
Prediction of Shampoo Formulation Phase Stability Using Large Language Models

Abstract
1. Introduction
2. Materials and Methods
2.1. Data
2.2. Data Sampling
2.3. Choice of LLM Models and Deployment
2.4. LLM Prompting
2.4.1. Prompting with Full Context
2.4.2. Prompting Without Context
2.5. Processing of the LLM Response
2.6. Benchmarking Against Conventional ML
3. Results
3.1. Conventional ML Benchmark
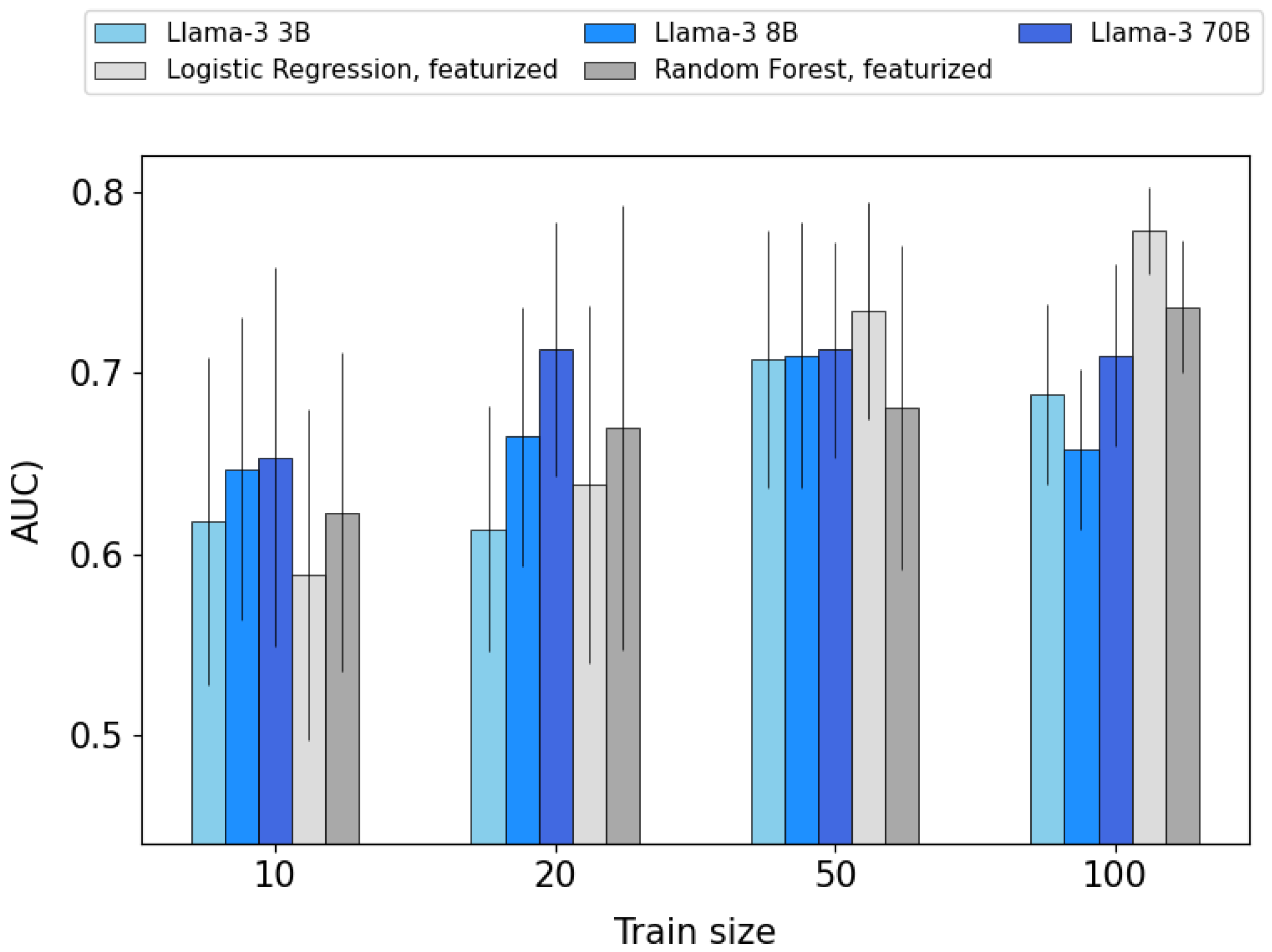
- For each algorithm/featurization scheme combination, the AUC increases on increasing the train size, as expected.
- Regardless of the featurization scheme, the LGBM always performs worse than Logistic Regression or Random Forest, which may be explained by (i) the absence of hyper-parameter optimization and (ii) the small train sizes compared to reference benchmarks giving an advantage to LGBM over Random Forest, which have been typically reported for train sizes of thousands or tens of thousands of samples.
- Random Forest is better than Logistic Regression when , and the opposite holds when (which suggests a crossover for some value between 20 and 50, and which was not further investigated).
- Overall performance is somehow comparable for the two-surfactant featurization schemes, with a slight advantage for “featurization” over “one-hot encoding” (yielding higher AUCs for 6 out of the 10 working algorithm/train size combinations).

3.2. Benchmarking the LLM-Based Approach Against Conventional ML
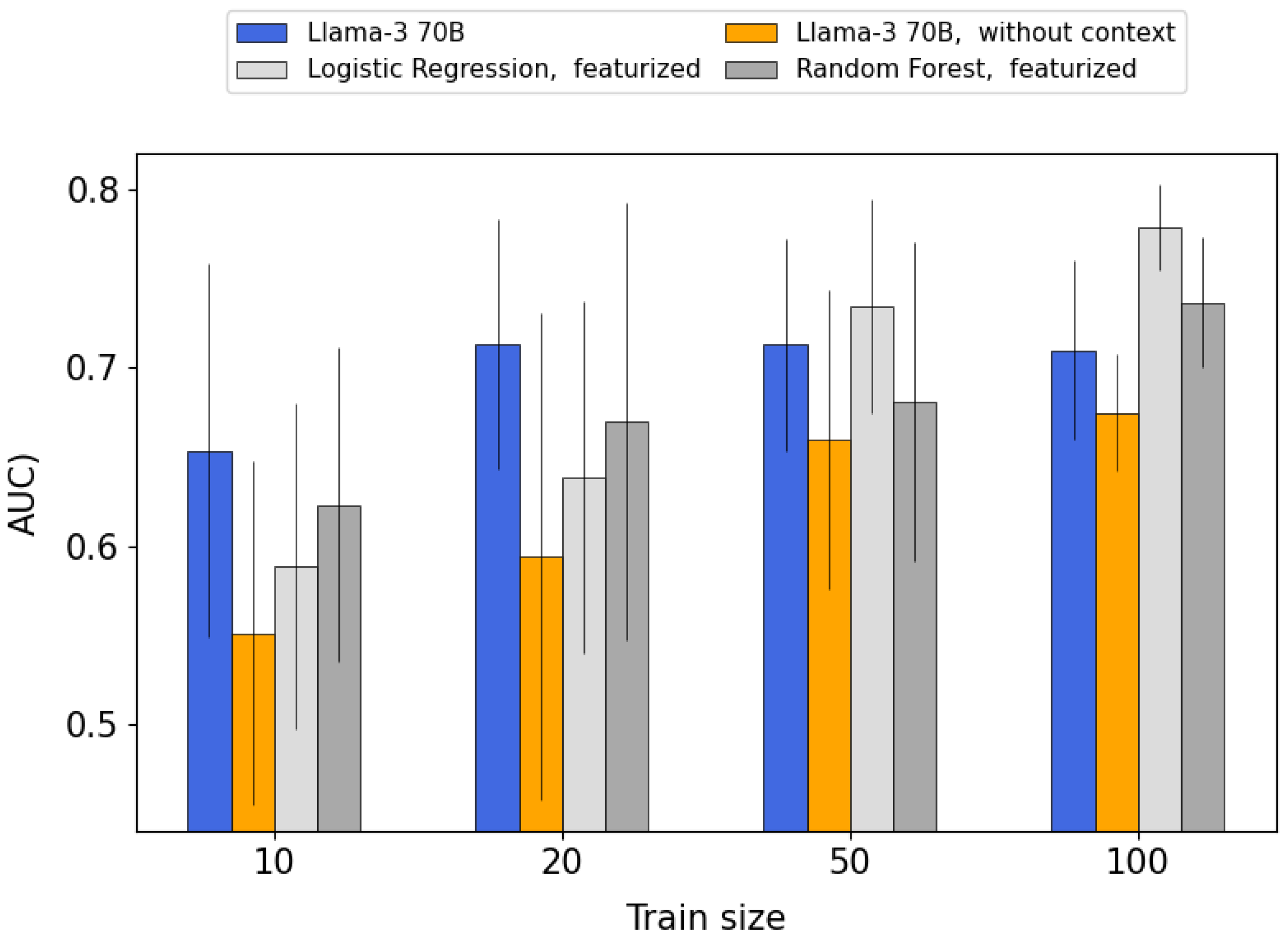
3.3. Investigating the Origin of the LLM Advantage
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| AUC | Area Under the Curve |
| CoT | Chain of Thought |
| DOE | Design Of Experiment |
| GPU | Graphics Processing Unit |
| ICL | In-Context Learning |
| LGBM | Light Gradient-Boosting Machine |
| LLM | Large Language Model |
| LoRA | Low-Rank Adaptation |
| LR | Logistic Regression |
| ML | Machine Learning |
| PEFT | Parameter-Efficient Fine-Tuning |
| RF | Random Forest |
| ROC | Receiver Operating Curve |
References
- Conte, E.; Gani, R.; Ng, K.M. Design of formulated products: A systematic methodology. AIChE J. 2011, 57, 2431–2449. [Google Scholar] [CrossRef]
- McDonagh, J.L.; Swope, W.C.; Anderson, R.L.; Johnston, M.A.; Bray, D.J. What can digitisation do for formulated product innovation and development? Polym. Int. 2021, 70, 248–255. [Google Scholar] [CrossRef]
- Kamairudin, N.; Abd Gani, S.S.; Fard Masoumi, H.R.; Basri, M.; Hashim, P.; Mokhtar, N.M.; Lane, M.E. Modeling of a natural lipstick formulation using an artificial neural network. RSC Adv. 2015, 5, 68632–68638. [Google Scholar] [CrossRef]
- Cao, L.; Russo, D.; Felton, K.; Salley, D.; Sharma, A.; Keenan, G.; Mauer, W.; Gao, H.; Cronin, L.; Lapkin, A.A. Optimization of Formulations Using Robotic Experiments Driven by Machine Learning DoE. Cell Rep. Phys. Sci. 2021, 2, 100295. [Google Scholar] [CrossRef]
- Bao, Z.; Bufton, J.; Hickman, R.J.; Aspuru-Guzik, A.; Bannigan, P.; Allen, C. Revolutionizing drug formulation development: The increasing impact of machine learning. Adv. Drug Deliv. Rev. 2023, 202, 115108. [Google Scholar] [CrossRef] [PubMed]
- Hornick, T.; Mao, C.; Koynov, A.; Yawman, P.; Thool, P.; Salish, K.; Giles, M.; Nagapudi, K.; Zhang, S. In silico formulation optimization and particle engineering of pharmaceutical products using a generative artificial intelligence structure synthesis method. Nat. Commun. 2024, 15, 9622. [Google Scholar] [CrossRef] [PubMed]
- Saldana, D.; Starck, L.; Mougin, P.; Rousseau, B.; Creton, B. On the rational formulation of alternative fuels: Melting point and net heat of combustion predictions for fuel compounds using machine learning methods. SAR QSAR Environ. Res. 2013, 24, 259–277. [Google Scholar] [CrossRef] [PubMed]
- Chitre, A.; Querimit, R.C.; Rihm, S.D.; Karan, D.; Zhu, B.; Wang, K.; Wang, L.; Hippalgaonkar, K.; Lapkin, A.A. Accelerating Formulation Design via Machine Learning: Generating a High-throughput Shampoo Formulations Dataset. Sci. Data 2024, 11, 728. [Google Scholar] [CrossRef] [PubMed]
- Bashir, A.; Lambert, P. Microbiological study of used cosmetic products: Highlighting possible impact on consumer health. J. Appl. Microbiol. 2020, 128, 598–605. [Google Scholar] [CrossRef] [PubMed]
- Pensé-Lhéritier, A.M. Recent developments in the sensorial assessment of cosmetic products: A review. Int. J. Cosmet. Sci. 2015, 37, 465–473. [Google Scholar] [CrossRef] [PubMed]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning. In Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Kelly, C.L. Addressing the sustainability challenges for polymers in liquid formulations. Chem. Sci. 2023, 14, 6820–6825. [Google Scholar] [CrossRef] [PubMed]
- Vieira, D.; Duarte, J.; Vieira, P.; Gonçalves, M.B.S.; Figueiras, A.; Lohani, A.; Veiga, F.; Mascarenhas-Melo, F. Regulation and Safety of Cosmetics: Pre-and Post-Market Considerations for Adverse Events and Environmental Impacts. Cosmetics 2024, 11, 184. [Google Scholar] [CrossRef]
- Chitre, A.; Semochkina, D.; Woods, D.C.; Lapkin, A.A. Machine learning-guided space-filling designs for high throughput liquid formulation development. Comput. Chem. Eng. 2025, 195, 109007. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Hegselmann, S.; Buendia, A.; Lang, H.; Agrawal, M.; Jiang, X.; Sontag, D. TabLLM: Few-shot classification of tabular data with large language models. In Proceedings of the 26th International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 25–27 April 2023; Volume 206, pp. 5549–5581. [Google Scholar]
- Wen, X.; Zhang, H.; Zheng, S.; Xu, W.; Bian, J. From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD’24, Barcelona, Spain, 25–29 April 2024; pp. 3323–3333. [Google Scholar] [CrossRef]
- Meta Llama on Huggingface. Available online: https://huggingface.co/meta-llama (accessed on 5 May 2025).
- Parsons, V.L. Stratified Sampling. In Wiley StatsRef: Statistics Reference Online; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2017; pp. 1–11. [Google Scholar] [CrossRef]
- Lapkin, A.A.; Chitre, A.; Querimit, R.C.; Rihm, S.D.; Karan, D.; Zhu, B.; Wang, K.; Wang, L.; Hippalgaonkar, K. Accelerating Formulation Design via Machine Learning: Generating a High-throughput Shampoo Formulations Dataset. figshare. Collection. Available online: https://springernature.figshare.com/collections/Accelerating_Formulation_Design_via_Machine_Learning_Generating_a_High-throughput_Shampoo_Formulations_Dataset/7132624 (accessed on 5 May 2025). [CrossRef]
- Meta Llama 3 Community License Agreement. Available online: https://www.llama.com/llama3/license/ (accessed on 5 May 2025).
- Available online: https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct (accessed on 5 May 2025).
- Available online: https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct (accessed on 5 May 2025).
- Available online: https://huggingface.co/RedHatAI/Llama-3.3-70B-Instruct-quantized.w8a8 (accessed on 5 May 2025).
- Kwon, W.; Li, Z.; Zhuang, S.; Sheng, Y.; Zheng, L.; Yu, C.H.; Gonzalez, J.; Zhang, H.; Stoica, I. Efficient Memory Management for Large Language Model Serving with PagedAttention. In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, Koblenz, Germany, 23–26 October 2023; pp. 611–626. [Google Scholar] [CrossRef]
- vLLM Home Page. Available online: https://docs.vllm.ai/en/stable/# (accessed on 5 May 2025).
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the Tenth International Conference on Learning Representations (ICLR 2022), Virtual Event, 25–29 April 2022. [Google Scholar]
- Liu, H.; Tam, D.; Muqeeth, M.; Mohta, J.; Huang, T.; Bansal, M.; Raffel, C.A. Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning. In Proceedings of the Thirty-Sixth Annual Conference on Advances in Neural Information Processing Systems, NIPS’22, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 1950–1965. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, NIPS’20, Virtual Event, 6–9 December 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS’22, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 27730–27744. [Google Scholar]
- Scikit-Learn: Machine Learning in Python; Scikit-Learn 1.6.1 Documentation. Available online: https://scikit-learn.org/stable/ (accessed on 5 May 2025).
- Chen, Y.; Zhong, R.; Zha, S.; Karypis, G.; He, H. Meta-learning via Language Model In-context Tuning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 719–730. [Google Scholar]
- Khattab, O.; Singhvi, A.; Maheshwari, P.; Zhang, Z.; Santhanam, K.; A, S.V.; Haq, S.; Sharma, A.; Joshi, T.T.; Moazam, H.; et al. DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines. In Proceedings of the Twelfth International Conference on Learning Representations ICLR 2024, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS’22, New Orleans, LA, USA, 28 November–9 December 2022; pp. 24824–24837. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS’22, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 22199–22213. [Google Scholar]
- Barel, A.O.; Paye, M.; Maibach, H.I. Handbook of Cosmetic Science and Technology; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar] [CrossRef]
- Homemade Shampoo Formulas|Make Your Own DIY Shampoo with Recipes|MakingCosmetics—makingcosmetics.com. Available online: https://www.makingcosmetics.com/Shampoo-Formulas_ep_90.html?lang=en_US (accessed on 5 May 2025).
- Van Breugel, B.; Van Der Schaar, M. Position: Why tabular foundation models should be a research priority. In Proceedings of the 41st International Conference on Machine Learning, ICML’24, Vienna, Austria, 21–27 July 2024; pp. 48976–48993. [Google Scholar]
- Tran, Q.M.; Hoang, S.N.; Nguyen, L.M.; Phan, D.; Lam, H.T. TabularFM: An Open Framework For Tabular Foundational Models. In Proceedings of the 2024 IEEE International Conference on Big Data, Washington, DC, USA, 15–18 December 2024; pp. 1694–1699. [Google Scholar] [CrossRef]
- Hollmann, N.; Müller, S.; Purucker, L.; Krishnakumar, A.; Körfer, M.; Hoo, S.B.; Schirrmeister, R.T.; Hutter, F. Accurate predictions on small data with a tabular foundation model. Nature 2025, 637, 319–326. [Google Scholar] [CrossRef] [PubMed]
- Qu, J.; Holzmüller, D.; Varoquaux, G.; Morvan, M.L. TabICL: A Tabular Foundation Model for In-Context Learning on Large Data. arXiv 2025, arXiv:cs.LG/2502.05564. [Google Scholar]
- Muffo, M.; Cocco, A.; Bertino, E. Evaluating Transformer Language Models on Arithmetic Operations Using Number Decomposition. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 291–297. [Google Scholar]
- Yan, Y.; Lu, Y.; Xu, R.; Lan, Z. Do PhD-level LLMs Truly Grasp Elementary Addition? Probing Rule Learning vs. Memorization in Large Language Models. arXiv 2025, arXiv:cs.CL/2504.05262. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Role | Message |
|---|---|
| System | You will be given weight concentrations of cosmetic ingredients from BASF mixed in water. Classify the phase stability of the mixture into one of the following categories: low, or high. Return only the name of the category, and nothing else. MAKE SURE your output is one of the two categories stated. |
| User | Plantapon ACG 50: 12.73 w/w%, Dehyton MC: 13.56 w/w%, Dehyquart CC6: 1.16 w/w%, Arlypon TT: 4.94 w/w%. Phase stability is -> |
| Assistant | low |
| User | Dehyton PK 45: 9.15 w/w%, Dehyquart A-CA: 9.38 w/w%, Salcare Super 7: 2.24 w/w%, Arlypon F: 4.14 w/w%. Phase stability is -> |
| Assistant | low |
| User | Plantapon ACG 50: 13.68 w/w%, Plantapon LC 7: 8.79 w/w%, Salcare Super 7: 1.35 w/w%, Arlypon F: 4.95 w/w%. Phase stability is -> |
| Assistant | high |
| User | Plantacare 818: 11.7 w/w%, Plantacare 2000: 8.48 w/w%, Luviquat Excellence: 1.22 w/w%, Arlypon TT: 3.95 w/w%. Phase stability is -> |
| Assistant | high |
| User | Plantacare 2000: 8.45 w/w%, Plantapon Amino KG-L: 8.76 w/w%, Luviquat Excellence: 1.7 w/w%, Arlypon TT: 3.06 w/w%. Phase stability is -> |
| Assistant | low |
| User | Plantapon ACG 50: 7.7 w/w%, Plantapon LC 7: 9.39 w/w%, Salcare Super 7: 2.71 w/w%, Arlypon TT: 2.59 w/w%. Phase stability is -> |
| Assistant | high |
| User | Dehyton MC: 11.07 w/w%, Dehyton PK 45: 12.64 w/w%, Salcare Super 7: 1.68 w/w%, Arlypon F: 4.88 w/w%. Phase stability is -> |
| Assistant | low |
| User | Texapon SB 3 KC: 4.18 w/w%, Dehyton PK 45: 10.24 w/w%, Dehyquart CC6: 1.26 w/w%, Arlypon TT: 4.09 w/w%. Phase stability is -> |
| Assistant | low |
| User | Plantapon ACG 50: 11.39 w/w%, Plantapon Amino KG-L: 9.27 w/w%, Dehyquart CC6: 2.03 w/w%, Arlypon TT: 4.14 w/w%. Phase stability is -> |
| Assistant | low |
| User | Dehyton MC: 9.13 w/w%, Dehyton ML: 9.8 w/w%, Luviquat Excellence: 3.08 w/w%, Arlypon TT: 2.59 w/w%. Phase stability is -> |
| Assistant | low |
| User | Plantapon ACG 50: 11.91 w/w%, Dehyton ML: 9.94 w/w%, Luviquat Excellence: 1.1 w/w%, Arlypon TT: 0.94w/w%. Phase stability is -> |
| Role | Message |
|---|---|
| System | You will be given characteristics of a sample. Classify the sample outcome into one of the following categories: 0, or 1. Return only the name of the category, and nothing else. MAKE SURE your output is one of the two categories stated. |
| User | C1 is 2.21, C5 is 2.58, C13 is 1.63, C17 is 2.75. Outcome is -> |
| Assistant | 0 |
| User | C6 is 1.85, C11 is 3.33, C15 is 2.17, C16 is 1.93. Outcome is -> |
| Assistant | 0 |
| User | C1 is 2.38, C2 is 2.42, C15 is 1.31, C16 is 2.31. Outcome is -> |
| Assistant | 1 |
| User | C3 is 3.33, C4 is 2.5, C12 is 1.2, C17 is 2.2. Outcome is -> |
| Assistant | 1 |
| User | C4 is 2.5, C10 is 2.43, C12 is 1.68, C17 is 1.7. Outcome is -> |
| Assistant | 0 |
| User | C1 is 1.34, C2 is 2.58, C15 is 2.63, C17 is 1.44. Outcome is -> |
| Assistant | 1 |
| User | C5 is 2.11, C6 is 2.55, C15 is 1.63, C16 is 2.28. Outcome is -> |
| Assistant | 0 |
| User | C0 is 3.33, C6 is 2.07, C13 is 1.77, C17 is 2.27. Outcome is -> |
| Assistant | 0 |
| User | C1 is 1.98, C10 is 2.57, C13 is 2.85, C17 is 2.3. Outcome is -> |
| Assistant | 0 |
| User | C5 is 1.74, C7 is 3.33, C12 is 3.04, C17 is 1.44. Outcome is -> |
| Assistant | 0 |
| User | C1 is 2.07, C7 is 3.38, C12 is 1.09, C17 is 0.52. Outcome is -> |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bigan, E.; Dufour, S. Prediction of Shampoo Formulation Phase Stability Using Large Language Models. Cosmetics 2025, 12, 145. https://doi.org/10.3390/cosmetics12040145
Bigan E, Dufour S. Prediction of Shampoo Formulation Phase Stability Using Large Language Models. Cosmetics. 2025; 12(4):145. https://doi.org/10.3390/cosmetics12040145
Chicago/Turabian StyleBigan, Erwan, and Stéphane Dufour. 2025. "Prediction of Shampoo Formulation Phase Stability Using Large Language Models" Cosmetics 12, no. 4: 145. https://doi.org/10.3390/cosmetics12040145
APA StyleBigan, E., & Dufour, S. (2025). Prediction of Shampoo Formulation Phase Stability Using Large Language Models. Cosmetics, 12(4), 145. https://doi.org/10.3390/cosmetics12040145