
RADAR#: An Ensemble Approach for Radicalization Detection in Arabic Social Media Using Hybrid Deep Learning and Transformer Models



Abstract
1. Introduction
2. Background and Literature Review
2.1. Understanding Radicalization in Online Contexts
2.2. Evolution of Online Radicalization Detection
2.3. AI/ML Advances in Architectures for Text Analysis
2.4. Challenges in Arabic Text Processing
2.5. Transformer Models for Arabic
2.6. Ensemble Methods in NLP
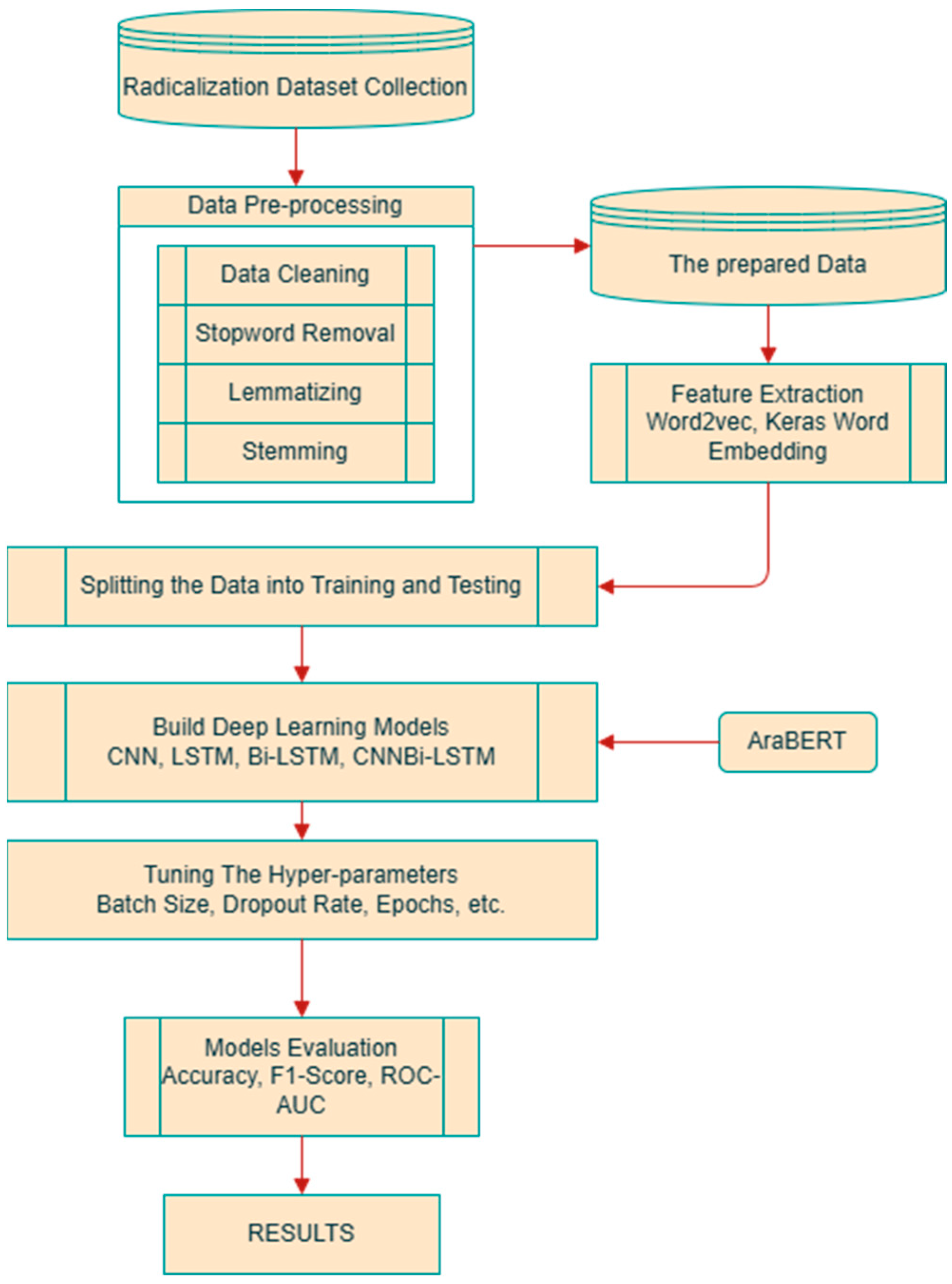
3. RADAR#: Radicalization Analysis Using Deep Arabic Recognition
3.1. Dataset Collection and Characteristics
3.2. Arabic Text Preprocessing Pipeline
Feature Engineering and Embedding
3.3. RADAR# Model Architecture
| Algorithm 1. Advanced Extremism Classification Algorithm for Arabic Tweets |
3.3.1. BiLSTM Layer
3.3.2. Attention Mechanism
3.3.3. Transformer Integration
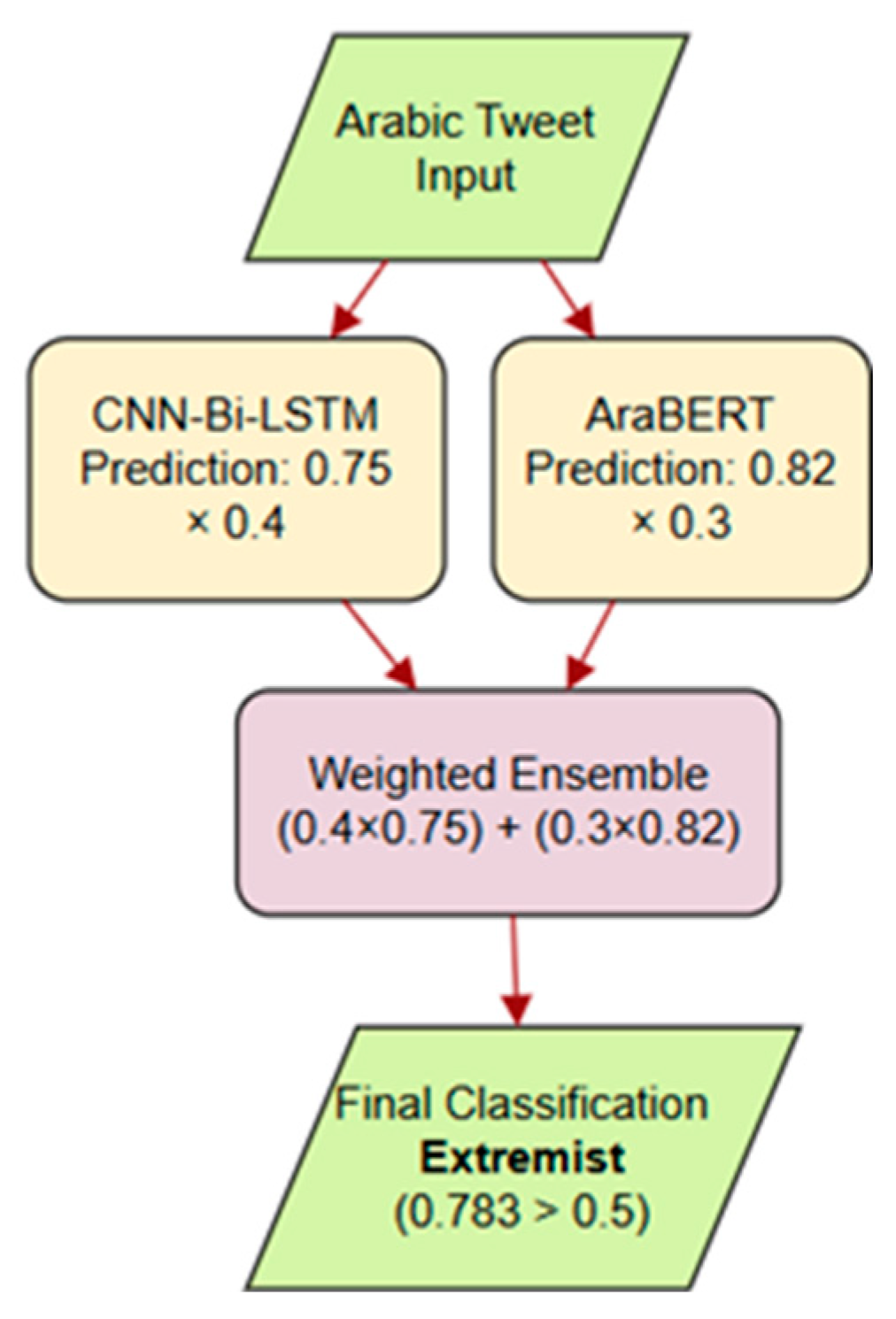
3.3.4. Example
4. Hyperparameter Optimization and Sensitivity Analysis
4.1. Cross-Validation Strategy
4.2. Parameter Analysis
4.3. Parameter Ranges and Grid Search
4.4. Training and Attention Mechanism
4.5. Sensitivity Analysis
4.6. Ensemble Integration
4.7. Evaluation Model
5. Results and Discussion
5.1. Performance Metrics and Error Analysis
- Incorporating pragmatic understanding to better handle sarcasm and irony;
- Expanding training data to capture more dialectal variation;
- Developing means to capture implicit content and coded meanings;
- Investigating methods that can take into account more context than single tweets.
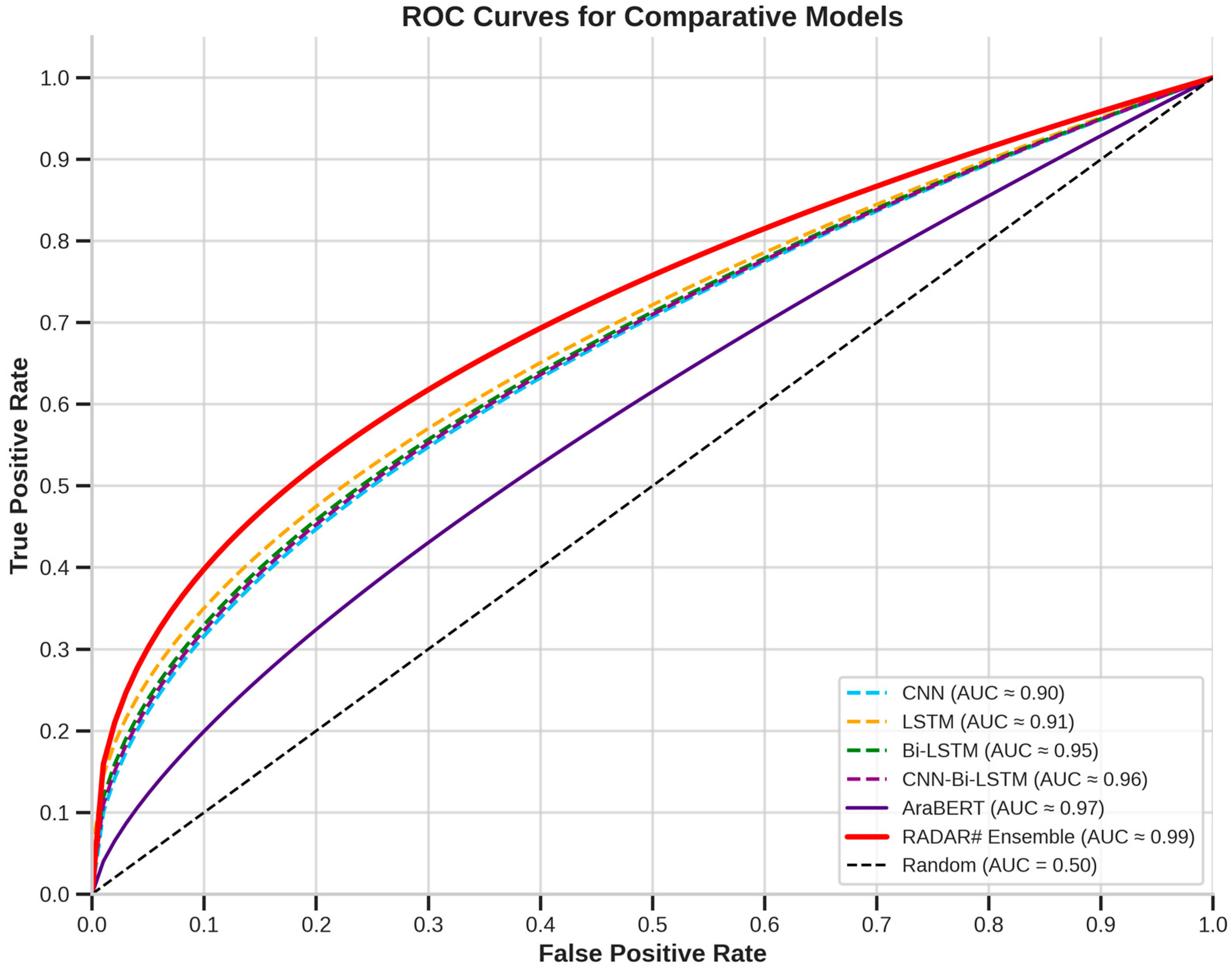
5.2. Comparative Analysis with Other Models
5.3. Ablation Studies
5.4. Attention Visualization
- Names of terrorist organizations (e.g., داعش/ISIS, القاعدة/Al-Qaeda)
- Words related to violence (e.g., قتل/kill, تفجير/bombing)
- Religious terminology used in extremist contexts (e.g., جهاد/jihad, كفار/infidels)
- Words expressing support or allegiance (e.g., مبايعة/pledge allegiance, نصرة/support)
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Enhanced Interpretability Analysis





References
- Aichner, T.; Grünfelder, M.; Maurer, O.; Jegeni, D. Twenty-five years of social media: A review of social media applications and definitions from 1994 to 2019. Cyberpsychol. Behav. Soc. Netw. 2021, 24, 215–222. [Google Scholar] [CrossRef] [PubMed]
- Forgeard, V. Why the World Is a Global Village. Brilliantio. 2021. Available online: https://brilliantio.com/why-the-world-is-a-global-village/ (accessed on 7 May 2024).
- Kaplan, A.M.; Haenlein, M. Users of the world, unite! The challenges and opportunities of Social Media. Bus. Horiz. 2010, 53, 59–68. [Google Scholar] [CrossRef]
- Al-Maqableh, R.; Al-Sobeh, A.; Akkawi, A. Cultural Drivers of Radicalization. Available online: https://dradproject.com/?publications=cultural-drivers-of-radicalization-in-jordan-2 (accessed on 1 September 2024).
- Alava, S.; Frau-Meigs, D.; Hassan, G. Youth and Violent Extremism on Social Media: Mapping the Research; UNESCO: Paris, France, 2017. [Google Scholar]
- Alsobeh, A.; Shatnawi, A. Integrating Data-Driven Security, Model Checking, and Self-adaptation for IoT Systems Using BIP Components: A Conceptual Proposal Model. In Proceedings of the 2023 International Conference on Advances in Computing Research (ACR’23); Springer: Cham, Switzerland, 2023; p. 700. [Google Scholar] [CrossRef]
- Gaikwad, M.; Ahirrao, S.; Phansalkar, S.; Kotecha, K. Online extremism detection: A systematic literature review. IEEE Access 2021, 9, 48364–48404. [Google Scholar] [CrossRef]
- Smith, A. 23 Essential Twitter Statistics to Guide Your Strategy in 2023. Sprout Social. 2023. Available online: https://sproutsocial.com/insights/twitter-statistics/ (accessed on 1 June 2025).
- Akram, W.; Kumar, R. A study on positive and negative effects of social media on society. Int. J. Comput. Sci. Eng. 2017, 5, 351–354. [Google Scholar] [CrossRef]
- Aldera, S.; Emam, A.; Al-Qurishi, M.; Alrubaian, M.; Alothaim, A. Exploratory data analysis and classification of a new arabic online extremism dataset. IEEE Access 2021, 9, 161613–161626. [Google Scholar] [CrossRef]
- Chen, H. Sentiment and affect analysis of dark web forums: Measuring radicalization on the internet. In Proceedings of the 2008 IEEE International Conference on Intelligence and Security Informatics, Taipei, Taiwan, 17–20 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 104–109. [Google Scholar]
- Zhaksylyk, K.; Batyrkhan, O.; Shynar, M. Review of violent extremism detection techniques on social media. In Proceedings of the 2021 16th International Conference on Computer Science and Software Engineering (CSSE), Almaty, Kazakhstan, 29–31 October 2021. [Google Scholar]
- Gupta, P.; Varshney, P.; Bhatia, M.P.S. Identifying Radical Social Media Posts Using Machine Learning; GitHub: San Francisco, CA, USA, 2017. [Google Scholar]
- Kaur, A.; Saini, J.K.; Bansal, D. Detecting radical text over online media using deep learning. arXiv 2019, arXiv:1907.12368. [Google Scholar]
- Mursi, K.T.; Alahmadi, M.D.; Alsubaei, F.S.; Alghamdi, A.S. Detecting Islamic radicalism Arabic tweets using natural language processing. IEEE Access 2022, 10, 72526–72534. [Google Scholar] [CrossRef]
- Davis, J. Social Media In The International Encyclopedia of Political Communication; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar] [CrossRef]
- Rekik, A.; Jamoussi, S.; Hamadou, A.B. Violent vocabulary extraction methodology: Application to the radicalism detection on social media. In Computational Collective Intelligence, Proceedings of the 11th International Conference, ICCCI 2019, Hendaye, France, 4–6 September 2019; Part II; Springer: Berlin/Heidelberg, Germany, 2019; pp. 97–109. [Google Scholar]
- Johnston, A.H.; Weiss, G.M. Identifying sunni extremist propaganda with deep learning. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–6. [Google Scholar]
- Trabelsi, Z.; Saidi, F.; Thangaraj, E.; Veni, T. A survey of extremism online content analysis and prediction techniques in Twitter based on sentiment analysis. Secur. J. 2023, 36, 221–248. [Google Scholar] [CrossRef]
- Becker, K.; Harb, J.G.; Ebeling, R. Exploring deep learning for the analysis of emotional reactions to terrorist events on Twitter. J. Inf. Data Manag. 2019, 10, 97–115. [Google Scholar]
- Ahmad, S.; Asghar, M.Z.; Alotaibi, F.M.; Awan, I. Detection and classification of social media-based extremist affiliations using sentiment analysis techniques. Hum.-Centric Comput. Inf. Sci. 2019, 9, 24. [Google Scholar] [CrossRef]
- Chen, L.C.; Lee, C.M.; Chen, M.Y. Exploration of social media for sentiment analysis using deep learning. Soft Comput. 2020, 24, 8187–8197. [Google Scholar] [CrossRef]
- Nizzoli, L.; Avvenuti, M.; Cresci, S.; Tesconi, M. Extremist propaganda tweet classification with deep learning in realistic scenarios. In Proceedings of the 10th ACM Conference on Web Science, Amsterdam, The Netherlands, 30 June–3 July 2019; ACM: New York, NY, USA, 2019; pp. 203–204. [Google Scholar]
- Nathani, V.G.; Patel, H.K. Twitter Sentiment Analysis for Hate Speech Detection Using a C-BiLstm Model. 2022. Available online: https://harshilpatel99.github.io/Research_paper.pdf (accessed on 1 June 2024).
- Rajendran, A.; Sahithi, V.S.; Gupta, C.; Yadav, M.; Ahirrao, S.; Kotecha, K.; Gaikwad, M.; Abraham, A.; Ahmed, N.; Alhammad, S.M. Detecting Extremism on Twitter During US Capitol Riot Using Deep Learning Techniques. IEEE Access 2022, 10, 133052–133077. [Google Scholar] [CrossRef]
- Alhayan, F.; Shaalan, K. Neural Networks and Sentiment Features for Extremist Content Detection in Arabic Social, 2025. Int. Arab. J. Inf. Technol. (IAJIT) 2025, 17, 522–534. [Google Scholar]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Kanerva, J.; Ginter, F.; Salakoski, T. Universal Lemmatizer: A sequence-to-sequence model for lemmatizing Universal Dependencies treebanks. Nat. Lang. Eng. 2021, 27, 545–574. [Google Scholar] [CrossRef]
- Sameer, R.A. Modified light stemming algorithm for Arabic language. Iraqi J. Sci. 2016, 57, 507–513. [Google Scholar]
- Al-Shawakfa, E.M.; Husni, H.H. A Two-Stage Machine Learning Classification Approach to Identify Extremism in Arabic Opinions. Int. J. 2021, 10, 2. [Google Scholar]
- Alfreihat, M.; Almousa, O.; Tashtoush, Y.; AlSobeh, A.; Mansour, K.; Migdady, H. Emo-SL framework: Emoji sentiment lexicon using text-based features and machine learning for sentiment analysis. IEEE Access 2024, 12, 81793–81812. [Google Scholar] [CrossRef]
- Alshattnawi, S.; Shatnawi, A.; AlSobeh, A.M.R.; Magableh, A.A. Beyond Word-Based Model Embeddings: Contextualized Representations for Enhanced Social Media Spam Detection. Appl. Sci. 2024, 14, 2254. [Google Scholar] [CrossRef]
- Radwan, A.; Amarneh, M.; Alawneh, H.; Ashqar, H.I.; AlSobeh, A.; Magableh, A.A. Predictive Analytics in Mental Health Leveraging LLM Embeddings and Machine Learning Models for Social Media Analysis. Int. J. Web Serv. Res. 2024, 21, 1–22. [Google Scholar] [CrossRef]
- Mahapatra, S. Why Deep Learning over Traditional Machine Learning? Towards Data Sci. 2018. Available online: https://medium.com/data-science/why-deep-learning-is-needed-over-traditional-machine-learning-1b6a99177063 (accessed on 21 June 2024).
- Oppermann, A. What Is Deep Learning and How Does It Work? Builtin. 2022. Available online: https://builtin.com/machine-learning/deep-learning (accessed on 1 June 2024).
- Yang, K.; Huang, Z.; Wang, X.; Li, X. A blind spectrum sensing method based on deep learning. Sensors 2019, 19, 2270. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NeurIPS 2017); Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, Marseille, France, 12 May 2020; European Language Resource Association: Paris, France; pp. 9–15. [Google Scholar]
- Abdul-Mageed, M.; Elmadany, A.; Nagoudi, E.M.B. ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics, Online, 5–6 August 2021; Association for Computational Linguistics: Kerrville, TX, USA; pp. 7088–7105. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraELECTRA: Pre-Training Text Discriminators for Arabic Language Understanding. In Proceedings of the Sixth Arabic Natural Language Processing Workshop (WANLP 2021), Abu Dhabi, United Arab Emirates, 20 May 2021; pp. 191–195. [Google Scholar]
- Abdelali, A.; Darwish, K.; Durrani, N.; Mubarak, H. Farasa: A Fast and Accurate Arabic Segmenter. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 1070–1074. [Google Scholar]
- Al-Twairesh, N.; Al-Negheimish, H. Surface and Deep Features Ensemble for Sentiment Analysis of Arabic Tweets. IEEE Access 2019, 7, 84122–84131. [Google Scholar] [CrossRef]
- Xia, R.; Zong, C.; Li, S. Ensemble of feature sets and classification algorithms for sentiment classification. Inf. Sci. 2011, 181, 1138–1152. [Google Scholar] [CrossRef]
- Wang, P.; Xu, B.; Xu, J.; Tian, G.; Liu, C.L.; Hao, H. Semantic expansion using word embedding clustering and CNN for improving short text classification. Neurocomputing 2016, 174, 806–814. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, H.; Zeng, Y.; Huang, Z.; Wu, Z. Content attention model for aspect based sentiment analysis. In Proceedings of the 2018 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1023–1032. [Google Scholar]
- Pappagari, R.; Zelasko, P.; Villalba, J.; Carmiel, Y.; Dehak, N. Hierarchical transformers for long document classification. In Proceedings of the 2019 IEEE ASRU Workshop, Sentosa, Singapore, 17–21 December 2019; pp. 838–844. [Google Scholar]
- Al-Sallab, A.; Ezzeldin, M.; Khalifa, M.; Habash, N.; El-Beltagy, S.R. Deep learning models for sentiment analysis in Arabic. In Proceedings of the Second Workshop on Arabic NLP, Valencia, Spain, 4 April 2017; pp. 9–17. [Google Scholar]
- Al-Zahrani, L.; Al-Yahya, M. Pre-Trained Language Model Ensemble for Arabic Fake News Detection. Mathematics 2024, 12, 2941. [Google Scholar] [CrossRef]
- AlSobeh, A.M.R. OSM: Leveraging model checking for observing dynamic behaviors in aspect-oriented applications. Online J. Commun. Media Technol. 2023, 13, e202355. [Google Scholar] [CrossRef]
- Alajmi, A.; Saad, E.M.; Darwish, R.R. Toward an ARABIC stop-words list generation. Int. J. Comput. Appl. 2012, 46, 8–13. [Google Scholar]
- Goldberg, Y. Neural Network Methods for Natural Language Processing; Morgan & Claypool: San Rafael, CA, USA, 2017. [Google Scholar] [CrossRef]
- Djaballah, K.A.; Boukhalfa, K.; Boussaid, O. Sentiment analysis of Twitter messages using word2vec by weighted average. In Proceedings of the 2019 International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 223–228. [Google Scholar]
- Kapoor, A.; Gulli, A.G.; Pal, S.; Chollet, F. Deep Learning with TensorFlow and Keras, 3rd ed.; Packt Publishing: Birmingham, UK, 2022; Available online: https://learning.oreilly.com/library/view/deep-learning-with/9781803232911/ (accessed on 1 January 2024).
- Wadud, M.A.H.; Mridha, M.F.; Rahman, M.M. Word embedding methods for word representation in deep learning for natural language processing. Iraqi J. Sci. 2022, 63, 1349–1361. [Google Scholar] [CrossRef]
- Alemu, H.; Wu, W.; Zhao, J. Feedforward Neural Networks with a Hidden Layer Regularization Method. Symmetry 2018, 10, 525. [Google Scholar] [CrossRef]
- Patterson, J.P.; Gibson, A. Deep Learning; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Liang, H.; Sun, X.; Sun, Y.; Gao, Y. Text feature extraction based on deep learning: A review. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 211. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Example of Arabic Tweet | Type of Cleaning | Tweets After Cleaning |
|---|---|---|
يوم الاثنين صلاه الغائب على الشيخ المجاهد ابوعبدالله أسامه بن لادن في مقبره صبحان  | Emojis | يوم الاثنين صلاه الغائب على الشيخ المجاهد ابوعبدالله أسامه بن لادن في مقبره صبحان |
| ولما بيخرجوهم دلوقت من السجون بقينا إحنا "الكفار" و "العملاء" اللي عايزين نوقع بين الشعب والجيش | Handles | ولما بيخرجوهم دلوقت من السجون بقينا إحنا "الكفار" و "العملاء" اللي عايزين نوقع بين الشعب والجيش |
| سوريا اليوم ما حد وقف جنبا ولا حد قال شو ذنبو هالشعب يروح بين الرجلين Syria stays in my heart | English | سوريا اليوم ما حد وقف جنبا ولا حد قال شو ذنبو هالشعب يروح بين الرجلين |
| أيها الثوار الخونة العملاء المجرمين #الملحدين #الليبراليين الاشتراكيين إلمشركين الكفار أعداء الإخوان والمجلس العسكري مش هنسيبكم فى حالكم | Hashtag symbol only | أيها الثوار الخونة العملاء المجرمين الملحدين الليبراليين الاشتراكيين إلمشركين الكفار أعداء الإخوان والمجلس العسكري مش هنسيبكم فى حالكم |
| عاجل | الجزيرة: مسؤول امريكي: وفاة الشيخ المجاهد أسامه بن لادن.. http://fb.me/107Cuj963 (accessed on 16 June 2025) | Links | عاجل | الجزيرة: مسؤول امريكي: وفاة الشيخ المجاهد أسامه بن لادن.. |
| ١٥٠شخص برئ توفوا بالانفجار وش ذنبهم هالابرياء لعنة الله عليكم | Numbers | شخص برئ توفوا بالانفجار وش ذنبهم هالابرياء لعنة الله عليكم |
| احتلال الكفار المباشر أفضل من حكم العملاء على الأقل سيعرف الناس الحق من الباطل | New line | احتلال الكفار المباشر أفضل من حكم العملاء على الأقل سيعرف الناس الحق من الباطل |
| برأيي انا هناك من يدعم داعش من تحت _ الطاولة لانها تدعم مصالحه | Underscore | برأيي انا هناك من يدعم داعش من تحت الطاولة لانها تدعم مصالحه |
| لإنبطاحي:لا يهتم لإنتهاك الأعراض , ولا لإحتلال الأراضي المسلمة , ولا لتسلط الكفار , ولا لخيانة العملاء ,إنما يهتم في تقديس السلاطين. | Punctuation | لإنبطاحي لا يهتم لإنتهاك الأعراض ولا لإحتلال الأراضي المسلمة ولا لتسلط الكفار ولا لخيانة العملاء إنما يهتم في تقديس السلاطين |
| Tweet 1 and Translation: | Metrics |
|---|---|
| ياحكام ﺍلعرﺏ ﺍلكفرﺓ وﺍلله لعنه ﺍلقتلى في سوﺭيا وليبيا وكل ﺍلمسلمين ستلاحقهم ﺍلى يوم ﺍلقيامه ياكلاﺏ ﺍليهوﺩ O you infidel Arab rulers, by God, the curse of the dead in Syria, Libya, and all Muslims will haunt you until the Day of Judgment, you dogs of the Jews. | Number of Hidden Layers: 2, 3, 4 (Best: 3) Number of Epochs: 20, 30, 40, 50 (Best: 40) Batch Size: 8, 16, 32 (Best: 16) |
| الجزيرة | مسؤول أمريكي | وفاة المجاهد الشيخ أسامة بن لادن وباراك أوباما سيلقي بيانًا قريبًا. Al Jazeera | U.S. Official | The death of the mujahid Sheikh Osama bin Laden, and Barack Obama will issue a statement shortly. | Number of Hidden Layers: 2, 3, 4 (Best: 4) Number of Epochs: 30, 40, 50, 60 (Best: 50) Batch Size: 16, 24, 32 (Best: 24) |
| لماذا يُطلق علينا اسم الرافضين، المجوس، الكفار، الخونة، العملاء؟ فقط للوقوف ضد الظلم، سؤال يجول في خاطري. Why are we called rejectionists, Zoroastrians, infidels, traitors, collaborators? Just for standing against injustice—a question that lingers in my mind. | Number of Hidden Layers: 2, 3, 4 (Best: 3) Number of Epochs: 20, 40, 60 (Best: 40) Batch Size: 8, 16, 24, 32 (Best: 16) |
| Parameter | Range Explored | Optimal Value | Impact on Performance |
|---|---|---|---|
| Learning Rate | [0.1, 0.01, 0.001, 0.2, 0.02, 0.002, 0.3, 0.03, 0.003] | 0.003 with cosine decay | +3.2% F1-score vs. fixed rate |
| Batch Size | [8, 16, 24, 32] | 24 | +1.8% F1-score vs. default (32) |
| Dropout Rate | [0.1, 0.2, 0.3, 0.4, 0.5] | 0.3 | +2.5% F1-score vs. no dropout |
| CNN Kernel Size | [3, 4, 6, 8) | 6 | +1.7% F1-score vs. size 3 |
| BiLSTM Units | [64, 128, 256] | 128 (each direction) | +2.1% F1-score vs. 64 units |
| Optimizer | [Adam, RMSprop, SGD] | Adam | +2.8% F1-score vs. SGD |
| L2 Regularization | [0, 1 × 10−5, 1 × 10−4, 1 × 10−3] | 1 × 10−4 | +1.5% F1-score vs. no regularization |
| Ensemble Weights | CNN-BiLSTM: [0.3–0.6], AraBERT: [0.4–0.7] | CNN-BiLSTM: 0.4, AraBERT: 0.6 | +2.2% F1-score vs. equal weights |
| Category | Precision | Recall | F1-Score | Samples | Error Rate |
|---|---|---|---|---|---|
| Explicit Radical Content | 98.7% | 97.9% | 98.3% | 12,453 | 2.1% |
| Implicit Radical Content | 94.2% | 92.8% | 93.5% | 8764 | 7.2% |
| Religious Extremism | 96.5% | 95.3% | 95.9% | 14,872 | 4.7% |
| Political Extremism | 93.8% | 91.6% | 92.7% | 9341 | 8.4% |
| Non-Radical Content | 97.3% | 98.1% | 97.7% | 44,386 | 1.9% |
| Overall | 96.1% | 95.1% | 95.6% | 89,816 | 4.9% |
| Model | Accuracy | Precision | Recall | F1-Score | ROC-AUC | Training Time (h) | Inference Time (ms/Sample) | Parameters (M) |
|---|---|---|---|---|---|---|---|---|
| RADAR# (Ours) | 96.1% | 96.1% | 95.1% | 95.6% | 0.983 | 4.2 | 18 | 124 |
| AraBERT-v2 [39] | 93.8% | 94.2% | 92.5% | 93.3% | 0.967 | 6.8 | 32 | 178 |
| MarBERT [40] | 94.2% | 94.8% | 92.9% | 93.8% | 0.971 | 7.2 | 35 | 183 |
| AraGPT2-base [40] | 91.5% | 92.1% | 90.3% | 91.2% | 0.952 | 5.3 | 28 | 135 |
| AraELECTRA [41] | 93.2% | 93.7% | 92.1% | 92.9% | 0.964 | 5.1 | 25 | 109 |
| CNN-BiLSTM [10] | 90.8% | 91.3% | 89.7% | 90.5% | 0.943 | 2.8 | 12 | 42 |
| Configuration | Accuracy | F1-Score | Change in F1-Score |
|---|---|---|---|
| Full RADAR# | 0.98 | 0.97 | - |
| Without CNN layers | 0.96 | 0.95 | −0.02 |
| Without attention mechanism | 0.95 | 0.94 | −0.03 |
| Without AraBERT | 0.97 | 0.96 | −0.01 |
| Without transformer models | 0.95 | 0.93 | −0.04 |
| Without preprocessing normalization | 0.96 | 0.94 | −0.03 |
| Without Farasa segmentation | 0.97 | 0.95 | −0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Shawakfa, E.M.; Alsobeh, A.M.R.; Omari, S.; Shatnawi, A. RADAR#: An Ensemble Approach for Radicalization Detection in Arabic Social Media Using Hybrid Deep Learning and Transformer Models. Information 2025, 16, 522. https://doi.org/10.3390/info16070522
Al-Shawakfa EM, Alsobeh AMR, Omari S, Shatnawi A. RADAR#: An Ensemble Approach for Radicalization Detection in Arabic Social Media Using Hybrid Deep Learning and Transformer Models. Information. 2025; 16(7):522. https://doi.org/10.3390/info16070522
Chicago/Turabian StyleAl-Shawakfa, Emad M., Anas M. R. Alsobeh, Sahar Omari, and Amani Shatnawi. 2025. "RADAR#: An Ensemble Approach for Radicalization Detection in Arabic Social Media Using Hybrid Deep Learning and Transformer Models" Information 16, no. 7: 522. https://doi.org/10.3390/info16070522
APA StyleAl-Shawakfa, E. M., Alsobeh, A. M. R., Omari, S., & Shatnawi, A. (2025). RADAR#: An Ensemble Approach for Radicalization Detection in Arabic Social Media Using Hybrid Deep Learning and Transformer Models. Information, 16(7), 522. https://doi.org/10.3390/info16070522