Multilingual and Multiword Phenomena in a lemon Old Occitan Medico-Botanical Lexicon

Abstract
:1. Introduction
- –
- the lexicographic domain, including the lemmatized forms (lemma, variants and corresponding terms in other ancient languages) and their linguistic and lexicographic description;
- –
- the documentation domain, giving the information source of each form of a term and its meaning, as well as a complete bibliography of the sources, editions and dictionaries;
- –
- the conceptual domain, describing the meaning of each term by means of subontologies for the fields of botany, zoology, mineralogy, human anatomy, diseases and therapy (medication, medical instruments).
2. Background: Representing Multilingual and Multialphabetical Simple Terms in lemon
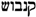 /QNBWŠ,
/QNBWŠ, 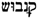 /QiNaBWuŠ,
/QiNaBWuŠ, 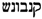 /QNBWNŠ. The form canabo is taken, by definition (The criteria for choosing a lemma are hierarchically: (i) the simple term is chosen over the compound term, e.g., oli not oli rossat; (ii) the form that corresponds to the lemma in most of the standard dictionaries is chosen, e.g., bleda is chosen over bleta (the form bleta is considered a cultism); (iii) the form that is closer to the etymon is chosen, e.g., oli not holi due to the Latin etymon < oleum; (iv) the most frequent form is chosen.), as lemma or leading variant. The form canabos is the plural form of the lemma canabo. It is classified as a morphological variant. The form canebe differs with respect to spelling and pronunciation. The form is thus classified as a grapho-phonetic variant. As a general definition, the variants in Hebrew characters are all alphabetical variants of the lemma. All forms are plural and marked as morphological variants. The forms
/QNBWNŠ. The form canabo is taken, by definition (The criteria for choosing a lemma are hierarchically: (i) the simple term is chosen over the compound term, e.g., oli not oli rossat; (ii) the form that corresponds to the lemma in most of the standard dictionaries is chosen, e.g., bleda is chosen over bleta (the form bleta is considered a cultism); (iii) the form that is closer to the etymon is chosen, e.g., oli not holi due to the Latin etymon < oleum; (iv) the most frequent form is chosen.), as lemma or leading variant. The form canabos is the plural form of the lemma canabo. It is classified as a morphological variant. The form canebe differs with respect to spelling and pronunciation. The form is thus classified as a grapho-phonetic variant. As a general definition, the variants in Hebrew characters are all alphabetical variants of the lemma. All forms are plural and marked as morphological variants. The forms 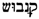 /QiNaBWuŠ,
/QiNaBWuŠ, 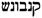 /QNBWNŠ additionally differ with respect to phonology. As indicated by the vowel signs, the initial syllable of
/QNBWNŠ additionally differ with respect to phonology. As indicated by the vowel signs, the initial syllable of 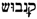 /QiNaBWuŠ has to be interpreted as <ki>instead of <ka>. The form
/QiNaBWuŠ has to be interpreted as <ki>instead of <ka>. The form  /QNBWNŠ (read: “canabons”) contains a so-called n-mobile, a particular phonological characteristic of Old Occitan; cf. [1]. Thus, the following aspects have been represented in lemon:
/QNBWNŠ (read: “canabons”) contains a so-called n-mobile, a particular phonological characteristic of Old Occitan; cf. [1]. Thus, the following aspects have been represented in lemon:- Type of script is introduced as a specific property ditmao:hasAlphabet, which ranges over Latn, Hebr or Arabvalues of the lemon:PropertyValue class.
- Transliteration: In order to represent the transliteration, we adopted lexinfo:transliteration, which is defined as a sub-property of lemon:representation. The specific transliteration alphabets are defined as sub-properties of lexinfo:transliteration. In addition to a transliteration of Hebrew, there is the need for a transliteration of Arabic. The former is labeled HebrTransliteration and the latter ArabTransliteration. HebrTrsl and ArabTrsl have been created as individuals of the class lemon:PropertyValue accordingly.
- Types of variants: We specify all types of variants as values of ditmao:variant, defined as a sub-property of lemon:property. This sub-property takes the following values ditmao:alphabeticalVariant, ditmao:graphicVariant, ditmao:morphologicalVariant and ditmao:graphophoneticVariant that have been created as individuals of the class lemon:PropertyValue.
 /QNBWNŠ figures as a synonym of the Arabic term
/QNBWNŠ figures as a synonym of the Arabic term 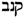 /QNB and the Hebrew term
/QNB and the Hebrew term 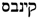 / QYNBS in the synonym lists edited in [2]. The meaning of all three terms is documented as ‘hemp’ (in particular, Cannabis sativa L.). However, even if the terms have exactly the same meaning, they should not be considered as synonyms in the modern understanding of the term, because they do not belong to the same language. For each ancient language, a separate lemon:Lexicon has been created and a relation established between terms of two different lexica. The ancient synonym relation has been introduced to model corresponding terms.
/ QYNBS in the synonym lists edited in [2]. The meaning of all three terms is documented as ‘hemp’ (in particular, Cannabis sativa L.). However, even if the terms have exactly the same meaning, they should not be considered as synonyms in the modern understanding of the term, because they do not belong to the same language. For each ancient language, a separate lemon:Lexicon has been created and a relation established between terms of two different lexica. The ancient synonym relation has been introduced to model corresponding terms.
- Corresponding terms: This relation has been modeled in lemon as the property ditmao:correspondence, defined as a sub-property of lemon:senseRelation. It relates two lexical entries of different lexica.
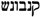 /QNBWNŠ as follows (Please note that the correspondence and the variant in Hebrew script are
/QNBWNŠ as follows (Please note that the correspondence and the variant in Hebrew script are 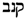 and
and 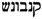 , respectively.).
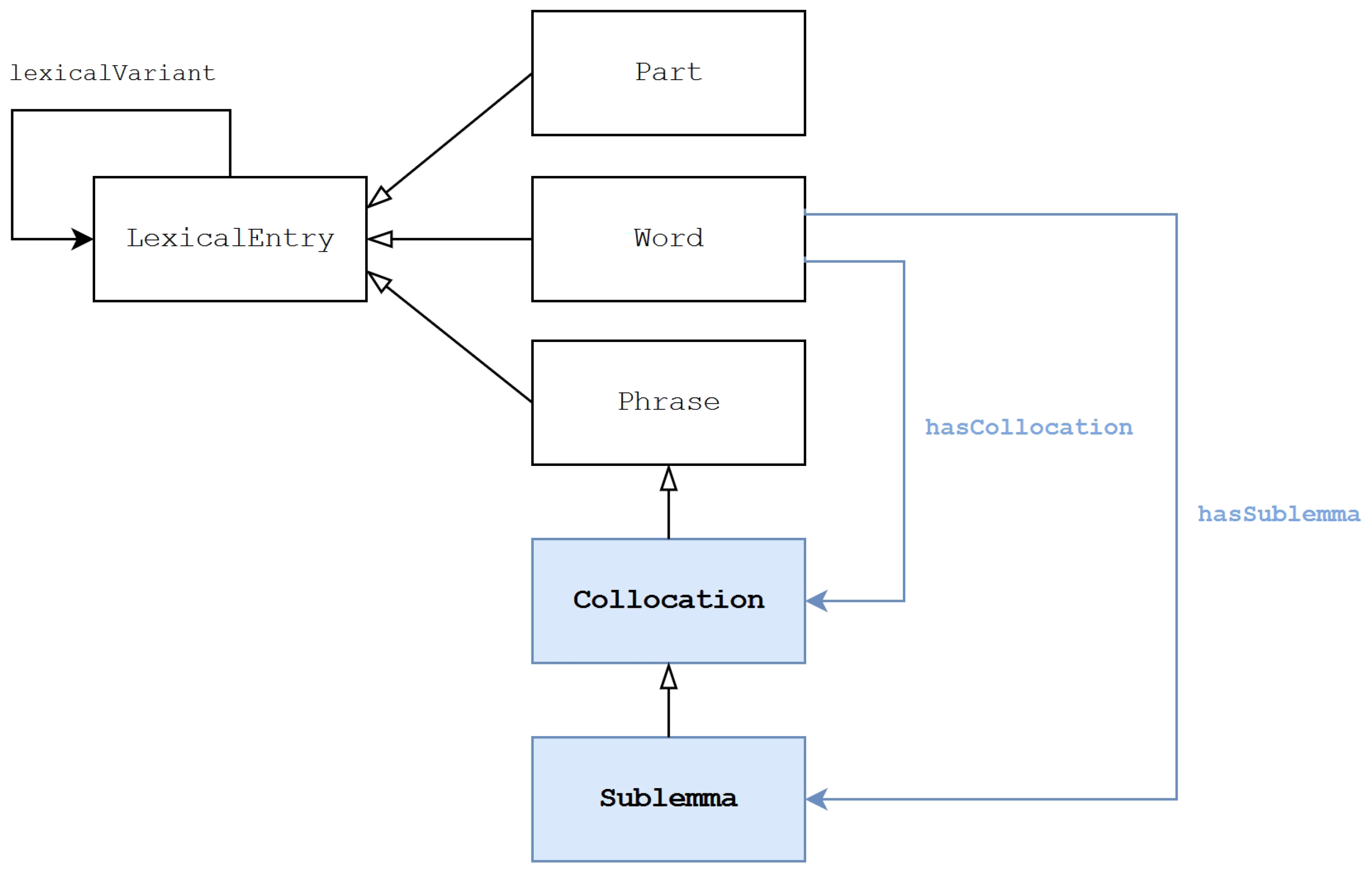
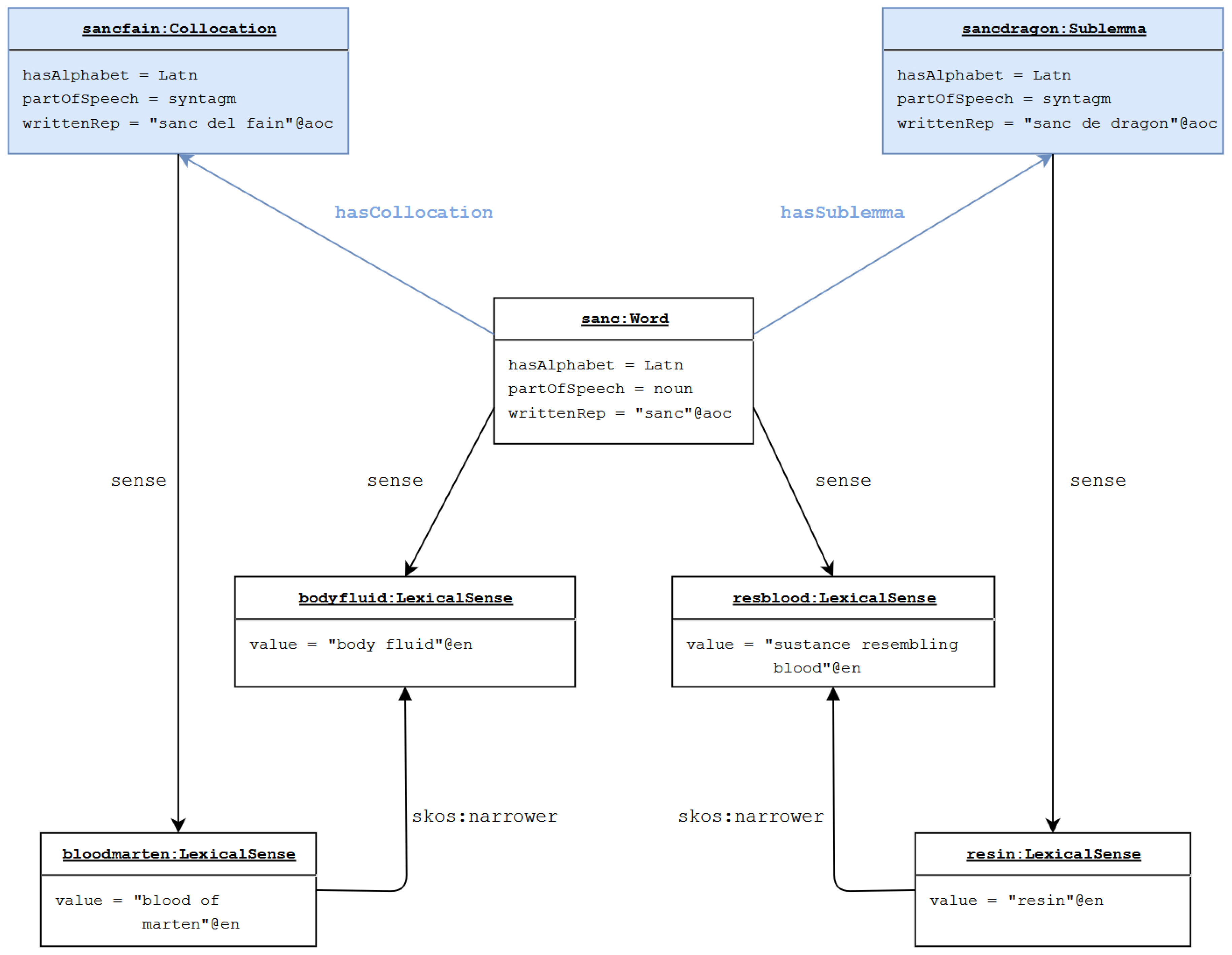
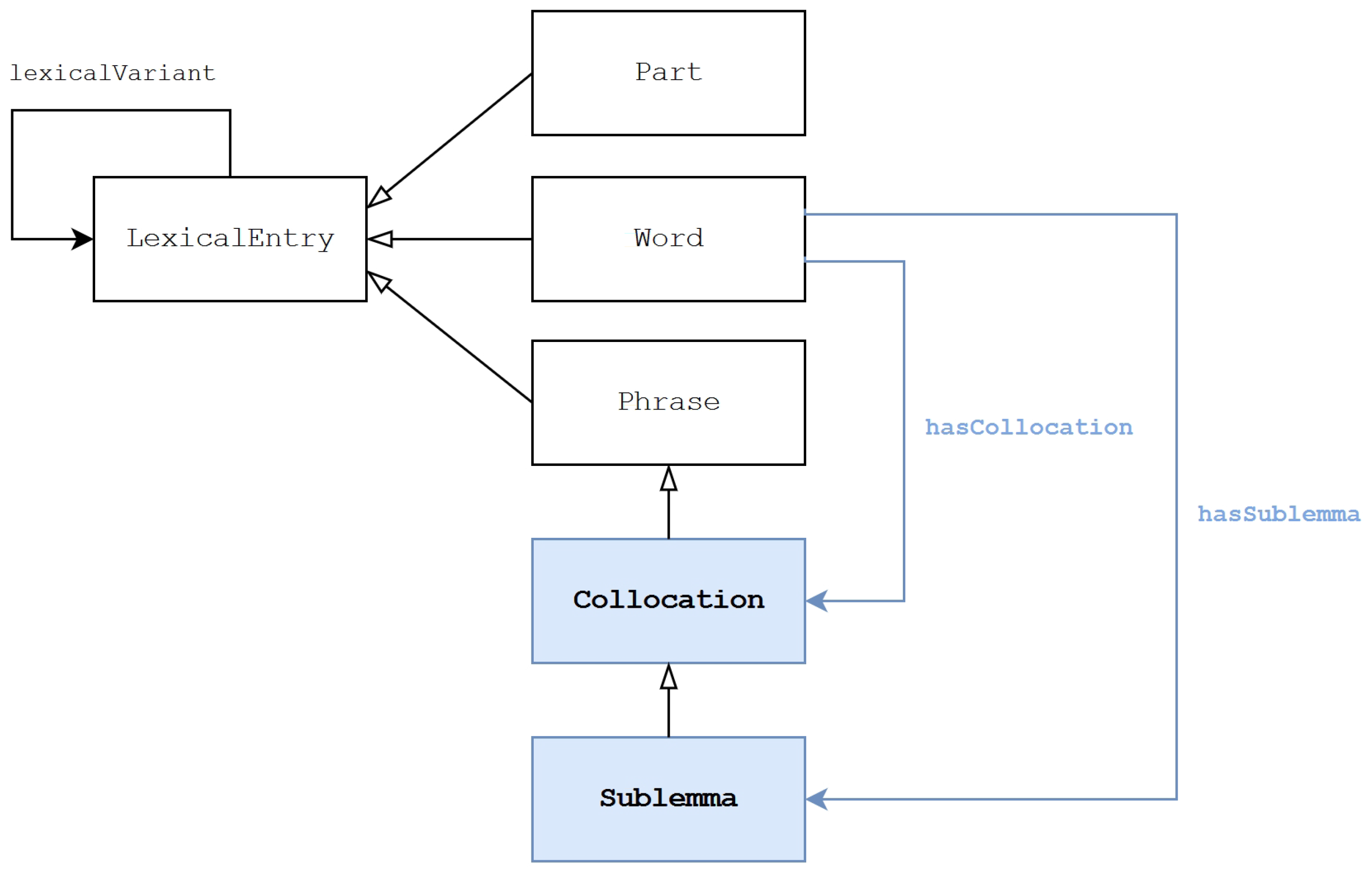
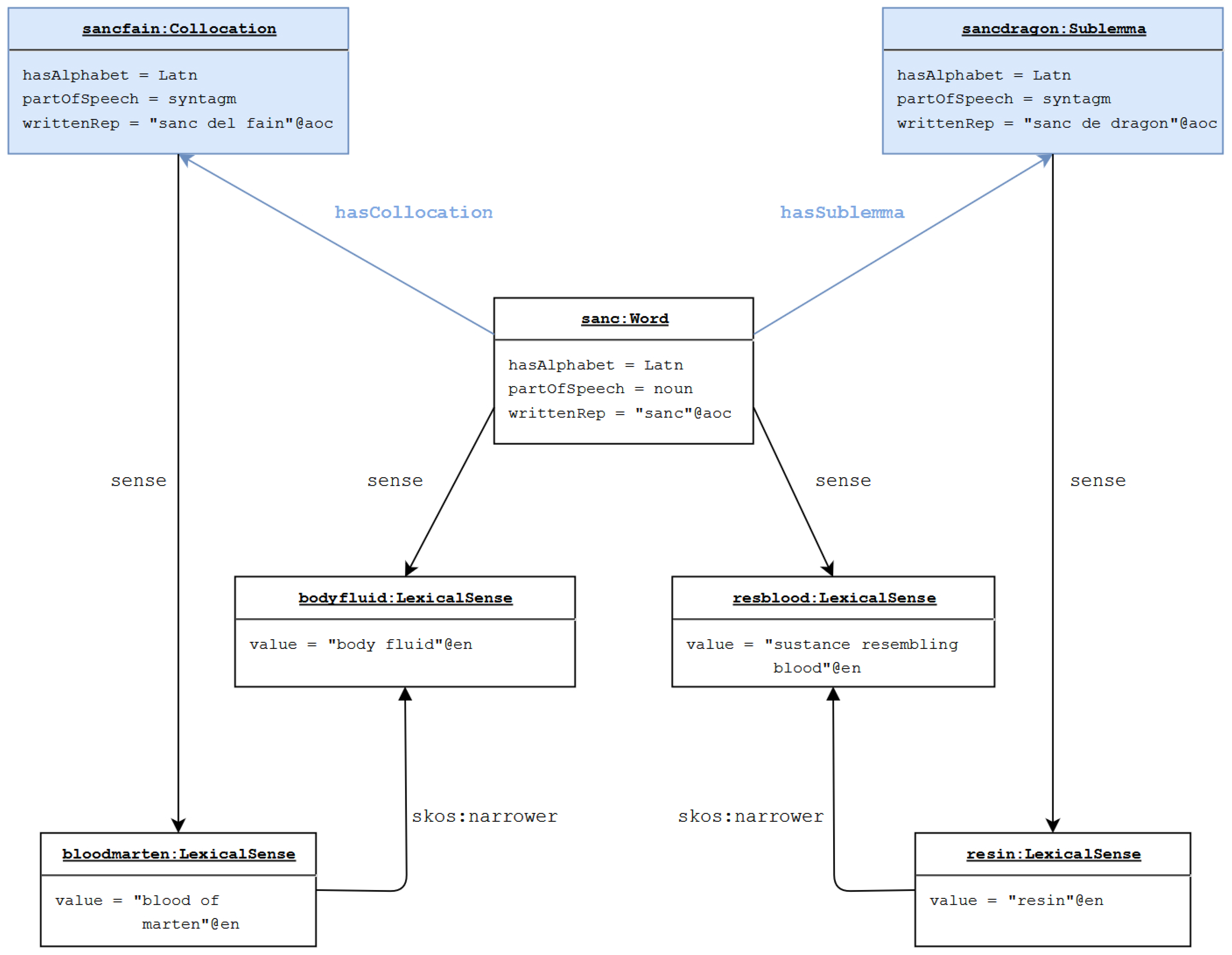
, respectively.).3. Representing Phrases in lemon: Sublemmata and Collocations
4. Multi-Lexicon Phrases
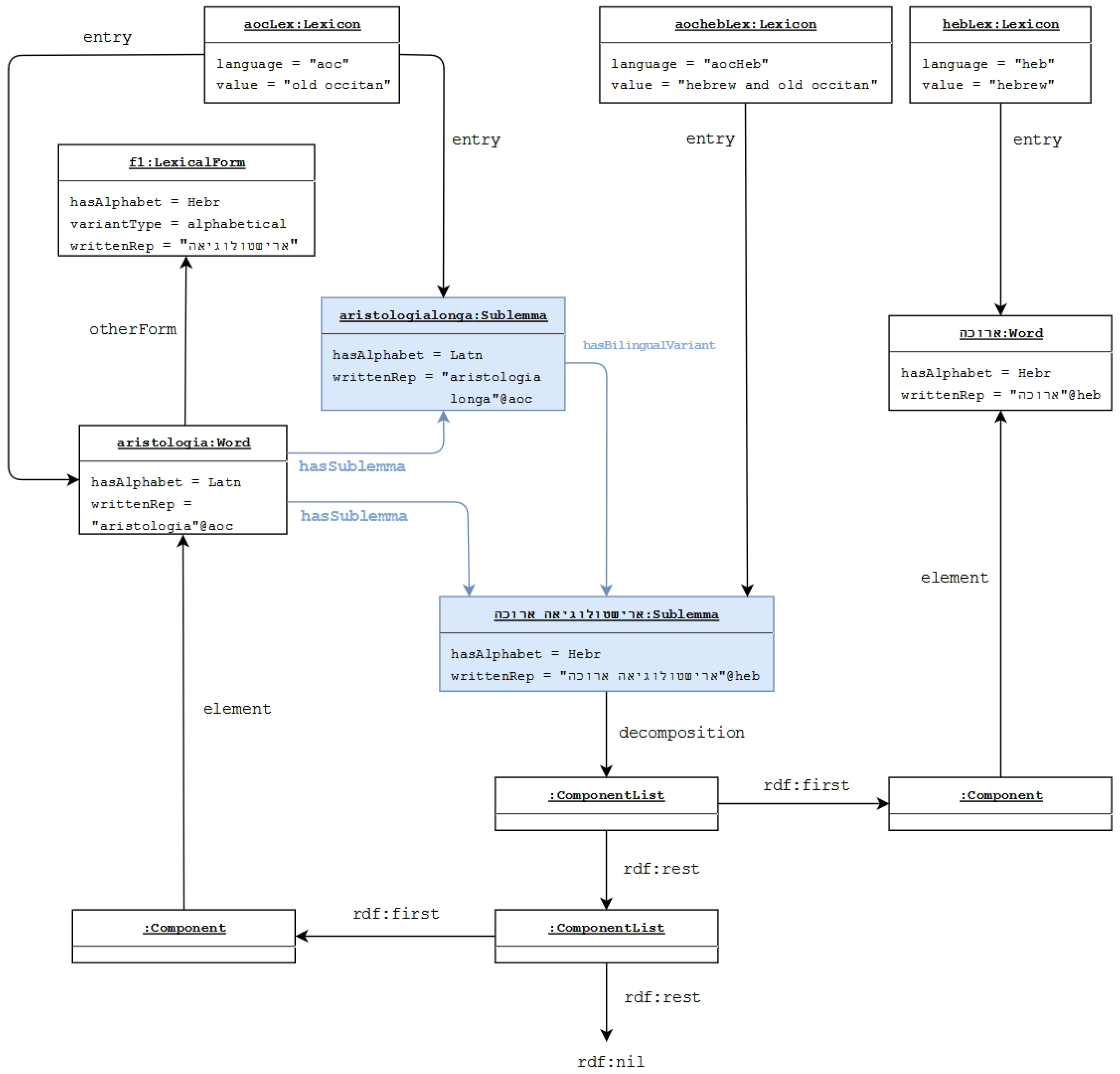
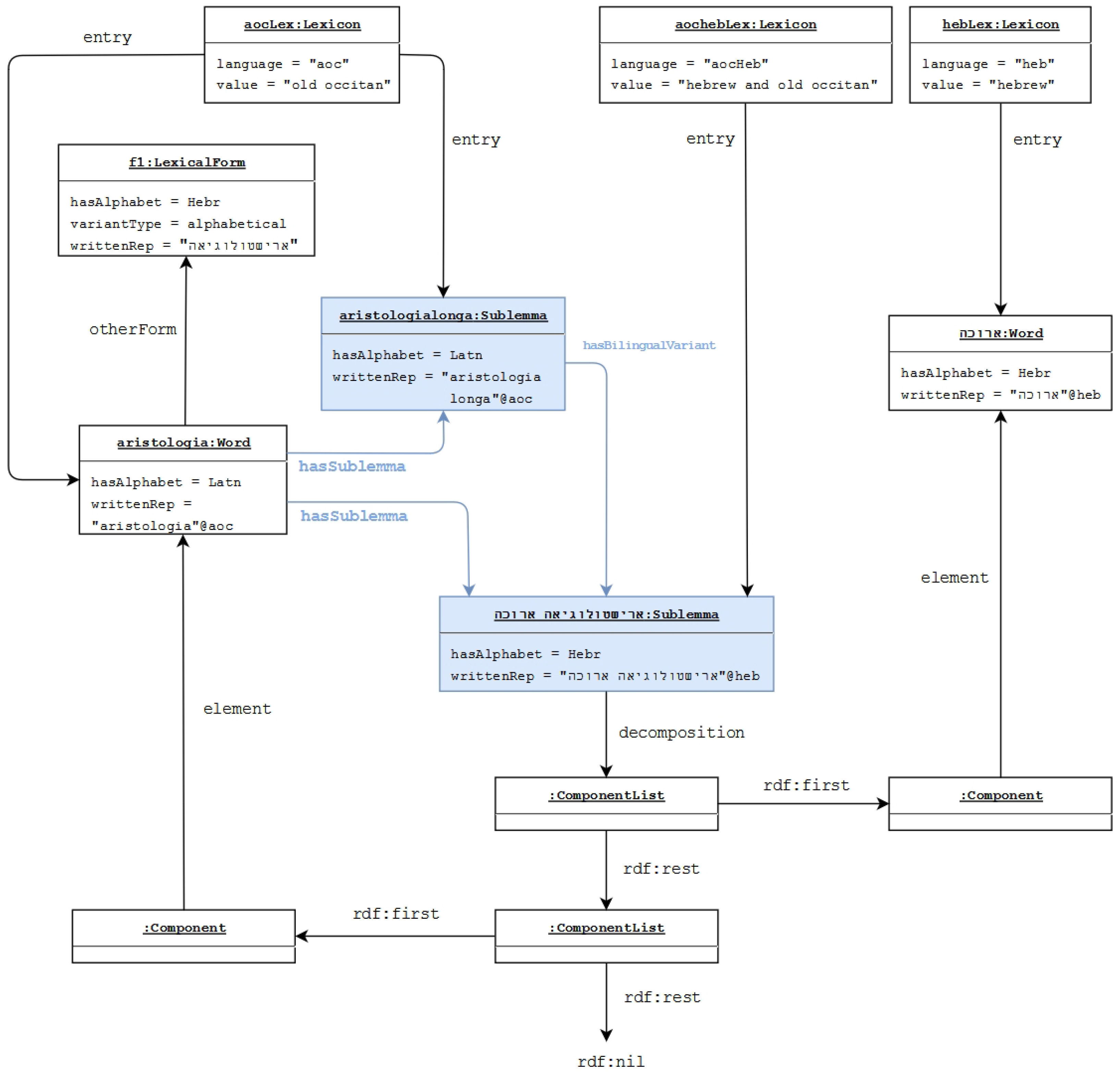
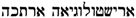 /’RYŠTWLWGY’H ’RWKH (read: “aristologia aruka”) consists of the Old Occitan term ‘RYŠTWLWGY’H, an alphabetical variant of aristologia and the Hebrew adjective
/’RYŠTWLWGY’H ’RWKH (read: “aristologia aruka”) consists of the Old Occitan term ‘RYŠTWLWGY’H, an alphabetical variant of aristologia and the Hebrew adjective  /’RWKH, meaning ‘long’, which is a Hebrew translation of the Old Occitan adjective . However, this term is not isolated. The texts contain also the complete Old Occitan forms, here aristologia longa, both in Latin and in Hebrew script. In [25], we argued that these terms should be classified as belonging to the Hebrew lexicon, because the terms mostly occur in Hebrew prose texts or in Hebrew translations. This is taken as an indication that the mixed term was part of the technical vocabulary used by Jewish physicians living in Southern France and the Hebrew, and Old Occitan part was most likely transparent for these physicians. Shortcomings of this solution are: (i) the vocabulary of Jewish physicians living in Southern France should not be equated to the Hebrew lexicon; (ii) the Old Occitan part should not be part of the Hebrew lexicon. These terms thus do not belong to either of the two languages, but the lemon model requires the language to be unique for a lexicon. The solution we propose is to introduce a bilingual lexicon, here an Old Occitan-Hebrew lexicon, but only for mixed terms that are not incorporated in one of the languages. As shown in Figure 3 below,
/’RWKH, meaning ‘long’, which is a Hebrew translation of the Old Occitan adjective . However, this term is not isolated. The texts contain also the complete Old Occitan forms, here aristologia longa, both in Latin and in Hebrew script. In [25], we argued that these terms should be classified as belonging to the Hebrew lexicon, because the terms mostly occur in Hebrew prose texts or in Hebrew translations. This is taken as an indication that the mixed term was part of the technical vocabulary used by Jewish physicians living in Southern France and the Hebrew, and Old Occitan part was most likely transparent for these physicians. Shortcomings of this solution are: (i) the vocabulary of Jewish physicians living in Southern France should not be equated to the Hebrew lexicon; (ii) the Old Occitan part should not be part of the Hebrew lexicon. These terms thus do not belong to either of the two languages, but the lemon model requires the language to be unique for a lexicon. The solution we propose is to introduce a bilingual lexicon, here an Old Occitan-Hebrew lexicon, but only for mixed terms that are not incorporated in one of the languages. As shown in Figure 3 below, 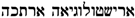 /’RYŠTWLWGY’H ’RWKH is part of the bilingual lexicon “aocheb”.
/’RYŠTWLWGY’H ’RWKH is part of the bilingual lexicon “aocheb”. /’RWKH to the Hebrew lexicon and
/’RWKH to the Hebrew lexicon and 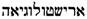 /’RYŠTWLWGY’H to the Old Occitan lexicon. Further, we can state the fact that
/’RYŠTWLWGY’H to the Old Occitan lexicon. Further, we can state the fact that 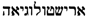 /’RYŠTWLWGY’H is an alphabetical variant of . Every part is aligned with the correct lexicon, and we are able to conceive of the mixed term as part of the Old Occitan medico-botanical vocabulary via the ditmao:sublemma and ditmao:hasBilingualVariant relations without classifying the term as belonging to the Old Occitan lexicon. A related issue concerns other terms like or that are morpho-phonologically Latin terms. The term occurs along with its Old Occitan equivalent in Old Occitan medico-botanical prose texts. This means that the term was commonly known to Old Occitan-speaking physicians and should therefore be considered as part of the Old Occitan medico-botanical vocabulary, but it belongs to the Latin lexicon. The term has no Old Occitan equivalent and should be considered as a foreign term used in Old Occitan medico-botanical vocabulary, but belonging to the Latin lexicon. These terms show that a distinction between a lexicon defined by morpho-phonological properties and a vocabulary/lexicon that contains foreign or loanwords and that reflects different degrees of incorporation in a certain language is necessary for an accurate representation of a multilingual, historical dictionary. In order to propose a formal representation in lemon, further research is necessary.
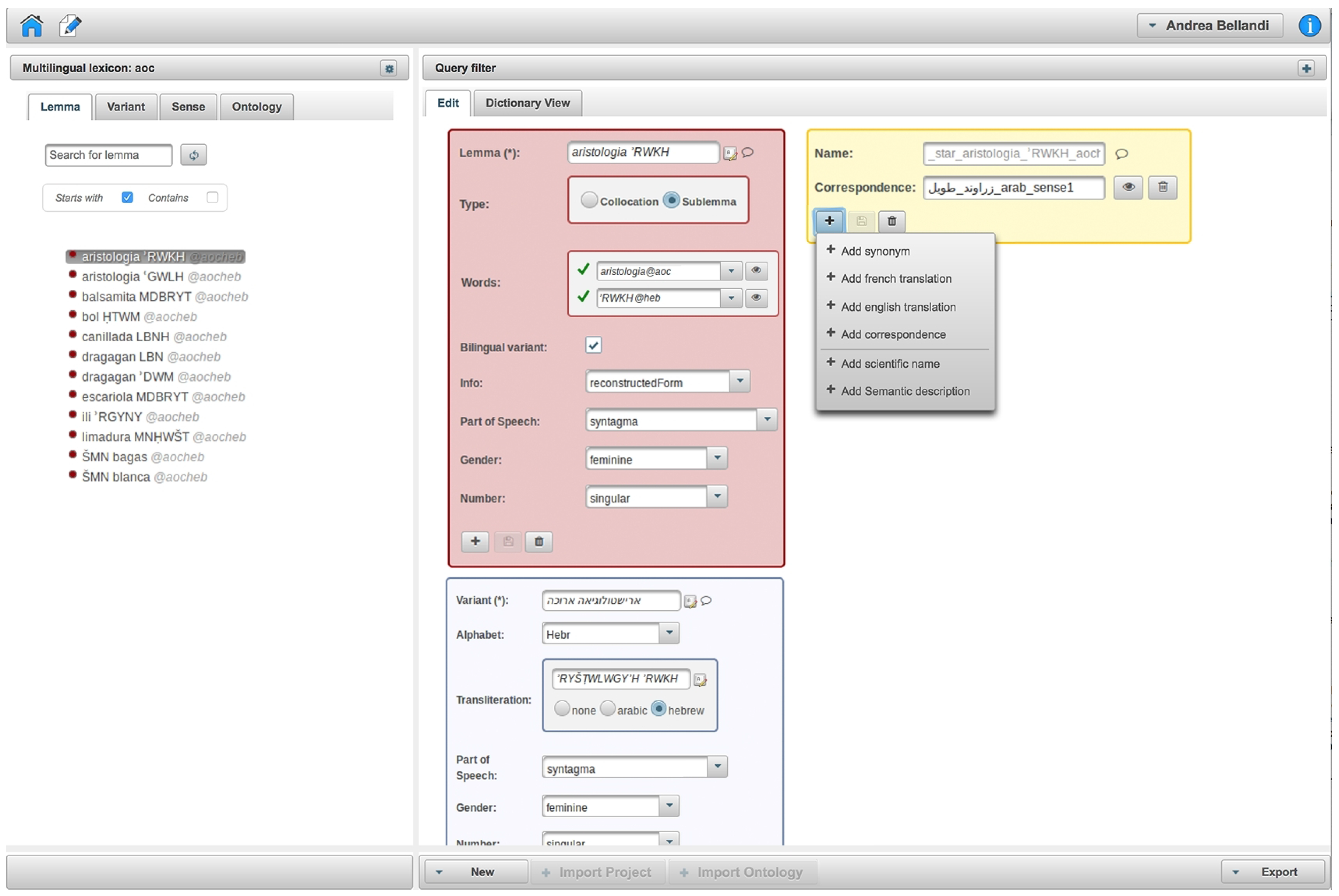
/’RYŠTWLWGY’H is an alphabetical variant of . Every part is aligned with the correct lexicon, and we are able to conceive of the mixed term as part of the Old Occitan medico-botanical vocabulary via the ditmao:sublemma and ditmao:hasBilingualVariant relations without classifying the term as belonging to the Old Occitan lexicon. A related issue concerns other terms like or that are morpho-phonologically Latin terms. The term occurs along with its Old Occitan equivalent in Old Occitan medico-botanical prose texts. This means that the term was commonly known to Old Occitan-speaking physicians and should therefore be considered as part of the Old Occitan medico-botanical vocabulary, but it belongs to the Latin lexicon. The term has no Old Occitan equivalent and should be considered as a foreign term used in Old Occitan medico-botanical vocabulary, but belonging to the Latin lexicon. These terms show that a distinction between a lexicon defined by morpho-phonological properties and a vocabulary/lexicon that contains foreign or loanwords and that reflects different degrees of incorporation in a certain language is necessary for an accurate representation of a multilingual, historical dictionary. In order to propose a formal representation in lemon, further research is necessary.5. LexO: Work in Progress
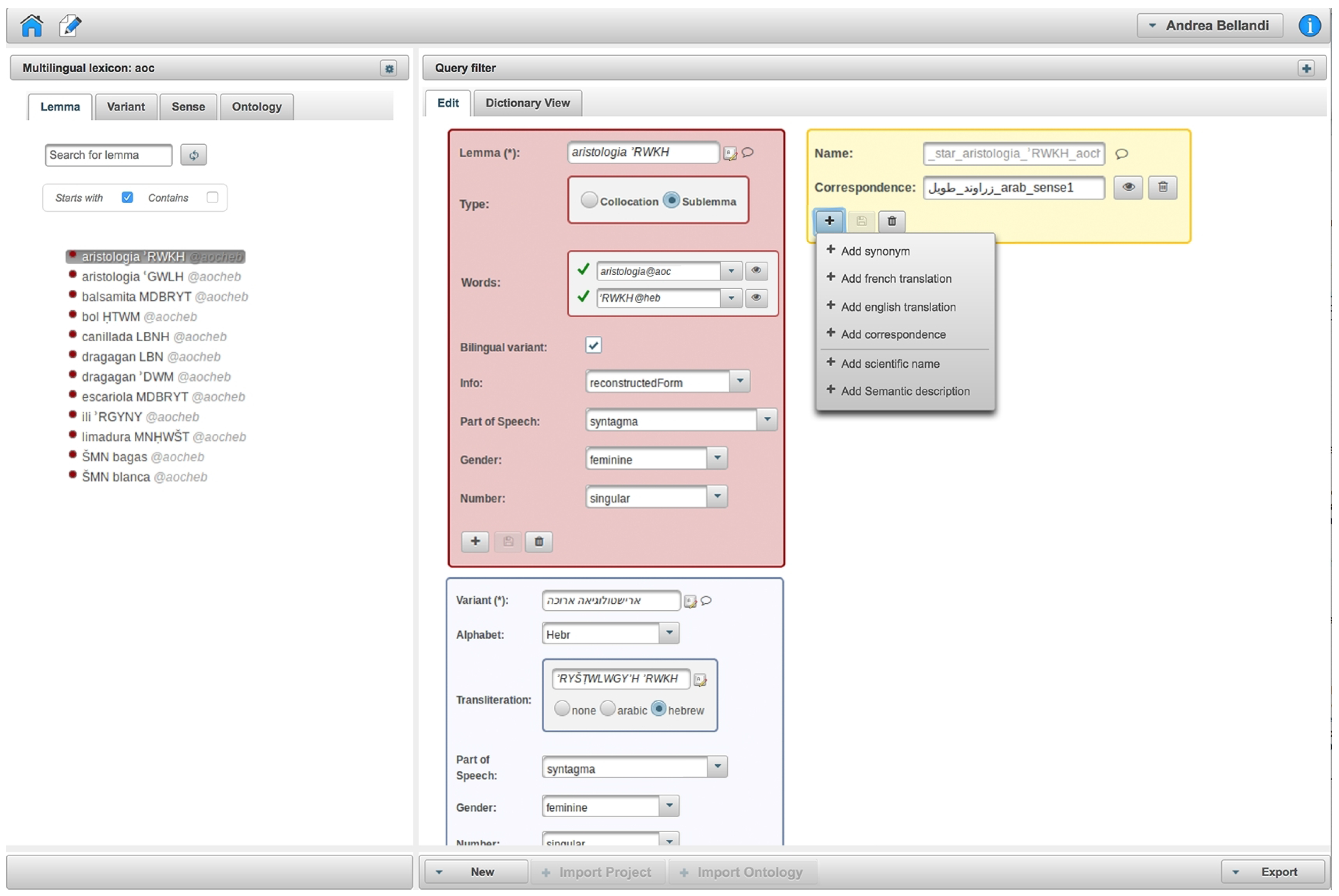
6. Discussion about the Model
- NH.1: sense-form association is not possible. Due to the multilingual corpus, in particular the synonym lists, there are some cases in which a (alphabetical) variant is associated with an additional meaning. For example
![Information 09 00052 i020]() /GWT’ (read: “gota”) is an alphabetical variant of the Old Occitan term , meaning ‘gout’. The variant features the Hebrew and Arabic terms
/GWT’ (read: “gota”) is an alphabetical variant of the Old Occitan term , meaning ‘gout’. The variant features the Hebrew and Arabic terms ![Information 09 00052 i021]() /KYPWN and
/KYPWN and ![Information 09 00052 i022]() /SR‘’, respectively meaning also ‘epilepsy’. In order to represent exactly the given state of documentation, we should be able to relate the variant to an additional meaning not given for other variants and the lemma.
/SR‘’, respectively meaning also ‘epilepsy’. In order to represent exactly the given state of documentation, we should be able to relate the variant to an additional meaning not given for other variants and the lemma. - NH.2: sublemma and collocation phrases are not representable. As shown in Section 3, a comprehensive construction of the DiTMAO lexicon needed the inclusion of two novel subtypes of the phrase, namely the sublemma and the collocation; in addition to the description of the parts that compose them (which can be done using lemon’s decomposition system), there is the need to specify the formal and semantic relations holding between them and the respective lemmata.
- WH.1: phrases’ decomposition should involve senses and forms instead of whole lexical entries. The expression cap de monge, mentioned in Section 3, designates a plant, and its meaning is non-compositional. However, the simple term with the meaning ‘head (of a human or animal)’ is documented. Thus, the decomposition would relate from a non-compositional plant name to the lexical entry with the meaning ‘head’, although the relation between the two occurrences of is a purely formal one. In this case, the decomposition should not relate to the whole lexical entry, but just to one of its senses.
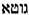
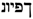
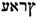
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bos, G.; Corradini, M.S.; Mensching, G. Le DiTMAO (Dictionnaire des Termes Médico-botaniques de l’Ancien Occitan): caractéristiques et organisation des données lexicales. In Proceedings of the XIen Congrès de l’Asociacion Internacionala d’Estudis Occitans (AIEO 2014), Universitat de Lleida, Lleida, Spain, 16–21 June 2014. [Google Scholar]
- Bos, G.; Hussein, M.; Mensching, G.; Savelsberg, F. Medical Synonym Lists from Medieval Provence: Shem Tov ben Isaak of Tortosa: Sefer ha-Shimmush. In Book 29. Part 1: Edition and Commentary of List 1 (Hebrew-Arabic-Romance/Latin); Brill: Leiden, The Netherlands, 2011. [Google Scholar]
- Corradini, M.S.; Mensching, G. Les méthodologies et les outils pour la rédaction d’un lexique de la terminologie médico-botanique de l’occitan du Moyen Âge. In Actes du XXVe Congrès International de Linguistique et de Philologie Romanes; Iliescu, M., Siller-Runggaldier, H., Danler, P., Eds.; Max Niemeyer: Tübingen, Germany, 2010; Volume 6, pp. 87–96. (In French) [Google Scholar]
- Corradini, M.S.; Mensching, G. Nuovi aspetti relativi al Dictionnaire de Termes Médico-botaniques de l’Ancien Occitan (DiTMAO): Creazione di una base di dati integrata con organizzazione onomasiologica. In Actas del XXVI Con-greso Internacional de Lingüística y de Filología Románicas; Casanova Herrero, E., Calvo Rigual, C., Eds.; Max Niemeyer: Tübingen, Germany, 2013; Volume VIII, pp. 113–124. (In Italian) [Google Scholar]
- Mensching, G.; Zwink, J. L’ancien occitan en tant que langage scientifique de la médecine. Termes vernaculaires dans la traduction hébraique du Zad al-musafir waqut alhadir (XIIIe). In Los Que Fan Viure Etresluire L’occitan (AIEO 2011); Alén Garabato, C., Torreilles, C., Verny, M.J., Eds.; Lambert-Lucas: Limoges, France, 2014; pp. 226–236. (In French) [Google Scholar]
- Bos, G.; Mensching, G. Arabic-Romance Medico-Botanical Glossaries in Hebrew Manuscripts from the Iberian Peninsula and Italy. In Aleph; Indiana University Press: Bloomington, IN, USA, 2015; Volume 15.1, pp. 9–61. [Google Scholar]
- Mensching, G. Per la terminologia medico-botanica occitana nei testi ebraici: Le liste di sinonimi di Shem Tov Ben Isaac di Tortosa. In Atti Del Convegno Internazionale: Giornate Di Studio Di Lessicografia Romanza; Corradini, M.S., Periñán, B., Eds.; ETS: Pisa, Italy, 2006; pp. 93–109. (In Italian) [Google Scholar]
- Mensching, G. Listes de synonymes hébraïques-occitanes du domaine médico-botanique au Moyen Âge. In La Voix Occitane. Actes Du VIIIe CongrèS Internationale D’ÉTudes Occitanes; Latry, G., Ed.; Presses Universitaires De Bordeaux: Bordeaux, France, 2009; Volume I, pp. 509–526. (In French) [Google Scholar]
- Mensching, G.; Savelsberg, F. Reconstrucció de la terminologia mèdica occitanocatalana dels segles XIII i XIV a través de llistats de sinònims en lletres hebrees. In Actes Del CongréS Per a L’estudi Dels Jueus en Territori De Llengua Catalana; Universidad de Barcelona: Barcelona, Spain, 2004; pp. 69–81. (In Catalan) [Google Scholar]
- Del Gratta, R.; Frontini, F.; Khan, F.; Monachini, M. Converting the parole simple clips lexicon into RDF with lemon. Semant. Web 2015, 6, 387–392. [Google Scholar] [CrossRef]
- Hayashi, Y. Direct and Indirect Linking of Lexical Objects for Evolving Lexical Linked Data. In Proceedings of the 2nd International Workshop on the Multilingual Semantic Web (MSW Volume 775), Bonn, Germany, 23 October 2011; pp. 62–67. [Google Scholar]
- Lezcano, L.; Sánchez-Alonso, S.; Roa-Valverde, A.J. A survey on the exchange of linguistic resources: Publishing linguistic linked open data on the web. In Program; Emerald Group Publishing Limited: Bingley, UK, 2013; Volume 47, pp. 263–281. [Google Scholar]
- McCrae, J.P.; Fellbaum, C.; Cimiano, P. Publishing and linking WordNet using RDF and lemon. In Proceedings of the Third Workshop on Linked Data in Linguistics, Reykjavik, Iceland, 27 May 2014. [Google Scholar]
- McCrae, J.; Spohr, D.; Cimiano, P. Linking Lexical Resources and Ontologies on the Semantic Web with Lemon. In Proceedings of the 8th Extended Semantic Web Conference (ESWC-11), Heraklion, Greece, 29 May–2 June 2011; Antoniou, G., Grobelnik, M., Simperl, E., Parsia, B., Plexousakis, D., De Leenheer, P., Pan, J., Eds.; Springer: Heidelberg, Germany, 2011; pp. 245–259. [Google Scholar]
- Declerck, T.; Buitelaar, P.; Wunner, T.; McCrae, J.P.; Montiel-Ponsoda, E.; Aguado de Cea, G. Lemon: An Ontology Lexicon model for the Multilingual Semantic Web. In Proceedings of the W3C Workshop: The Multilingual Web—Where Are We? Madrid, Spain, 26–27 October 2010. [Google Scholar]
- Khan, F.; Bellandi, A.; Boschetti, F.; Monachini, M. The Challenges of Converting Legacy Lexical Resources to Linked Open Data using OntoLex-Lemon: The Case of the Intermediate Liddell-Scott Lexicon. In Proceedings of the LDK workshops: OntoLex, TIAD and Challenges for Wordnets, Galway, Ireland, 18 June 2017; pp. 1–8. [Google Scholar]
- Gilles, S. DBnary: Wiktionary as a Lemon-based multilingual lexical resource in RDF. Semant. Web 2015, 6, 355–361. [Google Scholar]
- Eckle-Kohler, J.; McCrae, J.; Chiarcos, C. LemonUby-A large, interlinked, syntactically-rich lexical resource for ontologies. Semant. Web 2015, 6, 371–378. [Google Scholar] [CrossRef]
- Sánchez Rada, J.F.; Vulcu, G.; Iglesias Fernandez, C.A.; Buitelaar, P. EUROSENTIMENT: Linked data sentiment analysis. In Proceedings of the ISWC 2014 Posters & Demonstrations Track a track within the 13th International Semantic Web Conference (ISWC 2014), Riva del Garda, Italy, 19–23 October 2014; pp. 145–148. [Google Scholar]
- Rouces, J.; de Melo, G.; Katja, H. FrameBase: Enabling integration of heterogeneous knowledge. Semant. Web 2017, 8, 817–850. [Google Scholar] [CrossRef]
- Khan, F.; Federico, B.; Francesca, F. Using lemon to model lexical semantic shift in diachronic lexical resources. In Proceedings of the 3rd Workshop on Linked Data in Linguistics: Multilingual Knowledge Resources and Natural Language, Reykjavik, Iceland, 27 May 2014. [Google Scholar]
- Corcoglioniti, F.; Rospocher, M.; Aprosio, A.P.; Tonelli, S. PreMOn: A Lemon Extension for Exposing Predicate Models as Linked Data. In Proceedings of the LREC-16th International Conference on Language Resources and Evaluation, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Fiorelli, M.; Stellato, A.; Mccrae, J.P.; Cimiano, P.; Pazienza, M.T. LIME: The metadata module for OntoLex. In Proceedings of the European Semantic Web Conference, Portorož, Slovenia, 28 May–1 June 2017; Springer: Cham, Switzerlands, 2017; pp. 321–336. [Google Scholar]
- Bellandi, A.; Giovannetti, E.; Piccini, S.; Weingart, A. Developing LexO: A Collaborative Editor of Multilingual Lexica and Termino-ontological Resources in the Humanities. In Proceedings of the Language, Ontology, Terminology and Knowledge Structures Workshop (LOTKS 2017), Montpellier, France, 19–22 September 2017. [Google Scholar]
- Weingart, A.; Giovannetti, E. Extending the lemon Model for a Dictionary of Old Occitan Medico-Botanical Terminology. In The Semantic Web. ESWC 2016. Lecture Notes in Computer Science; Sack, H., Rizzo, G., Steinmetz, N., Mladenić, D., Auer, S., Lange, C., Eds.; Springer: Cham, Switzerlands, 2016; Volume 9989, pp. 408–421. [Google Scholar]
- McCrae, J.P.; Unger, C. Design patterns for engineering the ontology-lexicon interface. In Towards the Multilingual Semantic Web; Paul, B., Philipp, C., Eds.; Springer: Berlin, Germany, 2014; pp. 15–30. [Google Scholar]
- Gangemi, A. Ontology design patterns for semantic web content. In Proceedings of the International Semantic Web Conference, Galway, Ireland, 6–10 November 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 262–276. [Google Scholar]
- McCrae, J.; Montiel-Ponsoda, E.; Cimiano, P. Collaborative semantic editing of linked data lexica. In Proceedings of the 2012 International Conference on Language Resource and Evaluation (2012), Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- Fiorelli, M.; Lorenzetti, T.; Pazienza, M.T.; Stellato, A. Assessing VocBench Custom Forms in Supporting Editing of Lemon Datasets. In Proceedings of the International Conference on Language, Data and Knowledge, Galway, Ireland, 19–20 June 2017; pp. 237–252. [Google Scholar]
- Bosque-Gil, J.; Jorge, G.; Elena, M.-P. Towards a Module for Lexicography in OntoLex. In Proceedings of the 1st Workshop on the OntoLex Model (OntoLex-2017), Galway, Ireland, 18 June 2017. [Google Scholar]
- Bowers, J.; Laurent, R. Deep Encoding of Etymological Information in TEI. Available online: http://jtei.revues.org/1643 (accessed on 24 February 2018).
- Khan, F.; Jack, B.; Francesca, F. Situating Word Senses in their Historical Context with Linked Data. In Proceedings of the IWCS 2017—12th International Conference on Computational Semantics—Short papers, Kissimmee, FL, USA, 8–11 October 2017. [Google Scholar]
- Piccini, S.; Bellandi, A.; Benotto, G. Formalizing and Querying a Diachronic Termino-Ontological Resource: The CLAVIUS Case Study. In Proceedings of the From Digitization to Knowledge 2016 Workshop (D2K), Krakow, Poland, 11 July 2016. [Google Scholar]
- Carlyle, A. Understanding FRBR as a conceptual model: FRBR and the bibliographic universe. Bull. Am. Soc. Inf. Sci. Technol. 2007, 33, 12–16. [Google Scholar] [CrossRef]
- Kroeger, A. The road to BIBFRAME: The evolution of the idea of bibliographic transition into a post-MARC Future. Cat. Classif. Q. 2013, 41, 873–890. [Google Scholar] [CrossRef]
- Bellandi, A.; Boschetti, F.; Khan, F.; Del Grosso, A.M.; Monachini, M. Provando e riprovando modelli di dizionario storico digitale: Collegare voci, citazioni, interpretazioni. In Proceedings of the AIUCD 2017 Book of Abstracts, Rome, Italy, 24–28 January 2017. (In Italian). [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language | Lexical Entries | Sense Relations | ||||
|---|---|---|---|---|---|---|
| Word | Phrase | Synonym | Translation | Correspondence | ||
| Collocation | Sublemma | |||||
| Old Occitan (main language) | 1451 | 113 | 227 | 1424 | 2587 | 1225 |
| French | 717 | 294 | - | - | 1483 | - |
| English | 520 | 214 | - | - | 1104 | - |
| Hebrew | 225 | 109 | - | - | - | 379 |
| Arabic | 475 | 157 | - | - | - | 702 |
| Aramaic | 27 | 5 | - | - | - | 60 |
| Latin | 80 | 21 | 6 | 15 | - | 84 |
| total | 4641 ( + 3030 other forms) | 5251 (inverse properties are not counted) | ||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bellandi, A.; Giovannetti, E.; Weingart, A. Multilingual and Multiword Phenomena in a lemon Old Occitan Medico-Botanical Lexicon. Information 2018, 9, 52. https://doi.org/10.3390/info9030052
Bellandi A, Giovannetti E, Weingart A. Multilingual and Multiword Phenomena in a lemon Old Occitan Medico-Botanical Lexicon. Information. 2018; 9(3):52. https://doi.org/10.3390/info9030052
Chicago/Turabian StyleBellandi, Andrea, Emiliano Giovannetti, and Anja Weingart. 2018. "Multilingual and Multiword Phenomena in a lemon Old Occitan Medico-Botanical Lexicon" Information 9, no. 3: 52. https://doi.org/10.3390/info9030052
APA StyleBellandi, A., Giovannetti, E., & Weingart, A. (2018). Multilingual and Multiword Phenomena in a lemon Old Occitan Medico-Botanical Lexicon. Information, 9(3), 52. https://doi.org/10.3390/info9030052