
AREEBA: An Area Efficient Binary Huff-Curve Architecture


 , ,
, ,  ,
,
Abstract
:1. Introduction
1.1. Existing FPGA Architectures and Limitations
1.2. Settings and Contributions
- Settings:
- -
- Basis representation: This work employs a polynomial basis representation instead of a normal basis [18,19,20,21,22]. It is important to note that the BHC model of ECC requires frequent multiplications. To achieve frequent multiplications, the polynomial basis representation is more useful while the normal basis is convenient where repeated squarings are needed.
- -
- Coordinate system: An affine coordinate system requires an FF inversion during each PA and PD computation [7,18,19,20,21,22] which ultimately effects the latency of entire architecture. Consequently, to avoid the cost of FF inversion required during each computation of PA and PD operation, a projective (Lopez Dahab) coordinate system is selected in this article.
- Contributions:
- -
- PM architecture: We have presented a PM architecture with reduced area over for and 233 bits (details are given in Section 3).
- -
- Polynomial multiplier architecture: Towards area reduction, we have proposed a segmented least significant digit (segmented-LSD) multiplier with a digit size of -bits. Each created digit is segmented into four 8-bit digits. Subsequently, the multiplication over each 8-bit segment is performed by using a simple schoolbook multiplication method. This ultimately reduces the hardware resources (in terms of FPGA slices).
- -
- Dedicated controller: To efficiently control the inserted logic for the proposed low area PM architecture, a finite state machine (FSM)-based dedicated controller is employed.
2. Preliminaries
2.1. BHC Over
2.2. PM Over
| Algorithm 1: Double and Add the PM Algorithm (previously employed for BHC in [18,19,20,21,22]) |
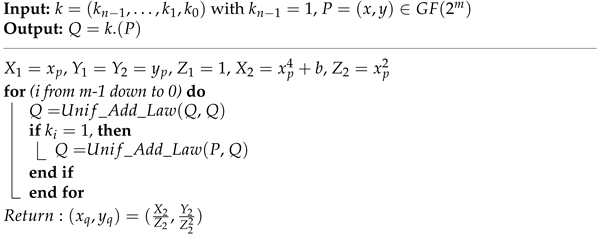 |
3. Proposed Hardware Architecture
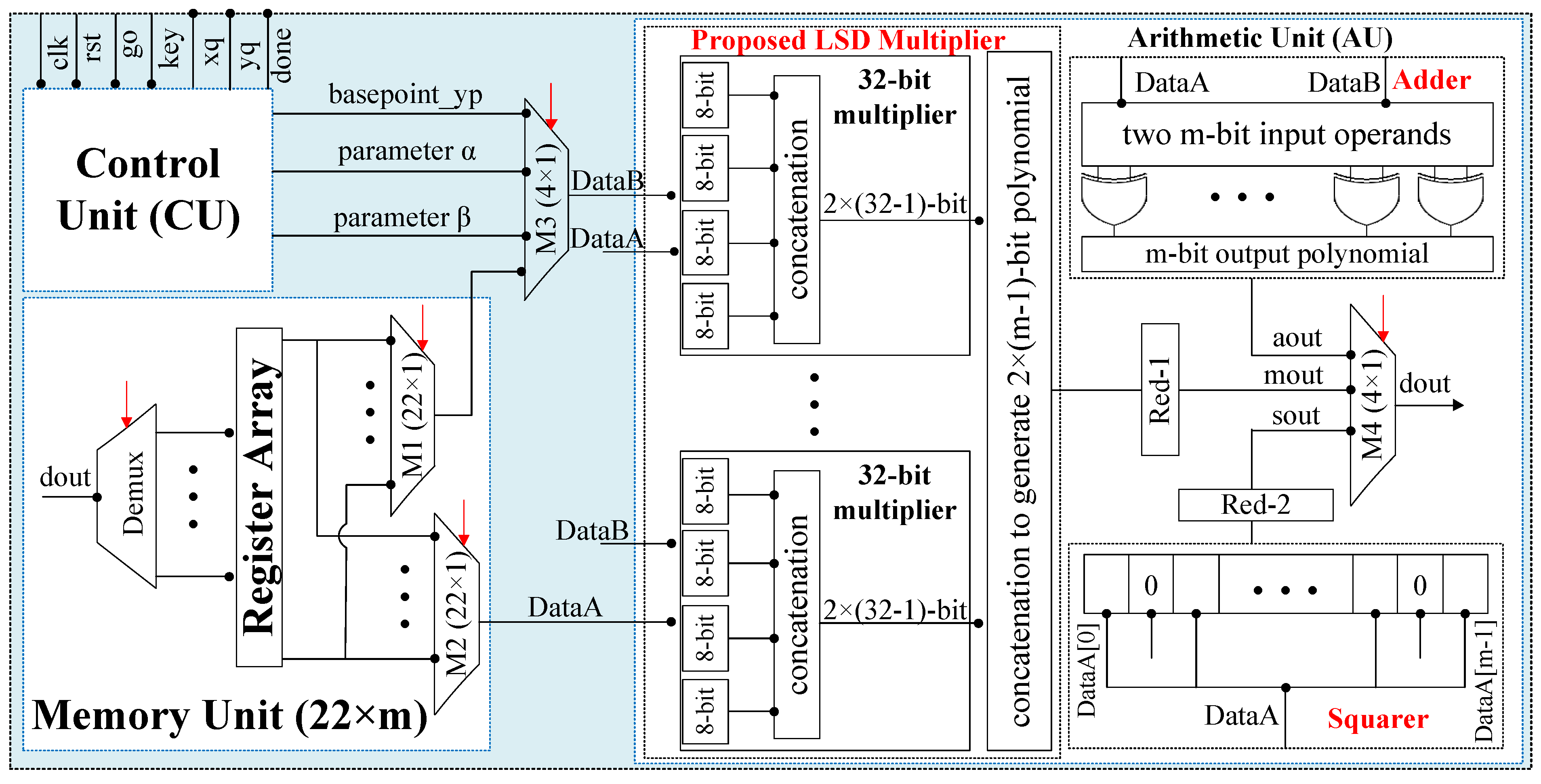
3.1. Memory Unit
3.2. Arithmetic Unit
- Adder: As compared to , the selected field provides a carry save addition. However, the adder unit in this work is implemented by performing a bitwise Exclusive-OR operation, as shown in Figure 1. For two m-bit input operands, m number of Exclusive-OR gates are required to produce an m-bit resultant polynomial after addition.
- Squarer: As provided in Section 1.2, the proposed architecture is developed to implement PM computation using a polynomial representations. The polynomial representation offers squaring computation by inserting an extra bit (i.e., 0) after each input data bit, as given in Figure 1. The squarer unit takes an m-bit operand as input and results a polynomial of length -bits after squaring.
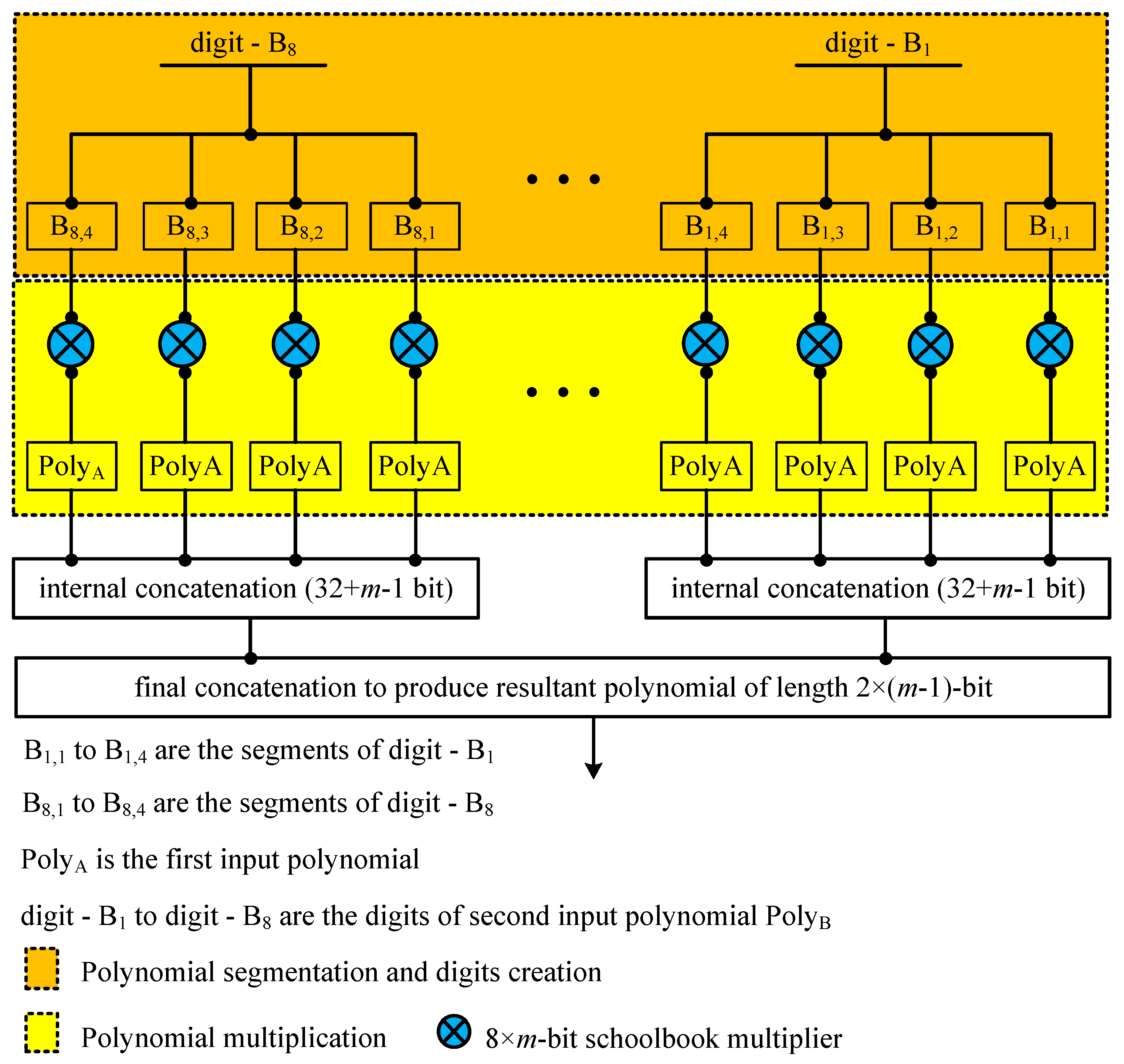
- Multiplier: A general overview of the proposed 32-bit segmented LSD multiplier is shown in Figure 1. Similarly, the detailed architecture of the proposed multiplier is presented in Figure 2. It consists of four units, i.e., polynomial segmentation and digit creation, digit multiplication, internal concatenation and the final concatenation. The description of these units is given as follows:
- -
- Polynomial segmentation and digits creation: In the proposed LSD multiplier architecture, the first operand (PolyA) is considered as m-bit. Similarly, the second operand (PolyB) of 32-bit is created. The total number of digits for an m-bit polynomial is calculated using . The n determines the total digits (i.e., digit- to digit-). On the other hand, the m and d show the operand length and digit size, respectively. As shown in Figure 2, each 32-bit digit is partitioned into four 8-bit segments. These segments are , , and . In the subscript of , the first integer (i.e., 1) determines the number of digits. Similarly, the second integer (i.e., 4) shows the number of segments. The same concept is employed to identify the created digits and the partitioned segments.
- -
- Polynomial multiplication: As shown in Figure 2, an m-bit PolyA and the created 8-bit segments of the corresponding digit are input to a schoolbook polynomial multiplier for multiplication. Therefore, it results four -bit polynomials as output (the length of the polynomials is not shown in Figure 2). We are thankful to the authors of [28], for sharing their open source repository of various polynomial multipliers, available at https://github.com/Centre-for-Hardware-Security/TTech-LIB, accessed on 8 May 2021. According to our requirements, we generated the Verilog (HDL) design of an -bit schoolbook polynomial multiplier by using the open source generator, provided by [28].
- -
- Internal concatenation: The multiplication, after each 8-bit segment to PolyA, results in a polynomial of length -bit. For each 32-bit digit multiplication, a concatenation over segmented polynomials of length -bit is performed to produce a resultant polynomial of length -bit.
- -
- Final concatenation: Once the multiplication over each 32-bit digit is completed, the final polynomial of length -bit is generated using a concatenation of -bit polynomials.
- Reduction: After each polynomial multiplication and squaring, the resultant polynomials are -bit. Therefore, a reduction operation is required to reduce -bit polynomials to m-bit. In this work, the reduction units (Reduction-1, connected serially after the LSD multiplier and Reduction-2, connected serially after the squarer unit) are implemented by considering the NIST recommended field reduction algorithms over and , respectively. For reduction algorithms, we refer interested readers to Algorithm 2.41 and Algorithm 2.42 from [29].
- Inversion: As shown in Algorithm 1, the inversion computation is required to perform reconversions from the projective to affine coordinated systems. To compute FF inversion, an Itoh–Tsujii algorithm [30] is used in this work. It requires only the multiplication and squaring operations. Consequently, the inversion is implemented by using hardware resources of an LSD multiplier and a squarer unit.
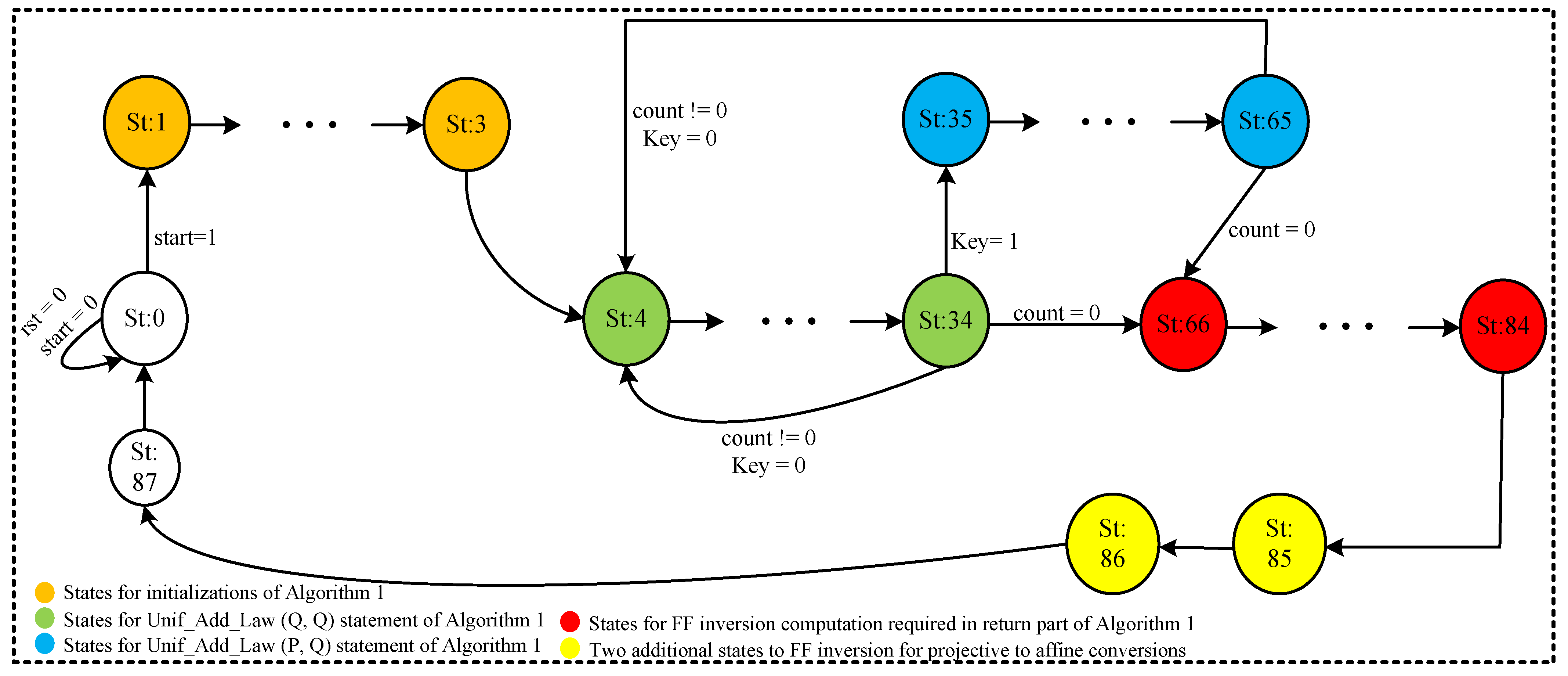
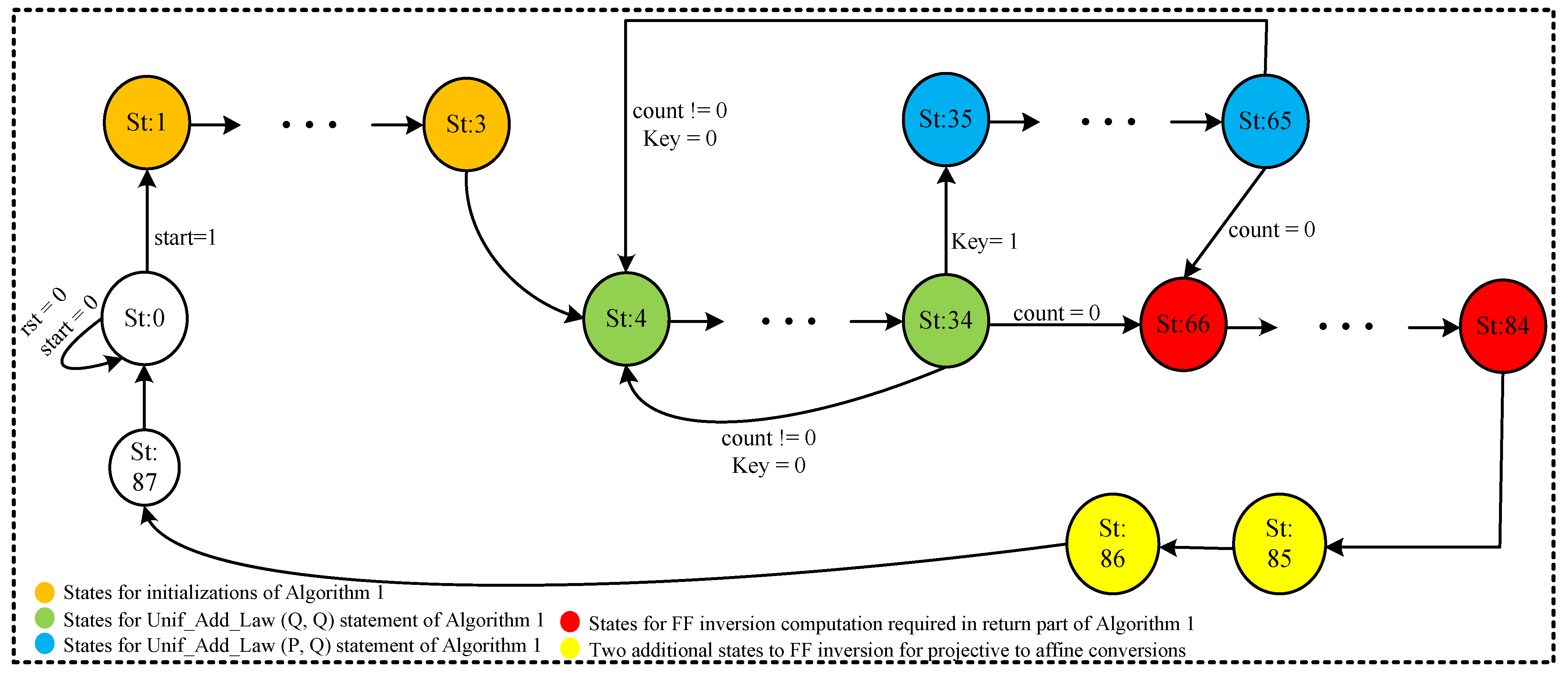
3.3. Control Unit
4. Implementation Results and Comparisons
4.1. Implementation Parameters
4.2. Implementation Results
4.3. Comparison with State of the Art Architectures
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mosenia, A.; Jha, N.K. A Comprehensive Study of Security of Internet-of-Things. IEEE Trans. Emerg.Top. Comput. 2017, 5, 586–602. [Google Scholar] [CrossRef]
- Bafandehkar, M.; Yasin, S.M.; Mahmod, R.; Hanapi, Z.M. Comparison of ECC and RSA Algorithm in Resource Constrained Devices. In Proceedings of the 2013 International Conference on IT Convergence and Security (ICITCS), Macao, China, 16–18 December 2013; pp. 1–3. [Google Scholar] [CrossRef]
- Yeh, L.Y.; Chen, P.J.; Pai, C.C.; Liu, T.T. Newblock An Energy-Efficient Dual-Field Elliptic Curve Cryptography Processor for Internet of Things Applications. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 1614–1618. [Google Scholar] [CrossRef]
- Choi, P.; Lee, M.K.; Kim, J.H.; Kim, D.K. Low-Complexity Elliptic Curve Cryptography Processor Based on Configurable Partial Modular Reduction Over NIST Prime Fields. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1703–1707. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Lange, T.; Rezaeian Farashahi, R. Binary Edwards Curves. In Cryptographic Hardware and Embedded Systems—CHES 2008; Oswald, E., Rohatgi, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 244–265. [Google Scholar] [CrossRef] [Green Version]
- Farashahi, R.R.; Joye, M. Efficient Arithmetic on Hessian Curves. In Public Key Cryptography—PKC 2010; Nguyen, P.Q., Pointcheval, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 243–260. [Google Scholar] [CrossRef] [Green Version]
- Devigne, J.; Joye, M. Binary Huff Curves. In Topics in Cryptology—CT-RSA 2011; Kiayias, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 340–355. [Google Scholar] [CrossRef]
- Islam, M.M.; Hossain, M.S.; Hasan, M.K.; Shahjalal, M.; Jang, Y.M. Design and Implementation of High-Performance ECC Processor with Unified Point Addition on Twisted Edwards Curve. Sensors 2020, 20, 5148. [Google Scholar] [CrossRef] [PubMed]
- Joye, M.; Tibouchi, M.; Vergnaud, D. Huff’s Model for Elliptic Curves. In Algorithmic Number Theory; Hanrot, G., Morain, F., Thomé, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 234–250. [Google Scholar] [CrossRef] [Green Version]
- Edwards, H.M. A normal form for elliptic curves. Bull. Am. Math. Soc. 2007, 44, 393–422. [Google Scholar] [CrossRef] [Green Version]
- Smart, N.P. The Hessian Form of an Elliptic Curve. In Cryptographic Hardware and Embedded Systems—CHES 2001; Koç, Ç.K., Naccache, D., Paar, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 118–125. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Yu, W.; Wang, K. Hashing into Generalized Huff Curves. In Information Security and Cryptology; Lin, D., Wang, X., Yung, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 22–44. [Google Scholar] [CrossRef]
- Antoniotti, L.; Caldarola, F.; Maiolo, M. Infinite Numerical Computing Applied to Hilbert’s, Peano’s, and Moore’s Curves. Mediterr. J. Math 2020, 17. [Google Scholar] [CrossRef]
- Basu, S.; Bardhan, A.; Gupta, K.; Saha, P.; Pal, M.; Bose, M.; Basu, K.; Chaudhury, S.; Sarkar, P. Cloud computing security challenges solutions—A survey. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 347–356. [Google Scholar] [CrossRef]
- Khan, S.; Jadhav, A.; Bharadwaj, I.; Rooj, M.; Shiravale, S. Blockchain and the Identity based Encryption Scheme for High Data Security. In Proceedings of the 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 11–13 March 2020; pp. 1005–1008. [Google Scholar] [CrossRef]
- Dyka, Z.; Langendörfer, P. Improving the Security of Wireless Sensor Networks by Protecting the Sensor Nodes against Side Channel Attacks. In Wireless Networks and Security: Issues, Challenges and Research Trends; Khan, S., Khan Pathan, A.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 303–328. [Google Scholar] [CrossRef]
- Calderoni, L.; Maio, D. Lightweight Security Settings in RFID Technology for Smart Agri-Food Certification. In Proceedings of the 2020 IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020; pp. 226–231. [Google Scholar] [CrossRef]
- Chatterjee, A.; Sengupta, I. High-Speed Unified Elliptic Curve Cryptosystem on FPGAs Using Binary Huff Curves. In Progress in VLSI Design and Test; Rahaman, H., Chattopadhyay, S., Chattopadhyay, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 243–251. [Google Scholar] [CrossRef]
- Ghosh, S.; Kumar, A.; Das, A.; Verbauwhede, I. On the Implementation of Unified Arithmetic on Binary Huff Curves. In Cryptographic Hardware and Embedded Systems—CHES 2013; Bertoni, G., Coron, J.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 349–364. [Google Scholar] [CrossRef] [Green Version]
- Jafri, A.R.; Islam, M.N.; Imran, M.; Rashid, M. Towards an Optimized Architecture for Unified Binary Huff Curves. J. Circ. Syst. Comput. 2017, 26, 1750178. [Google Scholar] [CrossRef]
- Rashid, M.; Imran, M.; Jafri, A.R.; Mehmood, Z. A 4-Stage Pipelined Architecture for Point Multiplication of Binary Huff Curves. J. Circ. Syst. Comput. 2020, 29, 2050179. [Google Scholar] [CrossRef]
- Imran, M.; Rashid, M.; Raza Jafri, A.; Najam-ul-Islam, M. ACryp-Proc: Flexible Asymmetric Crypto Processor for Point Multiplication. IEEE Access 2018, 6, 22778–22793. [Google Scholar] [CrossRef]
- Chatterjee, A.; Gupta, I.S. FPGA implementation of extended reconfigurable Binary Edwards Curve based processor. In Proceedings of the 2012 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 30 January–2 February 2012; pp. 211–215. [Google Scholar] [CrossRef]
- Rashidi, B.; Abedini, M. Efficient Lightweight Hardware Structures of Point Multiplication on Binary Edwards Curves for Elliptic Curve Cryptosystems. J. Circ. Syst. Comput. 2019, 28, 211–215. [Google Scholar] [CrossRef]
- Fournaris, A.P.; Koufopavlou, O. Affine Coordinate Binary Edwards Curve Scalar Multiplier with Side Channel Attack Resistance. In Proceedings of the 2015 Euromicro Conference on Digital System Design, Madeira, Portugal, 26–28 August 2015; pp. 431–437. [Google Scholar] [CrossRef]
- Huff, G.B. Diophantine problems in geometry and elliptic ternary forms. Duke Math. J. 1948, 15, 443–453. [Google Scholar] [CrossRef]
- NIST. Recommended Elliptic Curves for Federal Government Use. 1999. Available online: https://csrc.nist.gov/csrc/media/publications/fips/186/2/archive/2000-01-27/documents/fips186-2.pdf (accessed on 26 April 2021).
- Imran, M.; Abideen, Z.U.; Pagliarini, S. An Open-source Library of Large Integer Polynomial Multipliers. In Proceedings of the 2021 24th International Symposium on Design and Diagnostics of Electronic Circuits Systems (DDECS), Vienna, Austria, 7–9 April 2021; pp. 145–150. [Google Scholar] [CrossRef]
- Hankerson, D.; Menezes, A.J.; Vanstone, S. Guide to Elliptic Curve Cryptography; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–311. Available online: https://link.springer.com/book/10.1007/b97644 (accessed on 6 May 2021).
- Zode, P.; Deshmukh, R.B.; Samad, A. Fast Architecture of Modular Inversion Using Itoh-Tsujii Algorithm. In VLSI Design and Test; Kaushik, B.K., Dasgupta, S., Singh, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 48–55. Available online: https://www.springerprofessional.de/fast-architecture-of-modular-inversion-using-itoh-tsujii-algorit/15326436 (accessed on 11 February 2021).


{kind=link}
{kind=link}
{kind=link}
| of the BHC Model of ECC |
|---|
| , , |
| , , |
| , , |
| , |
| of the BHC Model of ECC |
|---|
| , , |
| , |
| , , |
| , , |
| Key Length (m) | Selected Parameters and the Corresponding Values |
|---|---|
| Key Length (m) | Platform | Slices | Frequency (in MHz) | Clock Cycles | Latency (in μs) |
|---|---|---|---|---|---|
| 163 | Virtex-4 | 5302 | 152 | 68 | |
| Virtex-5 | 2412 | 194 | 53 | ||
| Virtex-6 | 2982 | 200 | 51 | ||
| Virtex-7 | 3508 | 242 | 42 | ||
| 233 | Virtex-4 | 103 | 108 | ||
| Virtex-5 | 157 | 70 | |||
| Virtex-6 | 4370 | 164 | 67 | ||
| Virtex-7 | 4261 | 204 | 54 |
| Ref #. | Key Length (m) | Platform | Slices | Frequency (in MHz) | Clock Cycles | Latency (in μs) |
|---|---|---|---|---|---|---|
| Architectures for the unified BHC model of ECC | ||||||
| [18] | Virtex-4 | 81 | 5913 | 73 | ||
| [21] | Virtex-4 | 9763 | 329 | 39 | ||
| [21] | Virtex-5 | 6703 | 397 | 32 | ||
| [19] | Virtex-6 | 7150 | 172 | 7370 | 43 | |
| [20] | Virtex-6 | 7681 | 296 | 39 | ||
| [19] | Virtex-7 | 6032 | 183 | 7370 | 40 | |
| [20] | Virtex-7 | 6342 | 369 | 32 | ||
| [21] | Virtex-7 | 7017 | 434 | 30 | ||
| [22] | Virtex-7 | 6083 | 341 | 36 | ||
| Architectures for the unified BEC model of ECC | ||||||
| [23] | Virtex-4 | 48 | − | − | ||
| [24] | Virtex-5 | 5919 | − | − | ||
| [25] | Virtex-5 | 15,804 | 308 | − | − | |
| [8] | Virtex-6 | 6600 | 93 | − | 2130 | |
| AREEBA | Virtex-4 | 103 | 108 | |||
| Virtex-5 | 157 | 70 | ||||
| Virtex-6 | 4370 | 164 | 67 | |||
| Virtex-7 | 4261 | 204 | 54 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sajid, A.; Rashid, M.; Jamal, S.S.; Imran, M.; Alotaibi, S.S.; Sinky, M.H. AREEBA: An Area Efficient Binary Huff-Curve Architecture. Electronics 2021, 10, 1490. https://doi.org/10.3390/electronics10121490
Sajid A, Rashid M, Jamal SS, Imran M, Alotaibi SS, Sinky MH. AREEBA: An Area Efficient Binary Huff-Curve Architecture. Electronics. 2021; 10(12):1490. https://doi.org/10.3390/electronics10121490
Chicago/Turabian StyleSajid, Asher, Muhammad Rashid, Sajjad Shaukat Jamal, Malik Imran, Saud S. Alotaibi, and Mohammed H. Sinky. 2021. "AREEBA: An Area Efficient Binary Huff-Curve Architecture" Electronics 10, no. 12: 1490. https://doi.org/10.3390/electronics10121490
APA StyleSajid, A., Rashid, M., Jamal, S. S., Imran, M., Alotaibi, S. S., & Sinky, M. H. (2021). AREEBA: An Area Efficient Binary Huff-Curve Architecture. Electronics, 10(12), 1490. https://doi.org/10.3390/electronics10121490