Arabic Handwritten Digit Recognition Based on Restricted Boltzmann Machine and Convolutional Neural Networks

Abstract
:
1. Introduction
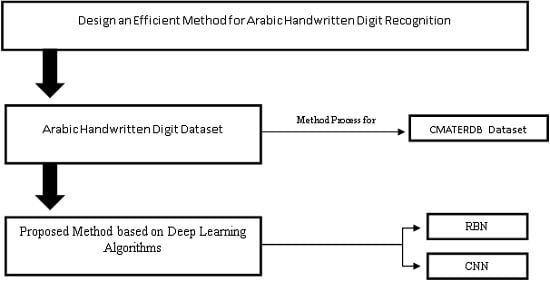
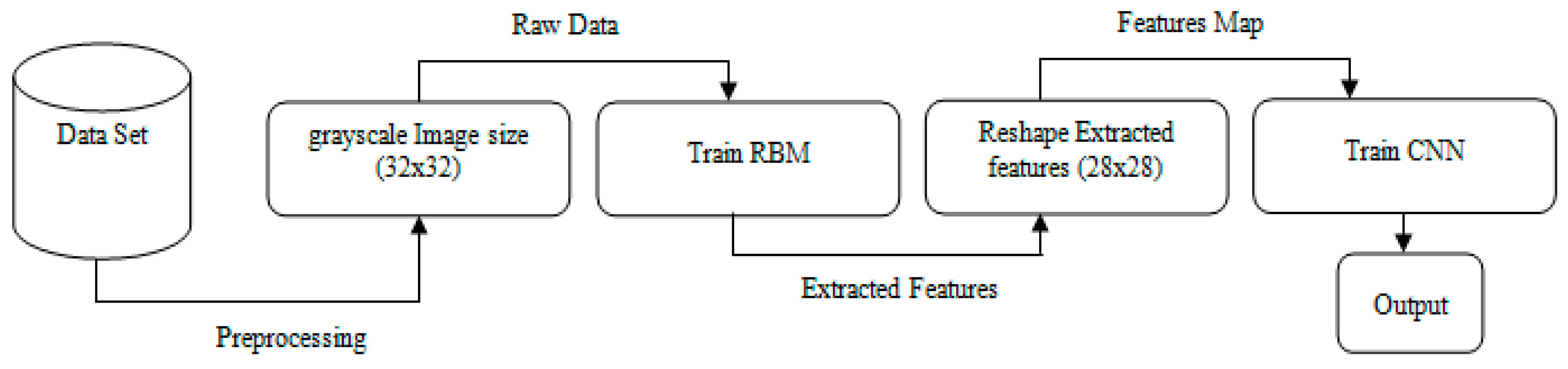
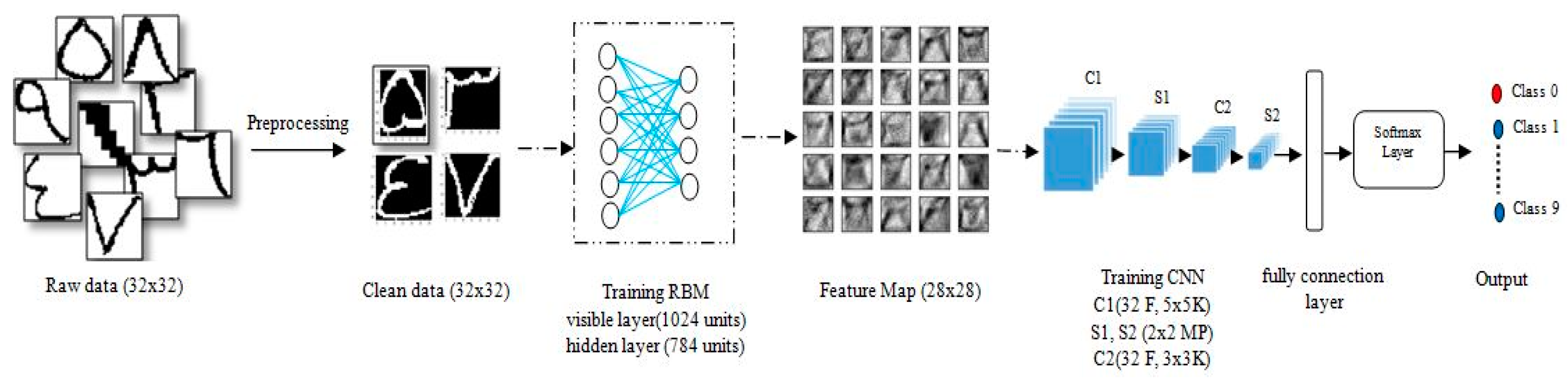
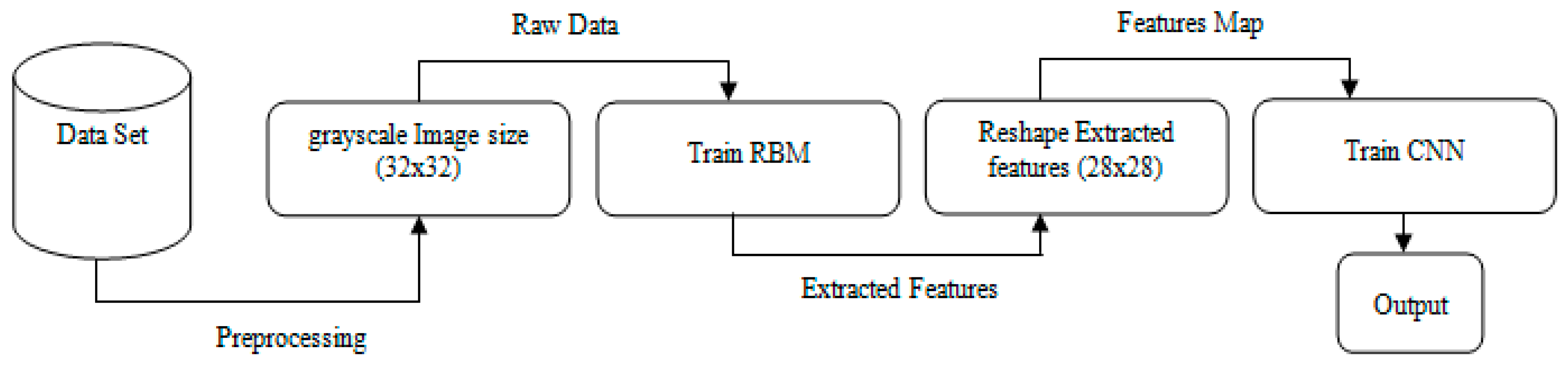
2. The Proposed Method
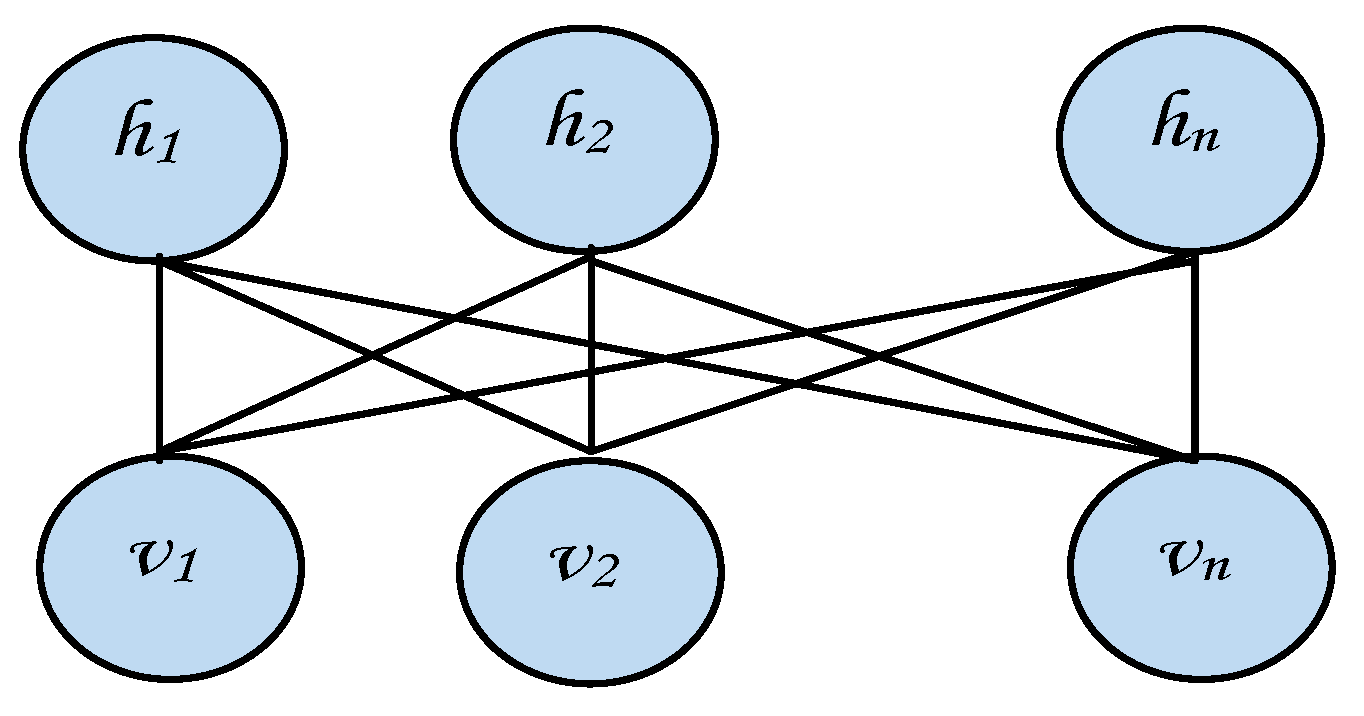
2.1. Restricted Boltzmann Machines
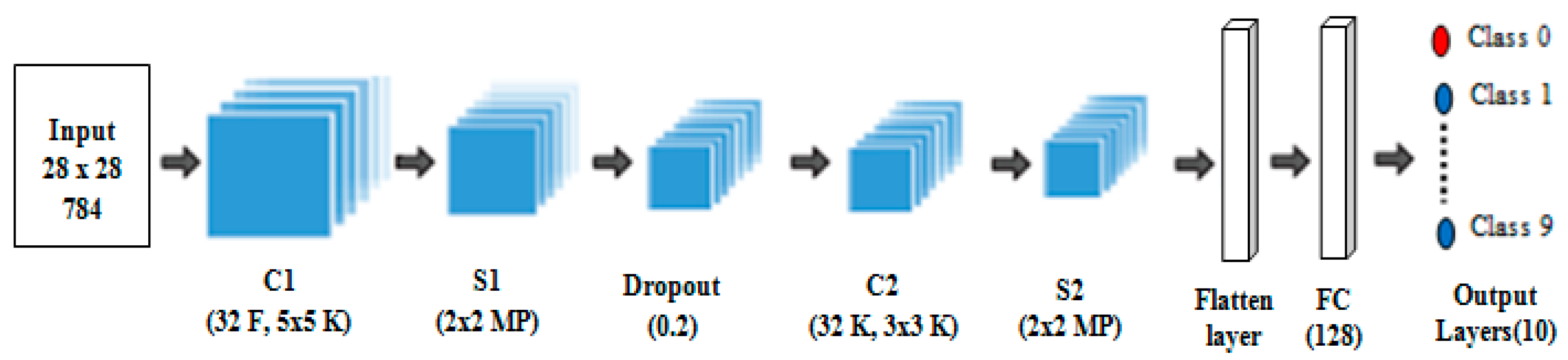
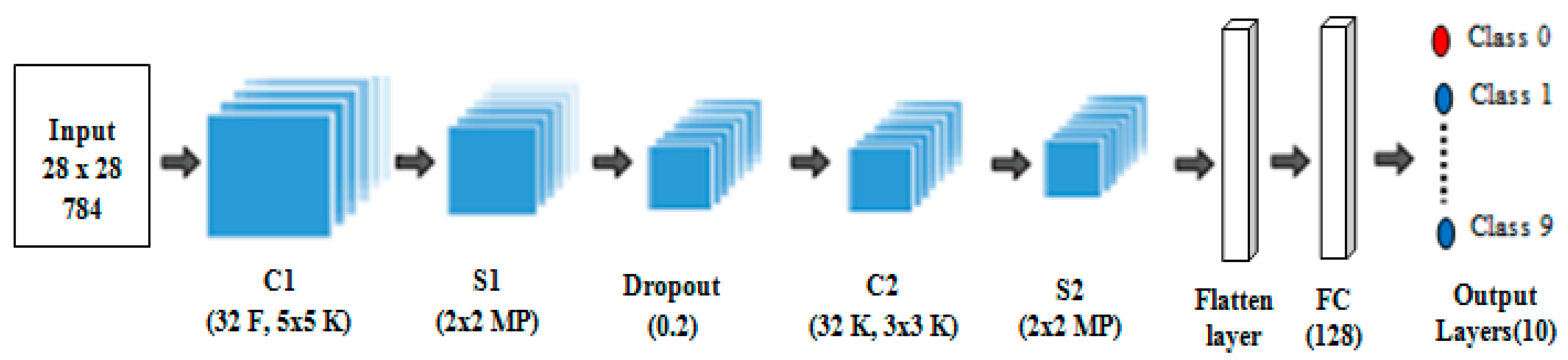
2.2. Convolutional Neural Network
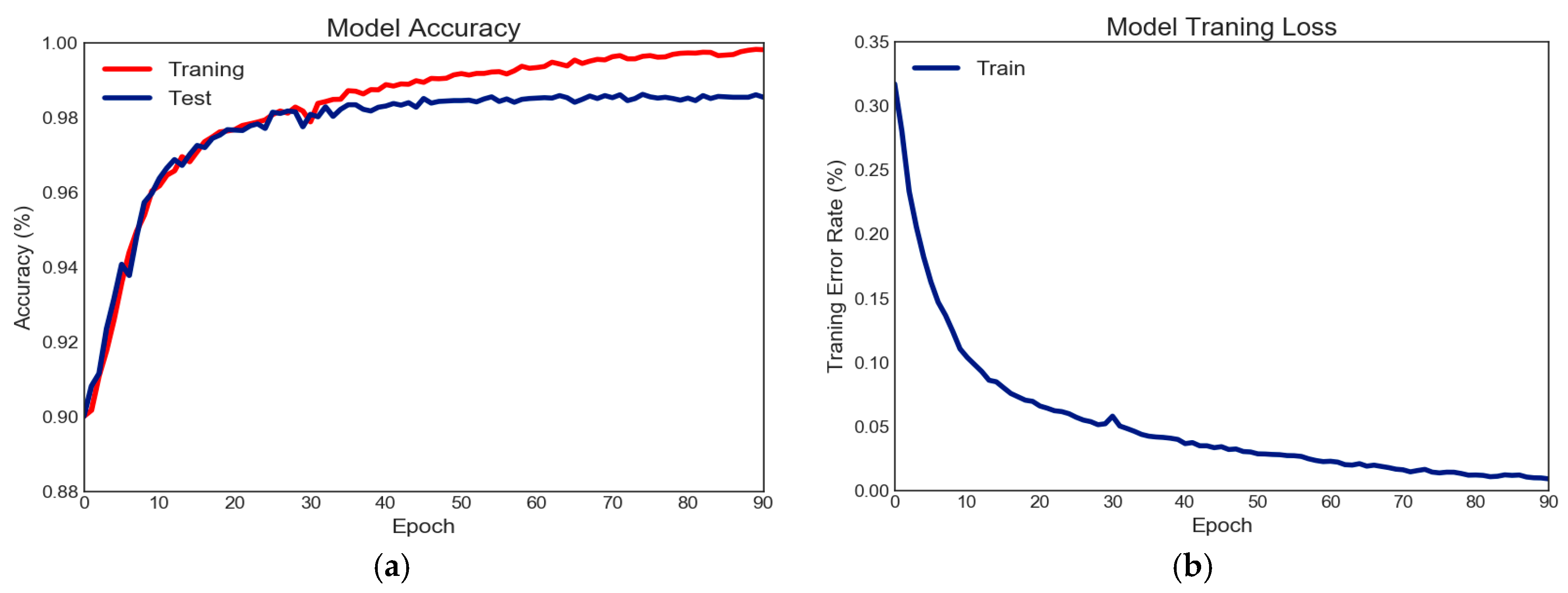
3. Experimental Results
3.1. Dataset Description
3.2. Evaluation Measures
- Precision (P), also called the positive predictive value, is the fraction of images that are correctly classified over the total number of images classified.
- Recall (R) is the fraction of correctly classified images over the total number of images that belong to class x.
- F1 combines Recall and Precision; the value of the F1 measure becomes high if and only if the values of Precision and Recall are high (Table 3). The F1 formula can be denoted as follows:
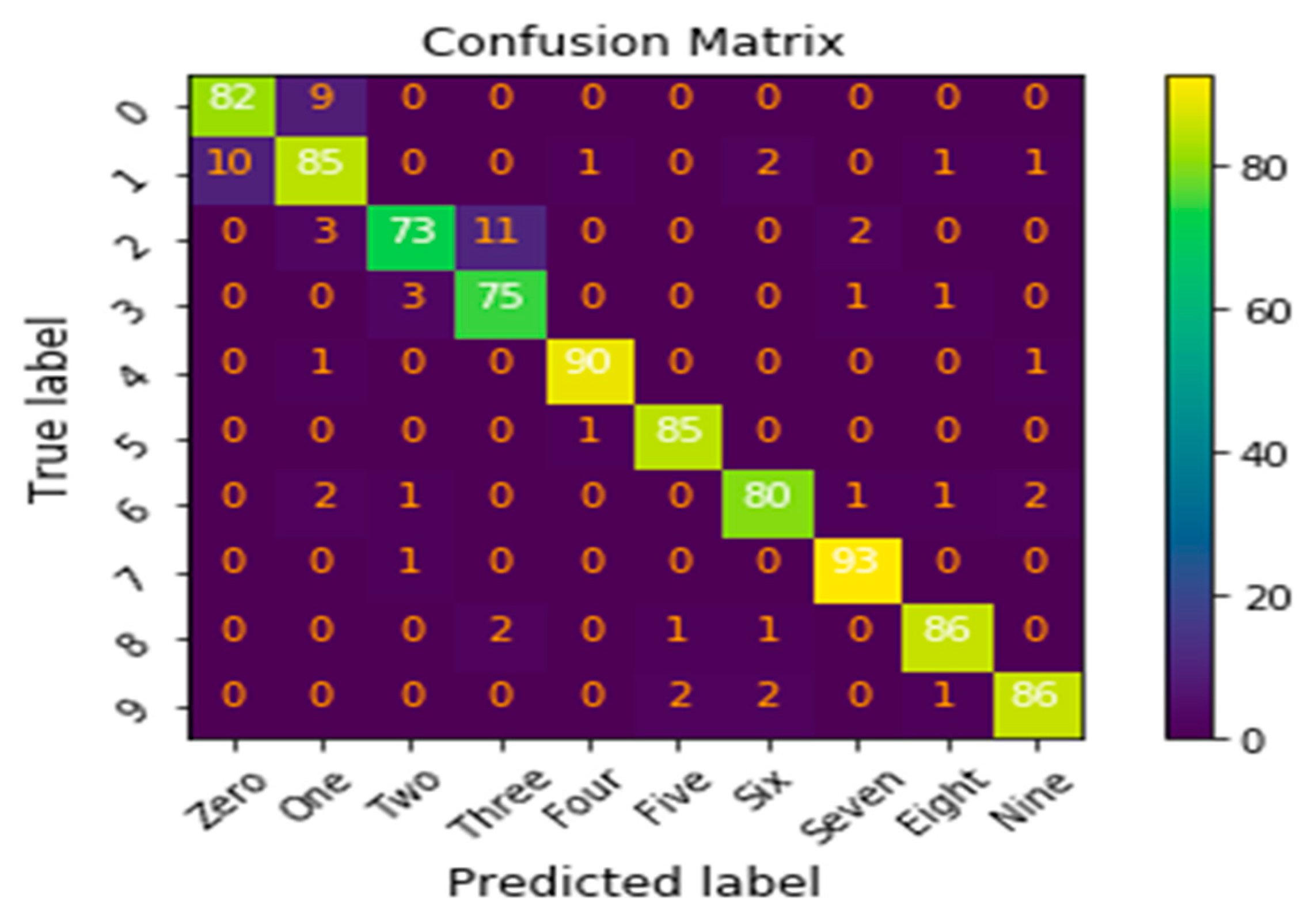
4. Comparison Results and Discussion
5. Conclusions
Acknowledgments
Conflicts of Interest
References
- Babu, U.R.; Venkateswarlu, Y.; Chintha, A.K. Handwritten digit recognition using k-nearest neighbour classifier. In Proceedings of the 2014 World Congress on Computing and Communication Technologies, (WCCCT 2014), Trichirappalli, India, 27 February–1 March 2014; pp. 60–65. [Google Scholar]
- Niu, X.X.; Suen, C.Y. A novel hybrid CNN-SVM classifier for recognizing handwritten digits. Pattern Recognit. 2012, 45, 1318–1325. [Google Scholar] [CrossRef]
- Al-omari, F.A.; Al-jarrah, O. Handwritten Indian numerals recognition system using probabilistic neural networks. Adv. Eng. Inform. 2004, 18, 9–16. [Google Scholar] [CrossRef]
- Ashiquzzaman, A.; Tushar, A.K. Handwritten Arabic Numeral Recognition using Deep Learning Neural Networks. In Proceedings of the 2017 IEEE International Conference on Imaging, Vision & Pattern Recognition, Dhaka, Bangladesh, 13–14 February 2017; pp. 3–6. [Google Scholar]
- Das, N.; Mollah, A.F.; Saha, S.; Haque, S.S. Handwritten Arabic Numeral Recognition using a Multi Layer Perceptron. In Proceedings of the National Conference on Recent Trends in Information Systems (ReTIS-06), Kolkata, India, 14–15 July 2006; pp. 200–203. [Google Scholar]
- Abdleazeem, S.; El-Sherif, E. Arabic handwritten digit recognition. Int. J. Doc. Anal. Recognit. 2008, 11, 127–141. [Google Scholar] [CrossRef]
- Impedovo, S.; Mangini, F.M.; Barbuzzi, D. A novel prototype generation technique for handwriting digit recognition. Pattern Recognit. 2014, 47, 1002–1010. [Google Scholar] [CrossRef]
- Mahmoud, S. Recognition of writer-independent off-line handwritten Arabic (Indian) numerals using hidden Markov models. Signal Process. 2008, 88, 844–857. [Google Scholar] [CrossRef]
- Suliman, A.; Sulaiman, M.N.; Othman, M.; Wirza, R. Chain Coding and Pre Processing Stages of Handwritten Character Image File. Electron. J. Comput. Sci. Inf. Technol. 2010, 2, 6–13. [Google Scholar]
- Szarvas, M.; Yoshizawa, A.; Yamamoto, M.; Ogata, J. Pedestrian Detection with Convolutional Neural Networks. In Proceedings of the 2005 IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; pp. 224–229. [Google Scholar]
- Mori, K.; Suz, T. Face Recognition Using SVM Fed with Intermediate Output of CNN for Face Detection. In Proceedings of the IAPR Conference on Machine VIsion Applications, Tsukuba Science City, Japan, 16–18 May 2005; pp. 1–4. [Google Scholar]
- Lauer, F.; Suen, C.Y.; Bloch, G. A trainable feature extractor for handwritten digit recognition. Pattern Recognit. 2007, 40, 1816–1824. [Google Scholar] [CrossRef]
- Cruz, R.M.O.; Cavalcanti, G.D.C.; Ren, T.I. Handwritten Digit Recognition Using Multiple Feature Extraction Techniques and Classifier Ensemble. In Proceedings of the 17th International Conference on Systems, Signals and Image Processing (IWSSIP 2010), Rio de Janeiro, Brazil, 17–19 June 2010; pp. 215–218. [Google Scholar]
- Awaidah, S.M.; Mahmoud, S.A. A multiple feature/resolution scheme to Arabic (Indian) numerals recognition using hidden Markov models. Signal Process. J. 2009, 89, 1176–1184. [Google Scholar] [CrossRef]
- Boukharouba, A.; Bennia, A. Novel feature extraction technique for the recognition of handwritten digits. Appl. Comput. Inform. 2017, 13, 19–26. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, D.; Member, S.; Frangi, A.F.; Yang, J. Two-Dimensional PCA: A New Approach to Appearance-Based Face Representation and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar] [CrossRef] [PubMed]
- Wshah, S.; Shi, Z.; Govindaraju, V. Segmentation of Arabic Handwriting Based on both Contour and Skeleton Segmentation. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009. [Google Scholar]
- Rajashekararadhya, S.V. Isolated Handwritten Kannada and Tamil Numeral Recognition: A Novel Approach. In Proceedings of the First International Conference on Emerging Trends in Engineering and Technology, Nagpur, Maharashtra, India, 16–18 July 2008; pp. 1192–1195. [Google Scholar]
- Jackel, L.D.L.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Le Cun, B.; Denker, J.; Henderson, D. Handwritten Digit Recognition with a Back-Propagation Network. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1990; pp. 396–404. [Google Scholar]
- Tomoshenko, D.; Grishkin, V. Composite face detection method for automatic moderation of user avatars. In Proceedings of the International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 27–28 March 2013. [Google Scholar]
- Cheng, G.; Ma, C.; Zhou, P.; Yao, X.; Han, J. Scene Classification of High Resolution Remote Sensing Images Using Convolutional Neural Networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 767–770. [Google Scholar]
- Cao, J.; Chen, Z.; Wang, B. Deep Convolutional Networks With Superpixel Segmentation for Hyperspectral Image Classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3310–3313. [Google Scholar]
- Chen, S.; Liu, G.; Wu, C.; Jiang, Z.; Chen, J. Image classification with stacked restricted boltzmann machines and evolutionary function array classification voter. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 4599–4606. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Bengio, Y. Learning Deep Architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Member, S. Deep feature extraction and classification of hyperspectral images based on Convolutional Neural Networks. IEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural net-works. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1–9. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the 13th European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Toshev, D.E.A.; Szegedy, C. Deep Neural Networks for Object Detection. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 1–9. [Google Scholar]
- Melhaoui, O.E.L.; El Hitmy, M.; Lekha, F. Arabic Numerals Recognition based on an Improved Version of the Loci Characteristic. Int. J. Comput. Appl. 2011, 24, 36–41. [Google Scholar] [CrossRef]
- Dash, K.S.; Puhan, N.B.; Panda, G. Unconstrained handwritten digit recognition using perceptual shape primitives. In Pattern Analysis and Applications; Springer: London, UK, 2016. [Google Scholar]
- Guo, X.; Huang, H.; Zhang, J. Comparison of Different Variants of Restricted Boltzmann Machines. In Proceedings of the 2nd International Conference on Information Technology and Electronic Commerce (ICITEC 2014), Dalian, China, 20–21 December 2014; Volume 1, pp. 239–242. [Google Scholar]
- Handwritten Arabic Numeral Database. Google Coe Archieve—Long-Term Storage for Google Code Project Hosting. Available online: https://code.google.com/archive/p/cmaterdb/downloads (accessed on 9 November 2017).
- Larochelle, H.; Bengio, Y. Classification using discriminative restricted Boltzmann machines. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 536–543. [Google Scholar]
- Li, M.; Miao, Z.; Ma, C. Feature Extraction with Convolutional Restricted Boltzmann Machine for Audio Classification. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 791–795. [Google Scholar]
- Papa, J.P.; Rosa, G.H.; Marana, A.N.; Scheirer, W.; Cox, D.D. Model selection for Discriminative Restricted Boltzmann Machines through meta-heuristic techniques. J. Comput. Sci. 2015, 9, 14–18. [Google Scholar] [CrossRef]
- Cai, X.; Hu, S.; Lin, X. Feature Extraction Using Restricted Boltzmann Machine for Stock Price Prediction. In Proceedings of the 2012 IEEE International Conference on Computer Science and Automation Engineering (CSAE), Zhangjiajie, China, 25–27 May 2012; pp. 80–83. [Google Scholar]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]
- JXia, Y.; Li, X.; Liu, Y.X. Application of a New Restricted Boltzmann Machine to Radar Target Recognition. In Proceedings of the Progress in Electromagnetic Research Symposimum (PIERS), Shanghai, China, 8–11 August 2016; pp. 2195–2201. [Google Scholar]
- Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The Application of Two-level Attention Models in Deep Convolutional Neural Network for Fine-grained Image Classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar]
- Liu, S.; Deng, W. Very Deep Convolutional Neural Network Based Image Classification Using Small Training Sample Size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition, Kuala Lumpur, Malaysia, 3–6 November 2015. [Google Scholar]
- Luong, T.X.; Kim, B.; Lee, S. Color Image Processing based on Nonnegative Matrix Factorization with Convolutional Neural Network. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 2130–2135. [Google Scholar]
- Dao-Duc, C.; Xiaohui, H.; Morère, O. Maritime Vessel Images Classification Using Deep Convolutional Neural Networks. In Proceedings of the Sixth International Symposium on Information and Communication Technology—SoICT 2015, Hue City, Vietnam, 3–4 December 2015; pp. 1–6. [Google Scholar]
- Scherer, D.; Andreas, M.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. In Proceedings of the 20th International Conference on Artificial Neural Networks (ICANN), Thessaloniki, Greece, 15–18 September 2010. [Google Scholar]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. Breast Cancer histopathological Image Classification using Convolutional Neural Networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 2560–2567. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Layers Operation | Feature Maps No. | Feature Maps Size | Window SIZE | Parameters No. |
|---|---|---|---|---|---|
| C1 | Convolution | 32 | 24 × 24 | 5 × 5 | 832 |
| S1 | Max-pooling | 32 | 12 × 12 | 2 × 2 | 0 |
| D | Dropout layer | 32 | 12 × 12 | 2 × 2 | 0 |
| C2 | Convolution | 32 | 10 × 10 | 3 × 3 | 9248 |
| S2 | Max-pooling | 32 | 5 × 5 | 2 × 2 | 0 |
| FC | Flatten layer | 800 | N/A | N/A | 0 |
| FC | Fully connected | 128 | 1 × 1 | N/A | 102,528 |
| FC | Output layer | 10 | 1 × 1 | N/A | 1290 |
| Dimension | No. of Image | ||||||
|---|---|---|---|---|---|---|---|
| Dataset | Classes | Width | Height | Depth | Dataset | Training | Test |
| CMATERDB 3.3.1 | 10 | 32 | 32 | 1 | 3000 | 70% | 30% |
| Relevant | Non-Relevant | |
|---|---|---|
| Retrieved | TP | FP |
| Not-Retrieved | FN | TN |
| Evaluation Measures | ||||
|---|---|---|---|---|
| Proposed Method | Precision | Recall | F1 Score | Accuracy |
| RBM-CNN | 0.98 | 0.98 | 0.98 | 98.59 |
| Author | Techniques | Accuracy |
|---|---|---|
| Ashiquzzaman and Tushar [4] | CNN | 97.4 |
| X. Guo et al. [33] | RBM-SVM | 96.9 |
| X. Guo et al. [33] | Sparse RBM-SVM | 97.5 |
| Our approach | RBM-CNN | 98.59 |
| Our CNN Proposed Architecture | CNN Architecture as Proposed in [4] | ||||
|---|---|---|---|---|---|
| Layers Operation | Feature Maps No. | Window Size | Layers Operation | Feature Maps No. | Window Size |
| Convolution | 32 | 5 × 5 | Convolution | 30 | 5 × 5 |
| Max-pooling | 32 | 2 × 2 | Max-pooling | 30 | 2 × 2 |
| Dropout layer | 20% | Convolution | 15 | 3 × 3 | |
| Convolution | 32 | 3 × 3 | Max-pooling | 15 | 2 × 2 |
| Max-pooling | 32 | 2 × 2 | Dropout layer | 25% | |
| Flatten layer | 800 | N/A | Flatten layer | - | N/A |
| Fully connected | 128 | N/A | Fully connected | 128 | N/A |
| Dropout layer | 50% | ||||
| Output layer | 10 | N/A | Output layer | 10 | N/A |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alani, A.A. Arabic Handwritten Digit Recognition Based on Restricted Boltzmann Machine and Convolutional Neural Networks. Information 2017, 8, 142. https://doi.org/10.3390/info8040142
Alani AA. Arabic Handwritten Digit Recognition Based on Restricted Boltzmann Machine and Convolutional Neural Networks. Information. 2017; 8(4):142. https://doi.org/10.3390/info8040142
Chicago/Turabian StyleAlani, Ali A. 2017. "Arabic Handwritten Digit Recognition Based on Restricted Boltzmann Machine and Convolutional Neural Networks" Information 8, no. 4: 142. https://doi.org/10.3390/info8040142
APA StyleAlani, A. A. (2017). Arabic Handwritten Digit Recognition Based on Restricted Boltzmann Machine and Convolutional Neural Networks. Information, 8(4), 142. https://doi.org/10.3390/info8040142