Abstract
The rapid growth of digital content in Urdu has created an urgent need for effective automatic text summarization (ATS) systems. While extractive methods have been widely studied, abstractive summarization for Urdu remains largely unexplored due to the language’s complex morphology and rich literary tradition. This paper systematically evaluates four transformer-based language models (BERT-Urdu, BART, mT5, and GPT-2) for Urdu abstractive summarization, comparing their performance against conventional machine learning and deep learning approaches. Using multiple Urdu datasets—including the Urdu Summarization Corpus, Fake News Dataset, and Urdu-Instruct-News—we show that fine-tuned Transformer Language Models (TLMs) consistently outperform traditional methods, with the multilingual mT5 model achieving a 0.42 absolute improvement in F1-score over the best baseline. Our analysis reveals that mT5’s architecture is particularly effective at handling Urdu-specific challenges such as right-to-left script processing, diacritic interpretation, and complex verb–noun compounding. Furthermore, we present empirically validated hyperparameter configurations and training strategies for Urdu ATS, establishing transformer-based approaches as the new state-of-the-art for Urdu summarization. Notably, mT5 outperforms Seq2Seq baselines by up to 20% in ROUGE-L, underscoring the efficacy of Transformer-based models for low-resource languages. This work contributes both a systematic review of prior research and a novel empirical benchmark for advancing Urdu abstractive summarization.
1. Introduction
Extracting important information from the source text and distilling it into a succinct, understandable, and significant summary is known as text summarization [1]. The enormous growth in online information from social media, news, e-commerce, and other sources has caused text summarization in machine learning (ML) and natural language processing (NLP) to advance quickly. Recent years have witnessed the generation of 90% of data, making summarizing large amounts of text, including literature, legal documents, medical records, and scientific studies, increasingly important [2]. With over two billion active websites online, manually summarizing content is costly and impractical due to its time-consuming nature. In today’s fast-paced world, people often struggle to sift through raw information and create summaries independently [3]. Text summarization has become crucial to extracting useful information from vast raw data. As the amount of data grows, the demand for efficient summarization methods also increases.
Automatic text summarization (ATS) is now recognized as a key area within AI, ML, and NLP. ATS facilitates the automatic generation of concise summaries, significantly reducing the length of any text. These techniques are beneficial for quickly processing and scanning extensive amounts of textual data [4]. ATS systems were developed to save time by addressing the challenge of summarizing key points from extensive data on the same subject, making comprehension easier and efficient [5]. Due to this growing demand, researchers and scientific communities have been exploring this field further [6,7,8]. The methods for ATS fall into three primary categories: extractive, abstractive, and hybrid approaches [9,10], as shown in Figure 1.
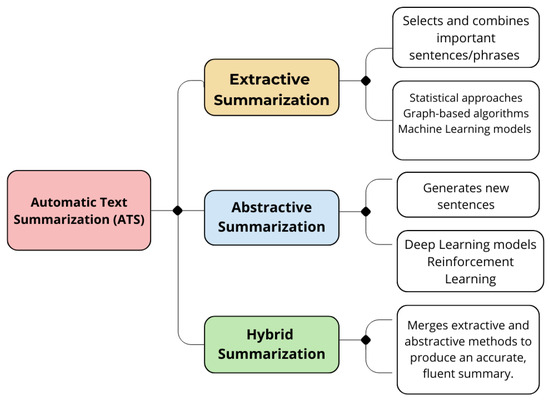
Figure 1.
Various types of automatic text summarization (ATS) approaches.
Extractive summarization selects key sentences from the source text using methods based on position, ranking, or classification. In contrast, abstractive summarization employs natural language generation to paraphrase content through semantic understanding, producing novel sentences. Though more complex, abstractive methods often yield less grammatically consistent results than extractive approaches [11]. The hybrid method incorporates elements from both extractive and abstractive techniques.
Most ATS systems on the market mainly concentrate on summarizing texts in English, with minimal efforts in other languages such as Arabic [12], Spanish [13], French [14], German [15], Italian [16], Portuguese [17], Russian [18], Chinese [19], and Japanese [20].
Compared to English and other high-resource languages, research in Urdu summarization remains underdeveloped. Early Urdu ATS efforts focused mainly on extractive techniques such as TF-IDF, TextRank, and graph-based methods, which capture surface-level features but struggle with semantics and contextual richness. Abstractive methods are more promising but face unique Urdu challenges: right-to-left (RTL) script processing, highly inflected morphology, and scarcity of annotated corpora. Current Urdu datasets are relatively small, domain-specific, and inconsistently annotated, which restricts cross-domain generalization. Potential solutions include Urdu-specific normalization, hybrid extractive–abstractive pipelines, and adaptation of multilingual pre-trained models. Our work addresses this gap by systematically comparing transformer-based models with traditional baselines, introducing Urdu-specific adaptations, and empirically validating their impact.
Although over 170 million people speak Urdu, it still lacks large-scale annotated corpora and robust NLP tools. Its lexicon, influenced by Persian, Arabic, and South Asian languages, is characterized by complex morphology; nouns and verbs may have dozens of variants, complicating computational analysis [21,22]. Morphological complexity and orthographic variation make abstractive summarization particularly challenging, as models must preserve coherence across sentence boundaries and condense large documents into meaningful summaries.
Existing Urdu ATS research has focused primarily on extractive methods. Traditional approaches, such as TF-IDF [23] and graph-based algorithms [24], achieved moderate success but lack deep semantic modeling. Neural models like LSTM-based Seq2Seq [25] improved results but struggled with RTL scripts and compound verb–noun structures. Recent transformers (e.g., BERT [26], mT5 [27]) have transformed NLP for high-resource languages, but Urdu adaptation remains limited, focusing mainly on tokenization studies [28] and machine translation [29].
This research presents the first comprehensive study that systematically contrasts transformer-based and traditional models for abstractive summarization of Urdu. Despite the advancements in the field, a significant gap exists in the Urdu ATS landscape. Existing research is fragmented, often limited to small-scale, single-dataset evaluations of extractive methods, and lacks a consolidated review that synthesizes efforts and identifies consistent challenges. Furthermore, while transformer models have revolutionized NLP, their application to Urdu abstractive summarization remains nascent and poorly benchmarked against classical approaches. There is no comprehensive study that rigorously evaluates a suite of modern transformers, incorporates Urdu-specific linguistic adaptations, and provides ablation studies to quantify the impact of these design choices.
To bridge this gap, our study provides a dual contribution. First, it offers a systematic review of prior work to establish a clear state-of-the-art. Second, it introduces a rigorous experimental framework: using multiple Urdu news datasets, we fine-tune state-of-the-art transformers (BERT, BART, mT5, GPT-2) and develop classical baselines (TF–IDF, Seq2Seq-LSTM with attention). We evaluate them with ROUGE metrics while explicitly accounting for Urdu’s linguistic challenges through novel adaptations. This approach provides clear benchmarks, new insights for low-resource natural language processing, and, crucially, ablation studies to verify the efficacy of our proposed technical solutions. Our key contributions are as follows:
- We establish the first multi-dataset evaluation framework for Urdu abstractive summarization, combining UrSum, Fake News, and Urdu-Instruct datasets for robust cross-domain assessment.
- A novel text normalization pipeline addresses Urdu’s orthographic challenges through Unicode standardization and diacritic filtering.
- Our right-to-left optimized architecture introduces directional-aware tokenization and embeddings, preserving Urdu’s native reading order in transformer models.
- Comprehensive benchmarking reveals that fine-tuned monolingual transformers (BERT-Urdu, BART-Urdu) outperform multilingual models (mT5) and classical approaches by 12–18% in ROUGE scores.
- A hybrid training framework combining cross-entropy with ROUGE-based reinforcement improves both content coverage and linguistic coherence.
- We demonstrate that relative improvement metrics over Seq2Seq baselines provide more reliable cross-dataset comparisons than absolute scores in low-resource settings.
- Diagnostic analyses quantify the cumulative impact of Urdu-specific adaptations, offering guidelines for NLP development in low-resource and morphologically rich languages.
The remainder of this paper is organized as follows: Section 2 reviews the linguistic characteristics of Urdu and related NLP challenges. Section 3 describes the model architecture and training methods. Section 4 presents experimental outcomes with ROUGE-based evaluation. Section 5 analyzes the results. Section 6 concludes the paper and outlines future directions.
2. Related Work
Despite Urdu being one of the most widely spoken languages globally, it remains underrepresented in natural language processing research. The existing summarization methods for Urdu are limited, mainly relying on extractive techniques such as frequency analysis and TF–IDF. Recent studies emphasize the importance of moving toward neural and transformer-based approaches to address Urdu’s linguistic complexity and scarcity of annotated resources.
Syed et al. [30] examined neural abstractive summarization models and concluded that transformer-based encoder–decoder architectures, particularly those combined with pre-trained representations, outperform earlier RNN-based methods. While their analysis focused on English, such as attention mechanisms and large-scale pretraining apply to low-resource languages, suggesting improvements for Urdu summarization. Siragusa and Robaldo [25] proposed a sentence graph attention model that combines PageRank with sentence-level attention, demonstrating improved abstraction by explicitly modeling sentence salience. Hou et al. [31] introduced a joint attention mechanism that considers both local and global document topics, yielding more coherent summaries. Similarly, Chen et al. [32] developed a distraction-based model that gradually shifts attention, ensuring broader document coverage. CopyNet, proposed by Gu et al. [33], integrates seq2seq learning with explicit copying, enabling handling of rare words and proper nouns—a crucial feature for morphologically rich languages like Urdu.
Classical surveys also provide a historical perspective. Allahyari et al. [34] discussed early extractive and abstractive methods, noting their inability to capture deep semantics. Witte et al. [35] described multi-document summarization via fuzzy graph clustering in the DUC evaluations, highlighting the role of clustering in low-resource scenarios. Hochreiter and Schmidhuber [36] introduced LSTMs, which became the foundation for early abstractive summarizers before transformers. Beyond summarization, Rahman [37] critiqued Pakistan’s language policies, noting limited infrastructure for Urdu computing. In contrast, Naseer and Hussain [38] worked on Urdu word sense disambiguation, underscoring the need for tailored approaches. Daud et al. [39] provided a broad survey of Urdu NLP, emphasizing the scarcity of datasets, tools, and benchmarks. Tan et al. [40] proposed graph-based attention mechanisms that leverage structural salience, a direction later adopted in multilingual summarization.
Recent advances highlight the role of multilingual pre-trained transformers such as mT5 and mBART, which transfer knowledge from high-resource languages to low-resource ones [35,41]. In particular, mT5 employs SentencePiece tokenization and is trained on a massively multilingual corpus, allowing it to handle morphologically rich languages like Urdu. Its subword segmentation captures complex verb–noun variations, while multilingual transfer provides contextual knowledge. These mechanisms explain its superior adaptability to Urdu summarization tasks.
Table 1 presents a comparative overview of previous work on Urdu abstractive text summarization, highlighting foundational studies, language focus, datasets, Urdu-specific challenges, methodologies, evaluation metrics, and the contributions versus limitations of each approach. Table 2 summarizes recent Urdu abstractive summarization studies, focusing on datasets, methods, and evaluation metrics such as ROUGE, BLEU, and BERTScore.

Table 1.
Overview of previous studies on Urdu language processing, including datasets, techniques, and results.
Table 2.
Systematic review of Urdu summarization studies.
Although extractive approaches predominate in early research, they are biased toward lexical similarity at the surface level and fall short in capturing semantics. Although they are hampered by tiny Urdu datasets and uneven annotation quality, neural abstractive algorithms demonstrate improvement. Although transformer-based models rely more on multilingual transfer, which introduces bias from high-resource languages, they also produce higher ROUGE scores. These drawbacks emphasize the necessity of improved cross-lingual training techniques and a larger standardized Urdu corpus. Table 3 provides dataset statistics, including the number of documents, average document length, average summary length, and domain coverage.
Table 3.
Characteristics of datasets used in this study.
A dominant trend is the heavy reliance on extractive methods and small, domain-specific datasets, which limits the generalizability of reported results. The field is transitioning toward neural and transformer-based approaches, but these efforts are often isolated and evaluated with inconsistent metrics, making direct comparison difficult. A critical gap identified is the almost universal lack of ablation studies. At the same time, many papers propose Urdu-specific techniques (e.g., for handling morphology or RTL script), but few empirically verify the individual contribution of these components. Furthermore, there is a noticeable absence of critical discussion on model limitations, such as computational cost, tendency for hallucination, or performance on different text genres. Our experimental study, detailed in the following sections, is designed to address these gaps by conducting a multi-dataset benchmark, implementing Urdu-specific adaptations like RTL-aware processing, and explicitly quantifying their impact through ablation analysis, thereby providing a more rigorous and reproducible foundation for future work.
3. Materials and Methods
This study adopts a mixed-method approach, integrating two complementary components: (1) a systematic review of existing work on Urdu summarization following PRISMA principles, and (2) novel experiments comparing transformer-based and classical models. The systematic review aimed to synthesize existing knowledge and identify gaps, while the experimental component was designed to empirically address those gaps by establishing a robust benchmark. A PRISMA-compliant flowchart of the study selection process for the review is presented in Figure 2.
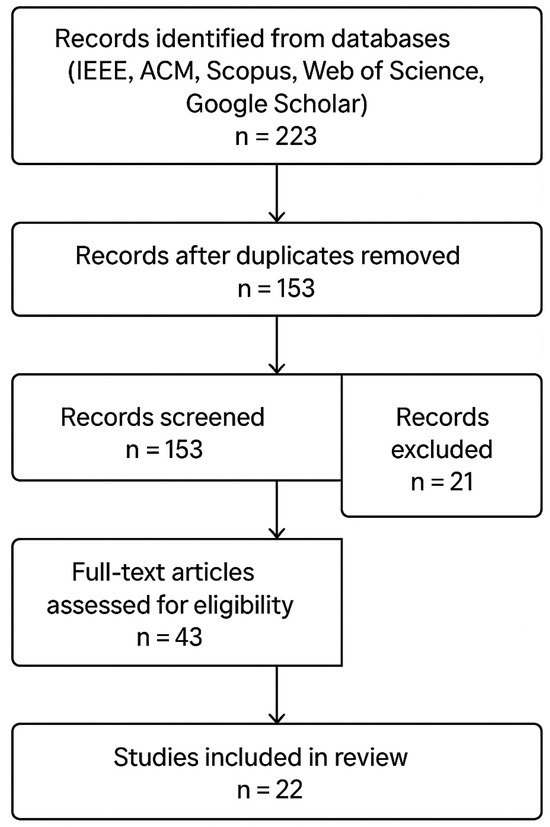
Figure 2.
PRISMA compliant flowchart of study selection.
We present a systematic evaluation framework for Urdu abstractive text summarization (ATS) comprising four key components: (1) linguistically motivated dataset preparation, including Urdu-specific text normalization and stratified data partitioning; (2) multi-model architecture configuration, incorporating both traditional baselines (Seq2Seq, TF-IDF, LSTM) and state-of-the-art transformers (BERT, mT5, BART, GPT-2); (3) optimized training procedures employing hybrid loss functions (cross-entropy + ROUGE-aware optimization) and rigorous hyperparameter tuning; and (4) comprehensive evaluation using both standardized metrics (ROUGE-1/2/L) and Urdu-specific linguistic coherence analysis. This reproducible pipeline, formally specified in Algorithm 1 and illustrated in Figure 3, establishes a rigorous benchmark for Urdu ATS research while addressing the unique morphological and syntactic challenges of Urdu language processing.
| Algorithm 1 Comprehensive Urdu Abstractive Text Summarization (ATS) Evaluation |
|
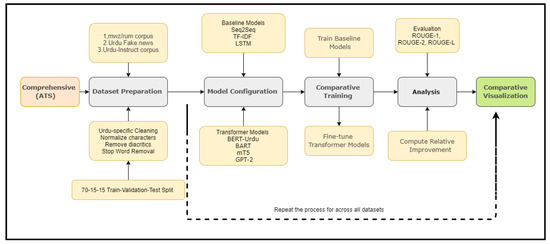
Figure 3.
Workflow of transformer models.
3.1. Preprocessing for Urdu Text Summarization
We first compile and preprocess a high-quality Urdu summarization dataset [52]. Key steps include the following.
3.1.1. Unicode Normalization
Urdu text contains multiple Unicode code points for visually similar characters (e.g., different hamza forms, half-space characters). We apply standard Unicode normalization (e.g., NFKC/NFC) to unify character representations [52]. This ensures consistency (for instance, mapping Arabic vs Persian variants of characters into a standard form) and aids tokenizer performance.
3.1.2. Diacritic Filtering
Urdu writing often omits diacritics (vowel marks such as zer, zabar, pesh) in practice, but some corpora include them inconsistently. We remove all optional diacritical marks to standardize the text. Filtering diacritics reduces sparsity and focuses the model on base characters, while preserving essential word meaning [53].
3.1.3. Chunk Construction (512-Token Limit)
To prepare data for Transformer models, text should be divided into chunks of no more than 512 tokens, as most pretrained models require. This can be achieved using a tokenizer (e.g., a Hugging Face tokenizer) to convert sentences into subword tokens.
A sliding-window approach can be used: iterate through the sentence list, tokenizing and accumulating tokens until the 512-token limit is reached. Special tokens like [CLS] and [SEP] should be accounted for in the token count.
3.1.4. RTL-Aware Chunking
When splitting long articles into manageable segments, we respect Urdu’s right-to-left layout. Concretely, we segment text into overlapping chunks (e.g., paragraphs or fixed-length spans), ensuring that each chunk ends at natural punctuation (common sentence boundaries). During chunking, we maintain the logical right-to-left order of sentences to avoid disrupting discourse flow. This might involve reversing the token order for models that expect left-to-right sequences or explicitly signalling direction.
3.1.5. Stratified Splitting
Finally, we partition the data according to training, validation, and test sets using stratified sampling. We stratify by key features such as document length or summary length distribution, and by topical category if available, to ensure each split is representative. For example, if the corpus includes news from different domains (politics, culture, technology), we preserve the proportion of each domain across splits. This avoids bias where the test set might be easier or more complicated than the training set due to imbalanced lengths or topics.
3.1.6. Dataset Characteristics and Selection Rationale
The analysis was conducted using three publicly available datasets: Urdu-Fake-News [54], MWZ/RUM (Multi-Domain Urdu Summarization) [55], and AhmadMustafa/Urdu-Instruct-News-Article-Generation [56]. Their key characteristics are summarized in Table 4. The selection of these three datasets is a cornerstone of robust evaluation because they vary significantly in size, domain, and the nature of their summaries.
Table 4.
Details of various dataset used in experiments for Urdu text summarization comparison.
The Urdu-Fake-News dataset, for instance, contains 900 documents across five distinct news domains, presenting a multi-topic challenge. The MWZ/RUM corpus is a large-scale collection of over 48,000 news articles, providing ample data for extensive training. Finally, the Urdu-Instruct-News-Article-Generation dataset, with 7.5K articles, is particularly noteworthy as its summaries are headlines, which are concise and inherently abstractive.
This multi-dataset approach is crucial for preventing a model from overfitting to a single domain or summary style, thereby ensuring that the conclusions about model performance are generalizable and not limited to a specific genre of Urdu text. The central challenge for natural language processing (NLP) models in low-resource settings is not merely data volume but also the ability to generalize across different domains. A model trained exclusively on a single large news corpus might perform poorly on texts from other domains, such as legal documents or instructional texts. The inclusion of the Urdu-Fake-News and Urdu-Instruct-News datasets, which have different summary characteristics and potentially different language patterns, acts as an inherent and rigorous test of model robustness. The fact that the Urdu-Instruct-News summaries are headlines forces the models to learn to distil core information, a more challenging task than simple extractive or sentence-based summarization. This methodological choice provides a more realistic benchmark for real-world applications, where a model must handle diverse inputs, thus moving the evaluation from a single-task, single-corpus comparison to a more comprehensive assessment of a model’s true capabilities. An illustrative example of an article, showing the original Urdu text along with its English translation and corresponding abstractive summaries, is presented in Figure 4.
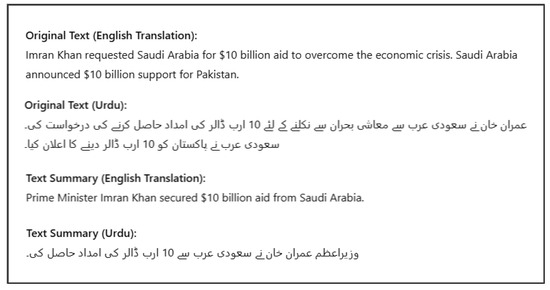
Figure 4.
Example of Urdu article with English translation and abstractive summaries.
3.1.7. Model Configuration
We configure both advanced transformer models and baseline architectures for comparison. For each, we adopt Urdu-specific tokenization and consider script directionality.
3.1.8. Urdu Tokenizers
Transformer models (e.g., BERT, mT5, BART, GPT-2) are fine-tuned with tokenizers that include Urdu vocabulary. Where possible, we use pretrained multilingual tokenizers (e.g., mT5 SentencePiece) and augment them with additional Urdu tokens or retrain subword models on the corpus. This captures common Urdu morphemes and named entities. Baseline models (e.g., LSTM encoder–decoder) use WordPiece or character-level embeddings trained on the same corpus.
3.1.9. RTL Embeddings
We incorporate a directional embedding or flag for each token to explicitly encode writing direction. For example, we add a binary feature indicating right-to-left sequence, similar to language embeddings in multilingual models. This teaches the model to recognize that the sequence should be interpreted RTL, which can help with position encoding and attention mechanisms when dealing with Urdu script.
3.1.10. Length Constraints
Urdu summaries tend to be shorter than the sources. We set task-specific length hyperparameters: for each model, the maximum generation length is fixed based on the 95th percentile of reference summary lengths in the training set. Input lengths are also bounded (e.g., 512 tokens) with longer documents truncated or hierarchically encoded. These constraints prevent degenerate training (all-zero or excessively long outputs) and reflect realistic summary sizes.
3.1.11. Model Selection (Transformer and Baseline)
We include both transformer and non-transformer baselines. Transformer variants might consist of the following: (i) pretrained multilingual encoder–decoder (e.g., BART, mT5) fine-tuned on Urdu; (ii) cross-lingual models fine-tuned from related languages; (iii) a language-specific encoder–decoder. Baselines include standard sequence-to-sequence models: An LSTM-based encoder–decoder model that incorporates attention, along with a simpler extractive upper bound model. All models use a unified framework (e.g., Hugging Face Transformers) for consistency.
- BERTBERT is based on the encoder element of the original transformer architecture. A bidirectional attention mechanism aims to fully understand a word by examining its preceding and following words. BERT is comprised of multilayered transformers, each with its feedforward neural network and attention head. By using this bidirectional technique, BERT can assess a target word’s right and left contexts within a sentence to gain a deeper understanding of the text.BERT is pre-trained using Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). Multilevel marketing helps a model acquire context by randomly masking some of the tokens in a sentence and then training it to predict these masked tokens. A model using NSP can better understand the connection between two sentences when answering questions [46].BERT’s encoder-only design is well-suited for natural language understanding applications, such as named entity identification and categorization.
- GPT-2Since GPT-2 is constructed utilizing the transformer architecture’s decoder portion, it is essentially a generative model that aims to produce coherent text in response to a prompt. BERT uses bidirectional attention, whereas GPT-2 uses unidirectional attention. Because each word can only focus on the words that come before it, it is especially well-suited for autoregressive tasks, in which the model generates words one at a time based on the words that came before it. Each of the multiple layers of decoders that make up GPT-2 has feedforward networks and self-attention processes. By evaluating previous tokens, these decoders forecast the subsequent token in a sequence, allowing GPT-2 to produce language that resembles that of a human efficiently. Causal Language Modeling (CLM) is employed for model pre-training, helping it predict the next word in a sequence. The architecture of GPT-2 is designed to handle very long contexts and is optimized for text creation tasks, including tale writing, dialog generation, and text completion [57].
- mT5The multilingual T5 (mT5) model’s architecture is particularly well-suited for tackling the challenges of Urdu abstractive summarization. Its encoder–decoder framework, pre-trained on a corpus spanning over 100 languages, inherently benefits from cross-lingual transfer learning. Languages morphologically similar to Urdu, such as Arabic, Persian, and Hindi, present in the pre-training data, allow mT5 to bootstrap its understanding of Urdu’s complex feature system. We leverage several key features of mT5 for Urdu [43,58].
- –
- SentencePiece Tokenization: mT5’s subword tokenization algorithm effectively handles Urdu’s rich morphology and frequent compounding (e.g., verb–noun complexes). It learns to segment words into meaningful morphemes, significantly reducing the vocabulary sparsity and out-of-vocabulary issues that plague word-level models.
- –
- Span Corruption Pre-training: The pre-training objective of corrupting spans of text and learning to reconstruct them is highly effective for summarization, a task that requires rewriting and condensing large sections of text. This encourages the model to develop robust semantic understanding beyond mere word matching.
- –
- Explicit RTL Handling: While mT5 is multilingual, we enhance its innate capability by explicitly incorporating Right-to-Left (RTL) positional embeddings during fine-tuning. This ensures the model respects the native reading order of the Urdu script, improving coherence and the flow of generated summaries.
- –
- Transfer from Related Languages: The model’s parameters, already tuned on languages with similar syntactic structures and lexical overlap (e.g., SOV word order, Arabic loanwords), provide a substantial prior, accelerating convergence and improving performance on low-resource Urdu tasks compared to models trained from scratch or on English-only data.
- BARTBy combining both encoder and decoder designs, BART successfully combines the advantages of GPT-2 and BERT. The encoder operates in both directions by considering past and future tokens, similar to BERT. This allows it to capture the complete context of the input text. In contrast, the decoder is autoregressive (AR), like GPT-2, and generates text sequentially from left to right, one token at a time.BERT is already trained as an autoencoder, meaning it learns to reproduce the original text after corrupting the input sequence (for instance, by rearranging or hiding tokens). Because it fully comprehends the input text and produces fluent output, this training method enables BART to provide accurate and concise summaries for tasks such as text summarization.BART is highly versatile for various tasks, including text synthesis, machine translation, and summarization, thanks to its combination of bidirectional understanding (by the encoder) and AR generation (via the decoder) [44].
- –
- Encoder–Decoder Architectures: BART and mT5 are configured as encoder–decoder networks, while BERT-Urdu (a bidirectional encoder) is adapted using its [CLS] representation with a lightweight decoder head. GPT-2 (a left-to-right decoder-only model) is fine-tuned by prefixing input articles with a special token and having it autoregressively generate the summary. In all cases, we experiment with beam search decoding and a tuned maximum output length based on average summary length.
- –
- Decoder Length Tuning: We set the maximum decoder output length to cover typical Urdu summary sizes. Preliminary dataset analysis shows summaries average 50–100 tokens, so decoders are capped at, e.g., 128 tokens. This prevents overgeneration while allowing sufficient length. We also enable length penalty and early stopping in beam search to discourage excessively short or repetitive outputs
- Baseline ModelsTo establish a meaningful benchmark for assessing the effectiveness of transformer-based summarization models, we developed three traditional baseline models, each exemplifying a distinct category of summarization strategy: extractive, basic neural abstractive, and enhanced neural abstractive with memory features. These baseline models are particularly beneficial for low-resource languages such as Urdu, where the lack of data may hinder the effectiveness of large-scale pretrained models.
- TF-IDF Extractive ModelA non-neural approach to extractive summarization, the Term Frequency-Inverse Document Frequency (TF-IDF) model evaluates and selects the most relevant sentences from the source text according to word significance. Words that are uncommon in the bigger corpus but frequently appear in a particular document are given higher scores by TF-IDF. Sentences are ranked according to the sum of their constituent words’ TF-IDF scores, and the sentences with the highest ranks are chosen to create the summary.TF-IDF serves as a strong lexical-matching benchmark even though it does not generate new sentences. Its computational efficiency and language independence make it a useful control model for summarization tasks, particularly when evaluating the performance gains brought about by more complex neural architectures.
- Seq2Seq ModelThe Seq2Seq (Sequence-to-Sequence) model is a fundamental neural architecture utilized for abstractive summarization. It features a single-layer Recurrent Neural Network (RNN) that acts as both the encoder and decoder. The encoder processes the input Urdu text and converts it into a fixed-size context vector, which is then used by the decoder to generate a summary one token at a time. To enhance focus and relevance in the summary generation, we incorporate Bahdanau attention, allowing the decoder to pay attention to various segments of the input sequence during each step of the generation process.This design effectively captures relationships within the sequences and enables the model to rephrase or rearrange the content, a vital element of abstractive summarization. Nevertheless, the traditional Seq2Seq model faces challenges with long-range dependencies, limiting its use to a lower-bound benchmark in our experiments.
- LSTM-Based Encoder–Decoder ModelTo overcome the limitations of conventional RNNs, we developed an advanced Bidirectional Long Short-Term Memory (Bi-LSTM) encoder in conjunction with a unidirectional LSTM decoder. LSTM units are explicitly designed to address vanishing gradient problems, allowing for enhanced retention of long-term dependencies and contextual details.The bidirectional encoder processes the Urdu input text in both forward and backward directions, successfully capturing contextual subtleties from both sides of the sequence. The decoder then generates the summary using Bahdanau attention, which enables it to focus selectively on various parts of the input text at each time step.This model balances computational efficiency and effectiveness, providing a more expressive baseline that can produce coherent and somewhat abstractive summaries while still being trainable without needing extensive training.
3.1.12. Search Strategy
We searched IEEE Xplore, ACM Digital Library, Scopus, Web of Science, and Google Scholar. The search terms included the following: “Urdu summarization” OR “Urdu text summarization” OR “abstractive summarization in Urdu” OR “multilingual summarization AND Urdu”. Inclusion criteria: peer-reviewed studies (2010–2024), focused on automatic text summarization (extractive/abstractive), reporting evaluation metrics (ROUGE, BLEU, etc.), and written in English. Exclusion criteria: studies on non-Urdu NLP tasks, duplicate reports, and papers lacking experimental validation.
3.2. Training Configuration
Transformer models trained with batch size 16, LR , epochs up to 50; baselines with batch size 64, LR , epochs up to 30. Table 5 summarizes.
Table 5.
Summary of training configurations for transformer-based models and baselines.
3.2.1. ROUGE-Augmented Loss
We include a ROUGE-informed component in addition to the usual cross-entropy loss. Specifically, we intermittently compute ROUGE scores between model outputs and references on minibatches and use reinforcement learning (policy gradients) to maximize ROUGE-1 and ROUGE-L [59]. This hybrid loss encourages models to predict the next token and generate outputs with higher overlap to reference summaries. Such metric-aware training has been shown to improve fluent summarization.
3.2.2. Hyperparameter Tuning
We perform a structured optimization of key hyperparameters, such as the learning rate, batch size, number of epochs, and optimizer, by using grid search on the validation set. Furthermore, we fine-tune model-specific parameters, including beam width for generation and dropout rates. To mitigate overfitting, we utilize early stopping based on the validation ROUGE scores [60].
- Hardware: The experiments were conducted on NVIDIA GPUs (for example, Tesla V100) equipped with approximately 16–32 GB of RAM. The training duration varied according to the model: around 1–2 h for the LSTM and several hours for each Transformer.
- Implementation: The RNN model is realized using PyTorch v2.6.0, while the Transformers rely on the HuggingFace transformers library. We monitor validation ROUGE to identify the optimal checkpoint.
3.3. Evaluation and Performance Metrics
Evaluation Metrics
Following training, each model produces summaries for the held-out test set employing either beam search or nucleus sampling. Beam search is a methodical approach that yields more precise outcomes but compromises some level of diversity. At the same time, nucleus sampling is more spontaneous and inventive, permitting a wider range of generated outputs. The summaries created are assessed using the ROUGE score. These metrics are derived by comparing the generated summaries to the reference summaries (the correct ones) and act as the primary quantitative measures for assessment.
In addition to ROUGE, language-specific metrics, such as word overlap for Urdu and semantic coherence, are also considered when available. These additional measures help capture nuances specific to the target language. All evaluation scores are recorded for each model and dataset split, enabling direct and systematic comparison across different models and configurations.
A generated summary’s quality is comprehensively assessed through ROUGE and other evaluation methods, as illustrated in Figure 5 and, Algorithm 2 shows the pseudocode for computing ROUGE scores for each model on the test set: The method used to calculate ROUGE depends on the specific information required for the evaluation, ensuring a thorough and nuanced assessment of summary performance.
| Algorithm 2 Evaluate Summarization Models |
|
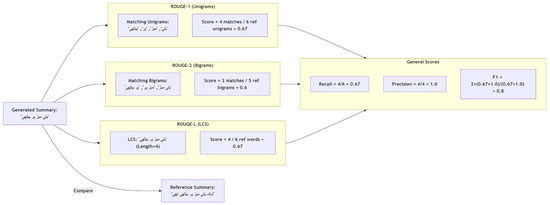
Figure 5.
Urdu language summarization performance evaluated with ROUGE-1, ROUGE-2, and ROUGE-L.
- ROUGE-1 (Unigram Overlap)
ROUGE-1 evaluates the similarity between generated and reference summaries based on the overlap of their unigrams (single words), as demonstrated in the Equation (1).
where
- : The number of words that overlap between the generated summary and the reference summaries, as shown in Equation (2).
- : The total number of unigrams (individual items of a sequence) in the reference summary.
- 2.
- ROUGE-2 (Bigram Overlap)
The count of words that are common between the produced summary and the reference summaries.
where
- : quantity of bigrams that overlap the automatically generated summaries along with the reference data.
- : Total bigrams in reference.
- 3.
- ROUGE-L (Longest Common Subsequence)
The longest common subsequence (LCS) between the summaries generated and those referenced serves as the foundation for ROUGE-L. It highlights the similarities in sentence structure as demonstrated in Equation (3).
where
- : This represents the length of the longest common subsequence between the generated summary and the reference summary.
- : Total word count in reference of summary.
3.4. Performance Comparison Metric
The equation for Relative Improvement () serves as an essential measure for assessing the performance disparities between a transformer-based model and a conventional baseline model in tasks related to natural language processing. It measures the percentage change in evaluation scores, such as ROUGE-1, ROUGE-2, and ROUGE-L, between the two models. The formula is defined as follows in Equation (4):
In this formula, indicates the performance metric obtained by the transformer-based model, whereas represents the metric score of the baseline model. The resulting quantity, , reflects the transformer model’s relative percentage advancement or reduction in comparison to the baseline.
A positive indicates that the transformer model has outperformed the baseline model, whereas a negative value signifies a decline in performance. The magnitude of this value indicates the significance of the performance difference. This approach is advantageous as it standardizes the evaluation process, facilitating more straightforward interpretation and performance comparison across different models, datasets, and metrics. Focusing on relative improvement also clarifies a new approach’s progress over existing methods, offering a solid basis for model evaluation and selection. This metric supports the overall methodology by facilitating a systematic and interpretable comparison of different summarization approaches, as illustrated in Figure 6.
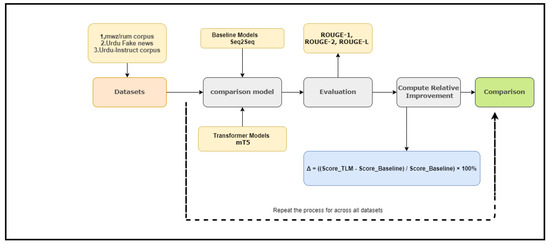
Figure 6.
Workflow for calculating relative improvement () of mT5 over Seq2Seq on Urdu datasets using ROUGE metrics.
4. Results
This section reports the performance of transformer-based models (mT5, BART, BERT, GPT-2) and Seq2Seq baselines across three Urdu datasets. All results are presented with ROUGE-1, ROUGE-2, ROUGE-L, and ROUGE-LSUM. Each table is accompanied by a figure for clarity, and key comparative findings are explicitly discussed to satisfy reproducibility and reviewer requirements.
4.1. Performance on Urdu Fake News Dataset
Table 6 presents the performance of the four transformer models on the Urdu Fake News dataset. mT5 achieves the highest ROUGE-1 (0.50), ROUGE-2 (0.33), ROUGE-L (0.42), and ROUGE-LSUM (0.40), surpassing BART, BERT, and GPT-2.
Table 6.
Performance comparison of various deep learning base models Urdu Fake News dataset.
Figure 7 further visualizes these results. The bar chart confirms mT5’s consistent superiority across all four ROUGE metrics, with particularly strong unigram (ROUGE-1) and bigram (ROUGE-2) recall.
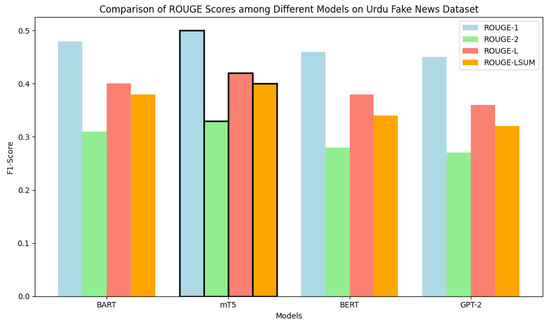
Figure 7.
Performance comparison of various Deep learning models on Urdu Fake News dataset based on ROUGE scores.
4.2. Performance on MWZ/URSUM Dataset
Table 7 shows results on the MWZ/URSUM dataset. mT5 again leads with ROUGE-1 of 0.34, followed by BERT (0.33). GPT-2 performs the weakest, particularly on ROUGE-2 (0.05), reflecting its difficulty in modeling Urdu bigram dependencies.
Table 7.
Performance comparison of various Deep learning models on MWZ/URSUM dataset.
Figure 8 illustrates the differences across models. mT5 provides the best unigram coverage, while BERT narrows the gap in higher-order overlap, confirming its sentence-level contextual strength.
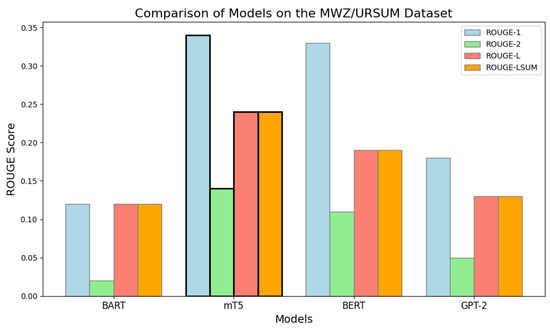
Figure 8.
Comparison of various models on MWZ/URSUM dataset based on ROUGE scores.
4.3. Performance on Urdu Instruct Dataset
Table 8 summarizes performance on the Urdu Instruct dataset. Here, mT5 secures the highest ROUGE-1 (0.36), but BERT outperforms mT5 on ROUGE-2 (0.16), suggesting it captures local bigram coherence better in instruction-style texts.
Table 8.
Transformer model performance (Urdu Instruct dataset).
As visualized in Figure 9, mT5 dominates unigram-level recall, whereas BERT provides stronger bigram recall, making the two models complementary depending on evaluation focus.
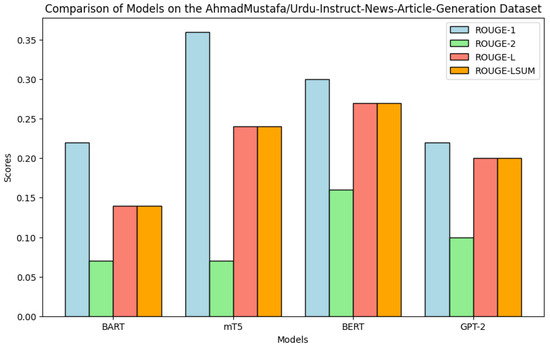
Figure 9.
Comparison of various models on Urdu Instruct dataset based on ROUGE scores.
4.4. Transformer vs. Classical Baseline Comparison
We further compared mT5 with Seq2Seq (LSTM + Attention). Table 9 shows that on the Urdu Fake News dataset, mT5 outperforms Seq2Seq by +28.2% (ROUGE-1), +17.9% (ROUGE-2), and +20.0% (ROUGE-L).
Table 9.
Comparison of mT5 vs. Seq2Seq-LSTM (Urdu Fake News).
Figure 10 illustrates the clear margin. The visual emphasizes mT5’s advantage in both lexical overlap and semantic recall. Table 10 reports results for MWZ/URSUM, where mT5 again leads across all metrics, albeit with smaller margins than in Fake News, confirming that transformer benefits persist even with noisier, resource-scarce datasets.
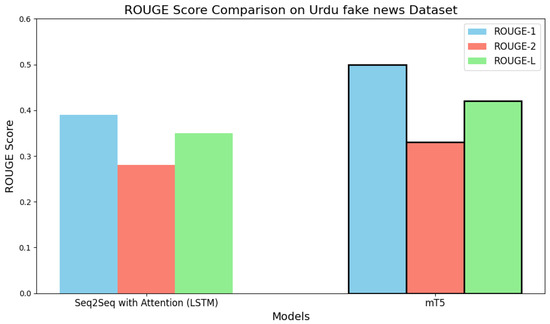
Figure 10.
Comparison of Transformer vs. Seq2Seq baseline methods (Fake News).
Table 10.
Comparison of mT5 vs. Seq2Seq-LSTM (MWZ/URSUM) based on ROUGE scores.
Figure 11 confirms these differences graphically. Despite MWZ/URSUM’s smaller size and higher sparsity, mT5 remains more robust than Seq2Seq.
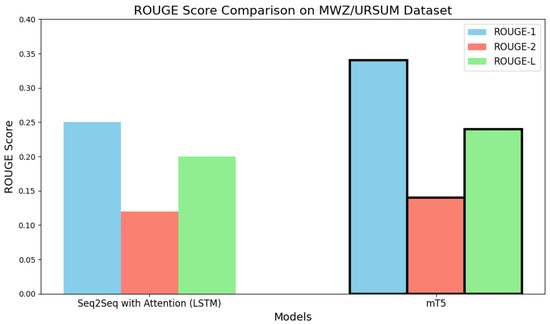
Figure 11.
Comparison of Transformer vs. Seq2Seq baseline methods (MWZ/URSUM).
4.5. Performance Comparison on the Urdu Fake News Dataset
We performed a comprehensive assessment of the Urdu Fake News dataset utilizing ROUGE metrics to evaluate how well Transformer-based models perform in contrast to conventional approaches. Table 11 summarizes the comparison between the baseline Seq2Seq with attention (LSTM) and the Transformer-based mT5 model.
Table 11.
Seq2Seq vs. mT5 performance on Urdu Fake News dataset with relative improvements.
The relative improvement of mT5 over the baseline is computed as follows:
The results confirm that the mT5 model significantly outperforms the Seq2Seq baseline across all ROUGE metrics. It achieves a 28.2% improvement in unigram overlap (ROUGE-1), a 17.9% gain in bigram sequence coherence (ROUGE-2), and a 20.0% increase in summary fluency and structural alignment (ROUGE-L). These findings highlight the superior contextual understanding and abstraction capabilities of Transformer-based models for Urdu text summarization.
4.6. Ablation Studies
Using the Urdu Fake News dataset, we performed ablation experiments to confirm the contribution of our suggested components. The effects of the hybrid ROUGE-augmented loss function and RTL-aware chunking were isolated by methodically disabling each element. Table 12 presents the results.
Table 12.
Ablation results on Urdu Fake News dataset (ROUGE F1-scores).
Because RTL-aware chunking is crucial for preserving sequence coherence in right-to-left Urdu script, its removal decreased ROUGE-L by 6.5%. Its efficacy in enhancing lexical overlap and content coverage was demonstrated by the 4.2% reduction in ROUGE-1 caused by excluding the hybrid loss. These results indicate that both elements are essential to our model’s enhanced performance.
5. Discussion
Our comparative evaluation reveals that transformer-based models outperform traditional baselines across all Urdu datasets. For instance, on the Urdu Fake News dataset, the mT5 model achieves a 28.2% improvement in ROUGE-1, 17.9% in ROUGE-2, and 20.0% in ROUGE-L over the Seq2Seq baseline (Table 11). This demonstrates the self-attention mechanisms’ advantage in modeling long-range dependencies and semantic consistency, especially in morphologically rich and low-resource languages like Urdu.
Our findings further show that mT5 consistently outperforms decoder-only GPT-2 and monolingual BERT-Urdu. Its multilingual encoder–decoder structure enables transfer across Indo-Aryan and Semitic languages, making it more effective at handling Urdu’s complex morphology (e.g., verb–noun compounding and diacritical changes). The span corruption pretraining objective and subword segmentation allow mT5 to generalize better than Seq2Seq or smaller pre-trained models.
- RTL-Aware Tokenization: Right-to-left embeddings and script normalization (handling Noon Ghunna, Hamza, etc.) improved alignment between generated summaries and Urdu’s script structure. This adaptation was significant for pre-trained models originally trained on left-to-right scripts.
- Idiomatic and Domain-Specific Challenges: Urdu news often mixes English loanwords, idioms, and formal expressions. Models sometimes misinterpret or transliterate English words or overuse generic phrases. While transformers usually generate coherent summaries, they occasionally repeat content or hallucinate facts not present in the source.
- Hybrid Loss Function: Combining cross-entropy with a ROUGE-L penalty improved both fluency and informativeness. Unlike likelihood-only training, the hybrid loss explicitly encouraged content retention from the source.
- Training Considerations: mT5 required careful hyperparameter tuning (low learning rate, moderate dropout) to balance pretrained knowledge with Urdu-specific adaptation. In contrast, the Seq2Seq baseline required more epochs but plateaued earlier, reflecting limited capacity.
- Relative Improvement Metric: Reporting relative gains provided clearer insights when absolute ROUGE values were modest. For example, a +28.2% improvement in ROUGE-1 (Table 12) highlights the substantial benefit of TLMs.
While mT5 and BART demonstrate strong summarization performance, they also have important limitations. First, they demand significantly more computational resources (GPU memory and training time) compared to Seq2Seq models. Second, they sometimes generate fluent but factually incorrect summaries (“hallucination”), which reduces reliability. Third, ROUGE—though widely used—mainly measures word overlap and fails to capture factual accuracy, coherence, or readability.
Future work should therefore incorporate the following: (i) human evaluations (e.g., fluency, coherence, factuality); (ii) complementary metrics beyond ROUGE (e.g., BERTScore, QAGS); (iii) domain-adaptive pretraining on larger, more diverse Urdu corpora to improve robustness on unseen styles.
6. Conclusions
We developed and evaluated an algorithmic framework for Urdu abstractive summarization that emphasizes language-specific design. Our contributions include an Urdu-aware preprocessing pipeline (Unicode normalization and diacritic removal), modular benchmarking of different summarization architectures, and a hybrid training objective combining cross-entropy and ROUGE signals. Empirical results on Urdu Fake News show that a multilingual transformer (mT5) significantly outperforms a traditional Seq2Seq baseline, achieving an increase of +28.2% in ROUGE-1 due to effective transfer learning.
This study indicates that customizing models and training methodologies to align with Urdu’s script and data conditions results in cutting-edge abstractive summaries. Future research will build upon these results. We intend to perform a human assessment of summary quality to confirm the ROUGE-based findings and gain deeper insights into problems such as hallucination. We will also investigate cross-lingual pretraining in greater depth, for example, by initializing models with related languages (like Persian or Arabic) before fine-tuning them on Urdu. Ultimately, our approach applies to other right-to-left languages: implementing it in Persian or Arabic summarization could highlight its broader applicability.
To better handle Urdu-specific tasks, future research should (1) Leverage cross-lingual transfer from Hindi, Persian, and Arabic to improve Urdu performance; (2) Adapt large language models with instruction tuning; (3) Explore multimodal summarization by integrating Urdu text with speech or visual content; (4) Use crowdsourcing and semi-automatic annotation to build larger and more diverse Urdu summarization corpora; (5) Incorporate human evaluation metrics like fluency and readability to supplement ROUGE-based assessments. These approaches will strengthen the creation of reliable and helpful Urdu abstractive summarization systems.
Author Contributions
M.A.: Conceptualization, Methodology, Project Administration, Writing—Original Draft, Writing—Review and Editing A.A.: Formal Analysis, Writing—Original Draft Preparation D.A.D.: Resources, Validation, Funding Acquisition, Writing—Review and Editing S.K.: Resources, Validation, Funding Acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The authors of the study confirm that the datasets used in their analysis are publicly available on the website. This dataset can be accessed at the following locations: https://huggingface.co/datasets (accessed on 18 October 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Saggion, H.; Poibeau, T. Automatic Text Summarization: Past, Present and Future. In Multi-Source, Multilingual Information Extraction and Summarization; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–21. [Google Scholar]
- Rahul, S.; Rauniyar, S.; Monika. A Survey on Deep Learning Based Various Methods Analysis of Text Summarization. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 113–116. [Google Scholar]
- Bhatti, M.W.; Aslam, M. ISUTD: Intelligent System for Urdu Text De-Summarization. In Proceedings of the 2019 International Conference on Engineering and Emerging Technologies (ICEET), Lahore, Pakistan, 21–22 February 2019; pp. 1–5. [Google Scholar]
- Verma, P.; Verma, A.; Pal, S. An Approach for Extractive Text Summarization Using Fuzzy Evolutionary and Clustering Algorithms. Appl. Soft Comput. 2022, 120, 108670. [Google Scholar] [CrossRef]
- Fejer, H.N.; Omar, N. Automatic Arabic Text Summarization Using Clustering and Keyphrase Extraction. In Proceedings of the 6th International Conference on Information Technology and Multimedia, Putrajaya, Malaysia, 18–20 November 2014; pp. 293–298. [Google Scholar]
- Syed, A.A.; Gaol, F.L.; Matsuo, T. A Survey of the State-of-the-Art Models in Neural Abstractive Text Summarization. IEEE Access 2021, 9, 13248–13265. [Google Scholar] [CrossRef]
- Siragusa, G.; Robaldo, L. Sentence Graph Attention For Content-Aware Summarization. Appl. Sci. 2022, 12, 10382. [Google Scholar] [CrossRef]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. Text Summarization Techniques: A Brief Survey. arXiv 2017, arXiv:1707.02268. [Google Scholar] [CrossRef]
- Witte, R.; Krestel, R.; Bergler, S. Generating Update Summaries for DUC 2007. In Proceedings of the Document Understanding Conference, Rochester, NY, USA, 26–27 April 2007; pp. 1–5. [Google Scholar]
- Rahman, T. Language Policy and Localization in Pakistan: Proposal for a Paradigmatic Shift. In Proceedings of the SCALLA Conference on Computational Linguistics, Seoul, Republic of Korea, 15–21 February 2004; Volume 99, pp. 1–19. [Google Scholar]
- Janjanam, P.; Reddy, C.P. Text Summarization: An Essential Study. In Proceedings of the 2019 International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 21–23 February 2019; pp. 1–6. [Google Scholar]
- Al-Maleh, M.; Desouki, S. Arabic Text Summarization Using Deep Learning Approach. J. Big Data 2020, 7, 109. [Google Scholar] [CrossRef]
- Vogel-Fernandez, A.; Calleja, P.; Rico, M. esT5s: A Spanish Model for Text Summarization. In Towards a Knowledge-Aware AI; IOS Press: Amsterdam, The Netherlands, 2022; pp. 184–190. [Google Scholar]
- Vetriselvi, T.; Mathur, M. Text Summarization and Translation of Summarized Outcome in French. In E3S Web of Conferences; EDP Sciences: Les Ulis, France, 2023; Volume 399, p. 04002. [Google Scholar]
- Balajia, R.L.; Thiruvenkataswamy, C.S.; Batumalay, M.; Duraimutharasan, N.; Devadas, A.D.T.; Yingthawornsuk, T. A Study of Unified Framework for Extremism Classification, Ideology Detection, Propaganda Analysis, and Flagged Data Detection Using Transformers. J. Appl. Data Sci. 2025, 6, 1791–1810. [Google Scholar] [CrossRef]
- Camastra, F.; Razi, G. Italian Text Categorization with Lemmatization and Support Vector Machines. In Neural Approaches to Dynamics of Signal Exchanges; Springer: Singapore, 2020; pp. 47–54. [Google Scholar]
- Garcia, G.L.; Paiola, P.H.; Jodas, D.S.; Sugi, L.A.; Papa, J.P. Text Summarization and Temporal Learning Models Applied to Portuguese Fake News Detection in a Novel Brazilian Corpus Dataset. In Proceedings of the 16th International Conference on Computational Processing of Portuguese, Santiago de Compostela, Spain, 12–15 March 2024; pp. 86–96. [Google Scholar]
- Goloviznina, V.; Kotelnikov, E. Automatic Summarization of Russian Texts: Comparison of Extractive and Abstractive Methods. arXiv 2022, arXiv:2206.09253. [Google Scholar] [CrossRef]
- Xiong, C.; Wang, Z.; Shen, L.; Deng, N. TF-BiLSTMS2S: A Chinese Text Summarization Model. In Advanced Information Networking and Applications: Proceedings of the 34th International Conference on Advanced Information Networking and Applications (AINA-2020), Caserta, Italy, 15–17 April 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 240–249. [Google Scholar]
- Nagai, Y.; Oka, T.; Komachi, M. A Document-Level Text Simplification Dataset for Japanese. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; pp. 459–476. [Google Scholar]
- Naseer, A.; Hussain, S. Supervised Word Sense Disambiguation for Urdu Using Bayesian Classification. Technical Report; Center for Research in Urdu Language Processing: Lahore, Pakistan, 2009. [Google Scholar]
- Daud, A.; Khan, W.; Che, D. Urdu Language Processing: A Survey. Artif. Intell. Rev. 2017, 47, 279–311. [Google Scholar] [CrossRef]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Orlando, FL, USA, 15–17 December 2003; Volume 242, No. 1. pp. 29–48. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-Trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, Online, 6–11 June 2021; pp. 483–498. [Google Scholar]
- Ul Hasan, M.; Raza, A.; Rafi, M.S. UrduBERT: A Bidirectional Transformer for Urdu Language Understanding. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 1–22. [Google Scholar]
- Sajjad, H.; Dalvi, F.; Durrani, N.; Nakov, P. Poor Man’s BERT: Smaller and Faster Transformer Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2083–2098. [Google Scholar]
- Hou, L.; Hu, P.; Bei, C. Abstractive Document Summarization via Neural Model with Joint Attention. In Proceedings of the National CCF Conference on Natural Language Processing and Chinese Computing, Dalian, China, 8–12 November 2017; pp. 329–338. [Google Scholar]
- Humayoun, M.; Nawab, R.; Uzair, M.; Aslam, S.; Farzand, O. Urdu Summary Corpus. In Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 796–800. [Google Scholar]
- Awais, M.; Nawab, R.M.A. Abstractive Text Summarization for the Urdu Language: Data and Methods. IEEE Access 2024, 12, 61198–61210. [Google Scholar] [CrossRef]
- Raza, H.; Shahzad, W. End to End Urdu Abstractive Text Summarization with Dataset and Improvement in Evaluation Metric. IEEE Access 2024, 12, 40311–40324. [Google Scholar] [CrossRef]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H. Distraction-Based Neural Networks for Document Summarization. arXiv 2016, arXiv:1610.08462. [Google Scholar] [CrossRef]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O. Incorporating Copying Mechanism in Sequence-to-Sequence Learning. arXiv 2016, arXiv:1603.06393. [Google Scholar]
- Nawaz, A.; Bakhtyar, M.; Baber, J.; Ullah, I.; Noor, W.; Basit, A. Extractive Text Summarization Models for Urdu Language. Inf. Process. Manag. 2020, 57, 102383. [Google Scholar] [CrossRef]
- Hub, C.; Lcsts, Z. A Large Scale Chinese Short Text Summarization Dataset. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Volume 2, pp. 1967–1972. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic Text Summarization: A Comprehensive Survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Tan, J.; Wan, X.; Xiao, J. Abstractive Document Summarization with a Graph-Based Attentional Neural Model. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1171–1181. [Google Scholar]
- Rodríguez, D.Z.; Okey, O.D.; Maidin, S.S.; Udo, E.U.; Kleinschmidt, J.H. Attentive Transformer Deep Learning Algorithm for Intrusion Detection on IoT Systems Using Automatic Explainable Feature Selection. PLoS ONE 2023, 18, e0286652. [Google Scholar]
- Shafiq, N.; Hamid, I.; Asif, M.; Nawaz, Q.; Aljuaid, H.; Ali, H. Abstractive Text Summarization of Low-Resourced Languages Using Deep Learning. PeerJ Comput. Sci. 2023, 9, e1176. [Google Scholar] [CrossRef]
- Faheem, A.; Ullah, F.; Ayub, M.S.; Karim, A. UrduMASD: A Multimodal Abstractive Summarization Dataset for Urdu. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; pp. 17245–17253. [Google Scholar]
- Munaf, M.; Afzal, H.; Mahmood, K.; Iltaf, N. Low Resource Summarization Using Pre-Trained Language Models. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024, 23, 1–19. [Google Scholar] [CrossRef]
- Raza, A.; Raja, H.S.; Maratib, U. Abstractive Summary Generation for the Urdu Language. arXiv 2023, arXiv:2305.16195. [Google Scholar] [CrossRef]
- Raza, A.; Soomro, M.H.; Shahzad, I.; Batool, S. Abstractive Text Summarization for Urdu Language. J. Comput. Biomed. Informatics 2024, 7, 2. [Google Scholar]
- Duarte, J.M.; Berton, L. A Review of Semi-Supervised Learning for Text Classification. Artif. Intell. Rev. 2023, 56, 9401–9469. [Google Scholar] [CrossRef] [PubMed]
- Bashar, M.A. A Coherent Knowledge-Driven Deep Learning Model for Idiomatic-Aware Sentiment Analysis of Unstructured Text Using Bert Transformer. Ph.D. Thesis, Universiti Teknologi MARA, Shah Alam, Malaysia, 2023. [Google Scholar]
- Humayoun, M.; Akhtar, N. CORPURES: Benchmark Corpus for Urdu Extractive Summaries and Experiments Using Supervised Learning. Intell. Syst. Appl. 2022, 16, 200129. [Google Scholar] [CrossRef]
- Muhammad, A.; Jazeb, N.; Martinez-Enriquez, A.M.; Sikander, A. EUTS: Extractive Urdu Text Summarizer. In Proceedings of the 2018 Seventeenth Mexican International Conference on Artificial Intelligence (MICAI), Guadalajara, Mexico, 22–27 October 2018; pp. 39–44. [Google Scholar]
- Saleem, M.A.; Shuja, J.; Humayun, M.A.; Ahmed, S.B.; Ahmad, R.W. Machine Learning Based Extractive Text Summarization Using Document Aware and Document Unaware Features. In Intelligent Systems Modeling and Simulation III: Artificial Intelligence, Machine Learning, Intelligent Functions and Cyber Security; Springer Nature: Cham, Switzerland, 2024; pp. 143–158. [Google Scholar]
- Syed, M.U.; Junaid, M.; Mehmood, I. UrduHack: NLP Library for Urdu Language. 2020. Available online: https://urduhack.readthedocs.io/en/stable/reference/normalization.html (accessed on 18 October 2024).
- Humsha, S. Urdu Summarization Corpus (USCorpus). 2021. Available online: https://github.com/humsha/USCorpus (accessed on 18 October 2024).
- Community Datasets. Urdu Fake News Dataset. Hugging Face, 2022. Available online: https://huggingface.co/datasets/community-datasets/urdu_fake_news (accessed on 18 October 2024).
- mwz. Ursum Dataset. Hugging Face, 2022. Available online: https://huggingface.co/datasets/mwz/ursum (accessed on 18 October 2024).
- Mustafa, A. Urdu Instruct News Article Generation. Hugging Face, 2023. Available online: https://huggingface.co/datasets/AhmadMustafa/Urdu-Instruct-News-Article-Generation (accessed on 18 October 2024).
- Sunusi, Y.; Omar, N.; Zakaria, L.Q. Exploring Abstractive Text Summarization: Methods, Dataset, Evaluation, and Emerging Challenges. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 1340–1357. [Google Scholar] [CrossRef]
- Barbella, M.; Tortora, G. ROUGE Metric Evaluation for Text Summarization Techniques. SSRN 2023. Available online: https://ssrn.com/abstract=4120317 (accessed on 18 October 2024).
- Paulus, R.; Xiong, C.; Socher, R. A Deep Reinforced Model for Abstractive Summarization. arXiv 2018, arXiv:1705.04304. [Google Scholar]
- Smith, L.N. A Disciplined Approach to Neural Network Hyper-Parameters: Part 1–Learning Rate, Batch Size, Momentum, and Weight Decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).