Integration of Web APIs and Linked Data Using SPARQL Micro-Services—Application to Biodiversity Use Cases †


Abstract
1. Introduction
- Vocabularies: Web APIs typically rely on standard representation formats such as JSON or XML, but how to invoke a Web API and interpret resource representations is usually documented in Web pages meant for human readers. By contrast, Linked Data best practices [7] advocate the use of standard protocols and common, well adopted vocabularies described in machine-readable formats. Consequently, consuming Web API data and RDF triples alike is often achieved through the development of Web API wrappers implementing bespoke vocabulary alignment.
- Resource identifiers: Web APIs commonly name resources using proprietary, internal identifiers. The downside is that such internal identifiers do not have any meaning beyond the scope of the Web API itself. Linked Data principles address this issue by relying on HTTP URIs to identify resources. Not only URIs are unique on the Web, but they can also establish uniform affordances of the resources in that they can be dereferenced to a description of the resource. Therefore, integrating Web APIs and Linked Data requires a mechanism to associate internal identifiers to URIs.
- Parsimony: Web APIs frequently consist of many different services (search by name/tag/group, organize content, interact with contents, etc.). Such that providing a Linked Data interface for all of these services may require substantial efforts, although a tiny fraction of them may fulfill the needs of most use cases. Therefore, a more parsimonious, on-demand approach may be more relevant.
- Suitable interface: Controversy exists with respect to the type(s) of interface(s) most suitable to query Web APIs in a way that allows for their integration with Linked Data. Each type of Linked Data interface has its own benefits and concerns. RDF dumps allow in-house consumption but do not fit in when data change at a high pace; URI dereferencing (i.e. looking up a URI to retrieve a resource representation in a negotiated media type such as one of the RDF serialization syntaxes) provides subject-centric documents hence lacking query expressiveness. At the other end of the spectrum, SPARQL [8], the W3C recommendation to query RDF graphs, is more expressive but puts the query processing cost solely on the server, and studies suggest that allowing clients to run arbitrary SPARQL queries against public endpoints leads to availability issues [9]. Besides, on-the-fly SPARQL querying of non-RDF databases proves to be challenging, as attested by the many works on SPARQL-based access to relational [10,11] or NoSQL [12,13] databases.
2. Background
2.1. Web APIs
2.2. Micro-Service Architectures
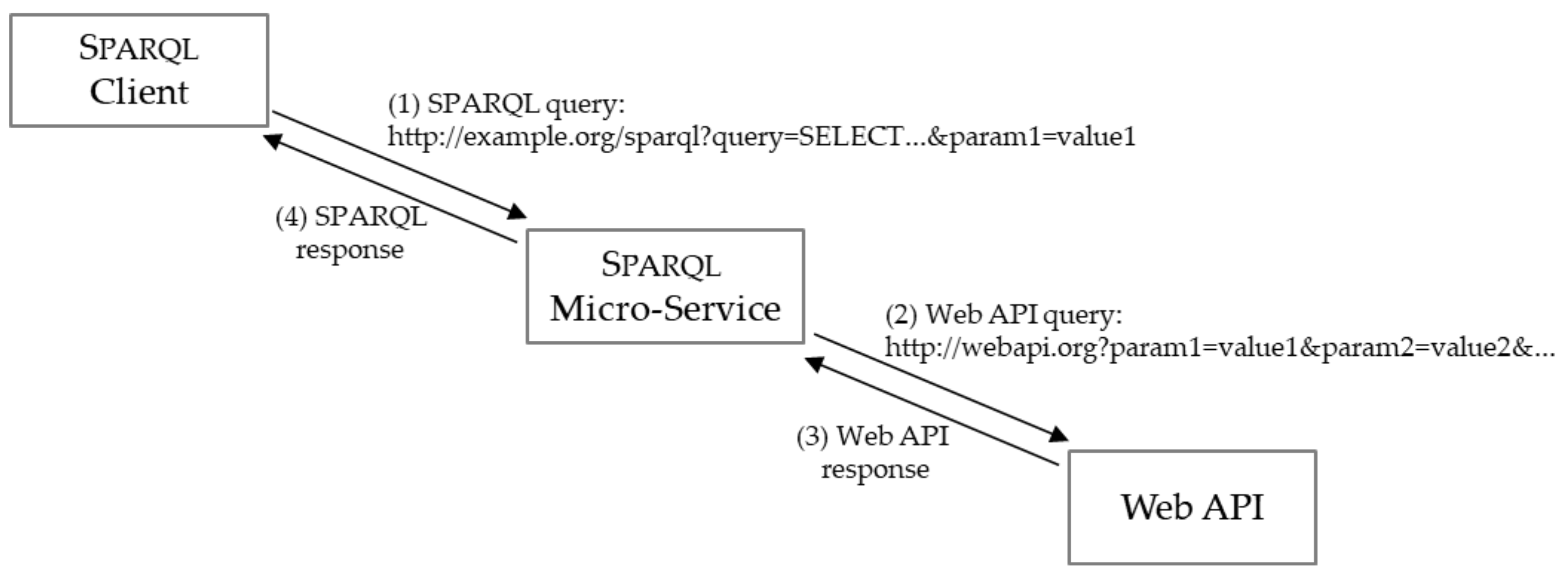
3. The SPARQL Micro-Service Architecture
3.1. Definition
- PREFIX s: <http://schema.org/>
- SELECT * WHERE {
- SERVICE <http://example.org/flickr/getPhotosByGroupByTag? \
- group_id=806927@N20&tags=taxonomy:binomial=Delphinus+delphis>
- { SELECT ?img WHERE { ?photo s:image ?img. } }
- }
3.2. Assigning URIs to Web API Resources
- http://example.org/flickr/getPhotosById?
- photo_id=38427227466&
- query=DESCRIBE\%20\%3Chttp\%3A\%2F\%2Fexample.org\%2Fld \
- \%2Fflickr\%2Fphoto\%2F38427227466\%3E
3.3. Analysis of SPARQL Micro-Services with the Linked Data Fragments Framework
4. Implementation
4.1. Processing SPARQL Queries
| Algorithm 1: Evaluation of a SPARQL query by a SPARQL micro-service . |
|
- { "@context": {
- "@vocab": "http://sms.i3s.unice.fr/schema/"
- }}
- { "head": {
- "vars": [ "img" ] },
- "results": {
- "bindings": [
- { "img": {
- "type": "uri",
- "value":
- "https://farm6.staticflickr.com/5718/31173091626_88c410c3f2_z.jpg" }
- }
- ] } }
4.2. URIs Dereferencing
- http://example.org/flickr/getPhotosById?photo_id=38427227466&query_mode=ld
4.3. Deployment
- config.ini: The micro-service main configuration file declares the arguments expected by the micro-service alongside the Web API invocation query string;
- profile.jsonld: The JSON-LD profile is used to translate a response from the Web API into an RDF graph;
- insert.sparql: This optional file provides an INSERT query meant to yield additional triples typically based on common vocabularies and ontologies;
- construct.sparql: This optional file provides a CONSTRUCT query meant to produce the response to URI look-up queries.
4.4. Discussion
- PREFIX api: <http://sms.i3s.unice.fr/schema/>
- PREFIX s: <http://schema.org/>
- SELECT ?img WHERE {
- SERVICE <http://example.org/flickr/getPhotosByGroupByTag>
- { ?photo s:image ?img;
- api:group_id "806927@N20";
- api:tags "taxonomy:binomial=Delphinus+delphis".
- }
- }
- SELECT ?img WHERE {
- SERVICE <http://example.org/flickr/getPhotosByGroupByTag>
- { ?photo s:image ?img.
- [] a api:Service;
- api:param [ api:name "group_id"; api:value "806927@N20" ];
- api:param [ api:name "tags"; api:value ?tag ].
- }
- }
- SELECT ?img WHERE {
- SERVICE <http://example.org/flickr/getPhotosByGroupByTag>
- { ?photo s:image ?img.
- <http://example.org/flickr/getPhotosByGroupByTag> a api:Service;
- api:execution [
- api:param [ api:name "group_id"; api:value "806927@N20" ];
- api:param [ api:name "tags"; api:value ?tag ].
- ].
- }
- }
- SELECT ?img WHERE {
- SERVICE <http://example.org/flickr/getPhotosByGroupByTag>
- { ?photo s:image ?img.
- BIND("806927@N20" AS ?group_id)
- BIND("taxonomy:binomial=Delphinus+delphis" AS ?tags)
- }
- }
5. Experimentation
- bhl/getArticlesByTaxon retrieves scientific articles mentioning a given species name from the Biodiversity Heritage Library (BHL) (http://biodiversitylibrary.org/).
- flickr/getPhotosByGroupByTag, already described in Section 3, is used to search the Encyclopedia of Life Images Flickr group (https://www.flickr.com/groups/806927@N20) for photos of a given species. Photos of this group are tagged with the scientific name of the species they represent, formatted as “taxonomy:binomial=<scientific name>”.
- macaulaylibrary/getAudioById retrieves audio recordings for a given species identifier from the Macaulay Library (https://www.macaulaylibrary.org/), a scientific media archive related to birds, amphibians, fishes, and mammals.
- musicbrainz/getSongByName searches the MusicBrainz music information encyclopedia (https://musicbrainz.org/) for music tunes whose title match a given name with a minimum confidence of 90%.
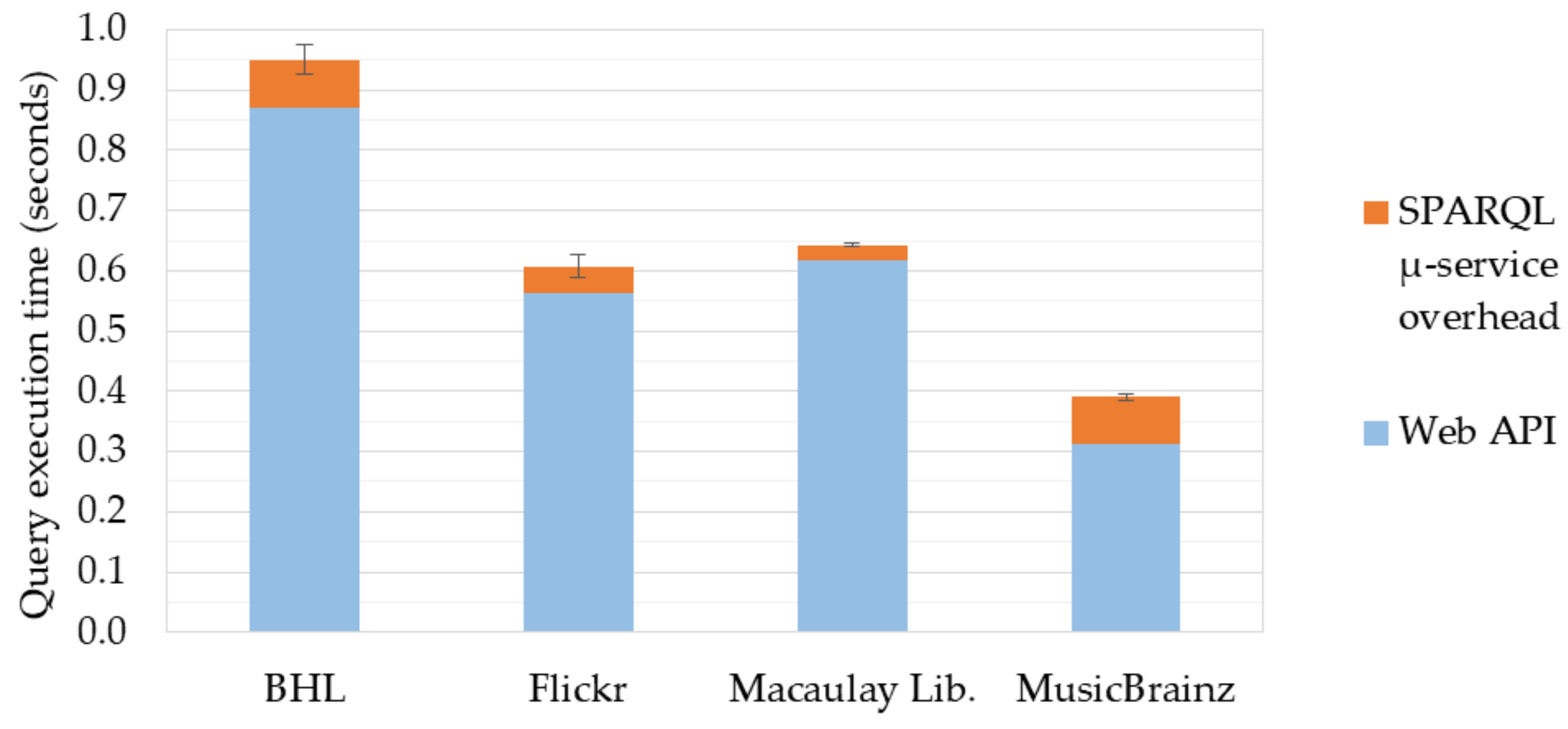
5.1. Performance of Individual SPARQL Micro-Services
5.2. Performance When Invoking Multiple SPARQL Micro-Services
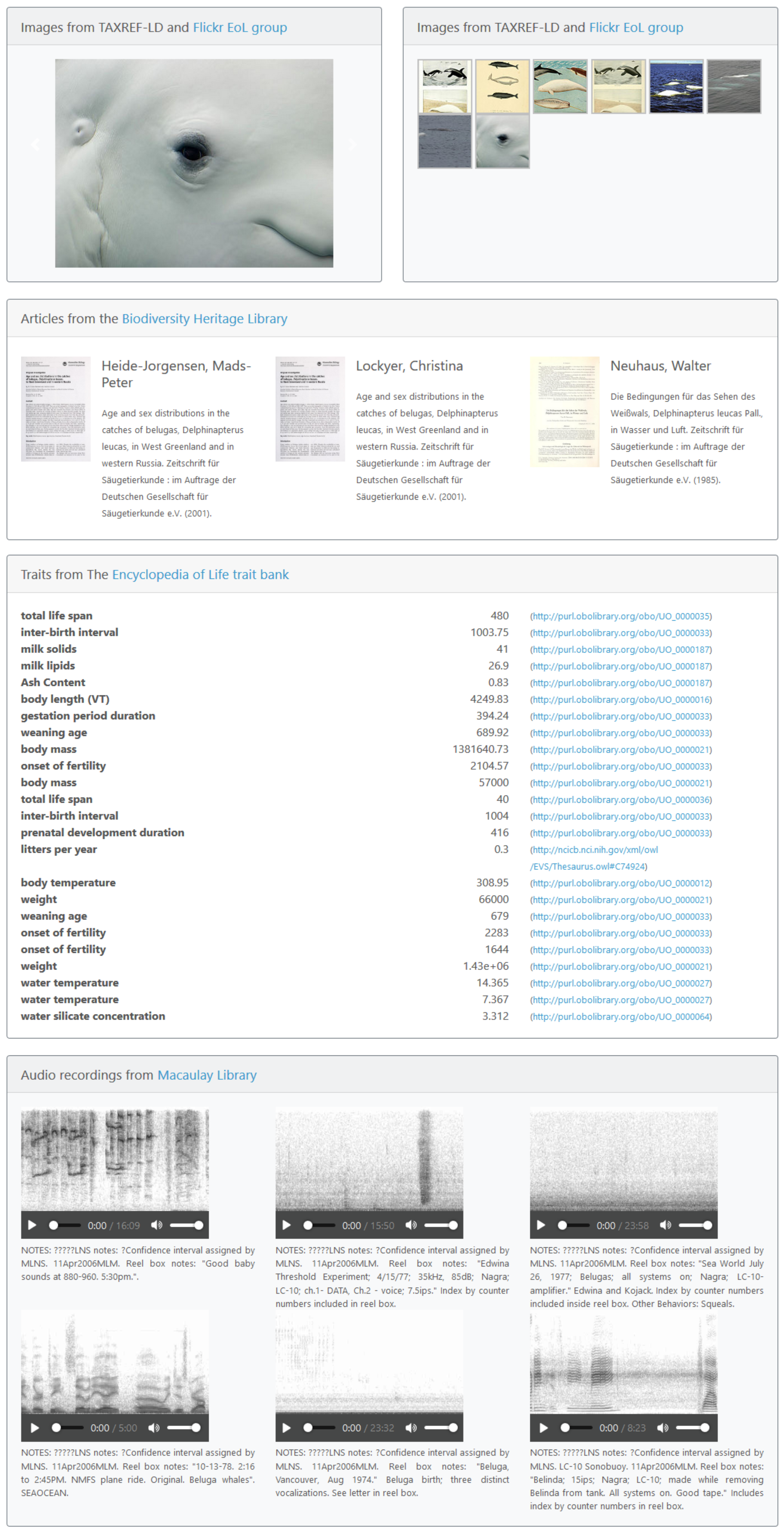
6. Biodiversity-Related Use Cases
6.1. Aggregating Various Types of Data Related to Biological Taxa
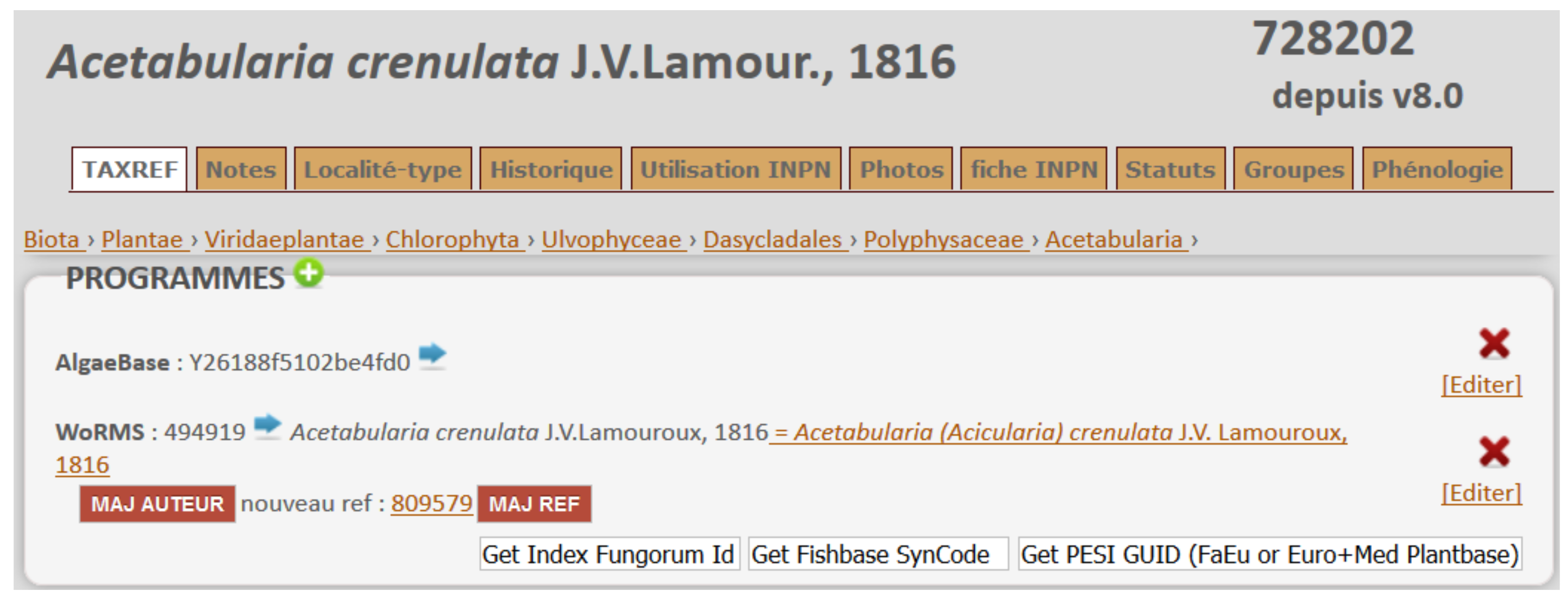
6.2. Assisting Biologists in Editing Taxonomic Information
- Synonymy disagreement: A taxon may be associated with a reference name (the preferred name used to refer to the taxon) and a set of synonyms. A disagreement may occur when a program states a reference name that is considered as a synonym in TAXREF, or when they disagree on the synonyms.
- Taxonomic rank disagreement: A taxon or name has different taxonomic ranks in different programs. For instance, a taxon is considered as a species in TAXREF but as a sub-species in WoRMS.
- Author disagreement: Different author names or different spellings and/or abbreviations.
- Habitat disagreement.
- Bibliographic references: Retrieve bibliographic references currently unknown in TAXREF, or point out and fix inconsistent references.
- Life traits: Query WoRMS, Fishbase, and EoL for life traits not referenced in TAXREF, or point out and fix inconsistencies.
- Multimedia material: Display material available in TAXREF, suggest adding links to photos in Flickr and audio/video recordings in the Macaulay library.
7. Related Works
8. Conclusions and Perspectives
Author Contributions
Funding
Conflicts of Interest
References
- Hecht, R.; Jablonski, S. NoSQL Evaluation: A Use Case Oriented Survey. In Proceedings of the International Conference on Cloud and Service Computing (CSC), Hong Kong, China, 12–14 December 2011; pp. 336–341. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: A Flexible Data Processing Tool. Commun. ACM 2010, 53, 72–77. [Google Scholar] [CrossRef]
- Máchová, R.; Lnenicka, M. Evaluating the Quality of Open Data Portals on the National Level. J. Theor. Appl. Electron. Commer. Res. 2017, 12, 21–41. [Google Scholar] [CrossRef]
- Triebel, D.; Hagedorn, G.; Rambold, G. An appraisal of megascience platforms for biodiversity information. MycoKeys 2012, 5, 45–63. [Google Scholar] [CrossRef]
- Heath, T.; Bizer, C. Linked Data: Evolving the Web into a Global Data Space, 1st ed.; Morgan & Claypool: San Rafael, CA, USA, 2011. [Google Scholar]
- Cyganiak, R.; Wood, D.; Lanthaler, M. RDF 1.1 Concepts and Abstract Syntax. W3C Recommendation. 2014. Available online: https://www.w3.org/TR/2014/REC-rdf11-concepts-20140225/ (accessed on 5 December 2018).
- Hyland, B.; Atemezing, G.; Villazón-Terrazas, B. Best Practices for Publishing Linked Data. W3C Consortium. 2014. Available online: https://www.w3.org/TR/2014/NOTE-ld-bp-20140109/ (accessed on 5 December 2018).
- Harris, S.; Seaborne, A. SPARQL 1.1 Query Language. W3C Recommendation. 2013. Available online: http://www.w3.org/TR/2013/REC-sparql11-query-20130321/ (accessed on 5 December 2018).
- Buil-Aranda, C.; Hogan, A.; Umbrich, J.; Vandenbussche, P.Y. SPARQL Web-Querying Infrastructure: Ready for Action? In Proceedings of the 12th International Semantic Web Conference, Sydney, Australia, 21–25 October 2018; pp. 277–293. [Google Scholar]
- Michel, F.; Montagnat, J.; Faron-Zucker, C. A Survey of RDB to RDF Translation Approaches and Tools. Research report. 2014. Available online: https://hal.archives-ouvertes.fr/hal-00903568v2/ (accessed on 5 December 2018).
- Spanos, D.E.; Stavrou, P.; Mitrou, N. Bringing Relational Databases into the Semantic Web: A Survey. Semant. Web J. 2012, 3, 169–209. [Google Scholar]
- Michel, F.; Faron-Zucker, C.; Montagnat, J. A Generic Mapping-Based Query Translation from SPARQL to Various Target Database Query Languages. In Proceedings of the 12th International Conference on Web Information Systems and Technologies (WebIST), Shanghai, China, 8–10 November 2016; Volume 2, pp. 147–158. [Google Scholar]
- Mugnier, M.L.; Rousset, M.C.; Ulliana, F. Ontology-Mediated Queries for NOSQL Databases. In Proceedings of the 30th Conference on Artificial Intelligence (AAAI), Rome, Italy, 23–25 April 2016. [Google Scholar]
- Newman, S. Building Microservices; O’Reilly Media: Newton, MA, USA, 2015. [Google Scholar]
- Fielding, R. Architectural Styles and the Design of Network-based Software Architectures. Ph.D. Thesis, University of California, Irvine, CA, USA, 2000. [Google Scholar]
- Zaveri, A.; Dastgheib, S.; Wu, C.; Whetzel, T.; Verborgh, R.; Avillah, P.; Korodi, P.; Terryn, R.; Jagodnik, K.; Assis, P.; et al. smartAPI: Towards a More Intelligent Network of Web APIs. In Proceedings of the 14th Extended Semantic Web Conference (ESWC), Portorož, Slovenia, 28 May 2017. [Google Scholar]
- Dragoni, N.; Giallorenzo, S.; Lafuente, A.L.; Mazzara, M.; Montesi, F.; Mustafin, R.; Safina, L. Microservices: Yesterday, today, and tomorrow. In Present and Ulterior Software Engineering; Springer: New York, NY, USA, 2017; pp. 195–216. [Google Scholar]
- Zimmermann, O. Microservices Tenets: Agile Approach to Service Development and Deployment. Comput. Sci.-Res. Dev. 2016, 32, 301–310. [Google Scholar] [CrossRef]
- Speicher, S.; Arwe, J.; Malhotra, A. Linked Data Platform 1.0. W3C Recommendation. 2015. Available online: https://www.w3.org/TR/2015/REC-ldp-20150226/ (accessed on 5 December 2018).
- Feigenbaum, L.; Todd Williams, G.; Grant Clark, K.; Torres, E. SPARQL 1.1 Protocol. W3C Recommendation. 2013. Available online: https://www.w3.org/TR/2013/REC-sparql11-protocol-20130321/ (accessed on 5 December 2018).
- Fielding, R.; Reschke, J. Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content; Proposed Standard; IETF: Fremont, CA, USA, 2014. [Google Scholar]
- Beckett, D.; Berners-Lee, T.; Prud’hommeaux, E.; Carothers, G. RDF 1.1 Turtle: Terse RDF Triple Language. W3C Recommendation. 2014. Available online: https://www.w3.org/TR/2014/REC-turtle-20140225/ (accessed on 5 December 2018).
- Verborgh, R.; Vander Sande, M.; Hartig, O.; Van Herwegen, J.; De Vocht, L.; De Meester, B.; Haesendonck, G.; Colpaert, P. Triple Pattern Fragments: A Low-cost Knowledge Graph Interface for the Web. Web Semant. Sci. Serv. Agents World Wide Web 2016, 37–38, 184–206. [Google Scholar] [CrossRef]
- Minier, T.; Skaf-Molli, H.; Molli, P. SaGe: Preemptive Query Execution for High Data Availability on the Web. arXiv, 2018; arXiv:1806.00227. [Google Scholar]
- Seaborne, A. SPARQL 1.1 Query Results JSON Format. W3C Recommendation. 2013. Available online: https://www.w3.org/TR/2013/REC-sparql11-results-json-20130321/ (accessed on 5 December 2018).
- Corby, O.; Faron-Zucker, C.F. The KGRAM Abstract Machine for Knowledge Graph Querying. In Proceedings of the International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Washington, DC, USA, 31 August–3 September 2010; pp. 338–341. [Google Scholar]
- Lanthaler, M.; Gütl, C. Hydra: A Vocabulary for Hypermedia-Driven Web APIs. In Proceedings of the 6th Workshop on Linked Data on the Web (LDOW2013), Rio de Janeiro, Brazil, 14 May 2013. [Google Scholar]
- Prud’hommeaux, E.; Buil-Aranda, C. SPARQL 1.1 Federated Query. W3C Recommendation. 2013. Available online: https://www.w3.org/TR/2013/REC-sparql11-federated-query-20130321/ (accessed on 5 December 2018).
- Michel, F.; Gargominy, O.; Tercerie, S.; Faron-Zucker, C. A Model to Represent Nomenclatural and Taxonomic Information as Linked Data. Application to the French Taxonomic Register, TAXREF. In Proceedings of the 2nd International Workshop on Semantics for Biodiversity (S4BioDiv) co-located with ISWC 2017, Vienna, Australia, 21–25 October 2017. [Google Scholar]
- Gargominy, O.; Tercerie, S.; Régnier, C.; Ramage, T.; Schoelink, C.; Dupont, P.; Vandel, E.; Daszkiewicz, P.; Poncet, L. TAXREF V10. 0, Référentiel Taxonomique Pour La France: Méthodologie, Mise En Oeuvre et Diffusion; Muséum national d’Histoire Naturelle: Paris, France, 2016. [Google Scholar]
- Parr, C.S.; Schulz, K.S.; Hammock, J.; Wilson, N.; Leary, P.; Rice, J.; Corrigan, R.J., Jr. TraitBank: Practical semantics for organism attribute data. Semant. Web 2016, 7, 577–588. [Google Scholar] [CrossRef]
- Corby, O.; Faron-Zucker, C. STTL: A SPARQL-based transformation language for RDF. In Proceedings of the 11th International Conference on Web Information Systems and Technologies (WEBIST), Lisbon, Portugal, 20–22 May 2015. [Google Scholar]
- Wiederhold, G. Mediators in the Architecture of Future Information Systems. IEEE Comput. 1992, 25, 38–49. [Google Scholar] [CrossRef]
- Mendes, P.N.; Passant, A.; Kapanipathi, P. Twarql: Tapping into the Wisdom of the Crowd. In Proceedings of the 6th International Conference on Semantic Systems, Graz, Austria, 1–3 September 2010. [Google Scholar]
- Lanthaler, M. Creating 3rd Generation Web APIs with Hydra. In Proceedings of the 22nd International Conference on World Wide Web, WWW’13 Companion, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 35–38. [Google Scholar]
- Serrano, D.; Stroulia, E.; Lau, D.; Ng, T. Linked REST APIs: A Middleware for Semantic REST API Integration. In Proceedings of the IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; pp. 138–145. [Google Scholar]
- Lefrançois, M.; Zimmermann, A.; Bakerally, N. A SPARQL extension for generating RDF from heterogeneous formats. In Proceedings of the 14th Extended Semantic Web Conference (ESWC), Portorož, Slovenia, 28 May 2017; pp. 35–50. [Google Scholar]
- Jünemann, M.; Reutter, J.L.; Soto, A.; Vrgoc, D. Incorporating API Data into SPARQL Query Answers. In Proceedings of the 15th International Semantic Web Conference (Posters and Demos), Kobe, Japan, 17–21 October 2016. [Google Scholar]
- Moreau, B.; Serrano-Alvarado, P.; Desmontils, E.; Thoumas, D. Querying non-RDF Datasets using Triple Patterns. In Proceedings of the 16th International Semantic Web Conference (Posters and Demos), Vienna, Austria, 21–25 October 2017. [Google Scholar]
- Dimou, A.; Sande, M.V.; Slepicka, J.; Szekely, P.; Mannens, E.; Knoblock, C.; Walle, R.V.D. Mapping Hierarchical Sources into RDF Using the RML Mapping Language. In Proceedings of the International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 16–18 June 2014; pp. 151–158. [Google Scholar]
- Michel, F.; Djimenou, L.; Faron-Zucker, C.; Montagnat, J. Translation of Relational and Non-Relational Databases into RDF with xR2RML. In Proceedings of the 11th International Conference on Web Information Systems and Technologies (WEBIST), Lisbon, Portugal, 1 October 2015; pp. 443–454. [Google Scholar]
- Beckett, D.; Broekstra, J.; Hawke, S. SPARQL Query Results XML Format, 2nd ed. W3C Recommendation. 2013. Available online: https://www.w3.org/TR/2013/REC-rdf-sparql-XMLres-20130321/ (accessed on 5 December 2018).
- Polleres, A.; Kamdar, M.R.; Fernandez, J.D.; Tudorache, T.; Musen, M.A. A More Decentralized Vision for Linked Data. In Proceedings of the 2nd Workshop on Decentralizing the Semantic Web (DeSemWeb) Co-Located with ISWC 2018, Monterey, CA, USA, 8 October 2018; Volume 2165. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Web API | Triples Produced | SPARQL -service Exec. Time | Web API Exec. Time | Overhead | Overhead (Percentage) |
|---|---|---|---|---|---|
| Biodiversity | 1161 | 0.950 ± 0.049 | 0.870 ± 0.048 | 0.080 ± 0.004 | 9.24% ± 0.44 |
| Heritage Lib. | |||||
| Flickr | 336 | 0.607 ± 0.039 | 0.564 ± 0.039 | 0.044 ± 0.008 | 7.74% ± 1.45 |
| Macaulay Library | 87 | 0.642 ± 0.050 | 0.617 ± 0.005 | 0.025 ± 0.004 | 4.11% ± 0.07 |
| MusicBrainz | 1160 | 0.391 ± 0.011 | 0.312 ± 0.009 | 0.079 ± 0.004 | 25.5% ± 1.22 |
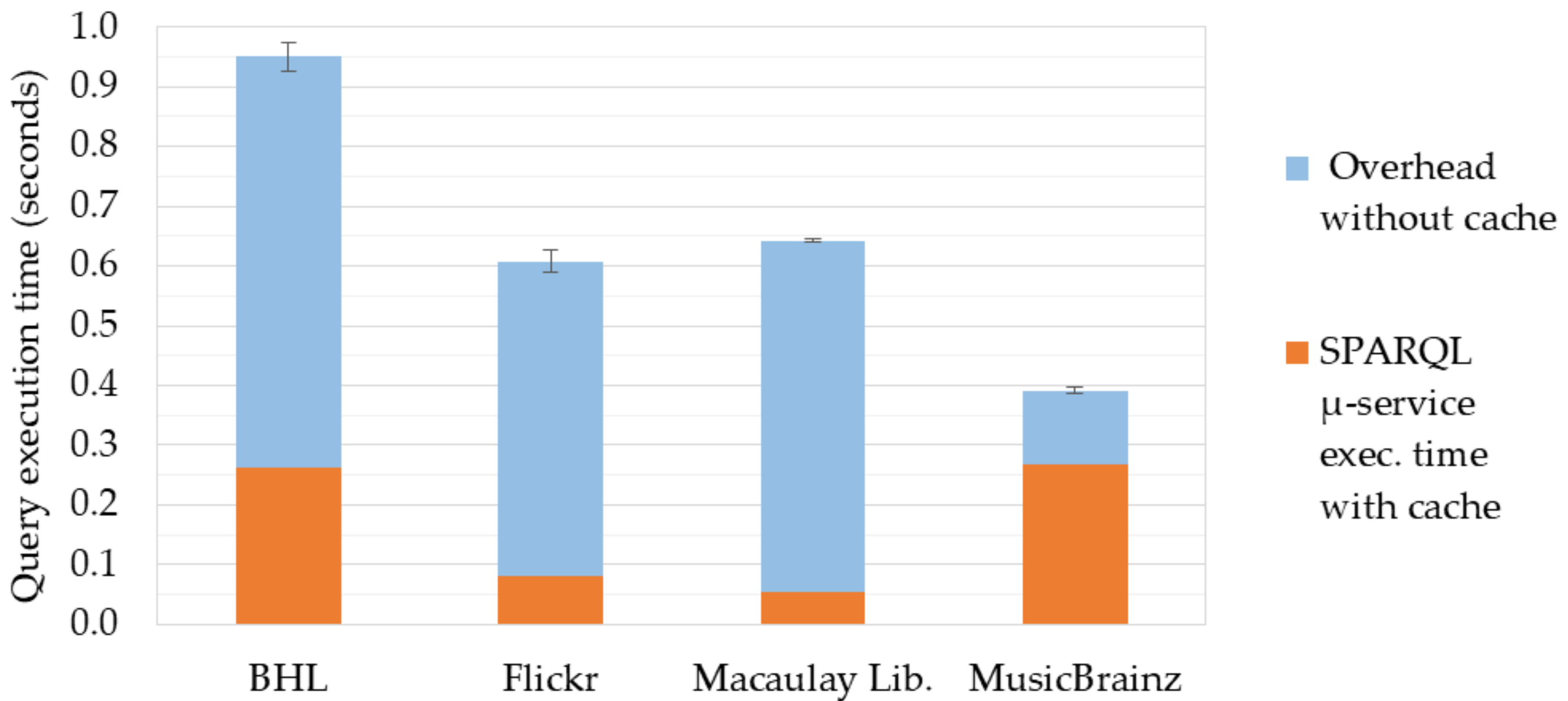
| Web API | SPARQL -Service Exec. Time without Cache | SPARQL -Service Exec. Time with Cache | Reduction (Percentage) |
|---|---|---|---|
| Biodiversity Heritage Lib. | 0.950 ± 0.048 | 0.264 ± 0.015 | 72.3% |
| Flickr | 0.607 ± 0.039 | 0.080 ± 0.012 | 86.9% |
| Macaulay Library | 0.642 ± 0.050 | 0.547 ± 0.010 | 91.5% |
| MusicBrainz | 0.391 ± 0.011 | 0.267 ± 0.027 | 31.7% |
| SPARQL Engine | Exec. Time without Cache | Exec. Time with Cache |
|---|---|---|
| Corese-KGRAM | 3.66 ± 0.10 | 1.68 ± 0.04 |
| Virtuoso | 411 ± 1 | 90.3 ± 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michel, F.; Faron Zucker, C.; Gargominy, O.; Gandon, F. Integration of Web APIs and Linked Data Using SPARQL Micro-Services—Application to Biodiversity Use Cases. Information 2018, 9, 310. https://doi.org/10.3390/info9120310
Michel F, Faron Zucker C, Gargominy O, Gandon F. Integration of Web APIs and Linked Data Using SPARQL Micro-Services—Application to Biodiversity Use Cases. Information. 2018; 9(12):310. https://doi.org/10.3390/info9120310
Chicago/Turabian StyleMichel, Franck, Catherine Faron Zucker, Olivier Gargominy, and Fabien Gandon. 2018. "Integration of Web APIs and Linked Data Using SPARQL Micro-Services—Application to Biodiversity Use Cases" Information 9, no. 12: 310. https://doi.org/10.3390/info9120310
APA StyleMichel, F., Faron Zucker, C., Gargominy, O., & Gandon, F. (2018). Integration of Web APIs and Linked Data Using SPARQL Micro-Services—Application to Biodiversity Use Cases. Information, 9(12), 310. https://doi.org/10.3390/info9120310