1. Introduction
Autism spectrum disorder (ASD) is a lifelong neurological disability that is characterized by significant social communication and behavioral deficits. The severity of this disorder can vary greatly from one individual to another. Generally, autism is a lifelong illness, and no cure has yet been found, and autism begins early in childhood and lasts throughout a person’s life [
1].
Children with ASD have a unique set of characteristics but most would have difficulty socializing with others, communicating verbally or non-verbally, and behaving appropriately in a variety of settings. Left untreated, an individual with ASD may not develop effective or appropriate social skills. If a child is not making friends, sustaining a conversation, able to play in an imaginative way, inflexible with routines, or overly preoccupied with certain objects, it is important to learn the cause of these behaviors and obtain support and services to help. Through early intervention, many things can be done to improve the quality of life of children. Robots are one of the best choices for accompanying children with autism [
2].
The expeditious developments in the fields of AI, deep learning technology, intelligent robots, and human–computer interactions have achieved substantial progress in recent years. Currently, intelligent robots possess increasingly human-like intelligence and abilities such as listening, speaking, reading, writing, vision, feeling, and consciousness [
3]. Ren et al. analyzed large quantities of statistical data based on the latest results in neurology and psychology to derive a mental state transition network, aimed at developing emotional measurement models and computer emotional simulation models for speakers [
4]. CGMVQA [
5] uses a pre-trained ResNet152 to extract medical image features and establishes a mature medical visual question and answering system to assist in diagnosis. Researchers have also explored emotional information accumulated from people’s daily writings (i.e., blogs) for the detection and prevention of suicide [
6].
The emergence of social robots dedicated to autism can be traced back to Emanuel’s pioneering research in which computer-controlled electrical equipment, such as a turtle-like robot moving via wheels on the floor, was used as a remedial tool for autistic children [
7]. In recent years, studies on the healthcare of autistic children and the elderly using intelligent robots have increased, and the robotic therapy developments in these studies are remarkable. For example, commercial animal robots, such as the AIBO developed by SONY and the NeCoRo developed by OMRON, are used with hospitalized child patients and the elderly in facilities. Through the use of volunteers, the influence of the interaction between subjects and intelligent robots has been observed, and questionnaire surveys have been conducted [
8,
9]. Dautenhahn et al. applied autonomous mobile robots and remotely operated robots for the treatment of autistic children, and they quantitatively analyzed their interactions [
10]. Currently, nearly 30 robots have been tested as remedial tools for ASD [
11].
However, in most studies, intelligent robots only act as an intermediary between autistic children and therapists. For most robots, the dialogue system uses traditional techniques to generate corresponding responses such as realizing preset responses. This requires a limited response based on large dialogue libraries. When the dialogue sentences are not recorded in the dialogue library, the robot cannot provide a meaningful response. We believe that robots must have the ability to communicate with autistic children autonomously without the intervention of therapists. In our previous research, the end-to-end deep neural network conversation model was introduced into an LEO robot, for the first time, to interact with autistic children [
12]. Experiments have shown that autistic children are more focused on interacting with robots without intervention by therapists.
In this paper, we aimed at solving the problem of having an insufficient dialogue corpus for deep neural network learning and put forward a brand new dialogue model and robot strategy selection model. In the experiment, we adopted a NAO robot as the platform for the proposed model and proved the effectiveness of the proposed method through large automatic evaluation metrics and human evaluation. The main contributions of this study are summarized below:
We designed a dialogue system based on a sequences-to-sequences model and changed its input mode to improve the sensitivity of the model to context;
We introduced a method of transfer learning, so that the transformation model could learn the basic dialogue of children from the dialogue corpus of healthy children, and then we finetuned the model to learn the discourse characteristics of autistic children;
We coordinated the consistency of the robot dialogue and action through a strategy selection model, which was installed in a NAO robot. A series of experiments proved the effectiveness of the language model.
3. Materials and Methods
3.1. Dialogue System
Human–robot conversational agents can be divided into two categories: retrieval-based agents and generation-based agents. Instead of generating new text, the retrieval-based model accesses a repository of predefined responses and selects the appropriate response based on the input. This method is usually used in the dialogue systems of traditional robots for autism treatment. The use of this method needs to be based on a large session database, which requires a large amount of guidance and help from a therapist in the process of interaction. Different from healthy people, when conversations are not recorded in the database, autistic children often do not have enough patience to interact. We advocate for the building of a dialogue system that can generate more meaningful responses without the intervention of a therapist.
In this section, we adopted the method of generation-based agents that uses recurrent neural networks to create effective models based on the sequences-to-sequences model, with the aim of generating meaningful and coherent dialogue responses given the dialogue history.
3.1.1. Model
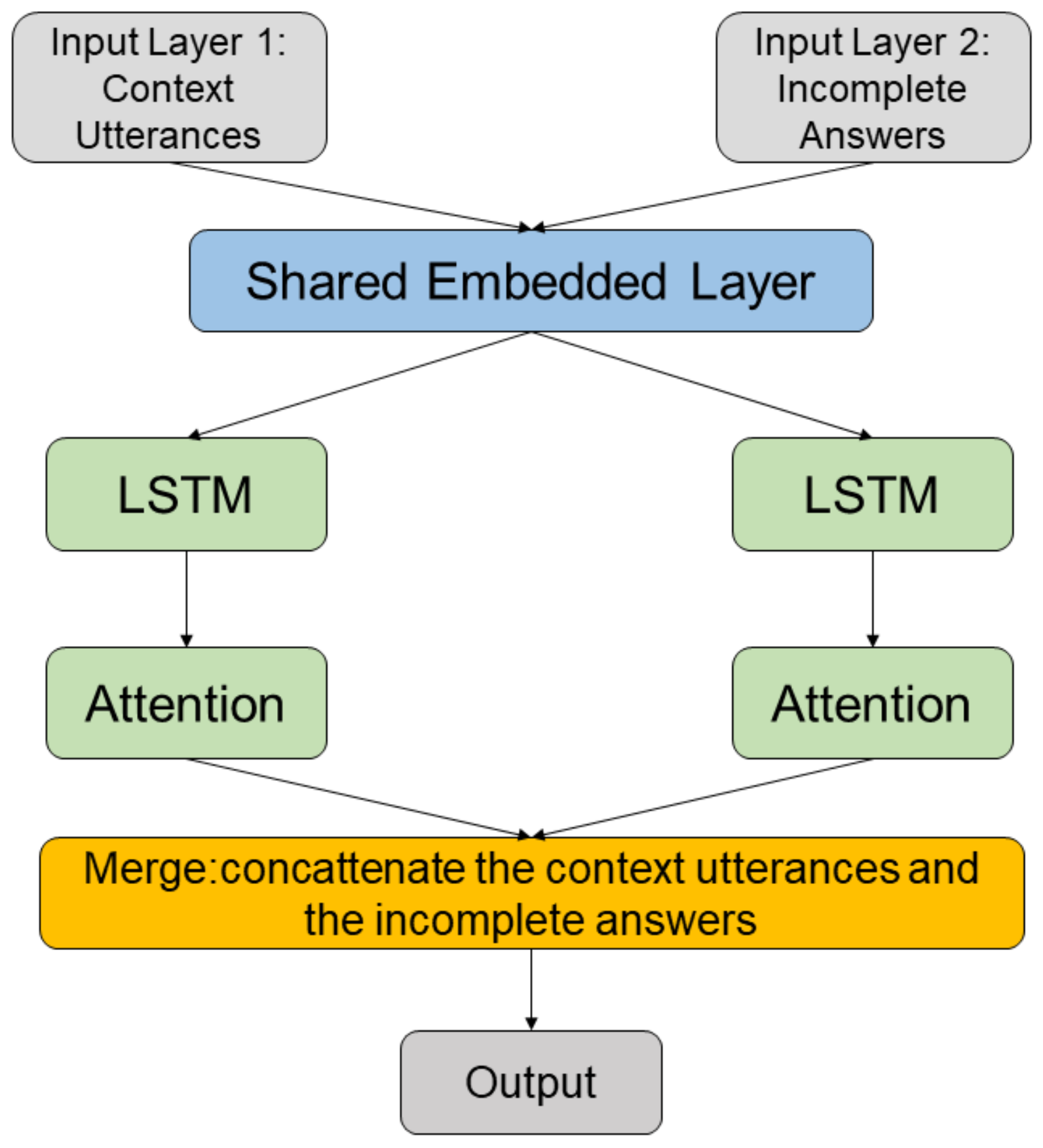
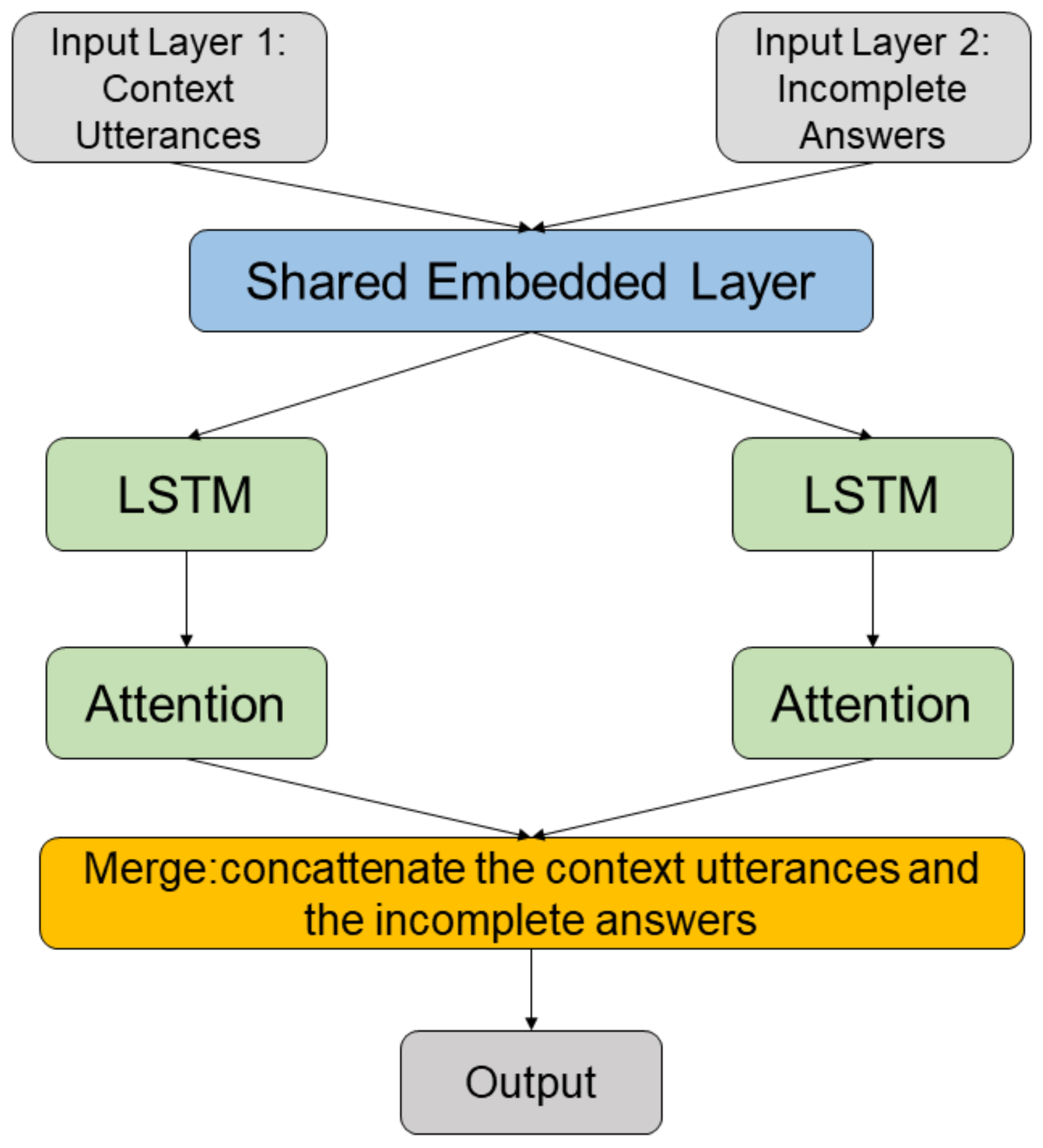
Figure 1 shows the framework of the dialogue model. A shared embedding layer provides input to the encoder–decoder structure.
Our work is closely related to the proposed generative conversational agents (GCAs) model of Ludwig et al. [
48], which shares an embedding layer between the encoding and decoding processes through the adoption of the model. The proposed end-to-end model adopts pre-trained GloVe [
49] as a shared embedding to generate dialogue vectors. The dialogue context utterances are arranged as a vector,
, that contains a sequence of token indexes filled with zeros and having the dimension
, which is an arbitrary value for sentence length. The elements
of
are encoded into one-hot vector representation,
. The same happens with the elements
from the dialogue of incomplete answers,
. These vectors are arranged to comprise the matrices
and
.
The dialogue context utterances and the dialogue of incomplete answers are processed into two dense matrices,
Ec and
Ea, by a pre-trained GloVe embedding layer. The model has two LSTM layers with the same architecture, one to process
and another to process
Ea. The processes of extracting the embedded vectors of context utterances and the dialogue of incomplete answers are expressed as follows:
and
are sets of parameters of two LSTM layers. We adopted an attention mechanism to focus on the core content of the dialogue. Attention mechanisms calculate the scores of hidden vectors of the decoder at time
t, and the hidden vectors of the encoder at each time to decide the weight of highlighting those words. This score can be used to calculate the weighted average of the hidden layer vector of the encoder and then calculate the hidden layer vector at time
t. The outputs of the two attention layers were concatenated and provided to two dense layers that utilized the ReLU activation function and softmax activation function, respectively.
The proposed model adopts the greedy decoding approach method, feeding the value of the larger output of the model back into the input layer on the model. This process continues until the token representing the end of the sentence is predicted.
3.1.2. Input Method
In the proposed conversation model, the input part is different from the canonical sequence-to-sequence model, and it is a structure with two input layers. In the dialogue corpus, the entire conversation was generally divided into QA pairs (query–answer) and provided to the neural network model for training. Such a trained conversation model can only realize single-round dialogue and poor understanding of the context of the conversation. In the data preprocessing stage, all dialogues in the corpus were processed into
and
like normal question and answer tasks.
Table 1 shows the two inputs corresponding to each step.
3.2. Implementation of Robot Systems
NAO is a small humanoid robot developed by Aldebaran Robotics. Each part has joints with 26 degrees of freedom, which are balanced by an inertial unit, and the surrounding environment is detected by multiple touch sensors and acoustic sensors on the head, hands, and feet. The dialogue is realized by 4 directional microphones and speakers, and the surrounding cameras capture the environment with high-resolution images. With such a rich expressive force, NAO can create various verbal and non-verbal interactions with people and provide communication support in important fields such as medical care, nursing, and education. This humanoid robot was purposely designed to look approachable and portray emotions like a toddler.
Figure 2 shows the appearance of the humanoid robot NAO.
The accompanying software, Choregrphe [
50], was used to generate NAO operations. Choregrphe was developed and designed by SoftBank Robotics Europe, and it is used for visual editing instructions for NAO. It has a graphical user interface (GUI), and uses software developed as an interface for humanoid robots such as Pepper, NAO, and Romeo. As mentioned in the related research, we put forward some basic movement strategies, such as standing, sitting, touching, and joint attention, as methods of interacting with autistic children.
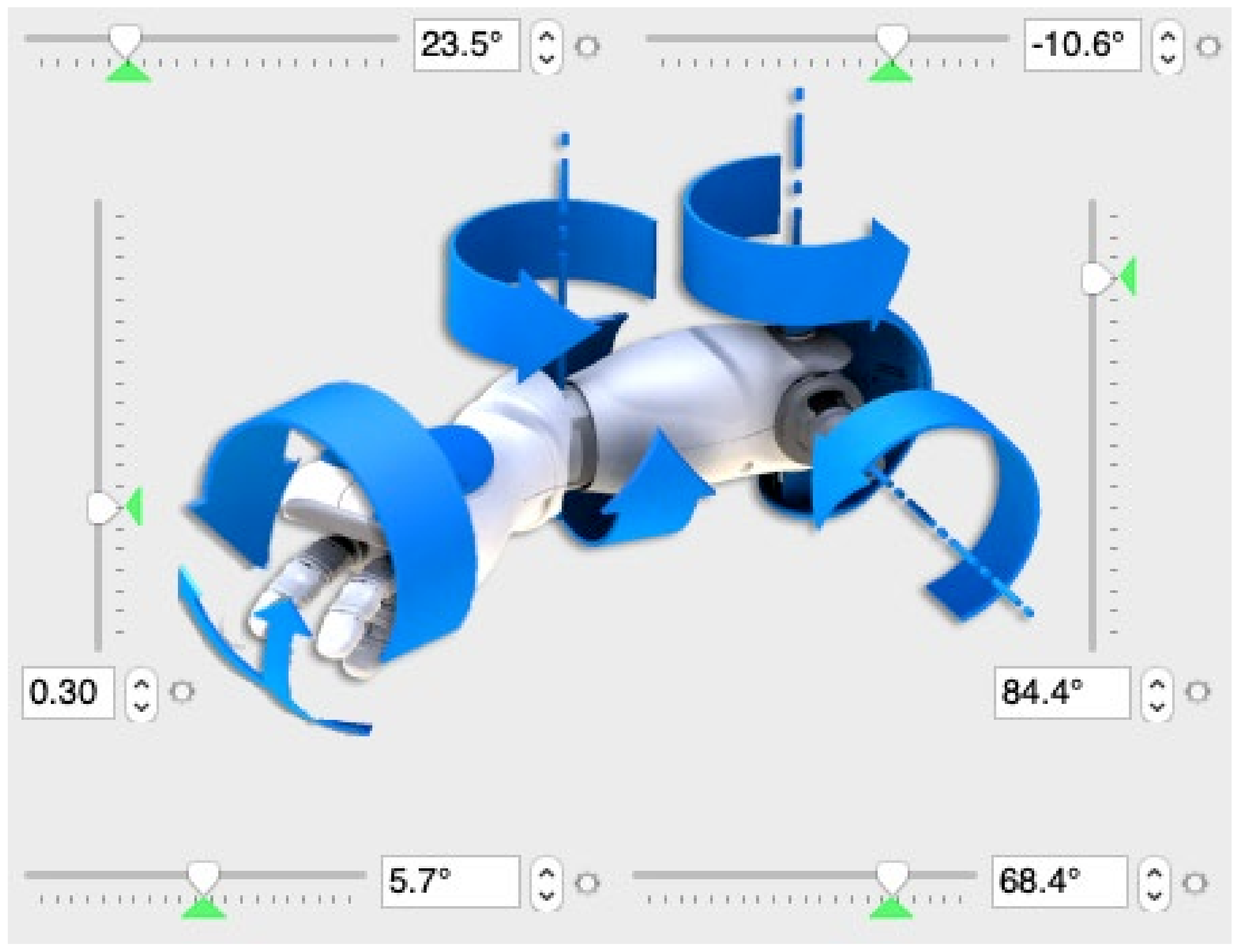
NAO has two joints in its head, two joints in its waist, six joints in its arms, and five joints in its feet. Considering the combination of each joint angle of the robot as a parameter, a pose of the robot with a degree of freedom
can be regarded as a point in space. Human attitude knowledge is regarded as fuzzy without a clear definition, for example, “attitude is the attitude when the joint is
X degree”. The action is generated by adjusting the angle of each branch of the NAO as shown in
Figure 3.
The robot’s movements can be subdivided into fixed postures. It can be considered that one action is a process of continuously generating multiple postures. Each posture has a wide range and is considered as using ambiguous knowledge of posture. We postulate that behavior is a transitional path composed of fuzzy postures,
, which can generate actions that interpolate among these postures. For example, the action of “waving” requires a combination of several poses. As shown in
Figure 4, the arm is first raised, then it swings diagonally back and forth, and finally the arm is lowered.
Figure 5 shows two basic movements of the NAO robot: “standing posture” and “sitting posture”.
When interacting with autistic children in a physical contact, it is necessary to be able to recognize the physical and psychological states of the touched object and predict the effect after contact. Each contact event is an important decision. Robots must have a clear understanding of their strength. When autistic children feel uncomfortable, they must cease contact. However, with today’s cognitive ability of robots, it is difficult to identify and predict each other’s state in the process of contact. Similarly, under such conditions, it is difficult for the NAO robot to have a clear understanding of its own state. Instead of allowing robots to try to initiate contact with autistic children, it would be a better strategy for autistic children to actively contact robots.
First, in order to find an object correctly, face recognition must continue until the end of the program. The NAO performs several eye-catching actions and greeting voices, and the voice synthesis part adopts the ALTextToSpeech module that the NAO comes with. Incidentally, the accuracy of the NAO’s own voice recognition function is not high; thus, the voice recognition API Google Speech Recognition was used in this system. In the process of communicating with children with autism, it is considered most important to maintain their attention and dialogue. When designing the dialogue, we used simple and easy-to-understand words, as much as possible, and rhetorical questions. Regarding motion generation, we also conferred top priority to motions that may interact with each other. However, it takes many man-hours to manually set the rules every time a new dialogue mode or new action selection was added. To address this problem, we aimed to use a method to automatically acquire rules using machine learning.
3.3. Data Sets and Learning Strategy
In order to achieve autonomous communication with autistic children, we used multiple data sets to train our conversation model and compare it with the baseline Seq2Seq model. The data sets used in this experiment were all collected and integrated from the “Child Language Data Exchange System” [
51]. Furthermore, our report summarizes the experimental results generated by the sessions from the text information of all benchmark data sets.
Table 2 shows the specific data distribution of the two corpora. Conversation scripts are different dialogue scenes, and each dialogue scene has several conversation utterances.
3.3.1. Healthy Children’s Dialogue Corpus
In the research field of dialogue generation, there is no open-source database related to children’s dialogue. Thus, we collected dialogue data on children’s health education and linguistics research and integrated them into a large data set. This data set contained the dialogue contents of ten healthy children’s dialogue datasets: “Gelman Corpus” [
52], “EllisWeismer Corpus” [
53], “Demetras-Working Corpus” [
54], “Demetras-Trevor Corpus” [
54], “Brown Corpus” [
55], “Braunwald Corpus” [
56], “Bohannon Corpus” [
57], “Bloom73 Corpus” [
58], “Bloom70 Corpus” [
59], and “Bliss Corpus” [
60]. These dialogues included a total of 352,256 sentences of dialogue data between mentally and physically healthy children and their parents, teachers, and friends in various scenarios such as games, eating, and work. All dialogue data were converted from audio or video to text data. Although these dialogue data were very realistic and close to daily life situations, which is suitable as samples for linguistic research, it was not the highest quality dialogue corpus for the neural network model.
3.3.2. Autistic Children’s Dialogue Corpus
Collecting conversational data sets of children with autism is an arduous task. Related research is inadequate in this direction, and it is difficult to extract effective conversations from materials or videos. We used three different English dialogue corpora of children with autism to train the model. The three corpora were as follows:
Tager–Flusberg Corpus [
10]: This corpus contains files from children with autism and children with Down’s syndrome. It contains behavioral dialogue observations of six children between the ages of 3 and 6 years, with 8–13 visits per child over a period of 1–2 years.
Nadig ASD English Corpus [
11]: This corpus contains files from videos. The overall goal of this project is to longitudinally examine word learning in children with autism (36–74 months). This corpus employs a variety of measures, including a natural language sample, during parent–child interactions. Twenty children participated at three-time points over the course of a year (between 2009 and 2012). The language sample that comprises this corpus was collected during free-play tasks with parents, children with autism, and children with Down’s syndrome. It contains behavioral dialogue observations of six children between the ages of 3 and 6 years, with 8–13 visits per child over a period of 1–2 years.
Rollins Corpus [
12]: This corpus consists of transcripts of video recordings of 5 male children with autism between the ages of 2 and 7 years. These children with autism met the following criteria:
Received an initial diagnosis of autistic symptoms by a psychologist or neurologist;
At least one year of a preschool program;
After the completion of the preschool program, children with autism had the ability to express several rich vocabularies.
In the preschool program, several videos were recorded for all autistic children who participated in the program over the entire semester. To capture each child’s optimal level of on-task communicative functioning, only intervals where the child was interacting one-on-one with his clinician were transcribed and coded for analyses.
The integrated conversational corpus for autistic children contains scripts that play various roles, totaling 39,336 conversations. Like a healthy children’s dialogue corpus, these corpora were used as conversational data in the field of medical language research for children with disabilities. We did not believe that these data sets were high-quality training data and test data for neural network models. In order to train the dialogue model for good performance, the data were corrected manually to remove noise, without affecting grammar, words, and semantics, so that the data were more suitable for the neural network model. For example, incorrect spelling, garbled characters, and repeated phrases when converted from audio files could be changed from “oink@o oink@o” to “oink oink”, “let go walk” to “let’s go walk”, “what do we hafta eat?” to “what do we eat?”, and “I dunno” to “I don’t know”.
3.3.3. Transfer Learning Strategy
Transfer learning is a machine learning method that can reuse the model developed for one task in another different task and serve as the starting point of another task model. Because in computer vision and natural language processing, the development of neural network model requires a large amount of computing and time resources, and the technical span is also relatively large; thus, the pre-trained model is usually reused as the starting point of computer vision and natural language processing tasks [
61].
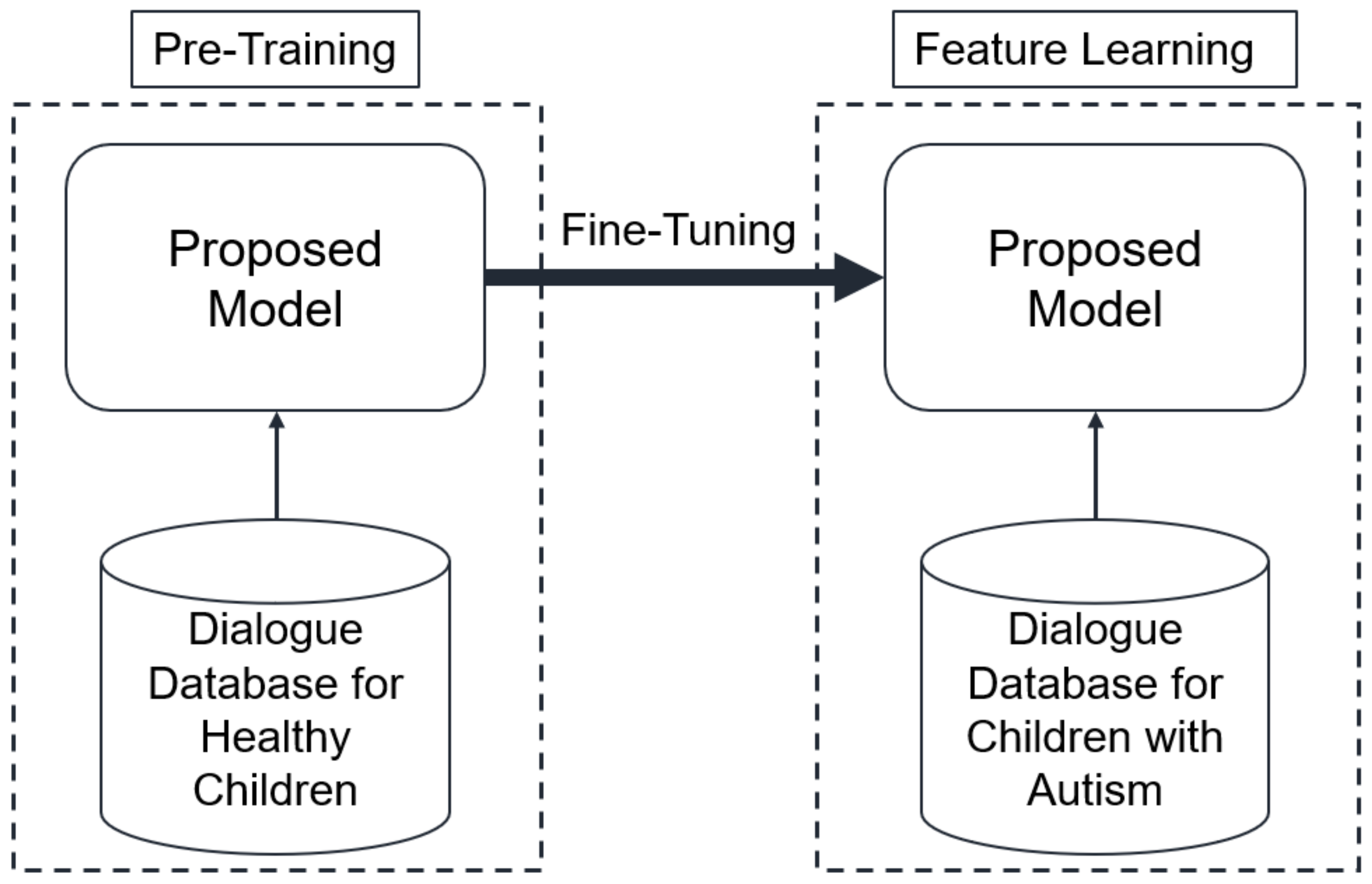
Due to the limitations of the ethics involved in autism research, there are only a handful of open-source-related research resources. Although we have collected and integrated a number of different dialogue corpora of children with autism, it is far from enough to train a well-trained dialogue model. We adopted new data sets to fine-tune the pre-trained model to solve this problem.
Figure 6 shows the specific process of training the model through the fine-tuning method. Considering that the new data sets were almost similar to the original data set used for pre-training, the features could be extracted from the new data sets with the same weight. Since we cannot collect large dialogue data sets from autistic children, we used a healthy children’s dialogue corpus with enough data sets to train the proposed dialogue model. In order to make this pre-training model understand the language features of autistic children, based on the fine-tuning method, the weight of the pre-training model was fixed, and the proposed model was refined using the dialogue corpus of autistic children.
3.4. Baselines
In the experiments, all of the baseline models were not been modified for the task of dialogue for children with autism. We compared our model with the following baselines:
Seq2Seq+Attention: A standard Seq2Seq model with an attention method that is widely used as a baseline in conversation generation tasks. The model did not use beam search. It is hereafter denoted as Seq2Seq.
GCA: GCA model is a new adversarial learning method for generative conversational agents. Adversarial training also yields a trained discriminator that can be used to select the best answer when different models are available. This approach improves the performance on questions not related to the training data. The adversarial method yields significant performance gains over the usual teacher forcing training.
BERT: BERT [
62] is, at its core, a transformer language model with a variable number of encoders and self-attention heads. BERT is an unsupervised language representation, and only uses a plain text corpus for pre-training. In this experiment, we used the BERT pre-trained model (24 layers, 1024 hidden layers, and 16 heads) to generate text vectors.
3.5. Metrics
In the evaluation of the non-task-oriented dialogue system, the accuracy of utterance selection and utterance generation were evaluated. In other words, we compare the utterance generated by the model with the response in the test data to verify the accuracy of the generated utterance. Another method is to consider the effect of the response sentence through the meaning of each word and to judge the relevance of the test data’s response. The word vector is the basis of this evaluation method. The advantage of using a word vector is that it can increase the diversity of answers to a certain extent because most of them are characterized by word similarity, which is much lower than the restriction of requiring identical words in word overlap.
BLEU [
63]: Measuring the consistency of emotional conversation generation without losing the syntax performance can effectively highlight the effect of conversation generation. As for objective syntax evaluation, BLEU, a syntax measure to compute n-gram overlaps between the generated response and the reference response, was also used to measure the syntax of the responses. The n-gram is used to compare the similar proportions of n groups of words between an utterance and a reference. A result of 1-gram represents the number of words in the text that were translated separately, so it reflects the fidelity of the translation. When we calculated more than 2-gram, more often the results reflected the fluency of the translation, and the higher the value, the better the readability of the article. BLEU uses the following formula to calculate the similarity between the generated response utterance and the reference of the test data based on the number of n-gram matches between two utterances.
pn compares the generated response sentence with the reference utterance of the entire test data set and calculates the n-gram matching rate. The score is calculated by calculating the geometric mean from 1-gram to N-gram. The BLEU score is represented by a real number from 0 to 1. The higher the value, the better the response generated.
Greedy Matching [
64]: The greedy matching method is a matrix matching method based on word level. For each word of the real response, the word with the highest similarity in the generated response is found, and the cosine similarity matching is added and averaged to the maximum extent. The same is performed for the generated response again and the average of the two is taken.
Embedding Average Cosine Similarity [
65]: The embedding average method directly uses sentence vectors to calculate the similarity between real response and generated response, while sentence vectors are obtained by the weighted average of each word vector, and then it uses cosine similarity to calculate the similarity between two sentence vectors.
Vector Extrema Cosine Similarity [
66]: The utterance vector is calculated by the word vector, and the cosine similarity between the utterance vectors is used to indicate the similarity between the two. The calculation of the speech vector is slightly different; here, the calculation method for the similarity of the speech vector is “Vector Extrema”.
Skip-Thought Cosine Similarity [
67]: Skip-thoughts vectors is the name given to simple neural network models for learning fixed-length representations of sentences in any natural language without any labeled data or supervised learning. With Word2vec, words can be displayed in distributed expressions, and the processing that takes into account the meaning of words can be performed. Kiros et al. let the model learn distributed expressions by learning to predict the words before and after a word in a sentence. This model is called the Skip-gram model of Word2vec. The model uses large novel texts as a training data set, and the encoder part of the model obtained with the help of the Seq2Seq framework is used as a feature extractor, which can generate vectors of arbitrary sentences. The trained Skip-Thoughts model encodes similar sentences that are close to each other in the embedding vector space. In this experiment, the cosine similarity was calculated based on the vector generated using the Skip-Thoughts model.
When comparing the frequency of words in different texts, the words to be compared are mostly predetermined by the analyst. Such a comparison method can statistically verify the hypothesis put forward by the analyst. However, in actual statistical analysis, it is not certain which word should be paid attention to in advance. Generally, the frequency of all words that appear in the text are compared, and the words with a large frequency difference between the texts are searched. This method does not consider the similarity of words according to their linguistic meanings but is based on the distribution of words appearing around the text set in space. With reference to the word frequency in the test data set, we analyzed the utterances generated by the proposed dialogue model and baselines and calculated their spatial similarity. The evaluation methods used were as follows:
Kullback–Leibler Divergence [
68]: The concept of KL divergence comes from probability theory and information theory. The definition of KL divergence is based on entropy. The KL divergence score quantifies how much one probability distribution differs from another probability distribution. In text generation, KL divergence is used to determine the difference between the distribution of the generated text and the reference text data.
Earth Mover’s Distance [
69]: The earth mover’s distance (EMD) is a method to evaluate the dissimilarity between two multi-dimensional distributions in some feature space where a distance measured is between single features. The EMD lifts this distance from individual features to full distributions. Specifically, WordNet is used to define the distance among the index words, and the document similarity is obtained considering the relevance between the index words. In addition, from a linguistic point of view, the value of the distance is used to express the relationship between words from the synonym dictionary that classifies words.
Human Evaluation: We randomly selected 10 scripts from the test data set. The dialogues of each script were independent of each other, and each script had at least 10 utterances and a total of 132 utterances; replies were generated from all of the compared baseline models. We then provided the relevant responses to 12 human annotators for scoring to better understand the quality of the context and responses generated. The score ranged from 1 point to 5 points; a score of 1 point denotes that there was a serious grammar error and was not suitable for the response, while a score of 5 point denotes that it had correct grammar and is suitable as a response for communicating with autistic children. The score calculation was defined as shown in Equation (8):
where
S,
CS, and
TS denote the evaluation score, the conversation score, and total score, respectively.
5. Discussion
Autism spectrum disorder is a lifelong illness, and no cure has yet been found. Autism begins early in childhood and lasts throughout a person’s life. Children with ASD have a unique set of characteristics, but most would have difficulty socializing with others, communicating verbally or non-verbally, and behaving appropriately in a variety of settings. Left untreated, an individual with ASD may not develop effective or appropriate social skills. If a child is not making friends, sustaining a conversation, able to play in an imaginative way, inflexible with routines, or overly preoccupied with certain objects, it is important to learn the cause of these behaviors and obtain support and services to help. Through early intervention, many things can be done to improve the quality of life of children. Robots are one of the better choices for accompanying people with autism who are in childhood. However, for most robots, the dialogue system uses traditional techniques to produce responses. This requires a limited response based on a large number of conversational databases. Robots cannot produce meaningful answers when the conversations have not been recorded in the database. Therefore, the purpose of the research was to improve the language ability of the dialogue system when interacting with children with autism so that it can generate a good response to short text input. The developed dialogue model based on the encoder–decoder structure was trained on the dialogue data of healthy children, and it learned how to have a dialogue with autistic children through the transfer learning method. We conducted experiments based on automatic evaluation indicators and human evaluation indicators.
Word overlap evaluation index: In the field of machine translation, 1-gram becomes an indicator of the correctness of word translation, and high-order n-gram is an indicator of translation fluency. Since n-grams only have the same words in the utterance, even synonyms would be regarded as different, thereby reducing the results. The proposal model had the best performance in the generation of the same single word, but compared to multiple words, it was not as good as GCA. Among all the results, the BLEU result was the lowest value overall. The response space in the dialogue system often diverged. BLEU did not care about grammar, only the distribution of content, which is suitable for measuring the performance of the data set, and it could not play a good role at the sentence level. In terms of evaluating non-task-oriented dialogue systems, it is difficult to say that BLEU was the best evaluation index. Therefore, it is of great significance to study appropriate evaluation indicators.
Word vector evaluation index: Compared with Seq2Seq, the proposed model made 0.13, 0.12, 0.14, and 0.49 improvements in greedy matching, embedding average cosine similarity, vector extrema cosine similarity, and skip-thought cosine similarity metrics, respectively. Likewise, for GCA, we also achieved 0.12, 0.18, 0.1, and 0.32 improvements, respectively. The word vector evaluation index focuses on comparing the semantic similarity between the generated sentence and the actual sample, but it is difficult to capture long-distance semantic information based only on the word vector. Intuitively, words with special meaning in the text should have a higher priority than the commonly used expressions. Since most texts show tendencies to a greater or lesser extent, if this method calculates the similarity in the vector space, higher-order general sentences would be output first. After adding the text vector generated by BERT, the overall results of each indicator were slightly improved. Because a context-free model (such as word2vec or GloVe) generates a word vector representation for each word in the vocabulary, it is prone to word ambiguity. However, the results of Seq2Seq+BERT on greedy matching and vector extrema dropped slightly, and similarly, the results of GCA+BERT on embedding average also decreased. We believe that the multi-head attention mechanism used in BERT did not place the position information of the text sequence in an important position. It can be seen from the results that our model’s choice of key information was due to the other two models, and our model could generate utterances corresponding to the key information of the input utterance.
Similarity index of word frequency distribution: Compared with Seq2Seq+BERT, the proposed model resulted in improvements of 1.92 and 1.91 in Kullback–Leibler divergence and earth mover’s distance metrics, respectively. Likewise, for GCA+BERT, we also achieved 0.39 and 0.65 improvements, respectively. We found that the text vector generated based on BERT resulted in a good performance improvement over the original model. However, due to the lack of information about short text input and the lack of important location information generated by BERT in the two baseline models, the performance of the model was not as good as expected. In the process of word segmentation, although the abbreviation and complete form of the word could be unified, the same word did not change according to the different tenses such as “do” and “did”. This is believed to be due to the fact that the NLTK toolkit does not integrate the morphology of the same word well during the process of word segmentation. In addition, stop words refer to words that are excluded from the processing target because of reasons such as general uselessness in natural language processing. Function words, such as auxiliary words and auxiliary verbs, appeared frequently but had no key information, which adversely affected the amount of calculations and performance. On the other hand, when calculating the frequency distribution similarity of the Kullback–Leibler divergence and earth mover’s distance, the weights of each word were set to be the same.
Human evaluation: For the scores of 396 individual response sentences, the average score of the proposal dialogue model was 3.05, the average score of the GCA model was 2.82, and the average score of the Seq2Seq model was 1.89. For the scoring of the contextual script, the average score of the proposal dialogue model was 3.23, the average score of the GCA model was 2.84, and the average score of Seq2Seq was 1.83. From the overall results, we can see that the average score of the proposed model was above 3 points. Especially in regard to the evaluation’s results of the contextual script, the average score was 3.2 points. Due to the architecture of the proposed model, the context could be learned, and we believe that the proposed model can predict the before and after responses. Furthermore, we observed that the generated response text had positive emotions. Although the grammar of the response sentence generated by the GCA model was fluent, the response sentence generated by this model was not strongly related to the expected context when the input sequence was short. We think this was because the model structure was not adjusted according to the language characteristics of children with autism. For the Seq2Seq model, large security response texts, such as “whit is it” and “ok”, were generated, and the model generated large sentences that lacked fluency and sentences irrelevant to the query. We believe that this was not only because of the poor quality of the autism corpus, but also because the Seq2Seq model did not consider any influencing factors and tended to generate general responses.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}