Abstract
Recent deep learning models succeed in achieving high accuracy and fast inference time, but they require high-performance computing resources because they have a large number of parameters. However, not all systems have high-performance hardware. Sometimes, a deep learning model needs to be run on edge devices such as IoT devices or smartphones. On edge devices, however, limited computing resources are available and the amount of computation must be reduced to launch the deep learning models. Pruning is one of the well-known approaches for deriving light-weight models by eliminating weights, channels or filters. In this work, we propose “zero-keep filter pruning” for energy-efficient deep neural networks. The proposed method maximizes the number of zero elements in filters by replacing small values with zero and pruning the filter that has the lowest number of zeros. In the conventional approach, the filters that have the highest number of zeros are generally pruned. As a result, through this zero-keep filter pruning, we can have the filters that have many zeros in a model. We compared the results of the proposed method with the random filter pruning and proved that our method shows better performance with many fewer non-zero elements with a marginal drop in accuracy. Finally, we discuss a possible multiplier architecture, zero-skip multiplier circuit, which skips the multiplications with zero to accelerate and reduce energy consumption.
1. Introduction
Deep learning has been advanced greatly in recent years and it has become an iconic computing technology in this digital era. The representative application area is image processing and computer vision [1,2,3]. There are famous image classification models such as ResNet [4] and VGGNet [5]. Although these latest models achieve high accuracy and fast inference time, they have a large number of parameters which consume large memory and computing resources [6,7]. Among the models mentioned, ResNet-50 has 23 million parameters and the VGG-16 has 138 million parameters. In recent systems, models with many more parameters work well, but not all systems have the latest hardware. Recently, there have been attempts to apply deep learning models to various low-performance edge devices such as IoT devices and smartphones. It is difficult to run a large deep learning model with millions of parameters smoothly on these edge devices. If the number of parameters of the model is reduced, the amount of computation is also reduced. Then, it is possible to run the model on the edge device.
In order to reduce the number of parameters, there is a well-known method named “pruning” that removes weights or filters that are considered relatively unimportant. Existing studies have presented various criteria to judge the “less important filters” to be removed when pruning the filters. However, experiments conducted in [8] showed that there is no significant difference in performance between random filter pruning and the filter pruning with various criteria. In this paper, we propose zero-keep filter pruning, which reduces the amount of computation by pruning filters that have fewer zeros, while substituting values with smaller absolute values among the elements of the filter with zeros. The idea of zero-keep filter pruning is to prune the filter to minimize the amount of computation if the criteria for selecting the filter to be pruned do not significantly affect performance.
The contributions of our paper can be summarized as follows. First, we proposed a novel pruning method that eliminates the filters having more non-zero parameters, and it maximizes the number of zeros in filters. This is opposite to the existing pruning method in which near-zero or zero weight parameters are the main targets of pruning. Second, using the proposed method, we were able to design an efficient model by replacing 82% of the multiplications with the zero-skip multiplications which do not consume the switching power/energy in the multiplication circuits. Finally, our scheme shows similar or better performance compared to the models designed with conventional methods even with a much smaller number of non-zero weight parameters. In order to utilize the benefit of the proposed zero-keep filter pruning, a zero-skip multiplier is needed to reduce the power and energy consumption from multiplication operations when there are zeros as operands. We discuss such a multiplier architecture in the Section 4.
The rest of the paper is structured as follows. In Section 1.1, we describe the related works on model pruning. In Section 2, “zero-keep filter pruning” is proposed and is explained in detail. In Section 3, experiment results are presented with interpretations and discussions. In Section 4, we suggest a circuit level design of a zero-skip multiplier. Finally, we conclude our work with a short summary in Section 5.
1.1. Related Works
Pruning is a process of eliminating individual weight parameters or filters/channels according to their importance evaluated by certain criteria. The pruning is an iterative process which is composed of three main steps: (1) evaluating the filter’s importance, (2) eliminating low importance filters and (3) re-training. The re-training is a sort of fine-tuning for adjusting parameters and it is essential for maintaining accuracy performance.
By the elimination of weight parameters or filters, the size of a deep learning model can be reduced effectively. Accordingly, it can accelerate the speed of inference computation thanks to the reduced model parameters/filters [6,7,9,10,11]. Furthermore, it has been revealed by Han et al. [12] that the pruning model can even be expected to improve accuracy performance through fine-tuning.
The typical filter pruning is to remove filters that are considered relatively unimportant. Li et al. [13] ranked the filters by calculating the -norm of each filter. He et al. [6] used the -norm. Hu et al. [14] proposed a method which uses the average percentage of zeros to rank filters. If a filter is less active when it passes the activation function, it is considered to have low importance and thus it can be removed. Another filter pruning method is to remove filters that are considered to be replaced by other filters. Zhou et al. [15] used a pre-trained model to make two similar filters into one cluster. They trained the two filters to be the same and pruned the filters by removing one of the two. In another method, He et al. [16] used the geometric median of filters to prune the filter that is close to the geometric median of multiple filters, considering that other filters contain the characteristics of the filter. Lin et al. [17] proposed a method using the ranks of feature maps. First, the ranks of the output feature maps for each filter are evaluated. If the rank of a feature map is evaluated as too low, the filter generating the low rank feature maps is removed. In [18], the shape of a filter was considered for pruning. They proposed stripe-wise filter pruning to maintain the shape of the filter.
On the other hand, recently many researchers have tried to prune deep learning models without a time-consuming pre-training step to reduce the whole training time for large models. Frankle et al. [19] had proposed a method which prunes an initial model. They pruned the network from a pre-trained model and reinitialize the weights to the initial weights of each filter. However, this method also requires the pre-trained model in order to prune the initial model. Researchers have proposed the methods that perform the pruning from the untrained model [19,20,21,22]. Wang et al. [21] added a scalar ‘gate value’ to measure the effectiveness of each filter in the initial model. Since this value is also trainable, they can find the filters which can be pruned without affecting accuracy performance. This method can shorten the training time when compared to [19], which requires training an entire model for pruning.
Meanwhile, Mittal et al. [8] had investigated the impacts of the various pruning criteria/strategies on the accuracy performance of the pruned model with the criteria. In their work, authors have evaluated and compared the accuracies of the models which are pruned with seven different filter pruning approaches. The seven different approaches include the random pruning method and the methods presented in [13,14]. The result shows that there is no significant difference between the random pruning approach and the l1-norm-based pruning approach which shows the best performance.
Based on the results from [8], if the method of pruning filters does not significantly affect the accuracy performance, at the viewpoint of power/energy consumption of a deep learning accelerator, we expect that it is beneficial to develop a model pruning strategy of minimizing the computation and power/energy consumption by maximizing zero elements in filters. This is contradictory to the previous conventional pruning methods in which zero weights or near zero weights in filters are a main target of pruning.
2. Zero-Keep Filter Pruning
When a feature map goes through a filter, many multiplication operations occur. The result of multiplication with a zero input value is trivially zero. In consequence, if there is any zero value on any of two inputs to a multiplier then we can skip the multiplication operations. Finally, if we can skip multiplications with zero input values, then we can accelerate inference and reduce the energy consumption caused by the unnecessary multiplications. Our pruning approach focuses on maximizing zero values in a deep learning model.
In a traditional filter pruning method, filters can be selected based on various criteria such as the norm or norm, etc. On the other hand, zero-keep filter pruning maximizes the number of zeros in a filter while also pruning the filter with the smallest zero elements in order to reduce the amount of computation. As mentioned earlier, there are millions of parameters in recent advanced deep learning models. Through simple investigation on the value distribution of those model parameters, we know that many parameters have very small values close to zero but parameters that are actually zero are very rare.
The proposed method uses the “count of zeros” as the criteria for pruning. In this paper, we set the pruning threshold to 5% of the filters. With this threshold, at each pruning iteration, 5% of the filters which have the smallest number of zeros will be removed. To produce best result in our approach, we first try to set near-zero parameters to zero. Typically the near-zero parameter elimination is called “weight pruning” and the neural network connections for the pruned parameter weights are eliminated. However, such element-wise eliminations introduce irregularity in matrix computations for the neural network. In our approach, weight connections are kept and pruning is performed at the level of a filter in a structured way.
Figure 1 shows the abstract view of the conventional method and the proposed method. Figure 1a shows the flow of a traditional filter pruning method where the filters with more zero weights are pruned. Figure 1b shows the flow of our proposed filter pruning method and the filters with less zeros are pruned. In consequence, the filters with more zero-weight elements are kept in the model and this leads to efficient inference computation due to there being less multiplications. The lower n% of parameter elements with the smallest absolute values are converted to zero and n% of filters in each layer are pruned.
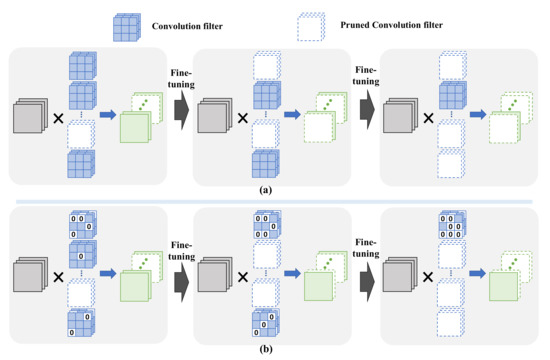
Figure 1.
The abstract view of the conventional method (a) and the proposed method (b).
Figure 2 shows the distribution of value of elements in each layer of a pre-trained VGG-16 model. In this figure, we can observe that the weight elements in the layers at the back of the model have much smaller values compared to the layers at the front or middle of the model. For example, the 1st to 5th layers have weight elements which are distributed mainly between −0.1 and 0.1 while the 9th to 13th layers have elements which have a much smaller value than 0.01. Therefore, if we pruned n% of the filters in all the layers, mostly the layers at the back of model will be pruned and it can cause an accuracy drop due to the “unbalanced” pruning among the layers. To solve this problem, we keep a layer-wise pruning rate so that the pruning happens at every layer in a balanced manner. The procedure is summarized in the Algorithm 1.
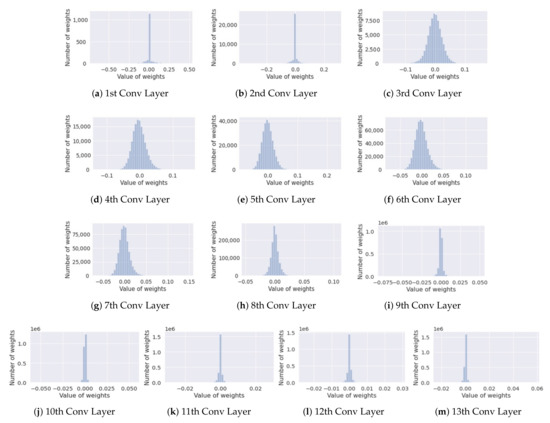
Figure 2.
The distribution of weight parameters in each layer of a pre-trained model (VGG-16).
| Algorithm 1 Zero-keep filter pruning algorithm. |
Input Pre-trained Network , Pruning rate n% Output Pruned Network
|
When we denote as the maximum number of iterations that satisfy the given condition, “Accuracy drop stays within a tolerable range”, at Line-13 of the algorithm and w as the maximum number of weight parameters in a layer, the time complexity of our algorithm can be described as follow:
The equation of “” is for the sorting operation in Line-7. At Line-12, the fine-tuning of the pruned model is included and executed at every iteration of the “repeat-until” loop. However, we cannot formalize the time complexity of the fine-tuning process (it is actually training). So we use ‘’ to denote the time complexity of the fine-tuning process.
3. Experiment
3.1. Setting Up of the Experiment
The CNN models used in our experiment are VGG-16 with the CIFAR-10 dataset and Resnet-50 with the Imagenet dataset. The input image size of CIFAR-10 is 32 × 32. We used 50,000 images for training and 10,000 images for testing in the CIFAR-10 dataset. For data augmentation, we increased the image size to 36 × 36 with padding and randomly cropped the augmented images to 32 × 32 size. Also we flipped the images horizontally at random to produce more train image samples. Regarding the Imagenet dataset, since it contains images of various sizes, we resized the images to 256 × 256 and randomly cropped to 224 × 224. Moreover, we flipped the images horizontally at random in the same manner as for teh CIFAR-10 dataset. We used 1281 thousand images for training the model and 50 thousand images for testing the model. The details of SW/HW specifications on the experimental environment are described in Table 1.

Table 1.
Description of hardware/software system.
For training, we used a Stochastic Gradient Descent (SGD) optimizer [23]. The SGD optimizer is an optimizer for updating the weights of deep learning models. This optimizer updates the weights using only a part of the dataset, not the entire dataset. Through the SGD, we can speed up training and help the model to avoid a local minima. Recently, new optimizers based on the well-known optimizers such as SGD and Adam [24] have been developed [25,26]. Later, such optimizers can be further investigated to improve accuracy performance as future work. We set the batch size to 64, initial learning rate to 0.1, momentum to 0.9 and weight decay rate to . We multiplied 0.1 to the learning rate at 150 and 250 epochs.
The experiment compares two methods: (1) random filter pruning, and (2) zero-keep filter pruning. We set the pruning percentage n% to 5% in each iteration step. After pruning filters at all the layers (Line-4∼Line-11 of Algorithm 1), we perform a fine-tuning process for the remained filters at every iteration as described in Line-12. The authors in [8] have mentioned that the result can be changed depending on the position of the pruned layer. Since the VGG-16 has 13 convolution layers in total, we constructed four different model configurations according to the pruned layers as follows:
- 1.
- Filter pruning happens in the layers from 1st to 13th.
- 2.
- Filter pruning happens in the layers from 5th to 13th.
- 3.
- Filter pruning happens in the layers from 1st to 11th.
- 4.
- Filter pruning happens in the layers from 5th to 11th.
The authors in [8] have also mentioned that there is no significant accuracy difference between different pruning approaches if the number of epochs for the fine-tuning is more than 12. Therefore, we set the number of epochs for the fine-tuning to 15. Unlike the experimental setting for VGG-16, it’s hard to apply the setting mentioned in [8] to a Resnet-50 model since it is divided into four large CNN blocks and sixteen bottleneck blocks. An amount of 15 epochs is too short to fine-tune the Resnet-50 model. So we applied “early stopping” to stop training if the accuracy does not increase for the 5 epochs.
3.2. Results
Figure 3 shows the “non-zero element rate versus accuracy performance trade-off” between random filter pruning and Figure 4 shows that of the proposed method. Basically, the non-zero element rate (NZER) means the ratio of “the number of non-zero weight elements” to “total number of weight elements” in a model as given in Equation (2). In addition to NZER, we conducted another metric, NZER_ORIG, which is defined by the ratio of “the number of non-zero weight elements” in a pruned model (PM) to “total number of weight elements” in a unpruned original model (UPOM) as given in Equation (3).

Figure 3.
Non zero element rate versus accuracy trade-off of random filter pruning on VGG-16.
Figure 4.
Non zero element rate versus accuracy trade-off of zero-keep filter pruning on VGG-16.
In Figure 3 and Figure 4, if two models have the same level of accuracy, then a model with fewer non-zero elements can be expected as a more efficient model in terms of computational complexity because less multiplication operations are performed. In those figures, a “Random 5-13” configuration shows the best efficiencies among the configurations with random pruning while a “Zero 5-13” configuration shows the best efficiency among the configurations with zero-keep pruning.
In Figure 3, we can observe that the accuracy performances of the two models without pruning on the 1st to 4th layers are better than the models of pruning the layers from the 1st to 4th layers in the case of employing random pruning. Similar results were obtained and are presented in Figure 4 when our zero-keep filter pruning scheme was used.
A graph showing “accuracy versus non-zero element rate trade-off” for the two pruning methods (random filter pruning and zero-keep filter pruning) is presented in Figure 5. In the graph, the model of pruning filters on the layers from 5th to 13th using our zero-keep pruning is the most efficient at certain accuracy ranges (“Zero 5-13” is evaluated as the most efficient scheme at the accuracy range from 92.9 to 92.20). Furthermore, in Figure 6, we can find that zero-keep pruning is also efficient in terms of the number of filters in some accuracy ranges. “Zero 5-13” has smallest number of filters at the accuracy range from 92.9 to 92.5. That leads to the lowest computation requirement since the lower number of filters implies a lower number of matrix multiplications. Our zero-keep pruning usually has similar accuracy with fewer filters when compared to random pruning. However, in some cases of pruning a only small number of filters, random running shows better accuracy performance than the proposed zero-keep pruning.
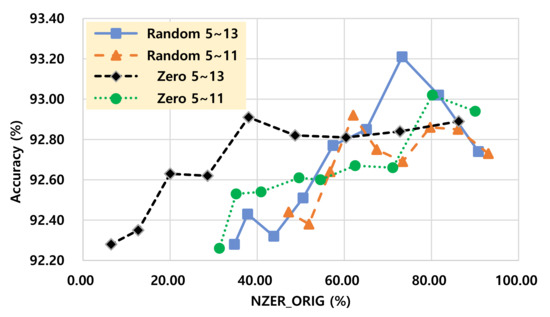
Figure 5.
Non zero element rate versus accuracy trade-off comparison on VGG-16.
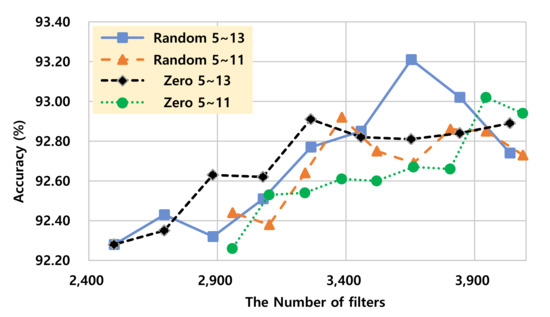
Figure 6.
The number of filters versus accuracy trade-off comparison on VGG-16.
The experiment results for the Resnet-50 model are presented in Figure 7 and Figure 8. As shown in the graphs, similar patterns are observed consistently with the results obtained from the VGG-16 model. We can see that the proposed method can be well applied not only to a typical CNN model such as VGG-16, but also to a complex model composed of bottleneck blocks and skip connections such as Resnet-50.
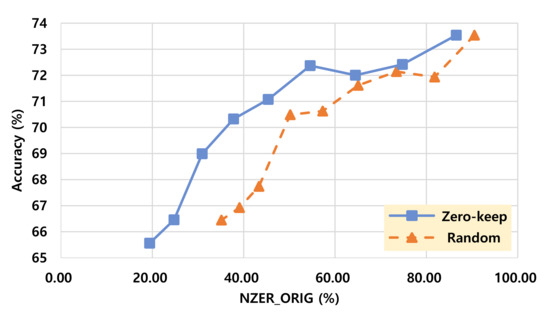
Figure 7.
Non zero element rate versus accuracy trade-off comparison on Resnet-50.
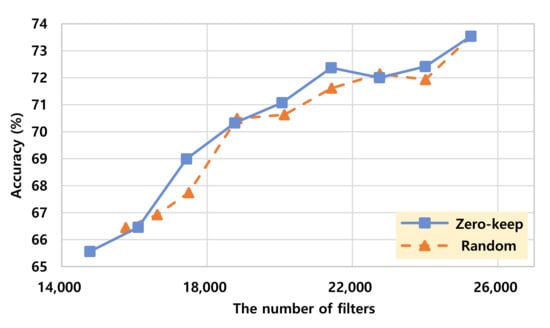
Figure 8.
The number of filters versus accuracy trade-off comparison on Resnet-50.
On the other hand, if we pruned a larger number of filters to improve computational efficiency of a model, we could obtain a higher accuracy with fewer filters in our proposed scheme. More detailed experiment results are shown in Table 2 and Table 3.
Table 2.
Experiment results of filter pruning on the layers from the 1st to the 13th on VGG-16.
Table 3.
Experiment results of filter pruning on the layers from the 5th to the 13th on VGG-16.
The results given in Table 2 are the results of pruning filters on the layers from the 1st to the 13th. It shows the results of the best compression ratio since the pruning happens at all the layers from 1 to 13. From Table 2, we know that “the case of pruning 15% of the filter with a random pruning scheme” has similar accuracy performance (92.53 versus 92.52) with “the case of pruning 20% of the filter with our zero-keep pruning”. The possibility of higher percentage of pruning means that our zero-keep filter pruning approach can have better computational efficiency thanks to the smaller number of filters and smaller NZER_ORIG and NZER. With the random pruning, we have 3598 filters and 72.52% non-zero weight element rate compared to the original model. However, with zero-keep pruning, we have fewer 3384 filters and 47.51% non-zero weight element rate.
When the pruning rate is 40%, almost the same number of filters is utilized in the two methods, but the accuracy is 91.45 and 91.50 for random pruning and zero-keep pruning, respectively. In this case, our zero-keep pruning shows slightly higher accuracy. Furthermore, the non-zero element rate of the random pruning is 36.20% while it is 10.79% for zero-keep pruning. The rate of the random pruning is more than three times higher than that of our zero-keep pruning.
Table 3 shows the detailed pruning results for the case of pruning the filters on the layers from the 5th to the 13th, which shows the best accuracy performance among the four different configurations as shown in Figure 3 and Figure 4. When pruning a small number of filters, the random pruning scheme performs better than ours in terms of accuracy. However, when pruning a large number of filters, our method gives better results. We can compare the results of 30% pruning with random pruning and 35% pruning with the zero-keep pruning. In this case, the random pruning has 92.51% in accuracy and our method achieves 92.63% with the smaller NZER_ORIG (50.52 (random) versus 20.01 (ours)) and a smaller number of filters (3078 (random) versus 2882 (ours)).
In addition, even in the case that both methods have the same accuracy, our approach has much smaller NZER_ORIG. With the pruning rate of 45% shown in the bottom line of Table 3, both methods have the same accuracy performance (92.28%), but the random pruning has 34.75 and our method has 6.45 in NZER_ORIG. It means that the proposed zero-keep pruning scheme shows the same level of accuracy performance with fewer filters and smaller non-zero elements in some ranges of accuracy performance.
In Table 4, pruning rates for each layer are presented for the random pruning approach and our approach. For random pruning, every layer has a similar NZER_ORIG, around ‘30’ except for the first layer, while the proposed zero-keep filter pruning has various NZER_ORIG from 3.35 to 18.63 at the different layers. In all the layers, our approach achieves much less NZER_ORIG. On average, we have 5.9 times less NZER_ORIG.
Table 4.
The number of nonzero elements in each layer (from the 1st to the 13th) for the 45% pruning rate on VGG-16.
- The computational benefit of the proposed scheme: In order to investigate possible impact of the proposed scheme on the computation and energy/power efficiencies, we tried to find out what percentage of the total multiplications can be skipped. To find the number of the multiplications that can be skipped, we counted the number of required multiplications in the convolutional layers in our deep learning models and checked the output of the multiplications. Since the ‘zero’ outputs of the multiplications imply that any of both input is zero, we can count the number of the multiplications that can be skipped without consuming circuit switching power/energy with a specially designed multiplier that will be discussed in the following section. Please note that one input operand of the multiplications comes from convolution filters while the other input operand comes from feature maps.
Figure 9 shows the estimated percentage of the skipped multiplications among the total number of multiplications. As you can see in the figure, in the proposed zero-keep pruning, 82% of multiplications in average over all the convolution layers can be skipped while less than 4.1% of multiplications are only skipped in typical random pruning. Compared to the random pruning, 19.9 times more multiplications can be skipped for accelerating performance and saving power/energy consumption. However, the benefits of the actual time performance and power/energy consumption can be evaluated with the detailed hardware design and implementation of all the deep learning models in ASIC or FPGA. Recently, hardware architectures for exploiting zeros in filters and feature maps have been proposed and designed to improve the efficiency of deep learning accelerators [27,28]. Such hardware architecture can work very efficiently with the proposed approach since our approach maximizes zeros in filters.
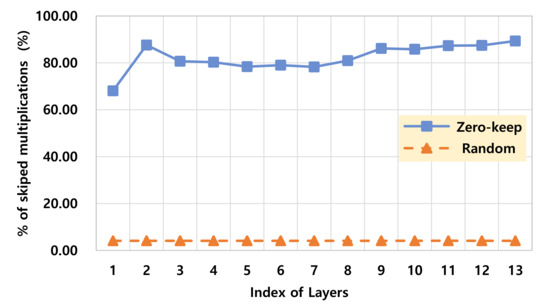
Figure 9.
The ratio of skipped multiplications in each layer for the 45% pruning rate on VGG-16.
The primary goal of current work is the new proposition of maximizing zeros in deep learning filters for improving the efficiency of utilizing time and power-consuming multiplications in deep learning accelerators. Actual design and implementation of the proposed scheme including all the circuit designs of deep learning model components will be a promising future work together with detailed evaluation of time and power/energy evaluations.
4. Discussion: Zero-Skip Multiplication
Our approach tries to maximize the number of zeros in filter channels by pruning channels with small numbers of zeros. Consequently, in order to maximize the benefit of the zero-keep filter pruning, we have to devise a deep learning acceleration architecture where any multiplication with a zero value on any of its two inputs is skipped (so, there will be no switching activity incurring power/energy consumption in the multiplier when the skip happens) for minimizing energy/power consumption.
Figure 10 shows a circuit architecture for a zero-skip multiplier. The ZD (zero detection) circuits in the figure check incoming data values and detect zero values. When either of the ZD circuits detect a zero value, a “skip” signal is asserted in the high direction. Then, the flip-flops for capturing the incoming data are disabled by the asserted “skip” signal. So, the flip-flops do not capture the data even at the rising clock edges. In consequence, the newly incoming input values for the multiplier are not changed and there will be no dynamic switching activity in the multiplier. It leads to energy and power savings.
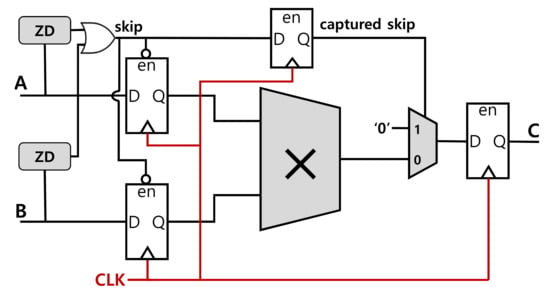
Figure 10.
A circuit architecture for the zero-skip multiplier.
In the proposed zero-skip multiplier, the “skip” signal has to be saved into a single bit flip-flop and then the captured skip signal is used to select the predefined result of the multiplication, ‘0’, as the output of the multiplier when the skip signal is high.
Figure 11 shows the timing simulation results for the proposed zero-skip multiplier. In the waveform, two input signals, A and B, are represented by the signals, a[31:0] and b[31:0]. The output signal, C, is represented by c[31:0]. If both of the input signal values are not zero, then typical multiplication happens. However, when any of the two inputs are zero (Case 1: A = B = 0 and Case 2: B = 0 in Figure 11), zero detection circuits detect a zero value (ZD_a for A and ZD_b for B) and the “captured_skip” signal goes high. When the “captured_skip” signal is high, there is no switching for the multiplications and the multiplier keeps the previous output (mul_result_comb) as a result. Although the multiplier keeps the previous output in those cases, the actual output becomes zero because the captured_skip selects ‘0’ as an output by controlling the two input MUXs given in Figure 10. The simulation was conducted with a Xilinx Vivado design tool (post-implementation timing simulation with the device setting of a Kintex-7 FPGA).
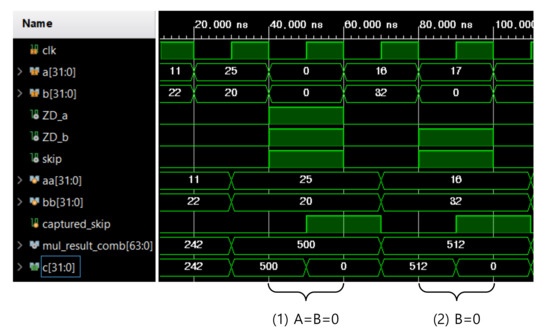
Figure 11.
Timing simulation results for the zero-skip multiplier.
The incoming data pairs (A and B in the figure) come from on-chip buffers storing “feature map data” and “filter weights”. The zero detection circuit can be implemented efficiently in a NAND-NOR tree structure. To further improve energy/power/performance, multiple zero-skip multipliers can be utilized in an accelerator with corresponding multiple on-chip buffer banks. The detailed validation of the circuit architecture together with its power and energy evaluations are our future work.
5. Conclusions
In this paper, we propose a new filter pruning method, “zero-keep filter pruning”, for computationally efficient deep learning inference. The basic idea of the scheme comes from the research result that filter pruning schemes do not significantly affect accuracy performance when they are applied to prune filters. With this observation, we focus on the minimizing non-zero weight elements (maximizing zero weight elements) in filters in order to improve computational and energy efficiency of a deep learning inference. When our proposed zero-keep filter pruning is compared with a random filter pruning scheme, experiment results show that the proposed method can achieve the almost same performance with many more zero elements. With the higher number of zero elements in filters, the large amount of power/energy consumption incurred by high multiplication computation is expected to be reduced significantly by using the zero-skip multiplier. Future work is detailed simulation or measurement of the actual performance and energy consumption of the proposed zero-keep filter pruning by extending the discussed multiplier designs.
Author Contributions
The individual contributions of the authors are as follows: conceptualization, J.-G.L. and Y.-W.K.; data curation, Y.W.; methodology, J.-G.L. and Y.-W.K.; software, Y.W.; investigation, Y.W.; validation, J.-G.L. and Y.-W.K.; writing—original draft preparation, Y.-W.K. and J.-G.L.; writing—review and editing, J.-G.L. and Y.-W.K.; funding acquisition, J.J. and D.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been supported in part by the National Research Foundation through the Basic Science Research Program under Grant 2018R1D1A1B07043399 and in part by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2018R1D1A1B07050931).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Dong, X.; Yang, Y. Searching for a robust neural architecture in four gpu hours. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1761–1770. [Google Scholar]
- Greenspan, H.; van Ginneken, B.; Summers, R.M. Guest editorial deep learning in medical imaging: Overview and future promise of an exciting new technique. IEEE Trans. Med. Imaging 2016, 35, 1153–1159. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, K.Q.; Maaten, L. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1–4. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 2234–2240. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Online Conference, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Mittal, D.; Bhardwaj, S.; Khapra, M.M.; Ravindran, B. Recovering from random pruning: On the plasticity of deep convolutional neural networks. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 848–857. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient transfer learning. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–17. [Google Scholar]
- Molchanov, P.; Mallya, A.; Tyree, S.; Frosio, I.; Kautz, J. Importance estimation for neural network pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11264–11272. [Google Scholar]
- Liang, T.; Glossner, J.; Wang, L.; Shi, S. Pruning and Quantization for Deep Neural Network Acceleration: A Survey. arXiv 2021, arXiv:2101.09671. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both weights and connections for efficient neural network. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient ConvNets. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Hu, H.; Peng, R.; Tai, Y.W.; Tang, C.K. Network trimming: A datadriven neuron pruning approach towards efficient deep architectures. arXiv 2016, arXiv:1607.03250. [Google Scholar]
- Zhou, Z.; Zhou, W.; Li, H.; Hong, R. Online filter clustering and pruning for efficient convnets. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 11–15. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4340–4349. [Google Scholar]
- Lin, M.; Ji, R.; Wang, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. HRank: Filter pruning using high-rank feature map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Online Conference, 14–19 June 2020; pp. 1529–1538. [Google Scholar]
- Meng, F.; Cheng, H.; Li, K.; Luo, H.; Guo, X.; Lu, G.; Sun, X. Pruning Filter in Filter. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Online Conference, 6–14 December 2020. [Google Scholar]
- Frankle, J.; Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the Value of Network Pruning. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, Y.; Zhang, X.; Xie, L.; Zhou, J.; Su, H.; Zhang, B.; Hu, X. Pruning from Scratch. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Movva, R.; Frankle, J.; Carbin, M. Studying the Consistency and Composability of Lottery Ticket Pruning Masks. In Proceedings of the Workshop on International Conference on Learning Representations (ICLR), Online Conference, 8 May 2021. [Google Scholar]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization methods for large-scale machine learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations(ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Dozat, T. Incorporating Nesterov momentum into Adam. In Proceedings of the International Conference on Learning Representations(ICLR) Workshop Track, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–19. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. In Proceedings of the International Conference on Learning Representations(ICLR), New Orleans, LA, USA, 6–9 May 2019; pp. 1–19. [Google Scholar]
- Kim, D.; Ahn, J.; Yoo, S. ZeNA: Zero-Aware Neural Network Accelerator. IEEE Des. Test 2018, 35, 39–46. [Google Scholar] [CrossRef]
- Ganesan, V.; Sen, S.; Kumar, P.; Gala, N.; Veezhinathan, K.; Raghunathan, A. Sparsity-Aware Caches to Accelerate Deep Neural Networks. In Proceedings of the Design, Automation and Test in Europe Conference and Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 85–90. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).