1. Introduction
Endowing data with semantics is a crucial task for many applications. Motivated by the emergence of ontologies and linked open data () in different fields (e.g., Cyc, DBpedia, Freebase, and YAGO), the amount of semantic data is rapidly increasing in various domains (e.g., the New York Times, BBC, and Thomson Reuters semantic data) and their involvement in different data centric systems is growing. Business intelligence (BI) systems are no exception. Data warehouses (s) are data management systems at the core of BI applications, used in small, medium, and large organizations for decision support. s integrate operational data coming from heterogeneous sources, and organize data using a multidimensional perception that identifies central subjects of analysis (called the Facts) according to different dimensions of analysis, to be exploited by OLAP (on-line analytical processing) techniques and tools.
The
community has undergone an important event materialized by the spectacular development of Semantic Web technologies that are intensively used in designing and exploring
s (for more details, refer to the survey paper [
1]). Many studies have used ontologies (an ontology is defined as a specification of a conceptualization) [
2] in order to facilitate
design. Unlike the traditional vision of
construction which concentrates on internal sources, the new generation of
s integrates both internal and external sources. Among external sources, recent research efforts have identified the interest of integrating the
in designing
. As part of the Big Data landscape,
initiatives bring new and publicly available semantic data on the web that are valuable for data analytics inside
systems. The value of
for
s manifests in their capabilities to answer requirements that are unsatisfied from internal sources, and to enrich the multidimensional expressiveness of the
model.
keep adding value to
s, since they are continuously changing (new concepts and knowledge). For instance, Yago has evolved from Yago to Yago3, passing by Yago2. Therefore, the added-value of
has to be managed continuously through an evolution process.
Traditional evolution approaches for
manage the evolution of internal sources (usually conventional relational databases). The use of external semantic data poses new challenges related to their evolution management: (i)
sources bring a new kind of heterogeneity since they are presented using the semantic formalism, based on the Resource Description Framework (RDF) (
https://www.w3.org/RDF/) language using the triple format to organize data in the form of
). The set of triples form a graph. (ii) The evolution events of
sources (e.g., addition, deletion, renaming, etc.) are gathered from the web using the triple format, which requires specific management tasks to identify the impact of such evolution events on the
system. (iii) Finally, different scenarios have been proposed in order to integrate
sources in the
that can be done at the schema level or at the query level. Contrary to traditional
s that manage evolution either from a source perspective or from a requirements perspective, ignoring the interrelated artifacts composing the
design cycle,
can be integrated at different steps of the
cycle, possibly impacting different artifacts. Such integration scenarios are conducted during the core phases of
design, namely:
requirements definition, the
extract–transform–load (ETL) phase composed of a set of ETL processes used to transform heterogeneous data in the
representation, and the
deployment phase which implements the
system. In this context, the
system can be seen as a set of components inherently intertwined with each other. This idea of managing evolution between different types of software artifacts or different representations of them is called “co-evolution” in the software engineering field.
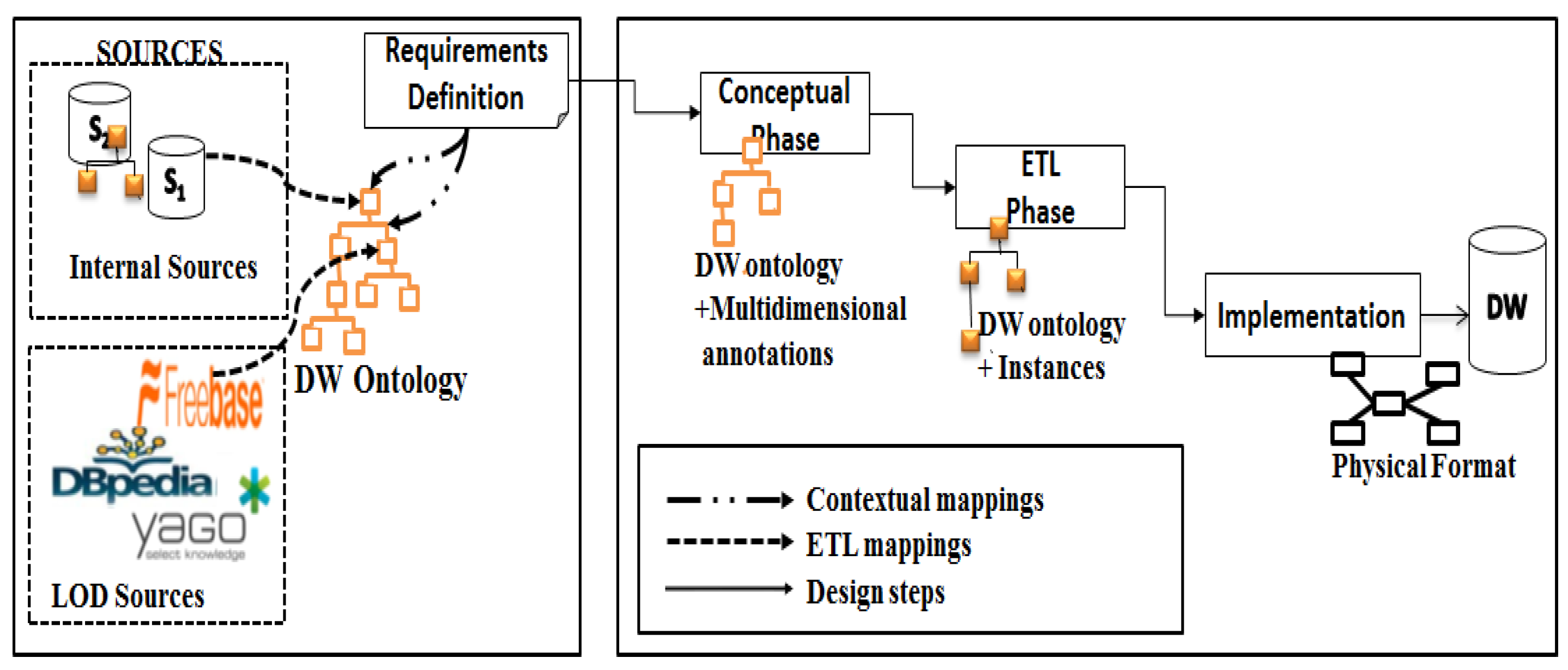
Our goal in this study was to define the impact of changes on a system populated by internal and external sources, by identifying design constructs (in each design phase) impacted by the changes, and to propagate these changes to the final system. Forward and backward evolution strategies are required to manage changes. The identification of design constructs is a significant contribution of our work, since evolution events may concern any of these interlinked constructs of different design levels. Our approach exploits the correlations between constructs in order to identify which part of the is sensitive to evolution events. The identification of change impact on the design-cycle requires an explicit representation of the design artifacts, their relationships, and their traces.
To the best of our knowledge, this work is the first study that manages co-evolution in the context of fed by sources. Moreover, the availability of the ontology model allows evolution to be addressed from the conceptual level, where the understanding of the evolution problem is easier to follow and to propagate to the other design levels. The main contributions of this work are (Figure 4): (1) We describe a traceability model that uniformly covers the most relevant constructs and artifacts. In order to define traces semantically, we extend the ontology meta-model by the design model. (2) We present an event-based approach for managing the co-evolution of the whole cycle, including a co-evolution mechanism for the annotation of constructs impacted by evolution events at the semantic level. Evolution events may concern primarily or other design constructs. Regarding changes, evolution is managed in asynchronously, which we consider to be the most suitable approach since the receive flows of changes, and only some of them are relevant for the . (3) We demonstrate the efficiency and feasibility of our approach through a case study related to the University domain.
Motivating Example
We illustrate our purpose by the following example:
Example 1. Let us consider a used for analysing the research publications of a university. The number of publications is analysed according to each department and according to the type of publication (conference or journal). Information related to publications are collected from internal sources related to the university researchers, and the characteristics of publications (impact factor, type, editor, etc.) are collected from like Thomson Reuters datasets. Inspired by DBpedia (one of the most popular portals), we assume that portals provide the set of changes periodically in the form of N-Triples files containing added, modified, and deleted triples. Identifying the impact of these changes when dealing with large amounts of triples is a particularly difficult and error-prone task if it is not automated. An ontological view is required for identifying the impact of these changes: (1) at the conceptual level (i.e., which concepts are concerned by these changes and are they involved in any ETL process feeding the ?); (2) at the requirements level (i.e., which requirements are concerned by these changes and are they still satisfied after applying the changes?); and (3) at the physical level (i.e., which ontological instances in the database management system (DBMS) are concerned with the changes?). Note that the reasoning skills of the ontology can also be used for inferring new traces of the impact of events evolution.
This paper is organized as follows:
Section 2 overviews the related work related to
design (from internal and external sources) and
evolution.
Section 3 gives the background and essential concepts for the comprehension of our approach.
Section 4 presents the
traceability model underlying the proposed approach.
Section 5 describes the proposed co-evolution approach.
Section 6 presents the case study (related to the University domain) used to evaluate the feasibility and effectiveness of our approach. The last section concludes the paper.
4. Traceability Model for Managing Co-Evolution
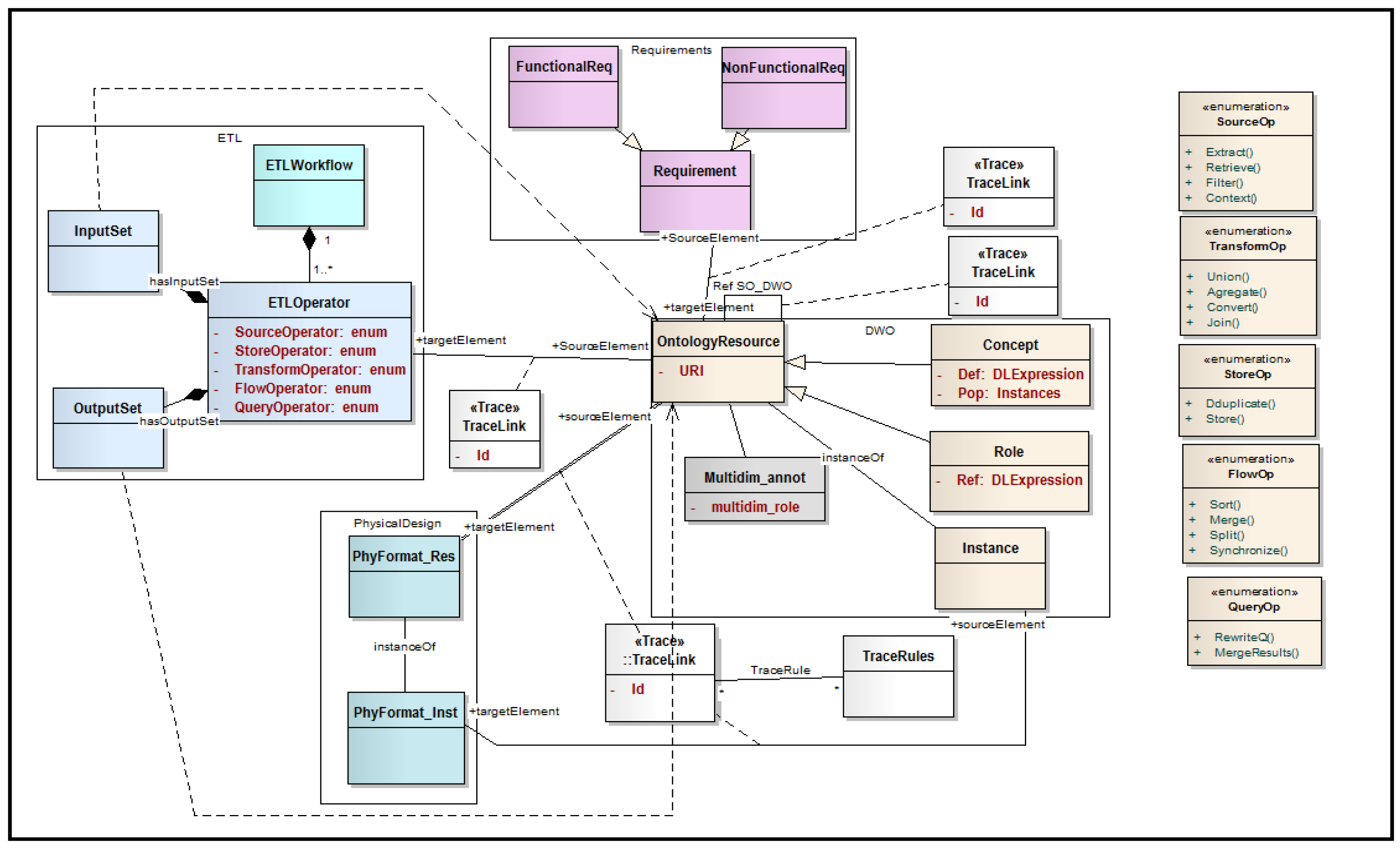
We propose a metamodel presenting the co-dependent artifacts used in DW design considering both internal and external sources, namely: requirements, ETL, and DW model (conceptual artifacts and physical storage artifacts). The model helps to identify the parts of the overall configuration that are most prone to being affected by the changes. Several approaches have been proposed to detect and manage traces in the context of s. We assume that traces are available and correctly maintained.
In our work, we use the traceability model that we proposed in [
48], the goal of which is to keep traces of the
during its design cycle. The model is illustrated in
Figure 2 as a UML class diagram. The model represents each design phase (framed in a box in the figure) including its main design artifacts. The central part of the model is related to the ontology model
OntologyResource class. Based on the previous formalization (
Section 3.2), this class subsumes three main classes:
Concept,
Role and
Instance. Note that the
OntologyResource class in the model designates the resources of sources (internal or external) and those of the DWO. Each ontology has a unique identifier (the URI), which is associated to each resource name composing the resource identifier. These resources are identified to satisfy some given requirements (
Requirement class). The set of resources are alimented using an ETL workflow composed of a set of ETL operators that defines the OutputSet (an OntologyResource of the DW) in terms of an expression InputSet (DL expression over resources of internal and external sources). Skoutas and Simitsis [
11] identified ten generic ETL operators for integrating internal data sources into the
system, namely: Extract, Retrieve, Filter, Union, Aggregate, Convert, Join, Sort, Merge, and Split. We introduce new ETL operators for managing
sources that cover the integration scenarios cited in
Section 2.1:
context operator (used for identifying
concepts to extract),
synchronize (for synchronizing the internal ETL flow with the external flow), and the
query operator for unifying the result of an ETL flow required by a given with the internal
. We classify these operators into five main classes:
Source operators,
Transform operators,
Store operators,
Flow operators, and
Query operators. The set of operators of each group is defined as enumerations in the model. Finally, the set of resources used are translated to their physical format using a set of defined translation rules.
The traces between design artifacts are illustrated using the trace links presented by the stereotype
. Each TraceLink involves the source of the trace and its target. For example, concept University (OntologyResource class) is the source of a trace, and the ETL process alimenting this concept is the target. Some
TraceLinks require the definition of trace rules (
TraceRules class) if the target element is generated from its source using defined rules (e.g., translation from the ontology layout to the
physical format). Source and target trace elements are defined in the model for each design phase. These traces facilitate the identification of change impact. For example, concept Organization can be considered as important since it subsumes other concepts (University, Academic press, Faculty, etc.). One requirement can be considered as sensitive if it involves different concepts of the
. We followed a meta-modeling approach for the definition of this traceability model. The ontology meta-model (class
OntologyResource) of the
is connected to the traceability model as presented in
Figure 3 (upper part). This figure is illustrated using Protege editor, where the ontology meta-model is extended with the traceability model described. The ontology illustrated in this figure is a fragment of Lehigh University BenchMark (LUBM) benchmark ontology that will be used in the case study section. The adoption of a meta-modeling approach is explained by the fact that traceability data are considered as meta-data. Additionally, this makes the approach independent of any particular modeling technique.
Note that the DBMS may keep track of meta-data and some ETL tools also keep track of the ETL processes, but it is achieved at the physical level and is not centralized in a single model. Extending the ontology model by the traceability model allows traces to be defined in a common model and allows semantic identification of all correlations between design constructs of different levels (ontology, ETL, requirements, etc.). This yields a conceptual representation of event changes (concepts, relationships, specializations), when the final
model normally lacks these concepts. The ontology is also used to reason on traces, and ontology editors offer powerful visualization tools (
Figure 3).
5. Evolution Management Approach
Our general proposed approach is illustrated in
Figure 4. The approach identifies the changes of
datasets and their impact on the
constructs at different design levels. Two main types of changes are identified for
sources [
16,
49]: simple and complex changes. Simple changes (addition, deletion, and modification of triples) are meant to capture fine-grained evolution events. Complex changes are defined on top of simple changes to capture more coarse-grained changes (e.g., schema changes, groupings of triple additions). Because it is unrealistic to capture all possible evolution types of complex changes that can be defined, simple changes can be considered as a “default” set of changes for describing evolution types [
49].
For each of the above events, the approach manages co-evolution by annotating constructs (DWO fragment) affected by the event and by applying the changes. We propose a co-evolution management approach that follows these steps:
1. Parsing the input files: The datasets that we analyzed and their different versions reflecting evolution events are available as ntriples files. Note that the files can be available in other formats serializing RDF data (e.g., N3 and Turtle). Our approach first considers a parser that analyses the input files (i.e., ntriple files of changes). The files concerning each type of change (add, delete, modify) are provided separately. The files can be visualized by the designer using Protege editor.
In these files, the set of changes concerning the dataset and those concerning the schema are declared without distinction as triples. This first step of our approach aims to semantically define the set of changes by distinguishing the data from schema changes. For example, the “add” file can include (American_Journal_of_Business, academicDiscipline, Business) as a triple of type instance addition and (publisher, type, Property) as a property addition. Because such triples are not intuitive enough for human designers, our approach parses the files in order to identify the concepts and all their instances that are concerned by the changes. This identification is achieved using a java script that reads the files using the OWL API (
http://owlcs.github.io/owlapi/).
The result of this parsing is a set of changes that belong to the space of potential events comprising the Cartesian product of two sub-spaces: the space of hypothetical actions (addition, deletion, and modification) over the space of resources of the knowledge base (Concept, Role, and Instance). Note that annotation properties related to Wikipedia (like WikiPageExtracted, WikiPageID, label, …) are considered as annotations. they are reflected only in the DWO ontology model, and are not propagated.
Once the concept representing the first impact of change management is identified, it is propagated to the other design artifacts. Our approach identifies the concepts that are concerned with the changes in the DWO using the ETL processes. That is, instances of the meta-concept ETLProcess in the ontology (representing the ETL workflow composed of a set of ETL operators). The identification of the ETL processes impacted by the change is the first step, because that is what links the schema with its sources. Note that we consider a Global as View (GaV) approach for defining the ETL processes, which is the approach usually followed in design. The GaV approach advocates for defining the concepts of the target schema (the DWO) in terms of the sources’ schemas (internal and external sources). We also assume that the mappings between sources and target data stores are achieved at the schema level (not at the instance level). After identifying the set of ETL processes concerned by the evolution event, the set of artifacts concerned by this event are then identified using a change propagation mechanism described in the next step.
The changes concerning design constructs (requirements, ETL) can also be defined in ntriples or OWL files, since our model defines all these constructs as ontological concepts. In this case, the files must have the same meta-model extension by the traceability model. The files are parsed similarly to match between concepts of the input files and concepts of the DWO. A simpler approach is to manually define these changes by the designer, since they occur less frequently than evolution events.
2. Propagating the changes: The core step of our approach consists of propagating the identified evolution events. We propose a concept-flow analysis algorithm entitled PropagateChange (presented in Algorithm 1) to identify the concepts concerned by the changes. When an evolution event is tested, the impact of the event is automatically computed throughout the ontology subset affected by the event. After the identification of the first impact of the evolution event on the DWO (the ETL processes concerned) in the previous step, Algorithm 1 propagates this impact. The propagation is achieved by identifying the set of concepts C of the DWO that are involved in the ETL processes identified. Then, the set of concepts related to C are also identified (Usage (C) in Algorithm 1, line 2).
Example: Assume that the following ETL processes are identified:
An evolution event on AcademicPress will identify this ETL process as the first impact and then Publisher as the second impact. The set of concepts related to Publisher are identified (e.g., Publication). The set of requirements involving these concepts are identified. For instance, requirement R1 analyzes the number of publications for each university, and it thus involves concept Publication in its parameters.
To do so, the algorithm uses trace links (instances of class TraceLink in
Figure 2). We identify two types of trace links: defined and inferred links. Reasoning on trace links is based on a transitive rule used to identify new traces. This rule states that if object x is related to object y and object y is in turn related to object z, then object x is also related to object z. The rule is formalized in Semantic Web Rule Language (SWRL) as follows:
Source(?T1, ?X), Source(?T2, ?Y), Target(?T1, ?Y), Target(?T2, ?Z) -> Target(?T1,?Z).
In this rule, Source(?T, ?X) (resp. Target(?T,?Y)) defines that a trace link T has design element X as source (resp. element Y as target). Source or target elements can be any TraceElement, that is, any instance of the meta-concepts extending the ontology meta-model as illustrated in
Figure 3 (DWO concepts, requirement concepts, ETL concepts, etc.). The algorithm relies on the results of an ontological reasoner (we used Pellet reasoner) to get inferred trace links. The impact of the evolution event is thus propagated to all design constructs of the concepts impacted by the change (Algorithm 1, lines 3–4). This final subset of a concept impacted by the change is consequently identified by including both its immediate and its transitive consumers. The impacted concepts are added into a queue to be processed in the next step for applying the changes (Algorithm 1, line 5). For each processed concept, its meta-concept is identified to apply the adapted evolution process (Algorithm 1, line 9).
| Algorithm 1 Change Propagation Algorithm |
Input: (1) an event e over a concept C,
(2) the ontology model extended by the traceability model,
(3) Q: Queue of concepts concerned by the event (Q = ∅)
Output: the fragment of the ontology impacted by the event
Enqueue (Q, usage(C))
for each TraceLink trace involving C do
Get concepts C’ included in trace
Enqueue (Q, C’)
end for
while Q ≠∅ do
C = Dequeue Q
Identify meta-concept of C % ETL process, Requirement or DWO concept
ApplyChange (C,event e)
end while |
We used Protege editor to visualize the fragment of the DWO concerned by the evolution events. Protege offers different visualization plugins. We chose the OntoGraph plugin, which provides a visualization in the form of a graph.
Figure 3 (lower part) illustrates the ontology fragment involved with concept Work (i.e., research works) in LUBM ontology. Note that in the figure the concept Conference is provided from DBpedia
, and other concepts defining design constructs are also identified (by their meta-concept). Note also that this mechanism propagates the changes regardless of the first impact, and consequently allows a forward and a backward strategy propagation of changes. Backward strategy refers to the ability to follow the trace links from a specific artifact back to its sources, from which it has been derived. Forward strategy refers to following the trace links to the artifacts that have been derived from the artifact under consideration. In this step, the impact of evolution events is propagated to the main design artifacts (source and target).
3. Applying the changes: At this step, the DWO can be reshaped to adjust to the new semantics incurred by the event. The list of changes is presented to the designer so that she can validate or reject some changes. This last step applies changes using the following rule: ON <event> TO <construct> THEN <policy>. The combination of events and annotations determines the policy to be followed for the handling of a potential change. For each annotated concept, the corresponding evolution policy is applied. For some cases, designer intervention is required to decide what should be done. We distinguish the following scenarios:
(i) Event in the DWO: This scenario concerns changes in DWO concepts (to be stored in the
). We define the evolution policy for each change type and for each design level as follows. We distinguish the schema level from the instance level.
Table 1 summarizes the change policies required for each type of change.
If the event is an
addition of a concept or a role from the
knowledge base, two types of additions are distinguished: adding a new concept C in the
knowledge base, or adding a sub-concept to concept C alimenting the
(i.e., extending the hierarchy of concepts). In the first case, no traces are identified because the new concept cannot be included in any ETL process. If the designer chooses to include this concept, this scenario requires redefining the design, which has been treated in existing studies (
Section 2.1). We focus on the second scenario of addition. In this case, the ETL traces are identified. This addition event is then propagated to the design artifacts detected by Algorithm 1 (requirements and DWO). The new concept is added to the identified requirement parameters. For instance, requirement R1 analyzes the number of research works for each university, and thus involves ResearchWork in its parameters. The addition of a new type of ResearchWork will impact this requirement. The new concept is added as an instance of the meta-concept “TargetElement” of the “TraceLink” concerning R1. The new concept may include a set of instances, which requires the re-execution of the identified ETL traces (processes).
For example, the ETL process ResearchWork Union (Work,Work), and Source S2 adds a new concept C (subclass of Work) in its hierarchy. After identifying the traces, the impacted ETL processes must consider this new concept. The maintenance of the ETL process at the implementation level will be described in scenario (iii).
If the event requires adding instances Inst, the approach first identifies the set of classes C, such as (Inst rdf:type C). The class is described in the input file if it is well-formed, otherwise it is possible to retrieve it from the SPARQL endpoint of the dataset. Then, the same process as described previously is achieved: the ETL processes involved, the set of classes of DWO, and the set of requirements concerned by the change are identified as traces. The ETL processes identified are re-executed to load the new instances.
Modification events may concern the schema level (concepts and role) or the instance level. The modification of concepts and roles requires the identification of traces concerning the ETL processes, the set of DWO concepts, and the set of requirements. The concept/role modified is updated in these traces. In cases where the type of role changes, the update of the ETL process requires the validation of the designer and its re-execution. The modification of instances (Inst) requires first identifying the set of classes C (Inst rdf:type C) of the knowledge base, then follows a similar process described for concepts and roles.
Deletion events require more careful treatment since they can impact some requirements and thus analysis possibilities. The validation of the designer is required for these events. A deletion event of a concept or a role first identifies the set of traces (ETL processes, DWO, and requirements) impacted by the event. The concept/role is then deleted from ETL processes and from the requirement parameters. The modified ETL processes are first validated by the designer and are then re-executed. The deletion of instances is easier to achieve. It requires the identification of traces and the re-execution of ETL processes concerned by the event.
(ii) Event in requirements constructs: An addition event in the requirements indicates the addition of a new requirement (performed by the designer). In this case, the requirement and its definition (defined in input file) are added in the traceability model. If the requirement needs new concepts, this is managed in the first scenario (i). Modification events are handled similarly by modifying related concepts in the traceability model. A deletion event is handled by the deletion of the requirement in the traceability model (without the deletion of the concerned concepts). For all the events, the traces are automatically updated using the reasoning rule defined.
(iii) Event in ETL processes: An evolution event in the ETL process may concern any ETL activity (input, output, or ETL operator) performed by the designer. All types of events require the re-execution of the new/modified ETL process. This can be achieved in two ways: (i) the re-execution of the ETL process concerned. Each ETL scenario is coded as PL∖SQL stored procedures in the DBMS (Oracle in our case). (ii) The use of the Protege Plugin for Oracle Database (
https://protegewiki.stanford.edu/wiki/Protege_4_Plugin_for_Oracle_Database), which provides the ability to view, edit, and save ontologies in Oracle Database with Protege Desktop (
Figure 5). This approach can be more suitable, as it provides a visualization tool associated to traces. Note that this option may not be available for all semantic DBMSs, which do not provide plugins for ontology editors.
The deletion of an ETL process requires the validation of the designer if it concerns its output concept, since this will imply a concept in the that will not be alimented by instances. The consistency of the DWO is checked using a reasoner. Note that evolution events may also concern a new translation rule. Our model stores the translation rules. If new rules are needed (in the case of a new storage design model), they can easily be stored in the proposed model to be executed. However, these events require the implementation of the rules to be executed in the DBMS. These evolution events are not implemented in our approach, but they are supported by the proposed model.
6. Case Study and Experiments
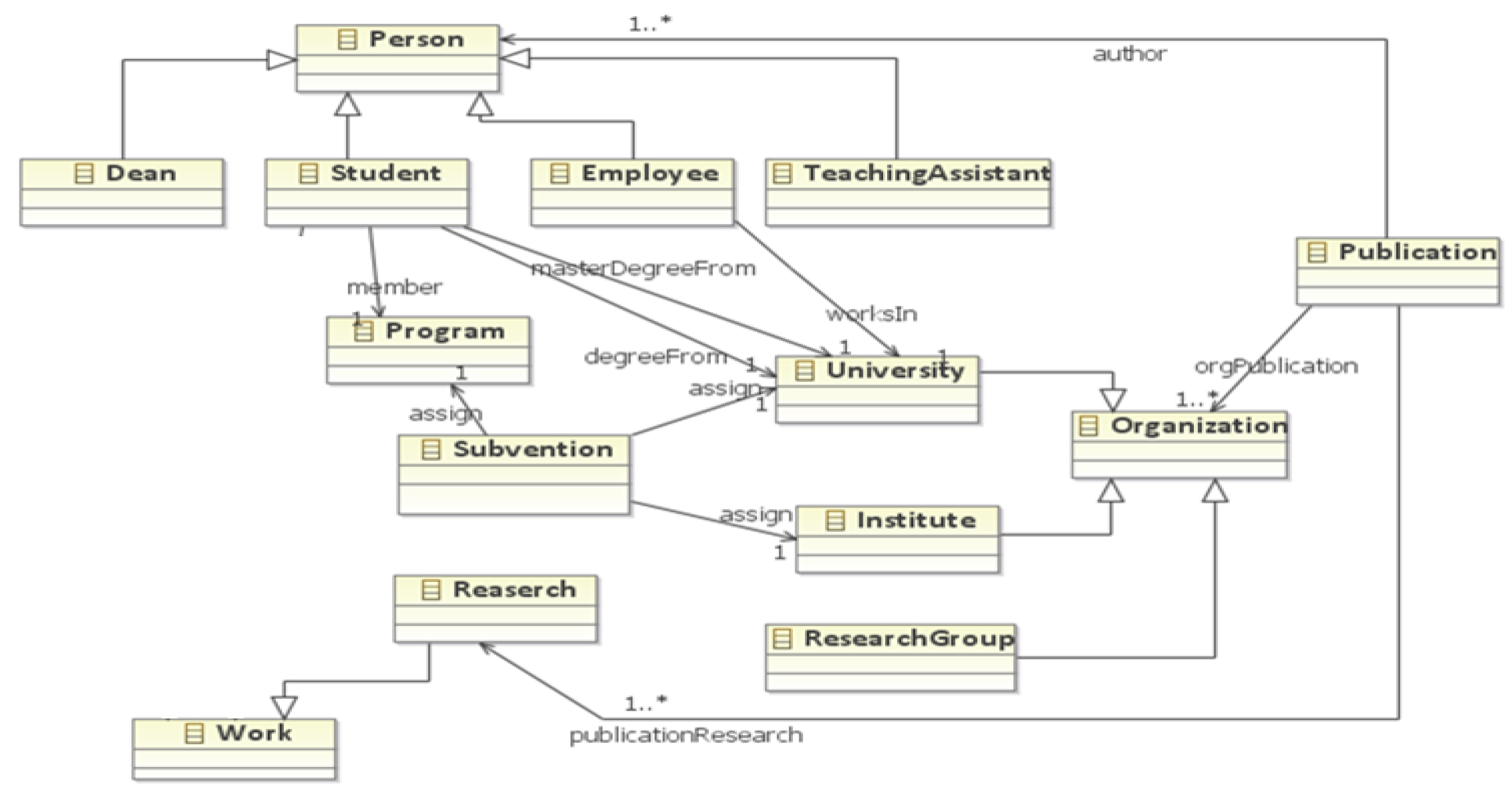
We conducted a set of experiments using the LUBM benchmark (
http://swat.cse.lehigh.edu/projects/lubm/) related to the University domain. LUBM provides an ontology schema called Univ-Bench which describes universities, departments, the activities that occur at them (courses, research activities, programs, publications, etc.), and the actors related to these activities (students, teachers, researchers, etc.). LUBM also provides a data generator tool (called UBA) used to create data over Univ-Bench ontology in the unit of a university. UBA provides synthetic data with varying size. We used these data-sets to simulate internal sources. We considered Univ-Bench as the DWO (
Figure 6). We also considered
as external sources, which were: DBpedia (
http://wiki.dbpedia.org/), Yago (
https://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/yago-naga/yago/), Scholarlydata (
http://www.scholarlydata.org/dumps/), and Thomson Reuters (
https://permid.org/download)
. We used the 14 queries of LUBM to express requirements. We defined ETL processes for each
concept from an internal source and from at least one
source.
The
datasets are usually available as ntriples files. DBpedia extracts structured information from Wikipedia, interlinks it with other
, and freely publishes the results on the Web using Linked Data and SPARQL. DBpedia release processes are heavy-weight, and releases are sometimes based on data that are several months old. DBpedia-Live solves this problem by providing a live synchronization method based on the update stream of Wikipedia. The set of changes are provided as ntriples files (
http://live.dbpedia.org/changesets/) that we considered as input files to test our approach. We considered 60 files (20 files for addition events, 20 for deletion, and 20 files for modification events) chosen so that they included concepts defined in Univ-Bench ontology. The distribution of events in these files is almost 80% events related to instances and 20% related to schema changes. In order to balance the set of events, we considered Bdpedia and other
(Yago, Scholarlydata and Thomson Reuters) by downloading datasets (ntriples) related to the University domain (e.g., Author, AcademicJournal, AcademicPress, ResearchProject, Book) matching with Univ-Bench conceptualization, that we considered as triples randomly concerned by the three types of events (addition/deletion/modification). For instance, we considered the AcademicPress concept and its instances, downloaded from Yago
as a new concept enriching the hierarchy of Organization concept of Univ-Bench ontology (schema addition event). All the steps of our approach were implemented in a Java script that uses OWL API for interacting with the ontology and the
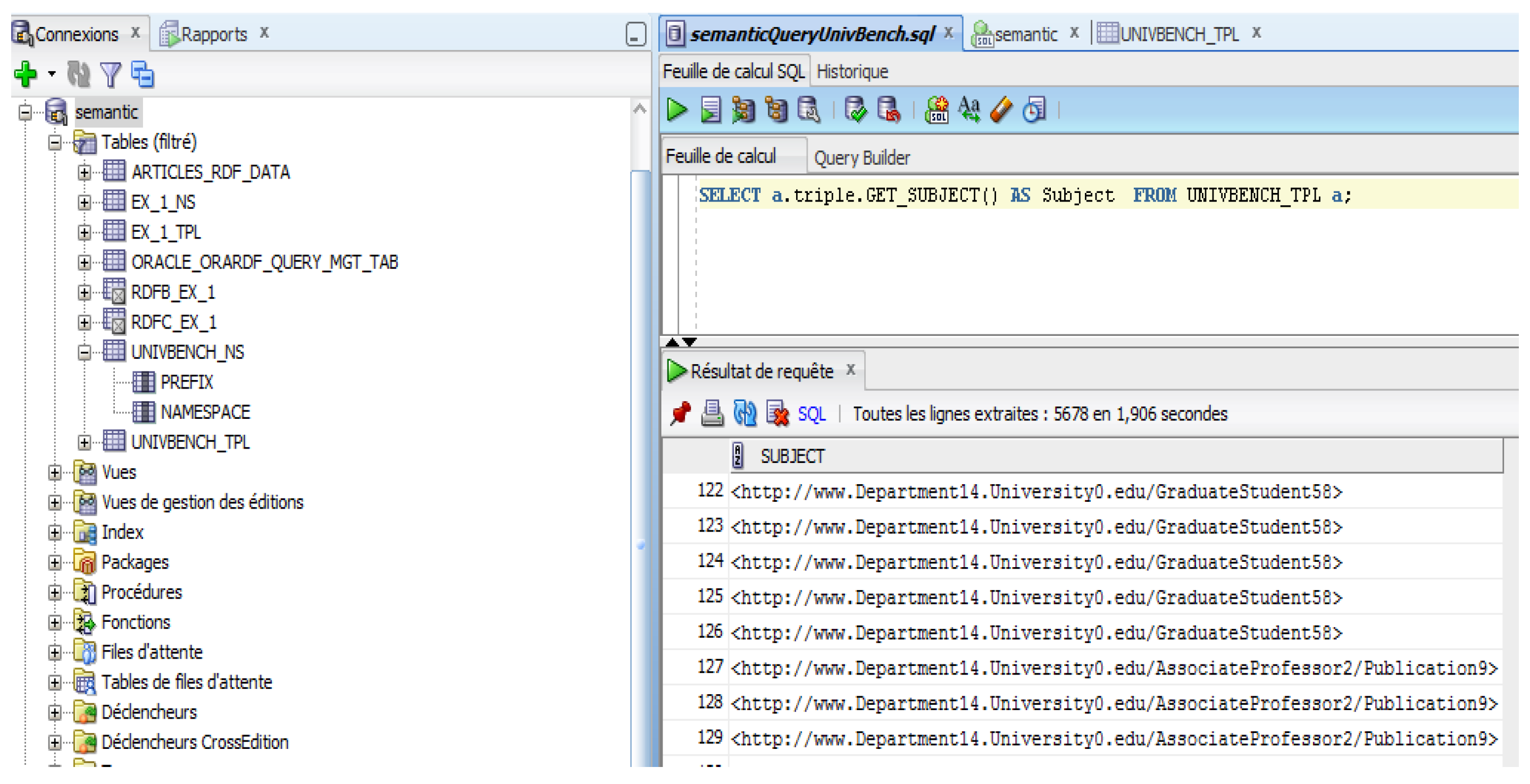
. We implemented this minimal prototype only for defining the input sources and running the propagating and evolution algorithms. We used Protege editor to visualize the DWO and Oracle Database Management System (RDF Semantic Graph 12c version (
https://docs.oracle.com/database/121/RDFRM/title.htm)) to implement the
(
Figure 7).
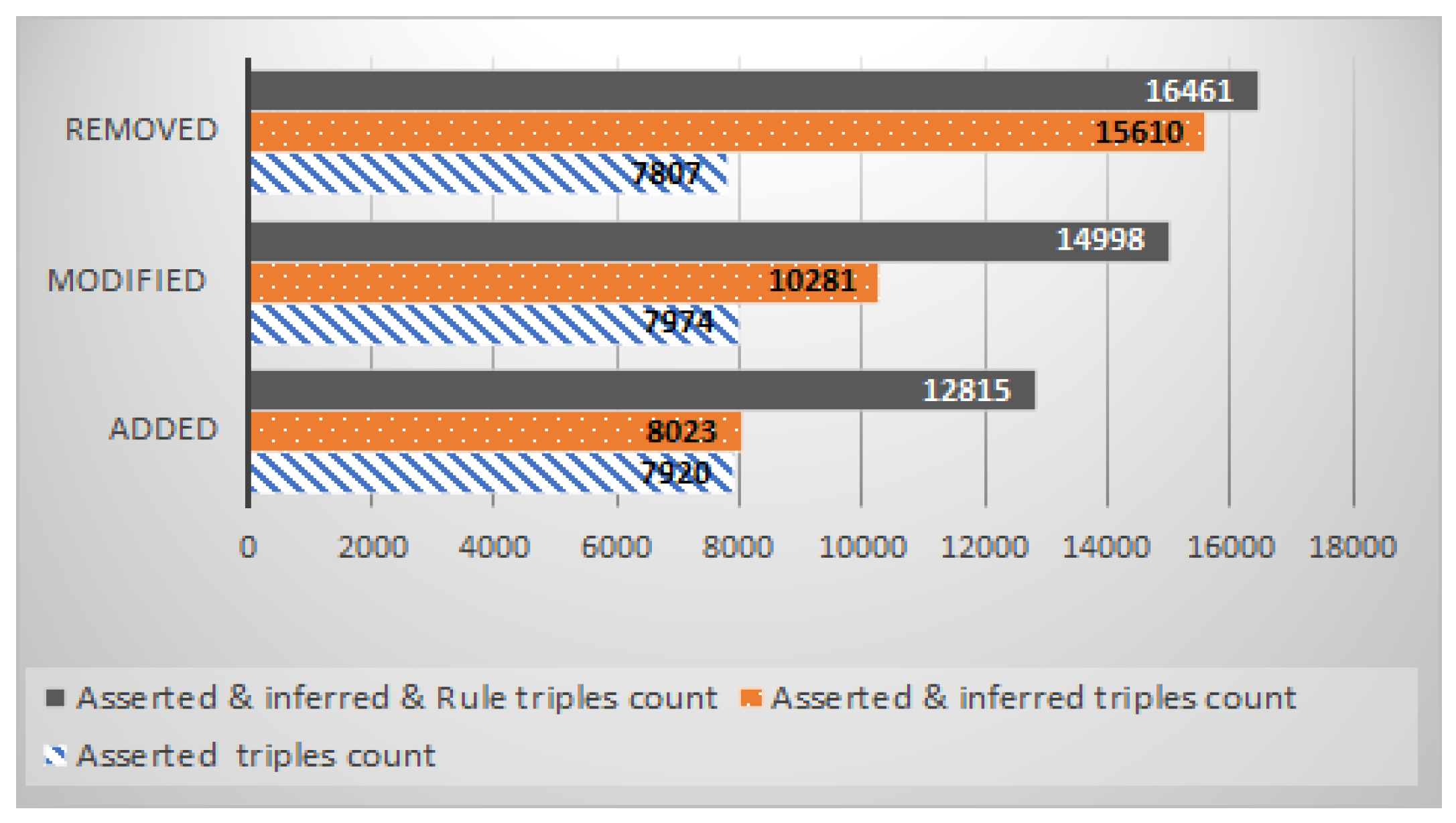
The first experiment shows the amount of triples (inserted, deleted, or modified) in the
after applying the approach for change management. The purpose of this experiment was to illustrate the impact of the evolution management at the instance level of the
.
Figure 8 shows the amount of triples asserted, the amount of triples inferred (using the ontology reasoner Pellet), and the amount of triples inferred using the reasoning rule we defined. We could assess the effort gain of a designer using the highlighting of affected concepts compared to the situation where this process had to be performed manually.
Figure 9a illustrates the amount of nodes (number of nodes and percentage) impacted by changes at different design levels: requirements, DWO, and ETL. We considered the set of concepts (including the traces) and roles (attributes and relationships) as nodes. The goal of this experiment was to illustrate the impact of co-evolution management at the schema level of the
, and the number of design constructs affected by changes. The designer knowledge of these constructs and their visualization is an integral part of the co-evolution management.
Figure 9b illustrates the precision of the process proposed for managing the changes. The precision was calculated as follows: the number of instances affected by the changes/total number of instances that should be affected (from the
). Since there is no “standard” for the precision measure in our study context, we used study [
50] to define this measure. We adapted the proposed precision measure to our context of
co-evolution management. We can conclude from the figure that the
could be effectively adapted to different kinds of events. Exceptions regarding the three types of events are due to the fact that for some concepts from the
that had to be added/deleted/modified, our process did not find a match with the corresponding concepts of the DWO.
As explained in the previous section, the process for propagating the changes starts by projecting the change events on the ETL processes, because they describe the link between the sources and the . During the parsing of files, our matching is strictly terminological (term matching). For instance, for the event <Event Add on Construct Concept>, the process tries to find if concept C is used in the ETL processes and then identifies the DWO concepts and the requirements concerned by this event. Because this matching is terminological, some concepts were missed (e.g., AcademicJournal is part of the evolution events that should be detected as a subclass of Publication). The matching can be enriched with other types of ontology matching mechanisms (semantic, conceptual, etc.), which is planned in further research.
Finally, we analyzed the set of requirements that were impacted to check if they can be satisfied after change propagation. The set of requirements can be translated to queries reflecting the analysis performed on the . We noticed that even for requirements where deletion events occurred, they could be answered after applying the changes. This is because the set of requirements are those of LUBM, referring to concepts from local sources that we extended to reference concepts from external sources. In the case of addition, modification, or deletion, the results of queries may change but requirements remain satisfied.
Note that comparing these results with other state-of-the-art papers is difficult to achieve because there is no study managing
co-evolution, and in the context of
evolution, most studies focus on the automation of the evolution process and not the precision quality of the results. In the context of
database evolution management, we consider [
50] as the most detailed study—their precision results were above 90%.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}