Conversion of the English-Xhosa Dictionary for Nurses to a Linguistic Linked Data Framework †

Abstract
1. Introduction
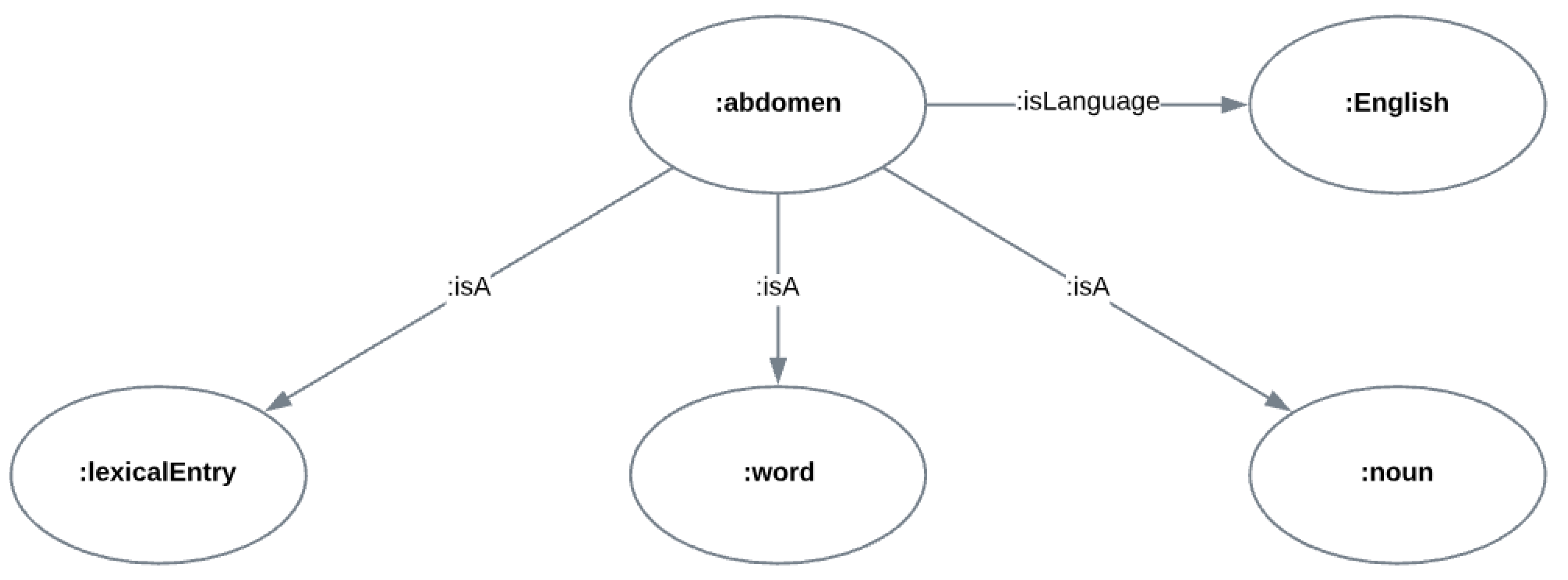
- Abdomen is a lexical entry.
- Abdomen is a word.
- Abdomen is a noun.
- Abdomen is an English term.
SubjectPredicateObject :abdomen :isA :lexicalEntry ; :isA :word ; :isA :noun ; :isLanguage :English .
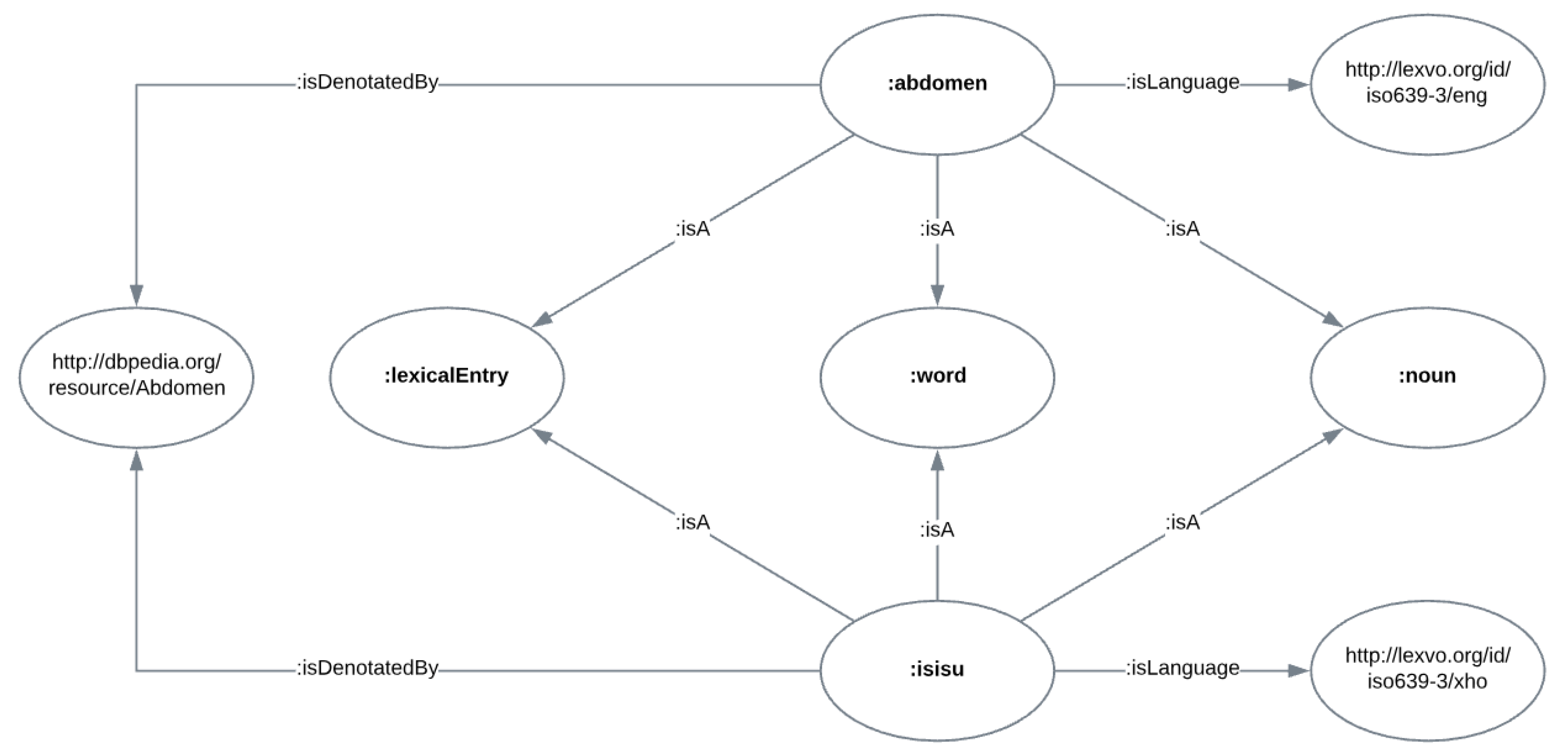
SubjectPredicateObject :abdomen :isA :lexicalEntry ; :isA :word ; :isA :noun ; :isLanguage http://lexvo.org/id/iso639-3/eng ; :isDenotedBy http://dbpedia.org/resource/Abdomen .
:isisu :isA :lexicalEntry ;
:isA :word ;
:isA :noun ;
:isLanguage http://lexvo.org/id/iso639-3/xho ;
:isDenotedBy http://dbpedia.org/resource/Abdomen .
- Use URIs as names for things
- Use HTTP URIs so that people can look up those names.
- When someone looks up a URI, provide useful information, using the standards (RDF*, SPARQL)
- Include links to other URIs, so that they can discover more things.
- which describes data in RDF,
- using a model designed for the representation of linguistic information,
- which adheres to Linked Data principles, and
- which supports versioning, allowing for change;
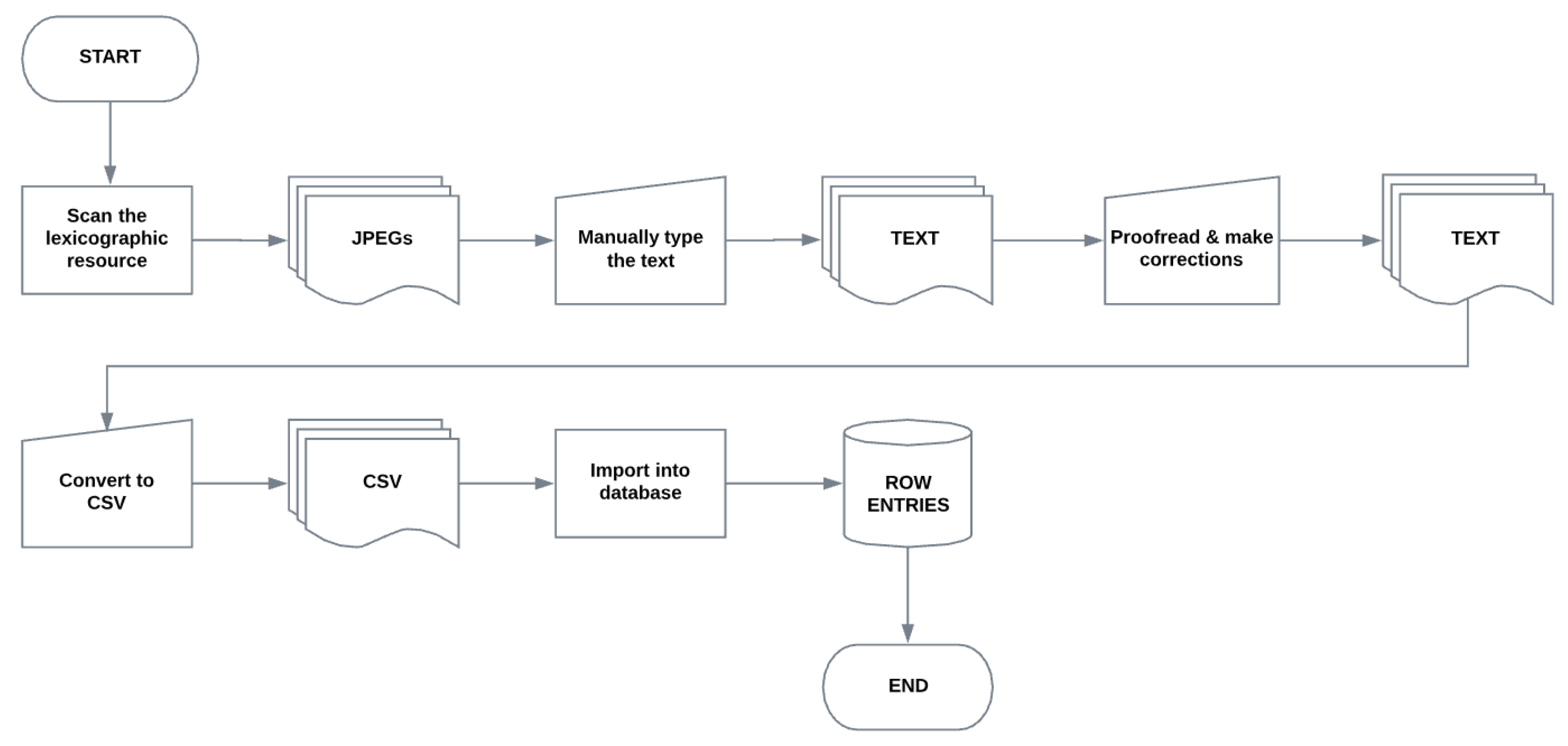
2. The Digitisation of EXDN
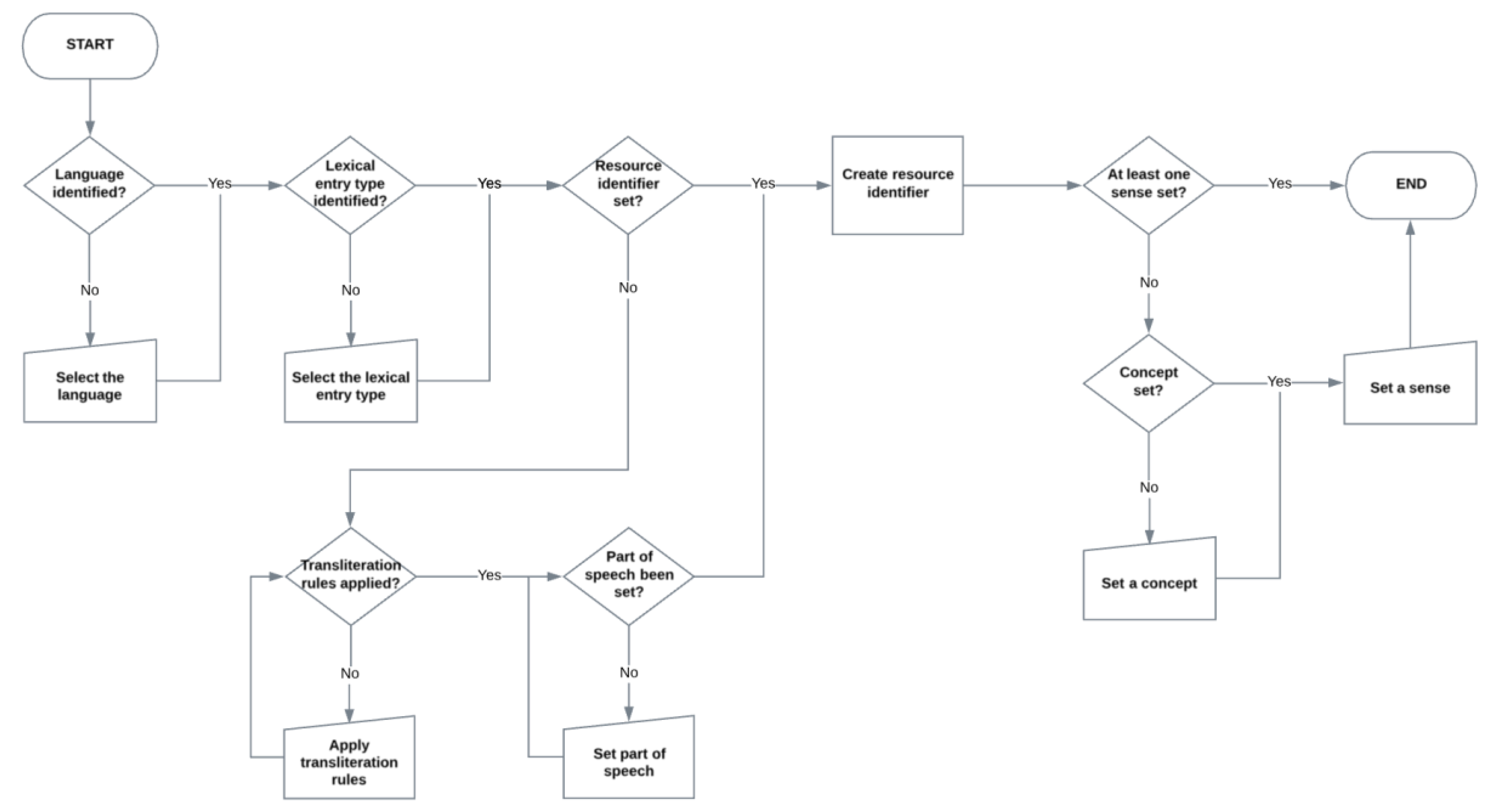
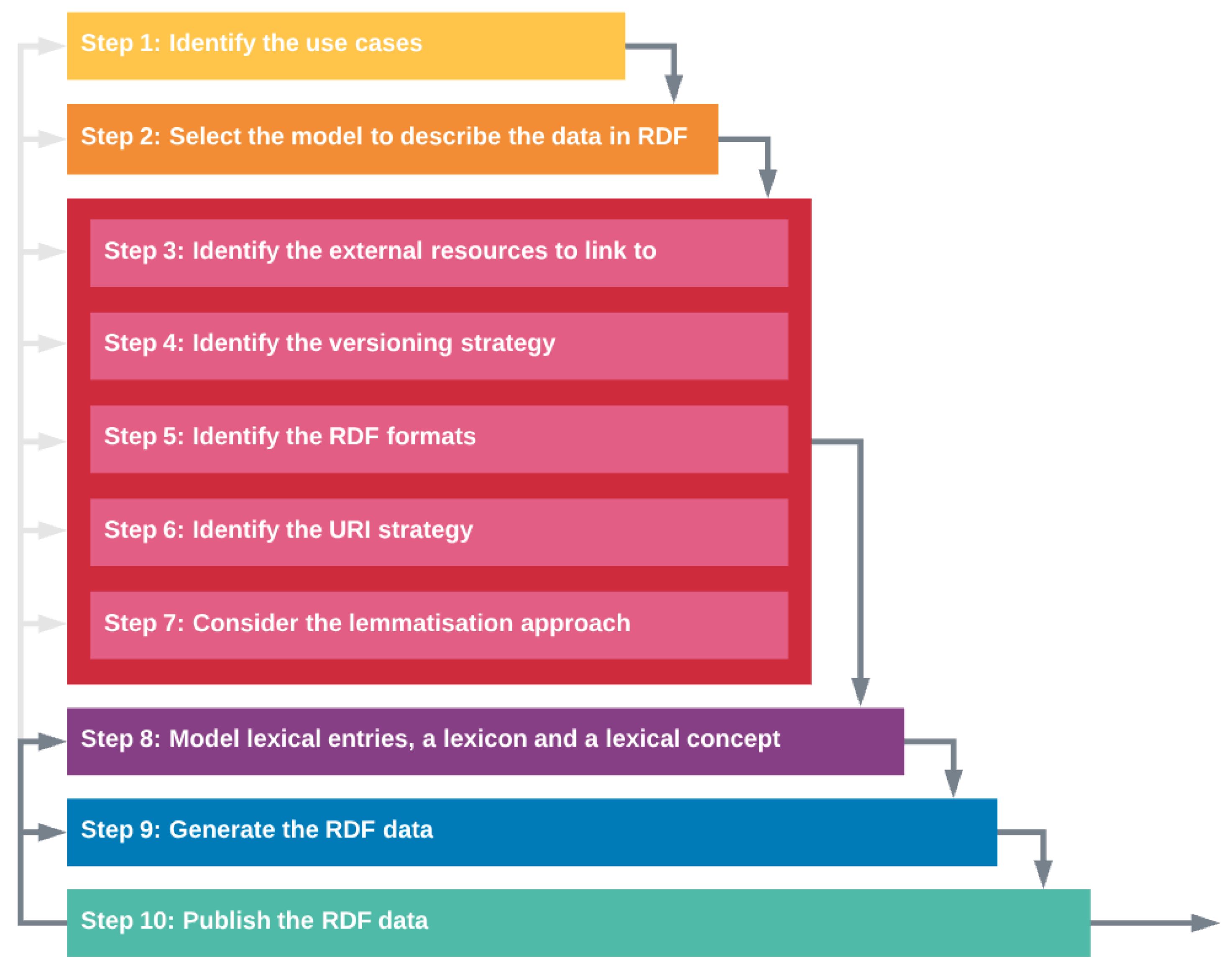
3. Methodological Guidelines for the Construction of a Linguistic Linked Data Framework
- Step 1:
- Identify the use cases
- Step 2:
- Select the model with which to describe the language data in RDF
- Step 3:
- Identify the external resources to link to
- Step 4:
- Identify the versioning strategy
- Step 5:
- Identify the RDF formats
- Step 6:
- Identify the URI strategy
- Step 7:
- Consider the lemmatisation approach
- Step 8:
- Model lexical entries, a lexicon, and a lexical concept
- Step 9:
- Generate the RDF data
- Step 10:
- Publish the RDF data
- M1:
- Modelling a lexical entry that offers a restricted treatment of the lemma sign.
- M2:
- Modelling a lexical entry that offers a paraphrase of meaning of the lemma sign.
- M3:
- Modelling a lexical entry that contains a cross-reference entry.
- M4:
- Modelling a lexical entry that offers a comment on semantics.
- M5:
- Modelling a plural form for an African language in the lexical entry.
- M6:
- Modelling a lexical entry with a stem as the lemma.
- M7:
- Modelling a lexical entry with a derived noun as the lemma.
- M8:
- Modelling a lexical entry for a derived noun, with the plural form as the lemma.
- M9:
- Modelling a translation relation between a source and target sense, which do not share the same lemmatisation approach.
- M10:
- Modelling a lexical entry which has an outdated sense.
- Interoperability;
- Separation and independence: where there is separation between the lexical and the ontological layer, with linguistic information able to be modelled separately;
- Linguistic information: where structured linguistic information can be captured;
- Morphological decomposition: necessary when working with an agglutinative language such as isiXhosa;
- Multilinguality: where there is support for multilingualism and translation relations, beyond language tagging;
- Ontological representation: where meaning can be represented by an external ontology entity (referred to as “arbitrary ontologies” in Cimiano et al.) [11] (p. 33);
- Linked Data principles: where there is adherence to the principles of Linked Data, listed in Section 1.
- DBpedia (a cross-domain ontology used to identify resources) [16];
- Dublin Core Metadata Initiative (used to describe the properties of resources) [42];
- FOAF (used to describe properties and identify resources) [43];
- Library of Congress Name Authority File (controlled vocabulary used to identify persons and organisations) [44];
- Library of Congress Subject Headings (controlled vocabulary used to categorise resources) [45];
- LexInfo (used to represent lexical information) [46];
- Medical Subject Headings (MeSH) (controlled vocabulary used to identify and categorise resources in the medical domain) [47];
- Multilingual Morpheme Ontology (MMoOn) (a multilingual morpheme ontology used to express linguistic concepts and relations) [48];
- PROV Ontology (PROV-O) (used to represent provenance information) [49];
- Princeton WordNet 3.1 (the RDF interface used for Princeton WordNet) [50]; and
- VoID Vocabulary (a vocabulary for expressing metadata about datasets) [51].
- The ontology changed invisibly, that is, there was no notification of the change, prior or post the event. From this, one scenario can result:
- A new version of the ontology replaces a previous version. Any previous versions are no longer available.
- The ontology changed visibly, that is, there was a notification of the change, prior or post the event. From this, several scenarios can result:
- A new version of the ontology replaces a previous version. Any previous versions are no longer accessible.
- A new version of the ontology replaces a previous version. Any previous versions remain accessible.
- A new version of the ontology replaces a previous version. Any previous versions remain accessible. There is also an explicit specification of the changes between the previous version and the new version.
- versioned URIs for lexical entries, lexicons, and lexical concepts,
- provenance metadata to describe the versions, with the latest version mapping to previous versions [57], and
- the change should be visible,
- previous versions should remain accessible, and
- a changelog between versions should be explicitly specified.
- it should be persistent,
- it should not be deleted,
- however, it can be deprecated or superceded [61] (p. 4).
3.1. Fragment Identifiers
3.2. The URI Pattern
- U1:
- A URI that identifies a resource
- U2:
- A URI that identifies a sub-resource in relation to the parent resource
- U3:
- A URI that identifies a version of the resource
- U4:
- A URI that identifies a version combined with a sub-resource
- U5:
- A URI that identifies a document describing the resource in U1
- U6:
- A URI that identifies a document describing the resource in U3
http://{domain}/{type}/{concept}/{reference}
where:- {domain} is the host,
- {type} is the resource being identified,
- {concept} refers to a real world object or a collection, and
- {http(s):} is the http: or https: scheme
- {Base URI} is the namespace
- {Resource Path} is, for example, entry for a lexical entry, and lexicon for a lexicon
- {Resource ID} is the resource identifier
- {Fragment ID} is the fragment identifier, for example, sense1
- {Version ID} is the version identifier, for example, 2017-09-19
- Using content negotiation, {Document} refers to the HTML page, for example, page, or to the RDF representation, for example, rdf, using any form of serialisation.
3.3. Resource Identifiers
{Language Code}-{POS}-{Lemma}
where:- {Language Code} is the lowercase form of an ISO 639 code
- {POS} is an abbreviated form of the part-of-speech
- {Lemma} is the lowercase form of the lemma, with diacritics removed and hyphens or spaces replaced with underscores
- a description of the lexical entry, linking to the external resources identified in Step 3;
- metadata of the lexical entry;
- provenance information;
- a brief description of any related resources;
- a description of the lexicon which contains the lexical entry;
- and a description of the document which describes the lexical entry.
1 :000000001
2 a skos:Concept , ontolex:LexicalConcept , prov:Entity ;
3 ontolex:lexicalizedSense :entry/en-n-abdomen#sense1 ;
4 ontolex:lexicalizedSense :entry/xh-n-isisu#sense1 ;
5 owl:sameAs mesh:M000005 ;
6 dct:subject mesh:D000005 ;
7 ontolex:isConceptOf dbr:Abdomen ;
8 dct:references pwn:05564576-n#abdomen-n ,
<https://wn.londisizwe.org/xh/000000001-n#isisu> .
- Umphefumlo is a translation equivalent
- Umphefumlo is a derived noun
- The stem is: -phefumlo
- The plural of breath is breaths
- The plural of umphefumlo (isiXhosa Noun Class 7) is imiphefumlo (isiXhosa Noun Class 8)
- Lexical entry: en-n-breath (of type Word)
- Lexical entry: xh-n-umphefumlo (of type Word)
- Lexical entry: xh-n-phefumlo (of type Stem)
- Lexical entry: xh-n-um (of type Affix)
- Lexical entry: xh-n-imi (of type Affix)
- Lexical concept: shared conceptualisation for en-n-breath, xh-n-umphefumlo and xh-n-phefumlo
1 :xh-n-umphefumlo
2 a ontolex:LexicalEntry , ontolex:Word , mmoon:DerivedNoun ;
3 lexinfo:partOfSpeech lexinfo:Noun ;
4 dct:language <http://id.loc.gov/vocabulary/iso639-2/xho> ,
<http://lexvo.org/id/iso639-1/xh> ;
5 mmoon:consistsOfStem :xh-n-phefumlo ;
6 rdfs:label "umphefumlo"@xh ;
7 ontolex:canonicalForm :xh-n-umphefumlo#lemma ;
8 ontolex:lexicalForm :xh-n-umphefumlo#singular ,
:xh-n-umphefumlo#plural ;
9 ontolex:sense :xh-n-umphefumlo#sense1 ;
10 ontolex:evokes <https://londisizwe.org/concept/000000000> .
11
12 :xh-n-umphefumlo#lemma
13 a ontolex:Form ;
14 ontolex:writtenRep "umphefumlo"@xh .
15
16 :xh-n-umphefumlo#singular
17 a ontolex:Form ;
18 ontolex:writtenRep "umphefumlo"@xh ;
19 lexinfo:number lexinfo:singular ;
20 mmoon:consistsOfAffix :xh-n-um ;
21 mmoon:consistsOfStem :xh-n-phefumlo ;
22 rdf:_1 :xh-n-um ;
23 rdf:_2 :xh-n-phefumlo ;
24 lonvoc:inNounClass lonvoc:IsiXhosaNC7 .
25
26 :xh-n-umphefumlo#plural
27 a ontolex:Form ;
28 ontolex:writtenRep "imiphefumlo"@xh ;
29 lexinfo:number lexinfo:plural ;
30 mmoon:consistsOfAffix :xh-n-imi ;
31 mmoon:consistsOfStem :xh-n-phefumlo ;
32 rdf:_1 :xh-n-imi ;
33 rdf:_2 :xh-n-phefumlo ;
34 lonvoc:inNounClass lonvoc:IsiXhosaNC8 .
35
36 :xh-n-umphefumlo#sense1
37 a ontolex:LexicalSense ;
38 ontolex:isLexicalizedSenseOf
<https://londisizwe.org/concept/000000000> .
where:- Line 2: indicates that it is a derived noun
- Line 5: indicates the lexical entry of the stem xh-n-phefumlo
- Lines 16–24: indicate the singular form
- Lines 20–21: indicate the affix and stem of this form
- Lines 22–23: indicate the order in which the derived noun is composed
- Line 24: indicates the isiXhosa noun class to which this form belongs
- Lines 26–34: indicate the plural form
- Lines 30–31: indicate the affix (note the difference to the singular form) and stem of this form
- Line 34: indicates the isiXhosa noun class to which this form belongs (note the difference to the singular form)
- M1:
- Modelling a lexical entry that offers a restricted treatment of the lemma sign.
- M5:
- Modelling a plural form for an African language in the lexical entry.
- M7:
- Modelling a lexical entry with a derived noun as the lemma.
- M9:
- Modelling a translation relation between a source and target sense, which do not share the same lemmatisation approach.
3.4. Provenance for a Lexical Entry and its Senses
as a record that describes the people, institutions, entities, and activities involved in producing, influencing, or delivering a piece of data or a thing.
- Each lexical entry, sense, and translation relation is identified as a prov:Entity.
- The prov:generatedAtTime property is recorded for each.
- The date a lexical entry or translation relation is changed is recorded using dct:modified.
- The person or organisation responsible for creating the lexical entry or sense is identified using dct:creator.
- The source from which a lexical entry is primarily derived is identified using the prov:hadPrimarySource property.
- The other sources from which a lexical entry, sense or translation relation is derived, is identified using the dct:source property.
- One or more contributors (a person, an organisation or a service) for a lexical entry, sense or translation relation is identified using dct:contributor.
- The licensing agreement for a lexical entry is identified using dct:license.
- For a lexical entry, dct:isPartOf is used to denote inclusion of a lexical entry in a lexicon, and inclusion of a sense in a lexical entry.
- For a translation relation, dct:hasPart is used to identify both the source and target language.
- For a lexical entry, owl:sameAs is used to indicate that U1 is the same as the latest version of U3.
- For a sense or translation relation, owl:sameAs is used to indicate that U2 is the same as the latest version of U4.
- For a lexical entry, sense or translation relation, the version is indicated using owl:versionInfo.
- For a lexical entry, sense or translation relation, dct:hasVersion is used to show the previously generated versions, using the versioned URIs (U3 for lexical entries and U4 for senses and translation relations).
:entry/xh-n-isisu
a ontolex:LexicalEntry , ontolex:Word , prov:Entity ;
lexinfo:partOfSpeech lexinfo:Noun ;
dct:language <http://id.loc.gov/vocabulary/iso639-2/xho> ,
<http://lexvo.org/id/iso639-1/xh> ;
dct:identifier "xh-n-isisu"^^xsd:string ;
rdfs:label "isisu"@xh ;
ontolex:canonicalForm :entry/xh-n-isisu#lemma ;
ontolex:sense :entry/xh-n-isisu#sense1 , :entry/xh-n-isisu#sense2 ;
ontolex:denotes dbr:Abdomen , dbr:Stomach ;
ontolex:evokes :concept/000000001 , :concept/000000002 ;
dct:isPartOf :lexicon/xh ;
prov:hadPrimarySource "The English-Xhosa Dictionary for Nurses"@en ;
dct:license <http://creativecommons.org/publicdomain/mark/1.0/> ;
dct:creator <https://londisizwe.org> ;
prov:generatedAtTime "2017-09-19T05:00:00Z|+02:00"^^xsd:dateTime ;
dct:modified "2018-01-10"^^xsd:date ;
owl:versionInfo"2018-01-10"^^xsd:string ;
owl:sameAs :entry/xh-n-isisu/2018-01-10 ;
owl:hasVersion :entry/xh-n-isisu/2017-09-19 ,
:entry/xh-n-isisu/2018-01-10 .
:entry/xh-n-isisu#lemma
a ontolex:Form ;
ontolex:writtenRep "isisu"@xh .
:entry/xh-n-isisu#sense1
a ontolex:LexicalSense , prov:Entity ;
ontolex:isLexicalizedSenseOf :concept/000000001 ;
dct:isPartOf :entry/xh-n-isisu ;
prov:generatedAtTime "2017-09-19T05:00:00Z|+02:00"^^xsd:dateTime ;
owl:versionInfo"2018-01-10"^^xsd:string ;
owl:hasVersion :entry/xh-n-isisu/2017-09-19#sense1 ,
:entry/xh-n-isisu/2018-01-10#sense1 .
:entry/xh-n-isisu#sense2
a ontolex:LexicalSense , prov:Entity ;
ontolex:isLexicalizedSenseOf :concept/000000002 ;
dct:isPartOf :entry/xh-n-isisu ;
prov:generatedAtTime "2018-01-10T05:00:00Z|+02:00"^^xsd:dateTime ;
owl:versionInfo"2018-01-10"^^xsd:string ;
owl:hasVersion :entry/xh-n-isisu/2018-01-10#sense2 .
3.5. Modelling Provenance for a Lexicon
- Each lexicon is identified as a lime:lexicon and a prov:Entity.
- The prov:generatedAtTime property is recorded for each.
- The date a lexicon is changed is recorded using dct:modified.
- Other lexicons within the same namespace are indicated using dct:references.
- owl:sameAs is used to indicate that U1 is the same as the latest version of U3.
- The version is indicated using owl:versionInfo.
- dct:hasVersion is used to show the previously generated versions, using the versioned URIs (U3 for lexicons).
:lexicon/xh/2017-09-19/1
a lime:Lexicon , void:Dataset , prov:Dictionary ,
prov:Collection , prov:Entity ;
lime:language "xh" ;
dct:language <http://id.loc.gov/vocabulary/iso639-2/xho> ,
<http://lexvo.org/id/iso639-1/xh> ;
lime:lexicalEntries"1"^^xsd:integer ;
lime:linguisticCatalog <http://www.lexinfo.net/ontologies/2.0/lexinfo> ;
dct:description"Londisizwe.org - isiXhosa lexicon"@en ;
dct:license <http://creativecommons.org/publicdomain/mark/1.0/> ;
dct:creator <https://londisizwe.org> ;
prov:generatedAtTime "2017-09-19T05:00:11Z|+02:00"^^xsd:dateTime ;
prov:specializationOf :lexicon/xh ;
dct:modified "2017-09-19"^^xsd:date ;
owl:versionInfo"2017-09-19/1"^^xsd:string ;
owl:hasVersion :lexicon/xh/2017-09-01/1 , :lexicon/xh/2017-09-19/1 ;
dct:references :lexicon/en ;
prov:derivedByInsertionFrom :lexicon/xh/2017-09-01/1 ;
prov:qualifiedInsertion [
a prov:Insertion;
prov:dictionary :lexicon/xh/2017-09-01/1;
prov:insertedKeyEntityPair [
a prov:KeyEntityPair ;
prov:pairKey "xh-n-isisu"^^xsd:string ;
prov:pairEntity :entry/xh-n-isisu ;
] ;
] .
:lexicon/xh/2017-09-01/1
prov:invalidatedAtTime "2017-09-19T05:00:11Z|+02:00"^^xsd:dateTime .
where:- The current version was derived from the previous version, :lexicon/xh/2017-09-01/1, by means of inserting a key-value pair.
- The key, indicated above with the prov:pairKey relation, shares the same string literal as that for the dct:identifier relation in the associated lexical entry.
- The previous version of the lexicon is indicated to be outdated with the prov:invalidatedAtTime relation.
- Any information about the previous version beyond identifying it as a prov:Dictionary is not included here. Instead, that information will have been listed in the file of the previously published URI: https://londisizwe.org/lexicon/xh/2017-09-01/1
- U1:
- U3:
- U3:
1 DirectoryCheckHandler On 2 RewriteEngine On 3 RewriteRule ^(.*)/$ /$1 [R,L] 4 5 RewriteCond %{HTTP_ACCEPT} text/turtle 6 RewriteRule ^concept/(.*)$ /rdf/concept/$1 [NC,R=302,L] 7 RewriteRule ^concept/(.*)$ /page/concept/$1 [NC,R=302,L] 8 9 RewriteCond %{REQUEST_FILENAME} !-f 10 RewriteRule ^rdf/(.*)$ /rdf/$1.ttl [L] 11 RewriteRule ^page/(.*)$ /script.php?file=$1 [L]where:
- Line 1: By default, DirectoryCheckHandler is set to Off. Because the resource identifier for https://londisizwe.org/concept/000000001 is the same as the directory name in https://londisizwe.org/concept/000000001/2017-09-19, Apache automatically appends a trailing slash to the resource identifier in the former URI; setting to On prevents this [78].
- Line 3: This removes a trailing slash appended to any URI/URLs.
- Line 5: This is a rule condition which checks if the HTTP header of the web browser or software agent is set to text/turtle [79]. If the condition is met, then the server proceeds to Line 6, otherwise the server proceeds to Line 7.
- Line 7: This is the RewriteRule which redirects the web browser (or software agent which did not have an HTTP_header of text/turtle) to a web page of the original URI (thereby providing a human-readable view of the URI) [79].
- Line 9: This is a rule condition which checks if the filename does not exist. For the URI https://londisizwe.org/concept/000000001, the filename would be 000000001. If the condition is met, the server proceeds to Line 10, otherwise it proceeds to Line 11 [79].
- Line 10: This is the RewriteRule which internally rewrites the URI for the RDF document from Line 6 to the URL as specified [81]. The URI from Line 6 will not change for the software agent.
- Line 11: This is the RewriteRule which internally rewrites the URI for the web page from Line 7 to the URL specified [81]. The URI from Line 7 will not change for the web browser / software agent. For selected browsers (such as Mozilla Firefox), when viewing a TTL file, despite a flag being set which changes the MIME type (for example, [T = text/plain,L]), an automatic download starts instead of it being displayed in the web browser [80]. To counter this, the URI is mapped to a script which retrieves the contents of the file and displays it to the end-user, with the Content-Type set to “text/plain” within the script [82].
4. Future Work and Conclusions
translation relations can be inferred between terms in different languages when they refer to the same ontology entity. These lexical senses with an equivalent ontology reference have been regarded as a translation pair to be modelled.
Funding
Acknowledgments
Conflicts of Interest
Appendix A
@prefix : <https://londisizwe.org/> . @prefix ontolex: <http://www.w3.org/ns/lemon/ontolex#> . @prefix lime: <http://www.w3.org/ns/lemon/lime#> . @prefix dbr: <http://dbpedia.org/resource/> . @prefix dct: <http://purl.org/dc/terms/> . @prefix foaf: <http://xmlns.com/foaf/0.1/> . @prefix lexinfo: <http://www.lexinfo.net/ontology/2.0/lexinfo#> . @prefix lonvoc: <https://ontology.londisizwe.org/nounclass#> . @prefix mesh: <http://id.nlm.nih.gov/mesh/> . @prefix mmoon: <http://mmoon.org/core/> . @prefix owl: <http://www.w3.org/2002/07/owl#> . @prefix prov: <http://www.w3.org/ns/prov#> . @prefix pwn: <http://wordnet-rdf.princeton.edu/rdf/id/> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix void: <http://rdfs.org/ns/void#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
References
- Gillis-Webber, F. Managing provenance and versioning for an (evolving) dictionary in linked data format. In Proceedings of the 6th Workshop on Linked Data in Linguistics: Towards Linguistic Data Science, Co-Located with LREC2018, Miyazaki, Japan, 7–12 May 2018; Available online: http://lrec-conf.org/workshops/lrec2018/W23/pdf/2_W23.pdf (accessed on 10 October 2018).
- Doke, C.M. The Southern Bantu Languages; International African Institute: London, UK, 1954. [Google Scholar]
- Subfamily: Nguni (S.40). Available online: http://glottolog.org/resource/languoid/id/ngun1276 (accessed on 11 February 2018).
- Herbert, R.K.; Bailey, R. The Bantu languages: sociohistorical perspectives. In Language in South Africa; Mesthrie, R., Ed.; Cambridge University Press: Cambridge, UK, 2002; pp. 50–78. [Google Scholar]
- Pretorius, L. The multilingual semantic web as virtual knowledge commons: the case of the under-resourced South African languages. In Towards the Multilingual Semantic Web; Buitelaar, P., Cimiano, P., Eds.; Springer: Berlin, Germany, 2014; pp. 49–66. [Google Scholar]
- Taljard, E.; Bosch, S.E. A comparison of approaches to word class tagging: Disjunctively vs. conjunctively written Bantu languages. Nord. J. Afr. Stud. 2006, 15, 428–442. [Google Scholar]
- Bosque-Gil, J.; Gracia, J.; Montiel-Ponsoda, E. Towards a module for lexicography in OntoLex. In Proceedings of the 1st Workshop on the OntoLex Model (OntoLex-2017), Galway, Ireland, 18 June 2017; Available online: http://ceur-ws.org/Vol-1899/OntoLex_2017_paper_5.pdf (accessed on 20 October 2018).
- Crystal, D. The Cambridge Encyclopedia of Language; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Cyganiak, R.; Wood, D.; Lanthaler, M. RDF 1.1 Concepts and Abstract Syntax—W3C Recommendation 25 February 2014; World Wide Web Consortium; Available online: https://www.w3.org/TR/rdf11-concepts/ (accessed on 15 October 2018).
- Tim Berners-Lee: The Next Web. 2009. Available online: http://www.ted.com/talks/tim_berners_lee_on_the_next_web.html (accessed on 15 April 2017).
- Berners-Lee, T. Linked Data. 2006. Available online: https://www.w3.org/DesignIssues/LinkedData.html (accessed on 25 December 2017).
- Hyvönen, E. Publishing and Using Cultural Heritage Linked Data on the Semantic Web; Morgan & Claypool Publishers: San Rafael, CA, USA, 2012. [Google Scholar]
- Van Hooland, S.; Verborgh, R. Linked Data for Libraries, Archives and Museums; Facet Publishing: London, UK, 2014. [Google Scholar]
- Wood, D.; Zaidman, M.; Ruth, L.; Hausenblas, M. Linked Data: Structured Data on the Web; Manning Publications Co: New York, NY, USA, 2014. [Google Scholar]
- Gracia, J. Introduction to linked data for language resources. In Proceedings of the 2nd Summer Datathon on Linguistic Linked Open Data, Cercedilla, Spain, 26–30 June 2017. [Google Scholar]
- About|DBpedia. Available online: https://wiki.dbpedia.org/about (accessed on 10 January 2018).
- Converting BabelNet as Linguistic Linked Data. Available online: https://www.w3.org/community/bpmlod/wiki/Converting_BabelNet_as_Linguistic_Linked_Data (accessed on 5 December 2017).
- Gracia, J.; Villegas, M.; Gómez-Pérez, A.; Bel, N. The Apertium bilingual dictionaries on the web of data. Semant. Web 2018, 9, 231–240. Available online: http://www.semantic-web-journal.net/system/files/swj1419.pdf (accessed on 31 December 2017). [CrossRef]
- Gouws, R.H.; Prinsloo, D.J. Principles and Practice of South African Lexicography; SUN MeDIA: Stellenbosch, South Africa, 2005. [Google Scholar]
- Grace’s Guide to British Industrial History: Bengers Food. Available online: https://www.gracesguide.co.uk/Bengers_Food (accessed on 12 October 2018).
- Haushofer, L. Between food and medicine: artificial digestion, sickness, and the case of Benger’s Food. J. Hist. Med. Allied Sci. 2018, 73, 168–187. [Google Scholar] [CrossRef] [PubMed]
- Villazón-Terrazas, B.; Vilches-Blázquez, L.M.; Corcho, O.; Gómez-Pérez, A. Methodological guidelines for publishing government linked data. In Linking Government Data; Wood, D., Ed.; Springer: New York, NY, USA, 2012; pp. 27–49. Available online: https://link.springer.com/chapter/10.1007/978-1-4614-1767-5_2 (accessed on 12 October 2018).
- Vila-Suero, D.; Gómez-Pérez, A.; Montiel-Ponsoda, E.; Gracia, J.; Aguado-de-Cea, G. Publishing linked data on the web: The multilingual dimension. In Towards the Multilingual Semantic Web; Buitelaar, P., Cimiano, P., Eds.; Springer: Berlin, Germany, 2014; pp. 101–117. [Google Scholar]
- Gracia, J.; Vila-Suero, D. Guidelines for Linguistic Linked Data Generation: Bilingual Dictionaries; Final Community Group Report 29 September 2015; W3C Best Practices for Multilingual Linked Open Data Community Group under the W3C Community Final Specification Agreement (FSA), World Wide Web Consortium, 2015; Available online: https://www.w3.org/2015/09/bpmlod-reports/bilingual-dictionaries/ (accessed on 25 December 2017).
- Zainal, Z. Case study as a research method. Jurnal Kemanusiaan 2007, 9, 1–6. [Google Scholar]
- 2nd Summer Datathon on Linguistic Linked Open Data (SD-LLOD-17). Available online: http://datathon2017.retele.linkeddata.es/ (accessed on 12 October 2018).
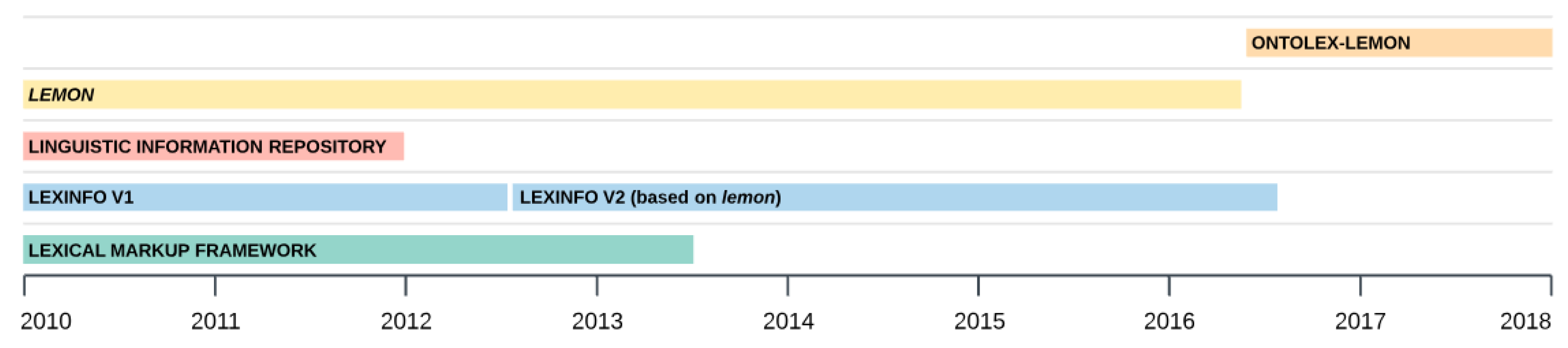
- Lemon—The Lexicon Model for Ontologies. Available online: https://lemon-model.net/ (accessed on 10 September 2018).
- Lexicon Model for Ontologies: Community Report, 10 May 2016. Final Community Group Report 10 May 2016, W3C Ontology-Lexica Community Group under the W3C Community Final Specification Agreement (FSA), World Wide Web Consortium: 2016. Available online: https://www.w3.org/2016/05/ontolex/ (accessed on 19 December 2017).
- Ontology-Lexica Community Group. Available online: https://www.w3.org/community/ontolex/ (accessed on 12 October 2018).
- McCrae, J.P.; Unger, C. Design patterns for engineering the ontology-lexicon interface. In Towards the Multilingual Semantic Web; Buitelaar, P., Cimiano, P., Eds.; Springer: Berlin, Germany, 2014; pp. 15–30. [Google Scholar]
- Francopoulo, G.; George, M. Model description. In LMF—Lexical Markup Framework; Francopoulo, G., Ed.; ISTE Ltd.: London, UK, 2013. [Google Scholar]
- McCrae, J. LMF. 2012. Available online: http://lemon-model.net/lemon-cookbook/node46.html (accessed on 20 October 2018).
- McCrae, J.; Spohr, D.; Cimiano, P. Linking lexical resources and ontologies on the semantic web with lemon. In The Semantic Web: Research and Applications; Antoniou, G., Grobelnik, M., Simperl, E., Parsia, B., Plexousakis, D., De Leenheer, P., Pan, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 245–259. [Google Scholar]
- Faab, G.; Bosch, S.E.; Gouws, R.H. A general lexicographic model for a typological variety of dictionaries in African languages. Lexikos 2014, 24, 94–115. [Google Scholar]
- Cimiano, P.; Buitelaar, P.; McCrae, J.; Sintek, M. LexInfo: A declarative model for the lexicon-ontology interface. Web Semant. Sci. Serv. Agents World Wide Web 2010, 9, 29–51. [Google Scholar] [CrossRef]
- Montiel-Ponsoda, E.; Vila-Suero, D.; Villazón-Terrazas, B.; Dunsire, G.; Escolano Rodríguez, E.; Gómez-Pérez, A. Style guidelines for naming and labeling ontologies in the multilingual web. In Proceedings of the International Conference on Dublin Core and Metadata Applications 2011, The Hague, The Netherlands, 21–23 September 2011; Available online: http://oa.upm.es/12469/1/INVE_MEM_2011_105132.pdf (accessed on 26 October 2018).
- Espinoza, M.; Gómez-Pérez, A.; Montiel-Ponsoda, E. Multilingual and localization support for ontologies. In The Semantic Web: Research and Applications; Aroyo, L., Traverso, P., Ciravegna, F., Cimiano, P., Heath, T., Hyvönen, E., Mizoguchi, R., Oren, E., Sabou, M., Simperl, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 821–825. [Google Scholar]
- Fang, Z.; Wang, H.; Gracia, J.; Bosque-Gil, J.; Ruan, T. Zhishi.lemon: On publishing Zhishi.me as linguistic linked open data. In The Semantic Web: ISWC 2016; Groth, P., Simperl, E., Gray, A., Sabou, M., Krötzsch, M., Lecue, F., Flöck, F., Gil, Y., Eds.; Springer: Cham, Switzerland, 2016; pp. 47–55. [Google Scholar]
- Khalfi, M.; Nahli, O.; Zarghili, A. Classical dictionary Al-Qamus in lemon. In Proceedings of the 2016 4th IEEE International Colloquium on Information Science and Technology (CiSt), Tangier, Morocco, 24–26 October 2016. [Google Scholar] [CrossRef]
- McCrae, J.P.; Bosque-Gil, J.; Gracia, J.; Buitelaar, P.; Cimiano, P. The Ontolex-Lemon model: Development and applications. In Proceedings of the eLex 2017 Electronic Lexicography in the 21st Century: Lexicography from Scratch, Leiden, The Netherlands, 19–21 September 2017; Available online: https://elex.link/elex2017/wp-content/uploads/2017/09/paper36.pdf (accessed on 26 October 2018).
- Tittel, S.; Chiarcos, C. Historical lexicography of Old French and linked open data: Transforming the resources of the Dictionnaire étymologique de l’ancien francais with Ontolex-Lemon. In Proceedings of the 6th Workshop on Linked Data in Linguistics: Towards Linguistic Data Science, Co-Located with LREC2018, Miyazaki, Japan, 12 May 2018; Available online: http://lrec-conf.org/workshops/lrec2018/W23/pdf/2_W33.pdf (accessed on 15 October 2018).
- DCMI Metadata Terms. Dublin Core Metadata Initiative: 2012. Available online: http://dublincore.org/documents/dcmi-terms/ (accessed on 10 January 2018).
- Brickley, D.; Miller, L. FOAF Vocabulary Specification 0.99. 2014. Available online: http://xmlns.com/foaf/spec/ (accessed on 10 January 2018).
- Library of Congress Names. Available online: http://id.loc.gov/authorities/names.html (accessed on 10 January 2018).
- Library of Congress Subject Headings. Available online: http://id.loc.gov/authorities/subjects.html (accessed on 10 January 2018).
- Wunner, T. LEXINFO Vocabulary. DERI Vocabularies: 2012. Available online: http://vocab.deri.ie/lexinfo# (accessed on 17 January 2018).
- Fact Sheet: Medical Subject Headings. Available online: https://www.nlm.nih.gov/pubs/factsheets/mesh.html (accessed on 10 January 2018).
- The Multilingual Morpheme Ontology: Home. Available online: http://mmoon.org/ (accessed on 17 January 2018).
- Lebo, T.; Sahoo, S.; McGuinness, D.; Belhajjame, K.; Cheney, J.; Corsar, D.; Garijo, D.; Soiland-Reyes, S.; Zednik, S.; Zhao, J. PROV-O: The PROV Ontology. W3C Recommendation 30 April 2013, World Wide Web Consortium: 2013. Available online: https://www.w3.org/TR/prov-o/ (accessed on 1 January 2018).
- WordNet RDF. Available online: http://wordnet-rdf.princeton.edu/ (accessed on 11 November 2017).
- Alexander, K.; Cyganiak, R.; Hausenblas, M.; Zhao, J. Describing Linked Datasets with the VoID Vocabulary. W3C Interest Group Note 03 March 2011, World Wide Web Consortium: 2011. Available online: https://www.w3.org/TR/void/ (accessed on 10 January 2018).
- Di Maio, P. Linked data beyond libraries. In Linked Data and User Interaction; Cervone, H.F., Svensson, L.G., Eds.; Walter de Gruyter GmbH: Berlin, Germany, 2015. [Google Scholar]
- McCrae, J.; Montiel-Ponsoda, E.; Cimiano, P. Integrating WordNet and Wiktionary with lemon. In Linked Data in Linguistics; Chiarcos, C., Nordhoff, S., Hellman, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 25–34. [Google Scholar]
- Bouda, P.; Cysouw, M. Treating dictionaries as a linked-data corpus. In Linked Data in Linguistics; Chiarcos, C., Nordhoff, S., Hellman, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 15–24. [Google Scholar]
- Klein, M.; Fensel, D. Ontology versioning on the Semantic Web. In Proceedings of the First International Conference on Semantic Web Working, California, CA, USA, 30 July–1 August 2001; Available online: https://pdfs.semanticscholar.org/417f/b1dd895a9416f9d56932e6b3870749ba582c.pdf (accessed on 18 October 2018).
- Flati, T.; Moro, A.; Matteis, L.; Navigli, R.; Velardi, P. Guidelines for linguistic linked data generation: Multilingual dictionaries (Babelnet). Final Community Group Report 29 September 2015, W3C Best Practices for Multilingual Linked Open Data Community Group under the W3C Community Final Specification Agreement (FSA), World Wide Web Consortium: 2015. Available online: https://www.w3.org/2015/09/bpmlod-reports/multilingual-dictionaries/ (accessed on 27 December 2017).
- Van Erp, M. Reusing linguistic resources: Tasks and goals for a linked data approach. In Linked Data in Linguistics; Chiarcos, C., Nordhoff, S., Hellman, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 57–64. [Google Scholar]
- Eckart, K.; Riester, A.; Schweitzer, K. A discourse information radio news database for linguistic analysis. In Linked Data in Linguistics; Chiarcos, C., Nordhoff, S., Hellman, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 65–76. [Google Scholar]
- De Rooij, S.; Beek, W.; Bloem, P.; van Harmelen, F.; Schlobach, S. Are names meaningful? Quantifying social meaning on the semantic web. In The Semantic Web: ISWC 2016; Groth, P., Simperl, E., Gray, A., Sabou, M., Krötzsch, M., Lecue, F., Flöck, F., Gil, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 184–199. [Google Scholar]
- Kiryakov, A.; Ognyanov, D. Tracking changes in RDF(S) repositories. In Proceedings of the 13th International Conference on Knowledge Engineering and Knowledge Management (EKAW 2002), Sig enza, Spain, 1–4 October 2002; Gómez-Pérez, A., Benjamins, V.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2473, pp. 373–378. Available online: https://pdfs.semanticscholar.org/9dec/6fddad51df8d708dfe5b97b752fb563fc08a.pdf (accessed on 20 October 2018).
- Bond, F.; Vossen, P.; McCrae, J.P.; Fellbaum, C. CILI: The Collaborative Interlingual Index. 2016. Available online: http://gwc2016.racai.ro/Slide-uri/day01/Bond,%20The%20Collaborative%20Interlingual%20Index.pdf (accessed on 18 October 2018).
- Heath, T.; Bizer, C. Linked Data: Evolving the Web into a Global Data Space; Morgan & Claypool Publishers: San Rafael, CA, USA, 2011. [Google Scholar]
- Archer, P.; Goedertier, S.; Loutas, N. D7.1.3—Study on Persistent URIs, with Identification of Best Practices and Recommendations on the Topic for the MSs and the EC. 2012. Available online: https://joinup.ec.europa.eu/sites/default/files/document/2013-02/D7.1.3%20-%20Study%20on%20persistent%20URIs.pdf (accessed on 26 December 2017).
- Hogan, A.; Umbrich, J.; Harth, A.; Cyganiak, R.; Polleres, A.; Decker, S. An empirical survey of linked data conformance. Web Semant. Sci. Serv. Agents World Wide Web 2012, 14, 14–44. [Google Scholar] [CrossRef]
- Simons, N.; Richardson, J. New Content in Digital Repositories: The Changing Research Landscape; Chandos Publishing: Oxford, UK, 2013. [Google Scholar]
- Keller, M.A.; Persons, J.; Glaser, H.; Calter, M. Report on the Stanford Linked Data Workshop, 27 June–1 July 2011. Available online: https://www.clir.org/wp-content/uploads/sites/6/LinkedDataWorkshop.pdf (accessed on 26 December 2017).
- Labra Gayo, J.E.; Kontokostas, D.; Auer, S. Multilingual Linked Data Patterns. Semant. Web J. 2015, 6. Available online: http://www.semantic-web-journal.net/system/files/swj495.pdf (accessed on 27 December 2017). [CrossRef]
- Sachs, J.; Finin, T. What Does It Mean for a URI to resolve? In Proceedings of the AAAI Spring Symposium on Linked Data Meets Artificial Intelligence, Palo Alto, CA, USA, 2010; Available online: http://ebiquity.umbc.edu/_file_directory_/papers/495.pdf (accessed on 26 December 2017).
- Prinsloo, D. Review: Oxford Bilingual School Dictionary: Zulu and English. Lexikos 2010, 20, 760–766. [Google Scholar] [CrossRef]
- De Schryver, G.-M. Revolutionizing Bantu lexicography—A Zulu case study. Lexikos 2010, 20, 161–201. [Google Scholar] [CrossRef]
- Zgusta, L. Manual of Lexicography; Academia, Publishing House of the Czechslovak Academy of Sciences: Prague, Czech Republic, 1971. [Google Scholar]
- Cookbook for Open Government Linked Data. Available online: https://www.w3.org/2011/gld/wiki/Linked_Data_Cookbook (accessed on 4 January 2018).
- MacVicar, N. “Breath”. In English-Xhosa Dictionary for Nurses, 2nd ed.; Lovedale Press: Lovedale, South Africa, 1935; p. 13. [Google Scholar]
- McCrae, J.P.; Gracia, J. Introduction to the Ontolex-Lemon Model. In Proceedings of the 2nd Summer Datathon on Linguistic Linked Open Data, Cercedilla, Spain, 26–30 June 2017. [Google Scholar]
- Faniel, I.M.; Yakel, E. Practices do not make perfect: Disciplinary data sharing and reuse practices and their implications for repository data curation. In Curating Research Data: Practical Strategies for Your Digital Repository; Johnston, L.R., Ed.; Association of College and Research Libraries: Chicago, IL, USA, 2017; pp. 103–126. [Google Scholar]
- Tennis, J.T. Scheme versioning in the semantic web. In Knitting the Semantic Web; Greenberg, J., Méndez, E., Eds.; CRC Press: Boca Raton, FL, USA, 2007; pp. 85–104. [Google Scholar]
- Missier, P.; Moreau, L.; Cheney, J.; Lebo, T.; Soiland-Reyes, S. PROV-Dictionary: Modeling Provenance for Dictionary Data Structures. W3C Working Group Note 30 April 2013, World Wide Web Consortium: 2013. Available online: https://www.w3.org/TR/2013/NOTE-prov-dictionary-20130430/ (accessed on 1 January 2018).
- Apache Module Mod_Dir. Available online: https://httpd.apache.org/docs/2.4/mod/mod_dir.html (accessed on 20 October 2018).
- Apache Module Mod_Rewrite. Available online: https://httpd.apache.org/docs/2.4/mod/mod_rewrite.html (accessed on 20 October 2018).
- RewriteRule Flags. Available online: https://httpd.apache.org/docs/2.4/rewrite/flags.html (accessed on 20 October 2018).
- Redirecting and Remapping with Mod_Rewrite. Available online: https://httpd.apache.org/docs/2.4/rewrite/remapping.html (accessed on 20 October 2018).
- PHP: header—Manual. Available online: http://php.net/manual/en/function.header.php (accessed on 31 October 2018).
- McArthur, T. Worlds of Reference; Cambridge University Press: Cambridge, UK, 1986. [Google Scholar]
- Verborgh, R.; Vander Sande, M.; Hartig, O.; Van Herwegen, J.; De Vocht, L.; De Meester, B.; Haesendonck, G.; Colpaert, P. Triple pattern fragments: A low-cost knowledge graph interface for the web. J. Web Semant. 2016, 37, 184–206. [Google Scholar] [CrossRef]
- Noy, N.F.; Musen, M.A. Ontology versioning in an ontology management framework. IEEE Intell. Syst. 2004, 19, 6–13. [Google Scholar] [CrossRef]
- Plessers, P.; De Troyer, O. Ontology change detection using a version log. In Proceedings of the 4th International Conference on The Semantic Web, Galway, Ireland, 6–10 November 2005; Available online: https://pdfs.semanticscholar.org/3c52/491aa37b6291b58630de25bcd8f2262aebb5.pdf (accessed on 19 October 2018).
- Gracia, J.; Kernerman, I.; Bosque-Gil, J. Toward linked data-native dictionaries. In Proceedings of the eLex 2017 Electronic Lexicography in the 21st Century: Lexicography from Scratch, Leiden, The Netherlands, 19–21 May 2017; Available online: https://elex.link/elex2017/wp-content/uploads/2017/09/paper33.pdf (accessed on 22 October 2018).
- Princeton WordNet 3.1. Available online: https://wordnet-rdf.princeton.edu/ttl/lemma/abdomen (accessed on 24 October 2018).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 Inter-operability | 2 Separation & Independence | 3 Linguistic Information | 4 Morphological Decomposition | 5 Multi-linguality | 6 Ontological Representation | 7 Linked Data Principles | |
| SKOS | Yes | No | No | No | No | No * | Yes |
| LMF | No | No | Yes | Yes | Yes | No | No |
| LexInfo | Yes | Yes | Yes | Yes | No | Yes | Yes |
| LIR | Yes | Yes | Yes | No | Yes | Yes | Yes |
| Ontolex-Lemon | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gillis-Webber, F. Conversion of the English-Xhosa Dictionary for Nurses to a Linguistic Linked Data Framework. Information 2018, 9, 274. https://doi.org/10.3390/info9110274
Gillis-Webber F. Conversion of the English-Xhosa Dictionary for Nurses to a Linguistic Linked Data Framework. Information. 2018; 9(11):274. https://doi.org/10.3390/info9110274
Chicago/Turabian StyleGillis-Webber, Frances. 2018. "Conversion of the English-Xhosa Dictionary for Nurses to a Linguistic Linked Data Framework" Information 9, no. 11: 274. https://doi.org/10.3390/info9110274
APA StyleGillis-Webber, F. (2018). Conversion of the English-Xhosa Dictionary for Nurses to a Linguistic Linked Data Framework. Information, 9(11), 274. https://doi.org/10.3390/info9110274