A Practical Framework to Study Low-Power Scheduling Algorithms on Real-Time and Embedded Systems

Abstract
:1. Introduction
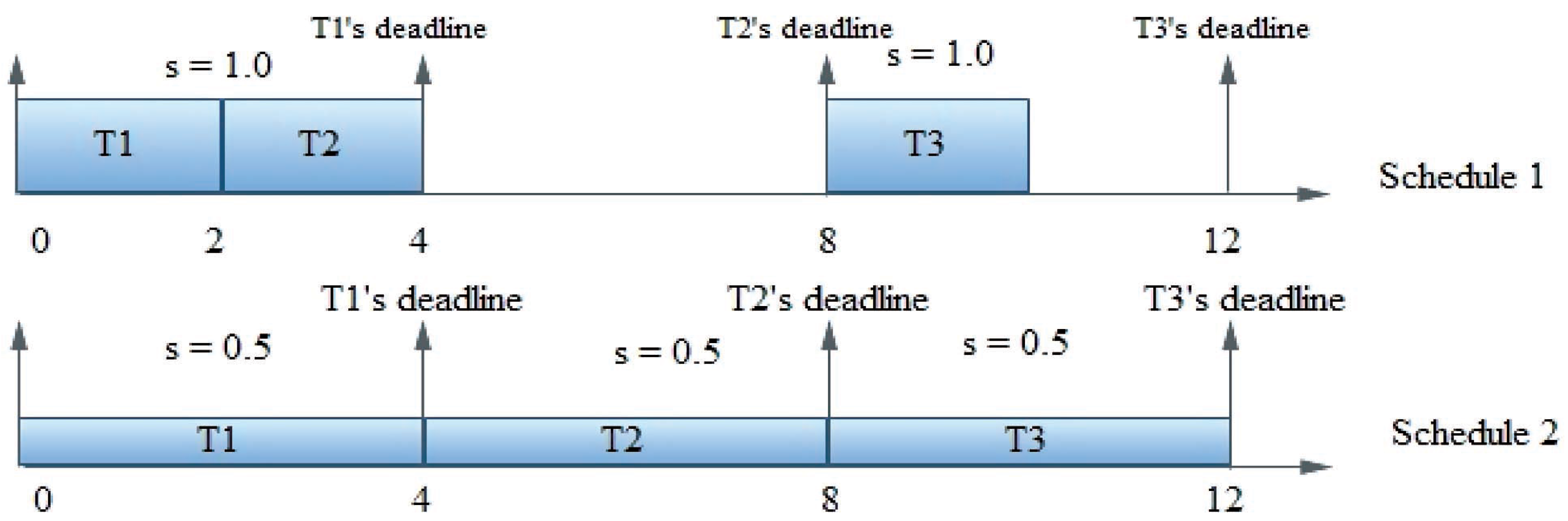

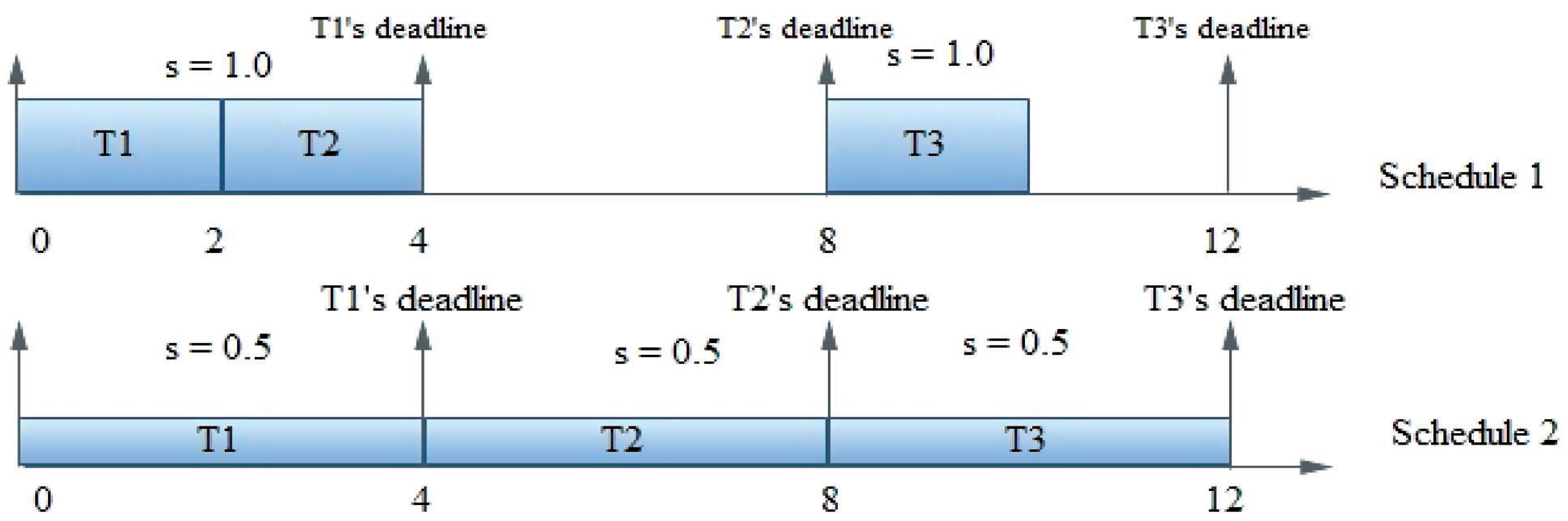{kind=link}
{kind=link}
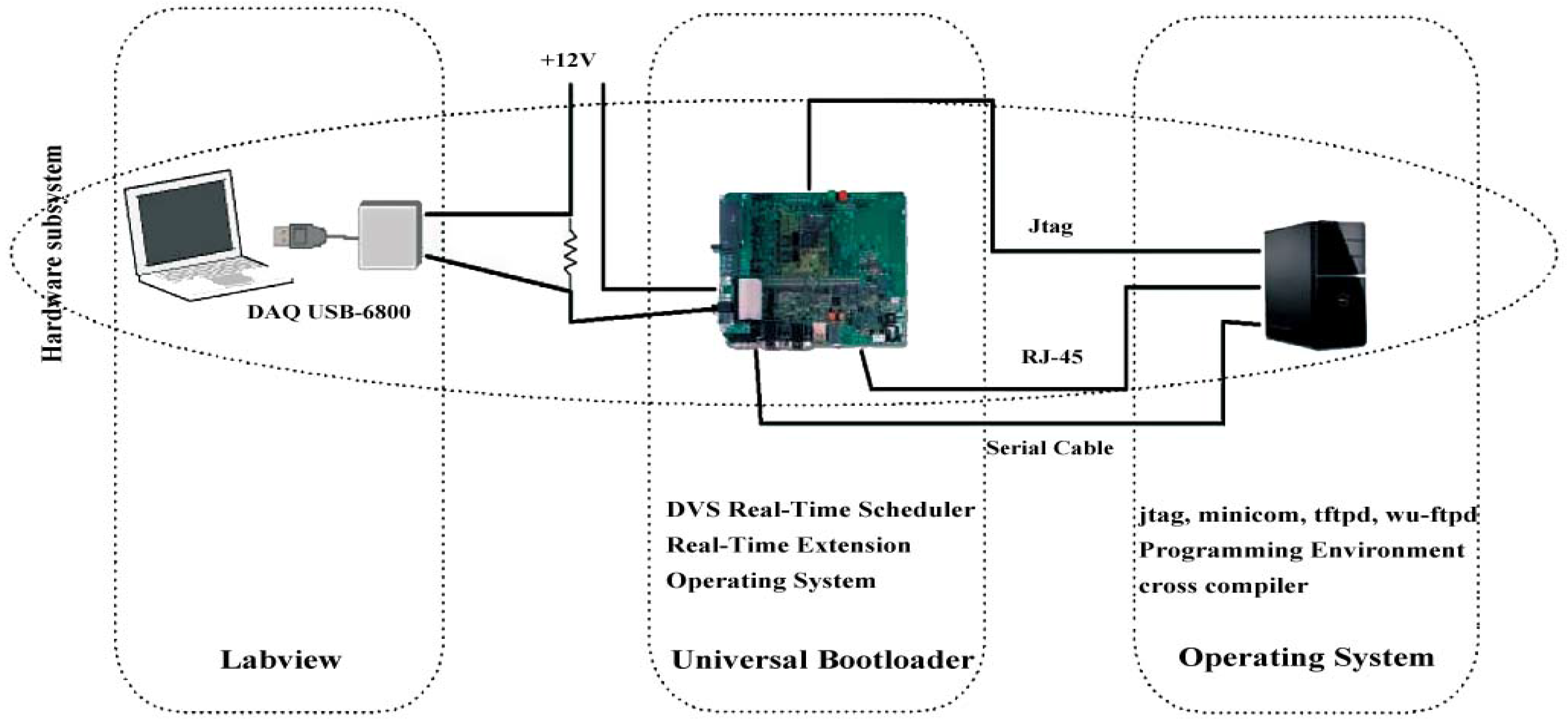{kind=link}
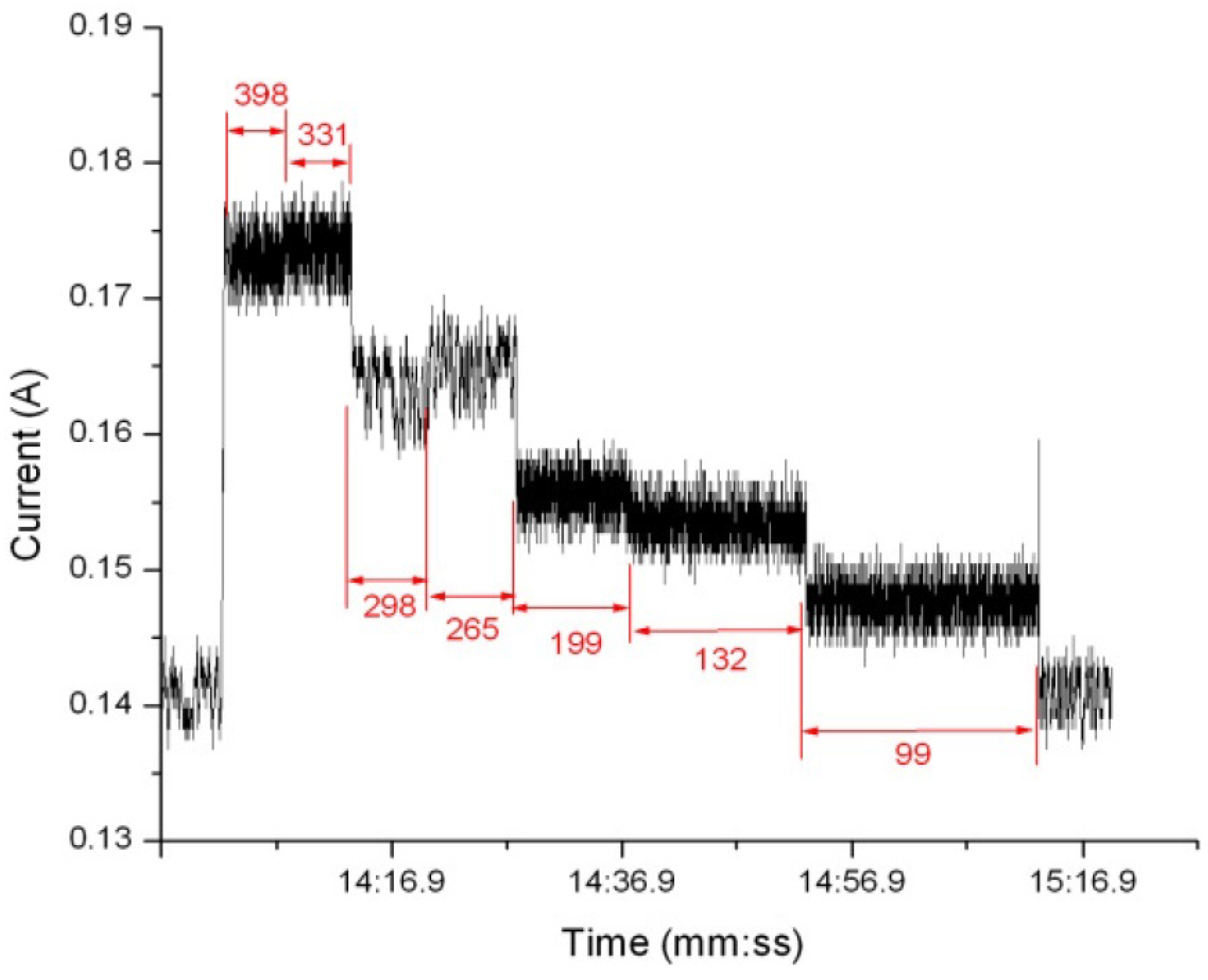{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task no. | Ready time and deadline | Execution time |
|---|---|---|
| T1 | (0, 4) | 2 |
| T2 | (2, 8) | 2 |
| T3 | (7, 12) | 2 |
2. Advances in Power-Aware Scheduling
2.1. Fundamental Techniques for Power-Aware Scheduling

2.2. Evaluations of the Performance of Power-Aware Algorithms
3. Real-Energy
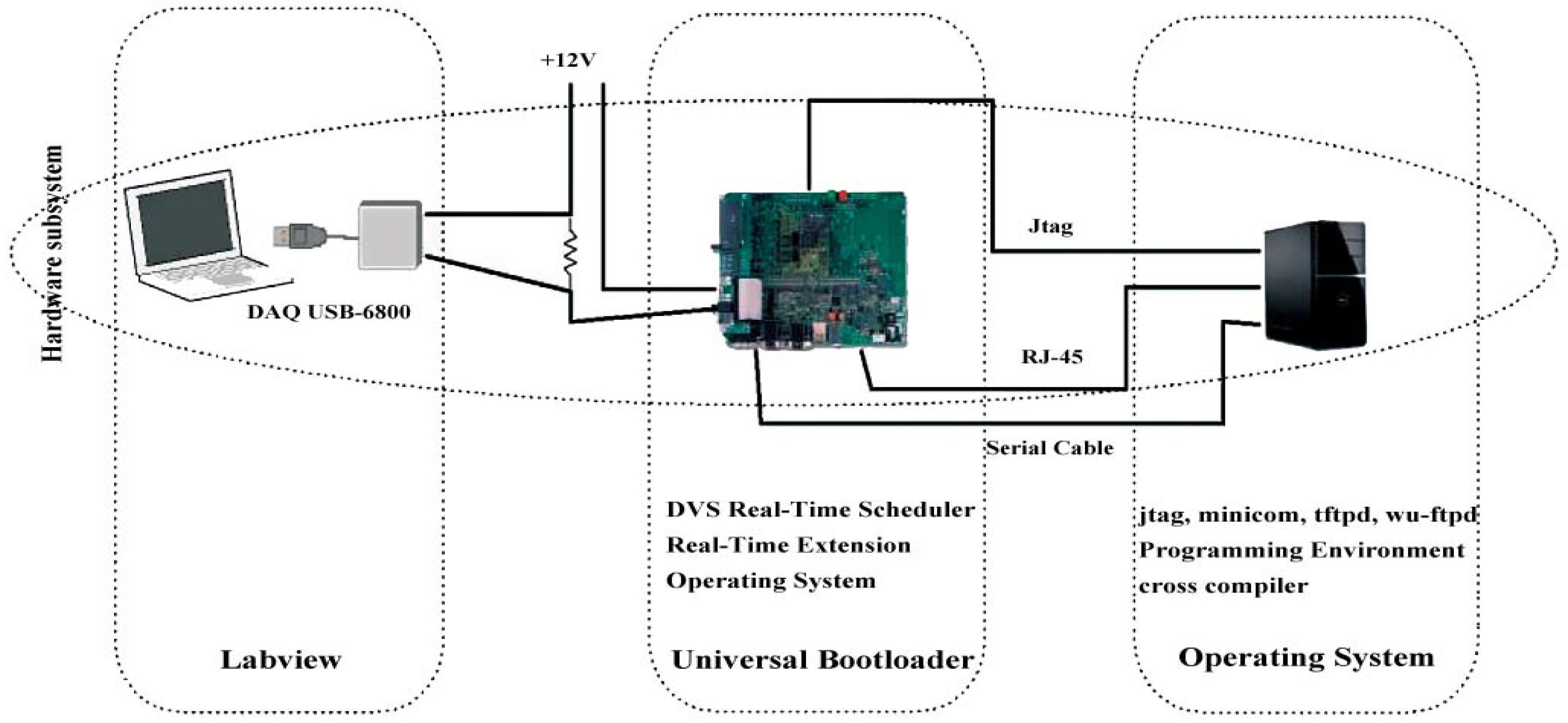
3.1. Environment Setup
| CPU frequency (MHz) at voltage (V) | Flash memory frequency (MHz) | SDRAM frequency (MHz) |
|---|---|---|
| 99.1 MHz at 1.0 V | 99.5 MHz | 99.5 MHz |
| 199.1 MHz at 1.0 V | 99.5 MHz | 99.5 MHz |
| 298.6 MHz at 1.1 V | 99.5 MHz | 99.5 MHz |
| 398.1 MHz at 1.3 V | 99.5 MHz | 99.5 MHz |
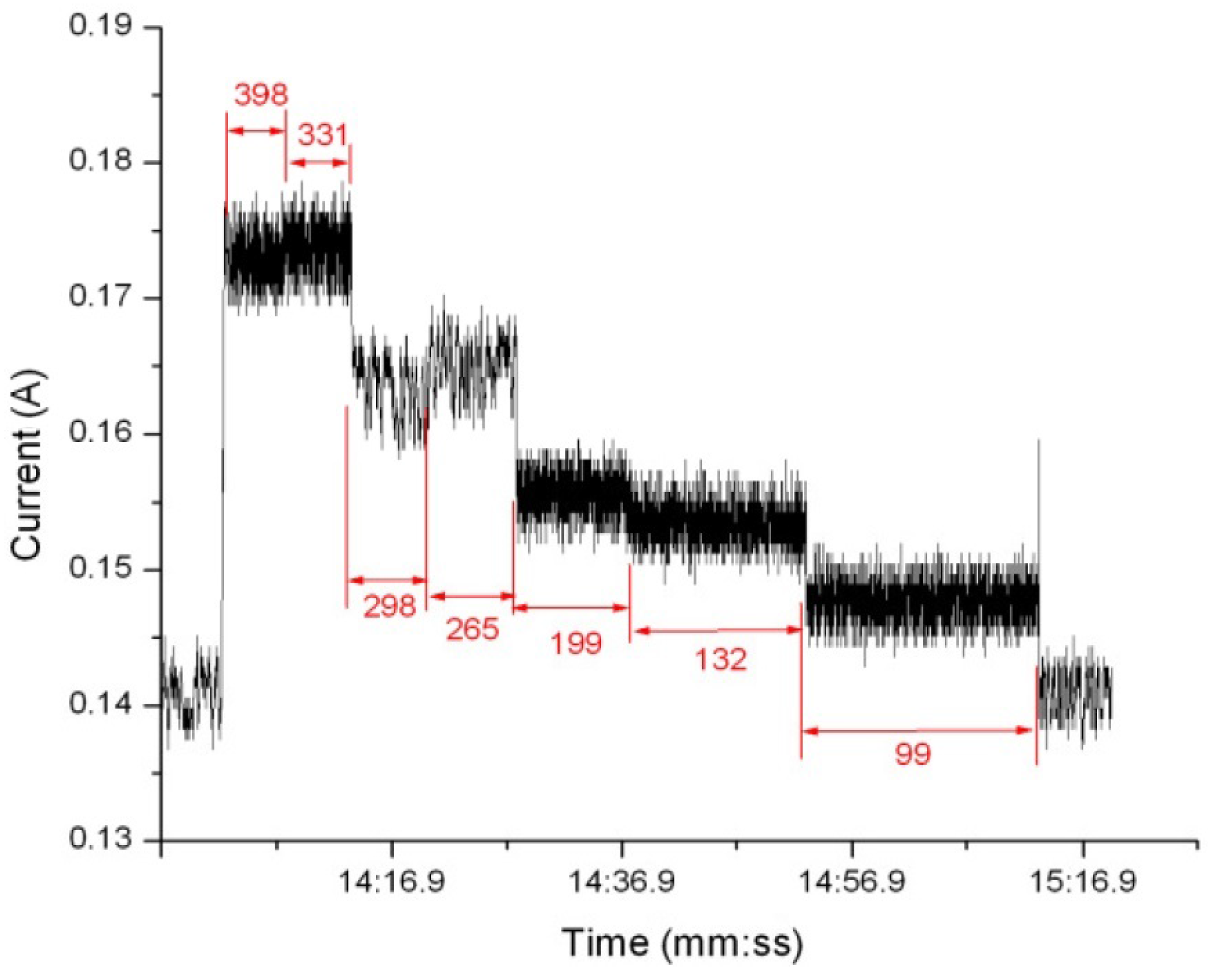
3.2. Measuring Energy Consumption
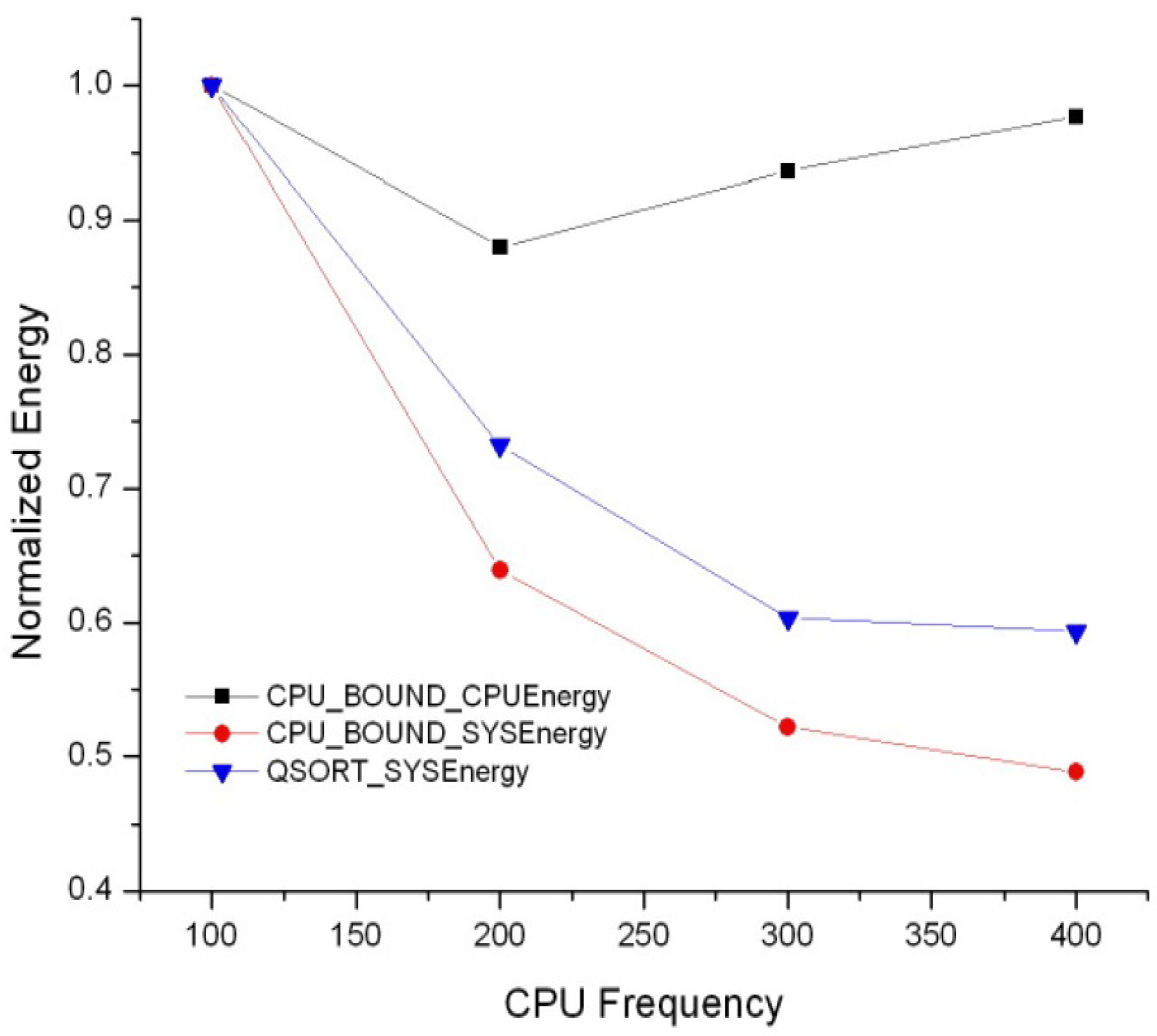
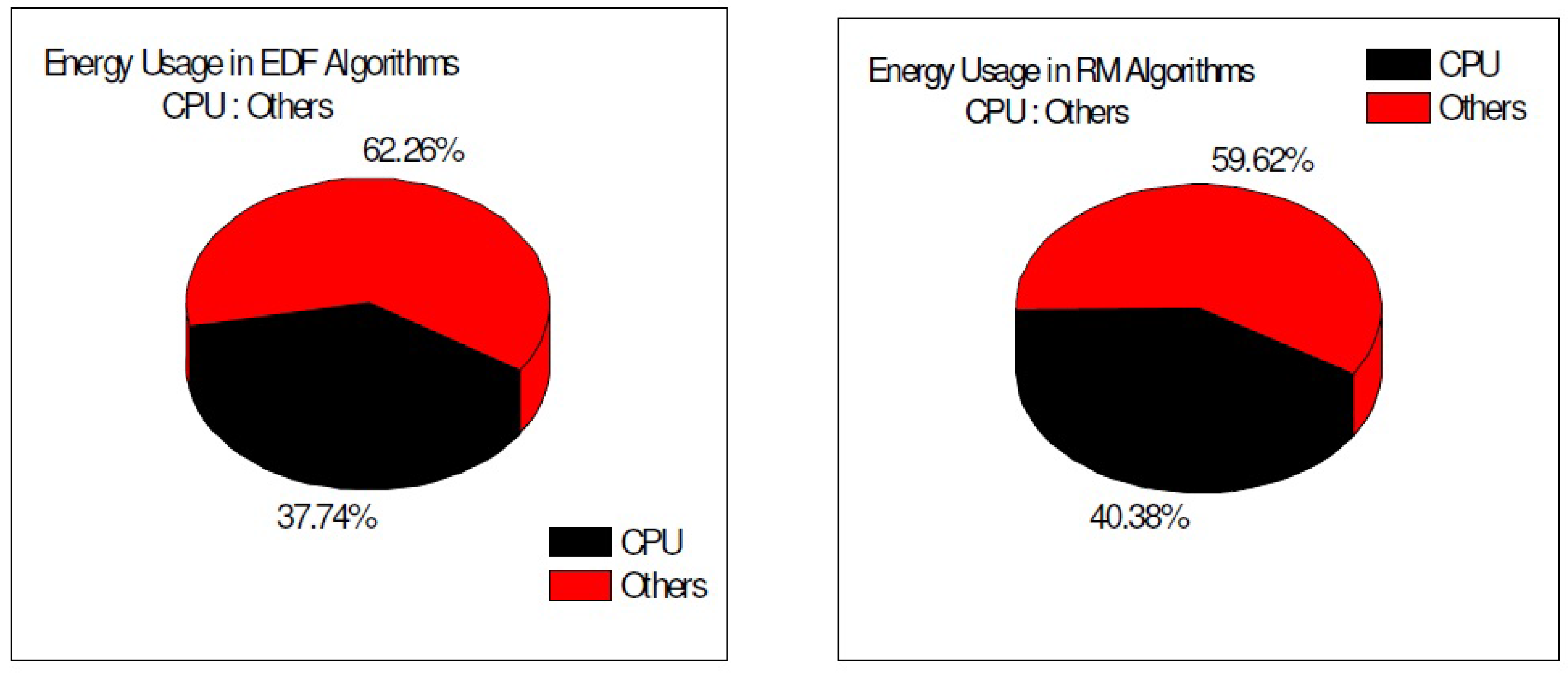
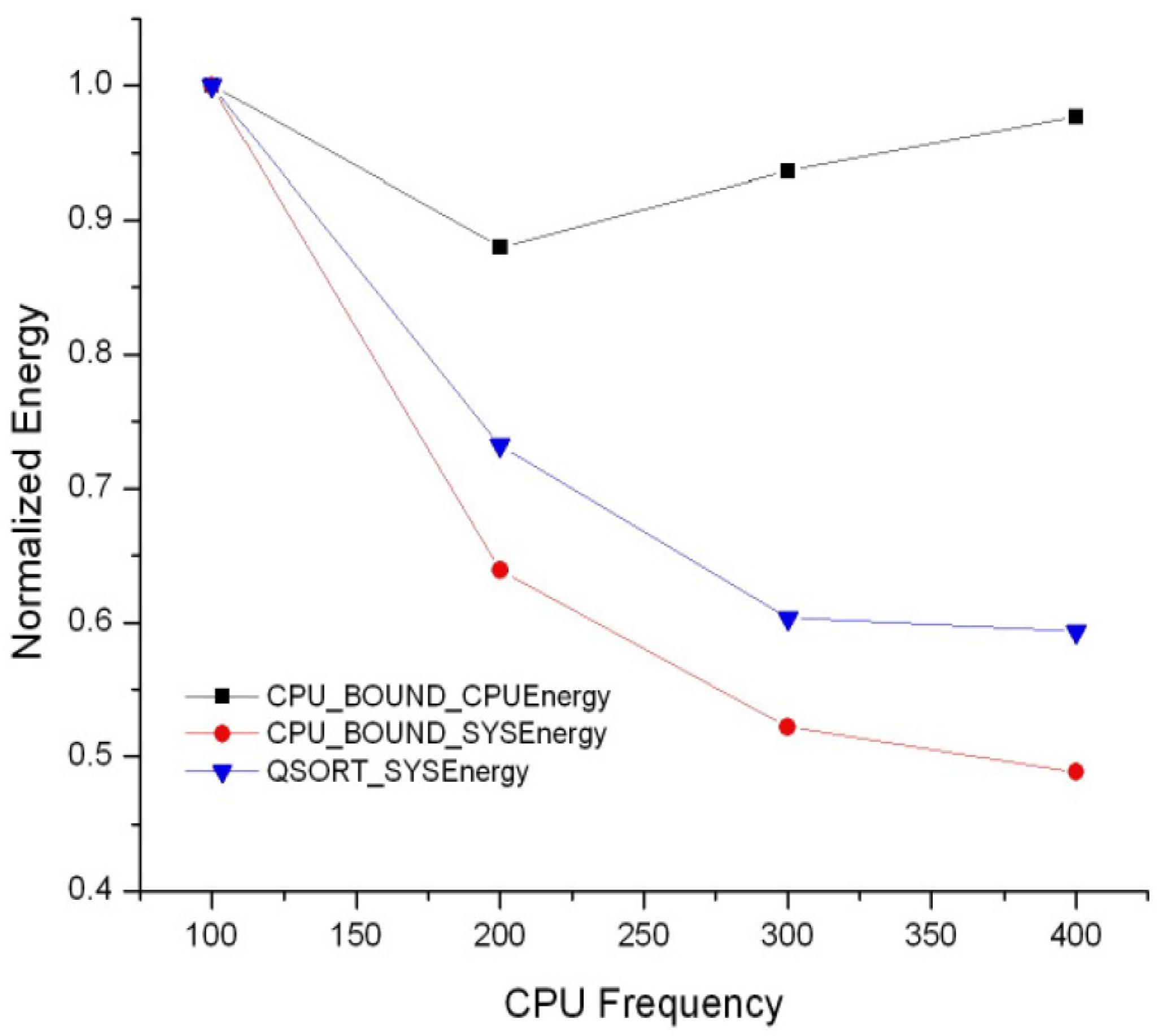
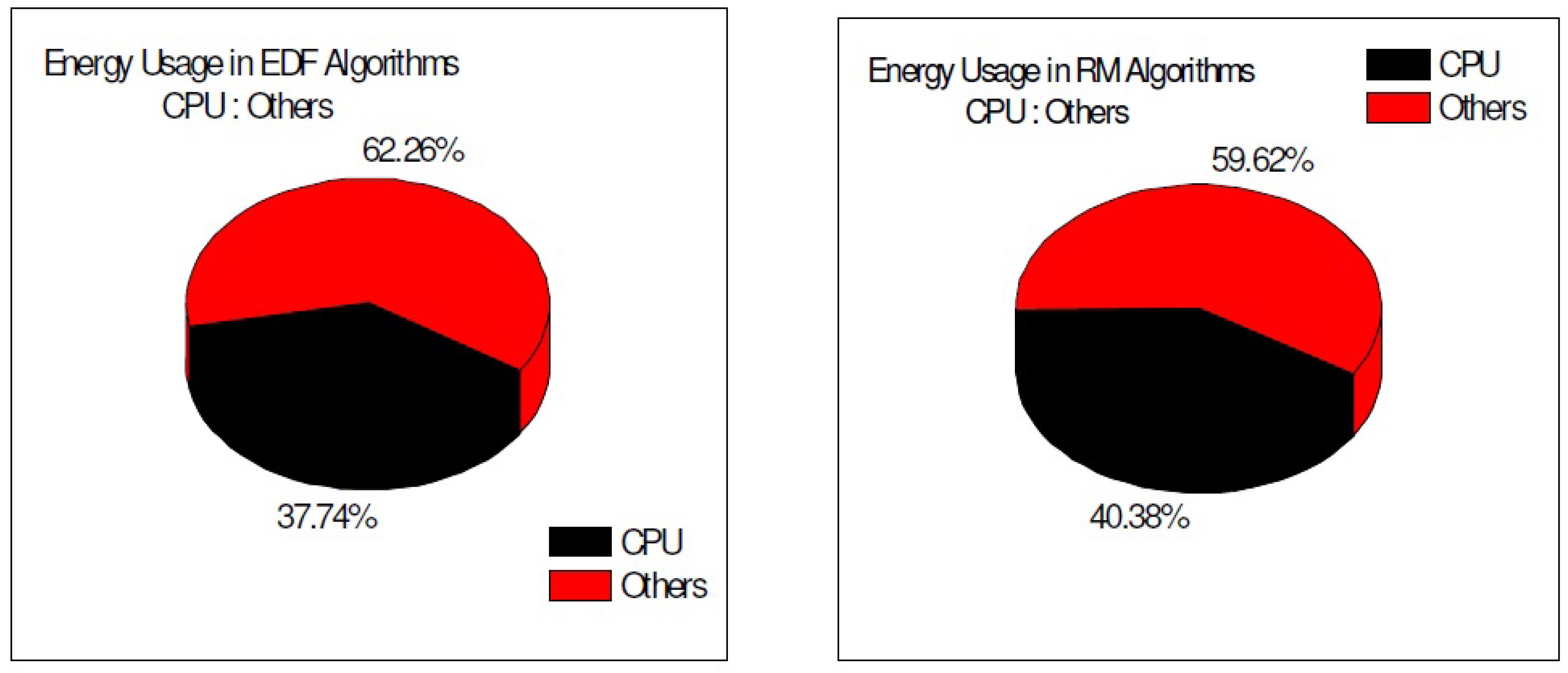
3.3. CPU Energy Consumption and System-Wide Energy Consumption
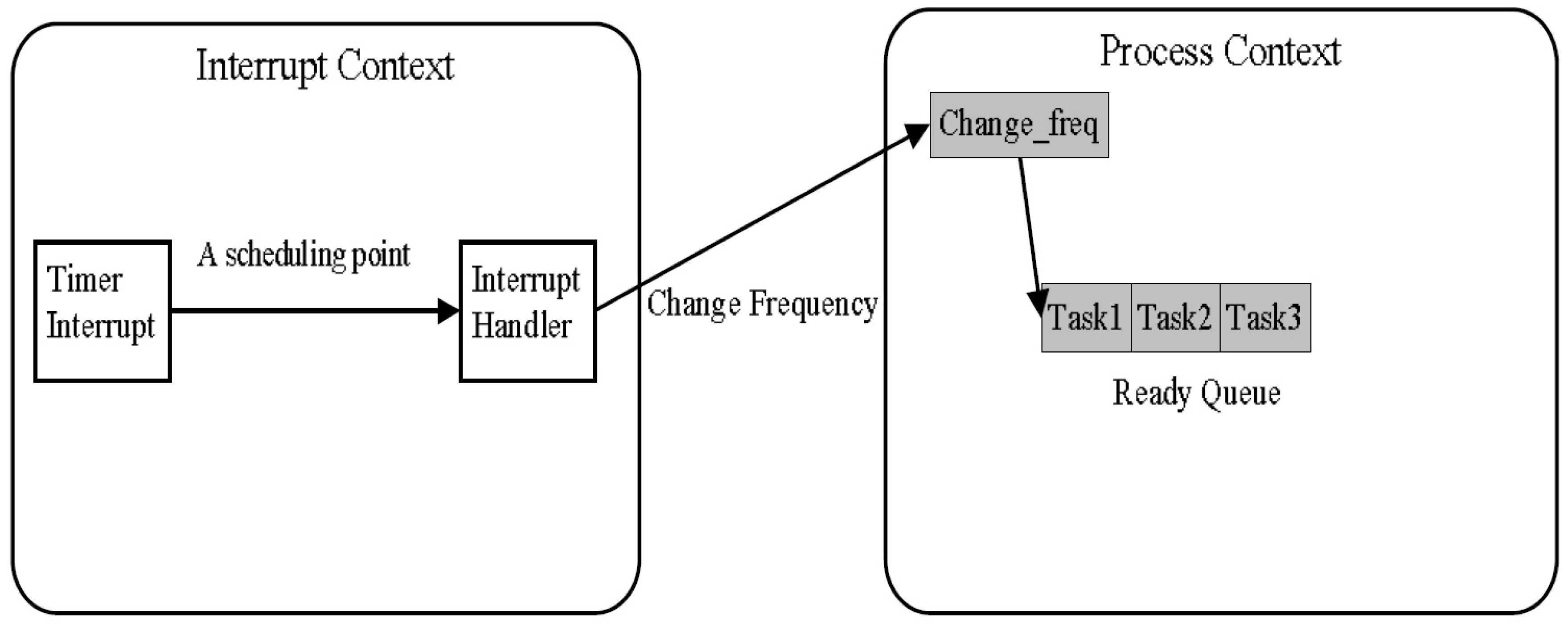
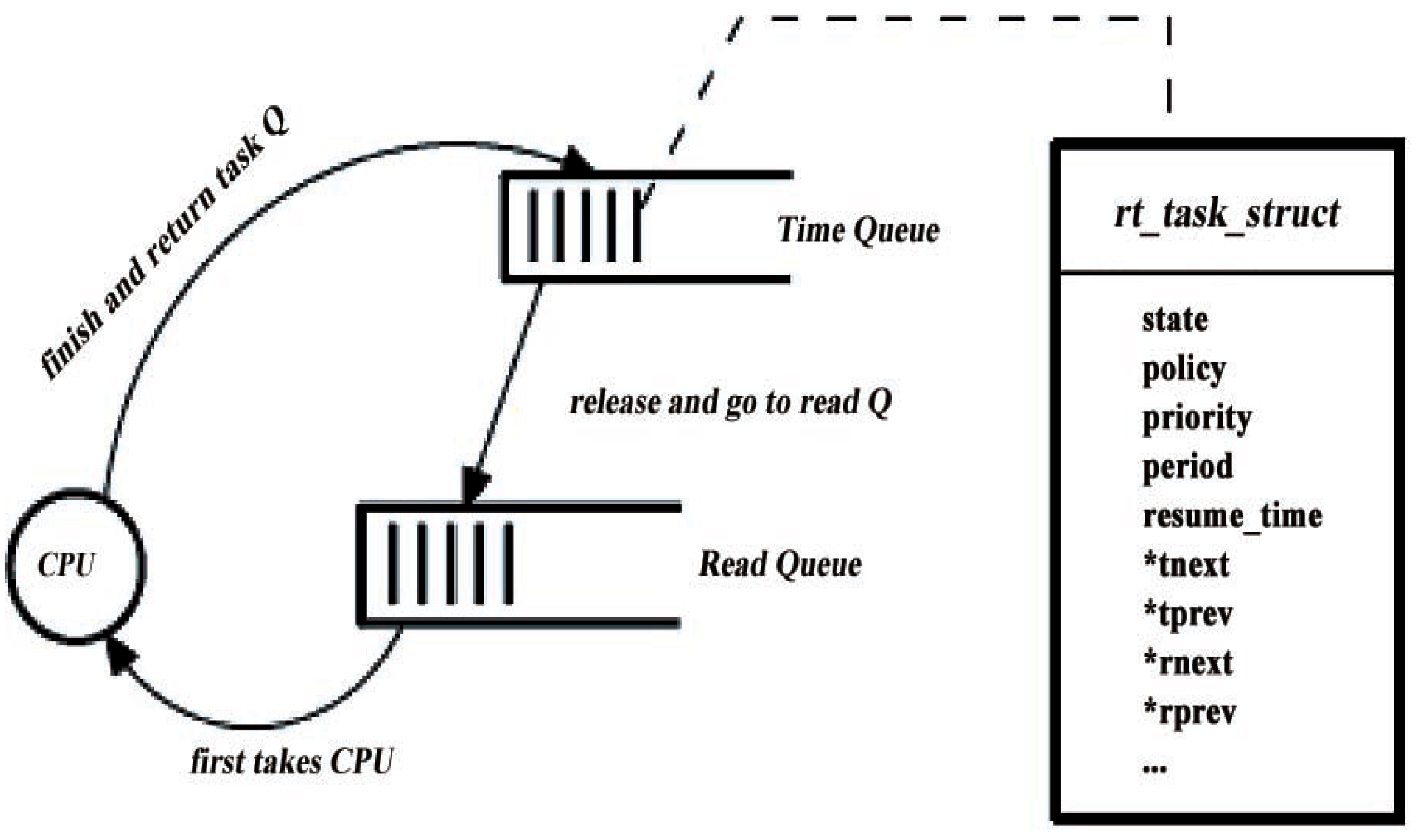
3.4. Programming Design
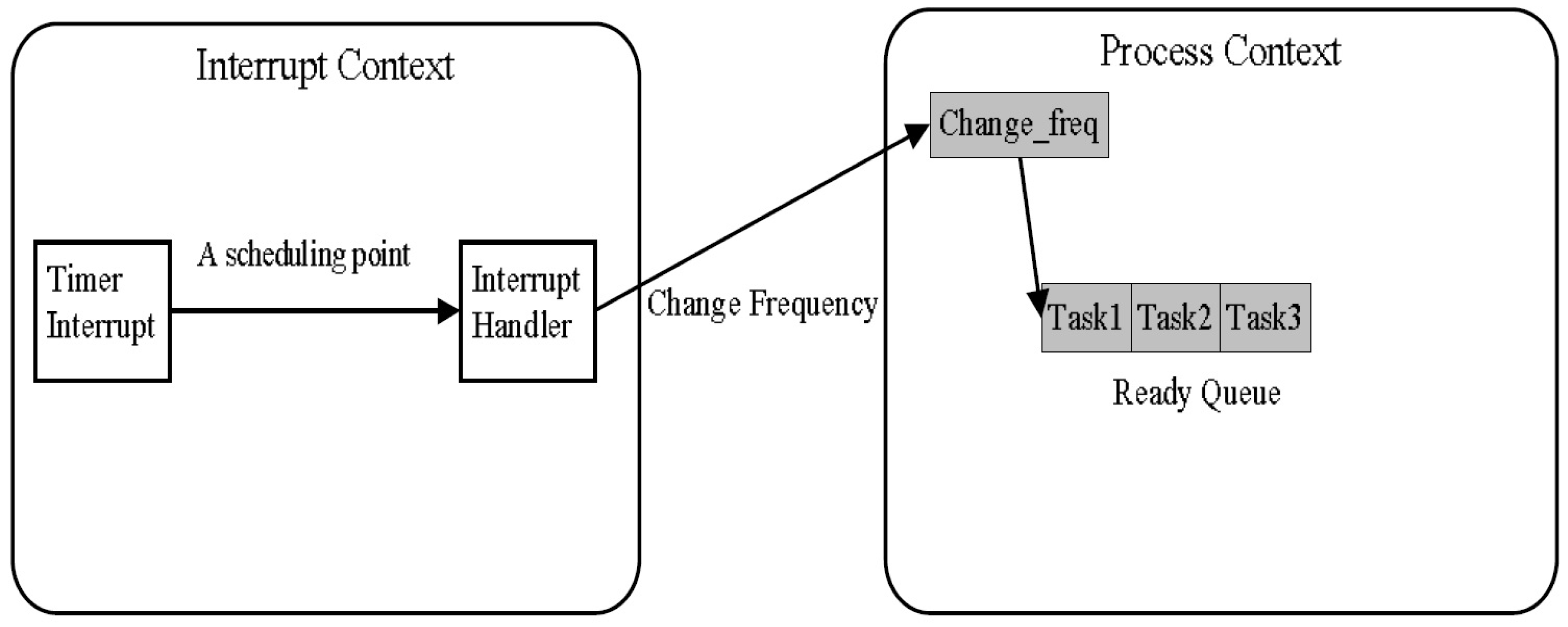
4. A Case Study
4.1. Experimental Setting
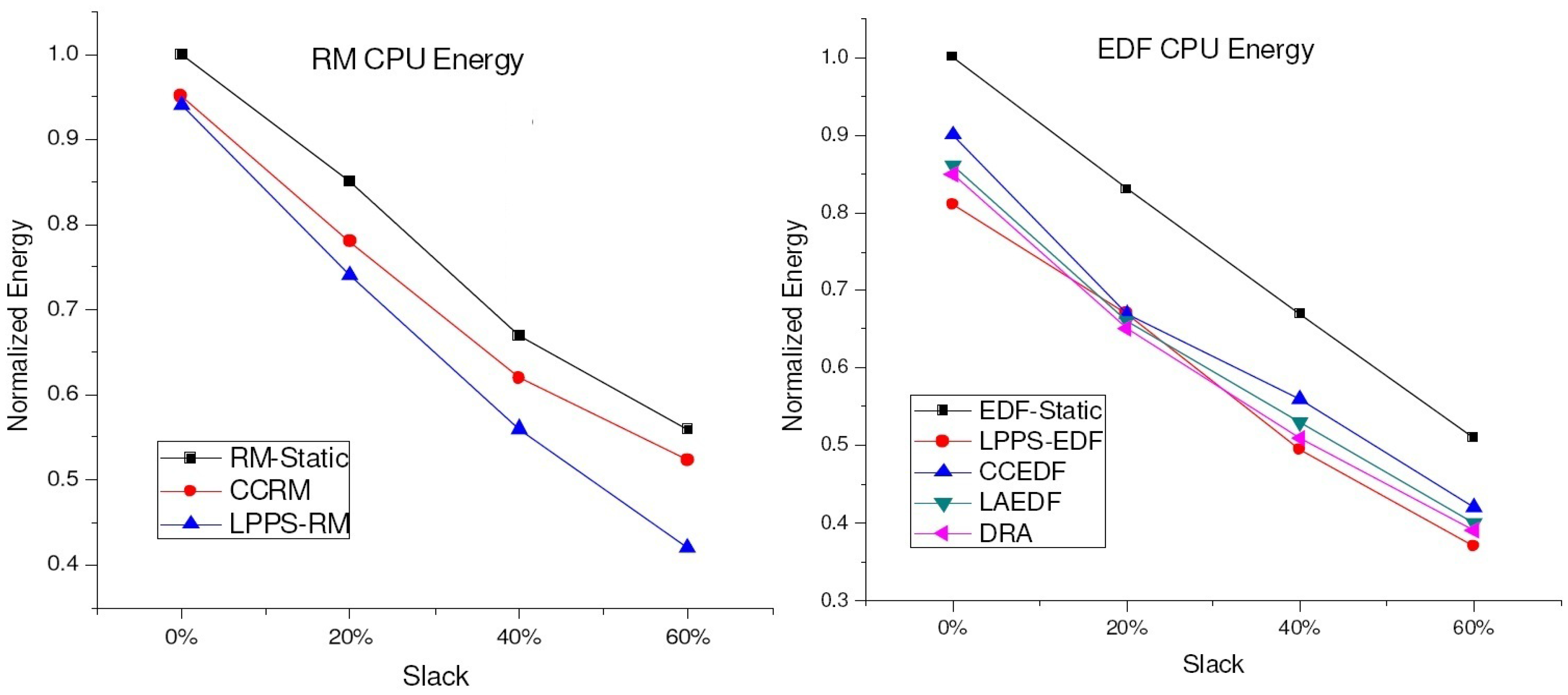
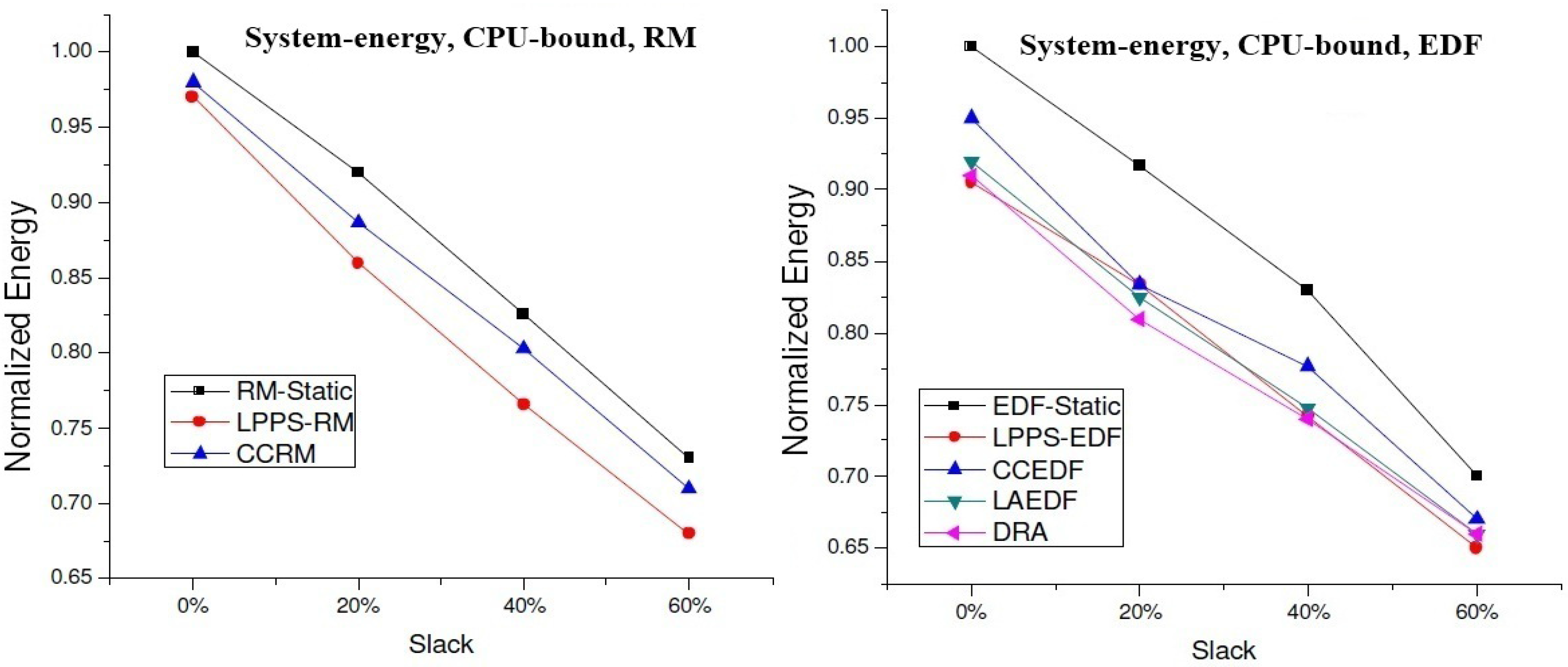
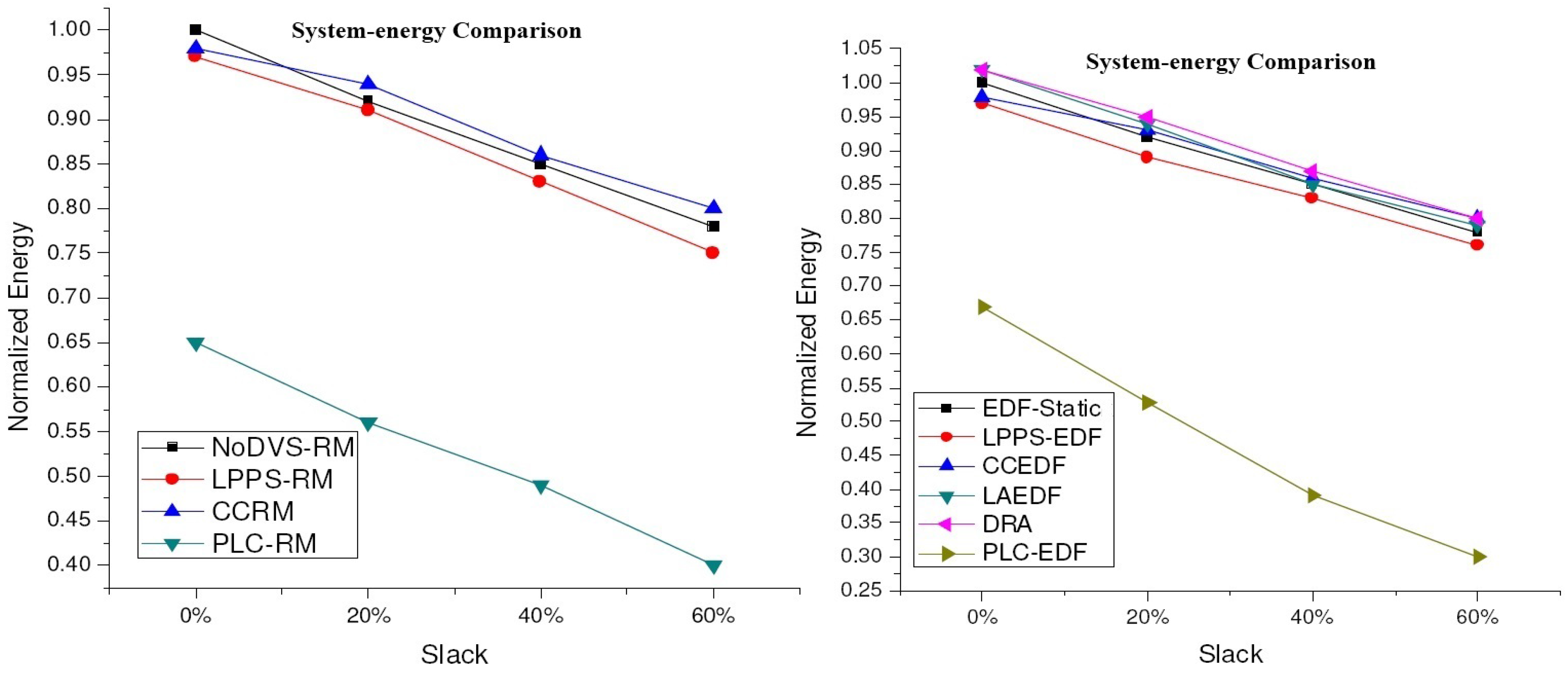
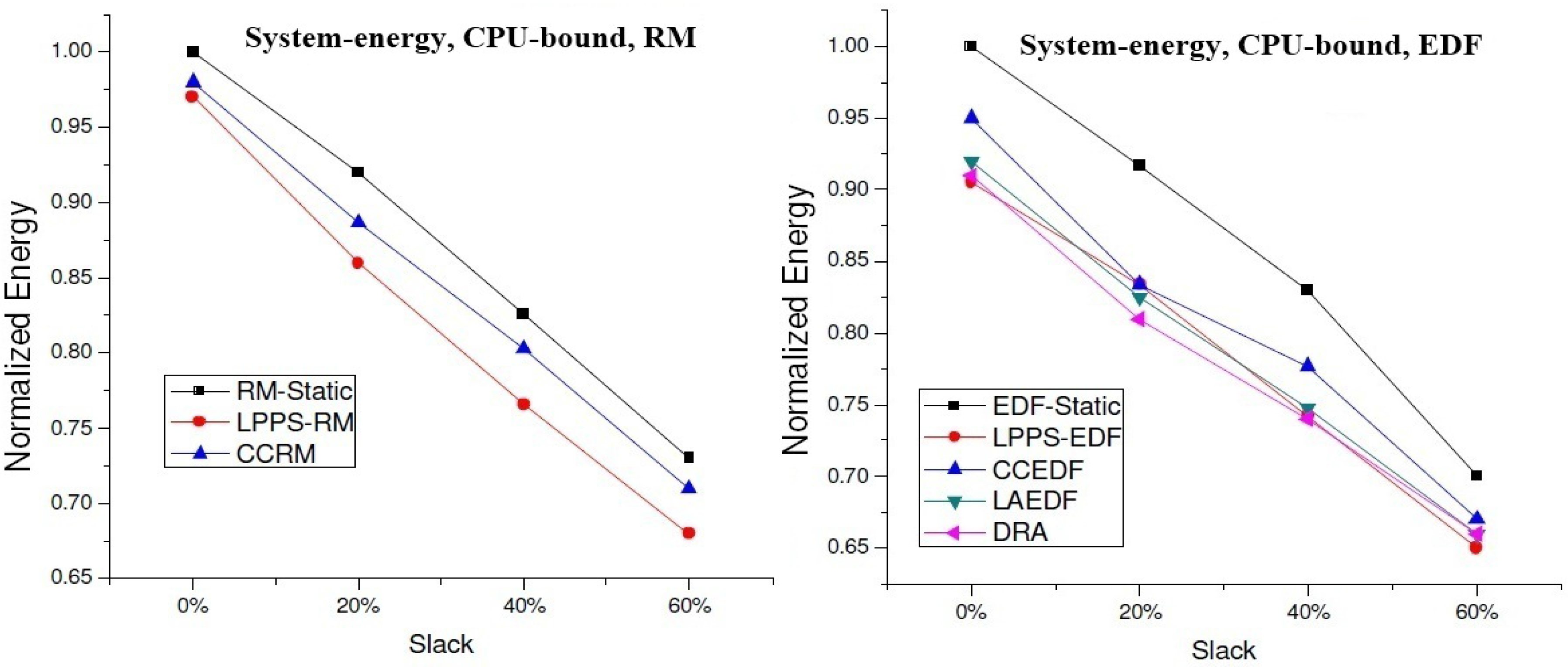
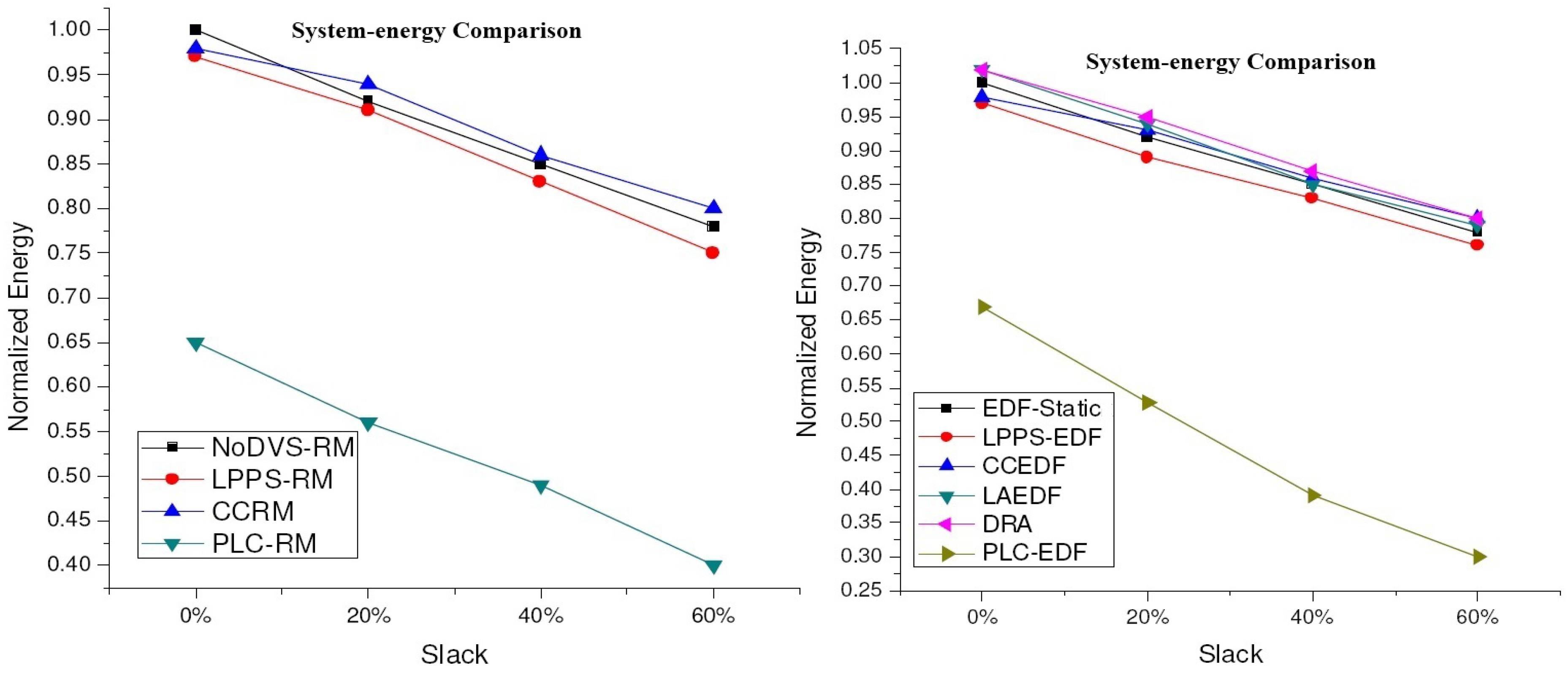
4.2. Experimental Results for DVS Algorithms
| EDF | lppsEDF [9]; ccEDF [8]; laEDF [8]; DRA [13]. |
| RM | lppsRM[9]; ccRM[8] |

4.3. Experimental Results of Procrastination Algorithms
| Algorithm 1: Revised procrastination algorithms. |
| 1 On a task’s arrival: |
| 2 If (CPU is active) |
| 3 Insert the task into the ready queue |
| 4 Else |
| 5 Do nothing |
| 6 End |
| 7 On a completion of a task: |
| 8 If(the ready queue is not empty) |
| 9 Execute the highest priority task in the queue |
| 10 Else |
| 11 The CPU enters into the sleep state |
| 12 The wake-up time is set at |
| 13 End |
| 14 On a CPU’s wake-up: |
| 15 Begin executing the tasks in the ready |
5. Conclusion
Acknowledgments
Conflicts of Interest
References
- Ditzel, M.; Otten, R.; Serdijn, W. Power-Aware Architecting for Data-Dominated Dpplications; Springer: Berlin, Germany, 2007. [Google Scholar]
- Intel StrongARM SA-1110 Microprocessor Developers Manual; Intel Corporation: Santa Clara, CA, USA, 2000.
- Intel PXA255 Processor Developers Manual; Intel Corporation: Santa Clara, CA, USA, 2004.
- Lin, J.; Song, W.; Cheng, A. Real energy: A new framework and a case study to evaluate power-aware real-time scheduling algorithms. In Proceedings of the ACM/IEEE International Symposium on Low Power Electronics and Design (ISLPED), Austin, TX, USA, 18–20 August 2010.
- Yao, F.; Demers, A.; Shenker, S. A scheduling model for reduced CPU energy. In Proceedings of the 36th Annual Symposium on Foundations of Computer Science, Milwaukee, WI, USA, 23–25 October 1995.
- Aydin, H.; Melhem, R.; Mosse, D.; Meja-Alvarez, P. Dynamic and aggressive scheduling techniques for power-aware real-time systems. In Proceedings of the 22nd IEEE Real-Time Systems Symposium, London, UK, 2–6 December 2001.
- Liu, J.W. Real-Time Systems; Prentice Hall: Englewood, Cliffs, NJ, USA, 2000. [Google Scholar]
- Pillai, P.; Shin, K.G. Real-time dynamic voltage scaling for low power embedded operating systems. In Proceedings of the Eighteenth ACM Symposium on Operating Systems Principles, Banff, AB, Canada, 21–24 October 2001.
- Shin, Y.; Choi, K.; Sakurai, K. Power optimization of real-time embedded systems on variable speed processors. In Proceedings of the 2000 IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 5–9 November 2000.
- Liu, C.L.; Layland, J.W. Scheduling algorithms for multi programming in a hard real time environment. J. ACM 1973, 20, 46–61. [Google Scholar] [CrossRef]
- Lehoczky, J.; Sha, L.; Ding, Y. The rate monotonic scheduling algorithm: Exact characterization and average case behavior. In Proceedings of the IEEE Real-Time Systems Symposium, Santa Monica, CA, USA, 5–7 December 1989.
- Lee, I.; Leung, J.; Son, S. Handbook of Real-Time and Embedded Systems; Chapman and Hall/CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Aydin, H.; Melhem, R.; Mosse, D.; Mejia-Alvarez, P. Dynamic and aggressive scheduling techniques for power-aware real-time systems. In Proceedings of the 22nd IEEE Real-Time Systems Symposium, London, UK, 2–6 December 2001.
- Andrei, S.; Cheng, A.; Radulescu, V.; McNicholl, T. Toward an optimal power-aware scheduling technique. In Proceedings of the 14th IEEE International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, Timisoara, Romania, 26–29 September 2012.
- Li, J.; Shu, L.; Chen, J.; Li, G. Energy-efficient scheduling in non-preemptive systems with real-time constraints. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 332–344. [Google Scholar] [CrossRef]
- Chen, J.; Hsu, H.; Chuang, K.; Yang, C.; Pang, A.; Kuo, T. Multiprocessor energy-efficient scheduling with task migration considerations. In Proceedings of the IEEE EuroMicro Conference on Real-Time Systems, Catania, Italy, 30 June–2 July 2004.
- Aydin, H.; Yang, Q. Energy-aware partitioning for multiprocessor real-time systems. In Proceedings of the IEEE 17th International Parallel and Distributed Processing Symposium, Nice, France, 22–26 April 2003.
- Lin, J.; Cheng, A.M.K. Real-time task assignment in rechargeable multiprocessor systems. In Proceedings of the IEEE 14th IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Kaohisung, Taiwan, 25–27 August 2008.
- Schmitz, M.; Al-Hashimi, B.; Eles, P. Energy-efficient mapping and scheduling for DVS enabled distributed embedded systems. In Proceedings of the IEEE Conference on Design, Automation and Test in Europe, Paris, France, 4–8 March 2002.
- Lin, J.; Cheng, A.M.; Kumar, R. Real-time task assignment in heterogeneous distributed systems with rechargeable batteries. In Proceedings of the IEEE International Conference on Advanced Information Networking, Bradford, UK, 26–29 May 2009.
- Luo, J.; Jha, N. Static and dynamic variable voltage dcheduling algorithms for realtime heterogeneous distributed embedded systems. In Proceedings of the 15th International Conference on VLSI Design, Bangalore, India, 7–11 January 2002.
- Lee, Y.; Reddy, K.P.; Krishna, C.M. Scheduling techniques for reducing leakage power in hard real-time systems. In Proceedings of the EcuroMicro Conference on Real Time Systems (ECRTS), Porto, Portugal, 2–4 July 2003.
- Jejruikar, R.; Gupta, P.K. Procrastination scheduling in fixed priority real-time systems. In Proceedings of the 2004 ACM SIGPLAN/SIGBED Conference on Languages, Compilers and Tools for Embedded Systems, Washington, DC, USA, 11–13 June 2004.
- Jekruikar, R.; Gupta, P.K. Dynamic slack reclamation with procrastination scheduling in real-time embedded systems. In Proceedings of the ACM IEEE Design Automation Conference, San Diego, CA, USA, 13–17 June 2005.
- Jekruikar, R.; Pereira, C.; Gupta, P.K. Leakage aware dynamic voltage scaling for real-time embedded systems. In Proceedings of the ACM IEEE Design Automation Conference, San Diego, CA, USA, 7–11 June 2004.
- Irani, S.; Shukla, S.; Gupta, R. Algorithms for power savings. In Proceedings of the 14th Annual ACM-SIAM Symposium on Discrete Algorithms, Baltimore, MD, USA, 12–14 January 2003.
- Lin, J.; Cheng, A. Energy reduction for scheduling a set of multiple feasible interval jobs. J. Syst. Archit. Embed. Softw. Des. 2011, 57, 663–673. [Google Scholar] [CrossRef]
- Chetto, M. A note on EDF scheduling for real-time energy harvesting systems. IEEE Trans.Comput. 2014, 63, 1037–1040. [Google Scholar] [CrossRef]
- Chetto, M. Optimal scheduling for real-time jobs in energy harvesting computing systems. IEEE Trans. Emerg. Top. Comput. 2014. [Google Scholar] [CrossRef]
- Liu, S.; Qiu, Q.; Wu, Q. Energy aware dynamic voltage and frequency selection for real-time systems with energy harvesting. In Proceedings of the Design, Automation, and Test in Europe, Munich, Germany, 10–14 March 2008.
- Liu, S.; Lu, J.; Wu, Q.; Qiu, Q. Harvesting-aware power management for real-time systems with renewable energy. IEEE Trans. Large Scale Integr. (VLSI) Syst. 2011, 20, 1473–1486. [Google Scholar]
- Kim, W.; Shin, D.; Yun, H.-S.; Kim, J.; Min, S.L. Performance comparison of dynamic voltage scaling algorithms for hard real-time systems. In Proceedings of the Real-Time and Embedded Technology and Applications Symposium, San Jose, CA, USA, 24–27 September 2002.
- Snowdon, D.; Ruocco, S.; Heiser, G. Power management and dynamic voltage scaling: Myths and facts. In Proceedings of the 2005 Workshop on Power Aware Real-time Computing, Jersey City, NJ, USA, 18–22 September 2005.
- Miyoshi, A.; Lefurgy, C.; Hensbergen, E.V.; Rajamony, R.; Rajkumar, R. Critical power slope: Understanding the runtime effects of frequency scaling. In Proceedings of the 16th Annual ACM International Conference on Supercomputing, New York, NY, USA, 22–26 June 2002.
- Weissel, A.; Bellosa, F. Process cruise control: Event-driven clock scaling for dynamic power management. In Proceedings of the International Conference on Compilers, Architecture and Synthesis for Embedded Systems (CASE 2002), Greenoble, France, 8–11 October 2002.
- Yang, C.; Chen, J.; Kuo, T. Preemption control for energy efficient task scheduling in systems with a DVS processor and Non-DVS Devices. In Proceedings of the 13th IEEE International Conferences on Embedded and Real-Time Computing Systems and Applications, Daegu, Korea, 21–24 August 2007.
- AlEnawy, T.A.; Aydin, H. Energy-aware task allocation for rate monotonic scheduling. In Proceedings of the 11th IEEE Real-time and Embedded Technology and Applications Symposium (RTAS’05), San Francisco, CA, USA, 7–10 March 2005.
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Lin, J.; Cheng, A.M.K.; Song, W. A Practical Framework to Study Low-Power Scheduling Algorithms on Real-Time and Embedded Systems. J. Low Power Electron. Appl. 2014, 4, 90-109. https://doi.org/10.3390/jlpea4020090
Lin J, Cheng AMK, Song W. A Practical Framework to Study Low-Power Scheduling Algorithms on Real-Time and Embedded Systems. Journal of Low Power Electronics and Applications. 2014; 4(2):90-109. https://doi.org/10.3390/jlpea4020090
Chicago/Turabian StyleLin, Jian, Albert M. K. Cheng, and Wei Song. 2014. "A Practical Framework to Study Low-Power Scheduling Algorithms on Real-Time and Embedded Systems" Journal of Low Power Electronics and Applications 4, no. 2: 90-109. https://doi.org/10.3390/jlpea4020090
APA StyleLin, J., Cheng, A. M. K., & Song, W. (2014). A Practical Framework to Study Low-Power Scheduling Algorithms on Real-Time and Embedded Systems. Journal of Low Power Electronics and Applications, 4(2), 90-109. https://doi.org/10.3390/jlpea4020090