1. Introduction
Many ultra-low power (ULP) systems, such as biomedical sensor nodes and implants, are expected to run on a single cubic-millimeter battery charge for days or even for years, and therefore are required to operate with extremely low power budgets. Aggressive supply voltage scaling, leading to near-threshold (near-
) or even to subthreshold (sub-
) circuit operation, is widely used in this context to lower both active energy dissipation and leakage power consumption, albeit at the price of severely degraded on/off current ratios (
) and increased sensitivity to process variations [
1]. The majority of these biomedical systems require a considerable amount of embedded memory for data and instruction storage, often amounting to a dominant share of the overall silicon area and power. Typical storage capacity requirements range from several kb for low-complexity systems [
2] to several tens of kb for more sophisticated systems [
3]. Over the last decade, robust, low-leakage, low-power sub-
memories have been heavily researched [
4,
5,
6]. In order to guarantee reliable operation in the sub-
domain, many new SRAM bitcells consisting of 8 [
7,
8], 9 [
5,
9], 10 [
4], and up to 14 [
2] transistors have been proposed. These bitcells utilize the additional devices to solve the predominant problems of write contention and bit-flips during read, and, in addition, some of the designs reduce leakage by using transistor stacks. All these state-of-the-art sub-
memories are based on static bitcells, while the advantages and drawbacks of dynamic bitcells for operation in the sub-
regime have not yet been studied.
Conventional 1-transistor-1-capacitor (1T-1C) embedded DRAM (eDRAM) is incompatible with standard digital CMOS technologies due to the need for high-density stacked or trench capacitors. Therefore, it cannot easily be integrated into a ULP system-on-chip (SoC) at low cost. Moreover, low-voltage operation is inhibited by the offset voltage of the required sense amplifier, unless special offset cancellation techniques are used [
10].
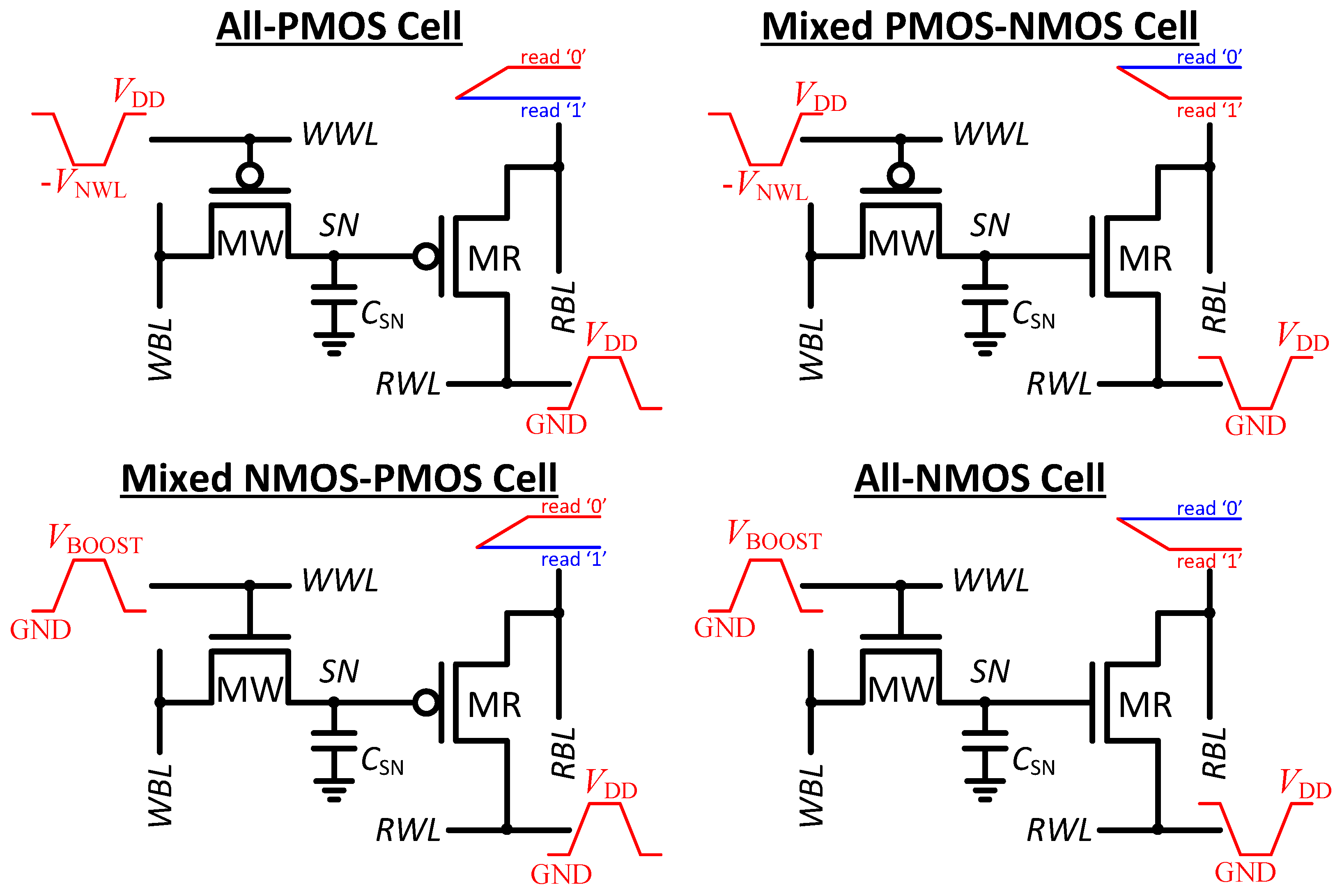
Gain-cells are a promising alternative to SRAM and to conventional 1T-1C eDRAM, as they are both smaller than any SRAM bitcell, as well as fully logic-compatible. Much of the previous work on gain-cell eDRAMs focuses on high-speed operation, in order to use gain-cells as a dense alternative to SRAM in on-chip processor caches [
11,
12], while only a few publications deal with the design of low-power near-
gain-cell arrays [
13,
14,
15]. A more detailed review of previous work in the field of gain-cell memories, including target application domains and circuit techniques, can be found in [
16]. The possibility of operating gain-cell arrays in the sub-
regime for high-density, low-leakage, and voltage-compatible data storage in ULP sub-
systems has not been exploited yet. One of the main objections to sub-
gain-cells is the degraded
current ratio, leading to rather short data retention times compared with the achievable data access times. However, the present study shows that these current ratios are still high enough in the sub-
regime to achieve short access and refresh cycles and high memory availability, at least down to 0.18 µm CMOS nodes. While gain-cells are considerably smaller than robust sub-
SRAM bitcells, they also exhibit lower leakage currents, especially in mature CMOS nodes where sub-
conduction is the dominant leakage mechanism. Recent studies for above-
, high-speed caches show that gain-cell arrays can even have lower retention power (leakage power plus refresh power) than SRAM (leakage power only) [
17]. However, a direct power comparison between gain-cell eDRAM and SRAM is difficult and not within the scope of this paper; for example, an ultra-low power sub-
SRAM implementation [
2] employs power gating of all peripheral circuits and of the read-buffer in the bitcell, while most power reports for gain-cell eDRAMs include the overhead of peripherals. Compared with SRAM, gain-cells are naturally suitable for two-port memory implementation, which provides an advantage in terms of memory bandwidth, and enables simultaneous and independent optimization of write and read reliability. Finally, while local parametric variations directly compromise the reliability of the SRAM bitcell (write contention, and data loss during read), such parametric variations only impact the access and retention times of gain-cells, which is not a severe issue when targeting the typically low speed requirements of ULP applications, such as sub-
sensor nodes or biomedical implants.
To start with, we consider sub-
gain-cell eDRAM design in a mature 0.18 µm CMOS node, which is typically used to: (1) easily fulfill the high reliability requirements of ULP systems; (2) reach the highest energy-efficiency of such ULP systems, typically requiring low frequencies and duty cycles [
18]; and (3) achieve low manufacturing costs. In a second step, we investigate the feasibility of sub-
gain-cell eDRAMs under the aspect of technology scaling. In particular, in addition to the mature 0.18 µm CMOS node, we analyze low voltage gain-cell operation in a 40 nm CMOS technology node. We show that deep-nanoscale gain-cell arrays are still feasible, despite the reduced retention times inherent to these nodes. Due to high refresh rates, we identify that the minimum supply voltage (
) that ensures an array availability of 97% is in the near-
domain.
1.1. Contributions:
The contributions of this work can be summarized as follows:
We investigate the minimum achievable supply voltage for ultra-low power gain-cell operation.
We analyze gain-cell arrays from a technology scaling perspective, examining the design trade-offs that arise due to the inherent characteristics of various technology nodes.
For the first time, we present a fully functional gain-cell array at a deeply scaled technology node, as low as 40 nm.
For the first time, we present a gain-cell array operated in the sub- domain.
1.2. Outline:
The remainder of this article is organized as follows.
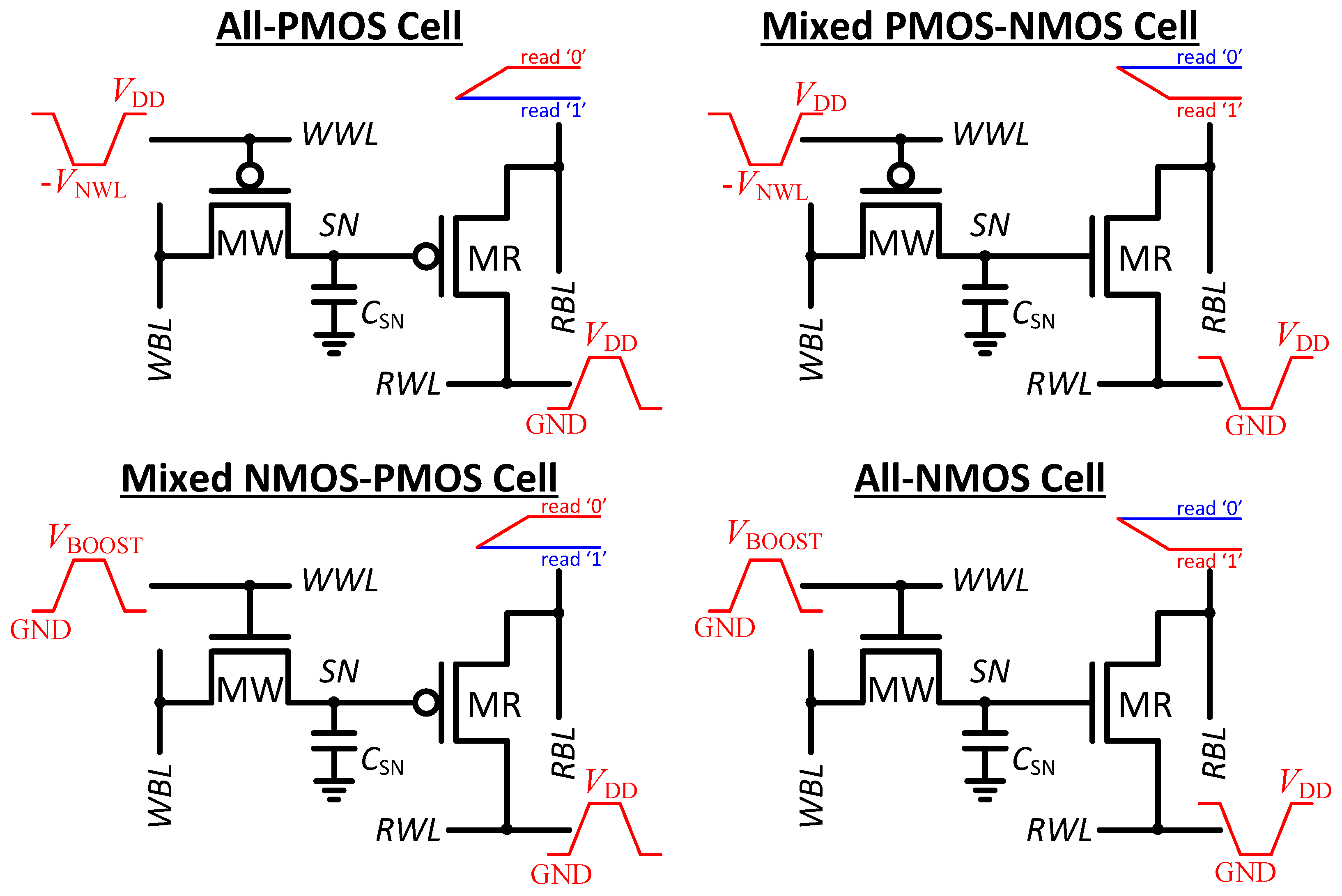
Section 2 explains the best-practice 2T gain-cell design in light of technology scaling, emphasizing the optimum choices of the write access transistor, read access transistor, storage node capacitance, and word line underdrive voltage for different nodes.
Section 3 and
Section 4 present detailed implementation results of a 2 kb gain-cell memory in a 0.18 µm and in a 40 nm CMOS node, respectively.
Section 5 summarizes the findings of this article.
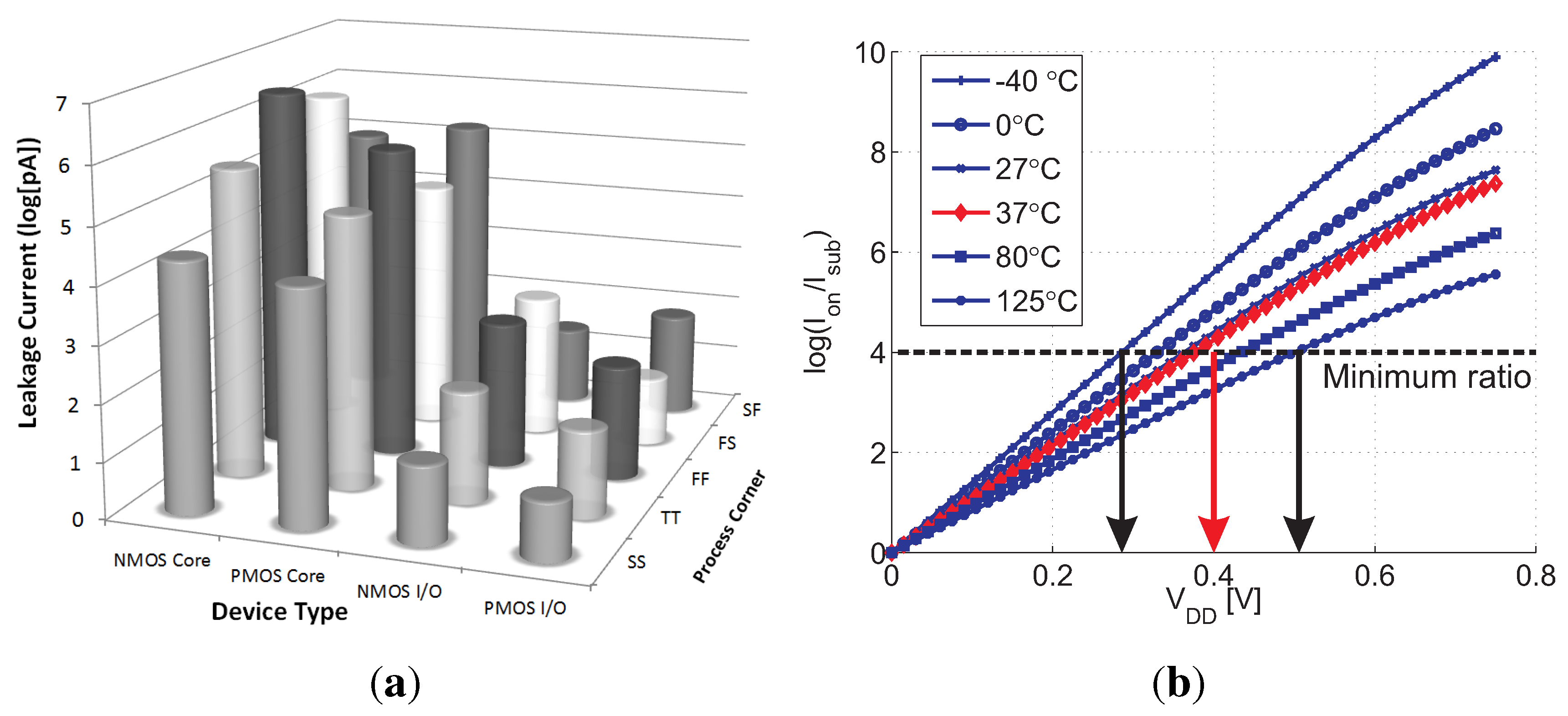
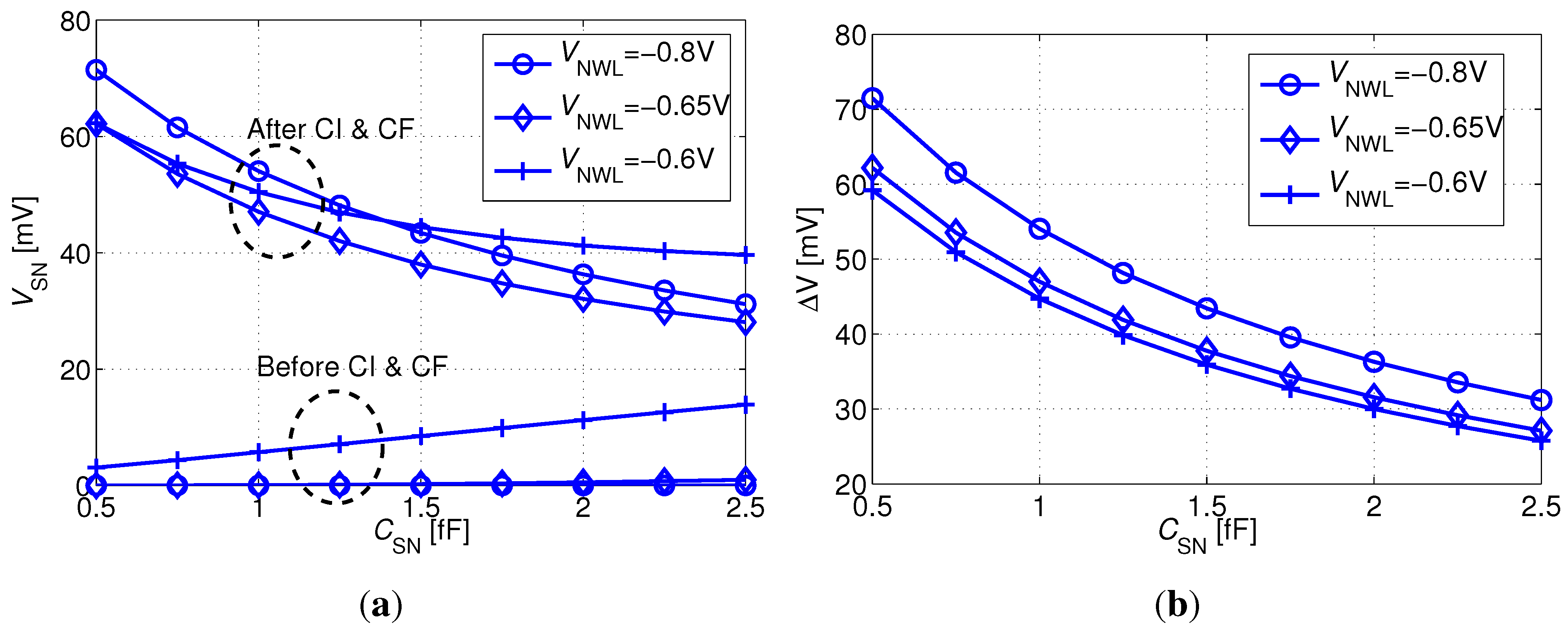
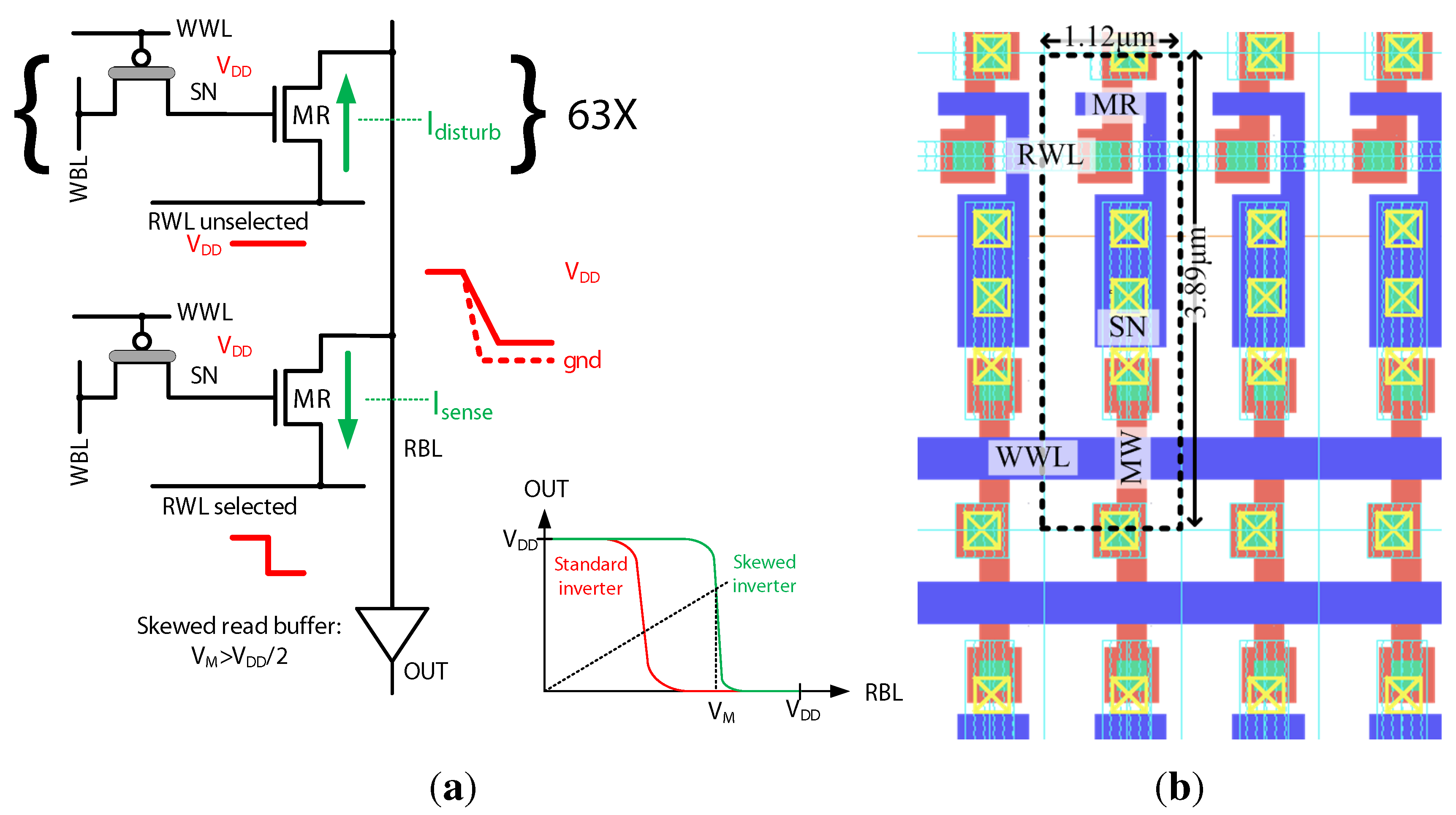
3. Macrocell Implementation in 0.18 µm CMOS
This section presents a 64 × 32 bit (2 kb) memory macro based on the previously elaborated 2T gain-cell configuration (
Figure 4(b)), implemented in a bulk CMOS 0.18 µm technology. The considered
of 400 mV is clearly in the sub-
regime, as
of MW and MR are −720 mV and 430 mV, respectively. Special emphasis is put on the analysis of the reliability of sub-
operation under parametric variations. While the address decoders and the sense buffers are built from combinational CMOS gates and operate reliably in the sub-
domain [
21], the analysis focuses on the write-ability, data retention, and read-ability of the gain-cell. All simulations assume a 1 µs write and read access time (1 MHz operation); a 3-metal SN capacitance of 2.5 fF, providing a retention time of 40 ms (according to previously presented worst case estimation); a temperature of 37
C and account for global and local parametric variations (1k-point Monte Carlo sampling).
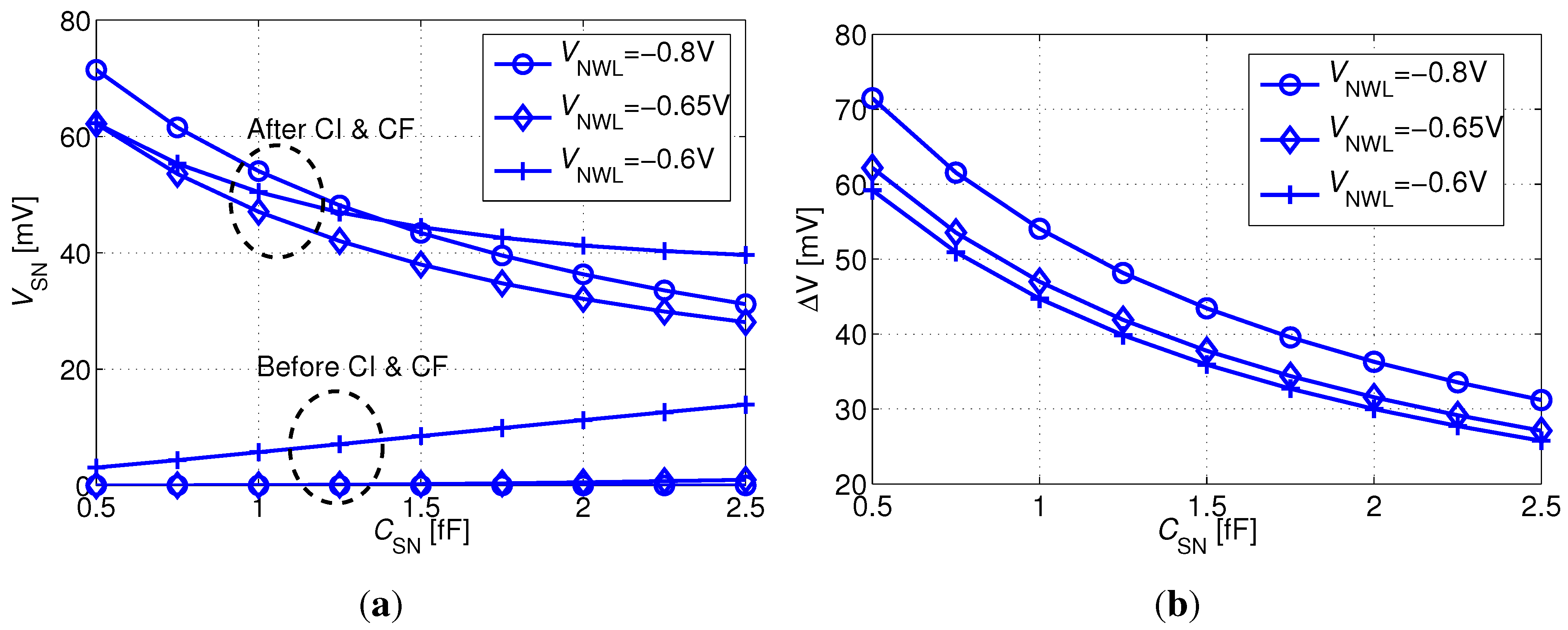
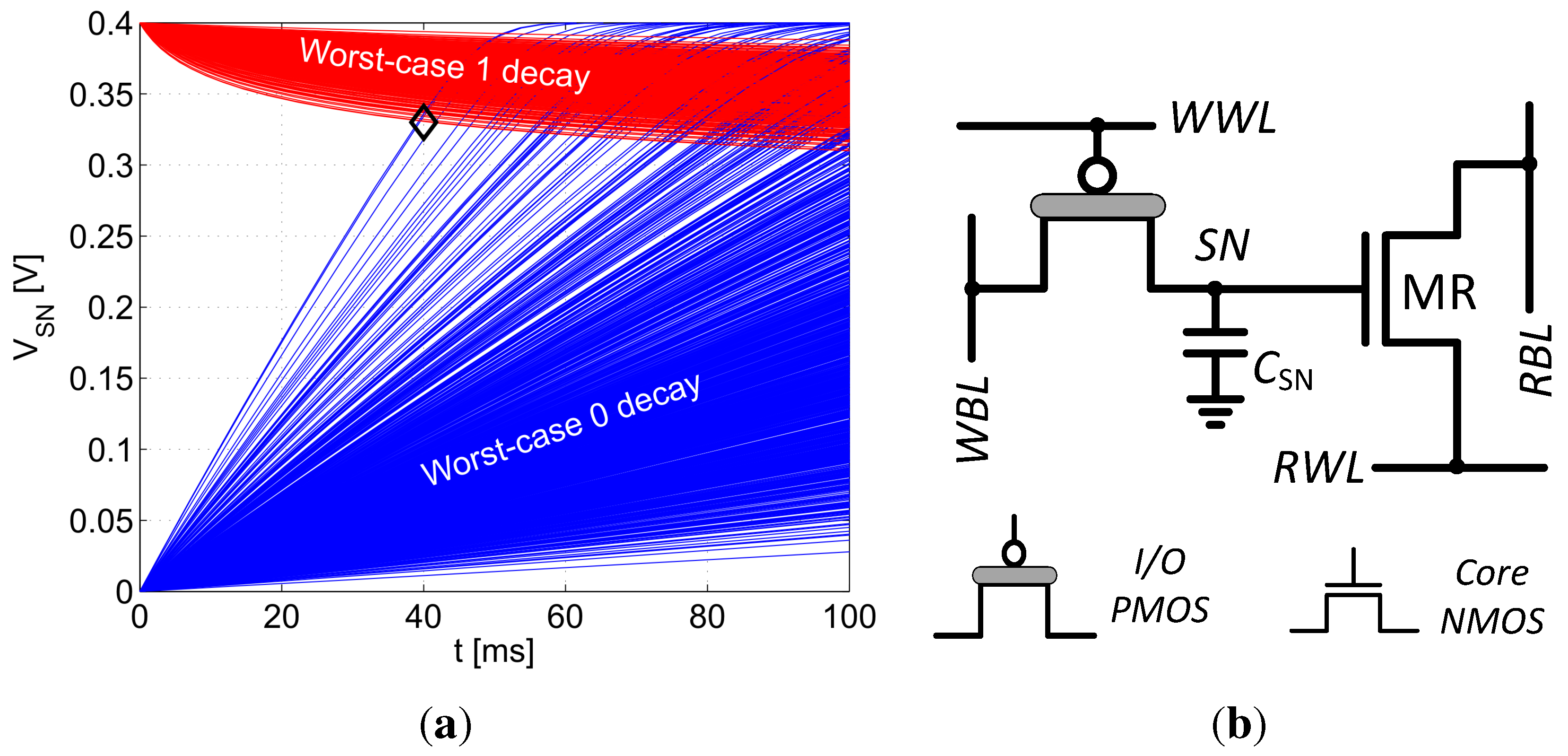
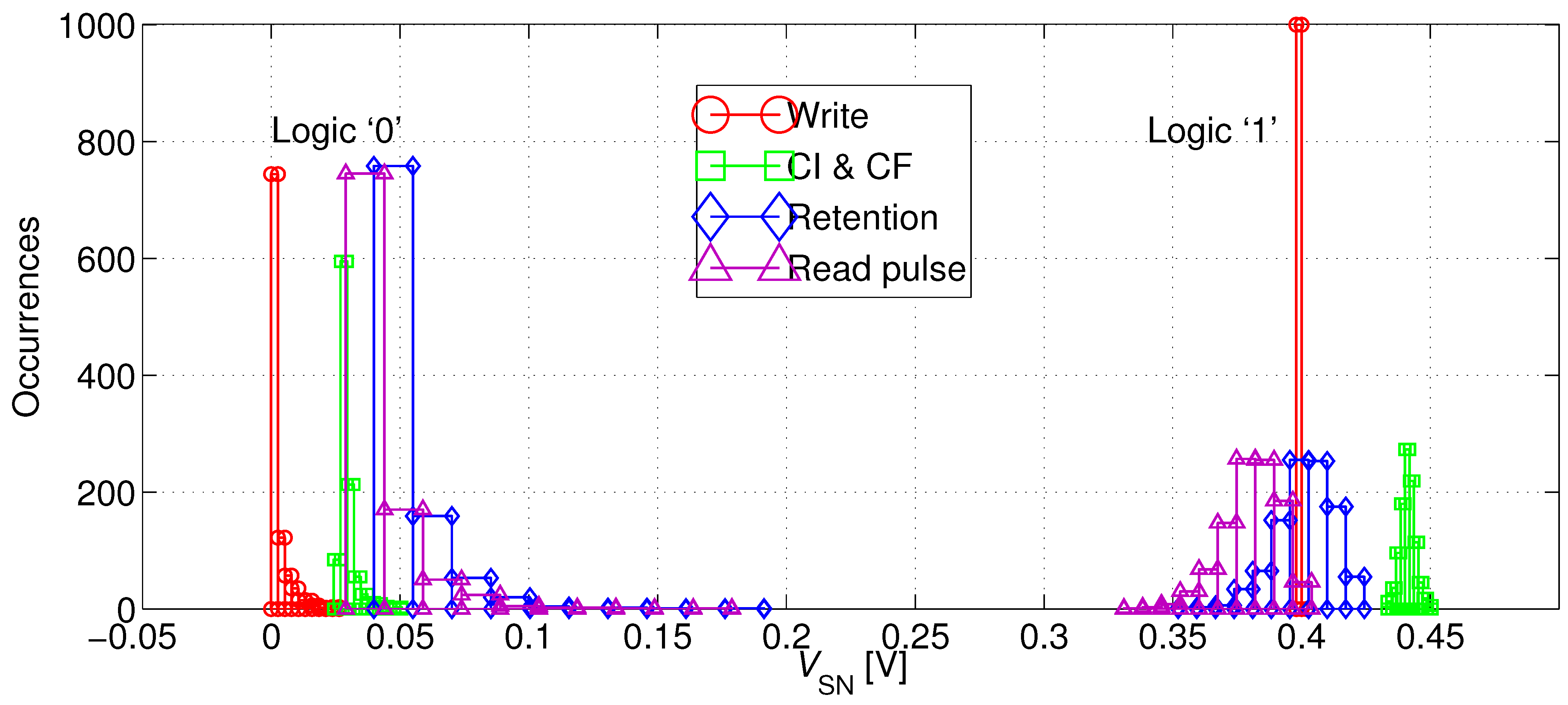
Figure 8 plots the distribution of the bitcell’s SN voltage at critical time points for the “0” and the “1” states. As expected, nominal 0 V and 400 mV levels are passed to SN just before the positive edge of the write pulse. CI and CF cause the internal levels to rise by 20–50 mV, resulting in a slightly degraded “0” level and an enhanced “1” level, while the distributions remain sharp. After a 40 ms retention period with a worst-case opposite WBL voltage, the distributions are spread out, but the “1” levels are still strong, while the extreme cases of the “0” levels have severely depleted, approaching 200 mV. However, the “0” and “1” levels are still well separated, and moreover, the “0” levels are improved following the falling RWL transition, resulting in a 10–20 mV decrease.
Figure 8.
Distribution of the SN voltage of a logic “0” and a logic “1” at critical time points: (1) [circles] directly after a 1 µs write access (before turning off MW); (2) [squares] after turning off MW; (3) [diamonds] after a 40 ms retention period under worst-case WBL conditions; and (4) [triangles] during a read operation.
Figure 8.
Distribution of the SN voltage of a logic “0” and a logic “1” at critical time points: (1) [circles] directly after a 1 µs write access (before turning off MW); (2) [squares] after turning off MW; (3) [diamonds] after a 40 ms retention period under worst-case WBL conditions; and (4) [triangles] during a read operation.
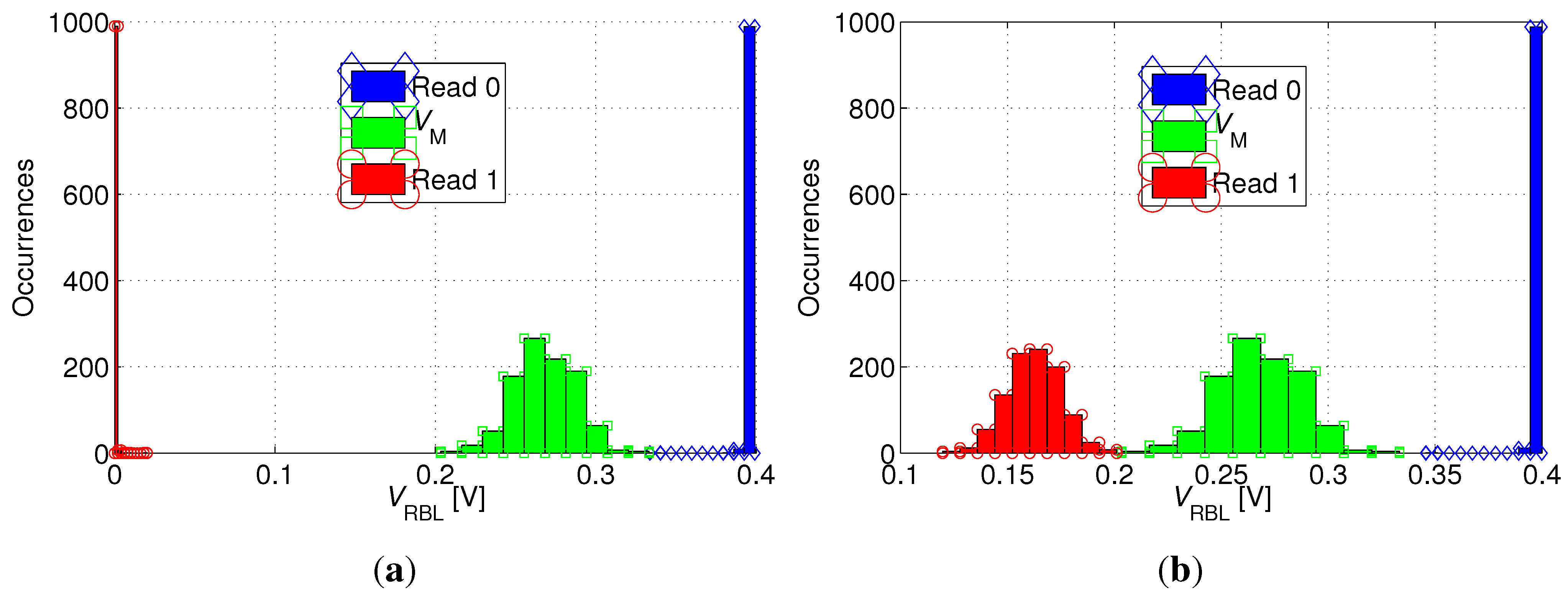
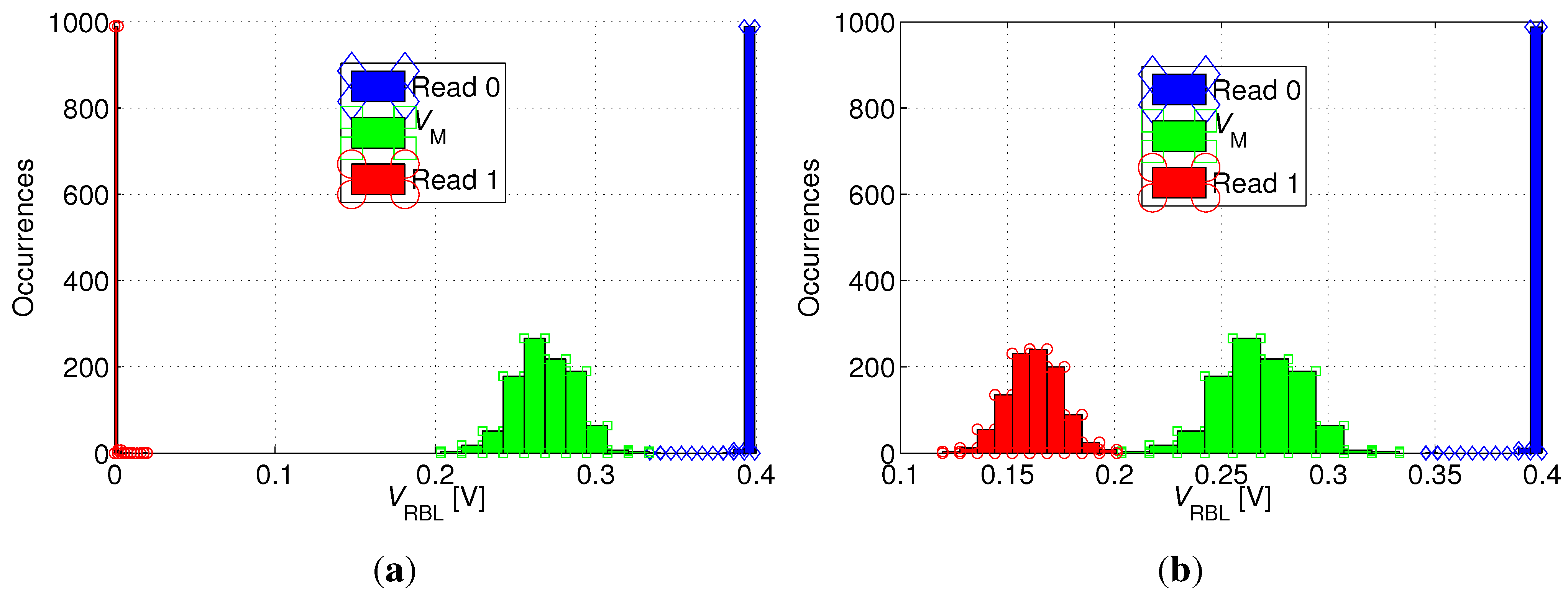
To verify the read-ability of the bitcell,
Figure 9 shows the distribution of the RBL voltage (
) following read “0” and read “1” operations after the 40 ms retention period. In addition, the figure plots the distribution of the trip-point (
) of the sense buffer. While read “0” is robust in any case (RBL stays precharged), read “1” is most robust if all unselected cells on the same RBL as the selected cell store “0” (see
Figure 9(a)), while it becomes more critical if all unselected cells store “1” (see
Figure 9(b)), thereby inhibiting the discharge of RBL through the selected cell. This worst-case scenario for a read “1” operation is illustrated in
Figure 10(a). In order to make the read operation more robust,
is shifted to a value higher than
by appropriate transistor sizing in the sense inverter. Ultimately, the
distributions for read “0” and read “1” are clearly separated, and the distribution of
is shown to comfortably fit between them, as shown in
Figure 9.
The layout of the 0.18 µm 2T gain-cell, comprising a PMOS I/O MW and an NMOS core MR, is shown in
Figure 10(b). The figure presents a zoomed-in view of one bitcell (surrounded by a dashed line) as part of an array. The chosen technology requires rather large design rules for the implementation of I/O devices; however, by sharing the n-well on three sides and stacking the bitlines, a reasonable area of 4.35 µm
2 per bitcell is achieved. In the same node, a single-ported 6T SRAM bitcell for above-
operation has a comparable area cost of 4.1 µm
2 (cell violates standard DRC rules), whereas SRAM bitcells optimized for robust operation at low voltages are clearly larger (e.g., the 14T SRAM bitcell in [
2] has an area cost of 40 µm
2). The depicted layout also enables metal stacking above the storage node to provide an increased SN capacitance of up to 5 fF (see
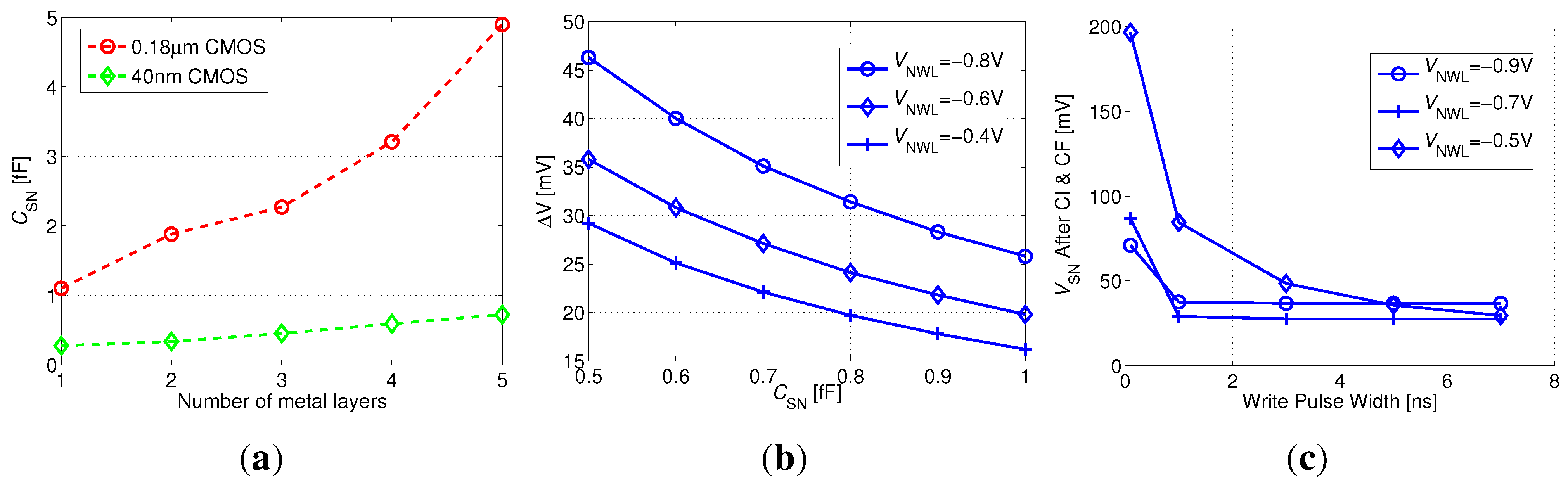
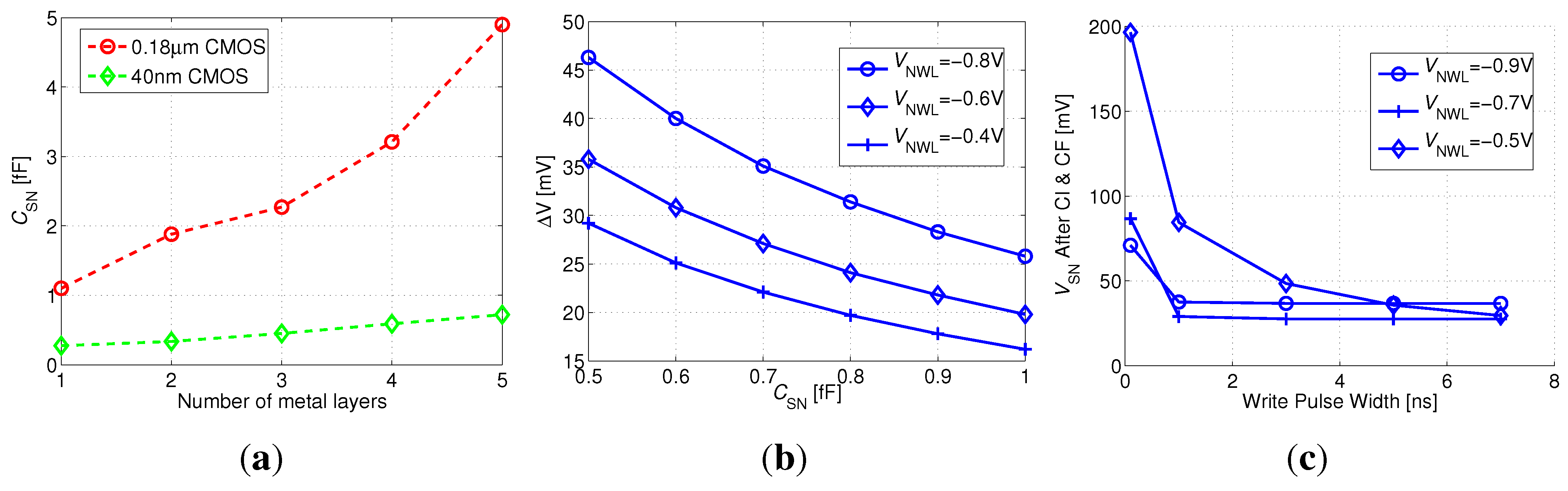
Figure 7(a)).
Figure 9.
Distribution of RBL voltage () after read “1” [circles] and read “0” [diamonds] operations and distribution of the trip-point of the read buffer [squares], for (a) favorable and (b) unfavorable read “1” conditions.
Figure 9.
Distribution of RBL voltage () after read “1” [circles] and read “0” [diamonds] operations and distribution of the trip-point of the read buffer [squares], for (a) favorable and (b) unfavorable read “1” conditions.
Figure 10.
180 nm gain-cell array: (a) Worst-case for read “1” operation: all cells in the same column store data “1”; to make the read “1” operation more robust, the sense inverter is skewed, with a trip-point ; (b) Zoomed-in layout.
Figure 10.
180 nm gain-cell array: (a) Worst-case for read “1” operation: all cells in the same column store data “1”; to make the read “1” operation more robust, the sense inverter is skewed, with a trip-point ; (b) Zoomed-in layout.
At an operating frequency of 1 MHz, a full refresh cycle of 64 rows takes approximately 128 µs. With a worst-case 40 ms retention time, the resulting availability for write and read is 99.7%. As summarized in
Table 1, the average leakage power of the 2 kb array at room temperature (27
C) is 1.95 nW, while the active refresh power of 1.68 nW is comparable, amounting to a total data retention power of 3.63 nW (or 1.7 pW/bit). This total data retention power is comparable with previous reports on low-voltage gain-cell arrays [
13], given for room temperature as well.
Table 1.
Figures of Merit.
Table 1.
Figures of Merit.
| Technology Node | 180 nm CMOS | 40 nm LP CMOS |
|---|
| Number of thin metal layers | 5 | 5 |
| Write Transistor | PMOS I/O | PMOS HVT |
| Read Transistor | NMOS Core | NMOS SVT |
| 400 mV | 600 mV |
| Storage Node Capacitance | 1.1 fF–4.9 fF | 0.27 fF–0.72 fF |
| Bitcell Size | 1.12 µm × 3.89 µm (4.35 µm2) | 0.77 µm × 0.42 µm (0.32 µm2) |
| Array Size | 64 × 32 (2 kb) | 64 × 32 (2 kb) |
| Write Access Time | 1 µs | 3 ns |
| Read Access Time | 1 µs | 17 ns |
| Worst-Case Retention Time | 40 ms | 44 µs |
| Leakage Power | 1.95 nW (952 fW/bit) | 68.3 nW (33.4 pW/bit) |
| Average Active Refresh Energy | 67 pJ | 21.2 pJ |
| Average Active Refresh Power | 1.68 nW (818 fW/bit) | 482 nW (235.5 pW/bit) |
| Average Retention Power | 3.63 nW (1.7 pW/bit) | 551 nW (268.9 pW/bit) |
| Array Availability | 99.7% | 97.1% |
4. Macrocell Implementation in 40 nm CMOS
Whereas gain-cell implementations in mature technologies have been frequently demonstrated in the recent past, 65 nm CMOS is the most scaled technology in which gain-cells have been reported to date [
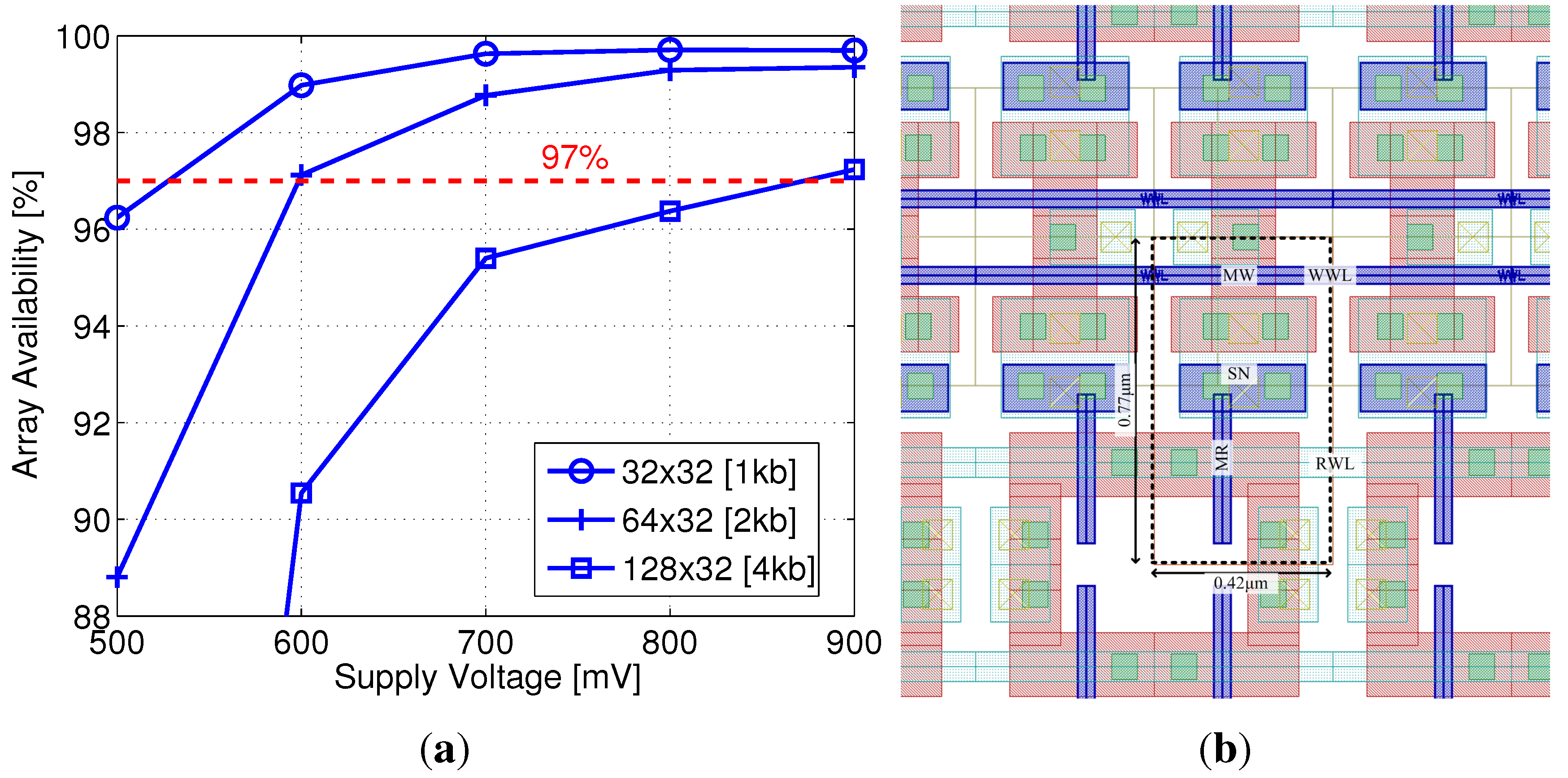
16]. In this section, for the first time, we present a 40 nm gain-cell implementation, and explore array sizes and the corresponding minimum operating voltages that result in sufficient array availability.
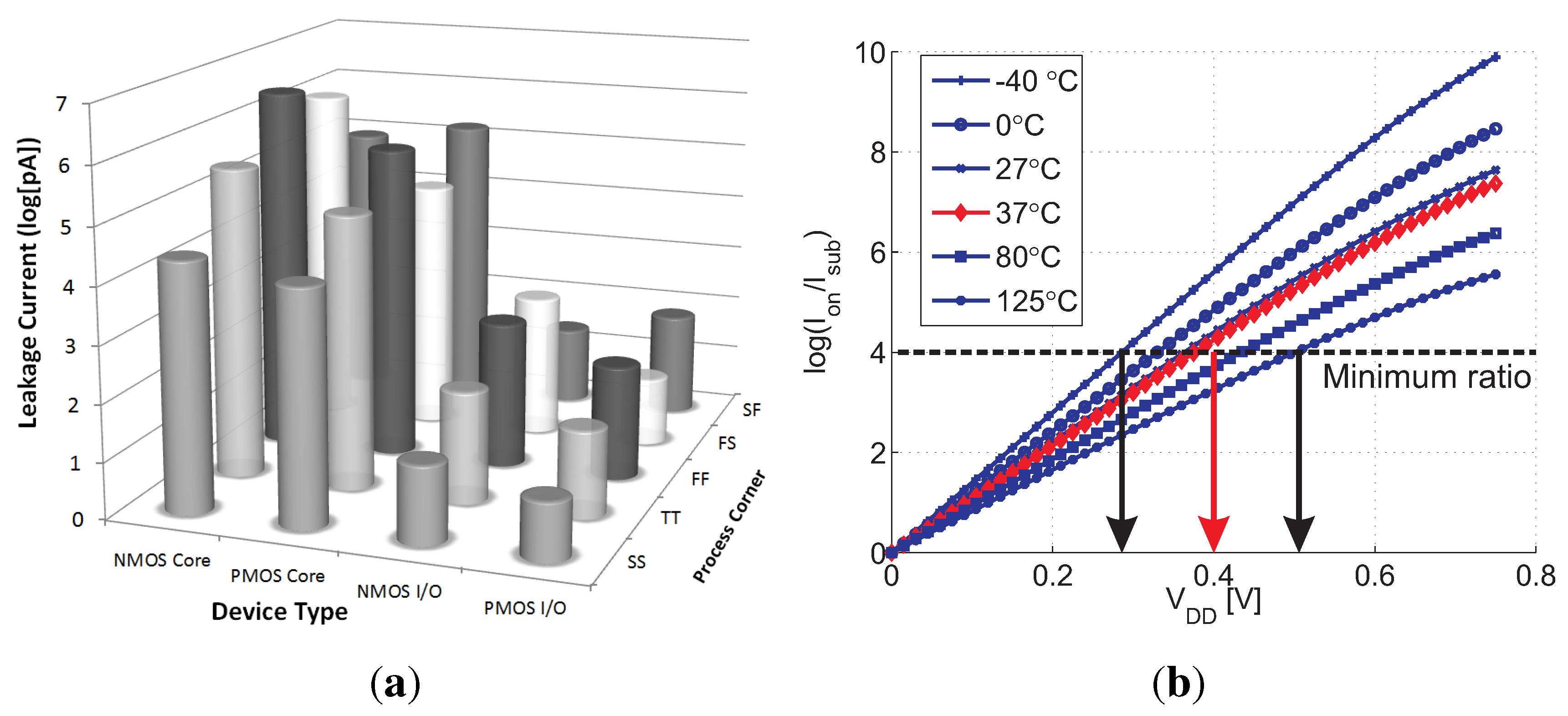
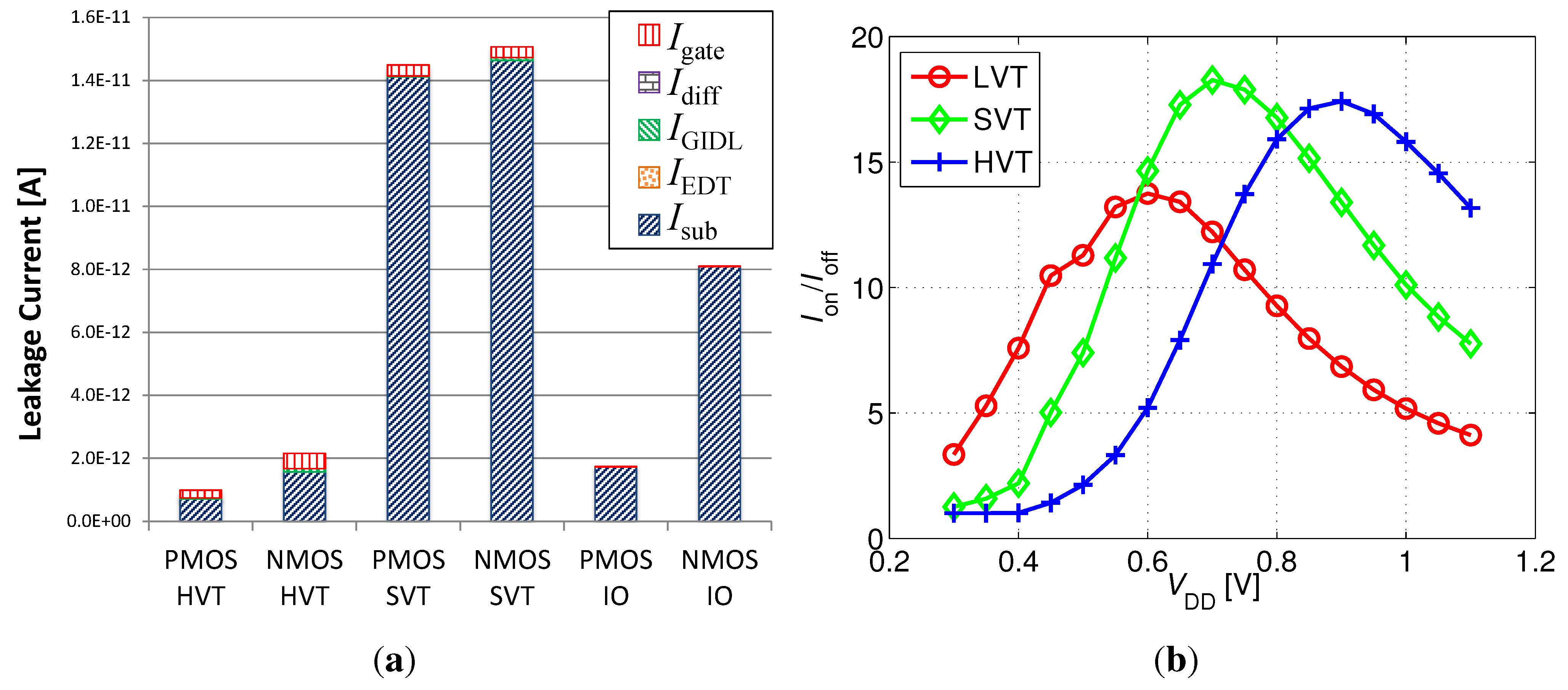
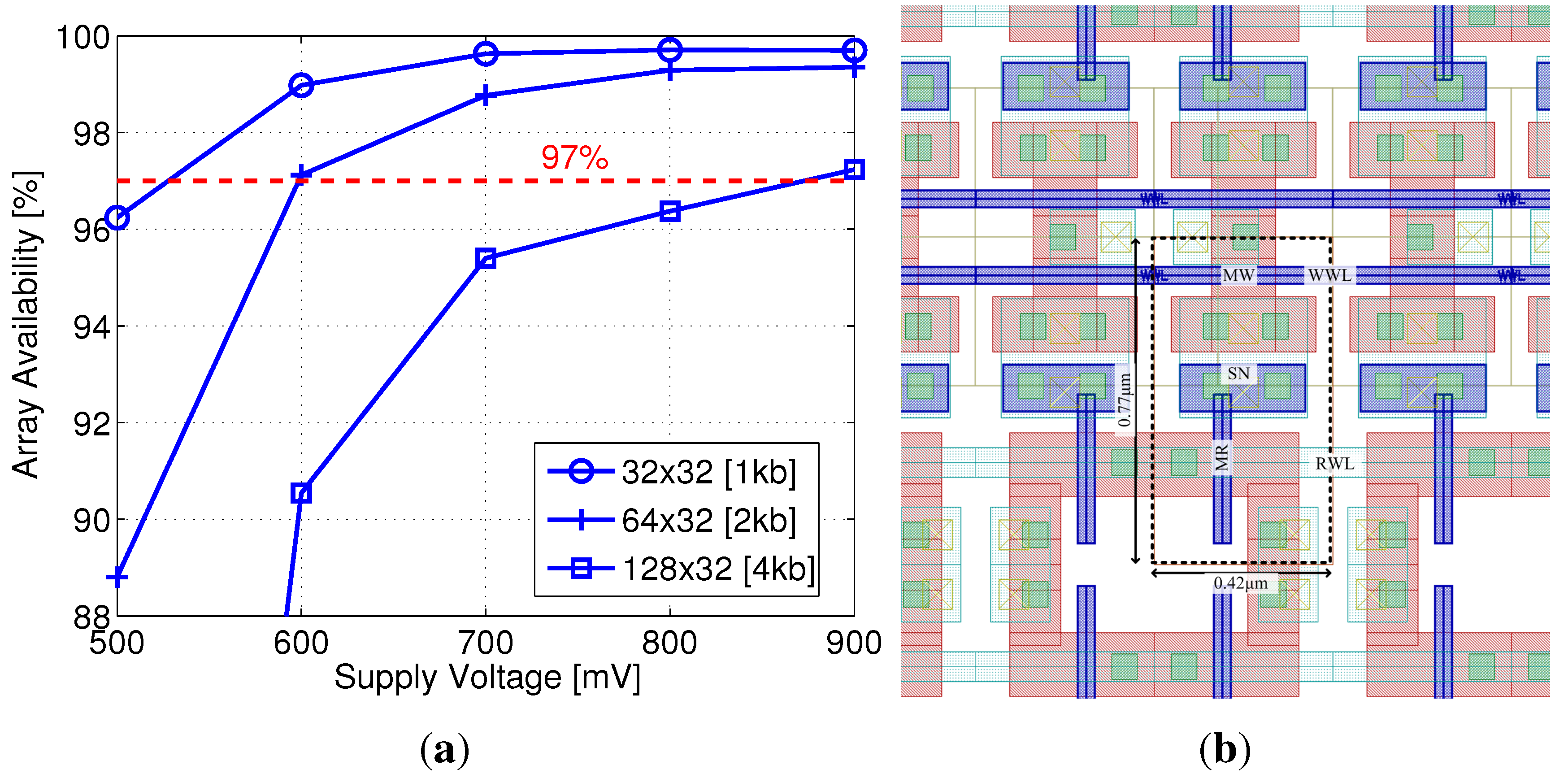
As previously described, core HVT devices are more efficient than I/O devices for write transistor implementation at scaled nodes, providing similar retention times with relaxed design rules (i.e., reduced area). In addition, the multiple threshold-voltage options for core transistors provide an interesting design space for the read transistor selection, trading off on and off currents, depending on supply voltage. Two additional factors that significantly impact the design at scaled nodes are the reduced storage node capacitance, due to smaller cell area and low-k insulation materials, and severely impeded retention times, due to lower storage capacitance and increasing leakage currents. Therefore, array availability becomes a major factor in gain-cell design and supply voltage selection. For this implementation, a minimum array availability of 97% was defined.
Considering a minimum array size of 1 kb (32 × 32), sufficient array availability is unattainable with the LVT MR implementation for a supply voltage lower than 500 mV, suitable for this device according to
Figure 5(b). Therefore, an SVT device was considered with near-threshold supply voltages above 500 mV.
Figure 11(a) shows the array availability achieved under varying supply voltages, considering array sizes from 1 kb to 4 kb. The red dashed line indicates the target availability of 97%, showing that this benchmark can be achieved with a 2 kb array at 600 mV. At this supply voltage, with a −700 mV underdrive write voltage, the write access time is 3 ns, and the worst-case read access time is 17 ns, while the worst-case retention time is 44 µs (see
Table 1).
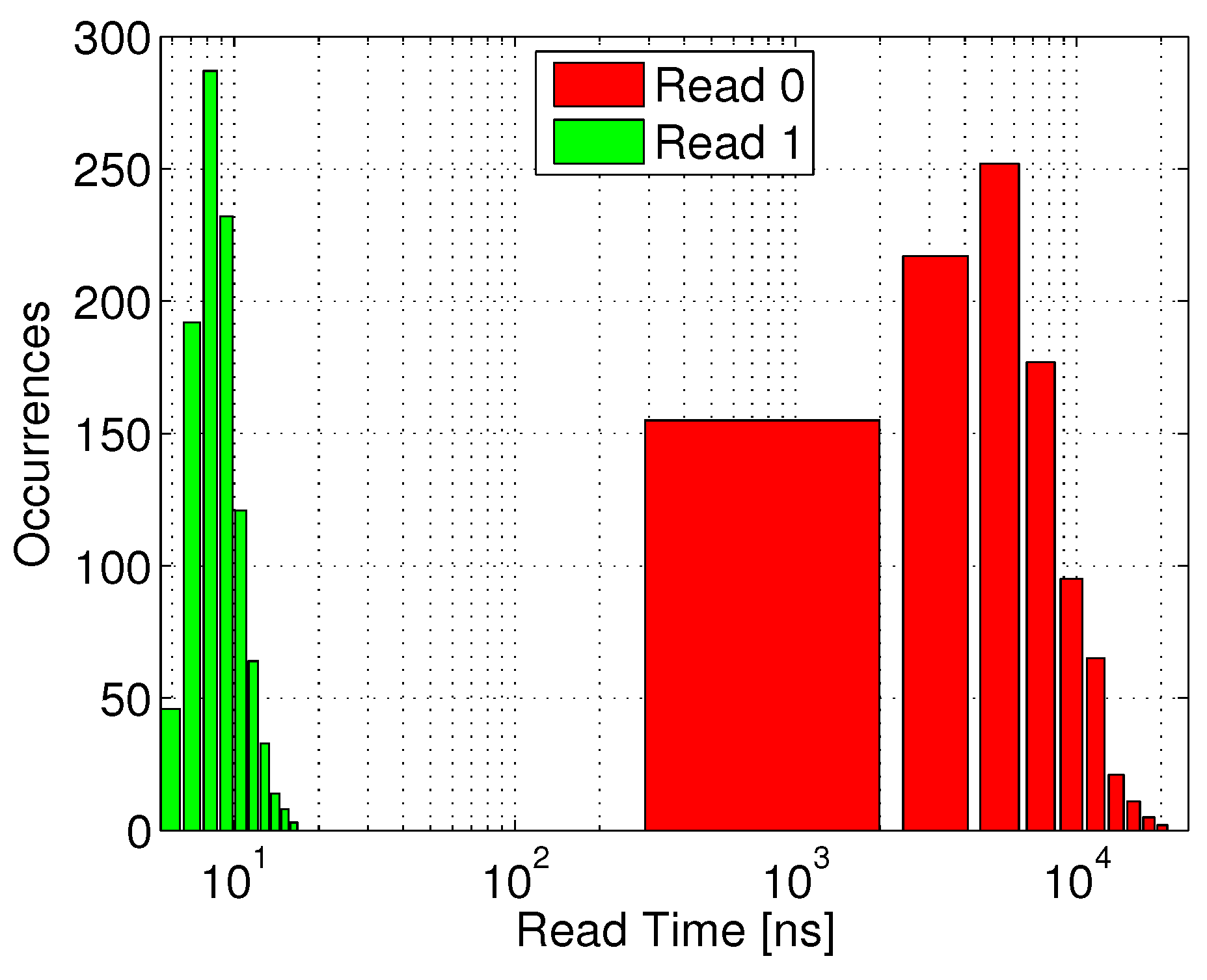
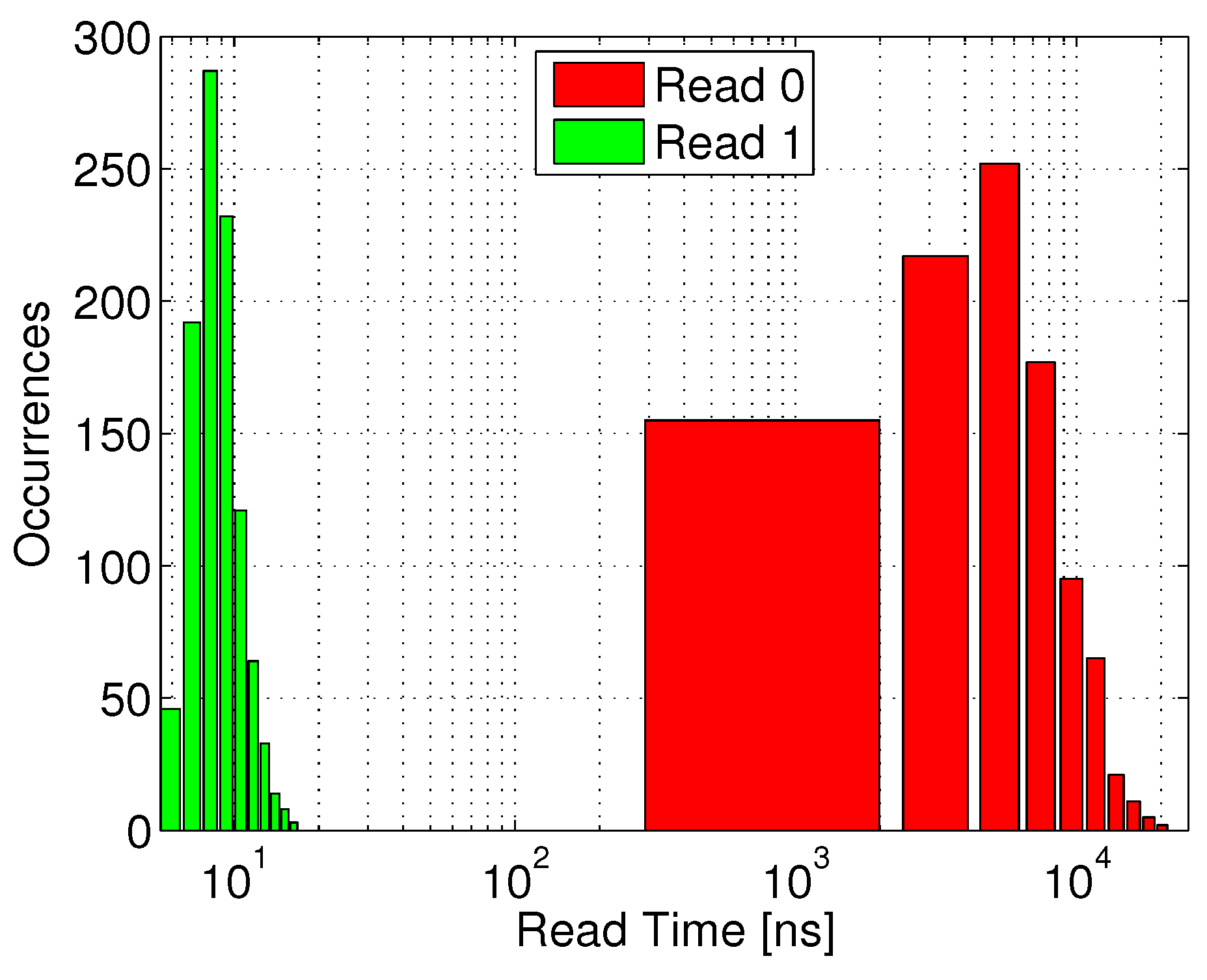
Figure 12 shows the distribution of the time required to sense the discharged voltage of RBL during a read “1” operation following a full retention period (green bars). The red bars (read “0”) represent an incorrect readout, caused by a slow RBL discharge through leakage, such that the read access time must be shorter than the first occurrence of an incorrect read “0”. The clear separation between the two distributions shows that by setting the read access time to 17 ns, the system will be able to robustly differentiate between the two stored states.
Figure 11.
40 nm gain-cell array: (a) Array availability as a function of supply voltage and array size; (b) Zoomed-in layout.
Figure 11.
40 nm gain-cell array: (a) Array availability as a function of supply voltage and array size; (b) Zoomed-in layout.
Figure 12.
Read access time distribution for the 40 nm gain-cell implementation: RBL discharge time for correct data “1” sensing, and undesired RBL discharge time till sensing threshold through leakage for data “0”.
Figure 12.
Read access time distribution for the 40 nm gain-cell implementation: RBL discharge time for correct data “1” sensing, and undesired RBL discharge time till sensing threshold through leakage for data “0”.
A zoomed-in layout of the 40 nm gain-cell array is shown in
Figure 11(b), with a bitcell area of 0.32 µm
2 (surrounded by the dashed line). For comparison, a single-ported 6T SRAM bitcell in the same node has a slightly larger silicon area of 0.572 µm
2, while robust low-voltage SRAM cells are considerably larger (e.g., the 9T SRAM bitcell in [
5] has an area cost of 1.058 µm
2). As shown in
Table 1, the implemented 40 nm array exhibits a leakage power of 68.3 nW, which is clearly higher than for the 0.18 µm array. Even though the active energy for refreshing the entire array is only 21.2 pJ, the required refresh power of 482 nW is again higher than for the 0.18 µm node, due to the three orders-of-magnitude lower retention time. Consequently, the total data retention power is around 150× higher in 40 nm CMOS, compared with 0.18 µm CMOS.
5. Conclusions
This paper investigates two-transistor sub- and near- gain-cell memories for use in ultra-low-power systems, implemented in two very different technology generations. For mature, above-100 nm CMOS nodes, the main design goals of the bitcell are long retention time and high data integrity. In the considered 0.18 µm CMOS node, a low-leakage I/O PMOS write transistor and an extended storage node capacitance ensure a retention time of at least 40 ms. At low voltages, data integrity is severely threatened by charge injection and capacitive coupling from read and write wordlines. Therefore, the positive storage-node voltage disturb at the culmination of a write operation is counteracted by a negative disturb at the onset of a read operation, which is only possible with an NMOS read transistor. Moreover, the write wordline underdrive voltage must be carefully engineered for proper level transfer at minimum voltage disturb during de-assertion. Monte Carlo simulations of an entire 2 kb memory array, operated at 1 MHz with a 400 mV sub- supply voltage, confirm robust write and read operations under global and local variations, as well as a minimum retention time of 40 ms leading to 99.7% availability for read and write. The total data retention power is estimated as 3.63 nW/2 kb, the leakage power and the active refresh power being comparable. The mixed gain-cell with a large I/O PMOS device has a large area cost of 4.35 µm2, compared with an all-PMOS or all-NMOS solution with core devices only.
In more deeply scaled technologies, such as the considered 40 nm CMOS node, subthreshold conduction is still dominant at reduced supply voltages. Gate tunneling and GIDL currents are still small, but of increasing importance, while reverse-biased pn-junction leakage and edge-direct tunneling currents are negligible. In the 40 nm node, the write transistor is best implemented with an HVT core PMOS device, which provides the lowest aggregated leakage current from the storage node, even compared with the I/O PMOS device. A write wordline underdrive voltage of −700mV is employed to ensure strong “0” levels with a short write access time. Among various NMOS read transistor options, an SVT core device maximizes the sense current ratio between a weak “1” and a weak “0” for near- supply voltages (600–800 mV) where 97% array availibility is achieved. Both the access times and the retention time are roughly three orders-of-magnitude shorter than in the 0.18 µm CMOS node, due to the increased leakage currents and smaller storage node capacitance. While the active refresh energy is low (21 pJ), the high refresh frequency results in high refresh power (482 nW), dominating the total data retention power (551 nW). As compared with the 0.18 µm CMOS implementation, the scaled down design provides better performance (17 ns read access and 3 ns write access), and a compact bitcell size of 0.32 µm2.
To conclude, this analysis shows the feasibility of sub- gain-cell operation for mature process technologies and near- operation for a deeply scaled 40 nm process, providing a design methodology for achieving minimum at these two very different nodes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}