Adaptive Multiswarm Comprehensive Learning Particle Swarm Optimization


Abstract
1. Introduction
2. Related Work
3. Adaptive Multiswarm Comprehensive Learning Particle Swarm Optimization
3.1. Multiswarm Comprehensive Learning Particle Swarm Optimization
| Algorithm 1. The brief working procedure of MSCLPSO. |
|
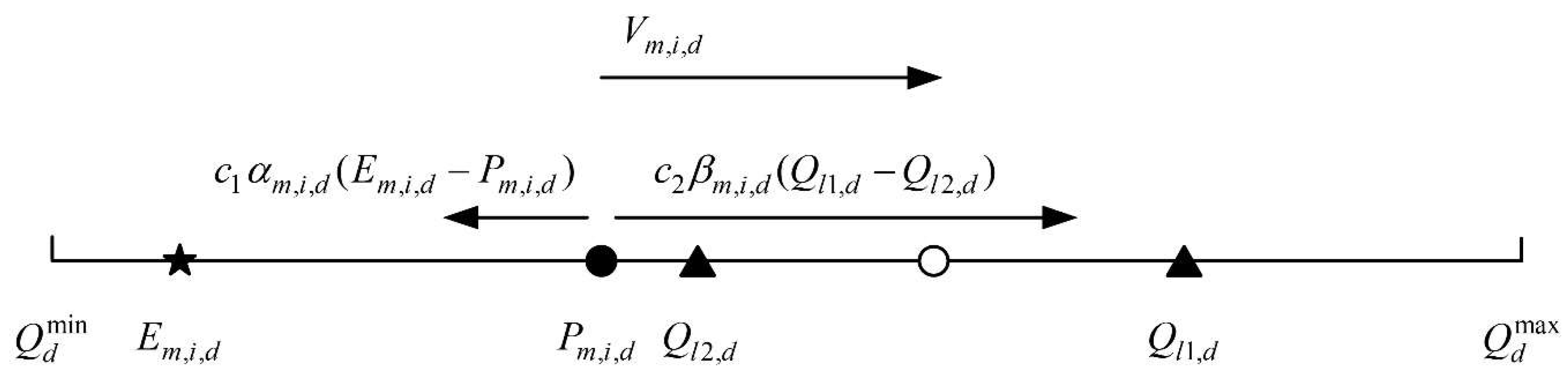
3.2. Adaptive Particle Velocity Update
4. Experimental Studies
4.1. Performance Metric
4.2. Multiobjective Benchmark Optimization Problems
4.3. Metaheuristics Compared and Parameter Settings
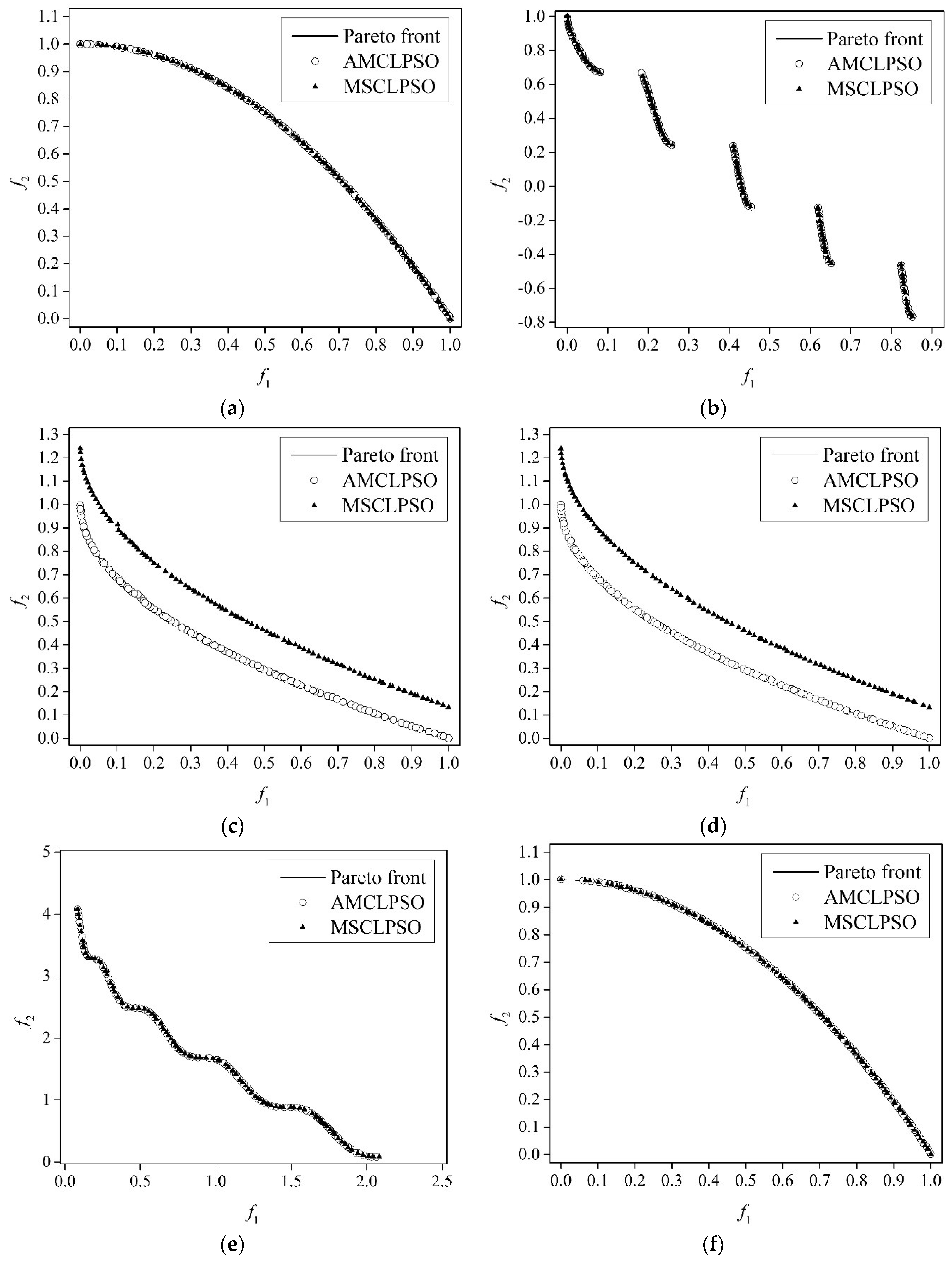
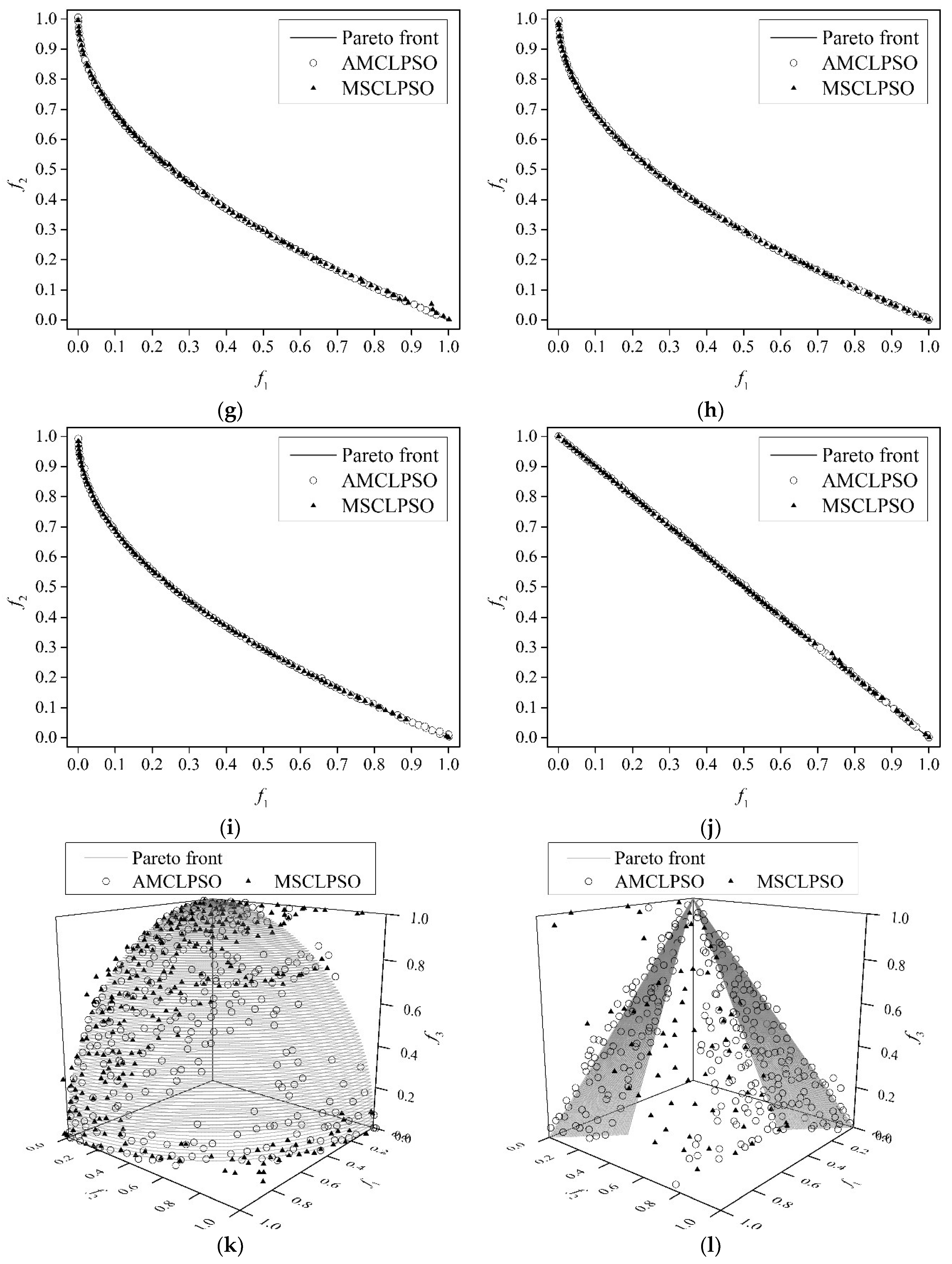
4.4. Experimental Results and Discussions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yu, X.; Zhang, X.-Q. Multiswarm comprehensive learning particle swarm optimization for solving multiobjective optimization problems. PLoS ONE 2017, 12, e0172033. [Google Scholar] [CrossRef] [PubMed]
- Jones, D.F.; Mirrazavi, S.K.; Tamiz, M. Multi-objective meta-heuristics: An overview of the current state-of-the-art. Eur. J. Oper. Res. 2002, 137, 1–9. [Google Scholar] [CrossRef]
- Zavala, G.R.; Nebro, A.J.; Luna, F.; Coello, C.A.C. A survey of multi-objective metaheuristics applied to structural optimization. Struct. Multidiscip. Optim. 2014, 49, 537–558. [Google Scholar] [CrossRef]
- Fister, I., Jr.; Yang, X.-S.; Fister, I.; Brest, J.; Fister, D. A brief review of nature-inspired algorithms for optimization. Elektrotehniski Vestnik 2013, 80, 116–122. [Google Scholar]
- Boussaïd, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Huang, V.L.; Suganthan, P.N.; Liang, J.J. Comprehensive learning particle swarm optimizer for solving multiobjective optimization problems. Int. J. Intell. Syst. 2006, 21, 209–226. [Google Scholar] [CrossRef]
- Horn, J.; Nafpliotis, N.; Goldberg, D.E. A niched Pareto genetic algorithm for multiobjective optimization. In Proceedings of the IEEE Congress on Evolutionary Computation, Orlando, FL, USA, 27–29 June 1994; pp. 82–87. [Google Scholar]
- Yang, D.-D.; Jiao, L.-C.; Gong, M.-G.; Feng, J. Adaptive ranks clone and k-nearest neighbor list-based immune multi-objective optimization. Comput. Intell. 2010, 26, 359–385. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Strength Pareto Evolutionary Algorithm; ETH: Zurich, Switzerland, 2001; pp. 1–21. [Google Scholar]
- Montalvo, I.; Izquierdo, J.; Pérez-García, R.; Herrera, M. Water distribution system computer-aided design by agent swarm optimization. Comput.-Aided Civ. Infrastruct. Eng. 2014, 29, 433–448. [Google Scholar] [CrossRef]
- Knowles, J.D.; Corne, D.W. The Pareto archived evolution strategy: A new baseline algorithm for Pareto multiobjective optimisation. In Proceedings of the IEEE Congress on Evolutionary Computation, Washington, DC, USA, 6–9 July 1999; pp. 98–105. [Google Scholar]
- Knowles, J.D.; Corne, D.W. Approximating the nondominated front using the Pareto archived evolution strategy. Evol. Comput. 2000, 8, 149–172. [Google Scholar] [CrossRef] [PubMed]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Pires, E.J.S.; de Moura Oliveira, P.B.; Machado, J.A.T. Multi-objective maximin sorting scheme. In Proceedings of the International Conference on Evolutionary Multi-Criterion Optimization, Guanajuato, Mexico, 9–11 March 2005; pp. 165–175. [Google Scholar]
- Kukkonen, S.; Deb, K. A fast and effective method for pruning of non-dominated solutions in many-objective problems. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Reykjavik, Iceland, 9–13 September 2006; pp. 553–562. [Google Scholar]
- Hu, W.; Yen, G.G. Adaptive multiobjective particle swarm optimization based on parallel cell coordinate system. IEEE Trans. Evol. Comput. 2015, 19, 1–18. [Google Scholar]
- Qiu, X.; Xu, J.-X.; Tan, K.C.; Abbass, H.A. Adaptive cross-generation differential evolution operators for multiobjective optimization. IEEE Trans. Evol. Comput. 2016, 20, 232–244. [Google Scholar] [CrossRef]
- Schaffer, J.D. Multiple objective optimization with vector evaluated genetic algorithms. In Proceedings of the International Conference on Genetic Algorithms, Pittsburgh, PA, USA, 24–26 July 1985; pp. 93–100. [Google Scholar]
- Parsopoulos, K.E.; Tasoulis, D.K.; Vrahatis, M.N. Multiobjective optimization using parallel vector evaluated particle swarm optimization. In Proceedings of the IASTED International Conference on Artificial Intelligence & Applications, Innsbruck, Austria, 16–18 February 2004; pp. 823–828. [Google Scholar]
- Zhan, Z.-H.; Li, J.-J.; Cao, J.-N.; Zhang, J.; Chung, H.S.-H.; Shi, Y.-H. Multiple populations for multiple objectives: A coevolutionary technique for solving multiobjective optimization problems. IEEE Trans. Cybern. 2013, 43, 445–463. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.-F.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Q.-F. Multiobjective optimization problems with complicated Pareto sets, MOEA/D and NSGA-II. IEEE Trans. Evol. Comput. 2009, 13, 284–302. [Google Scholar] [CrossRef]
- Zhang, Q.-F.; Liu, W.-D.; Li, H. The performance of a new version of MOEA/D on CEC09 unconstrained MOP test instances. In Proceedings of the IEEE Congress on Evolutionary Computation, Tronhdeim, Norway, 18–21 May 2009; pp. 203–208. [Google Scholar]
- Tan, Y.-Y.; Jiao, Y.-C.; Li, H.; Wang, X.-K. A modification to MOEA/D-DE for multiobjective optimization problems with complicated Pareto sets. Inf. Sci. 2012, 213, 14–38. [Google Scholar] [CrossRef]
- Qi, Y.-T.; Ma, X.-L.; Liu, F.; Jiao, L.-C.; Sun, J.-Y.; Wu, J.-S. MOEA/D with adaptive weight adjustment. Evol. Comput. 2014, 22, 231–264. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Fialho, A.; Kwong, S.; Zhang, Q.-F. Adaptive operator selection with bandits for a multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2014, 18, 114–130. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R.C. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 Novmber–1 December 1995; pp. 1942–1948. [Google Scholar]
- Liang, J.J.; Qin, A.K.; Suganthan, P.N.; Baskar, S. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions. IEEE Trans. Evol. Comput. 2006, 10, 281–295. [Google Scholar] [CrossRef]
- Zhan, Z.-H.; Zhang, J.; Li, Y.; Shi, Y.-H. Orthogonal learning particle swarm optimization. IEEE Trans. Evol. Comput. 2011, 15, 832–847. [Google Scholar] [CrossRef]
- Yu, X.; Zhang, X.-Q. Enhanced comprehensive learning particle swarm optimization. Appl. Math. Comput. 2014, 242, 265–276. [Google Scholar] [CrossRef]
- Montalvo, I.; Izquierdo, J.; Pérez-García, R.; Herrera, M. Improved performance of PSO with self-adaptive parameters for computing the optimal design of water supply systems. Eng. Appl. Artif. Intell. 2010, 23, 727–735. [Google Scholar] [CrossRef]
- Zitzler, E.; Deb, K.; Thiele, L. Comparison of multiobjective evolutionary algorithms: Empirical results. Evol. Comput. 2000, 8, 173–195. [Google Scholar] [CrossRef] [PubMed]
- Huband, S.; Hingston, P.; Barone, L.; While, L. A review of multiobjective test problems and a scalable test problem toolkit. IEEE Trans. Evol. Comput. 2006, 10, 477–506. [Google Scholar] [CrossRef]
- Zhang, Q.-F.; Zhou, A.-M.; Zhao, S.-Z.; Suganthan, P.N.; Liu, W.-D.; Tiwari, S. Multiobjective Optimization Test Instances for the CEC 2009 Special Session and Competition; University of Essex: Colchester, UK, 2009; pp. 1–30. [Google Scholar]
- Laumanns, M.; Thiele, L.; Deb, K.; Zitzler, E. Combining convergence and diversity in evolutionary multiobjective optimization. Evol. Comput. 2002, 10, 263–282. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| ZDT2 | ZDT3 | ZDT4-V1 | ZDT4-V2 | WFG1 | ZDT2-UF1 | |
| FEs | 30,000 | 30,000 | 40,000 | 200,000 | 500,000 | 500,000 |
| ZDT4-UF2 | UF1 | UF2 | UF7 | UF8 | UF9 | |
| FEs | 300,000 | 300,000 | 500,000 | 300,000 | 600,000 | 600,000 |
| Problem | IGD | AMCLPSO | MSCLPSO | Problem | IGD | AMCLPSO | MSCLPSO |
|---|---|---|---|---|---|---|---|
| ZDT2 | Mean | 4.37 × 10−3 | 4.36 × 10−3 | ZDT4-UF2 | Mean | 4.53 × 10−3 | 4.92 × 10−3 |
| SD | 1.45 × 10−4 | 1.07 × 10−4 | SD | 1.12 × 10−4 | 3.94 × 10−4 | ||
| Best | 4.09 × 10−3 | 4.15 × 10−3 | Best | 4.36 × 10−3 | 4.40 × 10−3 | ||
| Worst | 4.66 × 10−3 | 4.59 × 10−3 | Worst | 4.84 × 10−3 | 6.25 × 10−3 | ||
| ZDT3 | Mean | 4.89 × 10−3 | 4.94 × 10−3 | UF1 | Mean | 4.10 × 10−3 | 4.35 × 10−3 |
| SD | 1.08 × 10−4 | 1.57 × 10−4 | SD | 5.21 × 10−5 | 1.13 × 10−4 | ||
| Best | 4.71 × 10−3 | 4.71 × 10−3 | Best | 3.98 × 10−3 | 4.15 × 10−3 | ||
| Worst | 5.20 × 10−3 | 5.34 × 10−3 | Worst | 4.20 × 10−3 | 4.66 × 10−3 | ||
| ZDT4-V1 | Mean | 4.41 × 10−3 | 8.51 × 10−3 | UF2 | Mean | 4.32 × 10−3 | 4.90 × 10−3 |
| SD | 1.32 × 10−4 | 2.23 × 10−2 | SD | 1.82 × 10−4 | 5.76 × 10−4 | ||
| Best | 4.05 × 10−3 | 4.22 × 10−3 | Best | 4.08 × 10−3 | 4.12 × 10−3 | ||
| Worst | 4.67 × 10−3 | 1.26 × 10−1 | Worst | 4.75 × 10−3 | 7.01 × 10−3 | ||
| ZDT4-V2 | Mean | 4.32 × 10−3 | 8.34 × 10−3 | UF7 | Mean | 4.15 × 10−3 | 4.40 × 10−3 |
| SD | 7.23 × 10−5 | 2.22 × 10−2 | SD | 1.05 × 10−4 | 2.58 × 10−4 | ||
| Best | 4.17 × 10−3 | 4.09 × 10−3 | Best | 3.98 × 10−3 | 4.08 × 10−3 | ||
| Worst | 4.50 × 10−3 | 1.26 × 10−1 | Worst | 4.39 × 10−3 | 5.27 × 10−3 | ||
| WFG1 | Mean | 1.34 × 10−2 | 1.35 × 10−2 | UF8 | Mean | 4.78 × 10−2 | 5.31 × 10−2 |
| SD | 3.77 × 10−4 | 3.28 × 10−4 | SD | 3.19 × 10−3 | 9.97 × 10−3 | ||
| Best | 1.24 × 10−2 | 1.28 × 10−2 | Best | 4.15 × 10−2 | 4.50 × 10−2 | ||
| Worst | 1.45 × 10−2 | 1.41 × 10−2 | Worst | 5.73 × 10−2 | 8.60 × 10−2 | ||
| ZDT2-UF1 | Mean | 4.67 × 10−3 | 4.64 × 10−3 | UF9 | Mean | 2.64 × 10−2 | 3.30 × 10−2 |
| SD | 1.60 × 10−4 | 2.53 × 10−4 | SD | 2.13 × 10−3 | 2.56 × 10−2 | ||
| Best | 4.43 × 10−3 | 4.22 × 10−3 | Best | 2.40 × 10−2 | 2.41 × 10−2 | ||
| Worst | 5.08 × 10−3 | 5.12 × 10−3 | Worst | 3.61 × 10−2 | 1.68 × 10−1 |
| ZDT2 | ZDT3 | ZDT4-V1 | ZDT4-V2 | WFG1 | ZDT2-UF1 | |
| p-value result | 0.6973 | 0.3136 | 0.4761 | 0.1504 | 0.786 | 0.7191 |
| ZDT4-UF2 | UF1 | UF2 | UF7 | UF8 | UF9 | |
| p-value result | 9.557 × 10−9 | 1.64 × 10−15 | 1.366 × 10−8 | 6.816 × 10−7 | 3.025 × 10−11 | 4.576 × 10−9 |
| Problems | Swarm 1 | Swarm 2 | Swarm 3 | |||
| Mean | SD | Mean | SD | Mean | SD | |
| ZDT2 | 2.31 × 10−4 | 2.60 × 10−4 | 1.95 | 2.04 × 10−1 | - | - |
| ZDT3 | 2.68 × 10−4 | 1.98 × 10−4 | 1.22 | 2.15 × 10−1 | - | - |
| ZDT4-V1 | 2.41 × 10−4 | 2.43 × 10−4 | 7.63 × 10−1 | 3.25 × 10−1 | - | - |
| ZDT4-V2 | 1.35 × 10−5 | 2.09 × 10−5 | 2.55 × 10−1 | 2.38 × 10−1 | - | - |
| WFG1 | 2.44 | 6.06 × 10−2 | 8.30 × 10−2 | 3.18 × 10−11 | - | - |
| ZDT2-UF1 | 2.90 × 10−4 | 3.57 × 10−4 | 2.71 | 8.14 × 10−1 | - | - |
| ZDT4-UF2 | 18.30 | 3.70 | 1.24 × 10−1 | 2.17 × 10−2 | - | - |
| UF1 | 7.44 × 10−1 | 2.03 × 10−1 | 7.16 × 10−1 | 2.10 × 10−1 | - | - |
| UF2 | 1.27 × 10−1 | 2.48 × 10−2 | 1.90 × 10−1 | 4.34 × 10−2 | - | - |
| UF7 | 9.49 × 10−1 | 1.48 × 10−1 | 4.07 × 10−1 | 1.30 × 10−1 | - | - |
| UF8 | 5.44 × 10−1 | 2.80 × 10−1 | 4.40 × 10−1 | 2.24 × 10−1 | 6.44 × 10−1 | 3.51 × 10−1 |
| UF9 | 6.92 × 10−1 | 2.45 × 10−1 | 7.33 × 10−1 | 2.46 × 10−1 | 1.23 | 2.46 × 10−1 |
| Parameter Setting | Problem | Statistical IGD Results | |||
|---|---|---|---|---|---|
| Mean | SD | Best | Worst | ||
| Δrel = 0.1 | ZDT4-V2 | 8.42 × 10−3 | 2.22 × 10−2 | 4.14 × 10−3 | 1.26 × 10−1 |
| c1 = 0 | WFG1 | 1.50 × 10−2 | 1.42 × 10−3 | 1.34 × 10−2 | 1.95 × 10−2 |
| c1 = 1 | UF9 | 4.09 × 10−2 | 4.59 × 10−2 | 2.34 × 10−2 | 1.83 × 10−1 |
| c2 = 0.3 | UF2 | 4.47 × 10−3 | 3.72 × 10−4 | 4.17 × 10−3 | 5.93 × 10−3 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Estevez, C. Adaptive Multiswarm Comprehensive Learning Particle Swarm Optimization. Information 2018, 9, 173. https://doi.org/10.3390/info9070173
Yu X, Estevez C. Adaptive Multiswarm Comprehensive Learning Particle Swarm Optimization. Information. 2018; 9(7):173. https://doi.org/10.3390/info9070173
Chicago/Turabian StyleYu, Xiang, and Claudio Estevez. 2018. "Adaptive Multiswarm Comprehensive Learning Particle Swarm Optimization" Information 9, no. 7: 173. https://doi.org/10.3390/info9070173
APA StyleYu, X., & Estevez, C. (2018). Adaptive Multiswarm Comprehensive Learning Particle Swarm Optimization. Information, 9(7), 173. https://doi.org/10.3390/info9070173