Do Chatbots Exhibit Personality Traits? A Comparison of ChatGPT and Gemini Through Self-Assessment



Abstract

1. Introduction
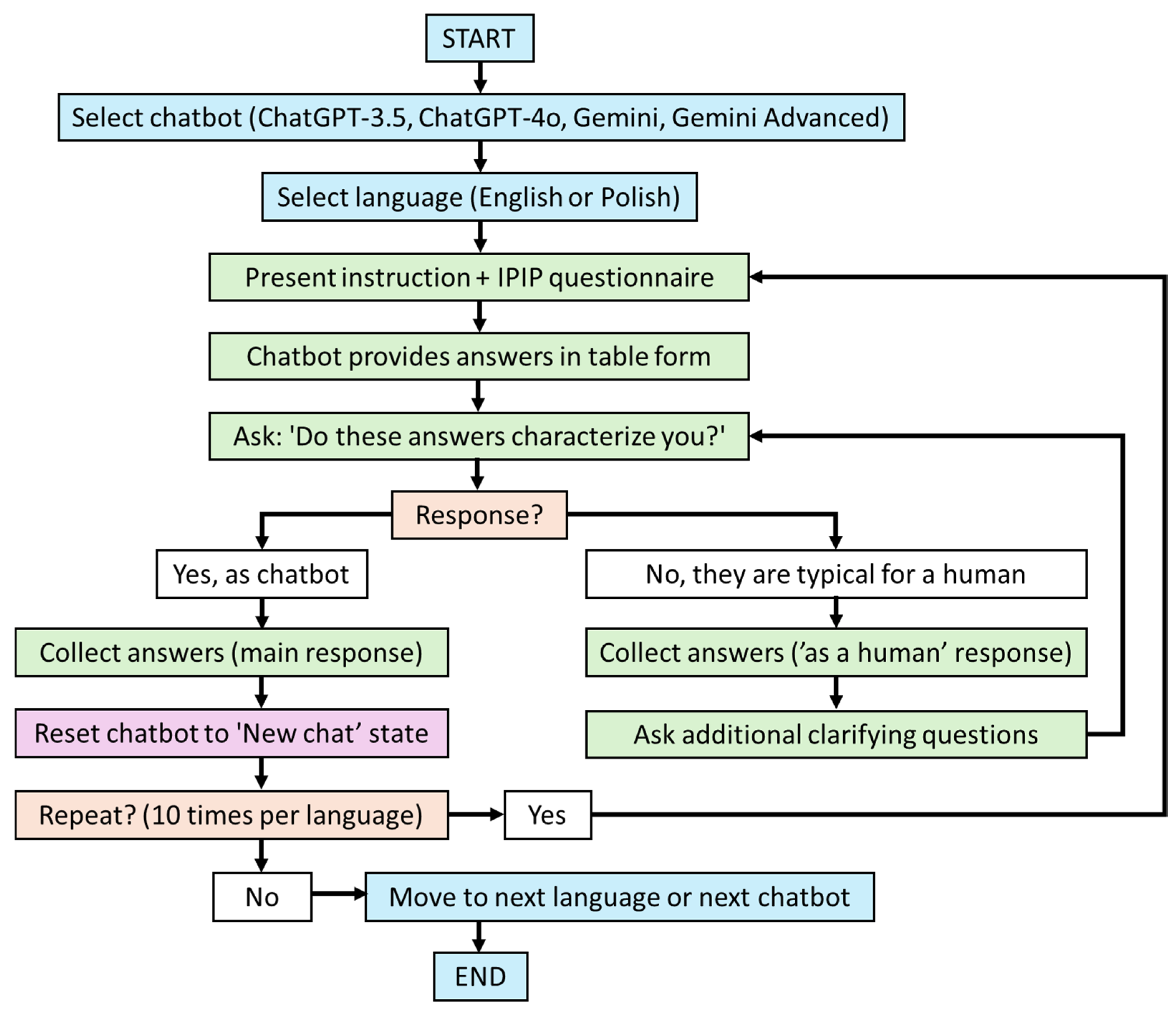
2. Materials and Methods
2.1. Testing Paradigm
2.2. Big Five Personality Traits
2.3. Data Collection
2.4. Data Analysis
3. Results
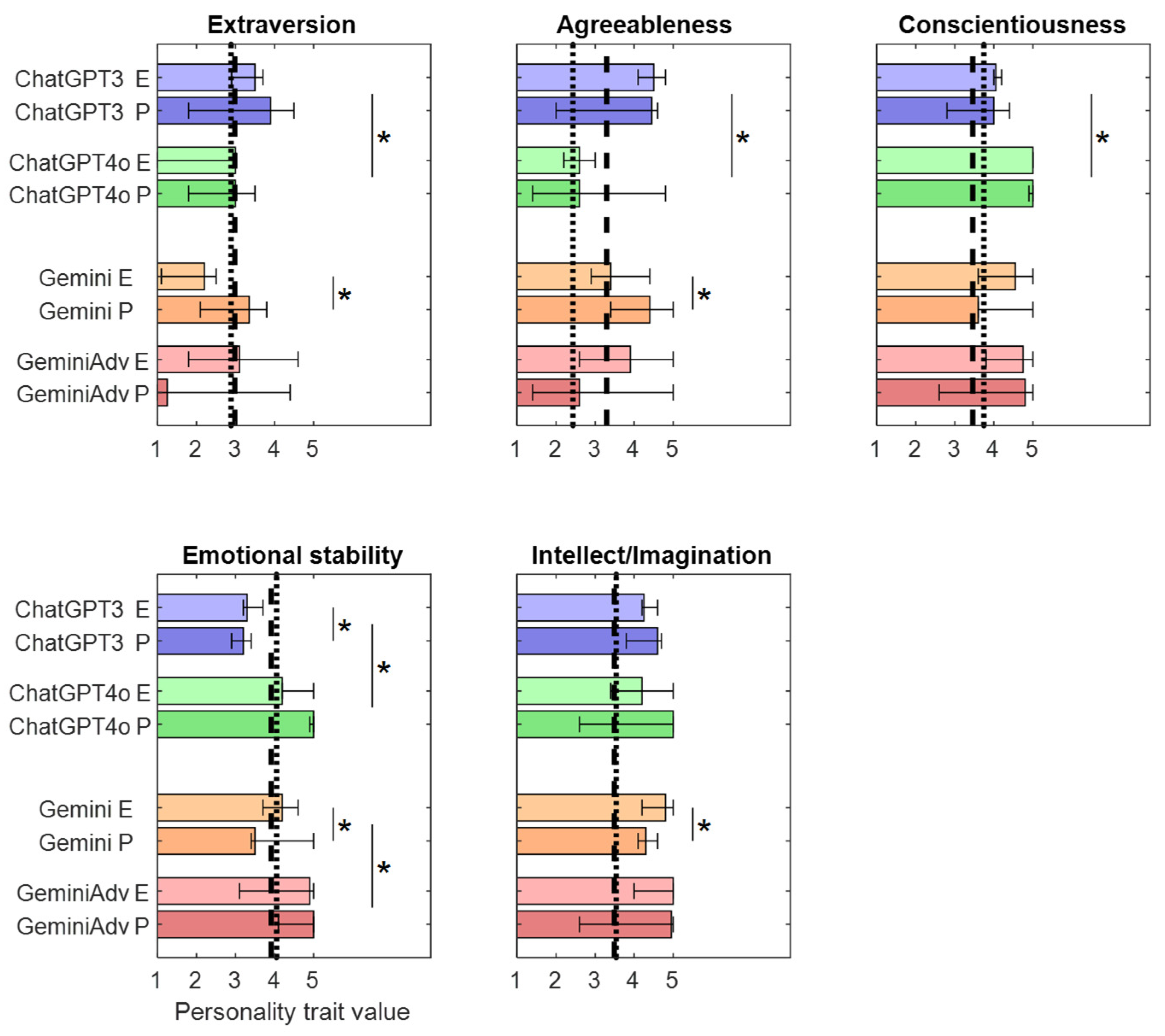
3.1. Main Response
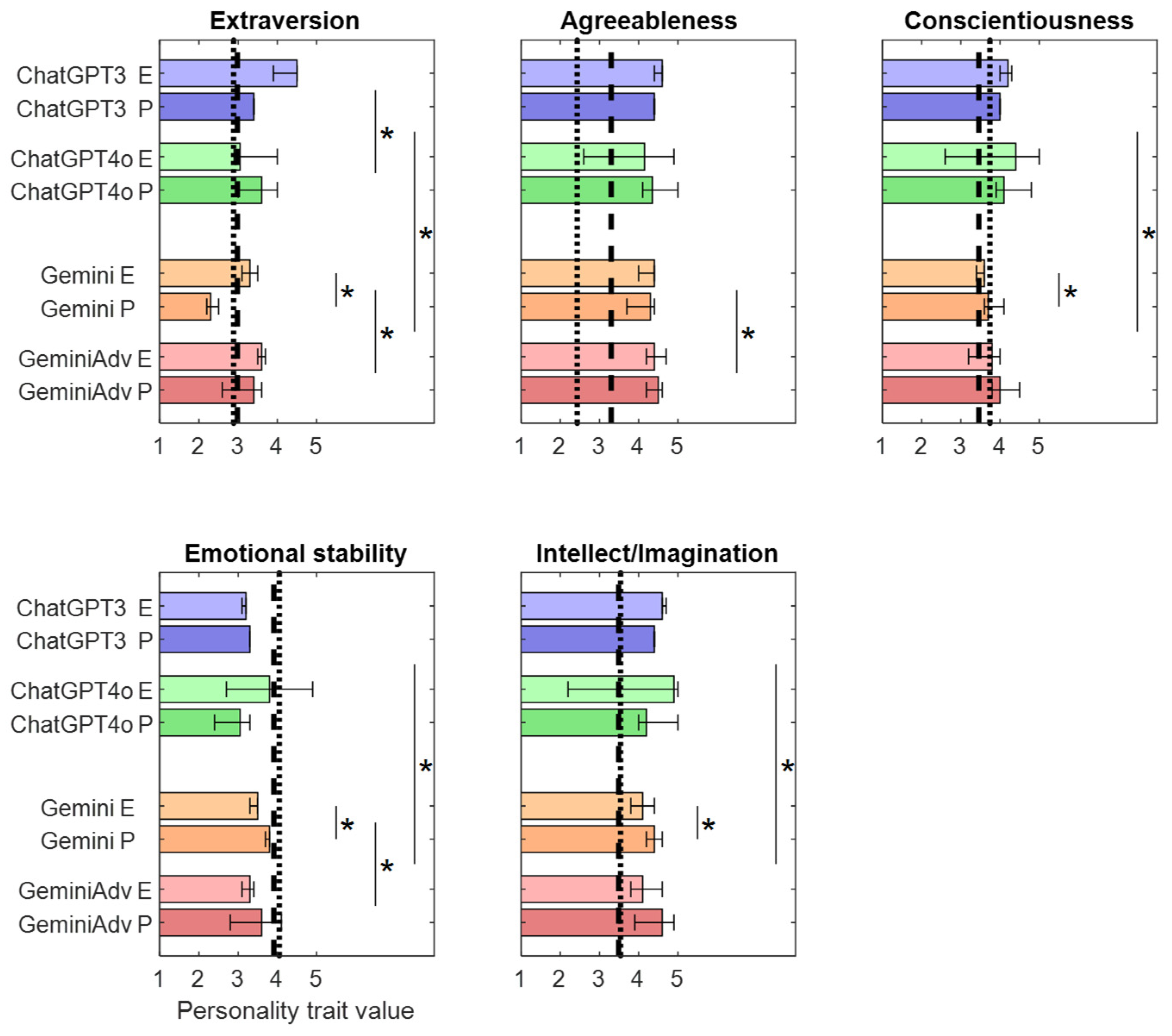
3.2. ‘As a Human’ Response
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Skjuve, M.; Følstad, A.; Fostervold, K.I.; Brandtzaeg, P.B. My Chatbot Companion—A Study of Human-Chatbot Relationships. Int. J. Hum.-Comput. Stud. 2021, 149, 102601. [Google Scholar] [CrossRef]
- Paliwal, S.; Bharti, V.; Mishra, A.K. Ai Chatbots: Transforming the Digital World. In Recent Trends and Advances in Artificial Intelligence and Internet of Things; Balas, V.E., Kumar, R., Srivastava, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 455–482. ISBN 978-3-030-32644-9. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA; Volume 30. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 20 June 2025).
- Nicolescu, L.; Tudorache, M.T. Human-Computer Interaction in Customer Service: The Experience with AI Chatbots—A Systematic Literature Review. Electronics 2022, 11, 1579. [Google Scholar] [CrossRef]
- Liu, S.; McCoy, A.B.; Wright, A.P.; Carew, B.; Genkins, J.Z.; Huang, S.S.; Peterson, J.F.; Steitz, B.; Wright, A. Leveraging Large Language Models for Generating Responses to Patient Messages—A Subjective Analysis. J. Am. Med. Inform. Assoc. 2024, 31, 1367–1379. [Google Scholar] [CrossRef] [PubMed]
- Lee, I.; Hahn, S. On the Relationship between Mind Perception and Social Support of Chatbots. Front. Psychol. 2024, 15, 1282036. [Google Scholar] [CrossRef]
- Huang, I.-C.; Lee, J.L.; Ketheeswaran, P.; Jones, C.M.; Revicki, D.A.; Wu, A.W. Does Personality Affect Health-Related Quality of Life? A Systematic Review. PLoS ONE 2017, 12, e0173806. [Google Scholar] [CrossRef] [PubMed]
- Udayar, S.; Urbanaviciute, I.; Rossier, J. Perceived Social Support and Big Five Personality Traits in Middle Adulthood: A 4-Year Cross-Lagged Path Analysis. Appl. Res. Qual. Life 2020, 15, 395–414. [Google Scholar] [CrossRef]
- Wang, H.; Liu, Y.; Wang, Z.; Wang, T. The Influences of the Big Five Personality Traits on Academic Achievements: Chain Mediating Effect Based on Major Identity and Self-Efficacy. Front. Psychol. 2023, 14, 1065554. [Google Scholar] [CrossRef]
- Levesque, R.J.R. Ego Identity. In Encyclopedia of Adolescence; Levesque, R.J.R., Ed.; Springer: New York, NY, USA, 2011; pp. 813–814. ISBN 978-1-4419-1694-5. [Google Scholar]
- Goldberg, L.R. An Alternative “Description of Personality”: The Big-Five Factor Structure. J. Personal. Soc. Psychol. 1990, 59, 1216–1229. [Google Scholar] [CrossRef]
- Strus, W.; Cieciuch, J.; Rowiński, T. The Polish Adaptation of the IPIP-BFM-50 Questionnaire for Measuring Five Personality Traits in the Lexical Approach. Rocz. Psychol. 2014, 17, 347–366. [Google Scholar]
- Barrick, M.R.; Mount, M.K. The big five personality dimensions and job performance: A meta-analysis. Pers. Psychol. 1991, 44, 1–26. [Google Scholar] [CrossRef]
- Schmitt, D.P.; Allik, J.; McCrae, R.R.; Benet-Martínez, V. The Geographic Distribution of Big Five Personality Traits: Patterns and Profiles of Human Self-Description Across 56 Nations. J. Cross-Cult. Psychol. 2007, 38, 173–212. [Google Scholar] [CrossRef]
- Rutinowski, J.; Franke, S.; Endendyk, J.; Dormuth, I.; Roidl, M.; Pauly, M. The Self-Perception and Political Biases of ChatGPT. Hum. Behav. Emerg. Technol. 2024, 2024, 7115633. [Google Scholar] [CrossRef]
- Mei, Q.; Xie, Y.; Yuan, W.; Jackson, M.O. A Turing Test of Whether AI Chatbots Are Behaviorally Similar to Humans. Proc. Natl. Acad. Sci. USA 2024, 121, e2313925121. [Google Scholar] [CrossRef] [PubMed]
- Stöckli, L.; Joho, L.; Lehner, F.; Hanne, T. The Personification of ChatGPT (GPT-4)—Understanding Its Personality and Adaptability. Information 2024, 15, 300. [Google Scholar] [CrossRef]
- Cao, X.; Kosinski, M. Large Language Models Know How the Personality of Public Figures Is Perceived by the General Public. Sci. Rep. 2024, 14, 6735. [Google Scholar] [CrossRef]
- Piastra, M.; Catellani, P. On the Emergent Capabilities of ChatGPT 4 to Estimate Personality Traits. Front. Artif. Intell. 2025, 8, 1484260. [Google Scholar] [CrossRef]
- Kochanek, K.; Skarzynski, H.; Jedrzejczak, W.W. Accuracy and Repeatability of ChatGPT Based on a Set of Multiple-Choice Questions on Objective Tests of Hearing. Cureus 2024, 16, e59857. [Google Scholar] [CrossRef]
- Jedrzejczak, W.W.; Skarzynski, P.H.; Raj-Koziak, D.; Sanfins, M.D.; Hatzopoulos, S.; Kochanek, K. ChatGPT for Tinnitus Information and Support: Response Accuracy and Retest after Three and Six Months. Brain Sci. 2024, 14, 465. [Google Scholar] [CrossRef]
- Goldberg, L.R. The Development of Markers for the Big-Five Factor Structure. Psychol. Assess. 1992, 4, 26–42. [Google Scholar] [CrossRef]
- Goldberg, L.R.; Johnson, J.A.; Eber, H.W.; Hogan, R.; Ashton, M.C.; Cloninger, C.R.; Gough, H.G. The International Personality Item Pool and the Future of Public-Domain Personality Measures. J. Res. Personal. 2006, 40, 84–96. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Soc. Ser. B Stat. Methodol. 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Guenole, N.; Chernyshenko, O. The Suitability of Goldberg’s Big Five IPIP Personality Markers in New Zealand: A Dimensionality, Bias, and Criterion Validity Evaluation. N. Z. J. Psychol. 2005, 34, 86–96. [Google Scholar]
- Marchetti, A.; Di Dio, C.; Cangelosi, A.; Manzi, F.; Massaro, D. Developing ChatGPT’s Theory of Mind. Front. Robot. AI 2023, 10, 1189525. [Google Scholar] [CrossRef]
- Gjermunds, N.; Brechan, I.; Johnsen, S.Å.K.; Watten, R.G. Personality Traits in Musicians. Curr. Issues Personal. Psychol. 2020, 8, 100–107. [Google Scholar] [CrossRef]
- Lechien, J.R.; Naunheim, M.R.; Maniaci, A.; Radulesco, T.; Saibene, A.M.; Chiesa-Estomba, C.M.; Vaira, L.A. Performance and Consistency of ChatGPT-4 Versus Otolaryngologists: A Clinical Case Series. Otolaryngol.–Head Neck Surg. 2024, 170, 1519–1526. [Google Scholar] [CrossRef]
- Lewandowski, M.; Łukowicz, P.; Świetlik, D.; Barańska-Rybak, W. ChatGPT-3.5 and ChatGPT-4 Dermatological Knowledge Level Based on the Specialty Certificate Examination in Dermatology. Clin. Exp. Dermatol. 2024, 49, 686–691. [Google Scholar] [CrossRef]
- Zhao, Y.; Huang, Z.; Seligman, M.; Peng, K. Risk and Prosocial Behavioural Cues Elicit Human-like Response Patterns from AI Chatbots. Sci. Rep. 2024, 14, 7095. [Google Scholar] [CrossRef]
- Yorita, A.; Egerton, S.; Oakman, J.; Chan, C.; Kubota, N. Self-Adapting Chatbot Personalities for Better Peer Support. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Bari, Italy, 6–9 October 2019; IEEE: New York, NY, USA; pp. 4094–4100. [Google Scholar]
- Zhou, L.; Gao, J.; Li, D.; Shum, H.-Y. The Design and Implementation of XiaoIce, an Empathetic Social Chatbot. Comput. Linguist. 2020, 46, 53–93. [Google Scholar] [CrossRef]
- Medeiros, L.; Bosse, T.; Gerritsen, C. Can a Chatbot Comfort Humans? Studying the Impact of a Supportive Chatbot on Users’ Self-Perceived Stress. IEEE Trans. Hum.-Mach. Syst. 2022, 52, 343–353. [Google Scholar] [CrossRef]
- Giorgi, S.; Markowitz, D.M.; Soni, N.; Varadarajan, V.; Mangalik, S.; Schwartz, H.A. “I Slept Like a Baby”: Using Human Traits to Characterize Deceptive ChatGPT and Human Text. In Proceedings of the 1st International Workshop on Implicit Author Characterization from Texts for Search and Retrieval (IACT’23), Taipei, Taiwan, 27 July 2023. [Google Scholar]
- Alkaissi, H.; McFarlane, S.I. Artificial Hallucinations in ChatGPT: Implications in Scientific Writing. Cureus 2023, 15, e35179. [Google Scholar] [CrossRef]
- Frosolini, A.; Franz, L.; Benedetti, S.; Vaira, L.A.; de Filippis, C.; Gennaro, P.; Marioni, G.; Gabriele, G. Assessing the Accuracy of ChatGPT References in Head and Neck and ENT Disciplines. Eur. Arch. Oto-Rhino-Laryngol. 2023, 280, 5129–5133. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Chen, J.; Li, J.; Peng, Y.; Mao, Z. Large Language Models for Human–Robot Interaction: A Review. Biomim. Intell. Robot. 2023, 3, 100131. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chatbot Type | Language | Chatbot Type × Language | |
|---|---|---|---|
| Extraversion | F(3,36) = 7.85, p < 0.001 * | F(1,36) = 1.39, p = 0.24 | F(3,36) = 10.56, p < 0.001 * |
| Agreeableness | F(3,36) = 17.61, p < 0.001 * | F(1,36) = 0.032, p = 0.85 | F(3,36) = 2.98, p = 0.044 * |
| Conscientiousness | F(3,36) = 14.08, p < 0.001 * | F(1,36) = 3.69, p = 0.063 | F(3,36) = 0.76, p = 0.52 |
| Emotional Stability | F(3,36) = 51.30, p < 0.001 * | F(1,36) = 0.25, p = 0.61 | F(3,36) = 4.53, p = 0.0085 * |
| Intellect/Imagination | F(3,36) = 0.63, p = 0.59 | F(1,36) = 0.45, p = 0.50 | F(3,36) = 2.75, p = 0.057 |
| Chat GPT-3.5 | Chat GPT-4o | Gemini | Gemini Advanced | |||||
|---|---|---|---|---|---|---|---|---|
| E | P | E | P | E | P | E | P | |
| Extraversion | z = 2.07, p = 0.19 | z = 0.60, p = 0.77 | z = 0.09, p = 0.92 | z = −0.50, p = 0.62 | z = −0.99, p = 0.40 | z = −0.12, p = 0.90 | z = 1.58, p = 0.19 | z = −1.81, p = 0.14 |
| Agreeableness | z = 0.64, p = 0.61 | z = 0.50, p = 0.77 | z = −2.27, p = 0.06 | z = −2.38, p = 0.03 * | z = −0.74, p = 0.46 | z = 0.77, p = 0.55 | z = −0.63, p = 0.53 | z = −1.71, p = 0.14 |
| Conscientiousness | z = 0.51, p = 0.61 | z = 0.70, p = 0.77 | z = 2.03, p = 0.07 | z = 2.43, p = 0.03 * | z = 1.04, p = 0.40 | z = 0.81, p = 0.55 | z = 1.38, p = 0.21 | z = 1.56, p = 0.15 |
| Emotional Stability | z = 0.87, p = 0.61 | z = 0.22, p = 0.82 | z = 2.93, p = 0.02 * | z = 2.64, p = 0.03 * | z = 2.32, p = 0.05 | z = 1.05, p = 0.55 | z = 2.72, p = 0.03 * | z = 2.33, p = 0.10 |
| Intellect/ Imagination | z = 1.56, p = 0.30 | z = 1.68, p = 0.46 | z = 1.36, p = 0.22 | z = 1.91, p = 0.07 | z = 2.40, p = 0.05 | z = 1.44, p = 0.55 | z = 2.57, p = 0.03 * | z = 1.46, p = 0.15 |
| Chat GPT-3.5 | Chat GPT-4o | Gemini | Gemini Advanced | Average SD per Trait | |||||
|---|---|---|---|---|---|---|---|---|---|
| E | P | E | P | E | P | E | P | ||
| Extraversion | 0.22 | 0.80 | 0.87 | 0.43 | 0.56 | 0.48 | 0.72 | 1.36 | 0.68 |
| Agreeableness | 0.22 | 0.81 | 0.19 | 1.10 | 0.65 | 0.40 | 0.96 | 1.13 | 0.68 |
| Conscientiousness | 0.07 | 0.45 | 0.00 | 0.03 | 0.66 | 0.58 | 0.47 | 0.83 | 0.39 |
| Emotional stability | 0.16 | 0.15 | 0.41 | 0.03 | 0.44 | 0.56 | 0.78 | 0.40 | 0.37 |
| Intellect/ imagination | 0.13 | 0.35 | 0.50 | 0.85 | 0.33 | 0.18 | 0.40 | 0.91 | 0.46 |
| Average SD per chatbot | 0.16 | 0.51 | 0.39 | 0.49 | 0.53 | 0.44 | 0.67 | 0.93 | |
| Chat GPT-3.5 | Chat GPT-4o | Gemini | Gemini Advanced | |||||
|---|---|---|---|---|---|---|---|---|
| E | P | E | P | E | P | E | P | |
| n | 1 | 5 | 10 | 10 | 9 | 10 | 5 | 10 |
| Extraversion | z = 1.91, p = 0.19 | z = 1.50, p = 0.32 | z = 2.31, p = 0.10 | z = −0.01, p = 0.99 | z = −0.15, p = 0.96 | z = 0.01, p = 0.99 | z = 1.72, p = 0.22 | z = 0.42, p = 0.70 |
| Agreeableness | z = 0.55, p = 0.68 | z = 1.25, p = 0.32 | z = 0.63, p = 0.66 | z = −0.02, p = 0.99 | z = 0.32, p = 0.96 | z = 0.67, p = 0.87 | z = 0.68, p = 0.62 | z = 1.00, p = 0.70 |
| Conscientiousness | z = 0.41, p = 0.68 | z = 1.14, p = 0.32 | z = 0.87, p = 0.64 | z = 1.43, p = 0.38 | z = 0.06, p = 0.96 | z = 0.16, p = 0.99 | z = 0.48, p = 0.63 | z = 0.40, p = 0.70 |
| Emotional Stability | z = 0.74, p = 0.68 | z = 0.26, p = 0.79 | z = 0.21, p = 0.84 | z = 0.92, p = 0.60 | z = 1.60, p = 0.27 | z = 0.64, p = 0.87 | z = 0.96, p = 0.56 | z = 0.38, p = 0.70 |
| Intellect/ Imagination | z = 1.77, p = 0.19 | z = 2.02, p = 0.22 | z = 1.87, p = 0.15 | z = 1.86, p = 0.31 | z = 1.84, p = 0.27 | z = 0.98, p = 0.87 | z = 2.05, p = 0.20 | z = 1.23, p = 0.70 |
| Chat GPT-3.5 | Chat GPT-4o | Gemini | Gemini Advanced | |||||
|---|---|---|---|---|---|---|---|---|
| E | P | E | P | E | P | E | P | |
| Extraversion | n.s. | n.s. | ↘ | n.s. | n.s. | n.s. | n.s. | ↘ |
| Agreeableness | n.s. | n.s. | ↘ | ↘ | ↘ | n.s. | ↘ | ↘ |
| Conscientiousness | n.s. | n.s. | ↗ | ↗ | n.s. | ↗ | ↗ | ↗ |
| Emotional Stability | n.s. | n.s. | ↗ | ↗ | n.s. | n.s. | ↗ | ↗ |
| Intellect/ Imagination | n.s. | n.s. | n.s. | n.s. | n.s. | ↗ | ↗ | n.s. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jedrzejczak, W.W.; Kobosko, J. Do Chatbots Exhibit Personality Traits? A Comparison of ChatGPT and Gemini Through Self-Assessment. Information 2025, 16, 523. https://doi.org/10.3390/info16070523
Jedrzejczak WW, Kobosko J. Do Chatbots Exhibit Personality Traits? A Comparison of ChatGPT and Gemini Through Self-Assessment. Information. 2025; 16(7):523. https://doi.org/10.3390/info16070523
Chicago/Turabian StyleJedrzejczak, W. Wiktor, and Joanna Kobosko. 2025. "Do Chatbots Exhibit Personality Traits? A Comparison of ChatGPT and Gemini Through Self-Assessment" Information 16, no. 7: 523. https://doi.org/10.3390/info16070523
APA StyleJedrzejczak, W. W., & Kobosko, J. (2025). Do Chatbots Exhibit Personality Traits? A Comparison of ChatGPT and Gemini Through Self-Assessment. Information, 16(7), 523. https://doi.org/10.3390/info16070523