Layer-Wise Network Compression Using Gaussian Mixture Model



Abstract
:1. Introduction
2. Related Works
3. The Proposed Method
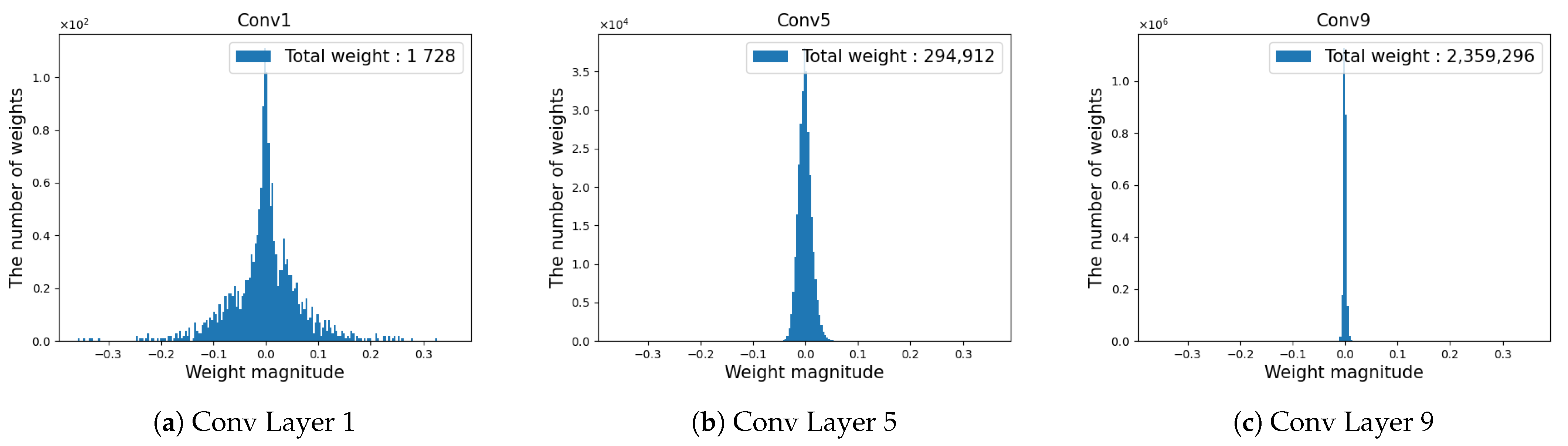
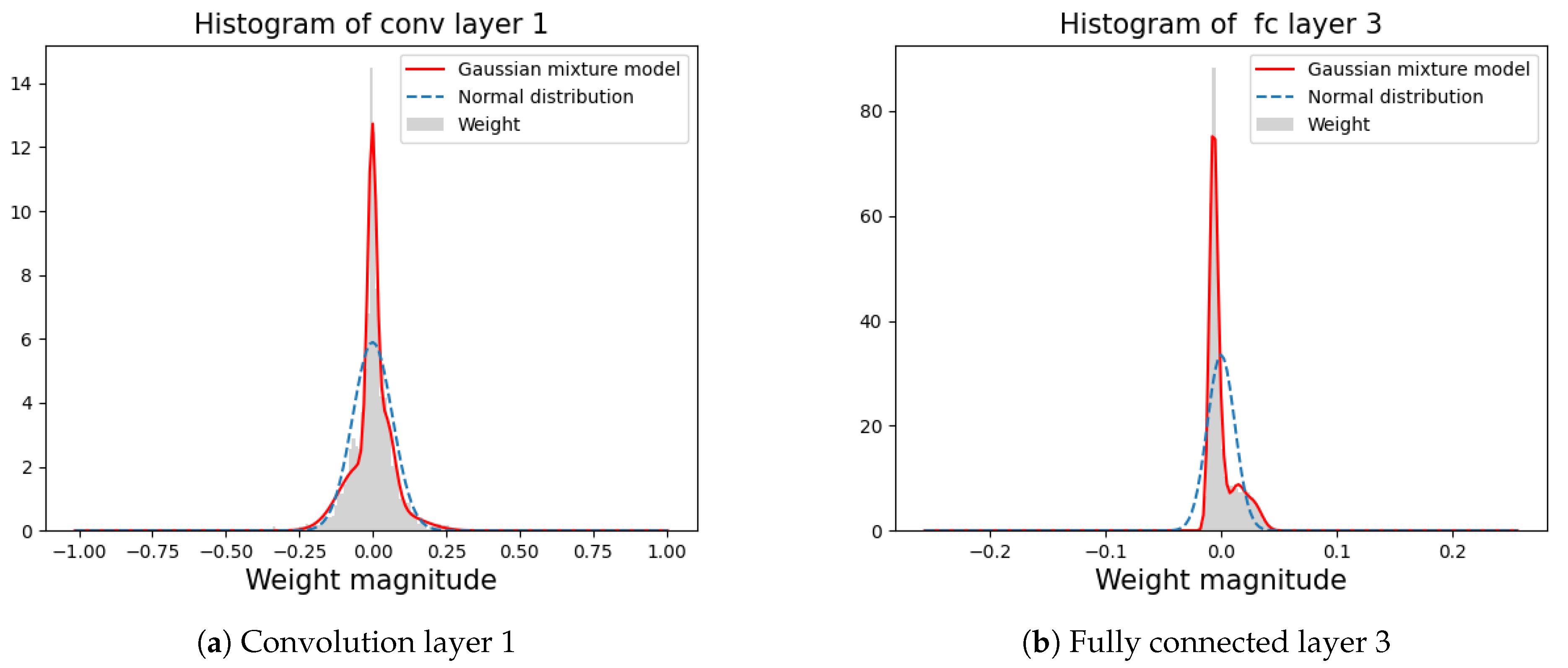
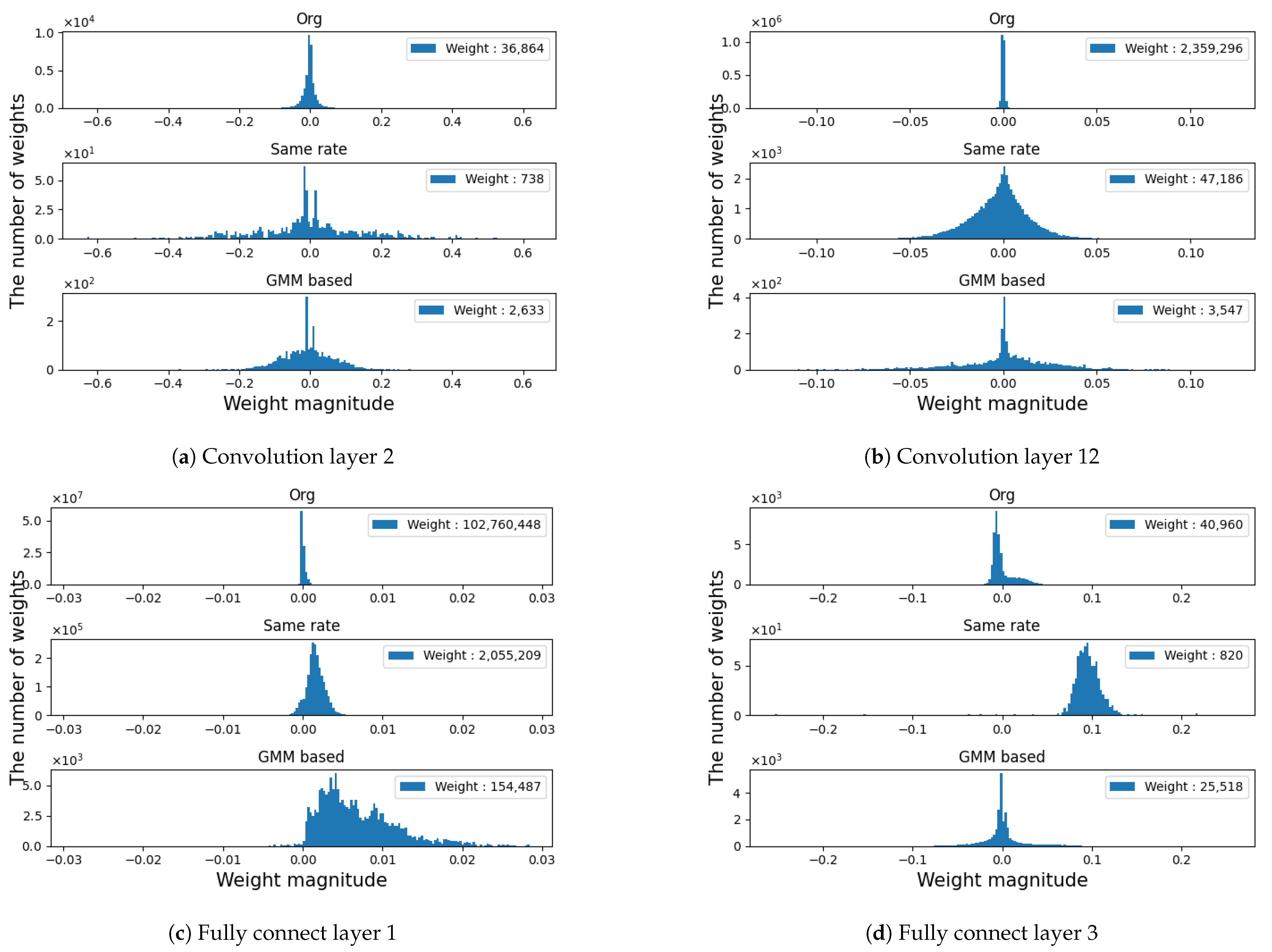
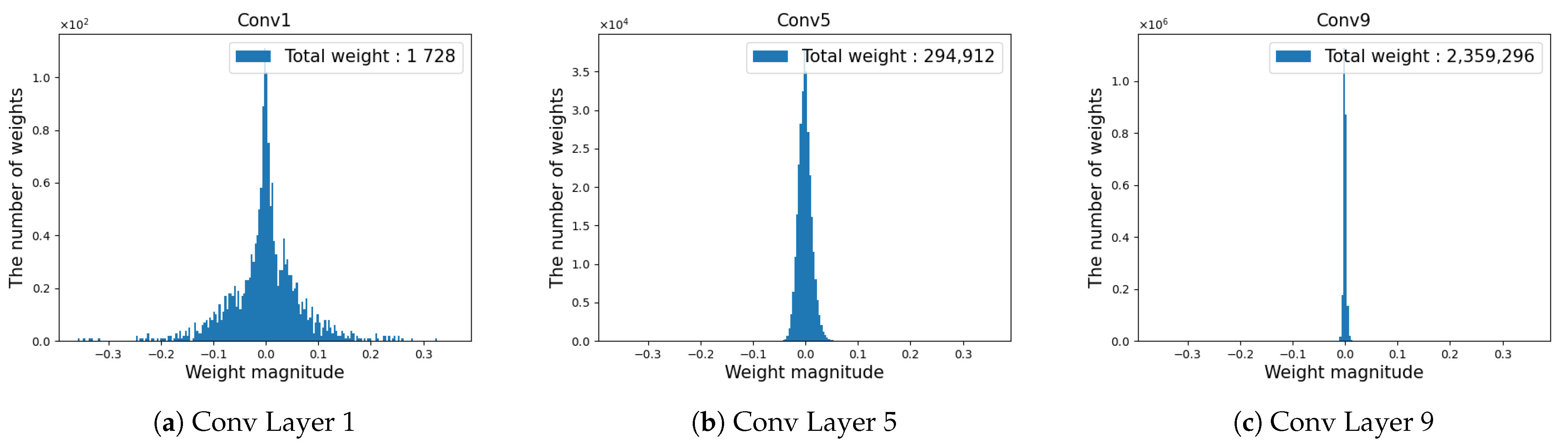
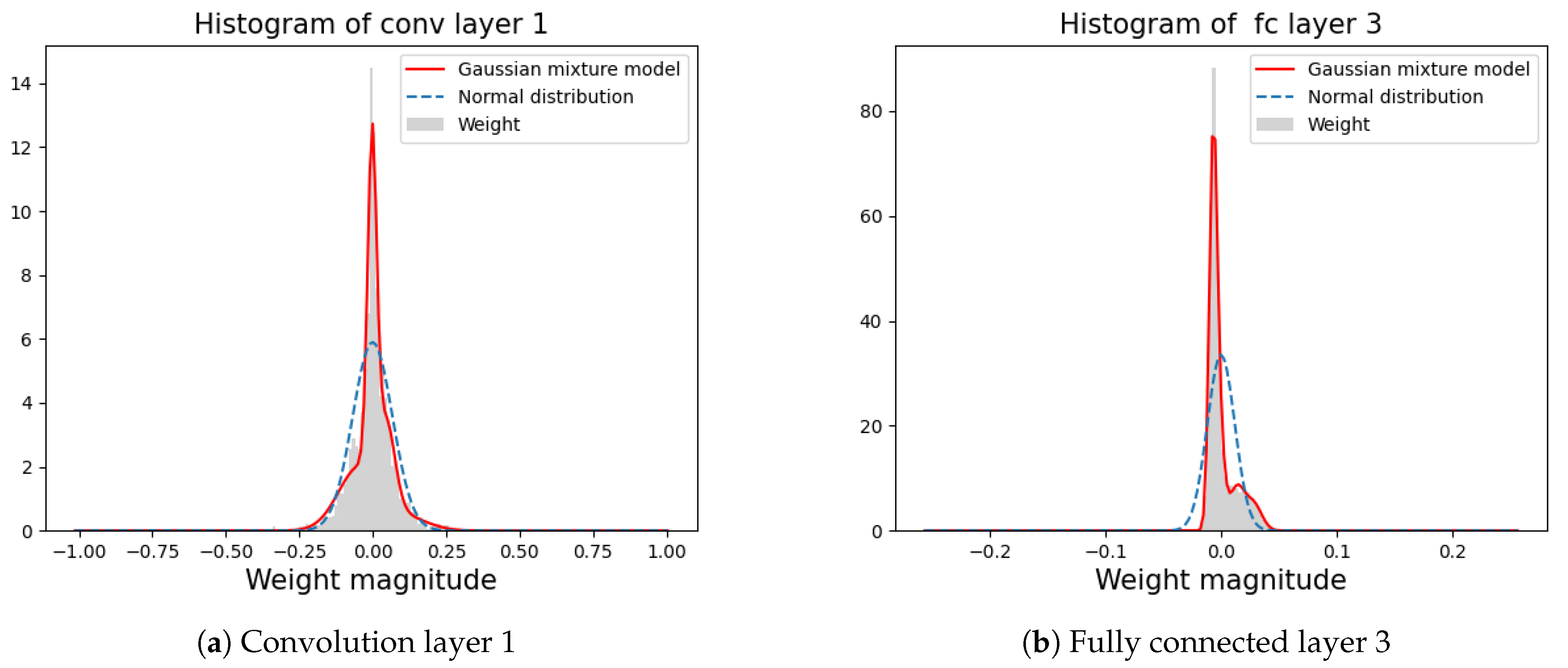
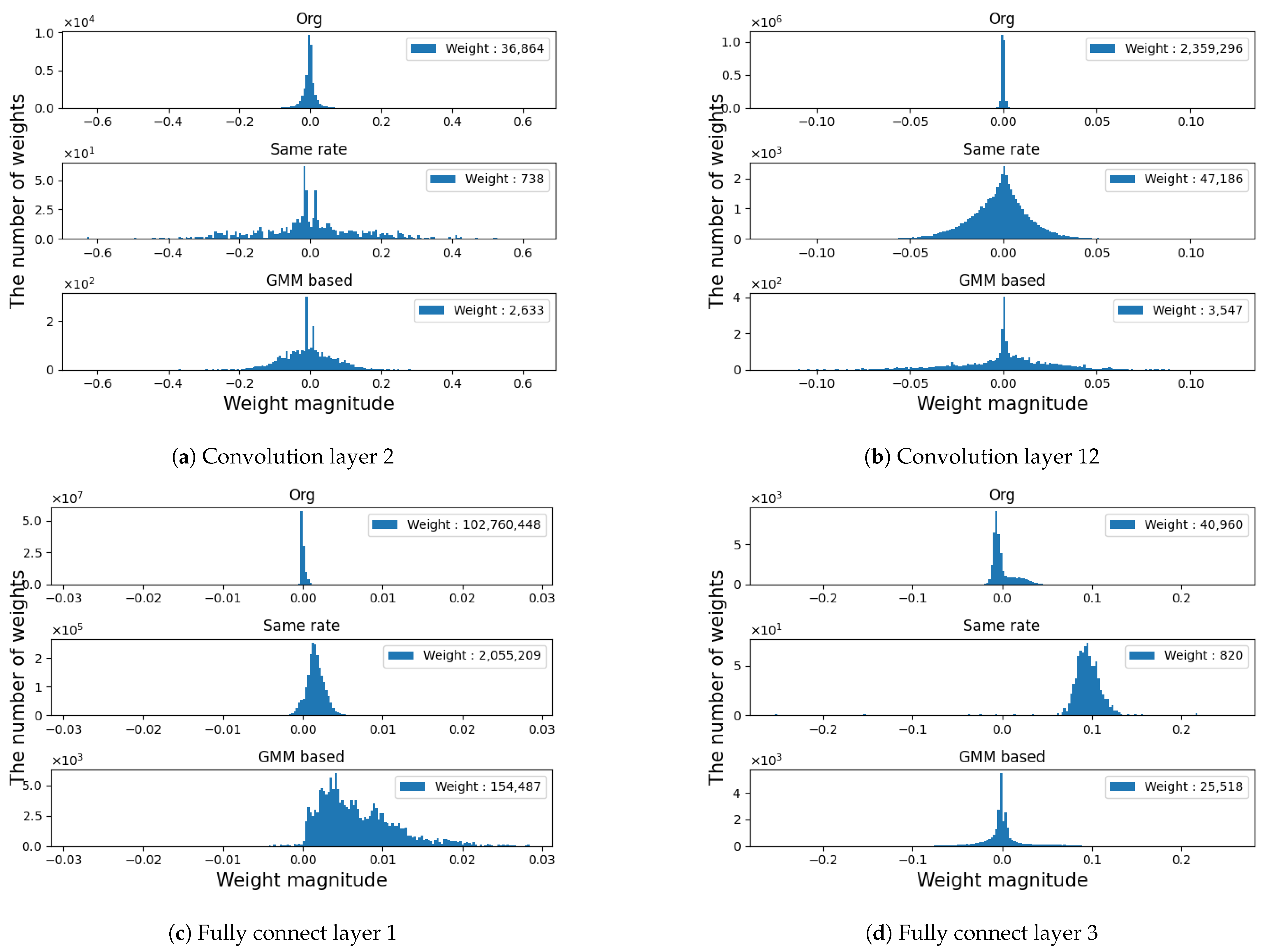
3.1. Estimating the Weight Distribution Using the GMM
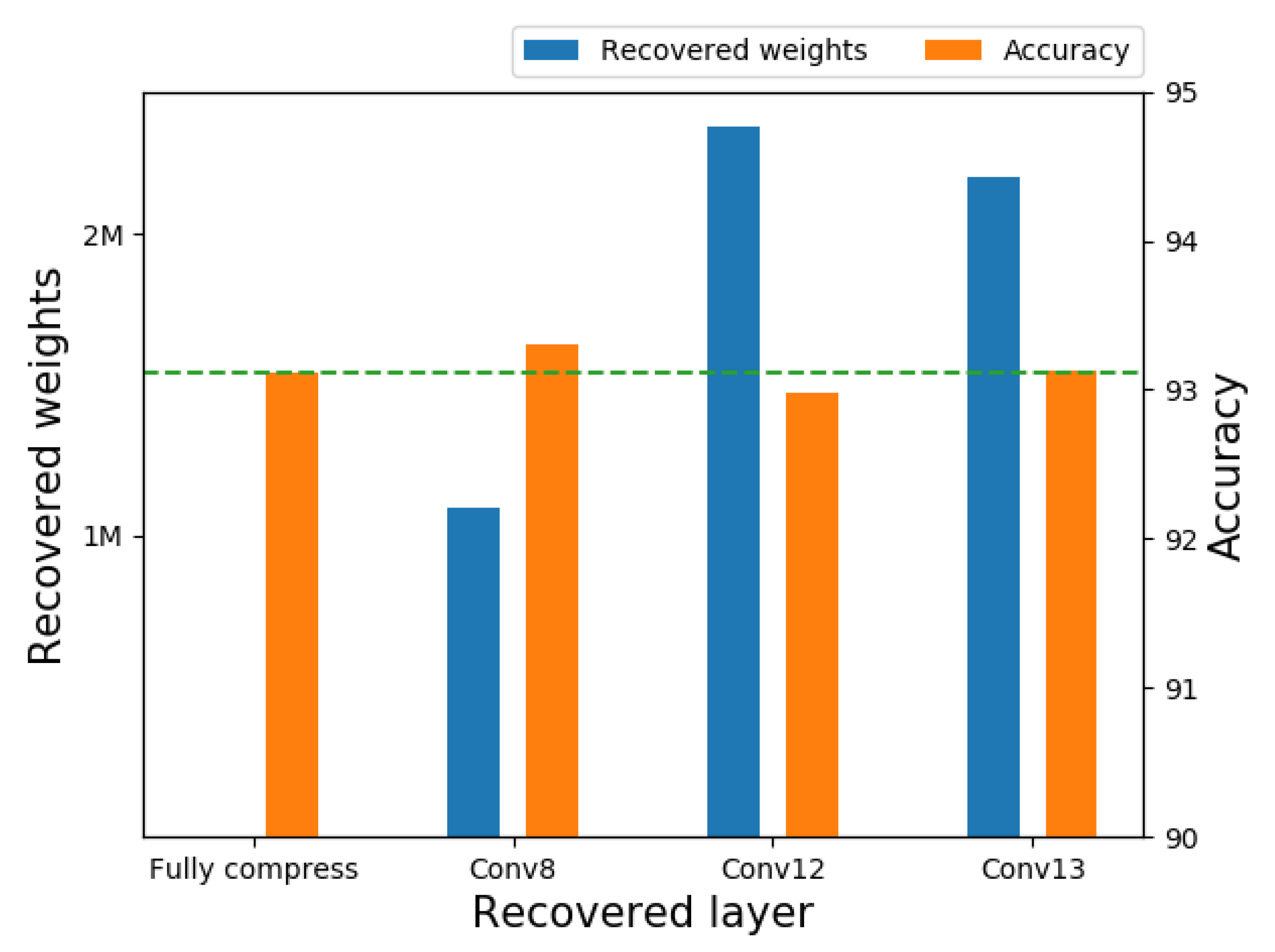
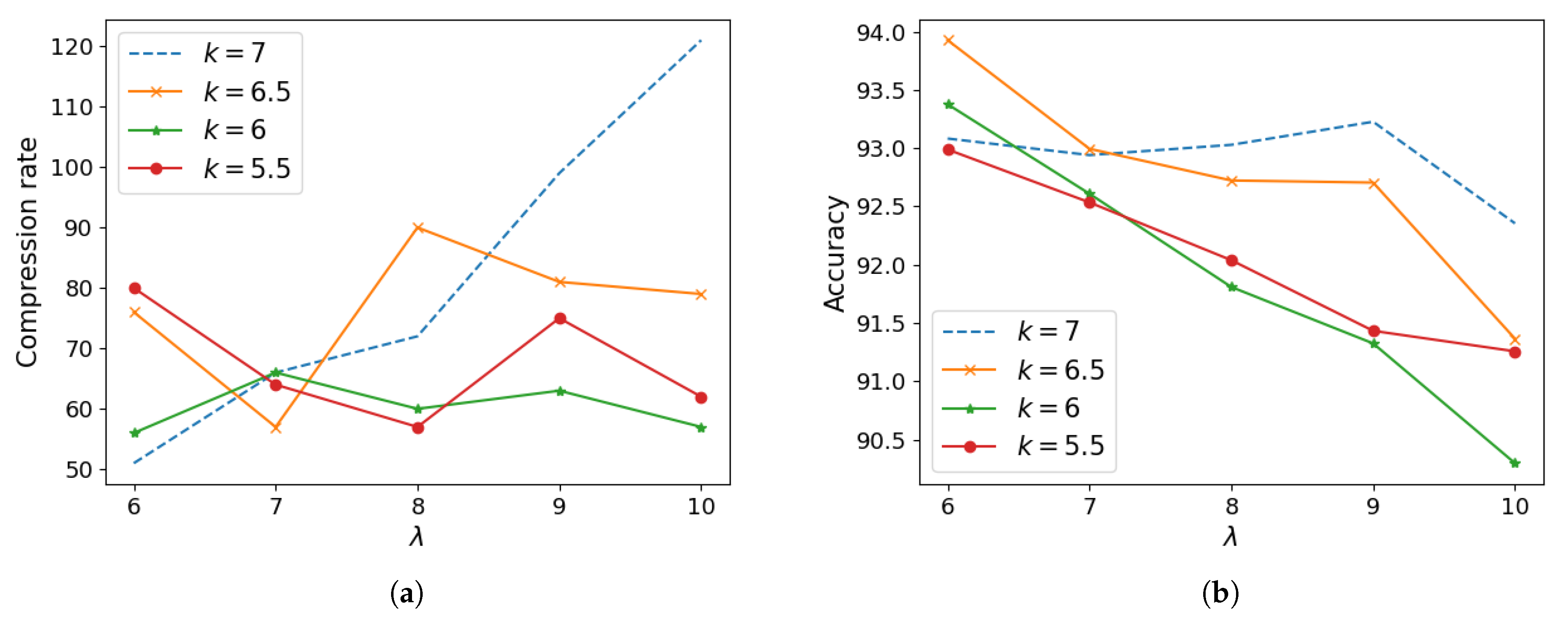
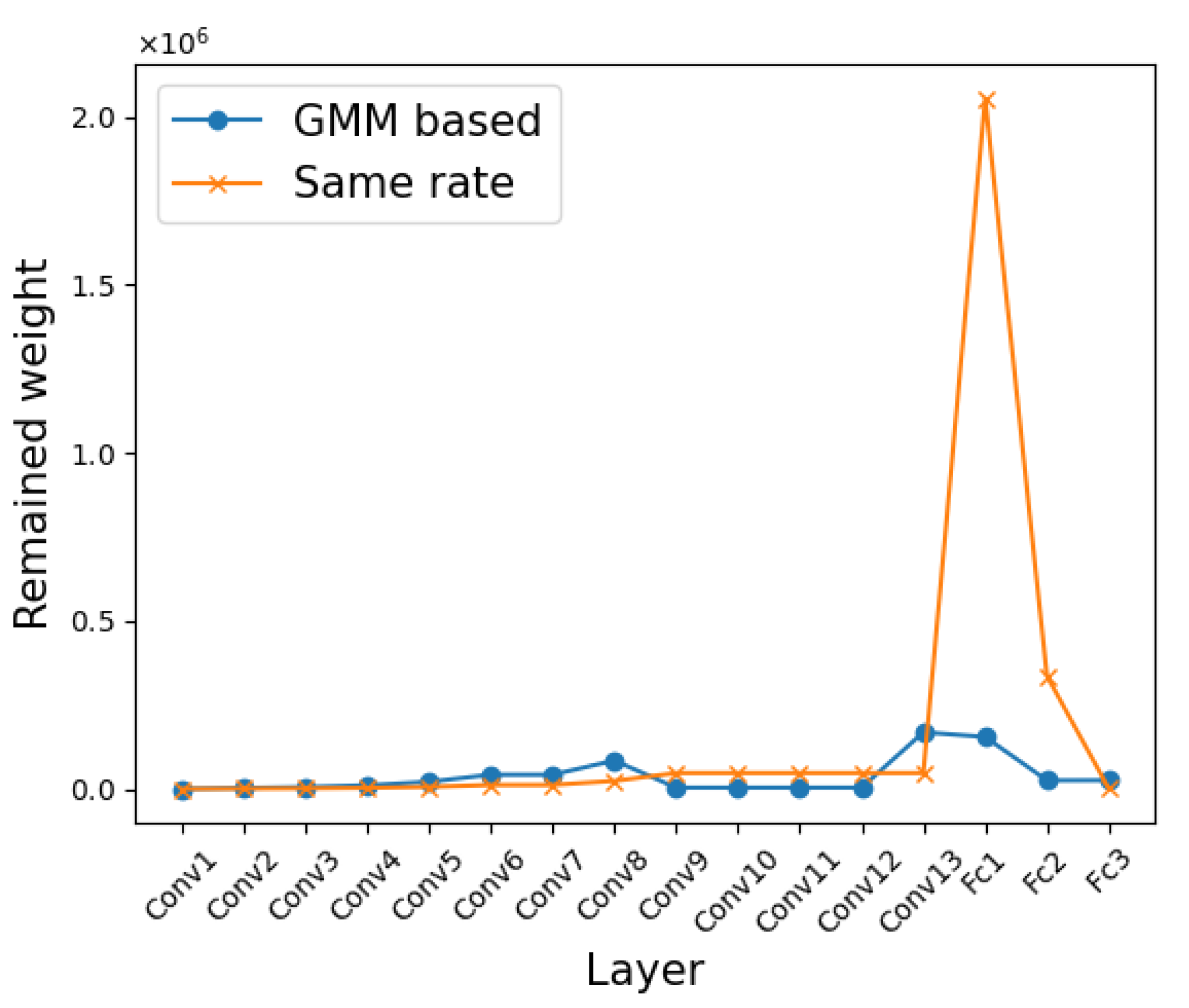
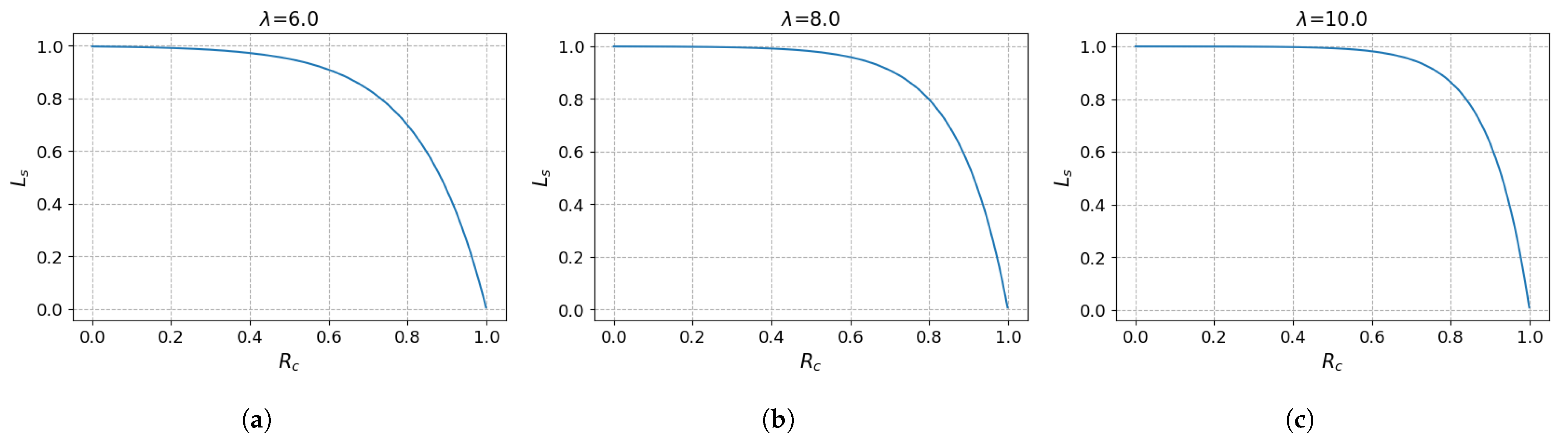
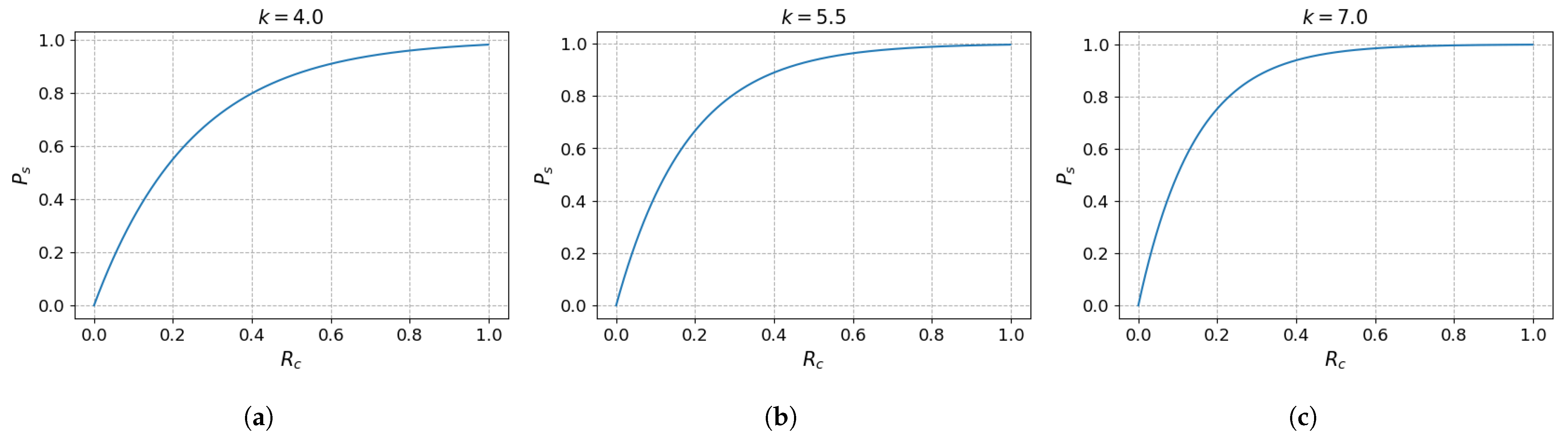
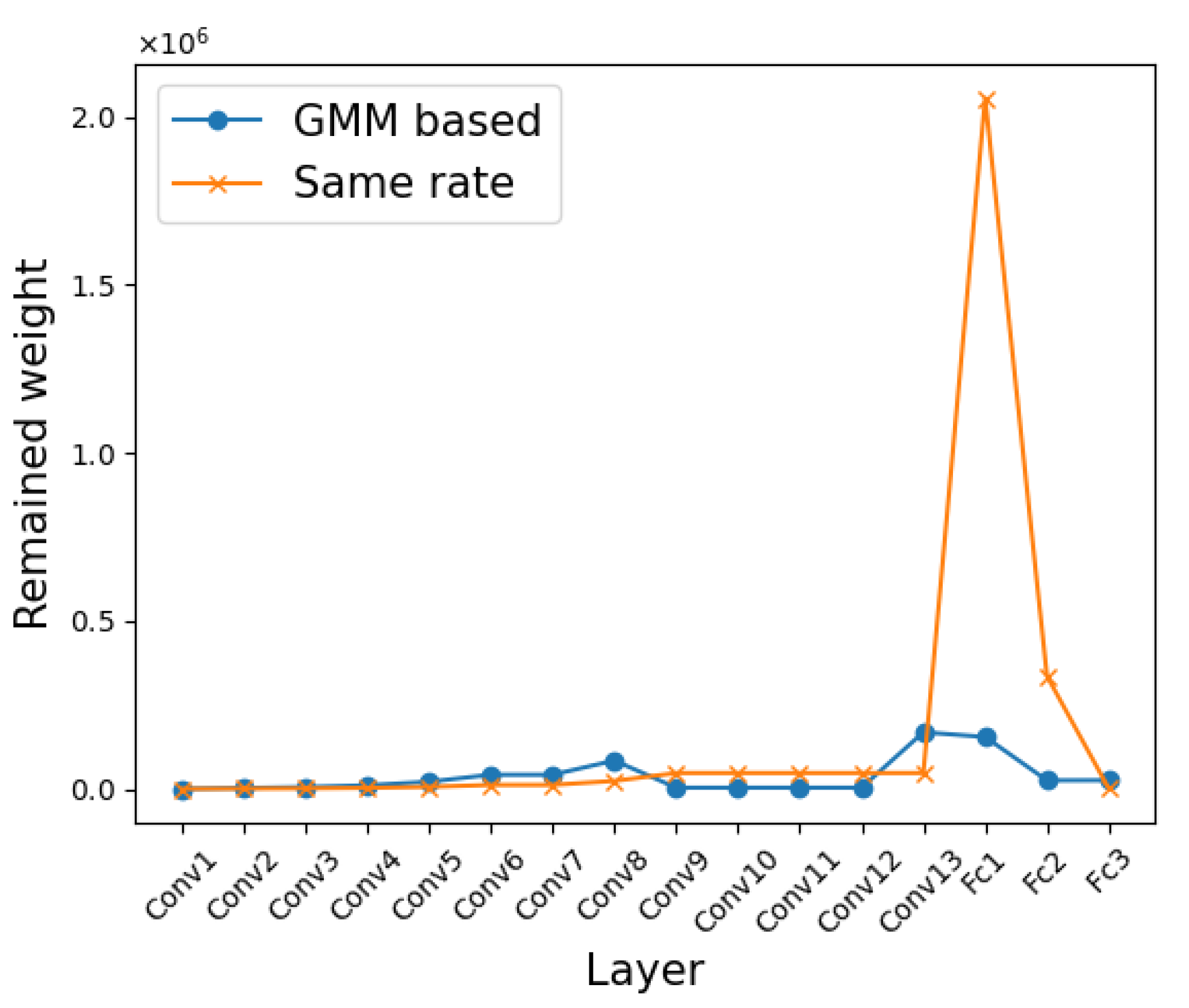
3.2. Layer Selection According to Redundancy
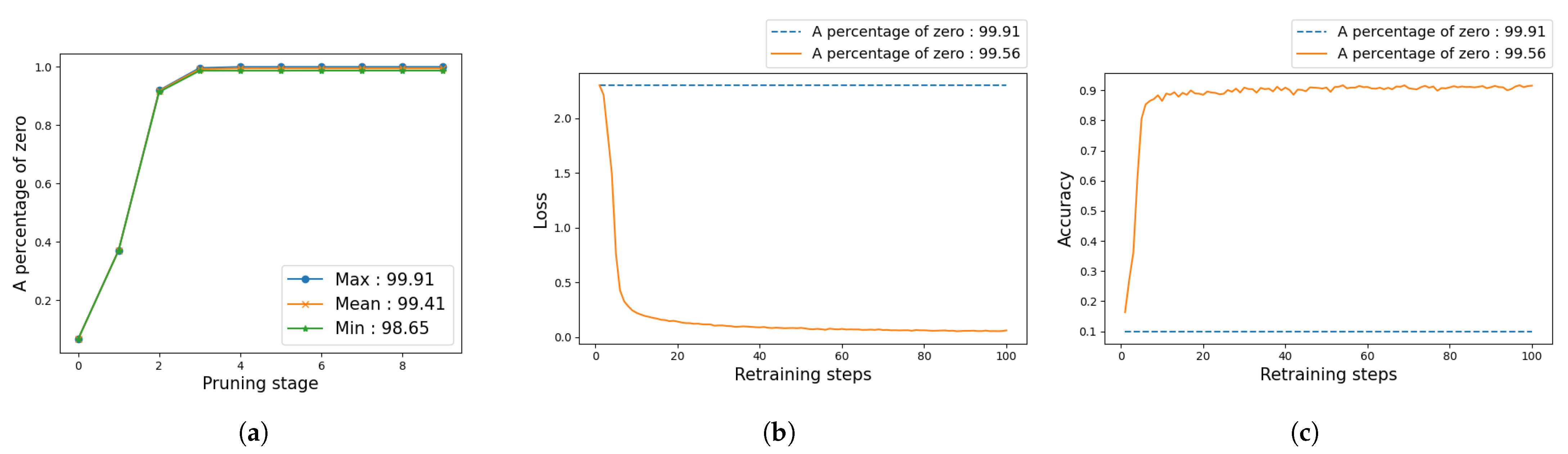
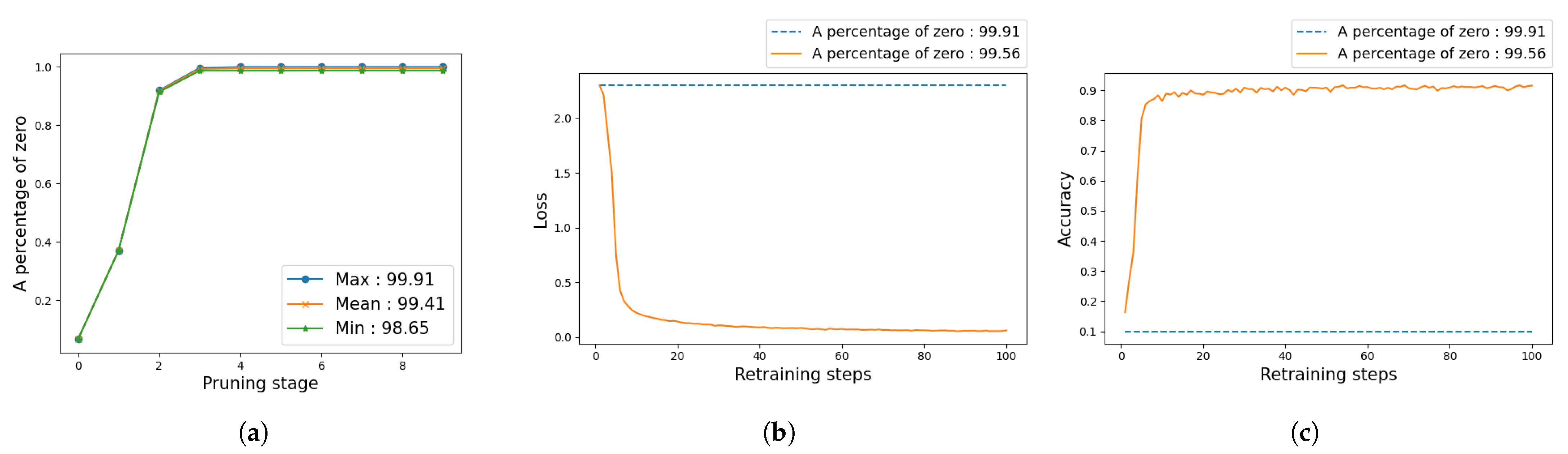
3.3. Pruning of Selected Layers
4. Experiments
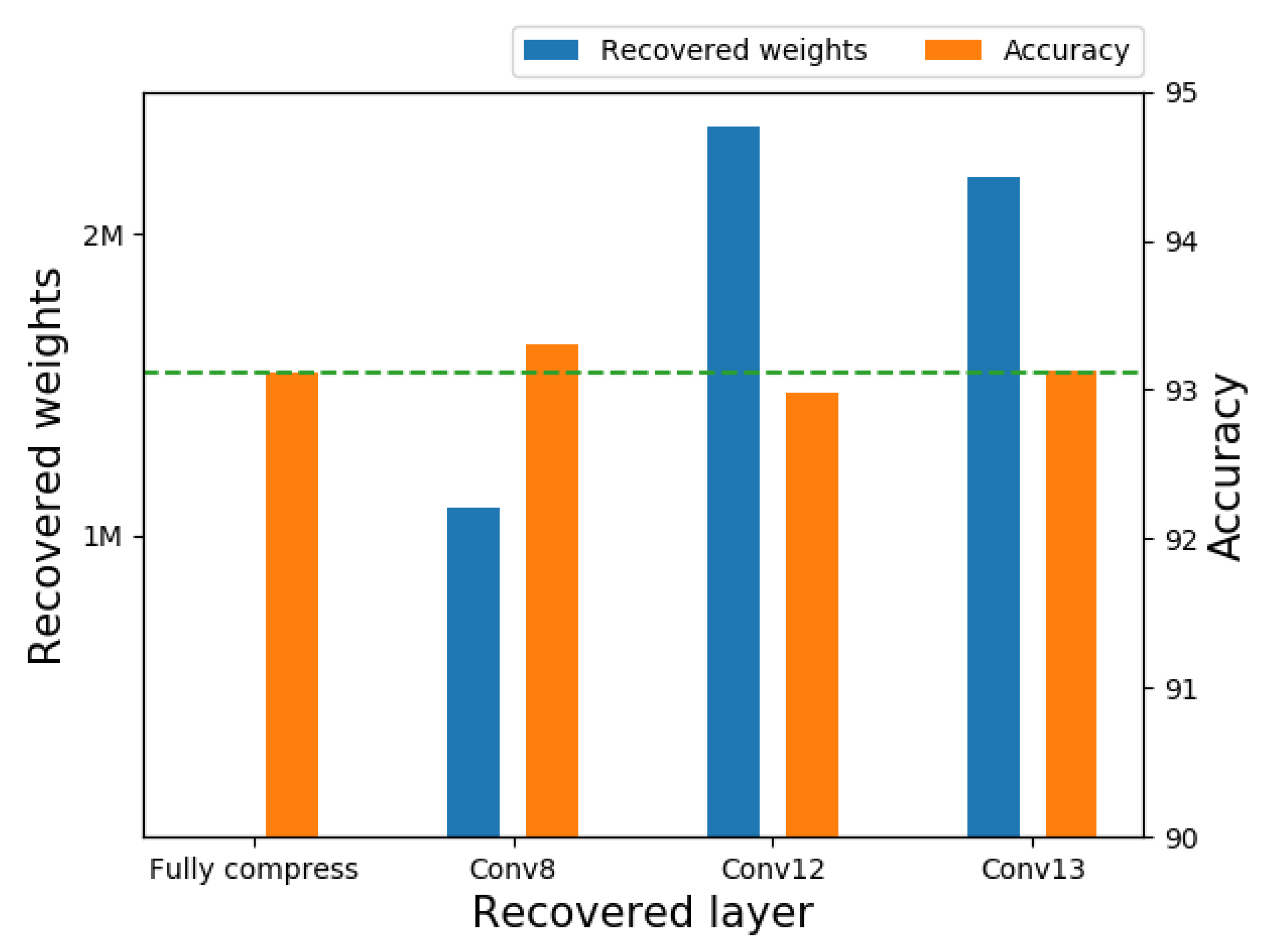
4.1. Image Classification
4.2. Semantic Segmentation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. ACNET: Attention Based Network to Exploit Complementary Features for RGBD Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Yang, K.; Hu, X.; Fang, Y.; Wang, K.; Stiefelhagen, R. Omnisupervised Omnidirectional Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2020, 1–16. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 11–13 June 2019; pp. 6105–6114. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 22–25 June 2017; pp. 4133–4141. [Google Scholar]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved Knowledge Distillation via Teacher Assistant. arXiv 2019, arXiv:1902.03393. [Google Scholar] [CrossRef]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 29 October–1 November 2019; pp. 3713–3722. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep learning with limited numerical precision. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1737–1746. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 525–542. [Google Scholar]
- Park, E.; Ahn, J.; Yoo, S. Weighted-entropy-based quantization for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HA, USA, 22–25 June 2017; pp. 5456–5464. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 18–20 June 2019; pp. 4340–4349. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. Adv. Neural Inf. Process. Syst. 2015, 28, 1135–1143. [Google Scholar]
- Xiao, X.; Wang, Z.; Rajasekaran, S. Autoprune: Automatic network pruning by regularizing auxiliary parameters. Adv. Neural Inf. Process. Syst. 2019, 32, 13681–13691. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Frankle, J.; Carbin, M. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Wang, L.; Yoon, K.J. Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks. arXiv 2020, arXiv:2004.05937. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 24–27 October 2017; pp. 5058–5066. [Google Scholar]
- Yu, R.; Li, A.; Chen, C.F.; Lai, J.H.; Morariu, V.I.; Han, X.; Gao, M.; Lin, C.Y.; Davis, L.S. Nisp: Pruning networks using neuron importance score propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9194–9203. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning structured sparsity in deep neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 2074–2082. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 24–27 October 2017; pp. 2736–2744. [Google Scholar]
- LeCun, Y.; Denker, J.S.; Solla, S.A. Optimal brain damage. Adv. Neural Inf. Process. Syst. 1990, 2, 598–605. [Google Scholar]
- Aghasi, A.; Abdi, A.; Nguyen, N.; Romberg, J. Net-trim: Convex pruning of deep neural networks with performance guarantee. Adv. Neural Inf. Process. Syst. 2017, 30, 3177–3186. [Google Scholar]
- Dong, X.; Chen, S.; Pan, S. Learning to prune deep neural networks via layer-wise optimal brain surgeon. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–7 December 2017; pp. 4857–4867. [Google Scholar]
- Tartaglione, E.; Lepsøy, S.; Fiandrotti, A.; Francini, G. Learning sparse neural networks via sensitivity-driven regularization. Adv. Neural Inf. Process. Syst. 2018, 31, 3878–3888. [Google Scholar]
- Zhuang, Z.; Tan, M.; Zhuang, B.; Liu, J.; Guo, Y.; Wu, Q.; Huang, J.; Zhu, J. Discrimination-aware channel pruning for deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 4–6 December 2018; pp. 875–886. [Google Scholar]
- Zhu, X.; Zhou, W.; Li, H. Improving Deep Neural Network Sparsity through Decorrelation Regularization. In Proceedings of the International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3264–3270. [Google Scholar]
- Molchanov, D.; Ashukha, A.; Vetrov, D. Variational Dropout Sparsifies Deep Neural Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 7–9 August 2017; pp. 2498–2507. [Google Scholar]
- Ayi, M.; El-Sharkawy, M. RMNv2: Reduced Mobilenet V2 for CIFAR10. In Proceedings of the IEEE 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NE, USA, 6–8 January 2020; pp. 0287–0292. [Google Scholar]
- Bartoldson, B.R.; Morcos, A.S.; Barbu, A.; Gordon, E. The generalization-stability tradeoff in neural network pruning. arXiv 2020, arXiv:1906.03728. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | CR | Error Rate |
|---|---|---|
| Zhuang et al. [39] | ×15.58 | 6.42% 6.69% |
| Zhu et al. [40] | ×8.5 | 6.01% 5.43% |
| Sparse VD [41] | ×65 | 7.55% 7.55% |
| AutoPrune [24] | ×75 | 7.60% 7.82% |
| GMM-Based-Layerwise [Ours] | ×225 | 7.03% 6.89% |
| Layer | Weight | Remaining Weight | Rate of Remainder |
|---|---|---|---|
| Conv 1 | 1728 | 124 | 7.18% |
| Conv 2 | 37 K | 2.6 K | 7.14% |
| Conv 3 | 74 K | 5.2 K | 7.14% |
| Conv 4 | 147 K | 11 K | 7.14% |
| Conv 5 | 294 K | 21 K | 7.14% |
| Conv 6 | 590 K | 42 K | 7.14% |
| Conv 7 | 590 K | 42 K | 7.14% |
| Conv 8 | 1.18 M | 84 K | 7.14% |
| Conv 9 | 2.36 M | 3.5 K | 0.15% |
| Conv 10 | 2.36 M | 3.5 K | 0.15% |
| Conv 11 | 2.36 M | 3.5 K | 0.15% |
| Conv 12 | 2.36 M | 3.5 K | 0.15% |
| Conv 13 | 2.36 M | 169 K | 7.14% |
| FC 1 | 102.76 M | 154 K | 0.15% |
| FC 2 | 16.78 M | 25 K | 0.15% |
| FC 3 | 41 K | 26 K | 62.3% |
| Total | 134 M | 596 K | 0.44% |
| Network | Method | Accuracy | CR | No. of Weights |
|---|---|---|---|---|
| MobileNet [42] | Original | 94.59 | - | 2.2 M |
| pruned by our method | 94.11 | ×6.01 | 0.36 M | |
| GoogleNet [29] | Original | 92.63 | - | 6.14 M |
| pruned by our method | 91.96 | ×10.78 | 0.57 M |
| Methods | CR | Remaining Weight | Accuracy | mIoU |
|---|---|---|---|---|
| SegNet [30] | - | 29 M | 57.71 | 20.50 |
| Same Rate [23] | ×50 | 0.58 M | 53.64 | 16.90 |
| GMM-Based-Layerwise (Ours) | ×64 | 0.44 M | 55.27 | 17.90 |
| Layer | Weight | Remaining Weight | Rate of Remainder |
|---|---|---|---|
| Encoder 1 | 1728 | 1.1 K | 66.44% |
| Encoder 2 | 37 K | 4.2 K | 11.27% |
| Encoder 3 | 74 K | 8.3 K | 11.27% |
| Encoder 4 | 147 K | 16.6 K | 11.27% |
| Encoder 5 | 295 K | 33.3 K | 11.27% |
| Encoder 6 | 590 K | 1.8 K | 0.31% |
| Encoder 7 | 590 K | 1.8 K | 0.31% |
| Encoder 8 | 1.18 M | 3.7 K | 0.31% |
| Encoder 9 | 2.36 M | 7.4 K | 0.31% |
| Encoder 10 | 2.36 M | 7.4 K | 0.31% |
| Encoder 11 | 2.36 M | 7.4 K | 0.31% |
| Encoder 12 | 2.36 M | 7.4 K | 0.31% |
| Encoder 13 | 2.36 M | 7.4 K | 0.31% |
| Decoder 1 | 2.36 M | 266.1 K | 11.27% |
| Decoder 2 | 2.36 M | 7.4 K | 0.31% |
| Decoder 3 | 2.36 M | 7.4 K | 0.31% |
| Decoder 4 | 2.36 M | 7.4 K | 0.31% |
| Decoder 5 | 2.36 M | 7.4 K | 0.31% |
| Decoder 6 | 1.18 M | 3.7 K | 0.31% |
| Decoder 7 | 590 K | 1.8 K | 0.31% |
| Decoder 8 | 590 K | 1.8 K | 0.31% |
| Decoder 9 | 295 K | 0.9 K | 0.31% |
| Decoder 10 | 147 K | 16.6 K | 11.27% |
| Decoder 11 | 74 K | 8.3 K | 11.27% |
| Decoder 12 | 37 K | 4.2 K | 11.27% |
| Decoder 13 | 7.5 K | 0.8 K | 11.28% |
| Total | 29 M | 0.44 M | 1.5% |
| Methods | mIoU | CR | Remaining Weight |
|---|---|---|---|
| Original ENet [6] | 52.85 | - | 0.34 M |
| Pruning 50% | 53.04 | ×2.35 | 0.15 M |
| Pruning 70% | 51.52 | ×3.51 | 0.10 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, E.; Hwang, Y. Layer-Wise Network Compression Using Gaussian Mixture Model. Electronics 2021, 10, 72. https://doi.org/10.3390/electronics10010072
Lee E, Hwang Y. Layer-Wise Network Compression Using Gaussian Mixture Model. Electronics. 2021; 10(1):72. https://doi.org/10.3390/electronics10010072
Chicago/Turabian StyleLee, Eunho, and Youngbae Hwang. 2021. "Layer-Wise Network Compression Using Gaussian Mixture Model" Electronics 10, no. 1: 72. https://doi.org/10.3390/electronics10010072
APA StyleLee, E., & Hwang, Y. (2021). Layer-Wise Network Compression Using Gaussian Mixture Model. Electronics, 10(1), 72. https://doi.org/10.3390/electronics10010072