1. Introduction
Additive manufacturing (AM), as a novel and fast-developing method for producing parts, enables the fabrication of complex geometries and customized components with minimal material waste compared to traditional “subtractive” and “equal-material” manufacturing methods. Its layer-by-layer deposition process offers huge flexibility, allowing parts to be precisely built according to pre-designed digital models [
1,
2]. As a “bottom-up” material accumulation method for fabricating parts, AM imposes new requirements in terms of process technology, materials, production environments, process monitoring, and industrial chains. It represents a disruptive innovation in traditional manufacturing and has garnered extensive attention from both industry and academia. Governments worldwide have formulated policy frameworks to prioritize its development, such as “Made in China 2025” (China), the “National Strategic Plan for Advanced Manufacturing” (USA), and the “Industrial 4.0 Strategic Plan Implementation Recommendations” (Germany). Under these national strategies, AM has been elevated to a critical developmental focus, giving rise to diverse manufacturing technologies. Currently, AM is widely applied across aerospace, transportation, nuclear power, defense, medical devices, energy, automotive manufacturing, and other fields [
3].
As the most cutting-edge and challenging technology within the AM system, metal AM technology represents a critical direction for advanced manufacturing development. It is poised to become a key pathway for achieving generational leaps in the structural performance of high-end industrial equipment. Current research on metal AM primarily focuses on four fabrication methods: Selective Laser Melting (SLM), Laser Metal Deposition (LMD), Electron Beam Melting (EBM), and Wire Arc Additive Manufacturing (WAAM) [
4]. However, the unique fabrication process of metal additive manufacturing components inherently induces damage precursors—such as low-density zones, residual stresses, and cracks—that degrade device performance. Pore-type damage precursors typically range from 5 µm to 20 µm in size, elongated damage precursors measure approximately 50 µm to 500 µm, and crack-type precursors exhibit lengths and openings generally below 100 µm. The presence of these precursors poses significant safety risks to precision-critical industries. Consequently, detecting and identifying various damage precursor types in metal AM components is crucial, as it not only enhances material utilization but also ensures operational safety in industrial applications. Traditional non-destructive evaluation (NDE) methods for damage precursors include X-ray inspection, ultrasonic testing, liquid penetrant testing, magnetic particle testing, and eddy current testing [
5]. Although traditional methods provide high detection accuracy, they suffer from elevated costs, operational complexity, and an inability to reconcile inspection precision with speed. In certain cases, these limitations may fail to fully meet practical production requirements. Consequently, it is imperative to develop a more efficient and cost-effective damage precursor inspection method.
In recent years, deep learning technologies have grown rapidly, with diverse machine learning and deep learning techniques being applied to the monitoring of AM processes. This trend has driven a gradual convergence toward smart manufacturing, paving the way for a hopeful future in intelligent industrial production [
6,
7,
8]. To detect damage precursors on liquid crystal display (LCD) panels, Chen et al. proposed a lightweight YOLO-ADPAM inspection method based on YOLOv4, incorporating an attention mechanism. First, they designed a K-means-CIoU++ clustering algorithm to cluster anchor box sizes within the damage dataset, enabling more accurate and stable bounding box regression. Subsequently, a parallel attention module was introduced, integrating the strengths of channel and spatial attention mechanisms to effectively enhance the network’s detection accuracy [
9]. To address the issue of slow detection speed in wind turbine surface damage precursor models, Zhang proposed a lightweight YOLOv5s-based inspection model. The YOLOv5s backbone network was replaced with a MobileNetv3 lightweight network for feature extraction, harmonizing and balancing the model’s lightweight design and accuracy. The final implementation achieved a 5.51% improvement in mean average precision and a 10.79 frames-per-second reduction in detection time compared to the original YOLOv5s model [
10].
Although existing deep learning-based methods have achieved high detection accuracy, they still face challenges in acquiring large-scale training samples and high annotation costs in practical applications. To address this, Zhu et al. utilized transfer learning by pre-training on an open-source damage precursor dataset (NEU-DEF). After transferring model parameters, they fine-tuned the model using their dataset of 240 small-sample objects, achieving a final mAP50 of 62% [
11]. In the inspection of damage precursors in photovoltaic (PV) cells, Wang et al. adopted the YOLOX model as the backbone network and implemented a transfer learning strategy to accelerate model convergence, mitigating accuracy limitations caused by the limited sample size of damage precursors. This method achieved promising results on the Photovoltaic Electroluminescence Anomaly Inspection dataset (PVEL-AD), attaining a mAP of 96.7% and a detection speed of 71.47 FPS [
12]. Li et al. integrated real experimental images obtained from a shearing imaging device to execute and discuss hybrid training strategies for deep learning-based damage precursor inspection. Their work demonstrated that, even with a limited number of experimental training images, the generalization capability of the deep learning network can be significantly enhanced without using any real damage precursor samples, shearing systems, or artificially generated simulated datasets [
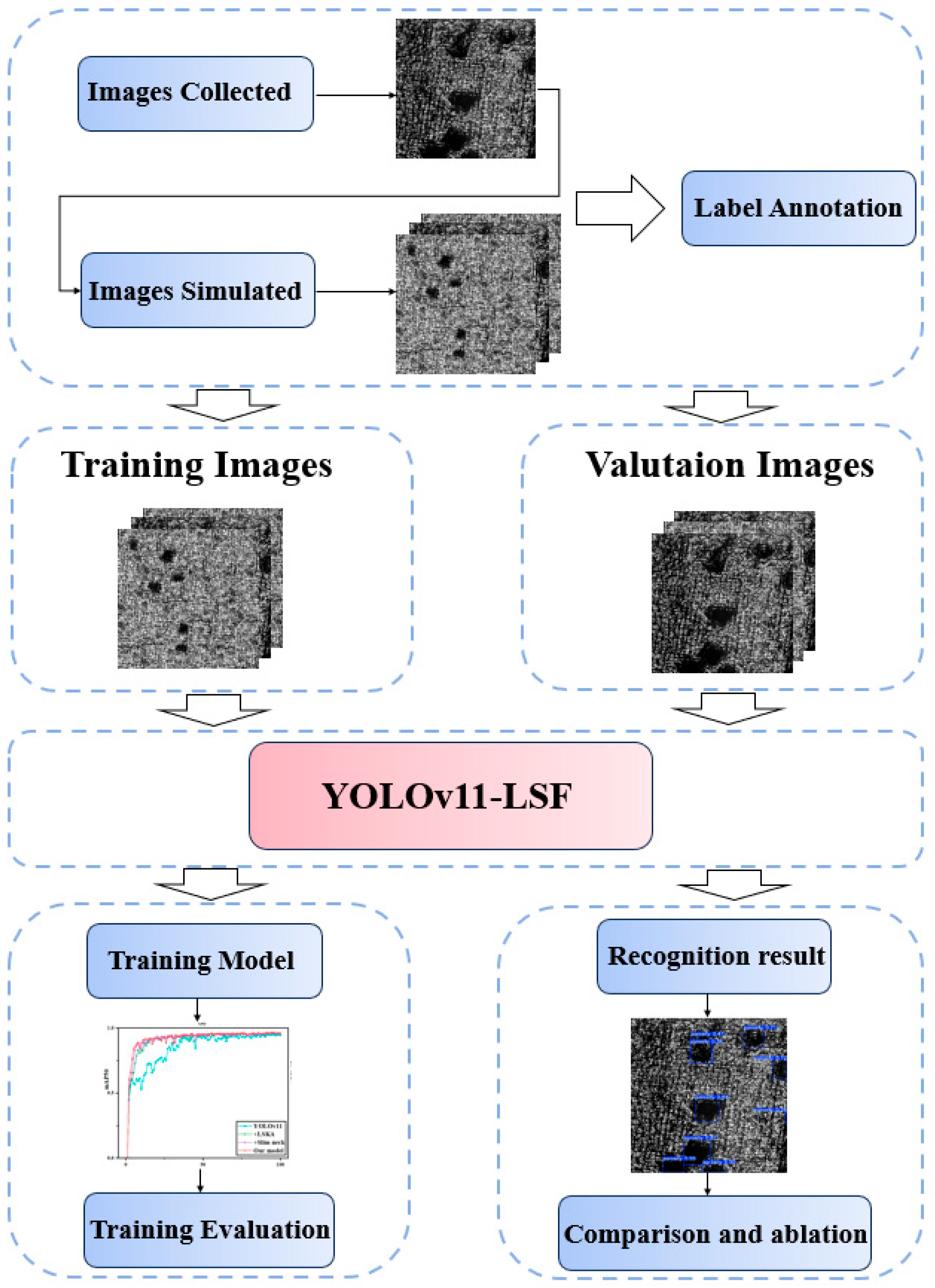
13]. To further improve the detection accuracy and speed of surface damage precursors in AM components, this study proposes the following enhancements to the YOLOv11 network architecture: (1) The Large Separable Kernel Attention is introduced into the original C2PSA module in the backbone, enhancing the model’s multi-scale adaptability and focus on target regions while suppressing interference from complex backgrounds on the component surfaces. (2) A Slim-neck structure is designed to reduce the model’s complexity without sacrificing accuracy, thereby accelerating detection speed. (3) For training, a hybrid strategy combining real damage precursor images captured by a custom hardware platform with simulated data is adopted, which addresses the challenge of acquiring sufficient training samples.
The main contributions of this paper are as follows:
The LSKA technique was incorporated into the Backbone by integrating it into the C2PSA module of YOLOv11. This configuration enhances the model’s performance in three dimensions: improving multi-scale target detection capability, strengthening focus on critical regions, suppressing interference from complex background information, and ultimately achieving synergistic optimization of detection accuracy and classification performance.
The construction of Slim-neck through the introduction of GSConv and VoV-GSCSP modules, which reduces the complexity of convolutional operations while effectively fusing feature maps from different stages. This design accelerates detection speed without losing accuracy, making the network more adaptable to real-time inspection requirements.
Synthetic damage precursor images are generated based on precursor features extracted from AM component surfaces using a hardware system. These synthetic images are combined with real captured damage precursor images to form a hybrid training dataset, effectively solving the challenge of not having enough training samples for damage precursor inspection networks.
This study innovatively integrates polarization imaging technology with deep learning algorithms, breaking the limitations of traditional detection methods imposed by target surface temperature and high-reflectance phenomena. The proposed approach effectively suppresses background clutter interference and achieves clear extraction of damage precursor features in complex environments. Through dual optimization of high-precision detection and geometric texture information reconstruction, the accuracy and reliability of inspection results are significantly enhanced. This technological breakthrough establishes a crucial foundation for quality control and safety assurance in related fields.
The structure of this paper is organized as follows:
Section 2 covers the surface damage precursor acquisition system of AM components, the hybrid training strategy integrating collected and synthetically generated precursor features, and the implementation methodology for damage precursor inspection experiments.
Section 3 breaks down the YOLOv11 model, the integration of the LSKA attention mechanism, and the proposed YOLOv11-LSF model with the Slim-neck architecture.
Section 4 presents the experiments on damage precursor inspection model training and analyzes the results.
Section 5 summarizes the key findings and discusses future research directions.
3. Proposed Method
3.1. YOLOv11 Model
In 2015, Redmon et al. dropped the You Only Look Once (YOLO) algorithm, marking a pivotal breakthrough in the field of object detection [
14]. This innovative method, as its name implies, processes the entire image in a single channel to detect objects and their locations. Diverging from the traditional two-stage detection process, the YOLO method frames object detection as a regression problem, thereby simplifying the detection pipeline compared to conventional methods. As the latest iteration in the YOLO series, YOLOv11 builds on the foundation of YOLOv1 and represents a significant leap in real-time object detection technology. Unveiled at the YOLO Vision 2024 (YV24) conference, YOLOv11 shows off the cutting-edge advancements in the field [
15]. The release of YOLOv11 has provided a robust foundation for our research. Furthermore, the advanced nature of YOLOv11 signifies its enhanced adaptability and scalability, which are critical to addressing challenges in specific vision tasks. However, we also recognize certain limitations of the YOLOv11 model in practical applications [
16]. For example, the model requires further improvement in accuracy and speed for practical applications and is less effective for samples with data acquisition challenges.
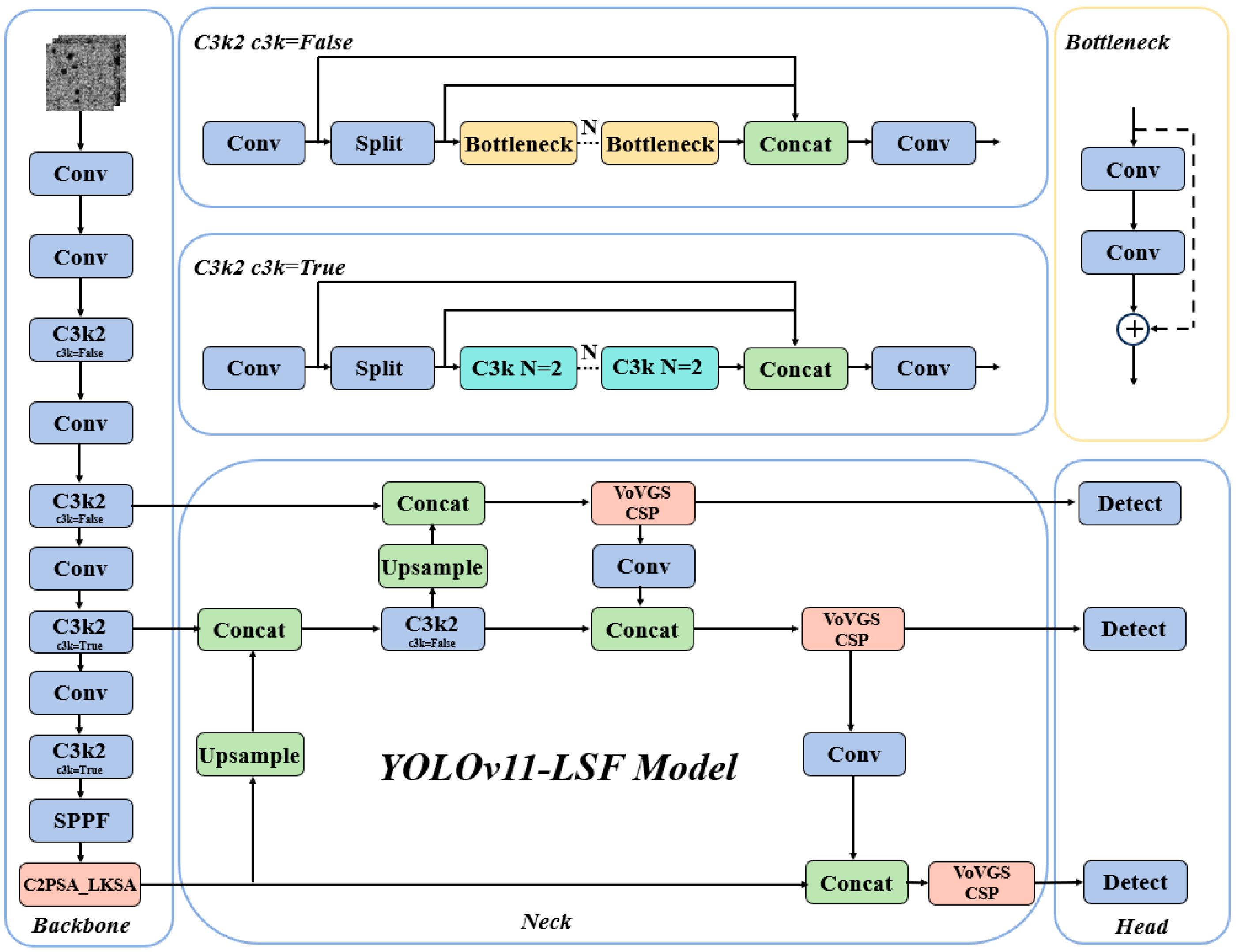
These challenges are particularly critical for our research because our objective is to develop an efficient and practical damage inspection system. Furthermore, while processing targets with significant scale variations, such as pores and scratches, the detection accuracy of YOLOv11 still needs improvement. This indicates that while YOLOv11 performs well in many aspects, more optimizations and adjustments are required for specific applications, such as AM damage precursor detection. This study proposes two improvements to the YOLOv11 network architecture. The enhanced architecture primarily comprises three components: the Backbone network, Neck network, and Head network, with its model structure illustrated in
Figure 5. First, the LSKA attention mechanism is integrated into the backbone, which replaces the original C2PSA module with the C2PSA_LKSA module, to enhance multi-scale target detection capabilities and improve the model’s overall detection and classification performance. Second, considering that introducing attention mechanisms may increase model complexity, a lightweight grouped convolution based on the Slim-neck concept is adopted to construct the VoV-GSCSP module, which enables the efficient fusion of feature maps across different stages. This achieves reduced computational complexity without sacrificing accuracy.
3.2. C2PSA_LKSA Module
Enhancing AM damage precursor detection requires models to adapt to multi-scale features, especially when identifying targets with extreme size variations like pores and scratches. Large kernel convolutions expand the receptive field and enhance global modeling capabilities, providing a stronger contextual understanding for target detection, which is especially suitable for multi-scale target localization and classification in complex scenarios. However, introducing large-kernel convolutions may lead to quadratic growth in computational and memory overhead, hindering the practical deployment of the model. The principle of LSKA attention addresses the limitations of the traditional Large Kernel Attention (LKA) module in Visual Attention Networks (VAN). The LKA module struggles with high computational and memory requirements when processing large-kernel convolutions. LSKA attention tackles these challenges through innovative kernel decomposition and cascaded convolution strategies, reducing computational and memory costs while preserving efficient image processing capabilities [
17]. The main formula of LSKA operation is as follows:
The input feature map
Undergoes factorized convolution processing:
here, ∘ denotes operation cascade, and
represents a depth wise separable convolution with a dilation rate of
d.Channel dimension is compressed via
convolution to generate attention weights:
In the formula, denotes the learnable 1×1 convolution kernel, ∗ represents the convolution operation, and the output is the spatial attention map.
Finally, feature enhancement is achieved via Hadamard product:
where
denotes the element-wise product, preserving the original feature resolution.
In this study, we introduce the LSKA attention mechanism into the backbone and propose the C2PSA_LKSA module, which enhances the model’s capability to detect multi-scale targets and focus on key regions without introducing excessive parameters. The structure of the C2PSA_LKSA module is illustrated in
Figure 6.
The C2PSA is a novel spatial attention module introduced in YOLOv11 after the feature pyramid module to enhance spatial attention in feature maps. This spatial attention mechanism allows the model to focus more effectively on critical regions within images. By spatially aggregating features, the C2PSA module enables YOLOv11 to concentrate on specific regions of interest, thereby potentially improving the detection accuracy for objects of varying sizes and locations. However, the traditional C2PSA module struggles to adapt to targets of varying scales. The introduction of the LKSA attention mechanism effectively addresses this limitation. The LSKA attention mechanism, the core of the C2PSA_LKSA module, differentiates itself from conventional large-kernel convolutions through an innovative strategy of kernel decomposition and cascaded convolutional operations. This approach enhances the model’s ability to detect multi-scale targets and focus on critical regions while avoiding excessive parameter expansion. Additionally, it suppresses interference from complex background information, thereby improving the model’s overall detection and classification accuracy in a computationally efficient manner.
3.3. Slim-Neck
While attention mechanisms can effectively enhance a model’s ability to detect multi-scale targets and focus on critical regions, they may inadvertently increase model complexity. To mitigate this issue and reduce complexity without sacrificing accuracy, we introduce
GSConv (Gather-and-Scatter Convolution) into the neck. Building upon the GSbottleneck, we design a cross-level fractional network module—termed the VoV-GSCSP module—using a single-aggregation strategy. Finally, the Slim-Neck, composed of
GSConv and VoV-GSCSP, simplifies computational and architectural complexity while maintaining high accuracy. The VoV-GSCSP module proposed in this work constructs a Path Aggregation Feature Pyramid Network, which seamlessly integrates the PAFPN with multi-scale information to achieve comprehensive feature fusion [
18]. In the backbone network of CNNs, input images almost always undergo a similar transformation process: spatial information is progressively transferred to the channel dimension. Each spatial compression and channel expansion of feature maps leads to a partial loss of semantic information. Channel-dense convolutions preserve the implicit connections between channels to the greatest extent, whereas channel-sparse convolutions completely sever these connections.
GSConv optimally preserves these connections while achieving lower computational complexity [
19]; its computational process can be decomposed as follows:
where
denotes Deep Separable Convolution,
represents Standard Convolution,
stands for Deep Convolution,
is the pointwise convolution kernel,
and
are learnable channel attention coefficients, and σ denotes the Swish/Mish nonlinear activation function. This dual-branch structure achieves an approximately 60% reduction in theoretical computational cost (FLOPs) compared to standard convolution, while the
branch compensates for the feature degradation inherent to
.
Figure 7 illustrates the data processing pipeline of
GSConv within a convolutional neural network. The input feature map first passes through a Standard Convolution (
) layer, followed by a Depthwise Separable Convolution (
) layer. Finally, the outputs of these two convolutional layers are concatenated, and a Shuffle Operation is applied to the merged feature map to optimize cross-channel feature representations. In this study, building upon
GSConv, we further investigate GSbottleneck and VOV-GSCSP, whose architectures are illustrated in
Figure 8. The GSbottleneck module is designed to enhance the network’s feature processing capability by stacking
GSConv modules to amplify model learning capacity. The VoV-GSCSP module adopts divergent structural designs to improve feature utilization efficiency and network performance, with its computational workflow defined as follows:
The Split operation divides the input channels into two parts, processes only the primary branch through n GSbottleneck operations, and finally achieves feature fusion via a convolution.
These module designs embody the Slim-neck philosophy, aiming to reduce computational complexity and inference time while maintaining accuracy. Through such modular design, the network architectures can be flexibly constructed to suit specific tasks as needed.
5. Conclusions
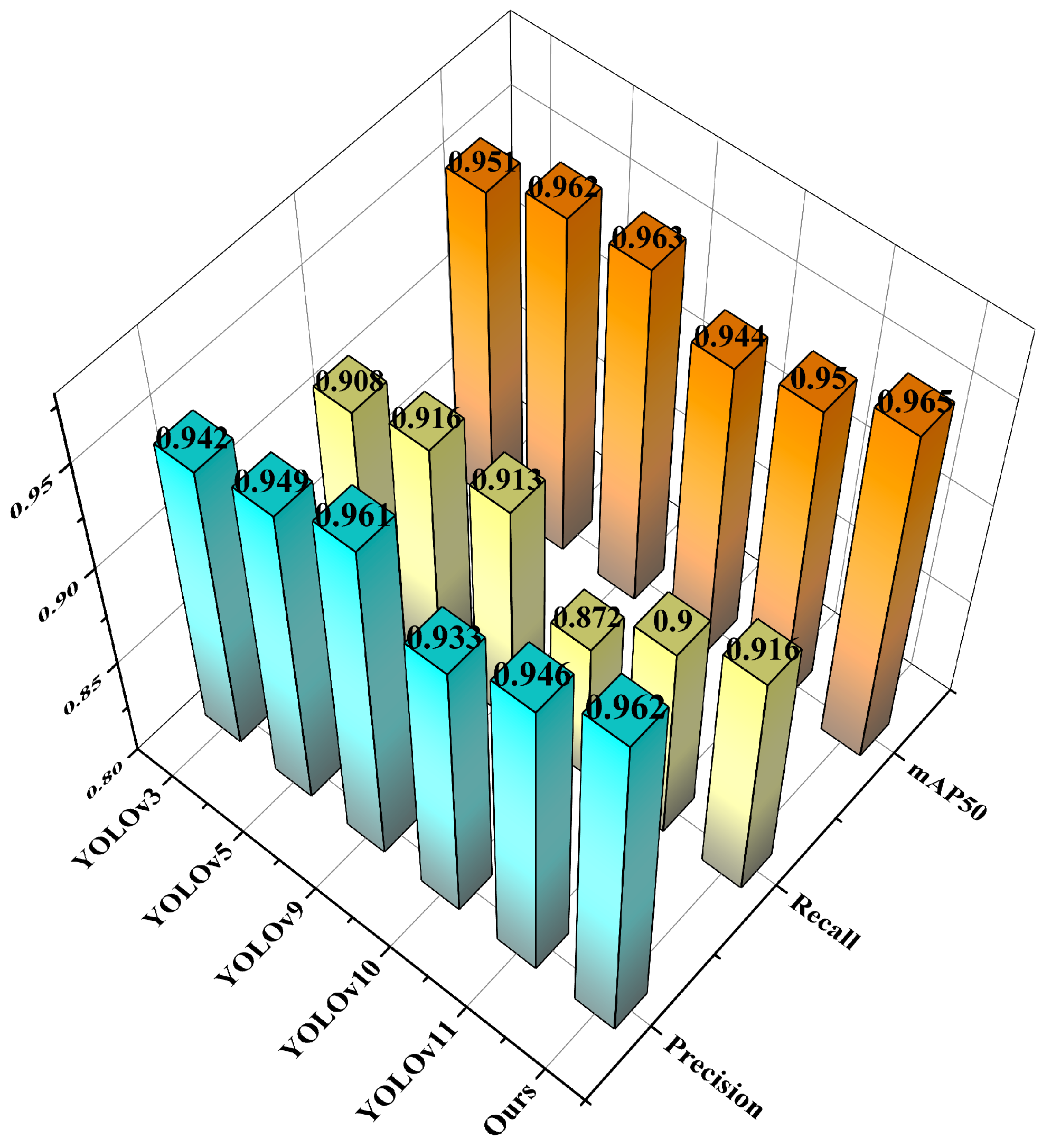
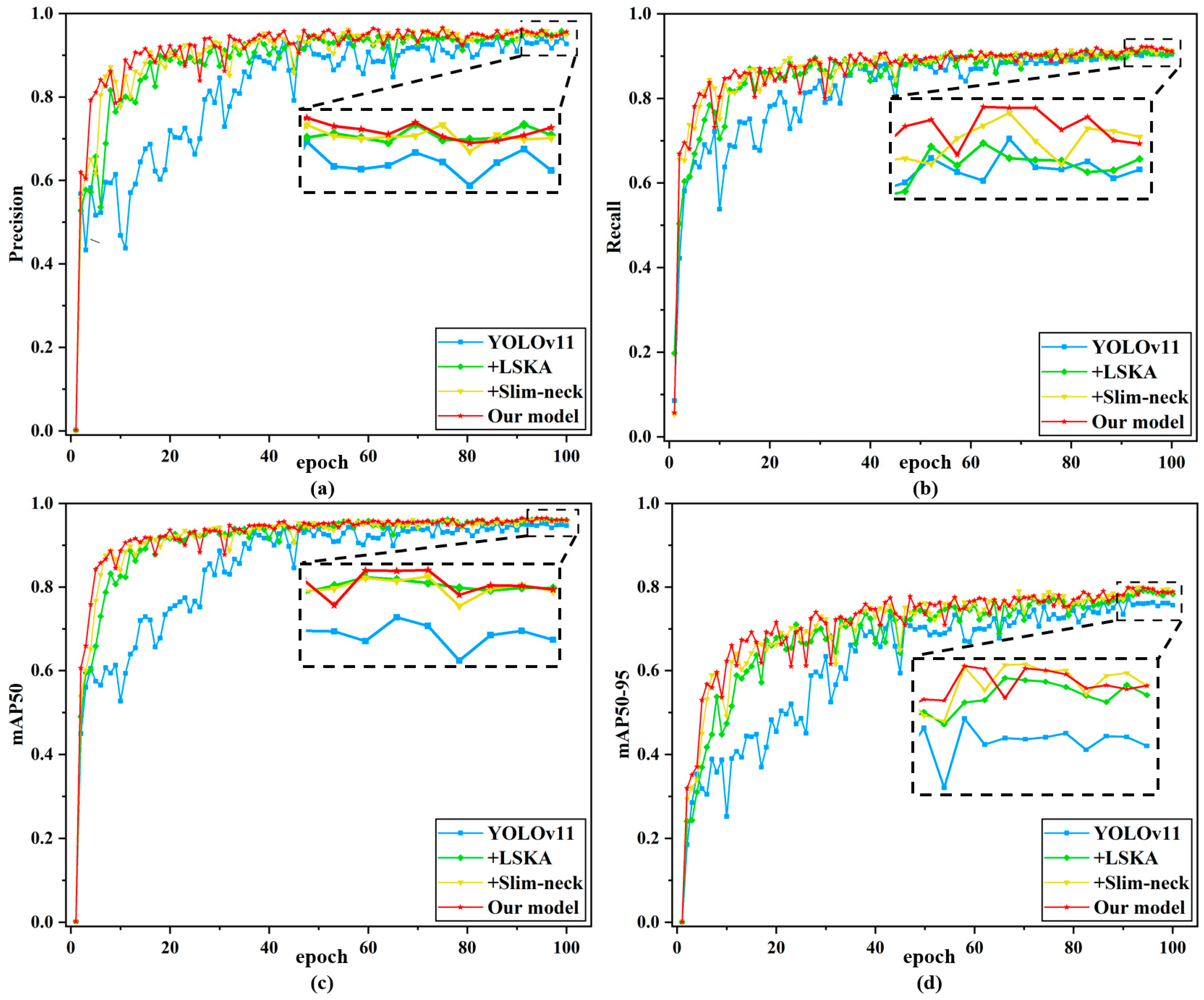
This paper mainly focuses on enhancing detection accuracy and efficiency for surface damage precursors in additive manufacturing components by proposing YOLOv11-LSF, an efficient detection network. Experimental validations yield the following conclusions. First, regarding model training, we performed feature-level simulations of damage precursors in hardware-collected data, then implemented a hybrid training strategy combining captured and simulated datasets. As a result, we effectively resolved the challenge of insufficient training samples. Through quantitative experimental analysis, this study conducts comparative experiments between the improved model and YOLOv3, YOLOv5, YOLOv9, YOLOv10, and YOLOv11. The results demonstrate that the proposed YOLOv11-LSF model achieves the highest detection accuracy and optimal overall performance, with significant improvements in precision for various damage precursor categories. These findings further validate the feasibility and practicality of the YOLOv11-LSF algorithm in detecting surface damage precursors for additive manufacturing. Ablation experiments prove the effectiveness of each module. By improving the C2PSA module in the original network architecture, designing the cross-stage local network VoV-GSCSP using GSConv and a single-path aggregation strategy, and constructing the Slim-neck structure, the model achieves the best performance. Compared to YOLOv11, the proposed YOLOv11-LSF demonstrates improvements of 1.6% in precision, 1.6% in recall, 1.5% in mAP50, and 2.8% in mAP50-95, further confirming its superiority in detecting surface damage for additive manufacturing.
While the proposed model demonstrates strong adaptability to multi-scale targets, it still has certain limitations [
35]. For instance, the model hits an impressive detection accuracy of 99% for porosity-related damage precursors, while its accuracy for cracks remains at 94%, indicating more work for improvement compared to porosity detection. The study attributes this discrepancy to two factors: cracks exhibit linear/dendritic/irregular shapes with micrometer-scale fissures, showing greater morphological diversity than porosity’s circular/elliptical pores. Such morphological diversity hinders the model from establishing unified feature representations. Additionally, cracks demonstrate greater randomness in length, width, and orientation, whereas porosity maintains at relatively stable sizes and shape distributions. These more complex scale variations substantially increase the model’s learning difficulty. Additionally, although the introduced attention mechanism enhances the model’s adaptability to multi-scale targets, it also increases model complexity. Therefore, we hope to design more lightweight attention mechanisms or methods in future work to strengthen the model’s capability to adapt to multi-scale targets.



 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

