1. Introduction
A multicloud strategy and a hybrid cloud strategy dominated last year [
1], and the IaaS cloud service model remains the most prevalent to manage performance, quality of services, and power consumption in cloud data centers. A wide range of modern information services and applications are provided by cloud data centers represented by complex systems to deliver high-performance and fault-tolerant IT services for users and tenants using a utility computing concept [
2].
Still, three main objectives for effective management of data center resource provisioning are (i) ensuring the service level agreement (SLA) between a cloud service provider and a user, (ii) reducing the power consumption of data centers, and (iii) reducing the operational costs of managing data center services.
An effective cloud data center resource utilization is mainly achieved by virtual machine (VM) consolidation, which determines how physical machine (PM) resources are allocated to run many VM instances to guarantee QoS requirements and reduce the total number of PMs used. VMs with different resource demands are usually placed in the same PM using the oversubscription technique, leading to resource contention, poor QoS, and, consequently, SLA violations. Nevertheless, data center administrators continue accepting VM consolidation methods despite all the drawbacks, such as performance and QoS degradation. Therefore, current issues in VM management schemas lead to the development and improvement of VM consolidation, considering the heterogeneity of resources, live VM migration, network and storage parameters, deployment platforms, workload patterns, and resource usage forecasting.
In the production data center, a mapping between VMs and PMs is usually performed with oversubscription according to the VM’s required resource capacity without considering long-term utilization. Moreover, the number of VMs and the intensity of VM workloads are continuously changing, requiring adaptive methods for dynamic VM management starting with a new VM placement request.
A VM consolidation problem is considered a bin-packing problem, where
N numbers of items (virtual machines) with different sizes in a multidimensional resource space are placed on
M numbers of bins (physical machines) to satisfy multiple objectives simultaneously. In this paper, the authors consider two: power consumption minimization and SLA violation minimization. The bin-packing problem is compounded by the variation of the item’s properties, requests to deploy new items, and reassigning existing items to other bins. As clients request services and submit jobs to be processed by one or multiple VMs, the workload in a cloud data center can change significantly over time. It requires solving an optimization problem to place new VMs and reallocate active VMs periodically using an asynchronous mode or after a defined number of steps. Other constraints while consolidating virtual machines are a restriction of the number of concurrent VM migrations per PM, a restriction of the PM’s resource utilization, and a limitation of the number (or time) of SLA violations [
3].
This paper investigates a problem of SLA-aware VM consolidation under dynamic workloads, uncertainty, and the changing number of VMs. The proposed method of dynamic VM management consists of two stages, which are performed in each time interval. The first stage of the method is determining overloaded and underloaded PMs. The second stage of the method is choosing VMs for migration and placement as well as running a migration plan using a beam search algorithm proposed by the authors in [
4]. The migration plan is executed by constructing a tree of possible target PMs for VM placement, which considers no more than
n vertices, where
n is a beamwidth. Each candidate vertex has an estimate by which the vertices are compared, so the best
n vertices are selected.
To rate VM consolidation schemas and approaches on the infrastructure level, the authors define six quality metrics related to SLA violations, power consumption, and VM migrations. To estimate beam search algorithm parameters, the authors propose an integral estimation method (IEM) that allows determining optimal power consumption parameters, considering the minimum area under each curve that approximates a specific chart. To conduct optimization, the authors define two objectives: a minimization of PMs’ uptime (the power consumption minimization, PCM) and a minimization of the number of SLA violations (the SLA violation minimization, SLAVM), aiming to determine model parameters for both objectives separately. The optimization results allow for obtaining some scientific insights into VM consolidation approaches regarding the thresholds for the specified resource utilization, the minimization objectives, SLA violations, a workload intensity on a specific resource, and a complementary VM placement.
The current study extends the author’s previous paper [
5] to the particular case of dynamic VM management based on the modified model and the modified VM consolidation method, resulting in determining different parameters of the proposed model and their effect on the quality metrics. As shown earlier, the approach presented in [
5] outperforms a basic best-fit heuristic regarding the SLA violation, the number of active physical machines, and the number of VM migrations.
In the research literature, the problem of VM management in cloud environments is often referred to as a multiobjective multidimensional bin-packing problem. Exploring VM management as a general instance of the initial VM placement and the consolidation of active VMs is an ongoing research track [
3,
6,
7]. It has been studied in the literature from a variety of perspectives, including the proactive resource allocation strategy [
8], the use of a responsive live migration approach for high-throughput computing (HTC) systems with various migration policies as a fault-tolerance mechanism [
9], the multiobjective genetic algorithm and Bernoulli simulation for the minimization of the number of active PMs [
10], the cloud infrastructure resource allocation framework based on reinforcement learning mechanism [
11], and setting upper and lower thresholds in VM consolidation schemas [
12], to mention a few.
In the literature, multiobjective VM consolidation schemes are the most commonly used approaches to manage cloud resources under uncertainty [
6,
7,
13,
14]. However, despite the numerous research studies, there is a lack of research results regarding the effect of different parameters of VM management schemes on quality metrics in a dynamic mode (i.e., considering new VM requests, the different VM lifetime, the dynamic compute-intensive, memory-intensive, storage-intensive, and network-intensive workloads).
With the aim of minimizing the number of active PMs and maximizing the resource utilization, the framework based on the multiobjective genetic algorithm and Bernoulli simulation was proposed in [
10]. Thus, two objectives were combined into one by the proposed weighted sum function as a fitness function of the genetic algorithm. However, the proposed framework considers only CPU and memory utilization and does not consider other PM resources and VM migrations.
In [
14], extensive lab experiments and simulations with different controllers and different workloads were conducted using 6 identical servers and 90 VMs. The authors proposed combining placement controllers with periodic reallocations to achieve the highest energy efficiency in dynamic environments. The combinations of demand-based placement controllers with reallocation controllers lead to fewer VM migrations than reservation-based placement controllers and lower server demand. However, the proposed algorithm takes into account only CPU and memory monitoring data as an input to the controller and does not consider other PM resources. Besides, the authors used the homogenous PM configuration during the experiments.
To optimize VM placement in dynamic cloud data centers, the authors of [
11] proposed an intelligent learning approach based on reinforcement learning (RL). The proposed RL approach learns optimized VM consolidation decisions under uncertainty of the incoming workload. However, the proposed algorithm does not account for the influence of the VM’s memory changes on the migration overhead.
In [
9], the authors proposed VM live migration as a fault-tolerance mechanism in HTC systems. The proposed responsive live migration approach for HTC systems with various migration policies demonstrates low performance and energy impact. It saves approximately 75% of the system wasted energy due to job evictions by user interruptions, where migration is not employed as a fault-tolerance mechanism. The proposed HTC-Sim simulation framework has been used for trace-driven simulations to explore the impact of the policies on performance and energy.
The authors of [
15] proposed the power-aware and performance-guaranteed VM placement method by developing the algorithm based on ant colony optimization. Based on the nonlinear power model of the PM and VM performance model, the authors formulated the VM placement problem as a biobjective optimization problem, which tries to minimize PM power consumption and guarantee VM performance. At the same time, storage utilization and VM migration overhead are not considered in the proposed models.
The proactive resource allocation method based on the adaptive prediction of the resource requests was proposed in [
8]. The method is based on the prediction of resource requests and the multiobjective resource allocation optimization model, which alleviates the latency of the resource allocation and balanced utilization of the CPU and memory of a PM. However, the proposed approach considers only CPU and memory utilization and does not consider other PM resources. Furthermore, the proposed method does not account for VM migration and VM consolidation.
The first issue of many VM consolidation schemes is employing strategies aiming to optimize resource allocation based only on CPU utilization [
11,
12,
16,
17]. However, application workloads inside VMs can also be compute-intensive, memory-intensive, storage-intensive, and network-intensive, which can be a significant challenge to such schemes. The second issue is using outdated or unbalanced hardware configurations used for simulating data center PMs [
10,
11,
12]. However, the modern PMs installed in data centers have very high performance and can host hundreds VMs. Therefore, evaluation results obtained by simulating data centers using PMs and VMs that differ little in performance are not helpful for real data centers. The third issue is using power consumption minimization and minimization of the number of migrations as the main objective function while minimizing the number of SLA violations according to the residual principle [
9,
14,
15]. However, a minimization of power consumption, including those based on adaptive thresholds, is always accompanied by aggressive consolidation, which always results in sufficient SLA violations and an increasing number of switching PMs between the active and sleep modes. Besides, with respect to this, it is questionable whether an adaptive threshold in VM management schemes is suitable for modern data centers compared with static thresholds.
In contrast to prior VM management schemes reported in the literature, in this paper, the authors are improving the client’s experience by minimizing SLA violations, thereby ensuring maximum service uptime for clients, with the concern of minimizing the number of VM migrations while reducing power consumption. Besides, heterogeneous PMs with typical widespread hardware configurations are used for simulations applying real workload traces as input data. The proposed method considers all SLA violations on the infrastructure level.
The remaining parts of the paper continue with
Section 2, where the authors develop the proposed dynamic VM management method.
Section 3 describes the simulation environment, the simulation settings, the model parameters, and the optimization results using two objectives.
Section 4 summarizes the revealed findings and scientific insights. Finally,
Section 5 presents conclusions with remarks on future work.
2. Materials and Methods
The System Model and Main Objectives
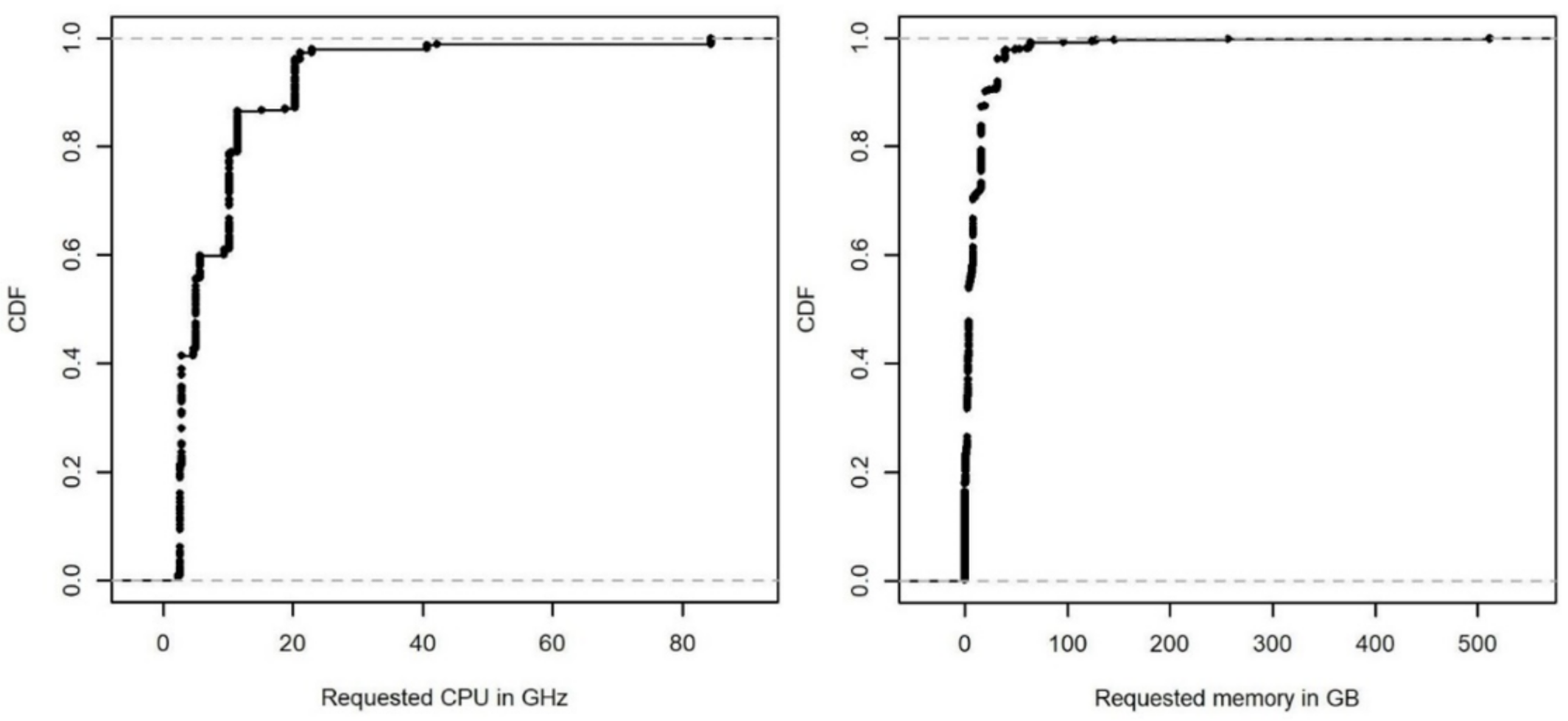
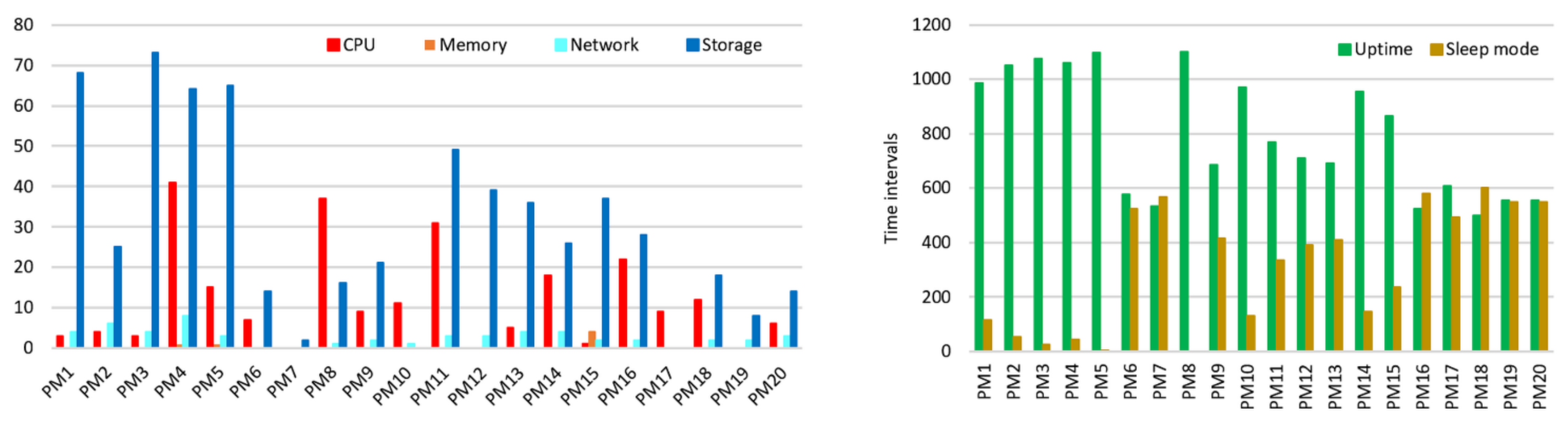
The cluster of cloud data centers is composed of M PMs and N VMs, . Each PM has a fixed amount of hardware resources, such as a CPU measured in MHz, a RAM measured in GB, a storage measured in IOPS (input/output operations per second), and a network throughput measured in Gbps. VM resource requirements can change over time. During the time interval (also called a management step), the number of PMs is constant, but the numbers of VMs and VM resource requirements change.
There are four types of resources in the model denoted by . The required resource k capacity of the j-th VM denoted by is determined by a workload served by a VM. The resource k capacity of the i-th PM denoted by is determined by the PM hardware configuration. The utilization of resource k of the i-th PM is denoted by . The number of VMs running on the i-th PM is denoted by . The variables and can be changed during the VM lifetime and the VM migration.
The rest of the variables of the model are defined as follows: is the weight of resource k, is the largest value of the required capacity of each resource k among VMs for normalization, rj is the required resource capacity of the j-th VM, is the largest value of the capacity of each resource k among PMs for normalization, Ri is the existing resource capacity of the i-th PM, ui is the utilization of resources of the i-th PM, is the threshold of the available resource k of the i-th PM, is the desired workload on the resource k, is the threshold of the available resource k of the i-th PM that is determined as underloaded, is the threshold of the available resource k of the i-th PM that can host migrating VMs, vi is the number of hosted VMs of the i-th PM, di is the deviation from the desired utilization of the i-th PM, is the deviation from the desired utilization level of the resource k, is the total number of resources available for all migrations, is the capacity of the resource k needed for VM migration, is an assessment of the VM migration possibility, A is a set with overloaded PMs, W is a set with underloaded PMs that is going to be set to sleep mode, B is a set of PMs that can accept migrating VMs, S is the total simulation time measured as the total number of simulations steps, and is the management step.
All PMs are subdivided into three sets: A, W, and B, , . The proposed method tries to switch PMs from set W of underloaded PMs to the sleep mode by migrating all their VMs to PMs from set B and offloads PMs of set A of overloaded PMs. For each PM from sets A and W, the proposed method searches for PM from set B, which can accept VM migrations from overloaded and underloaded PMs. Then, all PMs of set W can be switched to the sleep mode when all their VMs migrate to PMs of set B.
The defined variables are used for the dynamic model of a data center during each simulation step (i.e., the interval between time t and t + 1). A number of PMs operating at the current simulation step t is defined as . The SLA violation is measured in time intervals when a resource contention is observed in the proposed model. An SLA violation occurs when during one-time interval (management step t), namely, when the total demand for the resource k exceeds the available resource capacity.
The authors define two objectives for the problem. First, the problem of
a power consumption minimization can be formulated as follows:
Second, the problem of
an SLA violation minimization can be formulated as follows:
subject to
.
4. Discussion
Table 4 summarizes the influence of the model parameters on the quality metrics during the SLA violation minimization and the power consumption minimization (the objective functions as defined in
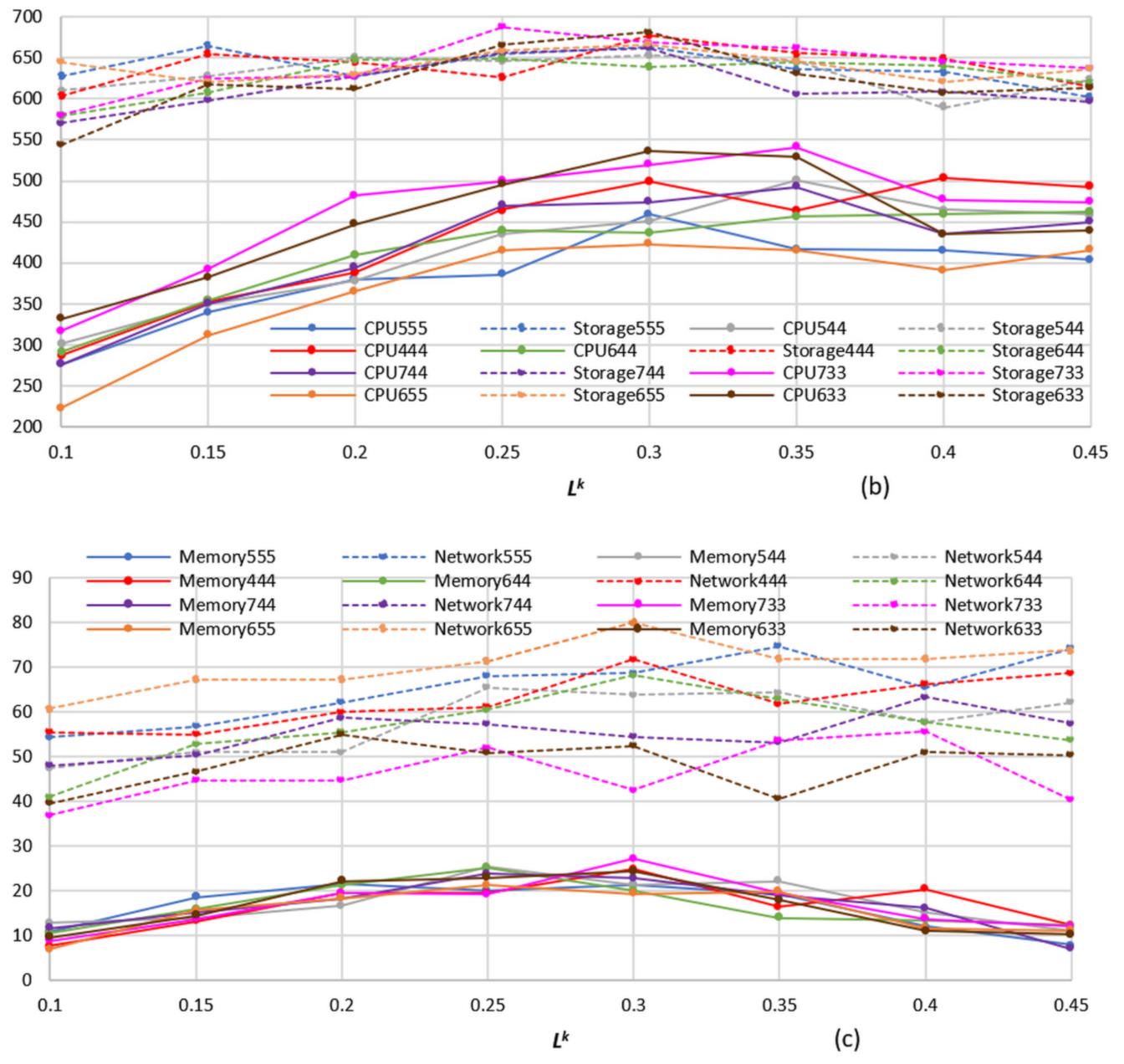
Section 2). Grey rows of the table indicate the power consumption minimization results. IEM is applied in the study’s first phase, whereas PCM and SLAVM are applied in the second phase.
The thresholds
Tk,
Dk,
Lk, and
Qk have a complex influence on each objective function’s quality metrics. There appears to be no benefit in using the threshold
Dk for VM management because it has a weak effect on both objectives’ quality metrics. The threshold
Tk strongly influences the five out of six quality metrics for the PCM objective function; therefore, it should be used for VM management. On the other hand, for SLAVM objective function,
Tk has a strong influence on three out of six quality metrics; therefore, it can be constant. The threshold
Lk strongly influences the five out of six quality metrics for both objective functions; therefore, it should also be used for VM management. The threshold
Qk strongly influences the four out of six quality metrics for both objective functions; therefore, it is recommended for VM management. From
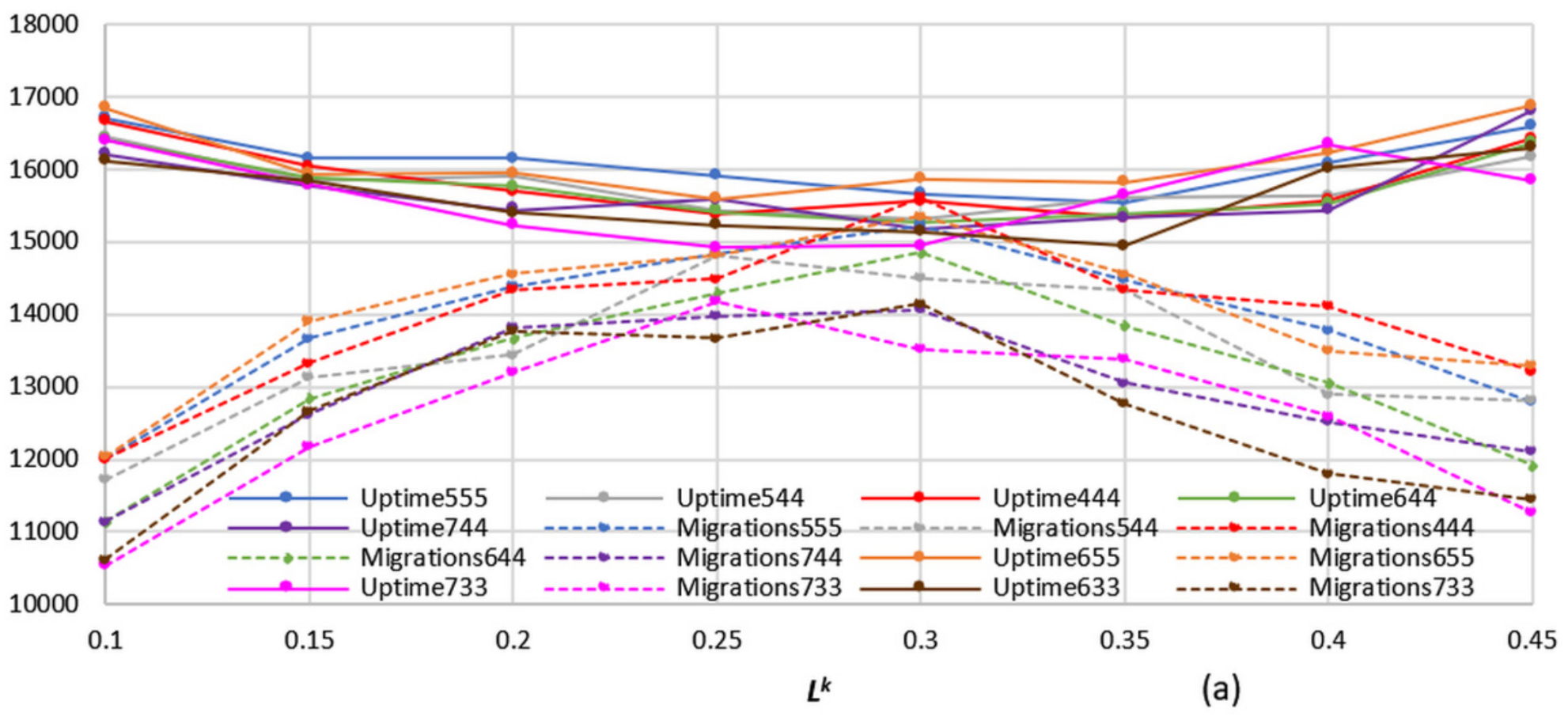
Figure 4,
Figure 5,
Figure 6 and
Figure 7 and
Figure 9,
Figure 10 and
Figure 11, it should be noted that the overall objective function sensitivity to the thresholds is not great, and consequently, the proposed model is practical.
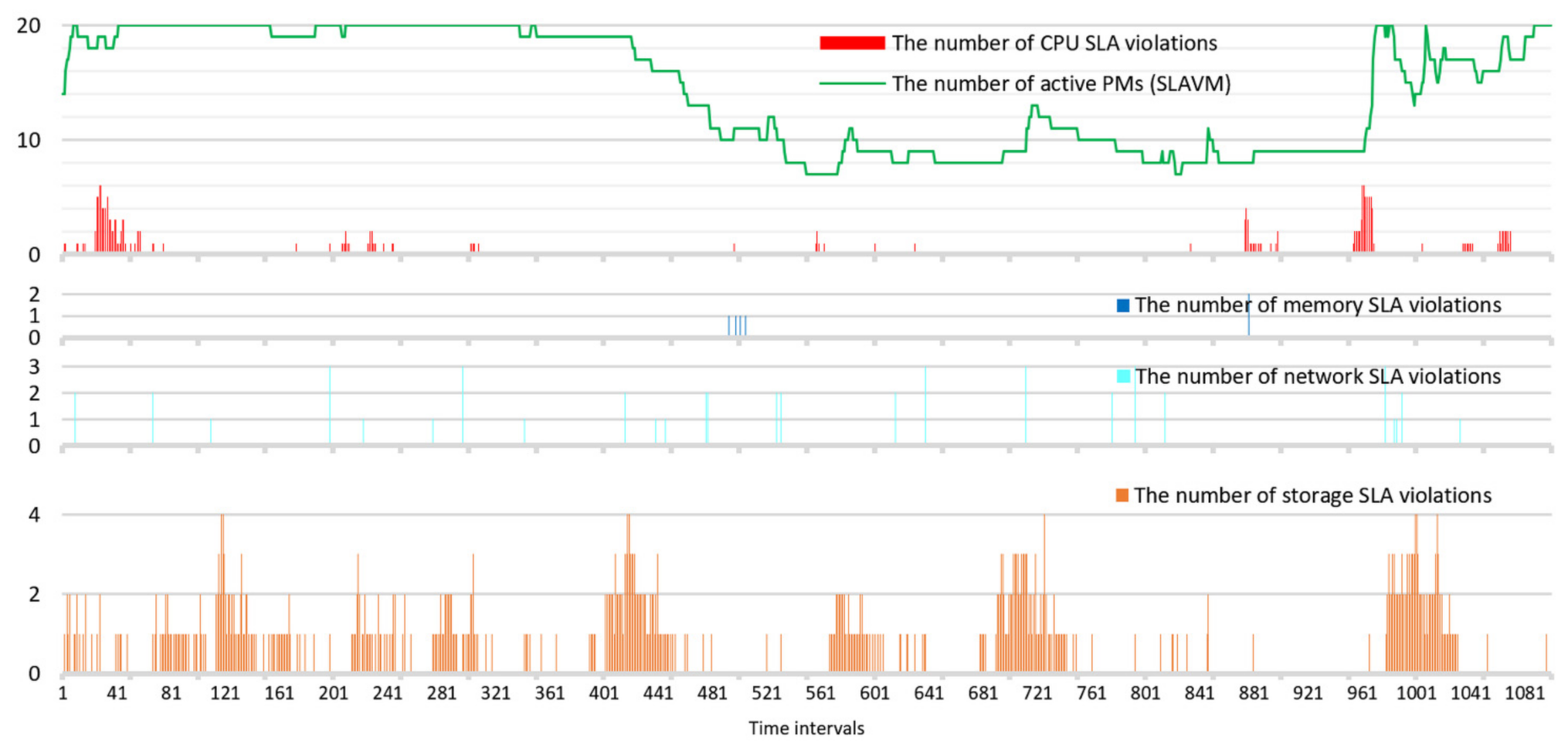
The memory SLA violation metric varies from around 5 cases up to 33 cases during simulation runs. However, compared with other quality metrics, memory SLA violations occur very rarely, which can be explained by the sufficient RAM capacity of PMs.
The parameters of the beam search algorithm have a substantial effect on the quality metrics except for memory and storage SLA violations. The storage SLA violation metric is affected only by the parameter Lk, which controls the number of underloaded PMs. This is explained by the unbalanced hardware configuration of PMs that were used for the study. Each VM migration increases storage utilization under other storage capacities except for storage based on storage area network.
The model parameter Dk has a negligible effect on the quality metrics. It means that the desired workload threshold cannot be applied in such hardware configurations with insufficient storage capacity and periodical storage SLA violations. This parameter can be taken into account when workload balancing schemas are applied. In all other cases, it can be set to 0.9.
In this study, minimizing the number of VM migrations is not considered but is taken into account when determining optimal model parameters according to defined objectives. Simulation results show the strong effect of SLAVM on the number of VM migrations (
Figure 14), which decreases the number of VM migrations by 16.4%.
Based on the minimization results using two defined objectives, the authors conclude that the SLA violation minimization is a preferred optimization technique compared with the power consumption minimization. It is explained by the significant improvement of SLA quality metrics, the decreased number of VM migrations, and a slight deterioration in the uptime metric directly related to power consumption.
The power consumption minimization is always followed by an increasing number of VM migrations that are usually not acceptable in production [
27]. Furthermore, switching a PM from the sleep mode to the active state (PM setup) takes significant time at a data center scale, and ignoring the power consumption during PM setup can be a serious drawback when many PMs change their states frequently [
28]. For example, during a setup, PMs consume about 200 W, which is close to the maximal rate for some PMs [
29,
30]. Furthermore, the setup time of PMs varies from 20 to 200 s depending on the hardware and software configuration and can be as large as 260 s [
31]. Thus, keeping some PMs in the active state, the VM management method will be more robust to the emergence of new VM schedule requests and VM migrations.
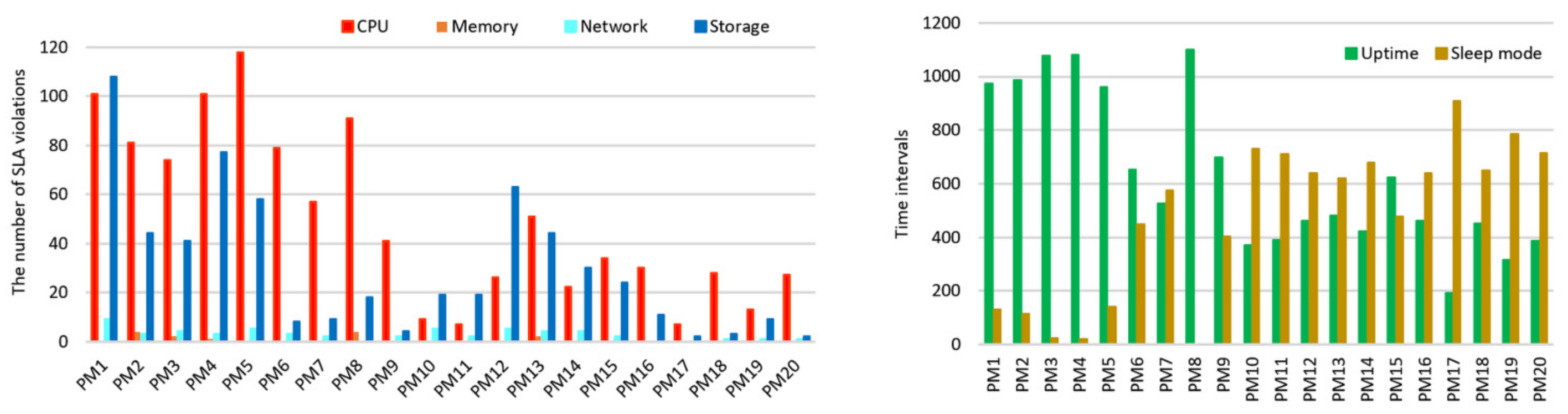
Figure 15 shows each resource utilization and the number of active PMs resulting from the power consumption minimization (red) and the SLA violation minimization (green) during each simulation run. It also shows summarized data from Bitbrains about each VM’s demands, namely, CPU, memory, network, and storage resources used by all VMs. The dashed lines show CPU, memory, network, and storage resources provisioned by PMs.
Notable amounts of network and memory resources are provisioned to serve a VM’s workload; therefore, these resources are underutilized. However, at the same time, the amounts of CPU and storage resources are not always enough for spikes of a VM’s workload, which results in an increased number of SLA violations.
In response to the increasing workload on any resource, many PMs switch from the sleep mode to the active state. The red chart (PCM) shows a significantly higher number of such switches than using SLAVM; therefore, from the perspective of power consumption, an increase in uptime by 14.9% may be comparable to switching overhead.
To summarize, the authors propose scientific insights into VM consolidation approaches:
1. The determined model parameters Lk = 0.1, Tk = 0.15, Dk = 0.95, and Qk = 0.4 can also be used with other VM consolidation methods and frameworks along with any dynamic workloads.
2. In many cases, there is no need to define adaptive thresholds for the specified resource utilization since experiments show that an aggressive policy of switching PMs into the sleep mode is not helpful to minimize the number of SLA violations and the presence of workload spikes mainly defines the thresholds. Furthermore, the sensitivity of many model parameters to a small range of changes does not significantly affect the quality metrics.
3. Generally speaking, objectives such as power consumption minimization and minimization of the number of migrations sometimes appear to be an end in themselves, as a deterioration in service quality level often accompanies them. However, a careful analysis of the above results reveals that it is preferred to transform these objectives into constraints for the well-known VM consolidation methods. At the same time, the SLA violation minimization has more chances to be used in an objective function. A set of simulation-based experiments shows that minimizing the number of SLA violations will decrease the number of VM migrations, and the uptime of PMs will increase insignificantly.
4. The proposed dynamic VM management method (probably as well as many others) copes well with VM consolidation if the SLA is violated by only one resource. However, if the SLA violations occur on two or more resources, it is necessary to use more balanced PM hardware configurations.
5. A consolidation, taking into account the mutual influence of VMs running on one PM at runtime (a complementary VM placement [
32]), is excessive here, since when the management method takes into account all PM resources, the availability of PM resources for VMs is verified using already-known resource requirements by default. Therefore, a VM consolidation focusing on a specific workload intensity is more promising, namely, a mixed VM consolidation with balanced compute-intensive, memory-intensive, storage-intensive, and network-intensive workloads. However, such a heuristic is not applied in this paper.
5. Conclusions
Effective power-aware VM management directly affects power consumption, cost, scalability, scheduling, and capacity planning. By being grounded in an extensive quantitative and qualitative analysis of the literature, the authors present the dynamic VM management method to effectively allocate new VMs and migrate active VMs by applying the beam search algorithm to offload overloaded and underloaded PMs. Furthermore, the proposed method consolidates VMs, considering all current workloads inside a VM, such as CPU, memory, storage, and network interface usage.
A new power-aware integral estimation method for determining the optimal beam search algorithm parameters for the defined problem is proposed, which considers the area under a polynomial trendline of degree 2 that approximates a specific chart. It considers multiple quality metrics defined as follows: the number of CPU SLA violations, the number of memory SLA violations, the number of network SLA violations, the number of storage SLA violations, the uptime of PMs, the number of VM migrations. The minimum area under all curves corresponding to the quality metrics is obtained using the following beam search algorithm parameters: n = 6, m = 3, and l = 3. The beam search algorithm parameters have sufficient influence on the CPU SLA violations, the number of network SLA violations, and the number of VM migrations, but less influence on the uptime of PMs and the number of storage SLA violations. Furthermore, the number of memory SLA violations has a negligible influence on the beam search algorithm parameters. The thresholds Tk, Lk, and Qk have a complex influence on the quality metrics, and they are recommended to be used in VM management frameworks based on the SLAVM or the PCM objectives.
The main models’ parameters that influence the quality metrics of the proposed method are obtained for two objectives, namely, the minimum power consumption and the minimum number of CPU SLA violations. Prior research in cloud computing shows that SLA violations cannot be completely avoided because of the nature of cloud workloads and oversubscription. However, the number of SLA violations is reduced significantly in the SLAVM optimization compared with the PCM optimization results. Thus, the authors conclude that the SLAVM is a preferred optimization technique compared with PCM. It is explained by a significant improvement of SLA quality metrics (the number of CPU SLA violations decreasing by 76.5%, the number of memory SLA violations decreasing by 53.8%, and the number of network SLA violations decreasing by 3.6%) accompanied by a decreased number of VM migrations (decreased by 16.4%) and by a slight deterioration in the uptime metric (increased by 14.9%), which is directly related to the power consumption.
Without entangling with the implementation aspects of applying thresholds, the obtained results provide sufficient insight into the critical challenges in VM management. These insights include: using the quality metrics defined in this paper to rate VM consolidation schemas and approaches on infrastructure level, an advantage of using static thresholds for the specified resource utilization, preferred usage of the SLA violation minimization as the main objective, transformation of the objectives such as the power consumption minimization and the number of migration minimizations into constraints to use with well-known VM consolidation methods, and considering a specific workload intensity and balanced VM consolidation instead of considering the mutual influence of VMs at runtime (complementary VM placement).
Future work can improve the dynamic VM management method by predicting resource demands, planning a preferred PM’s resource capacity used for dynamic VM consolidation, and considering all quality metrics with scaling by the factor associated with operating costs.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}