


Efficient Hotspot Detection in Solar Panels via Computer Vision and Machine Learning
 , , ,
, , ,  and
and
Abstract

1. Introduction
- The first is to evaluate 34 ML vs. 5 leading DL models. The study adopts a global approach, covering 34 ML models for 31 feature combinations. The feature extraction is carried out by the Automatic Content Extraction (ACE) media tool in ML models for five different datasets containing thermal images of solar panels with hotspots. The existing literature has predominantly focused on DL models and electrical parameter measurement of solar panel power generation.
- The second objective is to assess Explainable AI (XAI) interpretability via SHAP and What-if Analysis. The study employs a novel methodology that combines SHAP and What-if Analysis [7,8]. This enhances the interpretability of ML models, as part of the XAI [9] framework, in the context of (Unmanned Aerial Vehicle) UAV-based photovoltaic (PV) hotspot detection using thermal imagery. A novel methodology combining SHAP and What-if Analysis is employed to enhance the interpretability of ML models within the XAI framework, specifically for (Unmanned Aerial Vehicle) UAV-based photovoltaic (PV) hotspot detection using thermal imagery. This approach examines the linkage between the performance and computational complexity of both ML and DL models for this application. It highlights that feature-extraction-based ML models outperform DL models. In particular, transfer-learning-based CNNs trained on the ImageNet database lack effective generalization for domain-specific tasks like infrared-based solar panel hotspot detection [10,11].
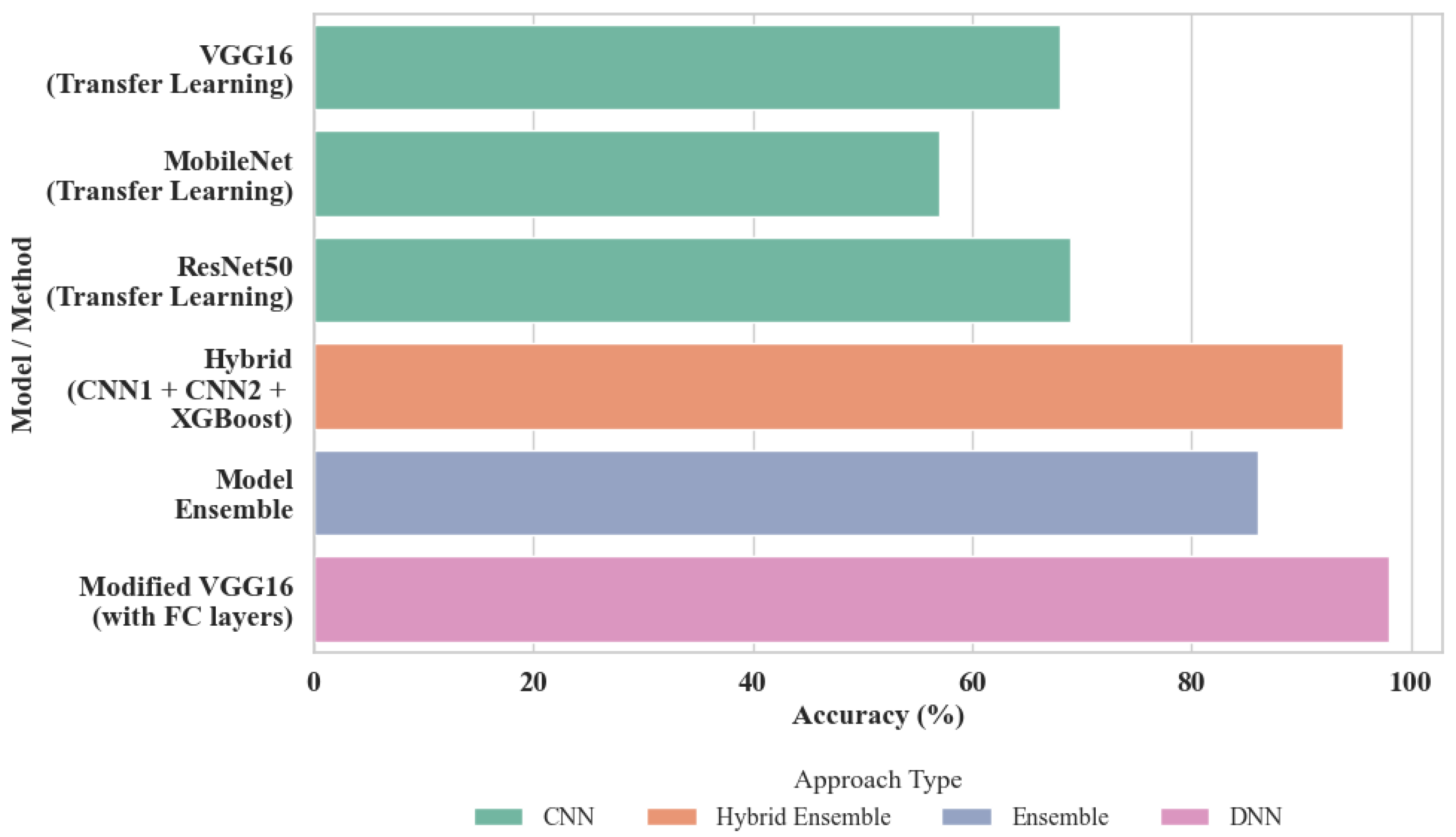
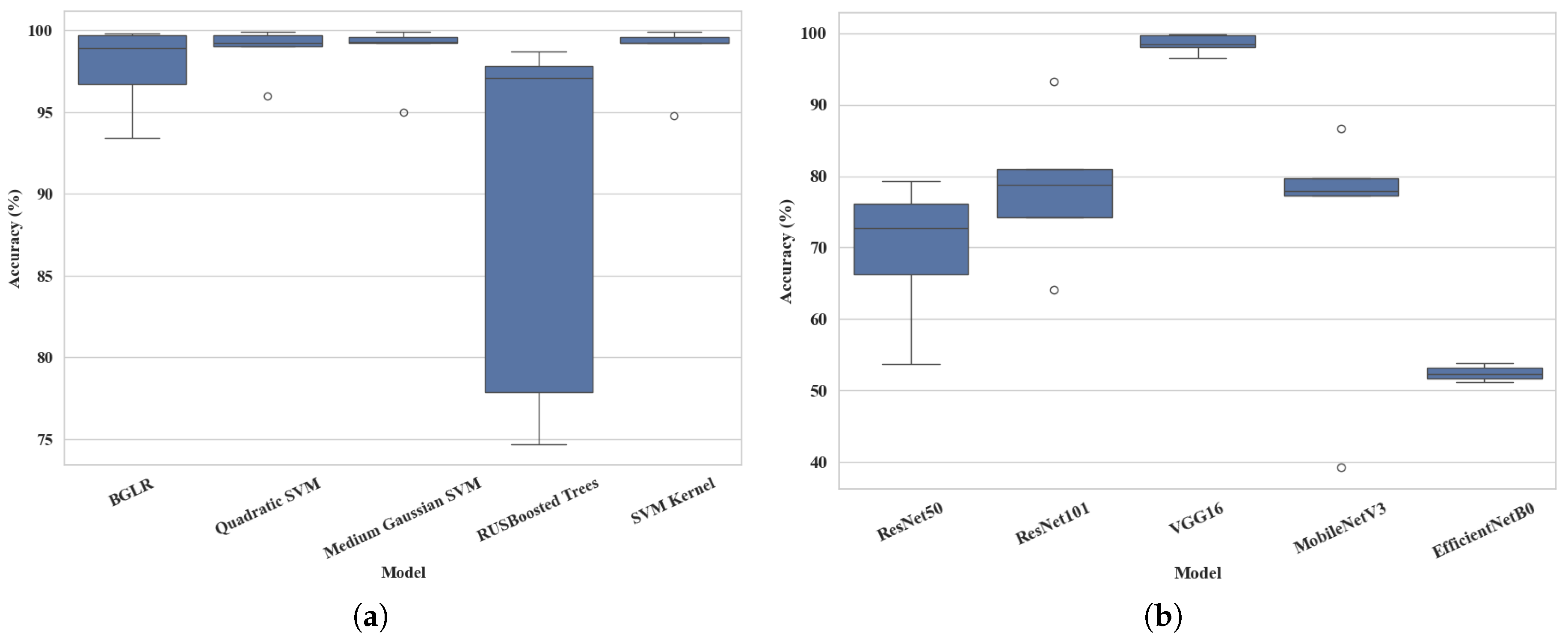
- The third is to evaluate the classification performance and computational efficiency of the top five ML and DL models: It provides comprehensive insights by plotting and summarizing accuracy and time-scale graphs. These graphs are based on five datasets. The analysis includes the top five high-performing ML models, which are Binary GLM Logistic Regression, Quadratic Support Vector Machine, Medium Gaussian Support Vector Machine, RUSBoosted Trees, and Support Vector Machine Kernel. In addition, five DL models are also considered: ResNet-50, ResNet-101, VGG-16, MobileNetV3Small, and EfficientNetB0. Further, the computational efficiency is analyzed, with an emphasis on training and inference times, to determine the feasibility of deployment in resource-constrained environments.
- The final objective is to synthesize and recommend the optimum performing ML model suitable for UAV deployment: Research identifies optimal models that ensure a balance between predictive accuracy, generalization across datasets, and computational resource requirements, thus supporting practical and scalable real-world deployment.
2. Literature Review
2.1. Study on Thermal Image-Based Feature Extraction for Solar PV Hotspot Detection
2.2. Investigation of ML-Based Techniques for Solar PV Hotspot Detection
2.3. Analysis of DL-Based Techniques for Solar PV Hotspot Detection
2.4. Review of Hotspot Detection Techniques in PV Systems
2.5. Significance of the Study
3. Methodology
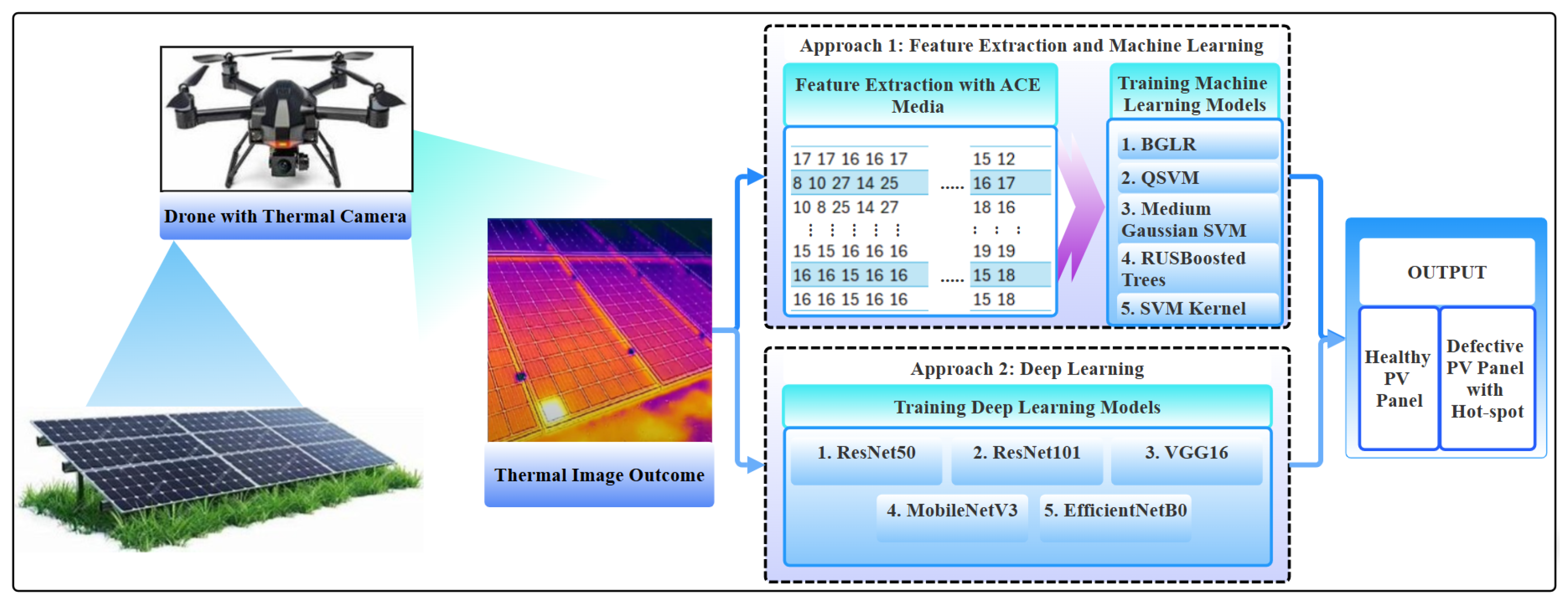
3.1. Background and Approach
- (1)
- Assess Selection of Solar Panel
- (2)
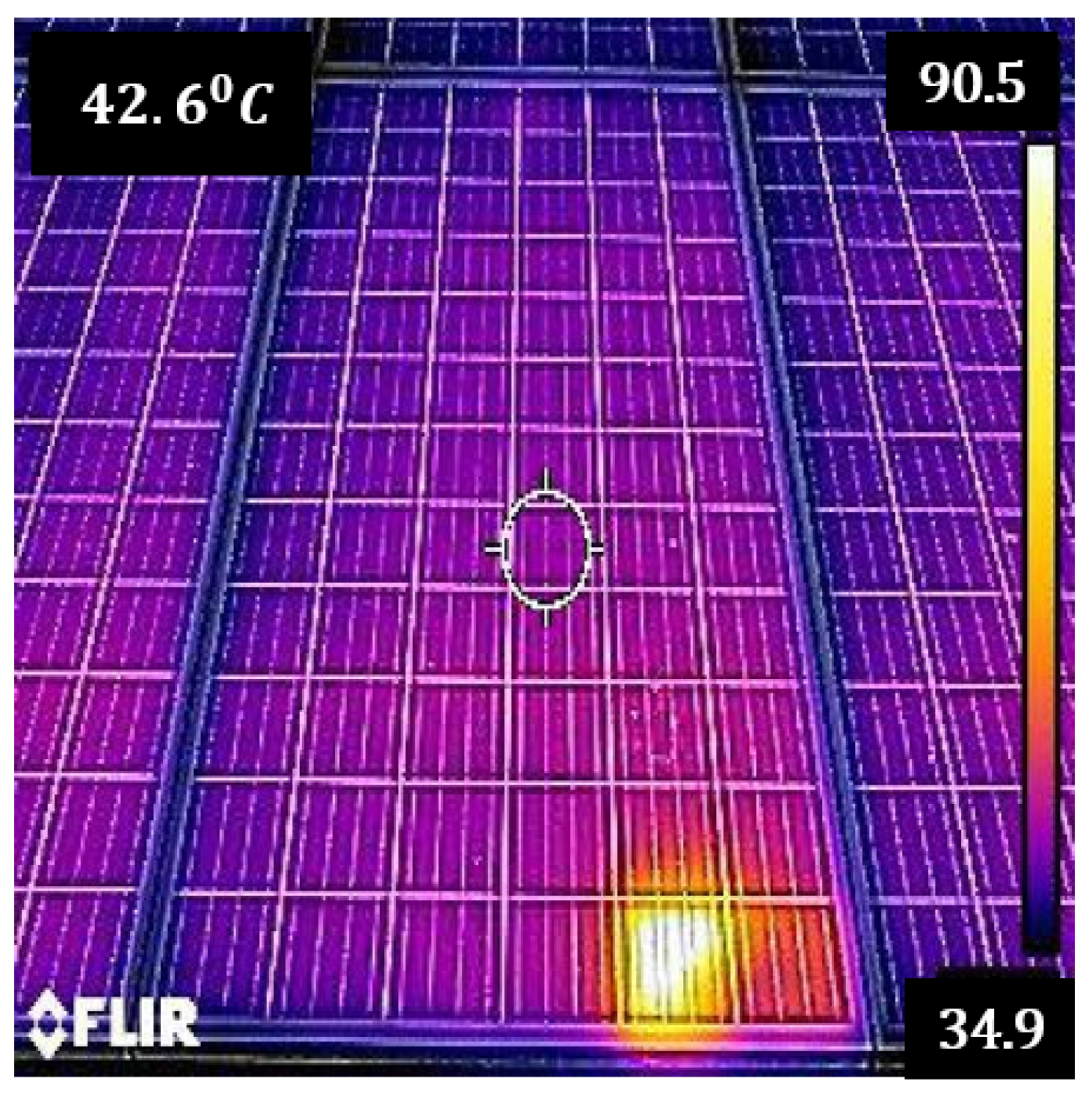
- Thermal Data Acquisition using UAV and Dataset Preparation
- (3)
- Categorization of Selected Five Datasets
- Evaluation of Datasets using Non Reference-based Image Quality Metrics
- Evaluation of Datasets using Reference-based Image Quality Metrics
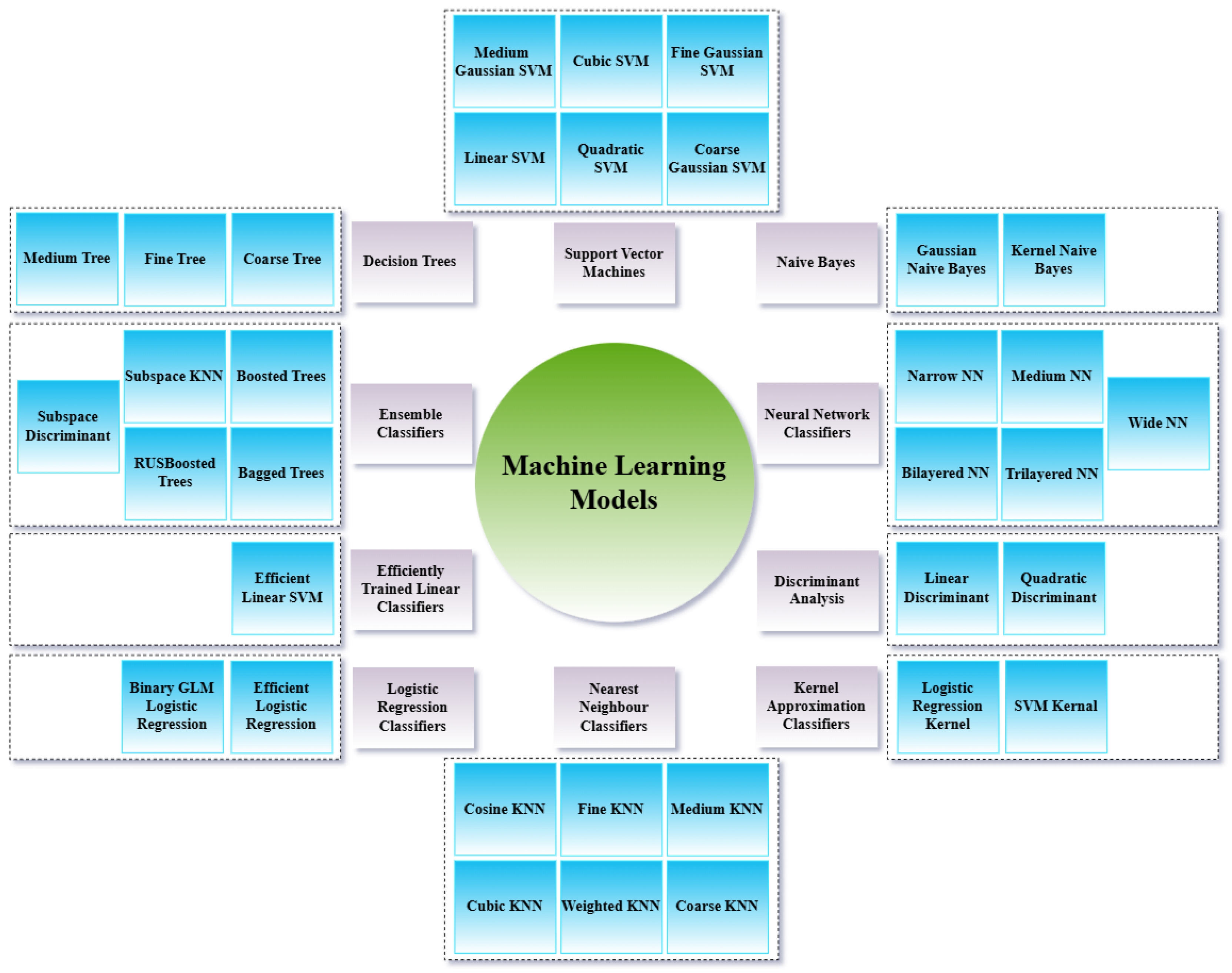
3.2. Approach 1: Feature Extraction Based Traditional ML
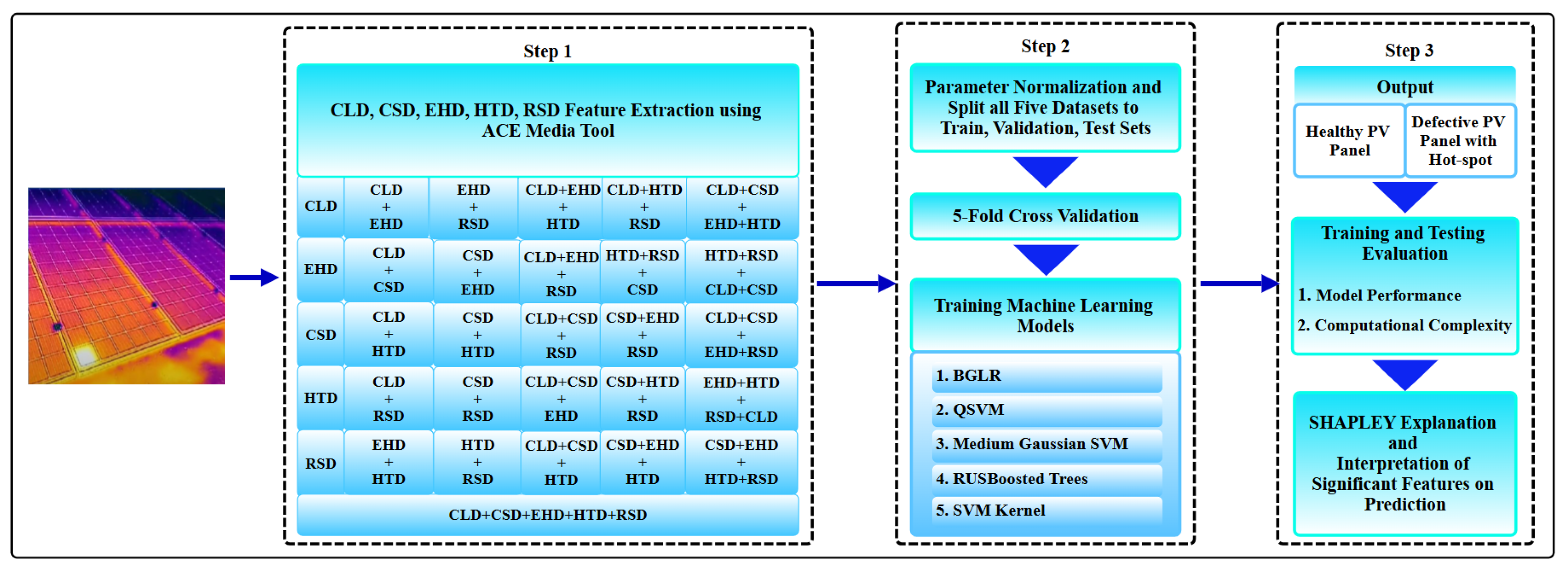
3.2.1. Method for Extracting Image Features and Modeling Pipeline
- Feature Descriptors
- Color Layout Descriptor (CLD):where are Discrete Cosine Transform (DCT) coefficients from the luminance channel and and are DCT coefficients from the chrominance channels. This descriptor gives a compact summary of where colors appear in the image.
- Color Structure Descriptor (CSD):where represents the histogram bin values corresponding to local color structures () and q denotes an additional global color quantization value. Thus, the CSD feature vector consists of 33 parameters in total. This shows how often different colors appear in small regions across the image.
- Edge Histogram Descriptor (EHD):where represents the local edge histogram values for vertical, horizontal, 45°, 135°, and non-directional edges across subdivided image blocks. This captures the texture and structure of the image based on edge patterns.
- Homogeneous Texture Descriptor (HTD):where values are energy features, values are deviation features across frequency bands, denotes mean energy deviation, and denotes energy mean. This tells us how rough or smooth different areas of the image are.
- Region Shape Descriptor (RSD):where values are shape-related features, such as Fourier coefficients or moment invariants, used to describe the shape characteristics. This helps understand the shapes of major objects in the image.
- Combined feature vector
3.2.2. Benchmarking and Selection of Best-Performing ML Algorithms
3.2.3. Hyperparameter Configuration of Selected ML Models
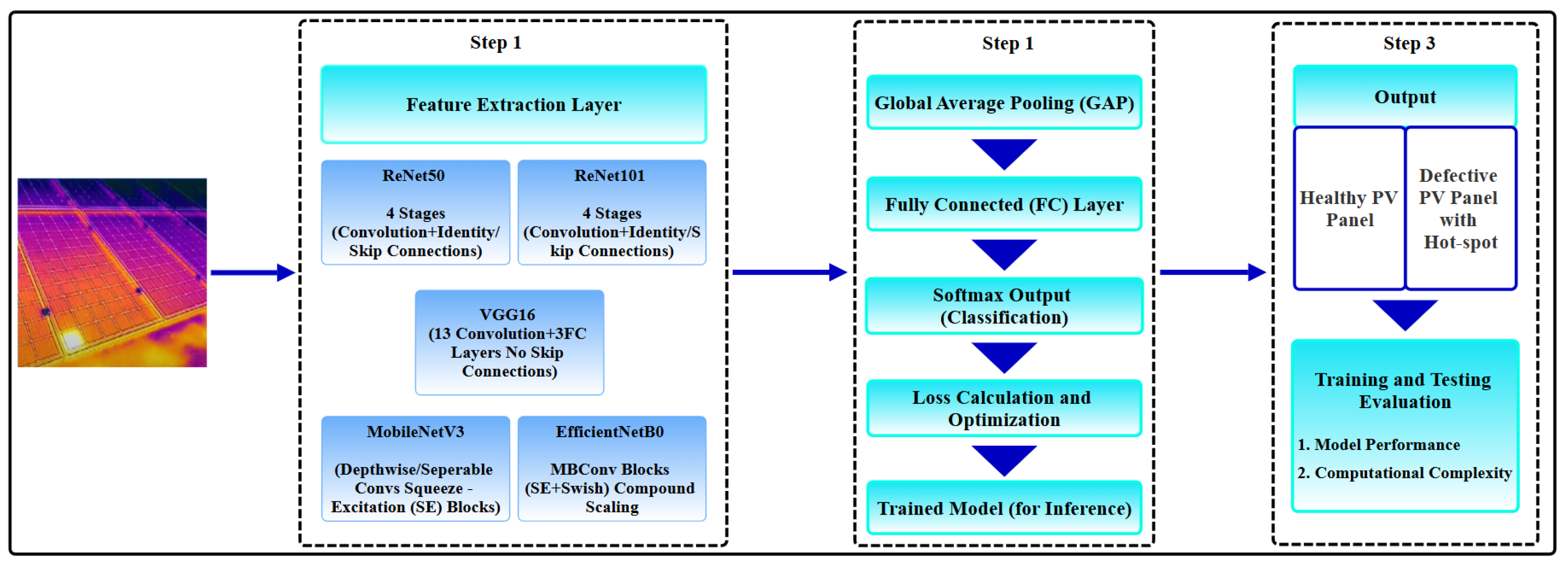
3.3. Approach 2: End-to-End DL
3.3.1. Selection Criteria of DL Models and Configuration of Hyperparameters for Selected Models
- Hyperparameter Tuning and Validation
3.3.2. End-to-End Training Pipeline Without Explicit Feature Extraction
3.4. XAI and What-If Analysis
4. Results
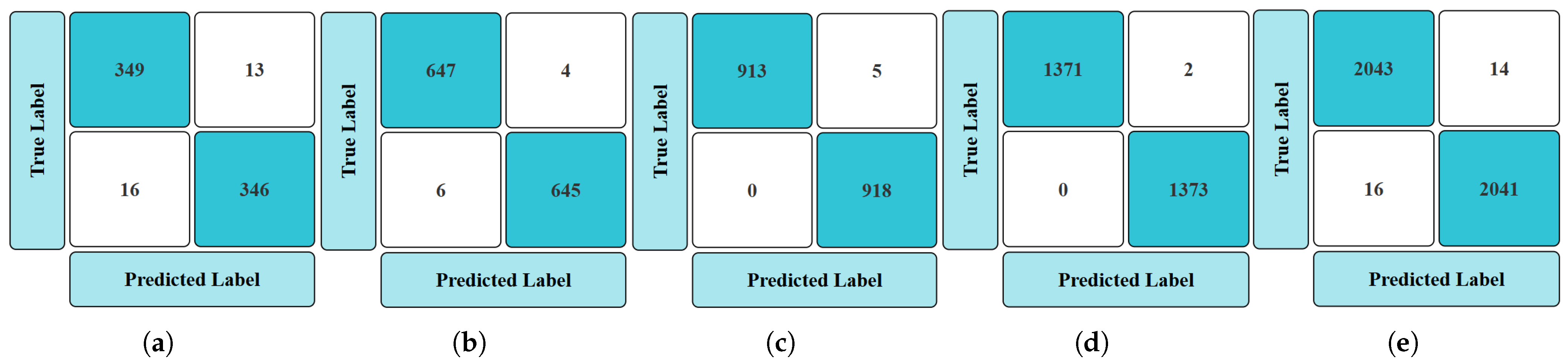
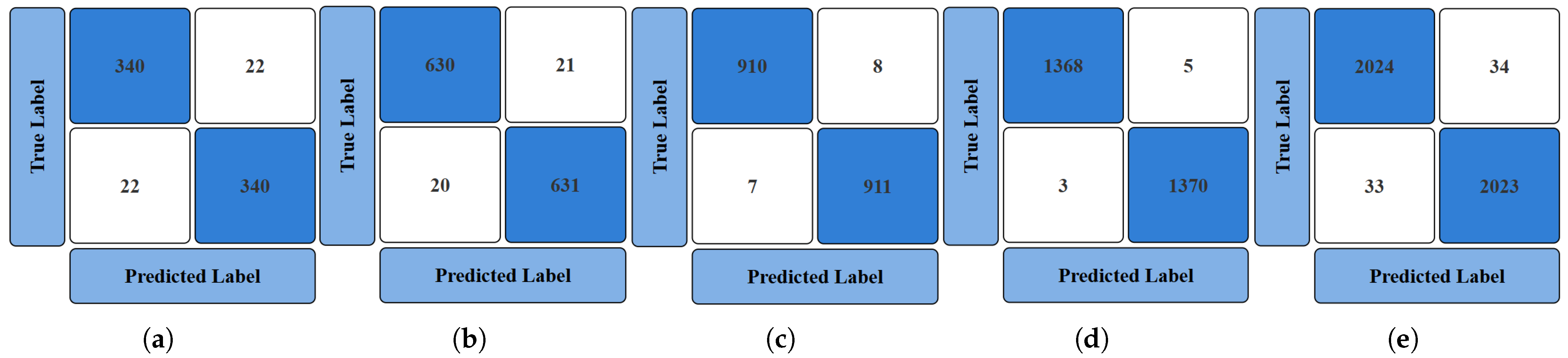
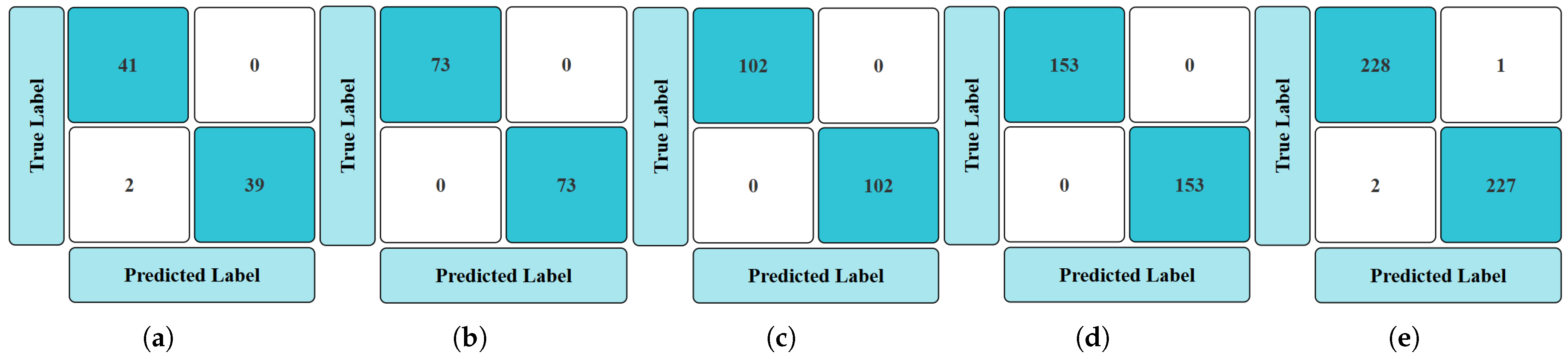
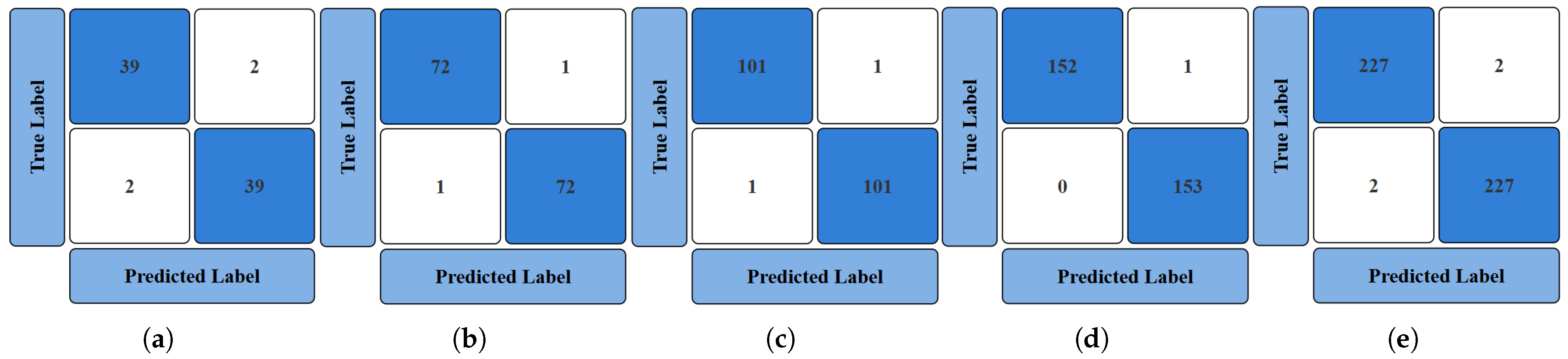
4.1. Comparison of Model Accuracies
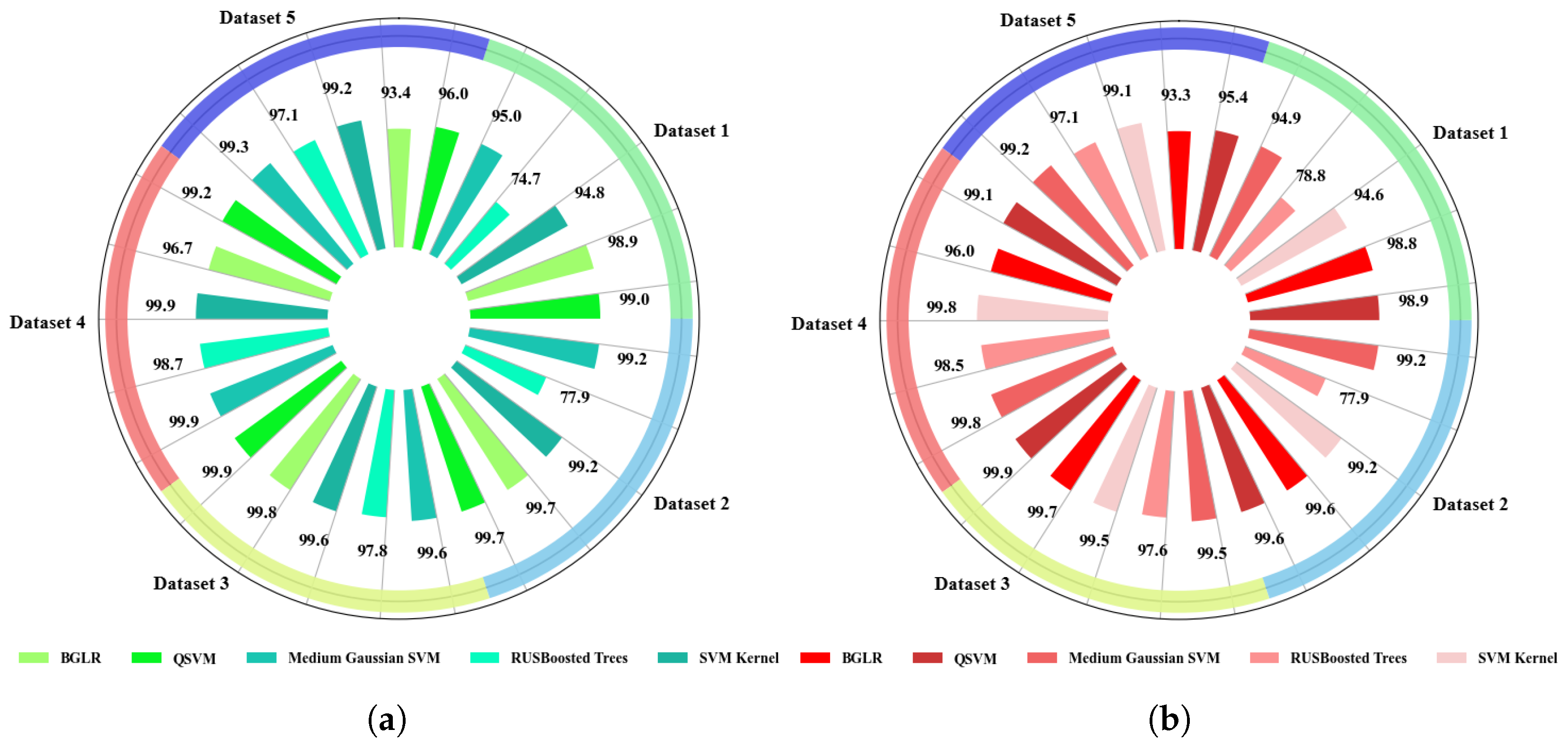
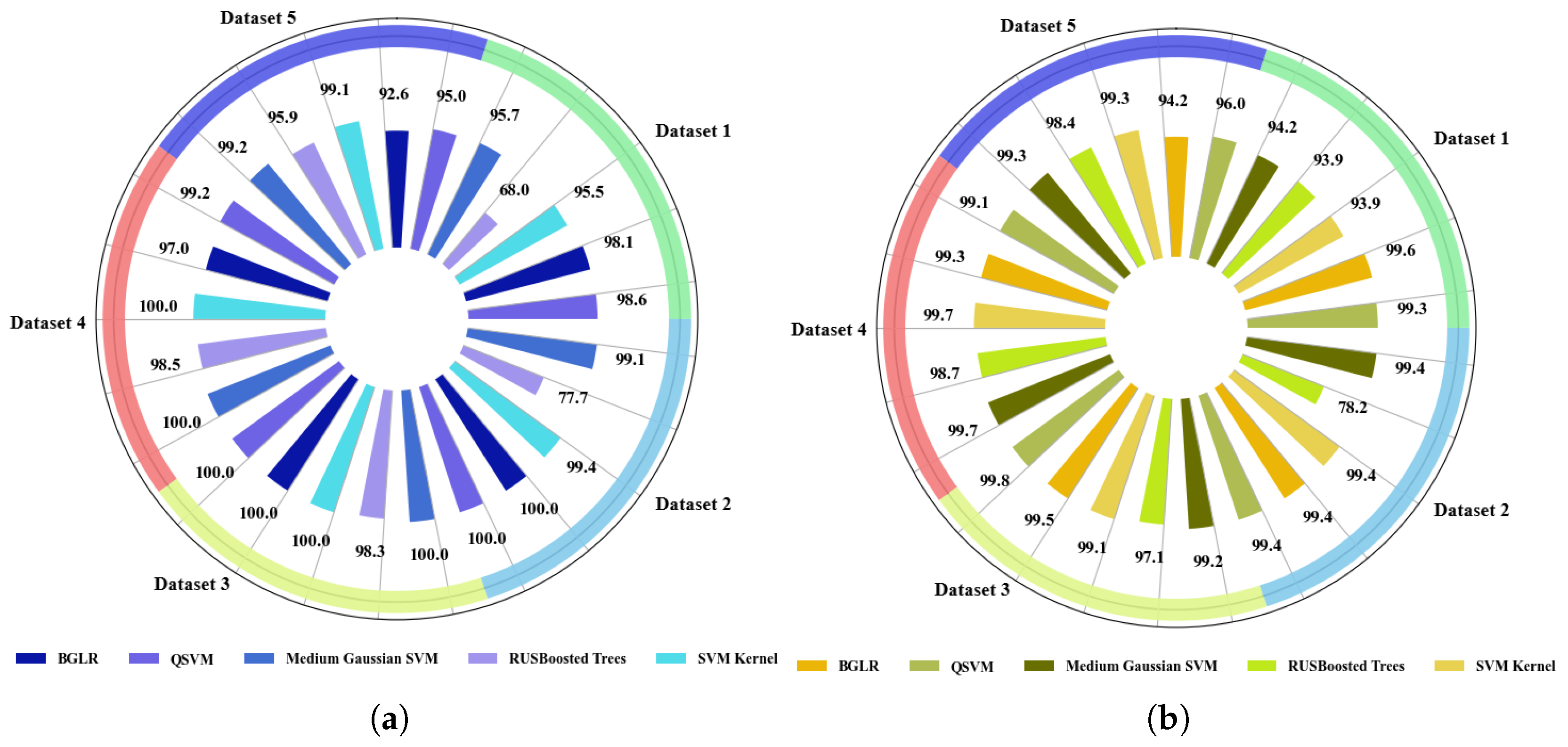
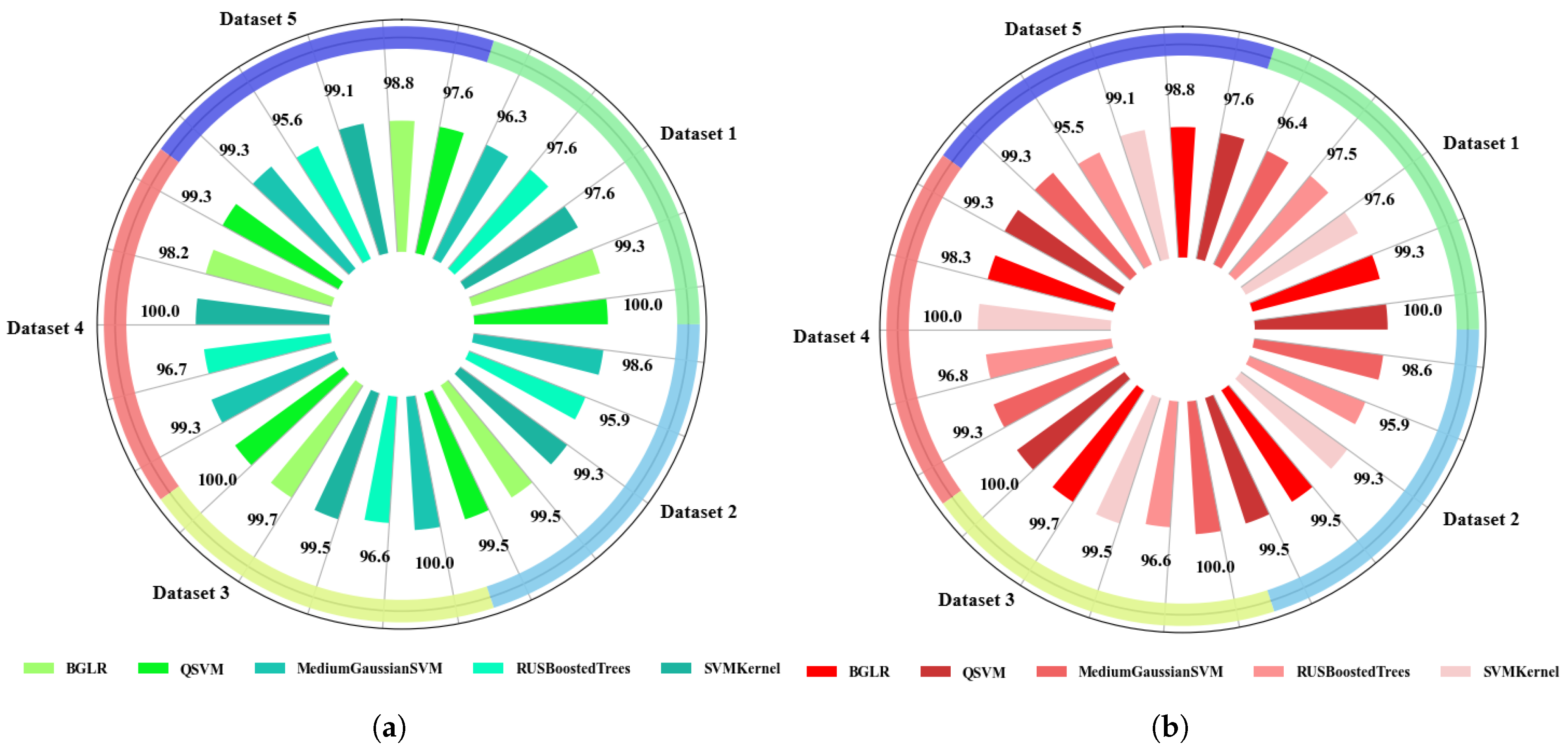
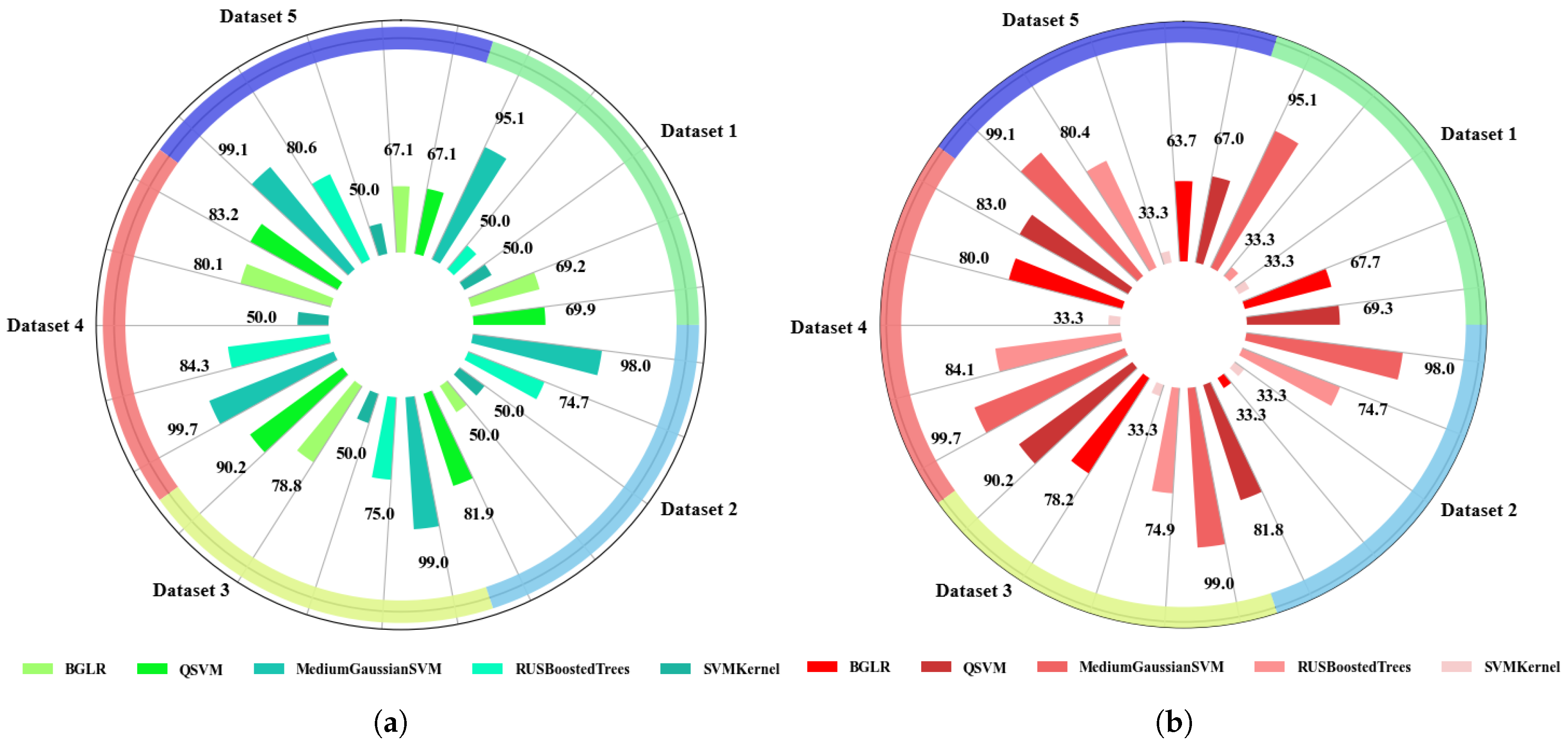
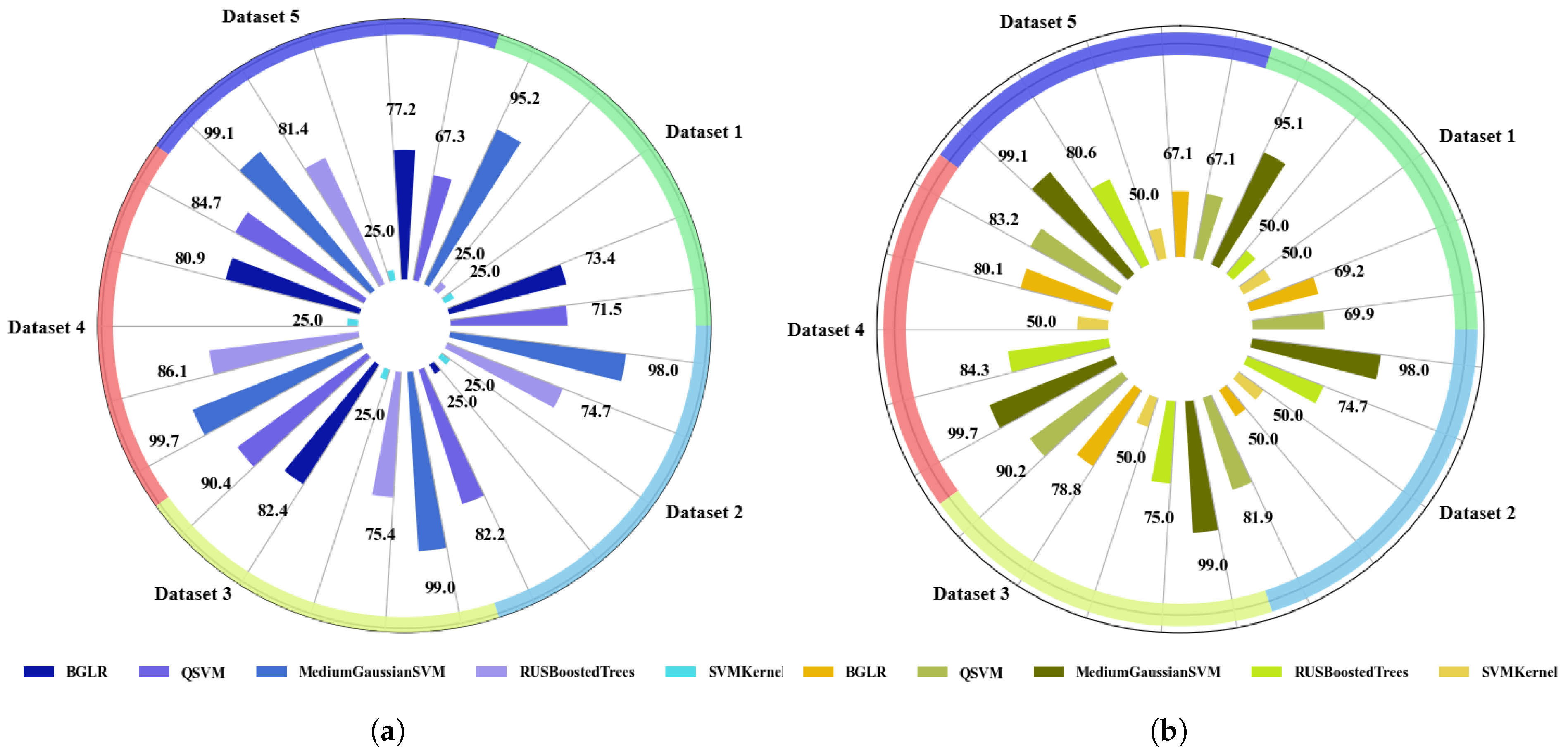
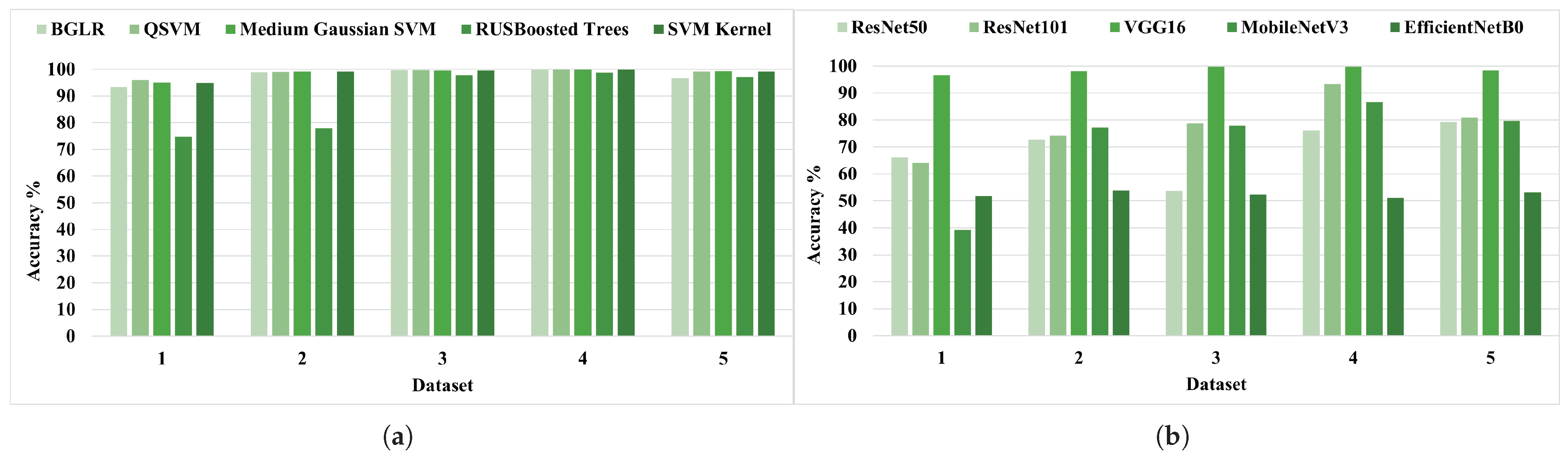
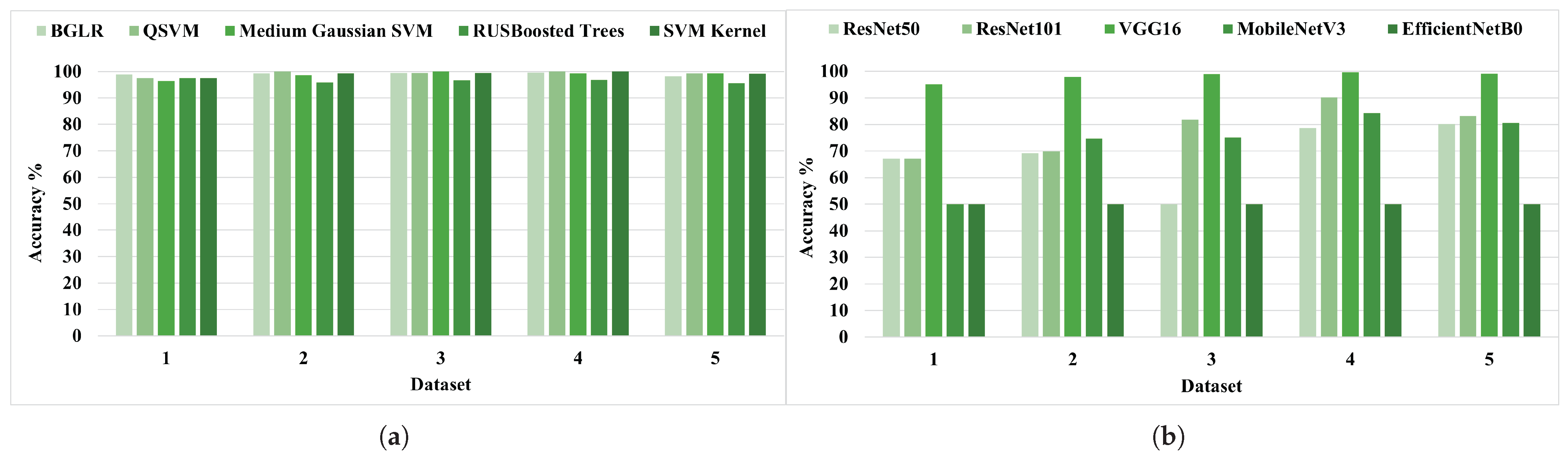
4.1.1. Accuracy Analysis in Traditional ML Models with Extracted Features
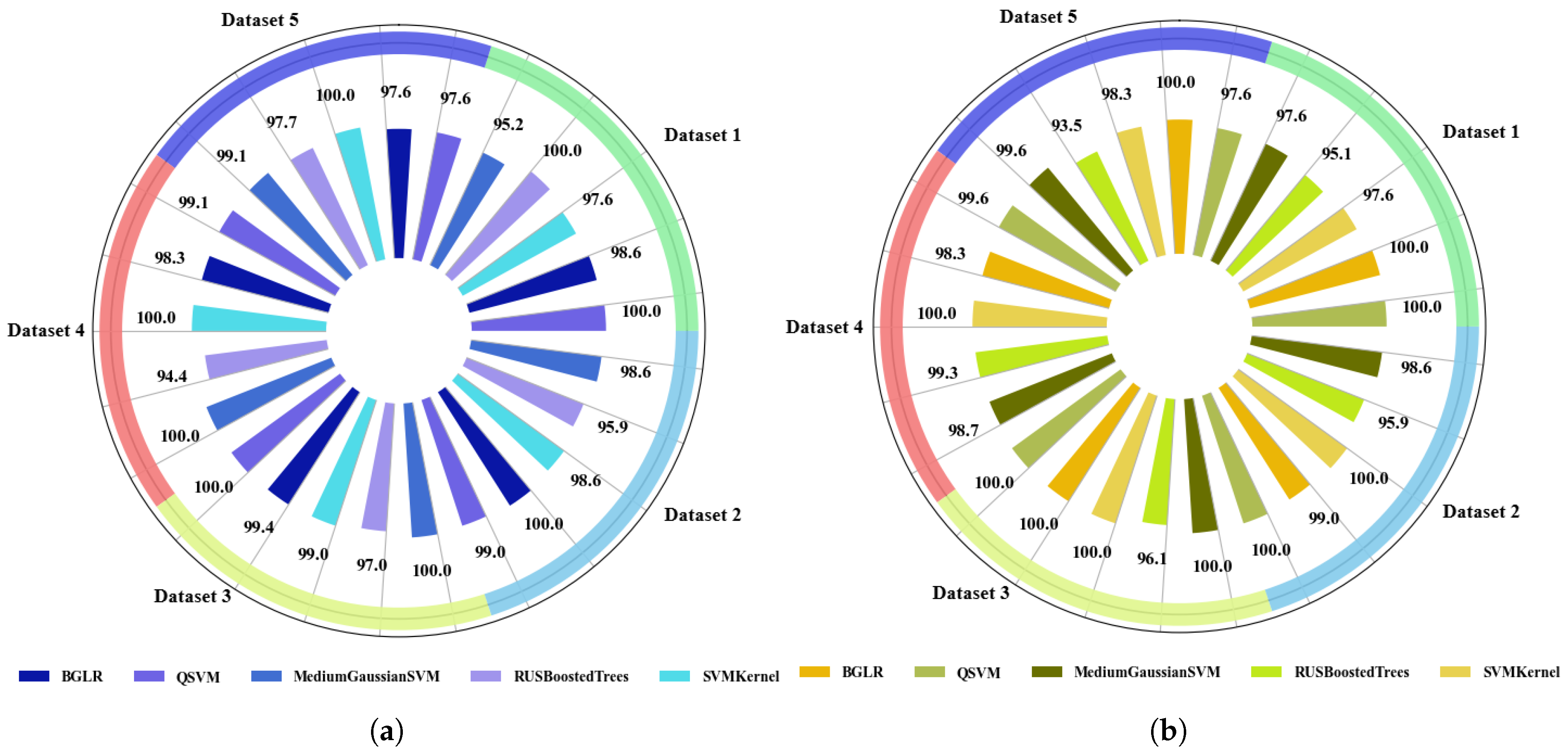
4.1.2. Accuracy Analysis of End-to-End DL
- Accuracy Plots of Training and Testing ML and DL Models
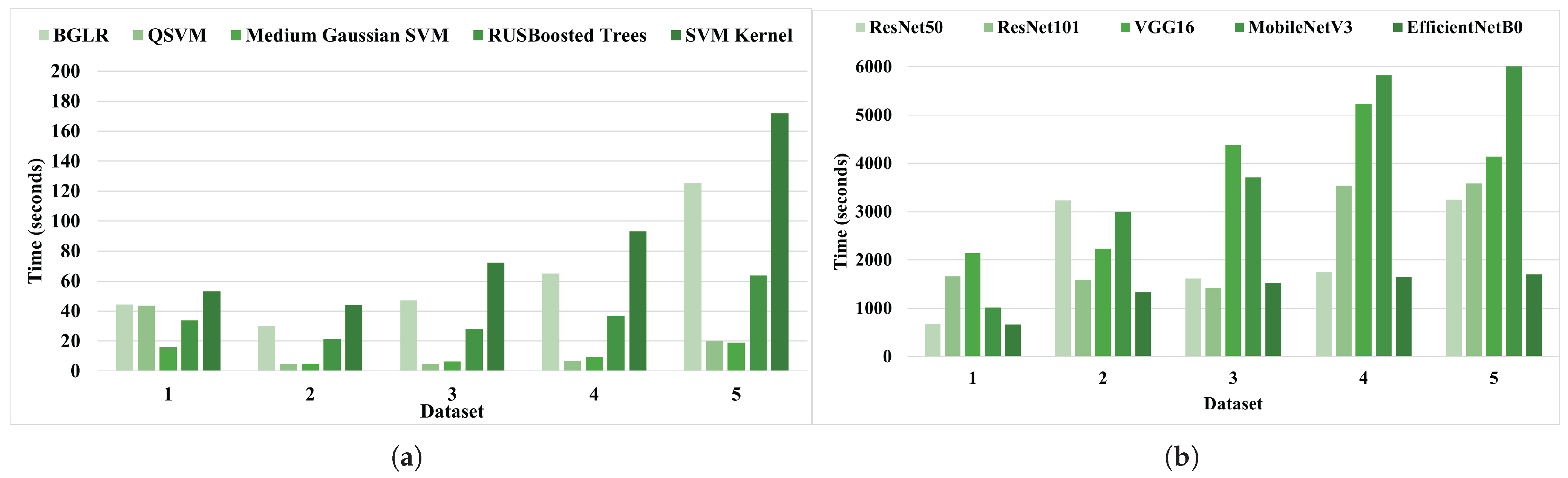
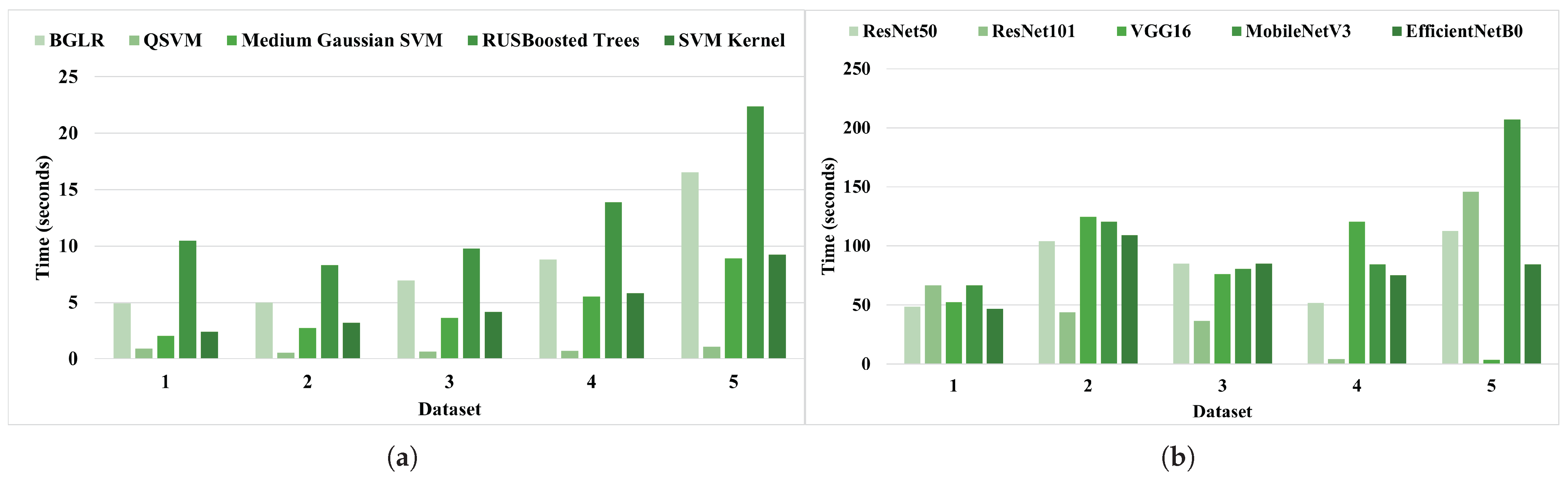
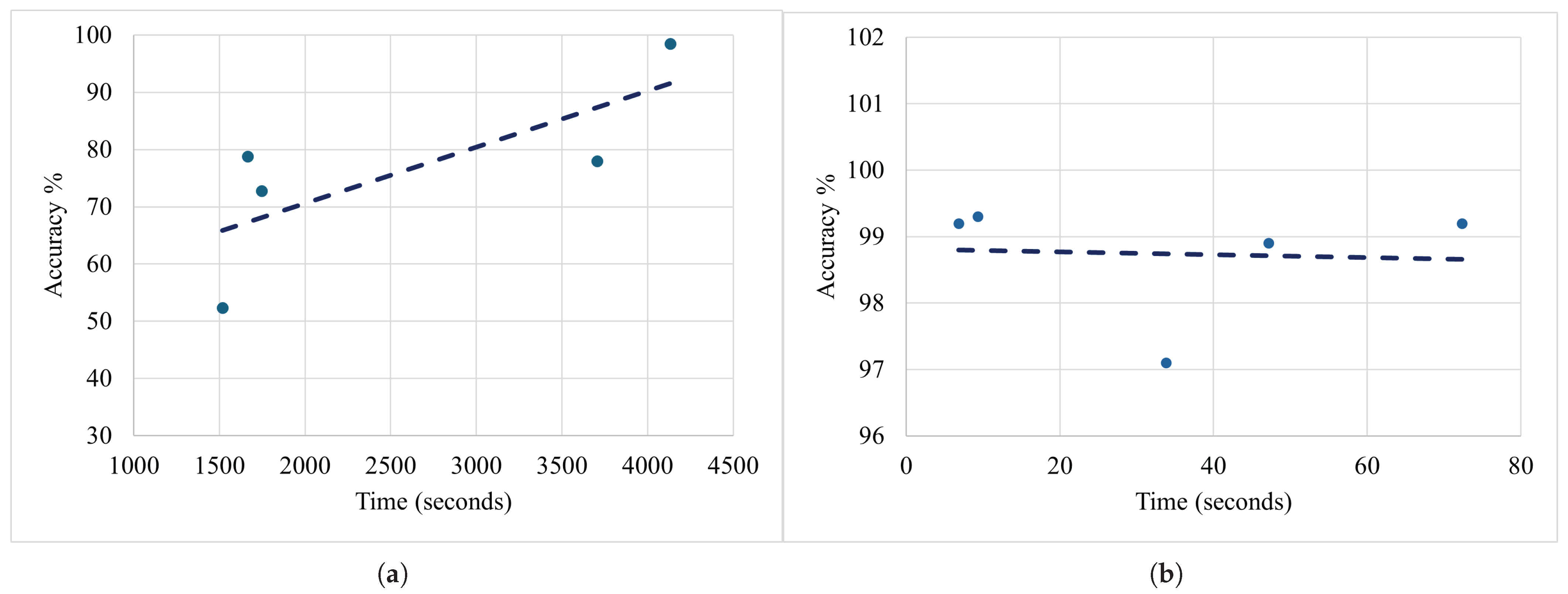
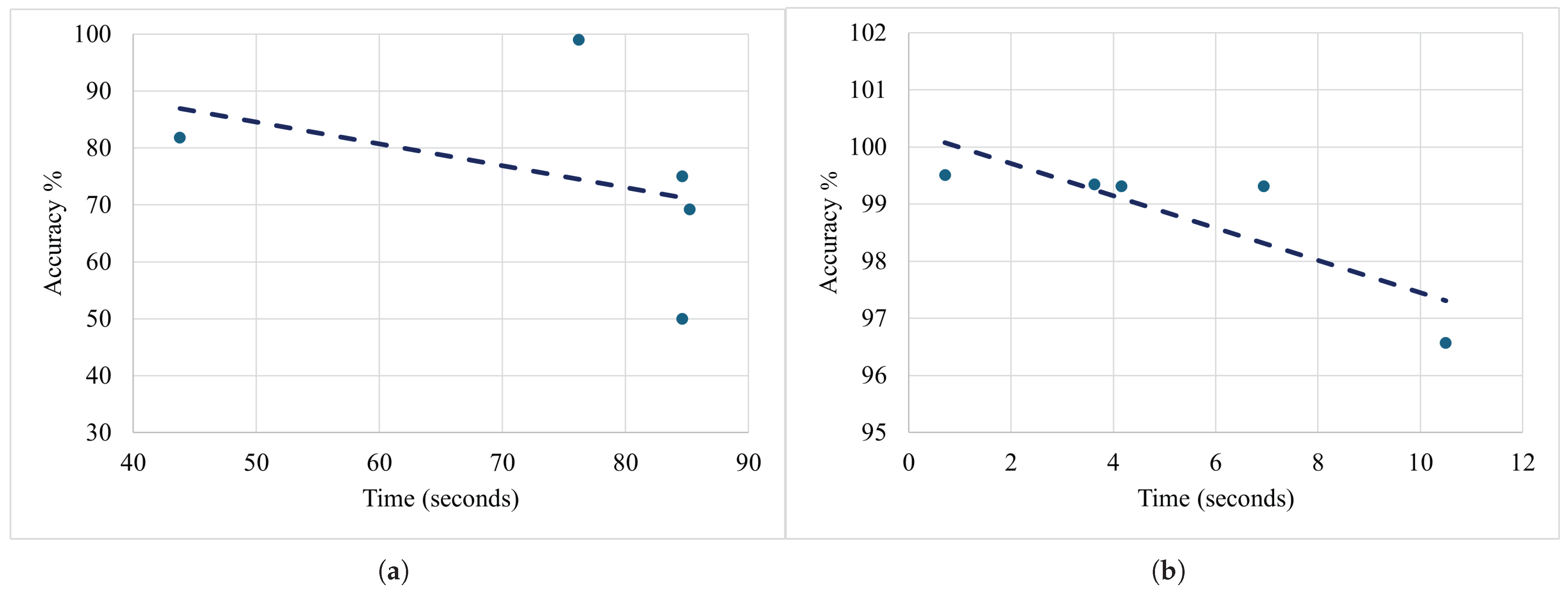
4.2. Resource Utilization Analysis: Computational Efficiency in Terms of Training and Inference Time
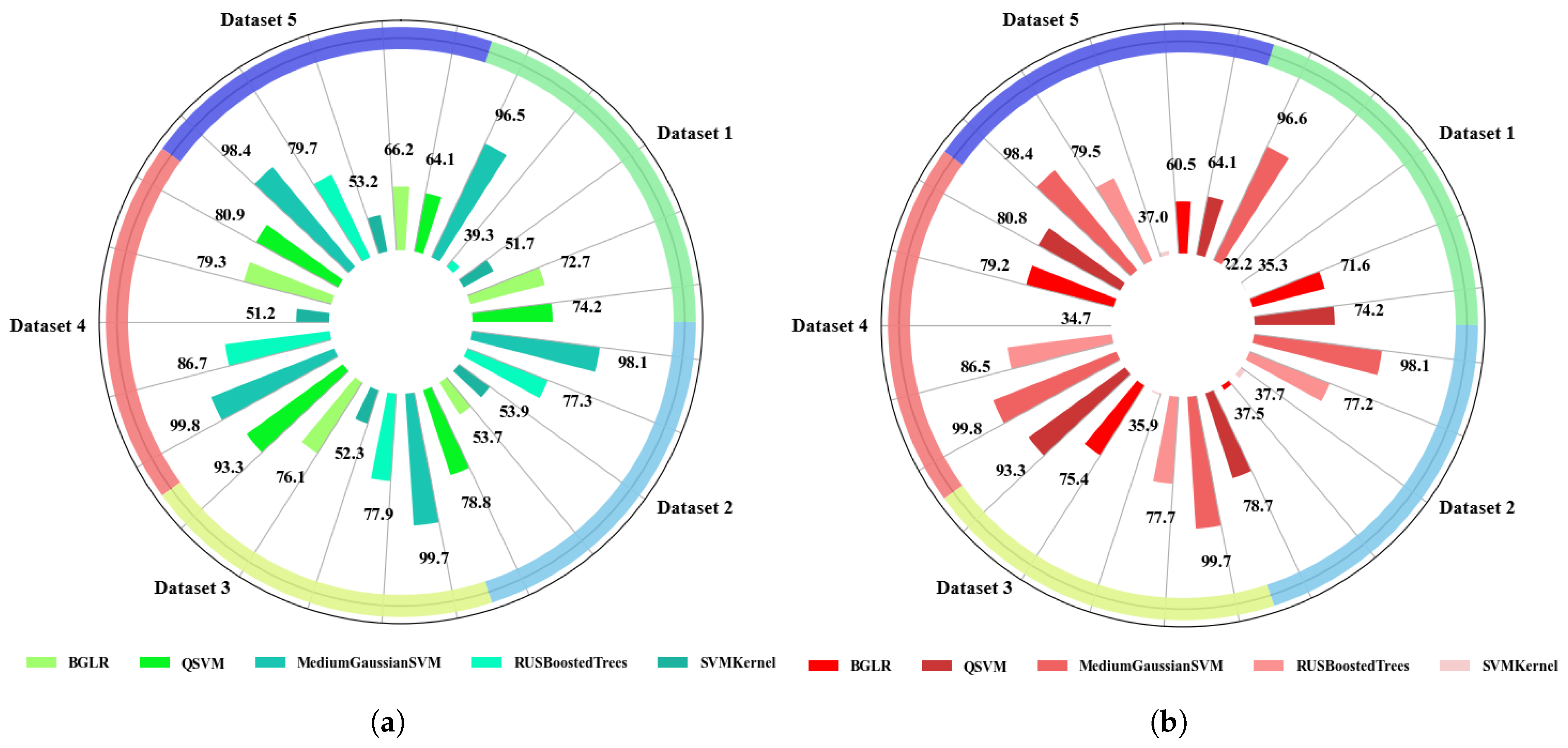
4.2.1. Resource Utilization Analysis of ML Models
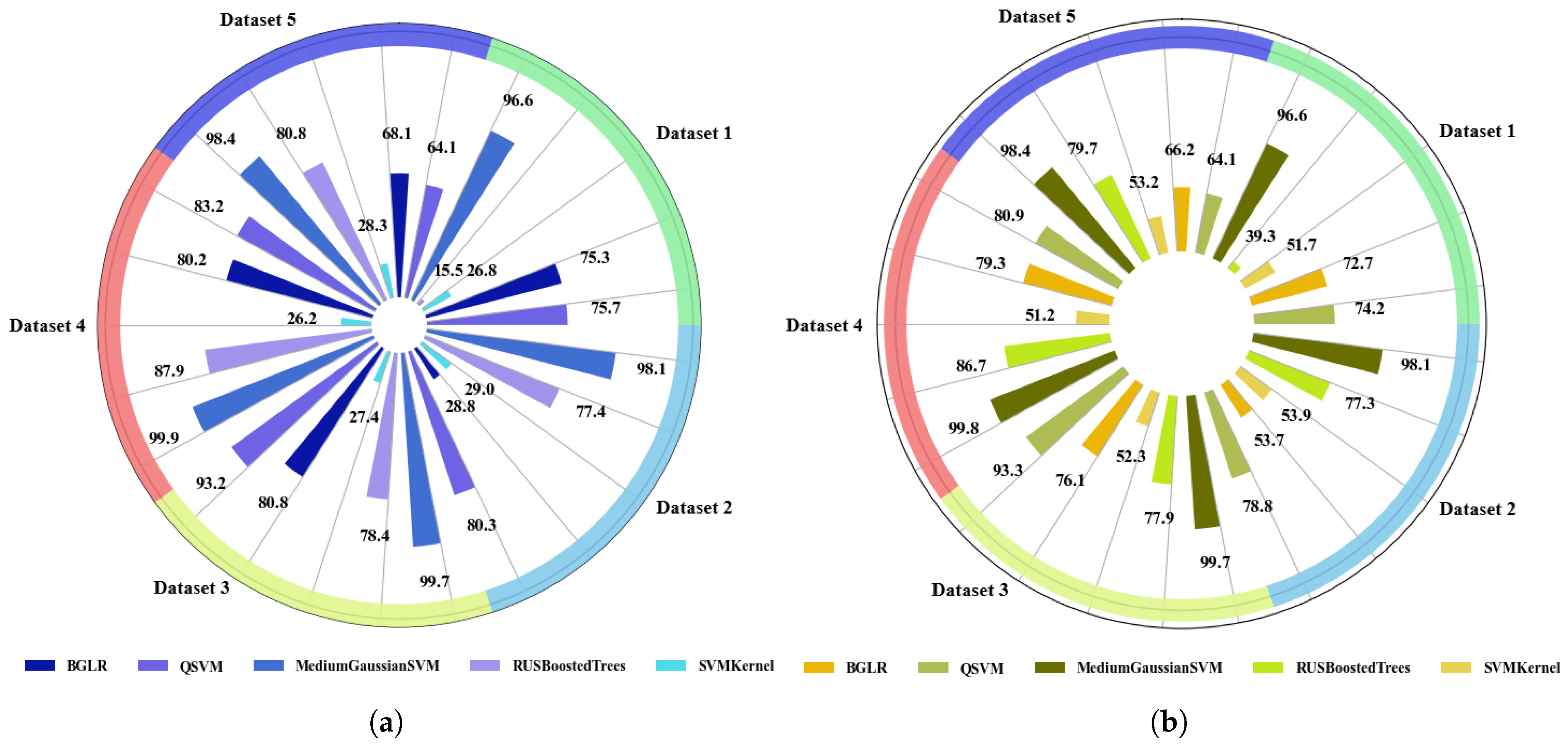
4.2.2. Resource Utilization Analysis of the DL Models
- Time Plots of Training and Testing ML and DL Models
4.3. Computational Efficiency Analysis of ML and DL Models
- ML Models
- DL Models
- Implications for UAV Deployment
4.4. Understanding the Constraints of DL Performance
5. Discussion
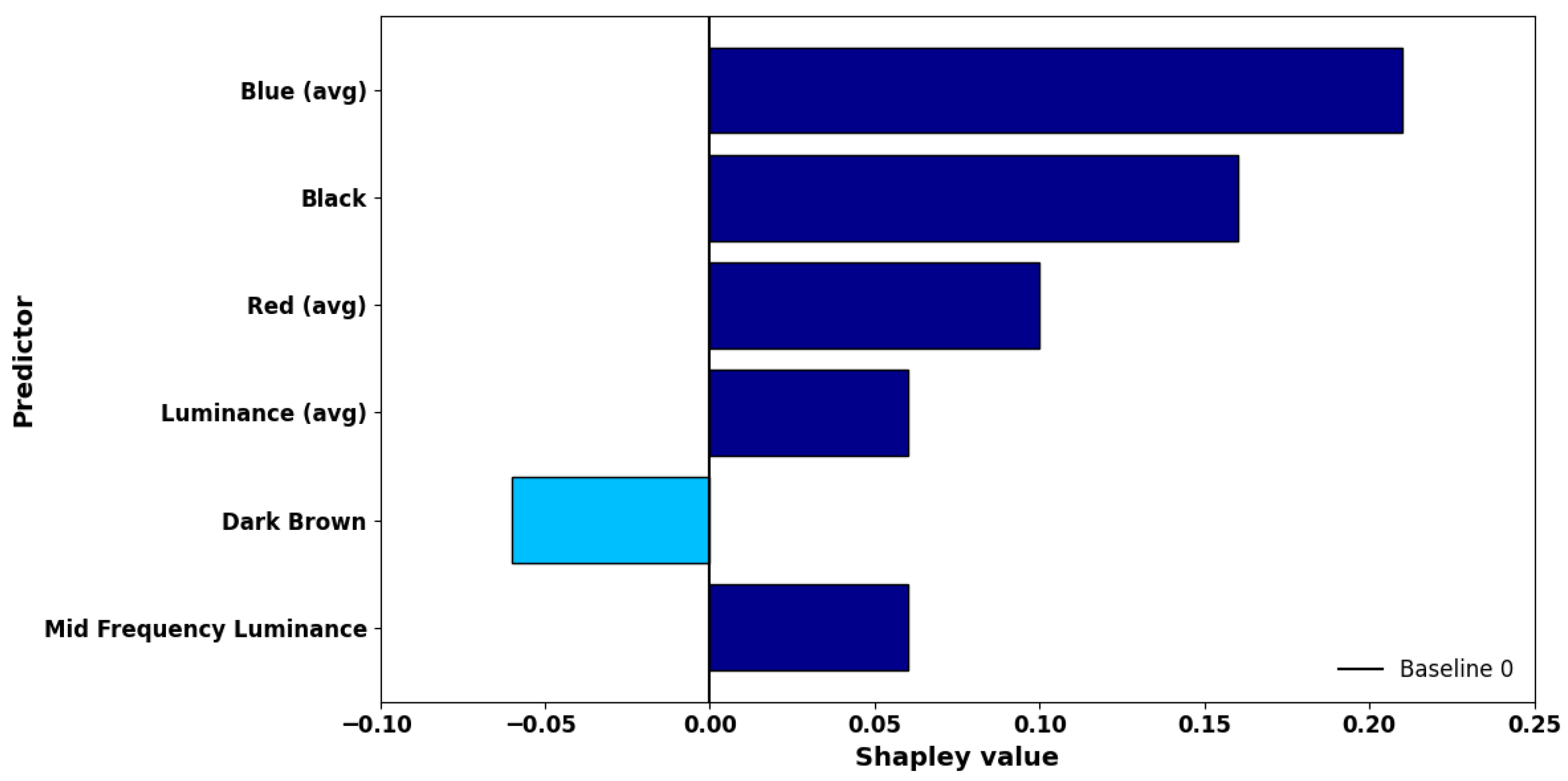
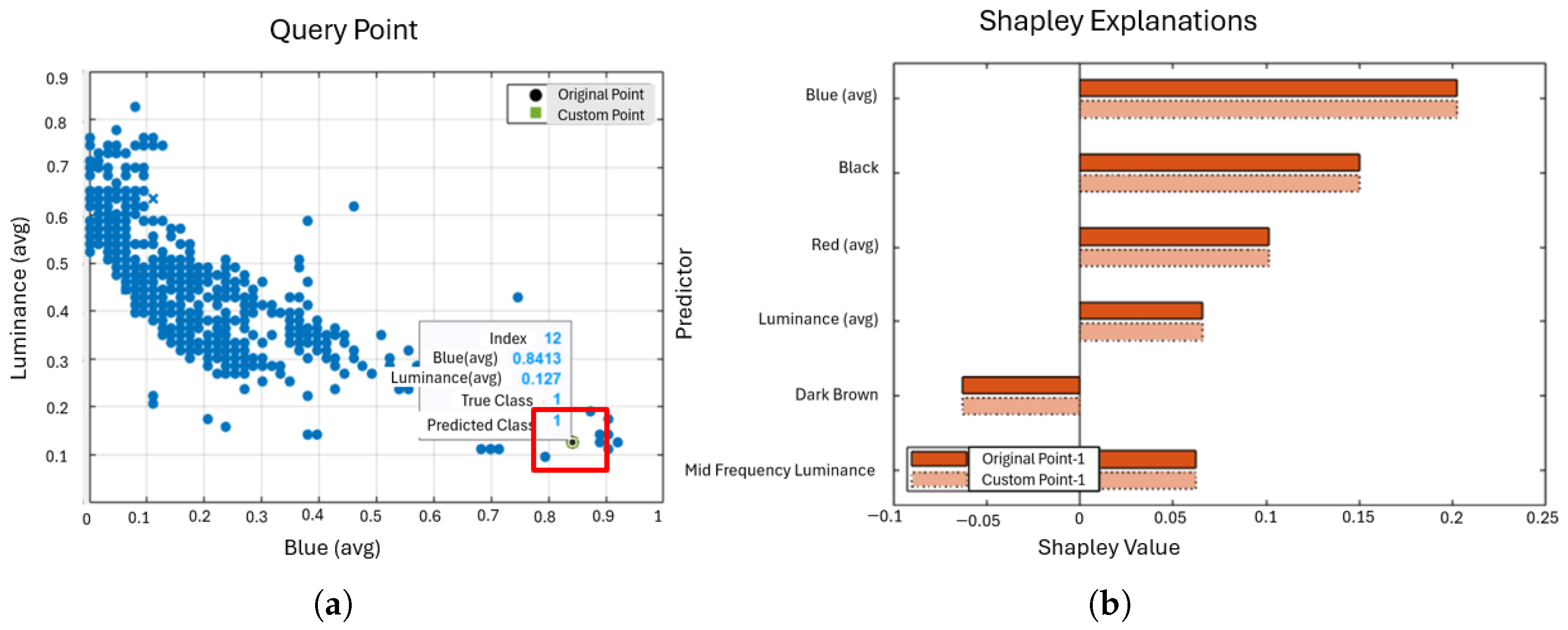
5.1. Local Interpretation of Input Feature Contributions Using SHAP for ML Model Predictions
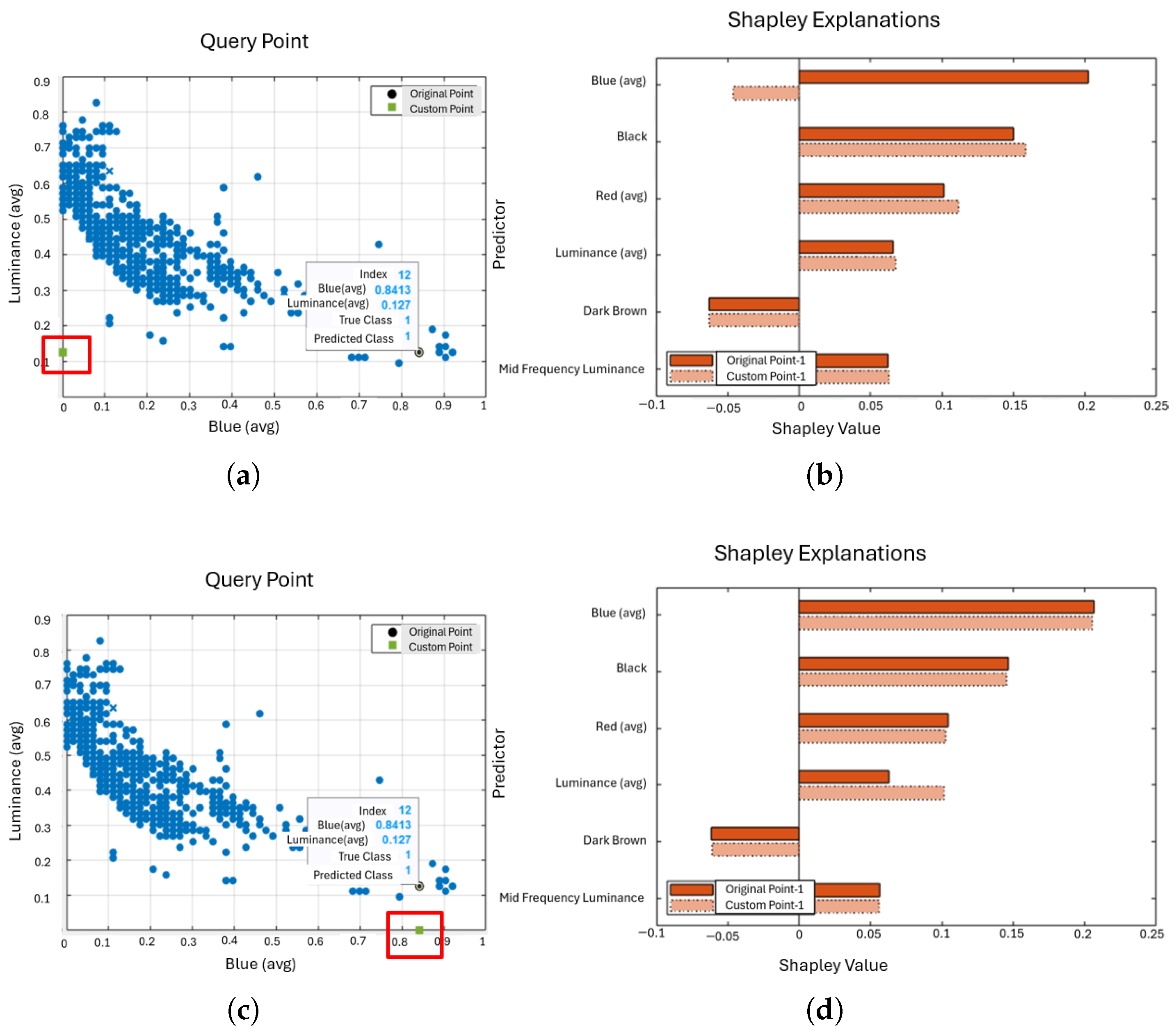
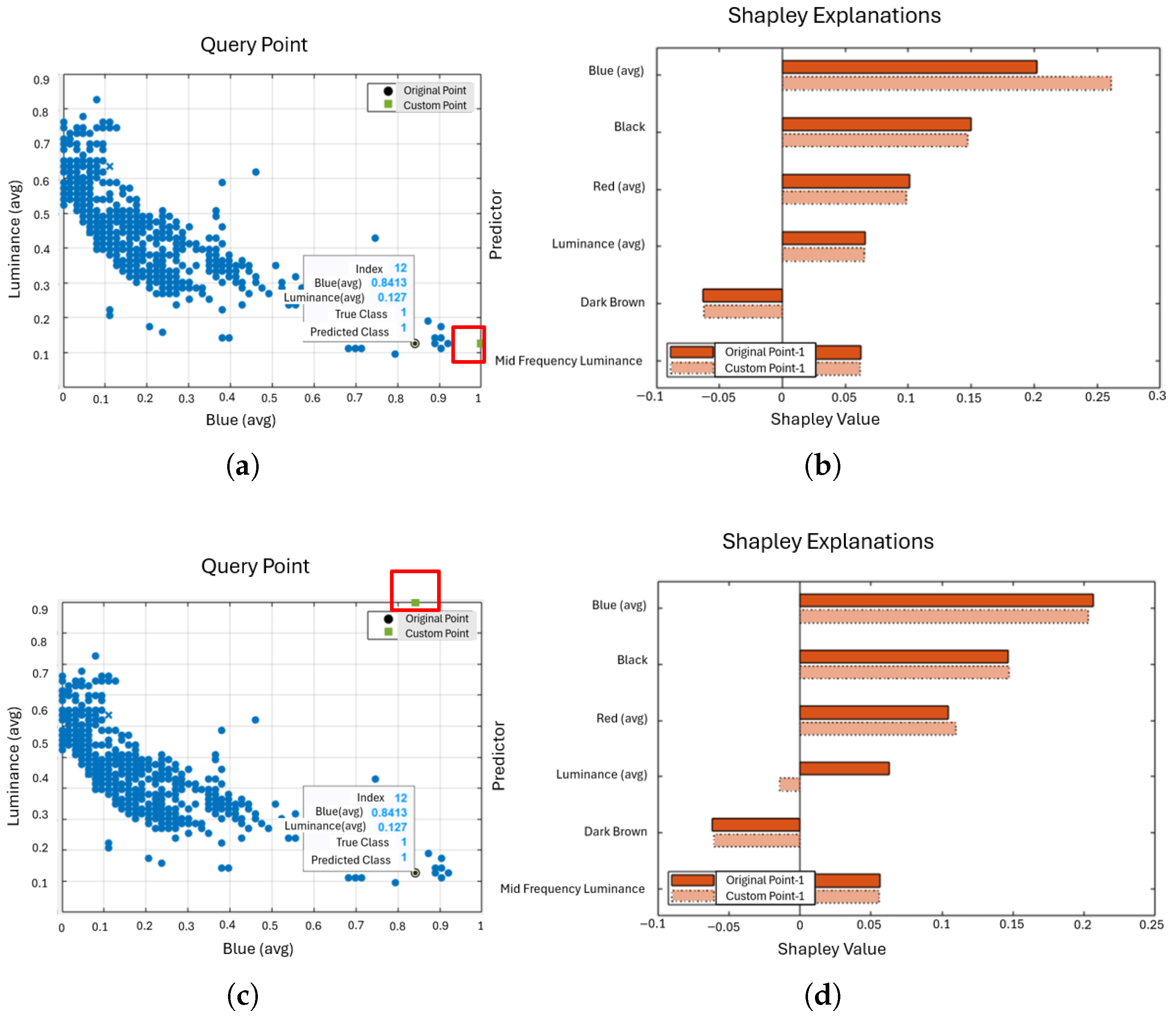
5.2. What-If-Analysis
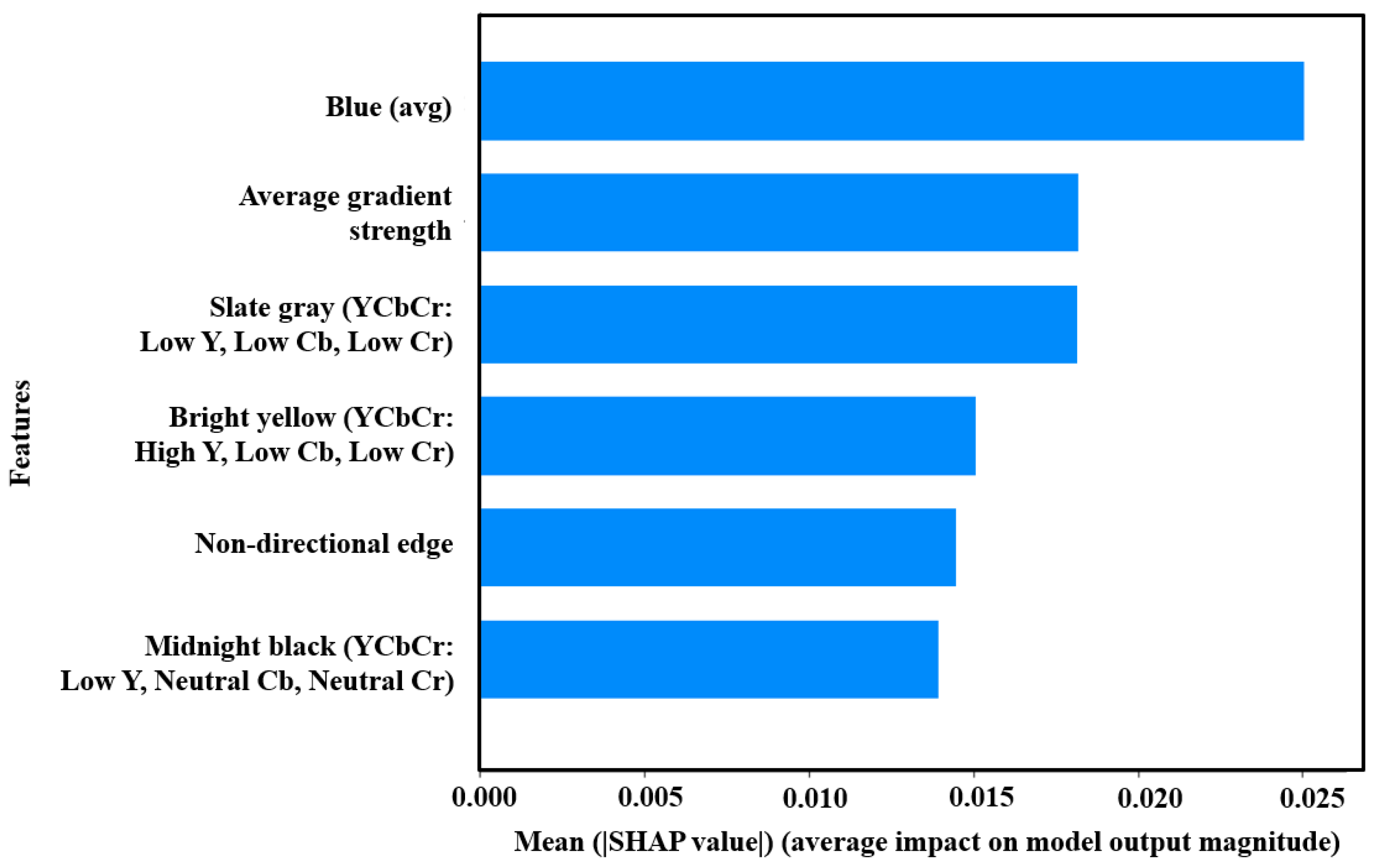
5.3. Global Interpretation of Feature Importance Using the SHAP Summary Plot for Solar Hotspot Detection in Thermal Imagery Classification
5.4. Comparative Analysis of ML and DL Models for Thermal Image Classification
5.5. In-Depth Discussion of the Advantages of ML over the Limitations of the DL Approach
5.6. Comparative Boxplot Analysis on Performance of ML and DL Models
5.7. Analysis of Trade-Offs Between Accuracy and Resource Utilization
5.7.1. Evaluating Training Efficiency: Accuracy vs. Time in DL and ML Models
5.7.2. Evaluating Testing Efficiency: Accuracy vs. Time in DL and ML Models
5.7.3. Statistical Validation of MPEG-7 Feature Behavior in Hotspot vs. Non-Hotspot Regions
5.8. Comparative Evaluation of the Proposed Method Within the Existing Literature
5.9. Balanced Assessment of Accuracy and Efficiency
6. Conclusions
- Why Data-driven Learning Outperforms Image Processing in PV Hotspot Detection
- Real-World Deployment Potential and Industrial Relevance
- Practical Recommendations and Directions for Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACE | Automatic Content Extraction |
| ART | Angular Radial Transform |
| BGLR | Binary GLM (Generalized Linear Model) Logistic Regression |
| BRISQUE | Blind/Referenceless Image Spatial Quality Evaluator |
| CI | Confidence Interval |
| CLD | Color Layout Descriptor |
| CM | Confusion Matrix |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| CSD | Color Structure Descriptor |
| DC | Discriminant Classifier |
| DCT | Discrete Cosine Transform |
| DNN | Deep Neural Network |
| DL | Deep Learning |
| DT | Decision Tree |
| EHD | Edge Histogram Descriptor |
| FC | Fully Connected |
| FSIM | Feature Similarity Index Measure |
| GPU | Graphics Processing Unit |
| HTD | Homogeneous Texture Descriptor |
| IR | Infrared |
| Short Circuit Current | |
| JST | Japan Science and Technology Agency |
| KNN | K Nearest Neighbor |
| MEXT | Ministry of Education, Culture, Sports, Science, and Technology |
| ML | Machine Learning |
| MPEG | Moving Picture Experts Group |
| MSE | Mean Squared Error |
| NIQE | Natural Image Quality Evaluator |
| PIQE | Perception-based Image Quality Evaluator |
| PSNR | Peak Signal-to-Noise Ratio |
| PV | Photovoltaic |
| PVPs | Photovoltaic Panels |
| Power of maximum power point | |
| QSVM | Quadratic SVM |
| RBF | Radial Basis Function |
| R-CNN | Regions with Convolutional Neural Networks |
| ResNet | Residual Network |
| RGB | Red-Green-Blue |
| ROC | Receiver Operating Characteristic |
| RSD | Region Shape Descriptor |
| RTK | GNSS Real-Time Kinematic Global Navigation Satellite System |
| SDG | Sustainable Development Goal |
| SHAP | SHapley Additive exPlanations |
| SSIM | Structural Similarity Index Measure |
| SVM | Support Vector Machines |
| UAV | Unmanned Aerial Vehicle |
| VGG | Visual Geometry Group |
| Open Circuit Voltage | |
| XAI | Explainable AI |
| YCbCr | Luma-Chrominance blue-Chrominance red |
References
- Dhimish, M.; Lazaridis, P.I. An empirical investigation on the correlation between solar cell cracks and hotspots. Sci. Rep. 2021, 11, 23961. [Google Scholar] [CrossRef]
- Precedence Research. Solar Power Market Size, Share, Growth. Available online: https://www.precedenceresearch.com/solar-power-market (accessed on 28 May 2025).
- Wen, D.; Gao, W.; Qian, F.; Gu, Q.; Ren, J. Development of solar photovoltaic industry and market in China, Germany, Japan and the United States of America using incentive policies. Energy Explor. Exploit. 2021, 39, 1429–1456. [Google Scholar] [CrossRef]
- Ali. Thermal Images of Solar Panels Dataset. Roboflow Universe. 2024. Available online: https://universe.roboflow.com/ali-uafwx/thermal-images-of-solar-panels (accessed on 2 January 2025).
- Rathnayake, N.; Dang, T.L.; Hoshino, Y. Performance comparison of the ANFIS based quad-copter controller algorithms. In Proceedings of the 2021 IEEE International Conference On Fuzzy Systems (FUZZ-IEEE), Luxembourg, 11–14 July 2021; pp. 1–8. [Google Scholar]
- Hong, Y.-W.; Yoo, D.-Y. Multiple Intrusion Detection Using Shapley Additive Explanations and a Heterogeneous Ensemble Model in an Unmanned Aerial Vehicle’s Controller Area Network. Appl. Sci. 2024, 14, 5487. [Google Scholar] [CrossRef]
- Abekoon, T.; Sajindra, H.; Rathnayake, N.; Ekanayake, I.U.; Jayakody, A.; Rathnayake, U. A novel application with explainable machine learning (SHAP and LIME) to predict soil N, P, and K nutrient content in cabbage cultivation. Smart Agric. Technol. 2025, 11, 100879. [Google Scholar] [CrossRef]
- Kularathne, S.; Perera, A.; Rathnayake, N.; Rathnayake, U.; Hoshino, Y. Analyzing the impact of socioeconomic indicators on gender inequality in Sri Lanka: A machine learning-based approach. PLoS ONE 2024, 19, e0312395. [Google Scholar] [CrossRef] [PubMed]
- Mampitiya, L.; Sumanasekara, H.S.; Rathnayake, N.; Hoshino, Y.; Rathnayake, U. Explainable artificial intelligence to estimate the Sri Lankan (Ceylon) Tea crop yield. Smart Agric. Technol. 2025, 11, 100999. [Google Scholar] [CrossRef]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do Better ImageNet Models Transfer Better? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2661–2671. [Google Scholar]
- Smirnov, E.A.; Timoshenko, D.M.; Andrianov, S.N. Comparison of Regularization Methods for ImageNet Classification with Deep Convolutional Neural Networks. AASRI Procedia 2014, 6, 89–94. [Google Scholar] [CrossRef]
- Starzyński, J.; Zawadzki, P.; Harańczyk, D. Machine Learning in Solar Plants Inspection Automation. Energies 2022, 15, 5966. [Google Scholar] [CrossRef]
- Ali, M.U.; Khan, H.F.; Masud, M.; Kallu, K.D.; Zafar, A. A Machine Learning framework to identify the hotspot in photovoltaic module using infrared thermography. Sol. Energy 2020, 208, 643–651. [Google Scholar] [CrossRef]
- Kirubakaran, V.; Preethi, D.M.D.; Arunachalam, U.; Rao, Y.K.; Gatasheh, M.K.; Hoda, N.; Anbese, E.M. Infrared Thermal Images of Solar PV Panels for Fault Identification Using Image Processing Technique. Int. J. Photoenergy 2022, 2022, 6427076. [Google Scholar] [CrossRef]
- Dhimish, M. Defining the best-fit Machine Learning classifier to early diagnose photovoltaic solar cells hotspots. Case Stud. Therm. Eng. 2021, 28, 101612. [Google Scholar] [CrossRef]
- Cardinale-Villalobos, L.; Jimenez-Delgado, E.; García-Ramírez, Y.; Araya-Solano, L.; Solís-García, L.A.; Méndez-Porras, A.; Alfaro-Velasco, J. IoT System Based on Artificial Intelligence for Hot Spot Detection in Photovoltaic Modules for a Wide Range of Irradiances. Sensors 2023, 23, 6749. [Google Scholar] [CrossRef] [PubMed]
- Ameerdin, M.I.; Jamaluddin, M.H.; Shukor, A.Z.; Kamaruzaman, L.A.H.; Mohamad, S. Towards Efficient Solar Panel Inspection: A YOLO-based Method for Hotspot Detection. In Proceedings of the 2024 IEEE 14th Symposium on Computer Applications & Industrial Electronics (ISCAIE), Penang, Malaysia, 24–25 May 2024; pp. 367–372. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Huerta Herraiz, Á.; Pliego Marugán, A.; García Márquez, F.P. Photovoltaic plant condition monitoring using thermal images analysis by convolutional neural network-based structure. Renew. Energy 2020, 153, 334–348. [Google Scholar] [CrossRef]
- Shayan, U.; Muhammad, S.Q.; Muhammad, U.N. Thermal Imaging and AI in Solar Panel Defect Detection. Int. J. Adv. Eng. Technol. Innov. 2024, 1, 73–95. [Google Scholar]
- Chang, S.-F.; Sikora, T.; Purl, A. Overview of the MPEG-7 standard. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 688–695. [Google Scholar] [CrossRef]
- Shaik, A.; Balasundaram, A.; Kakarla, L.S.; Murugan, N. Deep Learning-Based Detection and Segmentation of Damage in Solar Panels. Automation 2024, 5, 128–150. [Google Scholar] [CrossRef]
- Haidari, P.; Hajiahmad, A.; Jafari, A.; Nasiri, A. Deep learning-based model for fault classification in solar modules using infrared images. Sustain. Energy Technol. Assess. 2022, 52, 102110. [Google Scholar] [CrossRef]
- Pathak, S.P.; Patil, S.; Patel, S. Solar panel hotspot localization and fault classification using deep learning approach. Procedia Comput. Sci. 2022, 204, 698–705. [Google Scholar] [CrossRef]
- Wang, F.; Wang, Z.; Chen, Z.; Zhu, D.; Gong, X.; Cong, W. An Edge-Guided Deep Learning Solar Panel Hotspot Thermal Image Segmentation Algorithm. Appl. Sci. 2023, 13, 11031. [Google Scholar] [CrossRef]
- Le, M.; Luong, V.S.; Nguyen, D.K.; Dao, V.-D.; Vu, N.H.; Vu, H.H.T. Remote anomaly detection and classification of solar photovoltaic modules based on deep neural network. Sustain. Energy Technol. Assess. 2021, 48, 101545. [Google Scholar] [CrossRef]
- Korkmaz, D.; Acikgoz, H. An efficient fault classification method in solar photovoltaic modules using transfer learning and multi-scale convolutional neural network. Eng. Appl. Artif. Intell. 2022, 113, 104959. [Google Scholar] [CrossRef]
- Açikgöz, H.; Korkmaz, D.; Dandil, Ç. Classification of Hotspots in Photovoltaic Modules with Deep Learning Methods. Turk. J. Sci. Technol. 2022, 17, 211–221. [Google Scholar] [CrossRef]
- Shaharin, N.K.M.M.; Binti Omar, M.; Binti Salehuddin, N.F.; Bin Ibrahim, R.; Bin Zakaria, M.N.; Faqih, M. Deep Learning for Localization of Damaged Photovoltaic Panels with Hotspot Detection. In Proceedings of the 2024 59th International Universities Power Engineering Conference (UPEC), Cardiff, UK, 2–6 September 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Duranay, Z.B. Fault Detection in Solar Energy Systems: A Deep Learning Approach. Electronics 2023, 12, 4397. [Google Scholar] [CrossRef]
- Winston, D.P.; Murugan, M.S.; Elavarasan, R.M.; Pugazhendhi, R.; Singh, O.J.; Murugesan, P.; Gurudhachanamoorthy, M.; Hossain, E. Solar PV’s Micro Crack and Hotspots Detection Technique Using NN and SVM. IEEE Access 2021, 9, 127259–127269. [Google Scholar] [CrossRef]
- Guo, L.; Wang, Y.; Liu, Z.; Zhang, F.; Zhang, W.; Xiong, X. EQLC-EC: An Efficient Voting Classifier for 1D Mass Spectrometry Data Classification. Electronics 2025, 14, 968. [Google Scholar] [CrossRef]
- Cao, J.; Xu, Z. Providing a Photovoltaic Performance Enhancement Relationship from Binary to Ternary Polymer Solar Cells via Machine Learning. Polymers 2024, 16, 1496. [Google Scholar] [CrossRef]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-Column Deep Neural Networks for Image Classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar] [CrossRef]
- Yang, H.; Wang, J.; Wang, J. Efficient Detection of Forest Fire Smoke in UAV Aerial Imagery Based on an Improved Yolov5 Model and Transfer Learning. Remote Sens. 2023, 15, 5527. [Google Scholar] [CrossRef]
- Tang, S.; Xing, Y.; Chen, L.; Song, X.; Yao, F. Review and a Novel Strategy for Mitigating Hot Spot of PV Panels. Sol. Energy 2020, 211, 972–987. [Google Scholar] [CrossRef]
- Polymeropoulos, I.; Bezyrgiannidis, S.; Vrochidou, E.; Papakostas, G.A. Enhancing Solar Plant Efficiency: A Review of Vision-Based Monitoring and Fault Detection Techniques. Technologies 2024, 12, 175. [Google Scholar] [CrossRef]
- Goudelis, G.; Lazaridis, P.I.; Dhimish, M. A Review of Models for Photovoltaic Crack and Hotspot Prediction. Energies 2022, 15, 4303. [Google Scholar] [CrossRef]
- Tang, C.; Ren, H.; Xia, J.; Wang, F.; Lu, J. Automatic Defect Identification of PV Panels with IR Images through Unmanned Aircraft. IET Renew. Power Gener. 2023, 17, 1297–1304. [Google Scholar] [CrossRef]
- Alsafasfeh, M.; Abdel-Qader, I.; Bazuin, B.; Alsafasfeh, Q.; Su, W. Unsupervised Fault Detection and Analysis for Large Photovoltaic Systems Using Drones and Machine Vision. Energies 2018, 11, 2252. [Google Scholar] [CrossRef]
- Vergura, S. Correct Settings of a Joint Unmanned Aerial Vehicle and Infrared Camera System for the Detection of Faulty Photovoltaic Modules. IEEE J. Photovolt. 2021, 11, 124–130. [Google Scholar] [CrossRef]
- Liao, K.-C.; Wu, H.-Y.; Wen, H.-T. Using Drones for Thermal Imaging Photography and Building 3D Images to Analyze the Defects of Solar Modules. Inventions 2022, 7, 67. [Google Scholar] [CrossRef]
- Li, X.; Yang, Q.; Chen, Z.; Luo, X.; Yan, W. Visible Defects Detection Based on UAV-Based Inspection in Large-Scale Photovoltaic Systems. IET Renew. Power Gener. 2017, 11, 1234–1244. [Google Scholar] [CrossRef]
- Grimaccia, F.; Leva, S.; Niccolai, A. PV Plant Digital Mapping for Modules’ Defects Detection by Unmanned Aerial Vehicles. IET Renew. Power Gener. 2017, 11, 1221–1228. [Google Scholar] [CrossRef]
- Lee, D.H.; Park, J.H. Developing Inspection Methodology of Solar Energy Plants by Thermal Infrared Sensor on Board Unmanned Aerial Vehicles. Energies 2019, 12, 2928. [Google Scholar] [CrossRef]
- DJI. Matrice 300 RTK User Manual; DJI: Shenzhen, China, 2020; Available online: https://dl.djicdn.com/downloads/matrice-300/20200529/M300_RTK_User_Manual_EN_0604.pdf (accessed on 26 April 2025).
- DJI. Zenmuse H20 Series Specifications; DJI: Shenzhen, China, 2020; Available online: https://www.dji.com/global/zenmuse-h20-series/specs (accessed on 26 April 2025).
- Spala, P.; Malamos, A.G.; Doulamis, A.; Doulamis, N. Extending MPEG-7 for efficient annotation of complex web 3D scenes. Multimed. Tools Appl. 2012, 59, 463–504. [Google Scholar] [CrossRef]
- O’Connor, N.E.; Cooke, E.; Le Borgne, H.; Blighe, M.; Adamek, T. The aceToolbox: Low-level audiovisual feature extraction for retrieval and classification. In Proceedings of the 2nd European Workshop on the Integration of Knowledge, Semantics and Digital Media Technology (EWIMT 2005), London, UK, 30 November–1 December 2005. [Google Scholar] [CrossRef]
- Lin, S.-L. Application of Machine Learning to a Medium Gaussian Support Vector Machine in the Diagnosis of Motor Bearing Faults. Electronics 2021, 10, 2266. [Google Scholar] [CrossRef]
- Nikolic, S. Effective combining of color and texture descriptors for indoor-outdoor image classification. Facta Univ. Ser. Electron. Energ. 2014, 27, 399–410. [Google Scholar] [CrossRef]
- Cai, Y.; Pan, H.; Yang, J.; Liu, Y.; Gao, Q.; Wang, X. Geometry-Aware 3D Hand–Object Pose Estimation Under Occlusion via Hierarchical Feature Decoupling. Electronics 2025, 14, 1029. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Zhang, Q. A Novel ResNet-101 Model Based on Dense Dilated Convolution for Image Classification. SN Appl. Sci. 2022, 4, 1–13. [Google Scholar] [CrossRef]
- Mascarenhas, S.; Agarwal, M. A Comparison between VGG-16, VGG19 and ResNet-50 Architecture Frameworks for Image Classification. In Proceedings of the 2021 International Conference on Disruptive Technologies for Multi-Disciplinary Research and Applications (CENTCON), Bengaluru, India, 19–21 November 2021; pp. 96–99. [Google Scholar] [CrossRef]
- Mansurov, S.; Çetin, Z.; Aslan, E.; Özüpak, Y. A Deep Learning Approach for Fault Detection in Photovoltaic Systems Using MobileNetV3Small. Gazi Univ. J. Sci. Part A Eng. Innov. 2025, 12, 197–212. [Google Scholar] [CrossRef]
- Priyadarshini, R.; Manoharan, P.S.; Roomi, S. Efficient Net-Based Deep Learning for Visual Fault Detection in Solar Photovoltaic Modules. Teh. Vjesn. 2025, 32, 233–241. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar] [CrossRef]
- Mei, J.; Yuan, H.; Chu, X.; Ding, L. Efficient Optimization Method of the Meshed Return Plane Through Fusion of Convolutional Neural Network and Improved Particle Swarm Optimization. Electronics 2025, 14, 1035. [Google Scholar] [CrossRef]
- Ayunts, H.; Agaian, S.; Grigoryan, A. SlantNet: A Lightweight Neural Network for Thermal Fault Classification in Solar PV Systems. Electronics 2025, 14, 1388. [Google Scholar] [CrossRef]
- Jaybhaye, S.; Sirvi, V.; Srivastava, S.; Loya, V.; Gujarathi, V.; Jaybhaye, M.D. Classification and Early Detection of Solar Panel Faults with Deep Neural Network Using Aerial and Electroluminescence Images. J. Fail. Anal. Prev. 2024, 24, 1746–1758. [Google Scholar] [CrossRef]
- Di Renzo, A.B.; de Morais, H.R.F.; Lazzaretti, A.E.; de Arruda, L.V.R.; Lopes, H.S.; Martelli, C.; da Silva, J.C.C. Edge Device for the Classification of Photovoltaic Faults Using Deep Neural Networks. J. Control Autom. Electr. Syst. 2024, 35, 861–869. [Google Scholar] [CrossRef]
- Li, N.; Chen, H.; Sun, Z.; Gao, J.; Yi, D.; Liu, C.; Su, J. Real-Time Semantic Segmentation of Solar Photovoltaic Arrays for Autonomous UAV Flights. In Proceedings of the 2024 43rd Chinese Control Conference (CCC), Kunming, China, 28–31 July 2024; pp. 7292–7297. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; Le, Q.V.; et al. MobileNetV3: Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Yapici, M.; Ozturk, S.; Karakose, M.; Karakaya, M. Performance comparison of convolutional neural network models on GPU. In Proceedings of the 2019 IEEE 13th International Conference on Application of Information and Communication Technologies (AICT), Baku, Azerbaijan, 23–25 October 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Keras Team. Keras Applications. Available online: https://keras.io/api/applications/ (accessed on 21 May 2025).
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Suwannaphong, T.; Jovan, F.; Craddock, I.; McConville, R. Optimising TinyML with Quantization and Distillation of Transformer and Mamba Models for Indoor Localisation on Edge Devices. Sci. Rep. 2025, 15, 10081. [Google Scholar] [CrossRef] [PubMed]
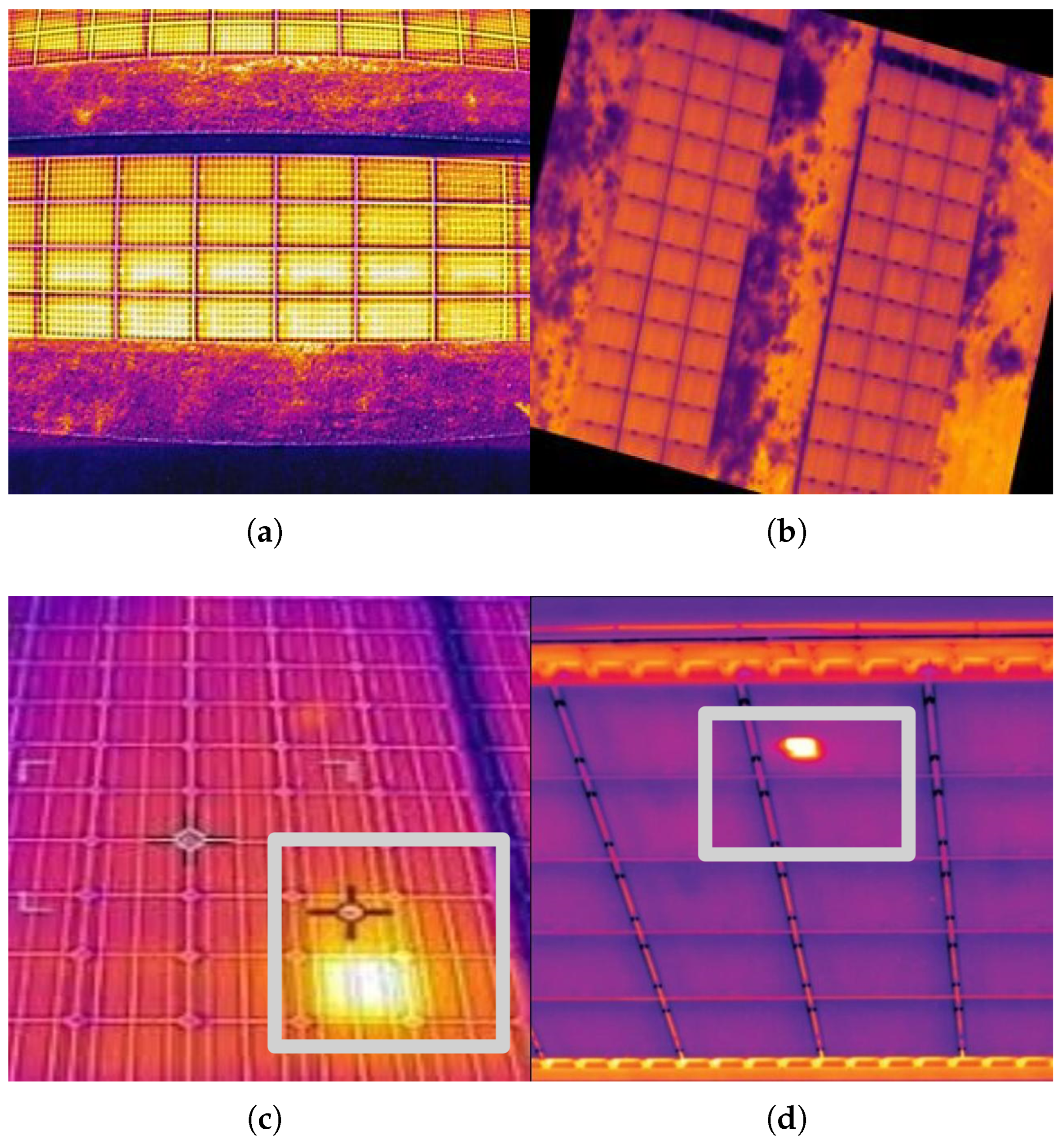


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BRISQUE | NIQE | PIQE | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Training and Validation Set | Testing Set | Avg Silhouette Score | Separation Ratio | Class 1 | Class 0 | Class 1 | Class 0 | Class 1 | Class 0 |
| 1 | 724 | 82 | 0.1163 | 0.6386 | 45.83 | 41.48 | 5.31 | 6.03 | 66.18 | 51.26 |
| 2 | 1302 | 146 | 0.2736 | 1.1327 | 38.47 | 41.38 | 4.90 | 6.06 | 63.31 | 43.36 |
| 3 | 1836 | 204 | 0.2690 | 1.1842 | 39.89 | 41.10 | 4.60 | 5.93 | 66.33 | 52.75 |
| 4 | 2746 | 306 | 0.2176 | 0.8559 | 36.77 | 41.32 | 3.91 | 5.95 | 41.69 | 52.19 |
| 5 | 4114 | 458 | 0.2045 | 0.7175 | 41.58 | 40.16 | 7.81 | 6.41 | 49.94 | 44.68 |
| Dataset | Training Set | Testing Set | FSIM | SSIM | PSNR (dB) | MSE |
|---|---|---|---|---|---|---|
| 1 | 724 | 82 | 0.6468 | 0.6468 | 17.5314 | 0.0303 |
| 2 | 1302 | 146 | 0.6129 | 0.6129 | 15.9699 | 0.0318 |
| 3 | 1836 | 204 | 0.7048 | 0.7048 | 16.9613 | 0.0248 |
| 4 | 2746 | 306 | 0.6316 | 0.6316 | 17.6230 | 0.0191 |
| 5 | 4114 | 458 | 0.2208 | 0.2208 | 11.2797 | 0.0770 |
| Model | Main Hyperparameter | Value |
|---|---|---|
| Quadratic SVM (QSVM) | Kernel Function | Quadratic |
| Box Constraint (C) | 1 | |
| Medium Gaussian SVM | Kernel Function | Gaussian |
| Box Constraint (C) | 1 | |
| Kernel Scale () | 15 | |
| SVM Kernel | Kernel Function | RBF (Radial Basis Function) |
| Box Constraint (C) | 1 | |
| Kernel Scale () | 1 | |
| RUSBoosted Trees | Number of Learners | 30 |
| Maximum Tree Splits | 20 | |
| Learning Rate | 0.1 | |
| Binary GLM (Logistic Regression) | Regularization Strength () | 1 |
| Iteration Limit | 100 |
| Model | Total Params | Trainable Params | Non-Trainable Params | Input Size | Optimizer Used |
|---|---|---|---|---|---|
| ResNet-50 | 24,112,513 | 524,801 | 23,587,712 | (224, 224, 3) | Adam |
| ResNet-101 | 43,182,977 | 524,801 | 42,658,176 | (224, 224, 3) | Adam |
| VGG-16 | 14,846,273 | 131,585 | 14,714,688 | (224, 224, 3) | Adam |
| EfficientNetB0 | 4,377,764 | 328,193 | 4,049,571 | (224, 224, 3) | Adam |
| MobileNetV3Small | 1,087,089 | 147,969 | 939,120 | (224, 224, 3) | Adam |
| Training Time (s) | |||||
|---|---|---|---|---|---|
| Model | Dataset 1 | Dataset 2 | Dataset 3 | Dataset 4 | Dataset 5 |
| Corresponding Number of Images | 724 | 1302 | 1836 | 2746 | 4114 |
| BGLR | 44.5 | 30.1 | 47.1 | 65.2 | 125.4 |
| QSVM | 43.6 | 4.7 | 4.8 | 6.8 | 20.0 |
| Medium Gaussian SVM | 16.3 | 4.8 | 6.3 | 9.3 | 18.8 |
| RUSBoosted Trees | 33.8 | 21.4 | 28.0 | 36.8 | 63.6 |
| SVM Kernel | 53.0 | 44.1 | 72.4 | 93.2 | 171.8 |
| Testing Time (s) | |||||
|---|---|---|---|---|---|
| Model | Dataset 1 | Dataset 2 | Dataset 3 | Dataset 4 | Dataset 5 |
| Corresponding Number of Images | 82 | 146 | 204 | 306 | 458 |
| BGLR | 4.9 | 5.1 | 6.9 | 8.8 | 16.5 |
| QSVM | 0.9 | 0.5 | 0.6 | 0.7 | 1.1 |
| Medium Gaussian SVM | 2.0 | 2.7 | 3.6 | 5.5 | 8.9 |
| RUSBoosted Trees | 10.5 | 8.3 | 9.8 | 13.9 | 22.4 |
| SVM Kernel | 2.4 | 3.2 | 4.2 | 5.8 | 9.3 |
| Training Time (s) | |||||
|---|---|---|---|---|---|
| Model | Dataset 1 | Dataset 2 | Dataset 3 | Dataset 4 | Dataset 5 |
| Corresponding Number of Images | 724 | 1302 | 1836 | 2746 | 4114 |
| ResNet-50 | 672.6 | 3234.6 | 1614.0 | 1748.4 | 3253.2 |
| ResNet-101 | 1666.8 | 1585.2 | 1423.2 | 3540.6 | 3580.2 |
| VGG-16 | 2145.6 | 2232.0 | 4374.6 | 5238.6 | 4134.0 |
| MobileNetV3Small | 1016.4 | 3003.6 | 3707.4 | 5822.4 | 6003.6 |
| EfficientNet-B0 | 662.4 | 1335.6 | 1518.6 | 1644.0 | 1696.2 |
| Testing Time (s) | |||||
|---|---|---|---|---|---|
| Model | Dataset 1 | Dataset 2 | Dataset 3 | Dataset 4 | Dataset 5 |
| Corresponding Number of Images | 82 | 146 | 204 | 306 | 458 |
| ResNet-50 | 48.6 | 103.8 | 85.2 | 51.6 | 112.8 |
| ResNet-101 | 66.6 | 43.8 | 36.6 | 4.2 | 145.8 |
| VGG-16 | 52.2 | 124.8 | 76.2 | 120.6 | 3.6 |
| MobileNetV3Small | 66.6 | 120.6 | 80.4 | 84.6 | 207.0 |
| EfficientNet-B0 | 46.8 | 109.2 | 85.2 | 75.0 | 84.6 |
| Model | Dataset 1 | Dataset 2 | Dataset 3 | Dataset 4 | Dataset 5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc. (%) | Time (s) | Acc. (%) | Time (s) | Acc. (%) | Time (s) | Acc. (%) | Time (s) | Acc. (%) | Time (s) | |
| VGG16 (DL) | 96.55 | 1016.4 | 98.08 | 3003.6 | 99.73 | 3707.4 | 99.82 | 5822.4 | 98.42 | 6003.6 |
| Medium Gaussian SVM (ML) | 95.00 | 16.29 | 99.20 | 4.76 | 99.60 | 6.32 | 99.90 | 9.31 | 99.30 | 18.81 |
| Dataset | Feature | p-Value | t-Statistic | Cohen’s d | Correlation with Label |
|---|---|---|---|---|---|
| Dataset 1 | HTD: Mean | −13.61 | −0.959 | −0.433 | |
| Dataset 2 | HTD: Mean | −36.84 | −1.937 | −0.696 | |
| Dataset 3 | HTD: Inverse Difference Moment | −43.23 | −1.914 | −0.692 | |
| Dataset 4 | EHD: Vertical Edge | −39.69 | −1.437 | −0.584 | |
| Dataset 5 | CSD: Warm Yellow (YCbCr: High Y, Low Cb, High Cr) | 40.03 | 1.184 | 0.510 |
| Dataset | Feature | Diff. Low | Diff. High | Solar CI Low | Solar CI High | Non-Solar CI Low |
|---|---|---|---|---|---|---|
| Dataset 1 | HTD: Mean | −0.1758 | −0.1315 | 0.2641 | 0.2998 | 0.4224 |
| Dataset 2 | HTD: Mean | −0.2898 | −0.2605 | 0.2039 | 0.2255 | 0.4799 |
| Dataset 3 | HTD: Inverse Diff. Moment | −0.2503 | −0.2286 | 0.1790 | 0.1961 | 0.4203 |
| Dataset 4 | EHD: Vertical Edge | −0.0084 | −0.0077 | 0.0027 | 0.0031 | 0.0106 |
| Dataset 5 | CSD: Warm Yellow | 0.0177 | 0.0196 | 0.0178 | 0.0196 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernando, N.; Seneviratne, L.; Weerasinghe, N.; Rathnayake, N.; Hoshino, Y. Efficient Hotspot Detection in Solar Panels via Computer Vision and Machine Learning. Information 2025, 16, 608. https://doi.org/10.3390/info16070608
Fernando N, Seneviratne L, Weerasinghe N, Rathnayake N, Hoshino Y. Efficient Hotspot Detection in Solar Panels via Computer Vision and Machine Learning. Information. 2025; 16(7):608. https://doi.org/10.3390/info16070608
Chicago/Turabian StyleFernando, Nayomi, Lasantha Seneviratne, Nisal Weerasinghe, Namal Rathnayake, and Yukinobu Hoshino. 2025. "Efficient Hotspot Detection in Solar Panels via Computer Vision and Machine Learning" Information 16, no. 7: 608. https://doi.org/10.3390/info16070608
APA StyleFernando, N., Seneviratne, L., Weerasinghe, N., Rathnayake, N., & Hoshino, Y. (2025). Efficient Hotspot Detection in Solar Panels via Computer Vision and Machine Learning. Information, 16(7), 608. https://doi.org/10.3390/info16070608