algorithm 1: Flooding algorithm. |
 |
| Algorithm 2: GetOptimalHost procedure. |
 |
6. Evaluation
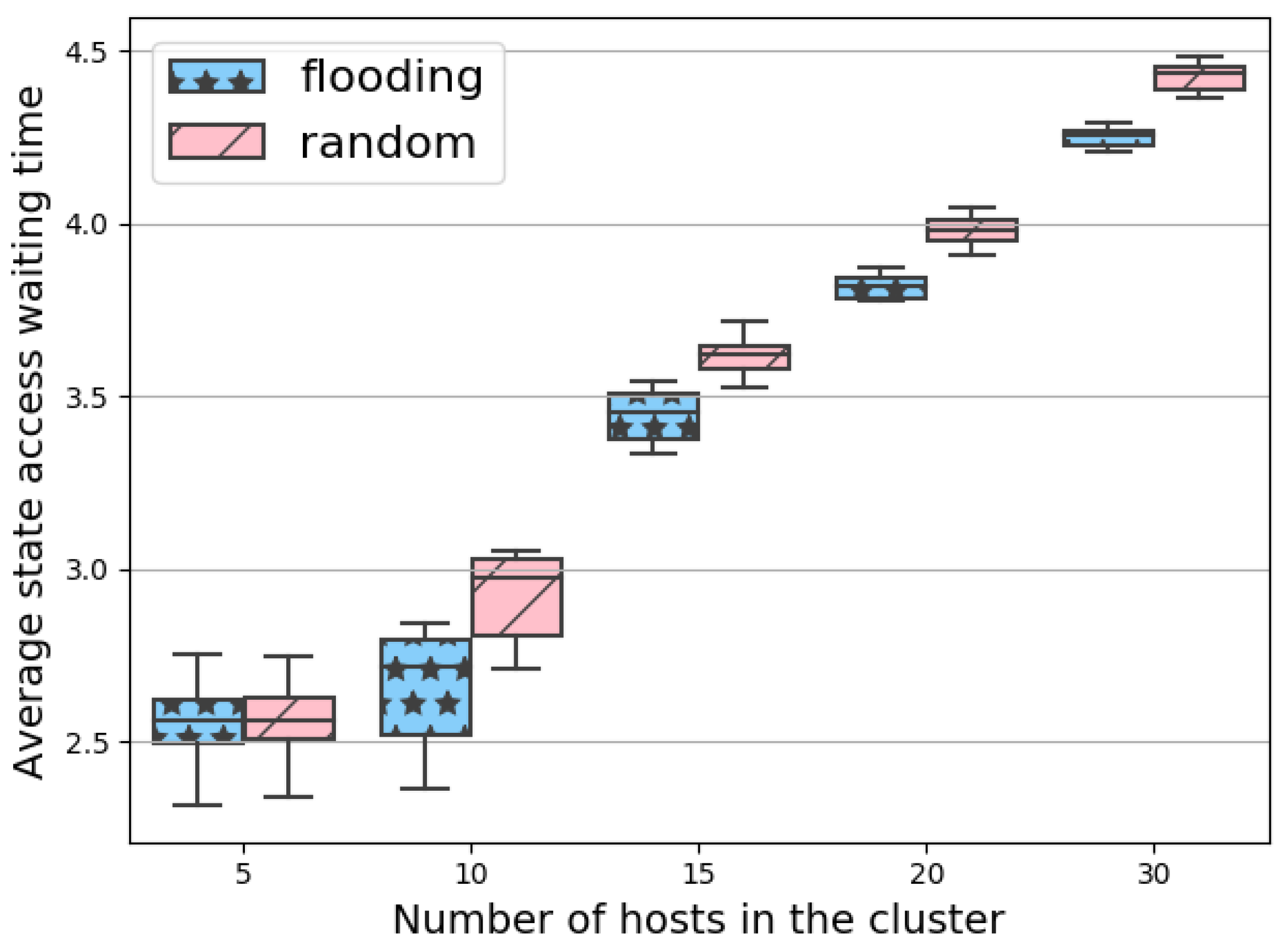
6.1. Performance of the Flooding State Placement
6.2. Replication Module Evaluation
6.3. Discussion
7. Related Work
7.1. Popular Key-Value Stores
7.2. Data/Replica Placement
7.3. Stateless Network Function Frameworks
7.4. Technologies Related to the Concept of State Externalization
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kablan, M.; Caldwell, B.; Han, R.; Jamjoom, H.; Keller, E. Stateless Network Functions. In Proceedings of the 2015 ACM SIGCOMM Workshop on Hot Topics in Middleboxes and Network Function Virtualization—HotMiddlebox’15, London, UK, 21 August 2015; ACM Press: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Kablan, M.; Alsudais, A.; Keller, E.; Le, F. Stateless network functions: Breaking the tight coupling of state and processing. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), Boston, MA, USA, 27–29 March 2017; pp. 97–112. [Google Scholar]
- Németh, G.; Géhberger, D.; Mátray, P. DAL: A Locality-Optimizing Distributed Shared Memory System. In Proceedings of the 9th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 17), Santa Clara, CA, USA, 10–11 July 2017. [Google Scholar]
- Woo, S.; Sherry, J.; Han, S.; Moon, S.; Ratnasamy, S.; Shenker, S. Elastic scaling of stateful network functions. In Proceedings of the 9th 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), Renton, WA, USA, 9–11 April 2018; pp. 299–312. [Google Scholar]
- Taleb, T.; Ksentini, A.; Sericola, B. On service resilience in cloud-native 5G mobile systems. IEEE J. Sel. Areas Commun. 2016, 34, 483–496. [Google Scholar] [CrossRef]
- Szalay, M.; Nagy, M.; Géhberger, D.; Kiss, Z.; Mátray, P.; Németh, F.; Pongrácz, G.; Rétvári, G.; Toka, L. Industrial-scale stateless network functions. In Proceedings of the 2019 IEEE 12th International Conference on Cloud Computing (CLOUD), Milan, Italy, 8–13 July 2019; pp. 383–390. [Google Scholar]
- Abbasi, A.A.; Al-qaness, M.A.; Elaziz, M.A.; Hawbani, A.; Ewees, A.A.; Javed, S.; Kim, S. Phantom: Towards Vendor-Agnostic Resource Consolidation in Cloud Environments. Electronics 2019, 8, 1183. [Google Scholar] [CrossRef]
- Abbasi, A.A.; Al-qaness, M.A.; Elaziz, M.A.; Khalil, H.A.; Kim, S. Bouncer: A Resource-Aware Admission Control Scheme for Cloud Services. Electronics 2019, 8, 928. [Google Scholar] [CrossRef]
- Varga, P.; Peto, J.; Franko, A.; Balla, D.; Haja, D.; Janky, F.; Soos, G.; Ficzere, D.; Maliosz, M.; Toka, L. 5g support for industrial iot applications–challenges, solutions, and research gaps. Sensors 2020, 20, 828. [Google Scholar] [CrossRef] [PubMed]
- Toka, L.; Recse, A.; Cserep, M.; Szabo, R. On the mediation price war of 5G providers. Electronics 2020, 9, 1901. [Google Scholar] [CrossRef]
- Intel. Network Function Virtualization: Quality of Service in Broadband Remote Access Servers with Linux and Intel Architecture; Intel: Santa Clara, CA, USA, 2014. [Google Scholar]
- Intel. Network Function Virtualization: Virtualized BRAS with Linux and Intel Architecture; Intel: Santa Clara, CA, USA, 2014. [Google Scholar]
- Mahmud, N.; Sandström, K.; Vulgarakis, A. Evaluating industrial applicability of virtualization on a distributed multicore platform. In Proceedings of the 2014 IEEE Emerging Technology and Factory Automation (ETFA), Barcelona, Spain, 16–19 September 2014; pp. 1–8. [Google Scholar]
- Szalay, M.; Mátray, P.; Toka, L. Minimizing state access delay for cloud-native network functions. In Proceedings of the 2019 IEEE 8th International Conference on Cloud Networking (CloudNet), Coimbra, Portugal, 4–6 November 2019; pp. 1–6. [Google Scholar]
- Szalay, M.; Matray, P.; Toka, L. AnnaBellaDB: Key-Value Store Made Cloud Native. In Proceedings of the 2020 16th International Conference on Network and Service Management (CNSM), Izmir, Turkey, 2–6 November 2020; pp. 1–5. [Google Scholar]
- Pallis, G.; Vakali, A. Insight and perspectives for content delivery networks. Commun. ACM 2006, 49, 101–106. [Google Scholar] [CrossRef]
- Bhamare, D.; Jain, R.; Samaka, M.; Erbad, A. A survey on service function chaining. J. Netw. Comput. Appl. 2016, 75, 138–155. [Google Scholar] [CrossRef]
- Ousterhout, J.; Gopalan, A.; Gupta, A.; Kejriwal, A.; Lee, C.; Montazeri, B.; Ongaro, D.; Park, S.J.; Qin, H.; Rosenblum, M.; et al. The RAMCloud storage system. ACM Trans. Comput. Syst. (TOCS) 2015, 33, 1–55. [Google Scholar] [CrossRef]
- Wu, C.; Sreekanti, V.; Hellerstein, J.M. Autoscaling tiered cloud storage in Anna. Proc. VLDB Endow. 2019, 12, 624–638. [Google Scholar] [CrossRef]
- Wu, C.; Faleiro, J.; Lin, Y.; Hellerstein, J. Anna: A kvs for any scale. IEEE Trans. Knowl. Data Eng. 2019, 33, 344–358. [Google Scholar] [CrossRef]
- Da Silva, M.D.; Tavares, H.L. Redis Essentials; Packt Publishing Ltd.: Birmingham, UK, 2015; ISBN 978-1-78439-245-1. [Google Scholar]
- Sivasubramanian, S. Amazon dynamoDB: A seamlessly scalable non-relational database service. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 729–730. [Google Scholar]
- Rausand, M.; Høyland, A. System Reliability Theory: Models, Statistical Methods, and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2003; Volume 396. [Google Scholar]
- Popescu, D.A.; Moore, A.W. A First Look at Data Center Network Condition Through The Eyes of PTPmesh. In Proceedings of the 2018 Network Traffic Measurement and Analysis Conference (TMA), Vienna, Austria, 26–29 June 2018; pp. 1–8. [Google Scholar]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Cplex, IBM ILOG. V12. 1: User’s Manual for CPLEX; International Business Machines Corporation: Armonk, NY, USA, 2009. [Google Scholar]
- Billionnet, A.; Elloumi, S.; Lambert, A. Linear reformulations of integer quadratic programs. In Proceedings of the International Conference on Modelling, Computation and Optimization in Information Systems and Management Sciences, Luxembourg, 8–10 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 43–51. [Google Scholar]
- Leiserson, C.E. Fat-trees: Universal networks for hardware-efficient supercomputing. IEEE Trans. Comput. 1985, 100, 892–901. [Google Scholar] [CrossRef]
- Memcached—A Distributed Memory Object Caching System. Available online: https://memcached.org/ (accessed on 16 December 2020).
- Lakshman, A.; Malik, P. Cassandra: A decentralized structured storage system. ACM SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Perron, M.; Castro Fernandez, R.; DeWitt, D.; Madden, S. Starling: A Scalable Query Engine on Cloud Functions. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 131–141. [Google Scholar]
- Lersch, L.; Schreter, I.; Oukid, I.; Lehner, W. Enabling low tail latency on multicore key-value stores. Proc. VLDB Endow. 2020, 13, 1091–1104. [Google Scholar] [CrossRef]
- Chandramouli, B.; Prasaad, G.; Kossmann, D.; Levandoski, J.; Hunter, J.; Barnett, M. Faster: A concurrent key-value store with in-place updates. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 275–290. [Google Scholar]
- Zhang, T.; Xie, D.; Li, F.; Stutsman, R. Narrowing the gap between serverless and its state with storage functions. In Proceedings of the ACM Symposium on Cloud Computing, Santa Cruz, CA, USA, 20–23 November 2019; pp. 1–12. [Google Scholar]
- Matri, P.; Costan, A.; Antoniu, G.; Montes, J.; Pérez, M.S. Towards efficient location and placement of dynamic replicas for geo-distributed data stores. In Proceedings of the ACM 7th Workshop on Scientific Cloud Computing, Kyoto, Japan, 1 June 2016; pp. 3–9. [Google Scholar]
- Mayer, R.; Gupta, H.; Saurez, E.; Ramachandran, U. Fogstore: Toward a distributed data store for fog computing. In Proceedings of the 2017 IEEE Fog World Congress (FWC), Santa Clara, CA, USA, 30 October–1 November 2017; pp. 1–6. [Google Scholar]
- Paiva, J.; Ruivo, P.; Romano, P.; Rodrigues, L. Autoplacer: Scalable self-tuning data placement in distributed key-value stores. ACM Trans. Auton. Adapt. Syst. (TAAS) 2014, 9, 1–30. [Google Scholar] [CrossRef]
- Agarwal, S.; Dunagan, J.; Jain, N.; Saroiu, S.; Wolman, A.; Bhogan, H. Volley: Automated data placement for geo-distributed cloud services. In Proceedings of the USENIX NSDI, San Jose, CA, USA, 28–30 April 2010. [Google Scholar]
- Mijumbi, R.; Serrat, J.; Gorricho, J.L.; Bouten, N.; De Turck, F.; Boutaba, R. Network function virtualization: State-of-the-art and research challenges. IEEE Commun. Surv. Tutor. 2015, 18, 236–262. [Google Scholar] [CrossRef]
- Turnbull, J. The Docker Book: Containerization Is the New Virtualization; James Turnbull: Melbourne, Australia, 2014. [Google Scholar]
- Baldini, I.; Castro, P.; Chang, K.; Cheng, P.; Fink, S.; Ishakian, V.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Slominski, A.; et al. Serverless computing: Current trends and open problems. In Research Advances in Cloud Computing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–20. [Google Scholar]
- Basta, A.; Kellerer, W.; Hoffmann, M.; Morper, H.J.; Hoffmann, K. Applying NFV and SDN to LTE mobile core gateways, the functions placement problem. In Proceedings of the 4th Workshop on All things Cellular: Operations, Applications, & Challenges, Chicago, IL, USA, 22 August 2014; pp. 33–38. [Google Scholar]
- Luizelli, M.C.; Bays, L.R.; Buriol, L.S.; Barcellos, M.P.; Gaspary, L.P. Piecing together the NFV provisioning puzzle: Efficient placement and chaining of virtual network functions. In Proceedings of the 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015; pp. 98–106. [Google Scholar]
- Roberts, M. Serverless Architectures. 2016, Volume 4. Available online: https://martinfowler.com/articles/serverless.html (accessed on 1 June 2020).
- Fox, G.C.; Ishakian, V.; Muthusamy, V.; Slominski, A. Status of serverless computing and function-as-a-service (faas) in industry and research. arXiv 2017, arXiv:1708.08028. [Google Scholar]
- Sreekanti, V.; Wu, C.; Lin, X.C.; Schleier-Smith, J.; Gonzalez, J.E.; Hellerstein, J.M.; Tumanov, A. Cloudburst: Stateful functions-as-a-service. Proc. VLDB Endow. 2020, 13, 2438–2452. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CDN | State Placement of Cloud-Native Applications | |
|---|---|---|
| Source of Data | One or multiple origin server | No specific server(s) are dedicated for this purpose, each node can store the master instances |
| How to bring data close to clients | Cache data locally at the client’s side | Optimize the location of both master and slave instances |
| Topology | Geographically scattered network (even over continents) | Single-cloud infrastructure |
| Type of Stored Content | Large files such as graphics, documents and videos | Small pieces of data like integers and strings |
| Size of Stored Content | Order of MB or GB | Order of bytes |
| Content Access Pattern | Rare content writes and modifications by the provider, and frequent reads by the users | Constantly changing, dynamic and frequent reads, writes and modifications by the users’ (applications). |
| Access Time | Order of seconds | Order of milliseconds |
| State Instance ID | Key | Value |
|---|---|---|
| M1 | 5.5.5.1 | 192.168.1.1 |
| M2 | 5.5.5.2 | 192.168.1.2 |
| S2 | 5.5.5.2 | 192.168.1.2 |
| M3 | 4:00–5:00 | False |
| M4 | 192.168.1.1 | Video server 1 |
| M5 | 192.168.1.2 | Video server 2 |
| Notation | Description |
|---|---|
| NF | set of NF instances and states |
| set of NF instances writing state s, | |
| set of NF instances reading state s, | |
| writing rate vector of state s, | |
| reading rate vector of state s, | |
| size of state | |
| number of state instances (master and slaves) of state |
| Notation | Description |
|---|---|
| H | set of hosts |
| set of hosts on which one or multiple NF instances that read state s run | |
| capacity of host | |
| minimum delay between any pair of hosts i and | |
| 1 if NF(s) exists on host i writing state , otherwise 0 | |
| total writing rate of state s from host | |
| 1 if NF(s) exists on host i reading state , otherwise 0 | |
| total reading rate of state s from host | |
| indicates whether master instance of s is placed onto host i | |
| indicates whether a slave instance of s is placed onto host i | |
| , that is, the min delay between host i and the host of master s or any of its slaves |
| Number of State Instances | |||||||
|---|---|---|---|---|---|---|---|
| load | 10 | 100 | 1k | 5k | 10k | ||
| Flood. | light | runtime | 0.007 | 0.06 | 6.31 | 122 | 566 |
| heavy | runtime | 0.007 | 0.07 | 4.58 | 121 | 578 | |
| Opt. | light | runtime | 238 | n.a. | n.a. | ||
| over 1 h | 0% | 4% | 26% | 100% | 100% | ||
| heavy | over 1 h | 0% | 90% | 95% | 100% | 100% | |
| Replication Support | Replication Factor | Data Placement | Data Access Acceleration Technique | |
|---|---|---|---|---|
| Redis [21] | ✓ | node level | range or hash partitioning | cache |
| Memcached [29] | ✗ | - | hash partitioning | cache |
| Cassandra [30] | ✓ | node level | consistent hashing | cache |
| DynamoDB [22] | ✓ | region level | hash partitioning | DAX, in-memory cache |
| Anna [19,20] | ✓ | node level | consistent hashing | dynamic replication factor for hot data |
| DAL [3] | ✓ | data level | access pattern aware placement for data | cache + data migration to the most querying server |
| RAMCloud [18] | ✓ | DC level | hash partitioning | keeps all data in DRAM |
| Our Solution | ✓ | data level | access pattern aware State Placement Optimization | dynamic replication factor for all data and data locality reoptimization |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szalay, M.; Mátray, P.; Toka, L. State Management for Cloud-Native Applications. Electronics 2021, 10, 423. https://doi.org/10.3390/electronics10040423
Szalay M, Mátray P, Toka L. State Management for Cloud-Native Applications. Electronics. 2021; 10(4):423. https://doi.org/10.3390/electronics10040423
Chicago/Turabian StyleSzalay, Márk, Péter Mátray, and László Toka. 2021. "State Management for Cloud-Native Applications" Electronics 10, no. 4: 423. https://doi.org/10.3390/electronics10040423
APA StyleSzalay, M., Mátray, P., & Toka, L. (2021). State Management for Cloud-Native Applications. Electronics, 10(4), 423. https://doi.org/10.3390/electronics10040423