Abstract
The success of large-scale deep learning models in remote sensing tasks has been transformative, enabling significant advances in image classification, object detection, and image–text retrieval. However, their computational and memory demands pose challenges for deployment in resource-constrained environments. Knowledge distillation (KD) alleviates these issues by transferring knowledge from a strong teacher to a student model, which can be compact for efficient deployment or architecturally matched to improve accuracy under the same inference budget. In this paper, we introduce Hierarchical Multi-Segment Knowledge Distillation (HIMS_KD), a multi-stage framework that sequentially distills knowledge from a teacher into multiple assistant models specialized in low-, mid-, and high-level representations, and then aggregates their knowledge into the final student. We integrate feature-level alignment, auxiliary similarity-logit alignment, and supervised loss during distillation. Experiments on benchmark remote sensing datasets (RSITMD and RSICD) show that HIMS_KD improves retrieval performance and enhances zero-shot classification; and when a compact student is used, it reduces deployment cost while retaining strong accuracy.
1. Introduction
Remote sensing has become indispensable across numerous domains, including environmental monitoring, precision agriculture, urban planning, and disaster management. The surge in high-resolution satellite and aerial imagery necessitates advanced techniques for efficiently processing and analyzing these vast datasets. Recently, Visual Language Models (VLMs) have emerged as essential tools in remote sensing, offering the ability to integrate visual and textual information for richer scene interpretation [1,2]. These models capture complex relationships between visual features and textual descriptions, yielding improvements in tasks like scene classification, ground object detection, and image–text retrieval. Despite their efficacy, deploying such models in real-world, resource-limited environments remains challenging due to their high computational and memory requirements.
Knowledge Distillation (KD) has emerged as a practical solution for deploying large models in constrained settings by transferring knowledge from a large, over-parameterized model (teacher) to a smaller, more efficient model (student) [3]. This process allows the student model to mimic the teacher’s performance while being much less resource-intensive, making it suitable for deployment in environments with limited computational resources. Traditional KD techniques [4,5] typically involve a straightforward transfer of knowledge from the teacher to the student, focusing on aligning logits or intermediate features and using cross-entropy loss to guide the student’s learning process. However, the conventional one-to-one teacher–student paradigm may not fully leverage the rich, multi-level features learned by the teacher due to the limited capacity of the student model.
To address the limitations of traditional KD methods, recent research has explored the use of assistant models [6] to bridge the gap between the teacher and student models. Assistant models act as intermediaries, refining and distilling specific aspects of the teacher’s knowledge before passing it on to the student. This hierarchical approach has demonstrated potential in improving the performance of the student model by enabling it to learn more nuanced and diverse features, leading to a more comprehensive understanding of the data.
Building on these advancements, we propose Hierarchical Multi-Segment Knowledge Distillation (HIMS_KD), a novel multi-stage, hierarchical distillation framework tailored for remote sensing tasks, as illustrated in Figure 1. The key innovation in our approach is the segmentation of the teacher model into distinct feature blocks, each corresponding to a different stage in the learning process (e.g., low-level features such as edges, mid-level object parts, and high-level semantic features). The difference between our approach and traditional KD models is highlighted in Figure 2.
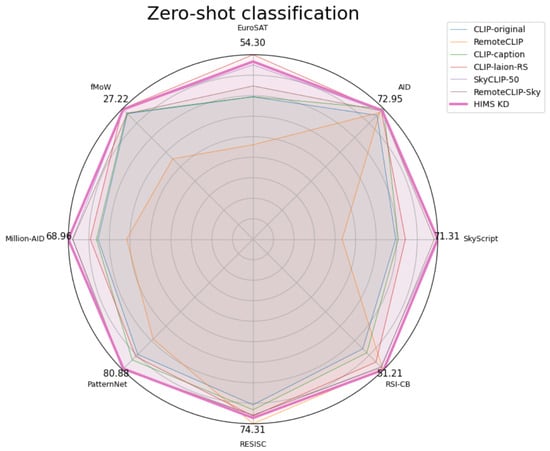
Figure 1.
Zero-shot classification performance on benchmarks. We compare state-of-the-art models with our proposed HIMS_KD across multiple datasets, showing improved generalization.
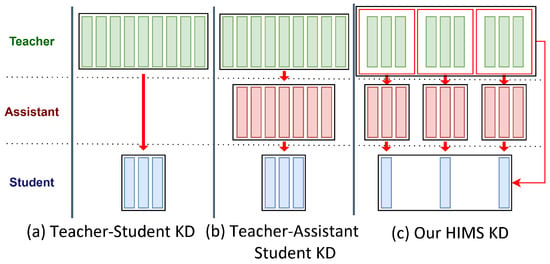
Figure 2.
Comparison of Knowledge Distillation Techniques. (a) Teacher–Student KD: Direct transfer from teacher to student. (b) Teacher–Assistant–Student KD: Assistant model bridges teacher and student. (c) HIMS_KD: Multiple assistants distill segmented features, which are then aggregated into the student model.
In the first stage of HIMS_KD, knowledge is distilled from the teacher model into multiple smaller assistant models, each dedicated to capturing and refining features from a specific segment of the teacher model. By focusing on distinct hierarchical levels of features, these assistant models decompose the teacher’s complex knowledge into manageable, interpretable components. This step not only reduces the complexity of the knowledge transfer process but also allows for targeted and efficient learning in subsequent stages. In the second stage, the knowledge distilled by the assistant models is aggregated and transferred to a final student model, which benefits from the collective knowledge of all assistant models. This approach results in a student model that is both efficient and capable of achieving performance levels comparable to, or even exceeding, those of the teacher model, particularly in tasks requiring deep understanding of multi-modal data.
Our main contributions are summarized as follows:
- Hierarchical Knowledge Transfer: We introduce a novel hierarchical distillation process that enhances the efficiency and effectiveness of knowledge transfer by strategically leveraging intermediate assistant models to capture multi-level features from the teacher model.
- Model Aggregation and Distillation: Our method for recombining and distilling knowledge from multiple assistant models into a cohesive student model improves overall performance in VLM tasks. This process allows the student model to integrate knowledge across feature levels, leading to superior generalization.
- State-of-the-Art Performance: Through extensive experiments on benchmark remote sensing datasets, RSITMD and RSICD, we demonstrate that our hierarchical, multi-stage approach not only bridges the gap between high-performance models and resource-constrained deployment but also surpasses existing state-of-the-art methods in image–text retrieval and zero-shot classification tasks. These results validate the effectiveness of the HIMS_KD framework in advancing efficient model transfer and, when a compact student is used, model compression for remote sensing applications.
2. Related Work
2.1. Knowledge Distillation on VLMs
Knowledge distillation (KD) [4] has been widely used to compress large foundation models, including large language models (LLMs) [7], visual foundation models (VFMs) [8] and vision-language multi-modal models (VLMs) [9,10]. Most KD methods train a smaller student model to match different forms of knowledge from a large-scale teacher model, such as hidden representations [11], attention distributions [12], and affinity information or weight inheritance [13]. Recently, the CLIP-KD [14] proposed several distillation approaches to distill small student CLIP models by transferring relationships, features and gradients from a large pre-trained CLIP teacher [15]. Experiments show the superiority of the distillation methods in enhancing small VLMs. However, the existing distillation methods for VLMs typically align knowledge directly between the teacher and the student, prior work has shown that introducing intermediate assistant models can improve distillation when there is a large capacity gap [6].
2.2. Large VLMs for Remote Sensing
Some attempts have explored the potential of VLMs for visual and textual understanding on remote sensing images and descriptions, such as image captioning and visual question answering (VQA). They primarily constructed a large-scale image–text paired remote sensing dataset [16,17] and fine-tuned general VLMs to develop domain-specific remote sensing VLMs (RSVLMs) [18,19,20]. Due to the impressive generalization ability of CLIP models [15] in various vision language learning tasks, some efforts have tried to develop RSVLMs initialized from the CLIP model by aligning text and image features using contrastive learning [16]. For example, Liu et al. introduced the RemoteCLIP [21], which is claimed to be the first vision-language foundation model for remote sensing. They proposed several conversion methods to expand the remote sensing dataset and contrastively pre-trained the RemoteCLIP model on the dataset. Another route of RSVLMs constructs the model architecture by combining a visual encoder with LLMs and integrates remote sensing expert knowledge into LLMs using instruction tuning technique [18,22]. Kuckreja et al. [23] established a multimodal instruction-following dataset to finetune LLaVA-1.5 [24] to create a multitask conversational model GeoChat, which is able to accomplish both image and region-level comprehension tasks for remote sensing imagery.
2.3. Assistant-Based Knowledge Distillation
Several works introduce intermediate assistant models to help students learn more effectively from teachers, especially when there is a large capacity gap between the student and the teacher [6,25]. Mirazadeh et al. [6] proposed teacher–assistant knowledge distillation (TAKD), which sequentially trains multiple assistant models between the teacher and the student. The SleepKD [26] further introduced multiple distillation modules for teacher–assistant and assistant–student alignment, including epoch features, sequence features, logits and labels. However, errors can accumulate in sequential assistant distillation pipelines. To mitigate this issue, densely guided knowledge distillation (DGKD) [25] distills knowledge from the teacher and multiple assistants directly to the target network to reduce erroneous knowledge transfer.
3. Method
3.1. Problem Definition
Knowledge distillation (KD) techniques aim to transfer feature knowledge, denoted as F, from one model to another to enhance generalization and robustness. These techniques typically employ a teacher–student or teacher–assistant–student framework, wherein the student learns from both hard labels (ground truth) and soft labels (feature representations) provided by the teacher or assistant. The traditional KD loss formulation is as follows:
Here, the first term represents the soft label loss, where denotes the teacher’s parameters. The scalars and balance the contributions of the soft and hard label losses, respectively.
Recent advancements in KD have explored various extensions and modifications to this basic framework. These include the use of multiple teachers, intermediate layer guidance, and adversarial training to further improve the performance of the student model. Additionally, KD has been successfully applied in various domains such as image classification, natural language processing, and speech recognition, demonstrating its versatility and effectiveness.
Inspired by the concept of knowledge distillation, our objective is to enable the student model to efficiently learn feature representations from the teacher model. By leveraging the hierarchical feature extraction capabilities of the teacher, we aim to enhance the student’s performance on both seen and unseen data. To achieve this, we incorporate an adaptive weighting mechanism for the KD loss, which dynamically adjusts the importance of soft and hard label losses during training. This approach not only improves the student’s learning efficiency but also ensures a more robust and generalized model.
3.2. The Proposed HIMS_KD
Understanding the features extracted by deep learning models from lower and higher layers is crucial for comprehending how these models process and interpret data. In deep learning, lower layers focus on capturing low-level features such as color, texture, and simple patterns like edges and shapes. These features typically retain high spatial resolution and maintain a close relationship with the input pixel values. In contrast, higher layers recognize more abstract concepts and capture more complex and abstract patterns. As the network deepens, the spatial resolution of the features generally decreases due to pooling operations, making the features more abstract and semantically meaningful (see Figure 3).
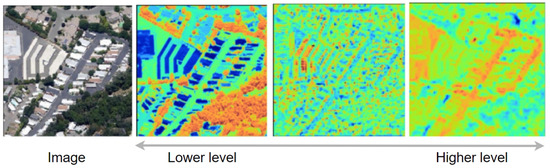
Figure 3.
Feature extraction at different levels: Low-level features (edges, textures), mid-level features (object parts, shapes), and high-level features (semantic concepts).
Inspired by the distinct characteristics of lower- and higher-layer features, we propose a hierarchical multi-segment knowledge distillation technique (HIMS_KD). An overview of HIMS_KD is shown in Figure 4. HIMS_KD is divided into two main components: assistant learning and student learning.
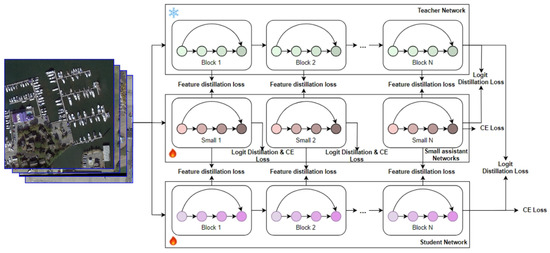
Figure 4.
Overview of the hierarchical multi-segment knowledge distillation (HIMS_KD).
The assistant learning component focuses on using the KD technique to transfer feature knowledge from the teacher model to multiple assistant models. Each assistant model learns features at different levels, effectively capturing a range of feature complexities.
The student learning component then focuses on transferring knowledge from the teacher and the multiple assistant models to the student model. This hierarchical approach ensures that the student model benefits from a comprehensive learning process, acquiring both low-level and high-level feature representations efficiently.
3.3. Multi-Level Feature Representations
To effectively transfer knowledge from the teacher model (T) to the student model (S), we introduce multiple assistant models () in our knowledge distillation framework to capture and learn multi-level features. We achieve this by partitioning the teacher model into I distinct blocks, where each block represents a unique level of feature abstraction within the model. Specifically, each block may contain a specific group of layers, such as convolutional layers or transformer blocks, that captures a distinct hierarchical feature representation. This hierarchical partitioning ensures that different levels of features are distilled progressively from the teacher model to the assistant models. For ViT backbones, we implement this partition by splitting the transformer layers into equal-depth segments (we use in our experiments, corresponding to low/mid/high-level segments).
The assistant models are trained to mimic the intermediate feature representations from each of these teacher blocks. The loss function for this feature-level knowledge distillation is computed using the L2 norm:
where denotes the feature from block i of the teacher model, and denotes the corresponding feature of the i-th assistant model. This loss function encourages each assistant model to align with the teacher’s multi-level feature representations, thus learning meaningful abstractions that are beneficial for the student model.
In addition to feature-level knowledge, we use a logit-based distillation between the teacher and assistant models to further ensure that each assistant learns from the teacher’s output distribution. This logit loss is defined as:
Transformer blocks output token embeddings rather than class logits. Therefore, for each partition boundary i, we compute an auxiliary similarity-logit vector by passing the boundary representation through a lightweight projection head and measuring cosine similarity against the text embeddings of the SkyScript training label set (training only). We denote these auxiliary logits by (teacher) and (assistant), and minimize their L2 distance as in Equation (3). This logit alignment encourages each assistant model to capture both feature-level representations and the predictive distribution of its respective block, resulting in more accurate and well-aligned intermediate representations.
Each assistant model also has the task of aligning its predictions with the ground truth labels, which we achieve through a cross-entropy (CE) loss:
where C is the number of classes (from the SkyScript classification training subset), is the ground truth label for class c, and is the predicted probability from the i-th assistant model. This dual-task setup allows each assistant model to not only distill knowledge from the teacher but also to improve its individual predictive capabilities by aligning with true labels.
The total loss function for each assistant model, integrating the feature-level, logit-based, and cross-entropy losses, is:
where , , and are hyperparameters that balance these three losses. This formulation ensures that each assistant model captures a well-rounded representation from the teacher model’s intermediate features, output distribution, and ground truth alignment, facilitating an effective multi-level knowledge transfer.
3.4. Multi-Level Feature Combination for Student Model
To aggregate the multi-level features learned by the assistant models into the final student model (S), we structure the student model into I blocks, similarly to both the teacher and assistant models. This alignment across blocks allows each block of the student model to correspond to a specific feature level learned by the assistant models.
The transfer of knowledge to the student model involves three main components: feature-level alignment, logit-based alignment, and cross-entropy loss.
3.4.1. Feature-Level Alignment
The feature-level alignment between the student and assistant models is measured by the L2 norm. The loss function for aligning features between each student block () and the corresponding assistant block () is given by:
This loss ensures that each block in the student model effectively mimics the features learned by the assistant model at the same hierarchical level.
3.4.2. Logit-Based Alignment
In contrast to Equation (3), which aligns logits between the teacher and assistants, the logit loss in the student model uses Kullback–Leibler (KL) divergence to transfer high-level information from the teacher to the student. The logit loss for aligning the predictive distributions between teacher and student is defined as:
where J is the number of classes, and and represent the predicted probabilities for class j from the teacher and student models, respectively. This KL divergence loss encourages the student model to closely approximate the teacher’s final output distribution.
3.4.3. Cross-Entropy Loss
Finally, the student model is also trained to predict the correct class labels by minimizing the cross-entropy loss:
where is the true label for class j, and is the predicted probability of the student model. This additional loss reinforces the student model’s alignment with the true labels, improving its predictive accuracy.
The combined loss for training the student model is expressed as:
with , , and as hyperparameters to balance the contributions of each loss term.
Through this structured, multi-level distillation process, the student model benefits from both high-level and intermediate representations captured from the teacher model via the assistant models. This approach enables the student to achieve robust performance and generalization while leveraging a compact and efficient architecture.
4. Experimental Results
In this study, we evaluated the proposed model on zero-shot classification and cross-modal retrieval tasks, comparing its performance with other VLMs and knowledge distillation models on various public datasets. Our analysis demonstrates that the proposed hierarchical knowledge distillation approach provides improvements in accuracy and computational efficiency; moreover, when a compact student is used, it reduces deployment cost (parameters and latency) compared with larger backbones.
4.1. Implementation Details
We base our knowledge distillation experiments on RemoteCLIP [21]. For zero-shot classification, we use RemoteCLIP/ViT-L/14 as the teacher model. The assistant models are implemented by partitioning the teacher backbone into three hierarchical segments and distilling each segment into an assistant. In HIMS_KD2, the final student backbone is ViT-L/14 (i.e., the same backbone size as the teacher); this setting is included to isolate the benefit of hierarchical teacher–assistant training on accuracy and generalization under an unchanged model size (it is not a compression setting). In contrast, HIMS_KD1 replaces the teacher with the original CLIP/ViT-L/14 while keeping the same hierarchical training pipeline. The performance comparison of HIMS_KD1 and HIMS_KD2 is shown in Table 1.

Table 1.
Benchmark results for zero-shot classification on eight public datasets. All methods are trained/fine-tuned on SkyScript and evaluated zero-shot on the downstream benchmarks.
To study compression, we also distill the same teacher (ViT-L/14) into a compact student backbone (ViT-B/32). We evaluate this compact student against other knowledge distillation methods in Table 2.
Table 2.
Comparison of knowledge distillation methods for a compact student (ViT-B/32) distilled from a ViT-L/14 teacher. The L-14 row reports the teacher upper bound, while all KD variants use the same ViT-B/32 student architecture at inference time.
For image–text retrieval tasks, we use the ViT-B/32 student to evaluate and compare performance, with the results shown in Section 4.3.
We will release the training and evaluation configuration used in this study. All models are trained on NVIDIA A40 × 8 for 32 epochs with a global batch size of 512. We use architecture-specific learning rates: ViT-L/14 uses and ViT-B/32 uses For Latency measurement (Table 3), we report the per-image forward-pass time under a fixed protocol (batch size ).
Table 3.
Inference time and classification accuracy comparison for KD methods (ViT-B/32 student).
4.2. Zero-Shot Classification
4.2.1. Public Remote Sensing Classification Datasets
We evaluate our model and baseline zero-shot classification models on several public benchmark datasets: AID [27], EuroSAT [28], fMoW [29], Million-AID [30], PatternNet [31], NWPU-RESISC45 [32], and RSI-CB256 [33]. In this paper, zero-shot refers to evaluation on these downstream benchmarks without using any images or labels from them during training, fine-tuning, or distillation. All training (including supervised loss terms used in distillation) is performed only on the SkyScript training data [17]. Details of the evaluation subsets and image counts are [17]. Nevertheless, when comparing our model with other state-of-the-art methods such as CLIP [15], RemoteCLIP, CLIP-caption, CLIP-laion-RS [17] and RemoteCLIP-Sky that use RemoteCLIP as base network and finetuned with SkyScript dataset, we found that our method achieves higher performance, with an average improvement of around 4–7% (see Figure 1). However, on fMoW and PatternNet, performance lags behind, likely due to limitations in the teacher model, RemoteCLIP, for these datasets. This finding suggests that the teacher model’s baseline effectiveness directly impacts distillation outcomes. For image and text retrieval tasks, we use the smaller model, ViT B-32, to evaluate and compare performance. The results are shown in Table 4.
Table 4.
Cross-modal image–text retrieval results on RSITMD and RSICD datasets.
4.2.2. Knowledge Distillation Comparison
We evaluate our knowledge distillation approach against several state-of-the-art techniques, including KD-Logit [4], KD-Feature [5], KD-TAKD [6], and DGKD (3-layer TA) [25]. KD-Logit transfers teacher knowledge at the output level by focusing on logits, while KD-Feature aims to replicate the internal feature representations of the teacher model. KD-TAKD extends these methods by incorporating an assistant model to bridge the complexity gap, combining both logit and feature-based distillation.
As shown in Table 2, when distilling into a compact ViT-B/32 student, our HIMS_KD strategy consistently improves accuracy compared with other distillation baselines (KD-Logit, KD-Feature, KD-TAKD, and DGKD) under the same student architecture. In particular, among ViT-B/32 students, HIMS_KD achieves the best results on EuroSAT (49.20%), fMoW (20.71%), RSI-CB (47.23%), PatternNet (79.61%), and AID (69.47%). For transparency, we also report the ViT-L/14 teacher performance as an upper-bound reference; these teacher numbers are not directly comparable in deployment cost to the compact student. Finally, to characterize deployment cost, we report parameter counts and per-image latency (Table 3). The primary inference-time gain comes from using a smaller student backbone (e.g., ViT-B/32 instead of ViT-L/14). Since all distillation variants in Table 2 share the same ViT-B/32 student architecture at inference, their latencies are expected to be comparable.
Although the KD-TAKD yields the highest performance in some cases, such as SkyScript and Million-AID, it generally falls short compared to our method in other datasets. This discrepancy suggests that while KD-TAKD effectively leverages both logit and feature-based distillation, our approach provides a more balanced and effective transfer of knowledge across various types of datasets.
The superior performance of our method demonstrates its ability to capture and transfer valuable knowledge from the teacher model more effectively than existing techniques. This improvement is particularly notable in datasets where other methods show limitations, highlighting the robustness and versatility of our knowledge distillation approach.
4.3. Image–Text Retrieval
4.3.1. Public Remote Sensing Retrieval Datasets
To evaluate the performance of image–text retrieval, we benchmark our model against other baseline retrieval models by performing image-to-text and text-to-image retrieval tasks on public datasets specifically designed for this purpose, namely RSITMD [46] and RSICD [47].
4.3.2. Results
In this section, we compare our model with other state-of-the-art retrieval methods, including VSE++ [34], SCAN [35], MTFN [36], AMFMN [37], LW-MRC [38], GaLR [39], CMFM-Net [40], HyperMatch [41], HVSA [42], FBCLM [43], DOVE [44], PIR [45], and CLIP. All experimental results are presented in Table 4. Table 4 provides a comprehensive comparison of different retrieval methods on the RSITMD and RSICD datasets. The performance is measured using Recall at K (R@K) metrics, where K is 1, 5, and 10. R@K indicates the percentage of relevant items found in the top K retrieved results.
Our ViT-B-32 model performs slightly worse than CLIP ViT-B-32 for R@1 but surpasses it in R@5 and R@10, indicating better performance in broader retrieval. This suggests that while our model might not always place the most relevant item at the top (R@1), it is more effective in retrieving a relevant set of items within the top 5 and 10 results. Compare to the original CLIP to our KD model, knowledge distillation involves training a model to replicate the behavior of larger, more complex models using their outputs as soft targets. This process often smooths the decision boundaries, leading to less confident R@1 predictions. Consequently, our model may struggle to place the most relevant item at the very top, resulting in slightly lower R@1 scores.
However, this smoothing helps our model generalize better, resulting in improved performance at higher recall levels (R@5 and R@10). This trade-off is particularly beneficial in retrieval tasks where retrieving a broader set of relevant items is more valuable than identifying the single most relevant item. Our model’s superior performance in these broader retrieval metrics indicates a robust ability to generalize and capture diverse patterns within the data.
Furthermore, the consistent improvement in R@5 and R@10 scores across both datasets highlights the effectiveness of our knowledge distillation approach. By leveraging the strengths of larger models and transferring this knowledge to a more compact model, we achieve a balance between accuracy and efficiency, making our model may highly suitable for real-world applications where both performance and resource constraints are critical considerations.
4.4. Ablation Study
To further validate the design choices of HIMS_KD, we conduct ablation studies in the compact-student setting (ViT-B/32 distilled from ViT-L/14). We report the same average downstream zero-shot classification accuracy as in Table 3.
4.4.1. Assistant Configurations
Table 5 presents the variations in the number of assistant models, their parameter budgets, and which hierarchical feature levels are distilled. Using more assistants and covering complementary feature levels consistently improves accuracy, with the best configuration using three assistants supervising low/mid/high representations.
Table 5.
Ablation on the number, parameter size, and feature levels of assistant models. Acc. denotes the average downstream zero-shot classification accuracy (Table 1).
4.4.2. Loss Components
Table 6 shows that combining logit-level and feature-level distillation is more effective than using either alone, and adding the supervised cross-entropy term yields the best performance.
Table 6.
Ablation on loss components for the student model (ViT-B/32). Acc. denotes average downstream zero-shot classification accuracy (Table 1).
5. Conclusions
In this paper, we introduced HIMS_KD, a hierarchical knowledge distillation framework that employs multiple assistant models as intermediary layers between the teacher and student. Unlike conventional teacher–student distillation approaches that perform direct knowledge transfer, our method leverages assistant models to capture low, mid, and high-level features, creating a comprehensive multi-level feature representation. This approach enables the student model to retain critical knowledge efficiently, achieving competitive performance with improved computational efficiency.
Our framework was rigorously evaluated on zero-shot classification and retrieval tasks using remote sensing datasets, demonstrating its effectiveness in complex, multi-modal scenarios. The results underscore our method’s capacity to enhance accuracy while maintaining efficiency, validating its potential for deployment in resource-constrained environments.
Author Contributions
Conceptualization, T.K.; Methodology, T.K.; Software, T.K.; Validation, T.K.; Formal analysis, T.K.; Investigation, T.K.; Resources, T.K. and P.S.; Data curation, T.K. and P.S.; Writing—original draft, T.K. and P.S.; Writing—review & editing, T.K. and P.S.; Visualization, T.K.; Supervision, P.S.; Project administration, P.S.; Funding acquisition, T.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62202435.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The experimental data used in this study are derived entirely from publicly available remote sensing image–text datasets. Specifically, we use the RSICD dataset, https://github.com/201528014227051/RSICD_optimal, accessed on 1 March 2025, and the RSITMD dataset, https://github.com/AICyberTeam/AMFMN/tree/main/RSITMD, accessed on 1 March 2025.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, X.; Wen, C.; Hu, Y.; Yuan, Z.; Zhu, X.X. Vision-Language Models in Remote Sensing: Current progress and future trends. IEEE Geosci. Remote Sens. Mag. 2024, 12, 32–66. [Google Scholar] [CrossRef]
- Li, J.; Hong, D.; Gao, L.; Yao, J.; Zheng, K.; Zhang, B.; Chanussot, J. Deep Learning in Multimodal Remote Sensing Data Fusion: A Comprehensive Review. arXiv 2022, arXiv:2205.01380. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vision 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. arXiv 2015, arXiv:1412.6550. [Google Scholar] [CrossRef]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved Knowledge Distillation via Teacher Assistant. Proc. Aaai Conf. Artif. Intell. 2020, 34, 5191–5198. [Google Scholar] [CrossRef]
- Gu, Y.; Dong, L.; Wei, F.; Huang, M. MiniLLM: Knowledge Distillation of Large Language Models. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna Austria, 7–11 May 2024. [Google Scholar]
- Liu, Y.; Kong, L.; CEN, J.; Chen, R.; Zhang, W.; Pan, L.; Chen, K.; Liu, Z. Segment Any Point Cloud Sequences by Distilling Vision Foundation Models. In Proceedings of the Advances in Neural Information Processing Systems; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2023; Volume 36, pp. 37193–37229. [Google Scholar]
- Zhou, A.; Wang, J.; Wang, Y.X.; Wang, H. Distilling Out-of-Distribution Robustness from Vision-Language Foundation Models. In Proceedings of the Advances in Neural Information Processing Systems; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2023; Volume 36, pp. 32938–32957. [Google Scholar]
- Sun, X.; Zhang, P.; Zhang, P.; Shah, H.; Saenko, K.; Xia, X. DIME-FM: DIstilling Multimodal and Efficient Foundation Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 15521–15533. [Google Scholar]
- Liang, C.; Yu, J.; Yang, M.H.; Brown, M.; Cui, Y.; Zhao, T.; Gong, B.; Zhou, T. Module-wise Adaptive Distillation for Multimodality Foundation Models. In Proceedings of the Advances in Neural Information Processing Systems; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2023; Volume 36, pp. 69719–69735. [Google Scholar]
- Fang, Z.; Wang, J.; Hu, X.; Wang, L.; Yang, Y.; Liu, Z. Compressing Visual-Linguistic Model via Knowledge Distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 1428–1438. [Google Scholar]
- Wu, K.; Peng, H.; Zhou, Z.; Xiao, B.; Liu, M.; Yuan, L.; Xuan, H.; Valenzuela, M.; Chen, X.S.; Wang, X.; et al. Tinyclip: Clip distillation via affinity mimicking and weight inheritance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 21970–21980. [Google Scholar]
- Yang, C.; An, Z.; Huang, L.; Bi, J.; Yu, X.; Yang, H.; Diao, B.; Xu, Y. CLIP-KD: An Empirical Study of CLIP Model Distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 15952–15962. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Zhang, Z.; Zhao, T.; Guo, Y.; Yin, J. RS5M and GeoRSCLIP: A Large Scale Vision-Language Dataset and A Large Vision-Language Model for Remote Sensing. arXiv 2024, arXiv:2306.11300. [Google Scholar] [CrossRef]
- Wang, Z.; Prabha, R.; Huang, T.; Wu, J.; Rajagopal, R. SkyScript: A Large and Semantically Diverse Vision-Language Dataset for Remote Sensing. arXiv 2023, arXiv:2312.12856. [Google Scholar] [CrossRef]
- Muhtar, D.; Li, Z.; Gu, F.; Zhang, X.; Xiao, P. LHRS-Bot: Empowering Remote Sensing with VGI-Enhanced Large Multimodal Language Model. arXiv 2024, arXiv:2402.02544. [Google Scholar]
- Zhan, Y.; Xiong, Z.; Yuan, Y. SkyEyeGPT: Unifying Remote Sensing Vision-Language Tasks via Instruction Tuning with Large Language Model. arXiv 2024, arXiv:2401.09712. [Google Scholar] [CrossRef]
- Hu, Y.; Yuan, J.; Wen, C.; Lu, X.; Li, X. RSGPT: A Remote Sensing Vision Language Model and Benchmark. arXiv 2023, arXiv:2307.15266. [Google Scholar] [CrossRef]
- Liu, F.; Chen, D.; Guan, Z.; Zhou, X.; Zhu, J.; Ye, Q.; Fu, L.; Zhou, J. RemoteCLIP: A Vision Language Foundation Model for Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2023, 62, 5622216. [Google Scholar] [CrossRef]
- Zhang, W.; Cai, M.; Zhang, T.; Zhuang, Y.; Mao, X. EarthGPT: A Universal Multimodal Large Language Model for Multisensor Image Comprehension in Remote Sensing Domain. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5917820. [Google Scholar] [CrossRef]
- Kuckreja, K.; Danish, M.S.; Naseer, M.; Das, A.; Khan, S.; Khan, F.S. GeoChat: Grounded Large Vision-Language Model for Remote Sensing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 27831–27840. [Google Scholar]
- Li, C.; Wong, C.; Zhang, S.; Usuyama, N.; Liu, H.; Yang, J.; Naumann, T.; Poon, H.; Gao, J. LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day. In Proceedings of the Advances in Neural Information Processing Systems; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2023; Volume 36, pp. 28541–28564. [Google Scholar]
- Son, W.; Na, J.; Choi, J.; Hwang, W. Densely Guided Knowledge Distillation Using Multiple Teacher Assistants. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9395–9404. [Google Scholar]
- Liang, H.; Liu, Y.; Wang, H.; Jia, Z. Teacher Assistant-Based Knowledge Distillation Extracting Multi-level Features on Single Channel Sleep EEG. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI, Macao, SAR, China, 19–25 August 2023; pp. 3948–3956. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Christie, G.; Fendley, N.; Wilson, J.; Mukherjee, R. Functional Map of the World. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6172–6180. [Google Scholar] [CrossRef]
- Long, Y.; Xia, G.S.; Li, S.; Yang, W.; Yang, M.Y.; Zhu, X.X.; Zhang, L.; Li, D. On Creating Benchmark Dataset for Aerial Image Interpretation: Reviews, Guidances, and Million-AID. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4205–4230. [Google Scholar] [CrossRef]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Li, H.; Dou, X.; Tao, C.; Wu, Z.; Chen, J.; Peng, J.; Deng, M.; Zhao, L. RSI-CB: A Large-Scale Remote Sensing Image Classification Benchmark Using Crowdsourced Data. Sensors 2020, 20, 1594. [Google Scholar] [CrossRef]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. VSE++: Improving Visual-Semantic Embeddings with Hard Negatives. arXiv 2018, arXiv:1707.05612. [Google Scholar]
- Lee, K.H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked Cross Attention for Image-Text Matching. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 212–228. [Google Scholar]
- Wang, T.; Xu, X.; Yang, Y.; Hanjalic, A.; Shen, H.T.; Song, J. Matching Images and Text with Multi-modal Tensor Fusion and Re-ranking. In Proceedings of the 27th ACM International Conference on Multimedia (MM ’19), Nice, France, 21–25 October 2019; pp. 12–20. [Google Scholar] [CrossRef]
- Hoxha, G.; Melgani, F.; Demir, B. Toward Remote Sensing Image Retrieval Under a Deep Image Captioning Perspective. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4462–4475. [Google Scholar] [CrossRef]
- Rahhal, M.M.A.; Bazi, Y.; Abdullah, T.; Mekhalfi, M.L.; Zuair, M. Deep Unsupervised Embedding for Remote Sensing Image Retrieval Using Textual Cues. Appl. Sci. 2020, 10, 8931. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Tian, C.; Rong, X.; Zhang, Z.; Wang, H.; Fu, K.; Sun, X. Remote Sensing Cross-Modal Text-Image Retrieval Based on Global and Local Information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5620616. [Google Scholar] [CrossRef]
- Yu, H.; Yao, F.; Lu, W.; Liu, N.; Li, P.; You, H.; Sun, X. Text-Image Matching for Cross-Modal Remote Sensing Image Retrieval via Graph Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 812–824. [Google Scholar] [CrossRef]
- Yao, F.; Sun, X.; Liu, N.; Tian, C.; Xu, L.; Hu, L.; Ding, C. Hypergraph-Enhanced Textual-Visual Matching Network for Cross-Modal Remote Sensing Image Retrieval via Dynamic Hypergraph Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 688–701. [Google Scholar] [CrossRef]
- Zhang, W.; Li, J.; Li, S.; Chen, J.; Zhang, W.; Gao, X.; Sun, X. Hypersphere-Based Remote Sensing Cross-Modal Text–Image Retrieval via Curriculum Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5621815. [Google Scholar] [CrossRef]
- Li, H.; Xiong, W.; Cui, Y.; Xiong, Z. A fusion-based contrastive learning model for cross-modal remote sensing retrieval. Int. J. Remote Sens. 2022, 43, 3359–3386. [Google Scholar] [CrossRef]
- Ma, Q.; Pan, J.; Bai, C. Direction-Oriented Visual–Semantic Embedding Model for Remote Sensing Image–Text Retrieval. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4704014. [Google Scholar] [CrossRef]
- Pan, J.; Ma, Q.; Bai, C. A Prior Instruction Representation Framework for Remote Sensing Image-text Retrieval. In Proceedings of the 31st ACM International Conference on Multimedia (MM ’23), Ottawa, ON, Canada, 29 October–3 November 2023; pp. 611–620. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Fu, K.; Li, X.; Deng, C.; Wang, H.; Sun, X. Exploring a Fine-Grained Multiscale Method for Cross-Modal Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2183–2195. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.