
BFT—Low-Latency Bit-Slice Design of Discrete Fourier Transform




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. DFT/FFT Algorithm: A Brief Overview
3. The Binary DFT
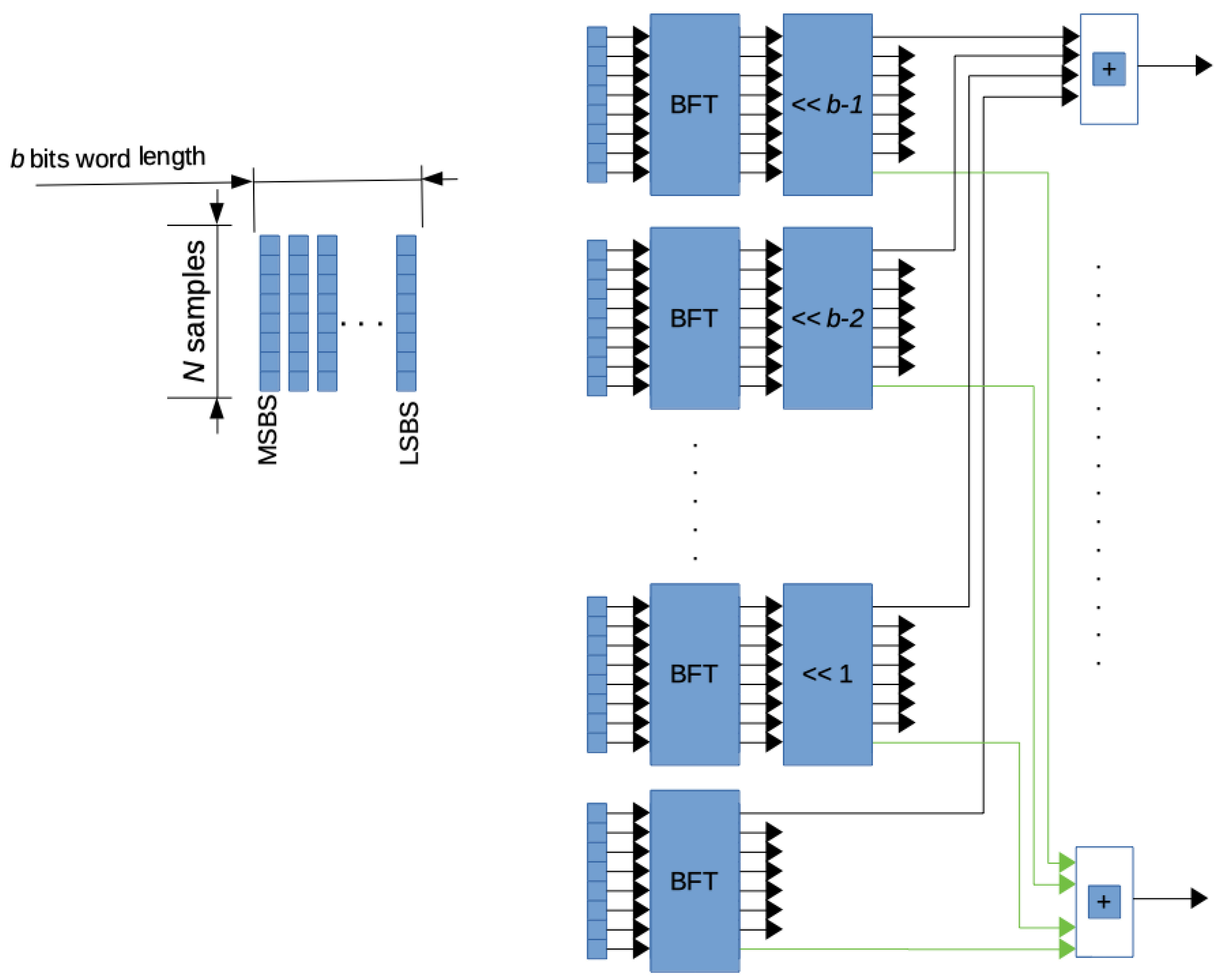
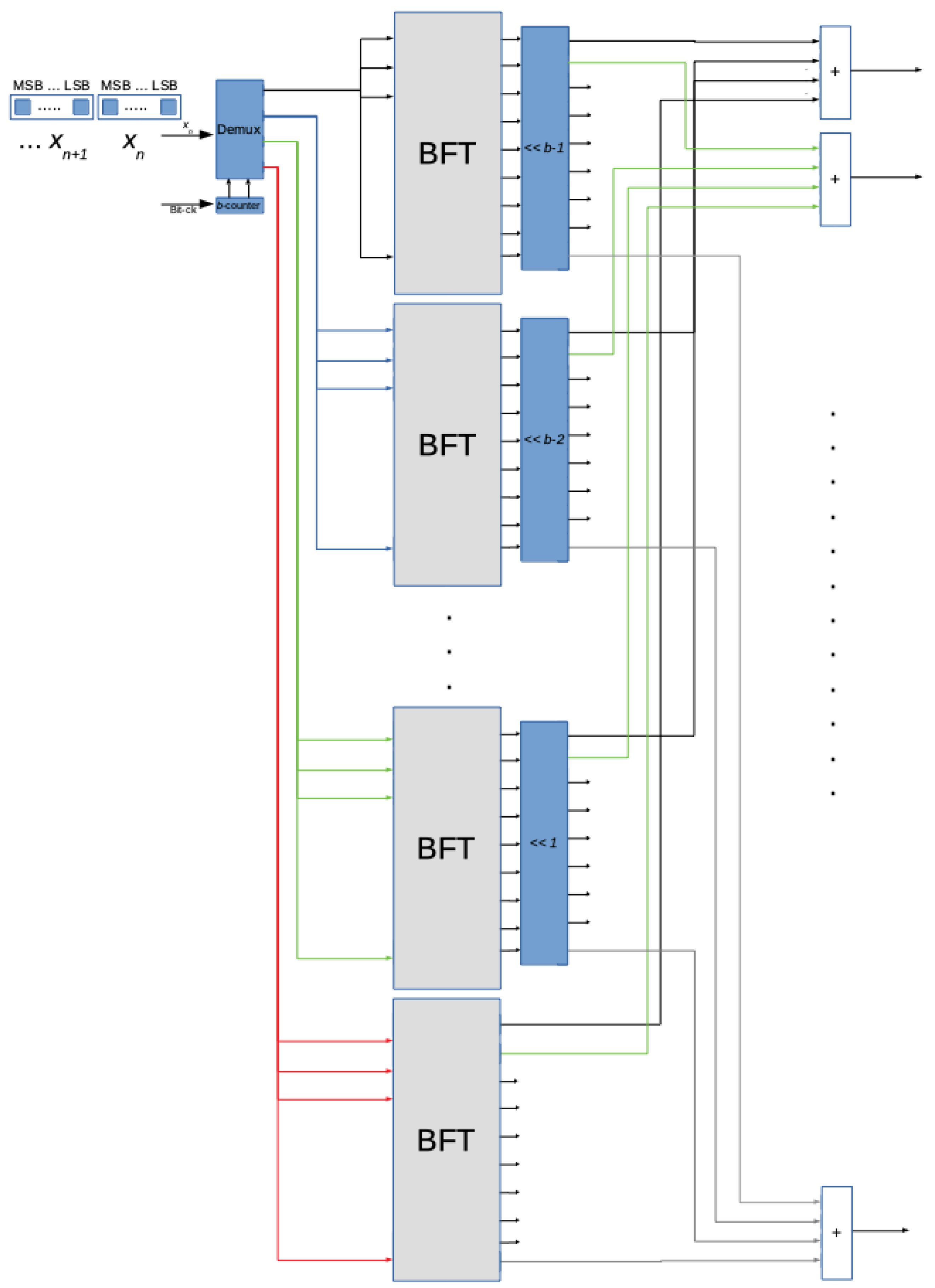
4. Functional Blocks of the Proposed System
4.1. The DEMUX Block
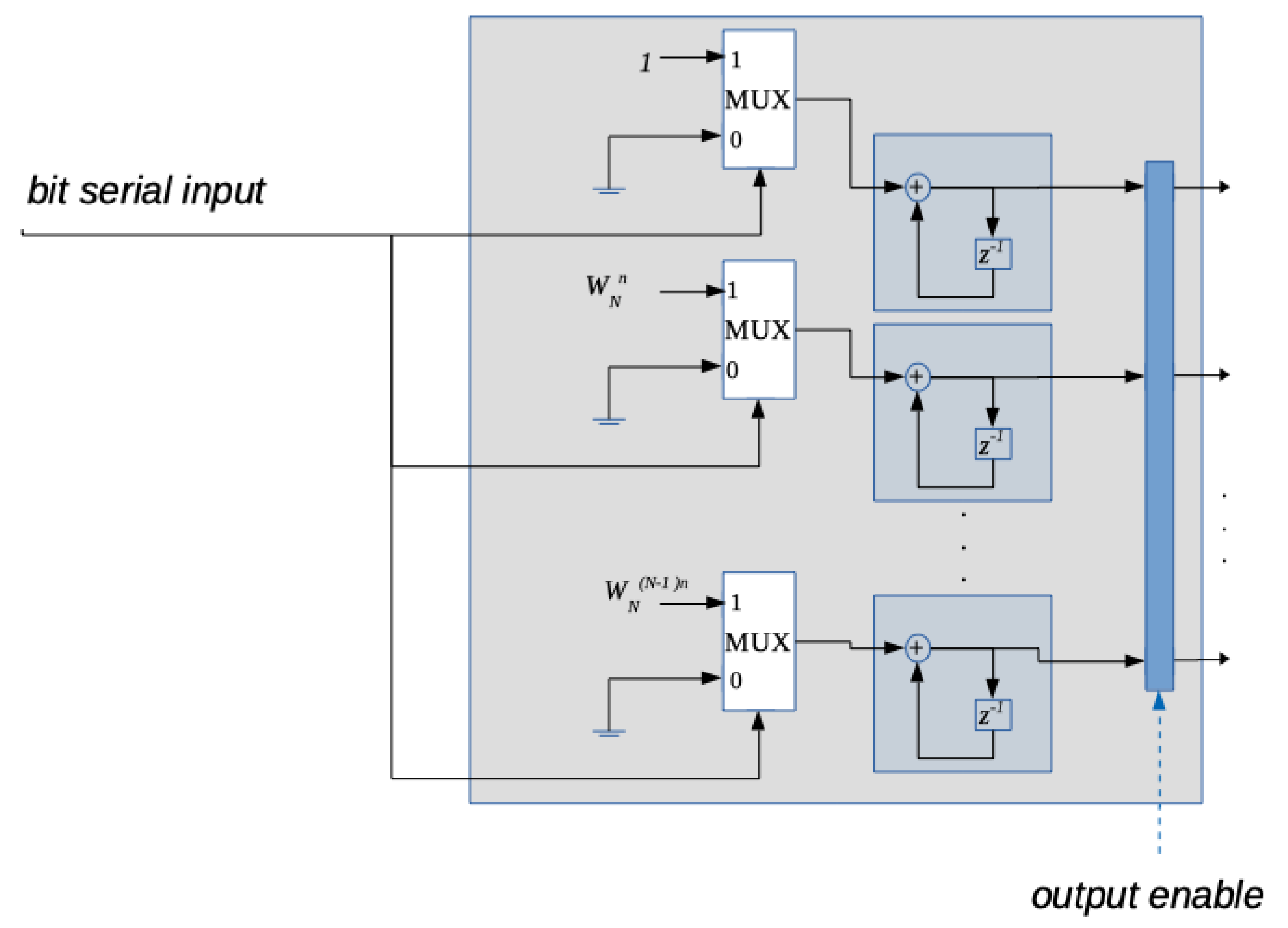
4.2. The BFT Block

4.3. The Left-Shift Block
4.4. The Adder Block

5. Hardware Architecture of the FPGA-Based System: An Application Example
5.1. OFDM Technique Characteristics
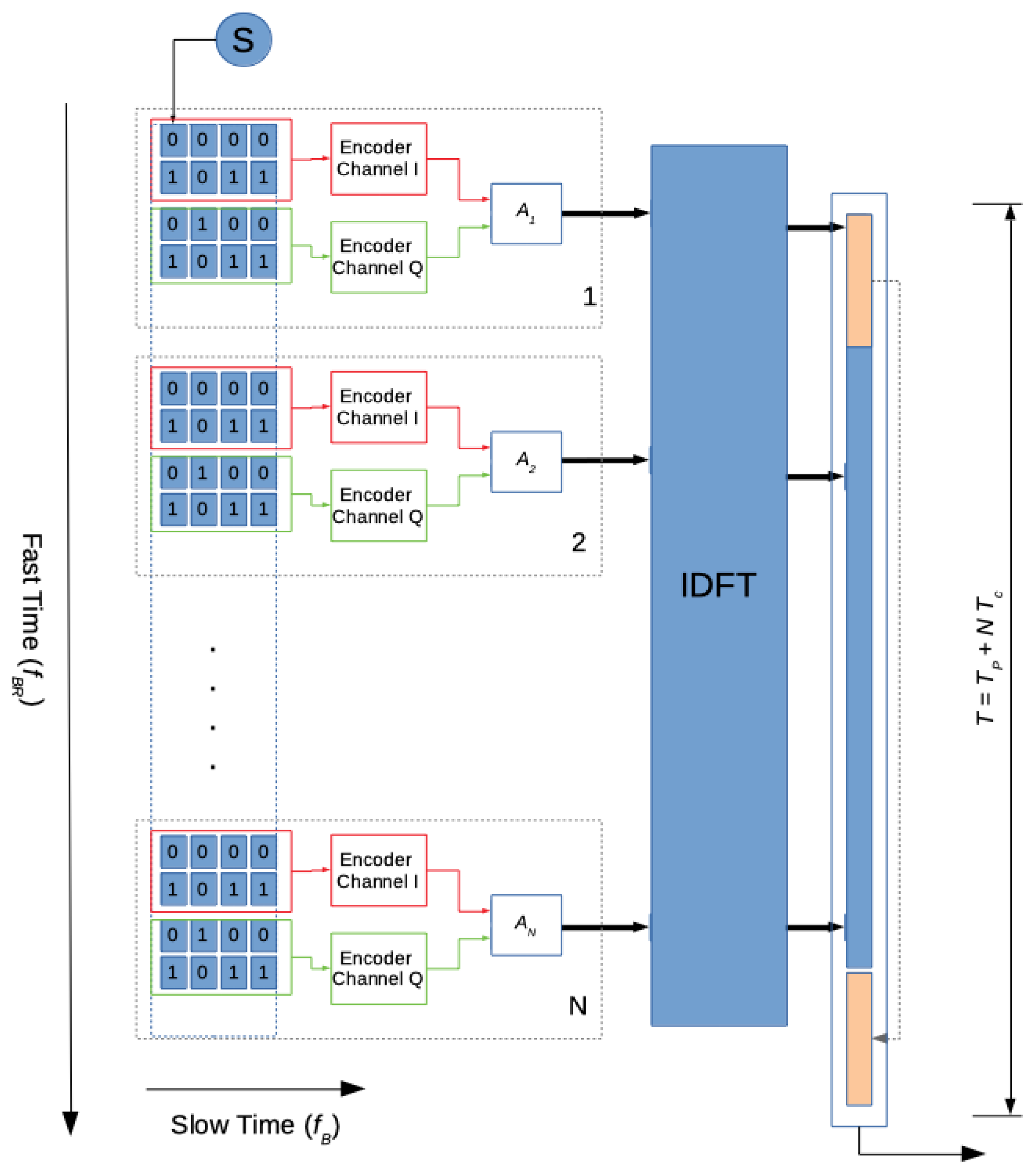
5.2. The Proposed FPGA-Based Architecture
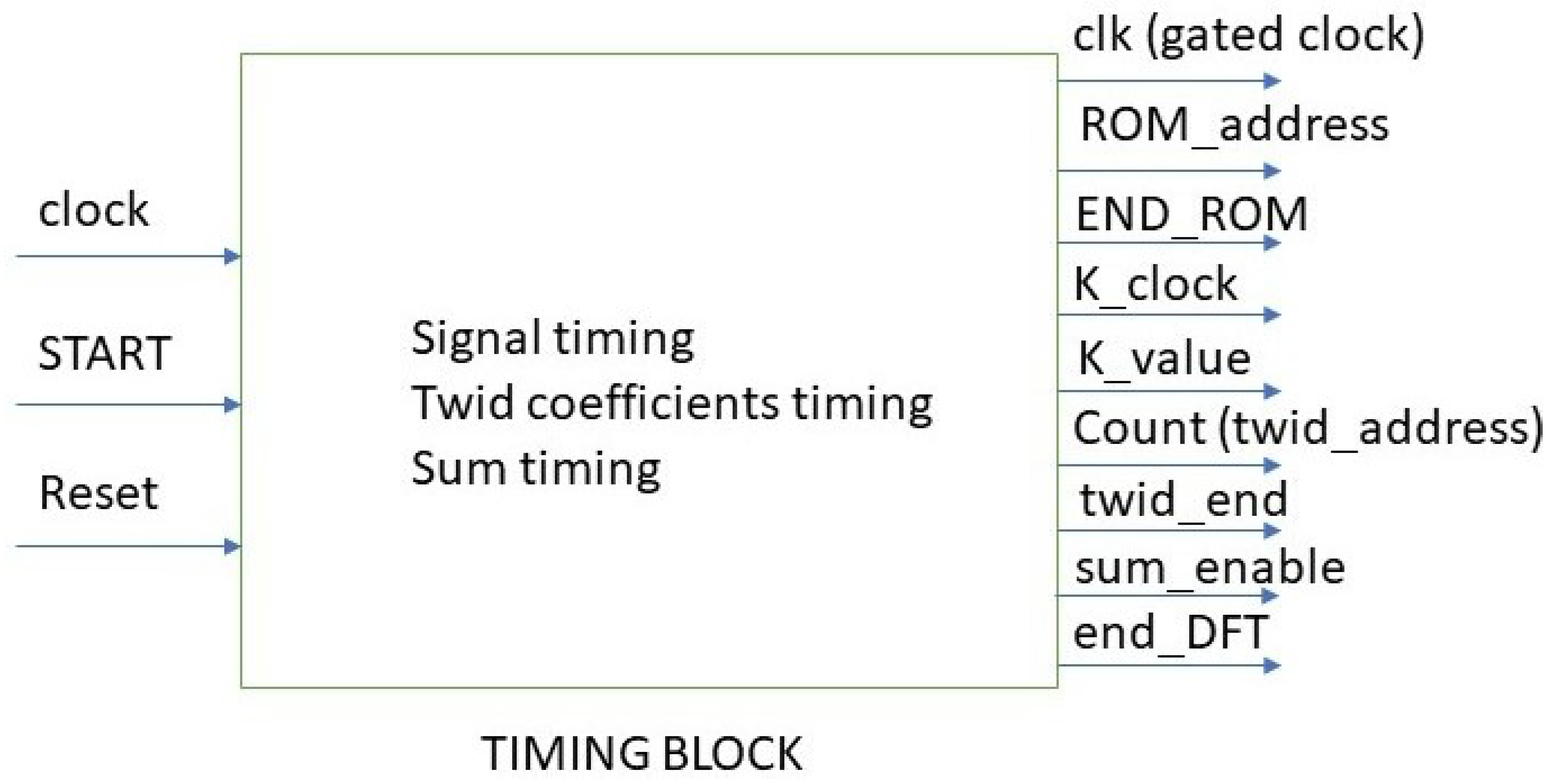
5.2.1. The Timing Block
- clk, which is the system clock, looked at the START signal. In fact clk is equal to 0 if START is 0 whatever the clock logic value;
- ROM_address, which is a 10-bit word. It addresses all the signal_ROM memory locations in which a function with 1024 samples is stored. Each sample is coded with 4 bits;
- END_ROM, which is a binary signal that takes a logic value of one after all the 1024 samples of the signal_ROM have been analyzed;
- K_clock, which is a timing signal for the sum block;
- K_value, which is a 10-bit word whose numerical value in decimal code indicates the current value of the k index in the expression for the BFT calculation;
- Count (twiddle address), which is a 10-bit word able to address the twiddle coefficients for their reading.
- Twid_end, which is a binary signal that reaches the logic 1 value once all the 1024 twiddle coefficients have been sent to the processing block. Selection of 1024 twiddle coefficients is necessary for each processing cycle.
- Sum_enable, which is a timing signal that controls the operation of adders in the processing block and the correct transmission of both test function samples and twiddle coefficients.
- End_DFT, which is a binary signal that takes the logic value 1 once all the processing cycles have ended and the BFT values are outputs.
- -
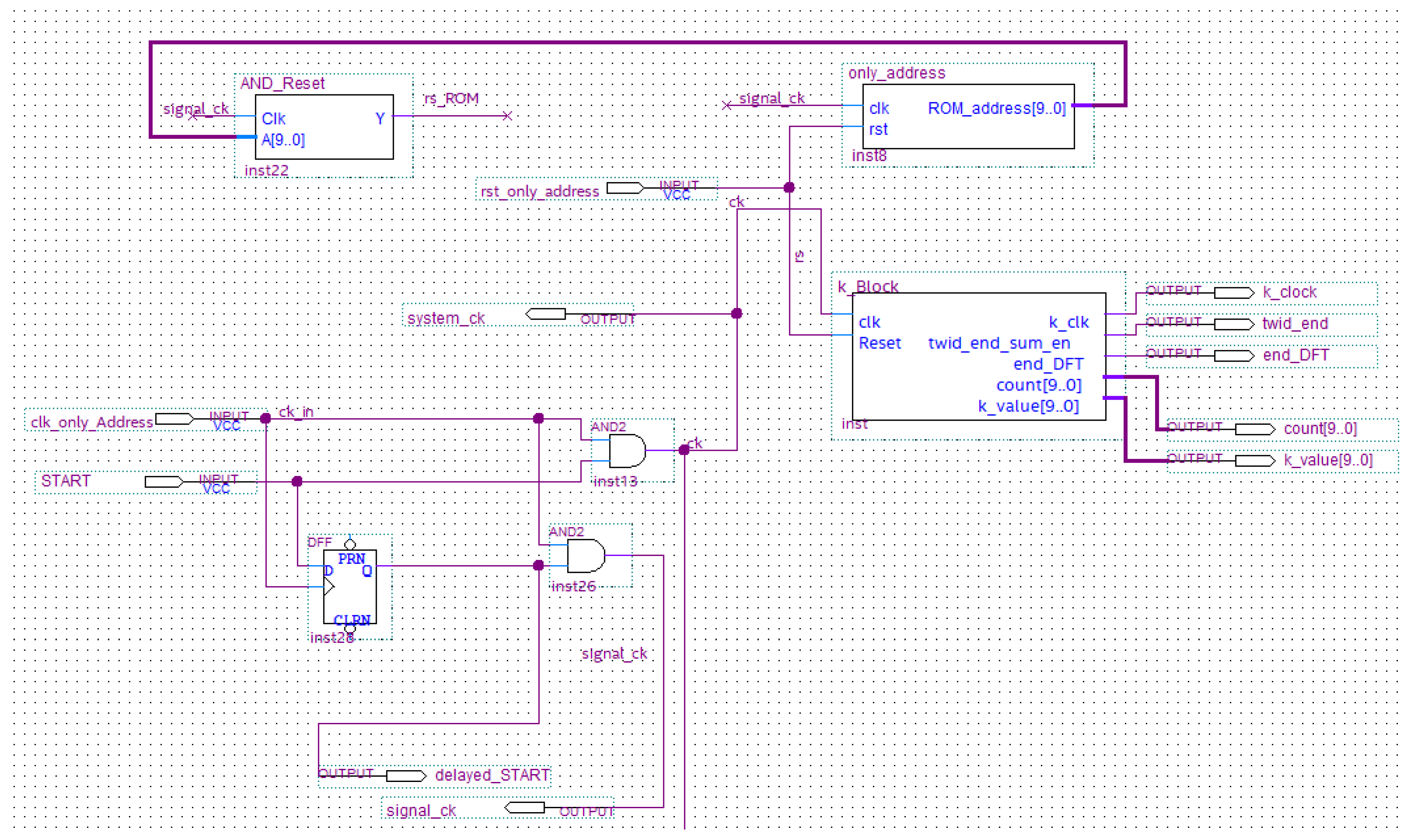
- AND gate for the implementation of the clock gating technique. The system clock (named ck) is obtained as output only when the START input is equal to 1;
- -
- only_Address (whose inputs are the system clock and the system reset) is a counter which generates the addresses of the ROM that stores the test signal. For each clock pulse, a 4-bit signal sample is available at the output. This module has been designed in-house by Authors adopting the Verilog hardware description language.
- -
- AND_reset which is a timed AND gate whose inputs are the system clock and the ROM addresses. The output (named end_ROM) achieves the logic 1 value once all the ROM addresses have been generated that is once all the 1024 samples of the stored function are sent to next stages for processing. Furthermore, this module is designed in-house by Authors in Verilog.
- -
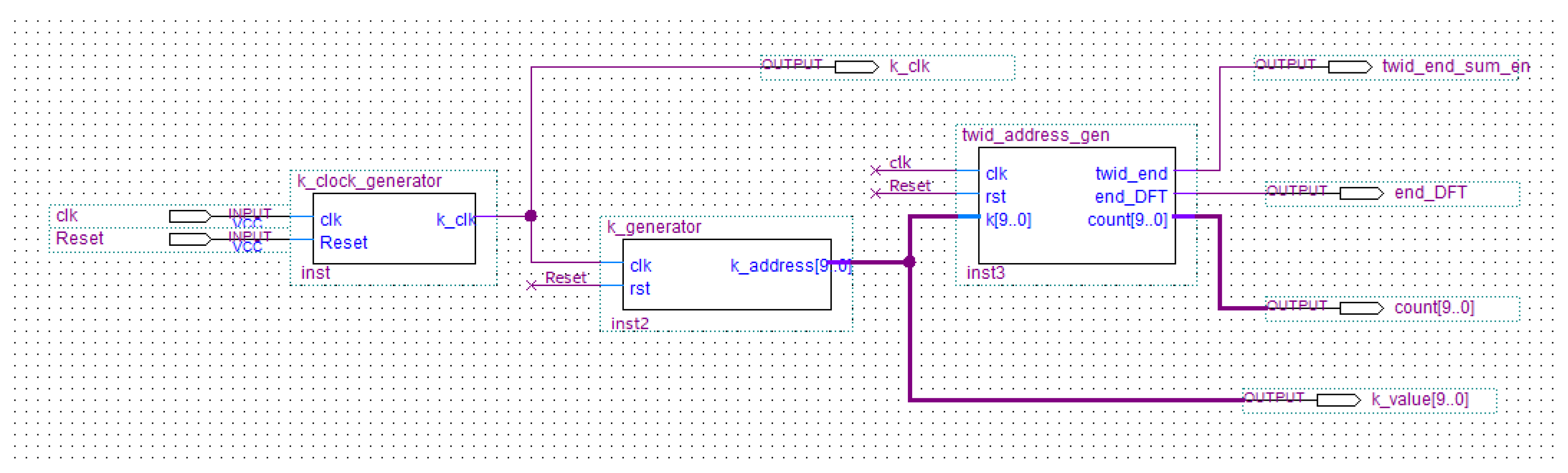
- k_block which generates ROM addresses (in which twiddle coefficients are stored), a signal for sum block enable and an acknowledge signal to indicate the end of the DFT calculation.
5.2.2. The ROM Block
- clk, which is the system gated clock;
- ROM_address, which are ROM addresses of the signal to be processed
- twid_address, which are ROM addresses of twiddle coefficients
- reset
- Bit Slice 3/2/1/0 are the four bits with which each signal sample is encoded
- Twid (Real part) and Twid (img part), which are the 32 bits composing the real and imaginary parts of each twiddle coefficient
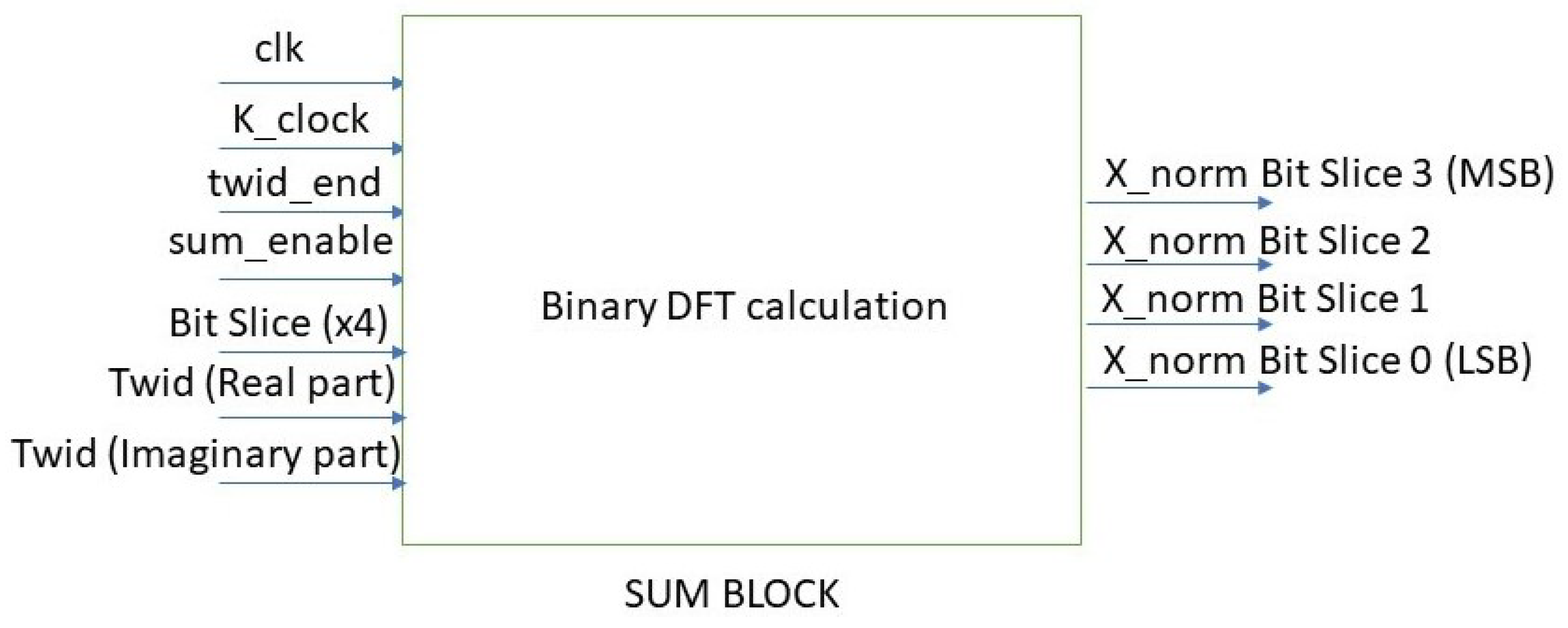
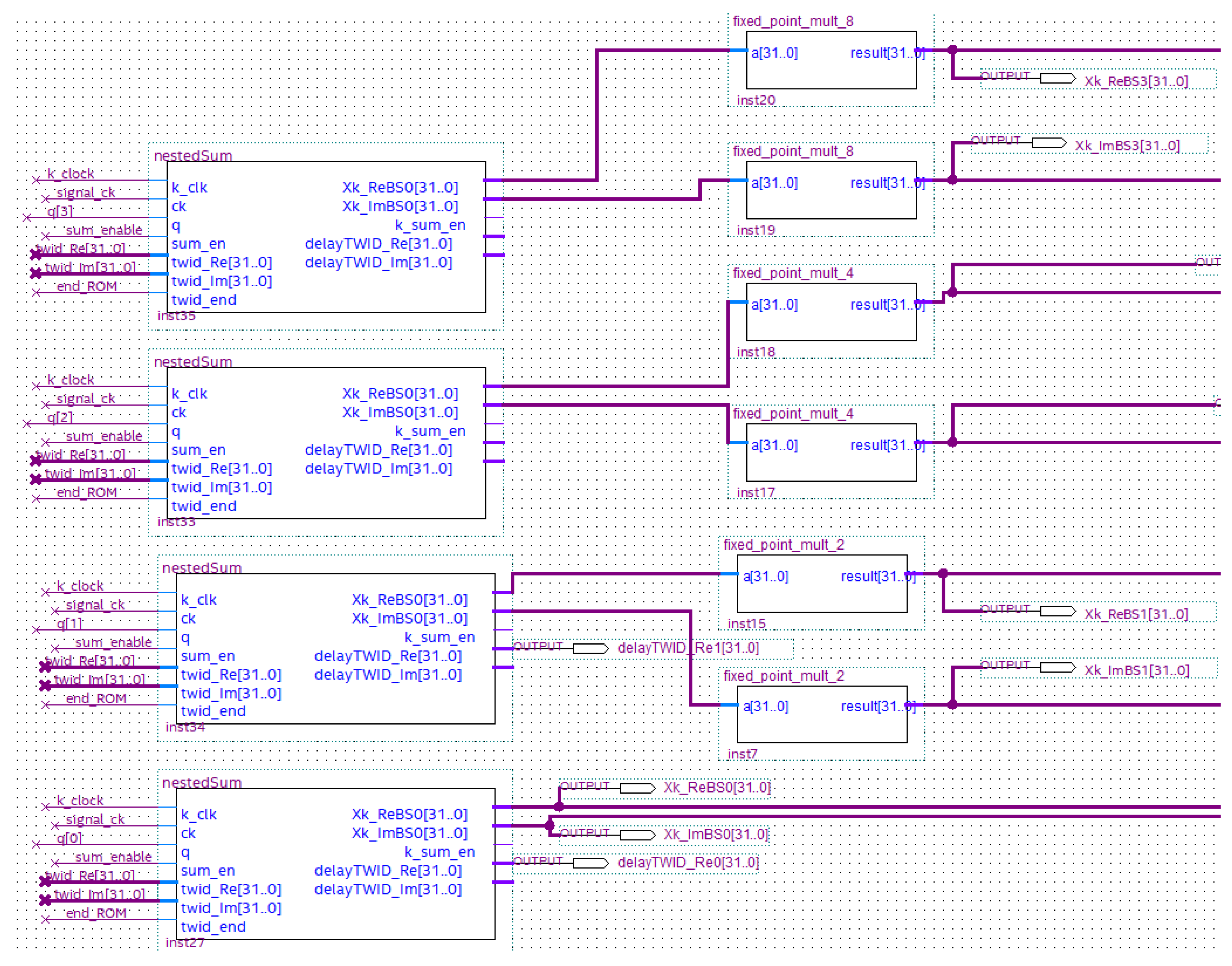
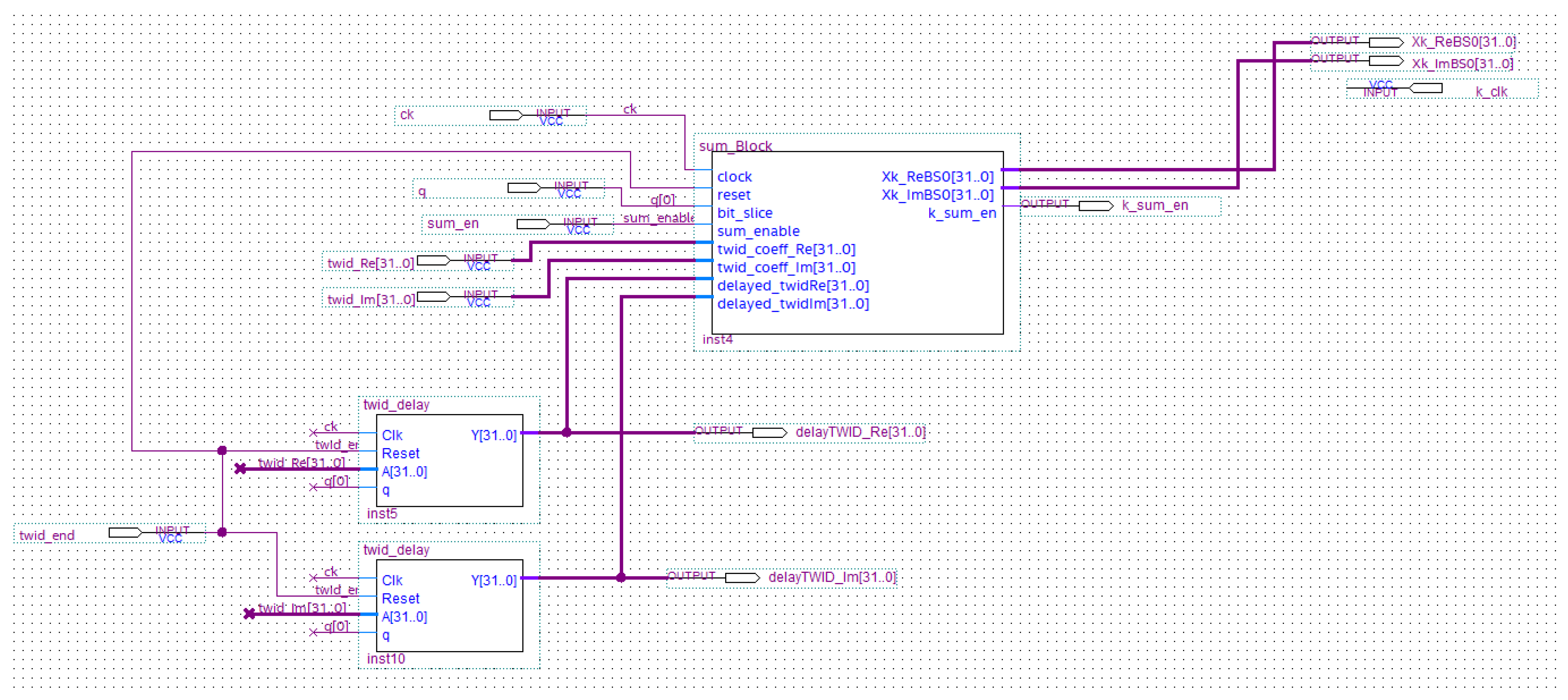
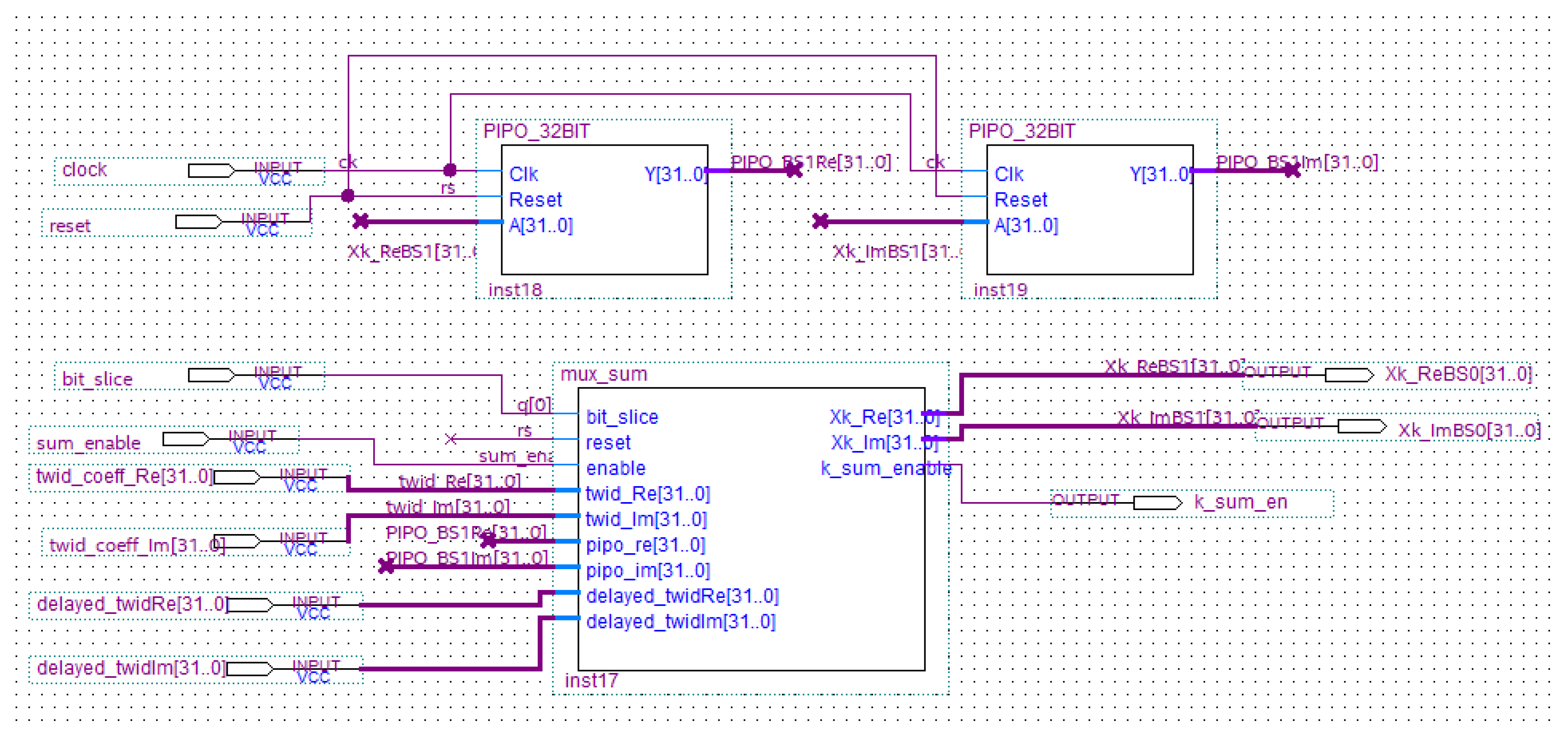
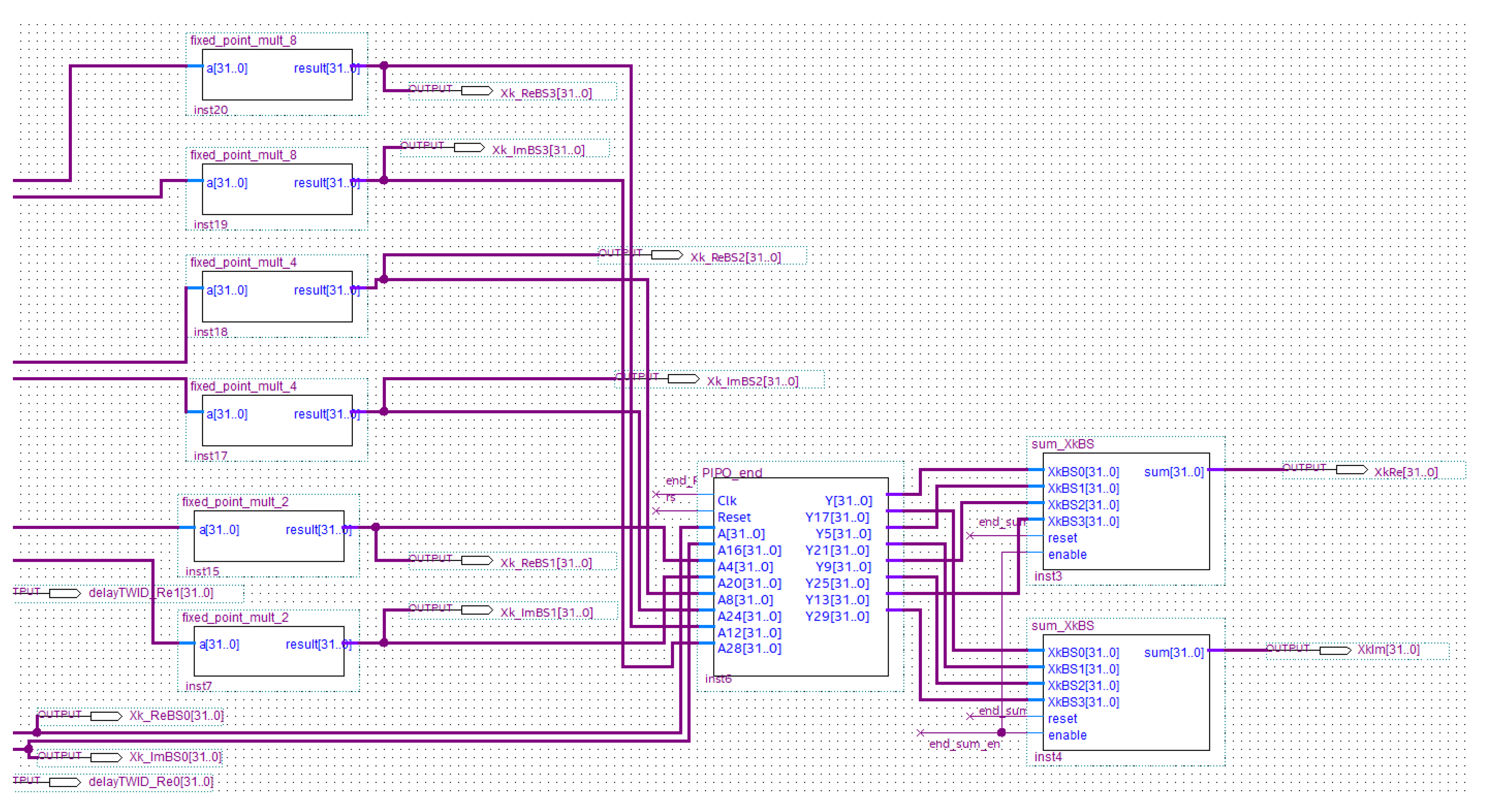
5.2.3. The Sum and Multiplier Block
- -
- -
- Two 32-bit PIPO registers, which store the calculated current value for one clock pulse;
- -
- twid_delay, which introduces a suitable delay for the correct twiddle coefficient management by the sum_Block, after the reset signal is generated as a result of the end of the calculation cycle for every k value.
- -
- end_sumBlock, which adds all the values (for ) as soon as the sum_block calculates them. It is composed of PIPO registers and an adder (named k_sum) which is designed in-house by Authors adopting the Verilog hardware description language (Figure 15);






6. Implementation of the FPGA-Based Embedded System
Efficiency of HW Design
- area occupancy and or amount of used hardware resources;
- latency, here defined as the time between the reception of the last sample at the input and the availability of the FFT at the output;
- power consumption due to the system processing activity;
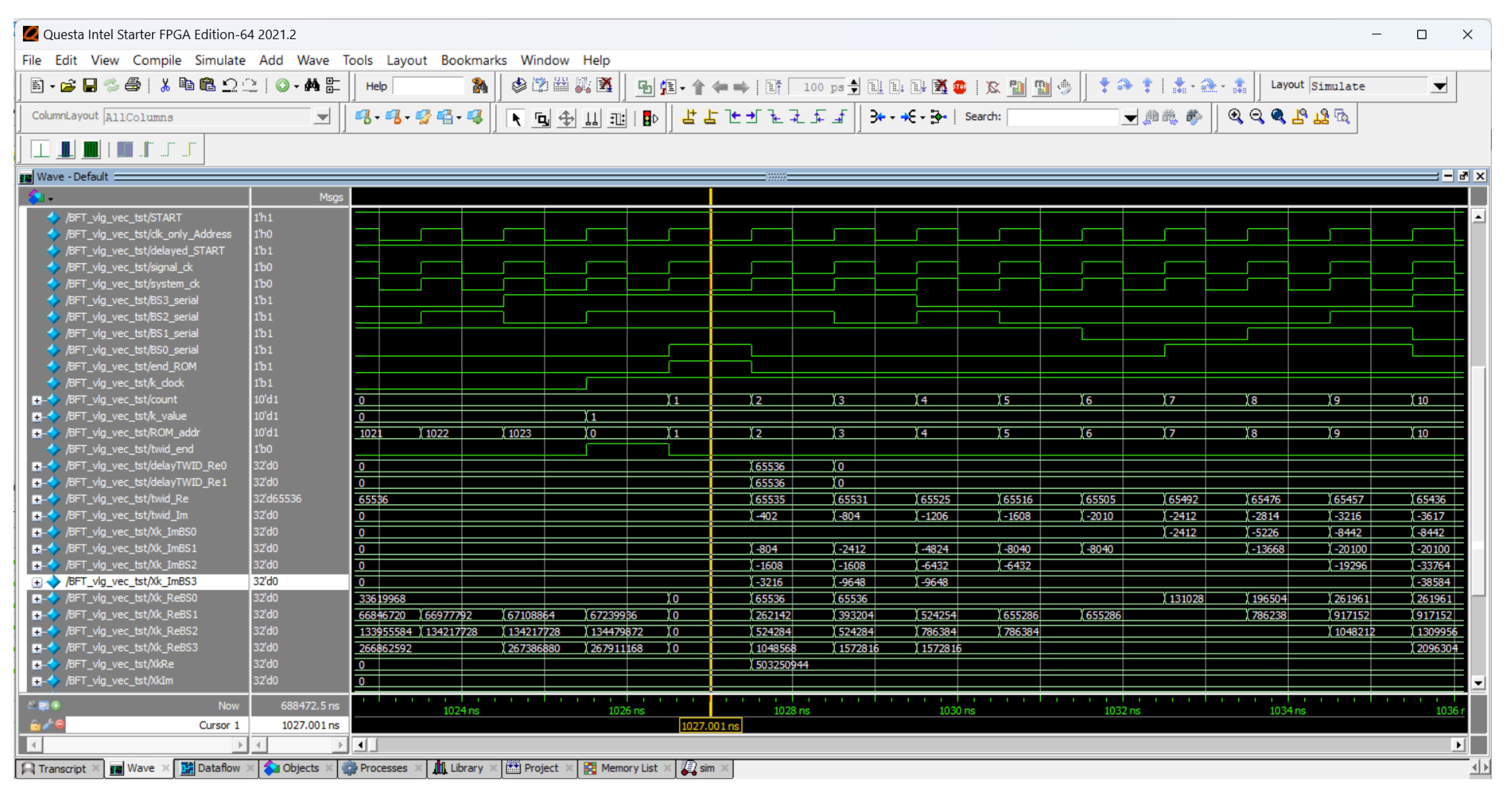
7. Experimental Evaluation and Results
8. Discussions and Conclusions
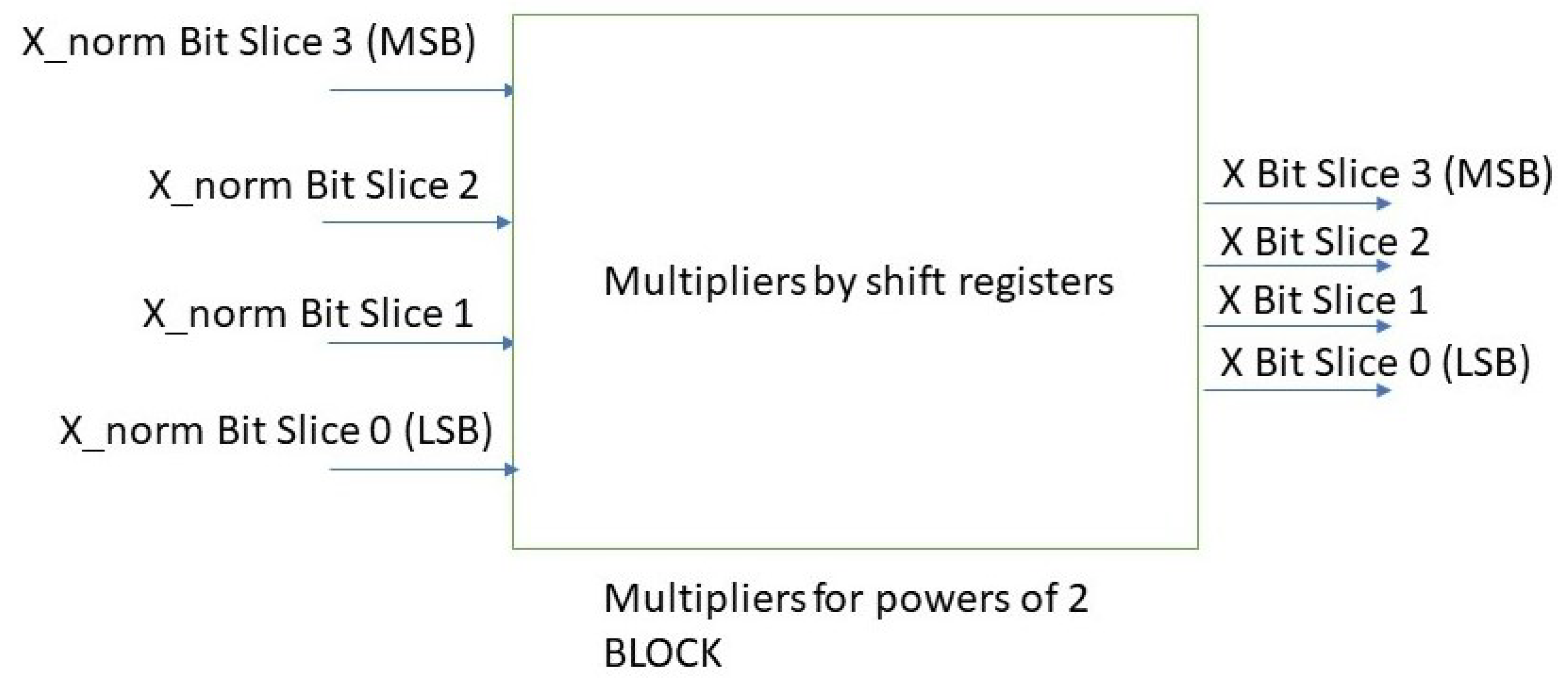
- Processes on different DFT slices can be carried out in parallel by different circuits with equal hardware structure;
- The implemented architecture is free of multipliers, and the DFT composition of BFT slices can be accomplished by left-bit shifts of the obtained results;
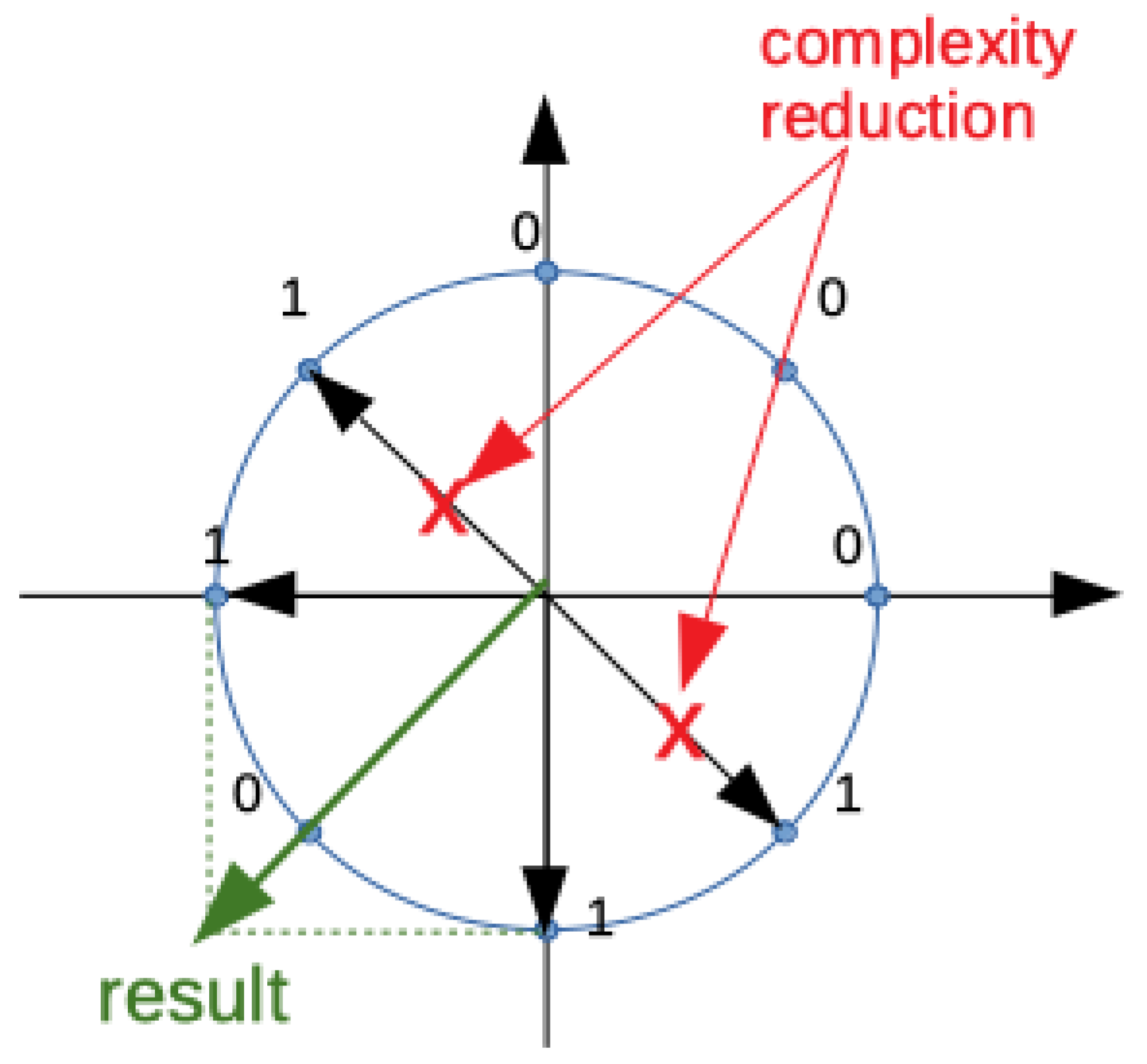
- The DFT of each bit slice introduces some approximations due to the twiddle factor precision: stated L, the number of bits used to describe twiddle factors, and b, the number of bits of the input sequence. The output Fourier-transformed coefficient can be described, at most, by bits, with N being the number of sample points and, consequently, the number of sums needed to compute the BFT coefficient; the b bits are more used to sum the bit slices after proper power of two shifts to compute the Fourier coefficients.
- Full precision can be accomplished in the DFT computation if no approximation is carried out at each computation step. The number of bits describing the DFT coefficients can be , after the recomposition of BFT slices into the DFT. In this case, the final approximation in DFT computation is limited by the number of bits used to describe the twiddle factors and a possible final truncation of the output coefficients;
- A simplification step can be implemented in each DFT slice due to the symmetry inherently present on twiddle factors;
- The algorithm needs N complex sums for the final DFT composition from BFTs and complex sums for the computation of all the b BFT slices in the worst case (that is when no complexity-reduction step is carried out). If bits are assumed equal in probability of occurrence, sums are necessary to obtain the DFT because only terms corresponding to ones are summed up. This value may decrease if complexity reduction occurs;
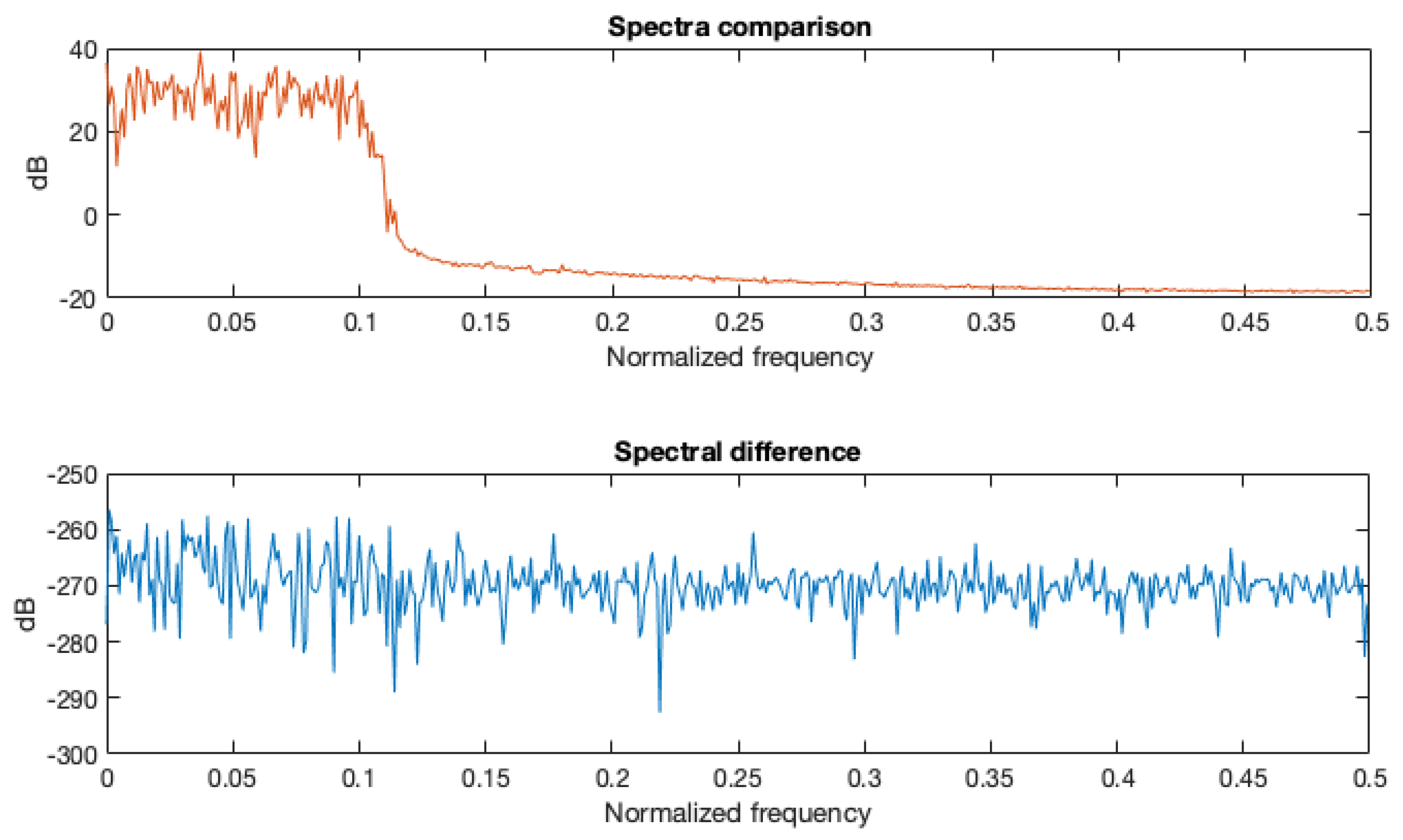
- A high-accuracy solution was designed. A SQNR above 109 dB is obtained, if compared with the MATLAB double-precision floating-point calculations for a pure sinusoid, and above 120 dB for a low-pass signal.
- A very low latency implementation of the 1024 points DFT calculation: a two-clock step value is obtained with a clock of .
- The proposed architecture occupies only a small percentage of the total area of the Cyclone IV FPGA (about 1%). It follows that a higher parallelism could be implemented by replicating processing blocks to reduce the latency.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kumar, G.G.; Sahoo, S.K.; Meher, P.K. 50 Years of FFT Algorithms and Applications. Circuits Syst. Signal Process 2019, 38, 5665–5698. [Google Scholar] [CrossRef]
- Manikandan, P.; Shrimathi, K.; Kiruthika, M.; Mubeena, A. Speech Recognition using Fast Fourier Transform Algorithm. Int. J. Eng. Res. Technol. (IJERT) ETEDM 2022, 10, 29–33. [Google Scholar]
- Desai, A.; Gupta, A.; Jambhale, M.S.; Chavan, V. Efficient Implementation Technique for OFDM on FPGA. In Proceedings of the fourth International Conference on Advances in Science & Technology (ICAST2021), Mumbai, India, 7 May 2021. [Google Scholar] [CrossRef]
- Cortes, A.; Velez, I.; Turrillas, M.; Sevilano, F. Fast Fourier Transform Processors: Implementing FFT and IFFT Cores for OFDM Communication Systems. In Fourier Transform—Signal Processing; InTech: Rijeka, Croatia, 2012. [Google Scholar] [CrossRef]
- Rizzi, M.; Guaragnella, C. A Decision Support System for Melanoma Diagnosis from Dermoscopic Images. Appl. Sci. 2022, 12, 7007. [Google Scholar] [CrossRef]
- Giorgio, A.; Guaragnella, C.; Rizzi, M. An Effective CAD System for Heart Sound Abnormality Detection. Circuits Syst. Signal Process 2022, 41, 2845–2870. [Google Scholar] [CrossRef]
- Sinchana, G.S.; Padaki, S.; Ravi, V.; Varshini, V.S.; Raghavendra, C.G. Software Implementation of FFT Algorithms and Analysis of their Computational Complexity. In Proceedings of the 2018 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Msyuru, India, 14–15 December 2018; IEEE: Toulouse, France, 2018; pp. 486–490. [Google Scholar] [CrossRef]
- Garrido, M. A Survey on Pipelined FFT Hardware Architectures. J. Signal Process. Syst. 2022, 94, 1345–1364. [Google Scholar] [CrossRef]
- Pattan, A.B.; Latha, M.M. Fast Fourier Transform Architectures: A Survey and State of the Art. Int. J. Electron. Commun. Technol. 2014, 5, 94–98. [Google Scholar]
- Joshi, S.M. FFT Architectures: A Review. Int. J. Comput. Appl. 2015, 116, 33–36. [Google Scholar]
- Xia, K.F.; Wu, B.; Xiong, T.; Ye, T.C. A Memory-Based FFT Processor Design with Generalized Efficient Conflict-Free Address Schemes. IEEE Trans. Very Large Scale Integr. Syst. 2017, 25, 1919–1929. [Google Scholar] [CrossRef]
- Giorgio, A.; Guaragnella, C.; Rizzi, M. FPGA-Based Decision Support System for ECG Analysis. J. Low Power Electron. Appl. 2023, 13, 6. [Google Scholar] [CrossRef]
- Elango, K.; Muniandi, K. Hardware Implementation of FFT/IFFT Algorithms Incorporating Efficient Computational Elements. J. Electr. Eng. Technol. 2019, 14, 1717–1721. [Google Scholar] [CrossRef]
- Li, Y.; Chen, H.; Xie, Y. An FPGA-Based Four-Channel 128k-Point FFT Processor Suitable for Spaceborne SAR. Electronics 2021, 10, 816. [Google Scholar] [CrossRef]
- Nash, J.G. Distributed-Memory-Based FFT Architecture and FPGA Implementations. Electronics 2018, 7, 116. [Google Scholar] [CrossRef]
- Pereira, P.T.L.; da Costa, P.U.L.; Ferreira, G.d.C.; de Abreu, B.A.; Paim, G.; Costa, E.A.C.d.; Bampi, S. Energy-Quality Scalable Design Space Exploration of Approximate FFT Hardware Architectures. IEEE Trans. Circuits Syst. Regul. Pap. 2022, 69, 4524–4534. [Google Scholar] [CrossRef]
- Nori, S.M.; Dawwd, S.A. Reduced area and low power implementation of FFT/IFFT processor. Iraqi J. Electr. Electron. Eng. 2018, 14, 108–119. [Google Scholar]
- Elango, K.; Muniandi, K. VLSI implementation of an area and energy efficient FFT/IFFT core for MIMO-OFDM applications. Ann. Telecommun. 2019, 17, 1–3. [Google Scholar] [CrossRef]
- Sanjeet, S.; Sahoo, B.D.; Parhi, K.K. Comparison of Real-Valued FFT Architectures for Low-Throughput Applications using FPGA. In Proceedings of the IEEE International Midwest Symposium on Circuits and Systems, Lansing, MI, USA, 9–11 August 2021; IEEE: Toulouse, France, 2021; pp. 112–115. [Google Scholar] [CrossRef]
- Godi, P.K.; Krishna, B.T.; Kotipalli, P. Design optimisation of multiplier-free parallel pipelined FFT on field programmable gate array. IET Circuits Devices Syst. 2020, 14, 995–1000. [Google Scholar] [CrossRef]
- Ingemarsson, C.; Gustafsson, O. SFF—The Single-Stream FPGA-Optimized Feedforward FFT Hardware Architecture. J. Signal Process. Syst. 2018, 90, 1583–1592. [Google Scholar] [CrossRef]
- Hassan, S.L.M.; Sulaiman, N.; Halim, I.S.A. Low Power Pipelined FFT Processor Architecture on FPGA. In Proceedings of the ninth IEEE Control and System Graduate Research Colloquium, Shah Alam, Malaysia, 3–4 August 2018; IEEE: Toulouse, France, 2018; pp. 31–34. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Zhang, Y. Small area high speed configurable FFT processor. In Proceedings of the 2019 International Conference on IC Design and Technology (ICICDT), Suzhou, China, 17–19 June 2019; IEEE: Toulouse, France, 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Oshana, R. 4—Overview of Digital Signal Processing Algorithms. In Embedded Technology, DSP Software Development Techniques for Embedded and Real-Time Systems; Newnes: Amsterdam, The Netherlands; Boston, MA, USA, 2006; pp. 59–121. ISBN 9780750677592. [Google Scholar] [CrossRef]
- Takahashi, D. Fast Fourier Transform. In Fast Fourier Transform Algorithms for Parallel Computers! High-Performance Computing Series; Springer: Singapore, 2019; Volume 2. [Google Scholar] [CrossRef]
- Sindhikar, A.; Mohani, S.P. Review of orthogonal frequency division multiplexing for wireless communication. Int. Res. J. Eng. Technol. 2018, 5, 3609–3612. [Google Scholar]
- Roy, S. Advanced Digital System Design: A Practical Guide to Verilog Based FPGA and ASIC Implementation; Ane Books Pvt. Ltd. Publisher: New Delhi, India, 2021; ISBN 978-81-9489-188-8. [Google Scholar]
- FPGA Designs with Verilog and SystemVerilog. Available online: https://www.academia.edu/42857396/FPGA$_$designs$_$with$_$Verilog$_$and$_$SystemVerilog?email$_$work$_$card=title (accessed on 1 June 2023).
- FPGAs Intel® FPGAs e SoC. Available online: https://www.intel.it/content/www/it/it/products/details/fpga.html (accessed on 1 June 2023).
- DE1-SoC Board. Available online: https://www.terasic.com.tw/cgi-bin/page/archive.pl?Language=English\&CategoryNo=165&No=836#contents (accessed on 1 June 2023).
- Intel® Quartus® Prime Software. Available online: https://www.intel.it/content/www/it/it/software/programmable/quartusprime/overview.html (accessed on 1 June 2023).










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guaragnella, C.; Giorgio, A.; Rizzi, M. BFT—Low-Latency Bit-Slice Design of Discrete Fourier Transform. J. Low Power Electron. Appl. 2023, 13, 45. https://doi.org/10.3390/jlpea13030045
Guaragnella C, Giorgio A, Rizzi M. BFT—Low-Latency Bit-Slice Design of Discrete Fourier Transform. Journal of Low Power Electronics and Applications. 2023; 13(3):45. https://doi.org/10.3390/jlpea13030045
Chicago/Turabian StyleGuaragnella, Cataldo, Agostino Giorgio, and Maria Rizzi. 2023. "BFT—Low-Latency Bit-Slice Design of Discrete Fourier Transform" Journal of Low Power Electronics and Applications 13, no. 3: 45. https://doi.org/10.3390/jlpea13030045
APA StyleGuaragnella, C., Giorgio, A., & Rizzi, M. (2023). BFT—Low-Latency Bit-Slice Design of Discrete Fourier Transform. Journal of Low Power Electronics and Applications, 13(3), 45. https://doi.org/10.3390/jlpea13030045