Adaptative Techniques to Reduce Power in Digital Circuits

Abstract
:1. Introduction
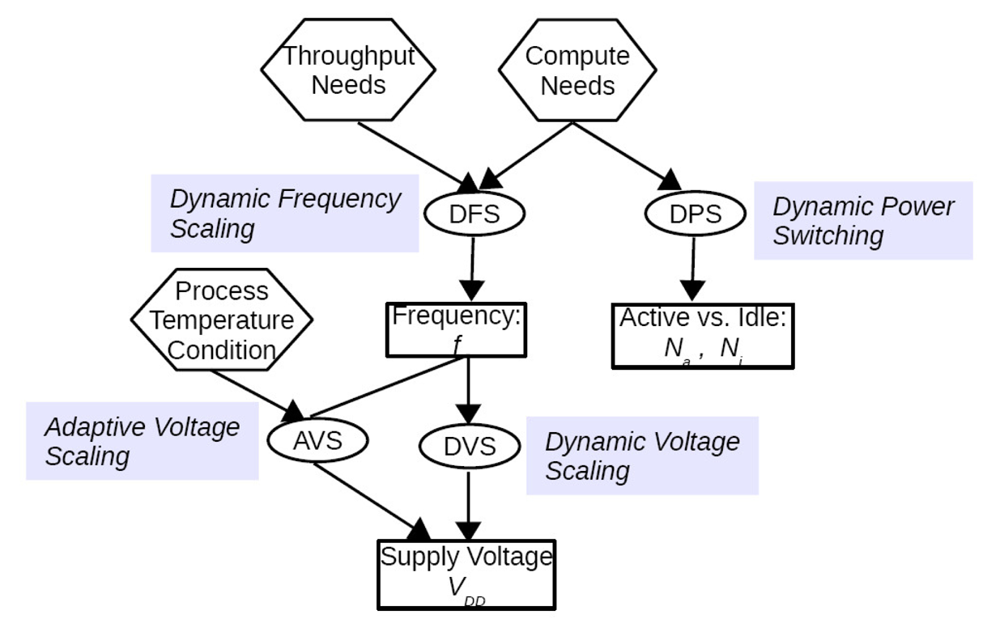
2. Dynamic Power Management
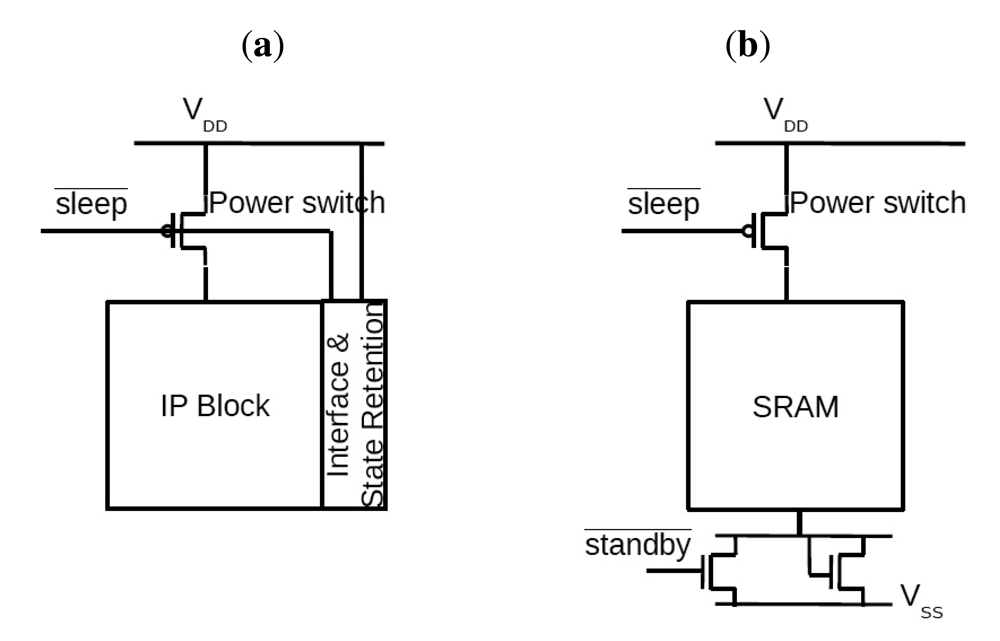
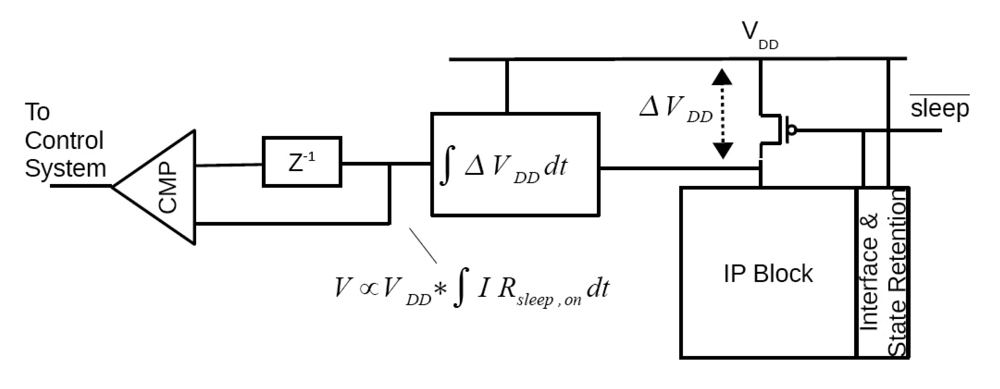
2.1. Dynamic Power Switching
2.2. Dynamic Frequency and Voltage Scaling
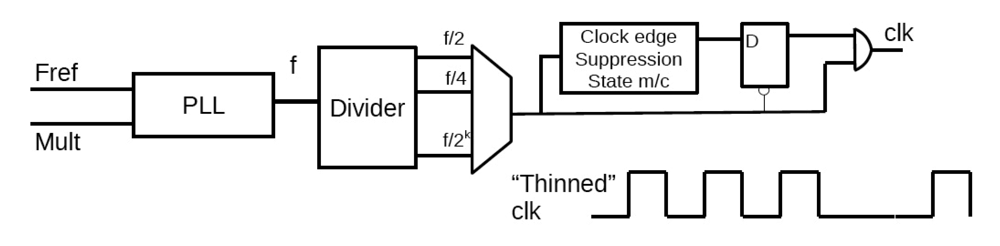
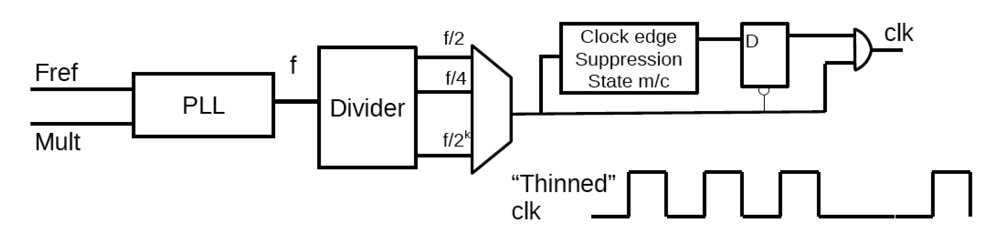
2.2.1. Dynamic Frequency Scaling (DFS)
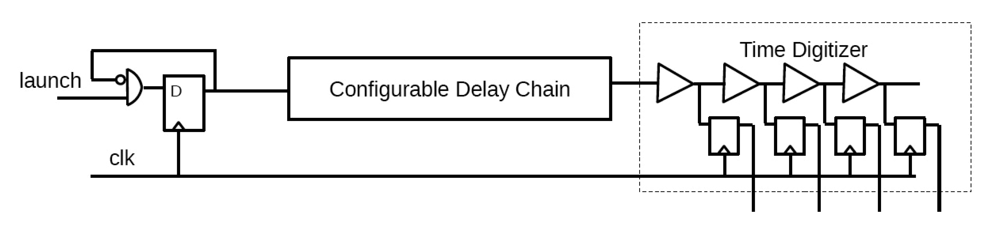
2.2.2. Dynamic Voltage Scaling (DVS)
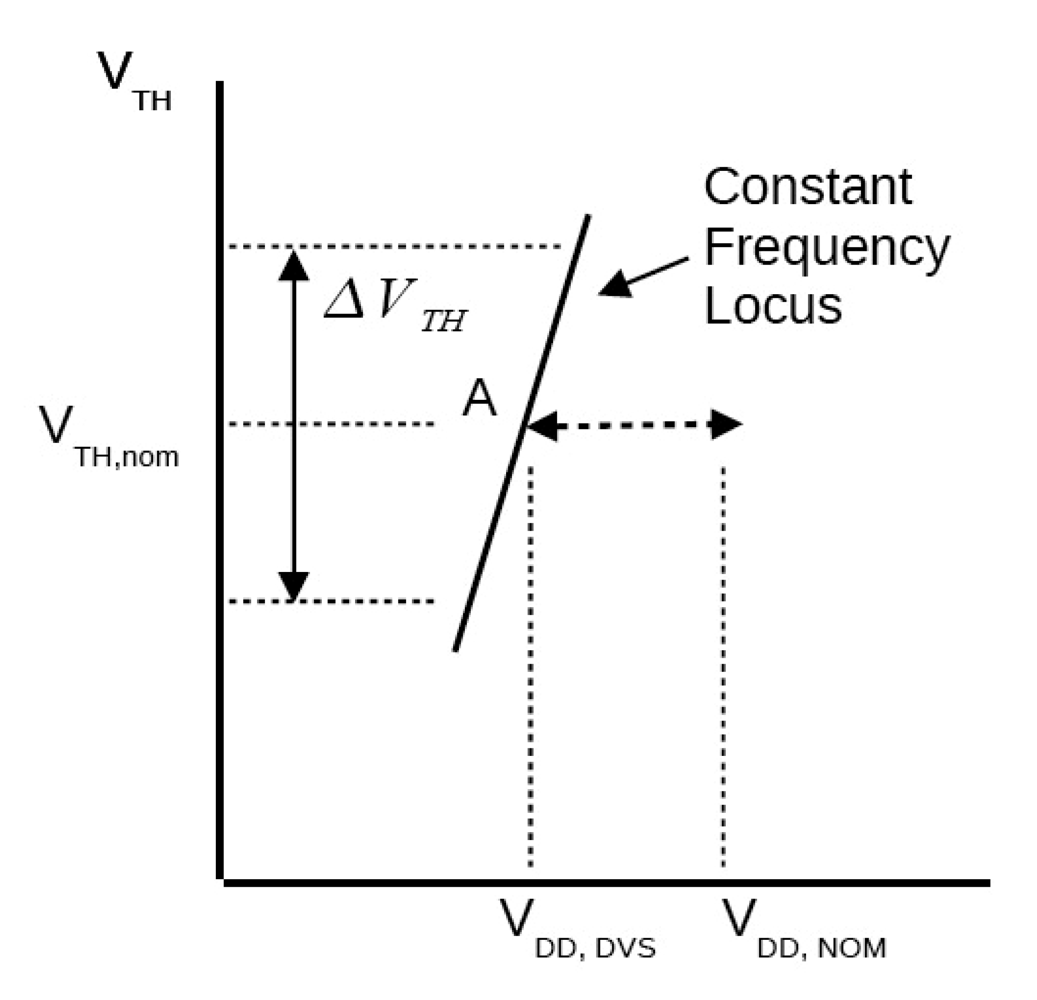
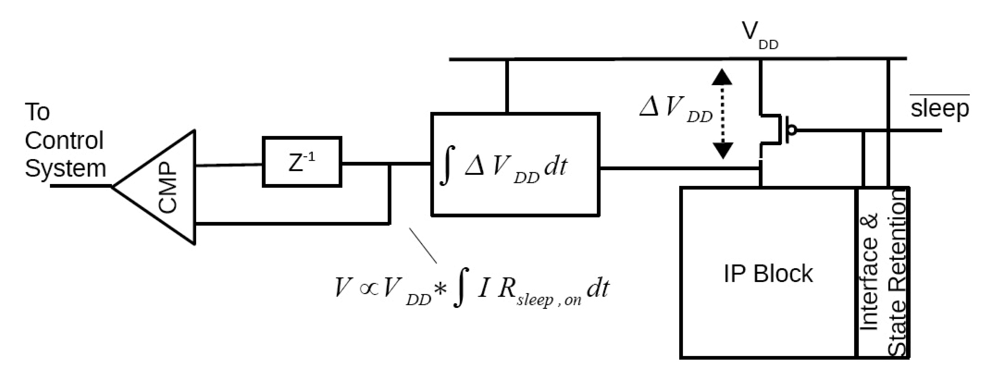
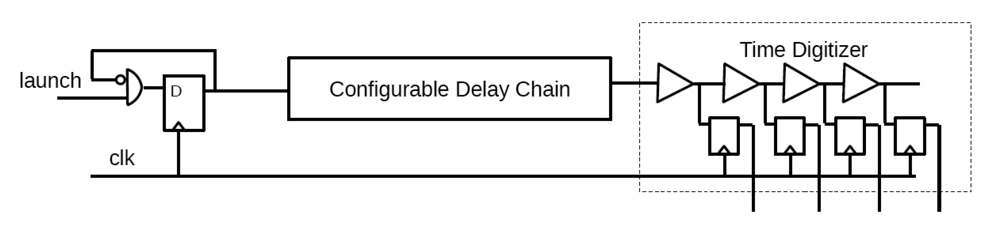
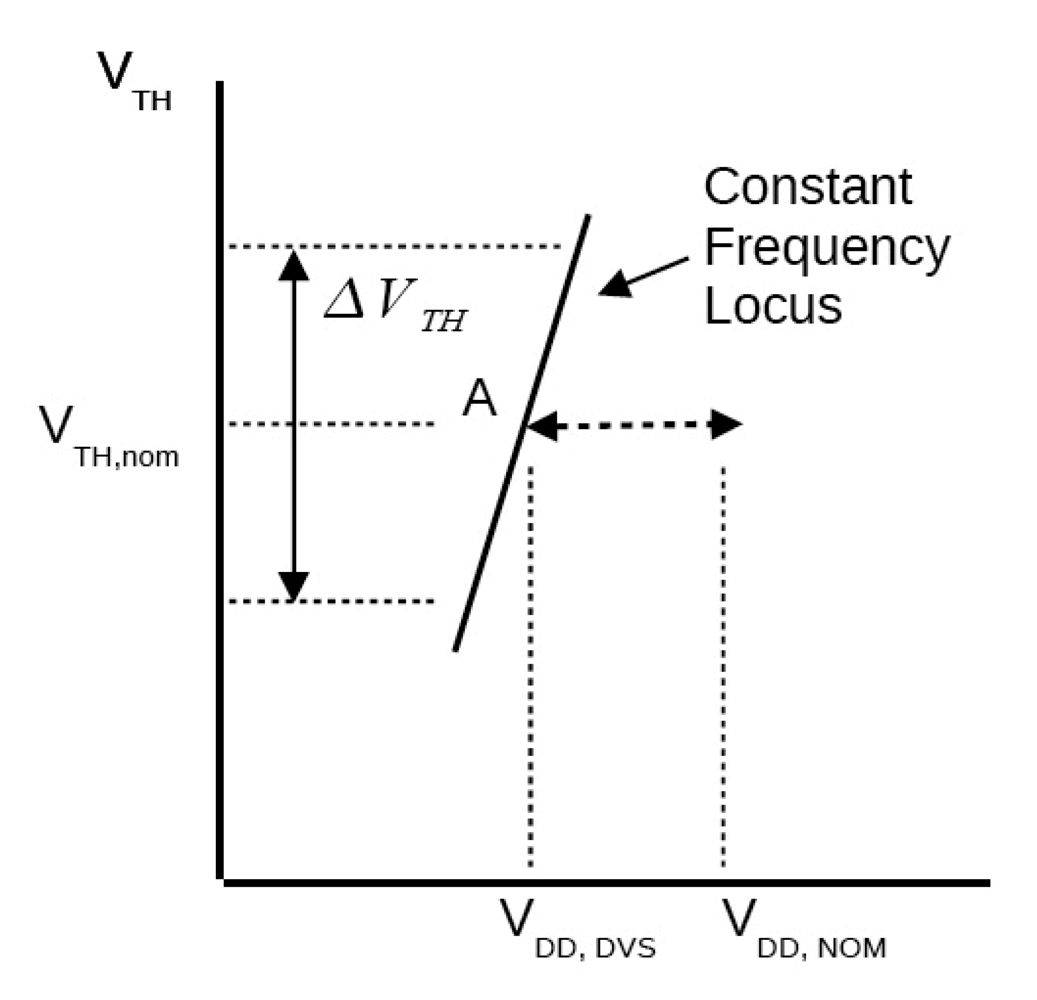
2.2.3. Adaptive Voltage Scaling (AVS)
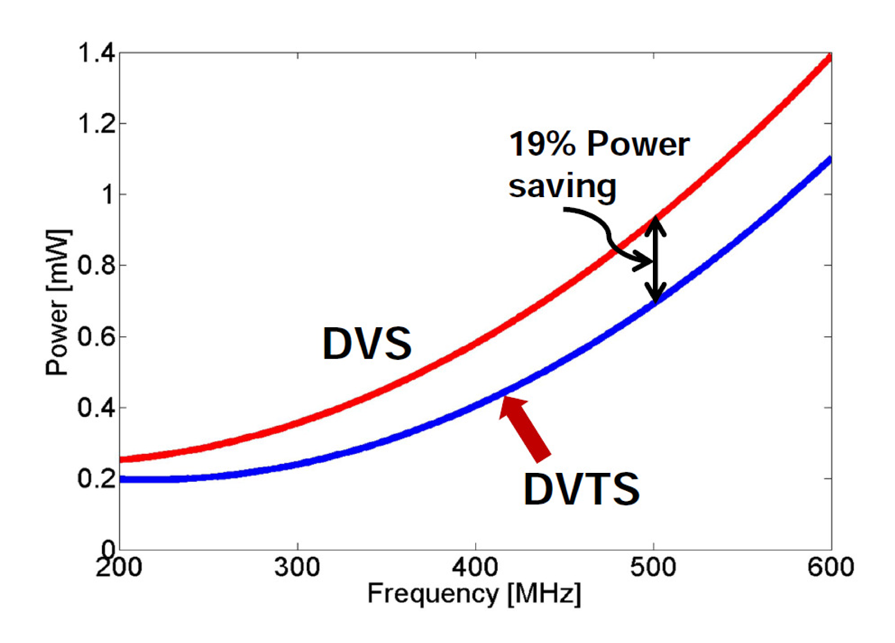
2.2.4. Dynamic Voltage and Threshold Scaling (DVTS)
3. Adaptive Computation
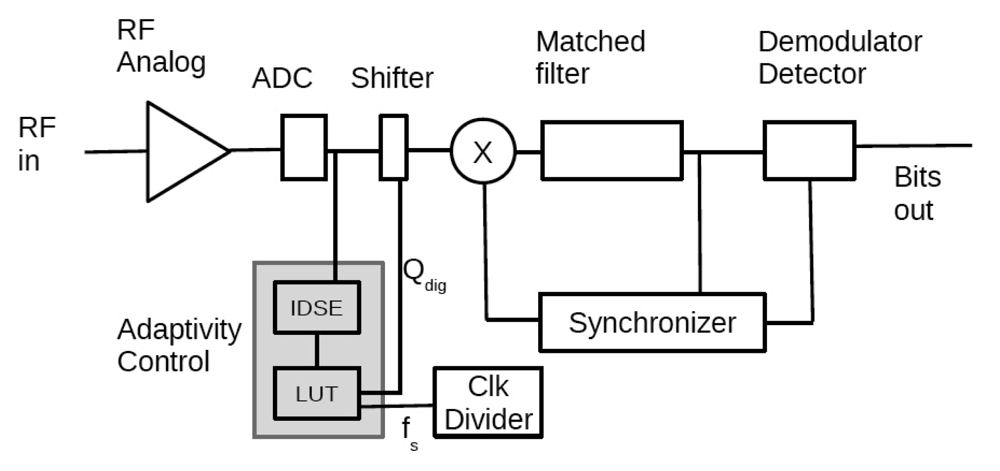
3.1. Adaptive Hardware Usage
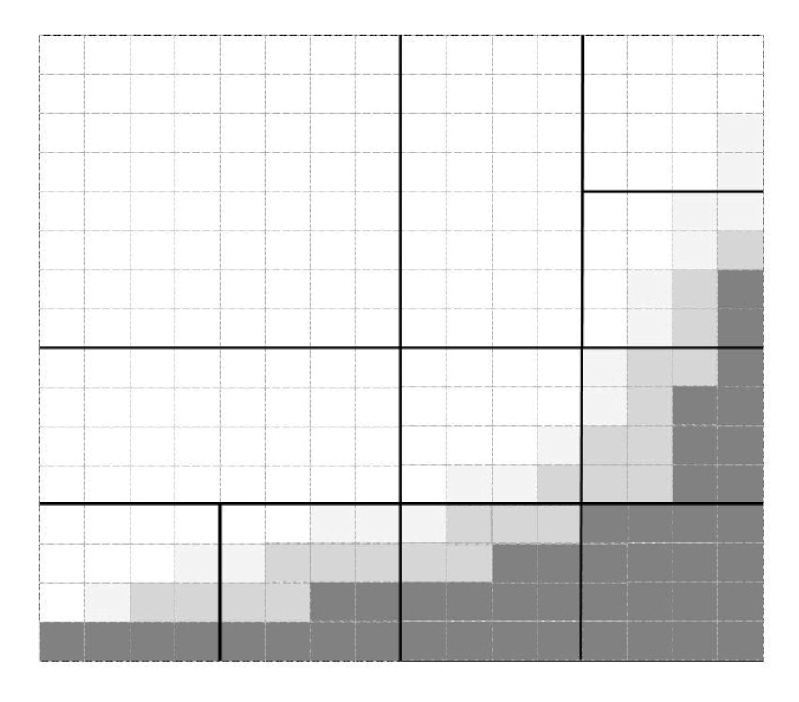
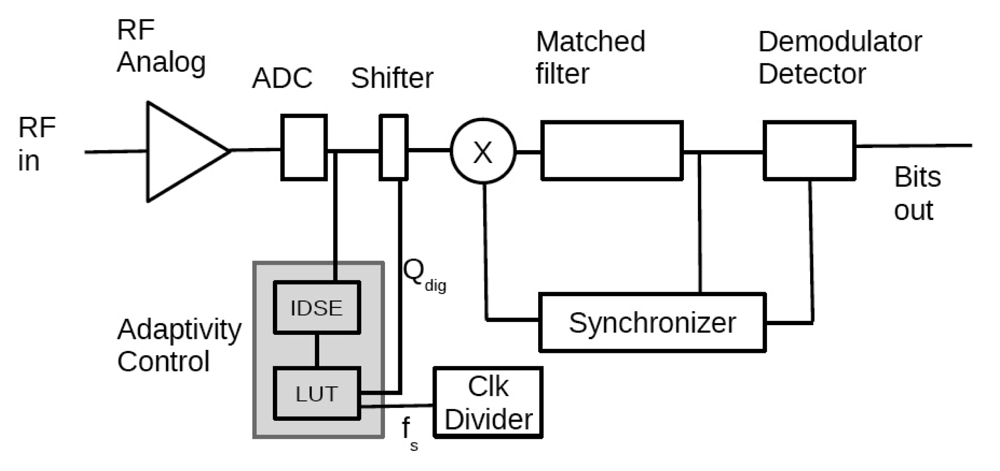
3.2. Adapting the Number of Operations
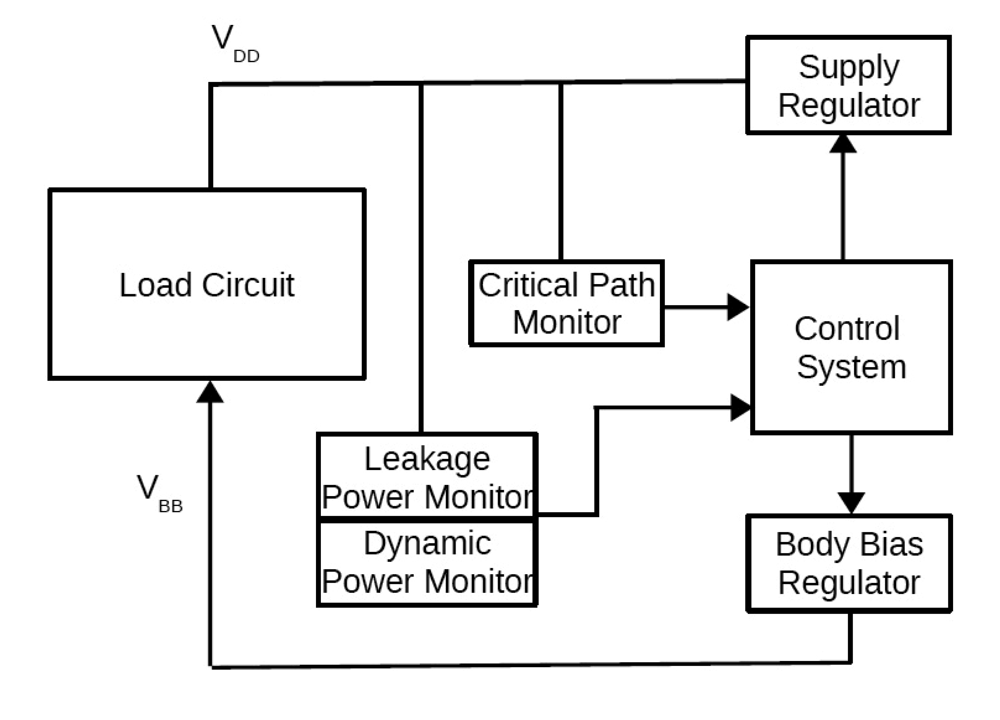
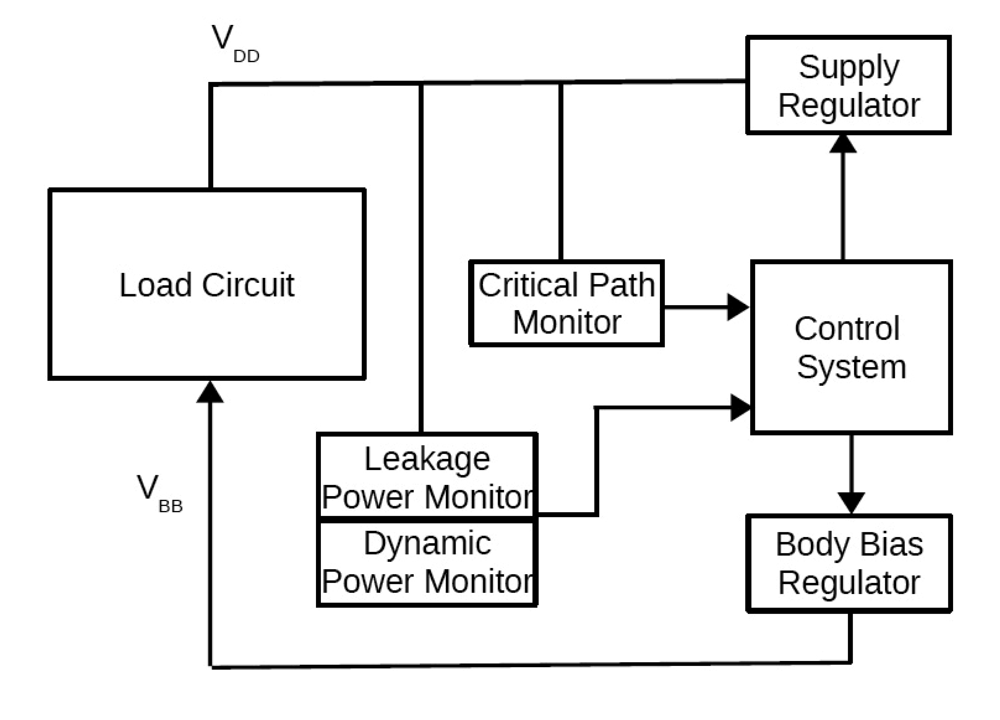
4. Dynamic Power Management System
5. Conclusions




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Low SNR | High SNR | |
|---|---|---|
| High Interference | 8-bits, 15 MHz, 3.3 mW | 1-bit, 2 MHz, 0.5 mW |
| Low Interference | 2-bits, 15 MHz, 2.49 mW | 1-bit, 2 MHz, 0.49 mW |
| Video Sequence, Resolution, Number of Frames | Computations Reduction | Power Reduction |
|---|---|---|
| Viper Train, 1920 × 1080, 316 | 66.15% | 78.15% |
| Riverbed, 1920 × 1080, 250 | 93.14% | 100.67% |
| Pedestrian, 1920 × 1080, 375 | 73.63% | 86.45% |
| Sunflower, 1920 × 1080, 494 | 84.28% | 95.81% |
Acknowledgments
References
- Staunstrup, J.; Wolf, W. Hardware/Software Co-Design: Principles and Practice; Kluwer Academic Publishers: Norwell, MA, USA, 2010. [Google Scholar]
- Rabaey, J. Low Power Design Essentials; Springer: New York, NY, USA, 2009. [Google Scholar]
- Benini, L.; de Micheli, G. Dynamic Power Management: Design Techniques and CAD Tools, 1st ed.; Kluwer Academic Publishers: Norwell, MA, USA, 1998. [Google Scholar]
- Gammie, G.; Wang, A.; Mair, H.; Lagerquist, R.; Chau, M.; Royannez, P.; Gururajrao, S.; Ko, U. SmartReflex power and performance management technologies for 90 nm, 65 nm, and 45 nm mobile application processors. Proc. IEEE 2010, 98, 144–159. [Google Scholar]
- Mutoh, S.; Douseki, T.; Matsuya, Y.; Aoki, T.; Shigematsu, S.; Yamada, J. 1-V power supply high-speed digital circuit technology with multi-threshold voltage CMOS. IEEE J. Solid-State Circuit 1995, 30, 847–854. [Google Scholar]
- Flynn, D.; Aitken, R.; Gibbons, A.; Shi, K.J. Low Power Methodology Manual: For System-on-Chip Design; Springer: New York, NY, USA, 2007. [Google Scholar]
- Jumel, F.; Royannez, P.; Mair, H.; Scott, D.; Er Rachidi, A.; Lagerquist, R.; Chau, M.; Gururajarao, S.; Thiruvengadam, S.; Clinton, M.; et al. A Leakage Management System Based on Clock Gating Infrastructure for a 65 nm Digital Base-Band Modem Chip. Proceedings of the IEEE Symposium of VLSI Circuits, Honolulu, HI, USA, June 2006; pp. 214–215.
- Nakai, M.; Akui, S.; Seno, K.; Meguro, T.; Seki, T.; Kondo, T.; Hashiguchi, A.; Kawahara, H.; Kumano, K.; Shimura, M. Dynamic voltage and frequency management for a low-power embedded microprocessor. IEEE J. Solid-State Circuit 2005, 40, 28–35. [Google Scholar]
- Nose, K.; Sakurai, T. Optimization of VDD and VTH for Low-Power and High-Speed Applications. Proceedings of the 2000 Asia and South Pacific Design Automation Conference, ASP-DAC '00, Yokohama, Japan, 25–28 January 2000.
- Burd, T.D.; Pering, T.A.; Stratakos, A.G.; Broderson, R.W. A Dynamic voltage scaled microprocessor system. IEEE J. Solid-State Circuit 2000, 35, 1571–1580. [Google Scholar]
- Dighe, S.; Vangal, S.R.; Aseron, P.; Kumar, S.; Jacob, T.; Bowman, K.A.; Howard, J.; Tschanz, J.; Erraguntla, V.; Borkar, N.; et al. Within-die variation-aware dynamic-voltage-frequency-scaling with optimal core allocation and thread hopping for the 80-Core TeraFLOPS processor. IEEE J. Solid-State Circuit 2011, 46, 184–193. [Google Scholar]
- Bull, D.; Das, S.; Shivashankar, K.; Dasika, G.; Flautner, K.; Blaauw, D. A Power-efficient 32 bit ARM processor using timing-error detection and correction for transient-error tolerance and adaptation to PVT variation. IEEE J. Solid-State Circuit 2011, 46, 18–31. [Google Scholar]
- Sreejith, K.; Amrutur, B.; Balivada, A. A workload based lookup table for minimal power operation under supply and body bias control. J. Low Power Electron. 2009, 5, 173–184. [Google Scholar]
- Nomura, M.; Ikenaga, Y.; Takeda, K.; Nakazawa, Y.; Aimoto, Y.; Hagihara, Y. delay and power monitoring schemes for minimizing power consumption by means of supply and threshold voltage control in active and standby modes. IEEE J. Solid-State Circuit 2006, 41, 805–814. [Google Scholar]
- Mehta, N.; Amrutur, B. Dynamic supply and threshold voltage scaling for CMOS digital circuits using in-situ power monitor. IEEE Trans. Very Large Scale Integr. Syst. 2011, 99, 1–10. [Google Scholar]
- Kikuchi, Y.; Takahashi, M.; Maeda, T.; Fukuda, M.; Koshio, Y.; Hara, H.; Arakida, H.; Yamamoto, H.; Hagiwara, Y.; Fujita, T.; et al. A 40 nm 222 mW H.274 full-HD decoding, 25 power domains, 14-core application processor with x512b stacked DRAM. IEEE J. Solid-State Circuit 2011, 46, 32–41. [Google Scholar]
- Chandrakasan, A.; Gutnik, V.; Xanthopoulos, T. Data Driven Signal Processing: An Approach for Energy Efficient Computing. Proceedings of the 1996 International Symposium on Low Power Electronics and Design, Monterey, CA, USA, 12–14 August 1996; pp. 347–352.
- Sinha, A.; Chandrakasan, A.P. Energy Efficient Filtering Using Adaptive Precision and Variable Voltage. Proceedings of the Twelfth Annual IEEE International ASIC/SOC Conference, IEEE ASIC '99, Washington, DC, USA, 15–18 September 1999; pp. 327–331.
- Nisar, M.; Chatterjee, A. Environment and Process Adaptive Low Power Wireless Baseband Signal Processing Using Dual Real-Time Feedback. Proceedings of the 22nd International Conference on VLSI Design, New Delhi, India, 5–9 January 2009.
- Dwivedi, S.; Amrutur, B.; Bhat, N. Power Scalable Digital Baseband Architecture for IEEE 802.15.4. Proceedings of the 24th International Conference on VLSI Design, Chennai, India, 2–7 January 2011.
- Gupte, A.; Amrutur, B. Adaptive global elimination algorithm for low power motion estimation. J. Low Power Electron. 2009, 5, 1–16. [Google Scholar]
- Huang, Y.-W.; Chien, S.-Y.; Hsieh, B.-Y.; Chen, L.-G. Global elimination algorithm and architecture for fast block matching motion estimation. IEEE Trans. Circuit Syst. Video Technol. 2004, 14, 898–907. [Google Scholar]
- Gutnik, V.; Chandrakasan, A. An Energy Efficient Controller for Variable Supply Voltage Low Power Processing. Proceedings of the 1996 International Symposium on Circuits and Systems, Atlanta, GA, USA, 12–15 May 1996; pp. 158–159.
- Lu, Z.; Hein, J.; Humphrey, M.; Stan, M.; Lach, J.; Skadron, K. Control-Theoretic Dynamic Frequency and Voltage Scaling for Multimedia Workloads. Proceedings of the 5th International Conference on Compilers, Architecture, and Synthesis for Embedded Systems, CASES '02, Greenoble, France, 8–11 October 2002.
- Lee, S.; Oh, J.; Park, J.; Kwon, K.; Kim, M.; Yoo, H.-J. A 345 mW heterogeneous many-core processor with an intelligent inference engine for robust object recognition. Proceedings of the 2010 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 7–11 February 2010; pp. 332–333.
- Simunic, T.; Benini, L.; Glynn, P.; de Micheli, G. Dynamic Power Management for Portable Systems. Proceedings of the 6th Annual International Conference on Mobile Computing and Networking (MobiCom '00), Boston, MA, USA, 6–11 August 2000.
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Amrutur, B.; Mehta, N.; Dwivedi, S.; Gupte, A. Adaptative Techniques to Reduce Power in Digital Circuits. J. Low Power Electron. Appl. 2011, 1, 261-276. https://doi.org/10.3390/jlpea1020261
Amrutur B, Mehta N, Dwivedi S, Gupte A. Adaptative Techniques to Reduce Power in Digital Circuits. Journal of Low Power Electronics and Applications. 2011; 1(2):261-276. https://doi.org/10.3390/jlpea1020261
Chicago/Turabian StyleAmrutur, Bharadwaj, Nandish Mehta, Satyam Dwivedi, and Ajit Gupte. 2011. "Adaptative Techniques to Reduce Power in Digital Circuits" Journal of Low Power Electronics and Applications 1, no. 2: 261-276. https://doi.org/10.3390/jlpea1020261
APA StyleAmrutur, B., Mehta, N., Dwivedi, S., & Gupte, A. (2011). Adaptative Techniques to Reduce Power in Digital Circuits. Journal of Low Power Electronics and Applications, 1(2), 261-276. https://doi.org/10.3390/jlpea1020261