Forecasting Electricity Consumption Using an Improved Grey Prediction Model


Abstract
1. Introduction
1.1. Background and Motivation
1.2. Literature Review
1.3. Contributions
- A novel optimized GM(1,1) model, which is based on data transformation for the original data sequence and combination interpolation optimization of the background value and is therefore abbreviated as DCOGM(1,1), is proposed.
- The proposed improved grey prediction model aims to achieve effective performance in electricity consumption forecasts. In our empirical studies, DCOGM(1,1) is successfully applied to electricity consumption forecasts and obtains favourable forecasting performance compared with the statistical analysis models, computational intelligence models, and seven grey modification models. Thus, the DCOGM(1,1) model is verified to be suitable for electricity consumption forecasting.
- DCOGM(1,1) model expands the application of a GM(1,1) model and, in the future, DCOGM(1,1) can be employed in other fields for short-term forecasts, such as GDP forecasting, tourism demand forecasting and natural gas consumption prediction under the condition of limited source data.
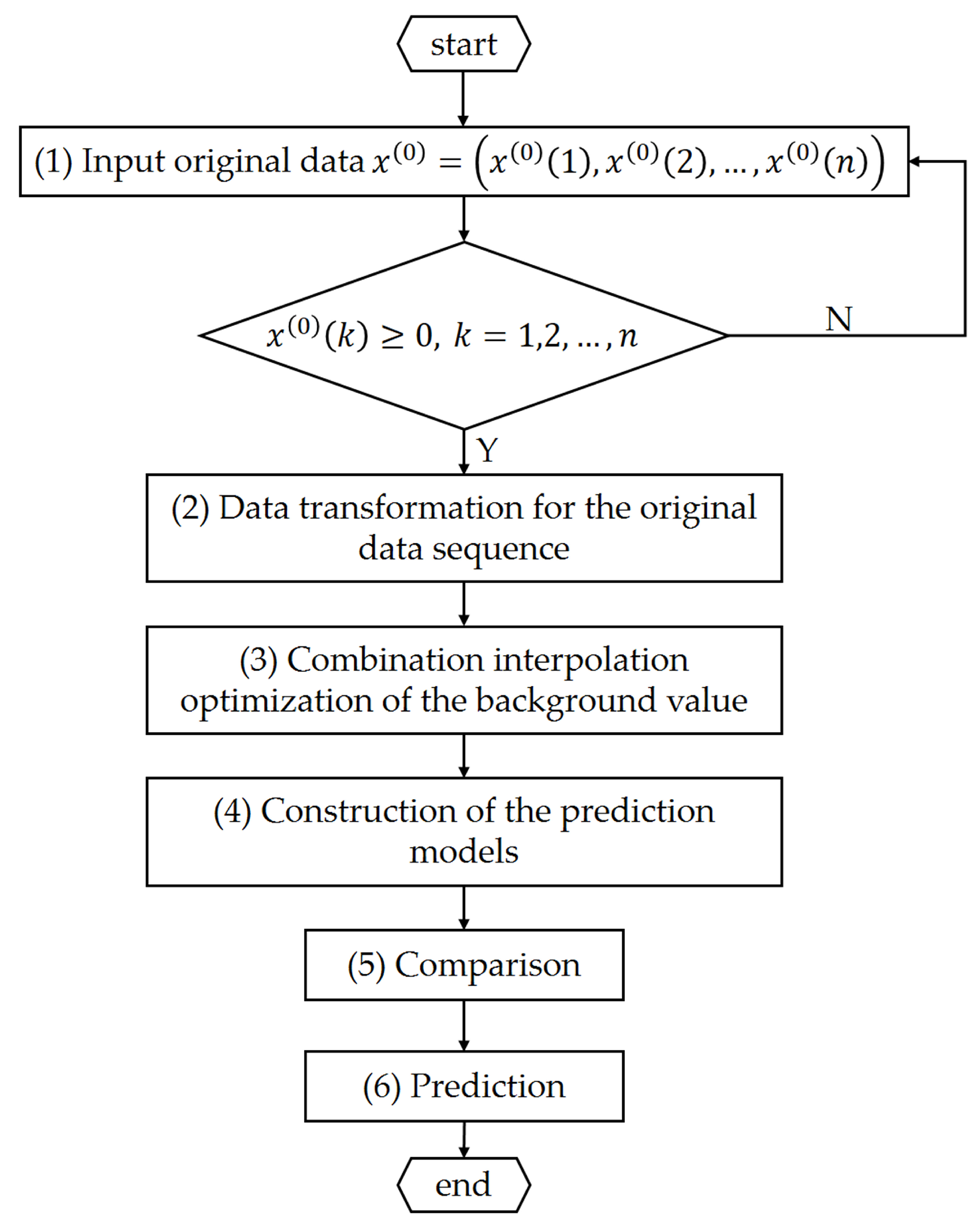
2. Materials and Methods
2.1. GM(1,1) Model
2.2. Methodology of the Combined Optimized GM(1,1) Model
2.2.1. Data Transformation for the Original Data Sequence
2.2.2. Combination Interpolation Optimization of the Background Value
3. Results
3.1. Evaluation Indices
3.2. Evaluation of the Improved GM(1,1) Model
3.2.1. Case 1: Prediction of Short-Term Electricity Consumption in APEC
3.2.2. Case 2: Prediction of Electricity Consumption in Turkey
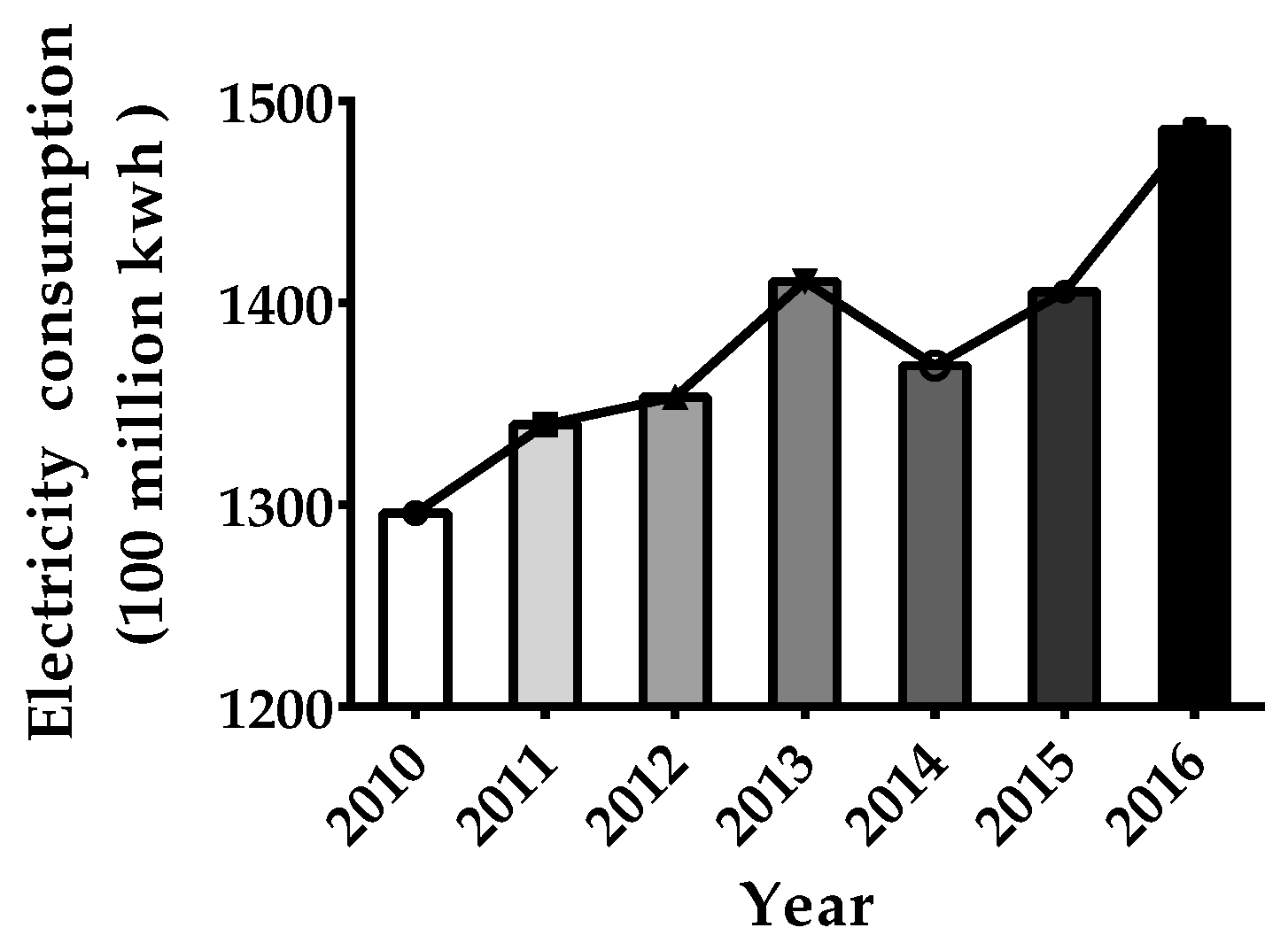
3.3. Case 3: Forecasts of Electricity Consumption for Shanghai City in China
3.3.1. Modelling Procedure of Shanghai’s Electricity Consumption Forecasting
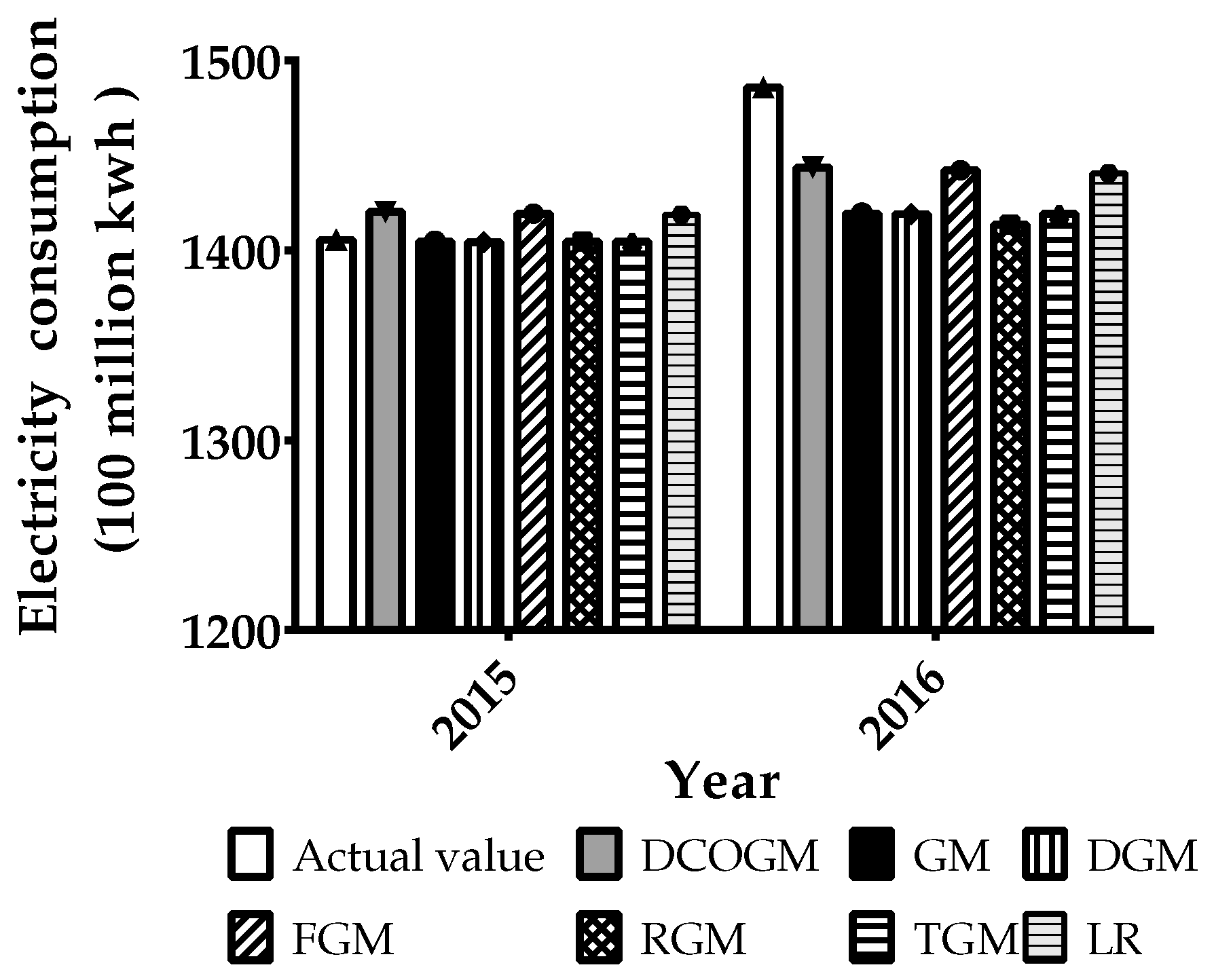
3.3.2. Comparison of the Forecasting Performances of the Predictive Models
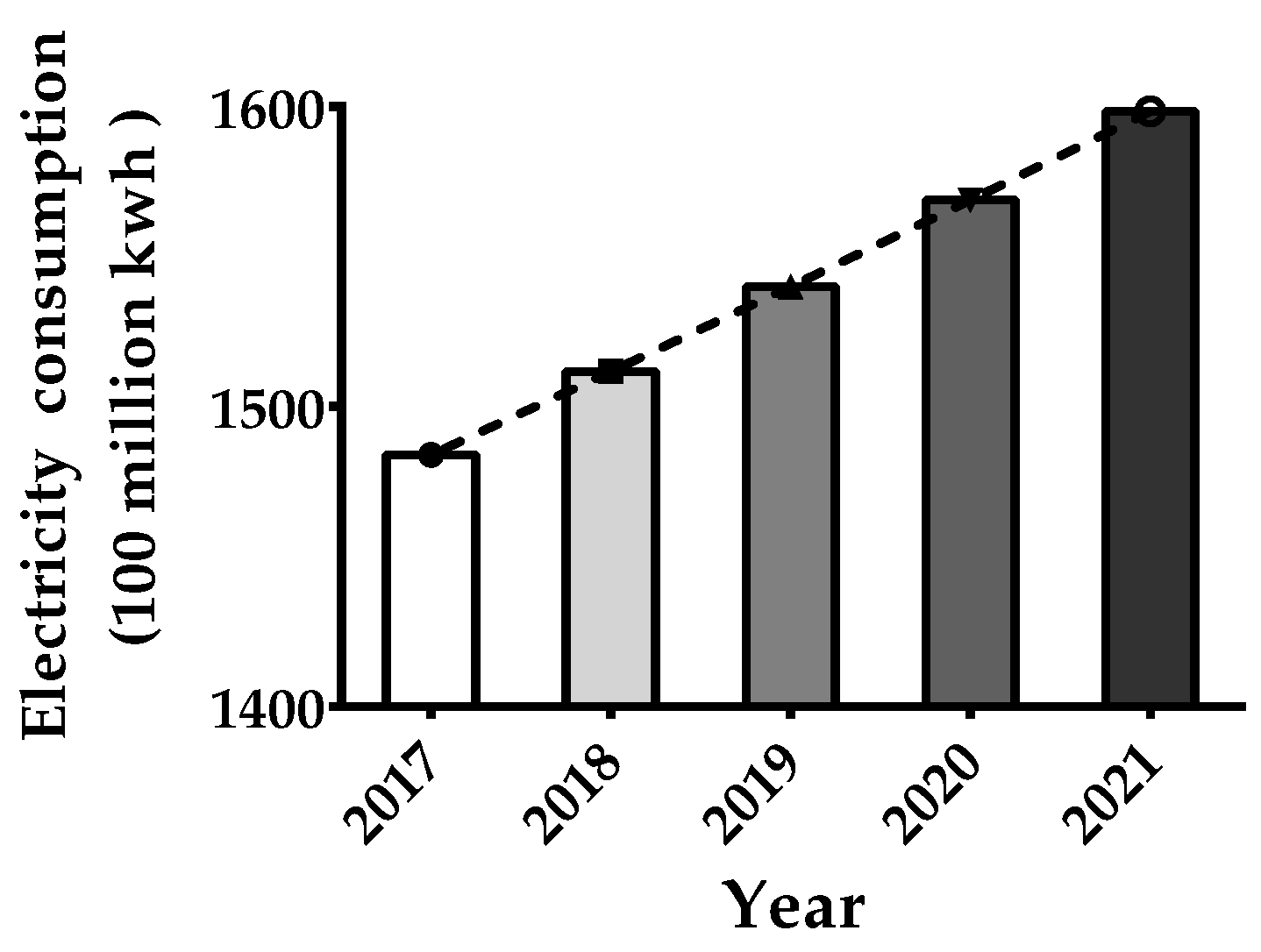
3.3.3. Forecasting the Total Electricity Consumption for Shanghai City in China during 2017–2021
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xiao, L.; Wang, C.; Liang, T.; Shao, W. A combined model based on multiple seasonal patterns and modified firefly algorithm for electrical load forecasting. Energy Policy 2016, 167, 135–153. [Google Scholar] [CrossRef]
- Li, S.; Ma, X.; Yang, C. A novel structure-adaptive intelligent grey forecasting model with full-order time power terms and its application. Comput. Ind. Eng. 2018, 120, 53–67. [Google Scholar] [CrossRef]
- Zhao, H.; Guo, S.; Xue, W. Urban saturated power load analysis based on a novel combined forecasting model. Information 2015, 6, 69–88. [Google Scholar] [CrossRef]
- Lebotsa, M.E.; Sigauke, C.; Bere, A.; Fildes, R.; Boylan, J.E. Short term electricity demand forecasting using partially linear additive quantile regression with an application to the unit commitment problem. Appl. Energy 2018, 222, 104–118. [Google Scholar] [CrossRef]
- Wang, Z.X.; Li, Q.; Pei, L.L. A seasonal GM(1,1) model for forecasting the electricity consumption of the primary economic sectors. Energy 2018, 154, 522–534. [Google Scholar] [CrossRef]
- Chung, Y.H. Electricity consumption prediction using a neural-network-based grey forecasting approach. J. Oper. Res. Soc. 2017, 68, 1259–1264. [Google Scholar]
- Al-Hamadi, H.M.; Soliman, S.A. Long-term/mid-term electric load forecasting based on short-term correlation and annual growth. Electr. Power Syst. Res. 2005, 74, 353–361. [Google Scholar] [CrossRef]
- Pao, H.T. Forecast of electricity consumption and economic growth in Taiwan by state space modeling. Energy 2009, 34, 1779–1791. [Google Scholar] [CrossRef]
- Hussain, A.; Rahman, M.; Memon, J.A. Forecasting electricity consumption in Pakistan: The way forward. Energy Policy 2016, 90, 73–80. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Srinivasan, D. Interval type-2 fuzzy logic systems for load forecasting: A comparative study. IEEE Trans. Power Syst. 2012, 27, 1274–1282. [Google Scholar] [CrossRef]
- Hernández, L.; Baladrón, C.; Aguiar, J.M.; Calavia, L.; Carro, B.; Sánchez-Esguevillas, A.; García, P.; Lloret, J. Experimental analysis of the input variables’ relevance to forecast next Day’s aggregated electric demand using neural networks. Energies 2013, 6, 2927–2948. [Google Scholar] [CrossRef]
- Lee, Y.S.; Tong, L.T. Forecasting energy consumption using a grey model improved by incorporating genetic programming. Energy Convers. Manag. 2011, 52, 147–152. [Google Scholar] [CrossRef]
- Červená, M.; Schneider, M. Short-term forecasting of GDP with a DSGE model augmented by monthly indicators. Int. J. Forecast. 2014, 30, 498–516. [Google Scholar] [CrossRef]
- Huang, Y.F.; Wang, C.N.; Dang, H.S.; Lai, S.T. Evaluating performance of the DGM(2,1) model and its modified models. Appl. Sci. 2016, 6, 73. [Google Scholar] [CrossRef]
- Mohamed, Z.; Bodger, P. Forecasting electricity consumption in New Zealand using economic and demographic variables. Energy 2005, 30, 1833–1843. [Google Scholar] [CrossRef]
- Nagbe, K.; Cugliari, J.; Jacques, J. Short-term electricity demand forecasting using a functional state space model. Energies 2018, 11, 1120. [Google Scholar] [CrossRef]
- Wang, F.; Wang, F.; Yu, Y.; Wang, X.; Ren, H.; Shafie-Khah, M.; Catalao, J.P.S. Residential electricity consumption level impact factor analysis based on wrapper feature selection and multinomial logistic regression. Energies 2018, 11, 1180. [Google Scholar] [CrossRef]
- Cabral, J.D.A.; Legey, L.F.L.; Cabral, M.V.D.F. Electricity consumption forecasting in Brazil: A spatial econometrics approach. Energy 2017, 126, 124–131. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, J.; Lu, H. Combining forecasts of electricity consumption in China with time-varying weights updated by a high-order Markov chain model. Omega 2014, 45, 80–91. [Google Scholar] [CrossRef]
- Bouzerdoum, M.; Mellit, A.; Pavan, A.M. A hybrid model (SARIMA-SVM) for short-term power forecasting of a small-scale grid-connected photovoltaic plant. Sol. Energy 2013, 98, 226–235. [Google Scholar] [CrossRef]
- Al-Hamadi, H.M.; Soliman, S.A. Short-term electric load forecasting based on Kalman filtering algorithm with moving window weather and load model. Electr. Power Syst. Res. 2004, 3, 47–49. [Google Scholar] [CrossRef]
- Ding, S.; Hipel, K.W.; Dang, Y.G. Forecasting China’s electricity consumption using a new grey prediction model. Energy 2018, 149, 314–328. [Google Scholar] [CrossRef]
- Wu, L.F.; Liu, S.F.; Cui, W.; Liu, D.L.; Yao, T.X. Non-homogenous discrete grey model with fractional-order accumulation. Neural. Comput. Appl. 2014, 25, 1215–1221. [Google Scholar] [CrossRef]
- Kaytez, F.; Taplamacioglu, M.C.; Cam, E.; Hardalac, F. Forecasting electricity consumption: A comparison of regression analysis, neural networks and least squares support vector machines. Int. J. Electr. Power 2015, 67, 431–438. [Google Scholar] [CrossRef]
- Hu, Y.C.; Jiang, P. Forecasting energy demand using neural-network-based grey residual modification models. J. Oper. Res. Soc. 2017, 68, 556–565. [Google Scholar] [CrossRef]
- Cao, G.; Wu, L. Support vector regression with fruit fly optimization algorithm for seasonal electricity consumption forecasting. Energy 2016, 115, 734–745. [Google Scholar] [CrossRef]
- Kavousi-Fard, A.; Samet, H.; Marzbani, F. A new hybrid modified firefly algorithm and support vector regression model for accurate short term load forecasting. Expert Syst. Appl. 2014, 41, 6047–6056. [Google Scholar] [CrossRef]
- Pozna, C.; Precup, R.E.; Tar, J.K. New results in modelling derived from Bayesian filtering. Knowl. Based Syst. 2010, 23, 182–194. [Google Scholar] [CrossRef]
- Xu, N.; Dang, Y.G.; Gong, Y.D. Novel grey prediction model with nonlinear optimized time response method for forecasting of electricity consumption in China. Energy 2017, 118, 473–480. [Google Scholar] [CrossRef]
- Deng, J.L. Control problem of grey systems. Syst. Control Lett. 1982, 1, 288–294. [Google Scholar]
- Liu, S.; Lin, Y. Grey Information: Theory and Practical Applications; Springer: London, UK, 2006. [Google Scholar]
- Talafuse, T.O.; Pohl, E.A. Small sample reliability growth modeling using a grey systems model. Qual. Eng. 2017, 29, 455–467. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, L.; Wang, S.; Wang, J.Z.; Liu, M. Predicting Beijing’s tertiary industry with an improved grey model. Appl. Soft. Comput. 2017, 57, 482–494. [Google Scholar] [CrossRef]
- Hsin, P.H.; Chen, C.I. Application of trembling-hand perfect equilibrium to Nash nonlinear Grey Bernoulli model: An example of BRIC’s GDP forecasting. Neural. Comput. Appl. 2016, 28, 269–274. [Google Scholar] [CrossRef]
- Li, Z.B.; Jiang, Y.; Yue, J.; Zhang, L.; Li, D. An improved gray model for aquaculture water quality prediction. Intell. Autom. Soft Comput. 2012, 18, 557–567. [Google Scholar] [CrossRef]
- Wu, L.; Liu, S.; Yao, L.; Xu, R.; Lei, X. Using fractional order accumulation to reduce errors from inverse accumulated generating operator of grey model. Soft. Comput. 2015, 19, 483–488. [Google Scholar] [CrossRef]
- Hu, Y.C.; Jiang, P.; Chiu, Y.J.; Tsai, J.F. A novel grey prediction model combining markov chain with functional-link net and its application to foreign tourist forecasting. Information 2017, 8, 126. [Google Scholar] [CrossRef]
- Li, G.D.; Masuda, M.; Nagai, M. The prediction for Japan’s domestic and overseas automobile production. Technol. Forecast. Soc. 2014, 87, 224–231. [Google Scholar] [CrossRef]
- Chang, C.J.; Yu, L.; Jin, P. A mega-trend-diffusion grey forecasting model for short-term manufacturing demand. J. Oper. Res. Soc. 2016, 67, 1439–1445. [Google Scholar] [CrossRef]
- Tang, H.W.V.; Yin, M.S. Forecasting performance of grey prediction for education expenditure and school enrollment. Econ. Educ. Rev. 2012, 31, 452–462. [Google Scholar] [CrossRef]
- Chen, Y.Y.; Liu, H.T.; Hsieh, H.L. Time series interval forecast using GM(1,1) and NGBM(1,1) models. Soft. Comput. 2017, 1–15. [Google Scholar] [CrossRef]
- Wu, L.; Gao, X.; Xiao, Y.; Yang, Y.; Chen, X. Using a novel multi-variable grey model to forecast the electricity consumption of Shandong Province in China. Energy 2018, 157, 327–335. [Google Scholar] [CrossRef]
- Xie, N.M.; Yuan, C.Q.; Yang, Y.J. Forecasting China’s energy demand and self-sufficiency rate by grey forecasting model and Markov model. Int. J. Electr. Power 2015, 66, 1–8. [Google Scholar] [CrossRef]
- Zhao, H.; Guo, S. An optimized grey model for annual power load forecasting. Energy 2016, 107, 272–286. [Google Scholar] [CrossRef]
- Liang, J.; Liang, Y. Analysis and modeling for China’s electricity demand forecasting based on a new mathematical hybrid method. Information 2017, 8, 33. [Google Scholar] [CrossRef]
- Hamzacebi, C.; Es, H.A. Forecasting the annual electricity consumption of Turkey using an optimized grey model. Energy 2014, 70, 165–171. [Google Scholar] [CrossRef]
- Zeng, B.; Zhou, M.; Zhang, J. Forecasting the energy consumption of China’s manufacturing using a homologous grey prediction model. Sustainability 2017, 9, 1975. [Google Scholar] [CrossRef]
- Zeng, B.; Meng, W.; Tong, M.Y. A self-adaptive intelligence grey predictive model with alterable structure and its application. Eng. Appl. Artif. Intell. 2016, 50, 236–2448. [Google Scholar] [CrossRef]
- Xie, N.M.; Liu, S.F.; Yang, Y.J.; Yuan, C.Q. On novel grey forecasting model based on non-homogeneous index sequence. Appl. Math. Model. 2013, 37, 5059–5068. [Google Scholar] [CrossRef]
- Tien, T.L. A new grey prediction model FGM(1,1). Math. Comput. Model. 2009, 49, 1416–1426. [Google Scholar] [CrossRef]
- Xie, N.M.; Liu, S.F. Discrete grey forecasting model and its optimization. Appl. Math. Model. 2009, 33, 1173–1186. [Google Scholar] [CrossRef]
- Deng, J. Introduction to grey system theory. J. Grey Syst. 1989, 1, 1–24. [Google Scholar]
- Li, K.; Liu, L.; Zhai, J.; Khoshgoftaar, T.M.; Li, L. The improved grey model based on particle swarm optimization algorithm for time series prediction. Eng. Appl. Artif. Intel. 2016, 55, 285–291. [Google Scholar] [CrossRef]
- Hsu, L.C. Using improved grey forecasting models to forecast the output of opto-electronics industry. Expert. Syst. Appl. 2011, 38, 13879–13885. [Google Scholar] [CrossRef]
- Turner, P.R. Numerical Integration. In Numerical Analysis; Macmillan College Work Out Series; Palgrave: London, UK, 1994. [Google Scholar]
- Li, D.C.; Chang, C.J.; Chen, C.C.; Chen, W.C. Forecasting short-term electricity consumption using the adaptive grey-based approach—Asian case. Omega 2012, 40, 767–773. [Google Scholar] [CrossRef]
- Akay, D.; Atak, M. Grey prediction with rolling mechanism for electricity demand forecasting of Turkey. Energy 2007, 32, 1670–1675. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, H.; Zhou, Q.; Wu, J.; Qin, S. China’s natural gas production and consumption analysis based on the multicycle Hubbert model and rolling Grey model. Renew. Sustain. Energy Rev. 2016, 53, 1149–1167. [Google Scholar] [CrossRef]
- Peng, G.Z.; Wang, H.W.; Song, X.; Zhang, H.M. Intelligent management of coal stockpiles using improved grey spontaneous combustion forecasting models. Energy 2017, 132, 269–279. [Google Scholar] [CrossRef]
- Lewis, C. Industrial and Business Forecasting Methods; Butterworth Scientific: London, UK, 1982. [Google Scholar]
- Wei, B.; Xie, N.; Hu, A. Optimal solution for novel grey polynomial prediction model. Appl. Math. Model. 2018, 62, 717–727. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coumtry | AGM(1,1) | BPN | SVR | DCOGM(1,1) |
|---|---|---|---|---|
| Australia | 1.50 | 3.02 | 6.71 | 1.29 |
| Brunei Darussalam | 6.45 | 4.31 | 6.22 | 2.69 |
| Canada | 1.86 | 1.73 | 2.46 | 1.33 |
| Chile | 2.70 | 4.75 | 11.40 | 2.37 |
| China | 4.74 | 14.08 | 30.03 | 4.43 |
| Chinese Taipei | 1.10 | 4.20 | 9.51 | 1.15 |
| Hong Kong, China | 0.57 | 1.76 | 3.56 | 0.64 |
| Indonesia | 9.58 | 7.41 | 6.79 | 8.44 |
| Japan | 1.57 | 2.11 | 3.80 | 2.35 |
| Malaysia | 0.97 | 5.12 | 11.72 | 1.64 |
| Mexico | 2.60 | 3.60 | 8.34 | 3.90 |
| New Zealand | 3.38 | 2.82 | 6.58 | 3.56 |
| Papua New Guinea | 12.52 | 8.23 | 7.93 | 11.48 |
| Peru | 3.98 | 7.26 | 13.08 | 1.46 |
| Philippines | 2.37 | 3.44 | 8.07 | 2.53 |
| Russia | 1.72 | 2.72 | 5.45 | 1.79 |
| Republic of Korea | 1.12 | 5.39 | 12.49 | 1.64 |
| Singapore | 0.96 | 3.83 | 8.18 | 0.64 |
| Thailand | 0.56 | 5.71 | 13.56 | 1.55 |
| USA | 0.96 | 1.81 | 3.68 | 1.55 |
| Vietnam | 3.78 | 13.78 | 29.74 | 1.99 |
| MAPE (%) | 3.10 | 5.10 | 9.97 | 2.78 |
| Year | Actual Value (TWh) | MAED | GPRM | BPN | RBFN | NNGM(1,1) | DCOGM(1,1) |
|---|---|---|---|---|---|---|---|
| 1994 | 61.40 | 8.83 | 5.66 | 3.16 | 2.27 | 5.05 | 4.35 |
| 1995 | 67.39 | 10.65 | 2.17 | 2.58 | 3.90 | 2.67 | 2.97 |
| 1996 | 74.16 | 9.54 | 3.80 | 4.72 | 15.71 | 3.01 | 0.74 |
| 1997 | 81.88 | 8.05 | 0.59 | 4.01 | 15.40 | 0.27 | 4.55 |
| 1998 | 87.70 | 9.89 | 2.76 | 0.56 | 4.14 | 2.94 | 5.30 |
| 1999 | 91.20 | 15.12 | 4.86 | 2.47 | 11.43 | 4.47 | 3.16 |
| 2000 | 98.30 | 16.35 | 1.72 | 2.54 | 14.98 | 2.05 | 4.36 |
| 2001 | 97.07 | 27.33 | 6.68 | 5.30 | 1.31 | 5.50 | 3.18 |
| 2002 | 102.95 | 29.76 | 1.46 | 1.86 | 8.40 | 2.55 | 3.73 |
| 2003 | 111.77 | 29.16 | 6.74 | 6.30 | 9.46 | 5.88 | 1.97 |
| 2004 | 121.14 | 28.78 | 1.33 | 6.78 | 16.11 | 0.87 | 0.50 |
| MAPE (%) | 17.59 | 3.43 | 3.66 | 9.37 | 3.21 | 3.17 |
| Year | Actual Value (TWh) | MAED | GPRM | BPN | RBFN | NNGM(1,1) | DCOGM(1,1) |
|---|---|---|---|---|---|---|---|
| 1994 | 34.14 | 16.18 | 10.09 | 4.46 | 0.72 | 9.95 | 6.83 |
| 1995 | 38.01 | 17.71 | 5.41 | 1.91 | 10.25 | 5.70 | 0.27 |
| 1996 | 40.64 | 21.31 | 2.90 | 2.91 | 8.20 | 1.58 | 1.95 |
| 1997 | 43.49 | 24.76 | 2.33 | 2.04 | 11.15 | 1.78 | 4.15 |
| 1998 | 46.14 | 29.39 | 0.77 | 0.94 | 2.47 | 0.72 | 5.43 |
| 1999 | 46.48 | 41.26 | 5.84 | 5.15 | 5.87 | 5.69 | 1.69 |
| 2000 | 48.84 | 47.82 | 0.88 | 0.70 | 4.81 | 1.49 | 1.96 |
| 2001 | 46.99 | 65.93 | 6.27 | 7.02 | 3.54 | 6.65 | 6.84 |
| 2002 | 50.49 | 66.81 | 5.05 | 4.69 | 4.74 | 4.32 | 4.75 |
| 2003 | 55.10 | 65.08 | 8.39 | 8.23 | 10.28 | 6.48 | 0.34 |
| 2004 | 59.57 | 64.93 | 0.08 | 4.99 | 7.30 | 0.01 | 2.52 |
| MAPE (%) | 41.93 | 4.36 | 3.91 | 6.30 | 4.23 | 3.30 |
| Year | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|---|---|---|
| Value | 1295.87 | 1339.62 | 1353.45 | 1410.61 | 1369.02 | 1405.56 | 1486.02 |
| Year | DCOGM(1,1) | GM(1,1) | DGM(1,1) | FGM(1,1) | RGM(1,1) | TGM(1,1) | LR |
|---|---|---|---|---|---|---|---|
| 2015 | 1420.43 | 1404.59 | 1404.27 | 1419.47 | 1404.59 | 1404.60 | 1418.90 |
| 2016 | 1443.70 | 1419.47 | 1419.02 | 1442.22 | 1413.49 | 1419.48 | 1440.63 |
| MAPE | 1.9529 | 2.2737 | 2.3003 | 1.9686 | 2.4749 | 2.2727 | 2.0018 |
| RMSE | 31.72 | 47.06 | 47.39 | 32.50 | 51.29 | 47.05 | 33.45 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Zhang, T. Forecasting Electricity Consumption Using an Improved Grey Prediction Model. Information 2018, 9, 204. https://doi.org/10.3390/info9080204
Li K, Zhang T. Forecasting Electricity Consumption Using an Improved Grey Prediction Model. Information. 2018; 9(8):204. https://doi.org/10.3390/info9080204
Chicago/Turabian StyleLi, Kai, and Tao Zhang. 2018. "Forecasting Electricity Consumption Using an Improved Grey Prediction Model" Information 9, no. 8: 204. https://doi.org/10.3390/info9080204
APA StyleLi, K., & Zhang, T. (2018). Forecasting Electricity Consumption Using an Improved Grey Prediction Model. Information, 9(8), 204. https://doi.org/10.3390/info9080204