
A YOLO11-Based Method for Segmenting Secondary Phases in Cu-Fe Alloy Microstructures

Abstract

1. Introduction
2. Related Work
- Efficient Segmentation Framework: Based on the YOLO11 backbone network, a segmentation architecture tailored for metallographic images is designed, balancing segmentation accuracy and computational efficiency to meet industrial automation detection requirements.
- Introduction of the EIEM Edge Enhancement Module, which strengthens the boundary perception of the secondary phase and improves the completeness and robustness of segmentation results by integrating explicit edge information with spatial features.
- The C2CGA module is proposed, introducing the Cascaded Group Attention (CGA) mechanism to enhance the model’s ability to recognize small-sized secondary phases and improve the accuracy of perceiving blurred boundaries.
- Design of the GDFPN feature fusion structure: By combining RepGFPN and DySample, the extraction of multi-scale features and the adaptive upsampling process are optimized to enhance the feature restoration capability for small targets.
- Development of a full-process metallographic image analysis system: An automated workflow from target detection to segmentation output is established, effectively enhancing the efficiency and consistency of traditional metallographic analysis.
3. Method
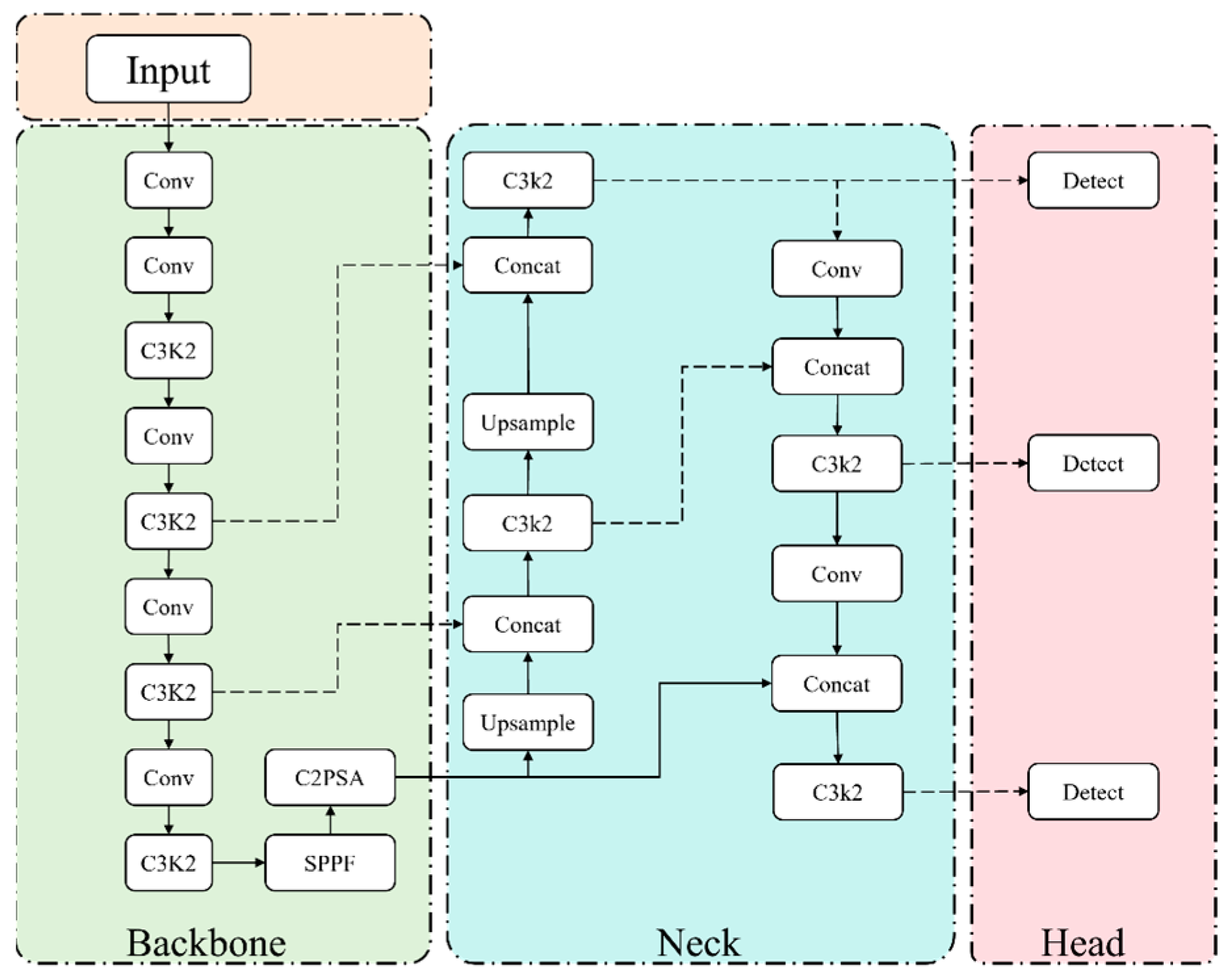
3.1. YOLO11 Network Structure
3.1.1. C3k2 Module
3.1.2. C2PSA Module
3.2. YOLO11 Algorithm Improvements
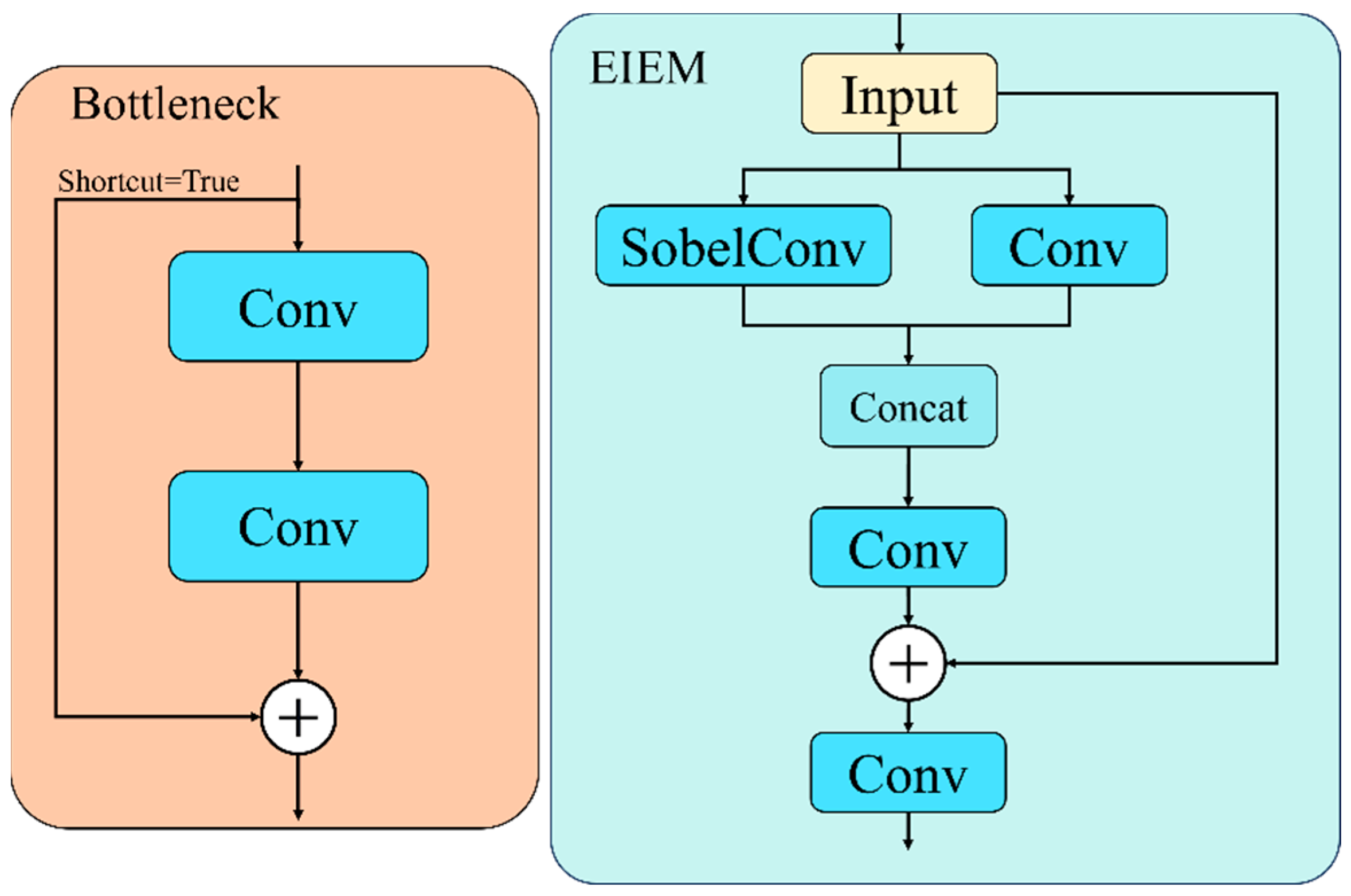
3.2.1. Edge Information Enhancement Module
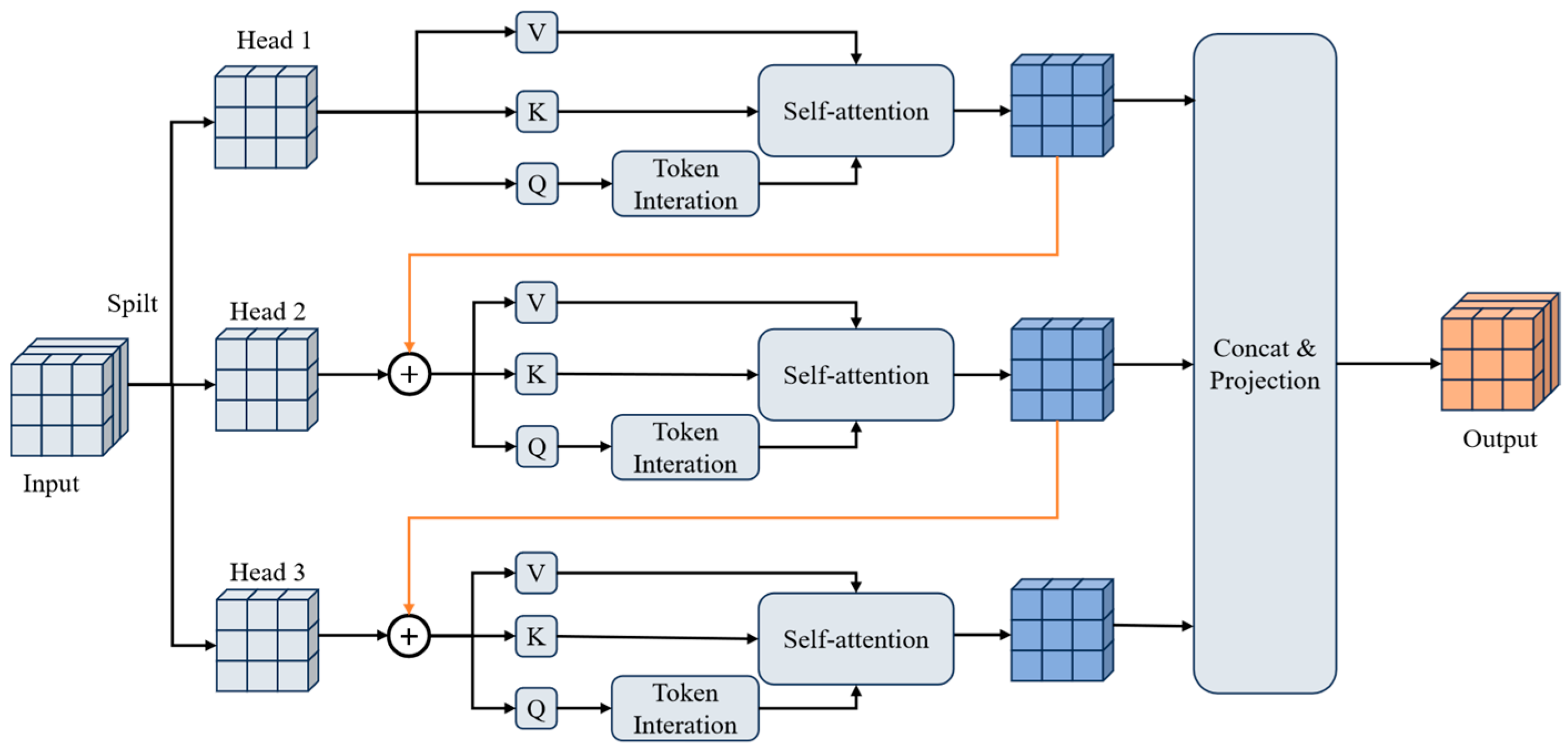
3.2.2. Cross Stage Partial with Cascaded Group Attention
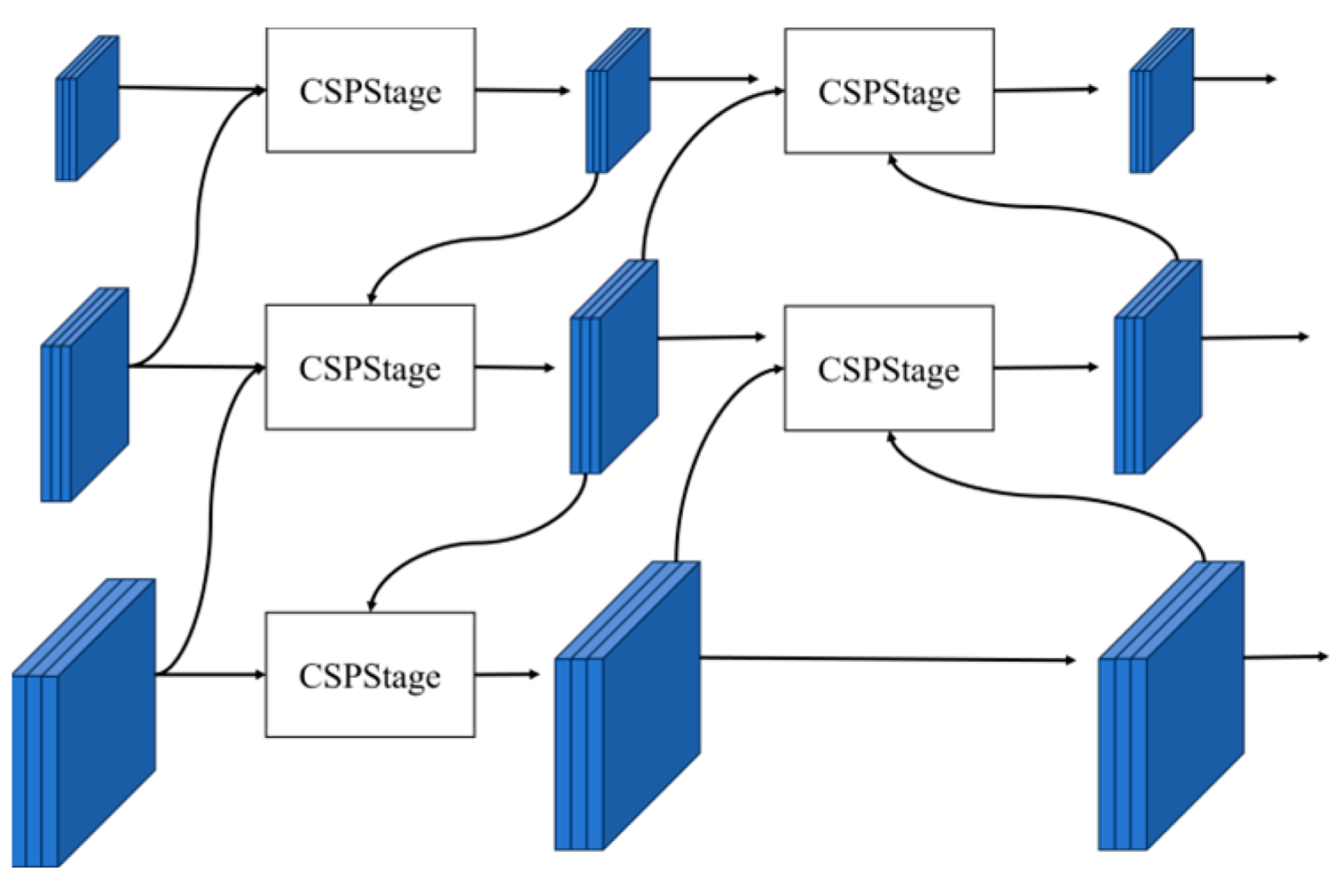
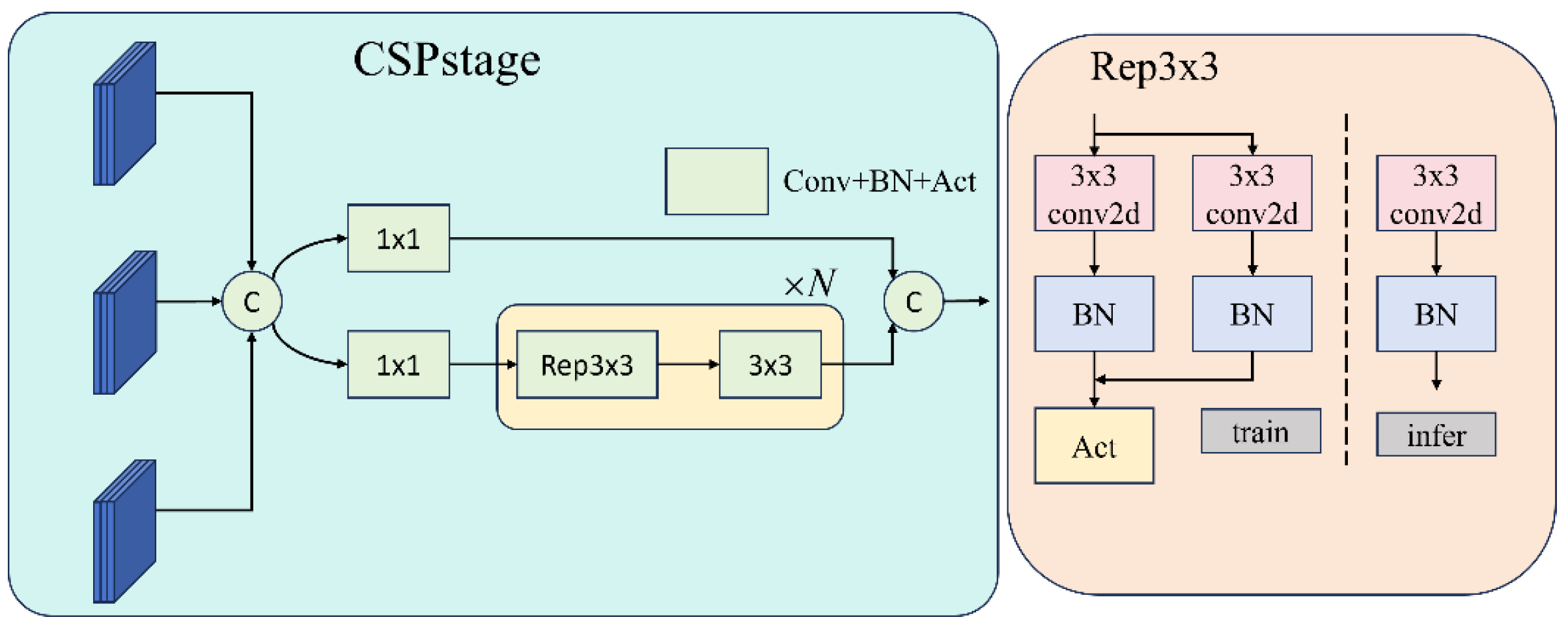
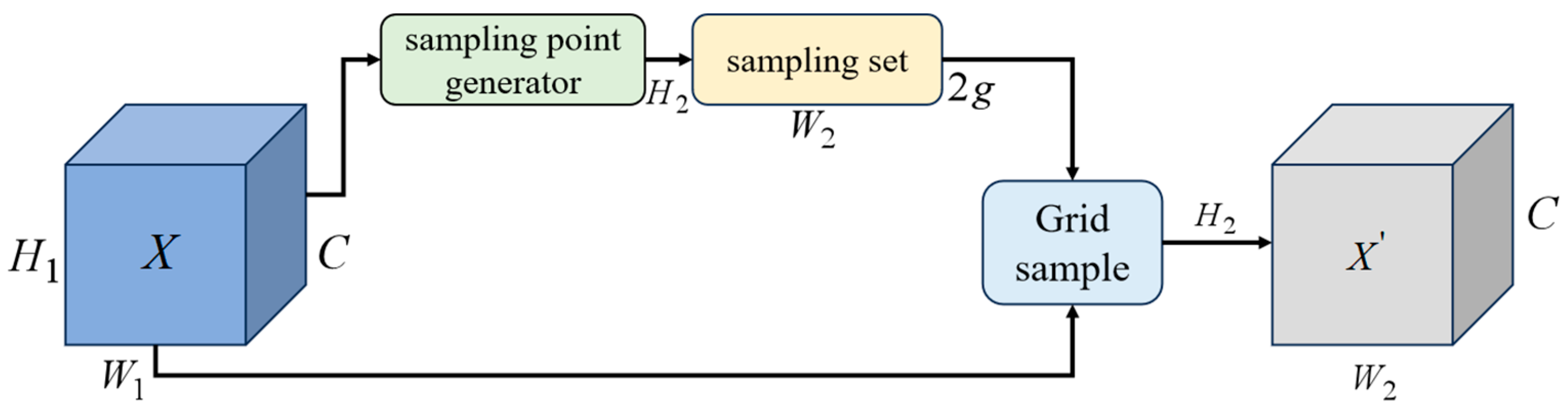
3.2.3. Efficient Feature Fusion and Dynamic Upsampling
4. Experimental
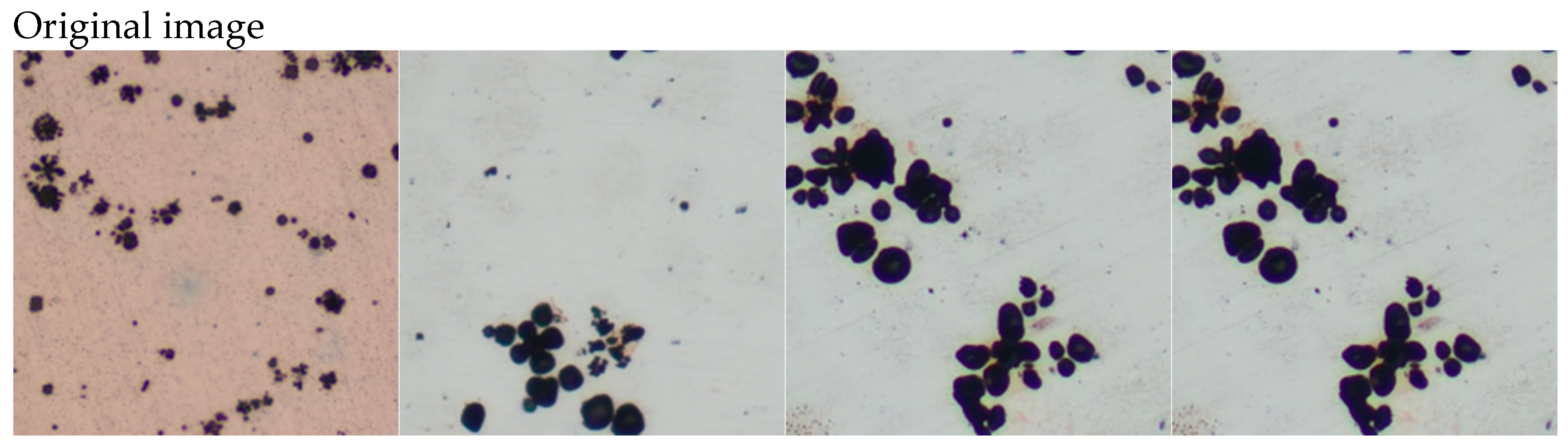
4.1. Experimental Environment and Dataset
4.2. Evaluation Metrics
4.3. Experimental Results and Analysis
4.3.1. Comparison of YOLO Series Algorithms
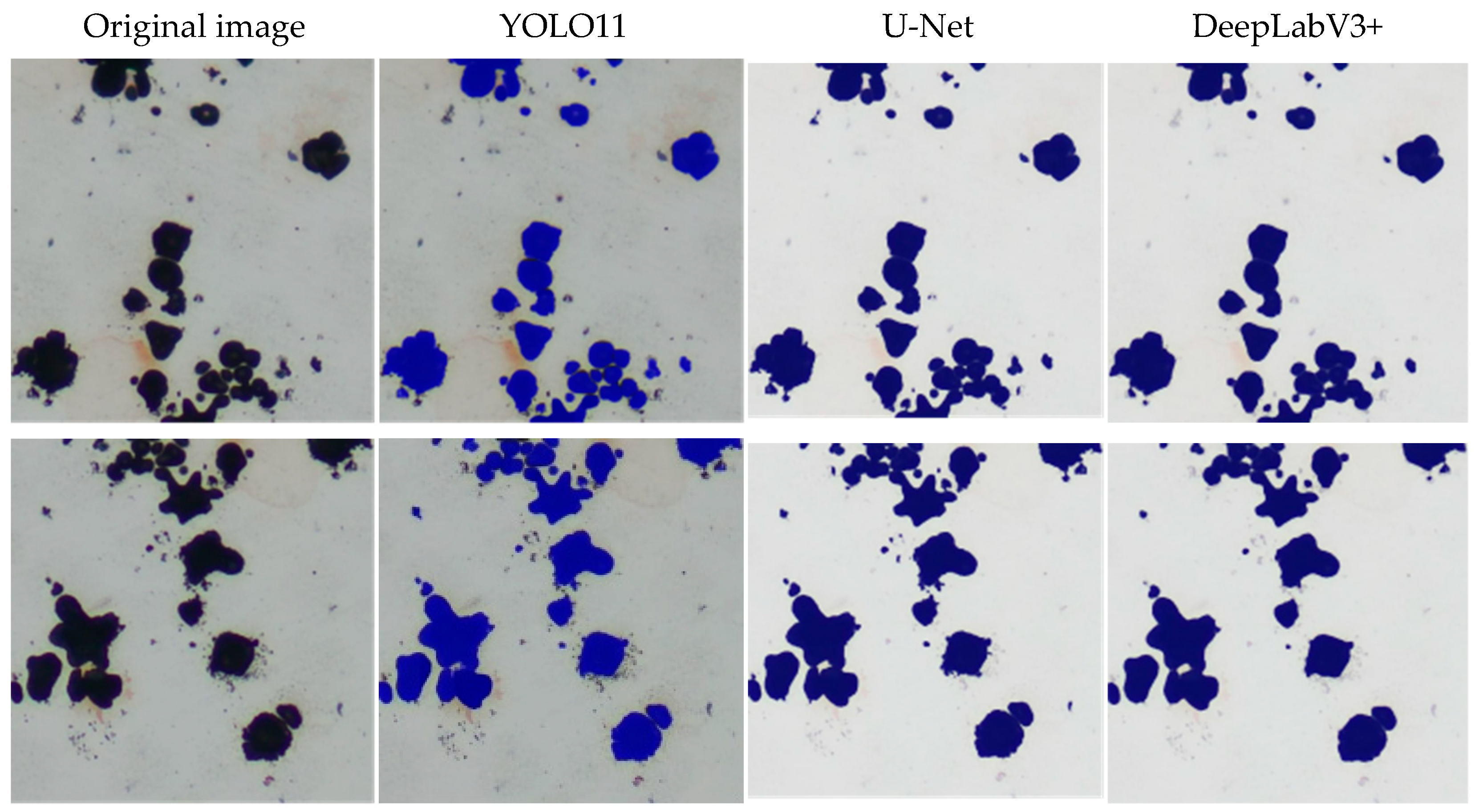
4.3.2. Comparison with Different Types of Segmentation Algorithms
4.3.3. Ablation Experiment and Performance Analysis
- (1)
- EIEM Module: After its introduction, Precision increased to 81.2% (+1.9%), Recall rose to 80.5% (+1.9%), and mAP reached 86.9% (+1.4%). Meanwhile, the parameter count decreased to 2.79 M, FPS improved to 270 (+62), model size slightly reduced to 6.0 MB, and computational cost slightly increased to 10.4 GFLOPs, achieving simultaneous improvements in accuracy and efficiency. The EIEM module enhances edge information perception, significantly improving the clarity and integrity of segmentation boundaries. This leads to a 1.9% increase in both precision and recall, effectively reducing mis-segmentation and ensuring detection accuracy and efficiency.
- (2)
- C2CGA Module: Recall showed a slight increase (+0.2%), mAP remained stable, and Precision slightly decreased (−0.7%). However, the parameter count reduced, FPS rose to 303, while computational cost and model size remained unchanged, enhancing efficiency and model lightweightness. This module employs a cascaded group attention mechanism to strengthen focus on small targets and detailed regions. Although precision slightly decreased, the improved recall indicates better detection of tiny targets alongside increased inference speed.
- (3)
- GDFPN Module: This module significantly improved Precision (+2.5%), Recall (+1.6%), and mAP (+1.2%). The trade-off was an increase in parameters to 3.99 M, GFLOPs to 12.4, and model size to 8.4 MB. Nevertheless, FPS stayed at 303, reflecting a good balance between performance and computational cost. GDFPN optimizes multi-scale feature fusion and adaptive upsampling, enhancing recognition of targets at varying scales and resulting in notable accuracy improvements without sacrificing inference speed.
- (4)
- All three modules combined: Precision increased to 84.6%, Recall to 81.0%, and mAP reached 89.0%, achieving the best overall performance. Although parameters increased to 3.91 M, GFLOPs to 12.2, and model size to 8.3 MB, FPS remained at 256. This combination balances accuracy, speed, and resource consumption, demonstrating the significant advantage of module synergy. Figure 14 presents a comparison of different model performances. The collaborative effect of these modules comprehensively enhances edge perception, small target attention, and multi-scale fusion, thereby significantly improving segmentation performance and model robustness while maintaining an optimal trade-off among accuracy, speed, and computational efficiency.
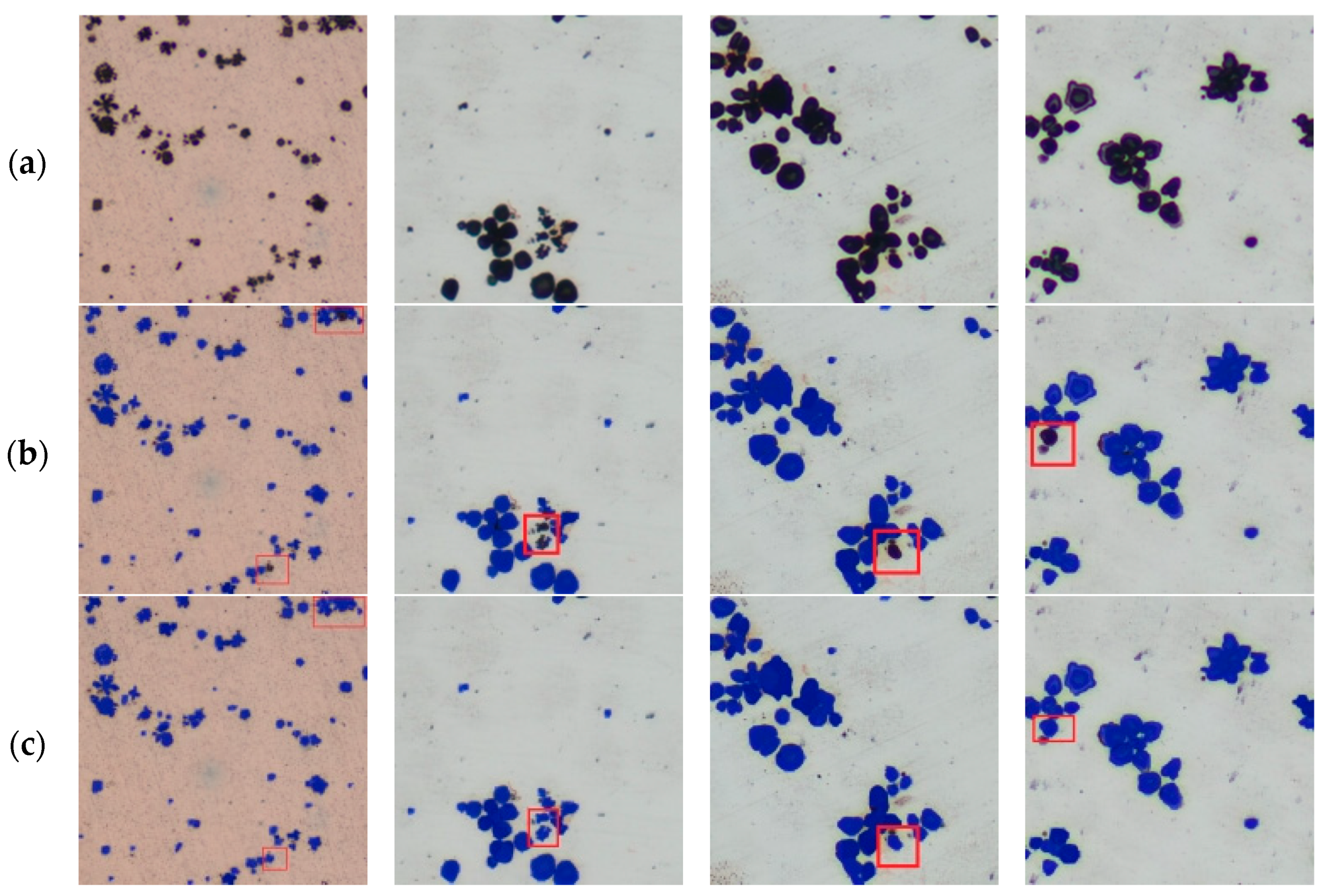
4.3.4. Experimental Summary
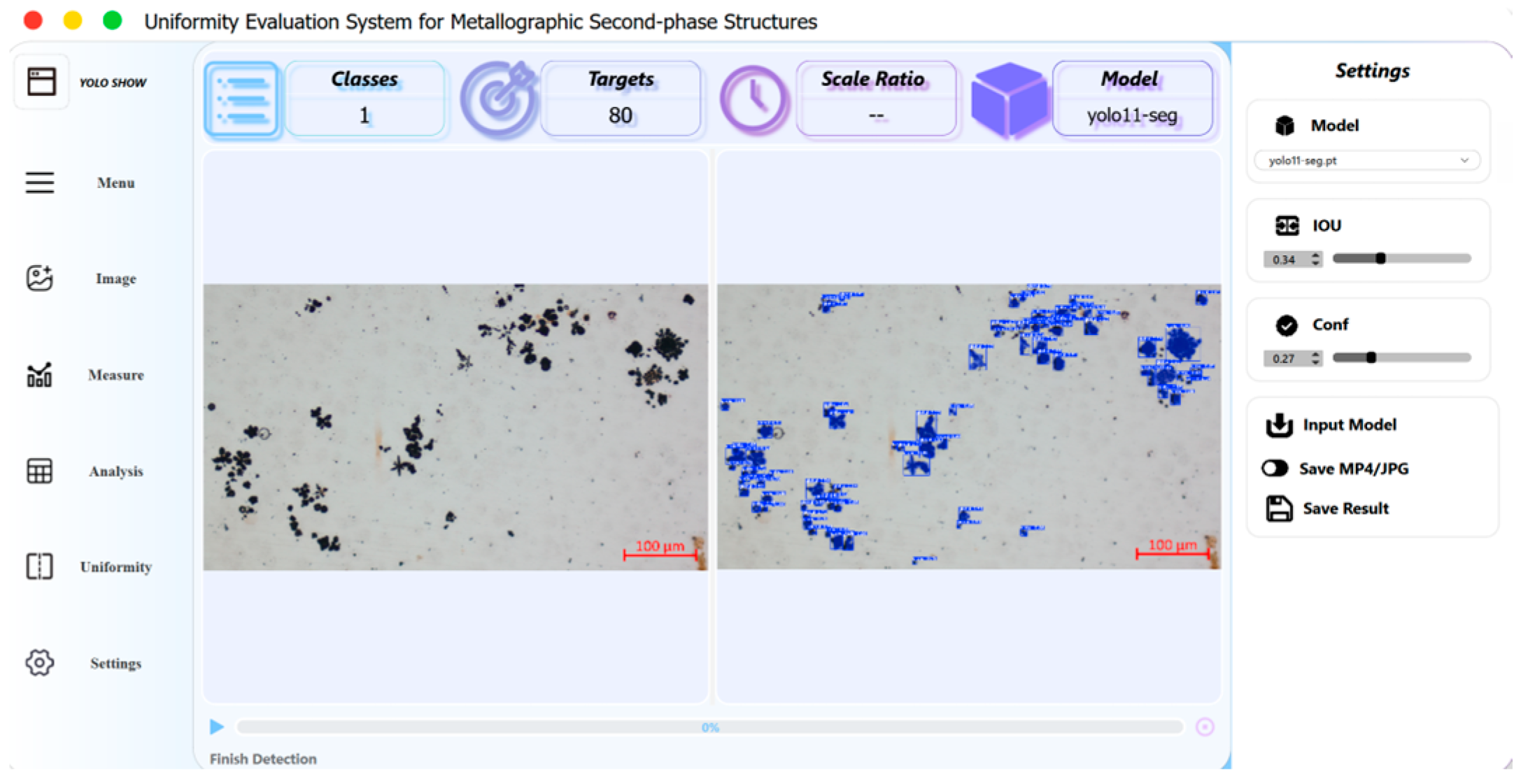
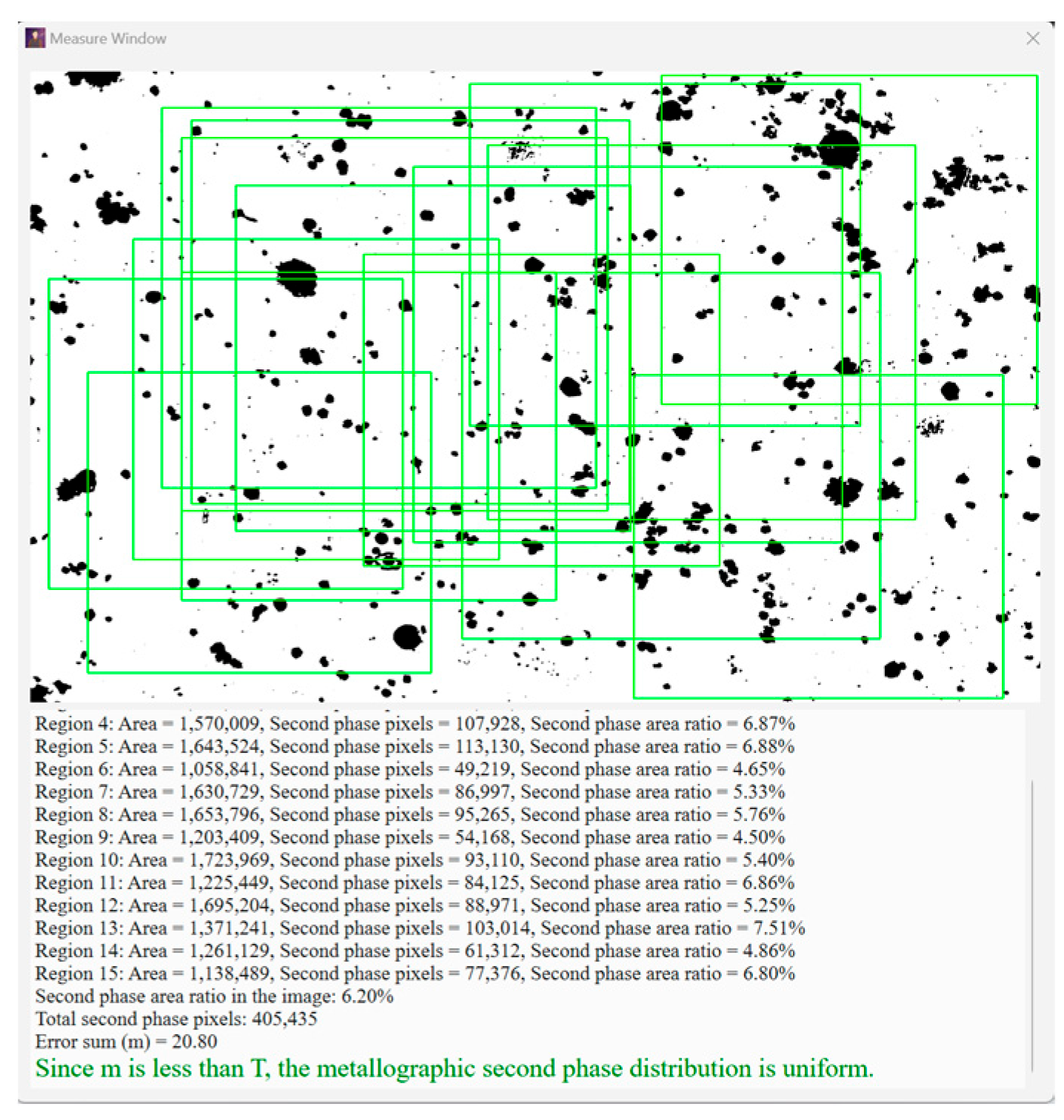
5. Application System
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, Y.X.; Lou, H.F.; Xie, H.F. Development Status and Prospects of Advanced Copper Alloy. Strateg. Study Chin. Acad. Eng. 2020, 22, 84–92. [Google Scholar] [CrossRef]
- Alireza, V.N.; Mahya, G.; Kazem, S.B. Advancements in Additive Manufacturing for Copper-Based Alloys and Composites: A Comprehensive Review. J. Manuf. Mater. Process. 2024, 8, 54. [Google Scholar] [CrossRef]
- Mi, X.J.; Lou, H.F.; Xie, H.F. Development strategy for advanced copper-based materials in China. Eng. Sci. China 2023, 25, 96–103. [Google Scholar] [CrossRef]
- Xu, Y.T.; Pei, L.; Dai, J.M. Comparison of Microstructure and Mechanical Properties of Several Cathode Copper Materials. Rare Met. Mater. Eng. 2023, 52, 4171–4183. [Google Scholar]
- Han, Z.E.; Wang, X.F.; Li, Y.G. Preparation and performance of Cu-Fe alloy. Foundry Eng. 2023, 44, 849–854. [Google Scholar] [CrossRef]
- Wang, K.H.; Xu, Y.Y. The effect of aging temperature on the precipitation of Cu-rich phase in Fe-Cu-Mn-Ni alloy was studied by field method. Met. Meat Treat. 2023, 48, 265–270. [Google Scholar]
- Sun, W.B.; Wu, S.R.; Wu, T.M. High performance Cu-Fe alloy strip and its short process preparation technology. J. Shenyang Univ. Technol. 2024, 46, 403–408. [Google Scholar]
- Wang, X.C.; Zhang, X.Y. Modern Analytical and Testing Techniques for Materials, 2nd ed.; National Defense Industry Press: Beijing, China, 2010. [Google Scholar]
- Yao, Y.C.; Du, Q.; Cai, H.; Jin, J.M. (Eds.) Metallographic Inspection and Analysis; China Machine Press: Beijing, China, 2021. [Google Scholar]
- Zhu, X.Y.; Zhang, Z.H.; Mao, Y. Applying deep learning in automatic and rapid measurement of lattice spacings in HRTEM images. Sci. China Mater. 2020, 63, 2365–2370. [Google Scholar] [CrossRef]
- Ban, X.J.; Su, Y.J.; Xie, J.X. Application and Challenges of Deep Learning in Microstructure Image Analysis of Materials. Mater. Sci. Technol. 2020, 28, 68–75. [Google Scholar]
- Sun, Y.L.; Huang, X.Y. CMAA: Channel-wise multi-scale adaptive attention network for metallographic image semantic segmentation. Expert Syst. Appl. 2025, 276, 126925. [Google Scholar] [CrossRef]
- Shi, W.; Zhao, H.; Zhang, H.R. Wire melted mark metallographic image recognition and classification based on semantic segmentation. Expert Syst. Appl. 2024, 238, 122146. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Zhang, Y.Z.; Bai, G.T. Study on the evaluation method of steel microstructure for thermal power units based on deep learning. Inn. Mong. Electr. Power Technol. 2024, 42, 78–83. [Google Scholar] [CrossRef]
- Azimi, S.M.; Britz, D.; Engstler, M. Advanced Steel Microstructural Classification by Deep Learning Methods. Sci. Rep. 2018, 8, 2128. [Google Scholar] [CrossRef] [PubMed]
- Tao, Y.T.; Li, P.P.; Xu, Y.T. Grain boundary segmentation and restoration based on deep learning and digital image processing. Rail Transit Mater. 2024, 3, 6–11. [Google Scholar]
- Yang, X.D. Study on classification and identification of metallographic structure based on ViT. Electron. Technol. Softw. Eng. 2022, 3, 154–158. [Google Scholar] [CrossRef]
- Xu, Y.F.; Zhang, Y.W.; Zhang, M.Z. Quantitative Analysis of Metallographic Image Using Attention-Aware Deep Neural Networks. Sensors 2021, 21, 43. [Google Scholar] [CrossRef]
- Dong, J.J.; Ren, Z.J.; Su, C. Carburized Gear Metallographic Image Segmentation Algorithm Based on Deep-Learning. Light Ind. Mach. 2024, 42, 66–73. [Google Scholar]
- Bu, S.C.; Cheng, K. Deep learning-based segmentation method for pure iron grain microstructure images. Comput. Digit. Eng. 2024, 52, 3697–3702. [Google Scholar]
- Ajioka, F.; Wang, Z.L.; Ogawa, T. Development of high accuracy segmentation model for microstructure of steel by deep learning. ISIJ Int. 2022, 60, 954–959. [Google Scholar] [CrossRef]
- Jang, J.; Van, D.; Jang, H. Residual neural network-based fully convolutional network for microstructure segmentation. Sci. Technol. Weld. Join. 2022, 25, 282–289. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Wu, S.W.; Cao, G.M. Deep learning-based strengthening and refinement analysis of microstructure characteristics of ultra-low carbon steel. Steel 2024, 60, 1–9. [Google Scholar] [CrossRef]
- Zhang, L.X.; Che, S.J.; Xu, Z.G. Residual network-based microstructure image segmentation method for high-temperature alloys. Sci. Technol. Eng. 2020, 20, 246–251. [Google Scholar]
- He, H.Z. Automation Recognition of Steel Metallographic Structure Based on Deep Learning. Master’s Thesis, Wuhan University of Engineering, Wuhan, China, 2022. [Google Scholar] [CrossRef]
- Ma, B.Y.; Liu, C.N.; Gao, M.F. Deep learning and region-aware method for polycrystalline microstructure image segmentation. Chin. J. Stereol. Image Anal. 2020, 25, 120–127. [Google Scholar] [CrossRef]
- Ye, W.L. Research on Identification and Segmentation Method of Metallographic Structure of Heat-Resistant Steel Based on Deep Learning. Master’s Thesis, . Inner Mongolia Agricultural University, Hohhot, China, 2024. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W. Damo-yolo: A report on real-time object detection design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6027–6037. [Google Scholar]
- He, R.; Tursun, M.; Liu, J.; Zhu, X.; He, C.; Dong, J.; Xu, L. Road Surface Crack Detection Based on Improved YOLOv8n. Mod. Comput. 2024, 30, 20–25. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Sun, Y.Y.; Wang, S. Rapid Development and Practical Projects with PySide6/PyQt6; China Industry and Information Publishing Group: Beijing, China: Beijing, China; Electronics Industry Press: Beijing, China, 2023. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Configuration Parameters |
|---|---|
| Operating System | Win10 |
| CPU Model | Intel(R) Core (TM) i7-14650HX 2.2 GHz |
| GPU Model | NVIDIA GeForce RTX 4060 Laptop GPU |
| RAM | 16 GB |
| Deep Learning Framework | PyTorch 2.2.2 + CUDA 12.1 + cuDNN 8.8.1 |
| Development Environment | Pycharm 2020.1.1 x64 |
| Model | Recall (%) | Precision (%) | mAP (%) | FPS | GFLOPS | Weight (MB) |
|---|---|---|---|---|---|---|
| YOLOv5 | 78.7 | 79.6 | 85.0 | 102 | 25.9 | 14.5 |
| YOLOv7 | 77.3 | 80.1 | 84.5 | 40 | 141.9 | 76.3 |
| YOLOv8 | 78.8 | 78.1 | 85.1 | 115 | 42.9 | 23.9 |
| YOLOv9 | 78.7 | 78.6 | 85.0 | 18 | 368.6 | 116.6 |
| YOLO11 | 78.6 | 79.3 | 85.5 | 208 | 10.2 | 6.1 |
| Model | mAP/MIOU (%) | FPS | GFLOPS | Parameters (M) |
|---|---|---|---|---|
| U-Net | 86.2 | 21.5 | 288.6 | 43.9 |
| DeepLabV3+ | 84.7 | 59.6 | 82.8 | 5.8 |
| YOLO11 | 85.5 | 208 | 10.2 | 2.7 |
| Modules | Precision (%) | Recall (%) | mAP (%) | Params (M) | FPS | GFLOPS | Weight (MB) | ||
|---|---|---|---|---|---|---|---|---|---|
| EIEM | C2CGA | GDFPN | |||||||
| ✗ | ✗ | ✗ | 79.3 | 78.6 | 85.5 | 2.83 | 208 | 10.2 | 6.1 |
| ✓ | ✗ | ✗ | 81.2 | 80.5 | 86.9 | 2.79 | 270 | 10.4 | 6.0 |
| ✗ | ✓ | ✗ | 78.6 | 79.4 | 85.5 | 2.81 | 303 | 10.2 | 6.1 |
| ✗ | ✗ | ✓ | 81.8 | 80.2 | 86.7 | 3.99 | 303 | 12.4 | 8.4 |
| ✓ | ✓ | ✗ | 82.6 | 80.7 | 88.1 | 2.77 | 256 | 10.4 | 6.0 |
| ✗ | ✓ | ✓ | 82.1 | 80.3 | 87.0 | 3.97 | 294 | 12.4 | 8.4 |
| ✓ | ✗ | ✓ | 82.7 | 81.3 | 88.3 | 3.94 | 178 | 12.2 | 8.3 |
| ✓ | ✓ | ✓ | 84.6 | 81.0 | 89.0 | 3.91 | 256 | 12.2 | 8.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, Q.; Wu, R.; Zhang, Z.; Li, Y.; Chang, Q.; Liu, W.; Huang, X. A YOLO11-Based Method for Segmenting Secondary Phases in Cu-Fe Alloy Microstructures. Information 2025, 16, 570. https://doi.org/10.3390/info16070570
Jing Q, Wu R, Zhang Z, Li Y, Chang Q, Liu W, Huang X. A YOLO11-Based Method for Segmenting Secondary Phases in Cu-Fe Alloy Microstructures. Information. 2025; 16(7):570. https://doi.org/10.3390/info16070570
Chicago/Turabian StyleJing, Qingxiu, Ruiyang Wu, Zhicong Zhang, Yong Li, Qiqi Chang, Weihui Liu, and Xiaodong Huang. 2025. "A YOLO11-Based Method for Segmenting Secondary Phases in Cu-Fe Alloy Microstructures" Information 16, no. 7: 570. https://doi.org/10.3390/info16070570
APA StyleJing, Q., Wu, R., Zhang, Z., Li, Y., Chang, Q., Liu, W., & Huang, X. (2025). A YOLO11-Based Method for Segmenting Secondary Phases in Cu-Fe Alloy Microstructures. Information, 16(7), 570. https://doi.org/10.3390/info16070570