Abstract
Large-scale computing clusters have been the basis of scientific progress for several decades and have now become a commodity fuelling the AI revolution. Dark Silicon, energy efficiency, power consumption, and hot spots are no longer looming threats of an Information and Communication Technologies (ICT) niche but are today the limiting factor of the capability of the entire human society and a contributor to global carbon emissions. However, from the end user, system administrators, and system integrator perspective, handling and optimising the system for these constraints is not straightforward due to the elevated degree of fragmentation in the software tools and interfaces which handles the power management in high-performance computing (HPC) clusters. In this paper, we present the REGALE Library. It is the result of a collaborative effort in the EU EuroHPC JU REGALE project, which aims to effectively materialize the HPC PowerStack initiative, providing a single layer of communication among different power management tools, libraries, and software. The proposed framework is based on the data distribution service (DDS) and real-time publish–subscribe (RTPS) protocols and FastDDS as their implementation. This enables the various actors in the ecosystem to communicate and exchange messages without any further modification inside their implementation. In this paper, we present the blueprint, functionality tests, and performance and scalability evaluation of the DDS implementation currently used in the REGALE Library in the HPC context.
1. Introduction
Despite HPC systems becoming increasingly streamlined and highly energy-intensive, and data center power demands becoming ever more unmanageable, there still is not a software stack nowadays capable of optimizing each specific level of this system [1,2]. In the exascale(supercomputers capable of reaching exa-flop/s performance) era, supercomputers that cost of hundreds of millions of euros, power consumption in the order of tens of megawatts [3] and a lifetime that reaches a decade at most, the judicious management of those resources is of utmost importance. Furthermore, it is essential to maintain a low environmental footprint and manageable operational costs while ensuring that its primary goal of providing robust computational capacity for demanding applications remains paramount. In this context, REGALE Library aims to effectively materialize the HPC PowerStack initiative (Section 2.3) within the REGALE project (Section 2.2), providing a single layer of communication among all the tools, libraries and software. This framework is based on the DDS and RTPS protocols and FastDDS as their implementation, enabling all the different entities involved in the REGALE ecosystem to communicate and exchange messages without any further internal modification. In this document, we present the blueprint, functionality tests, and initial evaluation tests made on the DDS implementation currently used in the REGALE Library (FastDDS) in the HPC context.
2. Background
This section introduces the fundamental concepts of HPC systems and their relation with the power management problem. Furthermore, it describes its current implementation and the taxonomy introduced by the HPC PowerStack and the REGALE initiative. The taxonomy and nomenclature defined in this section will be used in the implementation of the REGALE library.
2.1. HPC and Power Management
HPC refers to computational machines composed of clusters of tens or sometimes hundreds of nodes interconnected by low-latency networks. Each node is made up of dozens of processors and accelerators like CPUs, GPUs, and TPUs. Additionally, each node provides various types of memory with high capacity and bandwidth, which are shareable among the processors within it. Since the advent of exa-computers, the power needed to run these systems has exceeded the threshold by several MW. For this reason, data center power management has become increasingly complex each year. The term “Power Management” has been used over the years to encompass a variety of issues, all revolving around the concept of energy. Among these, we can include (i) power management for absorbed power, which can be further divided into (a) thermal design power (TDP) (the maximum thermal power a component can dissipate), (b) thermal design current or peak current (the maximum current deliverable by power supplies or processors), (ii) thermal management, handling dynamic or static temperature and (iii) energy management, managing sustainability and energy consumption. To operate correctly, power management systems must manage and monitor the power consumption, frequencies, and temperatures of processors within high-performance systems. This must be possible at various levels including the entire system, individual nodes, and specific components within the nodes. Starting from the lowest level, it is necessary to access actuators and sensors located within the cores both directly and remotely.
2.1.1. In-Band Services
In-band services access hardware resources through code executed on the processor itself. These are made possible by drivers that expose user-level controls to manage and monitor CPU frequencies and information facilitated by interfaces provided by the operating system.
2.1.2. Out-of-Band Services
Out-of-band services use side channels, which are alternative access channels to obtain the required data. This mechanism allows external hosts to access the information contained in the processor to be analysed. One of the most important components that perform this function is the Baseboard Management Controller (BMC), which is accessible through a separate channel usually provided with its network interface and/or specific buses.
2.2. REGALE Project
The REGALE project [4] started in April 2021 and ended after three years. It aimed to build a software stack that was not only capable of bringing efficiency to tomorrow’s HPC systems. It also would be open and scalable for massive supercomputers. REGALE brought together leading supercomputing stakeholders, prestigious academics, top European supercomputing centers, and end users from critical target sectors, covering the entire value chain in system software and applications for extreme-scale technologies. One of the objectives of the REGALE project was the implementation of the HPC PowerStack by combining partners’ power management tools. As a collateral result, we developed the REGALE Library to unify the power management communication among the different tools.
2.3. HPC PowerStack
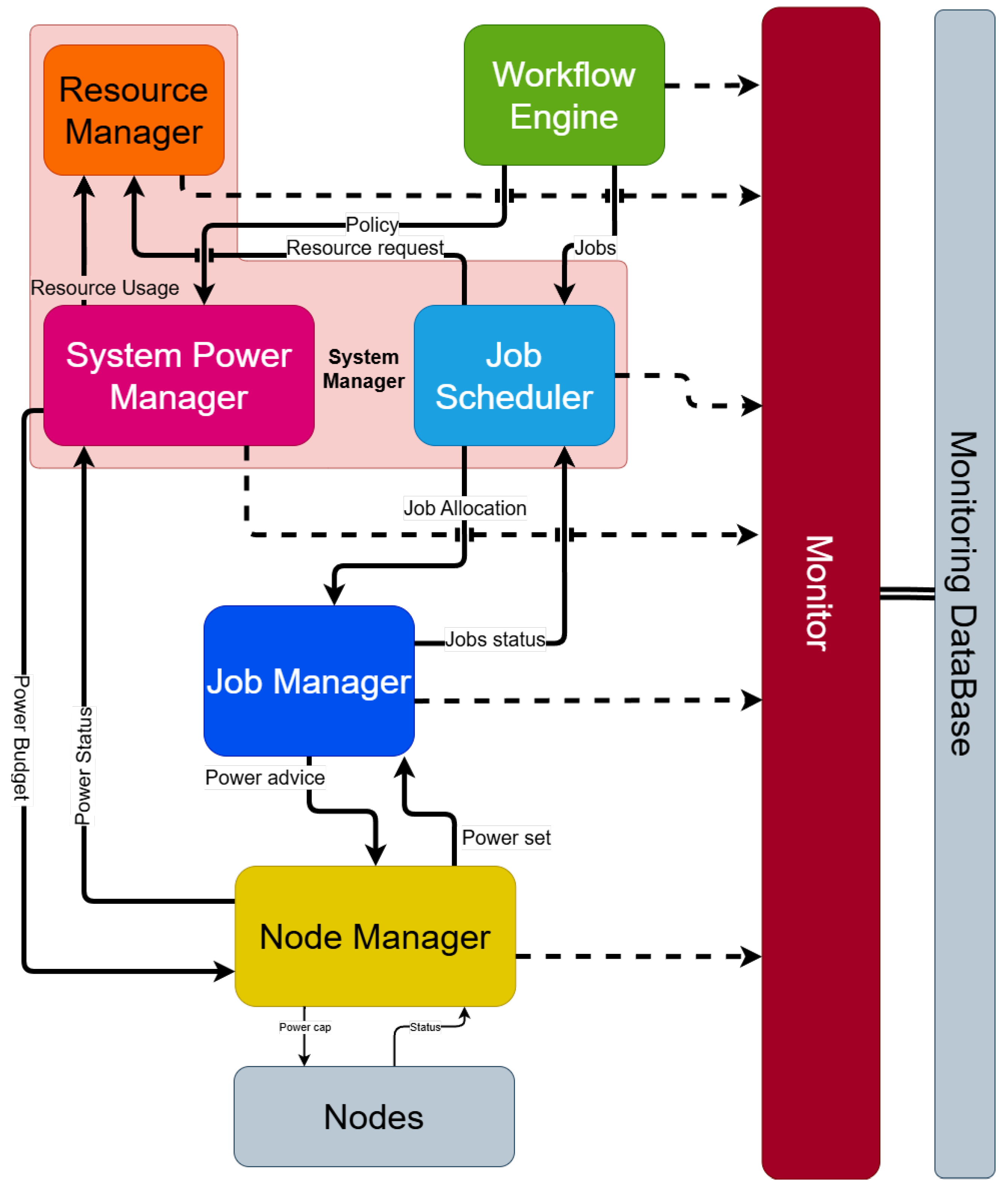
The HPC PowerStack depicted in Figure 1 is shorthand for a power management Software Stack encompassing various software tools designed to manage power across multiple levels [2]. This initiative with the REGALE project identified five actors of the power management software stack in large-scale HPC computers. These actors can be summarised as follows:
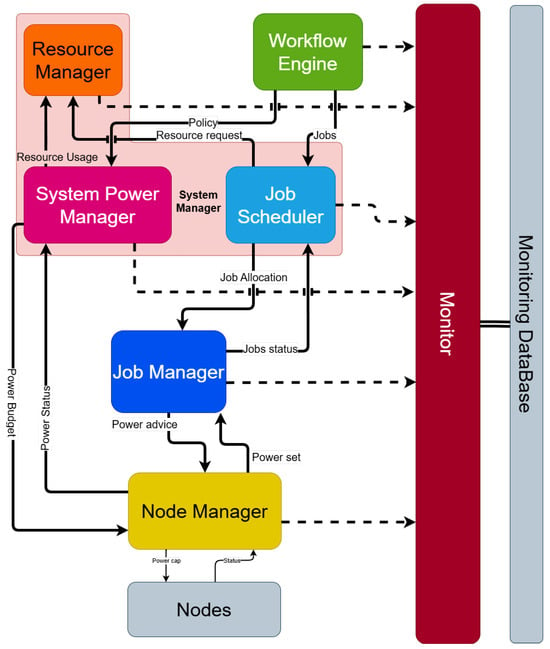
Figure 1.
HPC PowerStack improved scheme. This figure shows every interaction through every component (solid lines). In addition, there are all the metrics reported to the monitor (dotted lines).
- The system manager (SM)’s main purpose is to receive as input a set of jobs to be scheduled within the system and indicatively decide upon when to schedule each job, to which specific compute nodes to map it, and under which power budget or setting. For this, it constantly monitors and records power and energy telemetry data, and it controls power budgets/settings and/or user fairness. The system manager can be further divided into resource manager, system power manager, and job scheduler that handle specific sections of previous functions.
- The job manager (JM) performs optimisations considering the performance behavior of each application, its fine-grained resource footprint, its phases, and any interactions/dependencies dictated by the entire workflow it participates in. It manages the control knobs in all compute nodes participating in the job and optimises them during runtime to achieve the desired power consumption (at maximum possible performance), efficiency, or other settings. Additionally, it scalably aggregates application profile/telemetry data from each node servicing the given job through the system manager.
- The node manager (NM) provides access to node-level hardware controls and monitors. Moreover, the node manager implements processor-level and node-level power management policies as well as preserves the power integrity, security and safety of the node. For this reason, all the power management requests coming from the software stack are mediated by the node management.
- The workflow engine analyses the dependencies and resource requirements of each workflow and decides on how to break the workflow into specific jobs that will be fed to the system manager. Modern workflows may be composed of hybrid Big Data, Machine Learning, and HPC jobs; hence, its key role is to provide the right interfaces and abstractions in order to enable the expression and deployment of combined Big Data and HPC jobs. The distribution of jobs can vary depending on the objective goals defined by the optimisation strategy.
- The monitor is responsible for collecting in-band and out-of-band data for performance, resource utilisation, status, power, and energy. The monitor operates continuously without interfering with execution, with minimal footprint; it collects, aggregates, records, and analyses various metrics; and it pushes necessary real-time data to the system manager, the node manager, and the job manager.
2.4. Communication Protocols
The REGALE Library targets the creation of a distributed communication middleware for the HPC PowerStack where each actor should be able to exchange messages, commands, and information with others. In case a new actor is added or an existing one changes, instead of creating a new specific API for each actor, in this paper, we propose building a middleware based on DDS. This already provides a structured interface, allowing actors interested in exchanging messages to call the function of the REGALE Library to listen and send messages to the relevant entity. To achieve this, the DDS specification delineates a Data-Centric Publish–Subscribe (DCPS) model tailored for distributed application communication and integration in real-time environments. Through DDS, seamless data exchange occurs among software components across specific topics and domains. Additionally, DDS leverages Real-Time Publish–Subscribe (RTPS), enabling diverse communication types (intra-process, shared memory, UDP, TCP, etc.) across distributed heterogeneous systems. In parallel, Message Queuing Telemetry Transport (MQTT) represents a lightweight, higher-level publish–subscribe network protocol crafted for efficient and reliable message exchange, especially in bandwidth-constrained and high-latency environments. Operating atop TCP/IP, MQTT boasts minimal overhead, low power consumption, and supports real-time communication between devices. While similar to DDS in its adherence to the publish–subscribe paradigm, MQTT differs in that it adopts a centralized approach.
3. Related Work
To date, several solutions have emerged for power management in HPC equipment. Most of these solutions have been tailored to address specific challenges within individual vendor environments and computing centers. Consequently, when an end user, system administrator, facility manager, and system integrator wants to add a power management service into a large-scale HPC system, it is left alone, and there remains a notable absence of a unified global perspective and an integrated approach that can synergistically combine diverse solutions [1,5,6,7]. Furthermore, the absence of standardized communication interfaces across different software platforms places the responsibility on HPC system administrators, thereby restricting the widespread adoption and effectiveness of such solutions. So far at the node level, the Linux O.S. exposes the power governor interface which differs in different Instruction Set Architectures, requiring different research organizations to build software libraries and run-times to expose to the software stack common APIs. The most prominent ones are GEOPM (Intel) [8], Variorum (LLNL) [9], Meric (IT4I) [10], and PowerAPI (Sandia) [11,12]. Other power management tools that are worth mentioning are HDEEM (Atos) [13], EAR (BSC) [14], EXAMON (CINECA-UNIBO) [15] and DCDB (LRZ) [16]. All the differences between REGALE Library and other solutions are thoroughly outlined in Table 1. Despite their efforts in addressing power management challenges, these tools exhibit varying levels of compatibility and interoperability issues. This disparity underscores the pressing necessity for a comprehensive interoperability framework that facilitates seamless integration and collaboration among these tools.

Table 1.
Comparison of various libraries/frameworks such as Variorum, Global Extensible Open Power Manager (GEOPM), PowerAPI, MERIC, High Definition Energy Efficiency Monitoring (HDEEM), Exaflops Monitor(EXAMON), DataCenter DataBase (DCDB) and Energy Aware Runtime (EAR) with the REGALE Library.
4. The REGALE Library
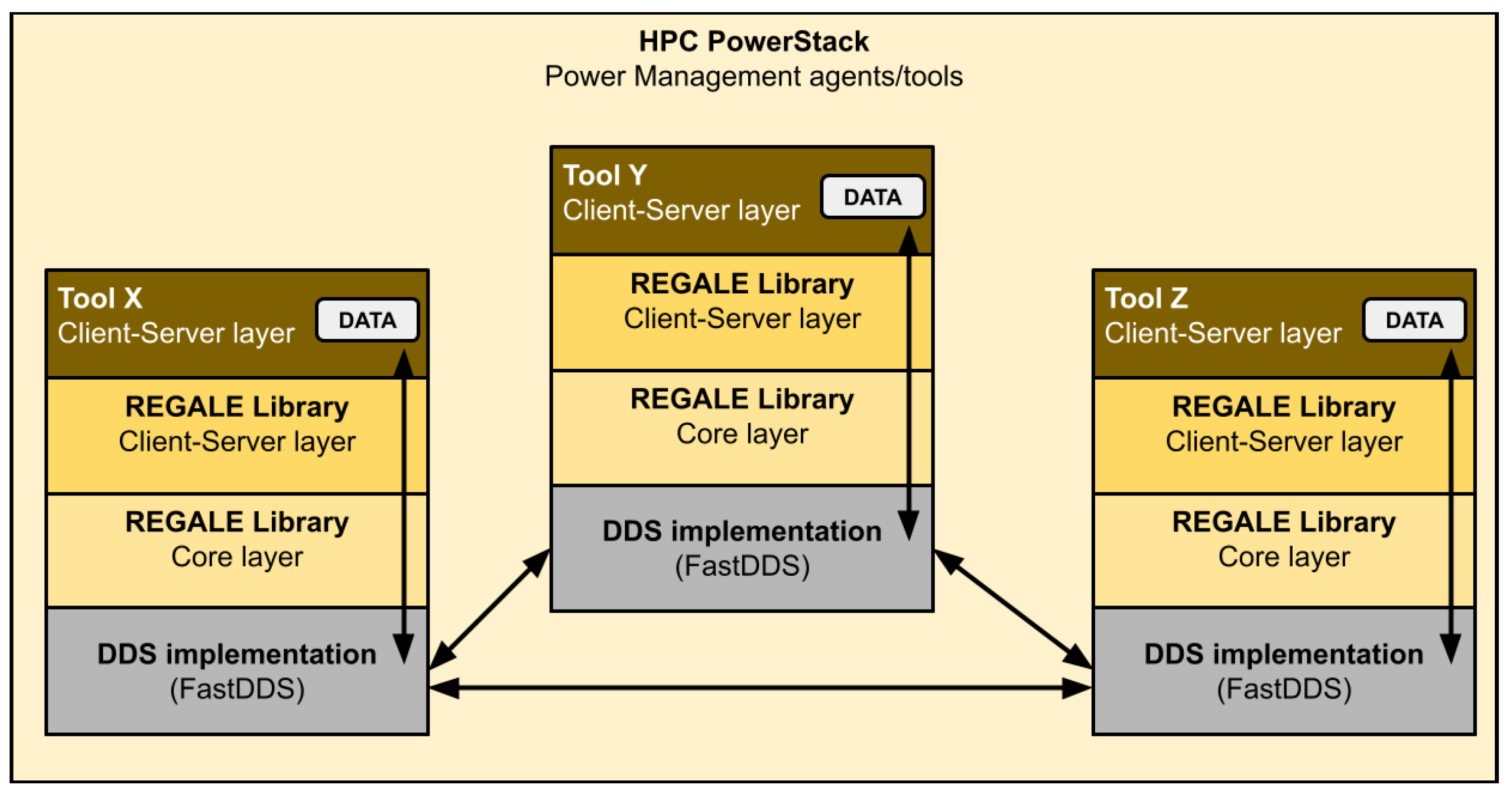
In this section, we present the REGALE Library which is the result of a joint effort among the REGALE project partners to design an interoperability layer for distributed power management in large-scale HPC systems. The purpose of the library is the creation of a standardized interoperability layer among all the tools involved in the HPC PowerStack. As such, every component interested in using it should just be coherent with its standard, respecting the declarations of its APIs and the definitions of the callbacks needed for the server side of the client/server APIs layer. Figure 2 depicts the software structure of the REGALE Library and its key components. From the bottom up, the REGALE Library is based on DDS functionalities, which are wrapped and made easy to use by the core layer. This part is responsible for the management of the publishers and subscribers as well as everything related to communication, features, and optimizations. In particular, DDS entities expose APIs that are uses from our regale core layer. This layer can instantiate DDS entities and manage it and expose higher-level features to the client/server layer. The main purpose of this last layer is to provide the common API for all the HPC PowerStack agents involved in the HPC power management ecosystem, which need to exchange information and interact.
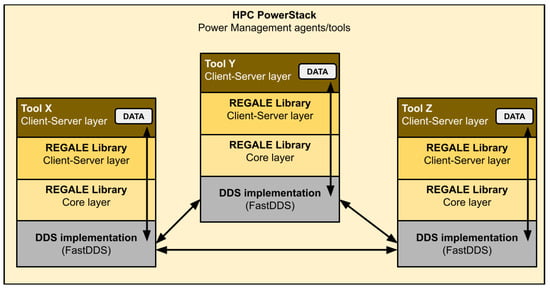
Figure 2.
REGALE Library structure scheme and the route of data through all components (arrows). The interactions between the various tools are represented, starting from the highest level and going down to the communication layer (DDS).
At the top of the stack, we find the power management software actors as defined by the HPC PowerStack initiative and further refined by the REGALE project. In this manuscript, we will evaluate the proposed REGALE Library interoperability layer considering the job manager, the node manager, the monitor, and several synthetic agents, whose aim is to emulate the behavior of the previously listed entities, deploying different (and more concise) implementations of their natural behavior. These are detailed in the next sub-sections.
4.1. Core Layer
This layer is composed of four main components:
- RegaleObject is a base class that defines the Quality of Service (QoS), topics, transports, and data types. This is implemented following the FastDDS approach to define data types which are dynamically extracted (get) and defined (set) by the Interface Definition Language (IDL). Instead of using IDL, we dynamically create specific data types stored in XML files, from which they are parsed. The same XML file is also used to specify other configurations like transport types (SHM, UDP, TCP).
- RegalePublisher, derived from RegaleObject, which defines its specific QoS and creates the Data Writer, to publish data on specific topic–partition pairs;
- RegaleSubscriber like before is a derived class from RegaleObject, which is responsible for the Subscriber QoS and the Data Reader to receive actual data if present on selected topic–partition.
- RegaleWrapper acts as a bridge for the underlying implementation allowing to use both C and C++ codes. For doing this, the RegaleWrapper implements the following methods:
- −
- Regale_init is the method used to initialize a RegaleStruct, which is the base element for the dynamic data type.
- −
- Regale_malloc/dealloc and Regale_finalize are the functions to allocate/deallocate memory for the total amount of RegaleStructs needed for the data type of a specific message.
- −
- Regale_create_publisher and Regale_create_subscriber are the methods to actually create the derived objects RegalePublisher and RegaleSubscriber.
- −
- Regale_publish is the method to publish the values for a specific data type.
- −
- Regale_delete destroys RegaleObjects previously created.
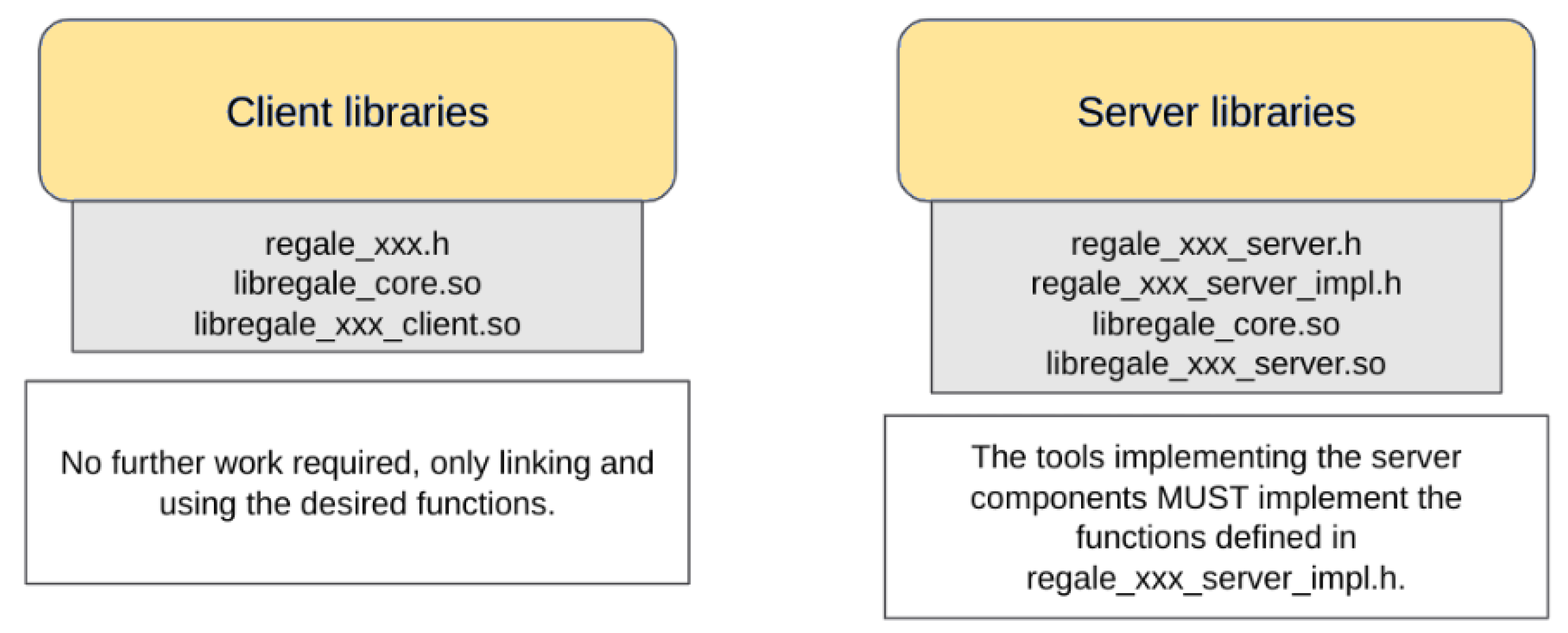
4.2. Client–Server Layer
The REGALE Library offers each HPC PowerStack actor a pair of client and server libraries that define their respective interfaces. These interfaces are internally called the core layer methods. The client–server libraries are illustrated in Figure 3. If a tool aims to be compliant with the REGALE Library, it must either call the proposed API (client side) or implement the defined “interfaces” for the server side, which manage the behavior of the callback used upon data receipt. The agent compliant with the client part of this layer has to achieve the following:
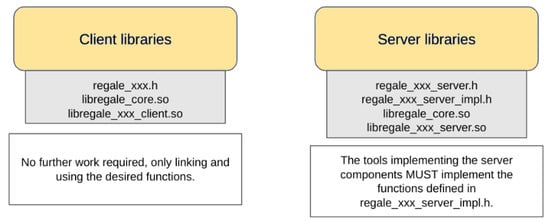
Figure 3.
REGALE client–server layer with relative libraries used by new power management agent.
- Call the regale_xxx_init (where xxx stands for NM, JB, etc.) method, which creates the publisher/subscriber pairs necessary for the communication and returns a regale_handler. One may specify a partition here with wildcards (*) to communicate only with the servers belonging to that partition;
- Call the specific functions of the particular agent. For example, retrieving the current power consumption of node manager servers or sending telemetry to monitor servers.
- Call the regale_xxx_finalize method, which given a handler created by the init function destroys the publisher/subscriber pairs and cleans up.
Regarding an agent which intends to act as a server-side of the REGALE Library, the steps are the following:
- Call the regale_xxx_service_init method, which creates the publisher/subscriber pairs necessary for the communication. The partition can be specified so that clients may use it as a filter.
- Call the specific server implementation API, which is a set of functions that will be called when requests are received. Some functions may require that certain structures are filled to be returned to the clients, while others are sending information to be processed.
- Call the regale_xxx_service_finalize, which deletes the publisher/subscriber pairs and stops processing messages from the clients.
5. Experimental Results
This section focuses on characterizing two critical aspects of the proposed REGALE Library, which are the use of the DDS for providing the communication transport between the different HPC PowerStack actors and the REGALE Library implementation itself. We thus report results obtained from (i) characterizing the scalability and performance of the different transport supported by the chosen DDS implementation into an HPC cluster and (ii) evaluating the REGALE Library implementations with a functional validation. For this purpose, we integrated with the REGALE Library three tools from the HPC PowerStack, each fulfilling a distinct role: EAR [14] as node manager, COUNTDOWN [17] as job manager, and EXAMON [15] as monitor.
5.1. DDS Characterisation
To evaluate the DDS layer, we conducted experiments on nodes of the Galielo100 (https://www.hpc.cineca.it/systems/hardware/galileo100/, accessed on 31 October 2024) (G100) production system at CINECA [18]. Each node is equipped with two Intel Cascade Lake 8260 CPUs, each featuring 24 cores with a total of 48 cores per node. We conducted two tests to characterize the FastDDS communication protocol: small scale to compare the different FastDDS supported transports and large scale to measure their scalability.
5.1.1. FastDDS Transport Performance
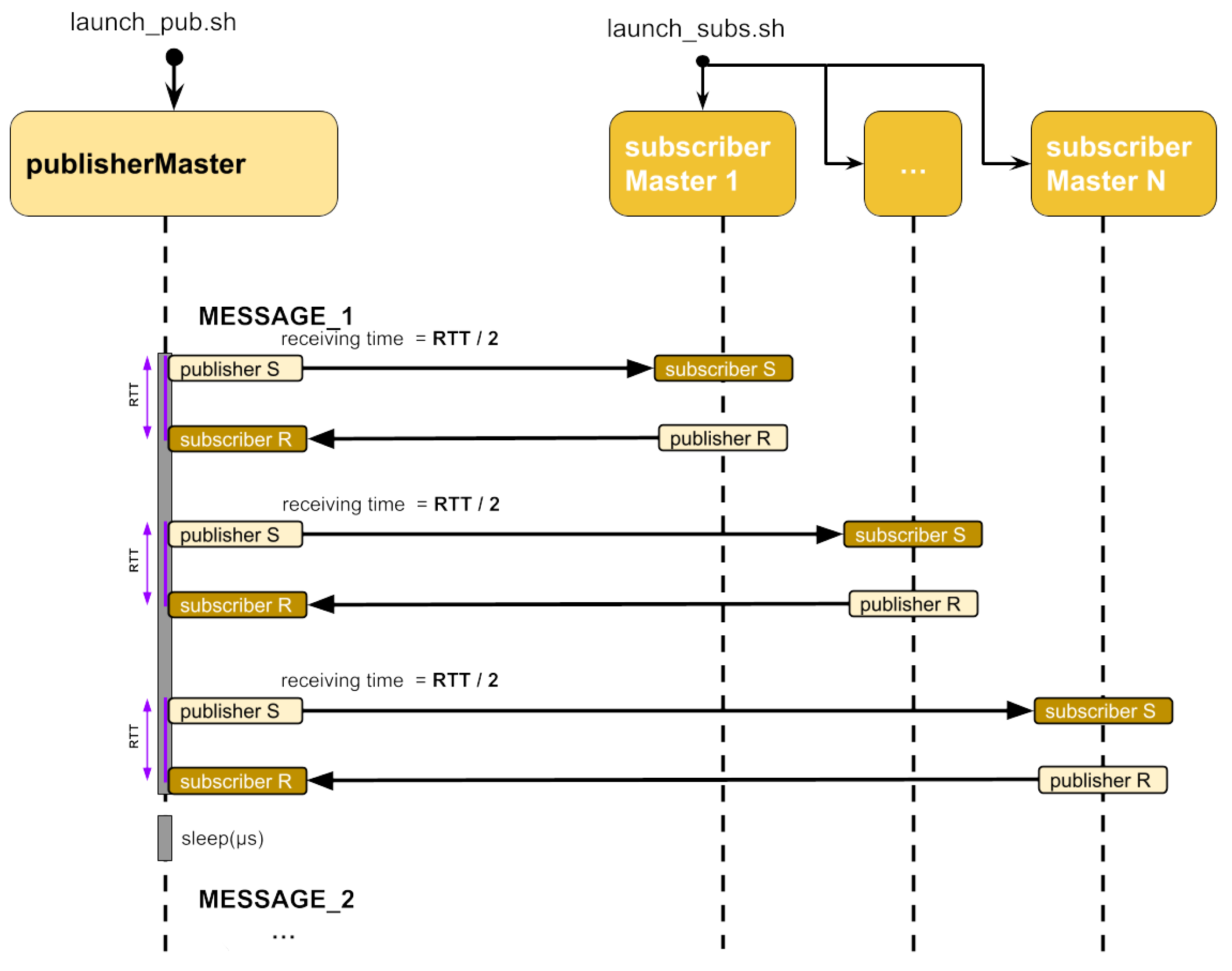
In this test, we instantiated an increasing number of DDS actors on single G100 compute nodes. Thus, we leveraged ad hoc jobs, submitted with the default batch scheduler (SLURM [19]), each instantiating, configuring, and executing a set of entities (DDS Publisher, DDS Subscriber) proportional to the allocated nodes. These entities are capped to a maximum of 40 for each compute node to avoid perturbation in the characterization results due to saturation effects. As shown in Figure 4, each message is exchanged from one publisher (publisherMaster) to N subscribers (subscriberMaster_N). Upon receiving a message, the subscriberMaster replies, sending back a message to the publisherMaster. Message latency is computed as half of the round-trip time, which is measured as the time interval that occurs between the publisherMaster sending the message and receiving the answer. The time interval is measured only at the publisherMaster side to avoid accounting for time drifts in different node clocks. The test is replicated by configuring the FastDDS middleware with the different supported transports: UDP, UDP Multicast (UDPM), shared memory (SHM), and TCP. For each configuration, we compute the average round-trip time as described in Figure 4 over 10K messages.
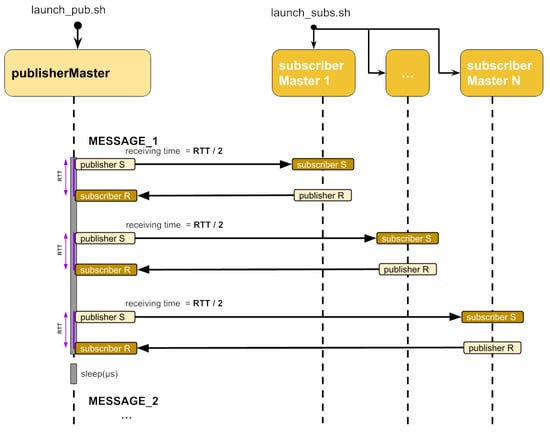
Figure 4.
UML Scheme of RTT test, using multiple DDS entities, for characterising FastDDS on HPC systems.
Table 2 reports for each transport the average time for receiving a message [μs] computed as half of the round-trip time as well as the peak throughput [kByte/s, kMsg/s] computed as the reciprocal of the latency.
Table 2.
Shows for the different protocols such as UDP, TCP, UDP Multicast (UDPM), and Shared Memory (SHM) the average latency and throughput over 40 entities allocated in one node.
The results show as expected that the lowest latency is achieved by the SHM protocol with an average receive time of ∼7 μs which is 1–2% of the on-chip power controller latency for intel architectures [17]. However, shared memory is not a valid protocol for multi-node communication. In this context, UDP and UDPM outperform TCP transport. We thus tested FastDDS with multiple nodes only with UDP and UDPM transports.
5.1.2. FastDDS Scalability
The scalability test employs the same testing infrastructure as the previous test but now allocates in the SLURM job an incremental number of nodes up to 32, which is a restriction in the queue used to run the tests. To compensate for this limitation, the test has been conducted, allocating more DDS entities for each node. There were up to 82 DDS entities per node with ~1 thread/core with a total number of 2560 DDS entities, which is comparable with the pre-exascale systems node count.
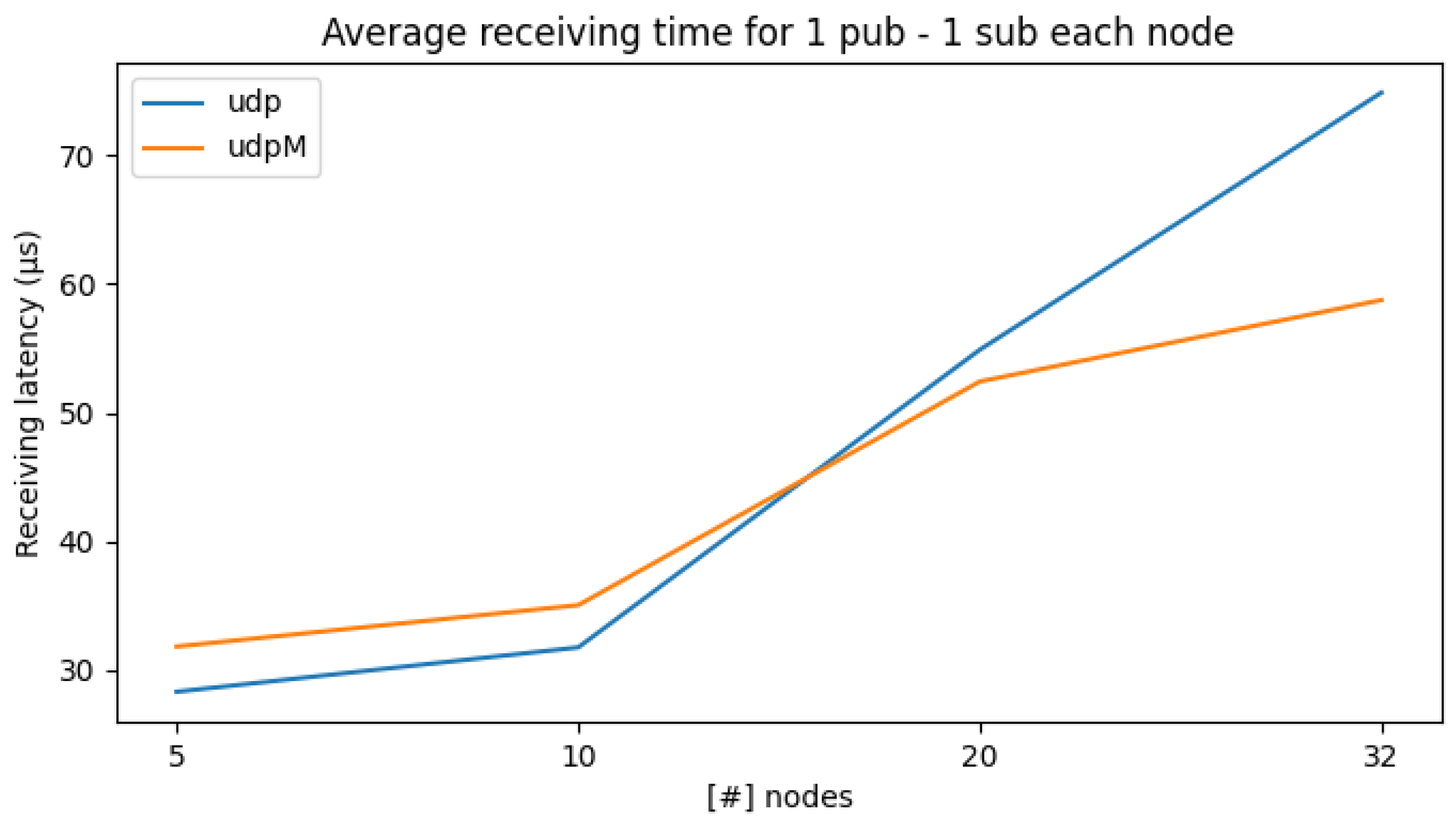
Figure 5 shows on the x-axis the number of nodes and on the y-axis the average latency (in μs) for the exchange of messages while increasing the number of subscribers that will match the number of nodes. First, we can see that the average latency for receiving a message increases with the number of nodes, and UDPM pays off for a larger number of entities. Moreover, when comparing the results in Figure 5 with the one reported in Table 2, we can notice that the average latency increases as an effect of the higher communication time the network interface takes. Still, for a single message, we are in the tens of μs time range.
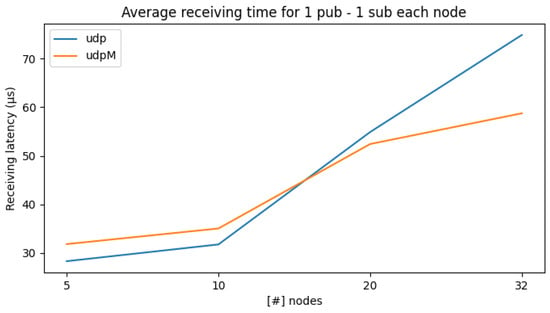
Figure 5.
Average receiving times with one subscriber per node while increasing the number of nodes.
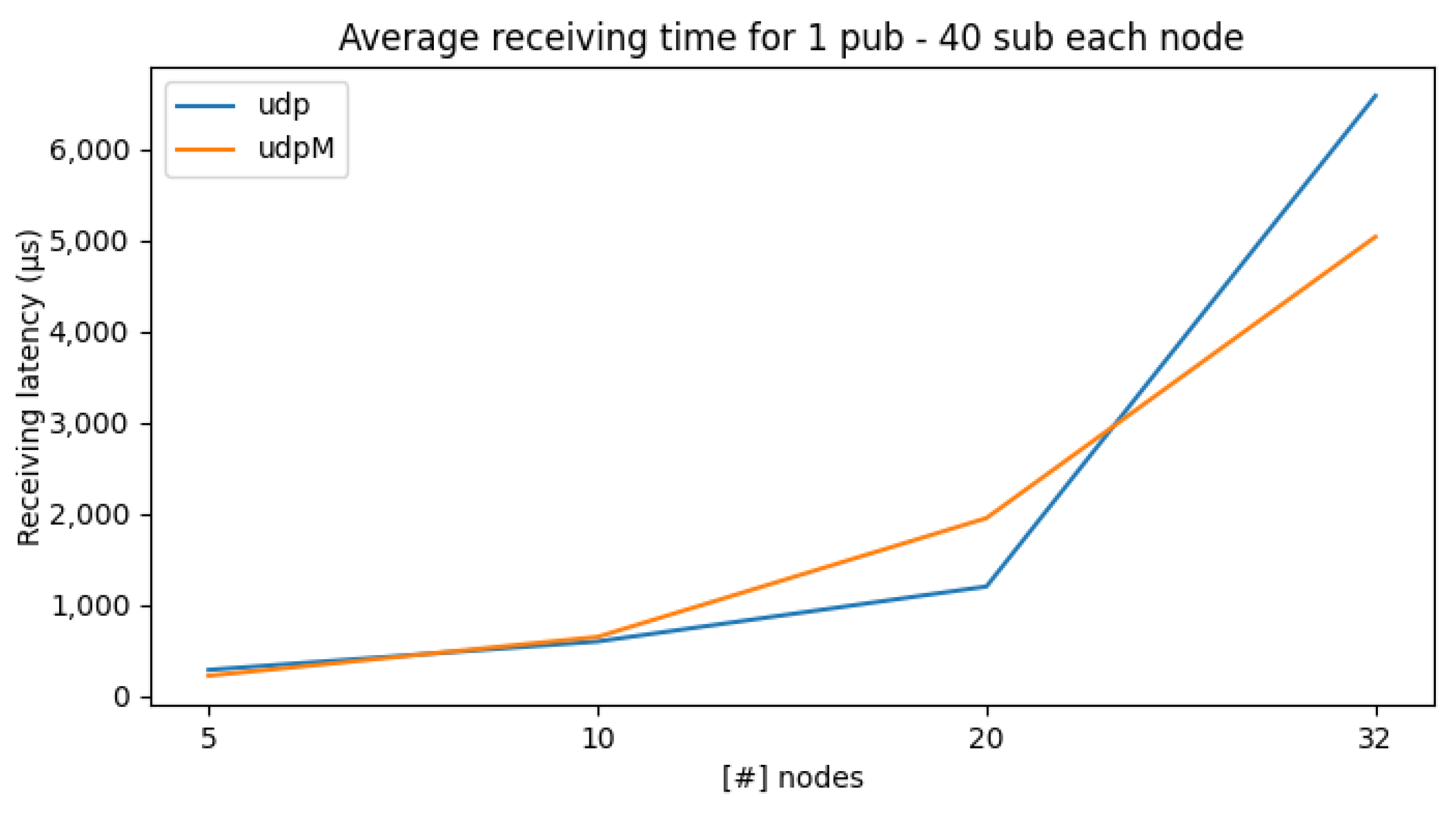
In Figure 6, we extended the previous test by incrementing the number of per-node subscribers to 40 to significantly increase traffic and observe the system’s behavior as it scales. The time reported in the plot refers to the latency for a single message. As we can see from the figure, the latency grows exponentially for UDP and quasi-linear for UDPM. The highest time is reached with 2560 ( Figure 4) FastDDS entities that exchange messages with each other.
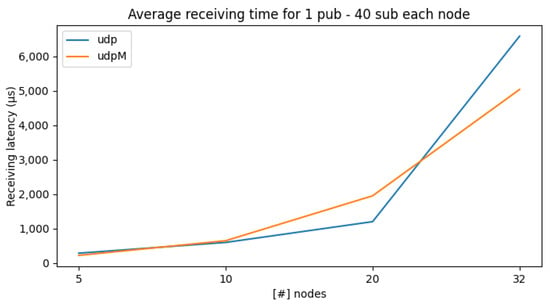
Figure 6.
Average receiving times with 40 subscribers per node while increasing the number of nodes.
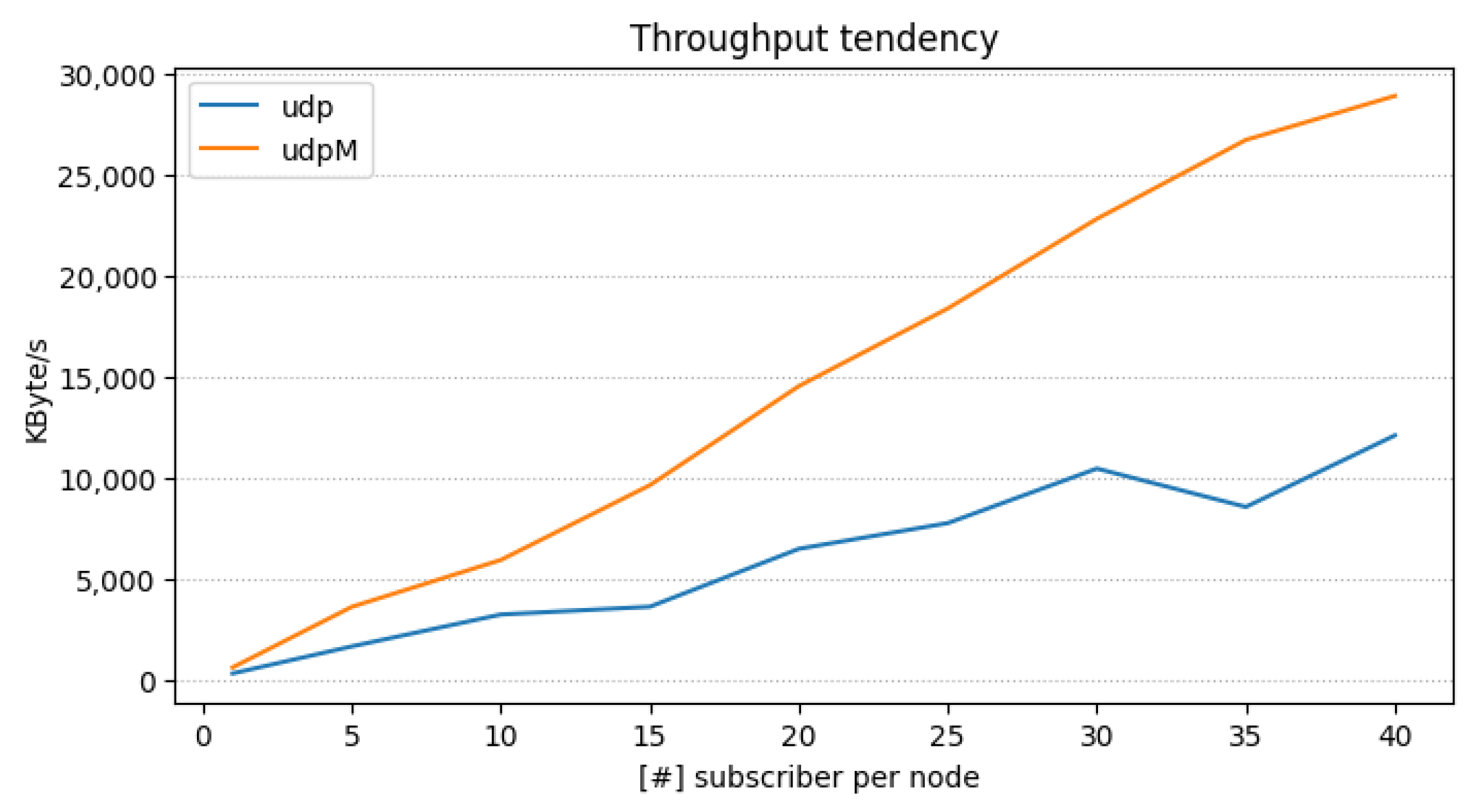
Finally, in Figure 7, we fixed the nodes to 10 while measuring the maximum throughput expressed as kBytes/s (on x-axis) while varying the number of subscribers per node (on y-axis). From the figure, we can observe that UDPM achieves always higher throughput than UDP, and it is the preferred choice for transport when a large amount of message and entities are instantiated. Based on the above results, we used in the REGALE Library the UDPM transport. It must be noted that the TCP has not been considered in the scalability analysis, as it is difficult to set within FastDDS using a slurm scheduler and has incurred higher latency than UDP and UDPM, as shown in Table 2 results.
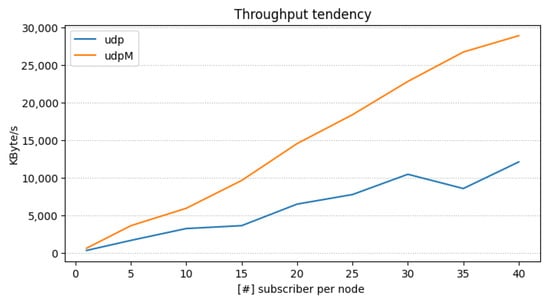
Figure 7.
Throughput with the number of subscribers varying for each node (10).
5.2. HPC PowerStack Prototype with Regale Library
This section presents the functional evaluation of a prototype implementation of the HPC PowerStack (NM, JM, Monitor) using the REGALE Library. For this purpose, we integrated the EAR [20], COUNTDOWN [21] and EXAMON [22] with the proposed REGALE Library [23] and its BridgeMQTT (actually not expected as part of HPC PowerStack [24]).
These tests were conducted on an HPC cluster hosted by E4 computing engineering [25] as it required administrator permissions. Each node in the cluster is equipped with two Intel Xeon Silver 4216 (manufactured by Intel Corporation, Santa Clara, CA, USA) CPUs.
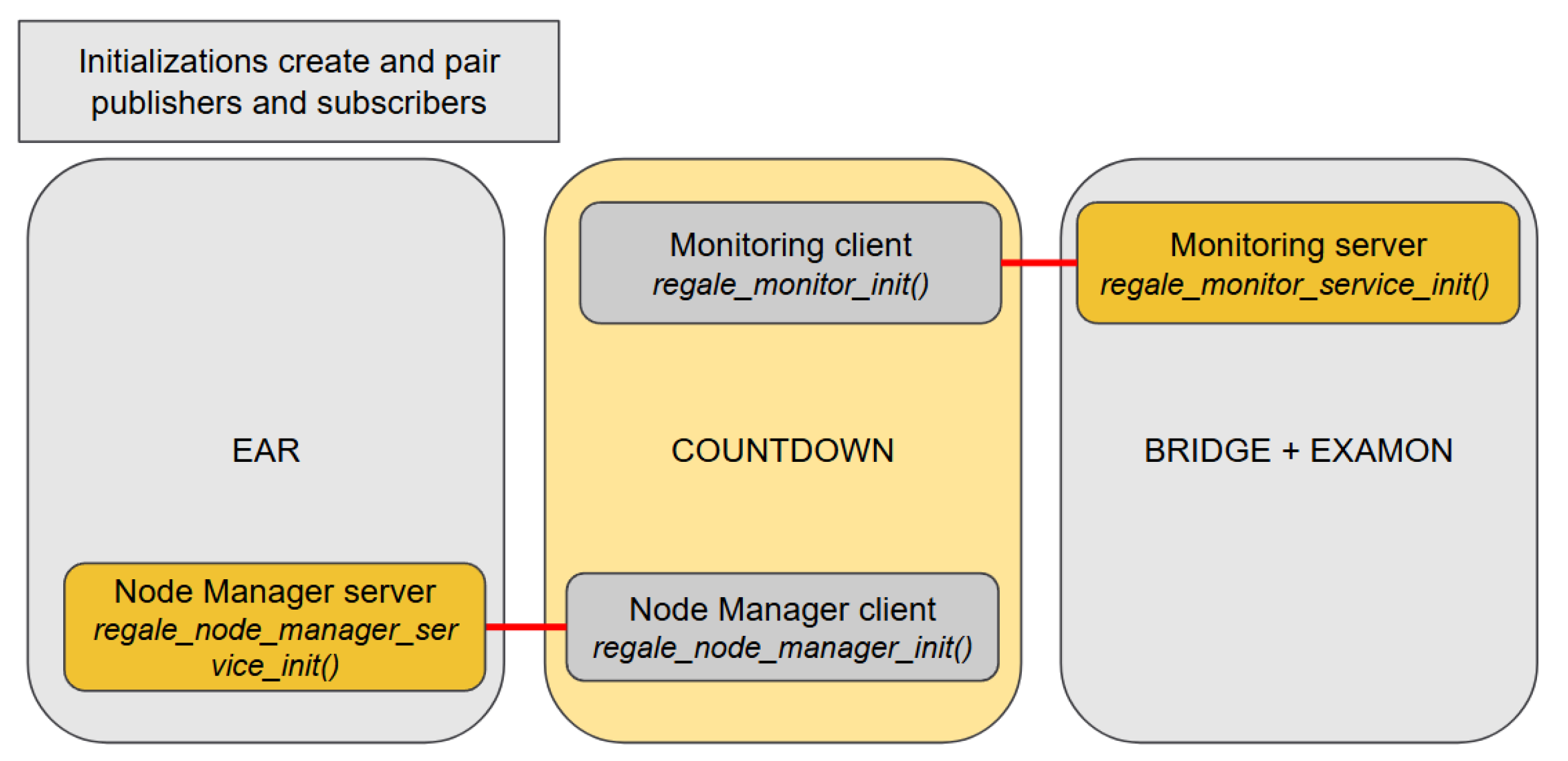
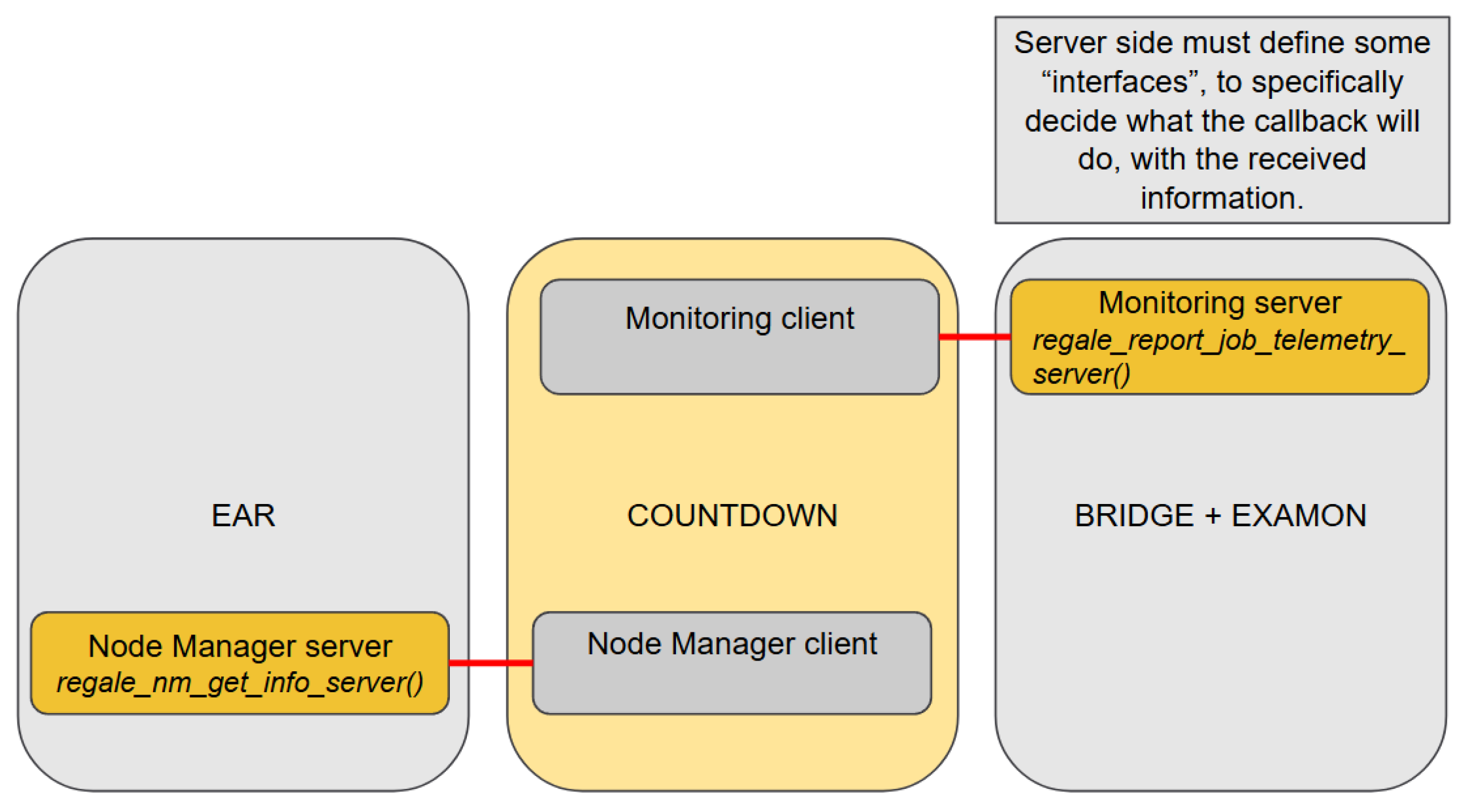
Figure 8 depicts the initialization phase of the prototype HPC PowerStack based on the proposed implementation of the REGALE Library. It includes the initialization for both the implementation of the client and the server sides, respectively, the client for COUNTDOWN and the server for EAR and the BRIDGE + EXAMON. The publishers and subscribers are initialized and paired: the xxx present in Figure 3 for the Client/Server layer methods are now replaced by the corresponding entities names: NM and monitor.
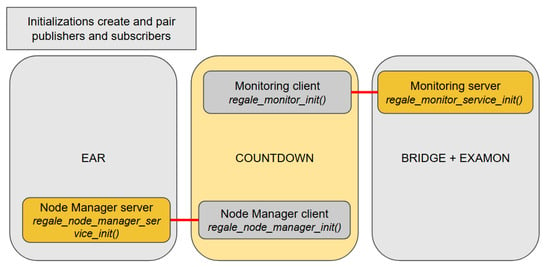
Figure 8.
Job manager initializes with the REGALE APIs (regale_xxx_init and regale_xxx_service_init) the channels with NM and monitor (red lines).
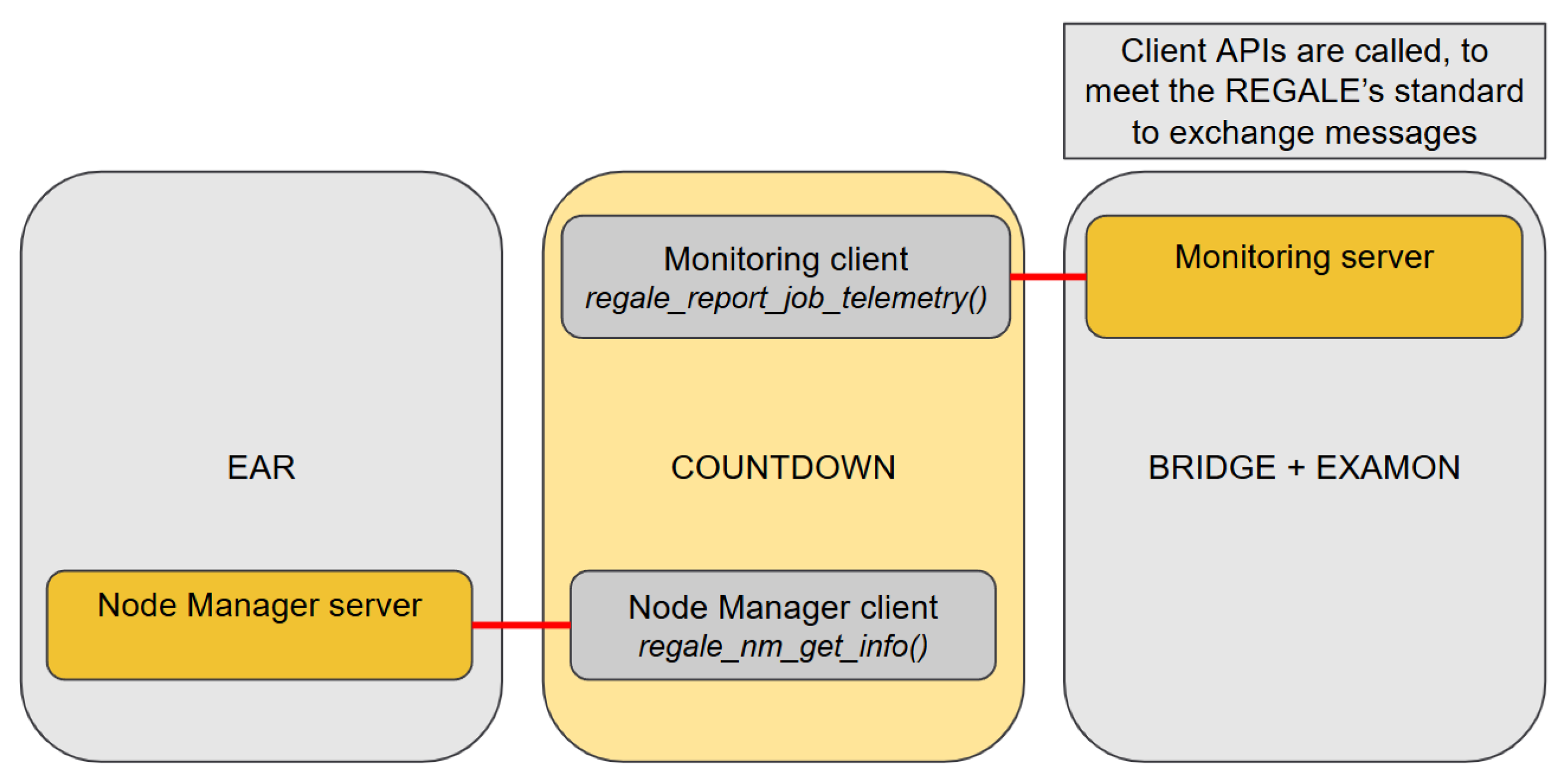
After the initialization phase, the specific APIs/functions are called from the client side to report the job telemetry and to obtain node-related information (regale_report_job_telemetry and regale_nm_get_info), as shown in Figure 9.
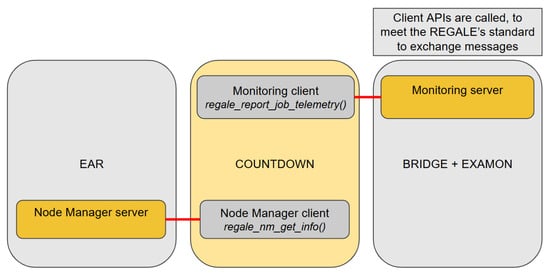
Figure 9.
The job manager (COUNTDOWN) client-side calls REGALE APIs to obtain info from the node manager (EAR) (with regale_nm_get_info) and to send info to the monitoring (EXAMON) system through MQTT-Bridge (with regale_report_job_telemetry).
The server side must implement the prototype function defined in the file regale_xxx_server_impl.h to reply to the requests of the client counterparts (see Figure 10). This integration example clarifies the role of the REGALE Library in the HPC PowerStack, which is to provide interoperability among different implementations of the entities in play. Indeed, the agent BRIDGE + EXAMON can be replaced by the synthetic component without changing anything in the JM implementation or calls’ list, nor in the Monitoring server side, other than the implementation of the regale_report_job_telemetry_server. The same applies to the EAR NM implementation: if plugged out and substituted by a synthetic component, nothing would be actually required to be modified in the JM or calls’ stack.
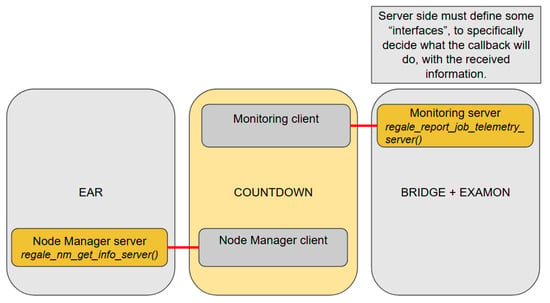
Figure 10.
The callback defined by the entities on the server side (EAR and EXAMON) can be triggered by the client (COUNTDOWN) using the REGALE Library API.
In the above description, the EXAMON + BRIDGE handles the communication between the REGALE Library and the MQTT, which is at the base of the EXAMON Monitor as well as other HPC Monitor tools. Since both MQTT and DDS are topic-oriented, this component simplifies the creation of a ”duplicate” interface for all entities that already support MQTT communication. Its operation involves listening to all the topics directed within one specific protocol (such as to-MQTT and to-DDS) and propagating the messages, with necessary transformation, to other protocols. In the current implementation, the BRIDGE captures most of the global communication originated from the DDS publishers (even those not directed to the monitor) and reports these messages to EXAMON using its specific protocol. This mechanism does not require any changes to the monitoring client. The server side of the REGALE monitoring APIs, which handles the specific callback functions, is triggered upon receiving DDS messages. It also manages the logic for converting and making the received information available to the existing MQTT monitoring system.
5.3. REGALE Library Functionality Tests
In this subsection, we used a simple MPI program performing MPI_Alltoall communications followed by computation to demonstrate the functionality of the HPC PowerStack implementation based on the REGALE Library described above. The COUNTDOWN logic will decrease the core’s clock frequency during communication phases. We executed the test on three different nodes each hosting one different entity: a JM, an NM, and a Monitoring System, to validate the exchange of messages among different nodes, using different transport protocols than the shared memory one; in this specific case, we used UDP. Regarding the JM, the COUNTDOWN implementation has been considered, while for the other two entities, we have used the synthetic components we developed as part of the REGALE Library repository, which acts as a template for the implementation/integration with power management tools absolving the role of the given entity. During the test, we observed the exchange of messages between the entities to verify the correct behavior. In the future, we will replace it with the actual implementation using real NM and monitor tools, like EXAMON and EAR. We underline that this replacement will happen without any modification in the JM as the interoperability is implemented by the REGALE Library middleware.
Figure 11 shows the breakdown of time in computation (APP time) and communication (MPI time).

Figure 11.
Total time of the run and its specific percentage into MPI phases and into APP phases (not MPI ones).
Figure 11 shows the average frequency reported by COUNTDOWN, which was 1.4 GHz (Figure 12), which is the correct expected value considering the percentage of time spent in MPI and APP considering the maximum available frequency is 2 GHz and the minimum one is 800 MHz.

Figure 12.
Final average (AVG) CPU frequency reported by COUNTDOWN.
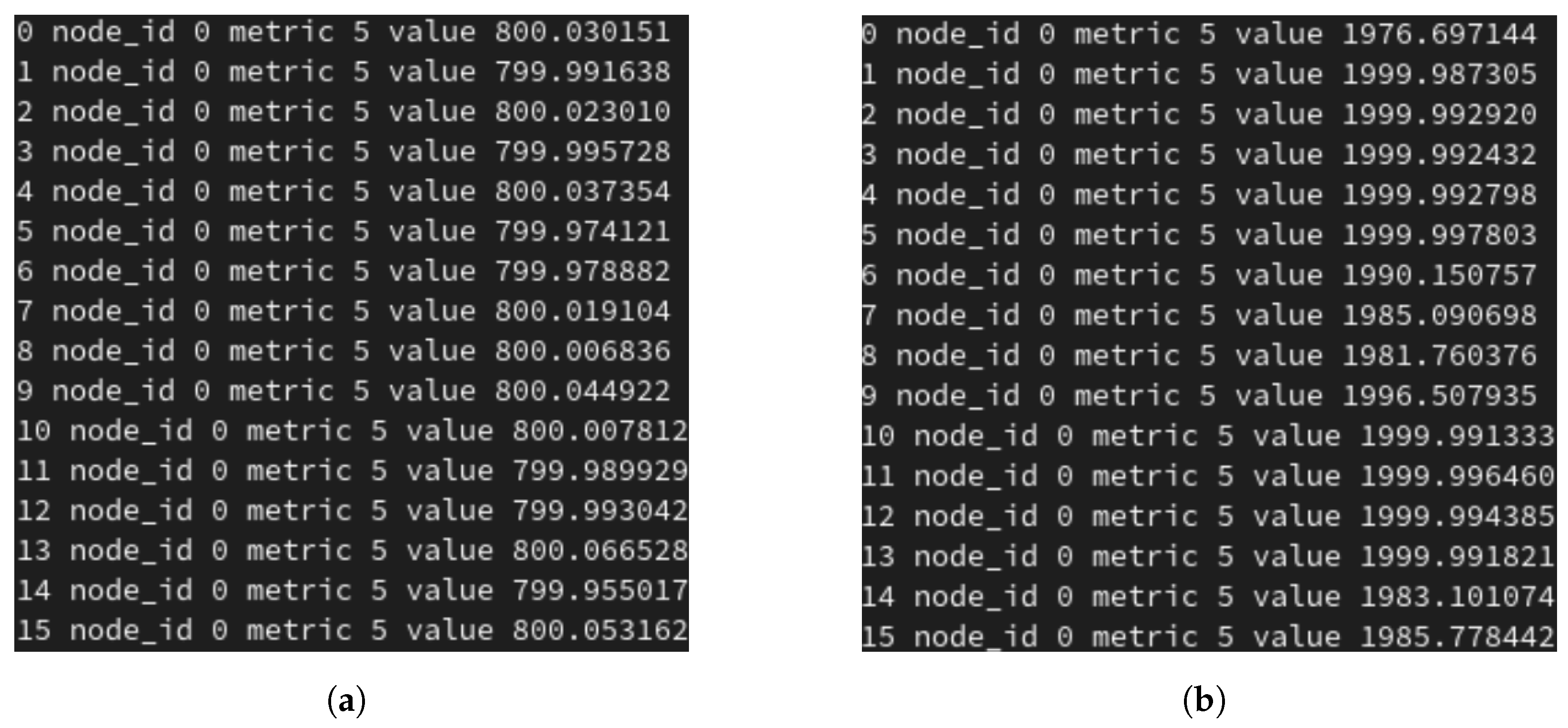
Furthermore, from Figure 13, we can see 16 MPI processes composing the benchmark that the monitor received from the NM regarding the correct frequency scaling events. Similar messages have been received by the NM who has propagated the DVFS command to the O.S. power manager interface. The report in the Figure 13a indicates the NM set frequency commands to the minimum DVFS operating point and in Figure 13b the NM set frequency commands to the maximum DVFS operating point.
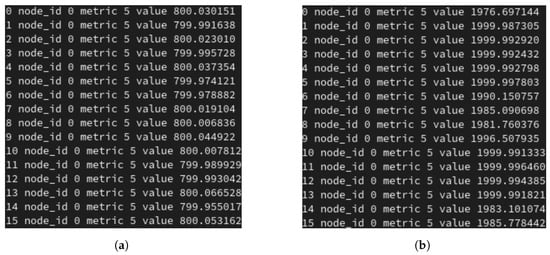
Figure 13.
Monitor reporting messages of frequency sent by job manager over different (16) MPI processes: (a) actual frequency inside the MPI_Alltoall (the minimum one feasible by the system, 800 MHz), (b) actual frequency set by the synthetic NM, which is 2 GHz.
These tests validate that the REGALE Library can be used to implement the HPC PowerStack requested functionalities supporting interoperable entity-to-entity communication. This facilitates the hot-swap replacement of the entity’s actual implementation. Here, in fact, we just added a couple of APIs in the JM to let it work and communicate with the NM and the Monitor. Specifically, the calls involved were
- regale_monitor_init to initialise the monitor client;
- regale_nm_init to initialise the node manager client;
- regale_report_job_telemetry to send current frequency to the monitoring system;
- regale_nm_get_current_conf to ask the node manager the actual maximum freq;
- regale_monitor_finalize to finalize the monitor client;
- regale_nm_finalize to finalize the node manager client.
5.4. REGALE Library Performance Tests
In this last result section, we executed the NAS parallel benchmark [26] (type: Fourier Transform FT.D) when using and not using the REGALE Library to measure the overhead in time-to-solutions (TTS) induced by the library. These tests were executed on the E4 cluster described in the previous Section 5.3. The test is executed by instantiating one node per actor while running the NAS benchmark on the same compute node where the JM (COUNTDOWN) executes. The JM executes the COUNTDOWN power management policy following the application phases and communicates over the REGALE Library. This traffic flows through the BRIDGE to the EXAMON Monitor database.
We repeated the test ten times, and the average results are reported in Table 3. From the table, we can see that the TTS overhead introduced by COUNTDOWN without the REGALE Library is 0.41%, while the overhead of COUNTDOWN with the REGALE Library is 0.45%. According to the test, the REGALE Library accounts for only 0.04% of the TTS overhead. In future works, we will conduct more extensive tests to validate the scalability of the proposed REGALE Library implementation with more complex and communication-rich HPC PowerStack implementation and scenarios.
Table 3.
Multiple runs of Numerical Aerodynamic Simulation (NAS) Fourier Transform (FT.D) benchmark using the REGALE Library with COUNTDOWN (CNTD) job manager, MQTT Bridge and EXAMON monitor.
6. Conclusions
This paper presented the REGALE Library, developed through the collaborative efforts of the EuroHPC JU REGALE project, which aims to realise the HPC PowerStack initiative by providing a unified communication layer among various power management tools, libraries, and software. After building the regale core that exploits the FastDDS implementation, we characterised our solution on an HPC system. In the second instance, after implementing the REGALE Library to a subgroup of HPC PowerStack (node manager, job manager, and monitor), we proved with functionality tests that different tools can cooperate to perform power management. Finally, with the latest test, we measured the overhead caused by the library and provided how this HPC PowerStack can be implemented, showing promising results.
Future work will target several key areas. First, it is essential to conduct more comprehensive testing of the infrastructure, which includes integrating all PowerStack components and evaluating the global overhead. Following this, a comparative analysis of REGALE with related works will offer valuable insights. Moreover, the code will also be optimized, refining the domain–topic–partition structure, and fine tuning the quality of service (QoS) settings of DDS. Ultimately, the goal is to deploy a full HPC PowerStack with the REGALE Library tool in an operational system.
Author Contributions
Conceptualization, A.B., D.C. and J.C.; methodology, A.B., G.M., F.T., D.C., L.A. and J.C.; software, G.M., F.T., L.A. and J.C.; validation, G.M., F.T., L.A. and J.C.; formal analysis, F.T., L.A. and J.C.; investigation, G.M., F.T., L.A. and J.C.; resources, A.B., F.T. and D.C.; data curation, G.M., F.T., L.A. and J.C.; writing—original draft preparation, G.M., F.T., L.A. and J.C.; writing—review and editing, G.M., F.T. and A.B.; visualization, A.B., D.C. and J.C.; supervision, A.B., D.C. and J.C.; project administration, A.B., D.C. and J.C.; funding acquisition, A.B., D.C. and J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially funded by EuroHPC JU REGALE (g.a. 956560), EUPEX (g.a 101033975), the EU HE GRAPH-MASSIVIZER (g.a. 101093202), DECICE (g.a 101092582) and the Spoke1 “FutureHPC & BigData” of the ICSC–Centro Nazionale di Ricerca in High Performance Computing, Big Data and Quantum Computing and hosting entity, funded by European Union–NextGeneationEU.
Data Availability Statement
The data supporting the findings of this study are included in the article. The code developed for the analysis and design is available in the GitLab repositories [20,21,22,23], accessed on 31 October 2024.
Acknowledgments
We would like to express our gratitude to Georgios Goumas and all the REGALE project partners and E4 Computer Engineering for their support and collaboration throughout this project and for providing the necessary computational resources and technical assistance.
Conflicts of Interest
Author Federico Tesser was employed by the company Eni Spa. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Mantovani, F.; Calore, E. Performance and Power Analysis of HPC Workloads on Heterogeneous Multi-Node Clusters. J. Low Power Electron. Appl. 2018, 8, 13. [Google Scholar] [CrossRef]
- Wu, X.; Marathe, A.; Jana, S.; Vysocky, O.; John, J.; Bartolini, A.; Riha, L.; Gerndt, M.; Taylor, V.; Bhalachandra, S. Toward an end-to-end auto-tuning framework in HPC PowerStack. In Proceedings of the 2020 IEEE International Conference on Cluster Computing (CLUSTER), Kobe, Japan, 14–17 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 473–483. [Google Scholar]
- Borghesi, A.; Conficoni, C.; Lombardi, M.; Bartolini, A. MS3: A Mediterranean-stile job scheduler for supercomputers—Do less when it’s too hot! In Proceedings of the 2015 International Conference on High Performance Computing ands Simulation (HPCS), Amsterdam, The Netherlands, 20–24 July 2015; pp. 88–95. [Google Scholar] [CrossRef]
- EuroHPC Joint Undertaking. Open Architecture for Future Supercomputers; EuroHPC Joint Undertaking: Luxembourg, 2021. [Google Scholar]
- Pourmohseni, B.; Glaß, M.; Henkel, J.; Khdr, H.; Rapp, M.; Richthammer, V.; Schwarzer, T.; Smirnov, F.; Spieck, J.; Teich, J.; et al. Hybrid Application Mapping for Composable Many-Core Systems: Overview and Future Perspective. J. Low Power Electron. Appl. 2020, 10, 38. [Google Scholar] [CrossRef]
- Giardino, M.; Schwyn, D.; Ferri, B.; Ferri, A. Low-Overhead Reinforcement Learning-Based Power Management Using 2QoSM. J. Low Power Electron. Appl. 2022, 12, 29. [Google Scholar] [CrossRef]
- Mamun, S.A.; Gilday, A.; Singh, A.K.; Ganguly, A.; Merrett, G.V.; Wang, X.; Al-Hashimi, B.M. Intra- and Inter-Server Smart Task Scheduling for Profit and Energy Optimization of HPC Data Centers. J. Low Power Electron. Appl. 2020, 10, 32. [Google Scholar] [CrossRef]
- Eastep, J.; Sylvester, S.; Cantalupo, C.; Geltz, B.; Ardanaz, F.; Al-Rawi, A.; Livingston, K.; Keceli, F.; Maiterth, M.; Jana, S. Global Extensible Open Power Manager: A Vehicle for HPC Community Collaboration on Co-Designed Energy Management Solutions. In Proceedings of the High Performance Computing, Orlando, FL, USA, 12–15 May 2017; pp. 394–412. [Google Scholar] [CrossRef]
- Labasan, S.; Delgado, R.; Rountree, B. Variorum: Extensible Framework for Hardware Monitoring and Contol; Technical Report; Lawrence Livermore National Lab. (LLNL): Livermore, CA, USA, 2017. [Google Scholar]
- Vysockỳ, O.; Beseda, M.; Říha, L.; Zapletal, J.; Lysaght, M.; Kannan, V. Evaluation of the HPC Applications Dynamic Behavior in Terms of Energy Consumption; Civil-Comp Press: Edinburgh, UK, 2017. [Google Scholar]
- DeBonis, D.; Grant, R.; Olivier, S.L.; Levenhagen, M.J.; Kelly, S.M.; Pedretti, K.P.; Laros, J.H. A Power API for the HPC Community; Technical Report; Sandia National Lab. (SNL-NM): Albuquerque, NM, USA, 2014. [Google Scholar]
- Grant, R.E.; Levenhagen, M.; Olivier, S.L.; DeBonis, D.; Pedretti, K.T.; Laros III, J.H. Standardizing Power Monitoring and Control at Exascale. Computer 2016, 49, 38–46. [Google Scholar] [CrossRef]
- Hackenberg, D.; Ilsche, T.; Schuchart, J.; Schöne, R.; Nagel, W.E.; Simon, M.; Georgiou, Y. HDEEM: High Definition Energy Efficiency Monitoring. In Proceedings of the 2014 Energy Efficient Supercomputing Workshop, New Orleans, LA, USA, 16 November 2014; pp. 1–10. [Google Scholar] [CrossRef]
- Corbalan, J.; Brochard, L. EAR: Energy Management Framework for Supercomputers; Barcelona Supercomputing Center (BSC) Working Paper; Barcelona Supercomputing Center (BSC): Barcelona, Spain, 2019. [Google Scholar]
- Bartolini, A.; Beneventi, F.; Borghesi, A.; Cesarini, D.; Libri, A.; Benini, L.; Cavazzoni, C. Paving the Way Toward Energy-Aware and Automated Datacentre. In Proceedings of the Workshop Proceedings of the 48th International Conference on Parallel Processing, New York, NY, USA, 5–8 August 2019; ICPP Workshops’19: Kobe, Japan, 2019. [Google Scholar] [CrossRef]
- Netti, A.; Müller, M.; Auweter, A.; Guillen, C.; Ott, M.; Tafani, D.; Schulz, M. From facility to application sensor data: Modular, continuous and holistic monitoring with DCDB. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 17–22 November 2019. [Google Scholar] [CrossRef]
- Cesarini, D.; Bartolini, A.; Bonfà, P.; Cavazzoni, C.; Benini, L. COUNTDOWN: A Run-time Library for Performance-Neutral Energy Saving in MPI Applications. arXiv 2019, arXiv:1806.07258. [Google Scholar] [CrossRef]
- Cineca. Cineca Galileo 100. 2021. Available online: https://www.hpc.cineca.it/hardware/galileo100 (accessed on 31 October 2024).
- Yoo, A.B.; Jette, M.A.; Grondona, M. SLURM: Simple Linux Utility for Resource Management. In Proceedings of the Job Scheduling Strategies for Parallel Processing, Seattle, WA, USA, 24 June 2003. [Google Scholar]
- BSC. EAR: Node Manager. Available online: https://gitlab.bsc.es/ear_team/ear (accessed on 10 October 2024).
- EEESlab. COUNTDOWN: Job Manager. Available online: https://github.com/EEESlab/countdown (accessed on 24 August 2024).
- EEESlab. EXAMON: Monitor. Available online: https://github.com/EEESlab/examon (accessed on 31 October 2024).
- REGALE Library. 2023. Available online: https://gricad-gitlab.univ-grenoble-alpes.fr/regale/tools/regale (accessed on 24 August 2024).
- ECS Lab. MQTT Bridge. 2023. Available online: https://gitlab.com/ecs-lab/tools/mqtt_bridge (accessed on 31 October 2024).
- E4 HPC Systems. Available online: https://www.e4company.com/ (accessed on 31 October 2024).
- Bailey, D.H.; Barszcz, E.; Barton, J.; Browning, D.S.; Carter, R.L.; Dagum, L.; Fatoohi, R.A.; Frederickson, P.O.; Lasinski, T.A.; Schreiber, R.S.; et al. The Nas Parallel Benchmarks. Int. J. High Perform. Comput. Appl. 1991, 5, 63–73. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).