TwitPersonality: Computing Personality Traits from Tweets Using Word Embeddings and Supervised Learning

 , , , and
, , , and
Abstract
1. Introduction
2. Related Work
3. Five Factor Model
- Openness to Experience (inventive/curious vs. consistent/cautious): it measures a person’s curiosity, intelligence, appreciation for art, seeking for new experiences and adventures. People low in Openness tend to be more conservative and close-minded.
- Conscientiousness (efficient/organized vs. easy-going/careless): it measures the capability of a person to be organized, reliable and consistent. Those who have a high score on Conscientiousness prefer planning rather than having a spontaneous behavior, and they opt for seeking long-term goals, while low Conscientiousness individuals tend to be more tolerant and less bound by rules and plans.
- Extraversion (outgoing/energetic vs. solitary/reserved): it measures the tendency to seek stimulation in the external world, the company of others and being more talkative. Those low in extraversion are reserved and solitary.
- Agreeableness (friendly/compassionate vs. challenging/detached): it measures the tendency of being altruistic and tender-minded. Those who have a high score in Agreeableness are trusting, altruistic, tender-minded, and are motivated to maintain positive relationships with others. Low Agreeableness is related to being suspicious, challenging and antagonistic towards other people.
- Neuroticism (sensitive/nervous vs. secure/confident): it measures the tendency to be impulsive and emotionally unstable, experiencing mood swings and negative emotions. Those who have a low score in Neuroticism are more calm and stable.
3.1. Assessing Personality with Surveys
3.2. Social Media Platforms as Sources to Deriving Personality Traits
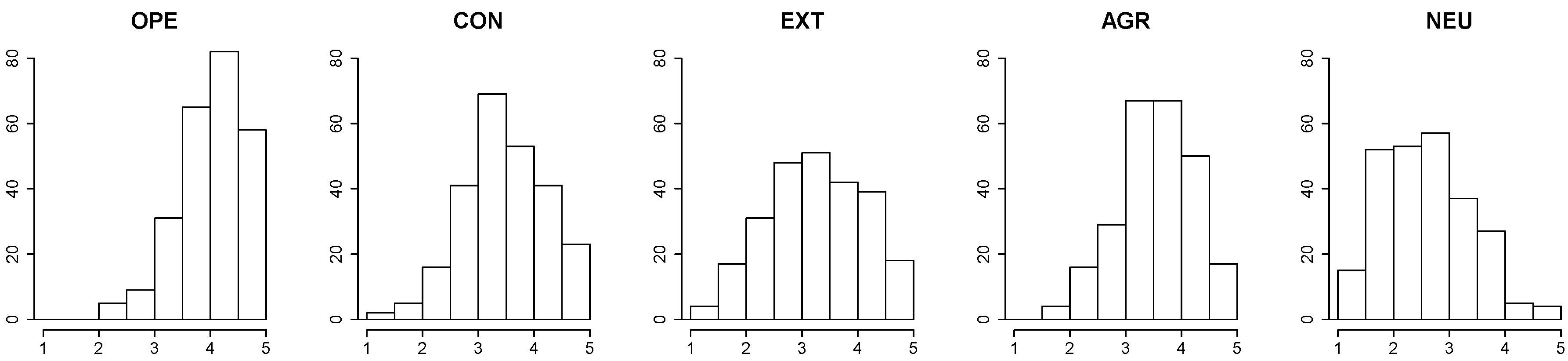
4. Gold Standards
5. Approach
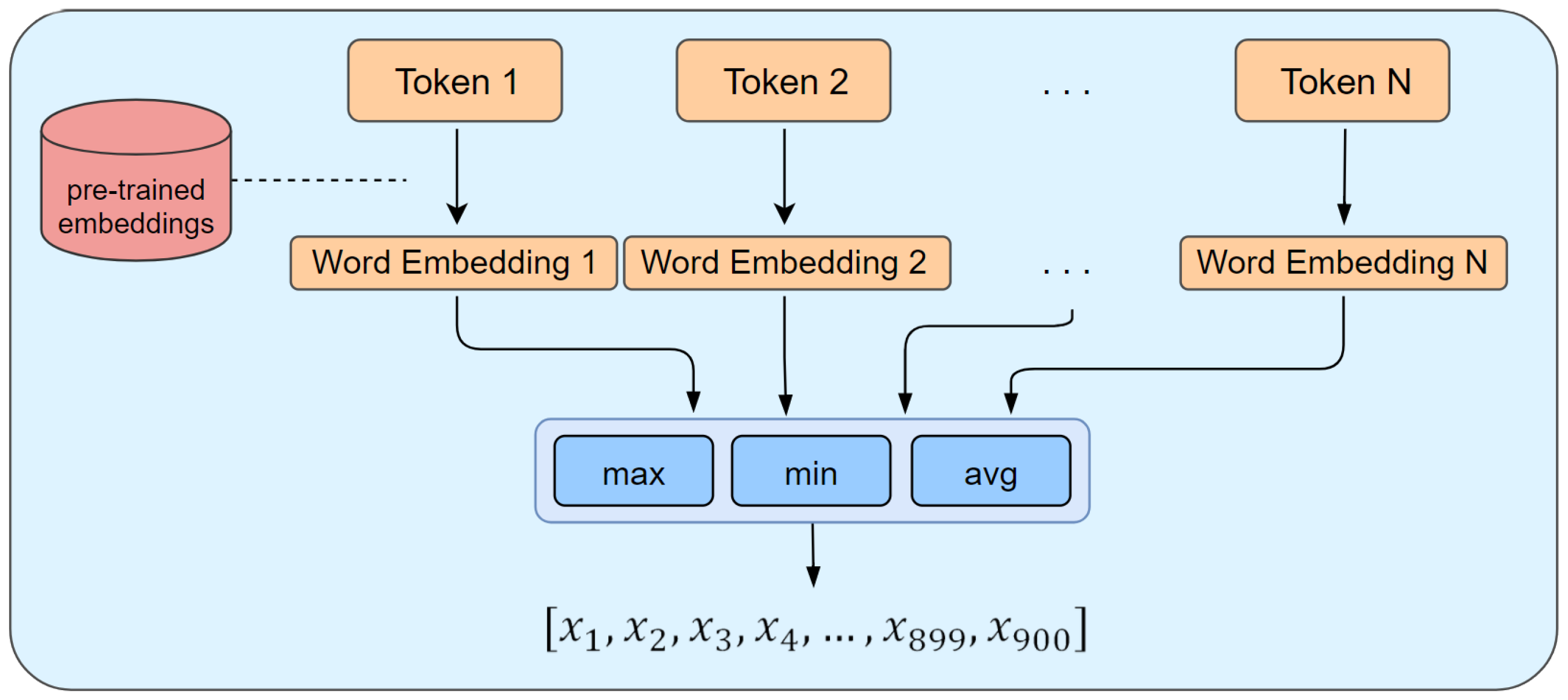
5.1. Text Processing
- Conversion to lowercase: “Today is a #sunny day!” → “today is a #sunny day!”.
- Stop-word removal: “today is a #sunny day!” → “today #sunny day!”.
- Punctuation removal: “today #sunny day!” → “today sunny day”.
- Tokenization: “today sunny day” → [today] [sunny] [day].
- Short post removal: it removes status updates with .
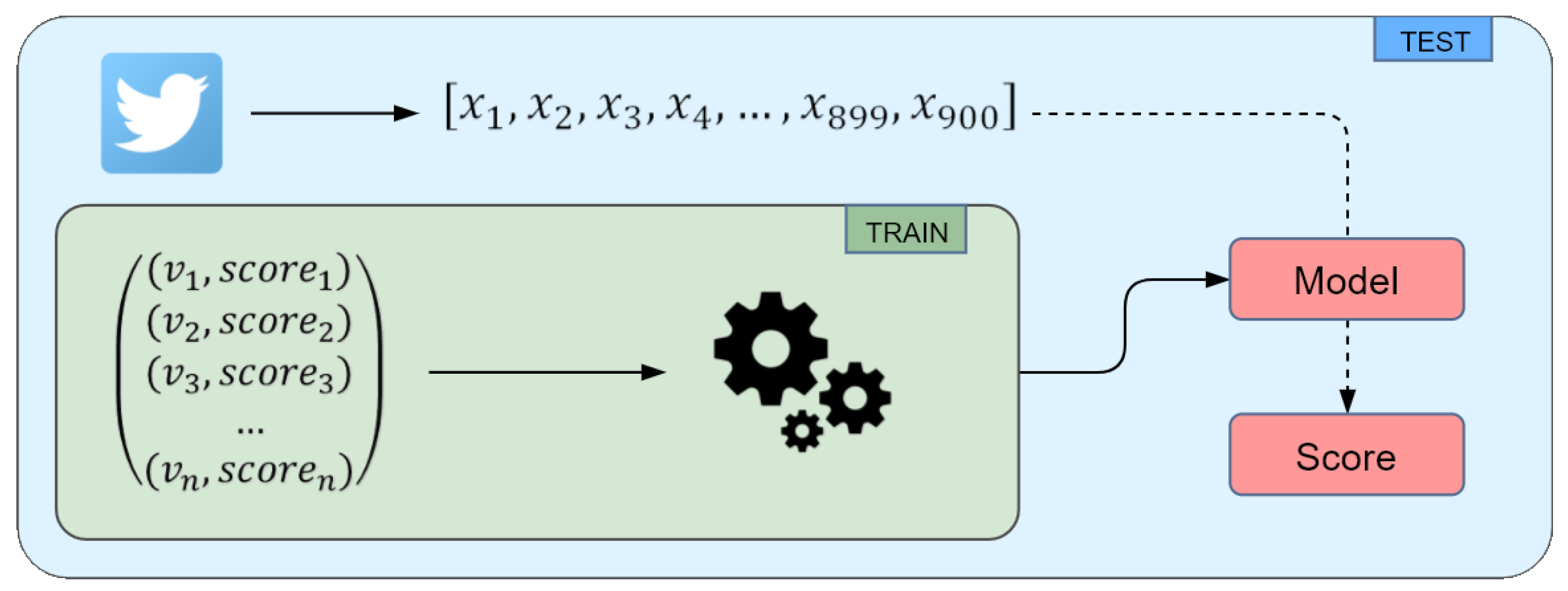
5.2. Learning Model
5.3. Model Optimization
- Kernel: linear, polynomial, radial basis function, hyperbolic tangent.
- C: the penalty factor that regulates the trade-off between misclassification and simplicity of the decision surface.
- Gamma: indicates how far the influence of a single training example reaches, with low values meaning far and high values meaning close, only meaningful for the rbf kernel.
- Degree: of the polynomial equation, only meaningful for a polynomial kernel.
5.4. Predicting Personality Traits from Tweets
- Pure retweet removal: When retweeting a tweet, if no personal text content is added, it will be represented as RT@tweet-owner: tweet-text tweet-url. We refer to this case as pure retweet. Since we base the prediction only on the textual features created by a user, all retweets without additional content are removed.
- URL removal: URLs may appear in retweets, sharing from other sources (e.g., YouTube video), or other cases. In the context of our study they are not informative, so they are removed from the tweets.
- Mentions removal: Users often mention their friends in their tweets, adding some noise to the text data; mentions are also found in retweets. We remove all mentions from our data.
- Hashtags removal: We choose not to remove the whole word, as in the previous cases. Instead, we keep the original word without the hash (#) symbol. This is because some tags consist of meaningful words (e.g., “I love #star #wars”) which we do not want to lose. This approach effectively addresses also the case of non-existing hashtag words (e.g., “#netNeutarlity2017”) that are ignored in the next step, when a corresponding word embedding will not be found.
6. Experimental Results
6.1. Model Verification
6.2. Transfer Learning Assessment
7. Discussion
8. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Kosinski, M.; Stillwell, D.; Graepel, T. Private traits and attributes are predictable from digital records of human behavior. Proc. Natl. Acad. Sci. USA 2013, 110, 5802–5805. [Google Scholar] [CrossRef] [PubMed]
- Gottschalk, L.A.; Gleser, G.C. The Measurement of Psychological States through the Content Analysis of Verbal Behavior; University of California Press: Oxford, UK, 1969. [Google Scholar]
- Graham, D.T.; Stern, J.A.; Winokur, G. Experimental investigation of the specificity of attitude hypothesis in psychosomatic disease. Psychosom. Med. 1958, 20, 446–457. [Google Scholar] [CrossRef] [PubMed]
- Mergenthaler, E. Emotion-abstraction patterns in verbatim protocols: A new way of describing psychotherapeutic processes. J. Consult. Clin. Psychol. 1996, 64, 1306–1315. [Google Scholar] [CrossRef] [PubMed]
- Pennebaker, J.; King, L.A. Linguistic Styles: Language Use as an Individual Difference. Personal. Soc. Psychol. 1999, 77, 1296–1312. [Google Scholar] [CrossRef]
- Argamon, S.; Dhawle, S.; Koppel, M.; Pennebaker, J. Lexical predictors of personality type. In Proceedings of the 2005 Joint Annual Meeting of the Interface and the Classification Society of North America, Cincinnati, OH, USA, 24–28 July 2005. [Google Scholar]
- Barrick, M.; Mount, M. The Big Five personality dimensions and job performance: A meta-analysis. Pers. Psychol. 1991, 44, 1–26. [Google Scholar] [CrossRef]
- Saulsman, L.; Page, A. The five-factor model and personality disorder empirical literature: A meta-analytic review. Clin. Psychol. Rev. 2004, 23, 1055–1085. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Wei, L.; Chen, Y. Detection of the Prodromal Phase of Bipolar Disorder from Psychological and Phonological Aspects in Social Media. arXiv, 2017; arXiv:1712.09183. [Google Scholar]
- Shaver, P.; Brennan, K. Attachment styles and the “Big Five” personality traits: Their connections with each other and with romantic relationship outcomes. Personal. Soc. Psychol. Bull. 1992, 18, 536–545. [Google Scholar] [CrossRef]
- Rentfrow, P.; Gosling, S. The do re mi’s of everyday life: The structure and personality correlates of music preferences. J. Personal. Soc. Psychol. 2003, 84, 1236–1256. [Google Scholar] [CrossRef]
- Dollinger, S. Research note: Personality and music preference: Extraversion and excitement seeking or openness to experience? Psychol. Music 1993, 21, 73–77. [Google Scholar] [CrossRef]
- Hansen, C.; Hansen, R. Constructing personality and social reality through music: Individual differences among fans of punk and heavy metal music. J. Broadcast. Electron. Media 1991, 35, 335–350. [Google Scholar] [CrossRef]
- Rawlings, D.; Ciancarelli, V. Music preference and the five-factor model of the NEO Personality Inventory. Psychol. Music 1997, 25, 120–132. [Google Scholar] [CrossRef]
- Jost, J.; West, T.; Gosling, S. Personality and ideology as determinants of candidate preferences and Obama conversion in the 2008 US presidential election. Du Bois Rev. 2009, 6, 3–124. [Google Scholar] [CrossRef]
- Cantador, I.; Fernandez-Tobias, I.; Bellogín, A.; Kosinski, M.; Stillwell, D. Relating Personality Types with User Preferences Multiple Entertainment Domains. In Proceedings of the 21st Conference on User Modeling, Adaptation, and Personalization (UMAP 2013), Rome, Italy, 10–14 June 2013; p. 997. [Google Scholar]
- Celli, F.; Lepri, B.; Biel, J.; Gatica-Perez, D.; Riccardi, G. The workshop on computational personality recognition 2014. In Proceedings of the 22nd ACM International Conference on Multimedia (MM ’14), Orlando, FL, USA, 3 November 2014; pp. 1245–1246. [Google Scholar]
- Tkalčič, M.; de Carolis, B.; de Gemmis, M.; Odić, A.; Košir, A. Preface: EMPIRE 2014-2nd Workshop Emotions and Personality in Personalized Services. In Proceedings of the 22st Conference on User Modeling, Adaptation, and Personalization (UMAP 2014), Aalborg, Denmark, 7–11 July.
- Hughes, D.; Rowe, M.; Batey, M.; Lee, A. A tale of two sites: Twitter vs. Facebook and the personality predictors of social media usage. Comput. Hum. Behav. 2011, 28, 561–569. [Google Scholar] [CrossRef]
- Bachrach, Y.; Kosinski, M.; Graepel, T.; Kohli, P.; Stillwell, D. Personality and patterns of Facebook usage. In Proceedings of the 4th Annual ACM Web Science Conference 2012 (WebSci’12), Evanston, IL, USA, 22–24 June 2012. [Google Scholar]
- Gosling, S.D.; Augustine, A.A.; Vazire, S.; Holtzman, N.; Gaddis, S. Manifestations of Personality in Online Social Networks: Self-Reported Facebook-Related Behaviors and Observable Profile Information. Cyberpsychol. Behav. Soc. Netw. 2011, 14, 483–488. [Google Scholar] [CrossRef] [PubMed]
- Quercia, D.; Kosinski, M.; Stillwell, D.; Crowcroft, J. Our twitter profiles, our selves: Predicting personality with twitter. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust (PASSAT) and 2011 IEEE Third Inernational Conference on Social Computing (SocialCom), Boston, MA, USA, 9–11 October 2011; pp. 180–185. [Google Scholar] [CrossRef]
- Jusupova, A.; Batista, F.; Ribeiro, R. Characterizing the Personality of Twitter Users based on their Timeline Information. In Proceedings of the Atas da 16 Conferência da Associacao Portuguesa de Sistemas de Informação, Porto, Portugal, 22–24 December 2016; Volume 16, pp. 292–299. [Google Scholar]
- Liu, F.; Perez, J.; Nowson, S. A Language-independent and Compositional Model for Personality Trait Recognition from Short Texts. arXiv, 2016; arXiv:1610.04345. [Google Scholar]
- Van de Ven, N.; Bogaert, A.; Serlie, A.; Brandt, M.J.; Denissen, J.J. Personality perception based on LinkedIn profiles. J. Manag. Psychol. 2017, 32, 419–429. [Google Scholar] [CrossRef]
- YouYou, W.; Kosinski, M.; Stillwell, D. Computer-based personality judgments are more accurate than those made by humans. Proc. Natl. Acad. Sci. USA 2014, 112, 1036–1040. [Google Scholar] [CrossRef] [PubMed]
- Nowson, S.; Oberlander, J. The Identity of Bloggers: Openness and gender in personal weblogs. In Proceedings of the AAAI Spring Symposium, Computational Approaches to Analysing Weblogs, Boston, MA, USA, 16–20 July 2006; pp. 163–167. [Google Scholar]
- Kalghatgi, M.P.; Ramannavar, M.; Sidnal, N.S. A neural network approach to personality prediction based on the bigfive model. Int. J. Innov. Res. Adv. Eng. 2015, 2, 56–63. [Google Scholar]
- Su, M.; Wu, C.; Zheng, Y. Exploiting turn-taking temporal evolution for personality trait perception in dyadic conversations. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 733–744. [Google Scholar] [CrossRef]
- Majumder, N.; Poria, S.; Gelbukh, A.; Cambria, E. Deep Learning-Based Document Modeling for Personality Detection from Text. IEEE Intell. Syst. 2017, 32, 74–79. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Mairesse, F.; Walker, M.; Mehl, M.; Moore, R. Using Linguistic Cues for the Automatic Recognition of Personality in Conversation and Text. J. Artif. Intell. Res. 2007, 30, 457–500. [Google Scholar]
- Turian, J.; Ratinov, L.; Bengio, Y. Word representations: A simple and general method for semi-supervised learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL ’10), Uppsala, Swede, 11–16 July 2010. [Google Scholar]
- Pasca, M.; Lin, D.; Bigham, J.; Lifchits, A.; Jain, A. Names and similarities on the web: Fact extraction in the fast lane. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics, (ACL-44), Sydney, Australia, 17–18 July 2006. [Google Scholar]
- Manning, C.; Raghavan, P.; Schtze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Shutze, H. Distributional part-of-speech tagging. In Proceedings of the seventh conference on European chapter of the Association for Computational Linguistics (EACL ’95), Dublin, Ireland, 27–31 March 1995; pp. 141–148. [Google Scholar]
- Ratinov, L.; Roth, D. Design challenges and misconceptions in named entity recognition. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL ’09), Boulder, CO, USA, 4–5 June 2009; pp. 147–155. [Google Scholar]
- Kuang, S.; Davison, B. Learning Word Embeddings with Chi-Square Weights for Healthcare Tweet Classification. Appl. Sci. 2017, 7, 846. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Volume 14, pp. 1532–1543. [Google Scholar]
- Lebret, R.; Legrand, J.; Collobert, R. Is deep learning really necessary for word embeddings? In Proceedings of the NIPS 2013 Deep Learning Workshop, Lake Tahoe, CA, USA, 5–10 December 2013. [Google Scholar]
- Dhillon, P.S.; Foster, D.; Ungar, L. Multi-view learning of word embeddings via cca. In Advances in Neural Information Processing Systems 24 (NIPS 2011); MIT Press Ltd.: Cambridge, MA, USA, 2011; p. 24. [Google Scholar]
- Tang, D.; Wei, F.; Yang, N.; Zhou, M.; Liu, T.; Qin, B. Learning sentiment-specific word embedding for twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22-27 June 2014; Volume 1, pp. 1555–1565. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M. Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Golbeck, J.; Robles, C.; Turner, K. Predicting personality with social media. In Proceedings of the CHI ’11 Extended Abstracts on Human Factors in Computing Systems (CHI EA ’11), Vancouver, BC, Canada, 7–12 May 2011; Volume 10, pp. 253–262. [Google Scholar]
- Jiang, L.; Yu, M.; Zhou, M.; Liu, X.; Zhao, T. Target-dependent twitter sentiment classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (HLT ’11), Portland, Oregon, 19–24 June 2011; Volume 1, pp. 151–160. [Google Scholar]
- Hu, X.; Tang, J.; Gao, H.; Liu, H. Unsupervised sentiment analysis with emotional signals. In Proceedings of the 22nd International Conference on World Wide Web (WWW ’13), Rio de Janeiro, Brazil, 13–17 May 2013; pp. 607–618. [Google Scholar]
- Mohammad, S.M.; Kiritchenko, S.; Zhu, X. Nrc-Canada: Building the state-of-the-art in sentiment analysis of tweets. In Proceedings of the Seventh International Workshop on Semantic Evaluation Exercises (SemEval-2013), Atlanta, GA, USA, 13–15 June 2013. [Google Scholar]
- Kanavos, A.; Nodarakis, N.; Sioutas, S.; Tsakalidis, A.; Tsolis, D.; Tzimas, G. Large Scale Implementations for Twitter Sentiment Classification. Algorithms 2017, 10, 33. [Google Scholar] [CrossRef]
- Dai, H.; Touray, M.; Jonnagaddala, J.; Shabbir, S.A. Feature Engineering for Recognizing Adverse Drug Reactions from Twitter Posts. Information 2016, 7, 27. [Google Scholar] [CrossRef]
- Chamberlain, B.P.; Humby, C.; Deisenroth, M.P. Probabilistic inference of twitter users’ age based on what they follow. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Skopje, Macedonia, 18–22 September 2017; pp. 191–203. [Google Scholar]
- Zhang, J.; Hu, X.; Zhang, Y.; Liu, H. Your Age Is No Secret: Inferring Microbloggers’ Ages via Content and Interaction Analysis. In Proceedings of the Tenth International Conference on Web and Social Media, Cologne, Germany, 17–20 May 2016. [Google Scholar]
- Burger, J.D.; Henderson, J.; Kim, G.; Zarrella, G. Discriminating gender on Twitter. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP ’11), Edinburgh, UK, 27–31 July 2011; pp. 1301–1309. [Google Scholar]
- Conover, M.D.; Gonalves, B.; Ratkiewicz, J.; Flammini, A.; Menczer, F. Predicting the political alignment of Twitter users. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust (PASSAT) and 2011 IEEE Third Inernational Conference on Social Computing (SocialCom), Boston, MA, USA, 9–11 October 2011; Volume 10, pp. 192–199. [Google Scholar]
- Cheng, Z.; Caverlee, J.; Lee, K. You are where you tweet: A content-based approach to geo-locating Twitter users. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management (CIKM ’10), Toronto, ON, Canada, 26–30 October 2010; pp. 759–768. [Google Scholar]
- Pennacchiotti, M.; Popescu, A.M. A machine learning approach to twitter user classification. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media (ICWSM-11), Catalonia, Spain, 17–21 July 2011; Volume 11, pp. 281–288. [Google Scholar]
- McCrae, R.R.; Oliver, P.J. An Introduction to the Five-Factor Model and Its Applications. J. Personal. 1992, 60, 175–215. [Google Scholar] [CrossRef]
- Tupes, E.; Christal, R. Recurrent Personality Factors Based on Trait Ratings. J. Personal. 1992, 60, 225–251. [Google Scholar] [CrossRef]
- Digman, J. Personality Structure: Emergence of the FiveFactor Model. Ann. Rev. Psychol. 1990, 41, 417–440. [Google Scholar] [CrossRef]
- Goldberg, L. The Structure of Phenotypic Personality Traits. Am. Psychol. 1993, 48, 26–34. [Google Scholar] [CrossRef] [PubMed]
- Mershon, B.; Gorsuch, R.L. Number of factors in the personality sphere: Does increase in factors increase predictability of real-life criteria? J. Personal. Soc. Psychol. 1988, 55, 675–680. [Google Scholar] [CrossRef]
- Paunonen, S.V.; Ashton, M.S. Big Five factors and facets and the prediction of behavior. J. Personal. Soc. Psychol. 2001, 81, 524–539. [Google Scholar] [CrossRef]
- McCrae, R.R.; Costa, P.T., Jr.; Busch, C.M. Evaluating comprehensiveness in personality systems: The California Q-Set and the five-factor model. J. Psychol. 1986, 54, 430–466. [Google Scholar] [CrossRef]
- Costa, P.T.; McCrae, R.R. Revised NEO Personality Inventory (NEO Pl-R) and NEO Five-Factor Inventory (NEO-FFI) Professional Manual; Psychological Assessment Resources: Odessa, FL, USA, 1992. [Google Scholar]
- International Personality Item Pool. Available online: http://ipip.ori.org (accessed on 18 May 2018).
- Goldberg, L.R. A broad-bandwidth, public domain, personality inventory measuring the lower-level facets of several five-factor models. Personal. Psychol. Eur. 1999, 7, 7–28. [Google Scholar]
- Johnson, J.A. Measuring thirty facets of the Five Factor Model with a 120-item public domain inventory: Development of the IPIP-NEO-120. J. Res. Personal. 2014, 51, 78–89. [Google Scholar] [CrossRef]
- Pennebaker, J.; Niederhoffer, K.; Mehl, M. Psychological Aspects of Natural Language Use: Our words, Our Selves. Ann. Rev. Psychol. 2003, 54, 547–577. [Google Scholar] [CrossRef] [PubMed]
- Oberlander, J.; Gill, A.J. Language with character: A stratified corpus comparison of individual differences in e-mail communication. Discour. Process. 2006, 42, 239–270. [Google Scholar] [CrossRef]
- Chang, C.; Saravia, E.; Chen, Y. Subconscious Crowdsourcing: A feasible data collection mechanism for mental disorder detection on social media. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; pp. 374–379. [Google Scholar]
- Chin, D.N.; Wright, W.R. Social Media Sources for Personality Profiling. In Proceedings of the 22nd Conference on User Modeling, Adaptation, and Personalization, Aalborg, Denmark, 7–11 July 2014; Volume 1181, pp. 79–85. [Google Scholar]
- Anderson, C.; John, O.; Keltner, D.; Kring, A. Who attains social status? Effects of personality and physical attractiveness in social groups. J. Personal. Soc. Psychol. 2001, 81, 116. [Google Scholar] [CrossRef]
- Berry, D.S.; Willingham, J.K.; Thayer, C.A. Affect and personality as predictors of conflict and closeness in young adults’ friendships. J. Res. Personal. 2000, 34, 84–107. [Google Scholar] [CrossRef]
- Rosen, P.; Kluemper, D. The impact of the Big Five personality traits on the acceptance of social networking website. In Proceedings of the Americas Conference on Information Systems (AMCIS 2008), Toronto, ON, Canada, 14–17 August 2008. [Google Scholar]
- Schrammel, J.; Köffel, C.; Tscheligi, M. Personality traits, usage patterns and information disclosure in online communities. In Proceedings of the 23rd British HCI Group Annual Conference on People and Computers: Celebrating People and Technology (BCS-HCI), Cambridge, UK, 1–5 September 2009; pp. 169–174. [Google Scholar]
- McPherson, M.; Smith-Lovin, L.; Cook, J.M. Birds of a Feather: Homophily in Social Networks. Ann. Rev. Sociol. 2001, 27, 415–444. [Google Scholar] [CrossRef]
- Buffardi, L.E.; Campbell, W.K. Narcissism and social networking Web sites. Personal. Soc. Psychol. Bull. 2008, 34, 1303–1314. [Google Scholar] [CrossRef] [PubMed]
- Mehdizadeh, S. Self-presentation 2.0: Narcissism and self-esteem on Facebook. Cyberpsychol. Behav. Soc. Netw. 2010, 13, 357–364. [Google Scholar] [CrossRef] [PubMed]
- Orr, E.S.; Sisic, M.; Ross, C.; Simmering, M.G.; Arseneault, J.M.; Orr, R.R. The influence of shyness on the use of Facebook in an undergraduate sample. Cyberpsychol. Behav. 2009, 12, 337–340. [Google Scholar] [CrossRef] [PubMed]
- Ross, C.; Orr, E.S.; Sisic, M.; Arseneault, J.M.; Simmering, M.G.; Orr, R.R. Personality and motivations associated with Facebook use. Comput. Hum. Behav. 2009, 25, 578–586. [Google Scholar] [CrossRef]
- Sheldon, P. The relationship between unwillingness-to-communicate and students’ Facebook use. J. Media Psychol. 2008, 20, 67–75. [Google Scholar] [CrossRef]
- Goldberg, L.R.; Johnson, J.A.; Eber, H.W.; Hogan, R.; Ashton, M.C.; Cloninger, C.R.; Gough, H.G. The international personality item pool and the future of public-domain personality measures. J. Res. Personal. 2006, 40, 84–96. [Google Scholar] [CrossRef]
- Celli, F.; Pianesi, F.; Stillwell, D.; Kosinski, M. Workshop on Computational Personality Recognition: Shared Task; AAAI: Menlo Park, CA, USA, 2013. [Google Scholar]
- Barthelemy, M. Betweenness centrality in large complex networks. Eur. Phys. J. B 2004, 38, 163–168. [Google Scholar] [CrossRef]
- List of Stopwords Used by Scikit-Learn. Available online: https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/feature_extraction/stop_words.py (accessed on 18 May 2018).
- John, O.P.; Naumann, L.P.; Soto, C.J. Paradigm shift to the integrative Big Five trait taxonomy. In Handbook of Personality: Theory and Research; History, Measurement, and Conceptual Issues; John, O.P., Robins, R.W., Pervin, L.A., Eds.; Guilford Press: New York, NY, USA, 2008; pp. 114–158. [Google Scholar]
- Li, Q.; Shah, S.; Fang, R.; Liu, X.; Nourbakhsh, A. Data Sets: Word Embeddings Learned from Tweets and General Data. arXiv, 2017; arXiv:1708.03994. [Google Scholar]
- Landauer, T.K.; Dumais, S.T. A solution to Plato’s problem: The Latent Semantic Analysis theory of the acquisition, induction, and representation of knowledge. Psychol. Rev. 1997, 104, 211–240. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.J.; Vapnik, V.N. Support vector regression machines. In Advances in Neural Information Processing Systems 9, NIPS; MIT Press: Cambridge, MA, USA, 1996; pp. 155–161. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory (COLT ’92), Pittsburgh, PA, USA, 27–29 July 1992. [Google Scholar]
- Kenney, J.F.; Keeping, E.S. Linear regression and correlation. Math. Stat. 1962, 15 Pt 1, 252–285. [Google Scholar]
- Tibshirani, R. Regression shrinkage selection via the LASSO. J. R. Stat. Soc. Ser. B 2011, 73, 273–282. [Google Scholar] [CrossRef]
- fastText English Word Vectors. Available online: https://fasttext.cc/docs/en/english-vectors.html (accessed on 18 May 2018).
- Back, M.; Stopfer, J.; Vazire, S.; Gaddis, S.; Schmukle, S.; Egloff, B.; Gosling, S. Facebook Profiles Reflect Actual Personality, Not Self-Idealization. Psychol. Sci. 2010, 21, 372–374. [Google Scholar] [CrossRef] [PubMed]
- TwitPersonality. Available online: https://github.com/D2KLab/twitpersonality (accessed on 18 May 2018).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Count | Lowest | Average | Highest |
|---|---|---|---|---|
| Total users | 250 | - | - | - |
| Total status updates | 9913 | - | - | - |
| Status updates per user | - | 1 | 39 | 223 |
| Total words | 146,128 | - | - | - |
| Total words after preprocessing | 72,896 | - | - | - |
| Unique words | 15,470 | - | - | - |
| Unique words after preprocessing | 15,185 | - | - | - |
| Word per status update | - | 1 | 14 | 113 |
| Word per status update after preprocessing | - | 0 | 7 | 57 |
| OPE | CON | EXT | AGR | NEU | |
|---|---|---|---|---|---|
| max | 5 | 5 | 5 | 5 | 4.75 |
| min | 2.25 | 1.45 | 1.33 | 1.65 | 1.25 |
| avg | 4.0786 | 3.5229 | 3.2921 | 3.6003 | 2.6272 |
| std | 0.5751 | 0.7402 | 0.8614 | 0.6708 | 0.7768 |
| Metrics | Count | Lowest | Average | Highest |
|---|---|---|---|---|
| Total users | 24 | - | - | - |
| Total tweets | 18,473 | - | - | - |
| Tweets per user | - | 9 | 769.7 | 2252 |
| Total words | 263,984 | - | - | - |
| Total words after preprocessing | 77,900 | - | - | - |
| Unique words | 173,867 | - | - | - |
| Unique words after preprocessing | 34,651 | - | - | - |
| Word per status update | - | 1 | 13.36 | 33 |
| Word per status update after preprocessing | - | 0 | 8.8 | 25 |
| Avg words per tweet per user | - | 5 | 6.8 | 8.8 |
| Number of followers | - | 12 | 1375.5 | 20,800 |
| OPE | CON | EXT | AGR | NEU | |
|---|---|---|---|---|---|
| max | 4.8 | 4.78 | 4.38 | 4.33 | 3.63 |
| min | 2.5 | 2.33 | 1.75 | 2.78 | 1.5 |
| avg | 3.8917 | 3.5513 | 3.2208 | 3.6438 | 2.6642 |
| std | 0.5763 | 0.5682 | 0.5449 | 0.3707 | 0.5250 |
| Kernel Name | Kernel Function |
|---|---|
| Linear | |
| Polynomial | |
| Radial basis function (rbf) | |
| Hyperbolic tangent (sigmoid) |
| Algorithm | Parameter | Value |
|---|---|---|
| SVM | Kernel | linear, rbf, poly |
| C | 1, 10, 100 | |
| Gamma | 0.01, 0.1, 1, 10 | |
| Degree | 2, 3 | |
| LASSO | Alpha |
| Trait | Kernel | C | Gamma | MSE |
|---|---|---|---|---|
| Openness | rbf | 1 | 1 | 0.3316 |
| Conscientiousness | rbf | 10 | 1 | 0.5300 |
| Extraversion | rbf | 10 | 1 | 0.7084 |
| Agreeableness | rbf | 10 | 1 | 0.4477 |
| Neuroticism | rbf | 10 | 10 | 0.5572 |
| Trait | Model | Configuration | MSE |
|---|---|---|---|
| Openness | LReg | - | 0.3915 |
| LASSO | alpha = 0.0001 | 0.3345 | |
| Conscientiousness | LReg | - | 0.6200 |
| LASSO | alpha = 0.0001 | 0.5363 | |
| Extraversion | LReg | - | 0.8210 |
| LASSO | alpha = 0.0001 | 0.7106 | |
| Agreeableness | LReg | - | 0.5407 |
| LASSO | alpha = 0.0001 | 0.4500 | |
| Neuroticism | LReg | - | 0.6625 |
| LASSO | alpha = 0.0001 | 0.5595 |
| Model | OPE | CON | EXT | AGR | NEU |
|---|---|---|---|---|---|
| SVM | 0.3316 | 0.5300 | 0.7084 | 0.4477 | 0.5572 |
| LASSO | 0.3345 (0.0029) | 0.5363 (0.0063) | 0.7106 (0.0022) | 0.4500 (0.0023) | 0.5595 (0.0023) |
| LReg | 0.3915 (0.0599) | 0.6200 (0.0900) | 0.8210 (0.1126) | 0.5407 (0.0930) | 0.6625 (0.1053) |
| Method | OPE | CON | EXT | AGR | NEU | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | std | Mean | std | Mean | std | Mean | std | Mean | std | |
| sum | 0.459 | 0.308 | 0.723 | 0.542 | 0.939 | 0.655 | 0.6 | 0.429 | 0.75 | 0.497 |
| maximum | 0.352 | 0.014 | 0.547 | 0.023 | 0.735 | 0.031 | 0.461 | 0.018 | 0.58 | 0.028 |
| minimum | 0.352 | 0.016 | 0.546 | 0.024 | 0.732 | 0.032 | 0.462 | 0.017 | 0.579 | 0.026 |
| average | 0.355 | 0.015 | 0.547 | 0.025 | 0.735 | 0.03 | 0.464 | 0.019 | 0.582 | 0.034 |
| concatenation | 0.352 | 0.01 | 0.548 | 0.016 | 0.736 | 0.026 | 0.463 | 0.018 | 0.583 | 0.024 |
| Dataset | Word Coverage | # of Word Vectors | avg OCEAN MSE |
|---|---|---|---|
| FastText | 95.08% | 1M | 0.517 |
| [86] Dataset 1 | 96.02% | 1.9M | 0.532 |
| [86] Dataset 2 | 95.31% | 2.9M | 0.551 |
| [86] Dataset 3 | 96.36% | 2.7M | 0.558 |
| [86] Dataset 4 | 95.69% | 4M | 0.541 |
| [86] Dataset 5 | 96.49% | 1.4M | 0.539 |
| [86] Dataset 6 | 95.91% | 3.1M | 0.518 |
| [86] Dataset 7 | 98.05% | 1.7M | 0.52 |
| [86] Dataset 8 | 97.45% | 3.7M | 0.541 |
| [86] Dataset 9 | 98.22% | 2.2M | 0.533 |
| [86] Dataset 10 | 97.65% | 4.4M | 0.537 |
| OPE | CON | EXT | AGR | NEU | |
|---|---|---|---|---|---|
| myPersonality | 0.3316 | 0.5300 | 0.7084 | 0.4477 | 0.5572 |
| Twitter sample | 0.3812 | 0.3129 | 0.3002 | 0.1319 | 0.2673 |
| Quercia et al. [22] | 0.4761 | 0.5776 | 0.7744 | 0.6241 | 0.7225 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carducci, G.; Rizzo, G.; Monti, D.; Palumbo, E.; Morisio, M. TwitPersonality: Computing Personality Traits from Tweets Using Word Embeddings and Supervised Learning. Information 2018, 9, 127. https://doi.org/10.3390/info9050127
Carducci G, Rizzo G, Monti D, Palumbo E, Morisio M. TwitPersonality: Computing Personality Traits from Tweets Using Word Embeddings and Supervised Learning. Information. 2018; 9(5):127. https://doi.org/10.3390/info9050127
Chicago/Turabian StyleCarducci, Giulio, Giuseppe Rizzo, Diego Monti, Enrico Palumbo, and Maurizio Morisio. 2018. "TwitPersonality: Computing Personality Traits from Tweets Using Word Embeddings and Supervised Learning" Information 9, no. 5: 127. https://doi.org/10.3390/info9050127
APA StyleCarducci, G., Rizzo, G., Monti, D., Palumbo, E., & Morisio, M. (2018). TwitPersonality: Computing Personality Traits from Tweets Using Word Embeddings and Supervised Learning. Information, 9(5), 127. https://doi.org/10.3390/info9050127