Chinese Microblog Topic Detection through POS-Based Semantic Expansion


Abstract
:1. Introduction
2. Materials and Methods
2.1. Semantic Representation of Chinese Microblog Posts
2.1.1. Initial Representation
2.1.2. Key Feature Extraction
- Time (with Date)
- Place
- People
- Event
- Theme
2.1.3. Semantic Representation Based on TYCCL
2.2. Microblog Clustering and Topic Detection
2.2.1. Microblog Post Clustering Based on the Single-Pass Algorithm
| Algorithm 1: Single-pass clustering based on 1NN |
| Step 1. Load the microblog data /* Process the microblog posts serially */ Step 2. Create the first cluster with the first post /* the first post is regarded as a cluster */ Step 3. For each subsequent post Calculate the cosine similarity between the current post and each clustered post If the similarity exceeds a specified threshold /* compare the current post with each post that has been clustered */ Add the current post into the cluster of the clustered post/* this cluster contains the post to which the current post is the most similar */ Else Create a new cluster with the current post /* the current post is regarded as a new cluster */ End for Step 4. Output all the clusters |
| Algorithm 2: Single-pass clustering based on dynamic model |
| Step 1. Load the microblog data /* Process the microblog posts serially */ Step 2. Create the first cluster with the first post and take the representation of the first post as the initial model of the first cluster /* the first post is regarded as a cluster and the representation of the first post is the initial representation of the first cluster.*/ Step 3. For each subsequent post Calculate the cosine similarity between the current post and each cluster If the similarity exceeds a specified threshold /* compare the current post with each cluster’s model */ Add the current post into the cluster of the clustered post/* the model of this cluster is the most similar to the current post */ Update the model of this cluster according to the current post /* the representation of the cluster is modified by the current post */ Else Create a new cluster with the current post /* the current post is regarded as a new cluster and its representation works as the initial model of this cluster.*/ End for Step 4. Output all the clusters |
2.2.2. IDF Calculation and Topic Representation
2.2.3. Topic Tracking and Detection Based a Joint of Classification and Clustering
3. Experiments and Results
3.1. Data Collection and Preprocessing
3.2. Evaluation Criteria
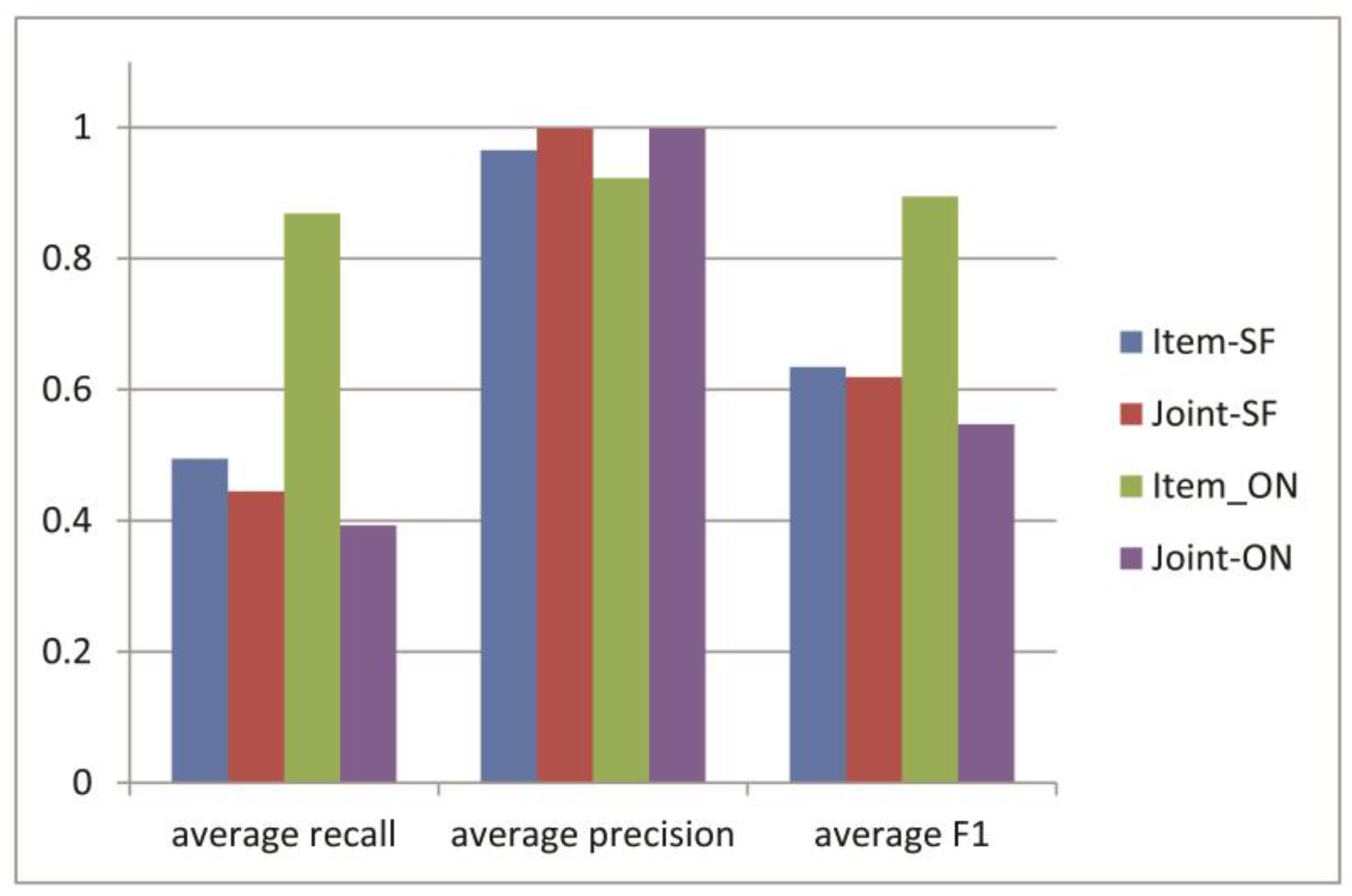
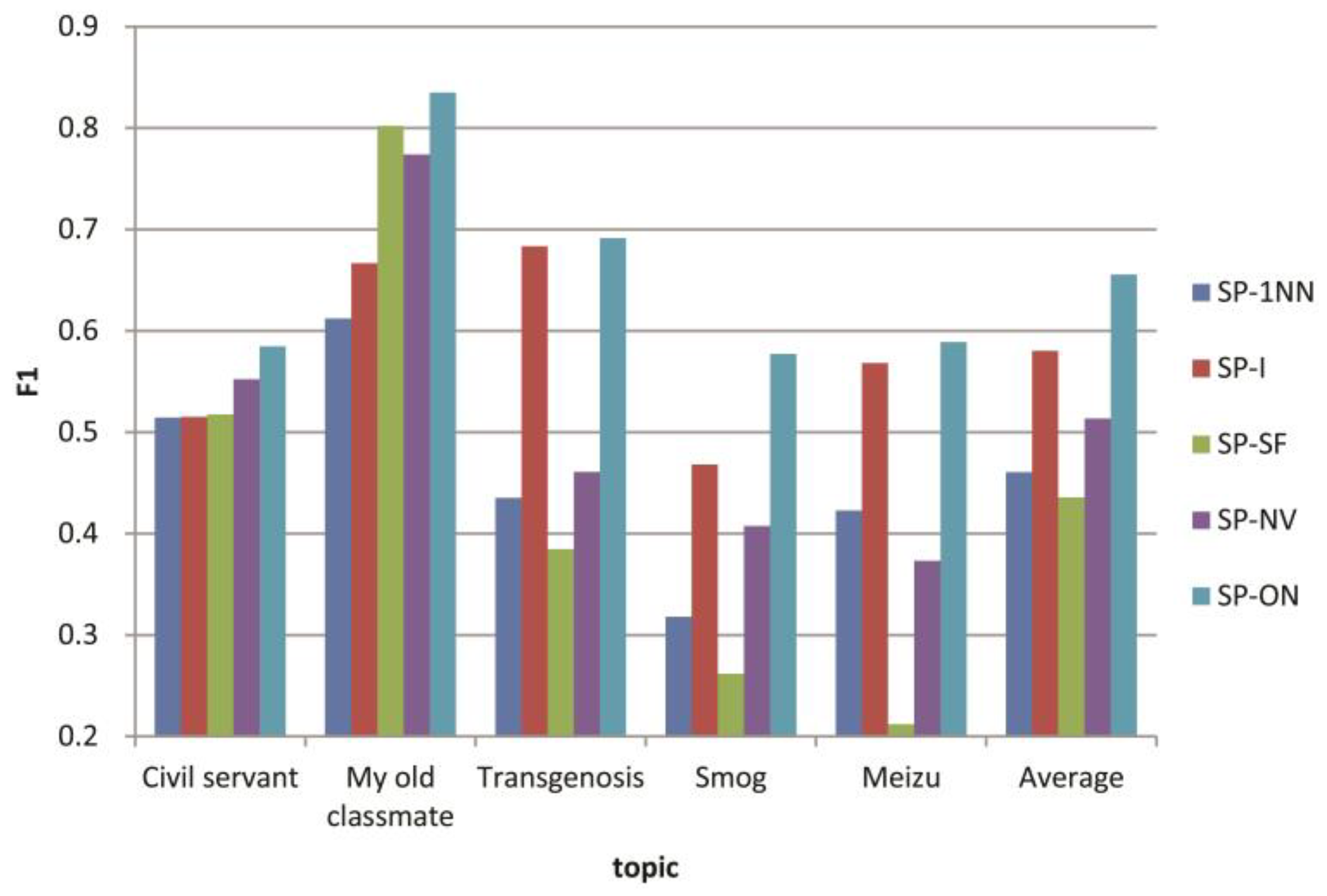
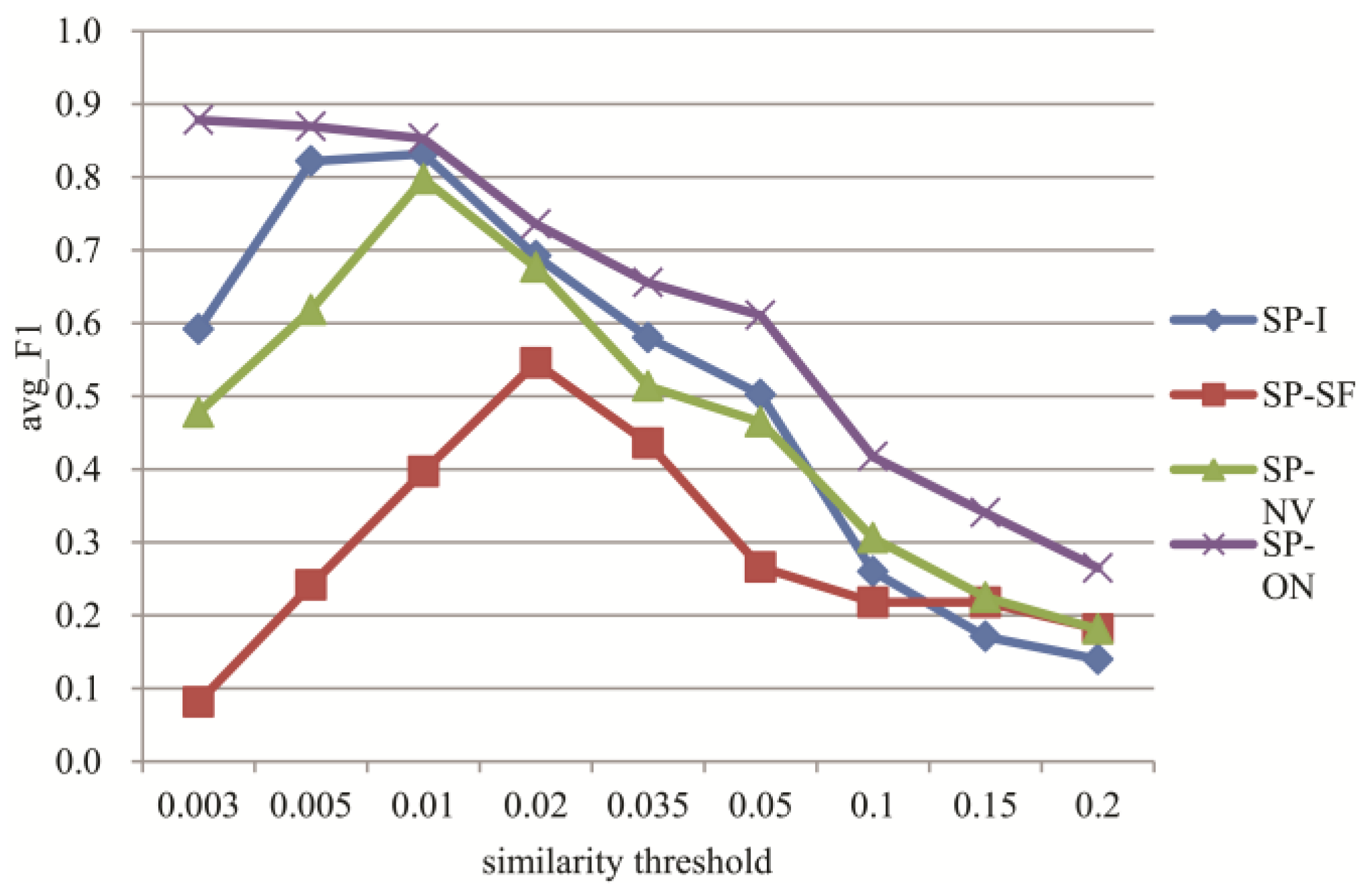
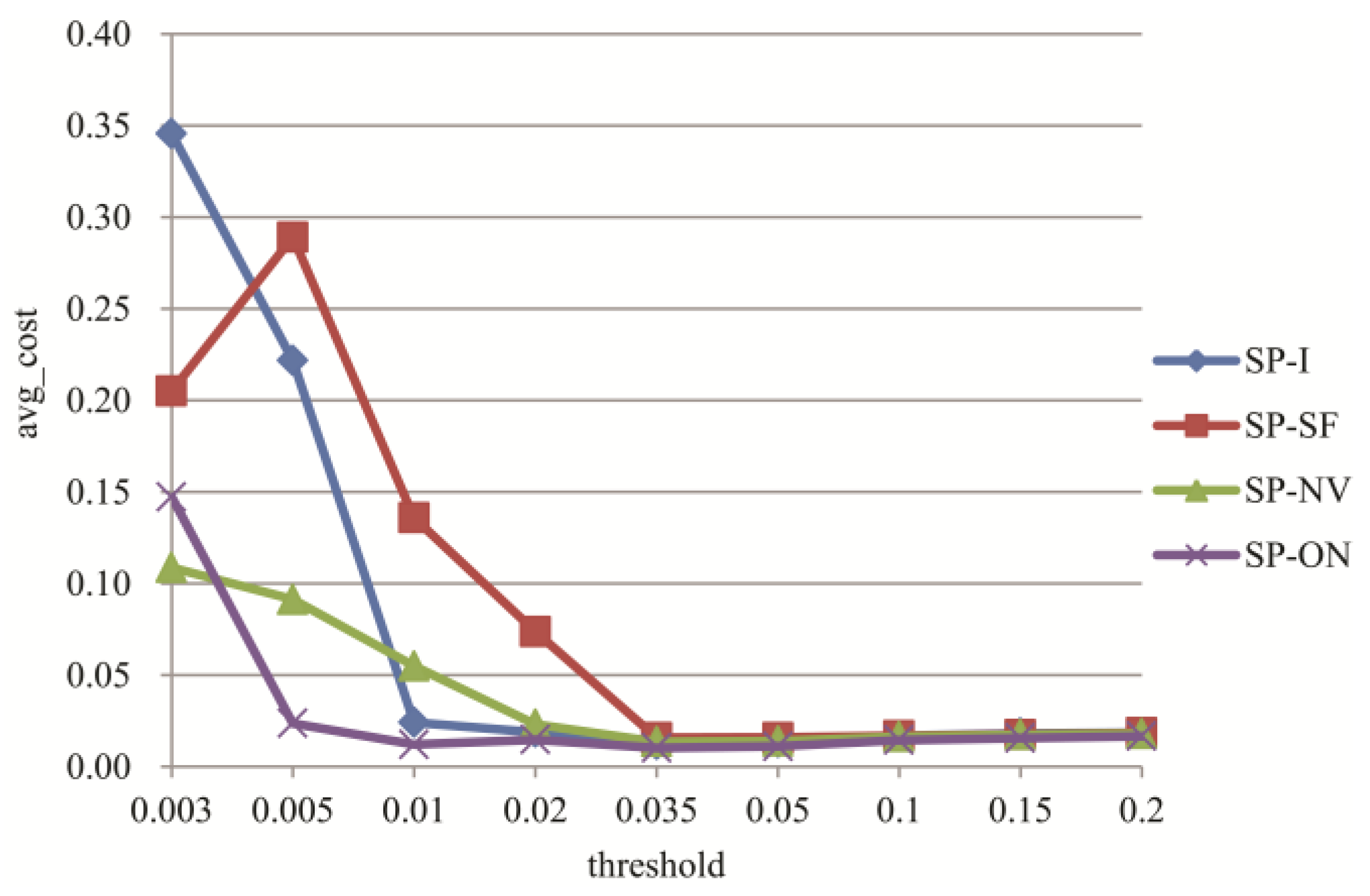
3.3. Experiments for Microblog Clustering Algorithm
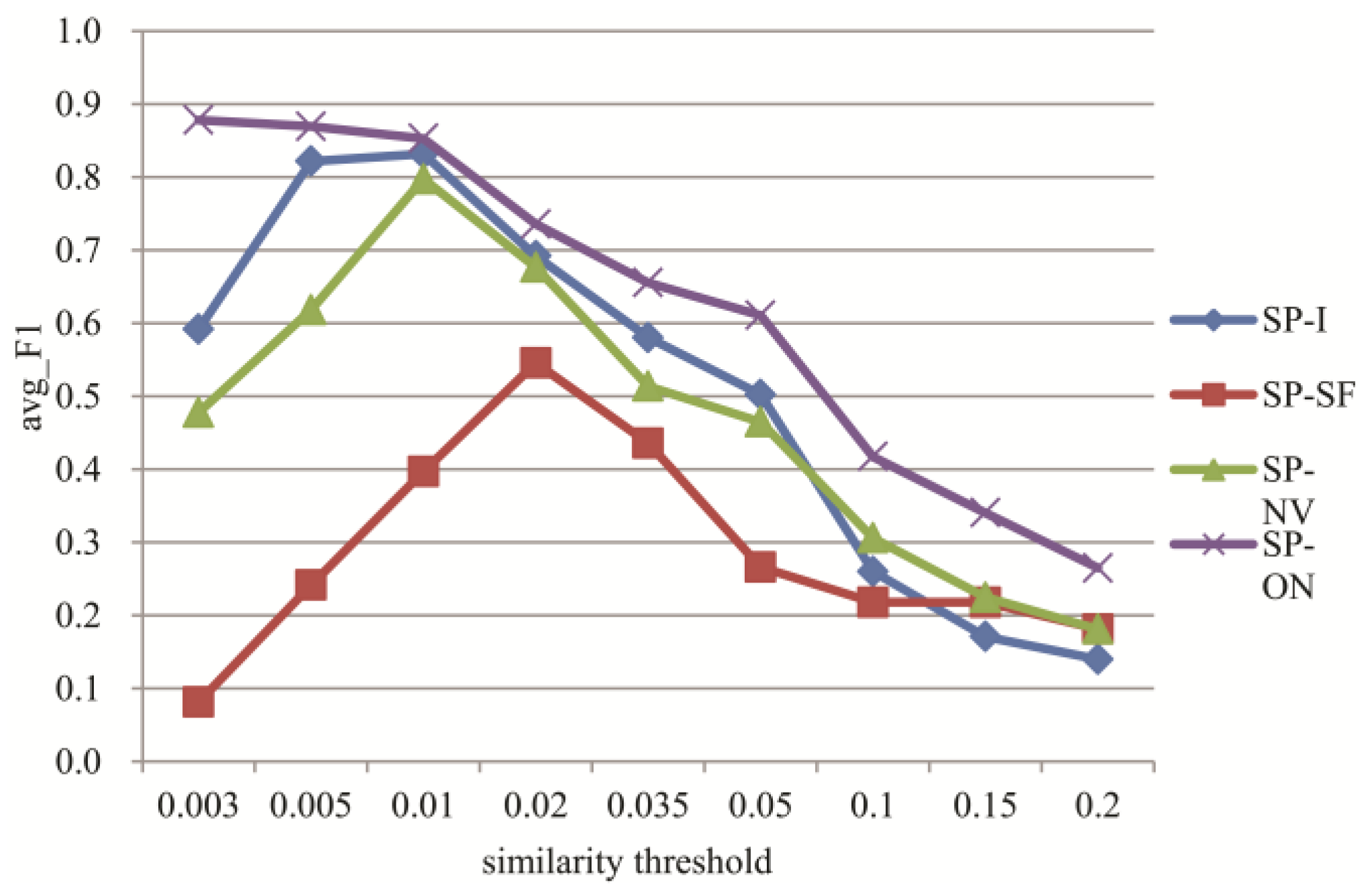
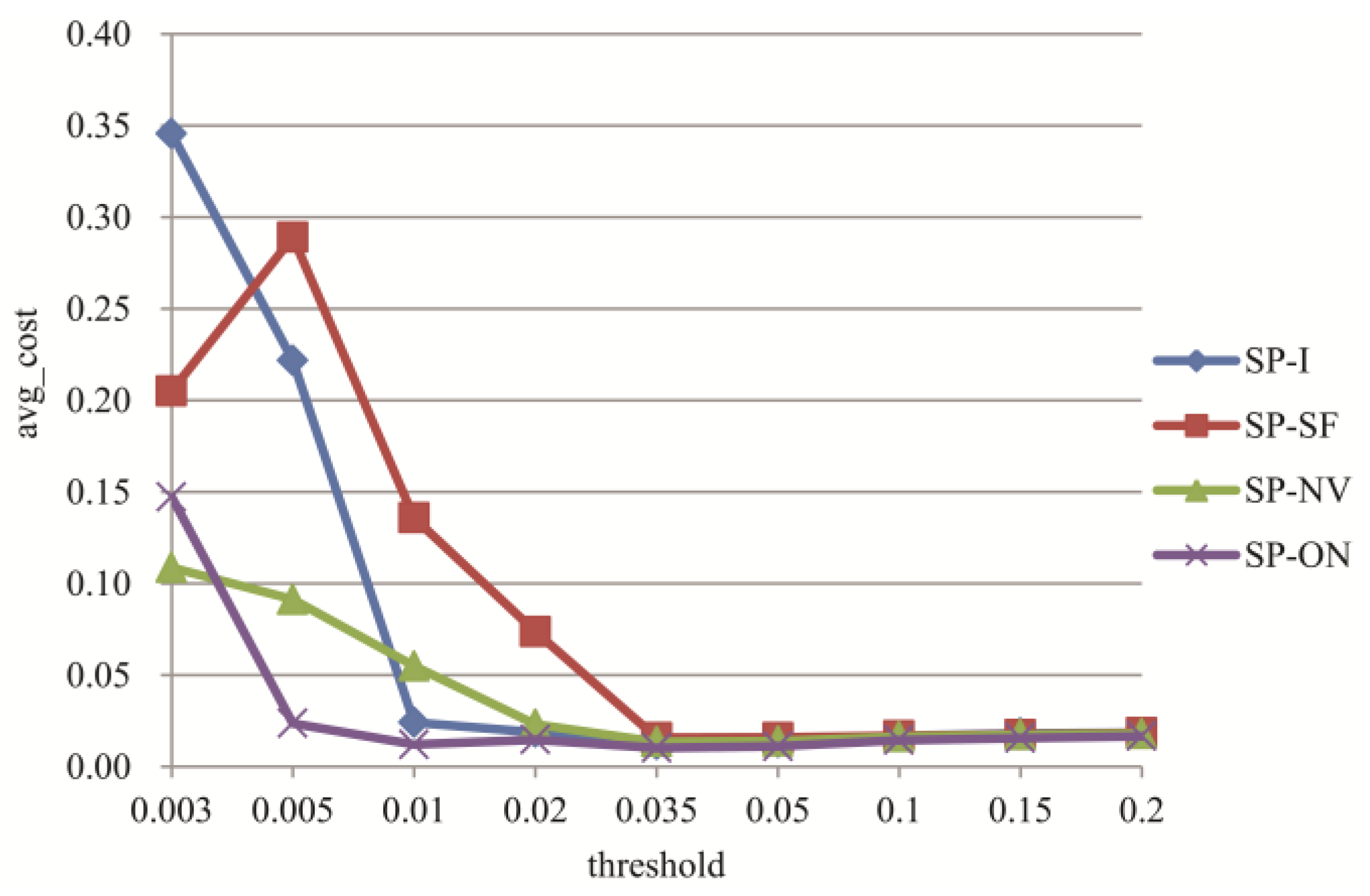
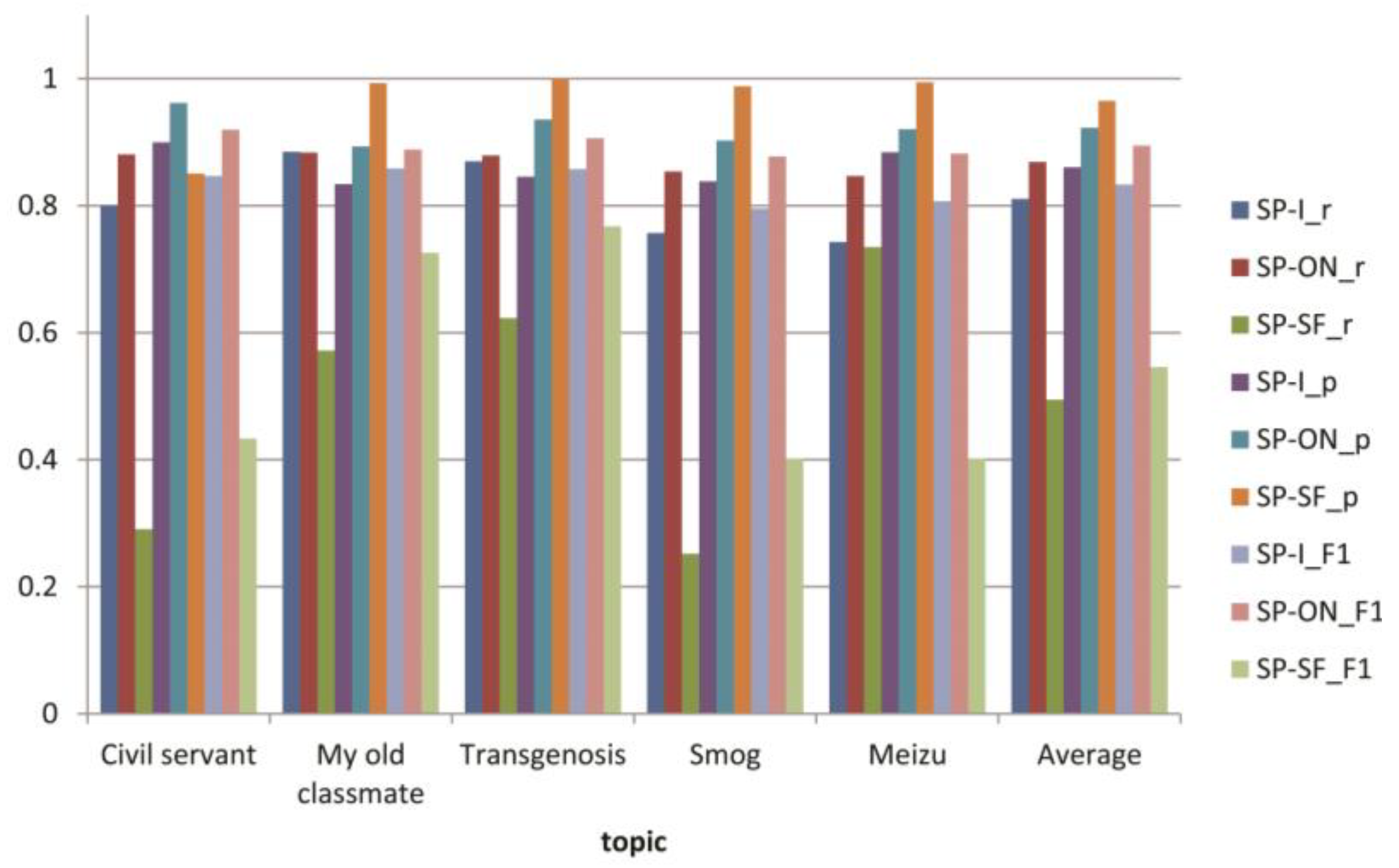
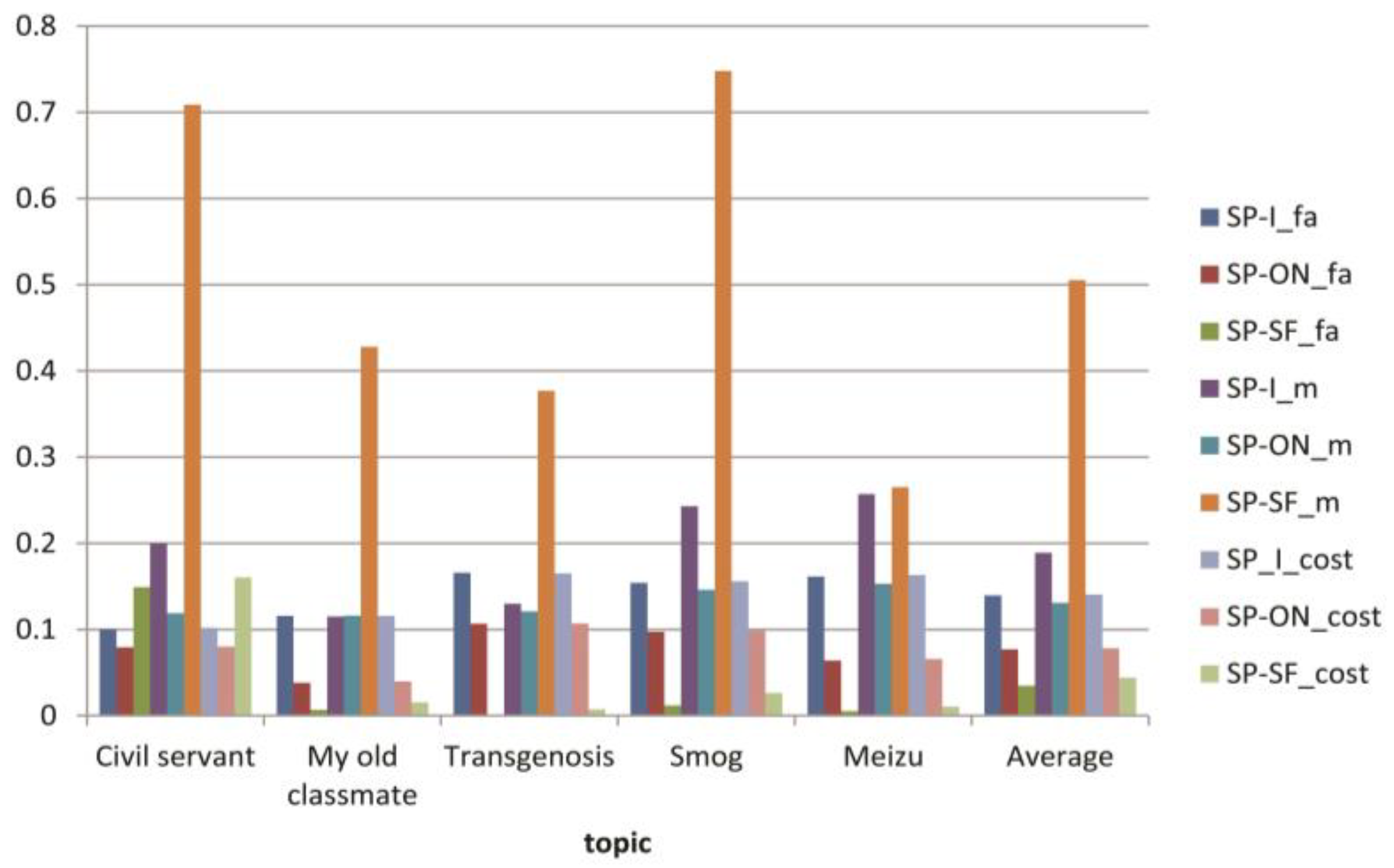
3.4. Experiments for Topic Tracking
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Castellanos, A.; Cigarrn, J.; Garca-Serrano, A. Formal concept analysis for topic detection. Inf. Syst. 2017, 66, 24–42. [Google Scholar] [CrossRef]
- Wu, F.; Song, Y.; Huang, Y. Microblog sentiment classification with heterogeneous sentiment knowledge. Inf. Sci. 2016, 373, 149–164. [Google Scholar] [CrossRef]
- Hu, J.; Fang, L.; Cao, Y.; Zeng, H.-J.; Li, H.; Yang, Q.; Chen, Z. Enhancing text clustering by leveraging Wikipedia semantics. In Proceedings of the 31st Annual International ACM SIGIR Conference Research and Development in Information Retrieval, Singapore, 20–24 July 2008; pp. 179–186. [Google Scholar]
- Meij, E.; Weerkamp, W.; Rijke, M.D. Adding semantics to microblog posts. In Proceedings of the 12th Conference WSDM, Seattle, WA, USA, 8–12 February 2012; pp. 563–572. [Google Scholar]
- Sahami, M.; Heilman, T.D. A web-based kernel function for measuring the similarity of short text snippets. In Proceedings of the ACM International Conference World Wide Web, Edinburgh, UK, 22–26 May 2006; pp. 377–386. [Google Scholar]
- Hu, X.; Sun, N.; Zhang, C. Exploiting internal and external semantics for the clustering of short texts using world knowledge. In Proceedings of the ACM International Conference Information and knowledge management, Hong Kong, China, 2–6 November 2009; pp. 919–928. [Google Scholar]
- Phan, X.H.; Nguyen, L.M.; Horiguchi, S. Learning to classify short and sparse text & web with hidden topics from largescale data collections. In Proceedings of the 17th ACM International Conference World Wide Web, Beijing, China, 21–25 April 2008; pp. 91–100. [Google Scholar]
- Quan, X.; Liu, G.; Lu, Z.; Ni, X.; Liu, W. Short text similarity based on probabilistic topics. Knowl. Inf. Syst. 2010, 25, 473–491. [Google Scholar] [CrossRef]
- Hu, X.; Tang, L.; Liu, H. Embracing information explosion without choking: Clustering and labeling in microblogging. IEEE Trans. Big Data 2015, 1, 35–46. [Google Scholar] [CrossRef]
- Banerjee, S.; Ramanathan, K.; Gupta, A. Clustering short texts using Wikipedia. In Proceedings of the 30th Annual International ACM SIGIR Conference Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 787–788. [Google Scholar]
- Amir, S.; Tanasescu, A.; Zighed, D.A. Sentence similarity based on semantic kernels for intelligent text retrieval. J. Intell. Inf. Syst. 2017, 48, 675–689. [Google Scholar] [CrossRef]
- Shirakawa, M.; Nakayama, K.; Hara, T. Wikipedia-based semantic similarity measurements for noisy short texts using extended naive bayes. IEEE Trans. Emerg. Top. Comput. 2015, 3, 205–219. [Google Scholar] [CrossRef]
- Zhang, W.H.; Xu, H.; Wan, W. Weakness Finder: Find product weakness from Chinese reviews by using aspects based sentiment analysis. Expert Syst. Appl. 2012, 39, 10283–10291. [Google Scholar] [CrossRef]
- Cao, D.; Ji, R.; Lin, D. A cross-media public sentiment analysis system for microblog. Multimed. Syst. 2016, 22, 479–486. [Google Scholar] [CrossRef]
- Fellbaum, C. WordNet: An. Electronic Lexical Database; MIT Press: Boston, MA, USA, 1998. [Google Scholar]
- Lu, Z.; Liu, Y.; Zhao, S.; Chen, X. Study on feature selection and weighting based on synonym merge in text categorization. In Proceedings of the IEEE International Conference Future Networks, Hainan, China, 22–24 January 2010; pp. 105–109. [Google Scholar]
- Zhang, X.; Liu, Z.; Liu, W. Event similarity computation in text. In Proceedings of the IEEE International Conference Internet of Things, and Cyber, Physical and Social Computing, Dalian, China, 19–22 October 2011; pp. 419–423. [Google Scholar]
- Li, L.; Ye, J.; Deng, F.; Xiong, S.; Zhong, L. A comparison study of clustering algorithms for microblog posts. Cluster Comput. 2016, 19, 1333–1345. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, D. NLPIR: A theoretical framework for applying natural language processing to information retrieval. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 115–123. [Google Scholar] [CrossRef]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a social network or a news media? In Proceedings of the ACM International Conference World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 591–600. [Google Scholar]
- Efron, M. Hashtag retrieval in a microblogging environment. In Proceedings of the 33th Annual International ACM SIGIR Conference Research and Development in Information Retrieval, SIGIR ’10, Geneva, Switzerland, 19–23 July 2010; pp. 787–788. [Google Scholar]
- Davidov, D.; Tsur, O.; Rappoport, A. Enhanced sentiment learning using twitter hashtags and smileys. In Proceedings of the International Computational Linguistics: Posters, COLING’10, Beijing, China, 23–27 August 2010; pp. 241–249. [Google Scholar]
- Tongyici Cilin (Extended). Available online: http://ir.hit.edu.cn/demo/ltp/Sharing Plan.htm (accessed on 9 August 2018). (In Chinese).
- Liu, Y.; Zhu, Y.; Xin, G. Chinese Text watermarking method based on TongYiCi CiLin. Int. Dig. Cont. Techn. Appl. 2012, 6, 465–473. [Google Scholar]
- Papka, R. On-line New Event Detection, Clustering, and Tracking. Ph.D. Thesis, Department of Computer Science, University of Massachusetts Amherst, MA, USA, 1999. [Google Scholar]
- Huang, B.; Yang, Y.; Mahmood, A. Microblog topic detection based on LDA model and single-pass clustering. In Proceedings of the International Rough Sets and Current Trends in Computing, Chengdu, China, 17–20 August 2012; pp. 166–171. [Google Scholar]
- Yang, Y.; Pierce, T.; Carbonell, J. A study of retrospective and on-line event detection. In Proceedings of the 21st Annual International ACM SIGIR Conference Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; pp. 28–36. [Google Scholar]
- Liu, D.; Peng, C.; Qian, G.; Zhou, G. The effect of TongYiCi CiLin in Chinese entity relation extraction. J. Chin. Inf. Proc. 2014, 28, 91–99. (In Chinese) [Google Scholar]
- Leacock, C.; Miller, G.; Chodorow, M. Using corpus statistics and WordNet relations for sense identification. Comput. Linguist. 1998, 24, 147–165. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code Position | Mark | Meaning | Level |
|---|---|---|---|
| 1 | C | large categories | F1 |
| 2 | b | medium categories | F2 |
| 3 | 0 | small categories | F3 |
| 4 | 2 | ||
| 5 | A | word group | F4 |
| 6 | 0 | word unit | F5 |
| 7 | 1 | ||
| 8 | =/#/@ | “=” means synonym “#” means related words “@” means independent words | |
| Created at | Repost | Comment | Like | Text |
|---|---|---|---|---|
| 2017/5/16 22:14 | 2 | 2 | 0 | 如今的雾霾天让我更加喜欢看老照片,因为那里有蓝天...... |
| 2017/5/10 23:12 | 0 | 5 | 6 | 最卡的手机排行,魅族排第二都没人敢排第一,现在就想翻出我的诺基亚砸烂手上的破烂玩意儿!(即将面临王者禁赛的我气得瑟瑟发抖 |
| 2017/5/8 21:03 | 0 | 0 | 0 | 如果记忆可以重写。我希望当初坐在我身边的还是你。——《同桌的你》 |
| 2017/5/8 21:31 | 1 | 12 | 13 | 其实吧,在小城市,考一个公务员编制是拉开幸福生活之门的关键,是解决生活绝大部分问题之源。考上,就有源源不断的优质相亲对象,抛开自身层次不说,对象的层次,就足以保证之后生活质量。我周围例子全部(没有夸张,对,就是全部)证明了这一点。 |
| 2017/5/9 21:07 | 2 | 1 | 0 | 哈哈读书时禁止恋爱 毕业立马要结婚 你以为对象是馅饼啊想掉就掉 |
| 2017/4/12 23:40 | 0 | 1 | 2 | 开学/放假背着一大坨书来回飞。。。搞得好像很爱学习的样子 呵呵 |
| Measure | Cluster Algorithm | Topic | Average | ||||
|---|---|---|---|---|---|---|---|
| 公务员 (Civil Servant) | 同桌的你 (My Old Classmate) | 转基因 (Transgenosis) | 雾霾 (Smog) | 魅族 (Meizu, a Popular Cell Phone) | |||
| p | SP-1NN | 0.630 | 0.561 | 0.690 | 0.357 | 0.448 | 0.537 |
| SP-I | 1.000 | 0.837 | 0.965 | 0.966 | 0.946 | 0.943 | |
| SP-SF | 0.872 | 0.988 | 0.572 | 0.817 | 0.438 | 0.737 | |
| SP-NV | 0.902 | 0.979 | 0.720 | 0.942 | 0.907 | 0.890 | |
| SP-ON | 0.957 | 0.996 | 0.987 | 0.927 | 0.964 | 0.966 | |
| r | SP-1NN | 0.435 | 0.674 | 0.318 | 0.287 | 0.400 | 0.423 |
| SP-I | 0.347 | 0.554 | 0.529 | 0.309 | 0.406 | 0.429 | |
| SP-SF | 0.368 | 0.675 | 0.290 | 0.156 | 0.140 | 0.326 | |
| SP-NV | 0.398 | 0.640 | 0.339 | 0.26 | 0.235 | 0.374 | |
| SP-ON | 0.421 | 0.719 | 0.532 | 0.419 | 0.424 | 0.503 | |
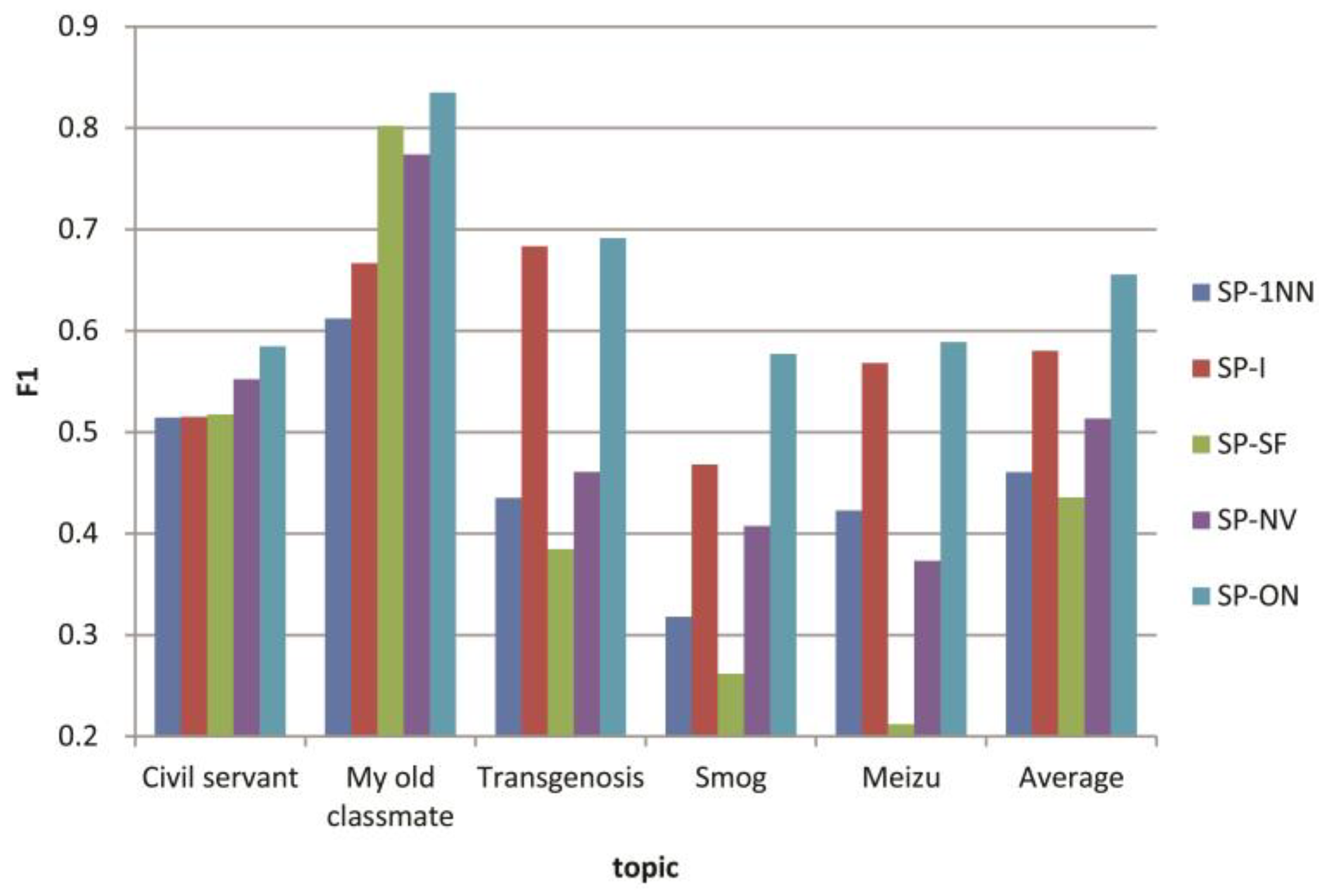
| F1 | SP-1NN | 0.514 | 0.612 | 0.435 | 0.318 | 0.423 | 0.461 |
| SP-I | 0.515 | 0.667 | 0.683 | 0.468 | 0.568 | 0.580 | |
| SP-SF | 0.518 | 0.802 | 0.385 | 0.262 | 0.212 | 0.436 | |
| SP-NV | 0.552 | 0.774 | 0.461 | 0.408 | 0.373 | 0.514 | |
| SP-ON | 0.585 | 0.835 | 0.691 | 0.577 | 0.589 | 0.655 | |
| m | SP-1NN | 0.565 | 0.326 | 0.682 | 0.713 | 0.600 | 0.577 |
| SP-I | 0.653 | 0.446 | 0.471 | 0.691 | 0.594 | 0.571 | |
| SP-SF | 0.632 | 0.325 | 0.710 | 0.844 | 0.860 | 0.674 | |
| SP-NV | 0.602 | 0.360 | 0.661 | 0.740 | 0.765 | 0.626 | |
| SP-ON | 0.579 | 0.281 | 0.468 | 0.581 | 0.576 | 0.497 | |
| fa | SP-1NN | 0.064 | 0.132 | 0.036 | 0.130 | 0.123 | 0.097 |
| SP-I | 0.000 | 0.027 | 0.005 | 0.003 | 0.006 | 0.008 | |
| SP-SF | 0.014 | 0.002 | 0.054 | 0.009 | 0.045 | 0.025 | |
| SP-NV | 0.011 | 0.004 | 0.033 | 0.004 | 0.006 | 0.011 | |
| SP-ON | 0.005 | 0.001 | 0.002 | 0.008 | 0.004 | 0.004 | |
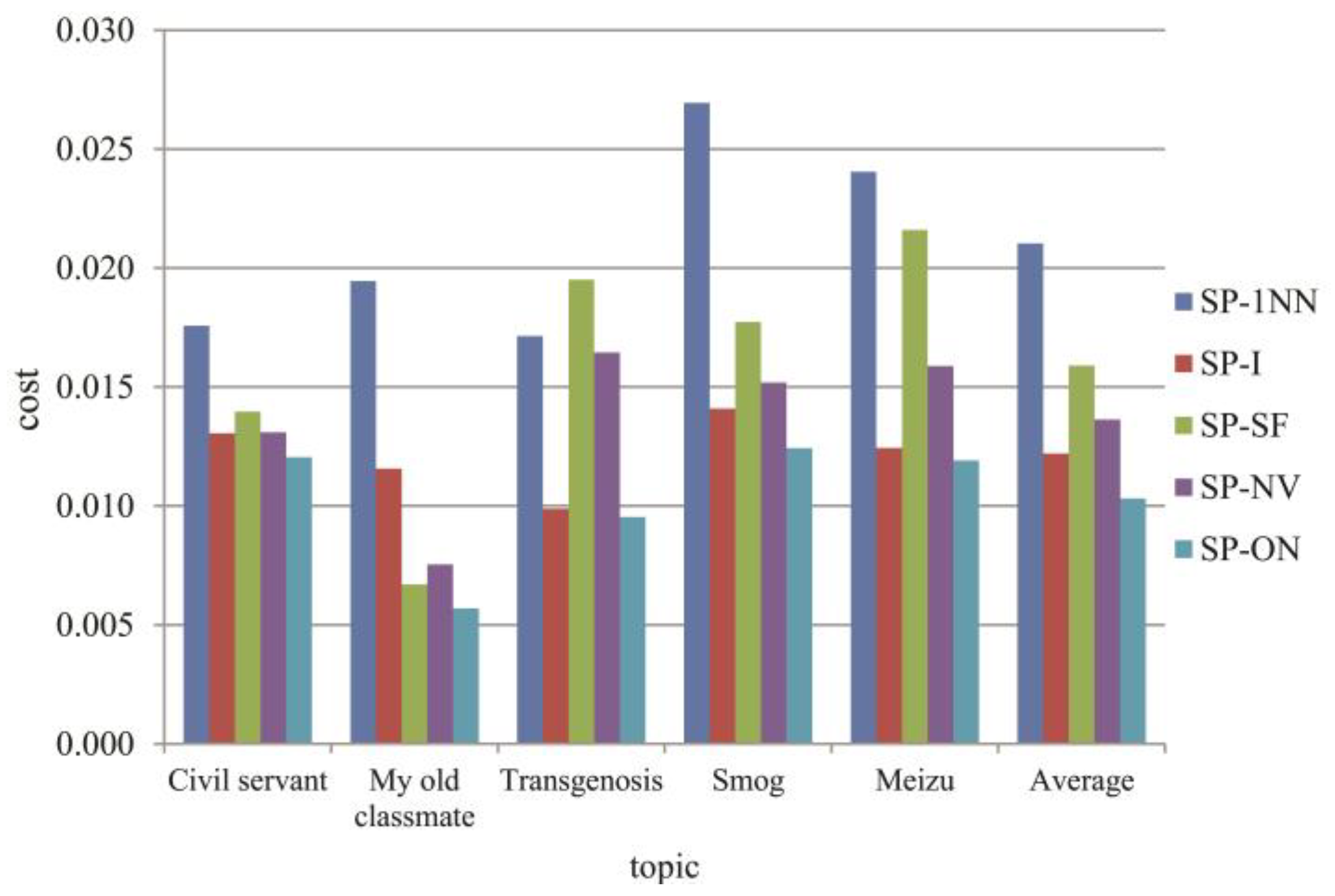
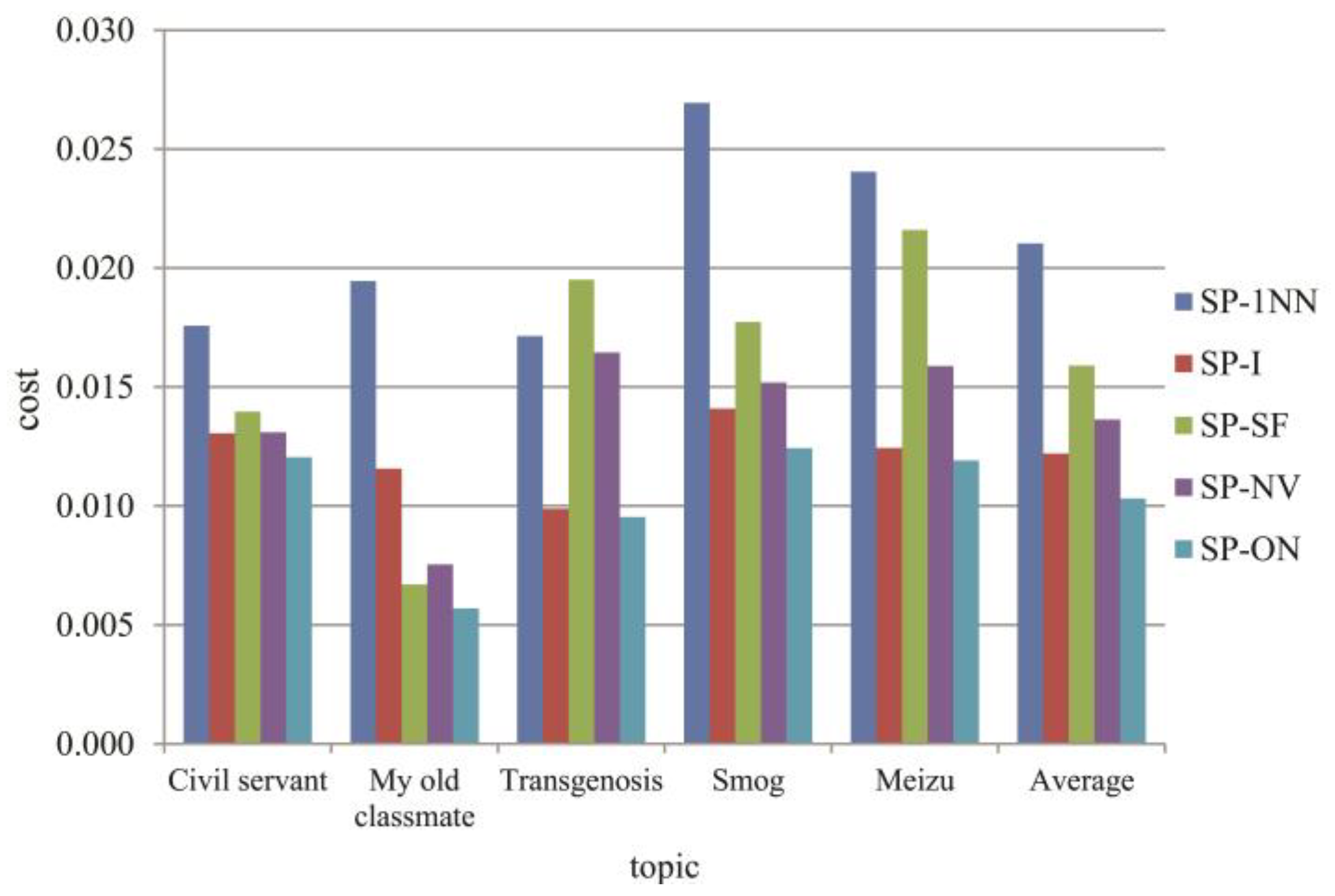
| Cost | SP-1NN | 0.018 | 0.019 | 0.017 | 0.027 | 0.024 | 0.021 |
| SP-I | 0.013 | 0.012 | 0.010 | 0.014 | 0.012 | 0.012 | |
| SP-SF | 0.014 | 0.007 | 0.020 | 0.018 | 0.022 | 0.016 | |
| SP-NV | 0.013 | 0.008 | 0.016 | 0.015 | 0.016 | 0.014 | |
| SP-ON | 0.012 | 0.006 | 0.010 | 0.012 | 0.012 | 0.010 | |
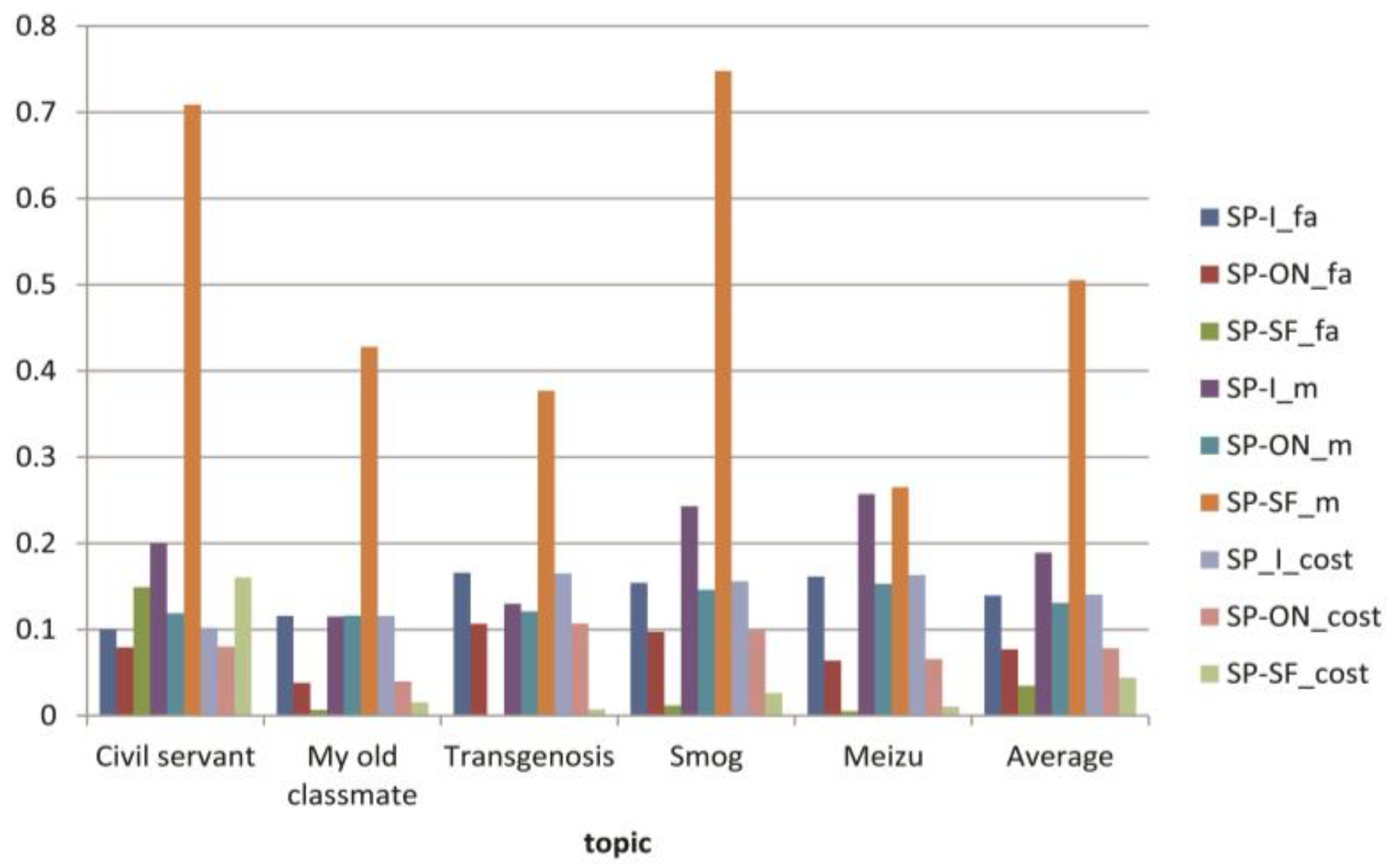
| Evaluation Criterion | Algorithm | Topic | Average | ||||
|---|---|---|---|---|---|---|---|
| 公务员 (Civil Servant) | 魅族 (Meizu) | 转基因 (Transgenosis) | 雾霾 (Smog) | 同桌的你 (my Old Classmate) | |||
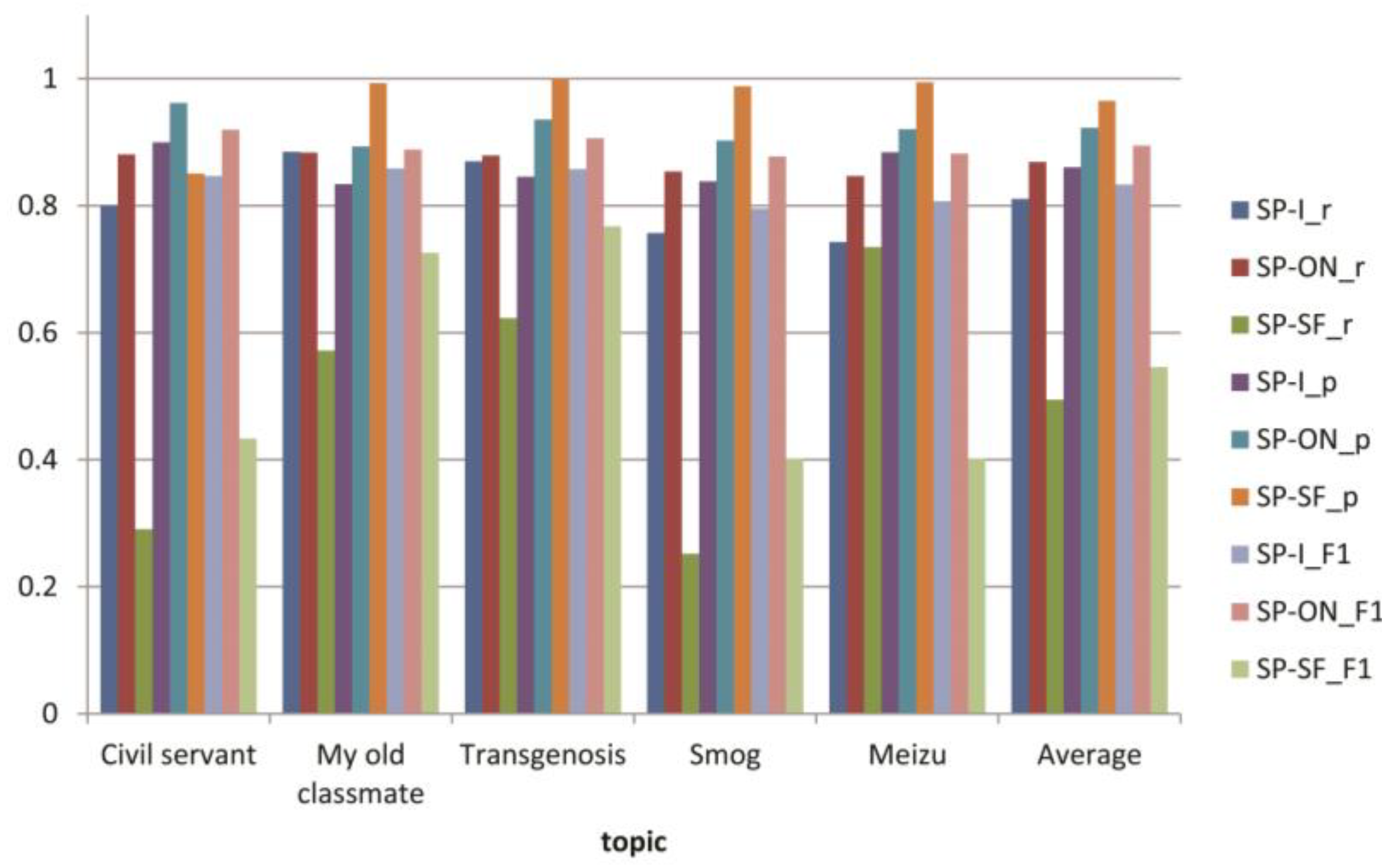
| Recall | SP-I | 0.800 | 0.743 | 0.87 | 0.757 | 0.885 | 0.811 |
| SP-ON | 0.881 | 0.847 | 0.879 | 0.854 | 0.884 | 0.869 | |
| Precision | SP-I | 0.900 | 0.884 | 0.846 | 0.839 | 0.834 | 0.861 |
| SP-ON | 0.921 | 0.962 | 0.893 | 0.903 | 0.936 | 0.923 | |
| F1-measure | SP-I | 0.847 | 0.807 | 0.858 | 0.796 | 0.859 | 0.833 |
| SP-ON | 0.920 | 0.882 | 0.907 | 0.878 | 0.889 | 0.895 | |
| False | SP-I | 0.100 | 0.161 | 0.166 | 0.154 | 0.116 | 0.139 |
| SP-ON | 0.079 | 0.064 | 0.107 | 0.097 | 0.038 | 0.077 | |
| Miss | SP-I | 0.200 | 0.257 | 0.13 | 0.243 | 0.115 | 0.189 |
| SP-ON | 0.119 | 0.153 | 0.121 | 0.146 | 0.116 | 0.131 | |
| Cost function | SP-I | 0.102 | 0.163 | 0.165 | 0.156 | 0.116 | 0.14 |
| SP-ON | 0.080 | 0.066 | 0.107 | 0.098 | 0.040 | 0.078 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, L.; Sun, B.; Shi, P. Chinese Microblog Topic Detection through POS-Based Semantic Expansion. Information 2018, 9, 203. https://doi.org/10.3390/info9080203
Ding L, Sun B, Shi P. Chinese Microblog Topic Detection through POS-Based Semantic Expansion. Information. 2018; 9(8):203. https://doi.org/10.3390/info9080203
Chicago/Turabian StyleDing, Lianhong, Bin Sun, and Peng Shi. 2018. "Chinese Microblog Topic Detection through POS-Based Semantic Expansion" Information 9, no. 8: 203. https://doi.org/10.3390/info9080203
APA StyleDing, L., Sun, B., & Shi, P. (2018). Chinese Microblog Topic Detection through POS-Based Semantic Expansion. Information, 9(8), 203. https://doi.org/10.3390/info9080203