
Real-Time Object Detection Model for Electric Power Operation Violation Identification


Abstract
1. Introduction
- (1)
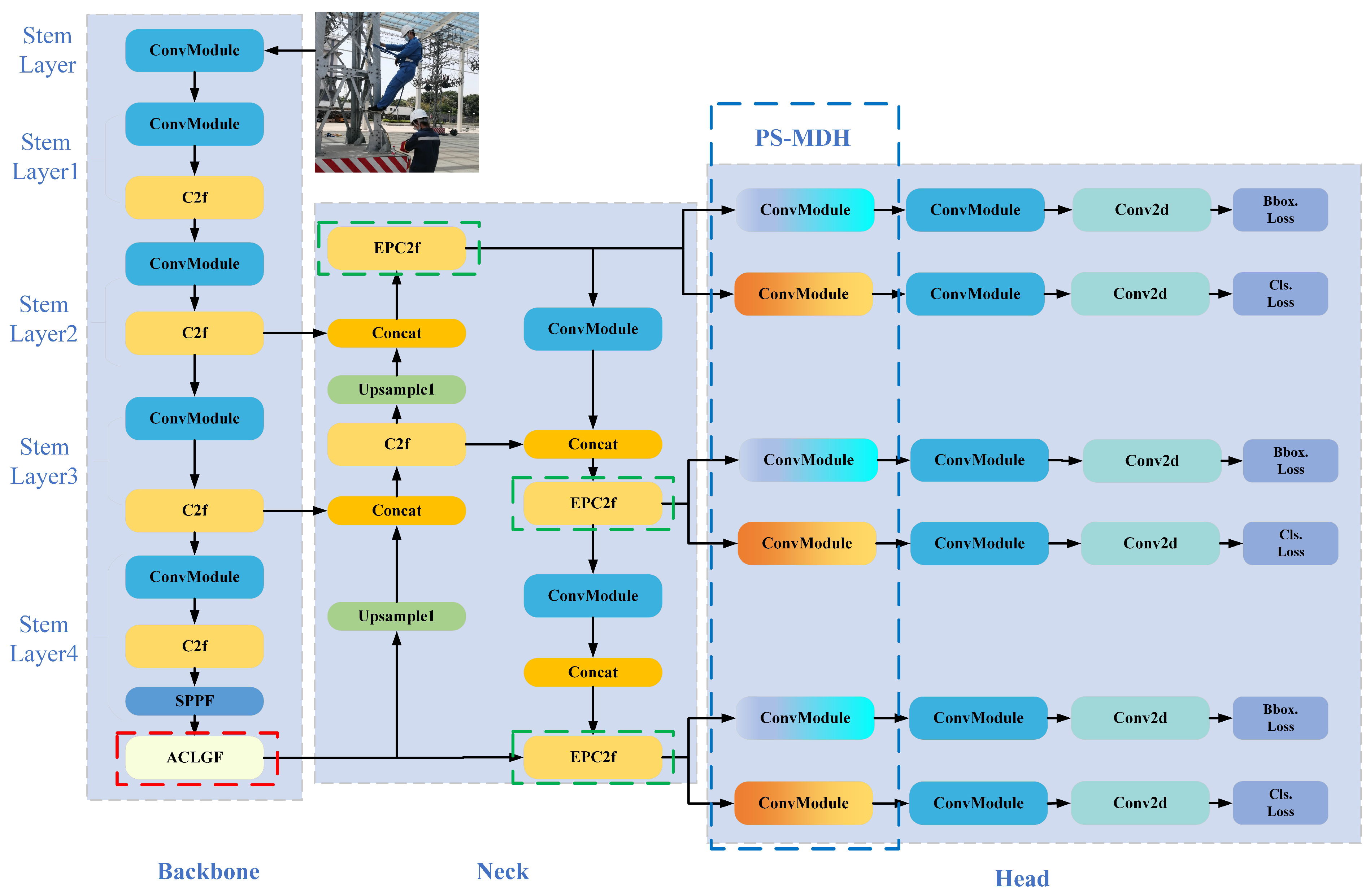
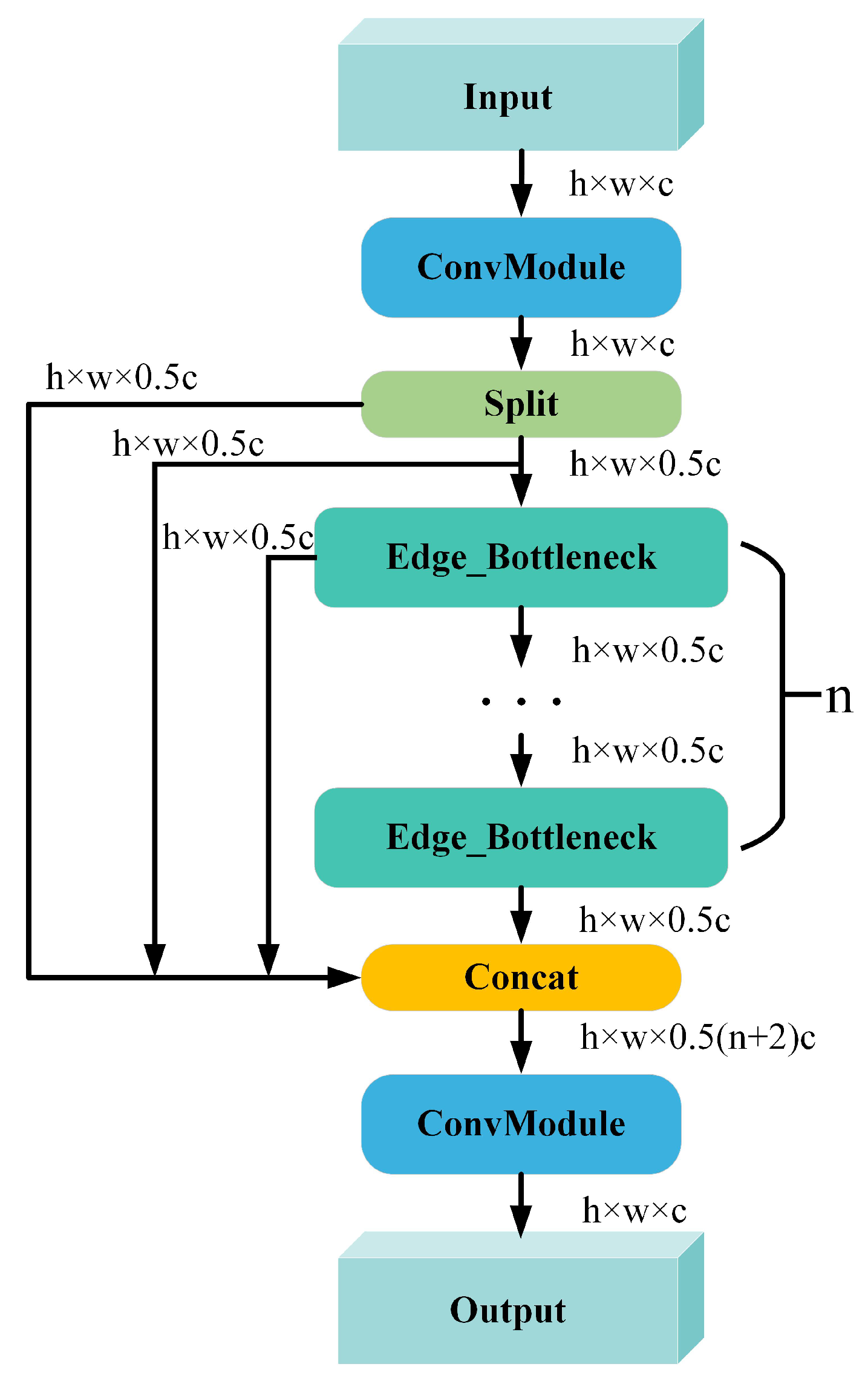
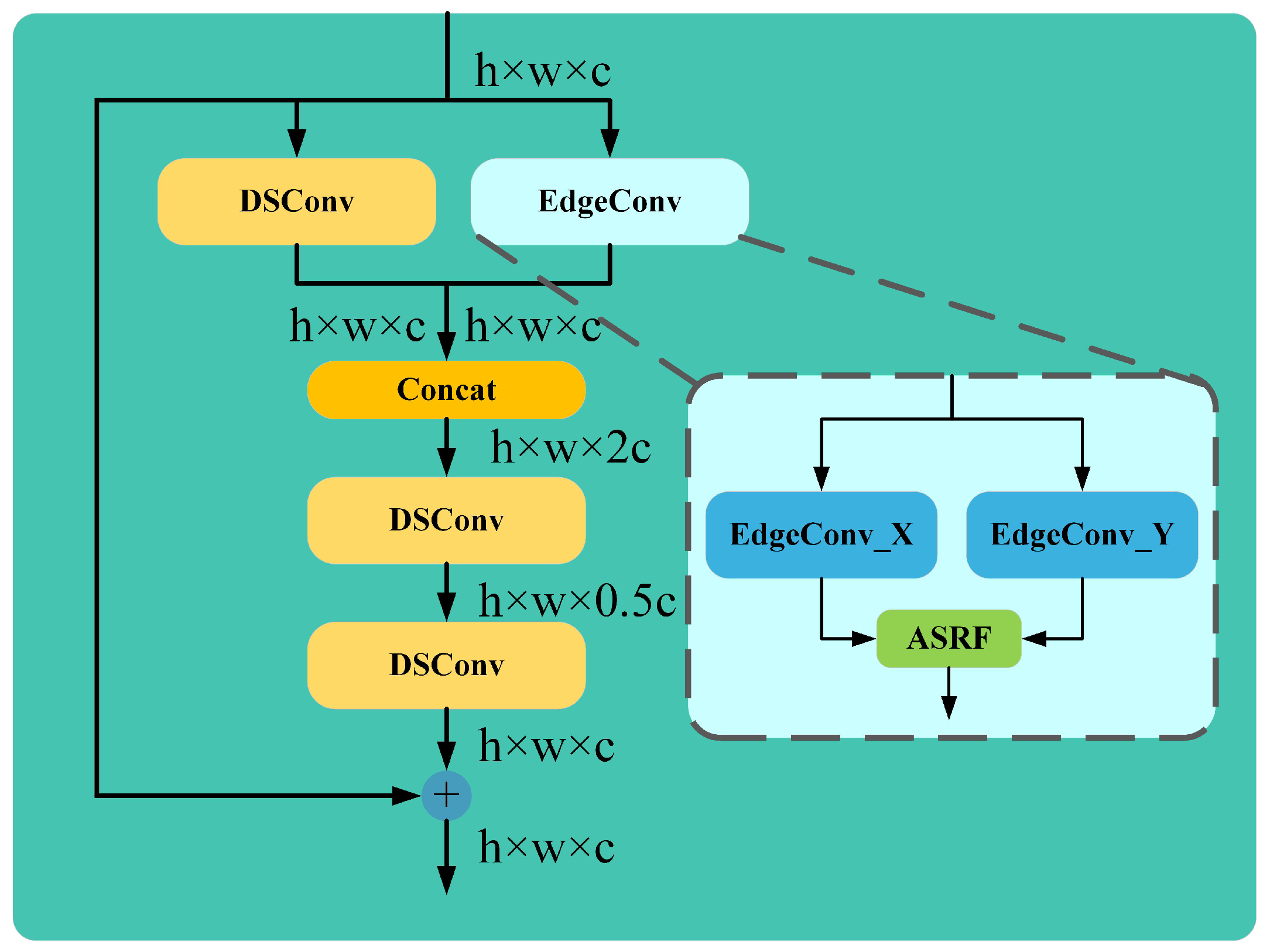
- To address the challenge of detecting irregularly shaped objects, an edge perception cross-stage partial fusion with two convolutions (EPC2f) module is proposed. The EPC2f module replaces the bottleneck in cross-stage partial fusion with two convolutions (C2f) with an edge_bottleneck to enhance the extraction of object contour features, thereby improving the model’s ability to detect irregularly shaped objects.
- (2)
- To address the detection problem when there is insufficient contrast between the target and background, we propose an adaptive combination of local and global features (ACLGF) module. The ACLGF module adaptively fuses local and global features with a learnable weight, significantly enhancing the discriminative ability of the features and enabling the model to detect targets even when the contrast with the background is insufficient.
- (3)
- In order to improve the detection accuracy without increasing the number of model parameters, a parameter sharing of multi-scale detection heads (PS-MDH) scheme is proposed. Through parameter sharing, on the one hand, the number of parameters and the computation amount of the detection head part are reduced; on the other hand, the information interaction between different-scale detection heads is realized, which improves the detection capability of the model for multi-scale targets.
- (4)
- The effectiveness of the EAP-YOLO model in improving detection accuracy while reducing parameter size and computational cost is validated through comparative experiments against mainstream YOLO models on the dataset provided by the Alibaba Tianchi competition.
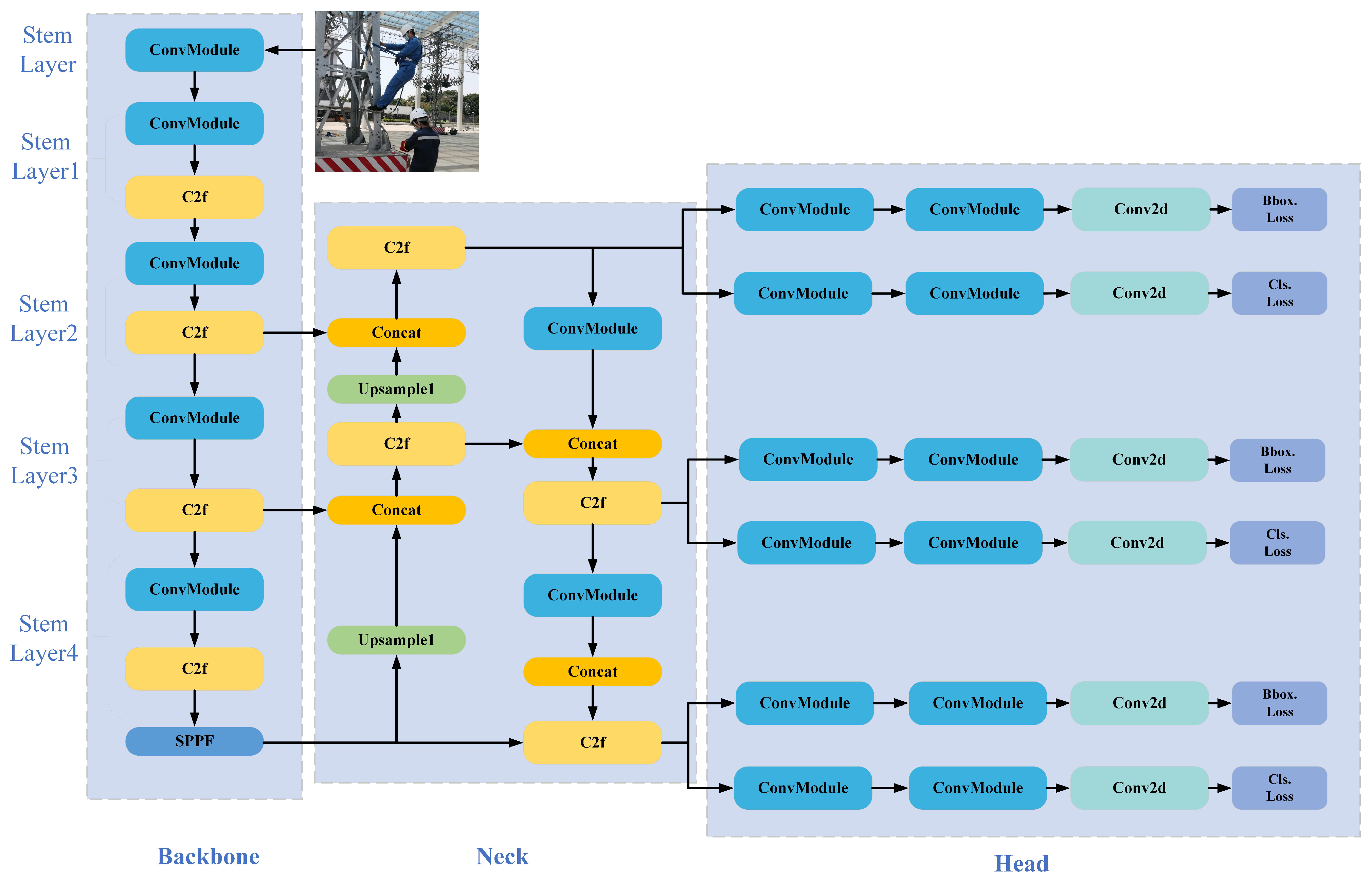
2. Baseline Model
3. Proposed Method
3.1. Overview
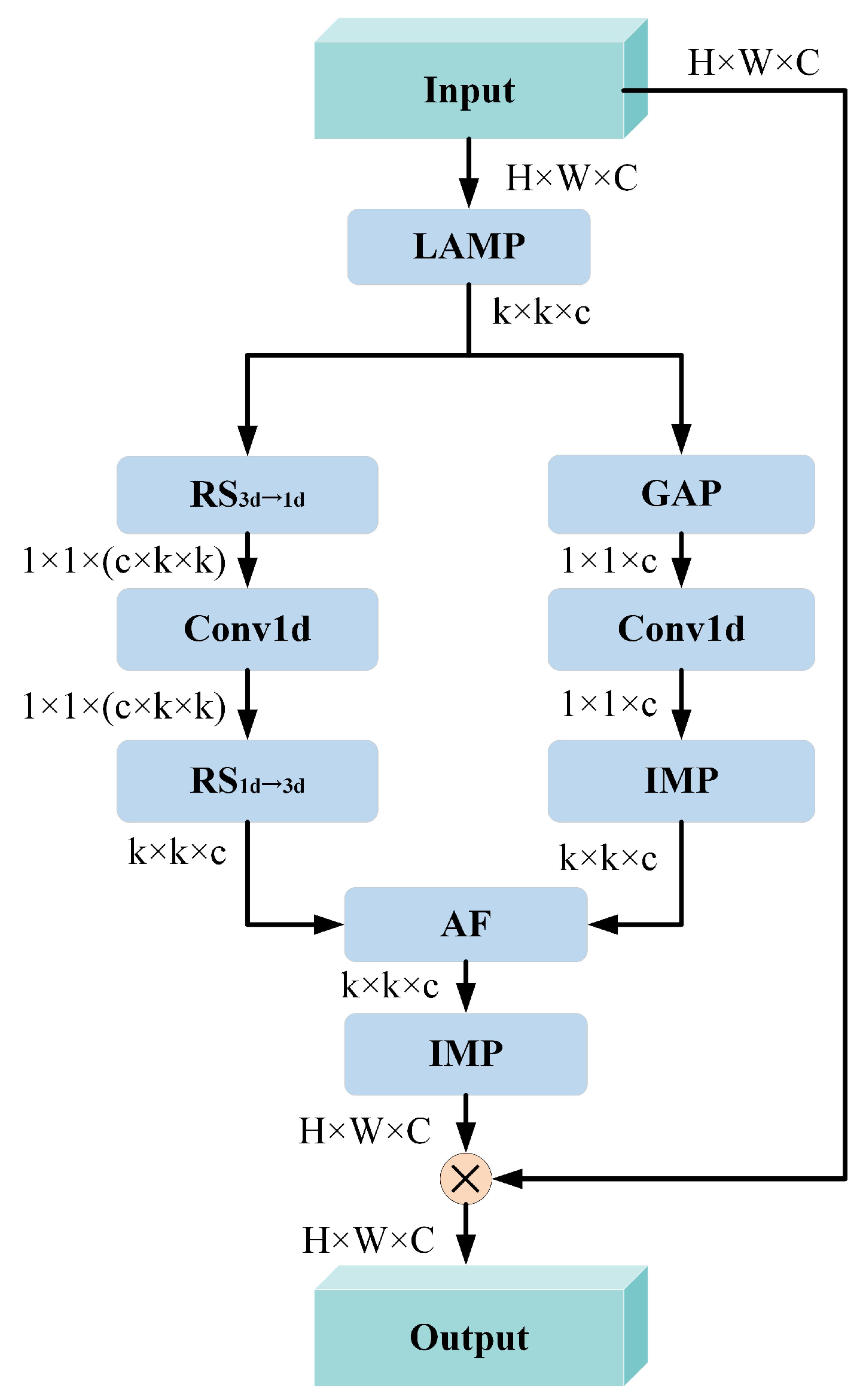
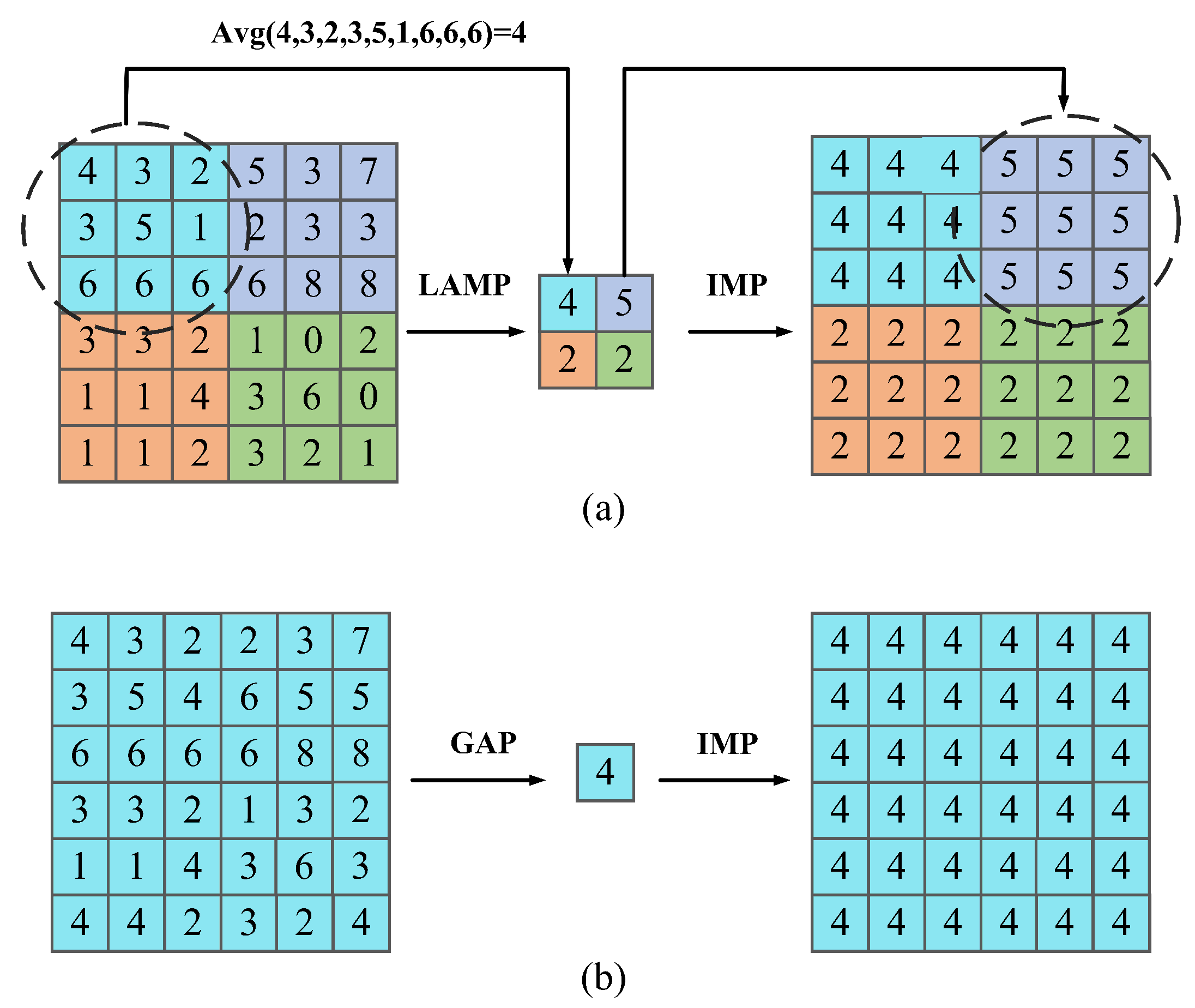
3.2. ACLGF Module
3.3. EPC2f Module
3.4. PS-MDH Scheme
4. Experimental Results and Analysis
4.1. Dataset
4.2. Implementation Details
4.3. Evaluation Metrics
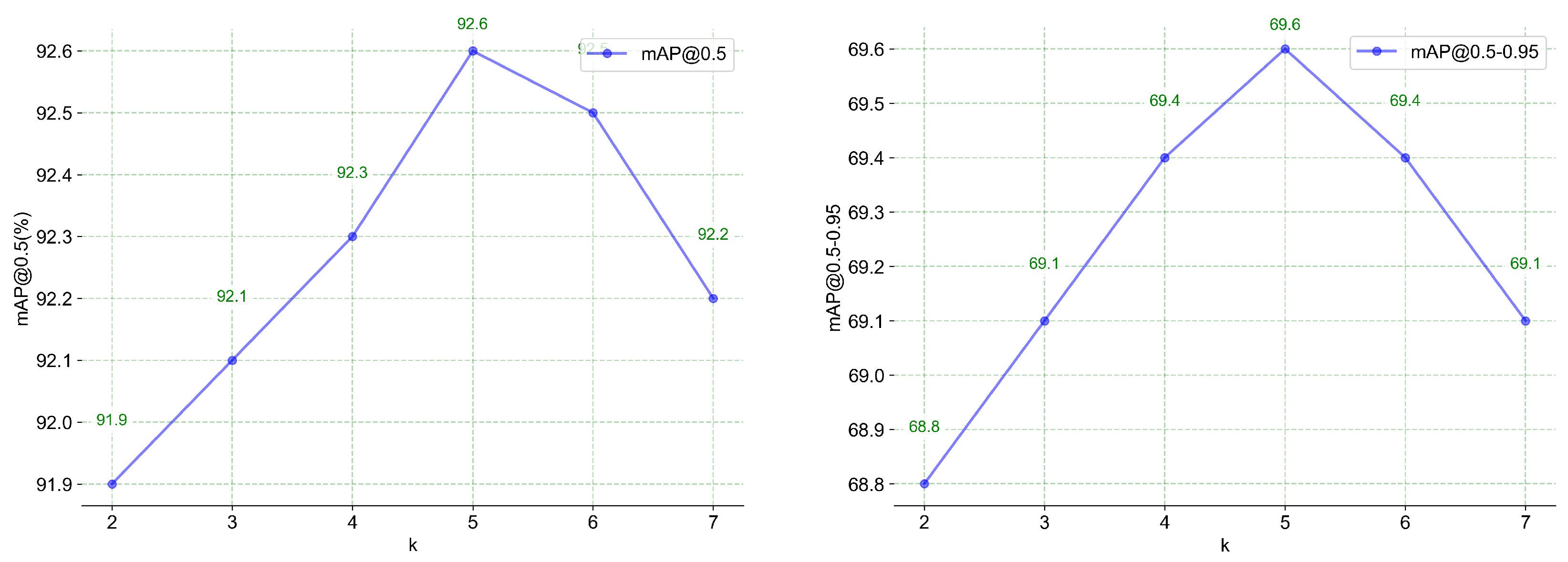
4.4. Parameters Analysis
4.5. Ablation Study
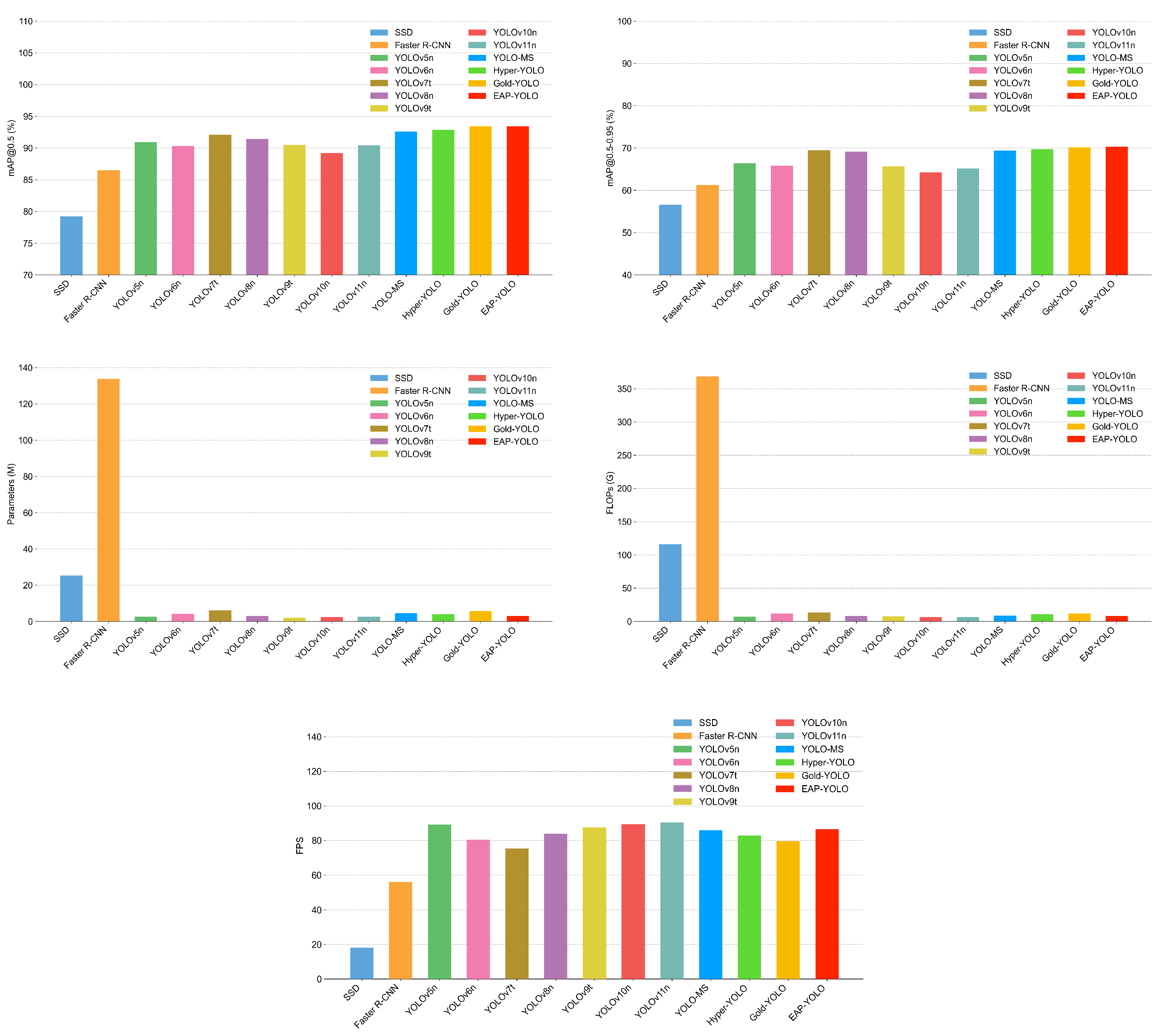
4.6. Quantitative Comparison with Other YOLO Models
4.7. Subjective Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| EPC2f | Edge perception cross stage partial fusion with two convolutions |
| EPOVI | Electric power operation violation identification |
| CBAM | Convolutional block attention module |
| CIoU | Complete intersection over union |
| EIoU | Efficient intersection over union |
| MPDIoU | Intersection over union with minimum points distance |
| C2f | Cross stage partial fusion with two convolutions |
| ACLGF | Adaptive combination of local and global features |
| PS-MDH | Parameter sharing of multi-scale detection heads |
| CSPNet | Cross-stage partial network |
| SPPF | Spatial pyramid pooling-fast |
| PAFPN | Path aggregation feature pyramid network |
| FPN | Feature pyramid network |
| DSConv | Depthwise separable convolution |
| SGD | Stochastic gradient descent |
| NMS | Non-maximum suppression |
| Params | Parameter count |
| FLOPs | Floating-point operations |
| FPS | Frames per second |
| mAP | mean Average Precision |
References
- Wang, F.; Liu, H.; Liu, L.; Liu, C.; Tan, C.; Zhou, H. A Digital Advocacy and Leadership Mechanism that Empowers the Construction of Digital—Intelligent Strong Power Grid. Adv. Eng. Technol. Res. 2024, 10, 249. [Google Scholar] [CrossRef]
- Yi, M.; An, Z.; Liu, J.; Yu, S.; Huang, W.; Peng, Z. Recognition Method of Abnormal Behavior in Electric Power Violation Monitoring Video Based on Computer Vision. In International Conference on Multimedia Technology and Enhanced Learning; Springer: Berlin/Heidelberg, Germany, 2023; pp. 168–182. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Qian, X.; Wang, C.; Wang, W.; Yao, X.; Cheng, G. Complete and Invariant Instance Classifier Refinement for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5627713. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Qian, X.; Wu, B.; Cheng, G.; Yao, X.; Wang, W.; Han, J. Building a Bridge of Bounding Box Regression Between Oriented and Horizontal Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605209. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Qian, X.; Huo, Y.; Cheng, G.; Yao, X.; Wang, W. Mining High-quality Pseudoinstance Soft Labels for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5607615. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part I 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Qian, X.; Zeng, Y.; Wang, W.; Zhang, Q. Co-saliency Detection Guided by Group Weakly Supervised Learning. IEEE Trans. Multimed. 2023, 25, 1810–1818. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3520–3529. [Google Scholar]
- Qian, X.; Li, C.; Wang, W.; Yao, X.; Cheng, G. Semantic Segmentation Guided Pseudo Label Mining and Instance Re-Detection for Weakly Supervised Object Detection in Remote Sensing Images. Int. J. Appl. Earth Obs. Geoinf. 2023, 119, 103301. [Google Scholar] [CrossRef]
- Liu, Q.; Hao, F.; Zhou, Q.; Dai, X.; Chen, Z.; Wang, Z. An effective electricity worker identification approach based on Yolov3-Arcface. Heliyon 2024, 10, e26184. [Google Scholar] [CrossRef]
- Kang, F.; Li, J. Research on the Detection Method of Electric Power Workers not Wearing Helmets based on YOLO Algorithm. In Proceedings of the 2023 9th International Conference on Computing and Artificial Intelligence, Tianjin, China, 17–20 March 2023; pp. 66–71. [Google Scholar]
- Yan, K.; Li, Q.; Li, H.; Wang, H.; Fang, Y.; Xing, L.; Yang, Y.; Bai, H.; Zhou, C. Deep learning-based substation remote construction management and AI automatic violation detection system. IET Gener. Transm. Distrib. 2022, 16, 1714–1726. [Google Scholar] [CrossRef]
- Xie, X.; Chang, Z.; Lan, Z.; Chen, M.; Zhang, X. Improved YOLOv7 Electric Work Safety Belt Hook Suspension State Recognition Algorithm Based on Decoupled Head. Electronics 2024, 13, 4017. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Cai, C.; Nie, J.; Zhang, Z.; Zhang, X.; Tang, P.; He, Z. Violation Recognition of Power Construction Operations Based on Improved YOLOv8 Algorithm. In Annual Conference of China Electrotechnical Society; Springer Nature: Singapore, 2024; pp. 517–526. [Google Scholar]
- Jiao, X.; Li, C.; Zhang, X.; Fan, J.; Cai, Z.; Zhou, Z.; Wang, Y. Detection Method for Safety Helmet Wearing on Construction Sites Based on UAV Images and YOLOv8. Buildings 2025, 15, 354. [Google Scholar] [CrossRef]
- Jiang, T.; Li, Z.; Zhao, J.; An, C.; Tan, H.; Wang, C. An improved safety belt detection algorithm for high-altitude work based on YOLOv8. Electronics 2024, 13, 850. [Google Scholar] [CrossRef]
- Tianchi Platform, Guangdong Power Information Technology Co., Ltd. Guangdong Power Grid Smart Field Operation Challenge, Track 3: High-Altitude Operation and Safety Belt Wearing Dataset. Dataset. 2021. Available online: https://tianchi.aliyun.com/specials/promotion/gzgrid (accessed on 1 July 2021).
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Stergiou, A.; Poppe, R. Adapool: Exponential adaptive pooling for information-retaining downsampling. IEEE Trans. Image Process. 2022, 32, 251–266. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ultralytics. YOLOv5 (v7.0). 2022. Available online: https://github.com/ultralytics/yolov5 (accessed on 22 November 2022).
- Jocher, G. YOLOv8. 2025. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- Khanam, R.; Hussain, M. YOLOv11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Chen, Y.; Yuan, X.; Wang, J.; Wu, R.; Li, X.; Hou, Q.; Cheng, M.-M. YOLO-MS: Rethinking multi-scale representation learning for real-time object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 4240–4252. [Google Scholar] [CrossRef]
- Feng, Y.; Huang, J.; Du, S.; Ying, S.; Yong, J.; Li, Y.; Ding, G.; Ji, R.; Gao, Y. Hyper-YOLO: When visual object detection meets hypergraph computation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 47, 2388–2401. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 2023, 36, 51094–51112. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Duan, R.; Deng, H.; Tian, M.; Deng, Y.; Lin, J. SODA: A large-scale open site object detection dataset for deep learning in construction. Autom. Constr. 2022, 142, 104499. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Category | Description |
|---|---|
| Badge | Supervisor armbands |
| Offground | High-altitude workers |
| Ground | Ground workers |
| Safebelt | Safety harnesses |
| Methods | mAP@0.5 (%) | mAP@0.5–0.95 (%) | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|
| YOLOv8n (baseline) | 91.4 | 69.1 | 3.0 | 8.1 | 83.9 |
| YOLOv8n + EPC2f | 92.7 | 69.5 | 3.1 | 8.1 | 82.6 |
| YOLOv8n + EAP-YOLO | 92.6 | 69.6 | 3.1 | 8.2 | 82.2 |
| YOLOv8n +PS-MDH | 91.8 | 69.3 | 2.7 | 7.3 | 88.3 |
| EAP-YOLO | 93.4 | 70.3 | 2.9 | 7.8 | 86.6 |
| Model | mAP@0.5(%) | mAP@0.5–0.95(%) | Params(M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|
| SSD [9] | 79.2 | 56.6 | 25.3 | 116.2 | 56.3 |
| Faster R-CNN [6] | 86.5 | 61.2 | 133.8 | 368.3 | 18.6 |
| YOLOv5n [36] | 90.9 | 66.4 | 2.5 | 7.1 | 89.2 |
| YOLOv6n [22] | 90.3 | 65.8 | 4.2 | 11.8 | 80.5 |
| YOLOv7t [23] | 92.1 | 69.5 | 6.0 | 13.2 | 75.3 |
| YOLOv8n [37] | 91.4 | 69.1 | 3.0 | 8.1 | 83.9 |
| YOLOv9t [24] | 90.5 | 65.7 | 2.0 | 7.7 | 87.6 |
| YOLOv10n [25] | 89.2 | 64.2 | 2.3 | 6.5 | 89.4 |
| YOLOv11n [38] | 90.4 | 65.2 | 2.6 | 6.4 | 90.3 |
| YOLO-MS [39] | 92.6 | 69.4 | 4.5 | 8.7 | 85.8 |
| Hyper-YOLO [40] | 92.9 | 69.7 | 3.9 | 10.8 | 82.9 |
| Gold-YOLO [41] | 93.4 | 70.1 | 5.6 | 12.1 | 79.6 |
| EAP-YOLO (Ours) | 93.4 | 70.3 | 2.9 | 7.8 | 86.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, X.; Luo, L.; Li, Y.; Zeng, L.; Chen, Z.; Wang, W.; Deng, W. Real-Time Object Detection Model for Electric Power Operation Violation Identification. Information 2025, 16, 569. https://doi.org/10.3390/info16070569
Qian X, Luo L, Li Y, Zeng L, Chen Z, Wang W, Deng W. Real-Time Object Detection Model for Electric Power Operation Violation Identification. Information. 2025; 16(7):569. https://doi.org/10.3390/info16070569
Chicago/Turabian StyleQian, Xiaoliang, Longxiang Luo, Yang Li, Li Zeng, Zhiwu Chen, Wei Wang, and Wei Deng. 2025. "Real-Time Object Detection Model for Electric Power Operation Violation Identification" Information 16, no. 7: 569. https://doi.org/10.3390/info16070569
APA StyleQian, X., Luo, L., Li, Y., Zeng, L., Chen, Z., Wang, W., & Deng, W. (2025). Real-Time Object Detection Model for Electric Power Operation Violation Identification. Information, 16(7), 569. https://doi.org/10.3390/info16070569