
Efficiency of the Adjusted Binary Classification (ABC) Approach in Osteometric Sex Estimation: A Comparative Study of Different Linear Machine Learning Algorithms and Training Sample Sizes

 ,
,  , and
, and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Data Splitting
2.3. Validation Method
2.4. Statistical Analysis, Modeling, and Visualization
2.4.1. Sexual Dimorphism
2.4.2. Feature Selection
Univariate Feature Selection
Multivariate Feature Selection
2.4.3. Fitting the Classification Models
Logistic Regression
Linear Discriminant Analysis
Boosted Generalized Linear Model
Support Vector Machine with Linear Kernel
2.4.4. Classification Performance Metrics
2.4.5. Adjusted Binary Classification (ABC) Algorithm
2.5. Assessing the Sample Size Effect
3. Results
3.1. Sexual Dimorphism
3.2. Classification Performances for Traditional pp Cutoff (0.5) in LGOCV Sample
3.3. Application of the ABC Approach in the Training Sample
3.4. Model Performance in the Testing Sample
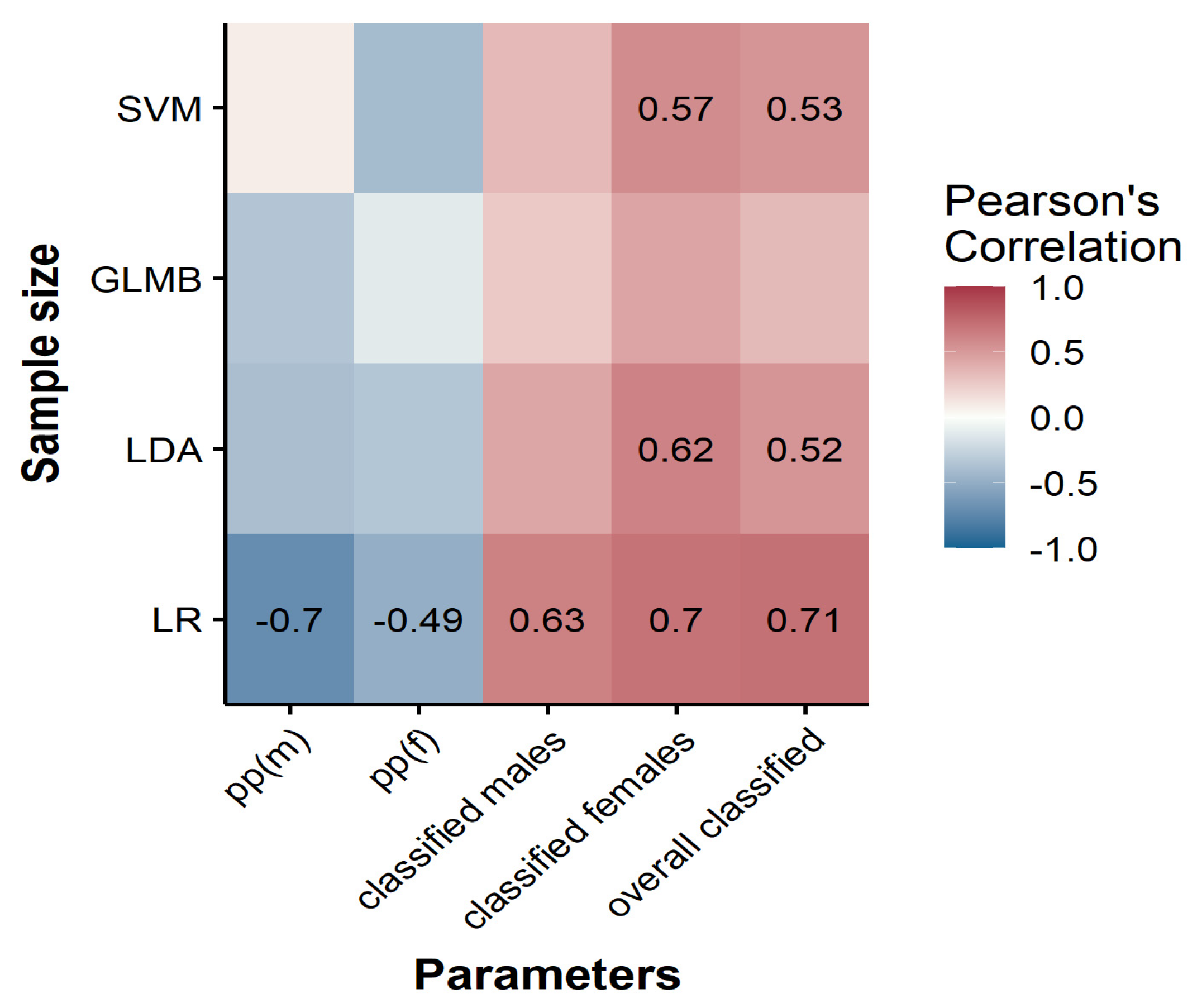
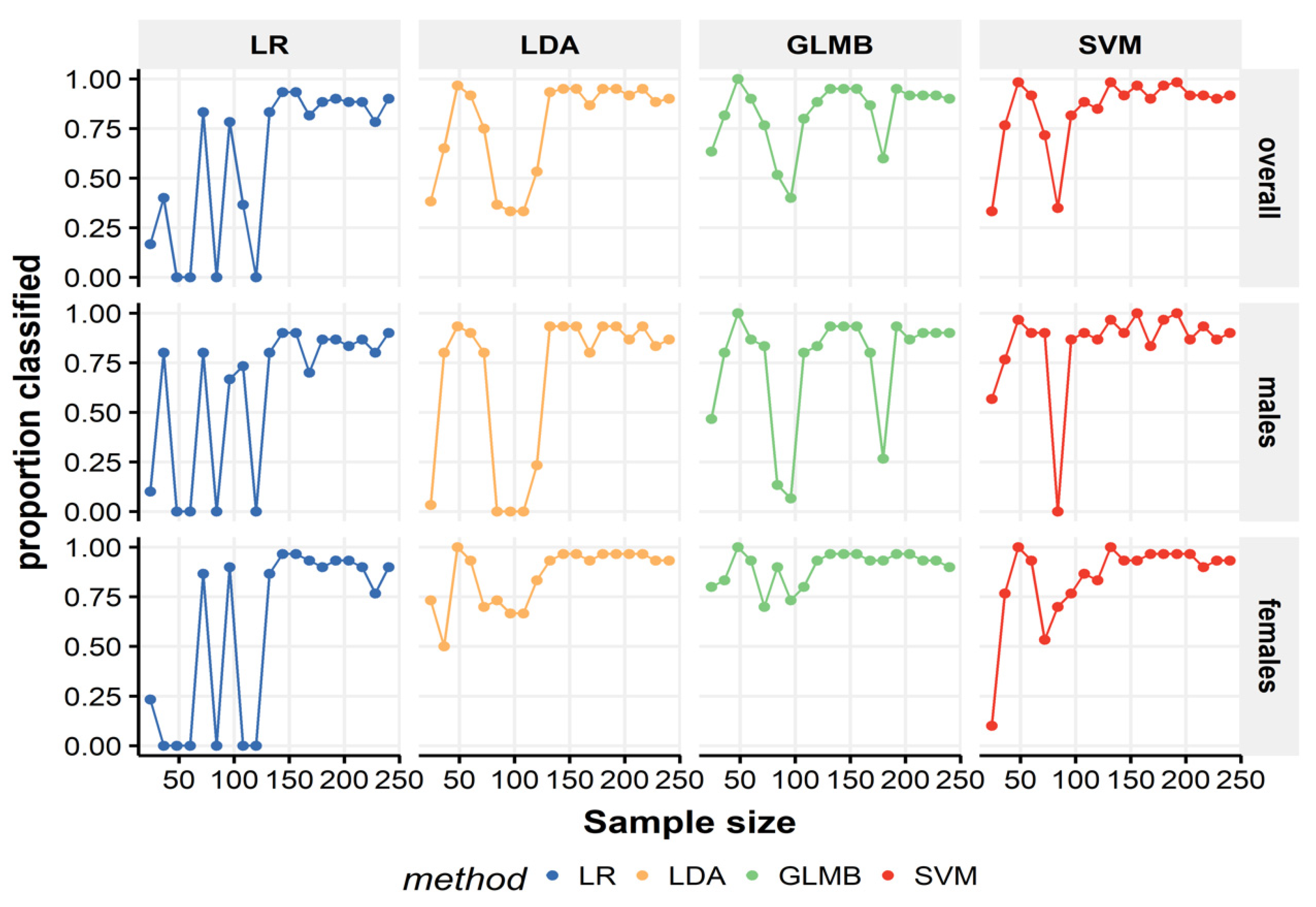
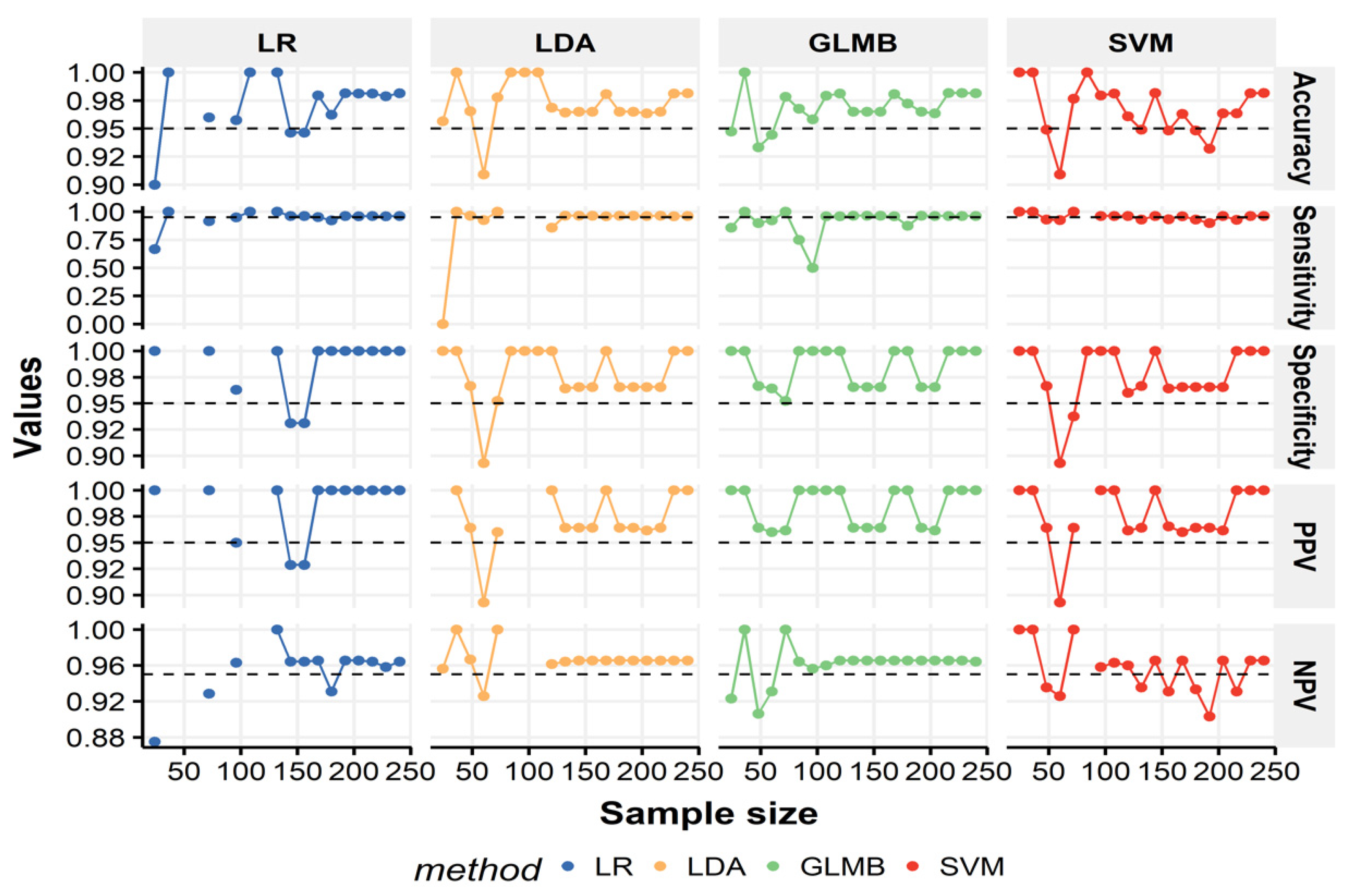
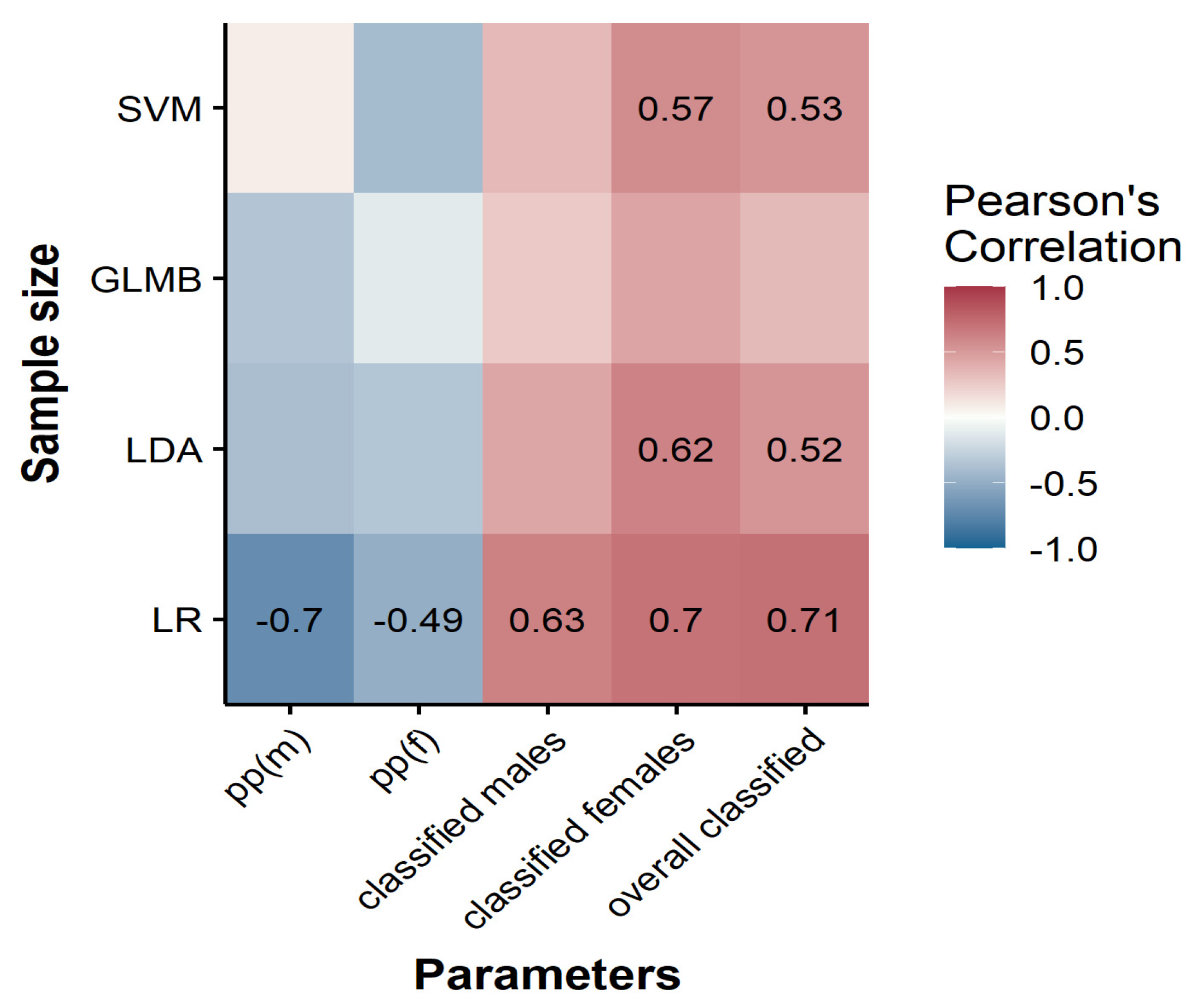
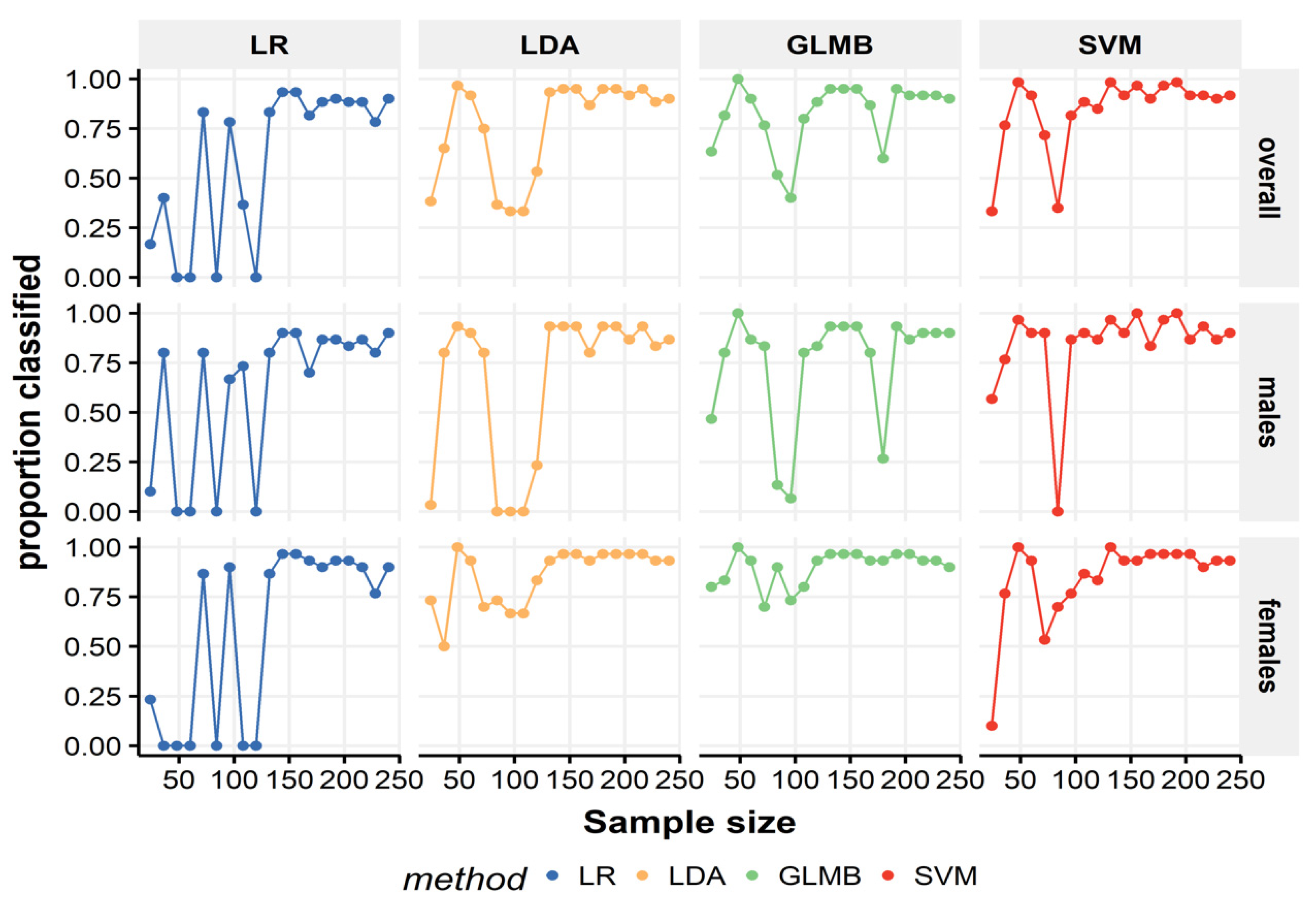
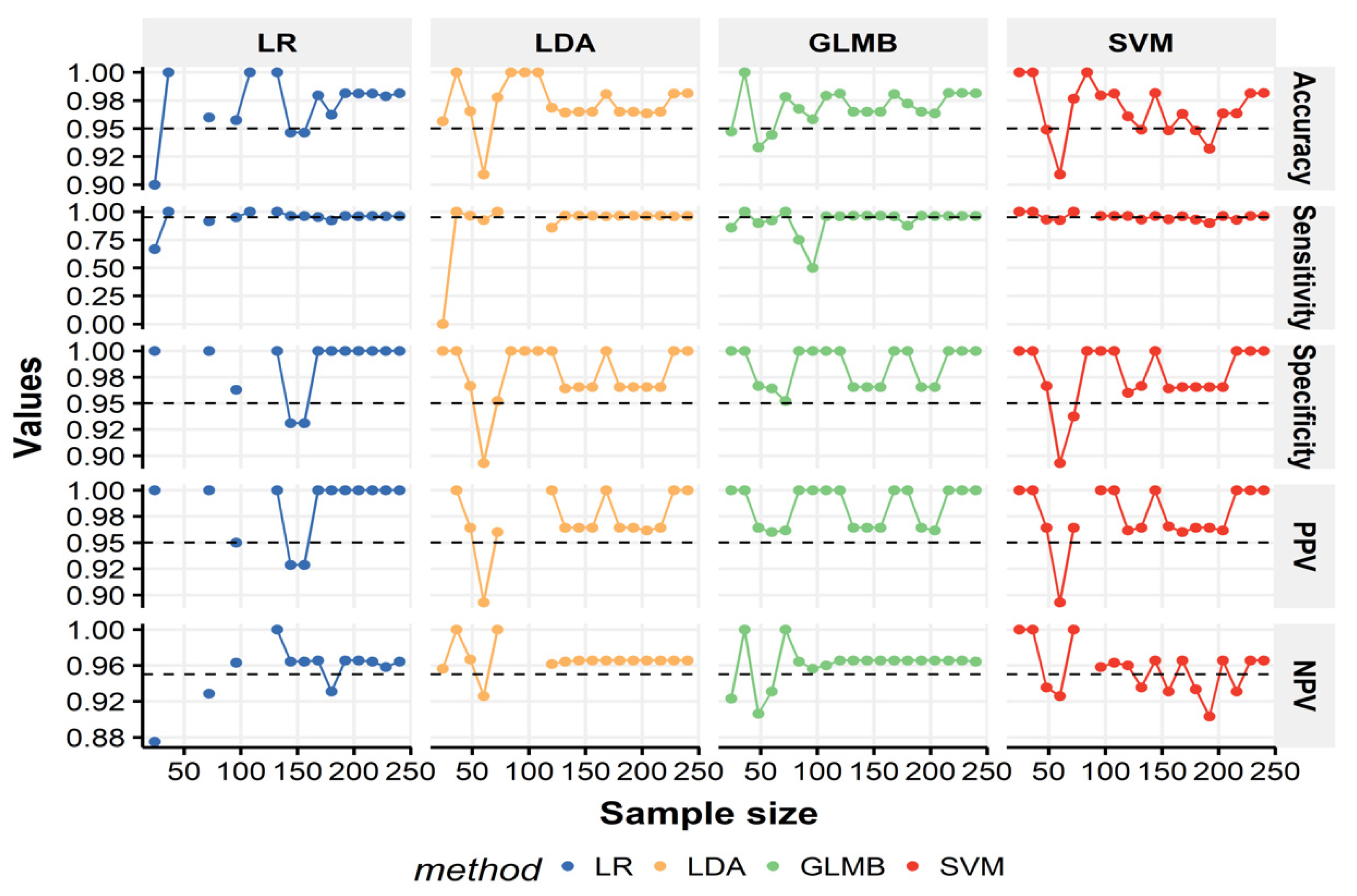
3.5. Sample Size Effect
4. Discussion
4.1. Sex Estimation Using the Default Cutoff Threshold of 0.5
4.2. Sex Estimation Using ABC Approach
4.3. The Training Sample Size Effect on the Performance of Multivariable Models
4.4. Study Limitations and Future Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ubelaker, D.H. Forensic anthropology: Methodology and applications. In Biological Anthropology of the Human Skeleton; Katzenberg, A., Grauer, A.L., Eds.; Wiley Blackwell: Oxford, UK, 2018; pp. 43–71. [Google Scholar]
- Klepinger, L.L. Fundamentals of Forensic Anthropology; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Galeta, P.; Brůžek, J. Sex estimation using continuous variables: Problems and principles of sex classification in the zone of uncertainty. In Statistics and Probability in Forensic Anthropology; Obertová, Z., Cattaneo, C., Stewart, A., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; pp. 155–182. [Google Scholar]
- Cabo, L.L.; Brewster, C.P.; Luengo Azpiazu, J. Sexual dimorphism: Interpreting sex markers. Companion Forensic Anthropol. 2012, 10, 248. [Google Scholar]
- Brůžek, J.; Santos, F.; Dutailly, B.; Murail, P.; Cunha, E. Validation and reliability of the sex estimation of the human os coxae using freely available DSP2 software for bioarchaeology and forensic anthropology. Am. J. Phys. Anthropol. 2017, 164, 440–449. [Google Scholar] [CrossRef]
- D’Oliveira Coelho, J.; Curate, F. CADOES: An interactive machine-learning approach for sex estimation with the pelvis. Forensic Sci. Int. 2019, 302, 109873. [Google Scholar] [CrossRef] [PubMed]
- Murail, P.; Bruzek, J.; Braga, J. A new approach to sexual diagnosis in past populations. Practical adjustments from Van Vark’s procedure. Int. J. Osteoarchaeol. 1999, 9, 39–53. [Google Scholar] [CrossRef]
- Avent, P.R.; Hughes, C.E.; Garvin, H.M. Applying posterior probability informed thresholds to traditional cranial trait sex estimation methods. J. Forensic Sci. 2022, 67, 440–449. [Google Scholar] [CrossRef]
- Santos, F.; Guyomarc’h, P.; Bruzek, J. Statistical sex determination from craniometrics: Comparison of linear discriminant analysis, logistic regression, and support vector machines. Forensic Sci. Int. 2014, 245, 204.e1–204.e8. [Google Scholar] [CrossRef]
- Milner, G.R.; Boldsen, J.L. Humeral and femoral head diameters in recent white American skeletons. J. Forensic Sci. 2012, 57, 35–40. [Google Scholar] [CrossRef]
- Jerković, I.; Bašić, Ž.; Anđelinović, Š.; Kružić, I. Adjusting posterior probabilities to meet predefined accuracy criteria: A proposal for a novel approach to osteometric sex estimation. Forensic Sci. Int. 2020, 311, 110273. [Google Scholar] [CrossRef]
- Hussein, M.H.A.; Abulnoor, B.A.E.-S. Sex estimation of femur using simulated metapopulation database: A preliminary investigation. Forensic Sci. Int. Rep. 2019, 1, 100009. [Google Scholar] [CrossRef]
- Attia, M.H.; Attia, M.H.; Farghaly, Y.T.; Abulnoor, B.A.E.-S.; Curate, F. Performance of the supervised learning algorithms in sex estimation of the proximal femur: A comparative study in contemporary Egyptian and Turkish samples. Sci. Justice 2022, 62, 288–309. [Google Scholar] [CrossRef]
- Curate, F.; Umbelino, C.; Perinha, A.; Nogueira, C.; Silva, A.M.; Cunha, E. Sex determination from the femur in Portuguese populations with classical and machine-learning classifiers. J. Forensic Leg. Med. 2017, 52, 75–81. [Google Scholar] [CrossRef] [PubMed]
- Attia, M.H.; Aboulnoor, B.A.E. Tailored logistic regression models for sex estimation of unknown individuals using the published population data of the humeral epiphyses. Leg. Med. 2020, 45, 101708. [Google Scholar] [CrossRef] [PubMed]
- Bartholdy, B.P.; Sandoval, E.; Hoogland, M.L.P.; Schrader, S.A. Getting Rid of Dichotomous Sex Estimations: Why Logistic Regression Should be Preferred Over Discriminant Function Analysis. J. Forensic Sci. 2020, 65, 1685–1691. [Google Scholar] [CrossRef] [PubMed]
- Papaioannou, V.A.; Kranioti, E.F.; Joveneaux, P.; Nathena, D.; Michalodimitrakis, M. Sexual dimorphism of the scapula and the clavicle in a contemporary Greek population: Applications in forensic identification. Forensic Sci. Int. 2012, 217, 231.e1–231.e7. [Google Scholar] [CrossRef] [PubMed]
- Hora, M.; Sládek, V. Population specificity of sex estimation from vertebrae. Forensic Sci. Int. 2018, 291, 279.e1–279.e12. [Google Scholar] [CrossRef]
- Navega, D.; Vicente, R.; Vieira, D.N.; Ross, A.H.; Cunha, E. Sex estimation from the tarsal bones in a Portuguese sample: A machine learning approach. Int. J. Leg. Med. 2015, 129, 651–659. [Google Scholar] [CrossRef]
- Konigsberg, L.W.; Frankenberg, S.R. Multivariate ordinal probit analysis in the skeletal assessment of sex. Am. J. Phys. Anthropol. 2019, 169, 385–387. [Google Scholar] [CrossRef]
- Konigsberg, L.W.; Algee-Hewitt, B.F.; Steadman, D.W. Estimation and evidence in forensic anthropology: Sex and race. Am. J. Phys. Anthropol. 2009, 139, 77–90. [Google Scholar] [CrossRef]
- Jantz, R.L.; Ousley, S.D. Sexual dimorphism variation in Fordisc samples. In Sex Estimation of the Human Skeleton; Klales, A.R., Ed.; Elsevier: Amsterdam, The Netherlands, 2020; pp. 185–200. [Google Scholar]
- Buikstra, J.E. Standards for Data Collection from Human Skeletal Remains: Proceedings of a Seminar at the Field Museum of Natural History; Arkansas Archeological Survey: Fayetteville, AR, USA, 1994; p. 206. [Google Scholar]
- Moore-Jansen, P.H.; Jantz, R.L. Data Collection Procedures for Forensic Skeletal Material; Forensic Anthropology Center, Department of Anthropology, University of Tennessee: Knoxville, TN, USA, 1994. [Google Scholar]
- Jerković, I.; Kolić, A.; Kružić, I.; Anđelinović, Š.; Bašić, Ž. Adjusted binary classification (ABC) model in forensic science: An example on sex classification from handprint dimensions. Forensic Sci. Int. 2021, 320, 110709. [Google Scholar] [CrossRef]
- Gulhan, O. Skeletal Sexing Standards of Human Remains in Turkey. Ph.D. Thesis, Cranfield University, Cranfield, UK, 2017. [Google Scholar]
- Gregory, J.S.; Aspden, R.M. Femoral geometry as a risk factor for osteoporotic hip fracture in men and women. Med. Eng. Phys. 2008, 30, 1275–1286. [Google Scholar] [CrossRef]
- Terzidis, I.; Totlis, T.; Papathanasiou, E.; Sideridis, A.; Vlasis, K.; Natsis, K. Gender and Side-to-Side Differences of Femoral Condyles Morphology: Osteometric Data from 360 Caucasian Dried Femori. Anat. Res. Int. 2012, 2012, 679658. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ul-Haq, Z.; Madura, J.D. Frontiers in Computational Chemistry: Volume 2: Computer Applications for Drug Design and Biomolecular Systems; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Ferrer, A.J.A.; Wang, L. Comparing the classification accuracy among nonparametric, parametric discriminant analysis and logistic regression methods. In Proceedings of the 1 Annual Meeting of the American Educational Research Association, Montreal, QC, Canada, 13–17 April 1999. [Google Scholar]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Team, R.C. Package ‘caret’. R J. 2020, 223, 7. [Google Scholar]
- Wickham, H.; Francois, R.; Henry, L.; Müller, K. dplyr: A Grammar of Data Manipulation. R package Version 0.4.3; R Foundation for Statistical Computing: Vienna, Austria, 2015; Available online: https://CRAN.R-project.org/package=dplyr (accessed on 24 April 2021).
- Pedersen, T. Patchwork: The Composer of ggplots. R Package Version 0.0.1; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Kassambara, A. rstatix: Pipe-Friendly Framework for Basic Statistical Tests. R package Version 0.6.0; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.A.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J. Welcome to the Tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
- Kassambara, A. ggpubr:“ggplot2” Based Publication Ready Plots (Version 0.1.7). 2018. Available online: https://CRAN.R-project.org/package=ggpubr (accessed on 19 May 2021).
- Leisch, F. mlbench: Machine Learning Benchmark Problems. R Package Version; R Foundation for Statistical Computing: Vienna, Austria, 2009; pp. 1.1–1.6. [Google Scholar]
- Pastore, M. Overlapping: A R package for estimating overlapping in empirical distributions. J. Open Source Softw. 2018, 3, 1023. [Google Scholar] [CrossRef] [Green Version]
- Sarkar, D.; Sarkar, M.D. The Lattice Package. Trellis Graphics for R. 2007. Available online: https://cran.r-project.org/web/packages/lattice/lattice.pdf (accessed on 19 May 2021).
- Smith, B. MachineShop: Machine Learning Models and Tools. R Package Version. 2020. Available online: https://cran.r-project.org/web/packages/MachineShop/MachineShop.pdf (accessed on 25 April 2021).
- Brownlee, J. Feature Selection with the Caret R Package. 2019. Available online: https://machinelearningmastery.com/feature-selection-with-the-caret-r-package/ (accessed on 24 April 2021).
- Nikita, E.; Nikitas, P. On the use of machine learning algorithms in forensic anthropology. Leg. Med. 2020, 47, 101771. [Google Scholar] [CrossRef]
- Toneva, D.; Nikolova, S.; Agre, G.; Zlatareva, D.; Hadjidekov, V.; Lazarov, N. Machine learning approaches for sex estimation using cranial measurements. Int. J. Leg. Med. 2021, 135, 951–966. [Google Scholar] [CrossRef]
- Tutz, G.; Binder, H. Generalized additive modeling with implicit variable selection by likelihood-based boosting. Biometrics 2006, 62, 961–971. [Google Scholar] [CrossRef] [Green Version]
- Williams, G. Data Mining Desktop Survival Guide. Usage2. html. 2006. Available online: http://www.togaware.com/datamining/survivor/. (accessed on 11 June 2021).
- Akter, T.; Satu, M.S.; Khan, M.I.; Ali, M.H.; Uddin, S.; Lio, P.; Quinn, J.M.; Moni, M.A. Machine learning-based models for early stage detection of autism spectrum disorders. IEEE Access 2019, 7, 166509–166527. [Google Scholar] [CrossRef]
- Lopes, M. Is LDA a Dimensionality Reduction Technique or a Classifier Algorithm. Available online: https://towardsdatascience.com/is-lda-a-dimensionality-reductiontechnique-or-a-classifier-algorithm-eeed4de9953a (accessed on 4 October 2019).
- Ripley, B.; Venables, B.; Bates, D.M.; Hornik, K.; Gebhardt, A.; Firth, D.; Ripley, M.B. Package ‘mass’. CRAN R 2013, 538, 113–120. [Google Scholar]
- Iworiso, J. On the Predictability of US Stock Market Using Machine Learning and Deep Learning Techniques. Ph.D. Thesis, University of Essex, Colchester, UK, 2020. [Google Scholar]
- Hind, J.; Hussain, A.; Al-Jumeily, D.; Montañez, C.A.C.; Chalmers, C.; Lisboa, P. Robust interpretation of genomic data in chronic obstructive pulmonary disease (COPD). In Proceedings of the 2018 11th International Conference on Developments in eSystems Engineering (DeSE), Cambridge, UK, 2–5 September 2018; pp. 12–17. [Google Scholar]
- Hofner, B.; Mayr, A.; Robinzonov, N.; Schmid, M. Model-based boosting in R: A hands-on tutorial using the R package mboost. Comput. Stat. 2014, 29, 3–35. [Google Scholar] [CrossRef] [Green Version]
- Olson, D.L.; Wu, D. Predictive Data Mining Models; Springer: Singapore, 2017. [Google Scholar]
- Lin, H.-T.; Lin, C.-J.; Weng, R.C. A note on Platt’s probabilistic outputs for support vector machines. Mach. Learn. 2007, 68, 267–276. [Google Scholar] [CrossRef] [Green Version]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. kernlab—An S4 package for kernel methods in R. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Bolger, F.; Wright, G. Reliability and validity in expert judgment. In Expertise and Decision Support; Springer: New York, NY, USA, 1992; pp. 47–76. [Google Scholar]
- Sordo, M.; Zeng, Q. On sample size and classification accuracy: A performance comparison. In Proceedings of the 6th International Symposium on Biological and Medical Data Analysis ISBMDA 2005, Aveiro, Portugal, 10–11 November 2005; Oliveira, J.L., Maojo, V., Martin-Sanchez, F., Pereira, A.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 193–201. [Google Scholar]
- Zhang, Y.; Ling, C. A strategy to apply machine learning to small datasets in materials science. NPJ Comput. Mater. 2018, 4, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Lei, P.-W.; Koehly, L.M. Linear discriminant analysis versus logistic regression: A comparison of classification errors in the two-group case. J. Exp. Educ. 2003, 72, 25–49. [Google Scholar] [CrossRef]
- Pohar, M.; Blas, M.; Turk, S. Comparison of logistic regression and linear discriminant analysis: A simulation study. Metodoloski Zv. 2004, 1, 143. [Google Scholar] [CrossRef]
- Mansournia, M.A.; Geroldinger, A.; Greenland, S.; Heinze, G. Separation in Logistic Regression: Causes, Consequences, and Control. Am. J. Epidemiol. 2018, 187, 864–870. [Google Scholar] [CrossRef] [Green Version]
- Stephan, C.N.; Norris, R.M.; Henneberg, M. Does sexual dimorphism in facial soft tissue depths justify sex distinction in craniofacial identification? J. Forensic Sci. 2005, 50, 1–6. [Google Scholar] [CrossRef]
- Raza, H.; Cecotti, H.; Li, Y.; Prasad, G. Adaptive learning with covariate shift-detection for motor imagery-based brain–computer interface. Soft Comput. 2016, 20, 3085–3096. [Google Scholar] [CrossRef]
- Parikh, R.; Mathai, A.; Parikh, S.; Chandra Sekhar, G.; Thomas, R. Understanding and using sensitivity, specificity and predictive values. Indian J. Ophthalmol. 2008, 56, 45–50. [Google Scholar] [CrossRef]
- Ortega, R.F.; Irurita, J.; Campo, E.J.E.; Mesejo, P. Analysis of the performance of machine learning and deep learning methods for sex estimation of infant individuals from the analysis of 2D images of the ilium. Int. J. Leg. Med. 2021, 135, 2659–2666. [Google Scholar] [CrossRef]
- Cao, Y.; Ma, Y.; Yang, X.; Xiong, J.; Wang, Y.; Zhang, J.; Qin, Z.; Chen, Y.; Vieira, D.N.; Chen, F. Use of deep learning in forensic sex estimation of virtual pelvic models from the Han population. Forensic Sci. Res. 2022, 7, 1–10. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Variables | Males (n = 120) | Females (n = 120) | t-Test | Overlapping | |||
|---|---|---|---|---|---|---|---|
| Mean ± SD (mm) | Range (mm) | Mean ± SD (mm) | Range (mm) | t | p | (%) | |
| FML | 443.78 ± 25.59 | 384.70–502.30 | 406.51 ± 21.20 | 359.24–453.13 | 12.289 | <0.001 * | 27.34 |
| FBL | 441.23 ± 25.76 | 382.12–501.03 | 404.73 ± 21.92 | 358.61–453.17 | 11.821 | <0.001 * | 28.52 |
| FTL | 425.65± 23.77 | 371.24–477.58 | 391.19 ± 21.05 | 342.70–439.45 | 11.890 | <0.001 * | 26.55 |
| MTD | 29.33 ± 2.20 | 22–34.14 | 28.09 ± 2.37 | 21.88–37.10 | 4.205 | <0.001 * | 63.39 |
| VHD | 49.19 ± 3.02 | 38.89–55.77 | 43.19 ± 2.89 | 36.48–50.84 | 15.715 | <0.001 * | 19.57 |
| FVDN | 36.75 ± 2.69 | 27.85–43.25 | 31.98 ± 2.24 | 25.77–37.47 | 14.916 | <0.001 * | 17.56 |
| FNAL | 102.20 ± 6.27 | 87.23–122.38 | 91.14 ± 5.36 | 79.92–103.27 | 14.682 | <0.001 * | 22.51 |
| FBP | 91.28 ± 5.88 | 71.49–108.42 | 81.61 ± 5.08 | 72.06–94.30 | 17.908 | <0.001 * | 23.00 |
| MLD | 32.95 ± 2.44 | 26.32–39.51 | 31.07 ± 2.24 | 26.16–37.41 | 6.231 | <0.001 * | 45.78 |
| FBCB | 74.71 ± 4.31 | 65.10–89.03 | 66.61 ± 4.19 | 58.78–76.38 | 14.777 | <0.001 * | 23.70 |
| FEB | 85.72 ± 4.42 | 76.46–98.06 | 76.70 ± 3.58 | 67.86–89.58 | 17.908 | <0.001 * | 17.15 |
| APDLC | 64.23 ± 3.67 | 53.58–73.84 | 58.32 ± 3.22 | 51.38–67.91 | 13.267 | <0.001 * | 23.82 |
| APDMC | 63.54 ± 3.70 | 53.97–73.21 | 57.79 ± 3.54 | 49.84–67.40 | 12.304 | <0.001 * | 28.69 |
| Variables | Accuracy (%) | Sensitivity (%) | Specificity (%) | PPV (%) | NPV (%) | c-Index |
|---|---|---|---|---|---|---|
| Logistic regression | ||||||
| FEB | 84.44 | 85.89 | 83 | 83.48 | 85.47 | 0.944 |
| VHD | 84.36 | 85.06 | 83.67 | 83.89 | 84.85 | 0.920 |
| FVDN | 86.33 | 85.44 | 87.22 | 86.99 | 85.70 | 0.914 |
| FBCB | 83 | 81.22 | 84.78 | 84.22 | 81.87 | 0.904 |
| FNAL | 82.25 | 83.17 | 81.33 | 81.67 | 82.85 | 0.903 |
| LR1 | 90.08 | 87.67 | 92.50 | 92.12 | 88.24 | 0.968 |
| Discriminant analysis | ||||||
| FEB | 84.89 | 85.28 | 84.50 | 84.62 | 85.16 | 0.944 |
| VHD | 84.72 | 86.44 | 83 | 83.57 | 85.96 | 0.920 |
| FVDN | 86.42 | 85.44 | 87.39 | 87.14 | 85.72 | 0.915 |
| FBCB | 83.06 | 81 | 85.11 | 84.47 | 81.75 | 0.905 |
| FNAL | 82.19 | 81.78 | 82.61 | 82.46 | 81.93 | 0.904 |
| DF1 | 89.58 | 86.22 | 92.94 | 82.44 | 87.09 | 0.959 |
| Boosted glm | ||||||
| FEB | 84.89 | 85.28 | 84.50 | 84.62 | 85.16 | 0.945 |
| VHD | 84.69 | 86.64 | 82.94 | 83.52 | 85.95 | 0.920 |
| FVDN | 86.42 | 85.44 | 87.39 | 87.14 | 85.72 | 0.914 |
| FBCB | 83.94 | 82.89 | 85 | 84.68 | 83.24 | 0.906 |
| FNAL | 82.19 | 81.78 | 82.61 | 82.46 | 81.93 | 0.904 |
| GLMB1 | 89.17 | 86 | 92.33 | 91.81 | 86.83 | 0.961 |
| SVM linear | ||||||
| FEB | 84.50 | 85.83 | 83.17 | 83.60 | 85.45 | 0.944 |
| VHD | 84.42 | 85.28 | 83.56 | 83.83 | 85.02 | 0.919 |
| FVDN | 86.50 | 85.61 | 87.39 | 87.16 | 85.86 | 0.914 |
| FBCB | 83.06 | 81.33 | 84.78 | 84.23 | 81.95 | 0.904 |
| FNAL | 82.22 | 83.17 | 81.28 | 81.62 | 82.84 | 0.904 |
| SVM1 | 89.78 | 88 | 91.56 | 91.24 | 88.41 | 0.958 |
| Variables | Posterior Probability Cutoff | % of Classified Cases | Accuracy (%) | Sensitivity (%) | Specificity (%) | PPV (%) | NPV (%) | c-Index | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Males | Females | Males | Females | Overall | |||||||
| Logistic regression | |||||||||||
| FEB | 0.691 | 0.883 | 82.05 | 65.94 | 71.94 | 95.08 | 96.14 | 93.77 | 95.05 | 95.13 | 0.978 |
| VHD | 0.741 | 0.994 | 68.28 | 9.50 | 38.89 | 95.21 | 99.76 | 62.57 | 95.04 | 97.27 | 0.898 |
| FVDN | 0.837 | 0.999 | 55.83 | 3 | 28 | 95.09 | 100 | 3.70 | 95 | 100 | 0.872 |
| FBCB | 0.930 | 0.854 | 33.78 | 51.56 | 42.58 | 95.17 | 92.40 | 96.98 | 95.23 | 95.14 | 0.984 |
| FNAL | 0.832 | 0.866 | 48.50 | 53.44 | 50.97 | 95.03 | 94.50 | 95.52 | 95.05 | 95.02 | 0.981 |
| LR1 | 0.734 | 0.778 | 86.94 | 86.22 | 86.58 | 95.03 | 95.08 | 94.97 | 95.02 | 95.04 | 0.980 |
| Discriminant analysis | |||||||||||
| FEB | 0.669 | 0.899 | 82.5 | 67.89 | 75.18 | 95.05 | 96.03 | 93.86 | 95.00 | 95.11 | 0.977 |
| VHD | 0.794 | 0.991 | 68.61 | 11.78 | 40.19 | 95.09 | 99.43 | 69.81 | 95.05 | 95.48 | 0.920 |
| FVDN | 0.838 | 0.999 | 56.28 | 3 | 29.64 | 95.13 | 100 | 3.70 | 95.11 | 100 | 0.894 |
| FBCB | 0.928 | 0.854 | 34.17 | 52.22 | 43.19 | 95.31 | 92.36 | 97.23 | 95.62 | 95.11 | 0.984 |
| FNAL | 0.880 | 0.870 | 48.72 | 53.89 | 51.31 | 95.13 | 94.53 | 95.67 | 95.18 | 95.08 | 0.981 |
| DF1 | 0.726 | 0.867 | 84.39 | 79.94 | 82.17 | 95.03 | 95.33 | 94.72 | 95.01 | 95.05 | 0.977 |
| Boosted glm | |||||||||||
| FEB | 0.625 | 0.830 | 82.39 | 67.83 | 75.11 | 95.04 | 95.95 | 93.93 | 95.06 | 95.02 | 0.978 |
| VHD | 0.705 | 0.975 | 68.67 | 12.67 | 40.67 | 95.22 | 99.51 | 71.93 | 95.05 | 96.47 | 0.926 |
| FVDN | 0.794 | 0.993 | 56.5 | 4.11 | 30.31 | 95.14 | 100 | 28.38 | 95.05 | 100 | 0.918 |
| FBCB | 0.885 | 0.806 | 39.11 | 53.50 | 46.31 | 95.20 | 93.32 | 96.57 | 95.22 | 95.19 | 0.985 |
| FNAL | 0.848 | 0.839 | 48.44 | 52.44 | 50.44 | 95.15 | 94.84 | 95.44 | 95.06 | 95.24 | 0.982 |
| BGLM1 | 0.639 | 0.815 | 85.89 | 78 | 81.94 | 95.05 | 95.54 | 94.52 | 95.05 | 95.06 | 0.979 |
| SVM linear | |||||||||||
| FEB | 0.672 | 0.864 | 81.89 | 66.06 | 73.97 | 95.08 | 96.07 | 93.86 | 95.10 | 95.06 | 0.977 |
| VHD | 0.723 | 0.990 | 68.22 | 10.06 | 39.14 | 95.03 | 99.51 | 64.64 | 95.02 | 95.12 | 0.908 |
| FVDN | 0.830 | 0.998 | 54.33 | 2.94 | 28.64 | 95.34 | 100 | 9 | 95.32 | 100 | 0.903 |
| FBCB | 0.915 | 0.839 | 34.22 | 52.17 | 43.19 | 95.11 | 92.37 | 96.91 | 95.15 | 95.09 | 0.983 |
| FNAL | 0.871 | 0.849 | 48.78 | 52.39 | 50.58 | 95.17 | 94.76 | 95.55 | 95.19 | 95.14 | 0.981 |
| SVM1 | 0.719 | 0.783 | 82.55 | 78.78 | 80.67 | 95.04 | 95.29 | 94.78 | 95.03 | 95.05 | 0.975 |
| Variables | % of Classified Cases | Accuracy (%) | Sensitivity (%) | Specificity (%) | PPV (%) | NPV (%) | c-Index | ||
|---|---|---|---|---|---|---|---|---|---|
| Males | Females | Overall | |||||||
| Logistic regression | |||||||||
| FEB | 80 | 83.33 | 81.67 | 91.84 | 95.83 | 88.00 | 88.46 | 95.65 | 0.987 |
| VHD | 63.33 | 13.33 | 38.33 | 100 | 100 | 100 | 100 | 100 | 1 |
| FVDN | 60 | 0 | 30 | 100 | 100 | / | / | / | / |
| FBCB | 40 | 53.33 | 46.67 | 96.43 | 91.67 | 100 | 100 | 94.12 | 0.953 |
| FNAL | 36.66 | 66.67 | 53 | 100 | 100 | 100 | 100 | 100 | 1 |
| LR1 | 90 | 90 | 90 | 98.15 | 96.30 | 100 | 100 | 96.43 | 0.989 |
| Discriminant analysis | |||||||||
| FEB | 80 | 83.33 | 81.67 | 91.84 | 95.83 | 88.00 | 88.46 | 95.65 | 0.987 |
| VHD | 66.33 | 13.33 | 38.33 | 100 | 100 | 100 | 100 | 100 | 1 |
| FVDN | 60 | 0 | 30 | 100 | 100 | / | / | / | / |
| FBCB | 40 | 53.33 | 46.67 | 96.43 | 91.67 | 100 | 100 | 94.12 | 0.953 |
| FNAL | 40 | 66.67 | 53.33 | 100 | 100 | 100 | 100 | 100 | 1 |
| DF1 | 86.67 | 93.33 | 90 | 98.15 | 96.15 | 100 | 100 | 96.55 | 0.990 |
| Boosted glm | |||||||||
| FEB | 80 | 83.33 | 81.67 | 91.84 | 95.83 | 88 | 88.46 | 95.65 | 0.987 |
| VHD | 63.33 | 13.33 | 38.33 | 100 | 100 | 100 | 100 | 100 | 1 |
| FVDN | 63.33 | 0 | 31.67 | 100 | 100 | / | / | / | / |
| FBCB | 40 | 60 | 50 | 96.67 | 91.67 | 100 | 100 | 94.74 | 0.951 |
| FNAL | 40 | 66.67 | 53.33 | 100 | 100 | 100 | 100 | 100 | 1 |
| BGLM1 | 90 | 90 | 90 | 98.15 | 96.30 | 100 | 100 | 96.43 | 0.989 |
| SVM Linear | |||||||||
| FEB | 80 | 83.33 | 81.67 | 91.84 | 95.83 | 88 | 88.46 | 95.65 | 0.987 |
| VHD | 63.33 | 13.33 | 38.33 | 100 | 100 | 100 | 100 | 100 | 1 |
| FVDN | 60 | 0 | 30 | 100 | 100 | / | / | / | / |
| FBCB | 40 | 53.33 | 46.67 | 96.43 | 91.67 | 100 | 100 | 94.12 | 0.953 |
| FNAL | 43.33 | 66.67 | 55 | 96.67 | 92.31 | 100 | 100 | 95.24 | 1 |
| SVM1 | 90 | 93.33 | 91.67 | 98.18 | 96.30 | 100 | 100 | 96.55 | 0.991 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Attia, M.H.; Kholief, M.A.; Zaghloul, N.M.; Kružić, I.; Anđelinović, Š.; Bašić, Ž.; Jerković, I. Efficiency of the Adjusted Binary Classification (ABC) Approach in Osteometric Sex Estimation: A Comparative Study of Different Linear Machine Learning Algorithms and Training Sample Sizes. Biology 2022, 11, 917. https://doi.org/10.3390/biology11060917
Attia MH, Kholief MA, Zaghloul NM, Kružić I, Anđelinović Š, Bašić Ž, Jerković I. Efficiency of the Adjusted Binary Classification (ABC) Approach in Osteometric Sex Estimation: A Comparative Study of Different Linear Machine Learning Algorithms and Training Sample Sizes. Biology. 2022; 11(6):917. https://doi.org/10.3390/biology11060917
Chicago/Turabian StyleAttia, MennattAllah Hassan, Marwa A. Kholief, Nancy M. Zaghloul, Ivana Kružić, Šimun Anđelinović, Željana Bašić, and Ivan Jerković. 2022. "Efficiency of the Adjusted Binary Classification (ABC) Approach in Osteometric Sex Estimation: A Comparative Study of Different Linear Machine Learning Algorithms and Training Sample Sizes" Biology 11, no. 6: 917. https://doi.org/10.3390/biology11060917
APA StyleAttia, M. H., Kholief, M. A., Zaghloul, N. M., Kružić, I., Anđelinović, Š., Bašić, Ž., & Jerković, I. (2022). Efficiency of the Adjusted Binary Classification (ABC) Approach in Osteometric Sex Estimation: A Comparative Study of Different Linear Machine Learning Algorithms and Training Sample Sizes. Biology, 11(6), 917. https://doi.org/10.3390/biology11060917