EmoSpell, a Morphological and Emotional Word Analyzer †



Abstract
:1. Introduction
1.1. Cognitive Processes
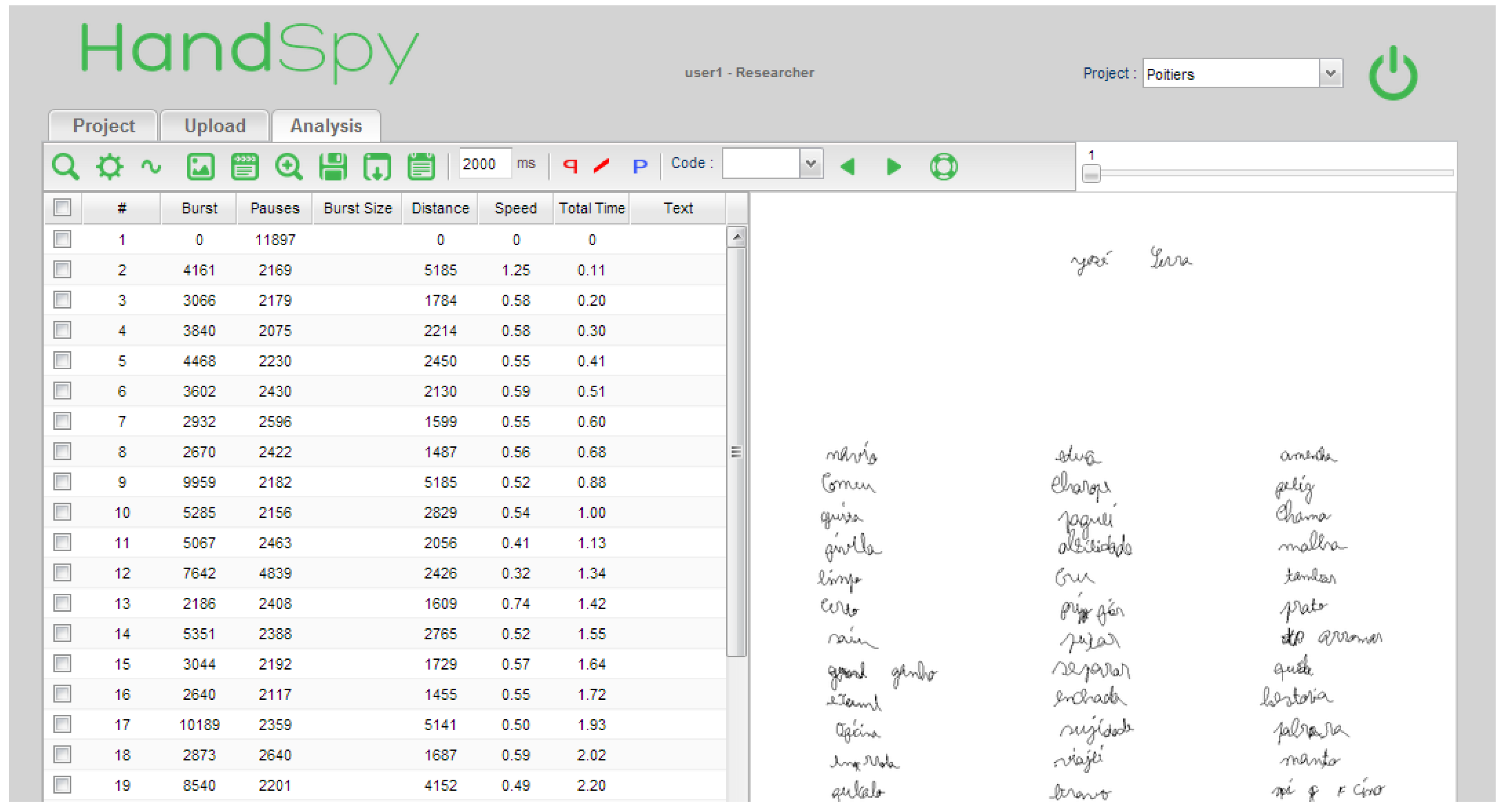
1.1.1. HandSpy
1.2. Sentiment Analysis
1.2.1. Applications and Challenges
1.2.2. Sentiment Lexicon
- General Inquirer (GI)—created in 1966, it is a content analysis tool that consists of a manually created database of words. It is used to count words of emotional categories and it has 182 categories, each one being a list of words and word senses, combining “Harvard IV-4” and “Lasswell” dictionaries. It is possible for the user to add more categories [19].
- Linguistic Inquiry and Word Count (LIWC)—a text analysis software program that calculates the degree of use for different categories of words across a wide array of texts. It uses the lexicon resource (the LIWC dictionary of words and word stems), each being filed into one or more sub-dictionaries. It classifies words in psychologically-relevant categories [20].
- SentiWordNet—an extension of WordNet. WordNet uses an English dictionary containing nouns, adjectives, verbs, and adverbs that can be called “synsets”. “Synsets” are sets of cognitive synonyms, linked by semantic and lexical relationships. With this linking of words, Wordnet groups them based on their meanings. [22]. SentiWordNet added three sentiment values to each “synset”. With this addition, the lexicon assigned three scores, and thus, each “synset” has positivity, negativity, and objectivity [23].
- Sentiment Orientation CALculator (SO-CAL)—a system that contains a dictionary of annotated words with semantic orientation. SO-CAL has two assumptions—the first is that the individual words have a “prior polarity”, which is a semantic orientation independent of context. The second is that this orientation can be identified with a numerical value—the strength [2].
1.2.3. Sentiment Analysis API
- TweetSentiments (https://www.mobomo.com/2010/11/sentiment-analysis-using-tweetsentimentscom-api/)—returns the sentiment of Tweets and is based on the supervised learning algorithm support vector machine (SVM). It has two online APIs that analyze Tweets from Twitter API calls, returned by a Twitter search query. It uses the LIBSVM library for SVM, which is implemented in C++ and also offers a Ruby and Rails implementation. This REST API can be used as a Web Service or as a standalone application, and the response format is in JSON.
- Text Processing (http://text-processing.com/)—an API with JSON over HTTP Web service. It is free and open-source. It performs a phrase extraction, sentiment analysis, part-of-speech tagging, and named entity recognition.
- ML Analyzer (http://mlanalyzer.sudo.me/)—provides several text analyses, including feelings, text classification, language detection, locations extractor, adult content analyzer, and article summarization. It contains a REST API with JSON response format.
- WebKnox Text-Processing(http://webknox.com/)—natural language processing of texts such as the determination of the feeling, identification of the language, classification of the quality of writing, auto-correction of a text, extraction of data and locations, and tagging of a text with part-of-speech tags. The response format is in JSON.
- Skyttle (http://www.skyttle.com/)—provides services to extract patterns from the text such as sentiment terms, constituent terms (meaningful expressions), and entities such as names of people, places, and things. Supported languages are English, French, German, and Russian. Is a SaaS (Software as a service) system that offers an option to receive the text with XML-annotated keywords and sentiment.
- nlpTools (http://nlptools.atrilla.net/web/)—text classification and sentiment analysis for natural language. It is an API focused on online news media. It is written in the PHP programming language and the API is JSON over HTTP RESTful Web service.
- Yactraq Speech2Topics (https://yactraq.com/)—converts audiovisual content into topic metadata. This conversion is done through speech recognition and natural language processing. It has a REST API with JSON response format.
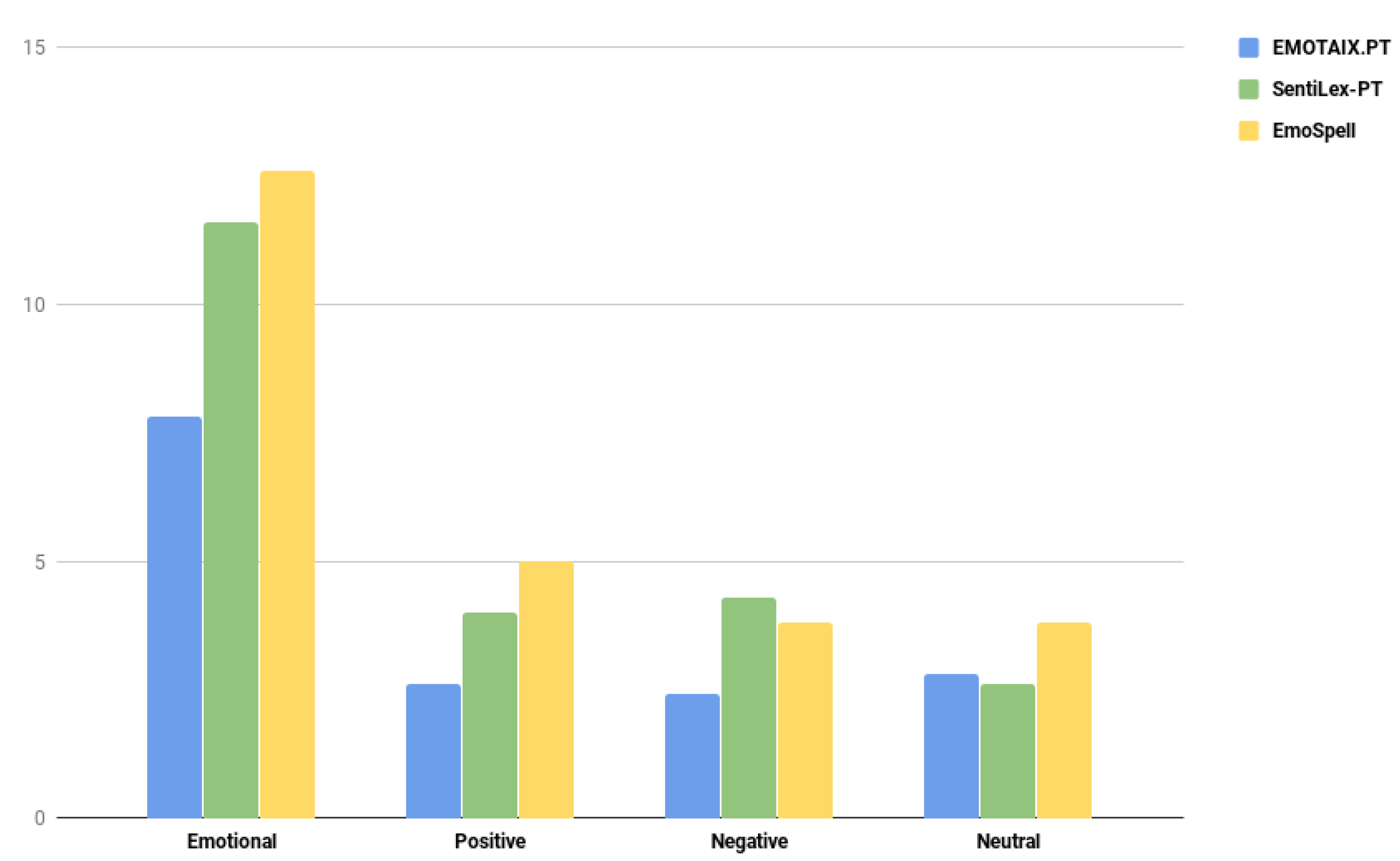
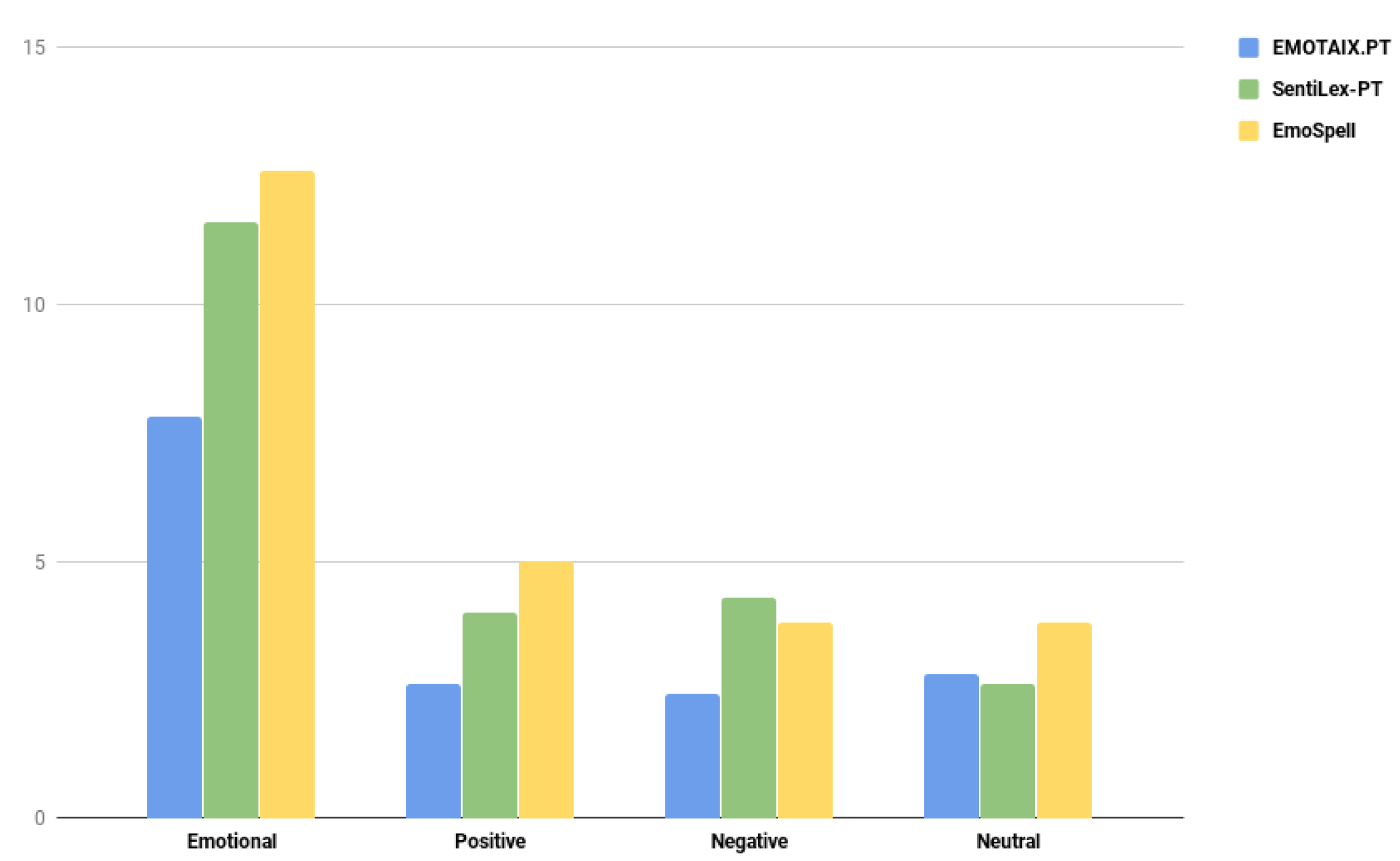
2. Results
3. Discussion
4. Materials and Methods
4.1. Lexical Bases
4.1.1. Jspell
- A lemma, which is a word from where you can get others by derivation or inflection. A lemma cannot be obtained by any other lemma;
- Morphological description, a list of morphological properties that are key-value pairs of grammatical classification of lemmas. They may contain macros for simplification, as explained later in this section;
- Derivation rules, which are a set of identifiers of derivation or inflection rules (flags), defined in a separate file called affix rules.
- CAT—Category
- G—Gender
- N—Number
- P—Person
- T—Tense
- TR—Transitivity
- GR—Degree
- FSEM—Semantic Role
4.1.2. SentiLex-PT
- Lemma;
- Grammar Category (adjective, noun, verb, or idiom);
- Sentiment Attributes (polarity and target of polarity, which corresponds to a human subject, N0 being the subject and N1 the complement).
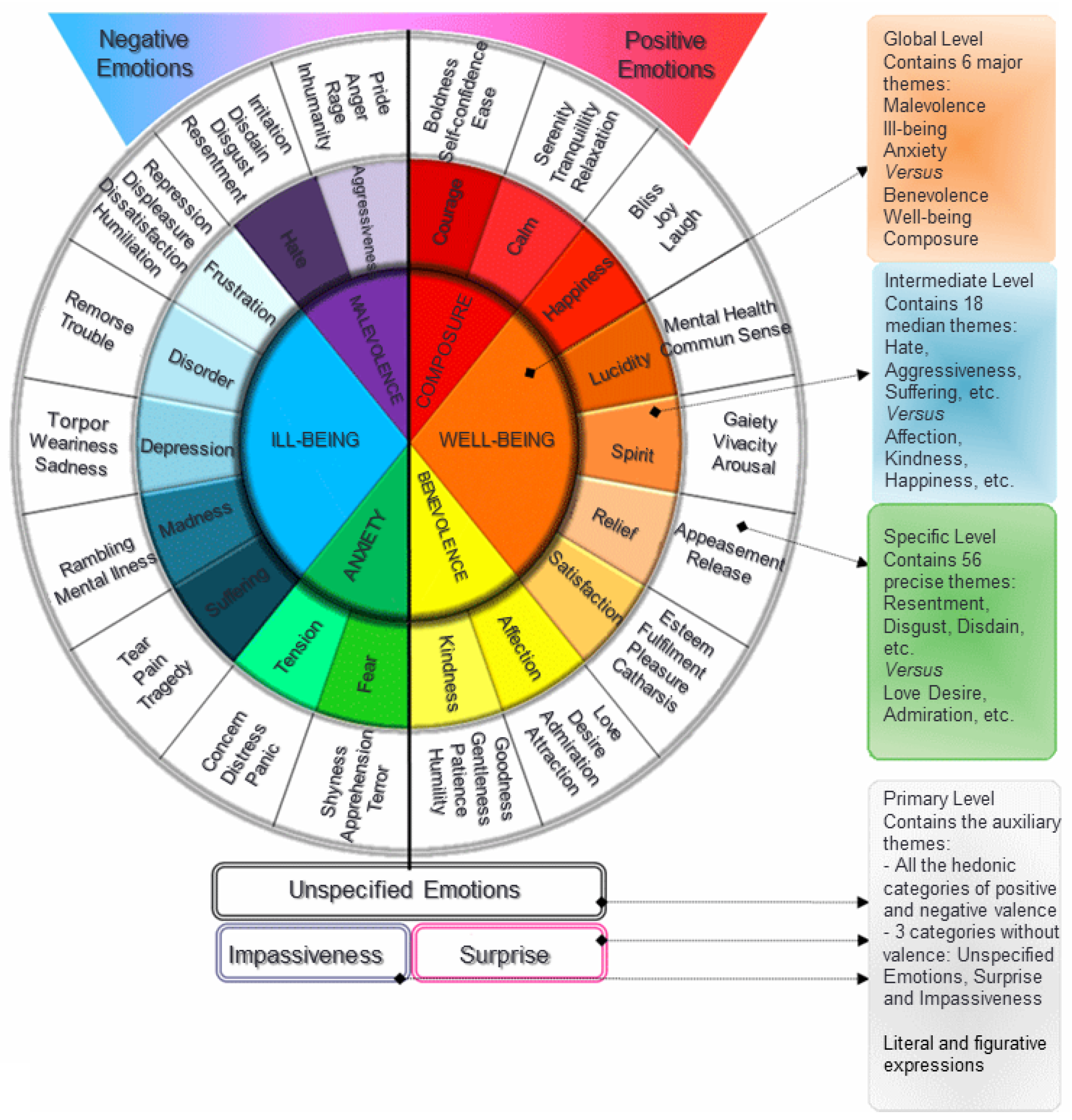
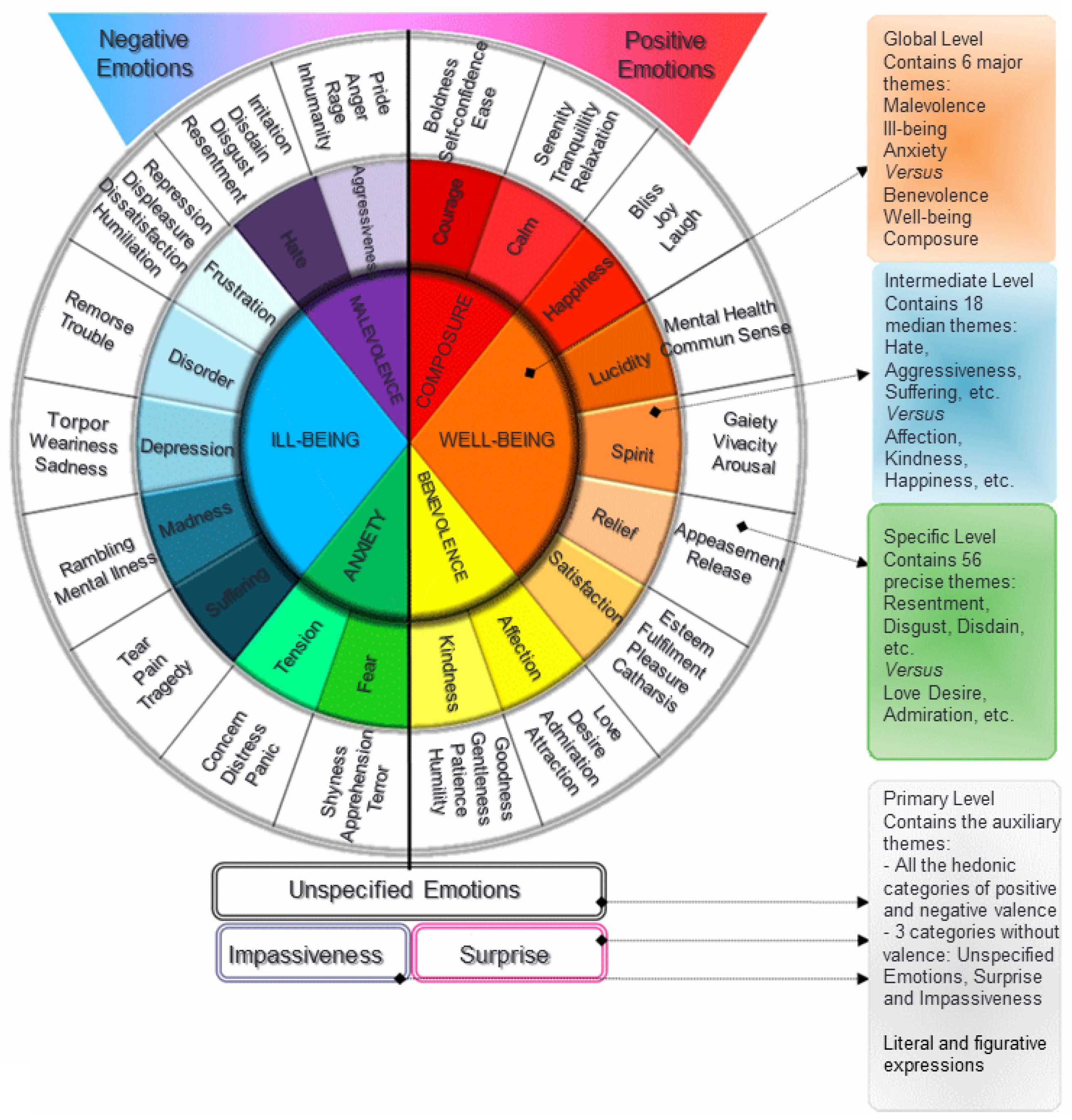
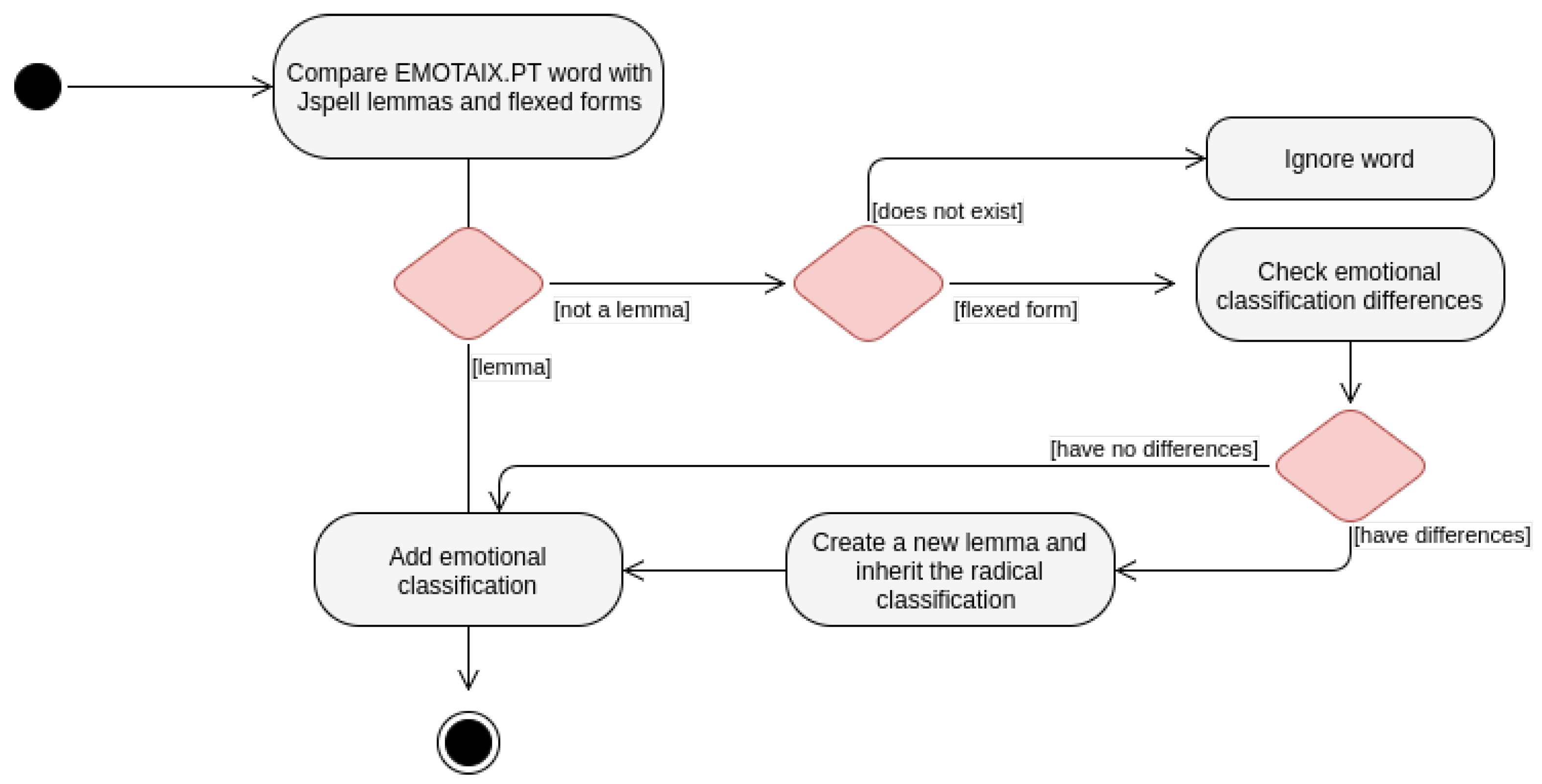
4.1.3. EMOTAIX.PT
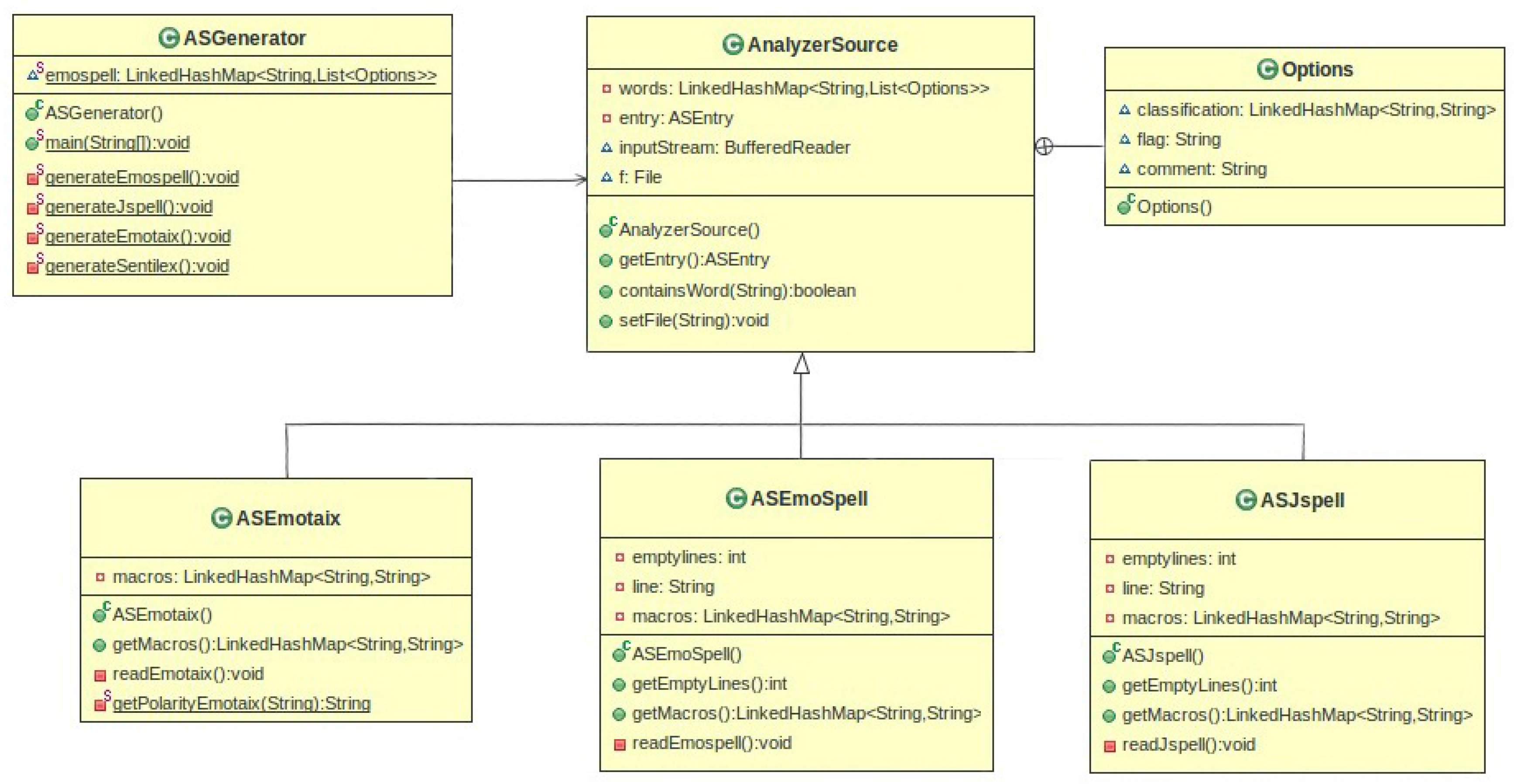
4.2. Creation of EmoSpell
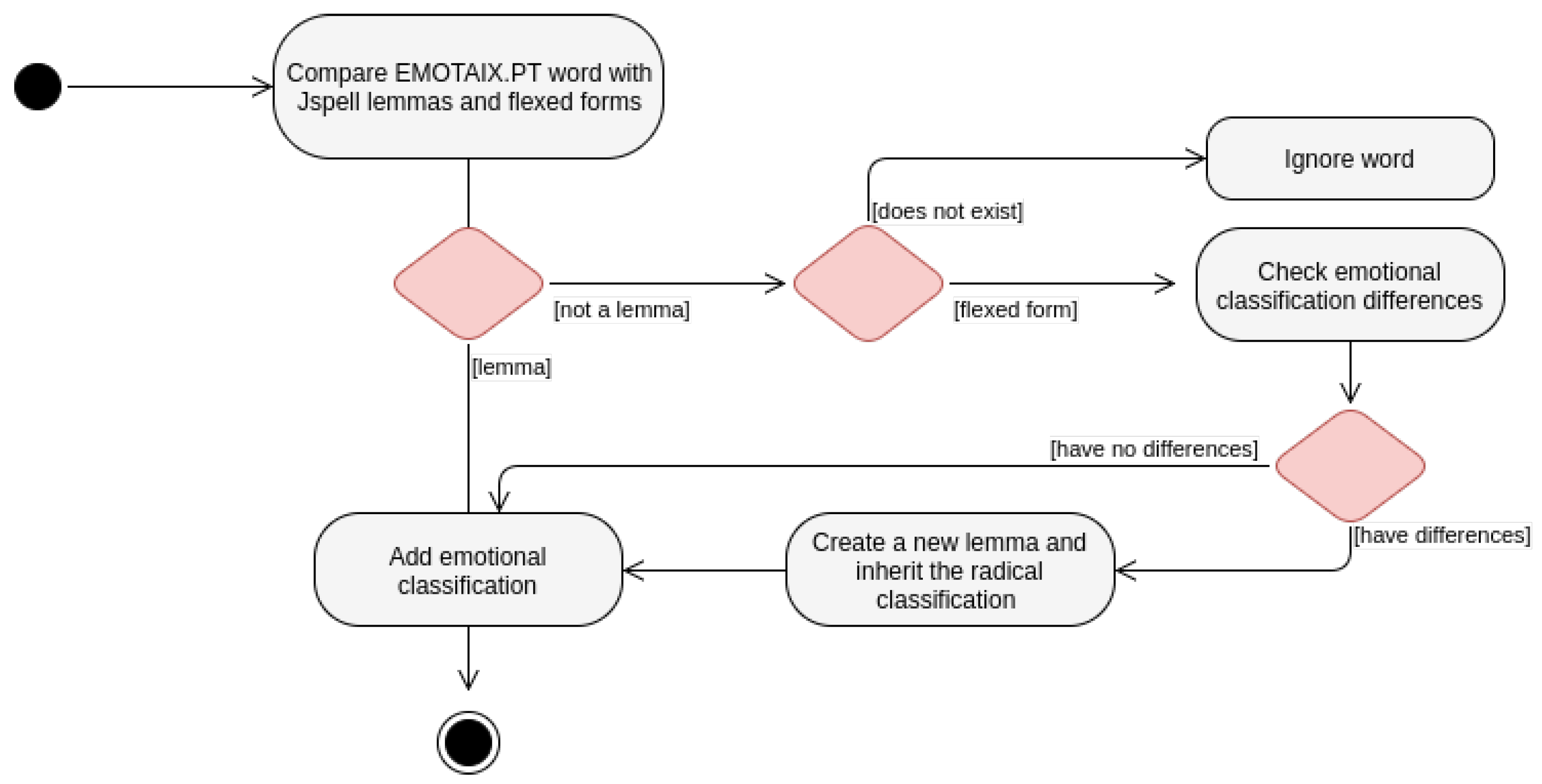
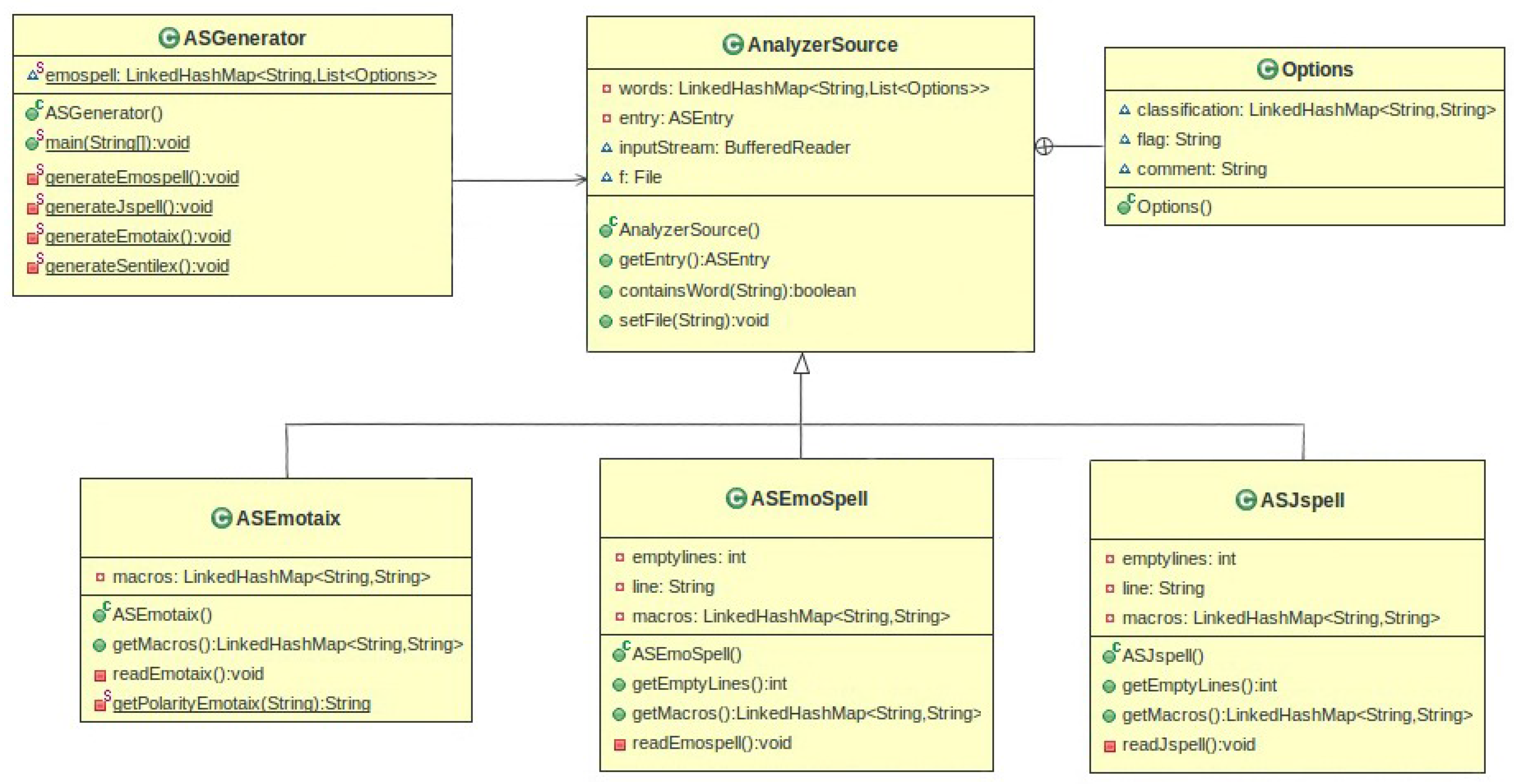
4.2.1. Dictionary Generation Procedure
4.2.2. Dictionary Generator
4.2.3. Text Analysis
medo
* medo 0 :lex(medo [CAT=nc,G=m,N=s,EmoGlobal=ansiedade,EmoIntermediate=medo,
EmoSpecific=pavor], [], [], [])
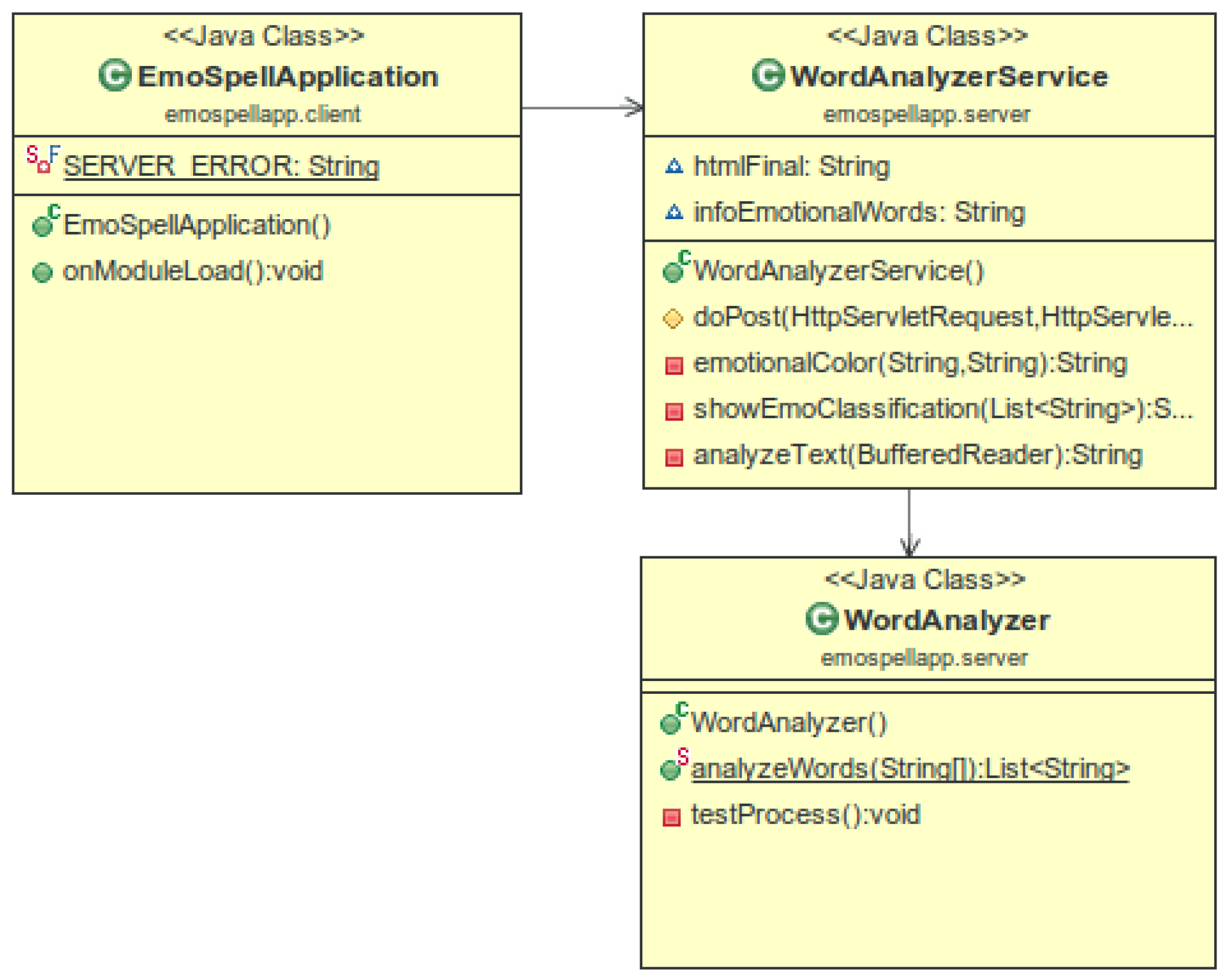
4.3. Interfaces
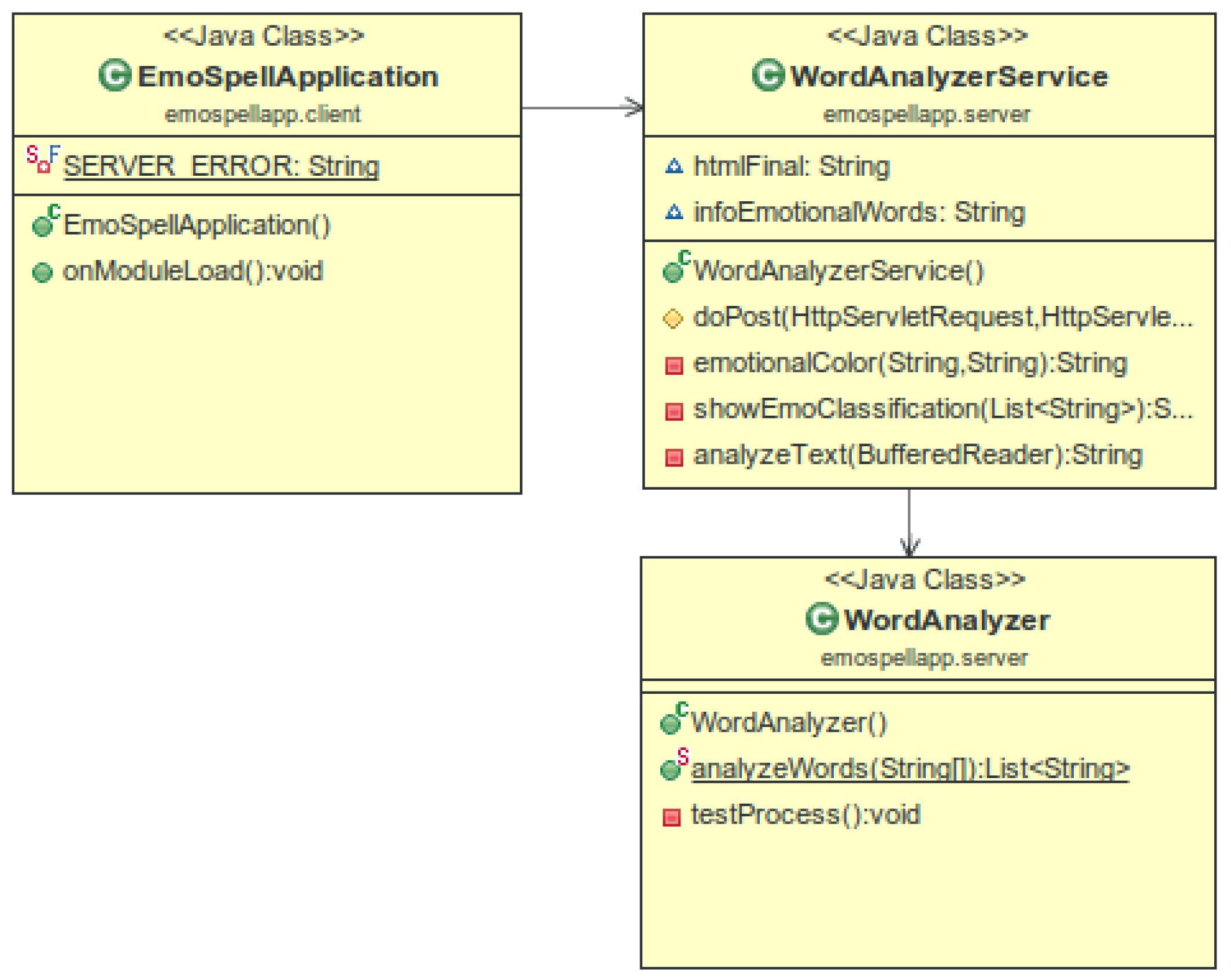
4.3.1. EmoSpell GUI
4.3.2. EmoSpell API
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 347–354. [Google Scholar]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Maia, M.I.; Leal, J.P. An emotional word analyzer for Portuguese. In Open Access Series in Informatics, Proceedings of the 6th Symposium on Languages, Applications and Technologies (SLATE 2017), Porto, Portugal, 26–27 June 2017; Schloss Dagstuhl – Leibniz-Zentrum für Informatik: Dagstuhl Publishing, Germany, 2017; pp. 17:1–17:14. [Google Scholar]
- Almeida, J.J.; Pinto, U. Jspell–um módulo para análise léxica genérica de linguagem natural. Presented at Actas do X Encontro da Associaçao Portuguesa de Linguıstica, Évora, Portugal; 1994; pp. 1–15. [Google Scholar]
- Costa, S.F.O. Adaptação e teste de uma base lexical de palavras emocionais para o português europeu: (EMOTAIX. PT); Faculdade de Psicologia e de Ciências da Educação é: Porto, Portugal, 2012. (In Portuguese) [Google Scholar]
- Silva, M.J.; Carvalho, P.; Sarmento, L. Building a sentiment lexicon for social judgement mining. In Proceedings of the International Conference on Computational Processing of the Portuguese Language, Coimbra, Portugal, 17–20 April 2012; pp. 218–228. [Google Scholar]
- Deane, P.; Odendahl, N.; Quinlan, T.; Fowles, M.; Welsh, C.; Bivens-Tatum, J. Cognitive models of writing: Writing proficiency as a complex integrated skill. ETS Res. Rep. Ser. 2008, 2008, i-36. [Google Scholar] [CrossRef]
- Guinet, E.; Kandel, S. Ductus: A software package for the study of handwriting production. Behav. Res. Methods 2010, 42, 326–332. [Google Scholar] [CrossRef] [PubMed]
- Monteiro, C.; Leal, J.P. Managing experiments on cognitive processes in writing with HandSpy. Comput. Sci. Inf. Syst. 2013, 10, 1747–1773. [Google Scholar] [CrossRef]
- Chee, Y.M.; Froumentin, M.; Watt, S.M. Ink markup language (InkML); W3C Working Draft; World Wide Web Consortium: Cambridge, MA, USA, 2006; Volume 23. [Google Scholar]
- Bray, T.; Paoli, J.; Sperberg-McQueen, C.M.; Maler, E.; Yergeau, F. Extensible markup language (XML). World Wide Web J. 1997, 2, 27–66. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining; Synthesis lectures on human language technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2012; Volume 5, pp. 1–167. [Google Scholar]
- Chamlertwat, W.; Bhattarakosol, P.; Rungkasiri, T.; Haruechaiyasak, C. Discovering Consumer Insight from Twitter via Sentiment Analysis. J. Universal Comput. Sci. 2012, 18, 973–992. [Google Scholar]
- O’Connor, B.; Balasubramanyan, R.; Routledge, B.R.; Smith, N.A. From tweets to polls: Linking text sentiment to public opinion time series. Int. Conf. Web Soc. Med. 2010, 11, 1–2. [Google Scholar]
- Leung, C.W.; Chan, S.C.; Chung, F.l. Integrating collaborative filtering and sentiment analysis: A rating inference approach. In Proceedings of the ECAI 2006 workshop on recommender systems, Riva del Garda, Italy, 28–29 August 2006; pp. 62–66. [Google Scholar]
- Vinodhini, G.; Chandrasekaran, R. Sentiment analysis and opinion mining: A survey. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 282–292. [Google Scholar]
- Riloff, E.; Qadir, A.; Surve, P.; De Silva, L.; Gilbert, N.; Huang, R. Sarcasm as contrast between a positive sentiment and negative situation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Mohammad, S.M. A practical guide to sentiment annotation: Challenges and solutions. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), San Diego, CA, USA, 12–17 June 2016; pp. 174–179. [Google Scholar]
- Stone, P.J.; Dunphy, D.C.; Smith, M.S. The General Inquirer: A Computer Approach to Content Analysis; Cambridge: London, UK, 1966. [Google Scholar]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic inquiry and word count: LIWC 2001. In Mahway: Lawrence Erlbaum Associates; LIWC.net: Austin, TX, USA, 2001. [Google Scholar]
- Piolat, A.; Bannour, R. EMOTAIX: un scénario de Tropes pour l’identification automatisée du lexique émotionnel et affectif. L’Année Psychologique 2009, 109, 655–698. (In French) [Google Scholar] [CrossRef]
- Fellbaum, C. WordNet; Wiley Online Library: Hoboken, NJ, USA, 1998. [Google Scholar]
- Esuli, A.; Sebastiani, F. SENTIWORDNET: A high-coverage lexical resource for opinion mining. Evaluation 2007, 1–26. [Google Scholar]
- Simões, A.; Almeida, J.J. jspell. pm: um módulo de análise morfológica para uso em processamento de linguagem natural; Associação Portuguesa de Linguística (APL): Évora, Portugal, 2001. (In Portuguese) [Google Scholar]
- Carvalho, P.; Silva, M.J. SentiLex-PT: Principais características e potencialidades. Oslo Stud. Lang. 2015, 7, 1. (In Portuguese) [Google Scholar]
- Ide, N.; Véronis, J. Text Encoding Initiative: Background and Contexts; Springer Science & Business Media: Berlin, Germany, 1995; Volume 29. [Google Scholar]
- Burkhardt, F.; Pelachaud, C.; Schuller, B.W.; Zovato, E.; Emotion, M.L. Multimodal Interaction with W3C Standards: Toward Natural User Interfaces to Everything; Dahl, D.A., Ed.; Springer: Cham, Switzerland, 2017; pp. 65–80. [Google Scholar]
- Asmi, A.; Ishaya, T. Negation identification and calculation in sentiment analysis. In Proceedings of the Second International Conference on Advances in Information Mining and Management, Venice, Italy, 21–26 October 2012; pp. 1–7. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotional | Positive | Negative | Neutral | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EX | ES | % | EX | ES | % | EX | ES | % | EX | ES | % | |
| 1-Pos | 10 | 15 | 50 | 4 | 6 | 50 | 1 | 2 | 100 | 5 | 7 | 40 |
| 1-Neg | 11 | 18 | 60 | 1 | 5 | 400 | 6 | 8 | 30 | 4 | 5 | 25 |
| 1-Neut | 2 | 3 | 50 | 2 | 3 | 50 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2-Pos | 10 | 14 | 40 | 4 | 5 | 25 | 4 | 5 | 25 | 2 | 4 | 100 |
| 2-Neg | 11 | 16 | 40 | 2 | 4 | 100 | 3 | 5 | 60 | 6 | 7 | 20 |
| 2-Neut | 3 | 9 | 200 | 1 | 2 | 100 | 0 | 5 | 0 | 2 | 2 | 0 |
| 3-Pos | 10 | 17 | 70 | 5 | 12 | 140 | 0 | 0 | 0 | 5 | 5 | 0 |
| 3-Neg | 12 | 18 | 50 | 4 | 7 | 75 | 7 | 7 | 0 | 1 | 4 | 300 |
| 3-Neut | 1 | 3 | 200 | 0 | 1 | ∞ | 1 | 2 | 100 | 0 | 0 | 0 |
| Average | 7.8 | 12.6 | 84 | 2.6 | 5 | 104 | 2.4 | 3.8 | 35 | 2.8 | 3.8 | 54 |
| Participant—Texts | Words | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Emotional | Positive | Negative | Neutral | |||||||||
| S | ES | % | S | ES | % | S | ES | % | S | ES | % | |
| 1-Pos | 13 | 15 | 15.4 | 5 | 6 | 20 | 5 | 2 | −60 | 3 | 7 | 133 |
| 1-Neg | 13 | 18 | 38.5 | 4 | 5 | 25 | 6 | 8 | 33.3 | 3 | 5 | 66.6 |
| 1-Neut | 8 | 3 | −62.5 | 5 | 3 | −40 | 1 | 0 | −100 | 2 | 0 | −100 |
| 2-Pos | 12 | 14 | 16.6 | 3 | 5 | 66.6 | 5 | 5 | 0 | 4 | 4 | 0 |
| 2-Neg | 9 | 16 | 77.7 | 0 | 4 | 0 | 6 | 5 | −16.6 | 3 | 7 | 133.3 |
| 2-Neut | 7 | 9 | 28.6 | 2 | 2 | 0 | 5 | 5 | 0 | 0 | 2 | 0 |
| 3-Pos | 15 | 17 | 13.3 | 9 | 12 | 33.3 | 3 | 0 | −100 | 3 | 5 | 66.6 |
| 3-Neg | 15 | 18 | 20 | 7 | 7 | 0 | 6 | 7 | 16.6 | 2 | 4 | 100 |
| 3-Neut | 7 | 3 | −57.1 | 1 | 1 | 0 | 2 | 2 | 0 | 4 | 0 | −100 |
| Average | 11 | 12.6 | 21.16 | 4 | 5 | 11.6 | 4.3 | 3.8 | −25.19 | 2.6 | 3.8 | 33.28 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maia, M.I.; Leal, J.P. EmoSpell, a Morphological and Emotional Word Analyzer. Information 2018, 9, 1. https://doi.org/10.3390/info9010001
Maia MI, Leal JP. EmoSpell, a Morphological and Emotional Word Analyzer. Information. 2018; 9(1):1. https://doi.org/10.3390/info9010001
Chicago/Turabian StyleMaia, Maria Inês, and José Paulo Leal. 2018. "EmoSpell, a Morphological and Emotional Word Analyzer" Information 9, no. 1: 1. https://doi.org/10.3390/info9010001
APA StyleMaia, M. I., & Leal, J. P. (2018). EmoSpell, a Morphological and Emotional Word Analyzer. Information, 9(1), 1. https://doi.org/10.3390/info9010001