Querying Workflow Logs


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
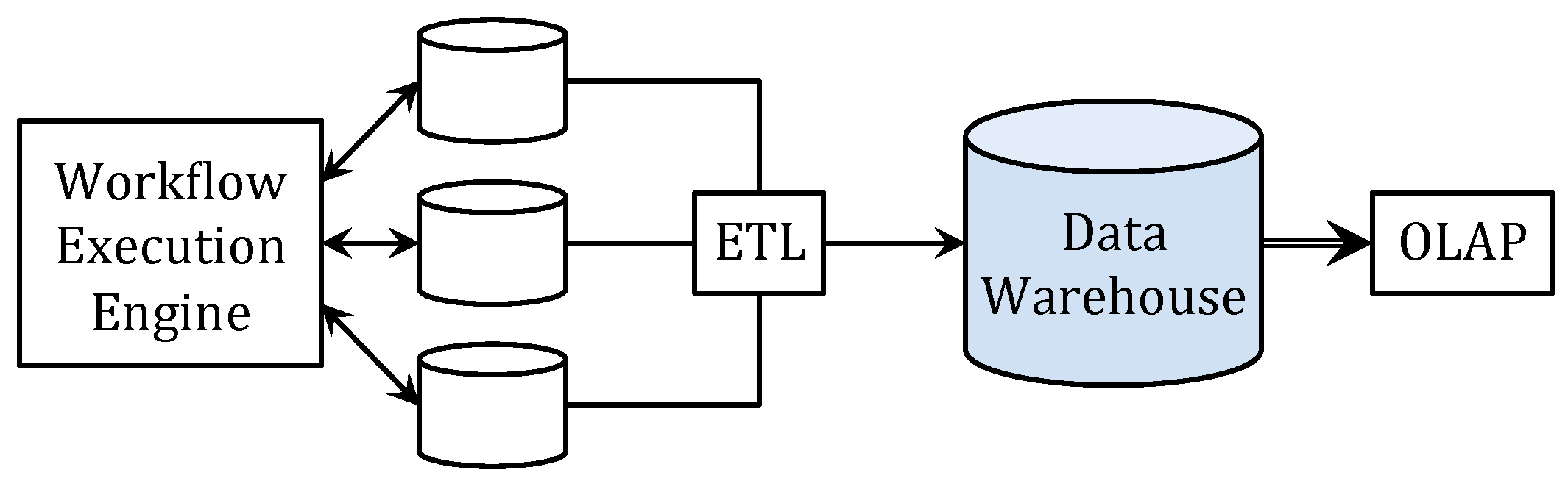
1. Introduction
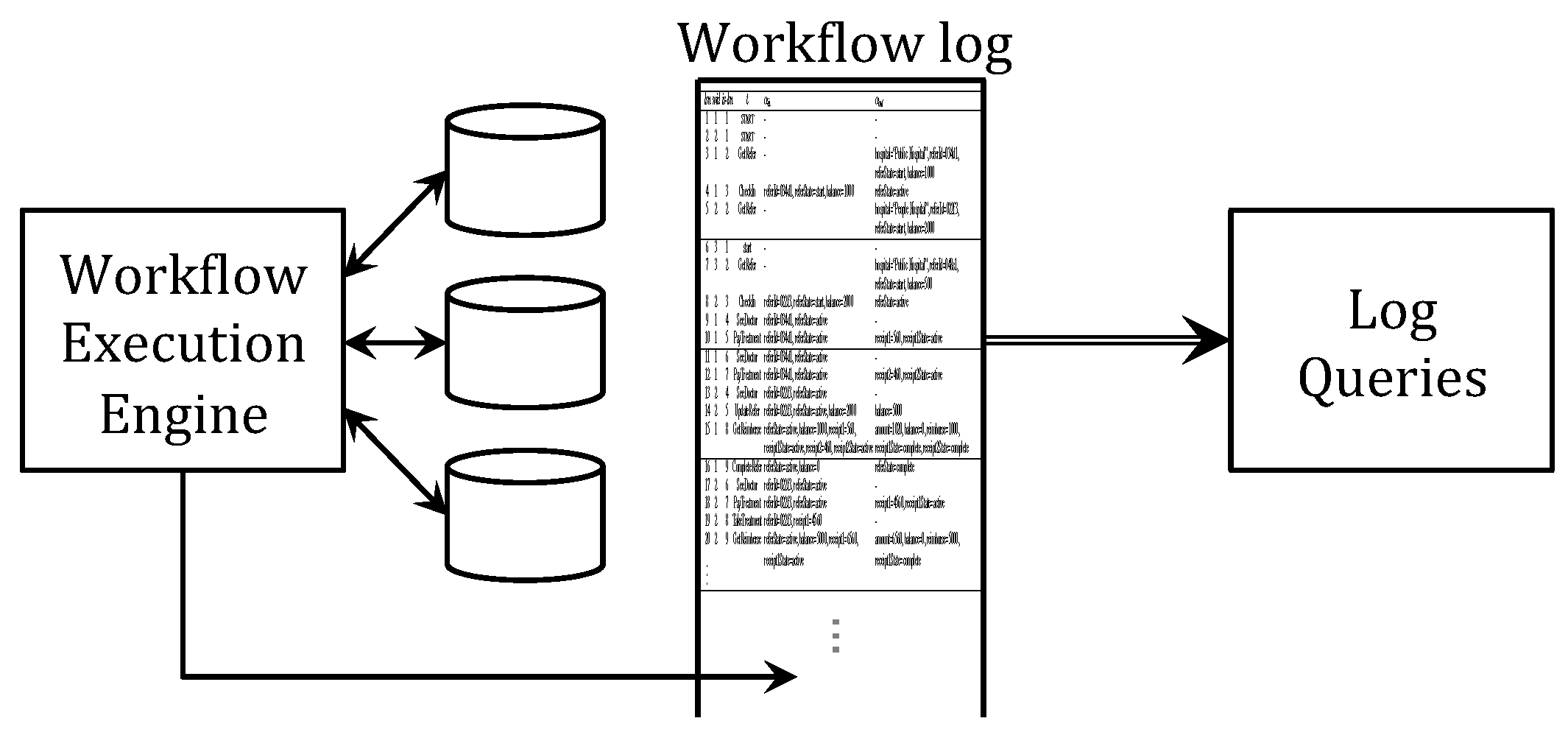
2. Logs and Incidents
- of attribute names,
- of activity names,
- of values, and
- of (positive) natural numbers.
- is a log sequence number,
- is a workflow instance id identifying the workflow instance to which this log record belongs,
- is an instance-specific log sequence number (unique within each instance),
- is an activity name,
- is an input map over the attributes read by activity t, and
- is an output map over the attributes written by activity t.
- 1.
- There is a bijection between the first natural numbers and the set of all log sequences numbers present in the log records in L, and
- 2.
- iff = start (each workflow instance begins with a start record),
- 3.
- If , then there is a log record such that , , and (for each workflow instance, is consecutive), and
- 4.
- If end, for all log records , implies (end is the last record for each workflow instance).
- activity patterns (atomic): t, , where is an activity name,
- consecutive pattern: ( and are consecutively executed),
- sequential pattern: ( is executed before ),
- choice pattern: (one of and is executed), and
- parallel pattern: ( and are executed in parallel and share no log records).
- Atomic: if where is an activity name, then o is an incident of p whenever is a singleton set of a log record such that ;if where is an activity name, then o is an incident of p whenever is a singleton set of a log record such that .In both cases, we define , , and finally ,
- Consecutive: if , then o is an incident of p whenever is an incident of (), , , and .Also, we define , , and .
- Sequential: if , o is an incident of p whenever is an incident of (), , , and .We define , , and .
- Choice: if , o is an incident of p whenever o is an incident of or .
- Parallel: if , o is an incident of p whenever is an incident of (), , , and .We define , , and .
3. Query Evaluation
3.1. Evaluation of Pattern Composition Operators
| Algorithm 1 Composite pattern operator evaluation algorithms | |
| Input: Incident sets inc1, inc2 | |
| Output: Incident set incL | |
| 1: | function Consecutive-Eval(inc1, inc2) |
| 2: | |
| 3: | for inc1, inc2 do |
| 4: | if then |
| 5: | .append(); |
| 6: | return |
| 7: | function Sequential-Eval(inc1, inc2) |
| 8: | |
| 9: | for inc1, inc2 do |
| 10: | if then |
| 11: | .append(); |
| 12: | return |
| 13: | function Choice-Eval(inc1, inc2) |
| 14: | |
| 15: | for inc1, inc2 do |
| 16: | if then |
| 17: | for ; i++; do |
| 18: | if o1[i] ≠ o2[i] then |
| 19: | break; |
| 20: | if then |
| 21: | .append(); |
| 22: | .append(); |
| 23: | return |
| 24: | function Parallel-Eval(inc1, inc2) |
| 25: | |
| 26: | for inc1, inc2 do |
| 27: | overlap ← False |
| 28: | for , do |
| 29: | if then |
| 30: | overlap = True |
| 31: | break; |
| 32: | if overlap = False then |
| 33: | .append(); |
| 34: | return |
- In the evaluation of a consecutive pattern , two pointers iterate over and , respectively. For each pair and , if , add to . If , the evaluation has time complexity and produces at most results.
- In the evaluation of a sequential pattern , two pointers iterate over and , respectively. For each pair and , if , add to . If , the evaluation has time complexity , and produces at most results.
- The evaluation of a choice pattern produces the set union of the input sets and . This requires the identification of duplicated incidents (i.e., sets of log records that are incidents of both and , and exclude the duplicates in the output set). If and are the number of activity names in and , respectively, checking that an incident of and an incident of are not identical is linear in . The time complexity of evaluating choice pattern p is thus . There are incidents in , with the maximum size occurring when the log contains one workflow instance and and share no incidents.
- The incident set of a parallel pattern contains the union of all pairs of incidents and such that and share no log records. Each incident is a sequence of log records ordered by their log sequence numbers. Assuming incidents are sorted, checking that two incidents are disjoint is linear in the number of activity names of the two incident. Letting be the number of activity names in pattern resp., the time complexity of evaluating a parallel pattern is . There are incidents in , with the maximal case occurring when the log contains one workflow instance and all pairs of incidents , are disjoint.
- can be computed in time and has size at most .
- can be computed in time and has size at most .
- can be computed in time , where is the number of activity names in , and has size at most .
- can be computed in time , and has size at most .
3.2. Evaluation of Incident Pattern Queries
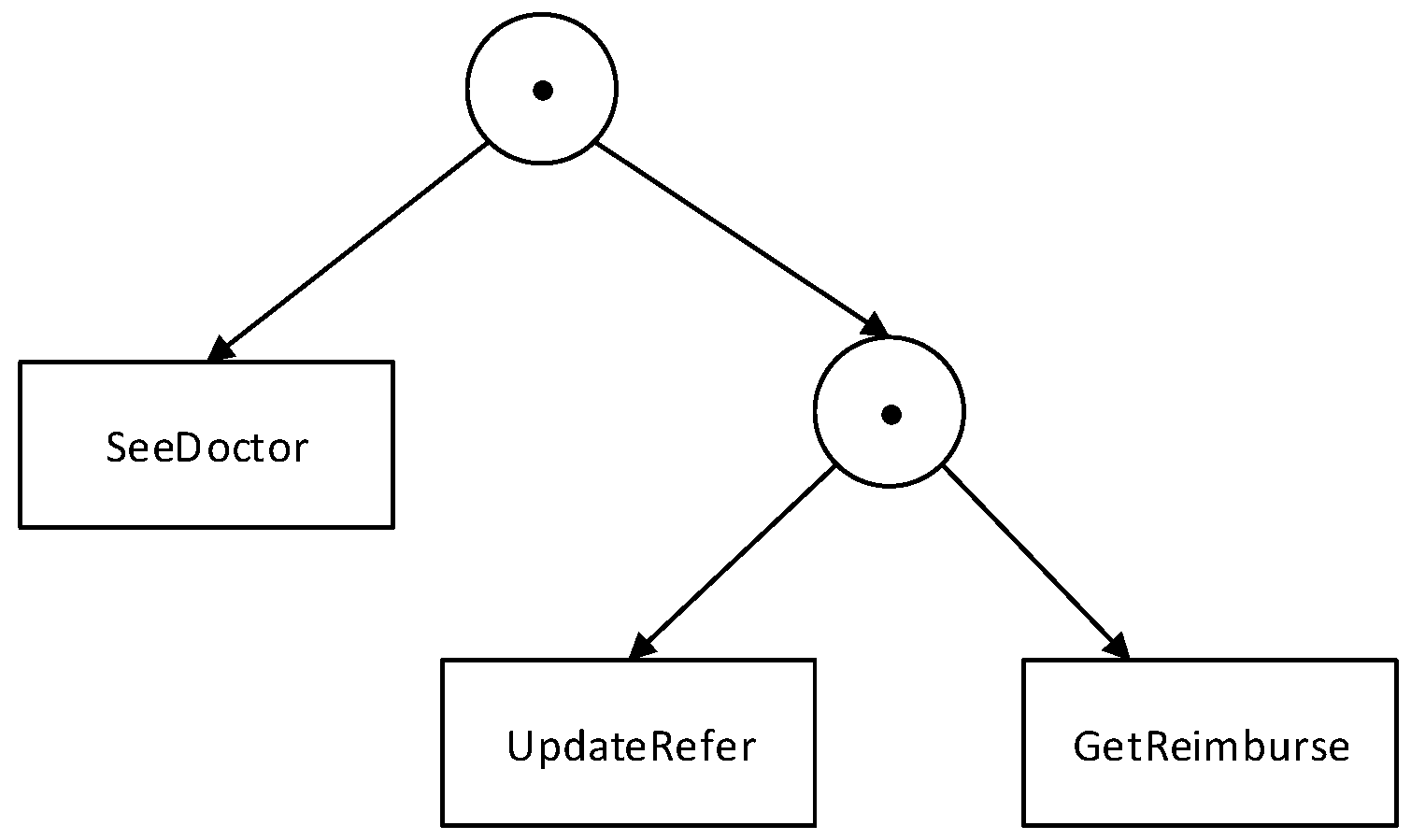
- An operator node has both left and right child nodes, and is labeled with a pattern operator, and
- An activity node is a leaf node, labeled with an activity name for positive atomic patterns, adding “¬” before the activity name in the case of negative activity patterns.
| Algorithm 2 Incident tree evaluation algorithm | |
| Input: Incident TreeNode , dictionary | |
| Output: Incident Set | |
| 1: | function Eval–Incident–Tree |
| 2: | ; |
| 3: | if root.type == ATOMIC then |
| 4: | for widSet do |
| 5: | if root.negated = False then |
| 6: | .append(LogRecordsDict[i](lr.activity_name = root.activity_name)); |
| 7: | else |
| 8: | .append(LogRecordsDict[i](lr.activity_name != root.activity_name)); |
| 9: | else |
| 10: | EvalIncidentTree(root.left, LogRecordsDict); |
| 11: | EvalIncidentTree(root.right, LogRecordsDict); |
| 12: | |
| 13: | for widSet do |
| 14: | OperatorEval(root.type, , ); |
| 15: | return incL |
| Algorithm 3 Incident tree generation algorithm | |
| Input: Incident pattern p (in postfix notation) | |
| Output: Incident Tree T, dictionary LogRecordsDict | |
| 1: | function BuildIncidentTree |
| 2: | TreeNode root ← new TreeNode(); |
| 3: | root.type ← p.type; ▹ operator_type {ATOMIC, CONS, SEQU, CHOICE, PARA} |
| 4: | if root.type==ATOMIC then |
| 5: | root.activity_name |
| 6: | root.negative = p.negative; ▹ p.negative is true iff p is a negative activity pattern |
| 7: | else |
| 8: | root.left ← EvalPattern(p.left_pattern); |
| 9: | root.right ← EvalPattern(p.right_pattern); |
| 10: | dictionary LogRecordsDict ; ▹ a dictionary mapping wid to log records of that wid |
| 11: | widSet |
| 12: | for do |
| 13: | LogRecordsDict[lr.wid].append(lr); |
| 14: | widSet + = lr.wid |
| 15: | return root, LogRecordsDict; |
4. Properties of Incident Operators
- (Consecutive operator.) Suppose . According to Definition 4, , where are incidents of , , resp., , and . The same definition further implies that there are two incidents such that is an incident of . Thus, the three incidents have the following properties: , , , and is an incident of for .From these incidents, we construct an incident of as follows. Let . From the properties listed above, is an incident of . This, together with and , establishes that . Observing that , it follows .It must also hold that incidents of the right hand side, elements of , are incidents of the left hand side, elements of . This case is symmetric.
- (Sequential operator.) The proof is nearly identical to the proof for the consecutive operator, and can be formed by making the following replacements:
- becomes ,
- becomes ,
- become , and
- becomes .
- (Choice operator.) Let o be an incident of . Using the definition of the choice operator, this occurs if and only if o is an incident of or o is an incident of . Applying the same deconstruction to , o is an incident of if o is an incident or an incident of . This results in three cases for o: (1) , (2) , or (3) . The statement can be deconstructed into the same three cases using nearly identical reasoning. Therefore, .
- (Parallel operator.) If o is an incident of , there exists incidents and , such that and . The incident is an instance of pattern , which indicates there exists such that and . Since and , . By the disjointedness of and , we have . Because and , it follows that . Thus, membership in implies membership in . The proof for is symmetric.
- 1.
- , and
- 2.
- .
- 1.
- (left-distributive), and
- 2.
- (right-distributive).
- (Consecutive operator.) Let . This is equivalent to such that , , , and . The choice operator yields two possible cases: (1) , or (2) . Because , in Case (1), o has necessary and sufficient properties such that . Similarly in Case (2), . Combining both cases of membership with the choice operator yields , because or .
- (Sequential operator.) A proof for the sequential operator is obtained by replacing the statement “” in the proof for the consecutive operator with “”.
- (Parallel operator.) Let . This is equivalent to such that , , , and . Rewriting by deconstructing the choice operator ⊗ yields or . Now observe that o has necessary and sufficient properties such that or , thus .
5. Related Work
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Group, G. Gartner Newsroom. 2011. Available online: http://www.gartner.com/it/page.jsp?id=1740414 (accessed on 18 January 2018).
- Su, J.; Yang, J. Yank Your Data Out of My Engine: A New Approach to Workflow System Design. In Proceedings of the 8th International Workshop on Evolutionary Business Processes (EVL-BP), Adelaide, Australia, 21–25 September 2015. [Google Scholar]
- Sun, Y.; Su, J.; Yang, J. Universal Artifacts: A New Approach to Business Process Management (BPM) Systems. ACM Trans. Manag. Inf. Syst. 2016, 7, 3. [Google Scholar] [CrossRef]
- Dayal, U.; Castellanos, M.; Simitsis, A.; Wilkinson, K. Data integration flows for business intelligence. In Proceedings of the 12th the International Conference on Extending Database Technology (EDBT), Saint Petersburg, Russia, 24–26 March 2009; pp. 1–11. [Google Scholar]
- Wrembel, R.; Koncilia, C. Data Warehouse and OLAP: Concepts, Architectures and Solutions; IRM Press: Hershey, PA, USA, 2007. [Google Scholar]
- Chaudhuri, S.; Dayal, U.; Narasayya, V. An overview of business intelligence technology. Commun. ACM 2011, 54, 88–98. [Google Scholar] [CrossRef]
- Damaggio, E.; Hull, R.; Vaculin, R. On the Equivalence of incremental and fixpoint semantics for business artifacts with Guard-Stage-Milestone lifecycles. Inf. Syst. 2013, 38, 561–584. [Google Scholar] [CrossRef]
- Van der Aalst, W.; ter Hofstede, A. YAWL: Yet another workflow language. Inf. Syst. 2005, 30, 245–275. [Google Scholar] [CrossRef]
- Hanson, J. Manage Your Business Processes with JBoss jBPM. 2006. Available online: http://www.javaworld.com/javaworld/jw-05-2006/jw-0522-jbpm.html (accessed on 18 January 2018). (See also http://www.jboss.org/jbpm/).
- “Shunting-Yard Algorithm”. Wikipedia, The Free Encyclopedia. Available online: https://en.wikipedia.org/wiki/Blueberry (accessed on 18 January 2018).
- Allen, W.M. Data Structures and Algorithm Analysis in C++; Pearson Education: Delhi, India, 2007. [Google Scholar]
- Chaudhuri, S.; Dayal, U. An Overview of Data Warehousing and OLAP Technology. SIGMOD Rec. 1997, 26, 65–74. [Google Scholar] [CrossRef]
- Berson, A.; Smith, S.J. Data Warehousing, Data Mining, and OLAP; McGraw-Hill, Inc.: New York, NY, USA, 1997. [Google Scholar]
- Watson, H.J.; Wixom, B.H. The current state of business intelligence. Computer 2007, 40, 96–99. [Google Scholar] [CrossRef]
- Karakasidis, A.; Vassiliadis, P.; Pitoura, E. ETL queues for active data warehousing. In Proceedings of the 2nd International Workshop on Information Quality in Information Systems, Baltimore, MD, USA, 17 June 2005; ACM: New York, NY, USA, 2005; pp. 28–39. [Google Scholar]
- Luo, G.; Naughton, J.F.; Ellmann, C.J.; Watzke, M.W. Transaction reordering and grouping for continuous data loading. In International Workshop on Business Intelligence for the Real-Time Enterprise; Springer: Berlin/Heidelberg, Germany, 2006; pp. 34–49. [Google Scholar]
- Thiele, M.; Lehner, W. Real-time BI and situational analysis. In Business Intelligence Applications and the Web: Models, Systems and Technologies; IGI Global: Hershey, PA, USA, 2012; pp. 285–309. [Google Scholar]
- Thomsen, E. OLAP Solutions: Building Multidimensional Information Systems; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Bucher, T.; Gericke, A.; Sigg, S. Process-centric business intelligence. Bus. Process Manag. J. 2009, 15, 408–429. [Google Scholar] [CrossRef]
- Grigori, D.; Casati, F.; Castellanos, M.; Dayal, U.; Sayal, M.; Shan, M.C. Business process intelligence. Comput. Ind. 2004, 53, 321–343. [Google Scholar] [CrossRef]
- Castellanos, M.; Alves de Medeiros, K.; Mendling, J.; Weber, B.; Weitjers, A. Business process intelligence. Handb. Res. Bus. Process Mod. 2009, 456–480. [Google Scholar] [CrossRef]
- Awad, A. BPMN-Q: A Language to Query Business Processes. Enterprise Modelling and Information Systems Architectures—Concepts and Applications. In Proceedings of the 2nd International Workshop on Enterprise Modelling and Information Systems Architectures (EMISA’07), St. Goar, Germany, 8–9 October 2007; pp. 115–128. [Google Scholar]
- Awad, A.; Polyvyanyy, A.; Weske, M. Semantic Querying of Business Process Models. In Proceedings of the 12th International IEEE Enterprise Distributed Object Computing Conference, Munich, Germany, 15–19 September 2008; pp. 85–94. [Google Scholar]
- Awad, A.; Weidlich, M.; Weske, M. Specification, Verification and Explanation of Violation for Data Aware Compliance Rules. In Proceedings of the 7th International Joint Conference on Service-Oriented Computing (ICSOC-ServiceWave), Stockholm, Sweden, 24–27 November 2009; pp. 500–515. [Google Scholar]
- Sakr, S.; Awad, A. A framework for querying graph-based business process models. In Proceedings of the 19th International Conference on World Wide Web (WWW), Raleigh, NC, USA, 26–30 April 2010; pp. 1297–1300. [Google Scholar]
- Jin, T.; Wang, J.; Wen, L. Querying Business Process Models Based on Semantics. In Proceedings of the 16th International Conference on Database Systems for Advanced Applications (DASFAA), Hong Kong, China, 22–25 April 2011; pp. 164–178. [Google Scholar]
- Ter Hofstede, A.H.M.; Ouyang, C.; Rosa, M.L.; Song, L.; Wang, J.; Polyvyanyy, A. APQL: A Process-Model Query Language. In Proceedings of the First Asia Pacific Conference on Asia Pacific Business Process Management (AP-BPM), Beijing, China, 29–30 August 2013; pp. 23–38. [Google Scholar]
- Eshuis, R.; Grefen, P.W.P.J. Structural Matching of BPEL Processes. In Proceedings of the Fifth IEEE European Conference on Web Services (ECOWS), Halle, Germany, 26–28 November 2007; pp. 171–180. [Google Scholar]
- Beeri, C.; Eyal, A.; Kamenkovich, S.; Milo, T. Querying Business Processes. In Proceedings of the 32nd International Conference on Very Large Data Bases (VLDB), Seoul, Korea, 12–15 September 2006; pp. 343–354. [Google Scholar]
- Beeri, C.; Eyal, A.; Milo, T.; Pilberg, A. Monitoring Business Processes with Queries. In Proceedings of the 33rd International Conference on Very Large Data Bases (VLDB), Vienna, Austria, 23–27 September 2007; pp. 603–614. [Google Scholar]
- Beeri, C.; Eyal, A.; Kamenkovich, S.; Milo, T. Querying business processes with BP-QL. Inf. Syst. 2008, 33, 477–507. [Google Scholar] [CrossRef]
- Beeri, C.; Eyal, A.; Milo, T.; Pilberg, A. BP-Mon: Query-based monitoring of BPEL business processes. SIGMOD Rec. 2008, 37, 21–24. [Google Scholar] [CrossRef]
- Beheshti, S.; Benatallah, B.; Nezhad, H.R.M.; Sakr, S. A Query Language for Analyzing Business Processes Execution. In Proceedings of the 9th International Conference on Business Process Management (BPM), Clermont-Ferrand, France, 30 August–2 September 2011; pp. 281–297. [Google Scholar]
- Beheshti, S.; Sakr, S.; Benatallah, B.; Nezhad, H.R.M. Extending SPARQL to Support Entity Grouping and Path Queries. arXiv, 2012; arXiv:abs/1211.5817. [Google Scholar]
- SPARQL Query Language for RDF. 2008. Available online: https://www.w3.org/TR/rdf-sparql-query/ (accessed on 18 January 2018).
- Mei, Y.; Madden, S. Zstream: A cost-based query processor for adaptively detecting composite events. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; ACM: New York, NY, USA, 2009; pp. 193–206. [Google Scholar]
- Abadi, D.J.; Carney, D.; Çetintemel, U.; Cherniack, M.; Convey, C.; Lee, S.; Stonebraker, M.; Tatbul, N.; Zdonik, S. Aurora: A new model and architecture for data stream management. VLDB J. 2003, 12, 120–139. [Google Scholar] [CrossRef]
- Carney, D.; Çetintemel, U.; Cherniack, M.; Convey, C.; Lee, S.; Seidman, G.; Stonebraker, M.; Tatbul, N.; Zdonik, S. Monitoring streams: A new class of data management applications. In Proceedings of the 28th International Conference on Very Large Data Bases, Hong Kong, China, 20–23 August 2002; pp. 215–226. [Google Scholar]
- Abadi, D.J.; Ahmad, Y.; Balazinska, M.; Cetintemel, U.; Cherniack, M.; Hwang, J.H.; Lindner, W.; Maskey, A.; Rasin, A.; Ryvkina, E.; et al. The Design of the Borealis Stream Processing Engine. In Proceedings of the 2005 CIDR Conference, Asilomar, CA, USA, 4–7 January 2005; Volume 5, pp. 277–289. [Google Scholar]
- Chandrasekaran, S.; Cooper, O.; Deshpande, A.; Franklin, M.J.; Hellerstein, J.M.; Hong, W.; Krishnamurthy, S.; Madden, S.R.; Reiss, F.; Shah, M.A. TelegraphCQ: Continuous dataflow processing. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, CA, USA, 9–12 June 2003; p. 668. [Google Scholar]
- Dindar, N.; Güç, B.; Lau, P.; Ozal, A.; Soner, M.; Tatbul, N. Dejavu: Declarative pattern matching over live and archived streams of events. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; ACM: New York, NY, USA, 2009; pp. 1023–1026. [Google Scholar]
- Sadri, R.; Zaniolo, C.; Zarkesh, A.; Adibi, J. Expressing and optimizing sequence queries in database systems. ACM Trans. Database Syst. 2004, 29, 282–318. [Google Scholar] [CrossRef]




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Mackey, I.; Su, J. Querying Workflow Logs. Information 2018, 9, 25. https://doi.org/10.3390/info9020025
Tang Y, Mackey I, Su J. Querying Workflow Logs. Information. 2018; 9(2):25. https://doi.org/10.3390/info9020025
Chicago/Turabian StyleTang, Yan, Isaac Mackey, and Jianwen Su. 2018. "Querying Workflow Logs" Information 9, no. 2: 25. https://doi.org/10.3390/info9020025
APA StyleTang, Y., Mackey, I., & Su, J. (2018). Querying Workflow Logs. Information, 9(2), 25. https://doi.org/10.3390/info9020025