
Identification of the Factors That Influence University Learning with Low-Code/No-Code Artificial Intelligence Techniques




Abstract
1. Introduction
2. Materials and Methods
2.1. Theoretical Foundation
2.1.1. Remote Education Model
2.1.2. Artificial Intelligence in Education
2.1.3. Low-Code/No-Code Artificial Intelligence Techniques
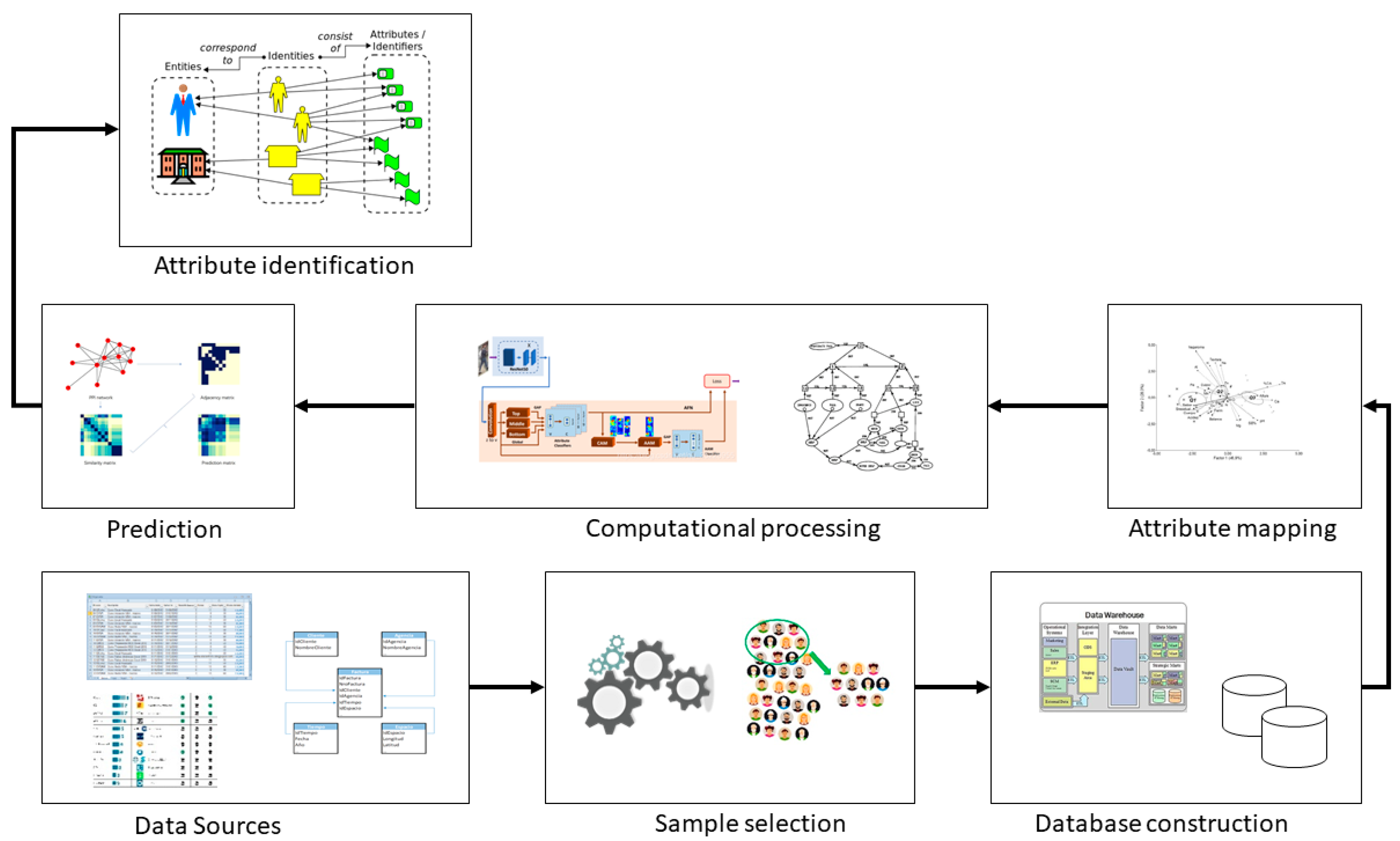
2.2. Analysis of the Factors That Influence Learning with the Use of Artificial Intelligence
- Data sources (surveys, xlms, databases)
- Sample selection
- Database construction
- Attribute mapping
- Computational processing
- Academic performance prediction
- Identification of influential attributes
- 1: never
- 2: rarely
- 3: sometimes
- 4: almost always
- 5: always.
- n: dimension of the sample.
- Z: confidence level,
- p: variation of success.
- q: variation of failure.
- M: number of students in the undergraduate program.
- e: sample error.
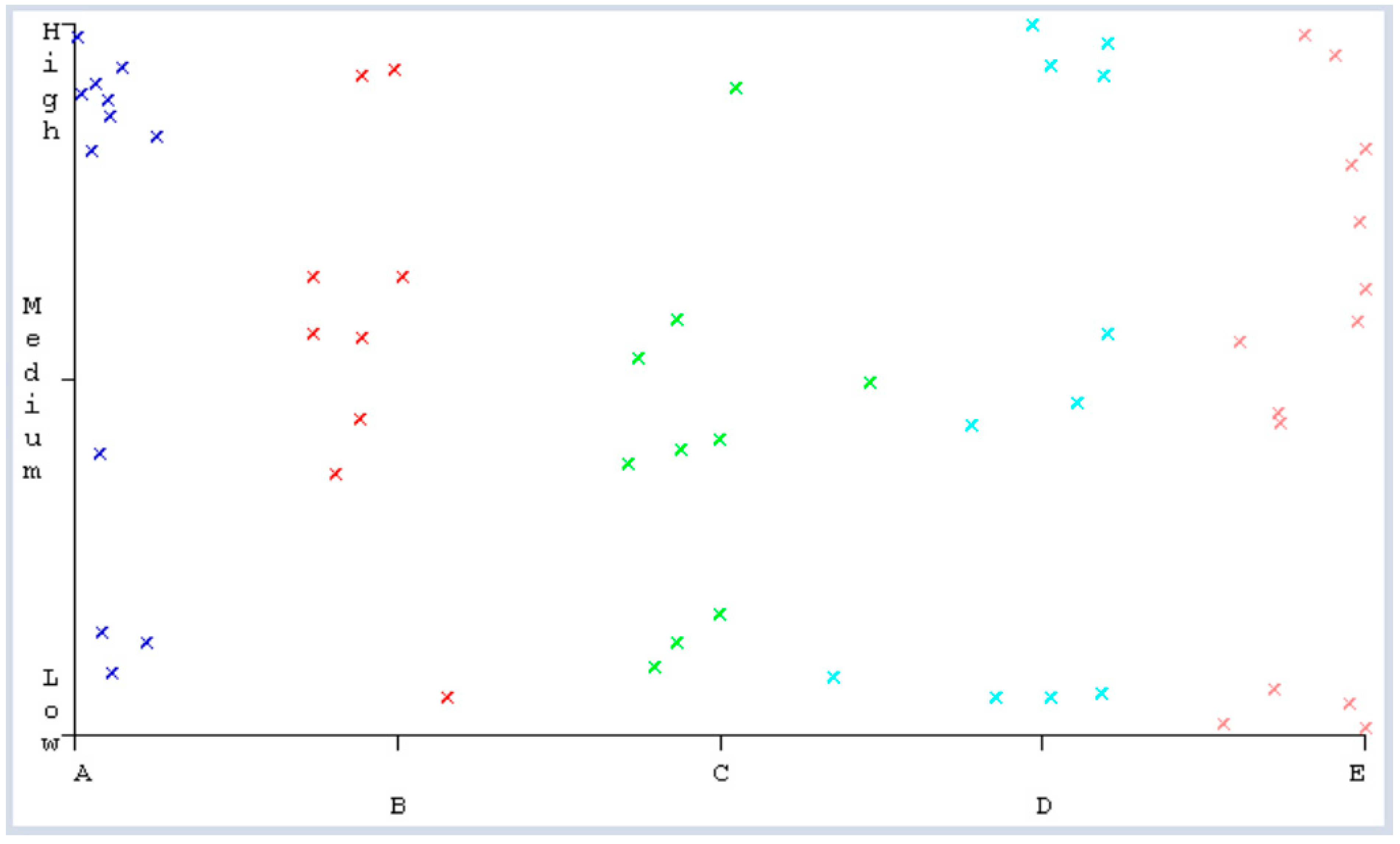
- A: Average between (8–10)
- B: average between (<8–6)
- C: average between (<6–4)
- D: average between (<4–2)
- E: average between (<2–0).
3. Results
- N = 320 is the total number of students who are part of the computer engineering academic program
- Z = 1645 confidence level.
- p = 0.5
- q = 0.5
- e = 0.10 (10% sampling error, for a 90% interval).
- Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
- Relation: student
- Instances: 21
- Attributes: 6
- Income_level
- ○
- Frequency-in-the-study
- ○
- Interaction
- ○
- Padagogy
- ○
- Academic_average
- ○
- Learning
- Test mode: 10-fold cross-validation
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Villegas-Ch, W.; Román-Cañizares, M.; Palacios-Pacheco, X. Improvement of an Online Education Model with the Integration of Machine Learning and Data Analysis in an LMS. Appl. Sci. 2020, 10, 5371. [Google Scholar] [CrossRef]
- Janssen, M.; van der Voort, H.; Wahyudi, A. Factors influencing big data decision-making quality. J. Bus. Res. 2017, 70, 338–345. [Google Scholar] [CrossRef]
- Guarin, C.E.L.; Guzman, E.L.; Gonzalez, F.A. A Model to Predict Low Academic Performance at a Specific Enrollment Using Data Mining. IEEE Rev. Iberoam. Tecnol. Aprendiz. 2015, 10, 119–125. [Google Scholar] [CrossRef]
- Bahasoan, A.N.; Ayuandiani, W.; Mukhram, M. Aswar Rahmat Effectiveness of Online Learning In Pandemic Covid-19. Int. J. Sci. Technol. Manag. 2020, 1, 100–106. [Google Scholar] [CrossRef]
- Cohen, J. Parents as Educational Models and Definers. J. Marriage Fam. 2016, 49, 339–351. [Google Scholar] [CrossRef]
- Hodges, C.B. Suggestions for the design of e-learning environments to enhance learner self-efficacy. IADIS Int. Conf. Cogn. Explor. Learn. Digit. Age CELDA 2013, 2013, 10–16. [Google Scholar]
- Horton, J. Identifying At-Risk Factors That Affect College Student Success. Int. J. Process Educ. 2015, 7, 83–102. [Google Scholar]
- Sidpra, J.; Gaier, C.; Reddy, N.; Kumar, N.; Mirsky, D.; Mankad, K. Sustaining education in the age of COVID-19: A survey of synchronous web-based platforms. Quant. Imaging Med. Surg. 2020, 10, 1422–1427. [Google Scholar] [CrossRef]
- Li, H.; Liu, S.-M.; Yu, X.-H.; Tang, S.-L.; Tang, C.-K. Coronavirus disease 2019 (COVID-19): Current status and future perspectives. Int. J. Antimicrob. Agents 2020, 55, 105951. [Google Scholar] [CrossRef]
- Green, J.K.; Burrow, M.S.; Carvalho, L. Designing for Transition: Supporting Teachers and Students Cope with Emergency Remote Education. Postdigital Sci. Educ. 2020, 2, 906–922. [Google Scholar] [CrossRef]
- Stroeva, O.; Zviagintceva, Y.; Tokmakova, E.; Petrukhina, E.; Polyakova, O. Application of remote technologies in education. Int. J. Educ. Manag. 2019, 33, 503–510. [Google Scholar] [CrossRef]
- Hernandez-Ortega, J.; Daza, R.; Morales, A.; Fierrez, J.; Ortega-Garcia, J. edBB: Biometrics and behavior for assessing remote education. arXiv 2019, arXiv:1912.04786. [Google Scholar]
- Picciano, A.G. The Evolution of Big Data and Learning Analytics in American Higher Education. J. Asynchronous Learn. Netw. 2012, 16, 9–20. [Google Scholar] [CrossRef]
- Lichtenstein, S.; Nguyen, L.; Hunter, A. Issues in IT Service-Oriented Requirements Engineering. Australas. J. Inf. Syst. 2005, 13, 176–191. [Google Scholar] [CrossRef]
- AlQurashi, E. Self-Efficacy In Online Learning Environments: A Literature Review. Contemp. Issues Educ. Res. (CIER) 2016, 9, 45–52. [Google Scholar] [CrossRef]
- Rios-Campos, C.; Campos, P.R.; Delgado, F.C.; Ramírez, I.M.; Hubeck, J.A.; Fernández, C.J.; Vega, Y.C.; Méndez, M.C. Covid-19 and Universities in Latin America. South Fla. J. Dev. 2021, 2, 577–585. [Google Scholar] [CrossRef]
- Quispe-Prieto, S.; Cavalcanti-Bandos, M.F.; Caipa-Ramos, M.; Paucar-Caceres, A.; Rojas-Jiménez, H.H. A Systemic Framework to Evaluate Student Satisfaction in Latin American Universities under the COVID-19 Pandemic. Systems 2021, 9, 15. [Google Scholar] [CrossRef]
- Sokkhey, P.; Okazaki, T. Hybrid Machine Learning Algorithms for Predicting Academic Performance. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 32–41. [Google Scholar] [CrossRef]
- Rivas, A.; González-Briones, A.; Hernández, G.; Prieto, J.; Chamoso, P. Artificial neural network analysis of the academic performance of students in virtual learning environments. Neurocomputing 2021, 423, 713–720. [Google Scholar] [CrossRef]
- Hellas, A.; Ihantola, P.; Petersen, A.; Ajanovski, V.V.; Gutica, M.; Hynninen, T.; Knutas, A.; Leinonen, J.; Messom, C.; Liao, S.N. Predicting academic performance: A systematic literature review. In Proceedings Companion of the 23rd Annual ACM Conference on Innovation and Technology in Computer Science Education, Larnaca, Cyprus, 2–4 July 2018; pp. 175–199. [Google Scholar] [CrossRef]
- Osmanbegovic, E.; Suljic, M. Data mining approach for predicting student performance. J. Econ. Bus. 2012, 10, 3–12. [Google Scholar]
- Haihao, L.; Rahul, M. Randomized Gradient Boosting Machine. SIAM J. Optim. 2018, 30, 2780–2808. [Google Scholar]
- Tchoubar, T.; Sexton, T.R.; Scarlatos, L.L. Role of Digital Fluency and Spatial Ability in Student Experience of Online Learning Environments. Intell. Comput. 2019, 1, 251–264. [Google Scholar] [CrossRef]
- Xu, A.; Liu, Z.; Guo, Y.; Sinha, V.; Akkiraju, R. A New Chatbot for Customer Service on Social Media. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 3506–3510. [Google Scholar]
- Chen, C. Personalized E-learning system with self-regulated learning assisted mechanisms for promoting learning performance. Expert Syst. Appl. 2009, 36, 8816–8829. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Gorham, J.; Zakahi, W.R. A comparison of teacher and student perceptions of immediacy and learning: Monitoring process and product. Commun. Educ. 1990, 39, 354–368. [Google Scholar] [CrossRef]
- Hasan, R.; Palaniappan, S.; Raziff, A.R.A.; Mahmood, S.; Sarker, K.U. Student Academic Performance Prediction by using Decision Tree Algorithm. In Proceedings of the 2018 4th International Conference on Computer and Information Sciences (ICCOINS), Jalandhar, India, 30–31 August 2018; pp. 1–5. [Google Scholar]
- Daniel, S.J. Education and the COVID-19 pandemic. Prospects 2020, 49, 91–96. [Google Scholar] [CrossRef] [PubMed]
- Humanante-Ramos, P.; García-Peñalvo, F.J.; Conde-González, M. Entornos personales de aprendizaje móvil: Una revisión sistemática de la literatura. RIED. Rev. Iberoam. Educ. Distancia 2017, 20, 73–92. [Google Scholar] [CrossRef]
- Zhou, L.; Wu, S.; Zhou, M.; Li, F. ’School’s Out, But Class’ On’, The Largest Online Education in the World Today: Taking China’s Practical Exploration During The COVID-19 Epidemic Prevention and Control As an Example. SSRN Electron. J. 2020, 4, 501–509. [Google Scholar] [CrossRef]
- Reinoso, G.G.L.; Barzola, K.M.; Caguana, D.M.; Lopez, R.P.; Lopez, J.C.P. M-learning, a path to ubiquitous learning in higher education in Ecuador. RISTI-Rev. Iber. Sist. Tecnol. Inf. 2019, 2019, 47–59. [Google Scholar]
- Huang, Y.-M.; Liang, T.-H.; Su, Y.-N.; Chen, N.-S. Empowering personalized learning with an interactive e-book learning system for elementary school students. Educ. Technol. Res. Dev. 2012, 60, 703–722. [Google Scholar] [CrossRef]
- Casañ, G.A.; Cervera, E.; Moughlbay, A.A.; Alemany, J.; Martinet, P. ROS-based online robot programming for remote education and training. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; IEEE: New York, NY, USA; Volume 2015-June, pp. 6101–6106. [Google Scholar]
- Lopatovska, I.; Williams, H. Personification of the amazon alexa: BFF or a mindless companion? In Proceedings of the 2018 conference on Human Information Interaction & Retrieval, New Brunswick, NJ, USA, 11–15 March 2018; pp. 265–268. [Google Scholar]
- Villegas-Ch, W.; Arias-Navarrete, A.; Palacios-Pacheco, X. Proposal of an Architecture for the Integration of a Chatbot with Artificial Intelligence in a Smart Campus for the Improvement of Learning. Sustainability 2020, 12, 1500. [Google Scholar] [CrossRef]
- Soh, J.; Singh, P. Introduction to Azure Machine Learning. In Data Science Solutions on Azure; Soh, J., Singh, P., Eds.; In Professional and Applied Computing; Apress: Berkeley, CA, USA, 2020; pp. 117–148. ISBN 978-1-4842-6405-8. [Google Scholar]
- Duriqi, R.; Raca, V.; Cico, B. Comparative analysis of classification algorithms on three different datasets using WEKA. In Proceedings of the 2016 5th Mediterranean Conference on Embedded Computing (MECO), Bar, Montenegro, 12–16 June 2016; pp. 335–338. [Google Scholar]
- Xiao, J.; Wang, M.; Jiang, B.; Li, J. A personalized recommendation system with combinational algorithm for online learning. J. Ambient. Intell. Humaniz. Comput. 2018, 9, 667–677. [Google Scholar] [CrossRef]
- Gramegna, A.; Giudici, P. Why to Buy Insurance? An Explainable Artificial Intelligence Approach. Risks 2020, 8, 137. [Google Scholar] [CrossRef]
- Bhalerao, S.; Kadam, P. Sample size calculation. Int. J. Ayurveda Res. 2010, 1, 55–57. [Google Scholar] [CrossRef] [PubMed]
- Gogtay, N.J.; Thatte, U.M. Principles of Correlation Analysis. J. Assoc. Physicians India 2017, 65, 78–81. [Google Scholar]
- Holmes, G.; Donkin, A.; Witten, I.H. WEKA: A machine learning workbench. In Proceedings of the Australian and New Zealand Conference on Intelligent Information Systems–Proceedings, Brisbane, Australia, 29 November–2 December 1994; pp. 357–361. [Google Scholar]
- Watson, J. Blending Learning: The Convergence of Online and Face-to-Face Education. Anal. Chim. Acta 2006, 572, 113–120. [Google Scholar]
- Wang, T.-H. Developing an assessment-centered e-Learning system for improving student learning effectiveness. Comput. Educ. 2014, 73, 189–203. [Google Scholar] [CrossRef]
- Hill, J.R.; Hannafin, M.J. Teaching and learning in digital environments: The resurgence of resource-based learning. Educ. Technol. Res. Dev. 2001, 49, 37–52. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Type of Data |
|---|---|
| Students (a) | Numeric |
| Income level (b) | Text -Numeric |
| Frequency in the study (c) | Numeric |
| Frequency in academic activities (d) | Numeric |
| Frequency at work (e) | Numeric |
| Environment (f) | Numeric |
| Family atmosphere (g) | Numeric |
| Educational resources (h) | Numeric |
| Interaction (i) | Numeric |
| Schedules (j) | Numeric |
| Padagogy (k) | Numeric |
| Academic average (l) | Numeric |
| Approves (m) | Text |
| Learning (n) | Text |
| Dependent variable (o) | Numeric |
| A | B | B-1 | C | D | E | F | G | H | I | J | K | L | M | N | O |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Low | 1 | 3 | 5 | 3 | 0 | 3 | 3 | 2 | 1 | 5 | 1 | False | E | 1 |
| 2 | Medium | 2 | 4 | 4 | 4 | 3 | 2 | 2 | 1 | 0 | 3 | 4 | False | C | 3 |
| 3 | High | 3 | 4 | 1 | 5 | 0 | 3 | 0 | 5 | 2 | 1 | 8 | True | A | 5 |
| 4 | High | 3 | 1 | 5 | 3 | 3 | 4 | 0 | 0 | 5 | 1 | 0 | False | E | 1 |
| 5 | Medium | 2 | 1 | 4 | 4 | 5 | 2 | 4 | 1 | 1 | 2 | 7 | True | B | 4 |
| 6 | Medium | 2 | 1 | 4 | 2 | 1 | 5 | 5 | 1 | 5 | 4 | 6 | True | B | 4 |
| 7 | High | 3 | 5 | 4 | 0 | 2 | 3 | 4 | 4 | 1 | 5 | 8 | True | A | 5 |
| 8 | Medium | 2 | 4 | 0 | 5 | 5 | 4 | 5 | 0 | 1 | 4 | 5 | False | C | 3 |
| 9 | High | 3 | 0 | 4 | 2 | 1 | 1 | 2 | 5 | 2 | 1 | 2 | False | D | 2 |
| 10 | Low | 1 | 4 | 1 | 3 | 2 | 5 | 1 | 4 | 3 | 0 | 2 | False | D | 2 |
| 11 | Low | 1 | 0 | 4 | 3 | 0 | 0 | 3 | 0 | 3 | 1 | 0 | False | E | 1 |
| 12 | Low | 1 | 4 | 5 | 0 | 3 | 3 | 1 | 3 | 5 | 2 | 1 | False | E | 1 |
| 13 | Medium | 2 | 0 | 2 | 2 | 1 | 0 | 5 | 1 | 1 | 1 | 0 | False | E | 1 |
| 14 | High | 3 | 3 | 1 | 4 | 5 | 0 | 0 | 1 | 5 | 5 | 6 | True | B | 4 |
| 15 | High | 3 | 3 | 4 | 2 | 2 | 3 | 3 | 5 | 2 | 4 | 10 | True | A | 5 |
| 16 | Medium | 2 | 3 | 2 | 5 | 1 | 1 | 2 | 0 | 4 | 0 | 0 | False | E | 1 |
| 17 | Low | 1 | 4 | 4 | 3 | 4 | 4 | 3 | 2 | 3 | 2 | 5 | False | C | 3 |
| 18 | High | 3 | 5 | 5 | 3 | 5 | 2 | 1 | 3 | 5 | 2 | 8 | True | A | 5 |
| 19 | Medium | 2 | 5 | 1 | 4 | 0 | 0 | 5 | 2 | 1 | 3 | 9 | True | A | 5 |
| 20 | Low | 1 | 3 | 2 | 2 | 5 | 4 | 1 | 2 | 3 | 4 | 9 | True | A | 5 |
| 21 | Medium | 2 | 0 | 2 | 2 | 5 | 4 | 5 | 1 | 1 | 3 | 4 | False | C | 3 |
| 22 | Medium | 3 | 2 | 2 | 3 | 4 | 3 | 5 | 1 | 2 | 2 | 4 | False | C | 3 |
| 23 | High | 2 | 2 | 4 | 1 | 5 | 4 | 2 | 3 | 3 | 4 | 8 | True | A | 5 |
| 24 | Medium | 1 | 1 | 2 | 5 | 5 | 1 | 4 | 3 | 1 | 2 | 1 | False | E | 1 |
| 25 | Low | 1 | 1 | 1 | 5 | 4 | 1 | 5 | 4 | 5 | 5 | 3 | False | D | 2 |
| 26 | Low | 1 | 1 | 3 | 3 | 4 | 4 | 3 | 2 | 5 | 1 | 1 | False | E | 1 |
| 27 | Low | 2 | 4 | 1 | 4 | 3 | 2 | 3 | 3 | 2 | 1 | 4 | False | C | 3 |
| 28 | Medium | 2 | 5 | 3 | 1 | 2 | 2 | 2 | 3 | 2 | 1 | 1 | False | E | 1 |
| 29 | Medium | 3 | 1 | 2 | 2 | 4 | 1 | 1 | 3 | 4 | 4 | 6 | True | B | 4 |
| 30 | High | 3 | 2 | 3 | 1 | 1 | 5 | 2 | 1 | 3 | 4 | 5 | False | C | 3 |
| 31 | High | 3 | 4 | 4 | 4 | 5 | 5 | 1 | 4 | 1 | 5 | 6 | True | B | 4 |
| 32 | High | 1 | 1 | 2 | 3 | 3 | 5 | 2 | 5 | 3 | 1 | 2 | False | D | 2 |
| 33 | Low | 3 | 5 | 5 | 4 | 3 | 3 | 5 | 5 | 2 | 2 | 9 | True | A | 5 |
| 34 | High | 1 | 1 | 4 | 2 | 5 | 4 | 5 | 2 | 4 | 4 | 3 | False | D | 2 |
| 35 | Low | 1 | 2 | 2 | 5 | 1 | 3 | 5 | 2 | 3 | 3 | 4 | False | C | 3 |
| 36 | Low | 2 | 2 | 5 | 5 | 1 | 3 | 2 | 5 | 2 | 2 | 7 | True | B | 4 |
| 37 | Medium | 3 | 4 | 5 | 3 | 3 | 1 | 2 | 1 | 5 | 3 | 7 | True | B | 4 |
| 38 | High | 3 | 5 | 1 | 4 | 5 | 3 | 1 | 5 | 4 | 2 | 8 | True | A | 5 |
| 39 | High | 3 | 5 | 1 | 1 | 3 | 4 | 5 | 5 | 3 | 5 | 8 | True | A | 5 |
| 40 | High | 3 | 5 | 5 | 4 | 3 | 3 | 1 | 4 | 2 | 2 | 3 | False | D | 2 |
| 41 | High | 2 | 2 | 2 | 4 | 1 | 2 | 4 | 5 | 1 | 1 | 1 | False | E | 1 |
| 42 | Medium | 2 | 1 | 2 | 4 | 2 | 2 | 2 | 2 | 3 | 2 | 1 | False | E | 1 |
| 43 | Medium | 2 | 5 | 5 | 2 | 5 | 1 | 2 | 3 | 5 | 5 | 6 | True | B | 4 |
| 44 | Medium | 2 | 1 | 3 | 1 | 1 | 3 | 4 | 1 | 3 | 2 | 3 | False | D | 2 |
| 45 | Medium | 1 | 1 | 5 | 2 | 5 | 5 | 1 | 4 | 3 | 3 | 5 | False | C | 3 |
| 46 | Low | 3 | 5 | 3 | 4 | 1 | 1 | 3 | 5 | 4 | 5 | 8 | True | A | 5 |
| 47 | High | 2 | 1 | 5 | 1 | 2 | 5 | 5 | 2 | 2 | 3 | 1 | False | E | 1 |
| 48 | Medium | 1 | 2 | 3 | 2 | 1 | 3 | 4 | 2 | 2 | 5 | 2 | False | D | 2 |
| 49 | Low | 2 | 1 | 4 | 4 | 4 | 5 | 4 | 2 | 2 | 3 | 3 | False | D | 2 |
| 50 | Medium | 2 | 4 | 4 | 5 | 4 | 5 | 5 | 2 | 3 | 1 | 3 | False | D | 2 |
| 51 | Medium | 2 | 1 | 1 | 1 | 2 | 3 | 4 | 5 | 3 | 3 | 7 | True | B | 4 |
| 52 | Medium | 1 | 1 | 3 | 1 | 3 | 1 | 3 | 5 | 4 | 1 | 5 | False | C | 3 |
| 53 | Low | 3 | 5 | 3 | 5 | 4 | 2 | 4 | 1 | 2 | 1 | 2 | False | D | 2 |
| 54 | High | 3 | 1 | 2 | 5 | 2 | 1 | 5 | 2 | 2 | 3 | 1 | False | E | 1 |
| 55 | High | 3 | 2 | 3 | 4 | 1 | 5 | 5 | 5 | 2 | 4 | 10 | True | A | 5 |
| 56 | High | 3 | 4 | 1 | 4 | 5 | 5 | 4 | 1 | 2 | 5 | 1 | False | E | 1 |
| Corr_coef | 0.40 | 0.41 | −0.02 | −0.07 | 0.13 | 0.04 | −0.10 | 0.40 | 0.06 | 0.40 | 0.98 |
| A | B | C | I | K | L | N |
|---|---|---|---|---|---|---|
| 1 | Low | 3 | 2 | 5 | 1 | E |
| 2 | Medium | 4 | 1 | 3 | 4 | C |
| 3 | High | 4 | 5 | 1 | 8 | A |
| 4 | High | 1 | 0 | 1 | 0 | E |
| 5 | Medium | 1 | 1 | 2 | 7 | B |
| 6 | Medium | 1 | 1 | 4 | 6 | B |
| 7 | High | 5 | 4 | 5 | 8 | A |
| 8 | Medium | 4 | 0 | 4 | 5 | C |
| 9 | High | 0 | 5 | 1 | 2 | D |
| 10 | Low | 4 | 4 | 0 | 2 | D |
| 11 | Low | 0 | 0 | 1 | 0 | E |
| 12 | Low | 4 | 3 | 2 | 1 | E |
| 13 | Medium | 0 | 1 | 1 | 0 | E |
| 14 | High | 3 | 1 | 5 | 6 | B |
| 15 | High | 3 | 5 | 4 | 10 | A |
| 16 | Medium | 3 | 0 | 0 | 0 | E |
| 17 | Low | 4 | 2 | 2 | 5 | C |
| 18 | High | 5 | 3 | 2 | 8 | A |
| 19 | Medium | 5 | 2 | 3 | 9 | A |
| 20 | Low | 3 | 2 | 4 | 9 | A |
| 21 | Medium | 0 | 1 | 3 | 4 | C |
| 22 | Medium | 2 | 1 | 2 | 4 | C |
| 23 | High | 2 | 3 | 4 | 8 | A |
| 24 | Medium | 1 | 3 | 2 | 1 | E |
| 25 | Low | 1 | 4 | 5 | 3 | D |
| 26 | Low | 1 | 2 | 1 | 1 | E |
| 27 | Low | 4 | 3 | 1 | 4 | C |
| 28 | Medium | 5 | 3 | 1 | 1 | E |
| 29 | Medium | 1 | 3 | 4 | 6 | B |
| 30 | High | 2 | 1 | 4 | 5 | C |
| 31 | High | 4 | 4 | 5 | 6 | B |
| 32 | High | 1 | 5 | 1 | 2 | D |
| 33 | Low | 5 | 5 | 2 | 9 | A |
| 34 | High | 1 | 2 | 4 | 3 | D |
| 35 | Low | 2 | 2 | 3 | 4 | C |
| 36 | Low | 2 | 5 | 2 | 7 | B |
| 37 | Medium | 4 | 1 | 3 | 7 | B |
| 38 | High | 5 | 5 | 2 | 8 | A |
| 39 | High | 5 | 5 | 5 | 8 | A |
| 40 | High | 5 | 4 | 2 | 3 | D |
| 41 | High | 2 | 5 | 1 | 1 | E |
| 42 | Medium | 1 | 2 | 2 | 1 | E |
| 43 | Medium | 5 | 3 | 5 | 6 | B |
| 44 | Medium | 1 | 1 | 2 | 3 | D |
| 45 | Medium | 1 | 4 | 3 | 5 | C |
| 46 | Low | 5 | 5 | 5 | 8 | A |
| 47 | High | 1 | 2 | 3 | 1 | E |
| 48 | Medium | 2 | 2 | 5 | 2 | D |
| 49 | Low | 1 | 2 | 3 | 3 | D |
| 50 | Medium | 4 | 2 | 1 | 3 | D |
| 51 | Medium | 1 | 5 | 3 | 7 | B |
| 52 | Medium | 1 | 5 | 1 | 5 | C |
| 53 | Low | 5 | 1 | 1 | 2 | D |
| 54 | High | 1 | 2 | 3 | 1 | E |
| 55 | High | 2 | 5 | 4 | 10 | A |
| 56 | High | 4 | 1 | 5 | 1 | E |
| Corr_coef | 0.40 | 0.41 | 0.40 | 0.40 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villegas-Ch., W.; García-Ortiz, J.; Sánchez-Viteri, S. Identification of the Factors That Influence University Learning with Low-Code/No-Code Artificial Intelligence Techniques. Electronics 2021, 10, 1192. https://doi.org/10.3390/electronics10101192
Villegas-Ch. W, García-Ortiz J, Sánchez-Viteri S. Identification of the Factors That Influence University Learning with Low-Code/No-Code Artificial Intelligence Techniques. Electronics. 2021; 10(10):1192. https://doi.org/10.3390/electronics10101192
Chicago/Turabian StyleVillegas-Ch., William, Joselin García-Ortiz, and Santiago Sánchez-Viteri. 2021. "Identification of the Factors That Influence University Learning with Low-Code/No-Code Artificial Intelligence Techniques" Electronics 10, no. 10: 1192. https://doi.org/10.3390/electronics10101192
APA StyleVillegas-Ch., W., García-Ortiz, J., & Sánchez-Viteri, S. (2021). Identification of the Factors That Influence University Learning with Low-Code/No-Code Artificial Intelligence Techniques. Electronics, 10(10), 1192. https://doi.org/10.3390/electronics10101192