1. Introduction
Extensible Markup Language (XML), which became a World Wide Web Consortium (W3C) Recommendation in 1998, still belongs to the main methods of exchanging data over the Internet. It also plays an important role in many aspects of software development, often to simplify data storage and sharing. Thus, efficient storing and querying of XML data are key tasks that have been extensively studied during the past few years [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15].
To be able to retrieve the data from XML documents, various query languages such as XPath [
16], XPointer [
17] and XLink [
18] have been designed. However, without a structural summary, query processing can be quite inefficient due to an exhaustive traversal on XML data. To achieve fast searching, we can preprocess the data subject and construct an index.
Basically, the problem of XML data indexing is constructing a data structure able to efficiently process XML query languages, such as XPath. There are two crucial issues connected with all indexing methods: first, the requirement for a small size of the index; second, very fast query processing, which ideally means that the answers to the queries are found in time linear to the size of the query and do not depend on the size of the subject where the queries are located. If these requirements are fulfilled, the index structure allows one to answer a number of queries with low requirements for both time and space complexity.
However, the flexibility of the specifications of XML queries adds to the challenge of indexing methods, and the creation of a universal index that is able to process all of the possible XML queries efficiently is a very challenging area. Using only the two most commonly-used XPath axes (child axis and descendant-or-self axis), the number of potential queries is exponential (e.g.,
for a simple linear XML tree with
n nodes [
19]). Therefore, there is always a tradeoff between the size and the power of an XML index. It either needs to be large to perform well or performs poorly as a consequence of saving space.
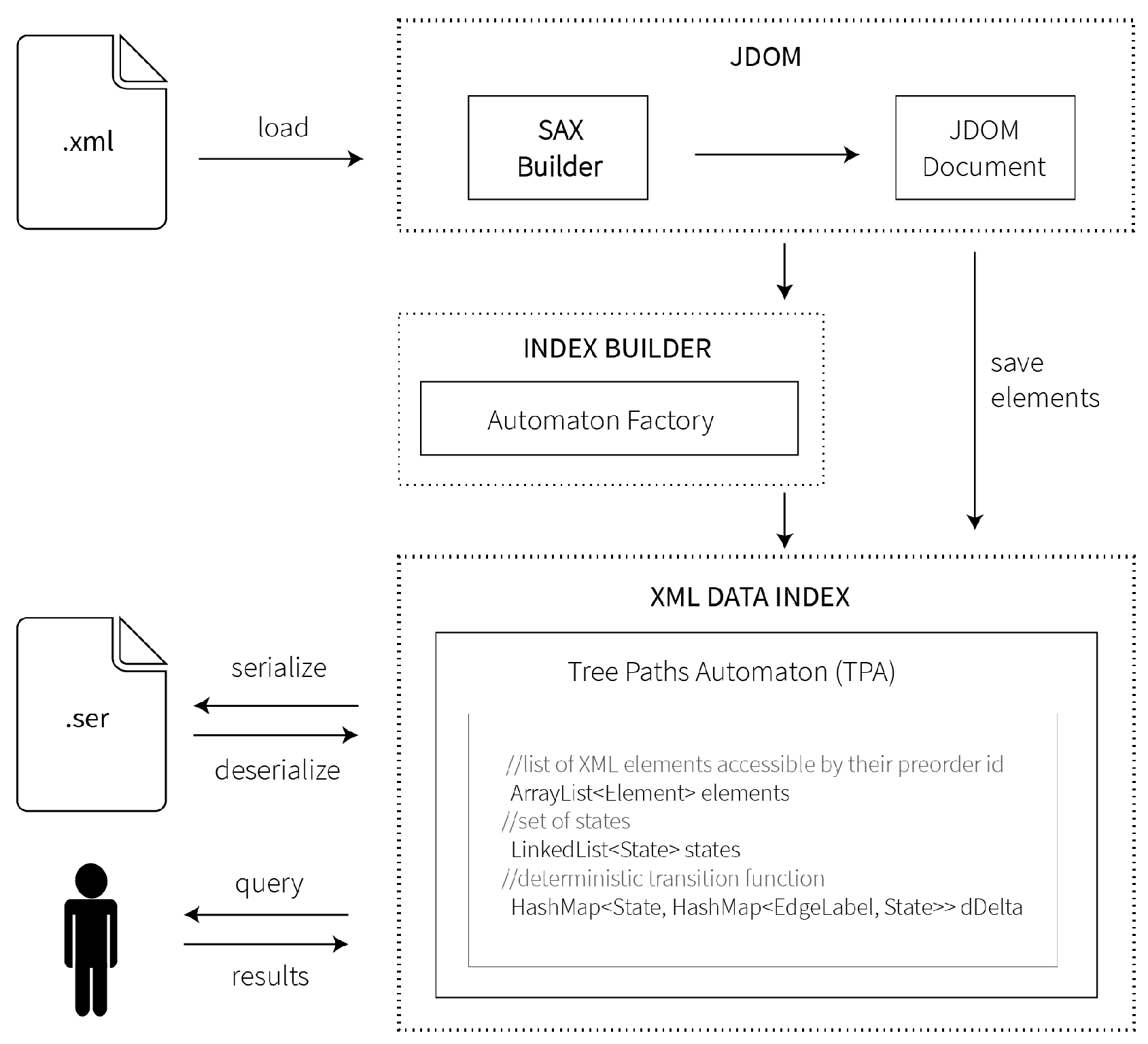
In this paper, we propose three indexing methods that are all based on finite state automata. These methods are simple and allow one to efficiently process a small subset of XPath. Therefore, having an XML data structure, our methods can be used efficiently as auxiliary data structures that enable answering a particular set of queries.
All automata presented in this paper support some fragments of linear XPath queries. In particular, we focused on the two common axes (i.e., child and descendant-or-self) with name tests. However, the techniques described here may be also relevant to the general XPath processing problem. First, we believe that a similar approach can be used to build automata that support other XPath axes (e.g, an automaton supporting the parent and ancestor axis). Second, processing linear expressions is a subproblem of processing more complex queries, as we can decompose them into linear fragments. Third, this can be seen as a building block for more powerful processors able to process branching queries. Moreover, it is easy to combine our indexes presented in this paper with other automata-based indexes using standard methods of automata theory.
First, we present Tree String Paths Automaton (TSPA) and Tree String Path Subsequences Automaton (TSPSA; introduced in [
20]), aimed at assisting in evaluating XPath queries with either child or descendant-or-self axes only. Then, we present Tree Paths Automaton (TPA; introduced in [
21]), which is designed to process XPath queries using any combination of child and descendant-or-self axes.
The rest of this paper is organized as follows.
Section 2 discusses state-of-the-art methods for XML data indexing.
Section 3 gives the necessary theoretical background including a brief description of both XML and XPath. Next, in
Section 4, we introduce our approach to XML data indexing using automata theory. The theoretical time and space complexities of the proposed methods and experimental evaluation are discussed in
Section 5 and
Section 6, respectively. Finally, we summarize the contributions of our research, discuss our future work directions and conclude the paper in
Section 7.
4. Automata Approach to XML Data Indexing
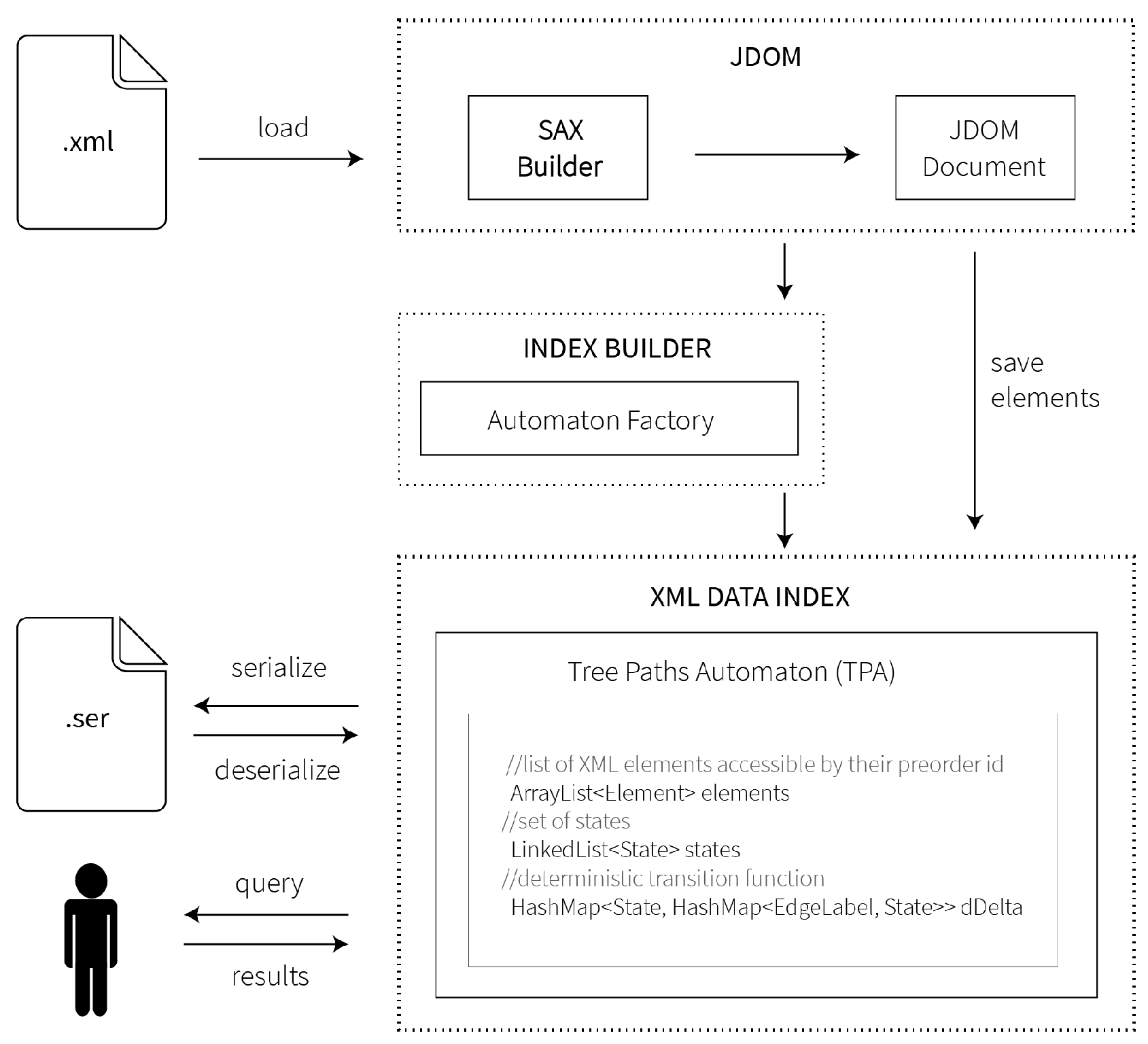
In this section, we introduce three new methods for the problem of XML data indexing using the automata theory and show that automata can be used efficiently for the purpose of indexing XML documents. These methods are simple and allow one to efficiently process a small subset of XPath. Therefore, having an XML data structure, our methods can be used efficiently as auxiliary data structures that enable answering a particular set of queries. Given an XML document and an input XPath query, the searching phase finds the answer of the query in time linear in the size of the query and does not depend on the size of the original XML document.
This section is organized as follows. First, we provide some common preliminaries. Next, we introduce the Tree String Paths Automaton (TSPA) representing an index for all linear XPath queries using the child axis (i.e., /) only, denoted as . After that, we present the Tree String Path Subsequences Automaton (TSPSA), an index for all queries using the descendant-or-self axis (i.e., //) only. Finally, we introduce the Tree Paths Automaton (TPA), which is designed to process all XPath queries with any combination of child (i.e., /) and descendant-or-self (i.e., //) axes, denoted as .
4.3. Tree String Path Subsequences Automaton
The Tree String Path Subsequences Automaton (TSPSA) is a finite state automaton that efficiently evaluates all linear XPath queries
where only the descendant-or-self axis (i.e., //-axis) is used. Again, we can represent such a fragment of XPath queries over an XML document
D by the context-free grammar as follows:
Definition 6 (Tree string path subsequences automaton).
Let D be an XML document. TSPSA accepts all queries of D, and for each query Q, it gives a list of elements satisfying Q.
As for the TSPA, the construction of TSPSA is very systematic. The given XML tree model
T is preprocessed and the string path set
obtained. However, to satisfy XPath queries with the //-axis, we are interested in subsequences of a string path rather than its prefixes. Which is why we construct a subsequence automaton for each string path
instead of a prefix automaton. The automaton solving the problem of subsequences for both single and multiple strings is also referred to as the Directed Acyclic Subsequence Graph (DASG) and is further studied in [
38,
39]. Therefore, we propose the XML index problem to be another application area of DASG.
There are three building algorithms for DASG for a set of strings available: right-to-left [
40], left-to-right [
41] and on-line [
39]. However, none of them is based on a subset construction, which gives the sets of positions serving as answers for input queries. Therefore, we propose a direct subset construction of a deterministic subsequence automaton; see Algorithm 3 and
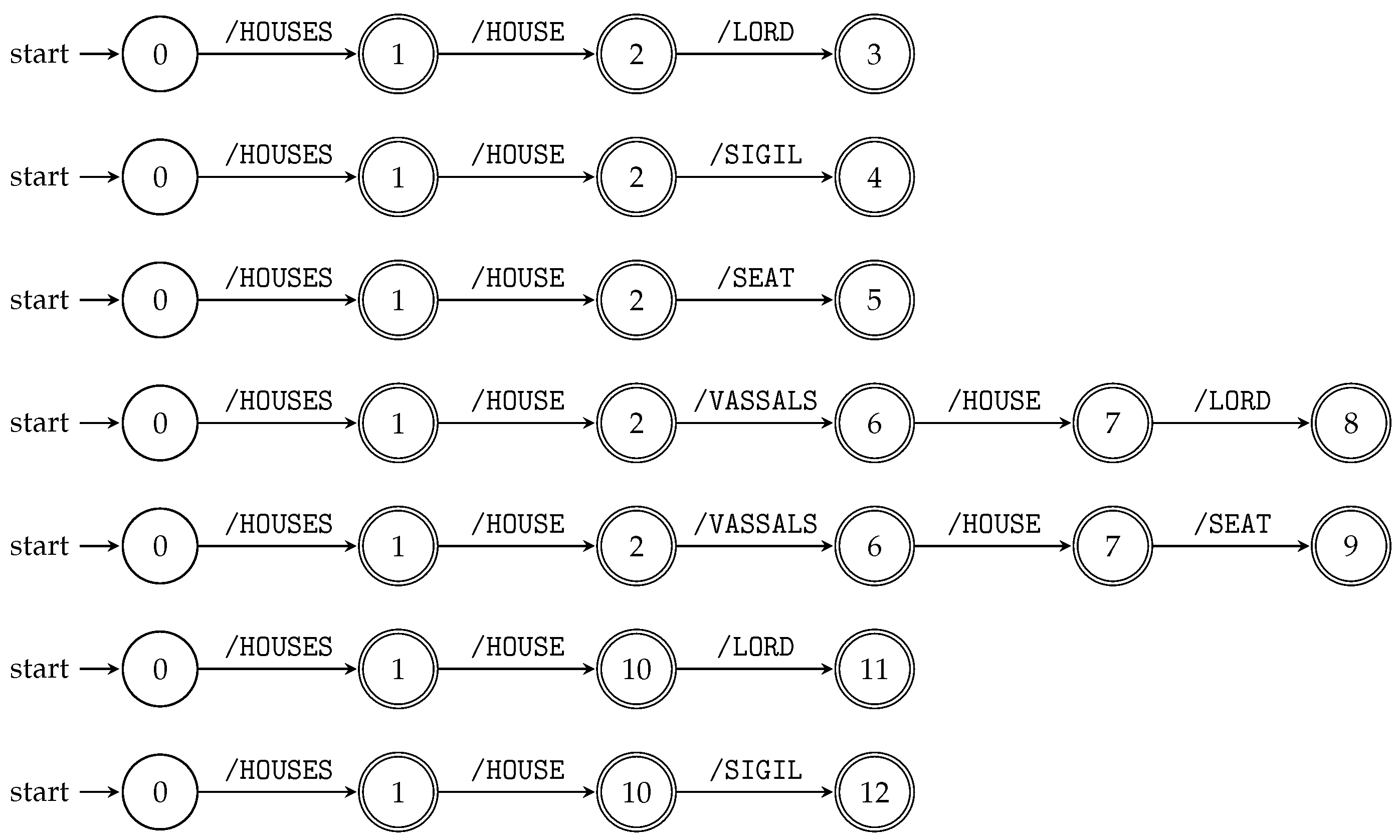
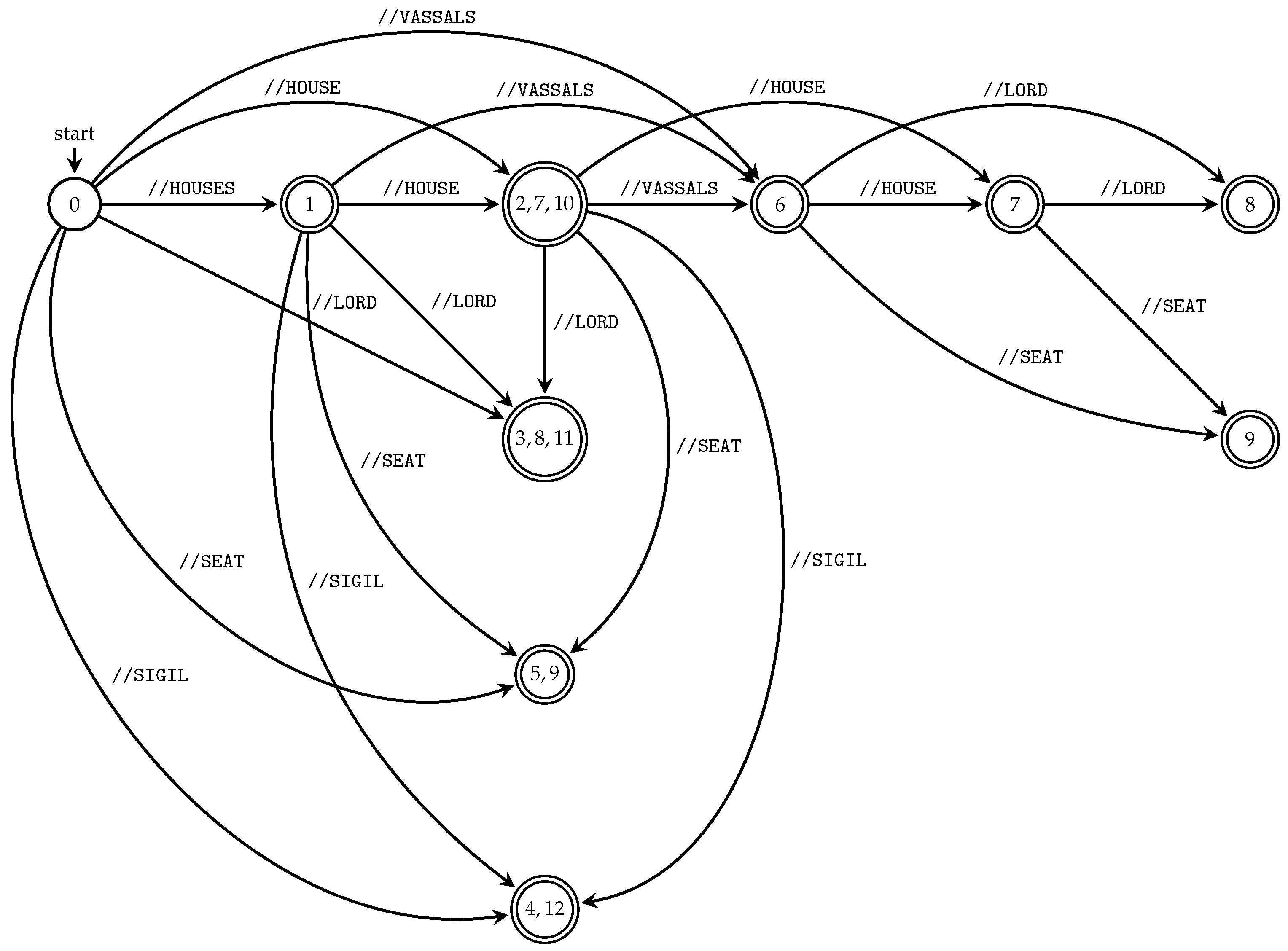
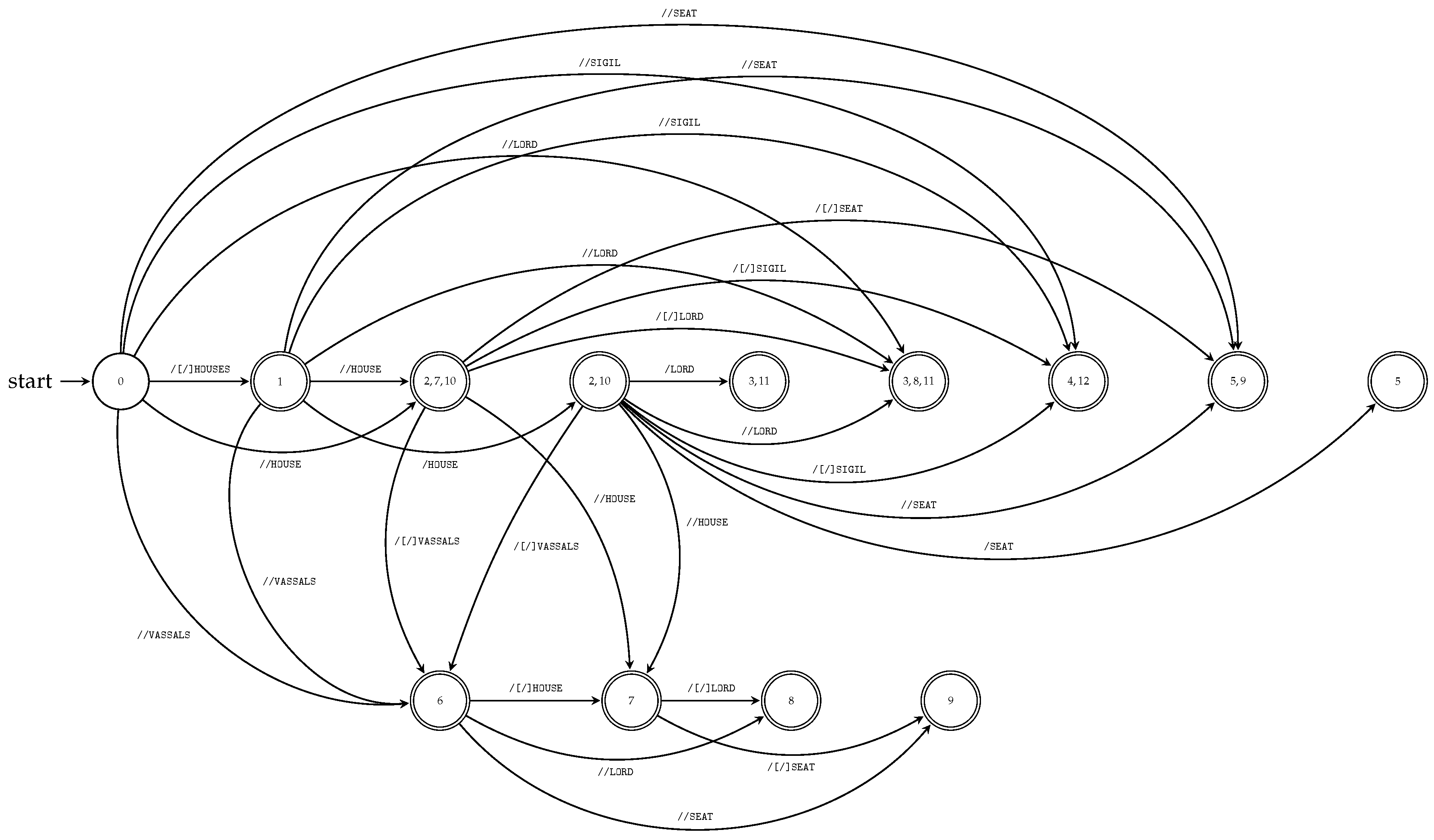
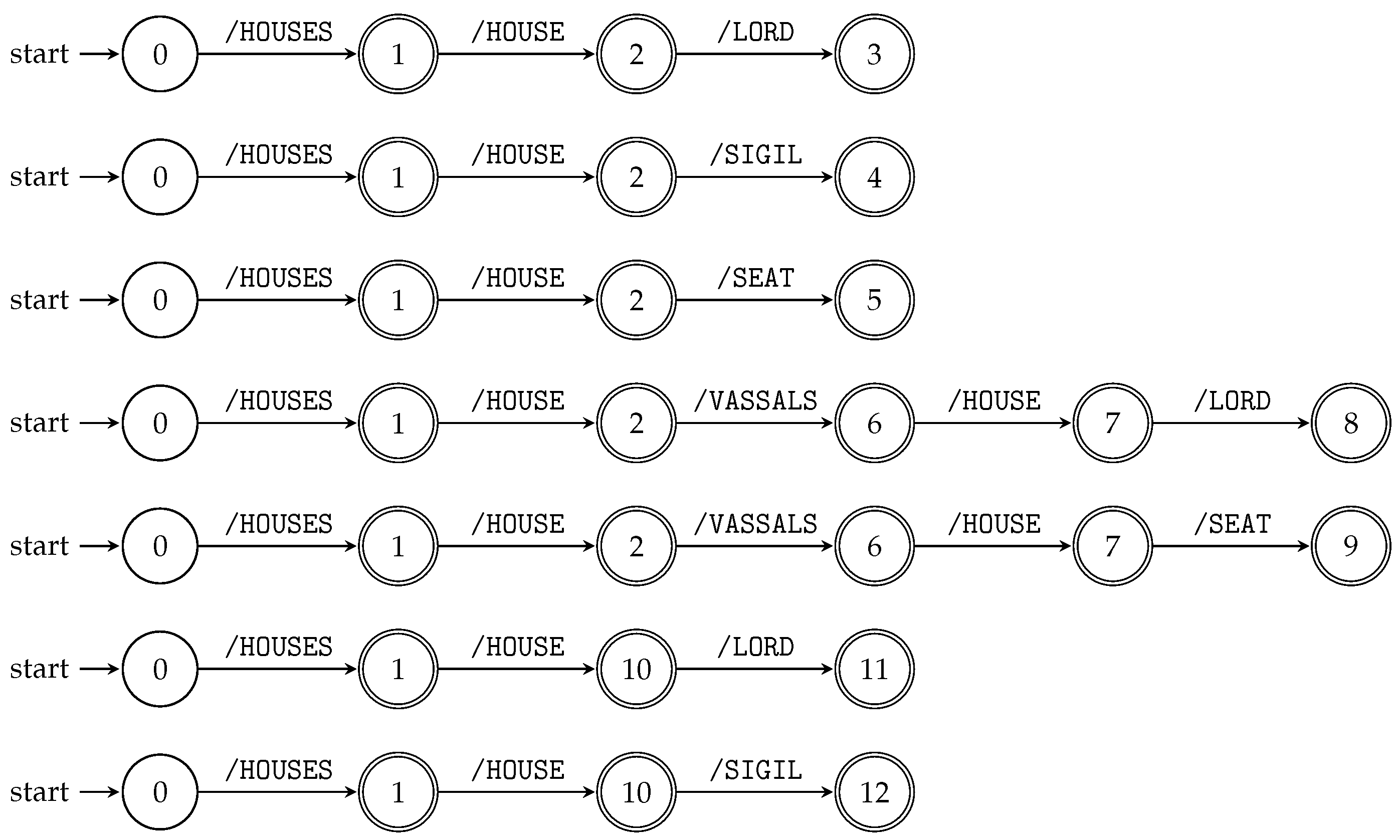
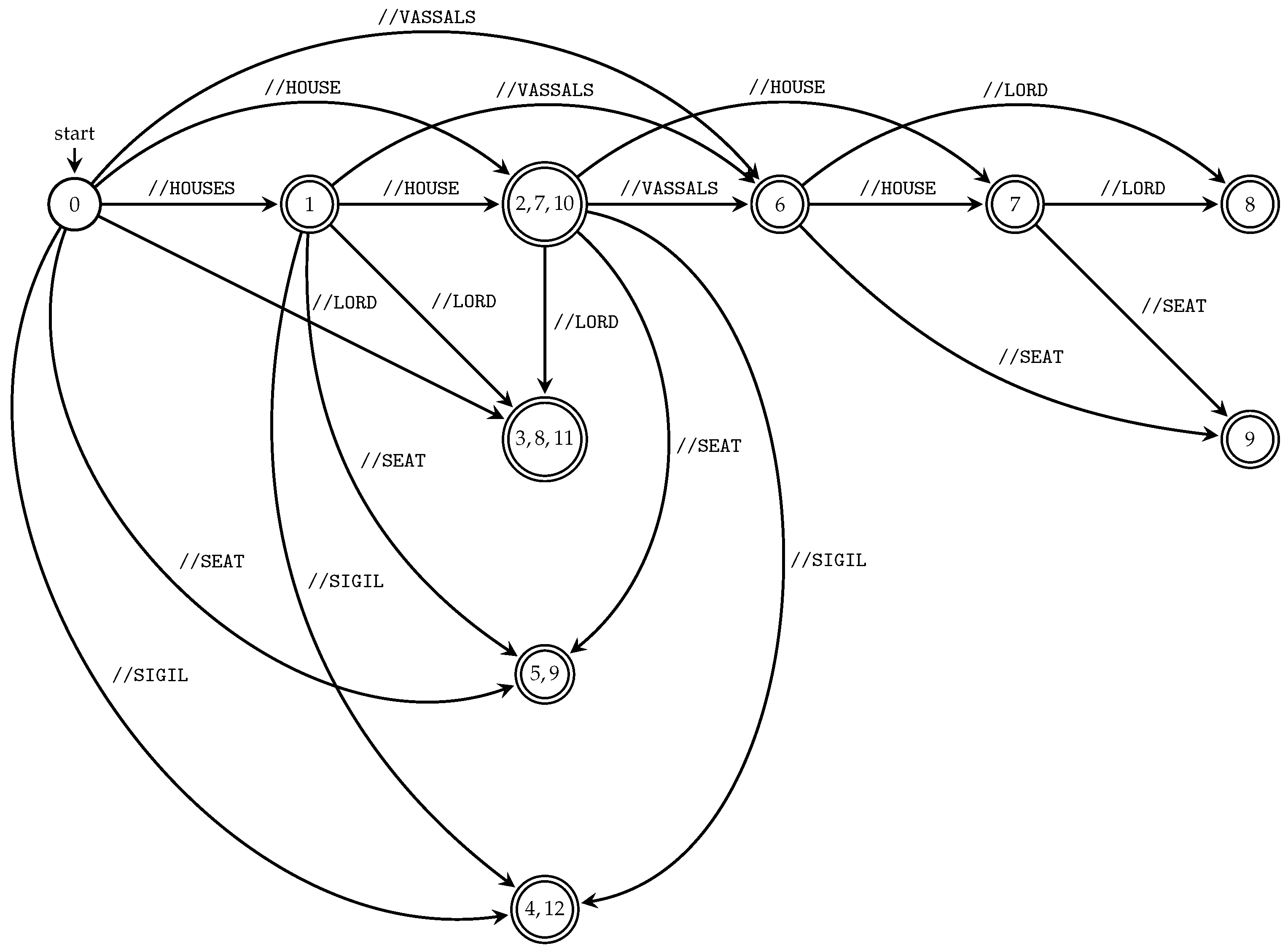
Figure 4.
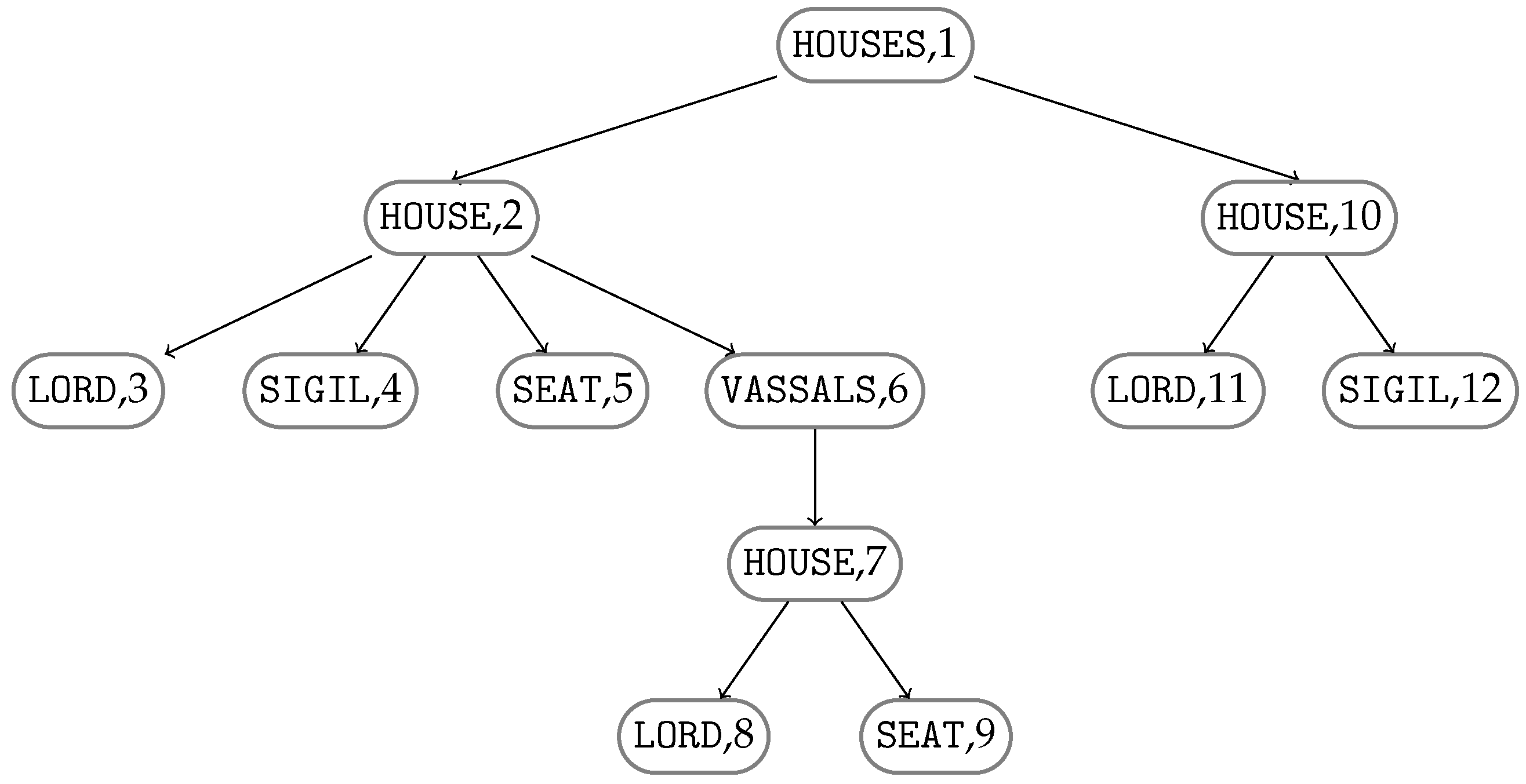
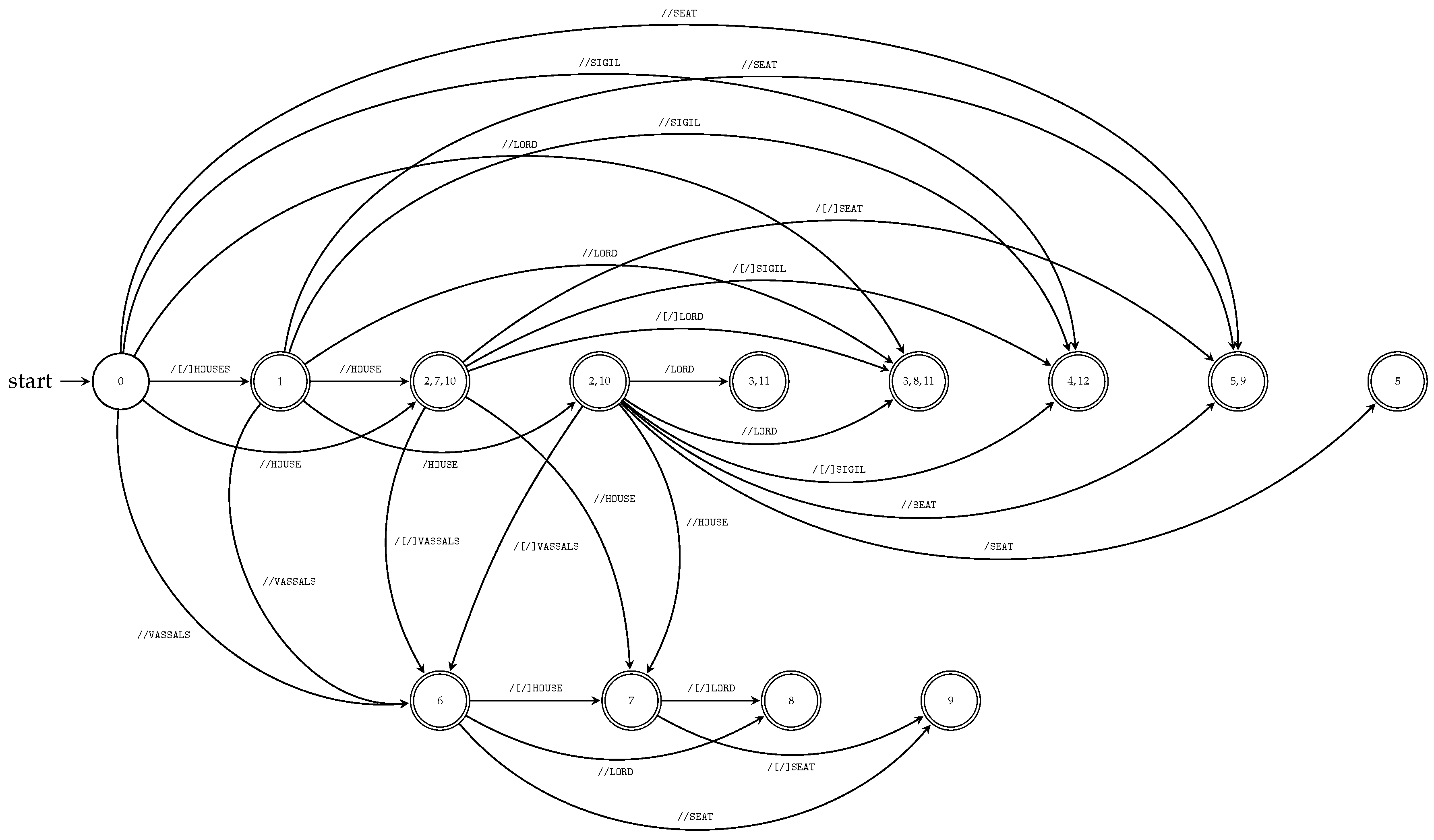
Figure 4 shows transition diagrams of the deterministic subsequence automata constructed by Algorithm 3 for all string paths contained in
, where
T is the XML tree model
T illustrated in
Figure 1.
| Algorithm 3: Construction of a deterministic subsequence automaton for a single string path. |
| Data: A string path . |
| Result: DFSA accepting all (non-empty) queries of P |
compute . Build the “backbone” of the finite state automaton :
- (a)
-
, , , - (b)
-
, where :
set state , add , .
Insert “additional transitions” into the automaton M:
, :
add , if there exists such where otherwise.
|
Definition 7 (Set of occurrences of an element label in a string path).
Let be a string path and e be an element label occurring at several positions in P (i.e., for some i). A set of occurrences of the element label e in P is a totally ordered set . The ordering is equal to ordering of element prefix identifiers as natural numbers.
Definition 8 (ButFirst).
Let P and be a string path and a set of occurrences of an element label e in the string path P, respectively. Then, we define a function .
Theorem 1. Given a string path , Algorithm 3 correctly constructs a deterministic finite state automaton M accepting all queries of P.
Proof. We will prove the following equivalence: M accepts a string X if and only if X is the query of the string path P.
If M accepts a string X, then X is the query of P.
If X is the query of P then M accepts X. Assume to the contrary that over the alphabet is the query of P and M does not accept X. If this is the case, either M reads the whole input and terminates in a non-final state or M does not read the whole input. In the first case, terminating in a non-final state means to stop in the initial state, contradicting our assumption that X is non-empty. The second case, reading just part of the input, means there exists such a symbol that M has no transition leading from the current state labeled by .
However, if the automaton reads some symbol, it always goes from the current state to the closest higher state representing an occurrence of that symbol. During Step ii, in Phase 2, all transitions added lead to the neighbor state, and during Step i, in Phase 3, we choose suitable higher state using two conditions. First, the state has to correspond to the correct symbol, which is satisfied by the first condition: there exists such where . Second, we need to ensure that the state is the closest possible, which is satisfied by the second condition: . Therefore, no subsequence is missed.
Thus, M reads , and the current state of M is . Due to Steps 2 and 3, there exists no transition from state to a state where (i.e., to the “left”); therefore, . Because of (2b)i., each state of M corresponds to a node of P. Because of (2b)ii. and 3i., there exists a transition from for such that occurs right of , as every transition leads from to the state with the incoming transition labeled with (the nonexistent part of 3i.). Therefore, is not the query of P, which is a contradiction. ☐
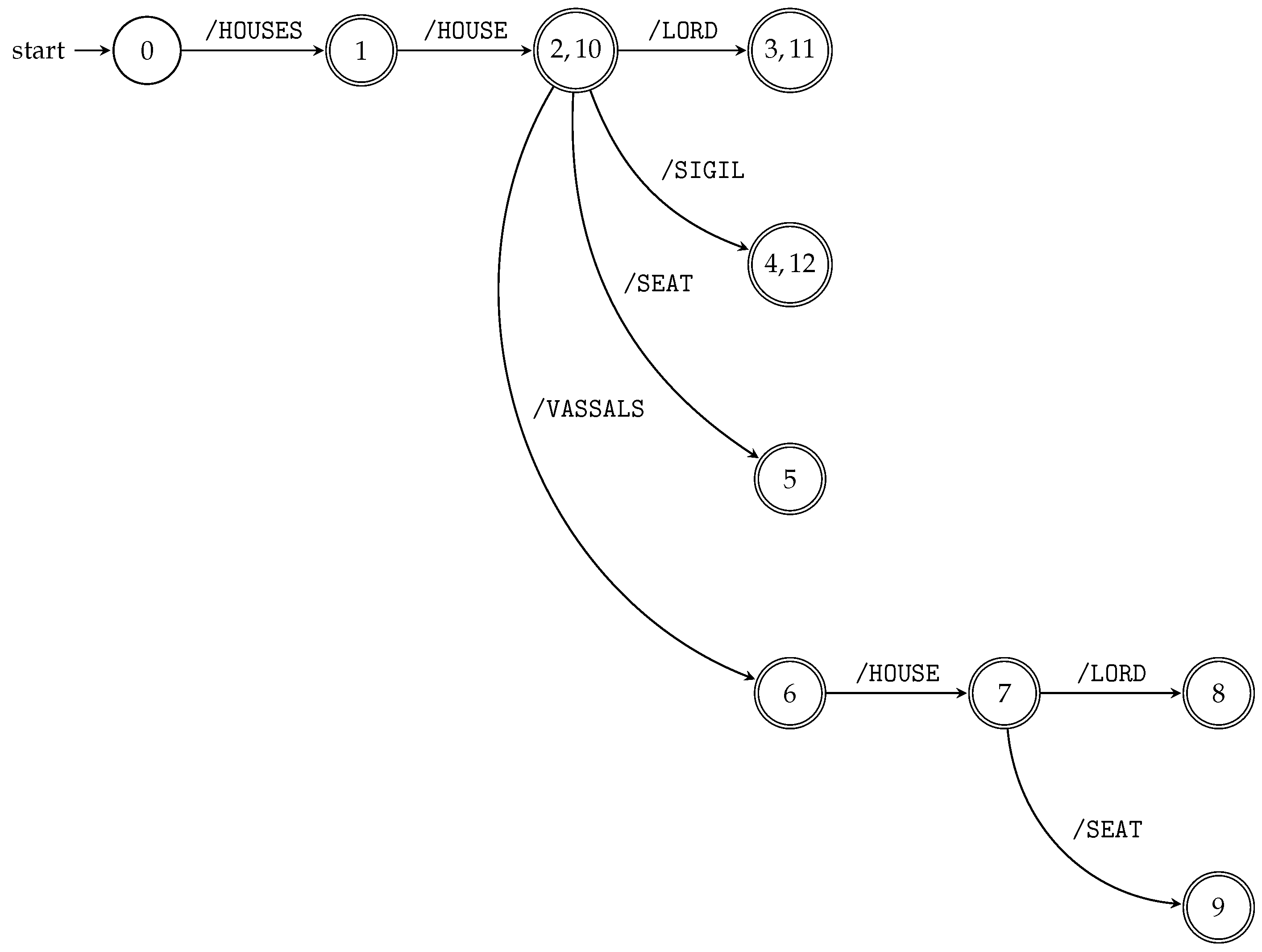
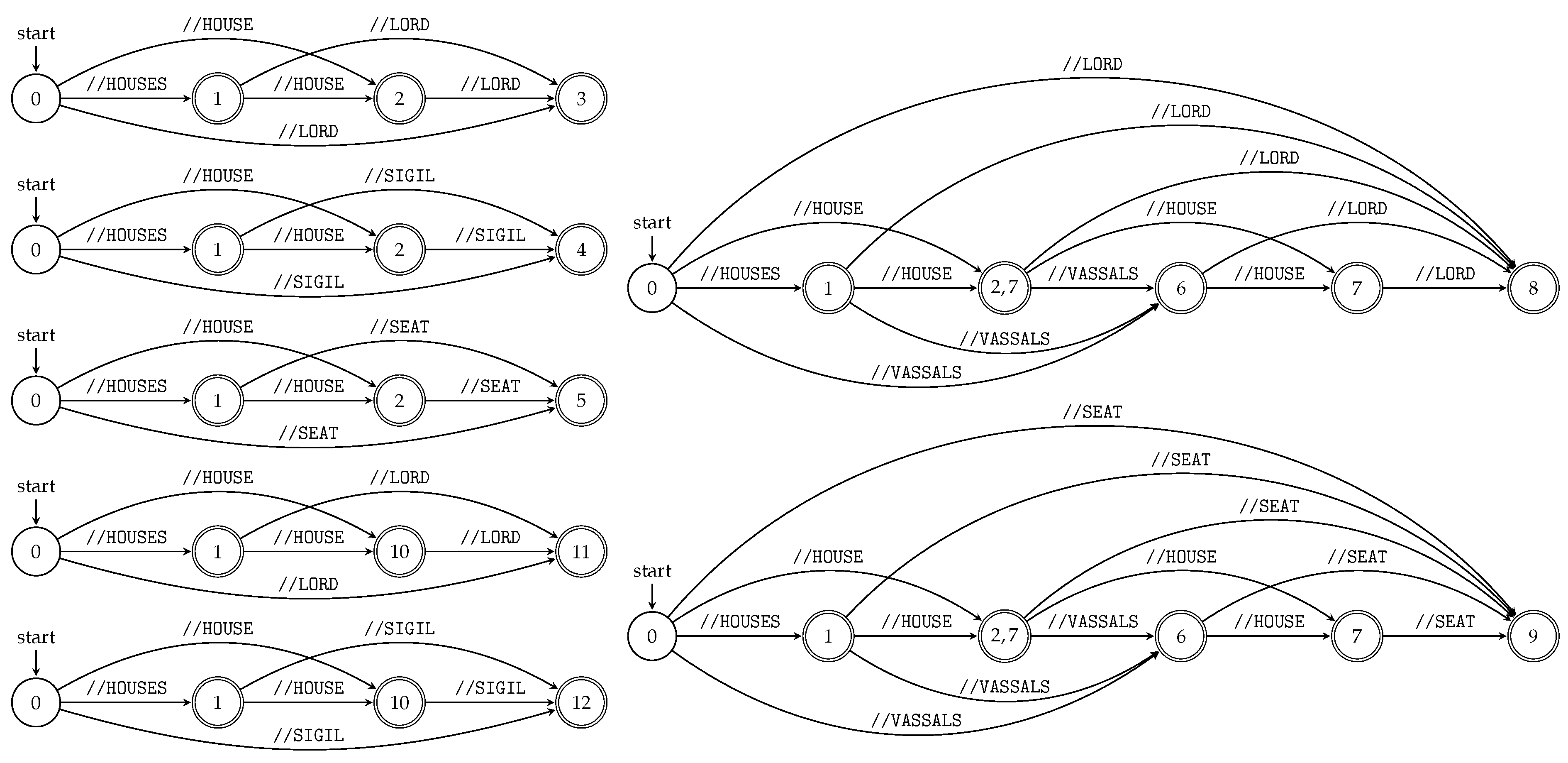
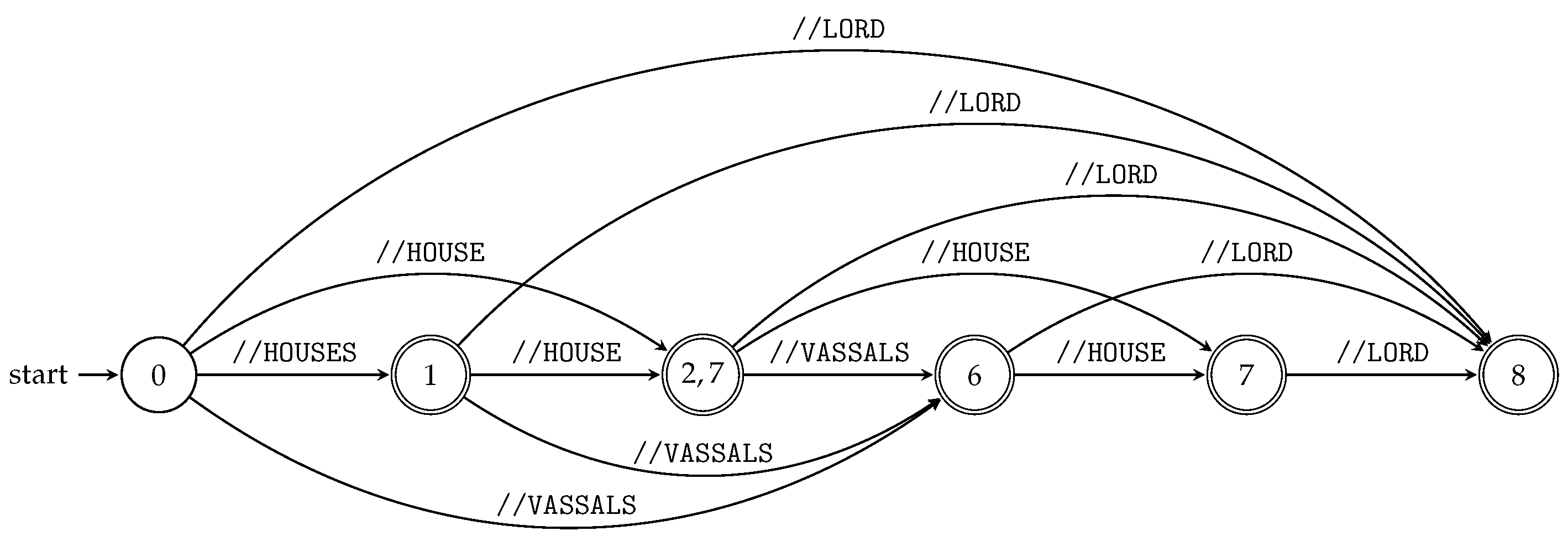
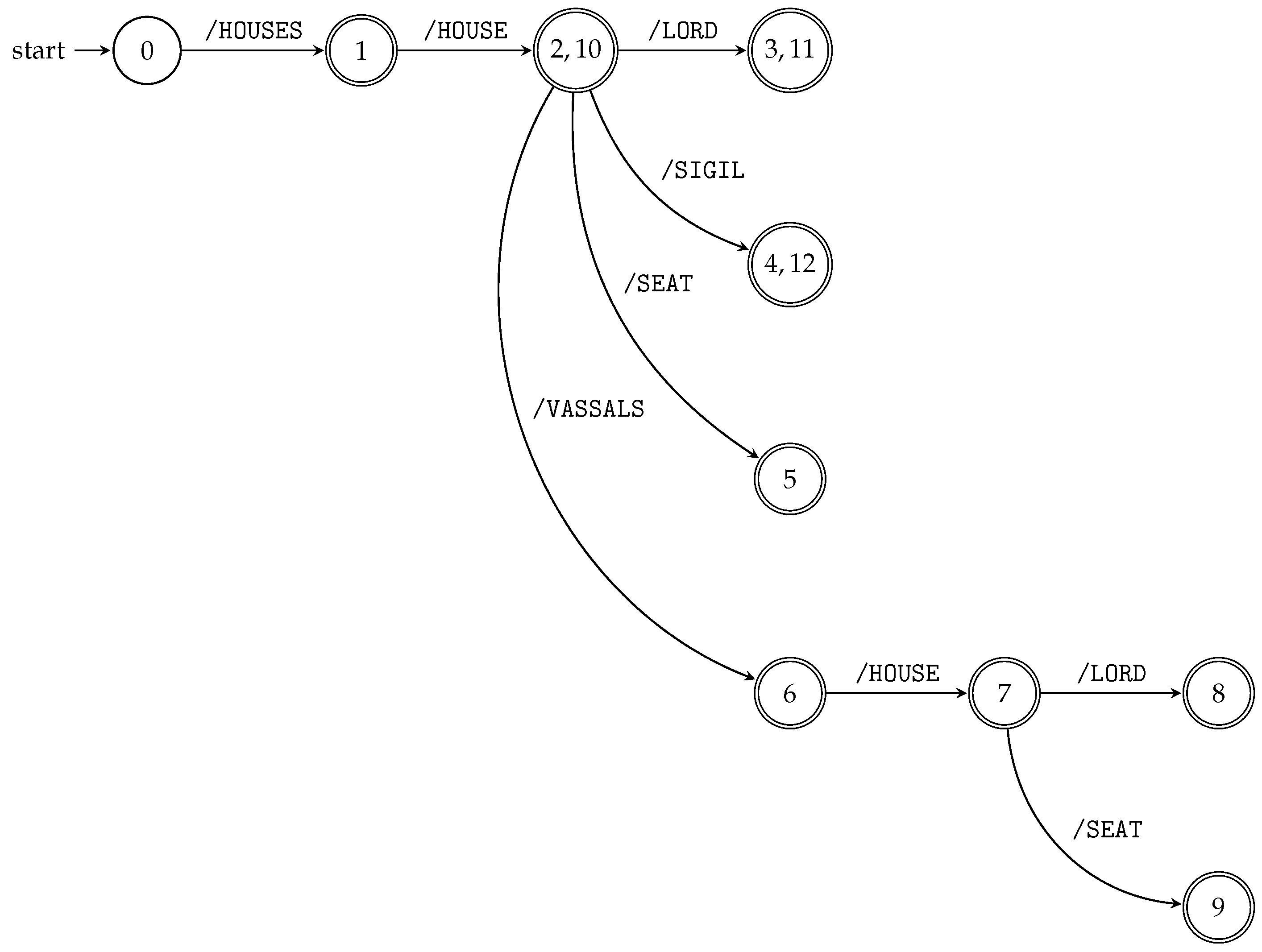
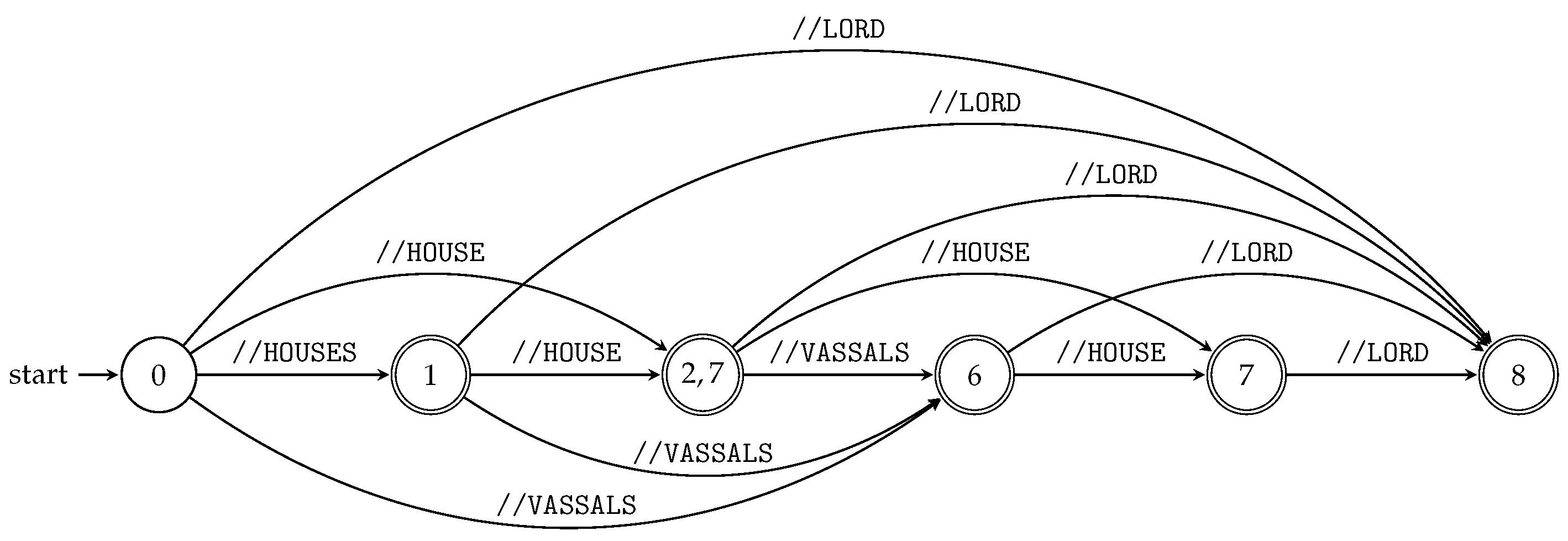
We can run all subsequence automata “in parallel” using the product construction (see
Section 3.1) and obtain the index for all
queries of the particular XML document; see Algorithm 4 and
Figure 5.
Figure 5 illustrates TSPSA constructed by Algorithm 4 for the XML document
D and its XML tree model
from Example 5 and
Figure 1, respectively.
The searching phase of TSPSA evaluates input queries in the same way as TSPA. Again, the answer for the input query is given by the d-subset contained in the terminal state.
| Algorithm 4: Construction of TSPSA for an XML document D. |
| Data: String paths set of XML tree model with k leaves. |
| Result: DFSA accepting all queries of the XML document D. |
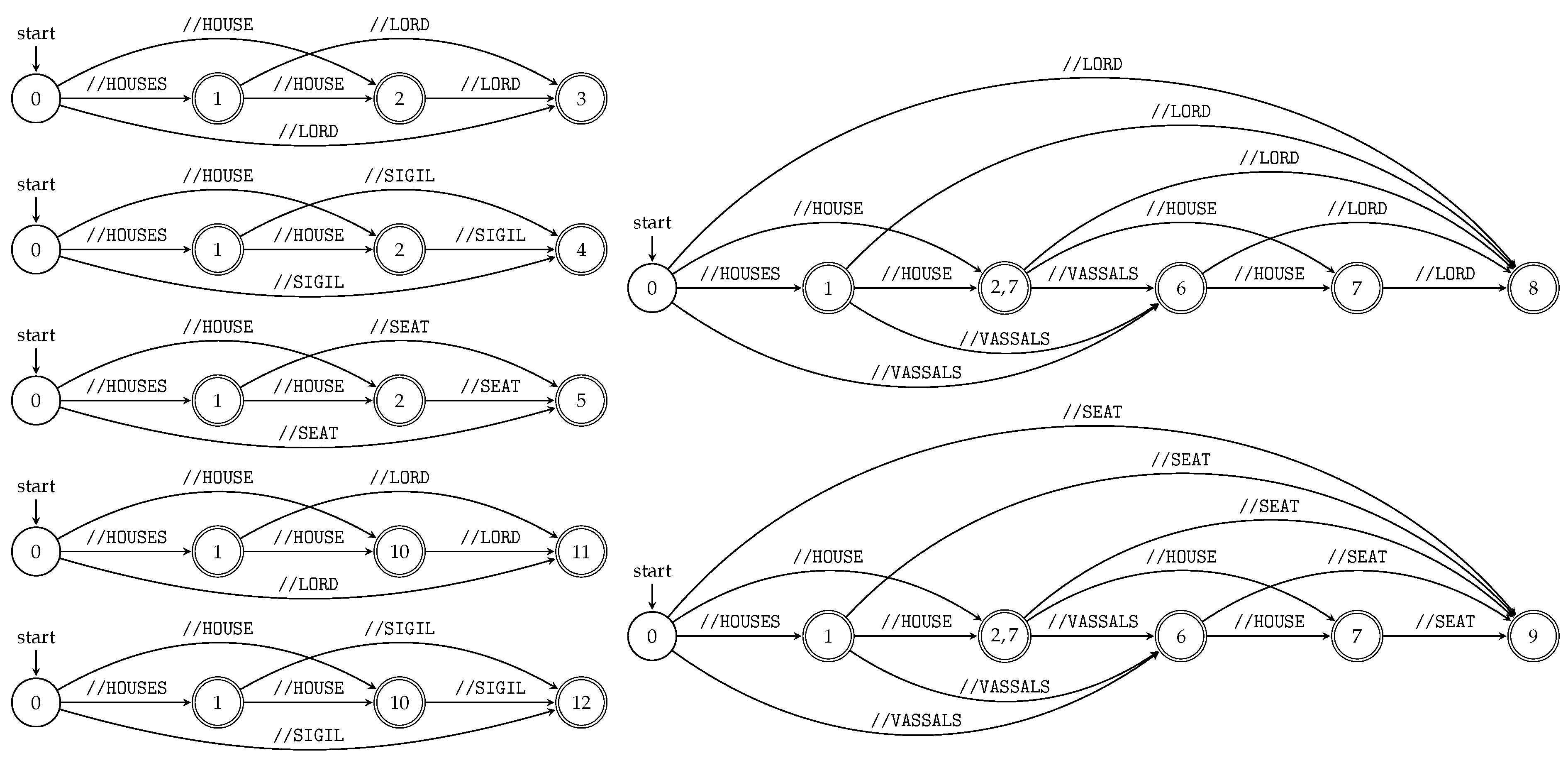
For all , construct a finite state automaton accepting all queries of using Algorithm 3. Construct the deterministic tree string path subsequences automaton accepting all queries of the XML document D using the product construction (union).
|
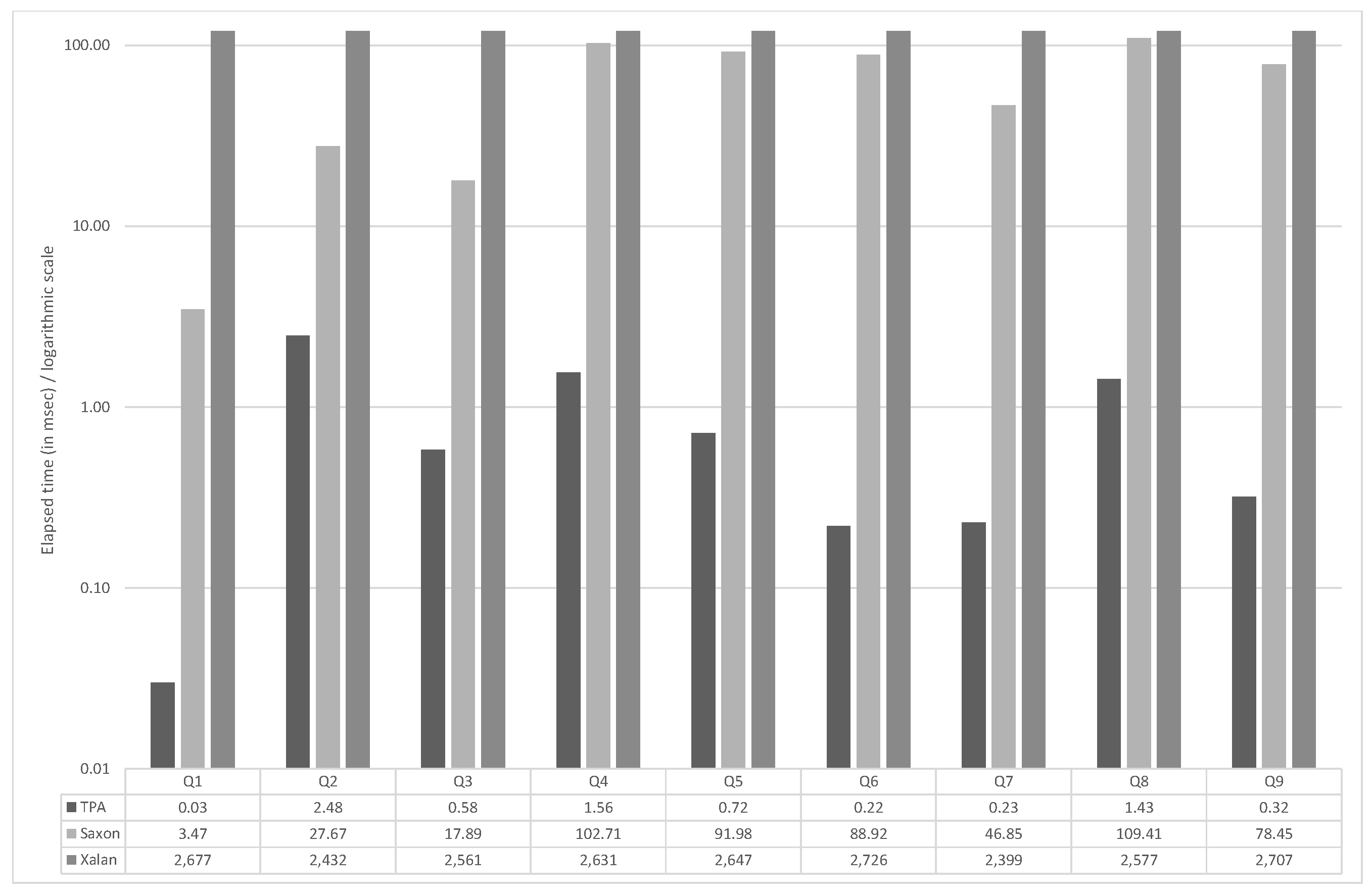
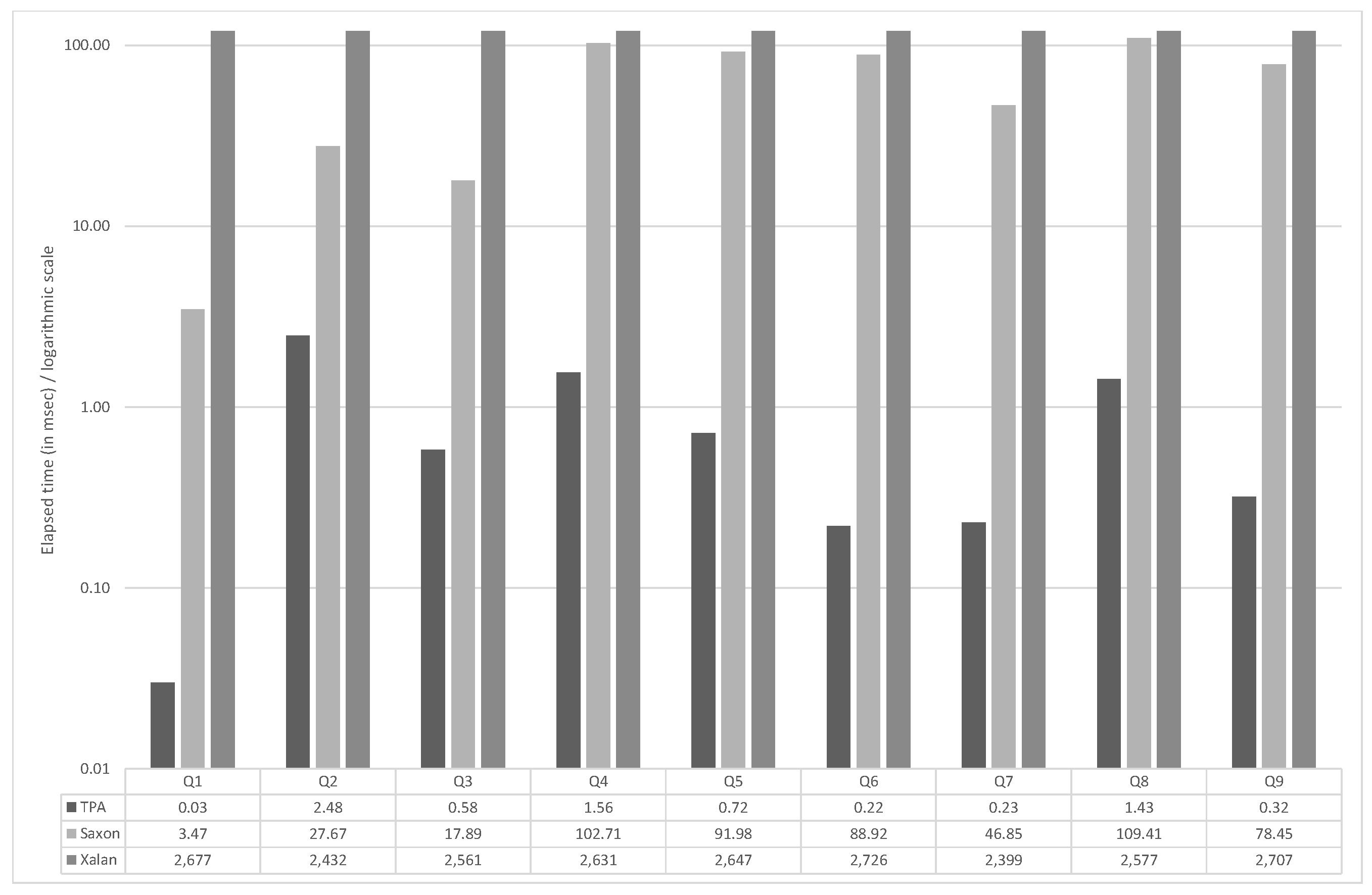
5. Discussion of Time and Space Complexities
5.2. Tree String Path Subsequences Automaton
TSPSA efficiently supports the evaluation of all queries of an XML document D. The runtime for a query of length m clearly becomes and does not depend on the size of the document D. Again, considering also the answering phase, the whole input query Q is evaluated in time , where k is the number of nodes in the XML document D satisfying the query Q. In practice the number of such nodes is expected to be much smaller than the size of the XML document.
The number of linear XPath queries using the //-axis only is exponential in the number of nodes of the XML tree model. For example, consider just a linear XML tree model
T with
n nodes. The number of
queries is
, which is determined by the following deduction: There are
combinations of
i elements
. Therefore, the exact number of all possible
queries is given by the following formula:
Each state of TSPSA corresponds to an answer of a single query or a collection of queries. Although the number of different queries accepted by TSPSA is exponential, usually many queries are equivalent (i.e., their result sets of elements are equal). Therefore, the equivalence problem of queries is closely related to the problem of the determination of the number of states of TSPSA. That is, if we know the number of unique query answers, we can construct a deterministic automaton answering all queries using exactly this number of states. On the other hand, we can obviously use the TSPSA to decide the equivalence of two queries and even determine equivalence classes.
From another point of view, we can examine the number of states of a TSPSA as a size of DASG for a set of strings (see [
40,
41]). For
k strings of length
h, the number of states can be trivially bounded by
, i.e., the size of a product of
k automata with
states. Therefore, the number of transitions of TSPSA is bounded by
. The lower bound for
strings is not known, while Crochemore and Troníček in [
38] showed that
states are required for
in the worst case.
However, considering the XML index problem, the set of strings is rather specific. Thanks to the branching tree structure, we can expect common prefixes in the set of strings, i.e., a lesser number of states (and transitions) in the resulting automaton. In the context of the XML index problem, k is a number of leaves in an XML tree model, and h is its height.
When space is more crucial, we do not need to combine the subsequence automata and just traverse them simultaneously. Finally, we return the union of resulting d-subsets of the automata that accept the input query as the answer. Given a query of length m, this approach obviously works in time complexity and space complexity. For parallel systems, each subsequence automaton can be handled by a different computing node.
For a common XML document (XML with the level (l)-property), in which nodes with the same label can only appear at the same level of the XML tree model, the asymptotic upper bound of the space complexity is . The necessary definitions and formal proof follow.
Definition 9 (Level property).
Let be a labeled directed rooted tree. Level property (l-property): Definition 10 (State level).
Let be an acyclic deterministic finite state automaton. A state level s of a state q is a maximal number of transitions leading from the initial state to q.
Theorem 4. Let D be an XML document and be its XML tree model satisfying the l-property with height h and k leaves. The number of states of deterministic TSPSA constructed for the XML document D by Algorithm 4 is .
Proof. There are k string paths in , for which we construct a set S of k deterministic subsequence automata of no more than h states each (due to the l-property). We can run all automata “in parallel”, by remembering the states of all automata by constructing k-tuples q while reading the input. This is achieved by the product construction. This way we construct TSPSA M for T.
Due to the l-property of T, it holds that: The target state of a transition labeled with is either a sink state or its state level is the same in each automaton in S. Hence, the k-tuples are restricted as follows: If the state level of is s, then each of is either a sink state or of state level s. If is a sink state, then is arbitrary, but each of is either a sink state or the same state level as . In addition, the k-tuples of Levels 0 and 1 are always and , respectively. Therefore, the maximum number of states of M is . ☐
Theorem 5. Let D be an XML document and be its XML tree model satisfying the l-property with height h and k leaves. The number of transitions of deterministic TSPSA constructed for the XML document D by Algorithm 4 is .
Proof. The maximum possible number of transitions leading from each state is . ☐




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}