Importance Degree Research of Safety Risk Management Processes of Urban Rail Transit Based on Text Mining Method


Abstract
1. Introduction
2. Proposed Methodology
2.1. Data Collection
2.2. Text Mining Method
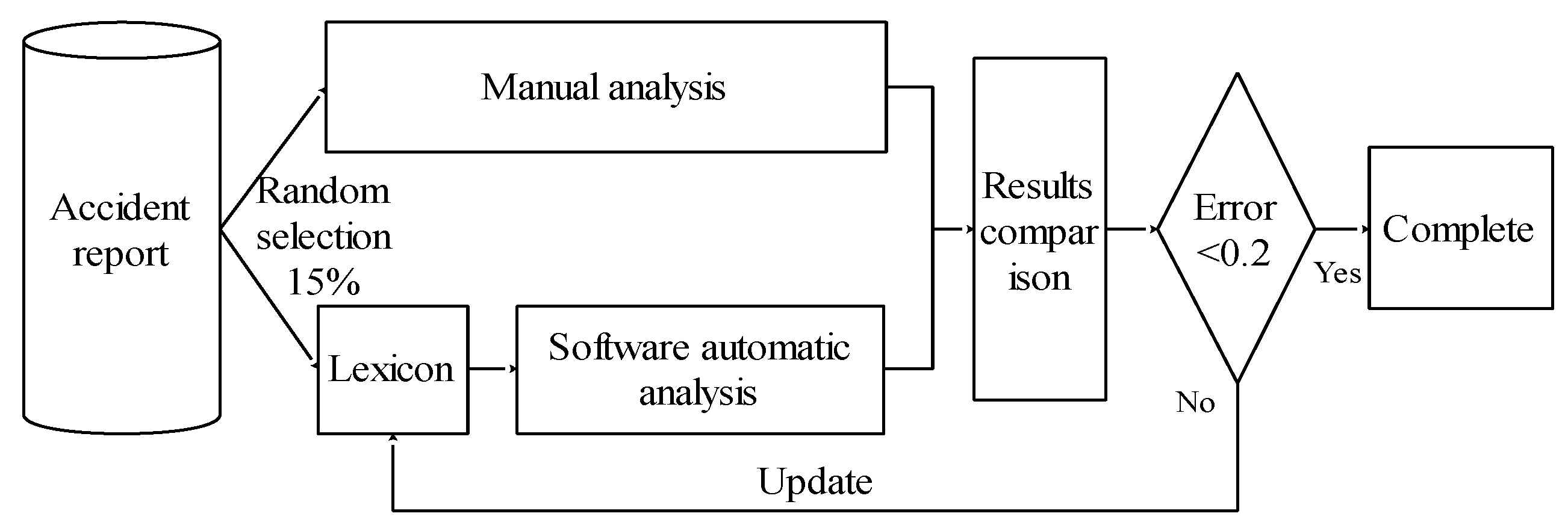
2.2.1. Lexicon Development and Keywords Identification
2.2.2. Cluster Analysis
2.2.3. Network Structure Analysis
2.2.4. Safety Risk Assessment
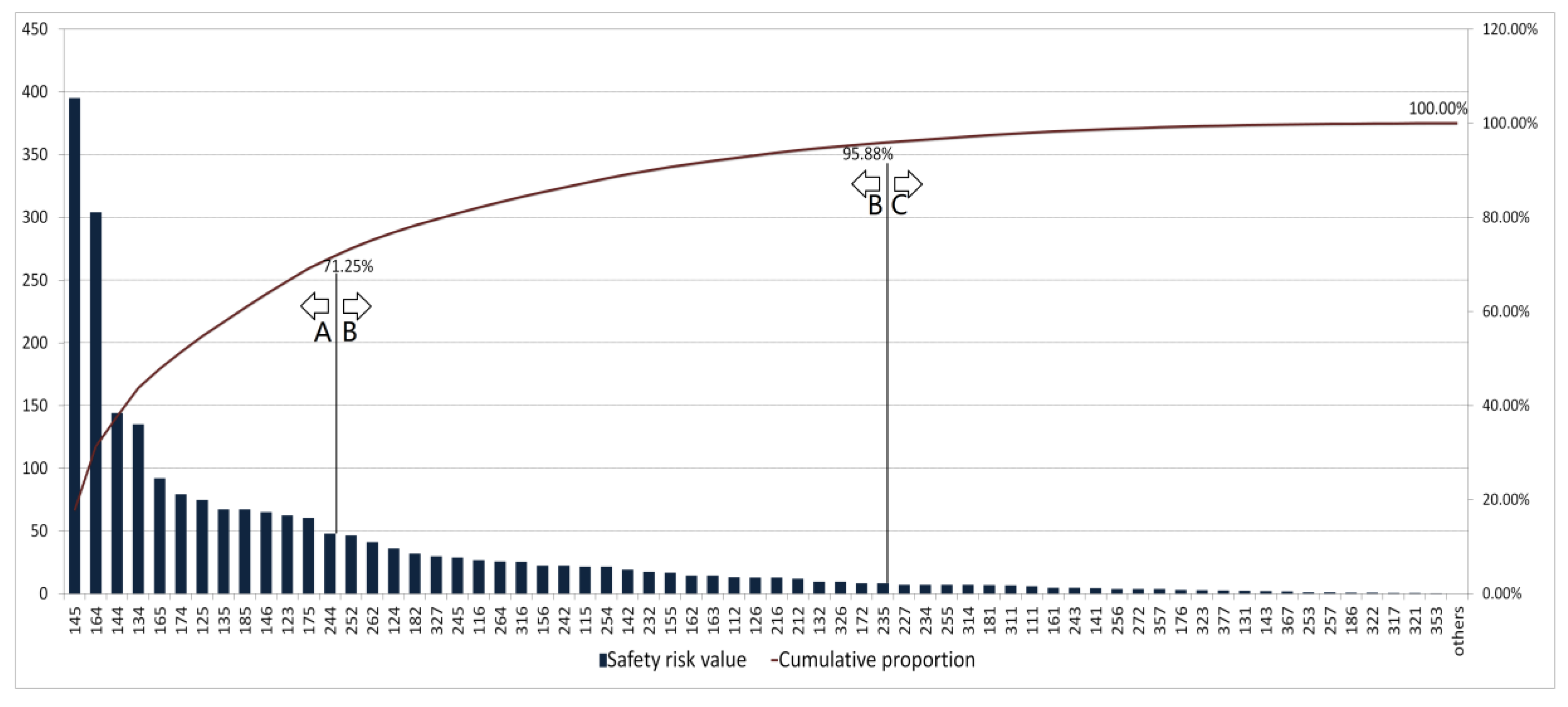
2.3. ABC Analysis Method
3. Results
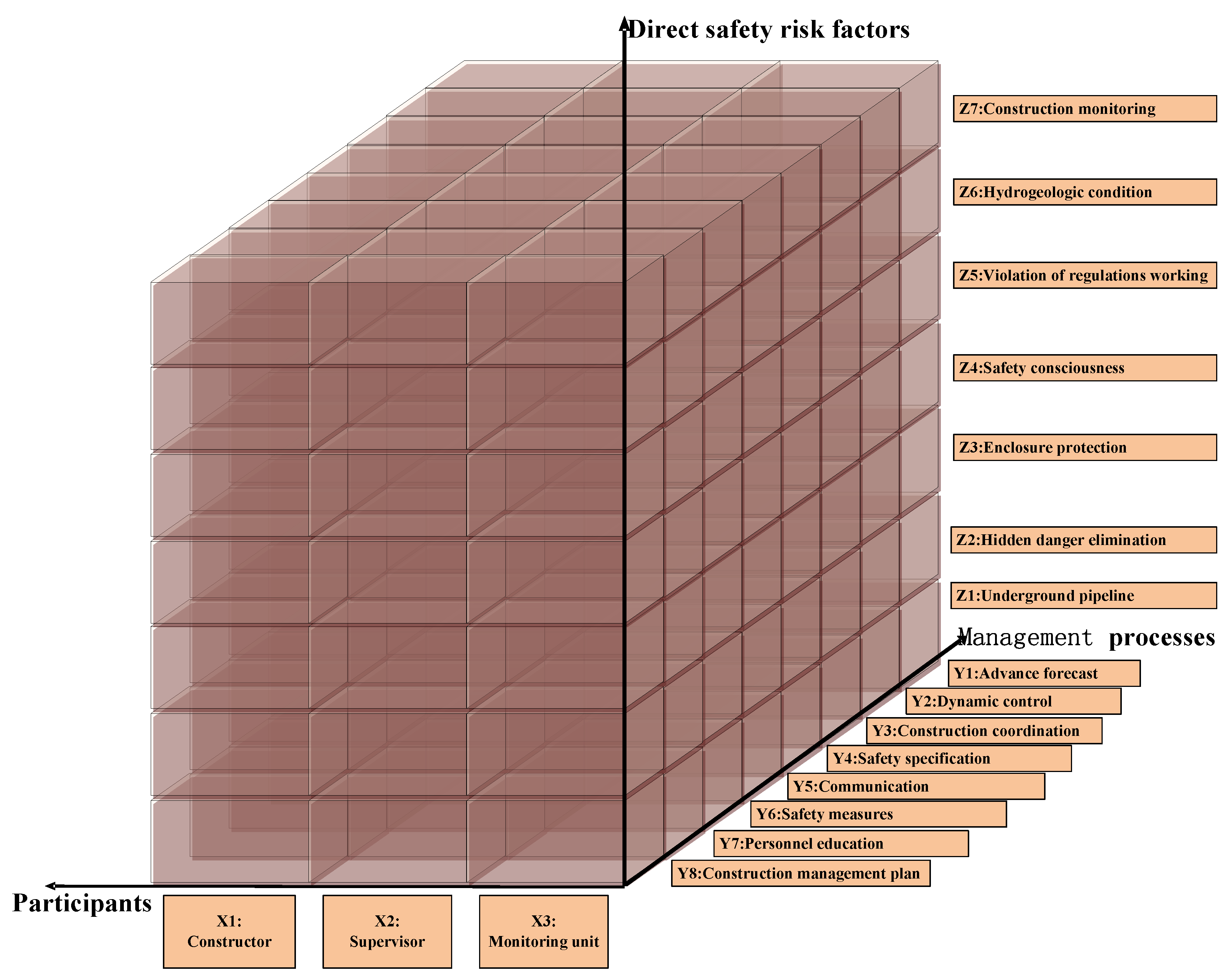
3.1. Safety Risk Factors and Participants Identification in URT Construction
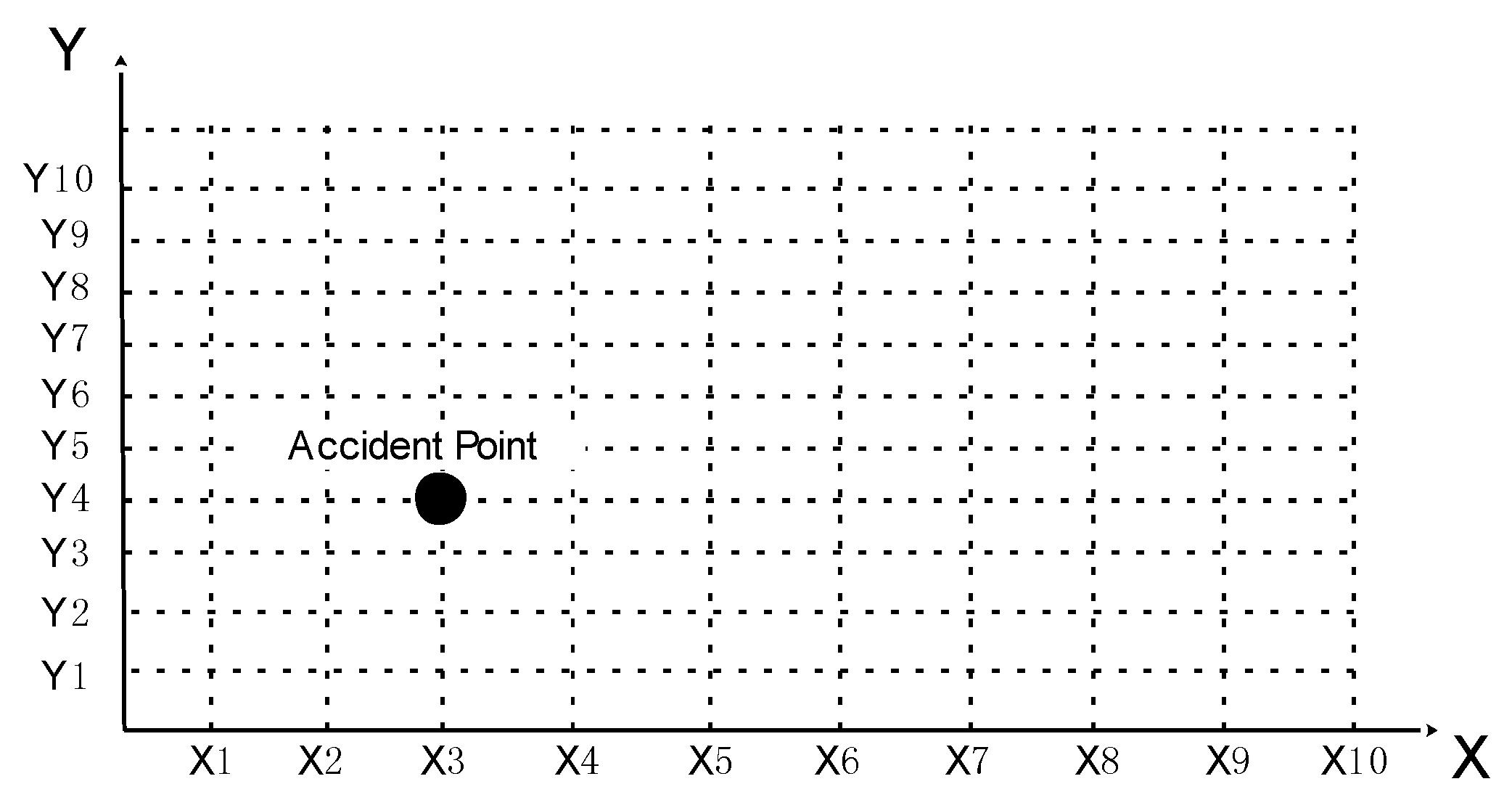
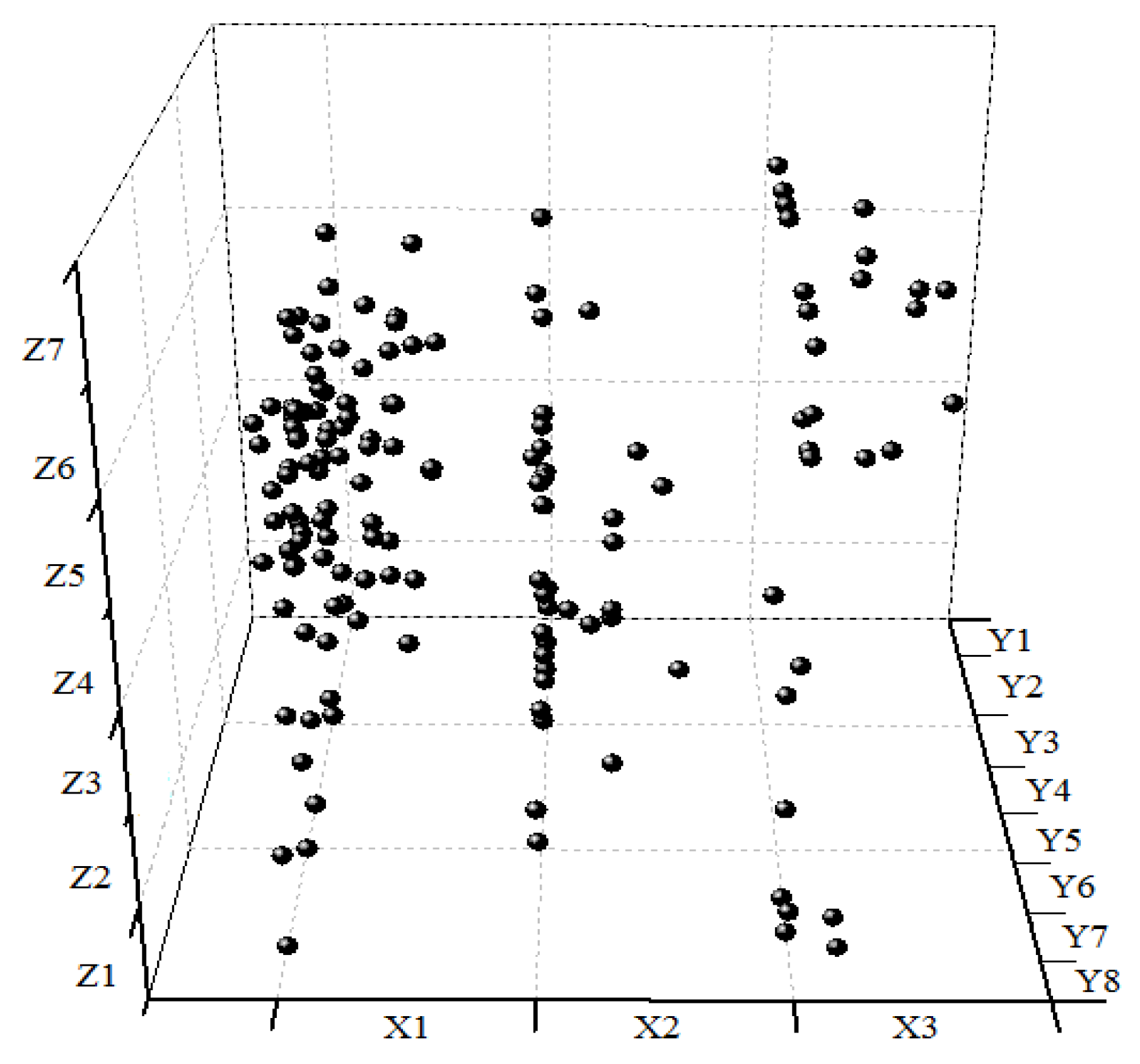
3.2. Safety Accident Descriptive Model of URT
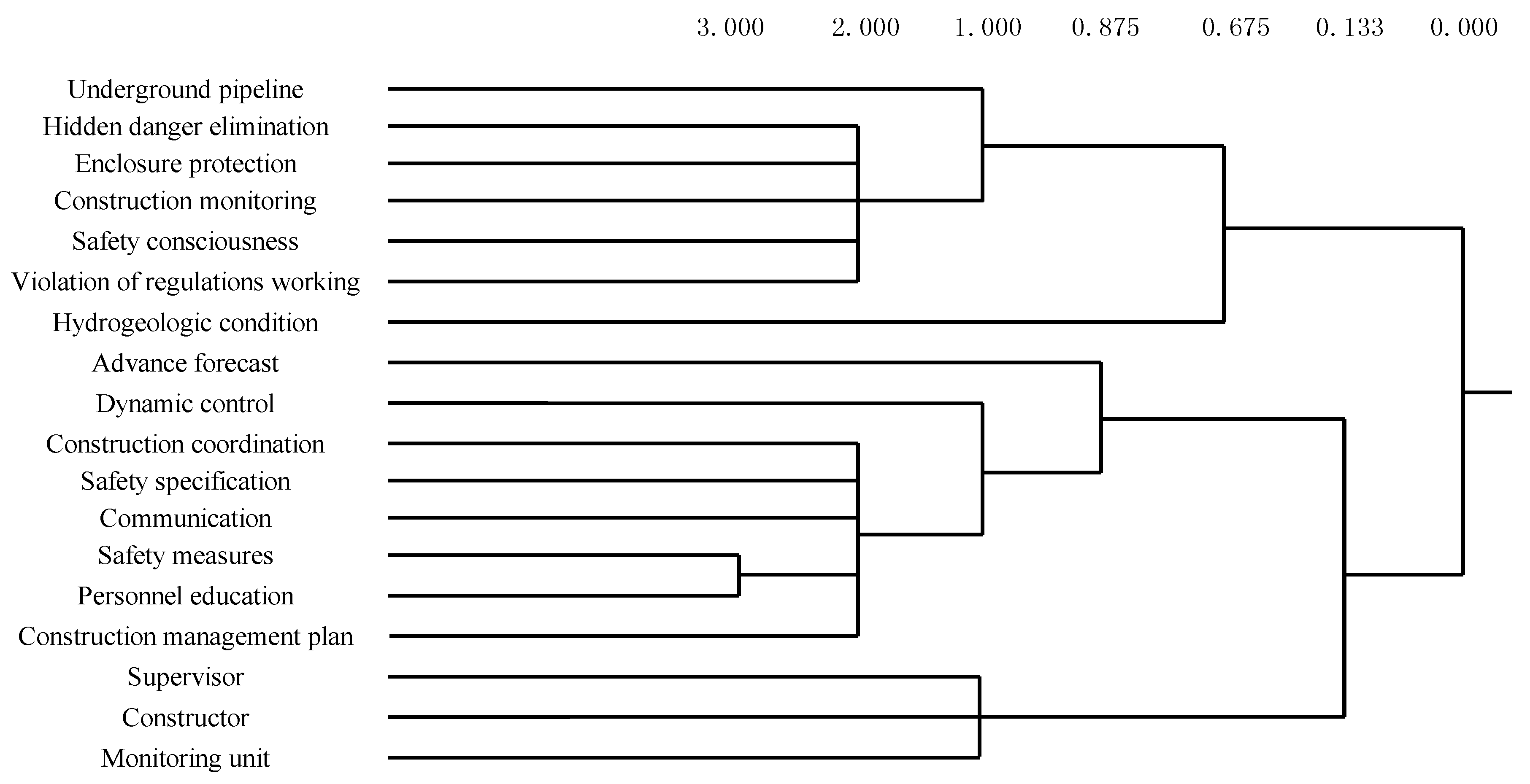
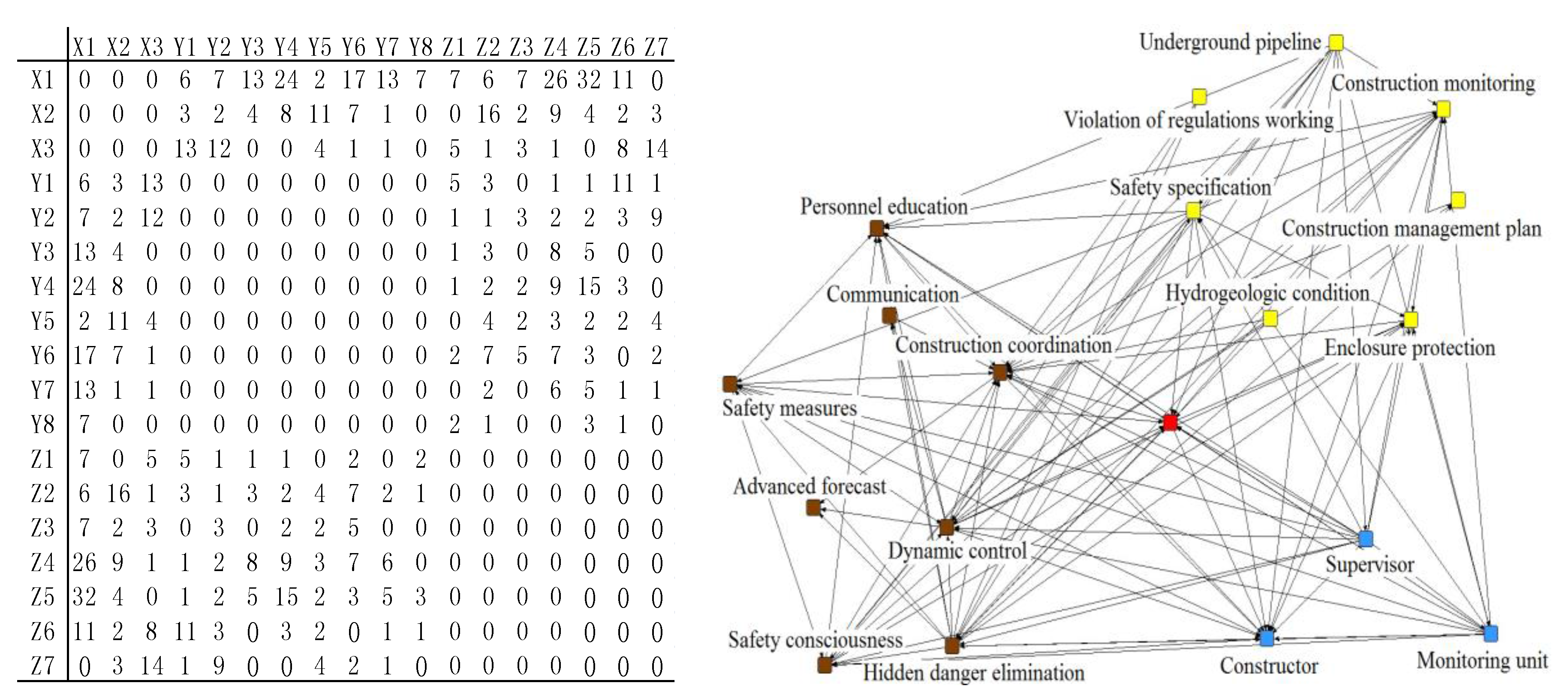
3.3. Network Structure Analysis and Assessment of Safety Risk Factors
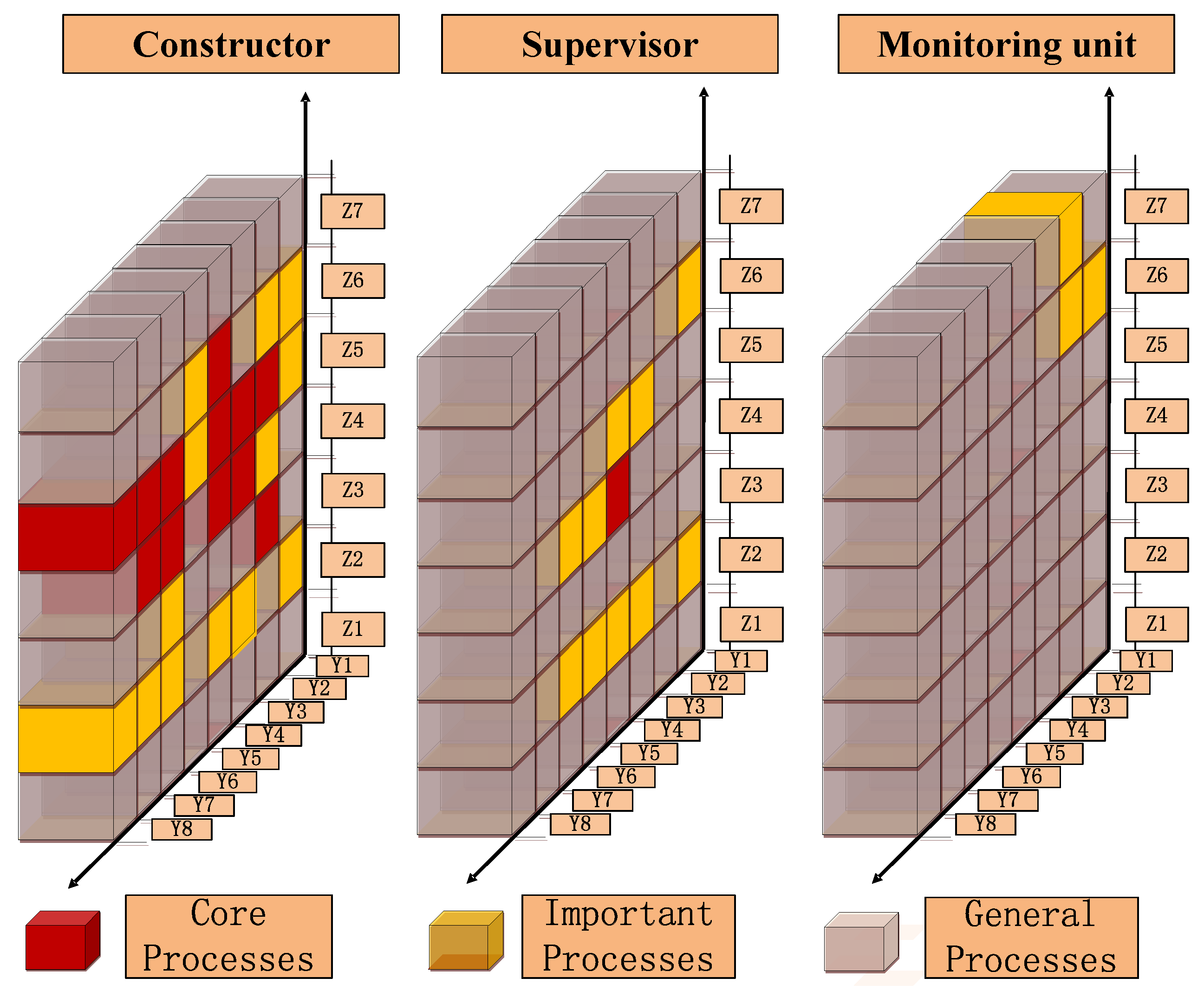
3.4. Importance Degree of Safety Risk Management Processes
4. Discussion
5. Conclusions and Limits
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gnoni, G.; Andriulo, S.; Maggio, G.; Nardone, P. Lean Occupational Safety: An Application for a Near-miss Management System Design. Saf. Sci. 2013, 53, 96–104. [Google Scholar] [CrossRef]
- Ministry of Housing and Urban-Rural Construction of the People’s Republic of China. Report on Safety of Municipal Works Production in 2016. 2016. Available online: http://www.mohurd.gov.cn/wjfb (accessed on 20 March 2017).
- Zhou, Z.P.; Irizarry, J. Integrated Framework of Modified Accident Energy Release Model and Network Theory to Explore the Full Complexity of the Hangzhou Subway Construction Collapse. J. Manag. Eng. 2016, 32, 131–139. [Google Scholar] [CrossRef]
- Esmaeili, B.; Hallowell, M. Attribute-Based Safety Risk Assessment I: Analysis at the Fundamental Level. J. Constr. Eng. Manag. 2015, 141, 15–21. [Google Scholar] [CrossRef]
- Khan, F.; Hashemi, S.J.; Paltrinieri, N. Dynamic Risk Management: A Contemporary Approach to Process Safety Management. Curr. Opin. Chem. Eng. 2016, 14, 9–17. [Google Scholar] [CrossRef]
- Ahmed, Q.; Khan, F.; Ahmed, S. Improving Safety and Availability of Complex Systems Using a Risk-based Failure Assessment Approach. J. Loss Prev. Process Ind. 2014, 32, 218–229. [Google Scholar] [CrossRef]
- Aven, T.; Renn, O.; Rosa, E.A. On the Ontological Status of the Concept of Risk. Saf. Sci. 2011, 49, 1074–1079. [Google Scholar] [CrossRef]
- Aven, T.; Zio, E. Foundational Issues in Risk Assessment and Risk Management. Risk Anal. 2013, 32, 1164–1172. [Google Scholar]
- Heinrich, H.W. Industrial Accident Prevention; McGraw-Hill: New York, NY, USA, 1931. [Google Scholar]
- Reason, J. Managing the Risks of Organizational Accidents; Routledge: New York, NY, USA, 1997. [Google Scholar]
- Hola, B.; Szostak, M. Methodology of Analysing the Accident Rate in the Construction Industry. Proced. Eng. 2017, 172, 355–362. [Google Scholar] [CrossRef]
- Swian, A.D. The Human Element in Systems Safety: A Guide for Modern Management; Industrial and Commercial Techniques: London, UK, 1974. [Google Scholar]
- Ferry, T.S. Modern Accident Investigation and Analysis; Wiley: New York, NY, USA, 1988. [Google Scholar]
- Grayson, G.B.; Hakkert, A.S. Accident Analysis and Conflict Behavior. Road Users Traffic Safety; VAN GORCUM & COMP BV: Assen, The Netherlands, 1987. [Google Scholar]
- Wen, S.; Xu, X. Risk Analysis of Double Shield TBM Construction Accident Induced by Tunnel Deformation. Chin. J. Rock Mech. Eng. 2011, S1, 3060–3065. [Google Scholar]
- Sousa, V.; Almeida, N.; Dias, L. Risk-based Management of Occupational Safety and Health in the Construction Industry-Part 2: Quantitative model. Saf. Sci. 2015, 74, 184–194. [Google Scholar] [CrossRef]
- Rivas, T.; Paz, M.; Martin, J.; Matias, J. Explaining and Predicting Workplace Accidents Using Data-mining Techniques. Reliab. Eng. Syst. Saf. 2011, 96, 739–747. [Google Scholar] [CrossRef]
- Weng, J.; Zheng, Y.; Yan, X. Development of a Subway Operation Incident Delay Model Using Accelerated Failure Time Approaches. Accid. Anal. Prev. 2014, 73, 12–19. [Google Scholar] [CrossRef] [PubMed]
- Leu, S.; Chang, C. Bayesian-network-based Safety Risk Assessment for Steel Construction Projects. Accid. Anal. Prev. 2013, 54, 22–123. [Google Scholar] [CrossRef] [PubMed]
- Sousa, V.; Almeida, N.D. Risk-based Management of Occupational Safety and Health in the Construction Industry-Part 1: Background Knowledge. Saf. Sci. 2014, 66, 75–86. [Google Scholar] [CrossRef]
- Gholizadeh, P.; Esmaeili, B. Electrical Contractors’ Safety Risk Management: An Attribute-based Analysis. Comput. Civ. Eng. 2015, 181–189. [Google Scholar] [CrossRef]
- Figueres-Esteban, M.; Hughes, P.; Gulijk, C.V. Visual Analytics for Text-based Railway Incident Reports. Saf. Sci. 2016, 89, 72–76. [Google Scholar] [CrossRef]
- Tixier, J.; Hallowell, M. Automated Content Analysis for Construction Safety: A Natural Language Processing System to Extract Precursors and Outcomes from Unstructured Injury Reports. Autom. Constr. 2016, 62, 45–56. [Google Scholar] [CrossRef]
- Hola, B. Identification and Evaluation of Processes in a Construction Enterprise. Arch. Civ. Mech. Eng. 2015, 15, 419–426. [Google Scholar] [CrossRef]
- Esmaeili, B.; Hallowell, M. Attribute-Based Risk Model for Measuring Safety Risk of Struck-By Accidents. Constr. Res. Congr. 2012, 289–298. [Google Scholar] [CrossRef]
- Rodrigues, R.S.; Balestrassi, P.P. Aircraft Interior Failure Pattern Recognition Utilizing Text Mining and Neural Networks. J. Intell. Int. Syst. 2012, 38, 741–766. [Google Scholar] [CrossRef]
- Fan, H.; Li, H. Retrieving Similar Cases for Alternative Dispute Resolution in Construction Accidents Using Text Mining Techniques. Autom. Constr. 2013, 34, 85–91. [Google Scholar] [CrossRef]
- Sanmiquel, L.; Rossell, J. Study of Spanish Mining Accidents Using Data Mining Techniques. Saf. Sci. 2015, 75, 49–55. [Google Scholar] [CrossRef]
- Tanguy, L.; Tulechki, N.; Urieli, A. Natural Language Processing for Aviation Safety Reports: From Classification to Interactive Analysis. Comput. Ind. 2016, 78, 80–95. [Google Scholar] [CrossRef]
- Stojadinovic, S.; Svrkota, I.; Petrovic, D. Mining Injuries in Serbian Underground Coal Mines-a 10-year Study. Injury 2012, 43, 2001–2005. [Google Scholar] [CrossRef] [PubMed]
- Baeza, Y. Modern Information Retrieval; ACM Press Books: New York, NY, USA, 1999. [Google Scholar]
- Kao, A.; Poteet, S.R. Natural Language Processing and Text Mining; Springer: Berlin, Germany, 2007. [Google Scholar]
- Esmaeili, B.; Hallowell, M.; Rajagopalan, B. Attribute-Based Safety Risk Assessment II: Predicting Safety Outcomes Using Generalized Linear Models. J. Constr. Eng. Manag. 2017, 141, 15–22. [Google Scholar] [CrossRef]
- Sugihara, K.; Okabe, A.; Satoh, T. Computational Method for the Point Cluster Analysis on Networks. GeoInformatica 2011, 15, 167–189. [Google Scholar] [CrossRef]
- Capo, M.; Perez, A.; Lozano, J. An Efficient Approximation to the K-means Clustering for Massive Data. Knowl. Based Syst. 2017, 117, 56–69. [Google Scholar] [CrossRef]
- Hola, B.; Sawicki, M. Tacit Knowledge Contained in Construction Enterprise Documents. Proced. Eng. 2014, 85, 231–239. [Google Scholar] [CrossRef]
- Kushwah, A.; Manjhvar, A. A Review on Link Prediction in Social Network. Int. J. Grid Distrib. Comput. 2016, 9, 43–50. [Google Scholar] [CrossRef]
- Yu, M.C. Multi-criteria ABC Analysis Using Artificial-intelligence-based Classification Techniques. Expert Syst. Appl. 2011, 38, 3416–3421. [Google Scholar] [CrossRef]
- Bhattacharya, A.; Sarkar, B. Distance-based Consensus Method for ABC Analysis. Int. J. Prod. Res. 2007, 45, 3405–3420. [Google Scholar] [CrossRef]
- Flores, B.E.; Whybark, D.C. Implementing Multiple Criteria ABC Analysis. Eng. Costs Prod. Econ. 1989, 15, 191–195. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level of Risk | A | B | C | D | E |
|---|---|---|---|---|---|
| Deaths | >10 | 3–9 | 1–2 | seriously wounded | slight injury |
| Economic loss(million) | >10 | 5–10 | 1–5 | 0.5–1 | <0.5 |
| Loss value | 100 | 40 | 15 | 7 | 3 |
| City | Quantity | City | Quantity |
|---|---|---|---|
| Beijing | 24 | Fuzhou | 3 |
| Shanghai | 20 | Shenyang | 3 |
| Guangzhou | 22 | Chongqing | 2 |
| Shenzhen | 21 | Nanning | 2 |
| Nanjing | 10 | Haerbin | 2 |
| Wuhan | 6 | Ningbo | 1 |
| Hangzhou | 6 | Kunming | 1 |
| Tianjin | 6 | Changchun | 1 |
| Xian | 5 | Changsha | 1 |
| Qingdao | 5 | Dongguan | 1 |
| Dalian | 4 | Chengdu | 1 |
| Zhengzhou | 3 | Xiamen | 1 |
| Updating Times | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Error values | 0.68 | 0.41 | 0.29 | 0.22 | 0.18 |
| No. | Safety Risk Factor | Report Amount (mi) | Total Report Amount (n) | Relative Risk Probability (RFi) |
| 1 | Underground pipeline | 36 | 156 | 23.08% |
| 2 | Hidden danger elimination | 69 | 156 | 44.23% |
| 3 | Enclosure protection | 36 | 156 | 23.08% |
| 4 | Safety consciousness | 108 | 156 | 69.23% |
| 5 | Violation of regulations working | 120 | 156 | 76.92% |
| 6 | Hydrogeologic condition | 63 | 156 | 40.38% |
| 7 | Construction monitoring | 48 | 156 | 30.77% |
| 8 | Advanced forecast | 66 | 156 | 42.31% |
| 9 | Dynamic control | 63 | 156 | 40.38% |
| 10 | Construction coordination | 51 | 156 | 32.69% |
| 11 | Safety specification | 96 | 156 | 61.54% |
| 12 | Communication | 51 | 156 | 32.69% |
| 13 | Safety measures | 75 | 156 | 48.08% |
| 14 | Personnel education | 45 | 156 | 28.85% |
| 15 | Construction management plan | 24 | 156 | 13.46% |
| No. | Participant | Report Amount (mi) | Total Report Amount (n) | Relative Risk Probability (RFi) |
| 1 | Constructor | 89 | 156 | 57.00% |
| 2 | Supervisor | 36 | 156 | 24.00% |
| 3 | Monitoring unit | 31 | 156 | 19.00% |
| No. | Relationship | Risk probability (RFi) | Casualties | Loss Value (RMi) | Risk Value (WH=8) (RVi) |
|---|---|---|---|---|---|
| Report 1 | X1-Y1-Z1 | 0.05 | 1 dead | 15 | 6.00 |
| Report 2 | X1-Y1-Z2 | 0.11 | 2 dead | 15 | 13.20 |
| Report 3 | X1-Y1-Z5 | 0.18 | 2 dead | 15 | 21.60 |
| Report 4 | X1-Y1-Z6 | 0.09 | 1dead 1slightly injured | 15 | 10.80 |
| Report 5 | X1-Y1-Z6 | 0.09 | 1dead | 15 | 10.80 |
| …… | …… | …… | …… | …… | …… |
| Report 153 | X3-Y5-Z7 | 0.02 | 1slightly injured | 3 | 0.48 |
| Report 154 | X3-Y5-Z7 | 0.02 | 1dead | 15 | 2.40 |
| Report 155 | X1-Y6-Z7 | 0.03 | 1seriously injured | 7 | 1.68 |
| Report 156 | X1-Y7-Z7 | 0.02 | 1dead | 15 | 0.30 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wang, J.; Xu, N.; Hu, Y.; Cui, C. Importance Degree Research of Safety Risk Management Processes of Urban Rail Transit Based on Text Mining Method. Information 2018, 9, 26. https://doi.org/10.3390/info9020026
Li J, Wang J, Xu N, Hu Y, Cui C. Importance Degree Research of Safety Risk Management Processes of Urban Rail Transit Based on Text Mining Method. Information. 2018; 9(2):26. https://doi.org/10.3390/info9020026
Chicago/Turabian StyleLi, Jie, Jianping Wang, Na Xu, Yunpeng Hu, and Caiyun Cui. 2018. "Importance Degree Research of Safety Risk Management Processes of Urban Rail Transit Based on Text Mining Method" Information 9, no. 2: 26. https://doi.org/10.3390/info9020026
APA StyleLi, J., Wang, J., Xu, N., Hu, Y., & Cui, C. (2018). Importance Degree Research of Safety Risk Management Processes of Urban Rail Transit Based on Text Mining Method. Information, 9(2), 26. https://doi.org/10.3390/info9020026