A Comparison of Emotion Annotation Approaches for Text



Abstract
:1. Introduction
2. Annotator Agreement Comparisons
2.1. Annotation Difference Metrics
2.1.1. Categorical Annotations (Multiple Categories Allowed)
2.1.2. Relative Dimensional Annotations
2.1.3. Rating Scale Annotations
2.2. Annotator Agreement
3. Cognitive Complexity of Annotation Tasks
4. Data Collection and Annotation
4.1. Annotation
4.1.1. Pilot Study
4.1.2. Primary Study
4.2. Data Availability and Privacy Protection
4.3. Predictive Model
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Mohammad, S.M. Sentiment Analysis: Detecting Valence, Emotions, and Other Affectual States from Text. In Emotion Measurement; Meiselman, H.L., Ed.; Woodhead Publishing: Sawston, UK; Cambridge, UK, 2016; pp. 201–237. [Google Scholar]
- Mohammad, S.; Bravo-Marquez, F. WASSA-2017 Shared Task on Emotion Intensity. In Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Copenhagen, Denmark, 8 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 34–49. [Google Scholar]
- Mohammad, S.M.; Bravo-Marquez, F.; Salameh, M.; Kiritchenko, S. SemEval-2018 Task 1: Affect in Tweets. In Proceedings of the International Workshop on Semantic Evaluation (SemEval-2018), New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Felbo, B.; Mislove, A.; Søgaard, A.; Rahwan, I.; Lehmann, S. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 1616–1626. [Google Scholar]
- Buechel, S.; Hahn, U. EMOBANK: Studying the Impact of Annotation Perspective and Representation Format on Dimensional Emotion Analysis. EACL 2017, 2017, 578. [Google Scholar]
- Abdul-Mageed, M.; Ungar, L. EmoNet: Fine-Grained Emotion Detection with Gated Recurrent Neural Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 718–728. [Google Scholar]
- Ekman, P.; Friesen, W.V.; O’Sullivan, M.; Chan, A.; Diacoyanni-Tarlatzis, I.; Heider, K.; Krause, R.; LeCompte, W.A.; Pitcairn, T.; Ricci-Bitti, P.E.; et al. Universals and cultural differences in the judgments of facial expressions of emotion. J. Pers. Soc. Psychol. 1987, 53, 712–717. [Google Scholar] [CrossRef] [PubMed]
- Osgood, C.E.; May, W.H.; Miron, M.S. Cross-Cultural Universals of Affective Meaning; University of Illinois Press: Champaign, IL, USA, 1975. [Google Scholar]
- Russell, J.A.; Mehrabian, A. Evidence for a three-factor theory of emotions. J. Res. Pers. 1977, 11, 273–294. [Google Scholar] [CrossRef]
- Fontaine, J.R.J.; Scherer, K.R.; Roesch, E.B.; Ellsworth, P.C. The World of Emotions is not Two-Dimensional. Psychol. Sci. 2007, 18, 1050–1057. [Google Scholar] [CrossRef] [PubMed]
- Bradley, M.M.; Lang, P.J. Affective Norms for English Text (ANET): Affective Ratings of Texts and Instruction Manual; Technical Report; University of Florida: Gainesville, FL, USA, 2007. [Google Scholar]
- Preotiuc-Pietro, D.; Schwartz, H.A.; Park, G.; Eichstaedt, J.C.; Kern, M.; Ungar, L.; Shulman, E.P. Modelling Valence and Arousal in Facebook posts. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 12–17 June 2016; pp. 9–15. [Google Scholar]
- Yu, L.C.; Lee, L.H.; Hao, S.; Wang, J.; He, Y.; Hu, J.; Lai, K.R.; Zhang, X. Building Chinese Affective Resources in Valence-Arousal Dimensions. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 12–17 June 2016; pp. 540–545. [Google Scholar]
- Bradley, M.M.; Lang, P.J. Measuring Emotion: The self-assessment manikin and the semantic differential. J. Behav. Theory Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Metallinou, A.; Narayanan, S. Annotation and processing of continuous emotional attributes: Challenges and opportunities. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Yannakakis, G.N.; Cowie, R.; Busso, C. The Ordinal Nature of Emotions. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, San Antonio, TX, USA, 23–26 October 2017. [Google Scholar]
- Yang, Y.H.; Chen, H.H. Ranking-Based Emotion Recognition for Music Organization and Retrieval. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 762–774. [Google Scholar] [CrossRef]
- Martinez, H.P.; Yannakakis, G.N.; Hallam, J. Don’t classify ratings of affect; rank them! IEEE Trans. Affect. Comput. 2014, 5, 314–326. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Mohammad, S.M. Best-Worst Scaling More Reliable than Rating Scales: A Case Study on Sentiment Intensity Annotation. In Proceedings of the 32nd International Conference on Computational Linguistics and the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Wood, I.; Ruder, S. Emoji as Emotion Tags for Tweets. In Proceedings of the Emotion and Sentiment Analysis Workshop LREC2016, Portorož, Slovenia, 23 May 2016; pp. 76–79. [Google Scholar]
- Jaccard, P. The distribution of the flora in the alpine zone. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Passonneau, R.J. Computing Reliability for Coreference Annotation. In Proceedings of the LREC, Reykjavik, Iceland, 26–31 May 2004. [Google Scholar]
- Passonneau, R. Measuring Agreement on Set-Valued Items (MASI) for Semantic and Pragmatic Annotation; Columbia University: New York, NY, USA, 2006. [Google Scholar]
- Louviere, J.J.; Woodworth, G. Best-Worst Scaling: A Model for the Largest Difference Judgments; Working Paper; University of Alberta: Edmonton, AB, Canada, 1991. [Google Scholar]
- Louviere, J.J.; Flynn, T.N.; Marley, A.A. Best-Worst Scaling: Theory, Methods and Applications; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Wood, I.D.; McCrae, J.P.; Buitelaar, P. A Comparison Of Emotion Annotation Schemes And A New Annotated Data Set. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Miyazaki, Japan, 2018. [Google Scholar]
- Bollen, J.; Mao, H.; Pepe, A. Modeling Public Mood and Emotion: Twitter Sentiment and Socio-Economic Phenomena; Icwsm; AAAI Press: Barcelona, Spain, 2011; Volume 11, pp. 450–453. [Google Scholar]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The Rise of Social Bots. Commun. ACM 2016, 59, 96–104. [Google Scholar] [CrossRef]
- Andryushechkin, V.; Wood, I.; O’Neill, J. NUIG at EmoInt-2017: BiLSTM and SVR ensemble to detect emotion intensity. In Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Copenhagen, Denmark, 18 June 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 175–179. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar]
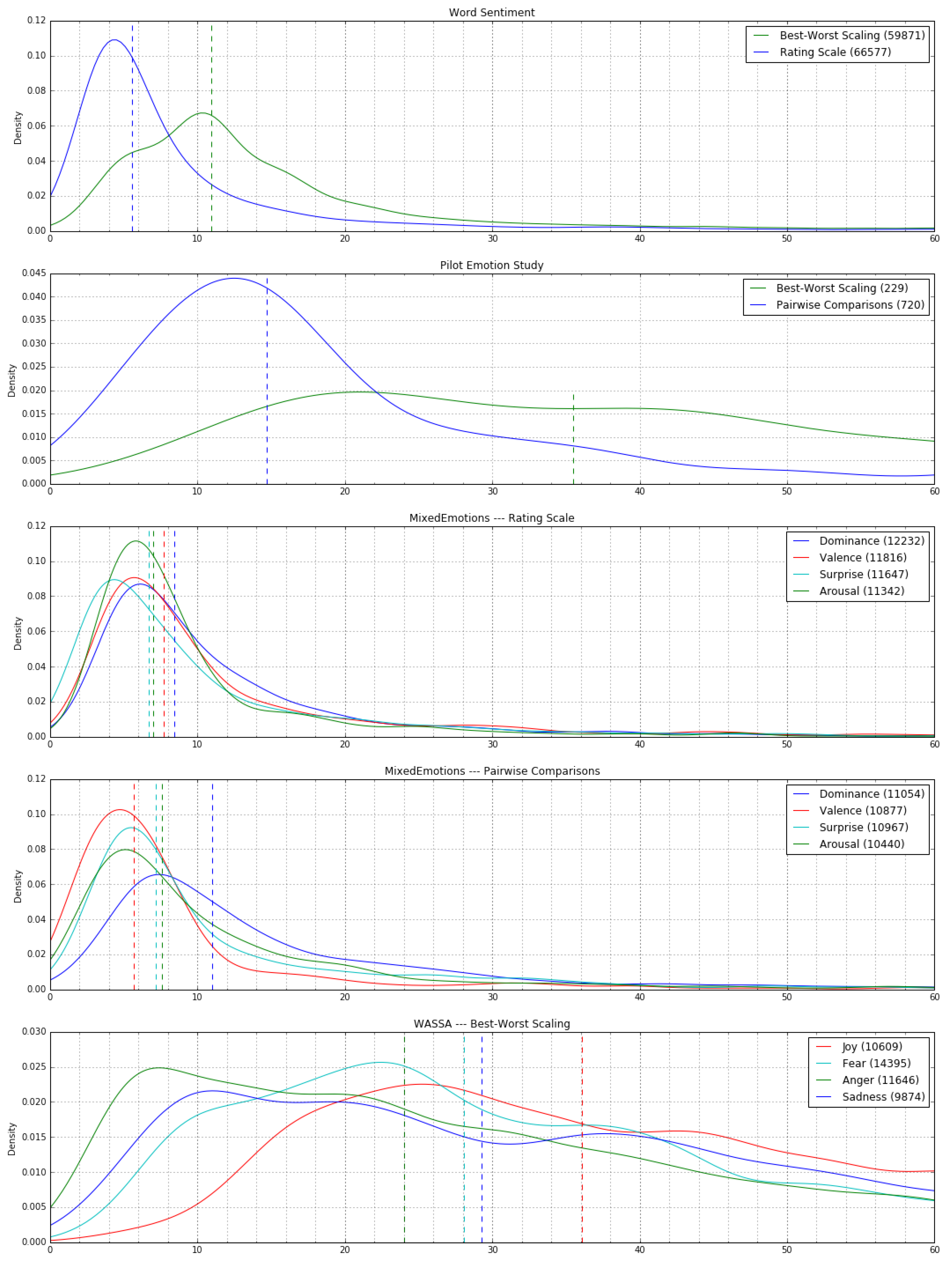

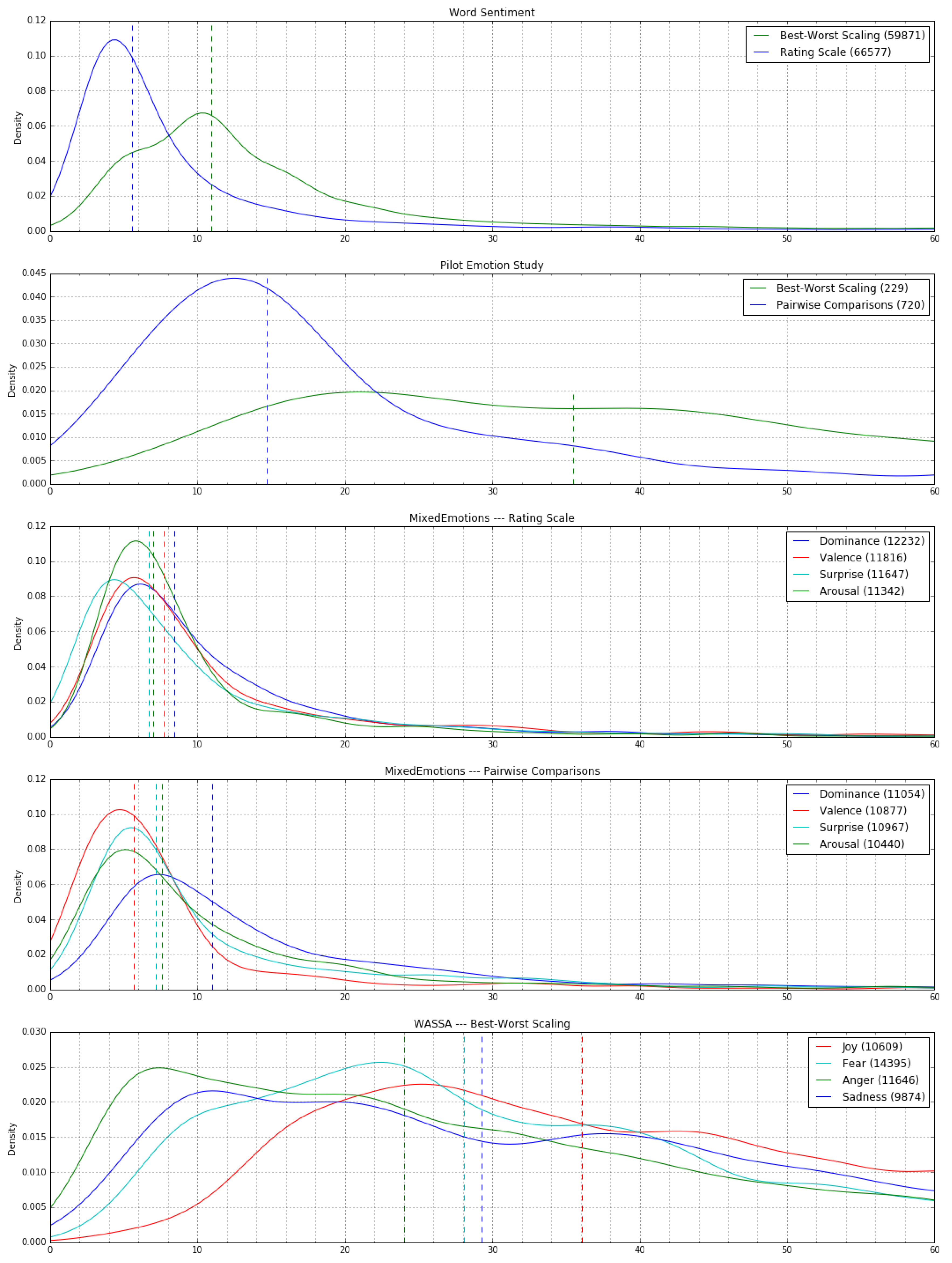{kind=link}
| Metric | Comparisons | Rating Scale | Rating Scale (As Comparisons) |
|---|---|---|---|
| Naive | 0.39 | 0.41 | 0.39 |
| Novel | 0.45 | 0.47 | 0.51 |
| Metric | Categorical |
|---|---|
| Wood | 0.33 |
| Masi | 0.30 |
| Jaccard | 0.31 |
| Passonneau | 0.32 |
| Emotion Dimension | Comparisons | Rating Scale | Rating Scale (As Comparisons) |
|---|---|---|---|
| Valence | 0.52 | 0.63 | 0.70 |
| Arousal | 0.45 | 0.49 | 0.60 |
| Dominance | 0.43 | 0.37 | 0.40 |
| Surprise | 0.40 | 0.23 | 0.38 |
| Data Set | Emotion Representation | Binary Comparisons | Rating Scale | Best-Worst Scaling |
|---|---|---|---|---|
| MixedEmotions [27] | VADS | 43,899 | 47,576 | — |
| MixedEmotions Pilot Study [27] | VADS | 745 | — | 258 |
| Sentiment Best/Worst [20] | Sentiment | — | 66,577 | 59,900 |
| WASSA 2017 [3] | 4xEkman | — | — | 51,861 |
| Heuristics |
|---|
| High proportion of very short words |
| High proportion #tags/@mentions |
| Multiple new-line characters |
| Large number of stop words |
| Apparent quotations |
| Weather channel tweets |
| Presence of obscure acronyms |
| Presence of “#Vote” |
| Presence of non English characters |
| Presence of “follow” or “followme” … |
| Dimension | Spearman Correlation (Regression Models) | F1 (Comparison Models) |
|---|---|---|
| Valence | 0.72 | 0.72 |
| Arousal | 0.64 | 0.69 |
| Dominance | 0.53 | 0.71 |
| Surprise | 0.42 | 0.63 |
| Average | 0.58 | 0.69 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wood, I.D.; McCrae, J.P.; Andryushechkin, V.; Buitelaar, P. A Comparison of Emotion Annotation Approaches for Text. Information 2018, 9, 117. https://doi.org/10.3390/info9050117
Wood ID, McCrae JP, Andryushechkin V, Buitelaar P. A Comparison of Emotion Annotation Approaches for Text. Information. 2018; 9(5):117. https://doi.org/10.3390/info9050117
Chicago/Turabian StyleWood, Ian D., John P. McCrae, Vladimir Andryushechkin, and Paul Buitelaar. 2018. "A Comparison of Emotion Annotation Approaches for Text" Information 9, no. 5: 117. https://doi.org/10.3390/info9050117
APA StyleWood, I. D., McCrae, J. P., Andryushechkin, V., & Buitelaar, P. (2018). A Comparison of Emotion Annotation Approaches for Text. Information, 9(5), 117. https://doi.org/10.3390/info9050117