

YOLO-SSFA: A Lightweight Real-Time Infrared Detection Method for Small Targets

Abstract
1. Introduction
- We designed a Scale-Sequence Feature Fusion (SSFF) neck to improve multi-scale feature representation for accurate small target detection.
- We develop LiteShiftHead, a lightweight detection head that significantly reduces computational cost, enabling deployment on resource-constrained platforms.
- We designed a Noise Suppression Network (NSN) that enhances attention to salient features by effectively mitigating interference from irrelevant background regions.
2. Related Work
3. Method
3.1. YOLO-SSFA
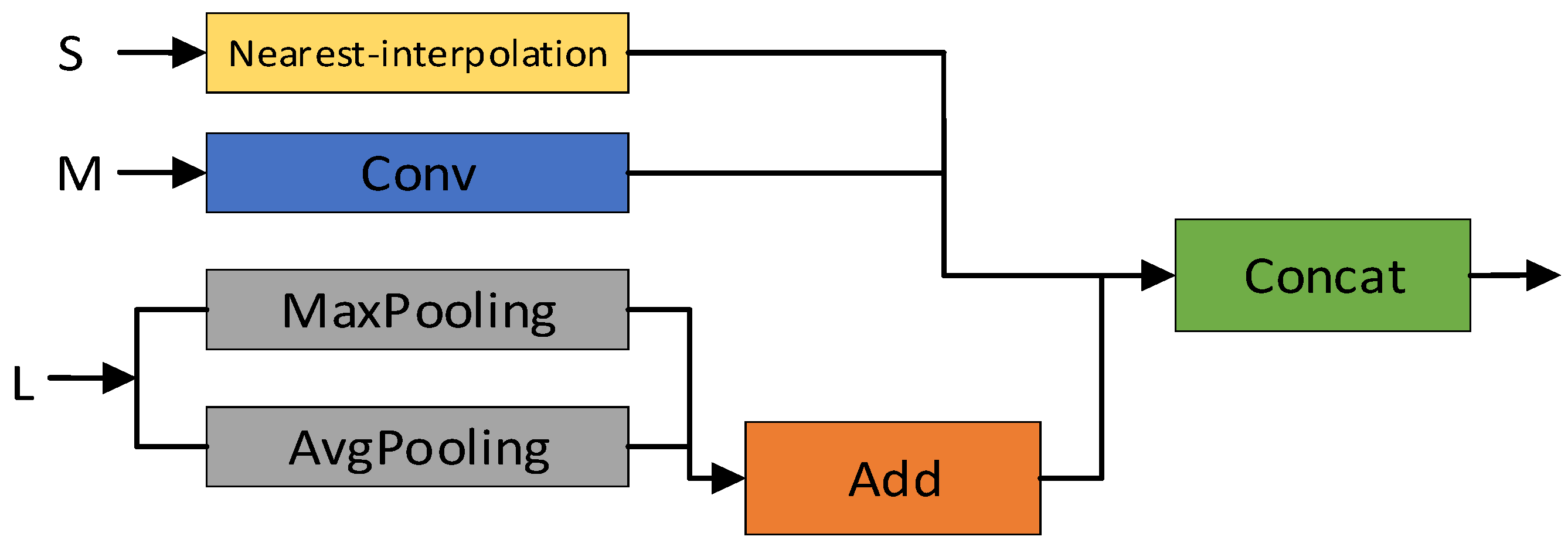
3.1.1. Feature Fusion Structure
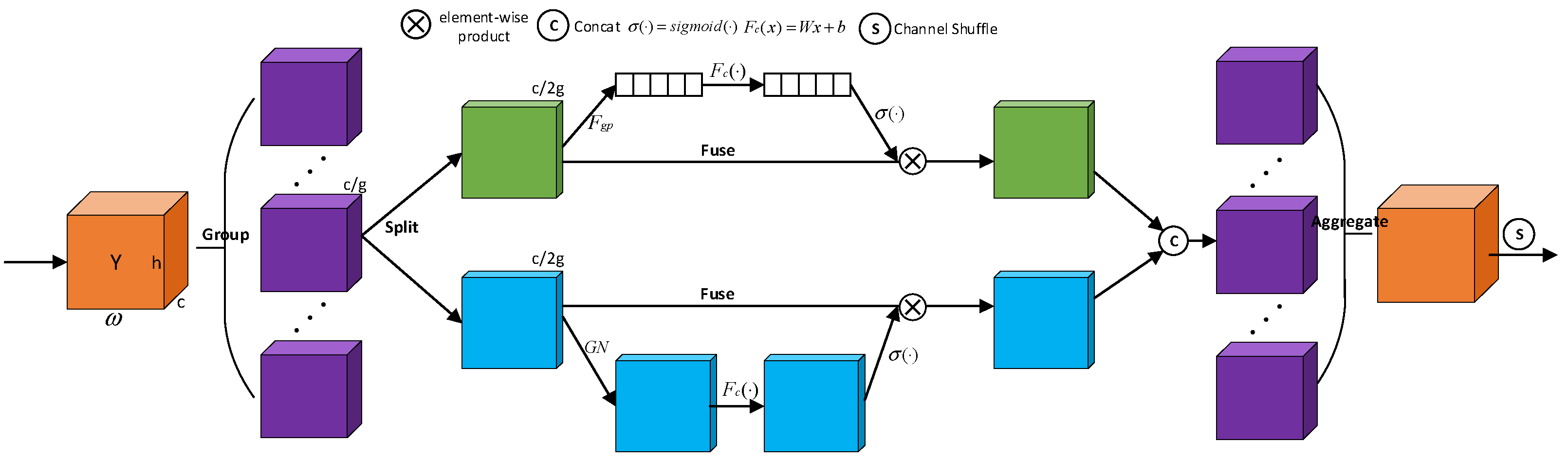
3.1.2. Noise Suppression Network
- Input Features. Let represent the input feature map, where B, C, H, and correspond to the batch size, channel count, height, and width, respectively.
- Feature grouping and channel segmentation. The feature map is reorganized into G groups, denoted as , where each sub-feature learns distinct semantic representations during training. An attention unit is then applied to each sub-feature to compute importance weights. Specifically, each is split into two branches along the channel dimension, denoted as .
- Channel attention calculation. The final output is computed as
- 4.
- Fusion. Finally, a “channel shuffling” strategy is applied to enhance inter-group feature interaction along the channel axis. The resulting output preserves the same shape as the input , allowing seamless integration of the NSN module into modern detection architectures.
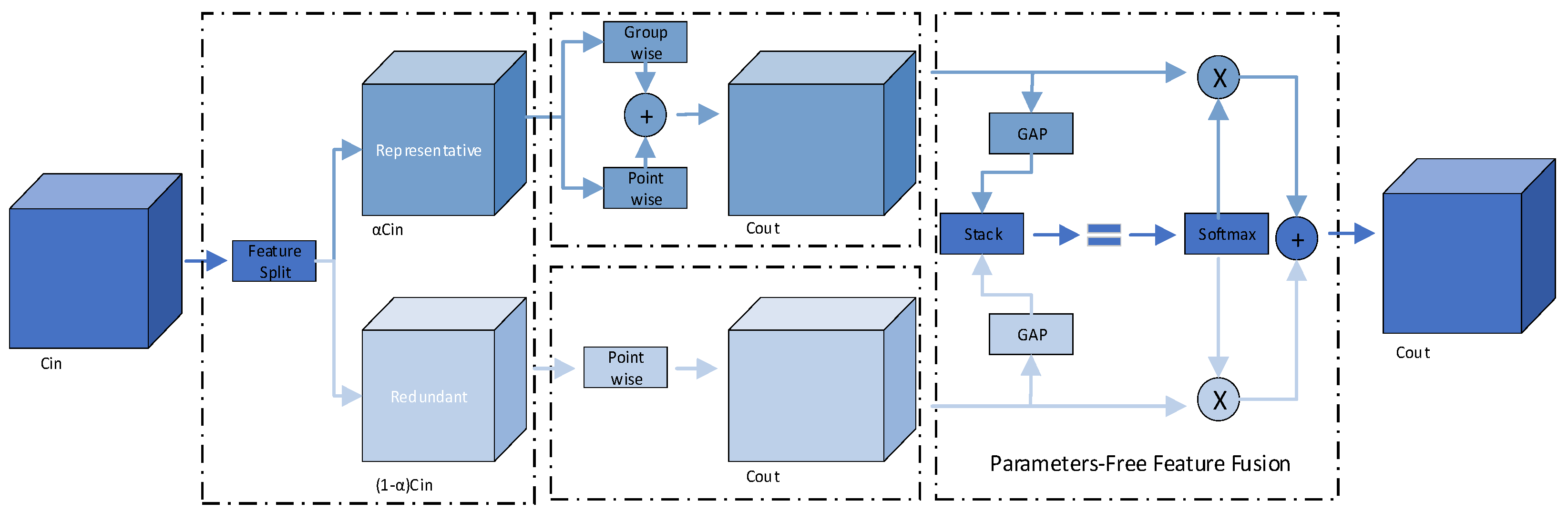
3.1.3. LiteShiftHead Detection Head
3.2. Datasets
3.3. Data Augmentation
3.4. The Evaluation Criteria
4. Results of the Experiments
4.1. Experiment Environment
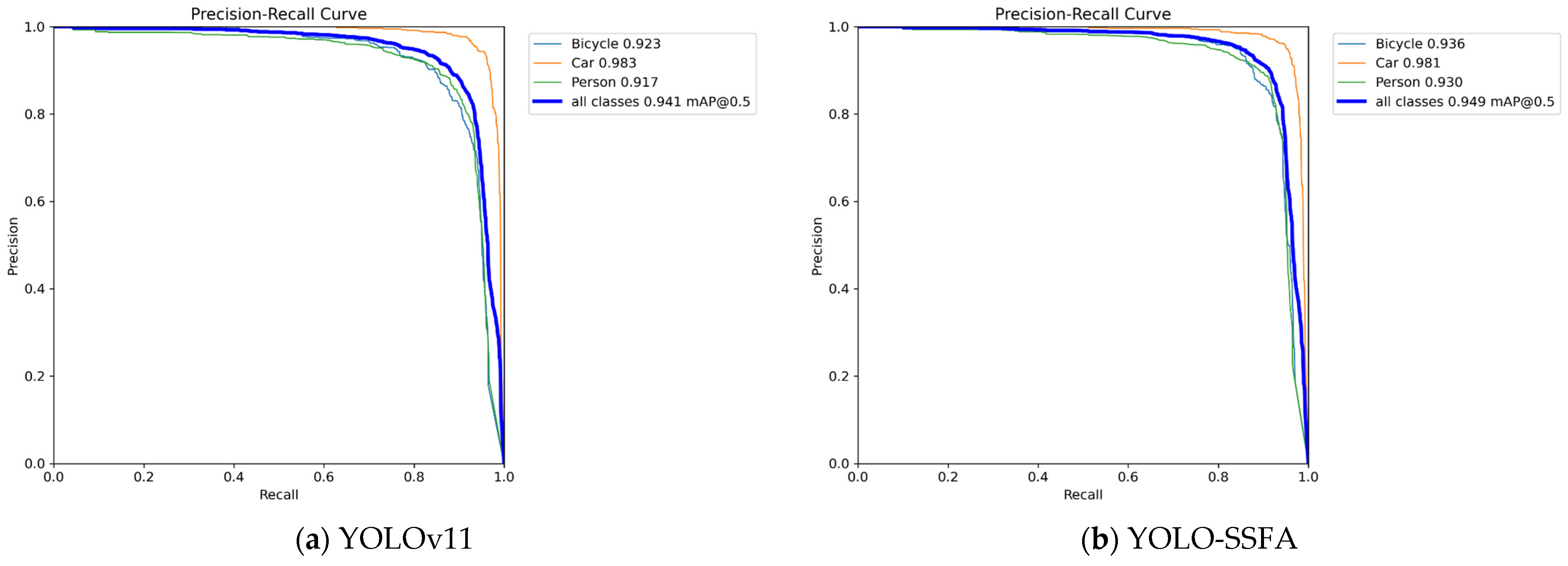
4.2. Comparison Studies and Analysis
4.3. Ablation Studies and Analysis
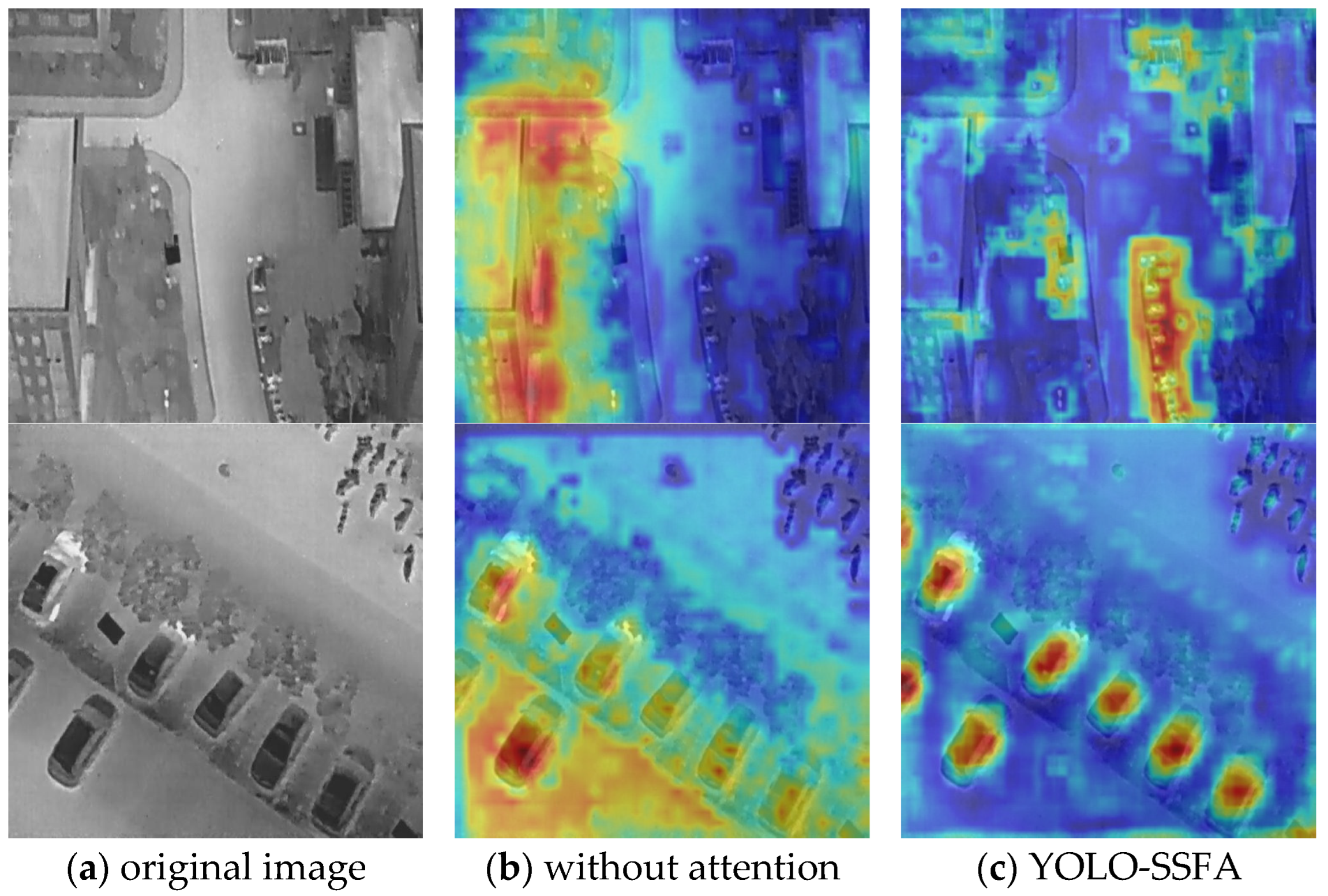
4.4. Comparative Analysis of Various Attention Mechanisms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, C.L.P.; Li, H.; Wei, Y.; Xia, T.; Tang, Y. A Local Contrast Method for Small Infrared Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 574–581. [Google Scholar] [CrossRef]
- Zhao, M.; Li, W.; Li, L.; Hu, J.; Ma, P.; Tao, R. Single-Frame Infrared Small-Target Detection: A Survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 87–119. [Google Scholar] [CrossRef]
- Wang, K.; Li, S.; Niu, S.; Zhang, K. Detection of Infrared Small Targets Using Feature Fusion Convolutional Network. IEEE Access 2019, 7, 146081–146092. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, L.; Wang, L. Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images. In Proceedings of the IEEE CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8508–8517. [Google Scholar]
- He, Y.; Deng, B.; Wang, H.; Cheng, L.; Zhou, K.; Cai, S.; Ciampa, F. Infrared machine vision and infrared thermography with deep learning: A review. Infrared Phys. Technol. 2021, 116, 103754. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wu, Y.; Wang, Y.; Liu, P.; Luo, H.; Cheng, B.; Sun, H. Infrared LSS-Target Detection Via Adaptive TCAIE-LGM Smoothing and Pixel-Based Background Subtraction. Photonic Sens. 2019, 9, 179–188. [Google Scholar] [CrossRef]
- Wang, X.; Lv, G.; Xu, L. Infrared dim target detection based on visual attention. Infrared Phys. Technol. 2012, 55, 513–521. [Google Scholar] [CrossRef]
- Wang, Y.; Tian, Y.; Liu, J.; Xu, Y. Multi-Stage Multi-Scale Local Feature Fusion for Infrared Small Target Detection. Remote Sens. 2023, 15, 4506. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Zhang, K.; Li, Z.; Hu, H.; Li, B.; Tan, W.; Lu, H.; Xiao, J.; Ren, Y.; Pu, S. Dynamic Feature Pyramid Networks for Detection. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo, (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yang, L.; Zhang, R.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2004, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 21002–21012. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Gupta, M.; Chan, J.; Krouss, M.; Furlich, G.; Martens, P.; Chan, M.; Comer, M.; Delp, E. Infrared Small Target Detection Enhancement Using a Lightweight Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3513405. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Ren, K.; Gao, Y.; Wan, M.; Gu, G.; Chen, Q. Infrared small target detection via region super resolution generative adversarial network. Appl. Intell. 2022, 52, 11725–11737. [Google Scholar] [CrossRef]
- Wang, C.; Qin, S. Adaptive detection method of infrared small target based on target-background separation via robust principal component analysis. Infrared Phys. Technol. 2015, 69, 123–135. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Tang, J.; Hu, X.M.; Jeon, S.W.; Chen, W.N. Light-YOLO: A lightweight detection algorithm based on multi-scale feature enhancement for infrared small ship target. Complex Intell. Syst. 2025, 11, 130. [Google Scholar] [CrossRef]
- Xing, M.; Liu, G.; Tang, H.; Qian, Y.; Zhang, J. Multi-level adaptive perception guidance based infrared and visible image fusion. Opt. Lasers Eng. 2023, 171, 107804. [Google Scholar] [CrossRef]
- Zuo, Z.; Tong, X.; Wei, J.; Su, S.; Wu, P.; Guo, R.; Sun, B. AFFPN: Attention Fusion Feature Pyramid Network for Small Infrared Target Detection. Remote Sens. 2022, 14, 3412. [Google Scholar] [CrossRef]
- Ryu, J.; Kim, S. Small infrared target detection by data-driven proposal and deep learning-based classification. In Proceedings of the Conference on Infrared Technology and Applications XLIV, Orlando, FL, USA, 16–19 April 2018. [Google Scholar]
- Bai, X.; Zhou, F. Analysis of new top-hat trans formation and the application for infrared dim small target detection. Pattern Recognit. 2010, 43, 2145–2156. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared Patch-Image Model for Small Target Detection in a Single Image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Yoshida, I.; Kondo, Y.; Numada, M.; Koshimizu, H.; Oshiro, K.; Saito, R. Edge-preserving smoothing filter using fast M-estimation method with an automatic determination algorithm for basic width. Sci. Rep. 2023, 13, 5477. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, R.; Zeng, Y.; Tong, L.; Lu, R.; Yan, B. MST-net: A multi-scale swin transformer network for EEG-based cognitive load assessment. Brain Res. Bull. 2024, 206, 110834. [Google Scholar] [CrossRef]
- Sun, Y.; Lin, Z.; Liu, T.; Li, B.; Yin, Q.; Chen, Y.; Dai, Y. Infrared Small Target Detection via Nonconvex Weighted Tensor Rank Minimization and Adaptive Spatial-Temporal Modeling. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5003918. [Google Scholar] [CrossRef]
- Xiong, Z.; Sheng, Z.; Mao, Y. Feature Multi-Scale Enhancement and Adaptive Dynamic Fusion Network for Infrared Small Target Detection. Remote Sens. 2025, 17, 1548. [Google Scholar] [CrossRef]
- Li, Y.; Li, Z.; Guo, Z.; Siddique, A.; Liu, Y.; Yu, K. Infrared Small Target Detection Based on Adaptive Region Growing Algorithm With Iterative Threshold Analysis. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5003715. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Cao, L.; Zhou, P.; Li, N.; Li, Y.; Wang, D. Infrared Small-Target Detection Based on Radiation Characteristics with a Multimodal Feature Fusion Network. Remote Sens. 2022, 14, 3570. [Google Scholar] [CrossRef]
- Yi, X.; Chen, H.; Wu, P.; Wang, G.; Mo, L.; Wu, B.; Yi, Y.; Fu, X.; Qian, P. Light-FC-YOLO: A Lightweight Method for Flower Counting Based on Enhanced Feature Fusion with a New Efficient Detection Head. Agronomy 2024, 14, 1285. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the 16th European Conference on Computer Vision, ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 20 October 2024).
- Zhao, X.; Xia, Y.; Zhang, W.; Zheng, C.; Zhang, Z. YOLO-ViT-Based Method for Unmanned Aerial Vehicle Infrared Vehicle Target Detection. Remote Sens. 2023, 15, 3778. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Size | Dataset | Precision | mAP50 (%) | Recall |
|---|---|---|---|---|---|
| YOLOv3-tiny | 640 | HIT-UAV | 0.857 | 87.0 ± 0.3 | 0.804 |
| YOLOv6n | 640 | HIT-UAV | 0.889 | 91.4 ± 0.3 | 0.863 |
| YOLOv8n | 640 | HIT-UAV | 0.898 | 93.2 ± 0.1 | 0.9 |
| YOLOv11 + BiFPN | 640 | HIT-UAV | 0.912 | 94.2 ± 0.1 | 0.9 |
| YOLOv11 + HSPAN | 640 | HIT-UAV | 0.92 | 94.4 ± 0.2 | 0.887 |
| YOLOv11 + CBAM | 640 | HIT-UAV | 0.899 | 94.1 ± 0.2 | 0.902 |
| YOLOv11 + SimAM | 640 | HIT-UAV | 0.907 | 93.5 ± 0.4 | 0.889 |
| YOLOv11 | 640 | HIT-UAV | 0.905 | 94.1 ± 0.3 | 0.89 |
| YOLO-SSFA | 640 | HIT-UAV | 0.913 | 94.9 ± 0.1 | 0.897 |
| Model | GFLOPs | Parameters | Precision | Recall | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|---|---|
| YOLOv11 | 6.3 | 2.58 | 0.905 | 0.89 | 94.1 ± 0.3 | 59.9 |
| YOLOv11 + BiFPN | 6.3 | 2 | 0.912 | 0.9 | 94.2 ± 0.1 | 59.6 |
| YOLOv11 + SSFF | 5.8 | 2.94 | 0.906 | 0.887 | 94.4 ± 0.2 | 59.4 |
| YOLO-SSFA | 8.1 | 3.3 | 0.913 | 0.897 | 94.9 ± 0.1 | 60.1 |
| Names | Related Configurations |
|---|---|
| Graphics processing unit | GeForce RTX 4060 Ti (NVIDIA Santa Clara, CA, USA) |
| Central processing unit | Intel(R) Core i7-13700KF (Intel Santa Clara, CA, USA) |
| GPU memory size | 8 G |
| Operating system | Win 11 |
| Computing platform | CUDA12.6 |
| Deep learning framework | Pytorch2.1.0 |
| Development Environment | Pycharm 2024.1.1 x64 |
| Image pixels | 640 × 640 |
| Batch size | 16 |
| Epochs | 300 |
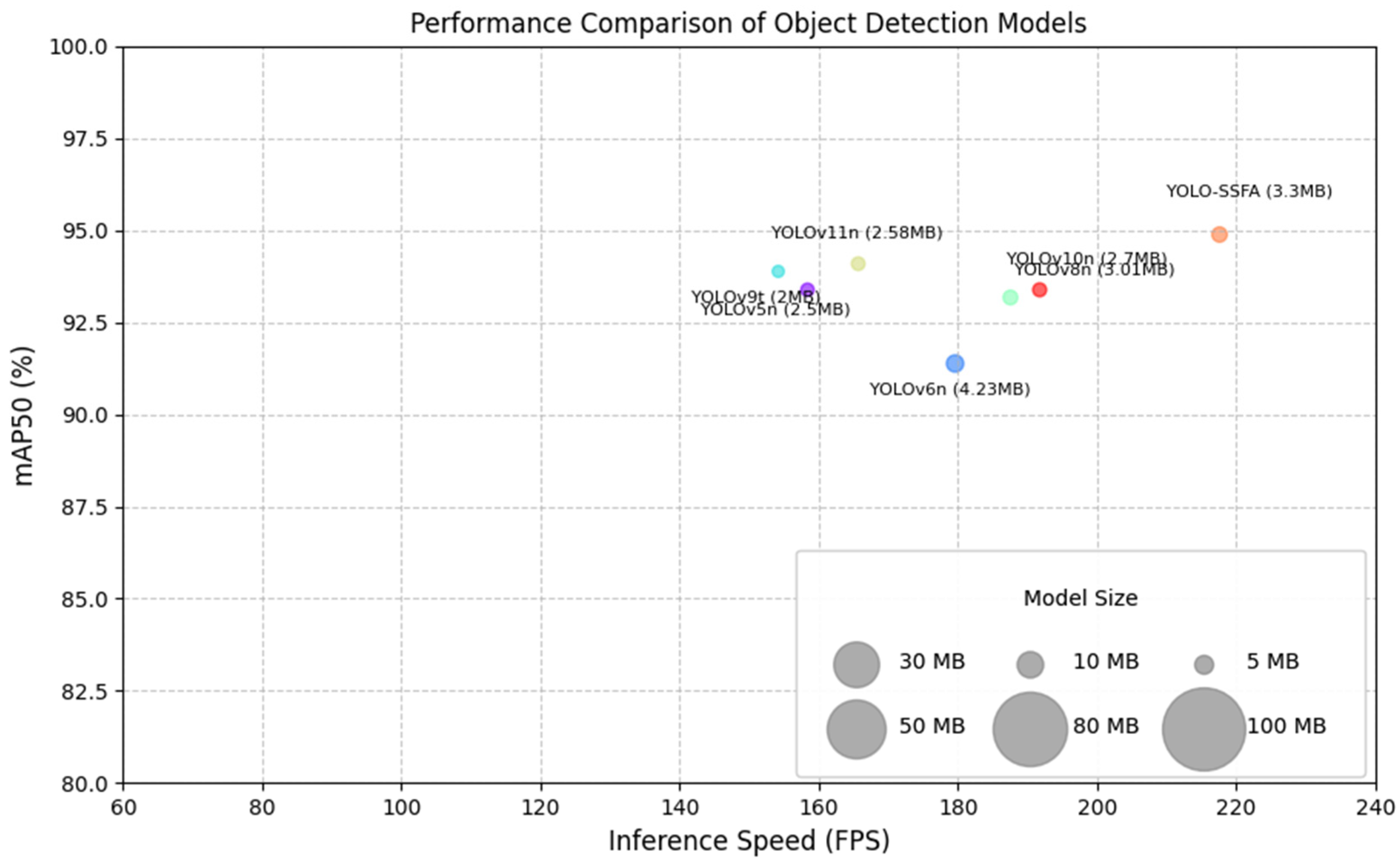
| Model | Size | Parameters | GFLOPs | F1 (%) | Precision | mAP50 (%) | mAP50-95 (%) | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv3-tiny | 640 | 12.13 | 18.9 | 82 | 0.857 | 87.0 ± 0.3 | 52 | 146.1 |
| YOLOv5n | 640 | 2.5 | 7.1 | 90 | 0.888 | 93.4 ± 0.2 | 57.9 | 158.3 |
| YOLOv6n | 640 | 4.23 | 11.8 | 88 | 0.889 | 91.4 ± 0.3 | 56.1 | 179.5 |
| YOLOv8n | 640 | 3.01 | 8.1 | 90 | 0.898 | 93.2 ± 0.1 | 58.9 | 187.5 |
| YOLOv8s | 640 | 11.13 | 28.4 | 90 | 0.909 | 94.2 ± 0.1 | 61.3 | 122.5 |
| YOLOv9t | 640 | 2 | 7.8 | 90 | 0.891 | 93.9 ± 0.3 | 59.4 | 154 |
| YOLOv10n | 640 | 2.7 | 8.2 | 89 | 0.893 | 93.4 ± 0.2 | 59.3 | 191.6 |
| YOLOv11n | 640 | 2.58 | 6.3 | 90 | 0.905 | 94.1 ± 0.3 | 59.5 | 165.5 |
| YOLO-SSFA | 640 | 3.3 | 8.1 | 91 | 0.913 | 94.9 ± 0.1 | 60.1 | 217.6 |
| Model | Size | Parameters | GFLOPs | F1 (%) | Precision | mAP50 (%) | mAP50-95 (%) | FPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv3-tiny | 640 | 12.13 | 18.9 | 73 | 0.806 | 73.7 ± 0.3 | 42.2 | 281.1 |
| YOLOv5n | 640 | 2.5 | 7.1 | 80 | 0.841 | 83.6 ± 0.1 | 49.2 | 384.0 |
| YOLOv6n | 640 | 4.23 | 11.8 | 78 | 0.819 | 81.5 ± 0.2 | 48.2 | 381.7 |
| YOLOv8n | 640 | 3.01 | 8.1 | 80 | 0.858 | 83.2 ± 0.1 | 49.8 | 332.1 |
| YOLOv8s | 640 | 11.13 | 28.4 | 82 | 0.85 | 85.7 ± 0.1 | 52.9 | 189.4 |
| YOLOv9t | 640 | 2 | 7.8 | 79 | 0.846 | 83.5 ± 0.3 | 49.9 | 292.9 |
| YOLOv10n | 640 | 2.7 | 8.2 | 78 | 0.829 | 82.5 ± 0.2 | 49.3 | 355.4 |
| YOLOv11n | 640 | 2.58 | 6.3 | 79 | 0.85 | 83.8 ± 0.3 | 50.8 | 299 |
| YOLO-SSFA | 640 | 3.3 | 8.1 | 80 | 0.867 | 85 ± 0.2 | 51.4 | 319.4 |
| Model | GFLOPs | Parameters | mAP50 (%) | mAP50-95 (%) | AP50 (%) | FPS | ||
|---|---|---|---|---|---|---|---|---|
| Bicycle | Car | Person | ||||||
| YOLOv11n | 6.3 | 2.58 | 94.1 ± 0.3 | 59.9 | 92.8 | 97.9 | 91.5 | 165.5 |
| DETR | 60.53 | 41.56 | 84.8 ± 0.1 | 45.4 | 50.5 | 75.4 | 32.6 | 51.2 |
| Swin Transformer | 172 | 36.86 | 72.5 ± 0.2 | 33.5 | 41.5 | 53.7 | 24.0 | 51.9 |
| YOLOX | 5.6 | 2.03 | 94.1 ± 0.2 | 57.8 | 92.3 | 97.7 | 91.1 | 225.9 |
| YOLO-SSFA | 8.1 | 3.3 | 94.9 ± 0.1 | 60.1 | 93.4 | 98.7 | 92.6 | 217.6 |
| Model | GFLOPs | Parameters | mAP50 (%) | mAP50-95 (%) | AP50 (%) | FPS | ||
|---|---|---|---|---|---|---|---|---|
| Bicycle | Car | Person | ||||||
| YOLOv11n | 6.3 | 2.58 | 83.8 ± 0.3 | 50.8 | 78.8 | 92.2 | 82.4 | 299 |
| DETR | 60.53 | 41.56 | 81.6 ± 0.1 | 44.2 | 56.8 | 65.6 | 35.5 | 51.4 |
| Swin Transformer | 172 | 36.86 | 76.6 ± 0.1 | 41.0 | 53.6 | 61.3 | 32.8 | 50.5 |
| YOLOX | 5.6 | 2.03 | 84.7 ± 0.1 | 48 | 78.6 | 92.3 | 82.1 | 288.54 |
| YOLO-SSFA | 8.1 | 3.3 | 85 ± 0.2 | 51.4 | 80.1 | 92.4 | 83.1 | 319.4 |
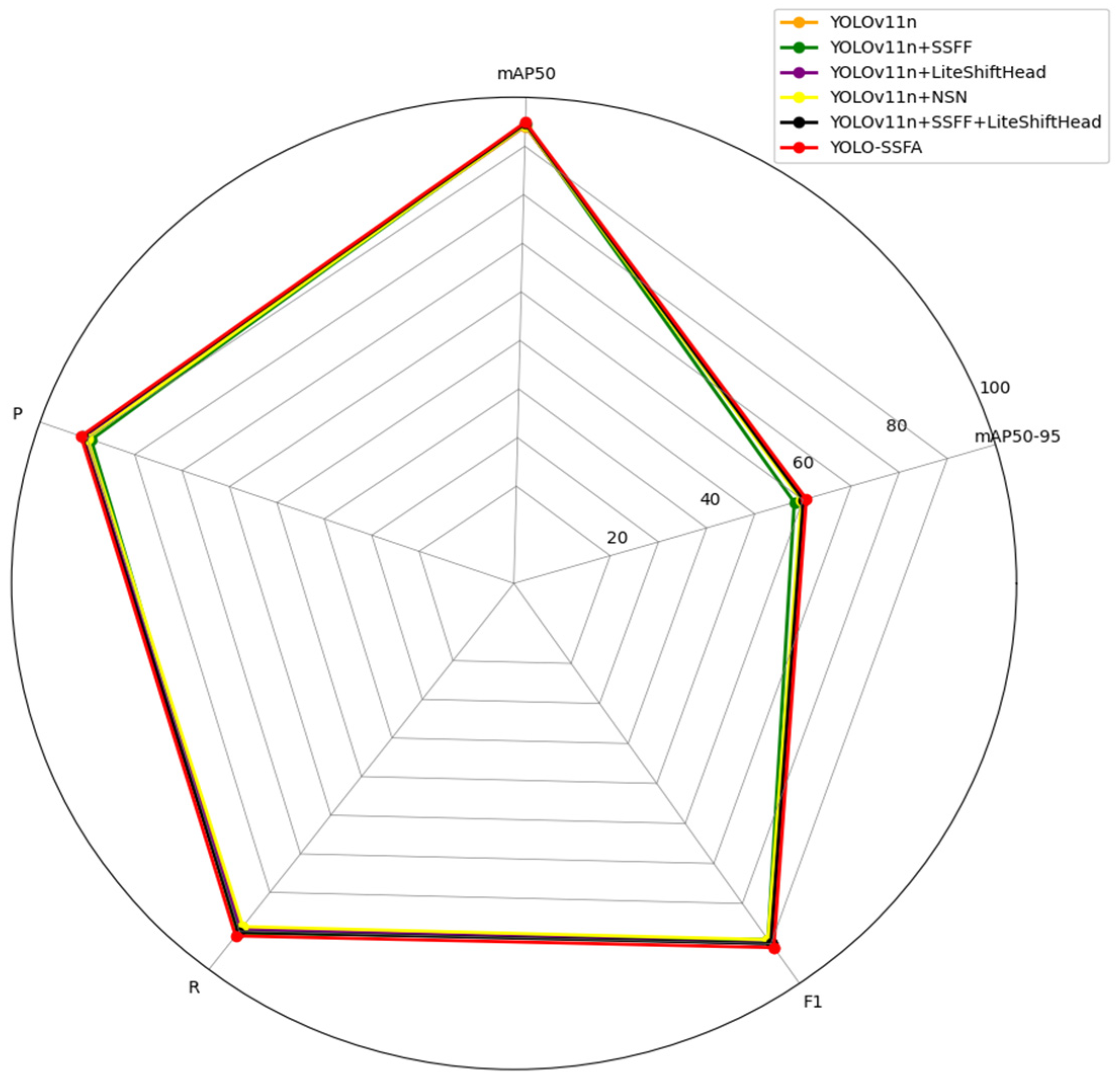
| Yolov11n | SSFF | LiteShiftHead | NSN | Parameters | F1 (%) | Precision | mAP50 (%) | mAP50-95 (%) | FPS |
|---|---|---|---|---|---|---|---|---|---|
| √ | 2.58 | 90 | 0.905 | 94.1 ± 0.3 | 59.9 | 165.5 | |||
| √ | √ | 2.94 | 89 | 0.906 | 94.4 ± 0.2 | 59.4 | 144.4 | ||
| √ | √ | 2.60 | 90 | 0.908 | 94.2 ± 0.2 | 59.9 | 189.4 | ||
| √ | √ | 2.83 | 89 | 0.898 | 94.3 ± 0.1 | 59.6 | 220.5 | ||
| √ | √ | √ | 3.01 | 90 | 0.911 | 94.6 ± 0.2 | 60.0 | 155.8 | |
| √ | √ | √ | √ | 3.3 | 91 | 0.913 | 94.9 ± 0.1 | 60.1 | 217.6 |
| Yolov11n | SSFF | LiteShiftHead | NSN | Parameters | F1 (%) | Precision | mAP50 (%) | mAP50-95 (%) | FPS |
|---|---|---|---|---|---|---|---|---|---|
| √ | 2.58 | 79 | 0.85 | 83.8 ± 0.3 | 50.8 | 299 | |||
| √ | √ | 2.94 | 79 | 0.841 | 84.3 ± 0.1 | 50.9 | 285.7 | ||
| √ | √ | 2.60 | 79 | 0.858 | 84.4 ± 0.2 | 51.0 | 312.2 | ||
| √ | √ | 2.83 | 80 | 0.844 | 84.1 ± 0.1 | 50.8 | 327.6 | ||
| √ | √ | √ | 3.01 | 80 | 0.86 | 84.6 ± 0.2 | 51.2 | 290.9 | |
| √ | √ | √ | √ | 3.3 | 80 | 0.867 | 85 ± 0.2 | 51.4 | 319.4 |
| Yolov11n | SSFF | LiteShiftHead | Attention | Parameters | F1 (%) | Precision | mAP50 (%) | mAP50-95 (%) | FPS |
|---|---|---|---|---|---|---|---|---|---|
| √ | √ | √ | CBAM | 3.36 | 90 | 0.91 | 94.2 ± 0.2 | 59.7 | 182.7 |
| √ | √ | √ | GAM | 4.2 | 90 | 0.912 | 93.6 ± 0.4 | 58.4 | 182.0 |
| √ | √ | √ | SimAM | 3.34 | 90 | 0.901 | 93.9 ± 0.3 | 58.8 | 164.7 |
| √ | √ | √ | SK | 14.4 | 90 | 0.909 | 94.5 ± 0.3 | 59.8 | 147.3 |
| √ | √ | √ | EMA | 3.5 | 91 | 0.915 | 93.9 ± 0.1 | 59.9 | 165.3 |
| √ | √ | √ | NSN | 3.3 | 91 | 0.913 | 94.9 ± 0.1 | 60.1 | 217.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Cao, M.; Yang, Q.; Zhang, Y.; Wang, Z. YOLO-SSFA: A Lightweight Real-Time Infrared Detection Method for Small Targets. Information 2025, 16, 618. https://doi.org/10.3390/info16070618
Wang Y, Cao M, Yang Q, Zhang Y, Wang Z. YOLO-SSFA: A Lightweight Real-Time Infrared Detection Method for Small Targets. Information. 2025; 16(7):618. https://doi.org/10.3390/info16070618
Chicago/Turabian StyleWang, Yuchi, Minghua Cao, Qing Yang, Yue Zhang, and Zexuan Wang. 2025. "YOLO-SSFA: A Lightweight Real-Time Infrared Detection Method for Small Targets" Information 16, no. 7: 618. https://doi.org/10.3390/info16070618
APA StyleWang, Y., Cao, M., Yang, Q., Zhang, Y., & Wang, Z. (2025). YOLO-SSFA: A Lightweight Real-Time Infrared Detection Method for Small Targets. Information, 16(7), 618. https://doi.org/10.3390/info16070618