1. Introduction
Malignant breast tumors are among the most prevalent types of cancer in women, and their incidence has shown a marked upward trend in recent years [
1]. Early diagnosis and intervention are critical for reducing breast cancer mortality. When a mass or nodule is detected in the breast during clinical examination, medical imaging modalities are employed to assess whether the lesion is malignant. Different imaging techniques, including computed tomography (CT), magnetic resonance imaging (MRI), and ultrasound, provide clinicians with macroscopic information regarding the location, size, and shape of breast tumors. Once the tumor site is identified, a biopsy is performed to confirm the diagnosis and to determine the tumor type and its growth characteristics within the breast tissue. In the field of clinical diagnosis, histopathological examination is widely recognized as the gold standard [
2] for the definitive diagnosis of breast cancer. Pathologists typically evaluate breast tissue images under a microscope by examining the morphological characteristics of cells, a process that is not only time-consuming and labor-intensive but also subject to inter-observer variability. Therefore, developing an efficient and accurate breast tumor classification method holds significant clinical value.
The complex spatial structures and texture details within breast tissue are critical factors for tumor classification. Therefore, it is essential to integrate local features and global contextual information in tissue images to make accurate judgments. Deep learning has made significant advancements in computer vision. Convolutional neural networks (CNNs) can automatically extract fine-grained features from images, such as edges and textures, through local receptive fields and have found widespread application in tumor detection at different levels. Musfequa et al. [
3]. designed a convolutional module guided by the Convolutional Block Attention Module (CBAM), which effectively highlights critical features while suppressing irrelevant information. In addition, a Deep Broad block was introduced to enhance the network’s adaptability to images with varying resolutions. The model achieved an accuracy of over 98.67% across all four magnification factors on the BreaKHis dataset. However, its computational complexity, measured in Floating Point Operations (FLOPS), reached 2.83 G, which poses challenges for deployment on mobile devices. Xu et al. [
4] proposed an improved high-precision breast cancer classification approach based on a modified CNN. They introduced three different variants of the MFSCNET model, which differ in terms of the insertion positions and the number of Squeeze-and-Excitation (SE) modules. However, due to the fixed receptive field of CNNs, it is difficult to recognize the complex morphological variations among different tumor types. Consequently, their model achieved an accuracy of only 94.36% at 100× magnification. Furthermore, the computational cost, measured in FLOPS, reached as high as 2.17 G. Rajendra Babu et al. [
5] designed a bidirectional recurrent neural network (BRNN) that leverages a pre-trained ResNet50 to extract coarse feature information from breast images. The network employs a residual branch as a collaborative module to ensure that critical features are retained and utilizes a Gated Recurrent Unit (GRU) to analyze spatial dependencies within tumor characteristics. BRNN effectively integrates multi-branch features, achieving an average classification accuracy of 97.25% on the BreaKHis dataset. However, due to its multi-branch architecture and feature fusion strategy, BRNN requires substantial computational resources, with FLOPS reaching approximately 8G, thereby limiting its inference efficiency. Liu et al. [
6] developed a model based on the EfficientNetB0 architecture, incorporating multi-branch convolutions and Squeeze-and-Excitation (SE) channel attention mechanisms to automatically focus on lesion regions at different scales, thereby enhancing the extraction of tumor features across various magnifications. The model achieved a binary classification accuracy of 95.34% and a multi-class classification accuracy of 95.97% on the BreaKHis dataset. However, this increased computational complexity and introduced unnecessary or redundant information, resulting in a parameter count of 49.85 M—approximately ten times that of the baseline network. Mahdavi [
7] improved conventional CNN architectures by replacing the ReLU activation function with K-winners, adopting the sparse random initialization of weights, and incorporating the k-nearest neighbors algorithm for tumor classification. These modifications enhanced the noise robustness of the CNN architecture. Wingates et al. [
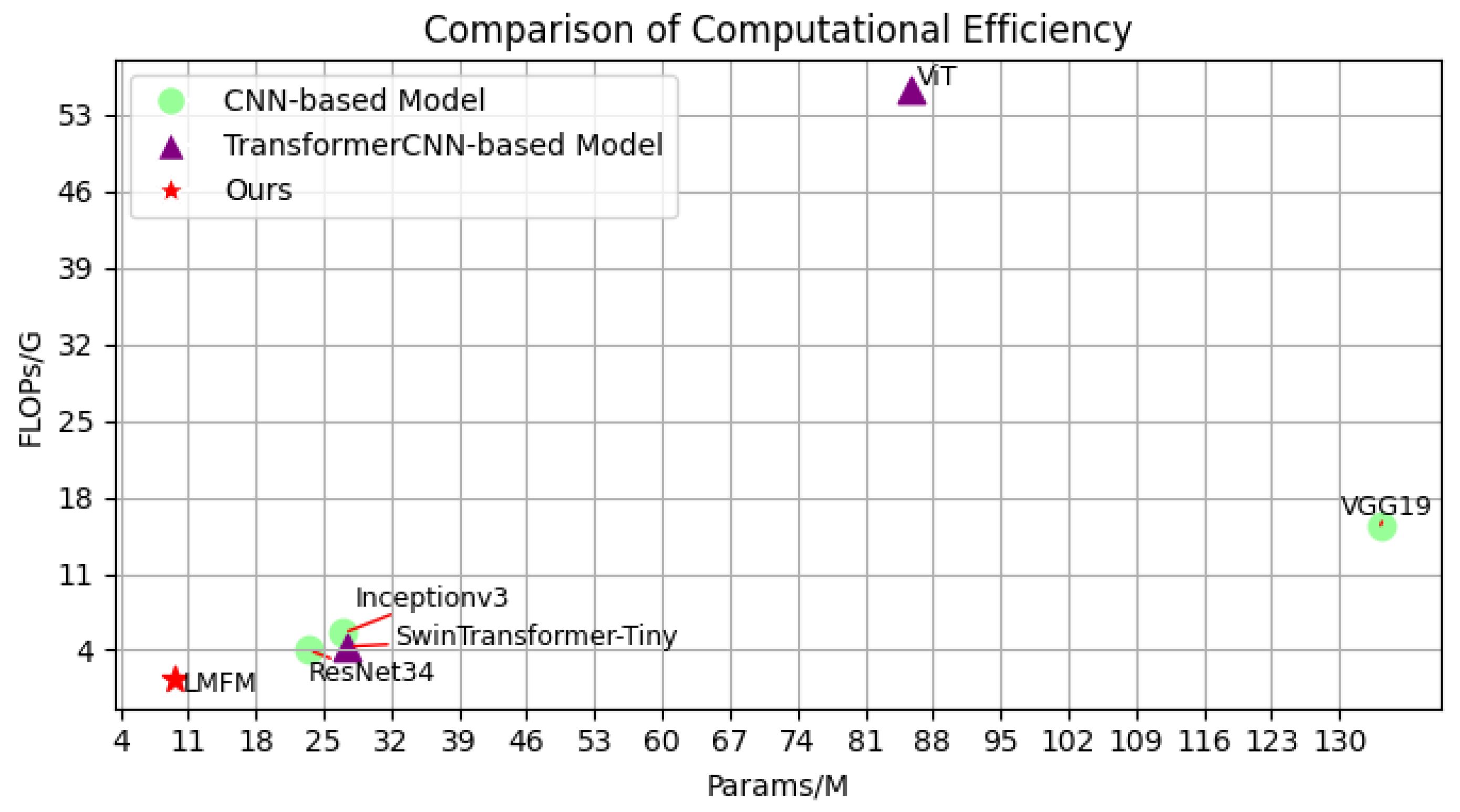
8] analyzed the performance of breast tumor classification using transfer learning across various CNN architectures. Among these, the ResNetV1-50 model achieved the highest computational complexity, with 4.1B FLOPS and 25.6 M parameters (Params), but only attained an accuracy of 92.53%. In contrast, architectures such as EfficientNet and MobileNet achieved classification accuracies exceeding 93% while maintaining much lower model complexity. These findings suggest that selecting a lightweight CNN model capable of delivering relatively high accuracy is more cost-effective for practical deployment. However, the F1-Scores of most CNN architectures fluctuate around 90%, indicating a potential issue of class imbalance in classification performance across different categories.
Due to the limited receptive field of convolution operations in CNNs, deeper network layers can only capture certain low-level information from the initial layers, resulting in the loss of global contextual relationships within features. The Vision Transformer (ViT) [
9] partitions images into patch tokens and incorporates positional encodings [
10], enabling the transformer architecture to capture the spatial positional information of different regions. By applying a self-attention mechanism across the entire image, the model can capture long-range dependencies between arbitrary regions and extract global feature representations with rich semantic information. Shiri et al. [
11] leveraged a pre-trained ViT to effectively process spatial information in histopathological images, utilizing supervised contrastive loss to enhance the discriminative capability of salient features within samples. To establish comprehensive spatial feature relationships, transformer models must exchange information between every patch, leading to excessive network complexity for Vision Transformers. Specifically, the Params and FLOPS reach 85.8 M and 55.3 G, respectively. The substantial computational burden incurred in pursuit of higher classification accuracy, at the expense of network efficiency, renders this approach unsuitable for deployment on mobile devices. Swin Transformer addresses this issue by partitioning the feature map into multiple non-overlapping regions of patch size, where local attention is first computed within each window. Subsequently, cross-region information exchange is performed to enhance global modeling capabilities. This hierarchical approach effectively reduces network complexity to a certain extent while maintaining competitive performance. Tummala et al. [
12] conducted multi-class breast tumor classification by ensembling four Swin Transformers, achieving an average classification accuracy of 93.9%, which surpasses most baseline CNN architectures. However, due to the window partitioning strategy, the capability to suppress background noise remains limited. However, it is noteworthy that Swin Transformer still requires 27.5 G Params, which exceeds those required by the vast majority of CNN architectures.
Currently, features extracted by a single network often fail to capture the differences between various breast tumor categories adequately. To effectively combine the respective strengths of both architectures, Zhang et al. [
13] proposed a parallel weighted ensemble of Swin Transformer and CNN for multi-class breast tumor classification. By integrating both local and global features of breast tumors, they reached a classification accuracy of 96.63%. Sreelekshmi et al. [
14] first extracted local breast tumor features using depthwise separable convolution (DSC) and then input these local features into a Swin Transformer framework to capture global information. The experimental results demonstrated that the SwinCNN architecture outperformed single-network models, improving classification accuracy on the BreaKHis dataset by up to 5.95 % and on the BACH dataset by up to 5.16%. Wang et al. [
15] innovatively proposed an LGVIT architecture, where a CNN extracts low-level breast tumor information to compensate for the Transformer’s limitations in local feature extraction. Subsequently, representative tokens from each window are processed through multi-head self-attention, facilitating the construction of cross-regional spatial information. However, its parallel integration inevitably leads to an increase in both the number of network Params and computational complexity. Additionally, the multi-branch structure introduces challenges in parameter tuning and may adversely affect convergence speed. Li et al. [
16] ingeniously integrated the strengths of ConvNeXt and Swin Transformer, enabling the model to capture fine-grained local features of breast tissue while also extracting critical global contextual information. In addition, by enhancing edge and texture features from a frequency-domain perspective, their approach achieved classification accuracies of 91.15% and 93.62% on the BreaKHis and BACH datasets, respectively. The model contains 68.45 M Params and 9.24 G FLOPs. By modifying the depth and hierarchical structure of the original baseline, fusing both CNN and Transformer architectures, and introducing frequency-domain operators, the method not only improved model performance but also reduced computational complexity. Vaziri et al. [
17] proposed recursive covariance computation and dimensionality reduction methods for EEG source localization, emphasizing the synergistic enhancement of feature representation capability and computational efficiency. Their approach reduced the computational workload by 66%, significantly improving the efficiency of the network. Although integrating CNN and Transformer architectures can enhance classification performance, direct fusion without explicit feature selection tends to introduce redundant information. Moreover, the varying importance of features across different scales and hierarchical levels during training with distinct architectures has not been adequately addressed. Mahdavi [
18] achieved high-precision segmentation of high-dimensional tumors by designing a multi-level output architecture and integrating multiple loss functions, including cross-entropy, Dice, and KL-Divergence, in conjunction with regularization strategies. Khaniki et al. [
19] incorporated a Feature Calibration Mechanism into Vision Transformers to calibrate multi-scale features. Furthermore, they employed Selective Cross-Attention to compute token correlations, enabling the selection of highly attentive features for global information construction. This strategy reduced network redundancy and enhanced the quality of feature extraction, resulting in a classification performance improvement of 3.92% compared to CNNs and 2.2% compared to standard ViT.
The above studies demonstrate that CNN and Transformer architectures can learn complementary strengths from each other, enabling the network to capture richer and more comprehensive image features. However, both CNN- and ViT-based architectures typically involve a large number of Params, requiring substantial computational resources and extended training times, which hinders their deployment on mobile or resource-constrained devices. Additionally, it is crucial to consider multi-level feature representations when dealing with complex breast tumor cell images. In current breast tumor classification methods, the low-frequency (LF) information of an image is primarily composed of structural features of tumor cells, while high-frequency (HF) information reflects intricate textural details. However, as the network depth increases, HF information is often smoothed or filtered out through repeated convolutions [
20], further diminishing image detail. Finally, breast tumor datasets often contain irrelevant background regions that adversely impact classification accuracy. Moreover, the diverse cellular morphologies across different tumor types present additional challenges, as conventional convolutions extract features with fixed receptive field shapes, limiting their ability to adapt to the complex and varied structures in breast tumor images.
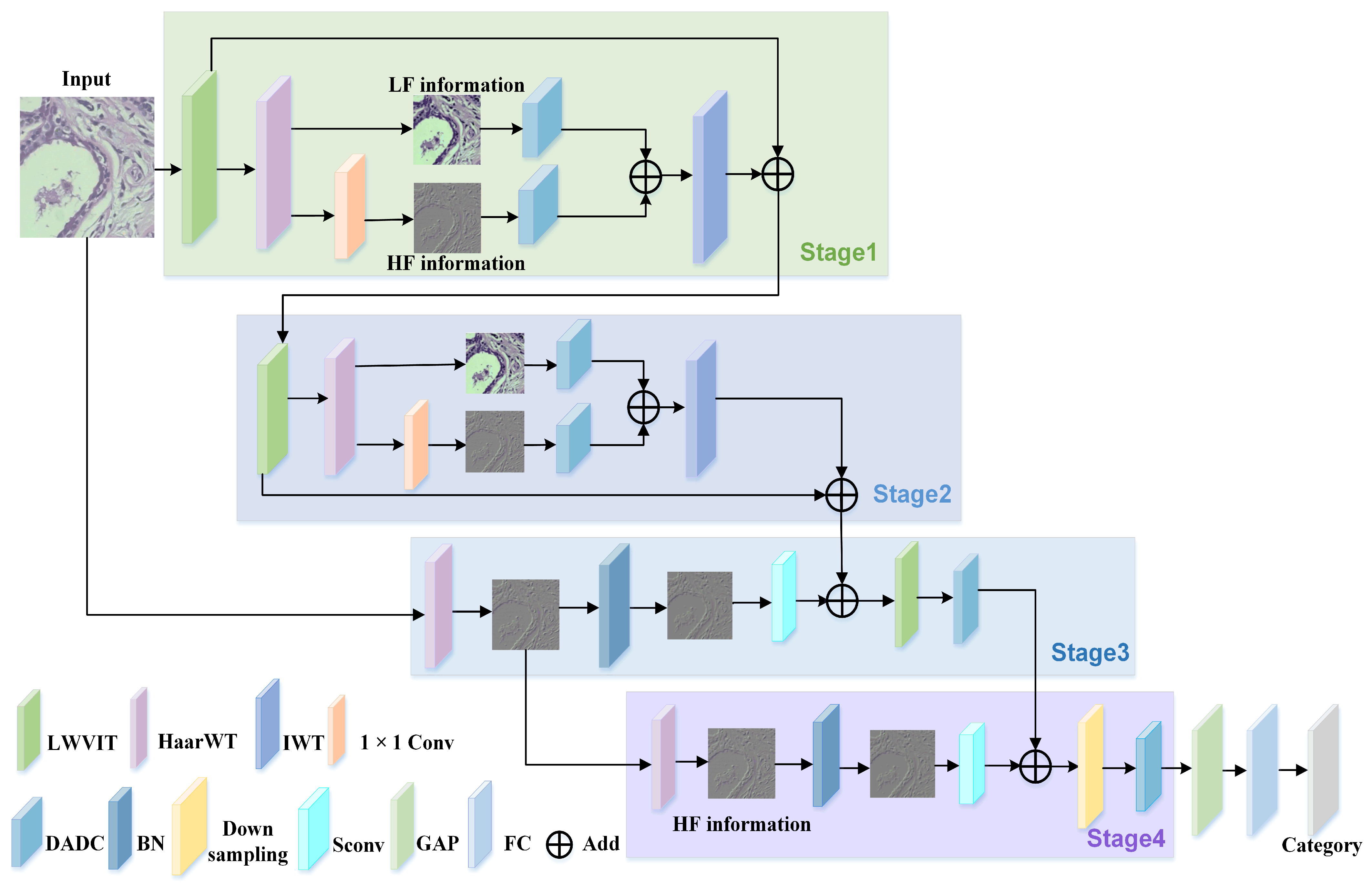
This paper proposes a lightweight multi-frequency feature fusion model (LMFM) for breast tumor classification to address the aforementioned challenges. The key contributions are as follows:
To reduce information loss in breast tumor tissue cells, this paper employs wavelet transform (WT) to decompose input images into HF and LF components, enabling separate feature extraction at different levels and enhancing the interpretability of the resulting features.
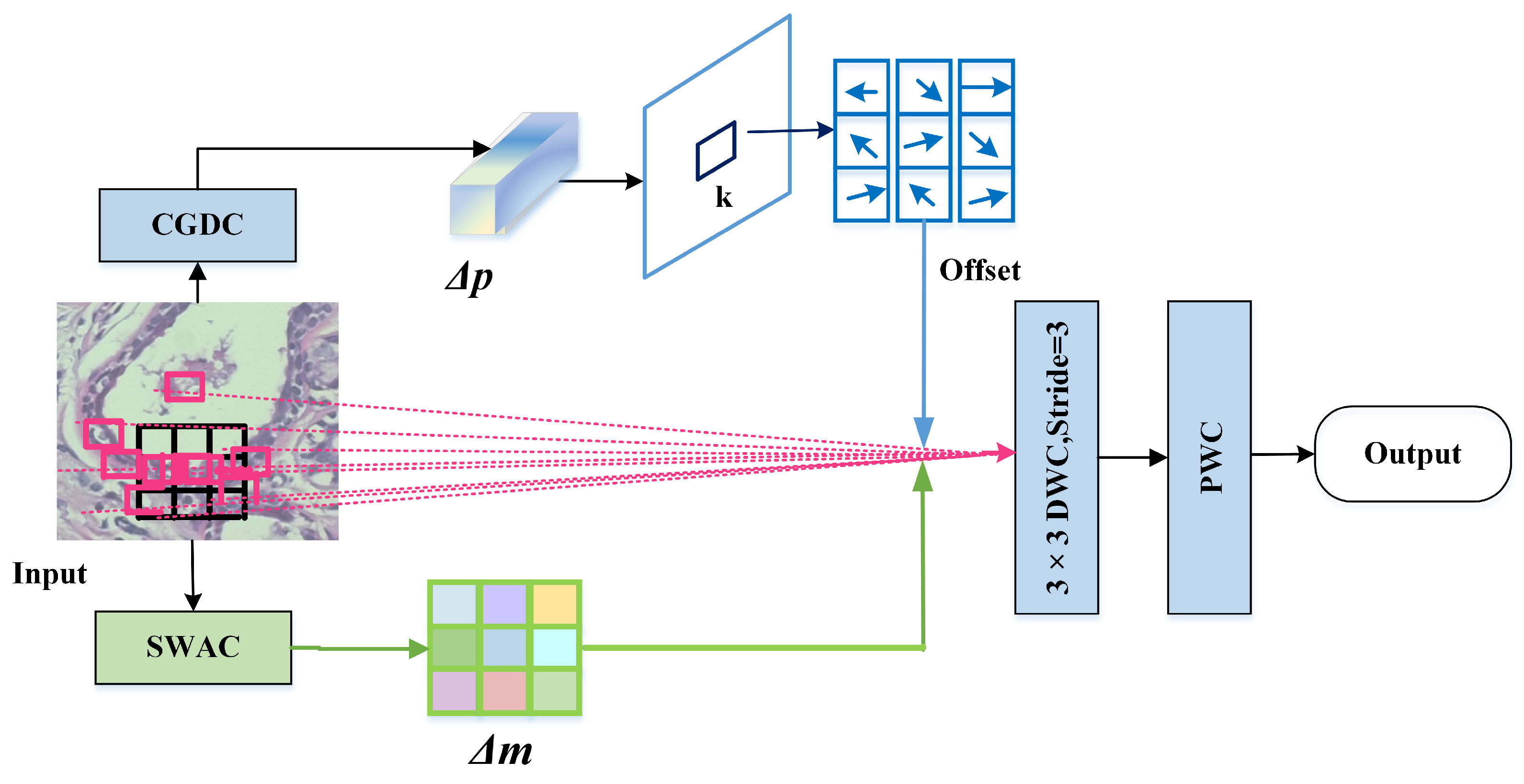
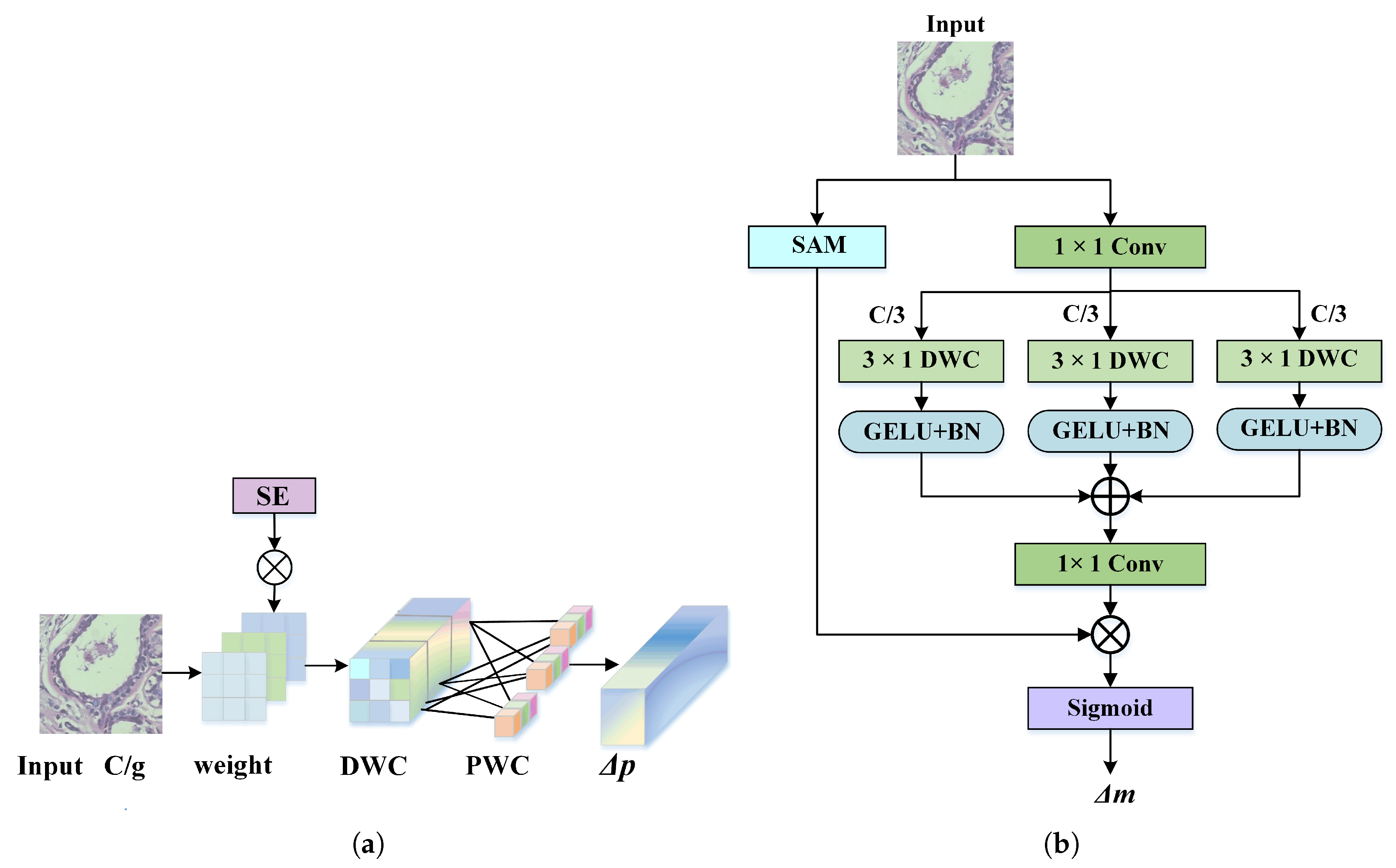
This paper designs a dynamic adaptive deformable convolution (DADC) method combined with DSC to capture local detail features. Channel Weight Multi-Group Dynamic Convolution (CGDC) is introduced to distinguish inter-channel feature offset characteristics, and Spatial Weight Asymmetric Convolution (SWAC) is incorporated to enhance features in regions of interest. This effectively mitigates the limitations of conventional convolutions in modeling irregular tumor shapes.
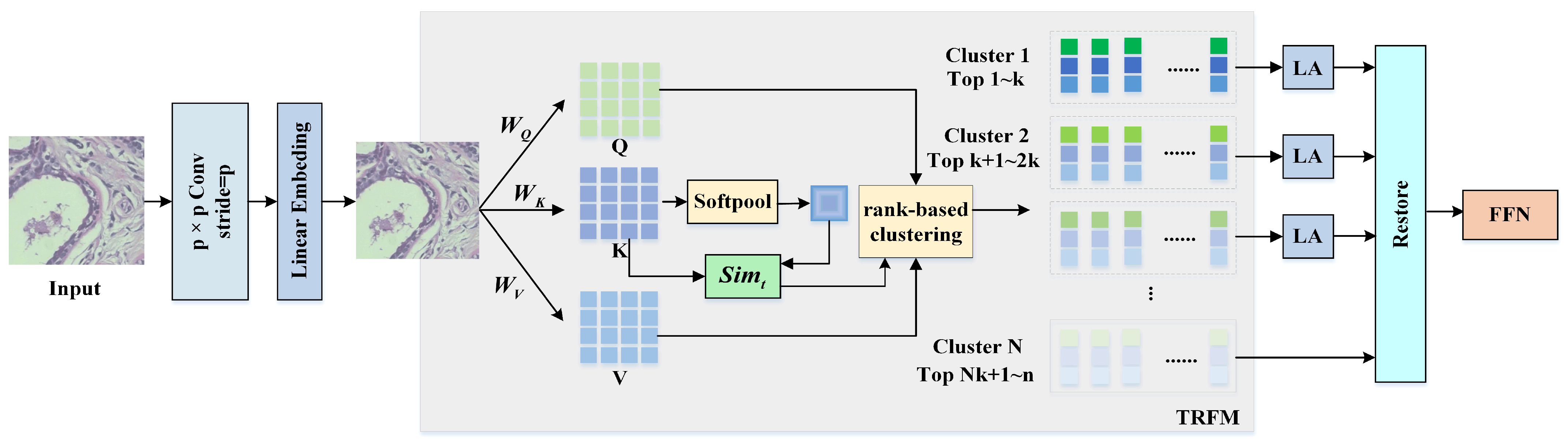
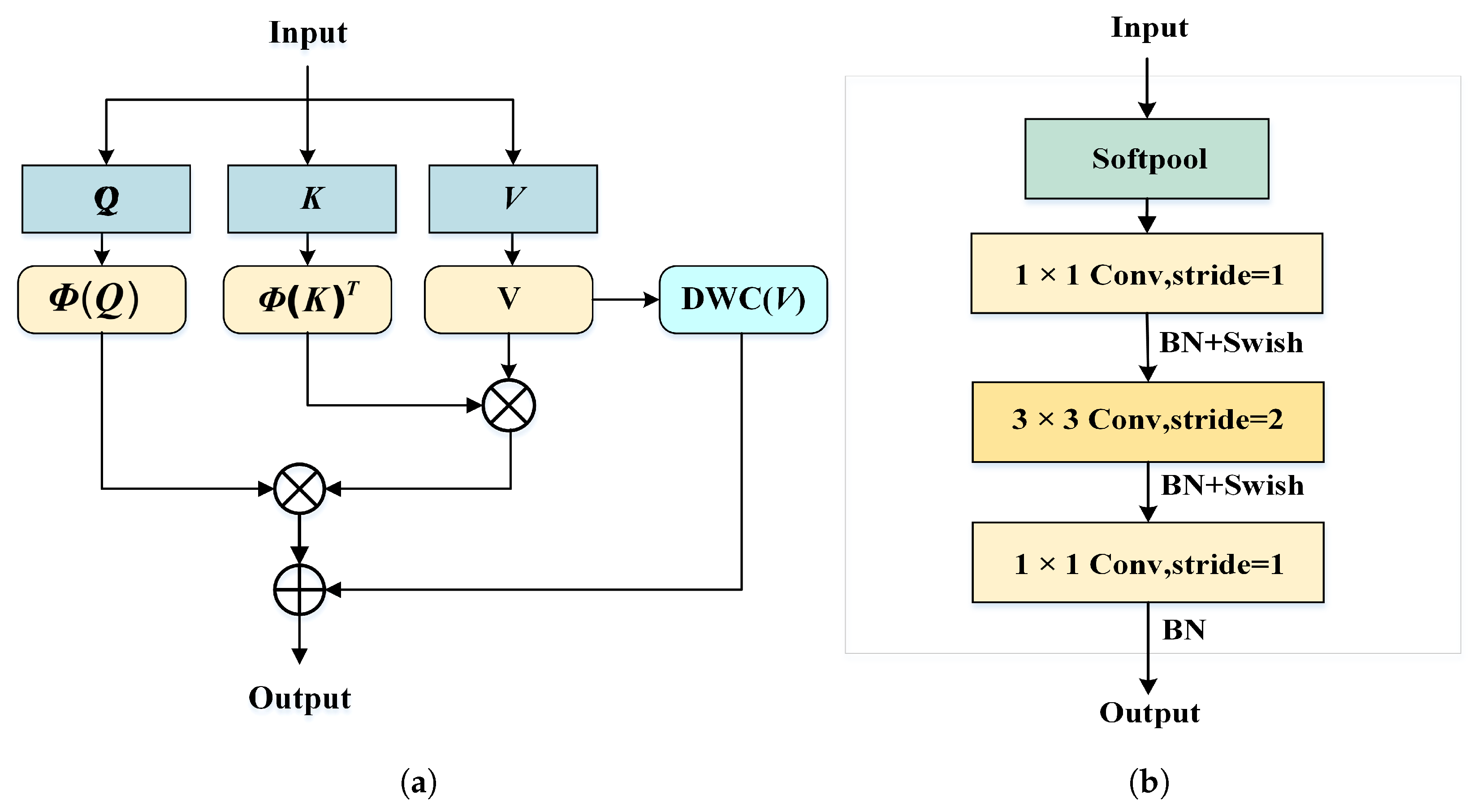
To reduce interference from irrelevant background regions, this paper proposes a lightweight Vision Transformer (LWVIT) for spatial feature refinement. Tokens with rich semantic information (TRFM) are processed via a global self-attention mechanism, focusing primarily on the tumor and surrounding areas. Moreover, the conventional self-attention in Transformers is replaced with a linear attention (LA) computation, and the order of information exchange is reorganized to decrease network complexity.
To further enhance the representation of local details in deep network layers, the original HF features of the image are incorporated into deeper layers, enhancing the model’s capacity to capture detailed information.
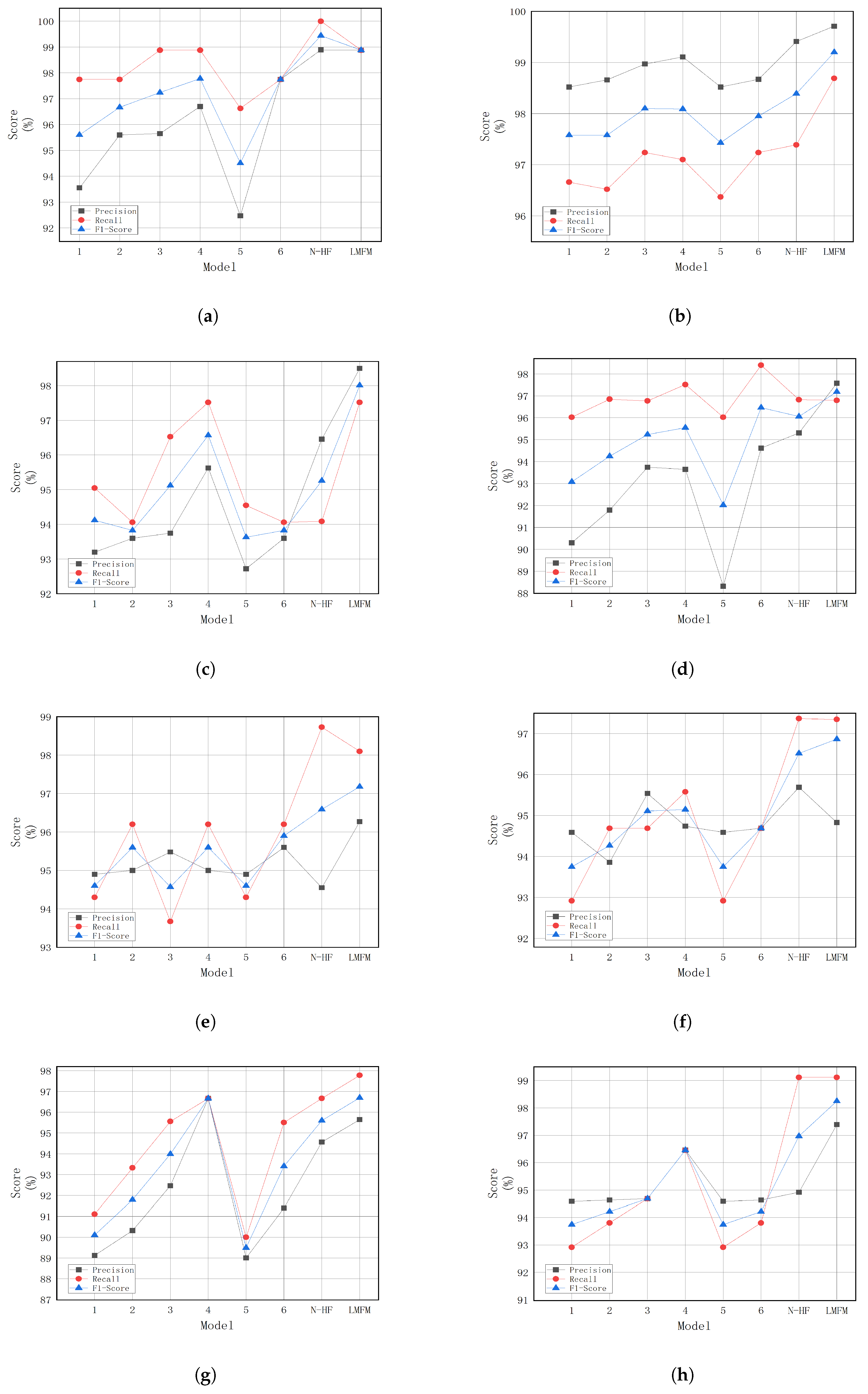
The LMFM model proposed in this study demonstrates superior accuracy and efficiency in breast tumor classification. Through efficient feature extraction and multi-frequency fusion, it enhances the recognition of tumor cell morphological characteristics, enabling not only the differentiation between benign and malignant tumors but also the precise identification of specific subtypes, thereby effectively reducing misdiagnosis in clinical practice. Its lightweight and efficient design makes it well-suited for resource-limited clinical settings, facilitating the broader adoption of breast cancer screening and improving diagnostic efficiency while reducing reliance on costly equipment. This, in turn, promotes the early detection and precise treatment of breast cancer in clinical practice.
The remainder of this paper is organized as follows:
Section 2 provides a description of the dataset and introduces a novel LMFM architecture along with its implementation. Subsequently,
Section 3 presents the experiments and results analysis to validate the effectiveness of the proposed model. Finally,
Section 4 concludes the paper and discusses future directions.


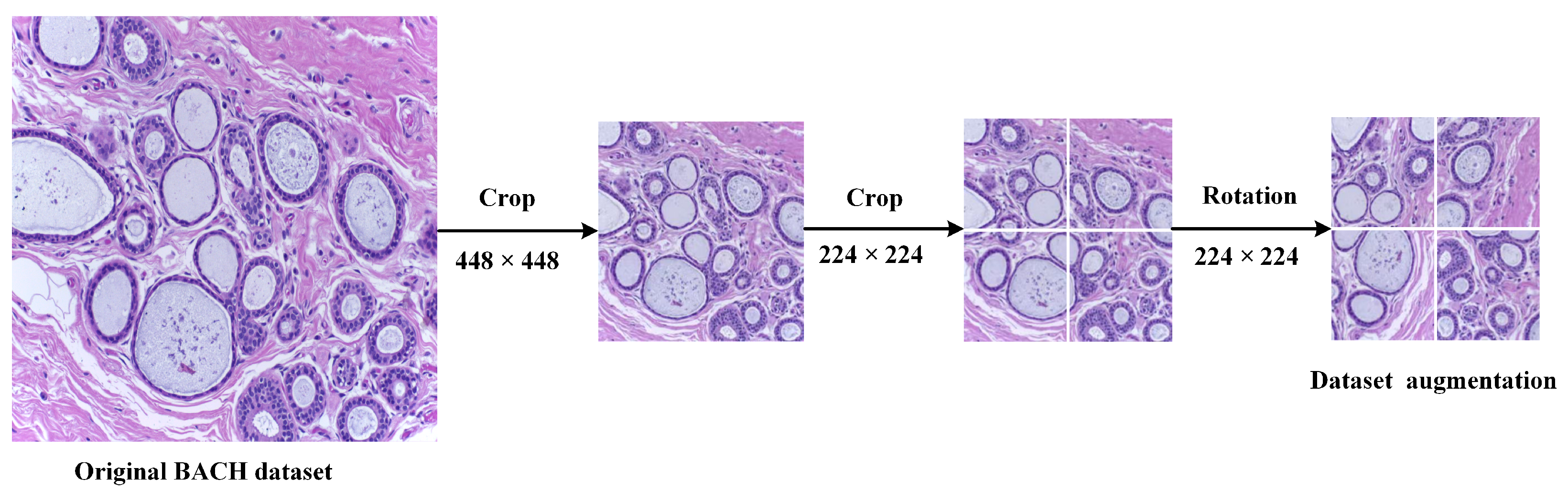



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}