The Impact of Message Replication on the Performance of Opportunistic Networks for Sensed Data Collection

 ,
, 

Abstract
1. Introduction
1.1. Message Transmission Overhead in OppNets
1.2. Authors’ Contribution
- First, we establish relevant characteristics that the presence of portable handheld user devices introduces to OppNets for sensed data collection. Then, we investigate the impact of these characteristics on existing message replication techniques, and suggest related design guidelines that need to be observed in order to improve routing performance and feasibility in real-world implementation.
- Second, we follow our design guidelines to propose a set of mechanisms that collectively form a message replication technique, namely Locality Aware Replication (LARep). When incorporated into relevant routing protocols, LARep reduces message transmission overhead without compromising throughput. Simulation results show that LARep achieves better performance as compared with existing replication techniques.
1.3. Organization of the Paper
2. Message Replication in OppNets for Sensed Data Collection
2.1. Need for Message Replication Techniques
2.2. Handheld User Devices and OppNets for Sensed Data Collection
2.2.1. General Characteristics
2.2.2. Characteristics Specific to Smart City Scenarios
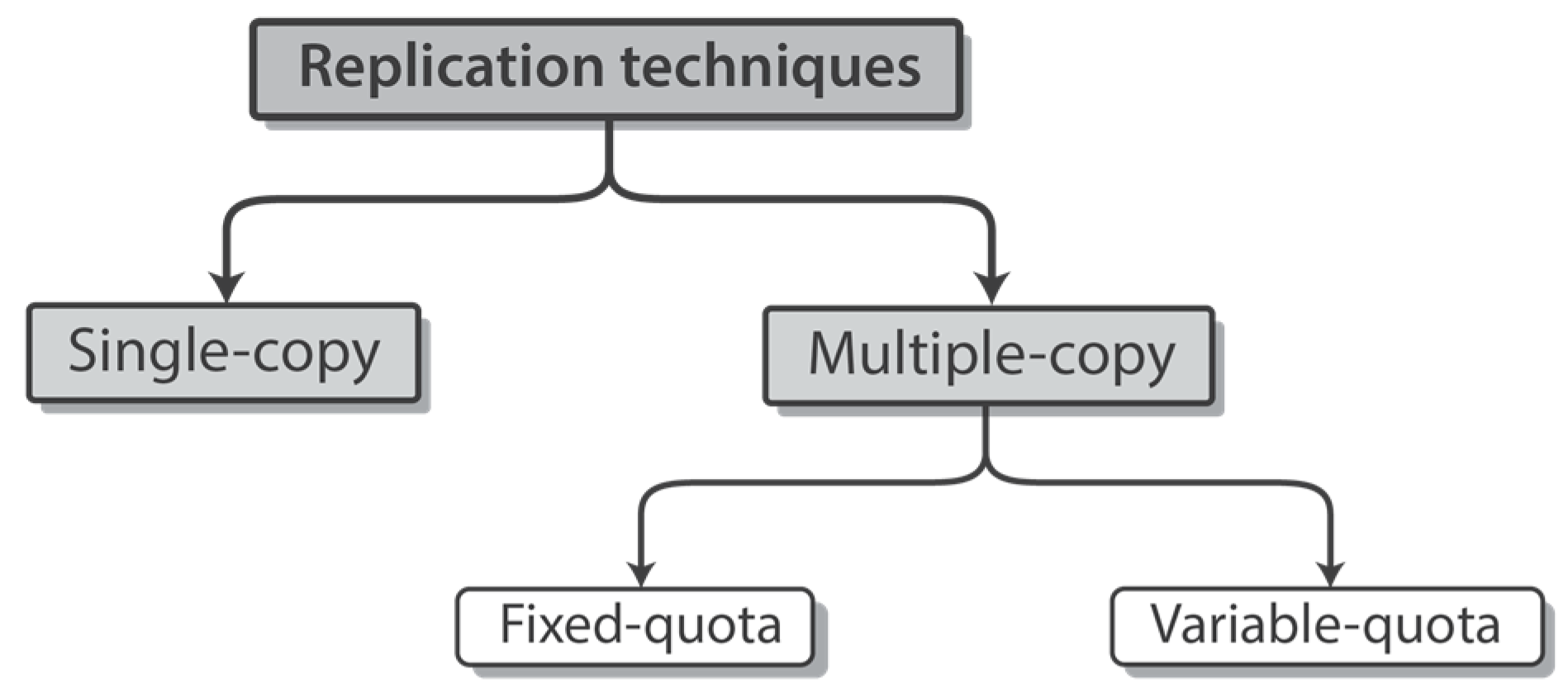
2.3. Existing Message Replication Techniques
2.3.1. Single-Copy Replication
2.3.2. Multiple-Copy Replication
2.4. Current State of Message Replication in OppNets
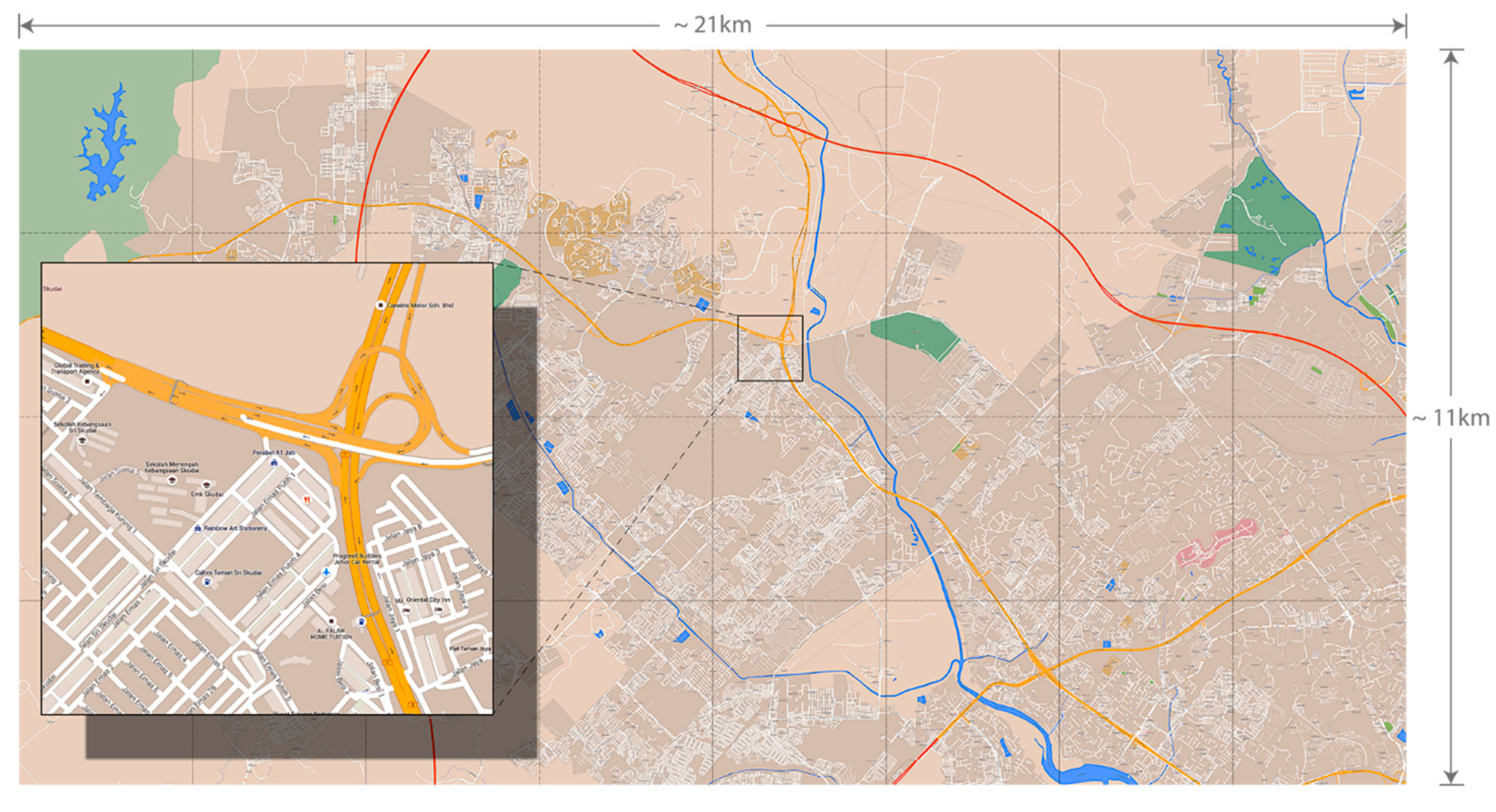
2.4.1. OppNet Movement Scenarios and Simulation Set-Up
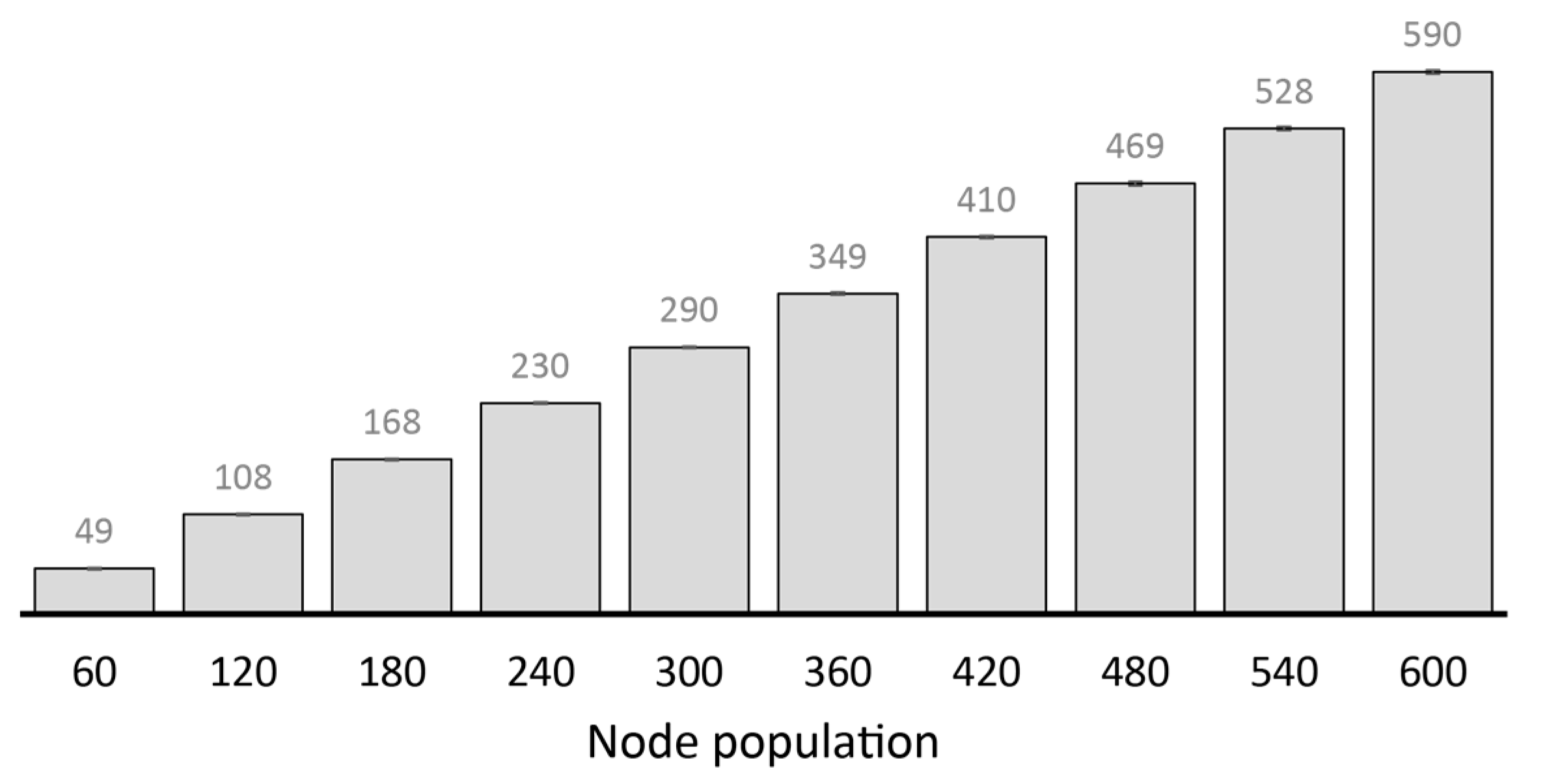
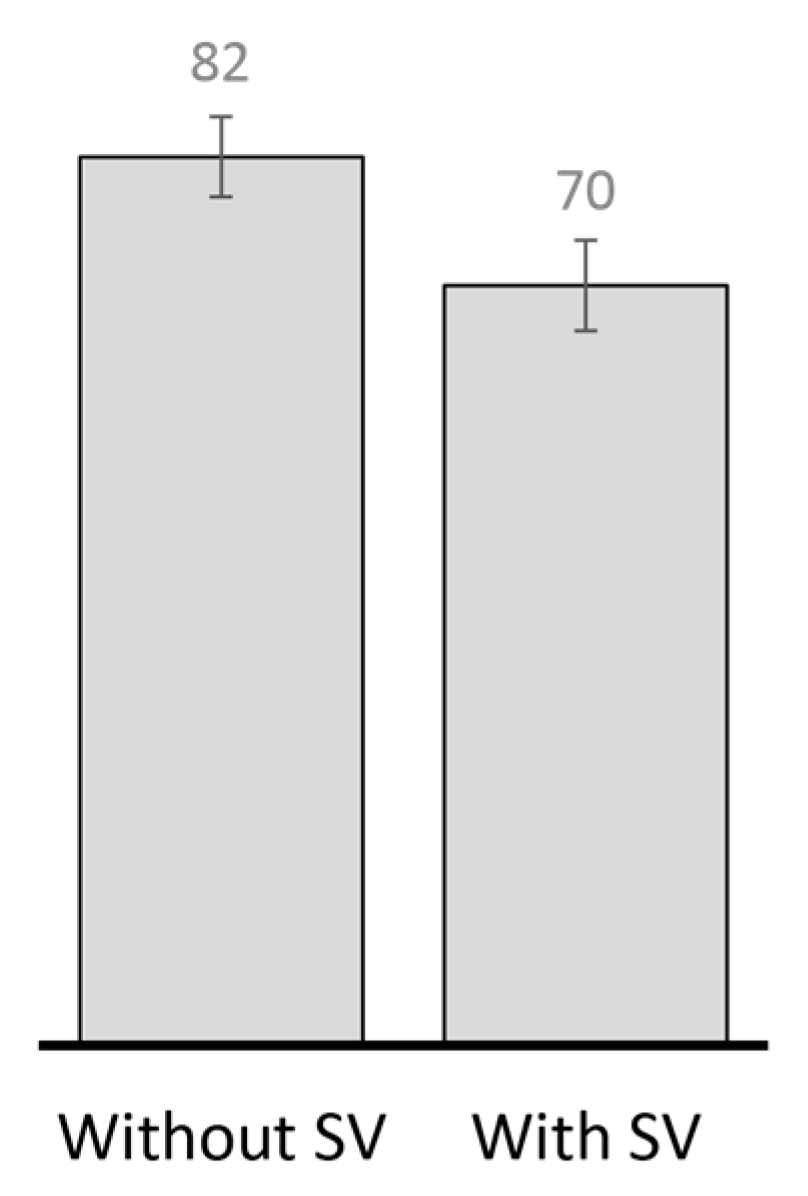
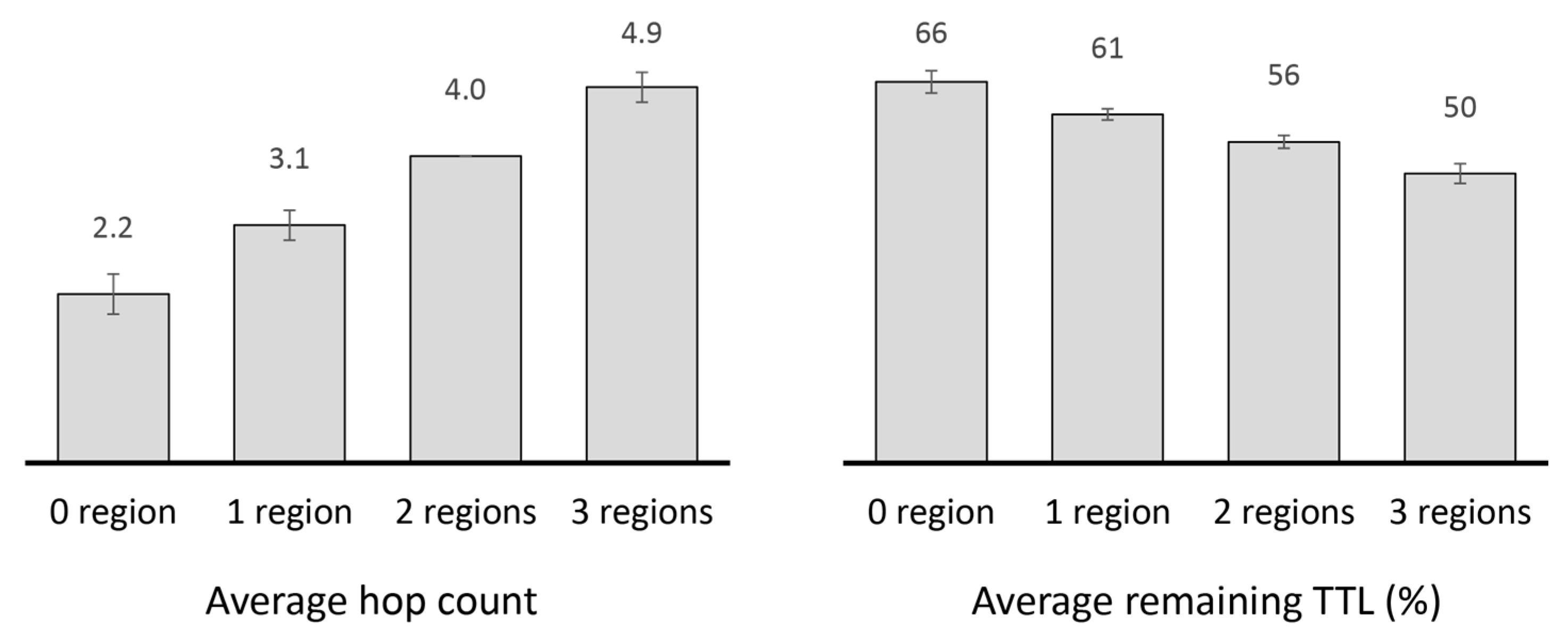
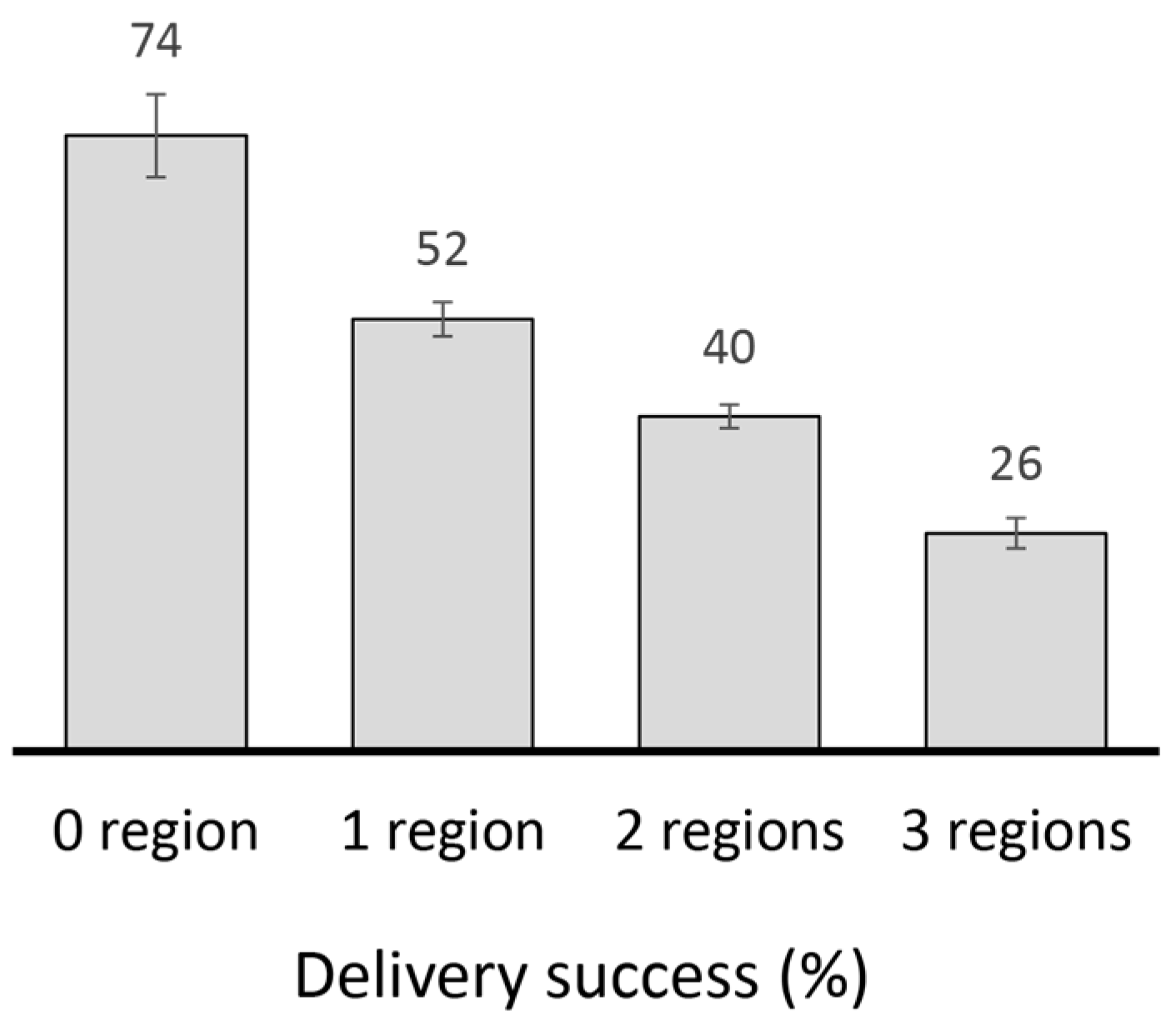
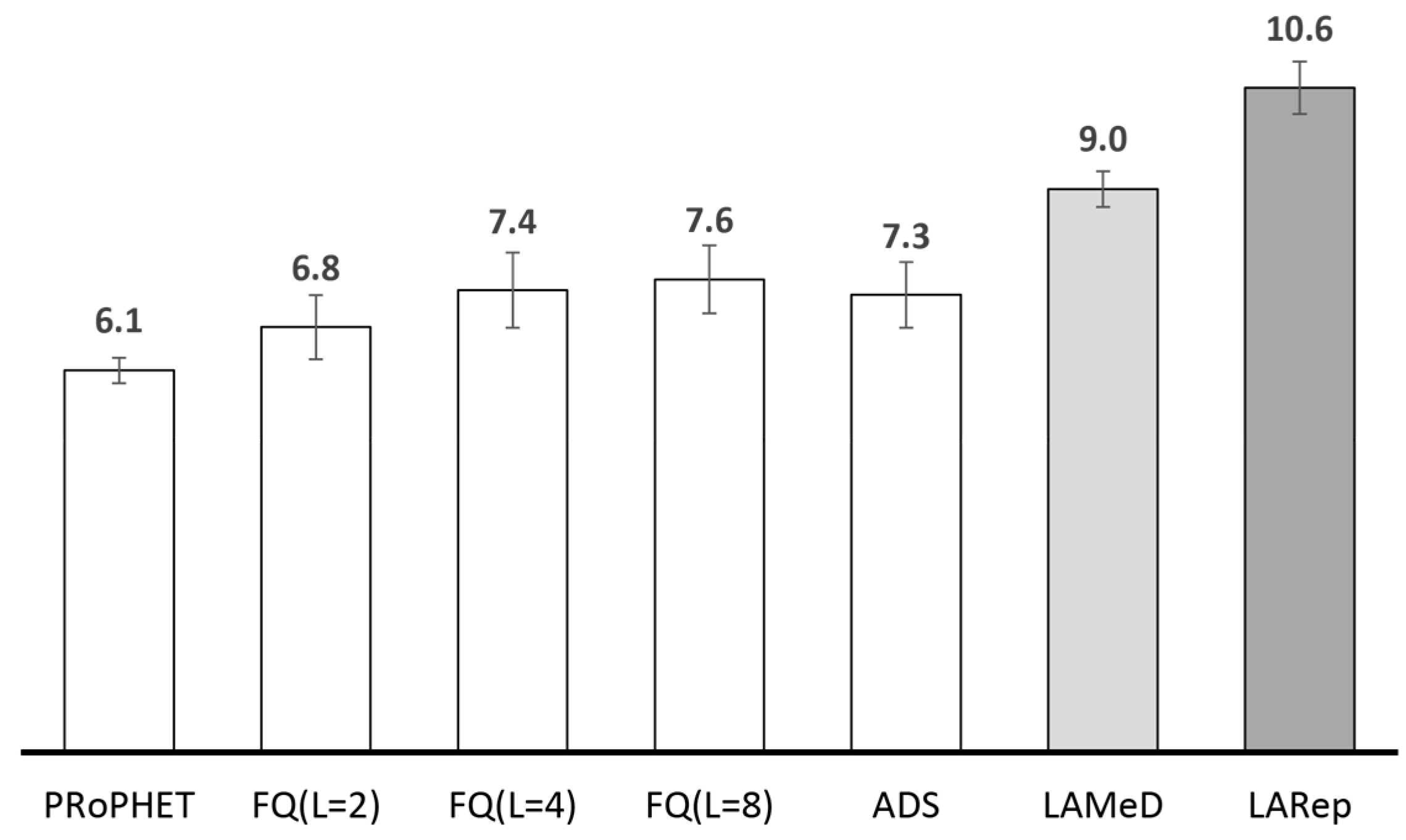
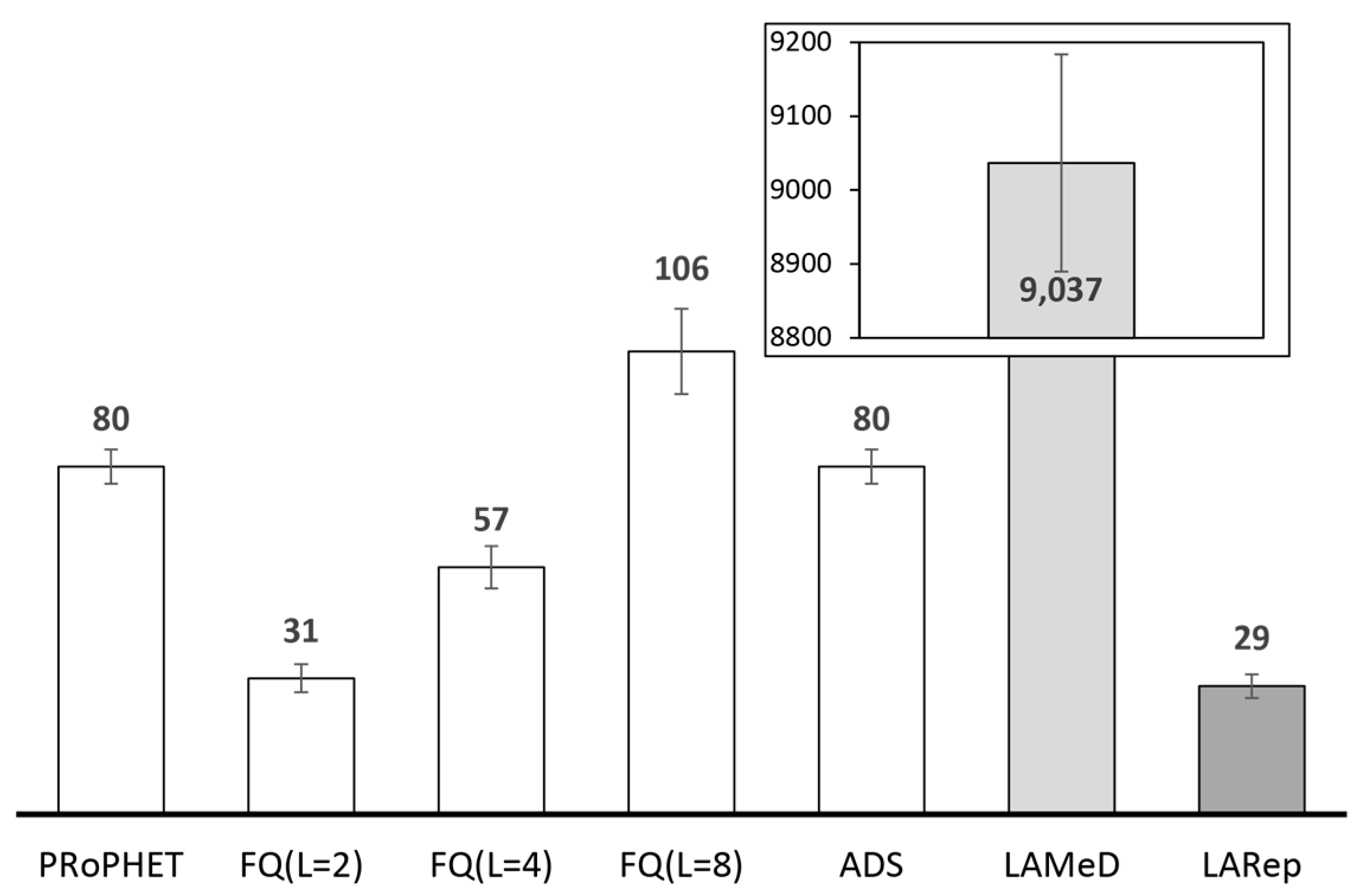
2.4.2. Performance Analysis of Existing Replication Techniques
2.5. Message Replication Guidelines for Collecting Sensed Data with OppNets
- The number of message copies should not increase at a high rate with node population. In other words, the transmission overhead incurred in high node population should remain relatively low. Messages could be replicated according to the progress they have made towards their respective destinations. However, the progress should be identified without incurring excessive metadata overhead, preferably perceived from existing message properties or new ones that may not incur significant overhead.
- While message replication can be controlled by selecting optimal thresholds for parameters such as the number of nodes currently in contact or message properties such as remaining TTL, adapting to different network conditions requires more than one optimal value for a threshold. The choice of these thresholds need to be made on the go, and should vary according to changing network conditions. In order to achieve this, network conditions that determine the optimal choice of these thresholds at every point in time need to be identified.
- The goal of message replication is to maintain an acceptable level of delivery guarantee with minimal message copies. This means that messages need to be replicated sparingly and every generated copy needs to contribute towards maximizing delivery. Achieving this becomes more challenging under higher degrees of spatial locality due to insufficient encounter opportunities between nodes from different regions. Maximizing message delivery with minimal copies may require knowledge about the relationship between spatial locality and encounter opportunities between different sets of nodes.
- Freeing node buffers of delivered messages is a direct approach towards minimizing redundant replication. However, notifying nodes through anti-packets may cause additional overhead, interfere with data transfer opportunities and may also take too long to disseminate. Optionally, message dropping policies could be designed to first drop messages that are more likely to have been delivered. It is important that such policies approach different messages according to their individual delivery criteria, as some messages may require more hops and buffer time than others to achieve the same delivery guarantees. Nodes also need to retain messages for which they have higher chances of delivery.
- Assumptions need to be in accordance with realistic node movement, especially one that exhibits spatial and temporal properties of human mobility. The absence of central administration, lack of end-to-end connectivity and highly dynamic network topology should also be considered. It should be noted that global knowledge about the network is almost impractical to acquire locally and the performance of replication techniques should not depend on obtaining information that may become stale too quickly. Also, the performance of replication techniques should not rely on the existence of particular network infrastructure, since their presence in the application scenario may not be guaranteed. Solutions should be able to perform acceptably under varying amounts of infrastructure support or none at all. This is to maintain the ability offload existing mobile networks if need be.
3. Reducing Transmission Overhead without Compromising Throughput
- An approach to determine the optimal quota for different messages on-the-go; and
- Achieving this with minimal metadata transmission overhead and realistic assumptions.
3.1. Overview of LARep
- Determining a measure for the relative distance between the source and destination nodes;
- Locally determining how much progress messages have made towards their destination nodes without frequent metadata transmissions;
- Dropping messages according to the progress they have made towards their destination nodes; and
- Varying message replication quota according to the distance between the source and destination nodes, and generating copies based on the progress messages have made towards their destination nodes.
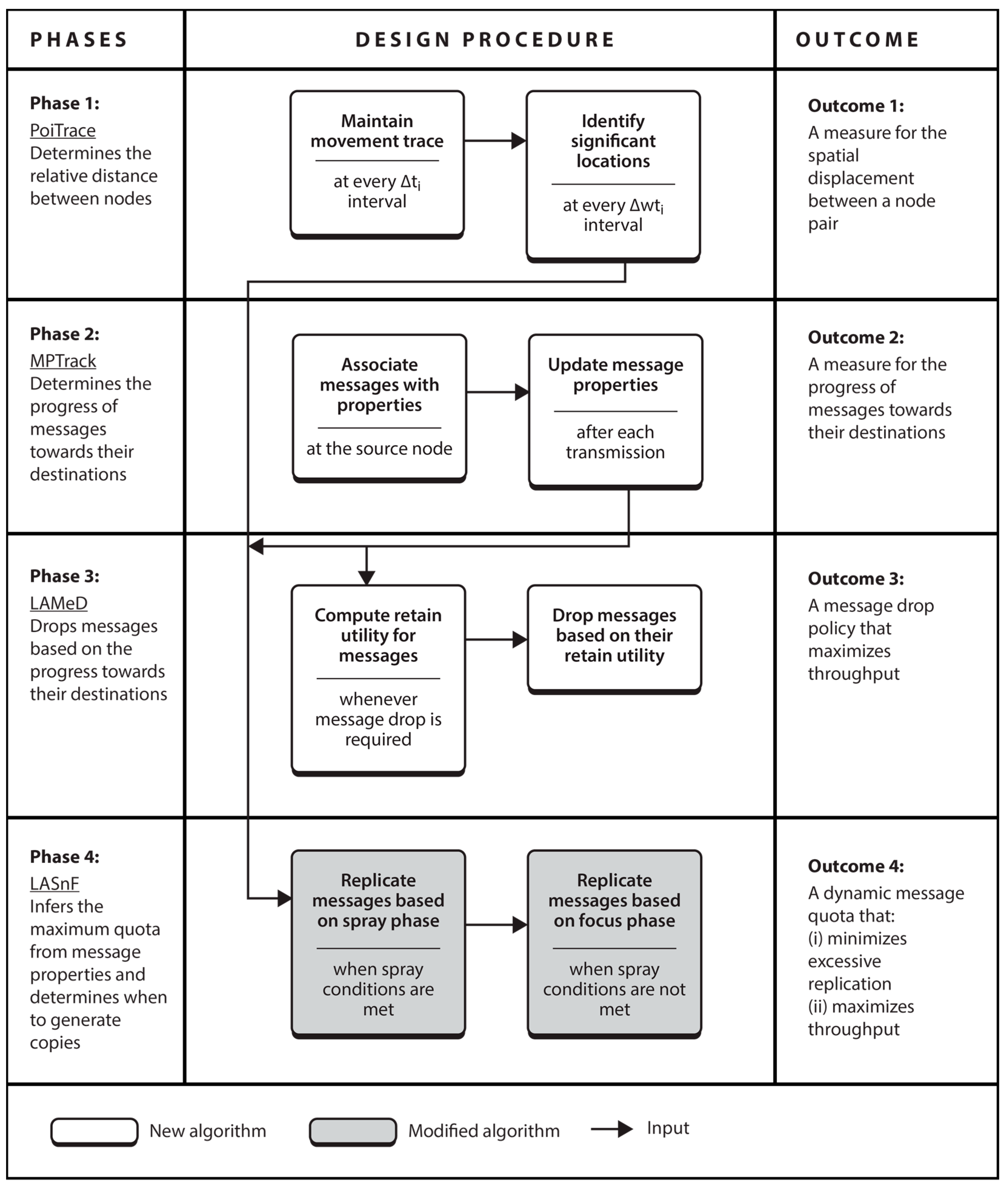
3.2. LARep Design
3.2.1. Phase 1: Determining the Relative Distance between Nodes
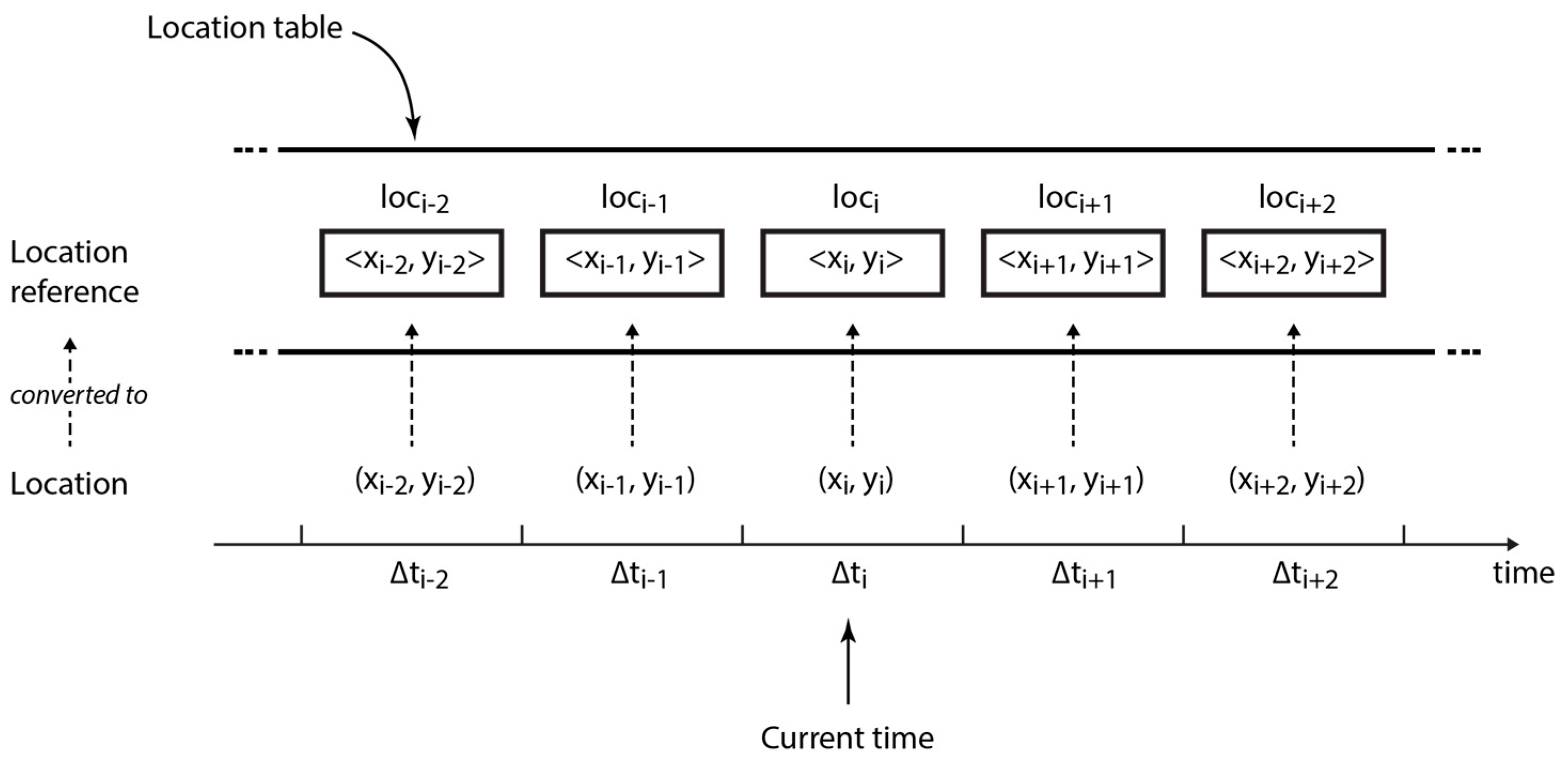
Collecting and Recording Location Information
| Algorithm 1 The algorithm for recording location information |
 |
Extracting Significant Locations
3.2.2. Phase 2: Determining Message Progress towards the Destination
3.2.3. Phase 3: Policy for Dropping Messages
| Algorithm 2 The algorithm for selecting the message set from which to drop a message | ||
| Input: , | ||
| Output: set from which to drop a message | ||
| 1 | if then | |
| 2 | Select the external message set; | |
| 3 | end | |
| 4 | if then | |
| 5 | Select the sensed data collection message set; | |
| 6 | end | |
| 7 | return set from which to drop a message; | |
3.2.4. Phase 4: Message Replication Phases
4. Evaluation
4.1. Evaluation Methodology
4.1.1. Simulation Set-Up
4.1.2. Performance Evaluation Metrics
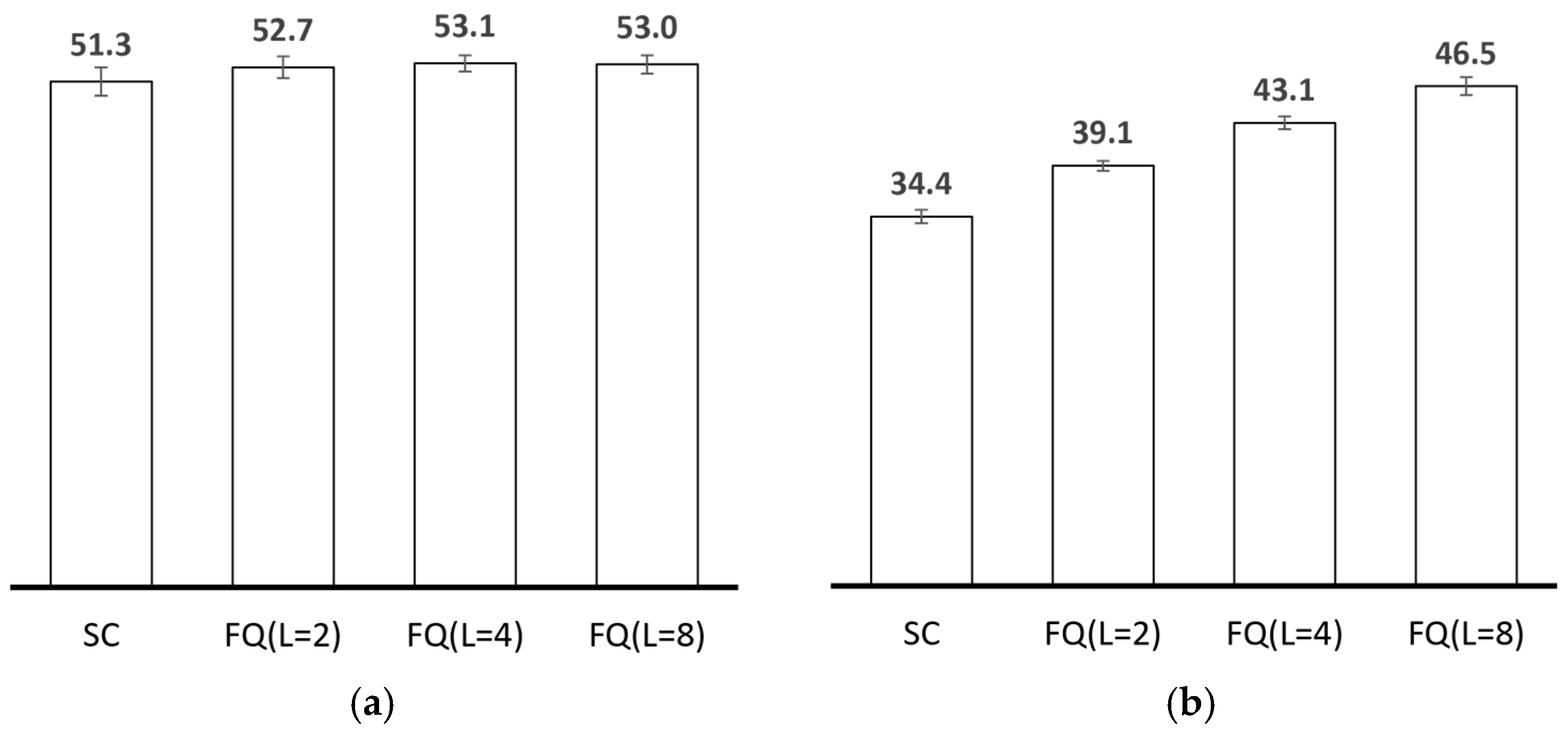
4.2. Results and Discussion
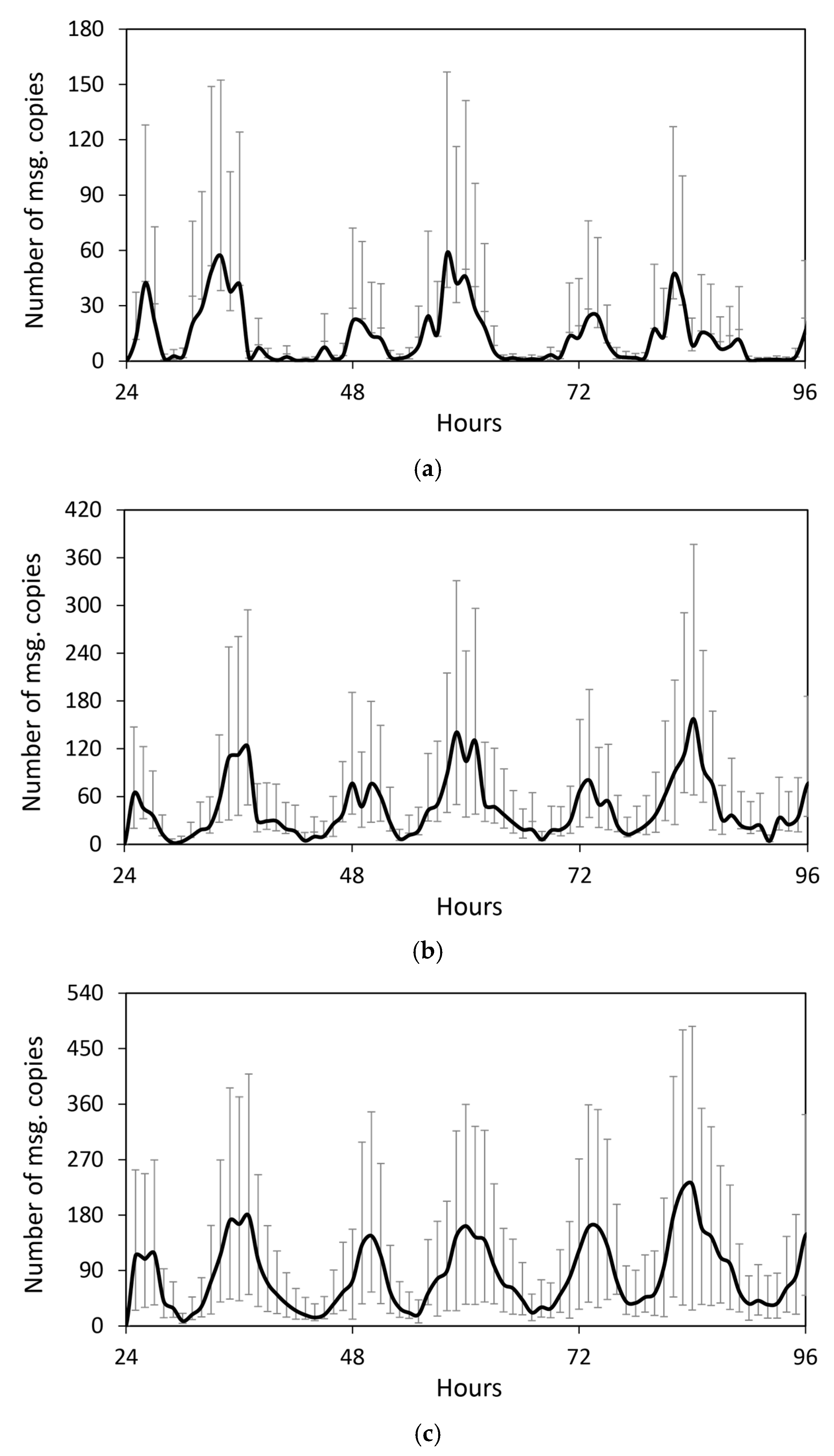
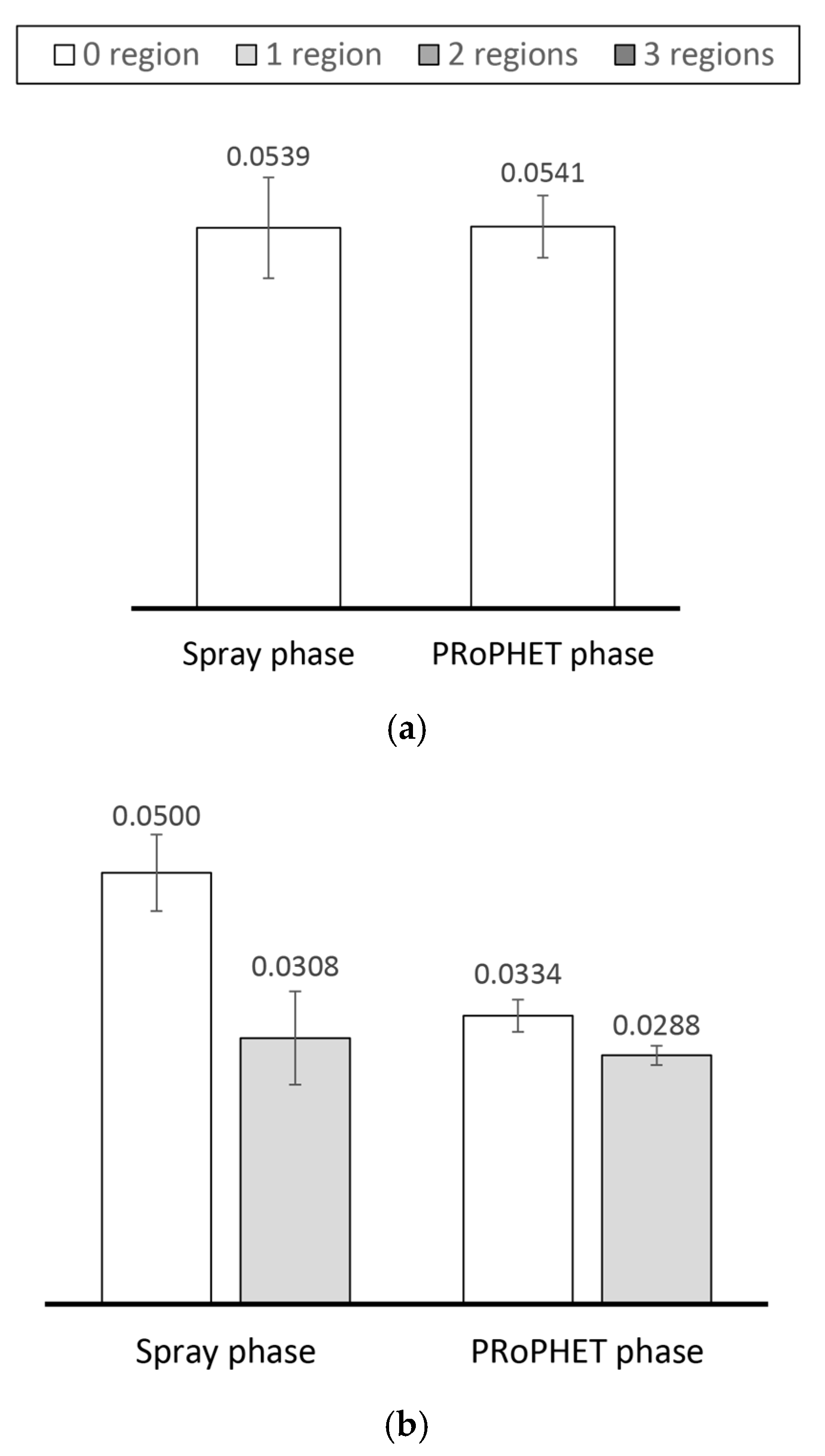
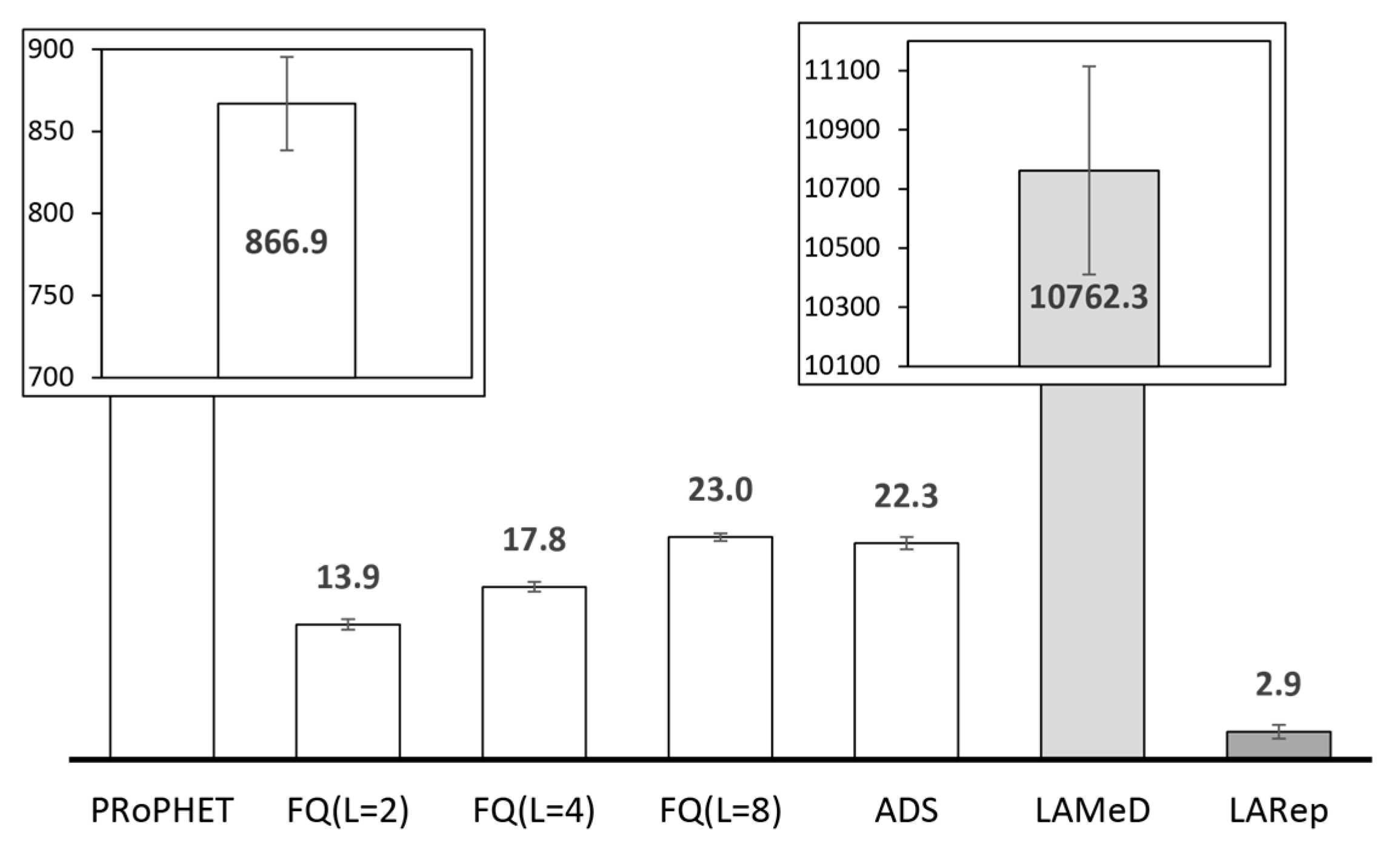
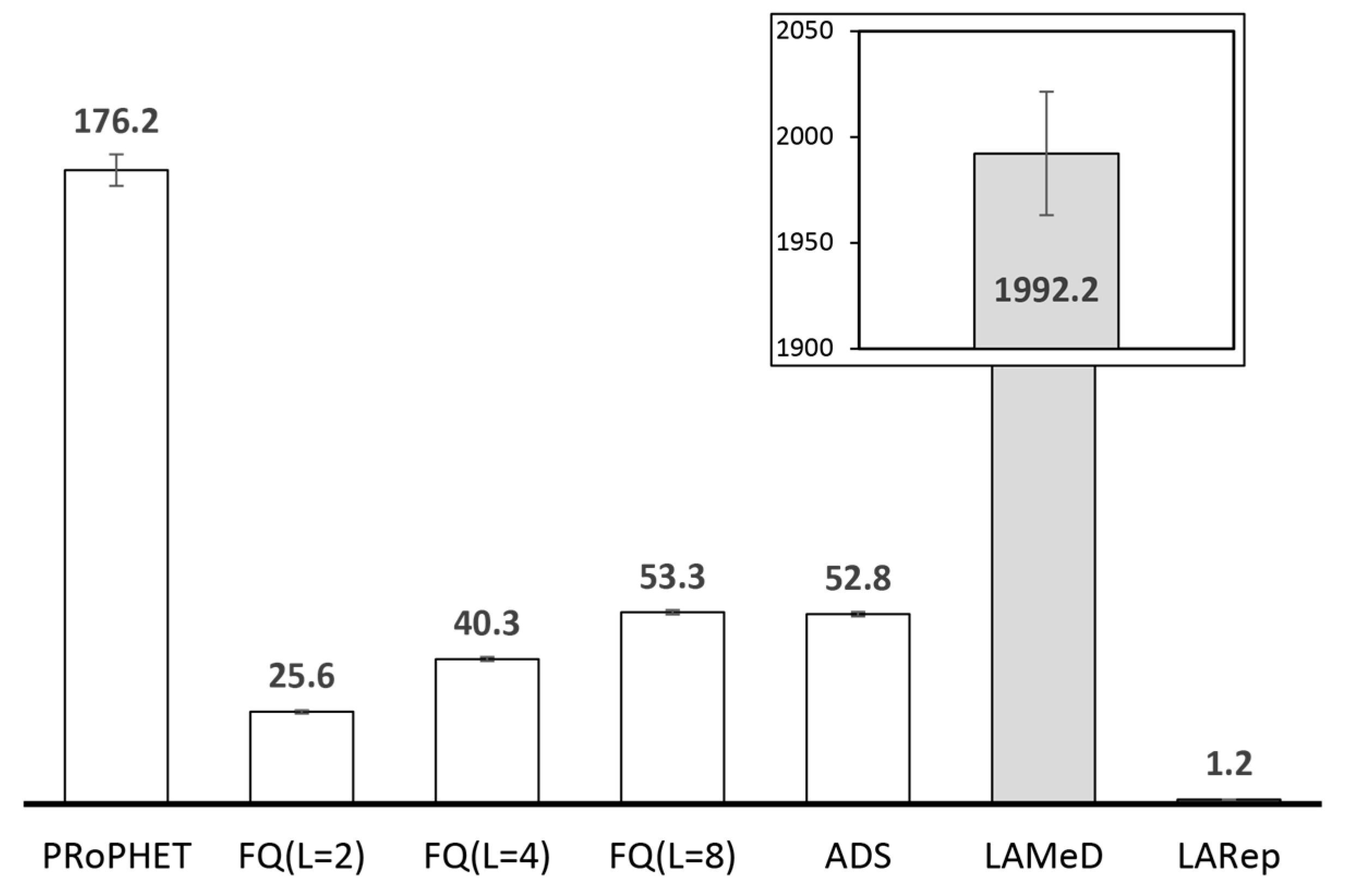
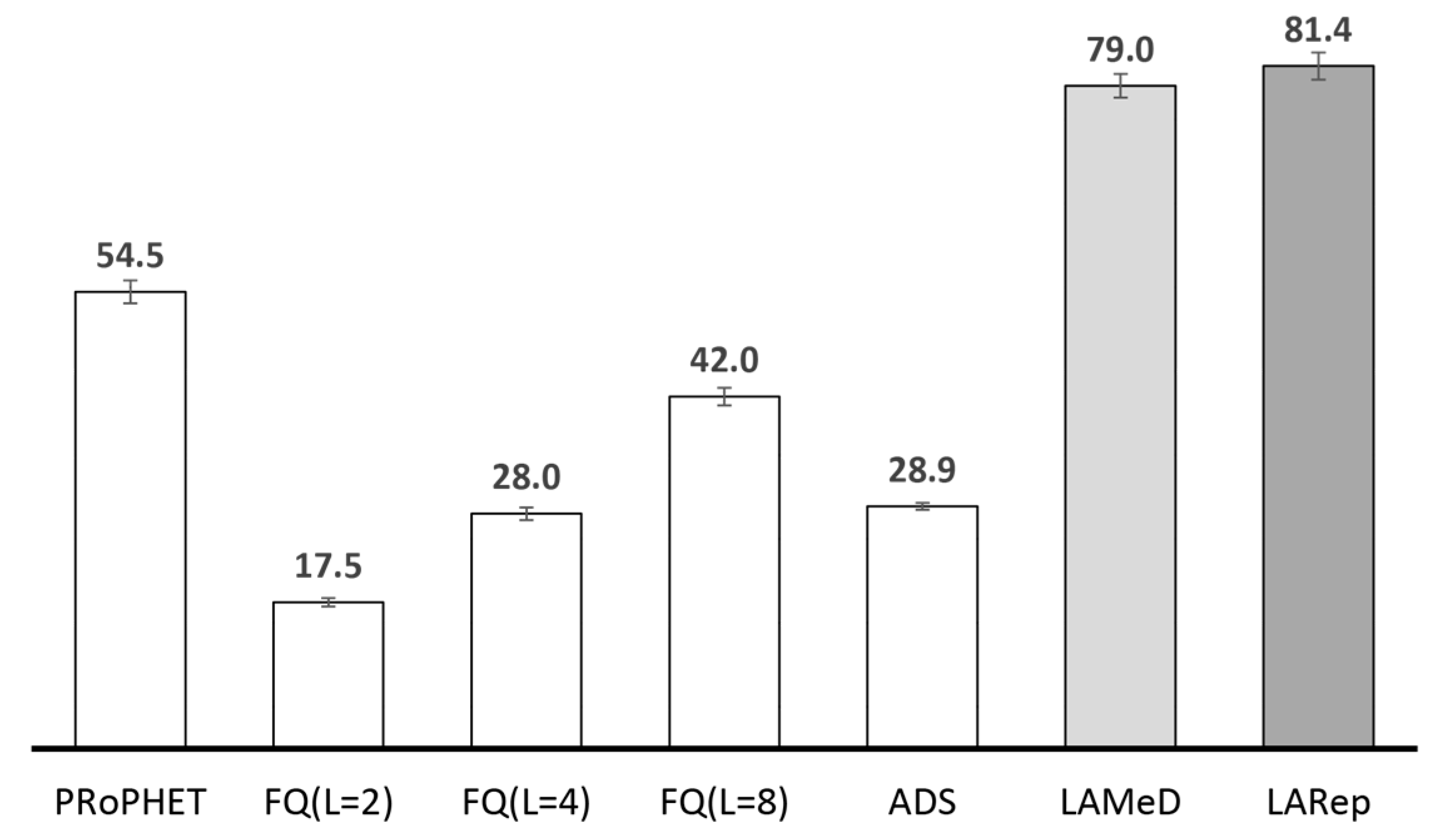
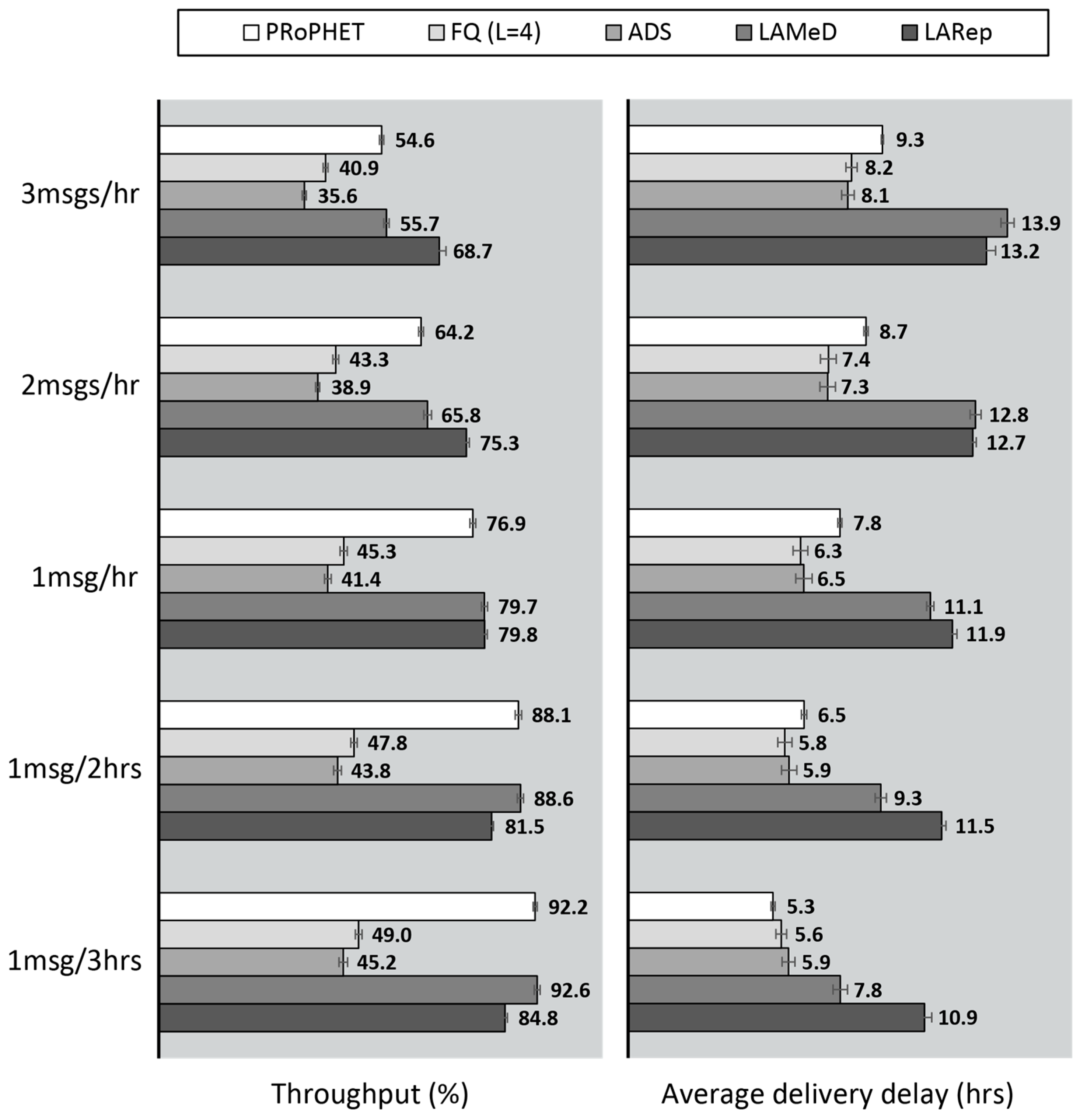
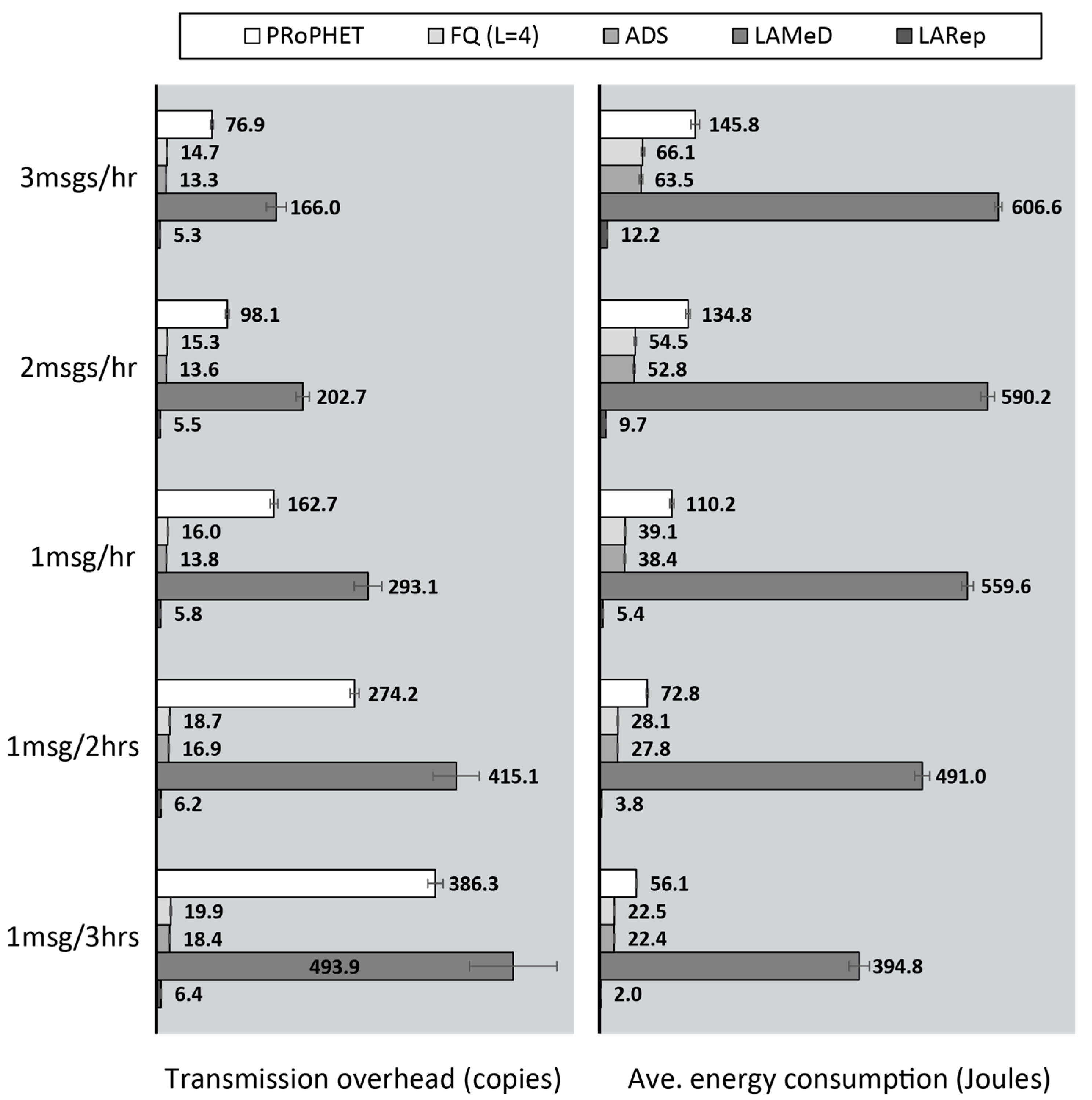
4.2.1. Performance Evaluation in the Skudai Scenario
4.2.2. Performance Evaluation in the Helsinki Scenario
5. Conclusions and Future Work
- We first established relevant characteristics of OppNets for sensed data collection introduced by the presence of portable handheld user devices, since existing message replication techniques are not specifically designed to cope with the characteristics. Then we investigated the impact of these characteristics on existing message replication techniques and suggested design guidelines that need to be observed in order to improve routing performance and feasibility in real-world implementation.
- Next, we followed our design guidelines to propose a set of mechanisms that collectively form LARep, a message replication technique that can be incorporated into existing encounter-based routing protocols to reduce message transmission overhead without compromising throughput. LARep exploits the concept of spatial locality to replicate messages according to the proximity of nodes’ preferred locations in the network. This allows different messages to be replicated at varying rates, thereby achieving a near optimal quota for each, without requiring global knowledge about the network. LARep also introduces a locality aware policy for dropping messages, which further improves throughput. Incorporating LARep into PRoPHET reduced message transmission overhead, reduced energy consumption and increased throughput. Experiments in the ONE simulator showed that LARep achieves better performance as compared with existing message replication techniques.
Author Contributions
Conflicts of Interest
References
- ITU-T Focus Group on Smart Sustainable Cities: An Overview of Smart Sustainable Cities and the Role of Information and Communication Technologies. Available online: http://www.itu.int/en/ITU-T/focusgroups/ssc/Documents/Approved_Deliverables/TR-Overview-SSC.docx (accessed on 2 September 2017).
- Gomez, C.; Paradells, J. Urban Automation Networks: Current and Emerging Solutions for Sensed Data Collection and Actuation in Smart Cities. Sensors 2015, 15, 22874–22898. [Google Scholar] [CrossRef] [PubMed]
- Clarke, R. Smart Cities and the Internet of Everything: The Foundation for Delivering Next-Generation Citizen Services. Available online: http://www.cisco.com/c/dam/en_us/solutions/industries/docs/scc/ioe_citizen_svcs_white_paper_idc_2013.pdf (accessed on 2 September 2017).
- Du, W.; Li, Z.; Liando, J.; Li, M. From Rateless to Distanceless: Enabling Sparse Sensor Network Deployment in Large Areas. IEEE/ACM Trans. Netw. 2016, 24, 2498–2511. [Google Scholar] [CrossRef]
- Mao, X.; Miao, X.; He, Y.; Li, X.; Liu, Y. CitySee: Urban CO2 monitoring with sensors. In Proceedings of the 31st Annual IEEE International Conference on Computer Communications, Orlando, FL, USA, 25–30 March 2012; pp. 1611–1619. [Google Scholar]
- Valerio, L.; Bruno, R.; Passarella, A. Cellular traffic offloading via opportunistic networking with reinforcement learning. Comput. Commun. 2015, 71, 129–141. [Google Scholar] [CrossRef]
- Baker, T.; Ngoko, Y.; Tolosana-Calasanz, R.; Rana, O.; Randles, M. Energy Efficient Cloud Computing Environment via Autonomic Meta-director Framework. In Proceedings of the 6th International Conference on Developments in eSystems Engineering, Abu Dhabi, United Arab Emirates, 16–18 December 2013; pp. 198–203. [Google Scholar]
- Aldawsari, B.; Baker, T.; England, D. Trusted Energy-Efficient Cloud-Based Services Brokerage Platform. Int. J. Intell. Comput. Res. 2015, 6, 630–639. [Google Scholar] [CrossRef]
- Baker, T.; Asim, M.; Tawfik, H.; Aldawsari, B.; Buyya, R. An energy aware service composition algorithm for multiple cloud based IoT applications. J. Netw. Comput. Appl. 2017, 89, 96–108. [Google Scholar] [CrossRef]
- Baker, T.; Al-dawsari, B.; Tawfik, H.; Reid, D.; Ngoko, Y. GreeDi: An energy efficient routing algorithm for big data on cloud. Ad Hoc Netw. 2015, 35, 83–96. [Google Scholar] [CrossRef]
- Ochiai, H.; Ishizuka, H.; Kawakami, Y.; Esaki, H. Agent based sensor data gathering for agricultural applications. IEEE Sens. J. 2011, 11, 2861–2868. [Google Scholar] [CrossRef]
- Tovar, A.; Friesen, T.; Ferens, K.; McLeod, B. A DTN wireless sensor network for wildlife habitat monitoring. In Proceedings of the 23rd Canadian Conference on Electrical and Computer Engineering, Calgary, AB, Canada, 2–5 May 2010; pp. 1–5. [Google Scholar]
- McDonald, P.; Geraghty, D.; Humphreys, I.; Farrell, S.; Cahill, V. Sensor Network with Delay Tolerance (SeNDT). In Proceedings of the 16th International Conference on Computer Communications and Networks, Honolulu, HI, USA, 13–16 August 2007; pp. 1333–1338. [Google Scholar]
- Velásquez-Villada, C.; Donoso, Y. Delay/Disruption Tolerant Network Based Message Forwarding for a River Pollution Monitoring Wireless Sensor Network Application. Sensors 2016, 16, 436. [Google Scholar] [CrossRef] [PubMed]
- Cheng, N.; Lu, N.; Zhang, N.; Shen, X.; Mark, J. Vehicle-assisted data delivery for smart grid: An optimal stopping approach. In Proceedings of the IEEE International Conference on Communications, Budapest, Hungary, 9–13 June 2013; pp. 6184–6188. [Google Scholar]
- Park, U.; Heidemann, J. Data muling with mobile phones for sensornets. In Proceedings of the 9th ACM Conference on Embedded Networked Sensor Systems, Seattle, WA, USA, 1–4 November 2011; pp. 162–175. [Google Scholar]
- Can, Z.; Demirbas, M. Smartphone-based data collection from wireless sensor networks in an urban environment. J. Netw. Comp. Appl. 2015, 58, 208–216. [Google Scholar] [CrossRef]
- Shi, F.; Adeel, U.; Theodoridis, E.; Haghighi, M.; McCann, J. OppNet: Enabling citizen centric urban IoT data collection through opportunistic connectivity service. In Proceedings of the IEEE 3rd World Forum on Internet of Things, Reston, VA, USA, 12–14 December 2016; pp. 723–728. [Google Scholar]
- Dimatteo, S.; Hui, P.; Han, B.; Li, V. Cellular Traffic Offloading through Wi-Fi Networks. In Proceedings of the IEEE 8th International Conference on Mobile Ad Hoc and Sensor Systems, Valencia, Spain, 17–22 October 2011; pp. 192–201. [Google Scholar]
- Petz, A.; Lindgren, A.; Hui, P.; Julien, C. Madserver: A server architecture for mobile advanced delivery. In Proceedings of the 7th ACM International Workshop on Challenged Networks, Istanbul, Turkey, 22–26 August 2012; pp. 17–22. [Google Scholar]
- Rebecchi, F.; Dias de Amorim, M.; Conan, V.; Passarella, A.; Bruno, R.; Conti, M. Data Offloading Techniques in Cellular Networks: A Survey. IEEE Commun. Surv. Tutor. 2015, 17, 580–603. [Google Scholar] [CrossRef]
- Wu, X.; Brown, K.; Sreenan, C. Analysis of smartphone user mobility traces for opportunistic data collection in wireless sensor networks. Pervasive Mob. Comput. 2013, 9, 881–891. [Google Scholar] [CrossRef]
- Wu, X.; Brown, K.; Sreenan, C. Exploiting Rush Hours for Energy Efficient Contact Probing in Opportunistic Data Collection. In Proceedings of the 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011; pp. 240–247. [Google Scholar]
- Aguilar, S.; Vidal, R.; Gomez, C. Opportunistic Sensor Data Collection with Bluetooth Low Energy. Sensors 2017, 17, 159. [Google Scholar] [CrossRef] [PubMed]
- Conti, M.; Boldrini, C.; Passarella, A. Context and resource awareness in opportunistic network data dissemination. In Proceedings of the 9th IEEE International Symposium on A World of Wireless, Mobile and Multimedia Networks, Newport Beach, CA, USA, 23–26 June 2008; pp. 1–6. [Google Scholar]
- Wang, W.; Amza, C. Motion-based routing for opportunistic ad-hoc networks. In Proceedings of the 14th ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Miami Beach, FL, USA, 31 October–4 November 2011; pp. 169–178. [Google Scholar]
- Picu, A.; Spyropoulos, T. Distributed stochastic optimization in opportunistic networks: the case of optimal relay selection. In Proceedings of the 5th ACM Workshop on Challenged Networks, Chicago, IL, USA, 20–24 September 2010; pp. 21–28. [Google Scholar]
- Amah, T.; Kamat, M.; Bakar, K.; Moreira, W.; Oliveira, A.; Batista, M. Spatial locality in pocket switched networks. In Proceedings of the 17th IEEE International Symposium on A World of Wireless, Mobile and Multimedia Networks, Coimbra, Portugal, 21–24 June 2016; pp. 1–6. [Google Scholar]
- Leguay, J.; Friedman, T.; Conan, V. Evaluating Mobility Pattern Space Routing for DTNS. In Proceedings of the 25th IEEE International Conference on Computer Communications, Barcelona, Spain, 23–29 April 2006; pp. 1–10. [Google Scholar]
- Mtibaa, A.; May, M.; Diot, C.; Ammar, M. Peoplerank: Social opportunistic forwarding. In Proceedings of the IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–5. [Google Scholar]
- Hui, P.; Crowcroft, J.; Yoneki, E. Bubble Rap: Social-based forwarding in delay-tolerant networks. IEEE Trans. Mob. Comput. 2011, 10, 1576–1589. [Google Scholar] [CrossRef]
- Moreira, W.; Mendes, P.; Sargento, S. Opportunistic routing based on daily routines. In Proceedings of the IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks, San Francisco, CA, USA, 25–28 June 2012; pp. 1–6. [Google Scholar]
- Nguyen, H.; Giordano, S. Context information prediction for social-based routing in opportunistic networks. Ad Hoc Netw. 2012, 10, 1557–1569. [Google Scholar] [CrossRef]
- Grasic, S.; Davies, E.; Lindgren, A.; Doria, A. The evolution of a DTN routing protocol—Prophetv2. In Proceedings of the 6th ACM Workshop on Challenged Networks, Las Vegas, NV, USA, 19–23 September 2011; pp. 27–30. [Google Scholar]
- McNett, M.; Voelker, G. Access and mobility of wireless PDA users. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2005, 9, 40–55. [Google Scholar] [CrossRef]
- Wang, S.; Liu, M.; Cheng, X.; Song, M. Routing in pocket switched networks. IEEE Wirel. Commun. 2012, 19, 67–73. [Google Scholar] [CrossRef]
- Hasan, S.; Schneider, C.; Ukkusuri, S.; González, M. Spatiotemporal patterns of urban human mobility. J. Stat. Phys. 2013, 151, 304–318. [Google Scholar] [CrossRef]
- Zhao, M.; Mason, L.; Wang, M. Empirical study on human mobility for mobile wireless networks. In Proceedings of the Military Communications Conference, San Diego, CA, USA, 16–19 November 2008; pp. 1–7. [Google Scholar]
- Zhu, K.; Li, W.; Fu, X. SMART: A Social and Mobile-Aware Routing Strategy for Disruption-Tolerant Networks. IEEE Trans. 2014, 63, 3423–3434. [Google Scholar] [CrossRef]
- Yu, C.; Bao, C.; Jin, H. Hierarchical Geographical Tags Based Routing Scheme in Delay/Disruption Tolerant Mobile Ad Hoc Networks. In Proceedings of the 1st International Conference on Human Centered Computing, Phnom Penh, Cambodia, 27–29 November 2014; Zu, Q., Hu, B., Gu, N., Seng, S., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 352–364. [Google Scholar]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C. Single-copy routing in intermittently connected mobile networks. In Proceedings of the 1st Annual IEEE Communications Society Conference on Sensor and Ad Hoc Communications and Networks, Santa Clara, CA, USA, 4–7 October 2004; pp. 235–244. [Google Scholar]
- Jain, S.; Fall, K.; Patra, R. Routing in a delay tolerant network. In Proceedings of the 2004 conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Portland, OR, USA, 30 August–3 September 2004; pp. 145–158. [Google Scholar]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C. Spray and focus: Efficient mobility-assisted routing for heterogeneous and correlated mobility. In Proceedings of the 5th Annual IEEE International Conference on Pervasive Computing and Communications Workshops, White Plains, NY, USA, 19–23 March 2007; pp. 79–85. [Google Scholar]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C. Spray and wait: An efficient routing scheme for intermittently connected mobile networks. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-Tolerant Networking, Philadelphia, PA, USA, 26 August 2005; pp. 252–259. [Google Scholar]
- Spyropoulos, T.; Turletti, T.; Obraczka, K. Routing in Delay Tolerant Networks Comprising Heterogeneous Node Populations. IEEE Trans. Mob. Comput. 2009, 8, 1132–1147. [Google Scholar] [CrossRef]
- Wang, E.; Yang, Y.; Chen, X.; Shen, C.; Han, L. The Improved Algorithm of Spray and Wait Routing Protocol in Delay Tolerant Network. Int. J. Adv. Comput. Technol. 2013, 5, 238–245. [Google Scholar]
- Sadat, N.; Tasnim, M. A Neighborhood Contact History Based Spraying Heuristic for Delay Tolerant Networks. In Proceedings of the 3rd International Conference on Informatics, Electronics & Vision, Dhaka, Bangladesh, 23–24 May 2014. [Google Scholar]
- Luo, G.; Zhang, J.; Huang, H.; Qin, K.; Sun, H. Exploiting intercontact time for routing in delay tolerant networks. Eur. Trans. Telecommun. 2013, 24, 589–599. [Google Scholar] [CrossRef]
- Lo, S.; Tsai, C.; Lai, Y. Quota-control routing in delay-tolerant networks. Ad Hoc Netw. 2014, 25, 393–405. [Google Scholar] [CrossRef]
- Niu, J.; Liu, M.; Liu, Y.; Shu, L.; Wu, D. A venues-aware message routing scheme for delay-tolerant networks. Wirel. Commun. Mob. Comput. 2015, 15, 1695–1710. [Google Scholar] [CrossRef]
- Huang, H.; Xiong, Z.; Wang, D. A Routing Strategy Based on Duplicates Adaptive Allocation and Rapid Spray in DTN. J. Comput. Inf. Syst. 2015, 11, 5681–5688. [Google Scholar]
- Iranmanesh, S.; Raad, R.; Chin, K. A Novel Destination-Based Routing Protocol (DBRP) in DTNs. In Proceedings of the 2012 International Symposium on Communications and Information Technologies, Gold Coast, QLD, Australia, 2–5 October 2012; pp. 325–330. [Google Scholar]
- Deok, S.; Won, Y. An Improved PRoPHET Routing Protocol in Delay Tolerant Network. Sci. World J. 2015. [Google Scholar] [CrossRef]
- Zhang, X.; Neglia, G.; Kurose, J.; Towsley, D. Performance Modeling of Epidemic Routing. Comput. Netw. Int. J. Comput. Telecommun. Netw. 2007, 51, 2867–2891. [Google Scholar] [CrossRef]
- Shin, K.; Kim, K.; Kim, S. Traffic management strategy for delay-tolerant networks. J. Netw. Comput. Appl. 2012, 6, 1762–1770. [Google Scholar] [CrossRef]
- Batabyal, S.; Bhaumik, P. Estimators for global information in mobile opportunistic network. Adv. Netw. Telecommun. Syst. 2013. [Google Scholar] [CrossRef]
- Iqbal, S.; Chowdhury, A. Adaptation of spray phase to improve the binary spray and Wait routing in Delay Tolerant Networks. Comput. Inf. Technol. 2012. [Google Scholar] [CrossRef]
- Miao, J.; Hasan, O.; Ben, S.; Brunie, L. A self-regulating protocol for efficient routing in mobile delay tolerant networks. Digit. Ecosyst. Technol. 2012. [Google Scholar] [CrossRef]
- You, L.; Li, J.; Wei, C.; Dai, C.; Xu, J.; Hu, L. A Hop Count Based Heuristic Routing Protocol for Mobile Delay Tolerant Networks. Sci. World J. 2014. [Google Scholar] [CrossRef] [PubMed]
- De Rango, F.; Amelio, S.; Fazio, P. Epidemic strategies in delay tolerant networks from an energetic point of view: Main issues and performance evaluation. J. Netw. 2015, 10, 4–14. [Google Scholar] [CrossRef]
- Keränen, A.; Ott, J.; Kärkkäinen, T. The ONE simulator for DTN protocol evaluation. In Proceedings of the 2nd International Conference on Simulation Tools and Techniques, Rome, Italy, 2–6 March 2009. [Google Scholar]
- Ekman, F.; Keränen, A.; Karvo, J.; Ott, J. Working Day Movement Model. In Proceedings of the 1st ACM SIGMOBILE workshop on Mobility models, Hong Kong, China, 26 May 2008; pp. 33–40. [Google Scholar]
- Silva, D.; Costa, A.; Macedo, J. Energy Impact Analysis on DTN Routing Protocols. In Proceedings of the 4th Extreme Conference on Communication, Zürich, Switzerland, 10–14 March 2012. [Google Scholar]
- Moreira, W.; Mendes, P.; Sargento, S. Social-aware opportunistic routing protocol based on user’s interactions and interests. Netw. Int. Archit. 2014. [Google Scholar] [CrossRef]
- Rajaei, A.; Chalmers, D.; Wakeman, I.; Parisis, G. GSAF: Efficient and flexible geocasting for opportunistic networks. In Proceedings of the 17th International Symposium on A World of Wireless, Mobile and Multimedia Networks, Coimbra, Portugal, 21–24 June 2016; pp. 1–9. [Google Scholar]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C. Efficient Routing in Intermittently Connected Mobile Networks: The Multiple-copy Case. IEEE/ACM Trans. Netw. 2008, 16, 77–90. [Google Scholar] [CrossRef]
- Bjurefors, F.; Gunningberg, P.; Rohner, C.; Tavakoli, S. Congestion avoidance in a data-centric opportunistic network. In Proceedings of the ACM SIGCOMM workshop on Information-centric Networking, Toronto, ON, Canada, 19 August 2011; pp. 32–37. [Google Scholar]
- Soelistijanto, B.; Howarth, M. Transfer Reliability and Congestion Control Strategies in Opportunistic Networks: A Survey. IEEE Commun. Surv. Tutor. 2014, 16, 538–555. [Google Scholar] [CrossRef]
- Ren, Z.; Liu, W.; Zhou, X.; Fang, J.; Chen, Q. Summary-Vector-Based Effective and Fast Immunization for Epidemic-Based Routing in Opportunistic Networks. IEEE Commun. Lett. 2014, 18, 1183–1186. [Google Scholar] [CrossRef]
- Huang, J.; Chen, Y.; Tung, L.; Chen, L. Using known vectors to improve data dissemination in opportunistic networks. Int. J. Ad Hoc Ubiquitous Comput. 2014, 17, 59–69. [Google Scholar] [CrossRef]
- Moreira, W.; Mendes, P. Social-Aware Opportunistic Routing: The New Trend. In Routing in Opportunistic Networks; Woungang, I., Dhurandher, S., Anpalagan, A., Vasilakos, A., Eds.; Springer: New York, NY, USA, 2013; pp. 27–68. [Google Scholar]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C. Multiple-Copy Routing in Intermittently Connected Mobile Networks. Available online: https://pdfs.semanticscholar.org/c265/5ff465df4ec85dc4bf5a1608a6d82fe919fb.pdf (accessed on 7 November 2017).
- Amah, T.; Kamat, M.; Abu Bakar, K.; Abd Rahman, S.; Mohammed, M.; Abali, A.; Moreira, W.; Oliveira, A. Collecting Sensed Data with Opportunistic Networks: The Case of Contact Information Overhead. Information 2017, 8, 108. [Google Scholar] [CrossRef]
- Cho, E.; Myers, S.; Leskovec, J. Friendship and Mobility: User Movement in Location Based Social Networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090. [Google Scholar]
- Henderson, T.; Kotz, D.; Abyzov, I. The changing usage of a mature campus-wide wireless network. Comput. Netw. 2008, 52, 2690–2712. [Google Scholar] [CrossRef]
- Nunes, I.; Celes, C.; Silva, M.; Vaz de Melo, P.; Loureiro, A. GRM: Group Regularity Mobility Model. In Proceedings of the 20th ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Miami Beach, FL, USA, 21–25 November 2017. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value(s) |
|---|---|
| Total simulation time (days) | 5 |
| Warm-up period (days) | 1 |
| Cool-down period (days) | 1 |
| Wireless communication interface | Bluetooth |
| Transmission range (m) | 10 |
| Transmission rate (MBps) | 2 |
| Buffer size (MB) | 10 |
| Message size (KB) | 10 to 15 |
| Message TTL (days) | 1 |
| Number of scenarios | 3 |
| Simulation area (Km2) | 4.5 × 3.4, 9 × 6.8 & 18 × 13.6 |
| Number of nodes | 19, 76 & 304 |
| Ave. message generation rate/node | 1 message every 10 to 15 min |
| Battery capacity (Joules) | 4800 |
| Receive/transmit energy (mW/s) | 0.08 |
| Replication Approach | Acceptable Performance Does Not Require | Suitable under Increasing | Scenario Adaptability | ||
|---|---|---|---|---|---|
| (Frequent) Metadata Transmission | Global Knowledge | Degrees of Spatial Locality | Node Population | ||
| Gossiping [54] | √ | √ | √ | × | × |
| Timer threshold [54] | √ | √ | √ | × | × |
| VACCINE [54] | × | √ | × | × | √ |
| Shin et al. [55] | × | × | √ | × | × |
| Iqbal & Chowdhury [57] | √ | √ | √ | × | × |
| Miao et al. [58] | √ | × | √ | × | × |
| Batabyal & Bhaumik [56] | √ | × | × | √ | × |
| Lo et al. [49] | × | √ | √ | × | √ |
| You et al. [59] | √ | × | × | √ | × |
| Deok & Won [53] | √ | √ | × | × | × |
| Huang et al. [51] | √ | √ | × | √ | √ |
| De Rango et al. [60] | √ | × | √ | × | × |
| Our proposal (LARep) | √ | √ | √ | √ | √ |
| Time Slot | Location | GPS Coordinates | Location Reference |
|---|---|---|---|
| Parameter | Value |
|---|---|
| Total simulation time (days) | 5 |
| Warm-up period (days) | 1 |
| Cool-down period (days) | 1 |
| Wireless communication interface | Bluetooth |
| Transmission range (m) | 10 |
| Transmission rate (MBps) | 2 |
| Buffer size (MB) | 10 |
| Message size (KB) | 10 to 15 |
| Message TTL (days) | 1 |
| Number of nodes | 1349 |
| Ave. message generation rate/node | 1 message/h |
| Battery capacity (Joules) | 4800 |
| Receive/transmit energy (mW/s) | 0.08 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amah, T.E.; Kamat, M.; Bakar, K.A.; Rahman, S.O.A.; Mohammed, M.H.; Abali, A.M.; Moreira, W.; Oliveira-Jr, A. The Impact of Message Replication on the Performance of Opportunistic Networks for Sensed Data Collection. Information 2017, 8, 143. https://doi.org/10.3390/info8040143
Amah TE, Kamat M, Bakar KA, Rahman SOA, Mohammed MH, Abali AM, Moreira W, Oliveira-Jr A. The Impact of Message Replication on the Performance of Opportunistic Networks for Sensed Data Collection. Information. 2017; 8(4):143. https://doi.org/10.3390/info8040143
Chicago/Turabian StyleAmah, Tekenate E., Maznah Kamat, Kamalrulnizam Abu Bakar, Syed Othmawi Abd Rahman, Muhammad Hafiz Mohammed, Aliyu M. Abali, Waldir Moreira, and Antonio Oliveira-Jr. 2017. "The Impact of Message Replication on the Performance of Opportunistic Networks for Sensed Data Collection" Information 8, no. 4: 143. https://doi.org/10.3390/info8040143
APA StyleAmah, T. E., Kamat, M., Bakar, K. A., Rahman, S. O. A., Mohammed, M. H., Abali, A. M., Moreira, W., & Oliveira-Jr, A. (2017). The Impact of Message Replication on the Performance of Opportunistic Networks for Sensed Data Collection. Information, 8(4), 143. https://doi.org/10.3390/info8040143