1. Introduction
A person’s hair information is important in assessing their appearance. Hair varies widely in color, length, pattern, and texture information depending on gender, age, fashion, culture, and personal taste. Appearance information, whether positive or negative, acts as an important factor in human-to-human interactions as well as in human interactions with robots [
1]. For robots to have social relationships with people they need to mimic the way people have social relationships [
2]. However, a strand of hair is very flexible and thin, which can be transformed into a variety of shapes, similar to skin color, or heavily influenced by external lighting, making it difficult to segment skin, hair, and background areas. Additionally, hair segmentation information can not only complement social robot applications and face recognition results, but it can also be used for a variety of applications, such as make-up changes and character photo editing [
3]. Thus, a variety of studies have been conducted recently on hair partitioning and recognition of style information [
3,
4,
5,
6], but the study is challenging because hair areas vary widely depending on complex backgrounds, different poses, reflected light, race, hair color, and dyeing.
Earlier hair split and color automatic recognition were proposed by Yacoob [
4], and hair areas were extracted using the ratio of face and color information and area grinding methods for the front of the face. Wang [
5] suggested a pre-learned hair segmentation classifier to automatically expand into the entire area if the hair seeded area was manually specified. However, this method has the weaknesses of having to manually designate hair areas and of having low division accuracy if the background and hair color are similar. Wang [
6] proposed the data-driven isomeric manifold inference method. This method manually enters the hair area from the labeled hair segmentation training image and produces a probability map that enables the generation of the seed area. This method also addresses the difficulties of manually designating the initial hair area, but the difficulties of the hair area not being split from the complex background remain.
Recently, there has been much success with deep neural networks (DNNs) and in many tasks, including semantic segmentation, DNN-based hair segmentation methods have been introduced. Guo and Aarabi [
7] presented a method for binary classification using neural networks that perform training and classification on the same data using the help of a pre-training heuristic classifier. They used a heuristic method to mine positive and negative hair patches from each image with high confidence and trained a separate DNN for each image, which was then used to classify the remaining pixels. Long [
8] demonstrated convolutional neural networks (CNNs) that first trained end-to-end and pixel-to-pixel for object segmentation. Fully convolutional networks (FCNs) predict dense outputs from free-sized inputs. Both training and inference are performed on the whole image at one time by back-propagation and dense feed-forward computation. Network up-sampling layers enable pixel-wise prediction and learning in nets with subsampled pooling. However, though this method has obtained good segmentation results, it has not been proposed for the purpose of hair segmentation but has only been used for general object segmentation. Chai [
3] attempted to create the first, fully automatic method for three-dimensional (3D) hair segmentation from a single input image, with no parameter tuning or user interaction. Moreover, Qin [
9] introduced the use of a fully connected conditional random field (CRF) and FCN to perform pixel-wise semantic segmentation on hair, skin, and background.
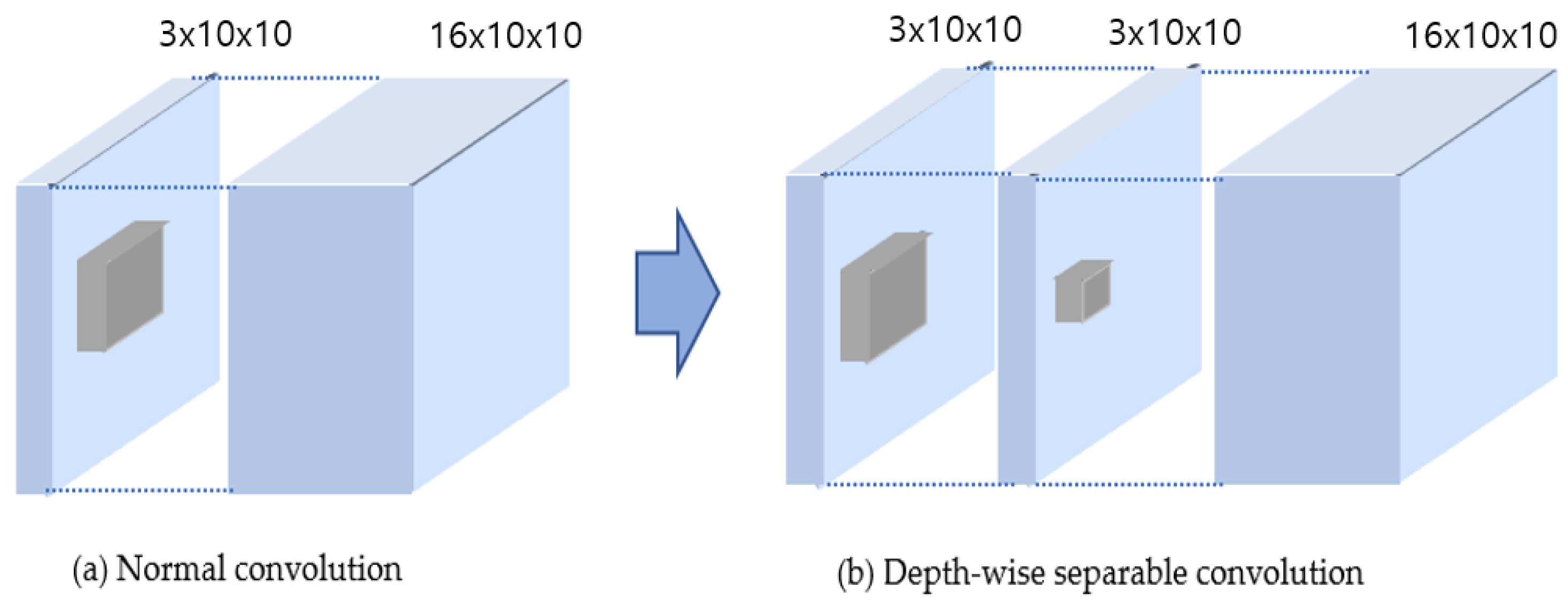
However, with the application of DNN in hair segmentation, the accuracy remarkably improves, but the applications on mobile devices or embedded platforms without a GPU (Graphics Processing Unit) are not easy to apply in real-time due to its unique, large number of parallel computations with fully connected heavy-weight network architectures. Therefore, adaptive importance learning [
10], knowledge distillation [
11], and MobileNet2 [
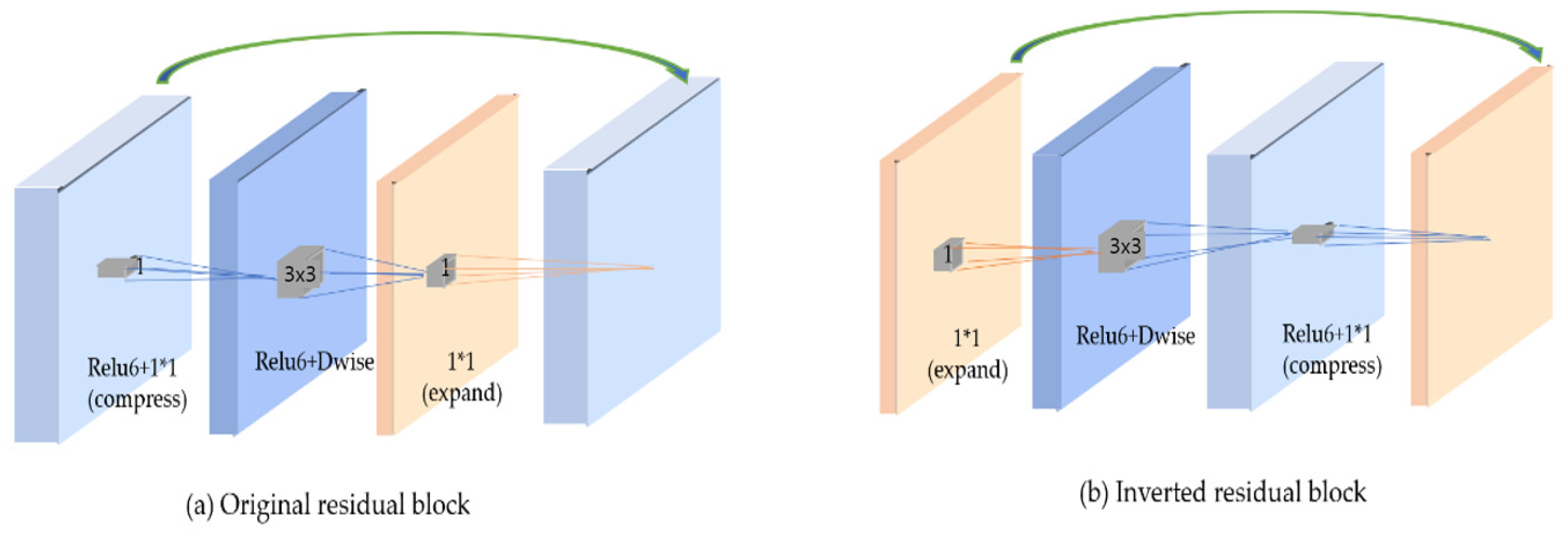
12] algorithms can be utilized to train a light-weight network for speed-up. Adaptive importance learning proposes a learning strategy to maximize the pixel-wise fitting capacity of a given light-weight network architecture. Knowledge distillation technology is utilized when a large (teacher) pre-trained network is used to train a smaller (student) network. These two methods are suitable for DNN models of CNN and ResNet architectures with general pipeline structures for detection or classification purposes, and a MobileNet2-based approach is more efficient for image segmentation based on U-Net with structures that segment through steps to compress and restore images.
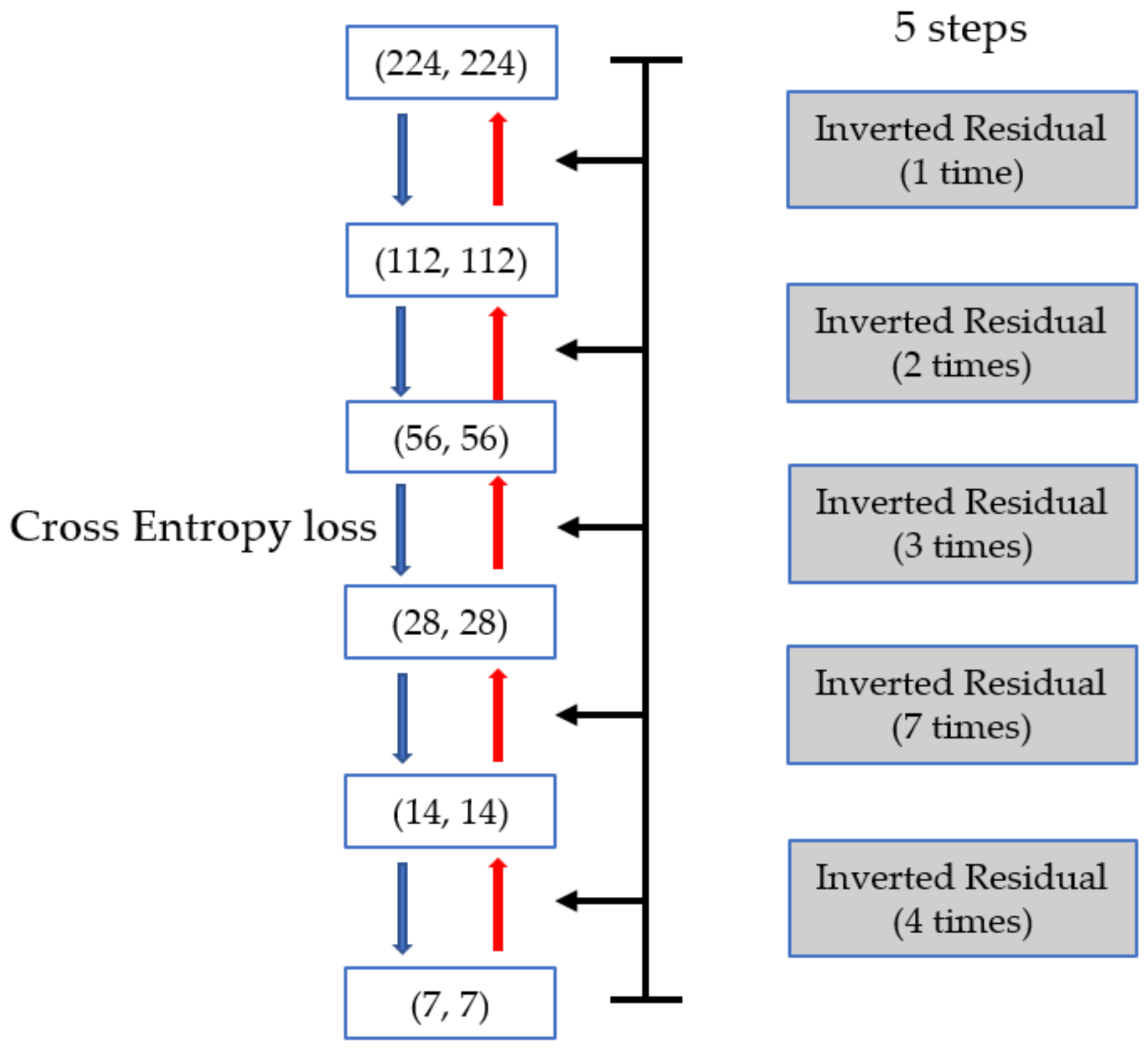
In this paper, we propose a new approach to a hair segmentation method with a light-weighted model based on Mobile-Unet for fast and accurate results. The proposed method includes the optimization techniques of depth-wise separable convolution and an inverted residual block. Furthermore, we have used the proposed generated and augmented datasets for training the deep neural networks model. This paper is organized as follows:
Section 2 presents the pre-processing steps, landmark detection, size normalization, data augmentation, and hair recoloring;
Section 3 describes the proposed method in detail, followed by the experimental results including the training datasets demonstrated in
Section 4; finally,
Section 5 concludes this paper.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}