1. Introduction
Financial forecasting of stock markets has always been an objective of great interest in modern economies, where precision and timeliness can yield significant economic and strategic advantages. Accurate predictions of stock market movements have a great effect on investors, policymakers, and financial institutions’ decisions, which are important for resource allocation, risk management, and return maximization. In this remarkably demanding and dynamic environment of financial markets, changes in stock prices depend heavily on traditional financial indicators, but also on macroeconomic conditions and market sentiment that constantly change. Technological improvements have also increased access to data, giving the opportunity to exploit the computing power of advanced Machine Learning (ML) techniques, which capture complex patterns in financial time series, beyond traditional forecasting models [
1].
Recent developments in financial market forecasting increasingly emphasize the effectiveness of Deep Learning (DL) models and the integration of sentiment analysis with traditional quantitative data. As highlighted in [
2], financial markets are complex systems affected by a wide range of factors. Recent research demonstrates that combining sentiment information from sources, such as tweets analyzed using advanced Natural Language Processing (NLP) models like enhanced RoBERTa, with quantitative market data can notably improve predictive accuracy. LSTM models excelled in this integrated approach for forecasting the Tehran Stock Exchange. Moreover, the research in [
3] systematically compares LSTM and GRU architectures for stock price prediction under identical conditions and finds that, while both models benefit from the inclusion of financial news sentiment, the presence of this sentiment data significantly enhances the performance of each, confirming its critical role in stock forecasting. Reinforcing these findings, the study in [
4] shows that deep neural networks (DNNs) substantially outperform traditional models like Ordinary Least Squares (OLS) and historical averages in equity premium prediction, especially when enriched with a diverse set of financial variables.
Financial forecasting was used mainly to rely on either fundamental analysis or technical indicators to forecast stock prices, until great progress was made in advanced forecasting technologies. Fundamental analysis is a technique that focuses on analyzing the financial health of a company and market conditions, while Technical Analysis (TA) examines past price and volume information to identify trends and patterns.
While technology improvements have introduced the integration of more sophisticated models, including those based on ML algorithms, which exploit temporal dependencies in stock data to improve performance, most of the previous studies examined datasets that either combine technical and sentimental factors or used them in isolation, without considering the impact of macroeconomic elements [
5,
6,
7,
8,
9,
10,
11,
12].
Macroeconomic indicators are essentially the result of the economic conditions that shape future expectations, and their public announcement can act as a driver of market trends. While sentiment analysis has a great importance in market forecasting, it can partially reflect market behavior that guides future market fluctuations. Conversely, ML models provide the possibility to incorporate various features that capture complex, non-linear patterns in stock market forecasting, but prior studies tend to overlook fundamental economic elements when investigating these trends using ML models.
This study addresses this research gap by incorporating macroeconomic indicators with technical and sentiment-based features in the task of stock price predictions. Such a combination serves to enrich the feature space with varied inputs, further enabling the understanding of various market dynamics, which improves accuracy.
It mainly aims to predict the daily adjusted closing price of the US stock market, using an enriched feature dataset, and to find the most effective ML model for stock market prediction. Specifically, it combines indicators into one framework for unified forecasting.
Research Questions and Objectives
Although sentiment analysis and technical indicators have been widely used in financial forecasting, macroeconomic indicators, reflecting the broader economic sentiment, have been relatively unexplored in this domain [
10,
11,
12]. The research questions addressed are:
How do macroeconomic indicators impact stock market prediction when combined with technical and sentiment indicators?
How well do different ML models capture and explain the impact of macroeconomic, technical, and sentiment indicators on stock prices?
To accomplish the above-mentioned aim, the following objectives are defined for the study:
To create a sophisticated dataset leveraging macroeconomic, technical, and sentiment scoring indicators that will be utilized in the prediction of the daily adjusted closing price of the S&P 500 index. While the explainability of technical and sentiment indicators has been already studied in the literature, macroeconomic indicators signal different aspects of the economic state that can enhance the predictability of the stock index when they are combined with these indicators.
To evaluate the efficiency of traditional and more advanced ML models, such as Linear Regression (LR), Random Forest (RF), Gradient Boosting (GB), XGBoost Regressor, and Multi-Layer Perceptron (MLP) in predicting stock prices. Each of these models leverage strengths of linear, tree-based, boosting, and related to Neural Network (NN) methods, such as the MLP model that can effectively capture the different aspects of the features and ensure a comprehensive stock index prediction.
To identify the optimal combination of features, by applying feature selection techniques.
To assess the contribution of each feature in the price movement by examining the performance through feature importance approach.
These objectives aim to enhance the state-of-the-art by investigating the integrated impact of macroeconomic conditions, technical indicators, and market sentiment on stock price predictions, and examines how ML models would perform under different feature combinations, with and without prior feature selection.
To accomplish the above objectives, this study utilized various techniques for sentiment scoring, data pre-processing and engineering, as well as feature selection, which generated a comprehensive dataset suitable to be utilized by the models. The models are trained, and their performance is evaluated, using Mean Absolute Error (MAE), Mean Squared Error (MSE) and R-squared (R2) which are more appropriate for continuous numerical predictions, since the study involves a regression task.
Overall, the study’s novelty lies in highlighting that a broader set of features enhances the predictability of ML models. However, limitations and weaknesses are also evident, based on the architecture developed, in terms of engineering and modeling, indicating the potential for improvement.
3. Data and Methods
This section details the methodological approach in this research, presenting each step of the process and analyzing the data utilized thoroughly.
Data creation and preprocessing are important steps for financial forecasting. An efficient database requires all relevant features, including technical indicators, macroeconomic data, and sentiment scores, to be collected and placed in some form of analytical format.
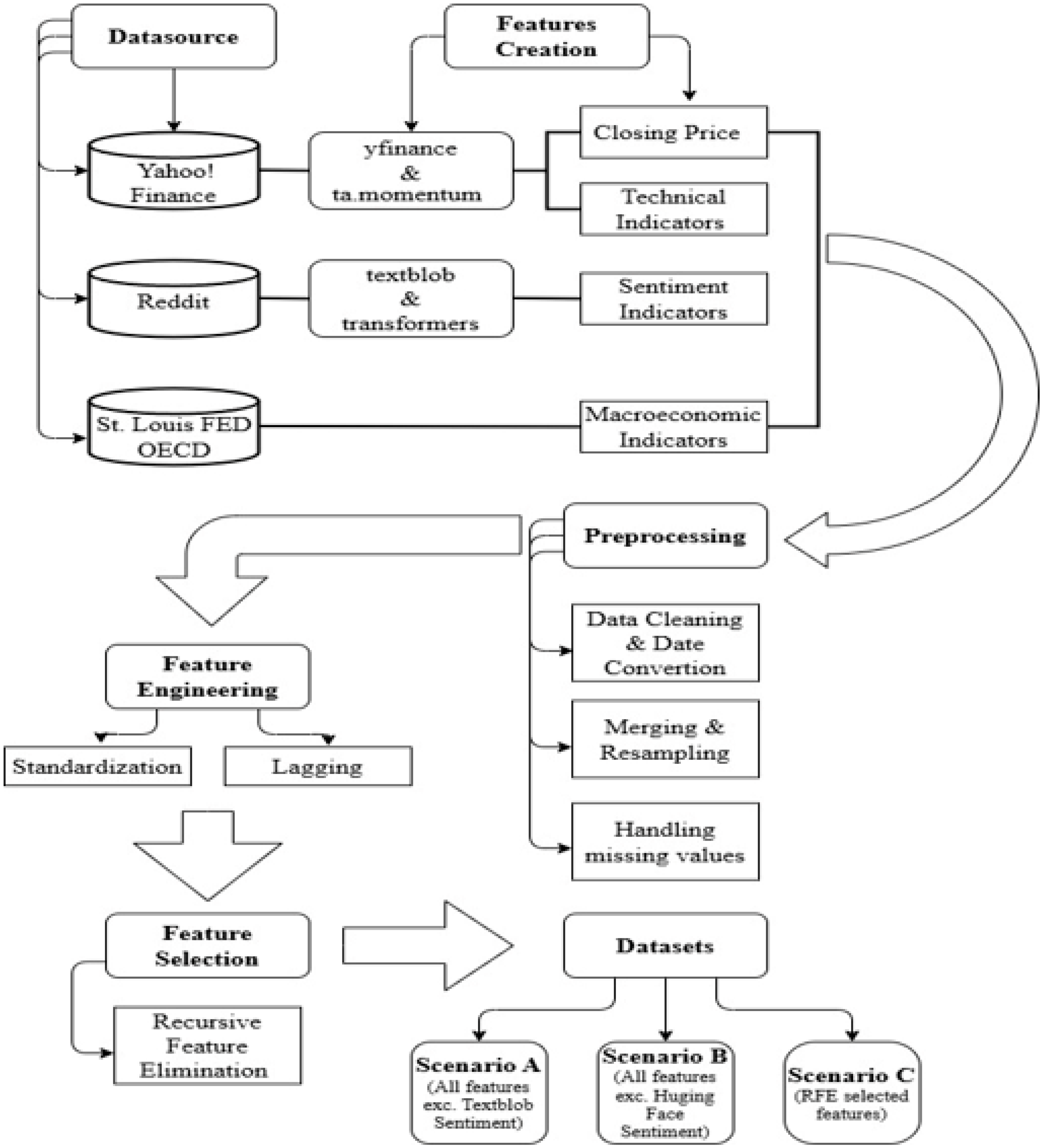
The financial dataset of this research was built on S&P 500 daily data, calculating technical indicators, while sentiment score was derived from news headlines. Macroeconomic indicators were retrieved directly from open access web sources, available in daily and monthly frequency.
Most of the preprocessing steps included resampling, filling monthly indicators with a forward fill approach, and applying lagged values with respect to capturing temporal dependencies. During preprocessing, the quality of the data was further enhanced by standardizing the formats, dealing with missing values, and matching data frequencies to ensure a consistent and accurate dataset on which models can efficiently be trained.
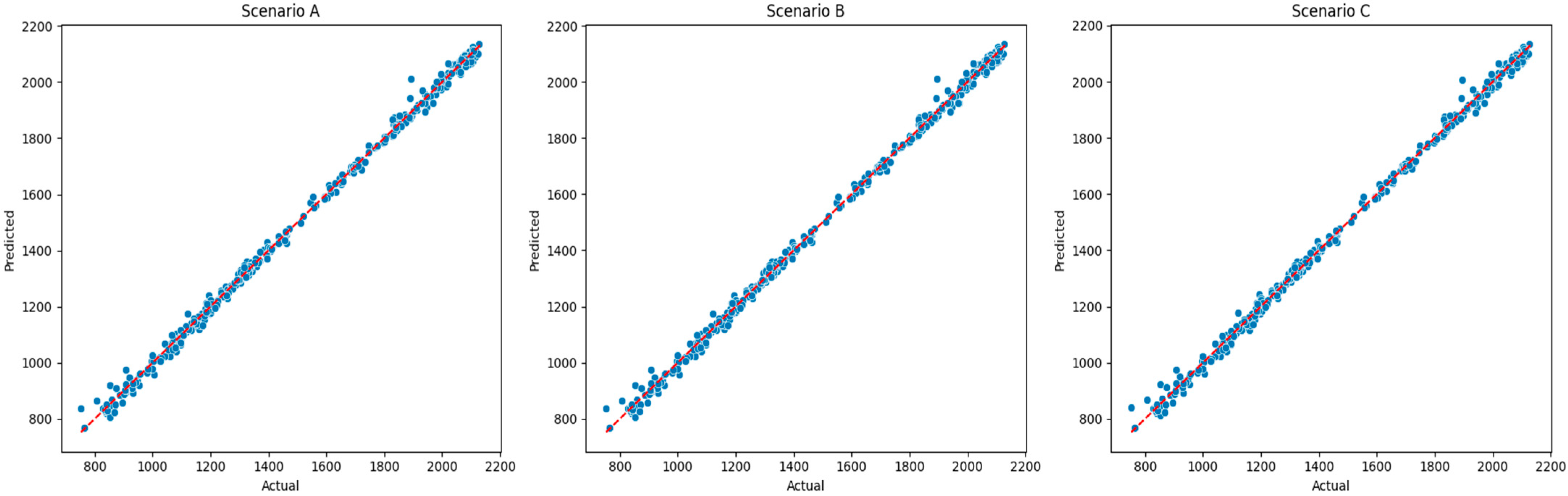
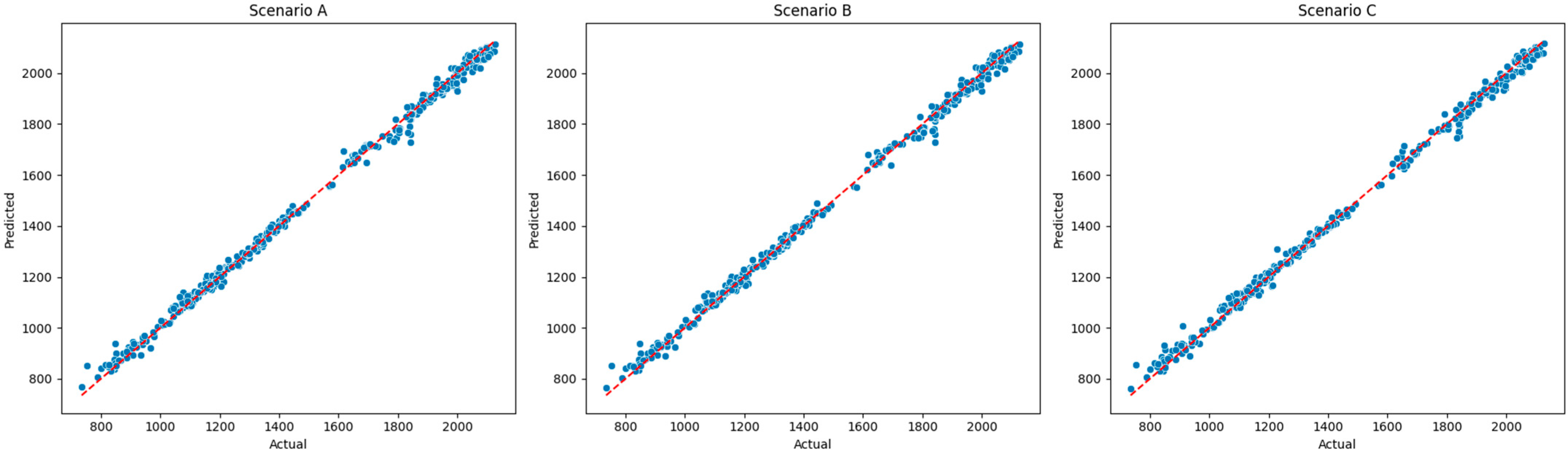
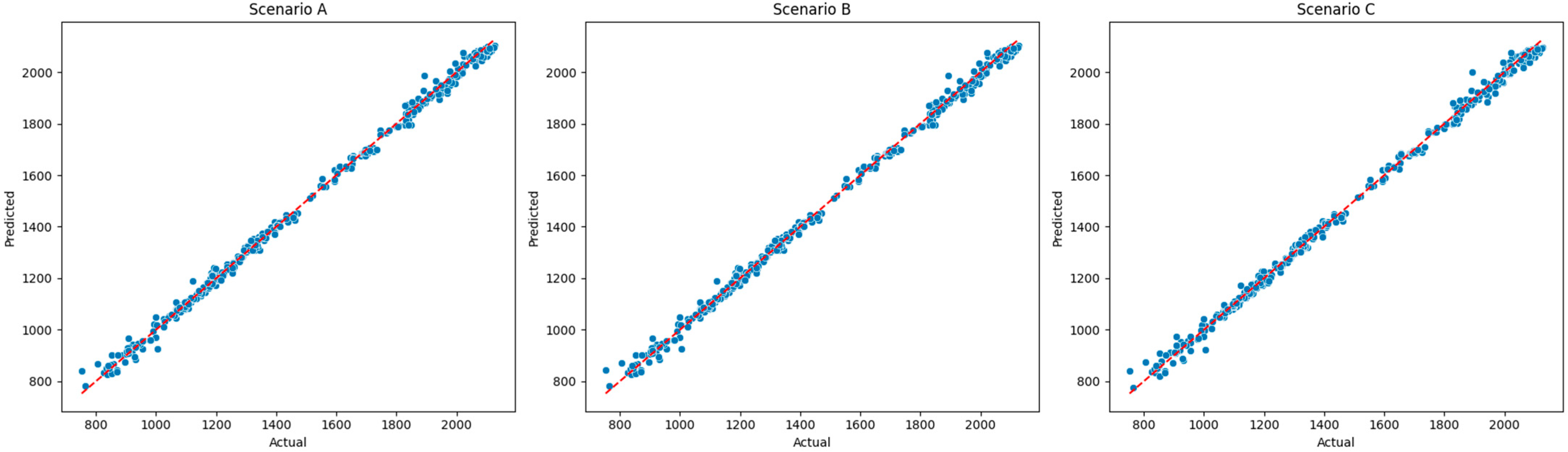
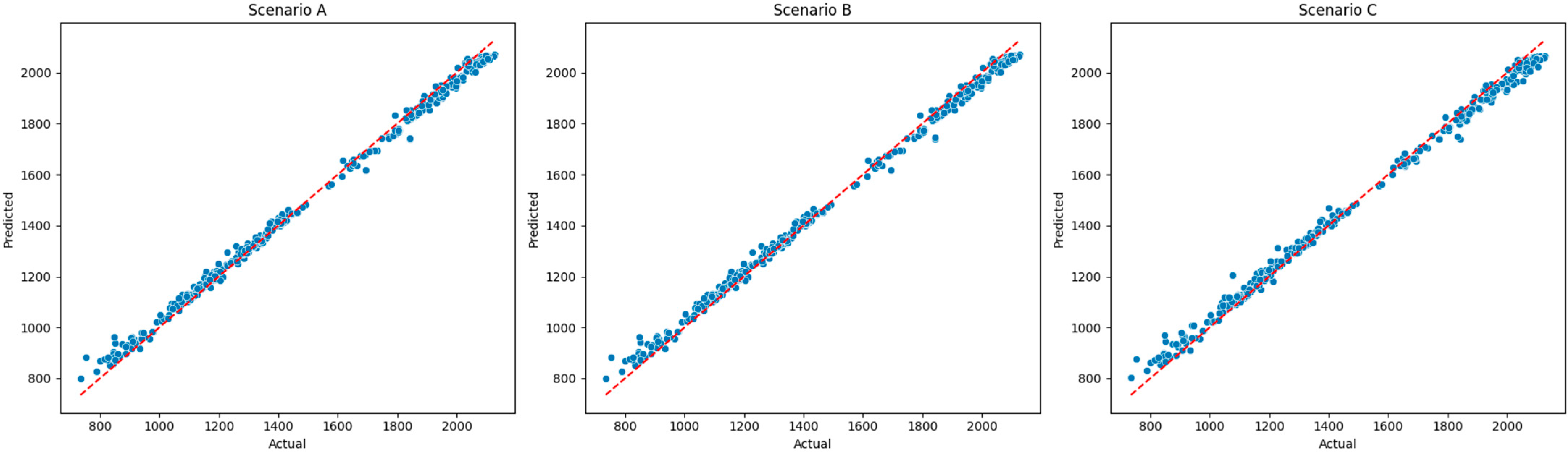
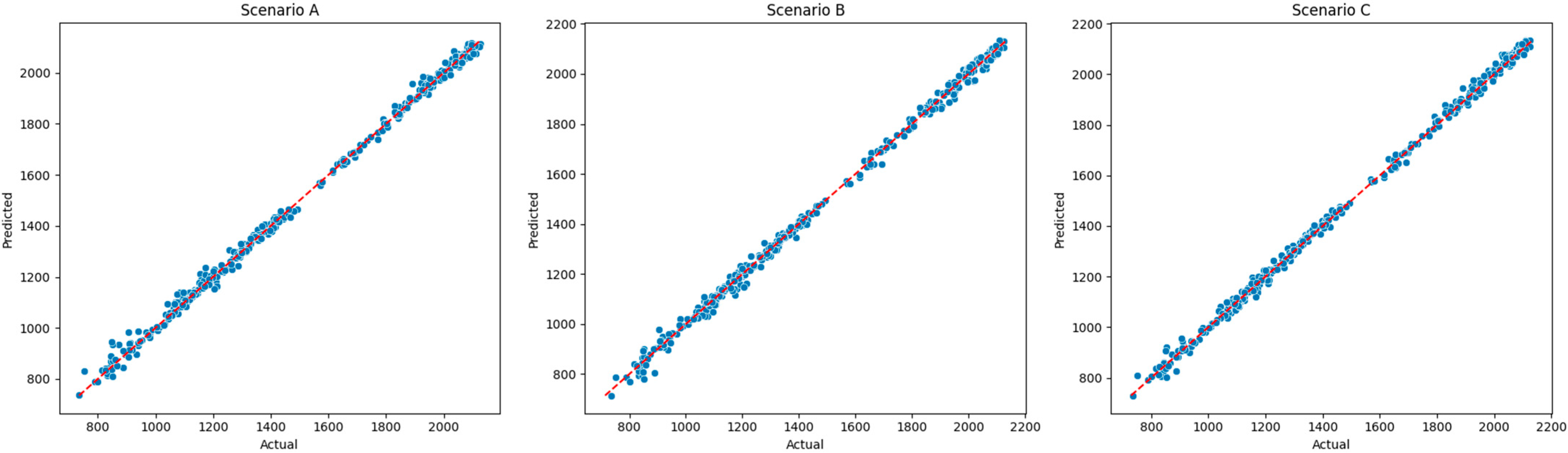
Feature engineering methods were also applied to ensure lower computational complexity. Based on the features created, two database scenarios (A and B) are initially generated differing only in the sentiment feature, in terms of the method employed for sentiment scoring. In addition, a feature selection technique is also employed to create Scenario C, based on the most important features. A sample of the final set of features, the standardized and lagged tested features and the actual values of the dependent variable against predicted values per scenario can be found in
Table A10,
Table A11 and
Table A12 in
Appendix F.
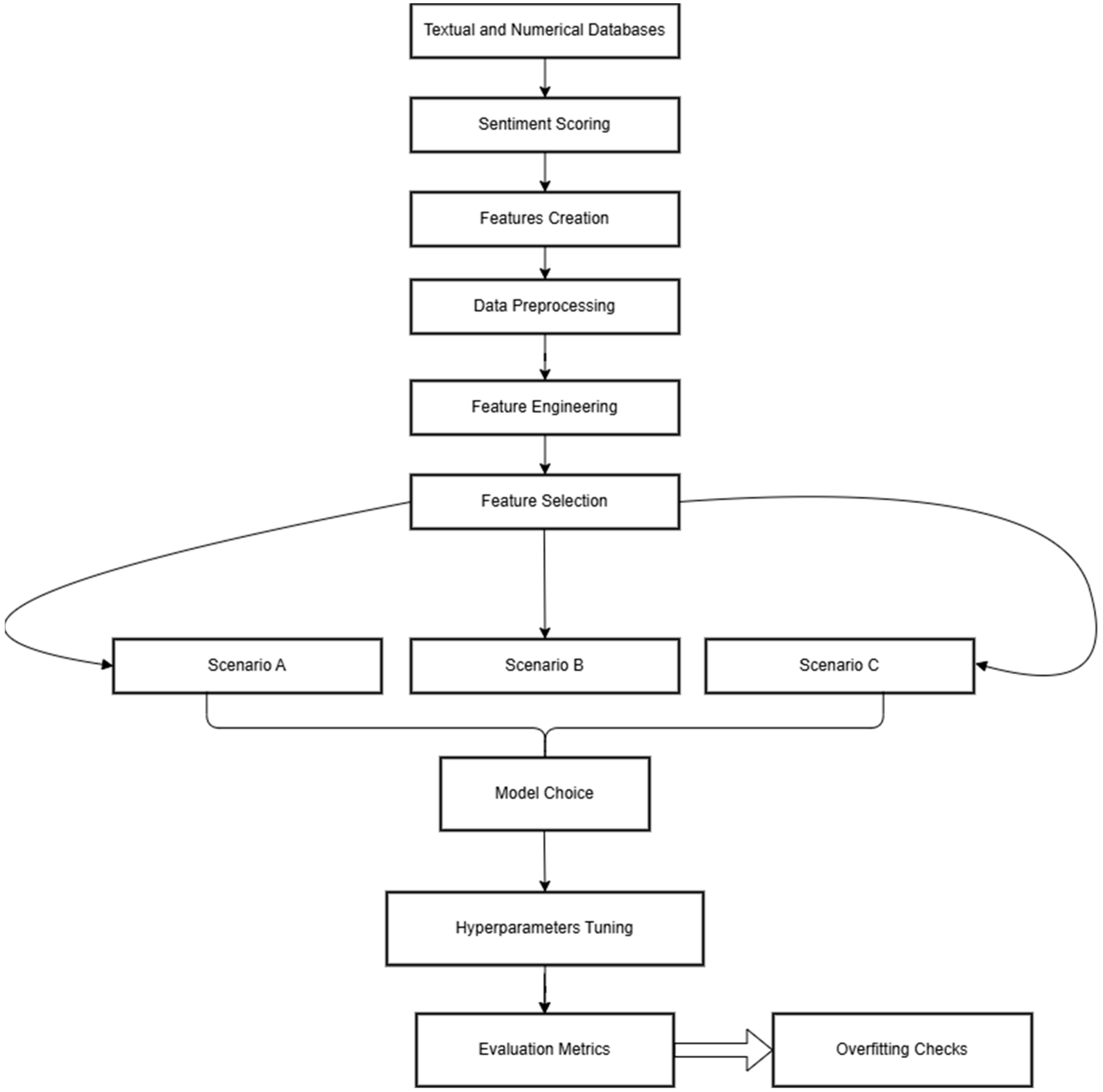
Accordingly, several ML models, namely LR, RF, GB, XGB Regressor, and MLP, were utilized to make predictions on S&P 500 index prices. Each of these models provides individual strengths in analyzing these factors for appropriate understanding of stock market movements. The visualization of this architecture is shown in
Figure 1.
3.2. Data Engineering
In this subsection, a description of the basic data preprocessing is analyzed. Data were initially converted into a standard format for consistency and then redundant columns of the dataset were deleted. In addition, the data were merged and resampled to align different time series, while missing values were handled with appropriate imputation techniques to provide solid foundation for modeling and analysis.
Historical data from the S&P 500 index were downloaded by employing the yfinance library. The initial dataset included fundamental columns, such as Date, Open, High, Low, Close, Adj Close, and Volume over the period of analysis. The yfinance library is regarded as a respected source in the aggregation of stock market information, as its main source of information is Yahoo Finance. Hence, the use of the yfinance library indicates commitment to data reliability and efficiency, as the extraction would be through automated means, with no need for manual intervention. For this reason, the study would be guaranteed to operate on updated and complete historical data, an essential ingredient for accurate forecasting models.
Technical indicators provide major tools in financial analysis that one employs to quantify the stock price trends, momentum, and volatility. For the calculation of the indicators used in this study the ta.momentum library was employed. This library is ideal for the creation of such indicators, as it provides useful methods for capturing market dynamics. The library ta.momentum automates indicator calculations in a consistent manner that is error-free from complex indicators. This also enables the addition of technical indicators in the data, which contributes to identifying short-term patterns that may have a significant effect on the model’s performance.
Investor sentiment has nowadays become a key determinant of market fluctuations. Sentiment analysis techniques help to quantify the positive, neutral, or negative tone of news headlines that may influence stock prices. In this work, two methods have been implemented for calculating sentiment scores: TextBlob and pre-trained DistilBERT-base-uncased model from Hugging Face’s (HF) transformer library [
52,
53]. Advanced lexicon approaches and transformer-based pipelines like TextBlob and HF’s transformer library surpass other lexicon-based approaches like VADER, due to their deep linguistic and contextual analysis capabilities, when then are applied to lengthy or complex world news headlines. VADER and similar approaches perform better when they are applied to short texts found in X posts or short reviews as they are capable of capturing nuances like slang, emoticons, and intensifiers. VADER is suitable for short texts sentiment analysis as its ability to analyze longer, nuanced textual data is constrained [
54].
Sentiment scores have been computed daily for 25 headlines related to world news. TextBlob is a lightweight library that uses the Natural Language Toolkit (NLTK) for sentiment analysis and is suitable at handling formal and structured language. Its methodology lays upon the idea of assigning for each text a polarity score, representing sentiment on a scale from −1 (negative) to 1 (positive) [
52]. The average sentiment score of the headlines on each day has been computed from 25 daily headlines and gives a consolidated measure of the sentiment on a given day. Despite its simplicity, Textzblob library offers advantages against other libraries in processing and comparing the sentiments of news titles and descriptions [
33].
In addition to Textblob library, the pre-trained DistilBERT-base-uncased model from HF transformers library was also employed to secure the effectiveness provided by Textblob and even more to enhance the results. This library gave access to a great number of pre-trained language models, enabling the comprehension of the meaning of news headlines. In contrast to TextBlob, that relies on a naïve polarity score, transformers-based models leverage DL models like BERT, RoBERTa, or DistilBERT to capture context, semantics, and nuances in text, making them ideal for complex texts, such as headlines. The daily average of the sentiment score was calculated in the same manner as in the case of TextBlob. Headlines with no string values were assigned with a 0-value indicating a rather neutral sentiment.
3.4. Modeling
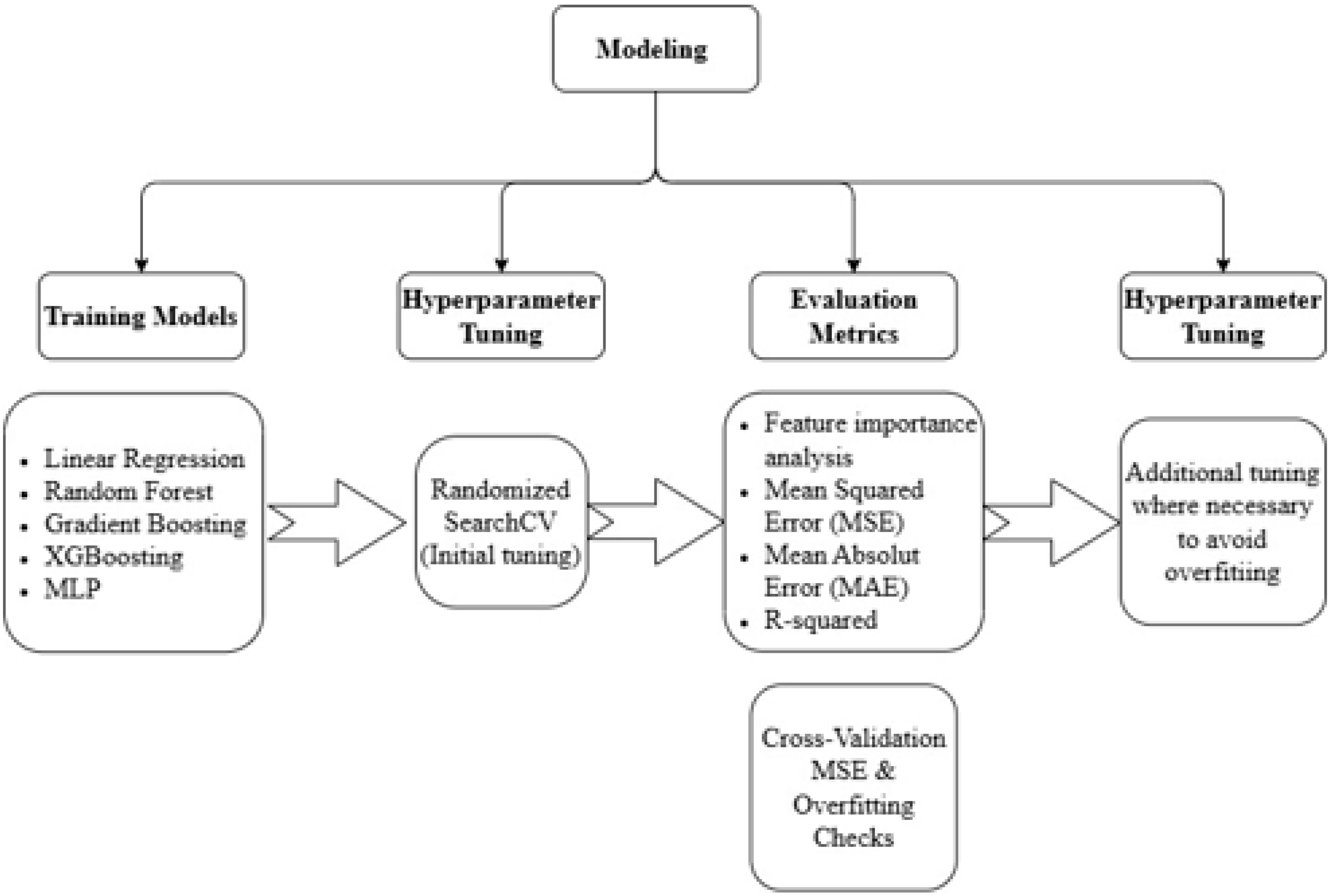
In this study, five ML models were employed to predict a one-day lead time of the S&P 500 index price: LR, RF Regressor, GB Regressor, XGBoost Regressor, and MLP Regressor. While it is standard practice in time series forecasting to preserve the chronological order of observations in a train/test split, in this study, a random 20% of the data was set aside as a holdout test set for each distinct scenario, as detailed below. Lagged features were engineered to capture short-term temporal dependencies, such as previous-day values, and were included as model inputs.
To evaluate the impact of different feature combinations, the models were tested under three distinct scenarios:
- (1)
All lagged features incorporated included only the sentiment score variable derived from pre-trained DistilBERT (Sentiment Score_pre-trained DistilBERT_lag1).
- (2)
All lagged features incorporated including only the sentiment score variable derived from TextBlob (Sentiment Score_Textblob_lag1).
- (3)
Only the features selected through RFE were incorporated up to level 2.
The dataset was then split into 80% for training and 20% for testing to facilitate unbiased model evaluation and ensure the generalizability of the results, as shown in
Figure 3.
The hyperparameters of these models were initially optimized using RandomizedSearchCV, a method that randomly samples candidates from the hyperparameter space [
55]. Computationally cheap, this approach generally yields comparable results to GridSearchCV, which performs an exhaustive search over a user-specified hyperparameter space [
56]. Whereas GridSearchCV will ensure that the best configuration is found, this comes at a far higher computational cost. These techniques are important, as they allow models to find the optimal performance of the model by systematically testing and choosing the best hyperparameters for the data and the given task.
Since the models used in this study focus on the prediction of continues values and not categories, we evaluated their prediction error from the actual prices using MSE and MAE. In addition, R2 was also a metric calculated in order to evaluate the proportion of the variance in the target variable that is explained by the model’s predictions. The purpose was to ensure that the tuning process was aligned with the goal of minimizing prediction error, while maximizing explanatory power. In addition, checks for overfitting were also employed using the Cross Validation (CV) technique and additional tuning to the hyperparameters of the models was made for those instances where overfitting was found.
Feature importance analysis was also conducted for all models to interpret the contribution of individual features to the predictions. This step is particularly useful in understanding what really drives the S&P 500 index price and thus provides insight into which technical, macroeconomic, or sentiment-based variables had greater predictive power. For ensemble models, such as RF and GB, feature importance was derived from the impurity or loss reduction attributed to each feature. Other models utilized coefficients or SHAP values to interpret feature contributions. Rigorous hyperparameter tuning and careful feature importance analysis boded well for models optimized for predictive accuracy, but also for being interpretable—a methodological alignment with the dual goals of robust forecasting and actionable insights.
5. Discussion
In this study, we aimed to predict the daily S&P 500 adjusted closing price, based on a diverged set of input features by employing a spectrum ranging from simple to advanced ML techniques. The combination of technical, macroeconomic, and sentiment indicators was introduced in three different scenarios in order to reflect the insight of price trends, broader economic conditions and behavioral dimension into the market’s price movements. While prior studies have utilized relative features to forecast market trends, immediate comparison with the dataset examined in this study is not possible. The novelty of this study is the incorporation of macroeconomic variables that are neither examined in isolation nor combined with other TA and sentiment factors in the literature. In addition, DistilBERT-base-uncased model has not been found in relevant prior studies for calculating sentiment scoring, thus it can be inferred that an immediate comparison is not possible, since no prior research has used the same data.
Results indicated a distinct relationship of these features in explaining their ability to predict the market. Initially, sentiment features were found to have a negligible contribution, suggesting a significant low impact to drive short market fluctuations. Macroeconomic features, while being a mirror of the economic conditions, produced subdued effects in short-term predictions, partially explained by their lagging nature and the daily prediction frequency. On the other hand, technical features related to momentum and volatility were found to contribute significantly, aligning with the TA theory that supports their ability to capture periods of overreaction and correction in financial markets.
In terms of the models’ predictive power, all models were found to provide a perfect fit, thoroughly explaining the variability of the input features in the S&P 500 price for all case scenarios. LR and MLP were the drivers among all models, providing high R2 and low errors, supporting the concept that traditional and more advanced models can provide comparable results. MLP was found to better capture the dependencies found in scenario C, where features were defined by RFE. Similar results were also found in other models, but overfitting was evident, even after the additional tuning of the initial architecture of the hyperparameters provided by the RandomizedSearchCV technique.
While these findings indicate that the combination of these features can perfectly predict index price movements, further balance between model complexity and generalizability is also evident. Despite the efforts towards mitigating overfitting, such as hyperparameter tuning, cross-validation, and feature selection using RFE, to draw more robust conclusions about the interplay between features and their contribution to market predictions, RF, GB and XGB Regressor were found to be not reliable.
In all, this analysis leads to the conclusion that stock market behavior is so complex that no single variable acts dominantly. The integration of technical, macroeconomic, and sentiment data provides a comprehensive perspective, but also brings out the requirement for rigorous preprocessing and thoughtful choice of modeling strategies. While predictive accuracy can be realized, the nuanced interactions between variables continue to be a limiting factor for financial time series forecasting.
5.1. Benchmarking Results Against Literature
The aim of this study was to challenge and further enhance the predictive power of the models employed in the literature in the scope of finding the optimal feature combination to predict the stock market. In addition, the different methodological-based approaches (linear, tree-based, DL), aimed to assess the performance with different architecturally designed models. While each study addresses distinct aspects of forecasting stock prices, the focus of this subsection is to highlight the limitations that this work aimed to overcome.
Sangeetha and Alfia (2024) and the current work share the objective of predicting the S&P 500 index but differ in their methodology [
8]. In their study, they use basic stock market features (Open, Close, Low, High, Volume) and implement the Evaluated Linear Regression-based ML (ELR-ML) technique, achieving an R
2 of 0.428 and an Adjusted R
2 of 0.352. Error metrics in their study show an SSE of 6 × 10
13 and an MSE of 9 × 10
12, suggesting higher prediction deviations. In contrast, the models in this study achieved R
2 values nearing 0.998 and much lower errors, with an MSE as low as 261.98 for GB, underscoring the advantages of diverse features and sophisticated models. While in their study they employ a simple feature set that limits its ability to capture complex market dynamics, our study’s integration of richer data sources improves accuracy significantly. This limitation highlights the weakness of LR to explain non-linear financial data, while the advanced algorithms of this study can excel with proper feature engineering. Combining our study’s diverse features with Sangeetha and Alfia (2024)’s [
8] residual analysis could refine both methodologies, emphasizing the importance of robust features and advanced techniques for accurate stock market forecasting.
Prime (2020) has also implemented LR and additionally NN in order to predict the stock price movements in Shanghai Stock Exchange using 21 indicators, categorized into macroeconomic, microeconomic, sentiment, and institutional investor data [
43]. In their study they found that NN generally outperformed Regression models supported by p-values ranging from 0.08 to 1.00 for paired t-tests, with NN showing lower APE in most sectors. While their work suggested the superiority of NN models against basic regression models, their improved ability is not that evident in sectors with lower volatility. The sophisticated models in our study offer the ability to handle non-linear relationships more effectively, possibly explaining their higher predictive accuracy compared to both NN and OLSR in Prime (2020) [
43].
The study from Jabeur et al. (2024) utilizes various ML models differentiating significantly from our work in their feature sets and target variables [
39]. Both studies highlight the effectiveness of XGBoost in forecasting financial data when various input variables are utilized. In Jabeur et al. (2024) [
39], XGBoost achieved the highest R
2 of 0.994 with RMSE of 34.921 and MAE of 21.968, showing strong accuracy in forecasting gold prices similar to the R
2 of 0.998 of our study. While errors were significantly lower than in our study for XGBoost and the other models (NN RMSE 195.961, LR RMSE 71.325), the advantage of ensemble models is evident in both studies, highlighting the importance of advanced algorithms for complex market data.
Compared to more advanced NN architectures studies in the literature, our study demonstrates the advantage of combining various features for broader market forecasting and, at the same time, the disadvantage of higher errors obtained when simpler models are implemented. In particular, Agrawal et al. (2019) [
6] employ deep NN (Optimal LSTM and ELSTM) to predict banking stock prices using only technical indicators. Their results show superior performance with high accuracies in prediction of 63.59% for HDFC, 56.25% for YES Bank, and 57.95% for SBI, surpassing classical models like SVM and Logistic Regression that were also tested and ranged between 49% and 56% accuracy. In addition, the obtained MSEs for deep NN model were found at 0.015 and 0.017, being significantly lower than our study’s results [
6]. While deep NN models performed significantly better in terms of error measurement, the importance of leveraging diverse features for a more comprehensive market analysis, as shown in our study, could be considered complementary to enhance the models.
Additional work that supports this novelty is further found in Chang et al. (2024), where they predict individual stock prices after employing DL models, such as GRU and LSTM, on their temporal dependencies and achieve an RMSE as low as 3.43 for Apple and 8.08 for Microsoft, significantly outperforming traditional methods [
7]. In addition, Bhandari et al. (2022) employ LSTM models with different neuron configurations in order to predict the S&P 500 price using a combination of fundamental, macroeconomic, and technical indicators and report RMSE values ranging from 46.5 to 167.5 and high R
2 values between 0.9935 and 0.9967 [
40].
5.2. Threats to Validity and Limitations
Despite the valuable insights of this study, there are still a few limitations. The first threat to validity of this study is linked to the selected indicators. Even though the selected technical and macroeconomic variables vary among their inferences, it is possible that other influential variables, such as sectoral metrics or global economic indicators, which could have greater contribution in forecasting, might have been left out. Not incorporating such a feature in the dataset could negatively affect the strength of the models in capturing stock market dynamics.
Secondly, the decision to incorporate macroeconomic indicators that calculate monthly values and lag them by one month raises questions about their temporal relevance. Economic conditions are generally reflected in the market over longer or variable time frames, and a uniform one-month lag may not adequately capture their effect. Similarly, lagging all other technical and macroeconomic indicators by one day may have constrained the analysis further, since they might require longer periods of lagging in order to reflect their impact accurately.
Forward-filling of monthly macroeconomic data is another threat in this research. While this approach is simple and effective to handle data, it can reduce model accuracy. In this study, forward-filling assumes that monthly values reflect the preceding days of the month, and this could potentially misrepresent trends or variations that could influence the market. Additionally, we acknowledge that a randomly selected sample of the test set does not immediately reflect real-world forecasting scenarios, as the test set is not exclusive to future data. As such, this evaluation should be interpreted as an exploratory assessment of model performance rather than a strict simulation of real-time forecasting.
Moreover, the scope of the sentiment analysis in this study is based on the effect of general world news on market price conditions. The open economic market that we reside in has set strong dependencies among countries, industries, and companies in order to achieve economic growth and development. The US economy is dominant worldwide and therefore companies that are incorporated in the S&P 500 can be heavily affected by world developments. While the focus in this study was to deviate from the usual implementation of examining sentiment from financial news and utilize the potential of highlighting the impact of world news on stock market movements, no significant relationship was found. A possible reason for this limitation could be the source and magnitude of the data retrieved from Reddit. As discussed in the data section, earlier data for sentiment retrieved from /r/worldnews can be considered a narrow perspective on market sentiment, as it does not particularly focus on world events relevant to business outcomes and may include information irrelevant to market impact. In order to provide a more detailed base of the behavior in the market, this could be further enriched by a more targeted source, such as business news or relevant social media.
In addition, another limitation of this study is that models were applied to historical data. While TA and macroeconomic indicators can be retrieved and applied in real time in the models, this is not possible for contextual data. Sentiment analysis would require specific setups for the retrieval and forecasting pipelines; hence, this is a limitation for live application of this research.
Furthermore, another limitation could be related to feature collinearity. For instance, RSI, EMA, and MACD are computed using overlapping calculations, which might induce redundancy and decrease the marginal contribution of each variable. This might affect the interpretability and the predictive performance of the model, thus requiring a more thorough selection and evaluation process.
These limitations highlight the complexity of financial forecasting and the trade-offs inherent in data preparation and modeling choices. These challenges call for the thoughtful refinement of methods and assumptions in future studies.
6. Conclusions and Future Work
The ability to predict stock market movements has always been of great importance in financial research and practice, due to the potential that it provides for investors, financial analysts, and policymakers to improve their decisions and manage risks. The aim of this study was to develop a comprehensive framework of financial modeling that integrates various input features, such as technical indicators, macroeconomic variables, and sentiment scores as predictors that can address the challenges that come with forecasting stock prices.
The practical application of the forecasting techniques proposed by this study could offer valuable insights for interested parties, such as investors, to adjust financial portfolio’s allocation, by alerting for potential short-term losses or enhanced short-term returns. Policymakers could also benefit from the model’s application by the long-term warning signals of turmoil in the markets, so that they could proactively act with changes in monetary or fiscal policy.
The financial modeling developed in this study utilizes ML regression models, including LR, RF, GB, XGBoost, and MLP, that aims to investigate how these factors combined can eventually provide better effectiveness in predicting the daily adjusted closing price of the S&P 500 index. Results suggest useful insights into the predictive power of different feature combinations, and the comparative performances of different ML models in this context.
One of the contributions of this study is that it introduces macroeconomic indicators into the forecasting architecture, in addition to more commonly used technical and sentiment-based features. Given the preprocessing steps and the feature engineering procedure as parts of the overall architecture, variables were lagged appropriately, indicating EMA and MACD as the features with the highest contribution. Macroeconomic factors, such as the BCI and CEI, were able to modestly explain market trends, confirming technical indicators’ established relevance for financial forecasting and modeling in the literature. For additional information, sentiment scores were computed using TextBlob and HF tools, but their contribution in this study was proved negligible.
Based on the feature dataset chosen for this study, modeling architecture exploits the effectiveness of various traditional and more advanced ML models to capture complex and non-linear relationships hidden in stock market data. Among the models tested, LR and MLP Regressor exhibited superior performance, achieving high R2 scores of 0.99 and low MSE and MAE rates averaging 350 and 13 points, respectively, across both training and test datasets. Additional techniques for robust feature selection, such as RFE, were also utilized, slightly improving model efficiency in terms of error prediction, as predictive accuracy was already high. However, challenges, such as overfitting found in other models, underscore the importance of careful hyperparameter tuning and cross-validation techniques to enhance generalizability.
While the results of this study indicate important implications for investors to identify market trends and for researchers to further explore hybrid models combining various sets of features with modern ML techniques, limitations are also evident, possibly threating the validity of the results. Shortcomings related to the choice of macroeconomic indicators, the lagging timeframe of features and resampling, the nature and quality of contextual data, the inability to use build up and pipelines for live sentiment analysis, and the possible collinearity of technical indicators can significantly challenge the credibility of the results.
In conclusion, this study aims to add value to the existent literature to understand stock market predictions dynamics by incorporating the macroeconomic factor in ML models. Despite its possible limitations, actionable findings that serve as a strong base can be identified to contribute to the growing field of financial forecasting.
Future Work
Implications for future work to enhance the robustness of the models for stock price predictions are evident. Additional metrics that reflect particular sectors of the market and macroeconomic conditions can enhance the prediction power of the models, while alternative sources to broaden the scope of sentiment analysis in order to capture behaviors from financial news social media discussions could strengthen financial modeling.
In addition, applying optimized methods like rolling window regression, transfer entropy, etc., to assess the optimal lag periods for the macroeconomic indicators could be vital for explaining market prediction. Similarly, the investigation of alternative imputation techniques for monthly data may reduce the risks associated with forward-filling and improve data fidelity.
Finally, Principal Component Analysis or feature selection through clustering could also be employed to avoid feature collinearity and improve model interpretability and performance [
59]. By addressing these issues, further work can build on the ground prepared by this study and advance financial modeling to produce more actionable insights.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}