1. Introduction
Addition is a fundamental operation that is pervasive in computer arithmetic [
1]. For example, approximately 80% of the operations in an ARM processor’s arithmetic and logic unit were found to be additions [
2]. Addition is physically realized using an adder, and the design of a high-speed and low power/energy-efficient adder is important for processing units. There are different types of adders ranging from the slowest ripple carry adder (RCA) to the fastest Kogge–Stone adder (KSA) [
3], which is a parallel-prefix adder (PPA). However, it may be noted that although the KSA is faster, the RCA is area- and power-efficient in comparison. Based on physical realization using a 32-28 nm CMOS standard digital cell library [
4], for a 32-bit addition, we noted that the KSA has a 78.5% reduced delay than the RCA while the RCA requires 86% less silicon area and dissipates 50.4% less power in comparison. The RCA and the KSA represent the two extremes in physically realizing addition where the former requires the least area and dissipates less power but is slower while the latter is of high-speed but requires more area and dissipates relatively more power. Nevertheless, there are many high-speed adders such as the carry look-ahead adder (CLA), the conditional sum adder (CSA), the carry-select adder (CSLA), and other PPAs that offer a trade-off between the standard design metrics, namely speed, power, and area. These high-speed adders lie between the extreme addition architectures, i.e., RCA and KSA. Hence, for a practical application, and particularly from a standard cell-based design perspective, the choice of an adder would be dependent upon the power budget and/or operational speed.
Besides speed (whose reciprocal is called delay i.e., critical path delay) and power, the product of power and delay, which is called the power-delay product (PDP), is representative of the energy consumption of digital circuits [
5]. PDP is considered to be a low-power and low-energy figure of merit. Since power and delay are preferred to be less for a digital circuit, therefore, PDP is preferred to be less. Hence, an adder that offers a good trade-off between speed, power, and energy (PDP) is preferable for generic applications. In this context, this paper presents a CLA architecture that is higher in speed and energy-efficient compared to a conventional CLA architecture. Additionally, this paper provides a comparison between the performance of different adders, which would be useful for a circuit designer to make an appropriate choice of an adder for a target application by considering the trade-offs in the design metrics.
CLA is an important member of the family of high-speed adders [
6]. Many implementations of the CLA at the transistor level have been presented in the literature [
7,
8,
9,
10,
11,
12,
13,
14], which correspond to different design styles such as the all N-type transistor logic, static CMOS, BiCMOS, domino logic, etc. Further, CLAs designed using post-CMOS technologies such as quantum dot cellular automata, memristors, hybrid CMOS-memristor logic, optical, carbon nanotube, vertically stacked nanowire transistors, etc. [
15,
16,
17,
18,
19,
20,
21], have also been presented in the literature. All these represent full-custom design approaches that require considerable manual effort to meet timing/power/energy requirements commensurate with an application. On the other hand, a semi-custom gate-level design would be generic and modular and a soft CLA core can be offered as a synthesizable RTL model that can be conveniently used/reused in any digital system design and can be implemented using any standard digital cell library. In this context, this paper presents a generic gate-level CLA architecture that is higher in speed and energy-efficient compared to the conventional gate-level CLA architecture.
The rest of the paper is organized into three sections.
Section 2 discusses the architectures of the conventional CLA and the proposed CLA.
Section 3 presents the design metrics of several 32-bit adders corresponding to different architectures, which were implemented using a 32-28 nm CMOS standard digital cell library and compares their performance.
Section 4 gives the conclusion.
2. Conventional and Proposed CLA Architectures
In an adder implementation, the sum bit corresponding to an input bit position is produced based on a knowledge of any carry input and the carry may be generated and/or propagated internally between the input bit positions. Hence, considering the worst-case addition scenario where the carry may propagate internally from the 0th bit position up to the (N–1)th bit position of an N-bit adder, speeding up the carry propagation internally would help to speed up the addition process. The linear time encountered in a rudimentary worst-case addition (which is the case with an RCA) can be reduced to a logarithmic time addition in the case of a CLA by generating future (look-ahead) carries in advance based on a knowledge of the carry input. The generalized carry look-ahead equation is given in (1), where Q represents a bit position, C
Q represents the carry input to the Qth bit position, C
Q+1 represents the carry output from the Qth bit position, G
Q refers to the generate signal, and P
Q refers to the propagate signal corresponding to the Qth bit position. In Equation (1), P
Q is obtained by performing a logical XOR of input bits X
Q and Y
Q (i.e., P
Q = X
Q ⊕ Y
Q), and G
Q is obtained by performing a logical AND of input bits X
Q and Y
Q (i.e., G
Q = A
QB
Q). The sum bit corresponding to the Qth bit position is produced based on Equation (2).
Equation (1) is fundamentally recursive in nature, and this property can be utilized to generate carries corresponding to successive bit positions in advance, which are called look-ahead carries. This is described by Equations (3)–(6), which represent the look-ahead carry output equations of four successive bit positions of an example 4-bit CLA. In Equations (3)–(6), C
K represents the carry input to a 4-bit CLA, P
K+3 to P
K represent the propagate signals, G
K+3 to G
K represent the generate signals, and C
K+4 to C
K+1 represent the look-ahead carry outputs derived. Equation (4) is deduced by substituting the expression of C
K+1 given in Equation (3), Equation (5) is deduced by substituting the expression of C
K+2 given in Equation (4), and Equation (6) is deduced by substituting the expression of C
K+3 given in Equation (5). In Equations (3)–(6), it can be observed that the look-ahead carry outputs C
K+1 up to C
K+4 are all dependent on only the carry input C
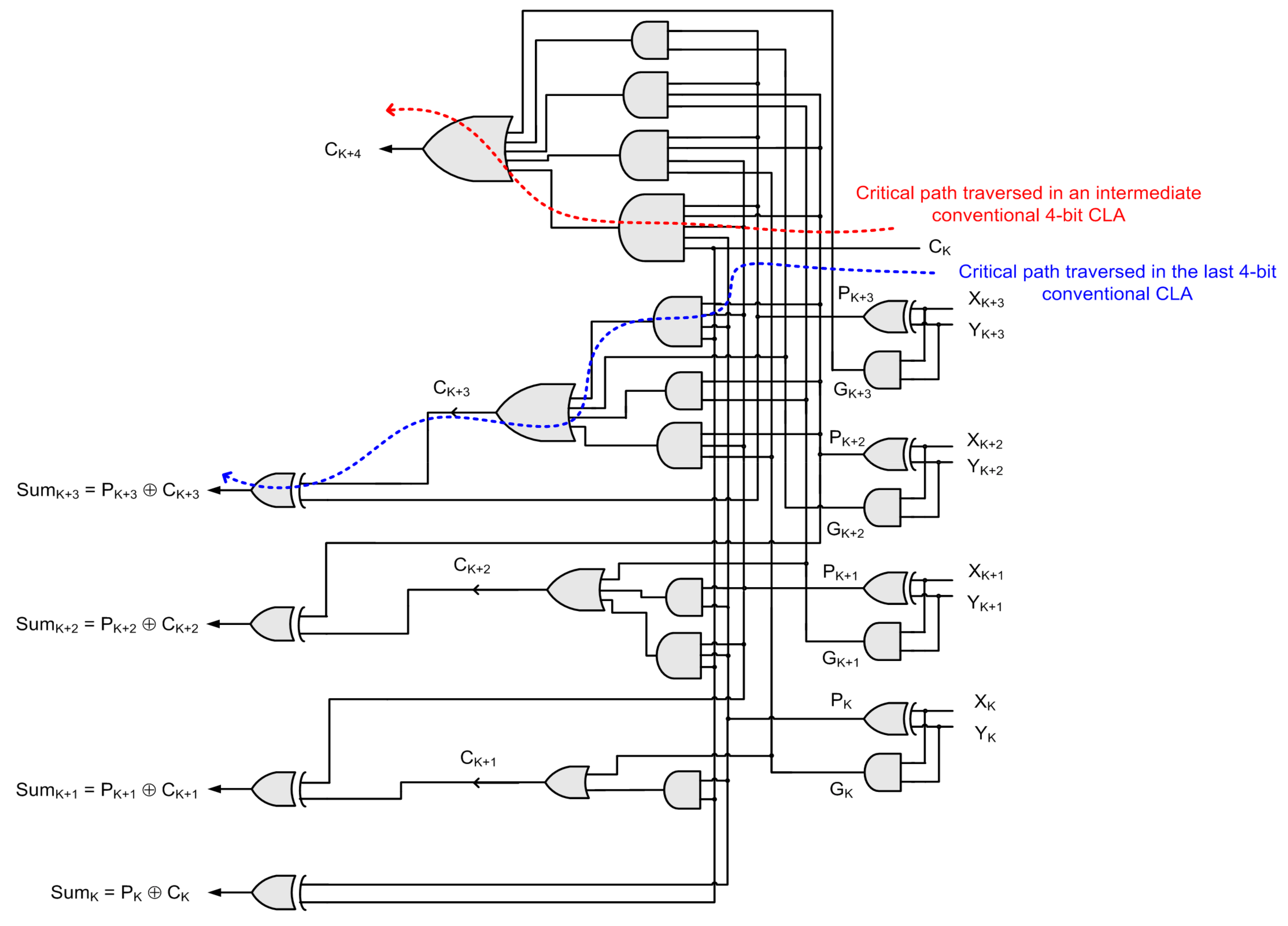
K. Hence, the look-ahead carry outputs can be generated in parallel, which can be used to generate the sum bits of the CLA in parallel and provide the carry input to the subsequent stage. The conventional CLA implementing Equations (3)–(6) is shown in
Figure 1.
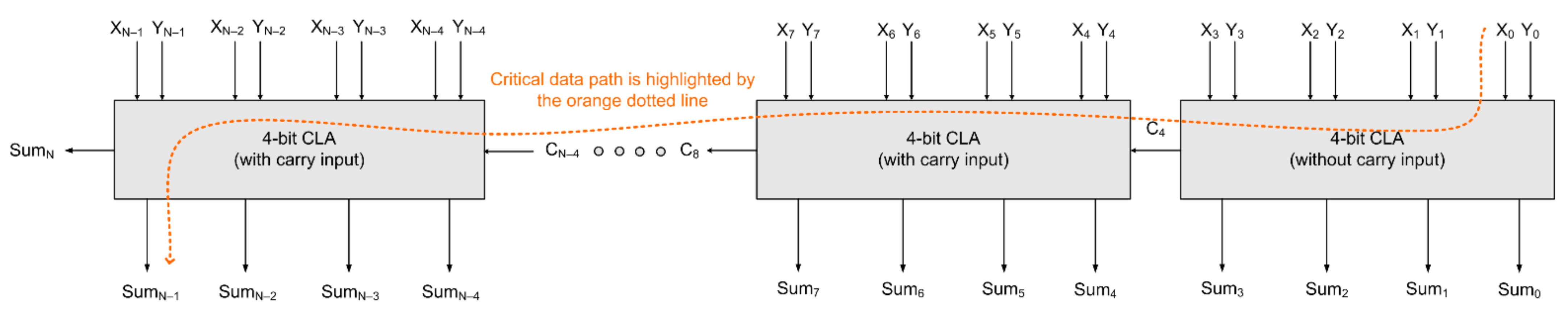
Typically, an N-bit CLA is constructed using a cascade of M-bit CLAs where N and M are even and N modulo M = 0. For example, a 32-bit CLA can be constructed by cascading eight 4-bit CLAs.
Figure 2 shows a block diagram of an N-bit CLA constructed using 4-bit CLAs, and the critical path is highlighted by the orange dotted line. Supposing that the 4-bit CLA shown in
Figure 1 is present in an intermediate stage of an N-bit CLA, as shown in
Figure 2, then theoretically the critical path that would be traversed through the 4-bit CLA would be as highlighted by the red dashed line in
Figure 1, which consists of a 5-input AND gate and a 5-input OR gate. In modern standard digital cell libraries, the fan-in of AND and OR gates are limited to four. So, a 5-input AND/OR gate may be decomposed into a combination of two 3-input AND/OR gates, respectively. Supposing the 4-bit CLA shown in
Figure 1 is present in the last stage of
Figure 2, then the critical path that would be traversed is highlighted by the blue dashed line shown in
Figure 1.
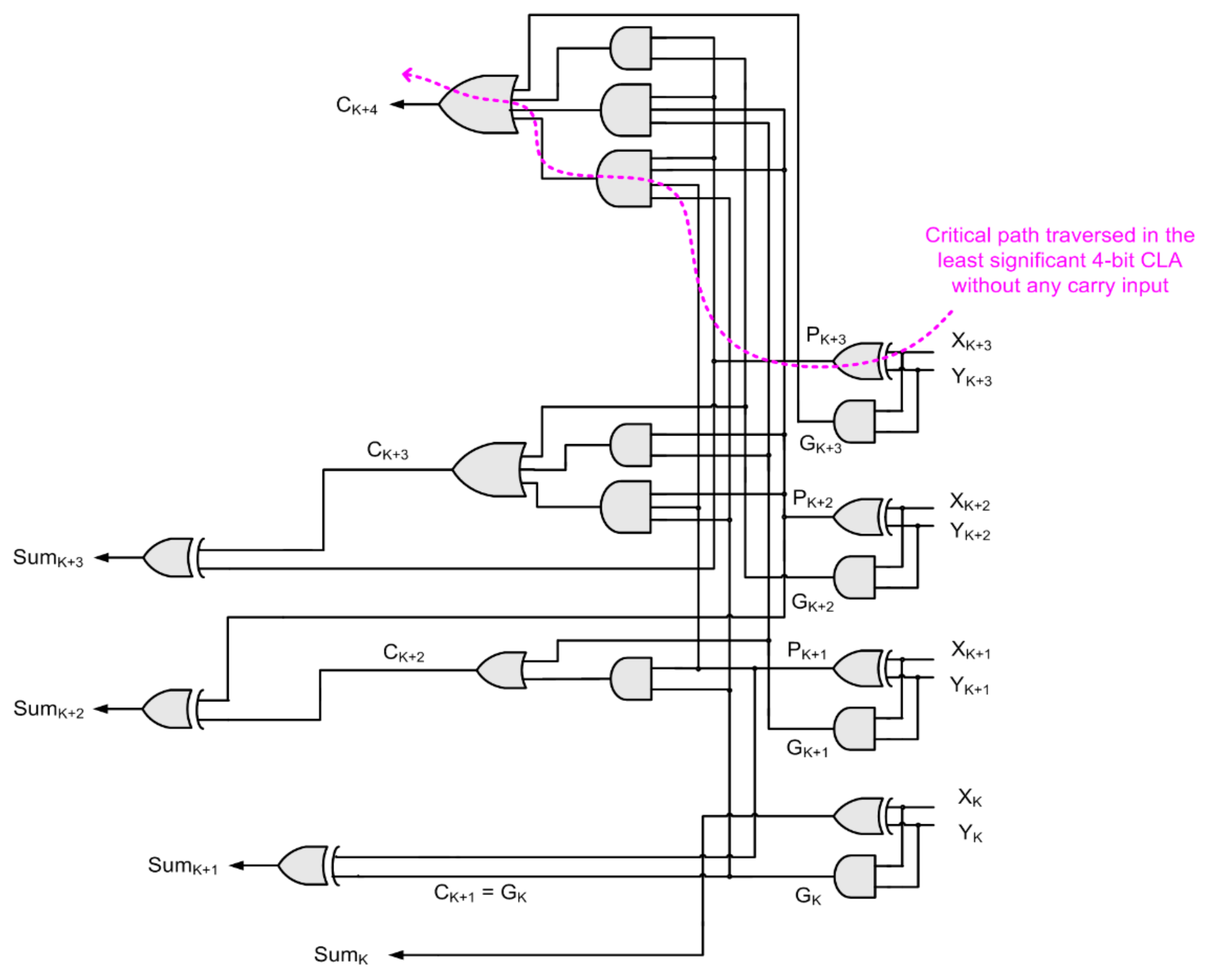
In
Figure 2, it can be seen that the first (least significant) 4-bit CLA does not have a carry input while the rest of the 4-bit CLAs have a carry input. Hence, in the absence of a carry input, i.e., considering C
K = 0 in Equations (3)–(6), the gate-level realization of a 4-bit CLA without any carry input would be as shown in
Figure 3, and its critical path is highlighted by the pink dashed line.
Referring to
Figure 1,
Figure 2 and
Figure 3, the theoretical critical path delay of a conventional N-bit CLA, which includes only gate delays, is expressed by Equation (7). In Equation (7), on the right-side, the first term given within brackets represents the propagation delay encountered in producing the penultimate sum bit Sum
N–1, the second term given within brackets represents the propagation delay encountered in traversing (M–2) 4-bit CLAs, and the last term represents the propagation delay encountered in traversing the least significant 4-bit CLA that does not have a carry input. The second term on the right-side of Equation (7) reflects the optimum decomposition of 5-input OR and 5-input AND gates seen in
Figure 1 into two 3-input OR gates and two 3-input AND gates, respectively.
Assuming that a 32-bit CLA has been constructed using eight conventional 4-bit CLAs (i.e., M = 8), and using the average propagation delay information of gates with minimum drive strength given in [
4], the theoretical critical path delay (
) of the conventional 32-bit CLA is calculated to be 2.106 ns.
For the new CLA design, we performed a specific grouping of the terms present in the look-ahead carry output equations such that the carry propagation would be minimized with respect to a gate-level realization. The general principle followed is that the literals associated with the carry input (C
K) are grouped into an intermediate product term and represented using a Boolean variable, and the remaining sum of product terms that do not involve the carry input are grouped and represented using another Boolean variable. With reference to Equations (4)–(6), to perform the grouping, we introduced some intermediate variables in the Boolean network, namely A
1, A
2, A
3, A
4, A
5, and A
6, where A
1 and A
2 are used for Equation (4), A
3 and A
4 are used for Equation (5), and A
5 and A
6 are used for Equation (6), and they are expressed by Equations (8)–(13) given below. In fact, this grouping procedure is generic and can be applied to a CLA of any size by incorporating only two intermediate variables in each look-ahead carry output equation. Supposing only two intermediate variables are present in a look-ahead carry output equation, as is the case with Equation (3), it can be retained as such, and no transformation needs to be done. In general, a CLA featuring L look-ahead carry outputs may require (2L–2) intermediate variables according to our proposition.
Given Equations (8)–(13), and substituting them back into Equations (4)–(6), we obtain their reduced forms as follows.
Consequently, the final logic level of the look-ahead carry outputs CK+1, CK+2, CK+3, and CK+4 can be uniformly realized using a single complex gate, viz., the AO21 gate. Assuming that A, B, and C are the inputs to an AO21 gate and Y is its output, an AO21 gate implements the logic function Y = AB + C, which requires eight transistors for a static CMOS logic design.
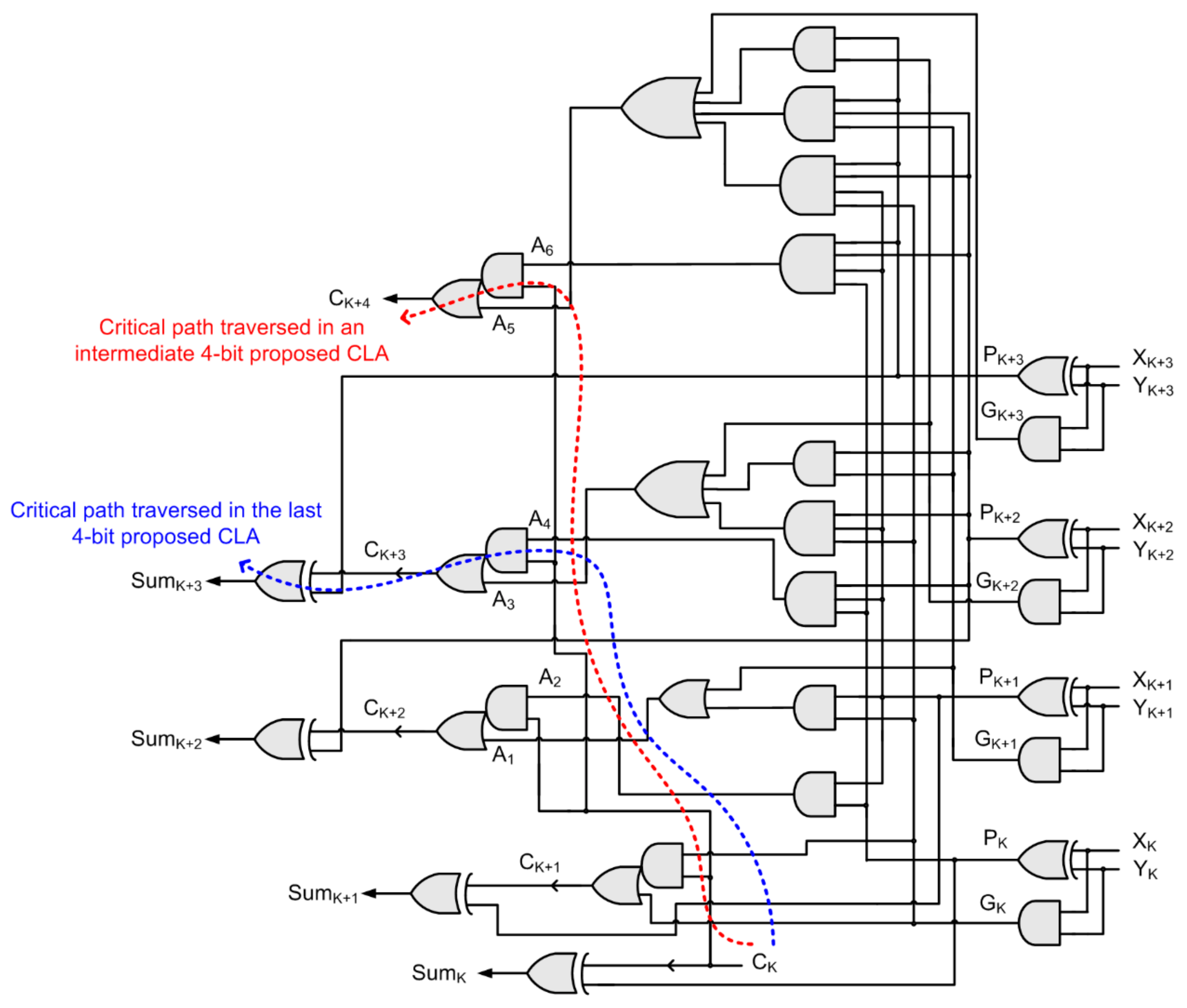
The logic realization of an example proposed 4-bit CLA, described by Equations (3) and (14)–(16), is portrayed by
Figure 4. The critical path that would be traversed when this 4-bit CLA would be present in an intermediate stage in
Figure 2 is highlighted by the red dashed line and the critical path that would be traversed when this 4-bit CLA would be present in the final stage in
Figure 2 is highlighted by the blue dashed line.
Comparing
Figure 1 and
Figure 4, it can be noted that the critical path of a conventional 4-bit CLA, when present in an intermediate stage, consists of a 5-input AND gate and a 5-input OR gate while the critical path of the proposed 4-bit CLA, when present in an intermediate stage, consists of just one AO21 complex gate. As a result, the theoretical critical path delay of the proposed N-bit CLA (shown in
Figure 2), when implemented using the proposed 4-bit CLA, is given by Equation (17). However, for the least significant 4-bit CLA that does not contain a carry input,
Figure 3 can be used as mentioned earlier.
Assuming that a 32-bit CLA has been constructed using eight proposed 4-bit CLAs (i.e., M = 8), and using the average propagation delay information of gates with the minimum drive strength given in [
4], the theoretical critical path delay (
) of the proposed 32-bit CLA is calculated to be 0.781 ns, which is 63% less than the theoretical critical path delay of the conventional CLA counterpart given by (7).
3. Implementation and Estimation of Design Metrics of Adders
In the existing literature, many papers dealt with specific adder designs, discussed their implementation, and presented the design metrics, but failed to provide a comparison with the design metrics of other adder architectures. For example, [
22] presented a new CSLA design and made a comparison between the design metrics of just the conventional CSLA and the new CSLA. Reference [
23] provided a comparison between CLA and CSLA architectures but the adders were custom-designed at the gate-level and interconnects were not taken into account in the estimation of design metrics—hence the design metric estimates provided are not rigorous. Here, we aim to provide a rigorous and extensive comparison between the performance of various adders corresponding to different architectures, including the proposed CLA, with all the adders realized using the same standard digital cell library. This comparative evaluation would be useful for a circuit designer to choose an appropriate adder when given specific design constraints. Towards this, we described many 32-bit adders corresponding to different architectures, viz., RCA, CLA, CSLA, CSA, and PPA structurally at the gate-level in Verilog HDL. We used Synopsys EDA tools for synthesis, simulation, and estimation of the design metrics. We had access to some Synopsys DesignWare library components that contain synthesizable RTL models of some high-speed adders such as the Ling adder [
24] (which is a variant of CLA), CSA [
25], and a few PPAs, namely the Brent–Kung adder (BKA) [
26] and the Sklansky adder [
27]. We considered all these adders for implementation and comparison in this paper. Besides, we considered the RCA, the conventional CLA, the proposed CLA, CSLAs without a binary to excess-one code (BEC) converter [
28] employing two different input partitions, viz., 8-8-8-8 and 8-7-6-4-3-2-2, CSLAs with a BEC converter employing the same two input partitions [
22], and the KSA. We used the gate-level description of a 32-bit KSA given in [
29] for implementation in this work.
To perform synthesis, we used the Synopsys Design Compiler and targeted a typical case PVT specification of a high V
th 32-28 nm CMOS standard digital cell library. The recommended supply voltage of 1.05V and an operating junction temperature of 25 °C was used. A default wire load model was included during synthesis and a fanout-of-4 drive strength was associated with all the output ports (i.e., sum bits) of the adders. The high-speed adder components present in the DesignWare library, i.e., the Ling adder, CSA, BKA, and Sklansky adder, were invoked during synthesis and these were synthesized along with the rest of the high-speed adders mentioned earlier by using the ‘compile’ command with speed defined as the optimization goal. To synthesize the RCA, the ‘compile_ultra’ command was used. After synthesis, the gate-level netlists generated by Design Compiler were used to perform a functional simulation using Synopsys VCS. To do this, a test bench comprising approximately 1000 randomly generated input vectors was supplied to the adders at an input frequency of 250 MHz and their functionality were verified and their corresponding switching activity were recorded. The switching activity information was then used to accurately estimate the total average power using Synopsys PrimePower. To accurately estimate the critical path delay of adders, we used Synopsys PrimeTime. The total area of the adders estimated after synthesis, including the cells area and interconnect area, was estimated using Design Compiler. The design metrics of the adders are given in
Table 1.
From
Table 1, it is seen that the RCA requires the least area and hence it dissipates less power. This is because the RCA is synthesized using 1 half adder and 31 full adders, and the full adder and half adder are available as cells in the standard digital cell library [
4], which are optimized for area and power. However, the critical path delay of the RCA is significantly greater compared to its counterparts, which makes it unsuitable for high-speed digital circuits and systems. For example, compared to the proposed CLA, the RCA has a 200% greater delay. As expected, in terms of speed, the KSA is faster than its counterparts—however, this comes at the expense of a substantially greater area and power dissipation. For example, compared to the proposed CLA, the KSA has a 35.3% reduced delay but requires a 125.3% greater area and dissipates 65.6% more power. The conventional CLA dissipates less power than the proposed CLA by 18.8% since it requires 26.4% less area but reports an approximate 124% increase in the delay. In terms of delay, the rest of the adders lie in between the two adders, viz., the RCA and the KSA with the former having the greatest delay and the latter having the least delay.
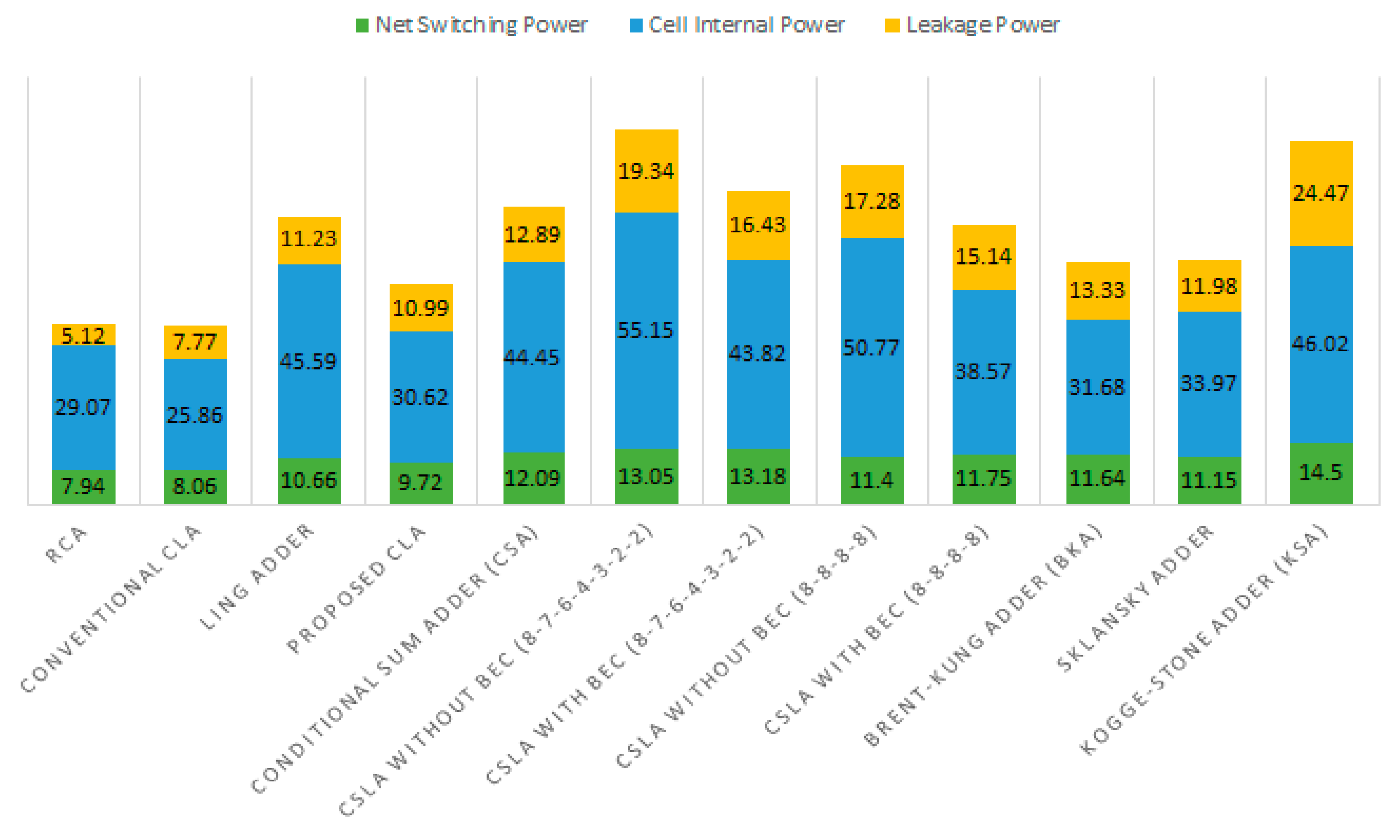
Figure 5 shows a split-up of the power components of different adders that includes the net switching power, the cell internal power, and the leakage power, as reported by Synopsys PrimePower. The sum of the net switching power and the cell internal power is referred to as dynamic power in Synopsys PrimePower. The total power is the sum of the dynamic power and leakage power. It may be seen that the proposed CLA reports increases in all the power components compared to the conventional CLA. This is mainly because the cells area and interconnect area of the proposed CLA are greater than the conventional CLA, as seen from
Table 1. Compared to the RCA and the conventional CLA, the proposed CLA reports an increase in total power due to an increase in all the power components, but the proposed CLA dissipates less total power compared to the other adders due to reductions achieved in the switching power, internal power, and leakage power, as seen from
Figure 5. Although the KSA is faster than its counterparts, as seen from
Table 1, it dissipates substantially more power and this is due to its greater area occupancy both in terms of cells and interconnect, which is reflected by its significant values of net switching power, cell internal power and leakage power in
Figure 5.
Besides the individual considerations of delay and power, it is important to analyze the performance of adders from an energy perspective, which is given by the product of total power and the critical path delay. This is because an evaluation of energy gives information about any trade-off between power and delay in a digital circuit [
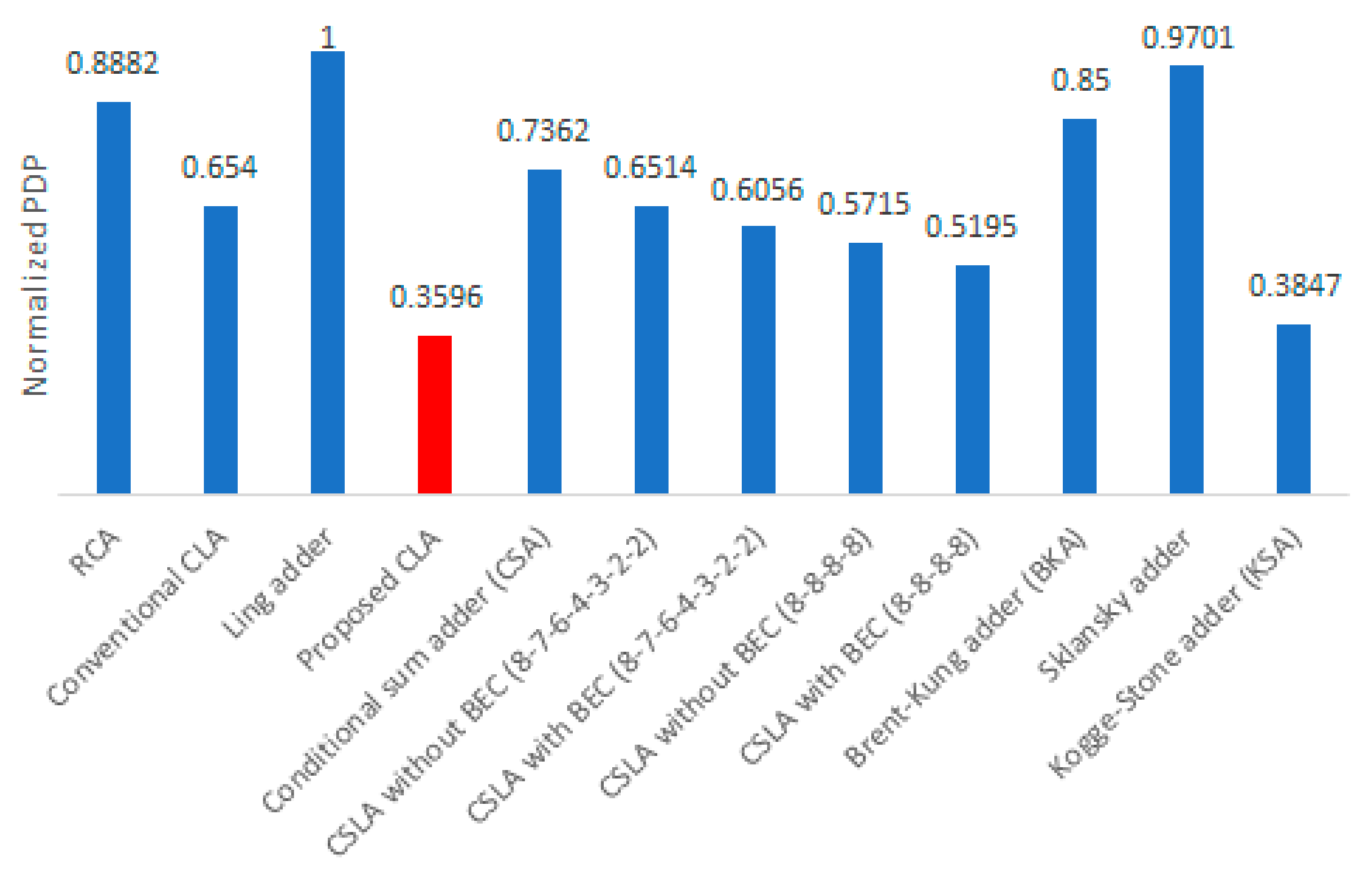
5]. Since power and delay are preferred to be less, therefore, the product of power and delay (PDP) is preferred to be less. In other words, the lesser the PDP, the more energy-efficient is a design. PDP was calculated for all the adders and those values were then normalized. To perform the normalization, the highest PDP value (corresponding to the Ling adder) was used to divide the actual PDP of all the adders. The normalized PDP plots of the adders are shown in
Figure 6 with the optimum plot shown in red. An adder with a lesser normalized PDP value is preferable. Given this, the Ling adder is found to be less energy-efficient compared to the other adders. From
Figure 6, it is seen that the proposed CLA has an optimized normalized PDP compared to its counterparts, which implies the proposed CLA is more energy-efficient. Compared to the conventional CLA, the proposed CLA is 45% more energy-efficient. The KSA consumes 7% more energy than the proposed CLA, although it is faster, and this is due to its increased power dissipation in comparison on account of its greater area occupancy. Hence, from
Table 1 and
Figure 6, it may be concluded that the proposed CLA offers a good trade-off between speed, power, and area compared to its counterparts.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}