1. Introduction and Motivation
Medical
Named Entity Recognition (NER) is a foundational
Natural Language Processing (NLP) technology designed to alleviate
Information Overload (IO) in the development of
Clinical Practice Guidelines (CPGs) [
1]. The creation of such guidelines typically relies on
Evidence-Based Medicine (EBM), which involves comprehensive research and meticulous documentation of evidence [
2]. As a result, medical professionals must analyze vast amounts of unstructured text, including scientific literature, research findings, and clinical studies. NER facilitates the extraction of knowledge from this unstructured data, transforming it into structured information in accordance with Kuhlen’s information model [
1,
3]. In medicine, specialized vocabularies are used to define diagnoses, findings, and treatments [
4]; thus, it is essential for medical NER to accurately identify such domain-specific
Named Entities (NEs). Recent advancements in
Artificial Intelligence (AI), particularly in
Machine Learning (ML) and Deep Learning, have significantly improved the performance of state-of-the-art NER systems [
5]. However, these developments have also led to a proliferation of diverse NER frameworks and models, with new systems emerging continuously [
6]. Therefore, systematically comparing these systems is crucial to determine the most suitable one for specific use cases. A generic approach that enables the integration, comparison, and selection of various NER frameworks—regardless of their implementation specifics—would offer substantial benefits. Because medical NER often requires the recognition of highly specific NEs, it is usually necessary to train or adapt ML-based NER models [
4]. However, these processes are often complex and inaccessible to medical experts who may lack a technical background.
Following this contextual and terminological overview, the motivation for this study is presented through relevant research initiatives. RecomRatio [
7], a European initiative, supports healthcare professionals in making informed decisions by presenting treatment options along with their respective advantages and disadvantages. It employs the
Content and Knowledge Management Ecosystem Portal (KM-EP) Knowledge Management System (KMS) to enable evidence-based decisions drawn from the medical literature. Developed collaboratively by the Chair of Multimedia and Internet Applications at the Faculty of Mathematics and Computer Science, FernUniversität, Hagen [
8], and the FTK e.V. Research Institute for Telecommunications and Cooperation [
9], this system incorporates emerging NEs into medical documentation [
10]. In the H2020 project proposal
Artificial Intelligence for Hospitals, Healthcare, and Humanity (AI4H3), a hub-centric architecture was proposed [
11], designed not only for managing medical and patient records but also for supporting clinical decision-making. This architecture includes a central AI hub with a semantic fusion layer for data and model storage. AI4H3 integrates KlinSH-EP, an evolution of the KM-EP system [
12]. Within the AI4H3 framework, the
Cloud-based Information Extraction (CIE) project [
13] was initiated to develop a cloud-based NER pipeline capable of handling large-scale datasets. The CIE architecture allows multiple users to configure cloud resources and train NER models in a scalable environment. Building on this, the
Framework-Independent Toolkit for Named Entity Recognition (FIT4NER) project [
14], part of CIE, supports medical professionals in text analysis through a generic approach utilizing a variety of NER frameworks. It enables experimentation with different frameworks and models within KM-EP, allowing users to evaluate and choose the most suitable solution for their specific tasks. KM-EP manages documents such as clinical and research findings, serving as an evidence base for CPGs. To enhance access to these documents, it provides classification via NER and a faceted search engine based on the extracted entities [
15]. The integrated ML-based NER models in KM-EP should ideally be trained by medical experts to account for domain-specific terminology, abbreviations, and potential spelling variations [
4].
Nonetheless, the dynamic nature of NER research presents several challenges. First, medical experts must compare a range of tools to identify the most appropriate ones [
6]. This comparison is often difficult due to numerous configurable parameters and differing performance metrics, complicating the identification of tools that effectively extract, analyze, and visualize NLP features. Second, the performance of selected tools is a critical success factor in NER projects [
6]. Third, users often lack the computational and storage capabilities necessary to train domain-specific NER models [
13]. While cloud computing offers a potential solution, many experts lack the technical expertise to utilize it effectively [
13].
Given these challenges, this study aims to develop and evaluate a flexible NER system that enables medical professionals to efficiently analyze domain-specific texts and compare NER frameworks [
16]. The primary
Research Objective (RO) is to design a generic approach that supports the integration of various NER frameworks. This leads to the following
Research Questions (RQs), addressed in a master’s thesis inspired by the CIE and FIT4NER projects [
17]:
RQ1: How can generic approaches standardize the training and evaluation process of ML-based NER models across different frameworks?
RQ2: How can an abstraction layer for the training process of ML-based NER models be implemented and evaluated in a prototype system to support the selection and comparison of various NER frameworks?
To comprehensively address these RQs, this study follows the Nunamaker methodology [
18], a structured and widely recognized approach. It outlines specific ROs across four phases:
Observation,
Theory Building,
System Development, and
Experimentation.
Section 2 covers the observational objectives through a detailed review of the state of the art.
Section 3 focuses on theory building by developing models to help medical professionals train ML-based NER systems using a generic approach.
Section 4 addresses system development by presenting the prototype for model training.
Section 5 discusses experimentation, including quantitative evaluation of the prototype. Finally,
Section 6 summarizes the study’s main findings.
2. State of the Art in Science and Technology
This section examines the observation phase, delivering a foundation for this work and pertinent research activities. It seeks to review the current state of the art and ascertain potential Remaining Challenges (RCs) within the domains addressed. Initially, NER is introduced, and a literature review is conducted to identify existing abstraction projects with similar objectives. Subsequently, the key elements of a general training and evaluation process are discussed. Finally, the suitability of various design patterns for developing an abstraction layer for NER frameworks across different programming languages is examined.
NER is a crucial NLP technique designed to extract named entities from unstructured text documents [
19]. In the medical domain, NER plays a pivotal role in
Clinical Decision Support Systems (CDSSs) and facilitates clinical information mining from
Electronic Health Records (EHRs) [
20]. Recent years have witnessed significant advances in NER, primarily driven by the development of novel techniques and models, including deep learning [
21]. These advances have substantially improved the performance of NER systems, establishing NER as one of the most extensively researched NLP tasks [
21]. Various approaches to NER exist, including traditional, ML-based, and hybrid methods [
22]. Traditional approaches rely on fixed rules or dictionaries, whereas ML-based approaches use statistical models that learn from annotated data [
22]. The popularity of approaches based on ML has increased due to their ability to efficiently process large unstructured datasets [
21].
Large Language Models (LLMs) such as BERT [
23], GPT-2 [
24], and RoBERTA [
25] have further improved NER performance and can be fine-tuned on smaller domain-specific datasets. Rapid evolution in the field of NER has led to the development of new tools and frameworks that address various challenges and use cases. Given the wide range of options available, it is essential to compare and select the most suitable tools for specific tasks. To integrate, compare, or interchange various NER frameworks regardless of their specific implementations, it is advisable to adopt a “generic approach”. In the engineering context, Murray-Smith defines a structure as
“generic” if it “allows reuse of simulation software for a wide range of different projects with relatively minor reorganisation” [
26] (p. 304, Chapter 9.4). Applied to NER, this leads to the development of a universal, reusable, and standardized interface or methodology that facilitates these processes independently of specific implementations. In the literature, there are several initiatives that aim to abstract and simplify the training of NLP models. A well-known example is Keras [
27], a high-level library based on TensorFlow [
28], an open-source framework from Google for creating and executing ML models. Keras is used primarily for deep neural networks and allows researchers to create deep learning models with minimal coding effort [
27]. Although Keras provides useful abstractions for general ML, it is often insufficient for NLP due to the complexity and variability of the data types in NLP [
29]. Another example is the OpenNMT neural machine translation toolkit, which was specifically developed for machine translation [
30]. OpenNMT offers a solid foundation for training models that translate text between languages, but it is limited to this specific task and provides little support for other NLP tasks such as text classification or NER [
30]. In the field of dialogue research, there is ParlAI [
31], a dialogue systems research platform that enables the training and comparison of various models [
31]. ParlAI is designed for the simulation and analysis of conversations and offers specialized tools for these tasks, but like OpenNMT, it is restricted to a specific application and offers limited flexibility for other NLP tasks [
31]. Unlike these specialized toolkits, AllenNLP [
29] provides a general platform for a wide range of NLP tasks. It abstracts not only model creation but also data processing and experimentation with different model architectures [
29]. These abstractions allow researchers to focus on the primary goals of their research without dealing with implementation details. A unique feature of AllenNLP is the ability to define models using declarative configuration files [
29]. These configuration files enable researchers to make key decisions about model architecture and training parameters without changing the code, promote the reproducibility of experiments, and facilitate the sharing of research results [
29]. Another approach in the medical field is MedNER [
32], a service-oriented framework for NER. MedNER allows medical professionals to work with various NER models but does not support the use of different NER frameworks or the training of custom ML-based NER models. The presented NLP abstraction projects offer some helpful approaches but are predominantly designed for other NLP areas and not directly tailored to the requirements of NER training. Keras provides a simplified abstraction for model training but is not natively optimized for NER. AllenNLP offers a structured approach to model configuration through declarative configuration files, which can support the reproducibility and standardization of NER experiments. OpenNMT and ParlAI focus on machine translation and dialogue-oriented applications, making their applicability to generic NER limited. In general, Keras and AllenNLP are valuable inspirations due to their abstraction and configuration approaches but are not suitable for the goal of cross-platform training and NER-focused training due to their focus on Python and other NLP areas. Therefore, RC1 remains to develop an abstraction layer for ML-based NER that supports the comparison and selection of NER frameworks.
Before developing an abstraction layer for ML-based NER, it is crucial to understand the phases involved in the development of an NER model. The process model for AI-based knowledge extraction support for CPG development (
Figure 1) divides this process into five phases [
1]: “Data Management and Curation”, “Analytics”, “Interaction and Perception”, “Model Deployment”, and “Insight and Effectuation”. This work focuses on the “Analytics” phase. In this phase, the primary actor is the defined stereotype “Model Definition User”, who selects an NER framework, defines the
Hyperparameters (HPs), and trains the model. Subsequently, the evaluation and comparison with other NER frameworks are made. These steps are performed iteratively until the Model Definition User is satisfied with the results and the model can be deployed in the subsequent phases for productive use. HPs are crucial factors in model training and significantly impact model performance. These parameters are set before the training process begins and dictate the behavior of the model during training [
33]. The optimal selection of HPs can greatly improve model performance. An example of an HP is the learning rate, which indicates how quickly the model learns during training. A learning rate that is too high can lead to instability, whereas a rate that is too low can slow down the convergence of the model [
34]. Therefore, choosing the optimal learning rate is vital for model performance. Another important HP is the number of epochs, which refers to the number of passes through the training dataset. Too few epochs can result in insufficient model adaptation, while too many can lead to overfitting. The correct choice of the number of epochs is also crucial. Other HPs that influence model behavior include the batch size, regularization parameters, and number of hidden layers in a neural network [
34]. Selecting and optimizing these HPs is a key task in model development and often requires experimental approaches and experience. After training, the model undergoes evaluation and validation. To assess the performance of an NER model or implementation, the results must be quantified [
35]. Standard metrics such as
Precision (P),
Recall (R), and
F-Score (F1) are used to measure the efficiency of an NER model [
35]. P indicates the percentage of entities correctly identified by the system [
36], while R describes the percentage of entities present in the corpus that are detected by the system [
36]. The F1, calculated as the harmonic mean of P and R, provides a comprehensive performance metric [
37]. Another important metric is Accuracy, which measures the proportion of correct predictions (both correct identifications and correct non-identifications) out of the total number of predictions. This metric offers a general overview of the model’s performance, considering both correct and incorrect decisions [
38]. Thus, RC2 remains to develop a standardized training process for medical experts that incorporates essential HPs such as the learning rate and the number of epochs, as well as evaluation metrics such as P, R, and F1.
As part of the FIT4NER project, a system has been designed to assist medical experts in creating domain-specific NER models using various frameworks [
16]. To achieve this, three NER frameworks were selected as examples: Stanford CoreNLP [
39], a proven Java-based NER framework that has been utilized in numerous projects, together with spaCy [
40] and Hugging Face Transformers [
41], which were chosen due to their widespread use among experts, as indicated by the previous survey [
6]. All aforementioned frameworks can be controlled through configuration files, thus supporting the concept of
Config-Driven Development (CDD) [
42]. CDD [
42] is an approach in which the configuration of an application or system is centralized and separated from the code logic, allowing adjustments and changes to be made through configuration files without altering the underlying code. Many other NER frameworks are expected to also support CDD. An abstraction layer is essential to ensure that the code is modular, extensible, and maintainable, with design patterns playing a crucial role [
43]. Particularly relevant are the Strategy Pattern, the Abstract Factory Pattern, and the Bridge Pattern [
43]. The Strategy Pattern [
43] facilitates the definition of a family of algorithms that can be interchanged independently of their context. It allows for the dynamic adaptation of algorithm implementations in different programming languages. However, it is less suitable for multilingual abstractions, as its focus is on algorithm interchangeability within a single programming language. The Abstract Factory Pattern [
43] provides an interface for creating related objects without specifying concrete classes. It can generate platform-independent instances of NER components in various languages. However, complexity increases with the number of components to manage, necessitating clearly defined interfaces. The Bridge Pattern [
43] decouples abstractions from their implementations, allowing both to evolve independently. It conceals implementation specifics behind a unified abstraction layer, enabling a clear separation between generic and specific levels. This pattern offers the flexibility needed to design abstractions that are easily extendable and adaptable. In summary, RC3 is to take advantage of the Bridge Pattern to develop a cross-platform abstraction layer that effectively supports the training of NER models across multiple programming languages.
In this section, a critical analysis of the current state of the art relevant to this research has been carried out, leading to the identification of three RCs. The first challenge (RC1) involves the development of an abstraction layer for ML-based NER that facilitates the comparison and selection of NER frameworks. The second challenge (RC2) focuses on establishing a standardized training process for medical professionals, incorporating fundamental HPs such as the learning rate and number of epochs, in conjunction with evaluation metrics such as P, R, and F1. The third challenge (RC3) concerns the implementation of the Bridge Pattern to construct a cross-platform abstraction layer that efficiently supports the training of NER models in various programming languages. The subsequent section provides a comprehensive account of the development of appropriate models designed to tackle all identified challenges (RCs 1–3).
3. Modeling
Subsequent to a comprehensive examination of the prevailing developments in science and technology, this section advances to the stage of theory building, with the formulation of fundamental models for an abstraction layer that aids medical experts in constructing NER models using various NER frameworks and evaluating their outputs. This endeavor is achieved by taking into account the RCs delineated in
Section 2, which mirror the most recent advancements in the field. For the purposes of design and conceptual modeling, the
User-Centered System Design (UCSD) method [
44] is adopted, with
Unified Modeling Language (UML) [
45] acting as the specification language. As part of the FIT4NER project, the
Framework-Independent Layer for Training and Applying Named Entity Recognition (FILTANER) subsystem was developed based on a master’s thesis [
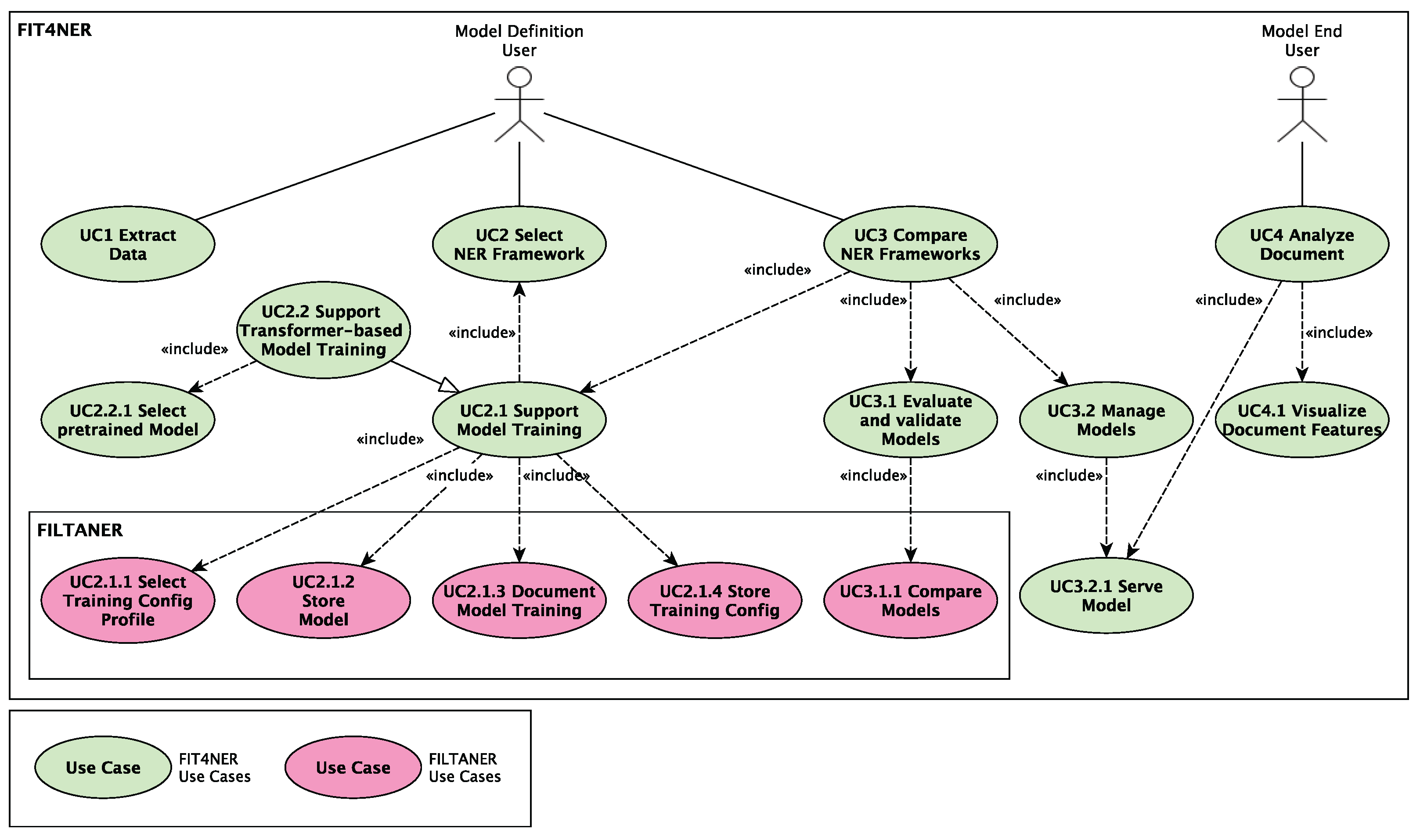
17]. The Use Cases (UCs) created in this work are shown in
Figure 2 and form the foundation of the study [
16]. The overarching FIT4NER UCs are depicted in green, while the detailed FILTANER UCs are shown in magenta. Based on these UCs, a generic training process for ML-based NER models is developed, which can be trained with various NER frameworks. This generic training process is then represented in an abstraction layer and integrated into the KM-EP system.
Initially, a concept for modeling a generic training and evaluation process for NER models is introduced, applicable to frameworks such as Hugging Face Transformers, Stanford CoreNLP, and spaCy. Despite differing implementations, these frameworks share similar resources and functionalities that enable a comparable training process, particularly in data processing, model training, and model evaluation. The proposed method serves as a foundation for abstracting the training process by decoupling training-specific parameters from the actual implementation of the framework. The studies mentioned in
Section 2 indicate that CDD is a promising approach for this purpose. This allows key settings, such as the learning rate and number of epochs, to be configured independently of the framework used. This separation facilitates designing and testing the training process for various models and frameworks within a unified framework, even when implementation details vary. The goal is to develop a generic approach based on the highest abstraction levels of the frameworks, controlled via a configuration file. The model shown in
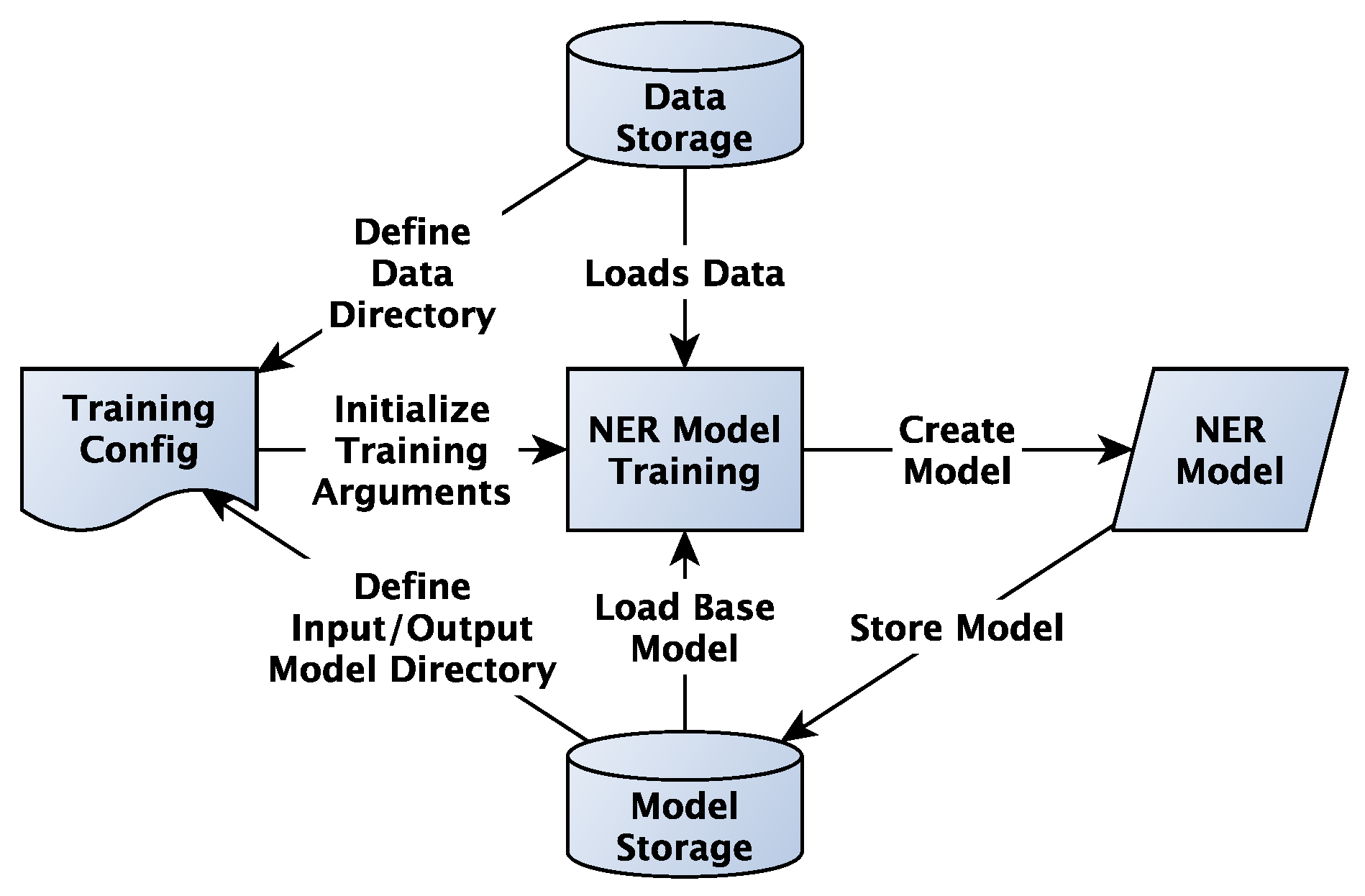
Figure 3 illustrates the resources required for NER training and demonstrates how interaction with these resources can be decoupled from implementation details through the use of CDD.
The generic process begins with the optional loading of a base model, especially when fine-tuning a pre-trained transformer model. This step can be skipped if the training dataset is sufficiently large to support training from scratch or if transformer-based models are not supported by the selected framework. Once any base model is initialized, data pre-processing follows—an essential step for transforming raw input into a standardized format compatible with the target framework. Typical pre-processing tasks include tokenization, normalization, and data formatting. Without thorough and consistent data preparation, irregularities or incompatible formats can significantly degrade model performance. The next key step involves initializing training parameters using a configuration file, which defines cross-framework HPs such as the learning rate, batch size, and number of training epochs. As introduced in
Section 2, careful selection of these HPs is critical and aligns with the system’s design objective: FIT4NER aims to empower medical domain experts to experiment with diverse NER frameworks without requiring in-depth ML expertise. To lower the entry barrier and reduce cognitive complexity, the user interface does not expose all framework-specific architectural options. Instead, the system provides predefined training profiles (e.g.,
Fast,
Medium, and
Accurate), which may internally configure framework-specific parameters [
16]. These profiles are designed to balance ease of use with performance, enabling domain-specific experimentation with minimal effort. Importantly, the system remains fully open to advanced users. All training configurations are documented, versioned, and reusable. Through advanced interfaces in CDD, users can directly modify framework-specific parameters via configuration files, enabling both low-threshold access for non-experts and high flexibility for experienced users. This decoupled approach enhances reusability and maintainability, as configuration files can be adapted independently of the core codebase. After training is complete, the resulting model is saved, allowing it to be reused for further evaluations or applications. The process concludes with model evaluation using validation data, which measures how effectively the model performs the intended task, assessing its robustness and generalization to unseen data.
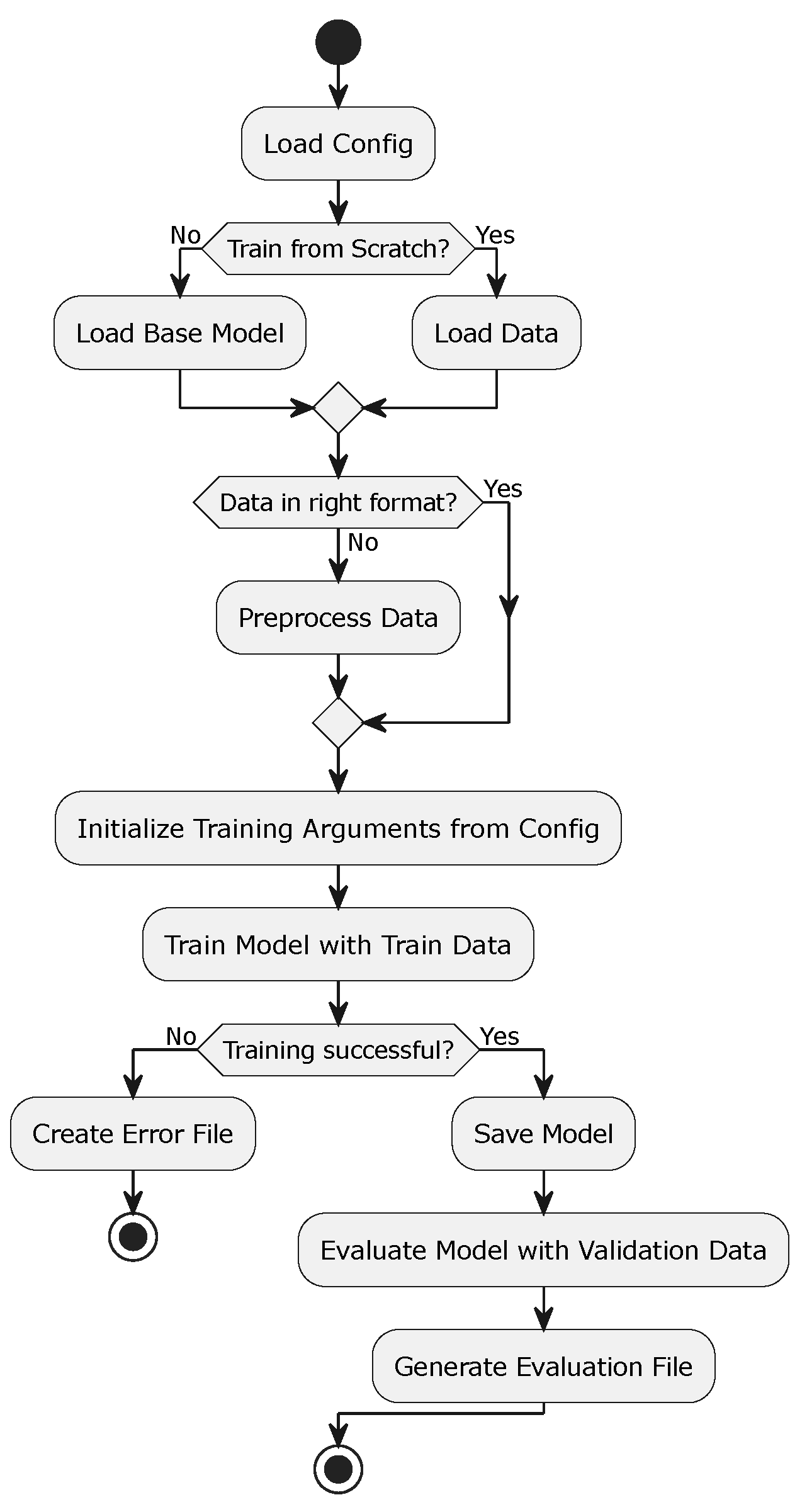
The model shown in
Figure 4 illustrates the generic training process as a UML activity diagram, designed to be implemented independently of the NER framework. The process begins with loading a configuration file that specifies all training parameters. Next, a base model is loaded, which can be either a pre-trained model or a new, empty model. After optionally loading a base model, the training data is read. If the data is not already in a format supported by the framework, it undergoes pre-processing, including tokenization, normalization, and annotation, with the appropriate entity tags. These prepared data serve as the basis for actual training. The training parameters are extracted from the configuration file and initialized. The model training proceeds iteratively, allowing the model to learn the relationships between words and their associated NEs. Upon completion of the training, the successful execution is verified, and the model is saved. Subsequently, the trained model is evaluated using a separate validation set to assess its generalization capability. The results of this evaluation are compiled into a detailed report. This process provides a structured framework for the development of NER models, offering the flexibility to test and compare various models and configurations.
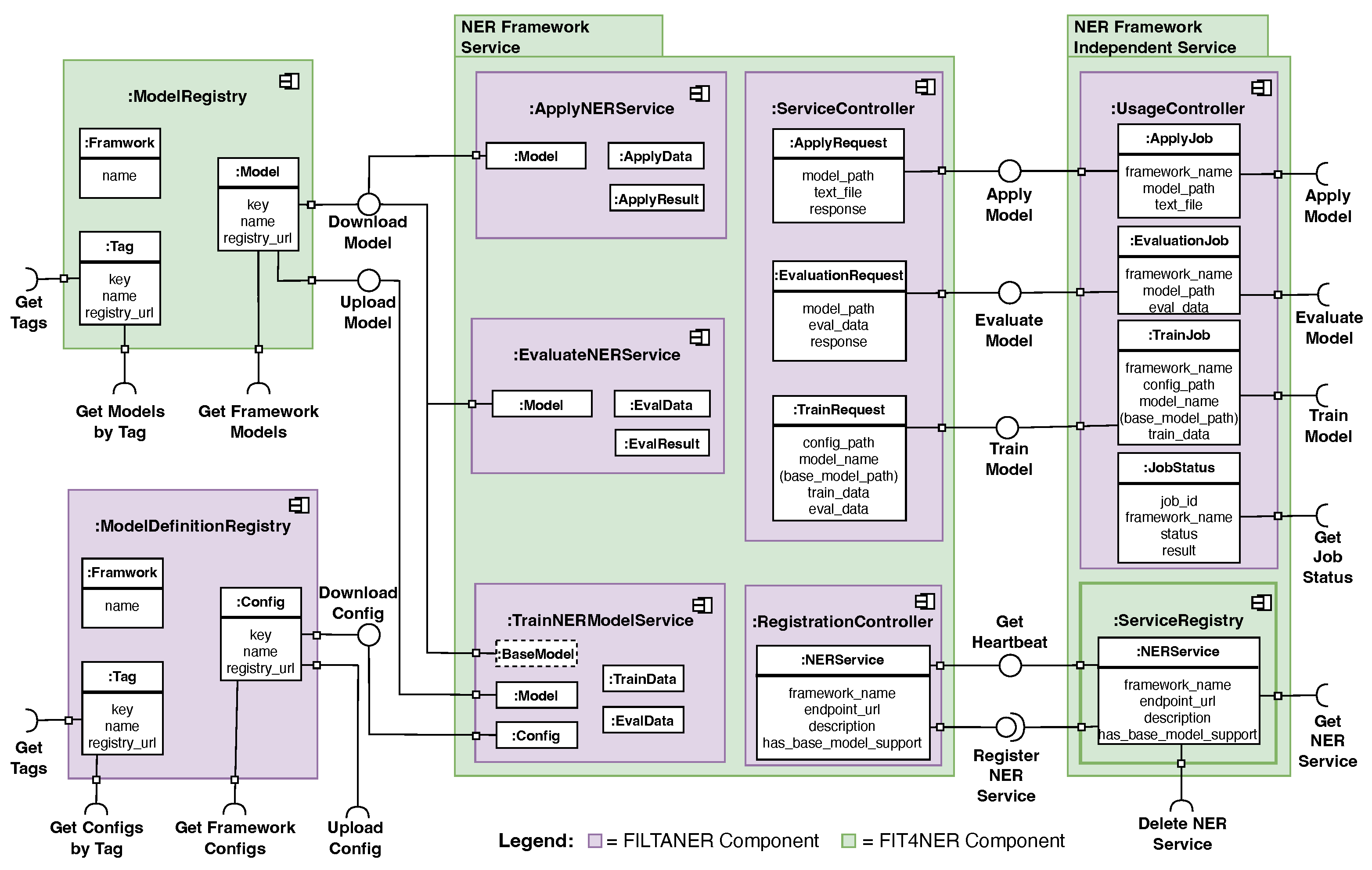
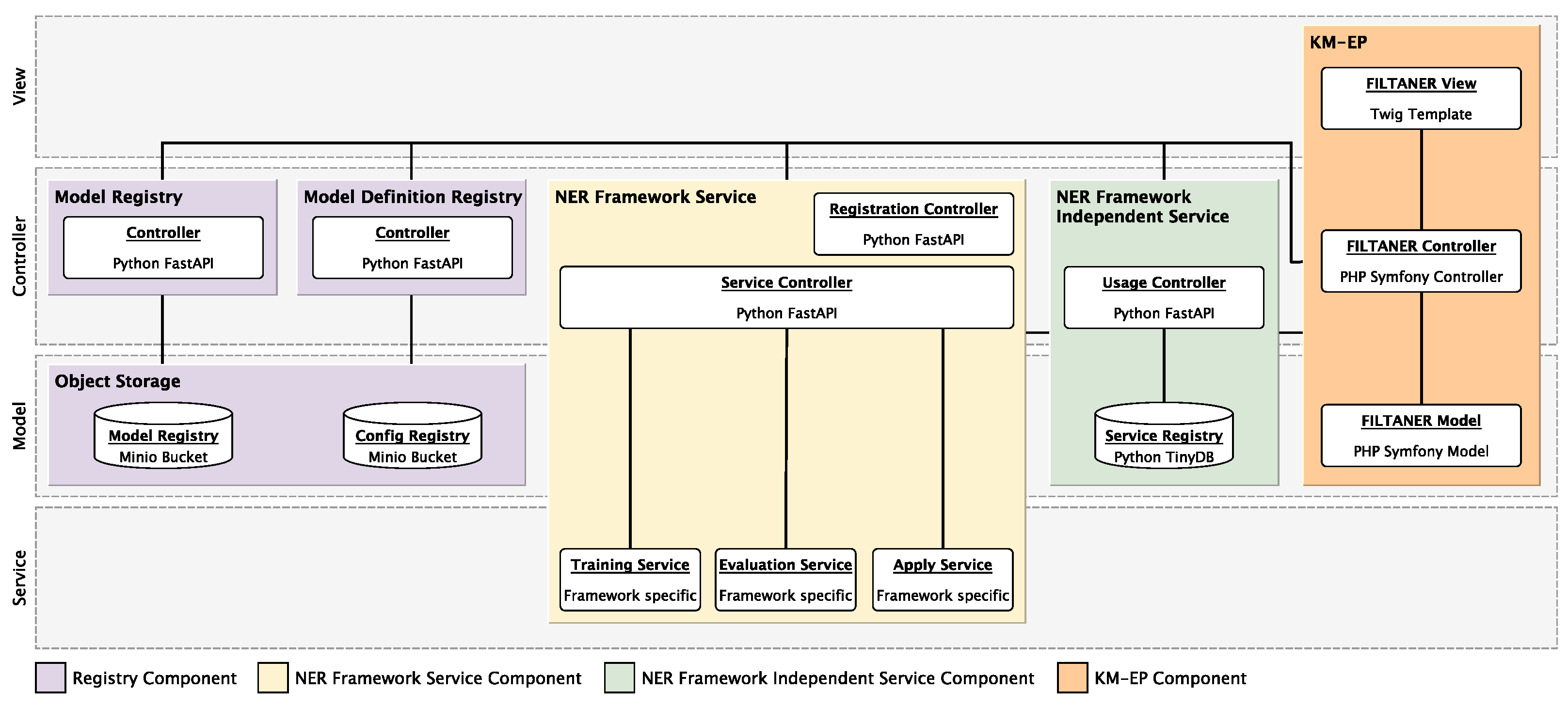
To integrate this generic training process into KM-EP, multiple components must work seamlessly.
Figure 5 provides a detailed description of the components and interfaces involved, which have already been thoroughly described in [
16]. The architecture introduces a modular and scalable structure for managing and deploying trained models and configurations, enabling the dynamic use of various NER frameworks. Key components include Model Registry, Model Definition Registry, and NER Framework Service, which facilitate model application, evaluation, and training. The NER Framework Independent Service acts as middleware, providing centralized control and access via REST interfaces. The Service Registry manages the registration and discoverability of NER services, while entities such as TrainJob, EvaluationJob, and ApplyJob represent training, evaluation, and application processes. The
Model-View-Controller (MVC) model shown in
Figure 6 illustrates the technical architecture, depicting the integration and interaction of individual elements within the overall system. It outlines the modular architecture and implementation of the Bridge Pattern of the system for the registration, configuration, training, evaluation, and application of NER models. The architecture is based on a clear separation of responsibilities across various components that communicate via REST interfaces. The following sections provide a detailed explanation of each component and its interactions. Central to the architecture are the registry components, which facilitate the storage and management of models and configurations. The
Object Storage, based on MinIO, is used to store trained models in the
Model Registry and configuration data in the
Config Registry. The
Model Registry Controller and the
Model Definition-Registry Controller, both implemented as microservices using Python FastAPI, enable access to these data. The
Model Registry Controller manages the model metadata and provides APIs for registering, retrieving, or updating models. The
Model Definition-Registry Controller offers similar functionalities for configurations, including versioning and profile management. The
NER Framework Service components form the functional core of the architecture. The
Training Service enables the training of NER models by processing training data, configurations, and optional base models. Training jobs implemented in Java or Python are initiated here. The
Evaluation Service, accessed via the same controller in the
NER Framework Service, evaluates trained models using validation data, executing evaluation jobs that generate metrics such as P, R, and F1. The application of the model is facilitated by the
Apply Service, which allows trained models to be applied directly to input texts, with the results forwarded to other components. The
NER Framework Independent Service implements the Bridge Pattern and acts as the interface between the
NER Framework Service and the KM-EP system. Also implemented with Python FastAPI, it includes a
Service Registry using Python TinyDB, storing information about available frameworks. The
Usage Controller translates user requests from the KM-EP system into calls to the respective microservices, retrieving data such as configuration profiles or models from the registry components and processing microservice results before returning them to the KM-EP system. The KM-EP system is the entry point for users. Through a user interface implemented in PHP with Symfony, tasks such as training or evaluating NER models can be initiated. The controller processes user requests and communicates with the microservices through the
NER Framework Independent Service. The results are then asynchronously retrieved by the
FILTANER Controller from the
Usage Controller and presented through the
FILTANER View. The
FILTANER Model within the KM-EP system manages the application logic and data models necessary for interaction with the
NER Framework Independent Service. The interaction between components is conducted consistently via REST protocols, ensuring clear and structured communication. This modular architecture achieves a clear separation of responsibilities, allowing the various microservices to be independently scalable and extendable. Simultaneously, the NER Framework Independent Service enables centralized coordination and unified management of models and configurations, providing a flexible and efficient solution for working with NER models. Thus, the developed models effectively address all outstanding challenges (RCs 1–3).
4. Implementation
This section covers the system development phase, focusing on the RO to develop a middleware that serves as an NER Framework Independent Service, providing a generic approach for the training, evaluation, and application of NER models while enabling the integration of frameworks such as Stanford CoreNLP, spaCy, and Hugging Face Transformers. Initially, the Model Definition Registry and Model Registry are described, which handle central management tasks for model and configuration data. Following this, the implementation of the NER Framework Service is explained, which operates as a standalone microservice responsible for the specific training, evaluation, and application processes of each framework. Based on this, the implementation of the NER Framework Independent Service is detailed, which acts as an abstraction layer and offers a consistent interface for overarching workflows.
The Model Registry and Model Definition Registry play a central role in managing resources related to NER models. Both registries have similar architectures and offer comparable functionalities, yet they differ in the type of objects they manage and their specific roles within the overall process. They are based on object-oriented data storage, housed in an S3-compatible object storage solution (MinIO). Models and configurations are identifiable by unique keys, such as the key, the name, and the registry_url. The registries provide FastAPI-developed interfaces for storing, retrieving, deleting, and tagging stored files, ensuring persistent storage and retrieval of collected models and necessary configuration files. The main differences lie in the type of stored data and the specific purpose of each registry. The Model Registry manages trained NER models, making them available to NER services for application, evaluation, or training. In contrast, the Model Definition Registry is responsible for storing and managing the configuration files required for creating and reproducing these models. The endpoints of these registries follow a similar schema, differing only in the specific designations for the stored artifacts, which simplifies integration with other system components. The deployment consists of three containers: MinIO for object storage of models and configuration files, and two FastAPI microservices—filtaner-model-registry for model versioning and filtaner-model-definition-registry for model definitions. MinIO provides the Model Bucket and the Config Bucket, where the registries can store and retrieve their data. The registries interact with these buckets to manage and provide models and definitions.
As part of this work, prototypes of the NER framework services for CoreNLP, spaCy, and Hugging Face Transformers were implemented. These prototypes utilize the FastAPI framework and employ individual scripts as well as specific implementations of the respective features. The basic structure of the implementation is similar across all services: The RegistrationController.py registers the service and loads configurations into the Model Definition Registry for training profiles. The Service Controller provides all FastAPI resources that can be used by individual services. All NER framework services use Pydantic models to ensure consistent, type-safe, and easily maintainable API interfaces. Each NER Framework Service must offer the following four endpoints: train_model, evaluate_model, apply_model, and get_heartbeat. Additionally, each service includes a dedicated folder where framework-specific implementations are performed. All microservices contain at least three files in these folders that fulfill the respective tasks (Train, Evaluate, and Use). In Stanford CoreNLP, the Java classes are additionally accessed via a Python subprocess call. In Listing 1, an example is provided of how the Python-based microservice interacts with the Java-based Stanford CoreNLP component. Initially, the training and evaluation data, originally in JSON format, are converted to the TSV format required by CoreNLP by changing the file extension from .json to .tsv and invoking the json_to_tsv function. Next, the create_temp_properties function generates a temporary properties file that contains all the configuration parameters and the paths to the TSV files. This properties file serves as the foundation for the subsequent training process. Using the Python subprocess module, a Java process is initiated, which allocates 8 GB of memory with the “-mx8g” argument and loads the necessary JAR files via the specified classpath. Through this process, the Java class edu.stanford.nlp.ie.crf.CRFClassifier is called, which initiates the training of the CRF-based model using the prepared properties file. In addition to using the official CoreNLP classes, two supplementary Java classes were developed for application and evaluation within the CoreNLP-NER service. The Java implementation in the ApplyCoreNLP class reads an input file and loads a trained NER model based on the model path provided to process the text using a Stanford CoreNLP pipeline. The detected NEs are then output in a structured JSON object, which includes the original text and details for each identified token (text, label, start, and end position). In the corresponding Python implementation, the Java process is initiated asynchronously via a Java jar call, and the JSON result is returned.
![Information 16 00554 i001]()
In the communication between the NER framework services and the registry components, the Model Definition Registry is used only for writing in the Registration Controller and reading during the training process. In contrast, the Model Registry is utilized across all resources. During registration, the respective NER Framework Service can specify whether a base model from the Model Registry can be used during training. If this is the case, the model is loaded from the registry as needed, and training continues. If such a feature is absent, as is the case with Stanford CoreNLP, the same model installed as a dependency by the service is used for each training process.
The prototypical implementation of the NER Framework Independent Service is based on a FastAPI application written in Python and deployed within a Docker container. This component has two primary functions: it acts as a Service Registry to manage various NER framework services and store their metadata, and it serves as a Usage Controller, overseeing the management and execution of training, evaluation, and application jobs that are asynchronously forwarded to the registered NER framework services. Additionally, a heartbeat mechanism is implemented to periodically check each stored service and remove it from the database if no response is received within a specified timeframe, ensuring that the registry remains consistent and only references operational services. The Service Registry utilizes three key endpoints for registering (POST/register-ner-service/), querying (GET/ner-services/), and deleting (DELETE/delete-ner-service/framework_name) NER services. Each request searches the TinyDB instance for an existing entry, which is either updated or newly created. The Usage Controller supports requests such as training new models, evaluating existing models, and applying models to text data, with dedicated endpoints for each: POST /framework_name/train_model/, POST /framework_name/evaluate_model/, and POST /framework_name/apply-model/. Each call creates a job in the TinyDB instance with a “pending” status, followed by an asynchronous task that handles the actual processing. The request is immediately acknowledged while the data is uploaded in the background and forwarded to the registered endpoint. Upon completion, the status in jobs_db is updated to “completed” or “failed”, allowing client applications to query the current status of a job at any time via GET /job-status/job_id. When the train_model object is invoked in the background, it calls the train-model endpoint of the respective NER Framework Service, passing the necessary and optional parameters. The result of the request is then stored in the job database. The endpoints for evaluating (POST /framework_name/evaluate_model/) and applying (POST /framework_name/apply-model/) models follow the same principle. They create a job upon invocation, execute evaluate_model or apply_model in the background, and set the final status upon completion. This status can be retrieved via GET /job-status/job_id to obtain results upon successful completion or detailed information in the case of failure.
Figure 7 summarizes the OpenAPI specification of the NER Framework Independent Service.
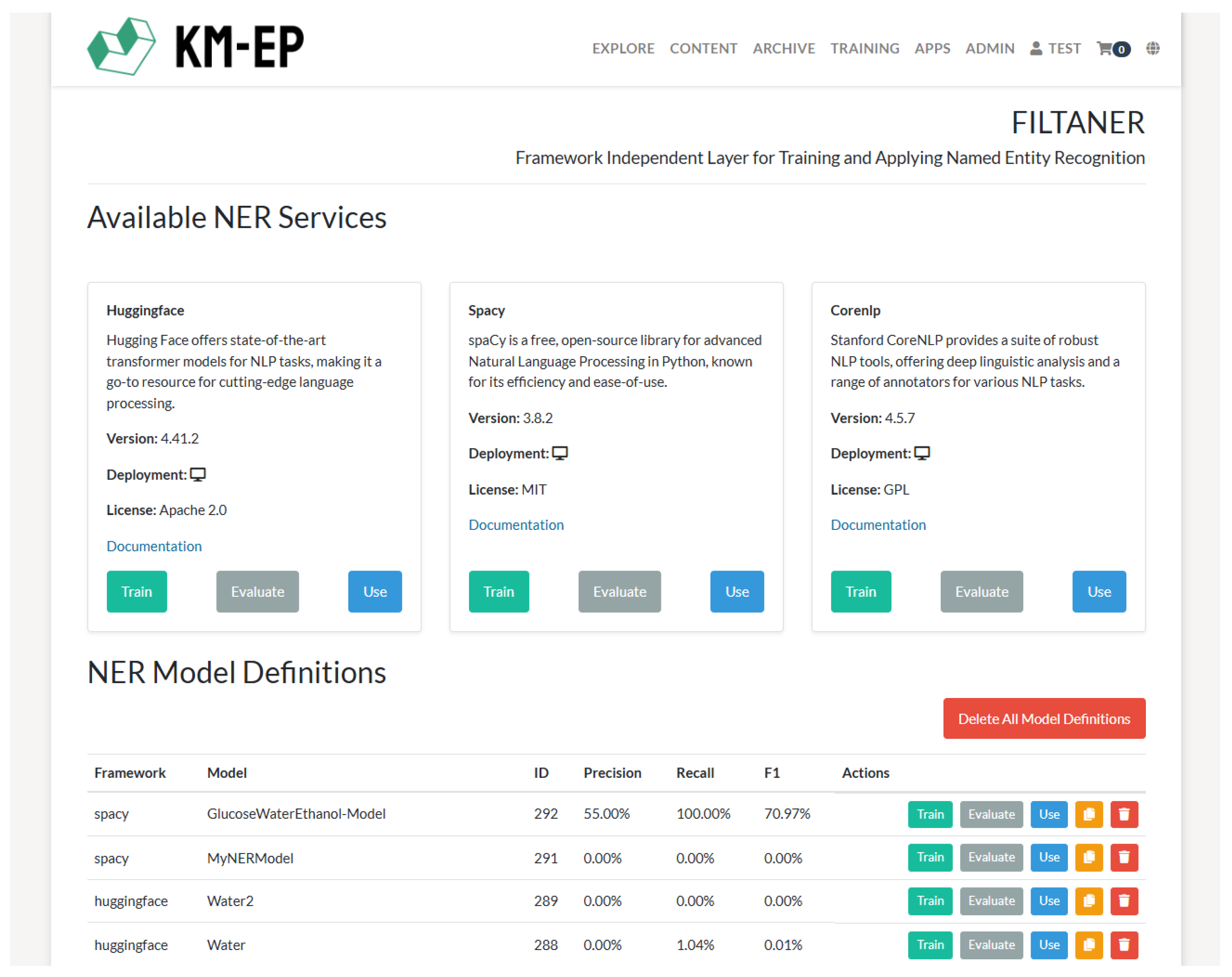
The KM-EP FILTANER Controller serves as the central management unit for the FILTANER components within KM-EP. It oversees the creation of model definitions, as well as the training, evaluation, and application of models. Essentially, it orchestrates the data flow between various services: it communicates with the NER Framework Independent Service for job creation and monitoring, with the Model Registry for model management, and with the Model Definition Registry for loading and creating configuration files. A key feature is asynchronous job management, which allows long-running training processes to be executed in the background and their status to be monitored. Following the MVC pattern, the controller also manages the PHP model based on Doctrine entities, where the FILTANER model objects represent the status and metadata of the models in the database. For user interaction, four different GUIs are provided via Twig templates: the FILTANER homepage (
Figure 8), the interface to define and train NER models, the GUI to evaluate trained NER models, and the interactive GUI to apply trained NER models to text documents. A detailed description of these GUIs has been published in [
16].
5. Evaluation
The previous section detailed the implementation of a prototype designed to assist medical experts in training ML-based NER models. This section focuses on the experimentation phase, addressing the RO of conducting and describing quantitative experiments on the developed prototype. The aim of the quantitative evaluation is to assess the performance of the NER framework services spaCy, Stanford CoreNLP, and Hugging Face Transformers, using metrics such as P, R, and F1, and to compare these results with other research initiatives. Although this study empirically evaluated only three widely used NER frameworks, FIT4NER is conceptually designed to be independent of specific NER frameworks. This independence is supported by both technical and methodological principles. As detailed in
Section 3, the architecture of FIT4NER abstracts individual NER frameworks through clearly defined interfaces, while the principle of CDD enables the decoupled integration of new frameworks with minimal adaptation effort. Throughout the development process and internal qualitative evaluations, various model architectures were intentionally tested to identify potential limitations to this framework’s independence. No fundamental constraints were found that would hinder the integration of additional NER systems. Furthermore, a cognitive walkthrough evaluation conducted with domain experts revealed no indications of limitations to framework independence [
16]. The selection of evaluated frameworks encompasses diverse paradigms—both statistical and transformer-based approaches—as well as different programming languages (Python and Java), ensuring broad functional coverage. Future work will aim to integrate and quantitatively evaluate additional NER frameworks (e.g., NLTK, Flair, and OpenNLP) to further validate and demonstrate the generalizability of the architecture.
To evaluate the prototype developed in this study, a suitable dataset is essential. The
Colorado Richly Annotated Full Text (CRAFT) corpus [
46] comprises 97 medical articles from PubMed, containing over 760,000 tokens, each meticulously annotated to identify entities such as genes, proteins, cells, cellular components, biological sequences, and organisms. Version 5 of the CRAFT corpus includes semantic annotations mapped to a variety of biomedical ontologies. Several studies have employed this corpus for quantitative evaluation. Basaldella et al. [
47], Hailu et al. [
48], and Langer et al. [
49] conducted experiments using ontologies such as
Chemical Entities of Biological Interest (CHEBI) [
50],
Cell Ontology (CL) [
51],
Protein Ontology (PR) [
52], and
Uber-anatomy Ontology (UBERON) [
53], all of which are incorporated within the CRAFT corpus.
However, a direct performance comparison with previous studies [
47,
48,
49]—which evaluated NER models trained on the CRAFT corpus using similar medical ontologies—is limited. These studies often lack transparency regarding the selection of ontology nodes (e.g., top-level vs. low-level hierarchies) and provide insufficient documentation of evaluation strategies and configuration details, making reproduction difficult. To assess the performance of the current prototype, the results from these prior works were used as a reference framework. The objective was not to achieve a direct numerical comparison, but rather to demonstrate that FIT4NER is capable of training and evaluating medical NER models effectively. Future work may pursue greater comparability through targeted reimplementations, leveraging available resources such as published models, source code, and configuration files. Nonetheless, the primary focus of this study is to validate the framework’s ability to support domain-specific evaluation processes under realistic conditions.
Before training experiments were conducted, the XML-based CRAFT annotations first needed to be transformed into the JSON format used internally by FILTANER. A conversion script was implemented for this purpose, following a four-step process: First, the ontology hierarchy was analyzed, then the raw annotations were loaded from the XML files and linked to the corresponding text documents. In the third step, the annotations were filtered according to specific biological target categories. The target categories (entity types) are listed by ontology in
Table 1. Finally, the prepared data was split into training and evaluation sets with an 80:20 train–test split (train_ratio = 0.8). The data was randomly shuffled before splitting to ensure a representative distribution in both subsets. For training with spaCy and Hugging Face Transformers, three epochs with an initial learning rate of 0.001 were chosen, matching spaCy’s initial learning rate. Stanford CoreNLP used the standard configuration. For Hugging Face Transformers, the base model prajjwal1/bert-tiny [
54,
55] was used. Evaluation metrics were calculated on the basis of entity spans and therefore may differ from token-based experiments. This configuration was used to establish a fair and consistent basis for comparison between the frameworks. The focus of the evaluation was not on maximizing model performance through targeted hyperparameter tuning, but rather on demonstrating that FIT4NER can train effective NER models under realistic conditions without extensive optimization. The aim was to show that the results achieved with FIT4NER are in a performance range similar to that of previous studies and can thus be considered comparable to the state of the art. Although systematic hyperparameter optimization could be pursued in future work, it would primarily enhance model performance without significantly affecting the fundamental insights regarding the functionality and applicability of the developed system.
Table 2 and
Table 3 summarize the results of the NER model training and compare them against the findings of Basaldella et al. [
47], Hailu et al. [
48], and Langer et al. [
49].
Table 1 provides a comprehensive overview of the data used. In the performance metrics shown in
Table 2, the spaCy framework achieves the best overall performance for the CHEBI ontology with an F1-score of 90.27% (highlighted in bold), followed by Hugging Face Transformers at 90.03%. SpaCy demonstrates the highest Precision (93.57%), while Hugging Face Transformers achieves the highest Recall (93.41%). Stanford CoreNLP lags significantly behind with 73.74%. These results surpass the models of Basaldella et al. [
47] and Hailu et al. [
48] and slightly exceed the model of Langer et al. [
49]. For the CL ontology, the model of Basaldella et al. [
47] achieves the best F1-score (91%), closely followed by spaCy (90.22%). Notably, Hugging Face Transformers (F1: 78.28%) is weaker, while CoreNLP (F1: 85.66%) has high Precision (94.23%) but lower Recall. The results for the PR ontology in
Table 3 show that spaCy leads in all three metrics (P: 96.43%; R: 84.14%; and F1: 89.87%), significantly surpassing the models of Basaldella et al. [
47] and Hailu et al. [
48]. Hugging Face Transformers achieves an F1-score of 81.57%, while CoreNLP reaches 72.97%. For the UBERON ontology, spaCy leads with an F1-score of 90.11%, while CoreNLP records the highest Recall (91.85%). Hugging Face Transformers achieves an F1-score of 84.23%, comparable to that of CoreNLP and better than that of the model of Hailu et al. [
48]. Overall, spaCy demonstrates the most consistent performance across all ontologies, achieving the highest F1-score in three out of four cases. CoreNLP and Hugging Face Transformers vary according to the ontology, with CoreNLP performing well in structural annotations (UBERON) and Hugging Face Transformers excelling in CHEBI. The results suggest that the developed information system can effectively train and evaluate NER models for the medical domain. The performance of the models appears comparable to that of the current state of research in several cases and even shows better values in certain areas. However, it is important to note that due to different evaluation strategies, ontology nodes used, and potentially varying data pre-processing methods, direct comparison is subject to significant methodological limitations.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}