
CNN-Based Road-Surface Crack Detection Model That Responds to Brightness Changes


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Development of a Road-Crack Detection System That Responds to Brightness Changes
3. Development of a Road-Surface Crack Detection Model
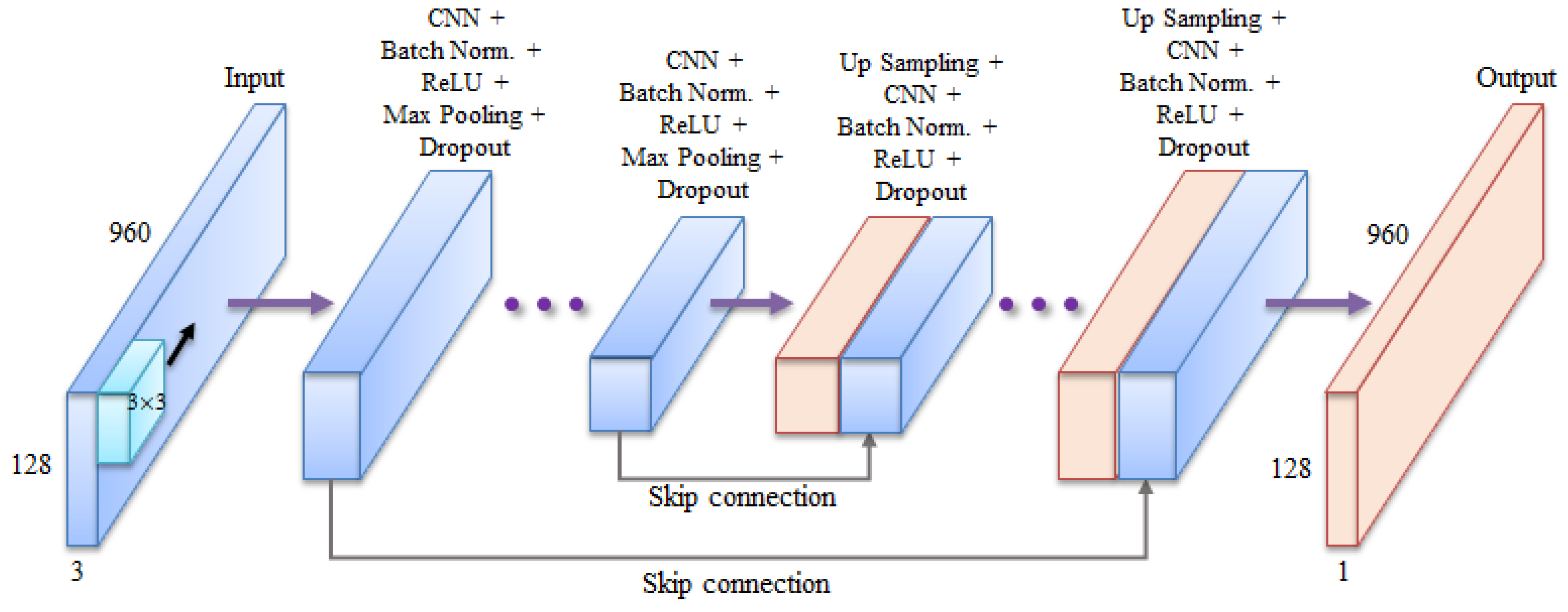
3.1. Structure of the Model
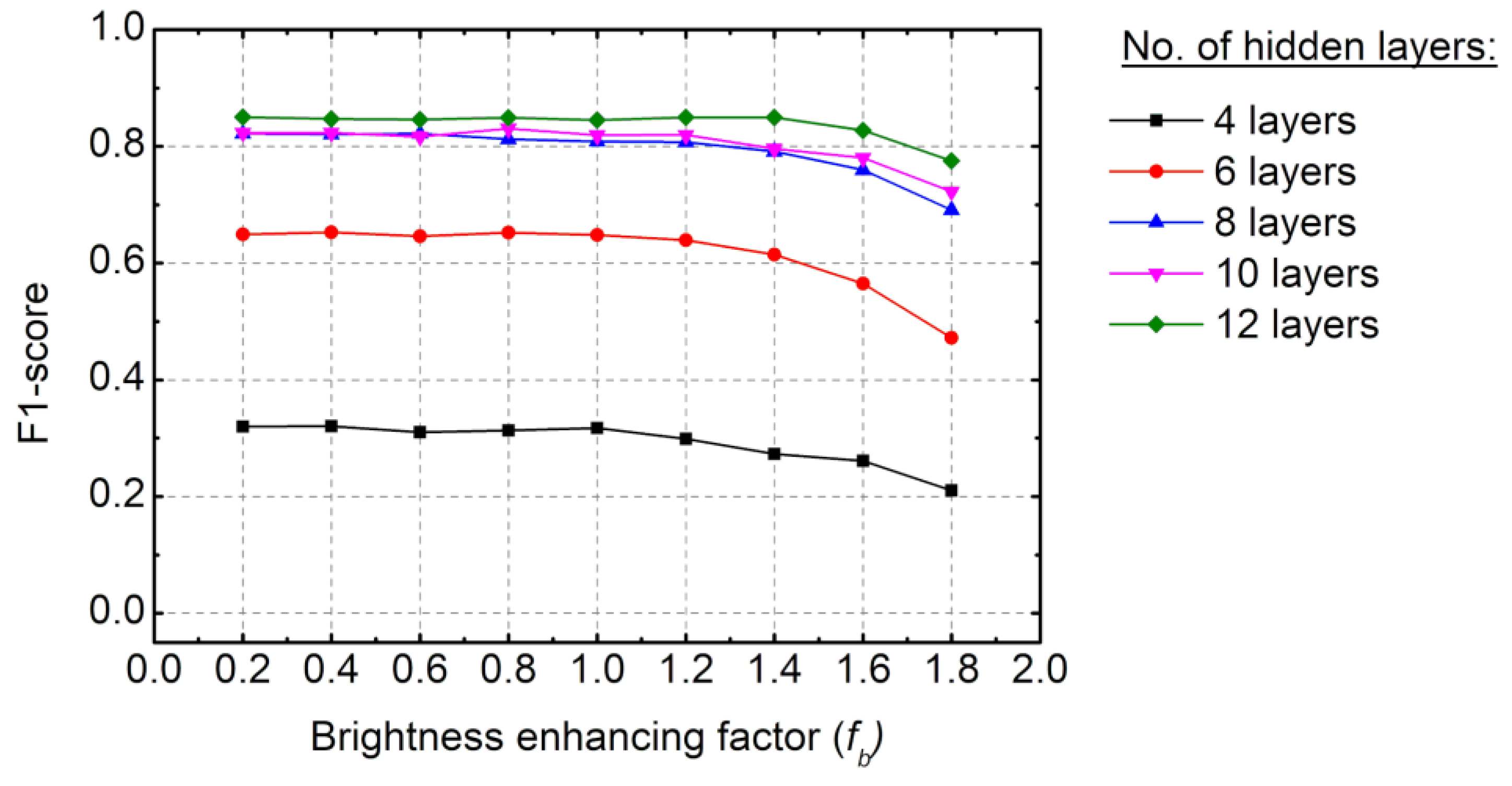
3.2. Model Training and Dataset Configuration for Testing
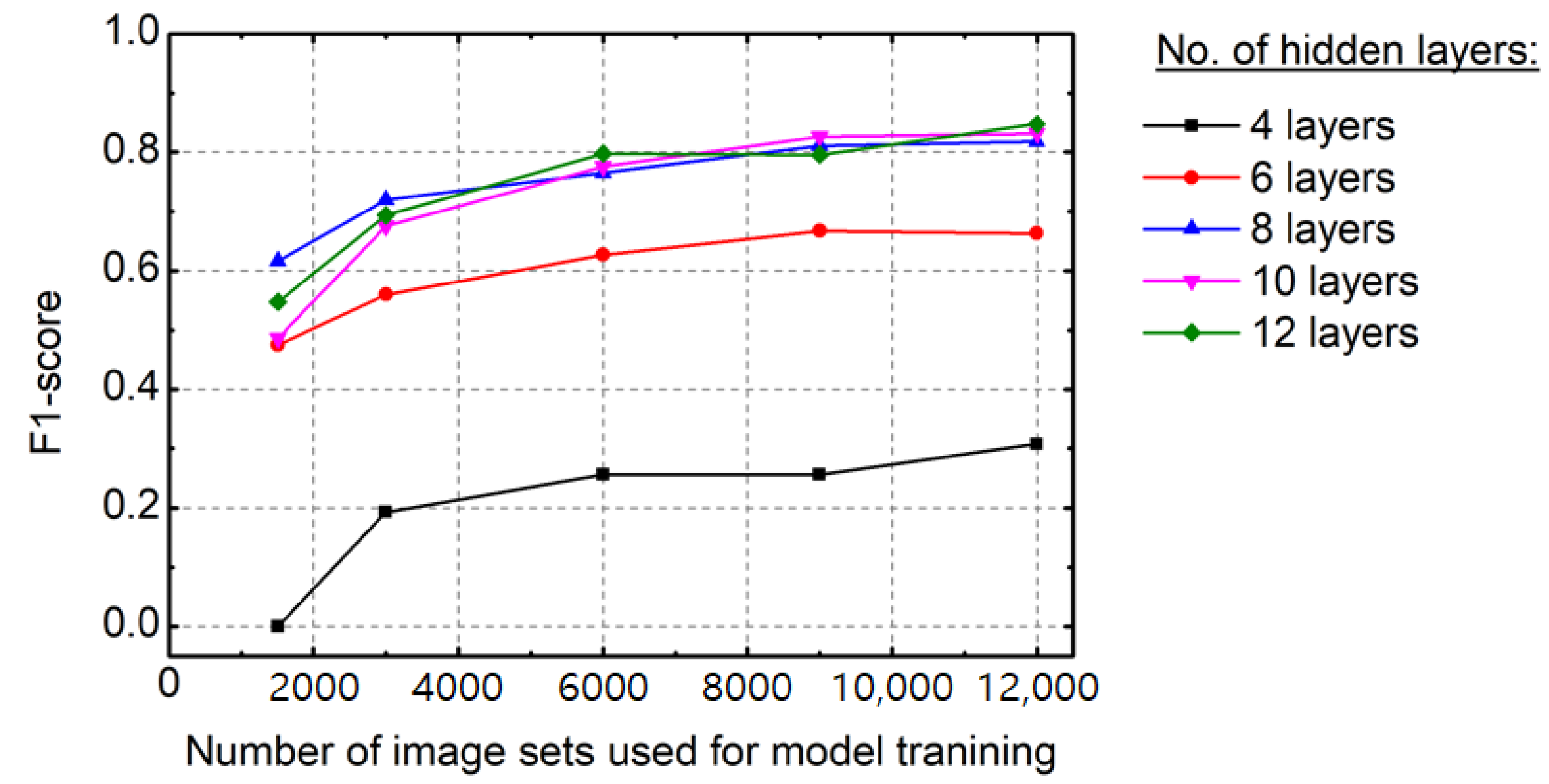
3.3. Learning Results by the Model
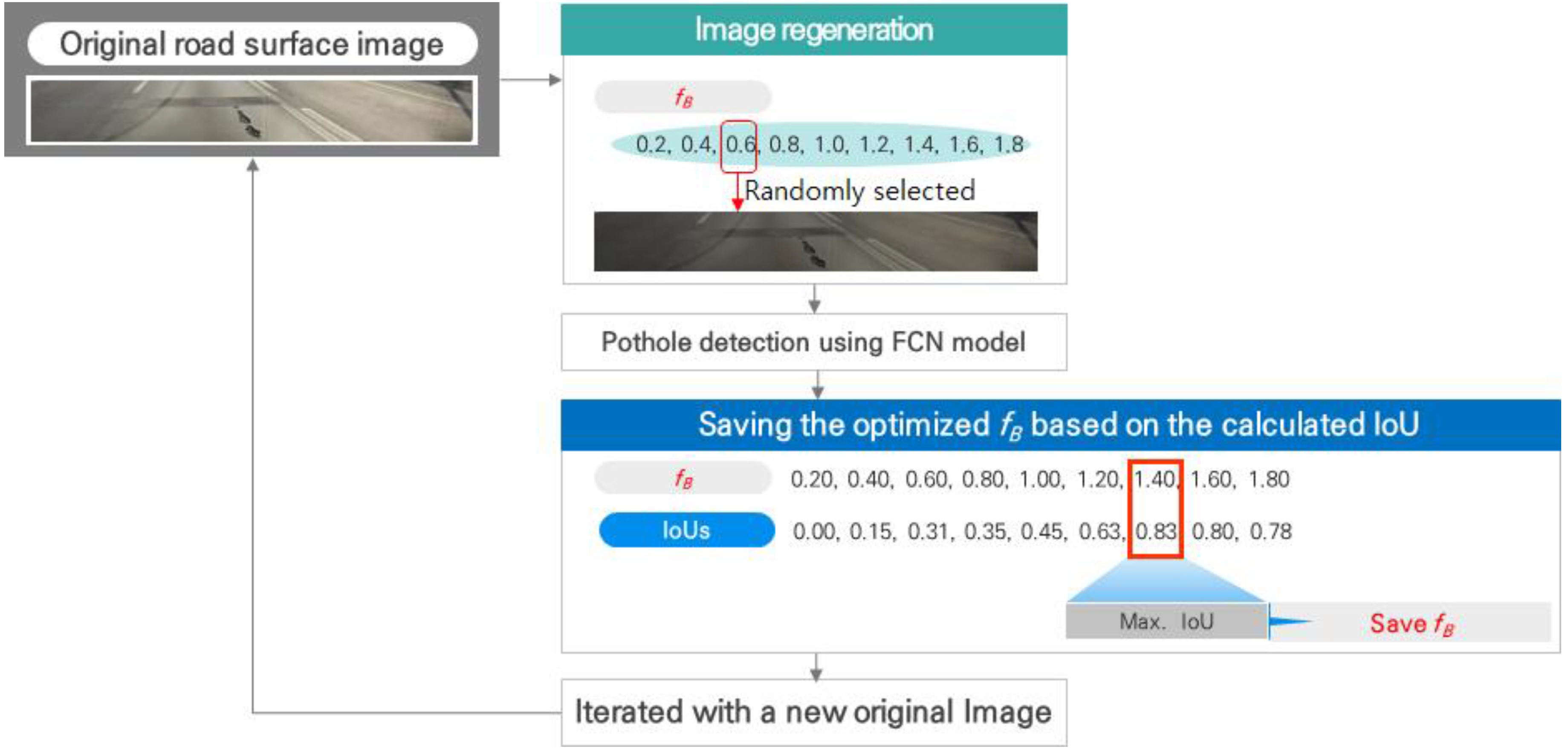
4. Development of Preprocessing Model for Adopting Brightness
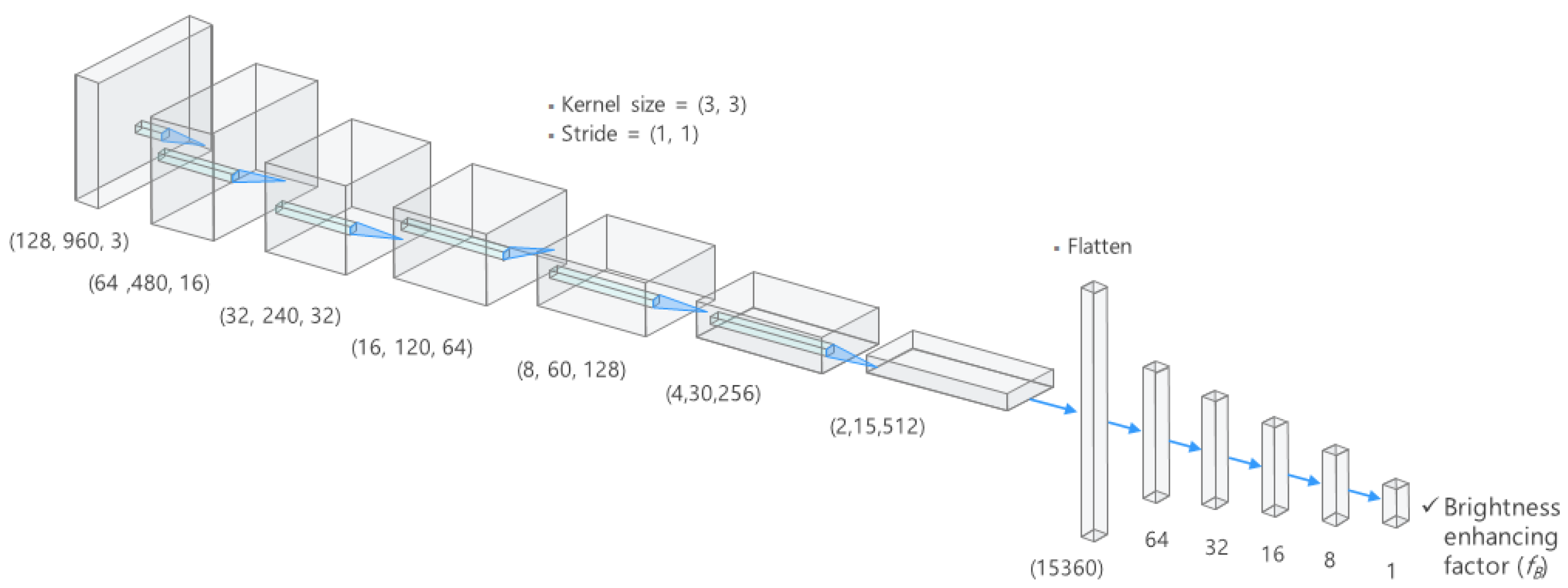
4.1. Structure of Preprocessing Model
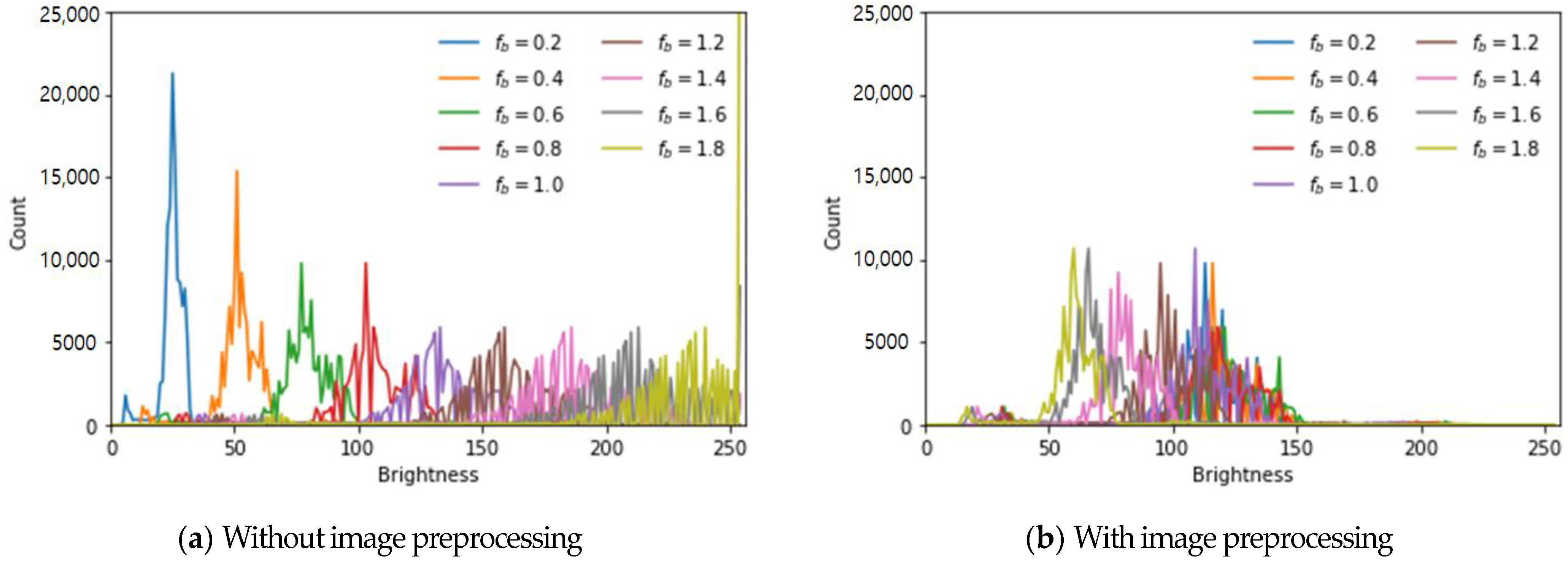
4.2. Training Dataset for the Image Preprocessing Model
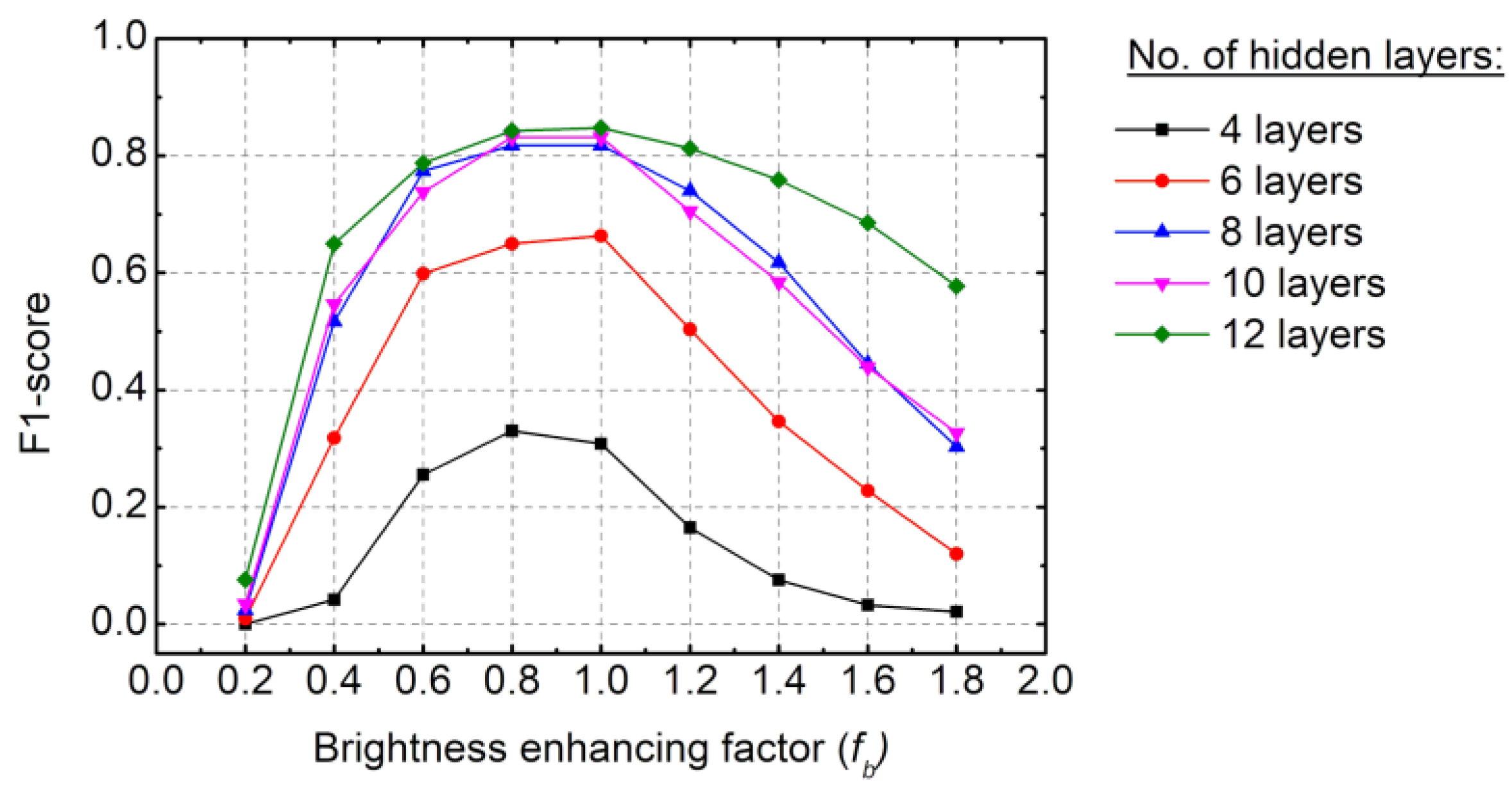
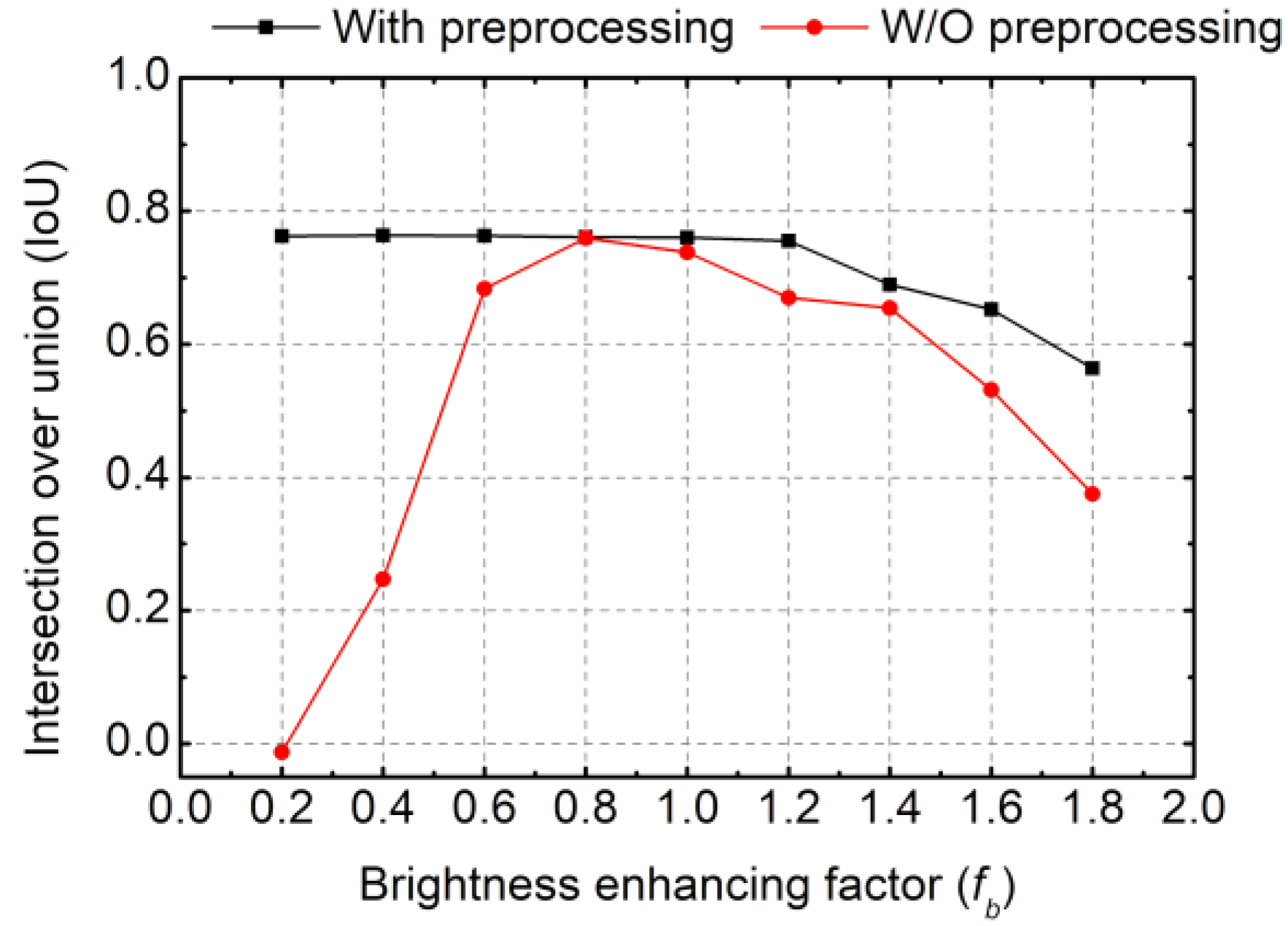
5. Performance Evaluation of the Road-Surface Crack Segmentation Model with Brightness Preprocessing
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Montreal, ON, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. Deepid3: Face recognition with very deep neural networks. arXiv 2015, arXiv:1502.00873. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Araucano Park, Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Kirillov, A.; He, K.; Girshick, R.B.; Rother, C.; Dollár, P. Panoptic Segmentation. arXiv 2018, arXiv:1801.00868. [Google Scholar]
- Xiong, Y.; Liao, R.; Zhao, H.; Hu, R.; Bai, M.; Yumer, E.; Urtasun, R. UPSNet: A Unified Panoptic Segmentation Network. arXiv 2019, arXiv:1901.03784. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Pauly, L.; Hogg, D.; Fuentes, R.; Peel, H. Deeper networks for pavement crack detection. In Proceedings of the 34th ISARC, Taipei, Taiwan, 28–31 June 2017; pp. 479–485. [Google Scholar]
- Feng, C.; Liu, M.Y.; Kao, C.C.; Lee, T.Y. Deep active learning for civil infrastructure defect detection and classification. In Proceedings of the ASCE International Workshop on Computing in Civil Engineering 2017, Seattle, DC, USA, 25–27 June 2017; pp. 298–306. [Google Scholar]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H. How to get pavement distress detection ready for deep learning? In A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks IJCNN, Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar]
- Rateke, T.; Justen, K.A.; von Wangenheim, A. Road surface classification with images captured from low-cost camera-road traversing knowledge (rtk) dataset. Rev. Inf. Teórica Appl. 2019, 26, 50–64. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection using deep neural networks with images captured through a smartphone. arXiv 2018, arXiv:1801.09454v1. [Google Scholar]
- Schmugge, S.J.; Rice, L.; Lindberg, J.; Grizziy, R.; Joffey, C.; Shin, M.C. Crack Segmentation by Leveraging Multiple Frames of Varying Illumination. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1045–1053. [Google Scholar]
- Stephen, L.; Chong, L.H.; Edwin, K.P.; Xu, T.; Wang, X. Automated Pavement Crack Segmentation Using U-Net-Based Convolutional Neural Network. IEEE Access 2020, 8, 114892–114899. [Google Scholar]
- Rateke, T.; Von Wangenheim, A. Road surface detection and differentiation considering surface damages. Auton. Robot. 2021, 45, 299–312. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Automated Multiple Concrete Damage Detection Using Instance Segmentation Deep Learning Model. Appl. Sci. 2020, 10, 8008. [Google Scholar] [CrossRef]
- Tan, C.; Uddin, N.; Mohammed, Y.M. Deep Learning-Based Crack Detection Using Mask R-CNN Technique. In Proceedings of the 9th International Conference on Structural Health Monitoring of Intelligent Infrastructure, St. Louis, MO, USA, 4–7 August 2019; pp. 1484–1490. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.-A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local deno ising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. Proc. Interspeech 2013, 1, 436–440. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the 27th European Conference on Advances in Information Retrieval Research (ECIR), Santiago de Compostela, Spain, 21–23 March 2005; pp. 345–359. [Google Scholar]













Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, T.; Yoon, Y.; Chun, C.; Ryu, S. CNN-Based Road-Surface Crack Detection Model That Responds to Brightness Changes. Electronics 2021, 10, 1402. https://doi.org/10.3390/electronics10121402
Lee T, Yoon Y, Chun C, Ryu S. CNN-Based Road-Surface Crack Detection Model That Responds to Brightness Changes. Electronics. 2021; 10(12):1402. https://doi.org/10.3390/electronics10121402
Chicago/Turabian StyleLee, Taehee, Yeohwan Yoon, Chanjun Chun, and Seungki Ryu. 2021. "CNN-Based Road-Surface Crack Detection Model That Responds to Brightness Changes" Electronics 10, no. 12: 1402. https://doi.org/10.3390/electronics10121402
APA StyleLee, T., Yoon, Y., Chun, C., & Ryu, S. (2021). CNN-Based Road-Surface Crack Detection Model That Responds to Brightness Changes. Electronics, 10(12), 1402. https://doi.org/10.3390/electronics10121402