
Performance Evaluation of Large Language Model Chatbots for Radiation Therapy Education


Abstract
1. Introduction
2. Materials and Methods
2.1. Architecture Design for LLM Chatbot
2.2. Knowledge Data Resource
2.3. Q&A Data
2.4. Performance Evaluation Methods
2.5. Semantic Similarity and Consistency
2.6. Response Time
3. Results
3.1. LLM Chatbot
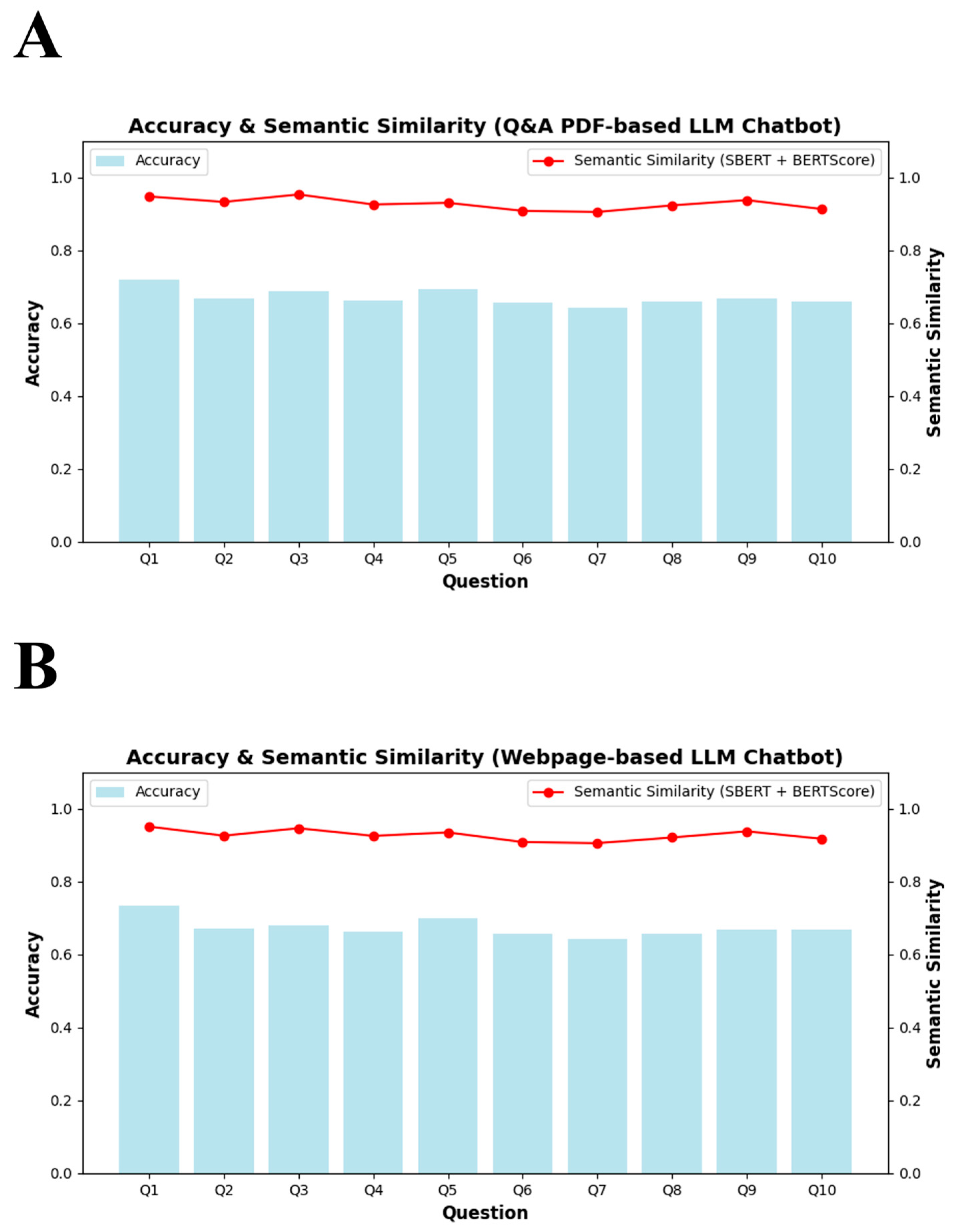
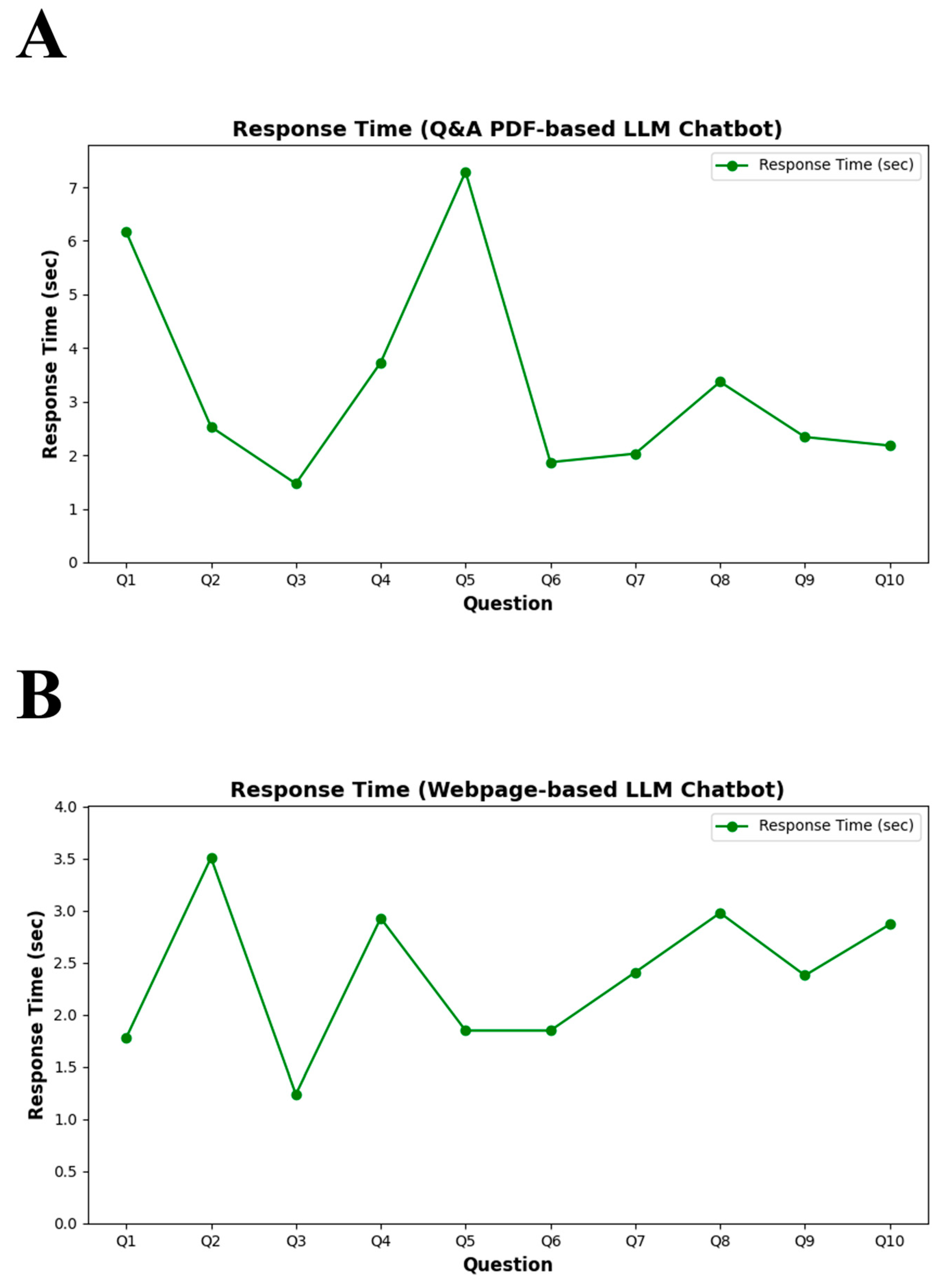
3.2. Performance Evaluation Results
4. Discussion
4.1. System Implementation and User Interface Design
4.2. Comparative Performance Evaluation of Chatbots
4.3. Study Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xin, Q.; Na, Q. Enhancing inference accuracy of Llama LLM using reversely computed dynamic temporary weights. TechRxiv 2024. [Google Scholar] [CrossRef]
- Hadi, M.U.; Al-Tashi, Q.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; et al. A survey on large language models: Applications, challenges, limitations, and practical usage. TechRxiv 2024. [Google Scholar] [CrossRef]
- Driess, D.; Xia, F.; Sajjadi, M.S.M.; Lynch, C.; Chowdhery, A.; Ichter, B.; Wahid, A.; Tompson, J.; Vuong, Q.; Yu, T.; et al. PaLM-E: An embodied multimodal language model. In Proceedings of the ICML’23: Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar] [CrossRef]
- Patnaik, S.S.; Hoffmann, U. Comparison of ChatGPT vs. bard to Anesthesia-related Queries. medRxiv 2023. [Google Scholar] [CrossRef]
- Koroteev, M.V. BERT: A review of applications in natural language processing and understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar] [CrossRef]
- Rajaraman, N.; Jiao, J.; Ramchandran, K. An analysis of tokenization: Transformers under markov data. In Proceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 9–15 December 2024. [Google Scholar]
- Chow, J.C.L.; Sanders, L.; Li, K. Design of an educational chatbot using artificial intelligence in radiotherapy. AI 2023, 4, 319–332. [Google Scholar] [CrossRef]
- Chow, J.C.L.; Wong, V.; Sanders, L.; Li, K. Developing an AI-Assisted Educational Chatbot for Radiotherapy Using the IBM Watson Assistant Platform. Healthcare 2023, 11, 2417. [Google Scholar] [CrossRef] [PubMed]
- Chow, J.C.L.; Li, K. Developing Effective Frameworks for Large Language Model-Based Medical Chatbots: Insights From Radiotherapy Education With ChatGPT. JMIR Cancer 2025, 11, e66633. [Google Scholar] [CrossRef] [PubMed]
- Eickhoff, T.; Hakoua, A.N.; Gobel, J.C. AI-assisted engineering data integration for small and medium-sized enterprises. In Proceedings of the NordDesign, Reykjavik, Iceland, 12–14 August 2024. [Google Scholar] [CrossRef]
- Kaplan, A.; Sayan, I.U.; Sahan, H.; Begen, E.; Bayrak, A.T. Response performance evaluations of ChatGPT models on large language model frameworks. In Proceedings of the 32nd Signal Processing and Communications Applications Conference (SIU), Mersin, Turkiye, 15–18 May 2024. [Google Scholar] [CrossRef]
- Deepchecks. EmbedChain Modeling. Available online: https://www.deepchecks.com/llm-tools/embedchain/ (accessed on 1 May 2025).
- Saxena, R.R. Beyond flashcards: Designing an intelligent assistant for USMLE mastery and virtual tutoring in medical education (A study on harnessing chatbot technology for personalized Step 1 prep). arXiv 2024, arXiv:2409.10540. [Google Scholar] [CrossRef]
- Ferreira, R.; Canesche, M.; Jamieson, P.; Vilela Neto, O.P.; Nacif, J.A.M. Examples and tutorials on using Google Colab and Gradio to create online interactive student-learning modules. Comput. Appl. Eng. Educ. 2024, 32, e22729. [Google Scholar] [CrossRef]
- Jetbrains. PyCharm Version 2024.1 [Computer Software]. Available online: https://www.jetbrains.com/pycharm (accessed on 1 May 2025).
- Jung, J.H.; Lee, K.B. Research of BERT-Based Q&A System for Radiation Therapy Education. J. Radiol. Sci. Technology 2025, 48, 171–178. [Google Scholar] [CrossRef]
- Podgorsak, E.B. (Ed.) Radiation Oncology Physics: A Handbook for Teachers and Students; International Atomic Energy Agency: Vienna, Austria, 2005. [Google Scholar]
- International Commission on Radiation Units and Measurements. Prescribing, Recording, and Reporting Photon-Beam Intensity-Modulated Radiation Therapy (IMRT); ICRU Report 83; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Huq, M.S.; Fraass, B.A.; Dunscombe, P.B.; Gibbons, J.P., Jr.; Ibbott, G.S.; Mundt, A.J.; Mutic, S.; Palta, J.R.; Rath, F.; Thomadsen, B.R.; et al. The report of Task Group 100 of the AAPM: Application of risk analysis methods to radiation therapy quality management. Med. Phys. 2016, 43, 4209–44262. [Google Scholar] [CrossRef] [PubMed]
- Siochi, R.A.; Peter, B.; Charles, D.B.; Santanam, L.; Blodgett, K.; Curran, B.H.; Engelsman, M.; Feng, W.; Mechalakos, J.; Pavord, D.; et al. A rapid communication from AAPM Task Group 201: Recommendations for the QA of external beam radiotherapy data transfer. AAPM TG 201: Quality assurance of external beam radiotherapy data transfer. J. Appl. Clin. Med. Phys. 2011, 12, 170–181. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Belouadi, J.; Eger, S. Reproducibility issues for BERT-based evaluation metrics. arXiv 2022, arXiv:2204.00004. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. ACL 2002. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002. [Google Scholar] [CrossRef]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Barcelona, Spain; 2024. Available online: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/07/was2004.pdf (accessed on 1 May 2025).
- Sharma, K.V.; Ayiluri, P.R.; Betala, R.; Kumar, P.J.; Reddy, K.S. Enhancing query relevance: Leveraging SBERT and cosine similarity for optimal information retrieval. Int. J. Speech Technol. 2024, 27, 753–763. [Google Scholar] [CrossRef]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating text generation with BERT. arXiv 2020, arXiv:1904.09675. [Google Scholar] [CrossRef]
- Ye, Y.; Simpson, E.; Rodriguez, R.S. Using similarity to evaluate factual consistency in summaries. arXiv 2024, arXiv:2409.15090. [Google Scholar] [CrossRef]
- Zheng, X.; Wu, H. Autoregressive linguistic steganography based on BERT and consistency coding. Secur. Commun. Netw. 2022, 2022, 9092785. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Framework | Primary Functionality | Key Features |
|---|---|---|
| EmbedChain | Embedding and retrieval support for document data | Document and PDF embedding; flexible search capabilities |
| LangChain | Optimizes response workflows with LLMs | Robust data pipeline supports multiple data sources |
| Haystack | Builds NLP applications and supports RAG (Retrieval-Augmented Generation) | Multi-backend support, document search, and Q&A; integration with Pinecone |
| Weaviate | Vector database with AI-powered search | Real-time search integrates with knowledge graphs |
| Chroma | Embedding and search engine for vector data | High-performance real-time search and storage |
| Pinecone | Vector-based search and memory expansion | API-based management of largescale vector data; real-time search |
| Feature | Description |
|---|---|
| API Key setup | Environment variable, secure, sensitive information |
| Instance creation | App class, chatbot initialization |
| Resource addition | URL compilation, radiation therapy, error handling |
| Query handling | {answer_query} function, user input processing, answer retrieval |
| Interface setup | Gradio UI, input fields, submit button, visual elements |
| Chatbot execution | App accessibility |
| Number | Question |
|---|---|
| 1 | What is the principle of radiation therapy? |
| 2 | What is the difference between IMRT and VMAT? |
| 3 | What are the advantages of proton therapy? |
| 4 | What are the side effects of radiation therapy? |
| 5 | What is the difference between diagnostic CT and therapeutic CT? |
| 6 | How is the radiation dose determined in radiation therapy? |
| 7 | What are the strategies for protecting normal tissues in radiation therapy? |
| 8 | What is the difference between SRS and SBRT? |
| 9 | What is the purpose of radiation therapy? |
| 10 | What is SGRT? |
| Performance | EmbedChain LLM Chatbot | |
|---|---|---|
| Q&A PDF | Webpage | |
| Accuracy | 0.672 | 0.675 |
| SBERT | 0.957 | 0.965 |
| BERTScore | 0.9 | 0.901 |
| Semantic similarity | 0.928 | 0.928 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, J.-H.; Kim, D.; Lee, K.-B.; Lee, Y. Performance Evaluation of Large Language Model Chatbots for Radiation Therapy Education. Information 2025, 16, 521. https://doi.org/10.3390/info16070521
Jung J-H, Kim D, Lee K-B, Lee Y. Performance Evaluation of Large Language Model Chatbots for Radiation Therapy Education. Information. 2025; 16(7):521. https://doi.org/10.3390/info16070521
Chicago/Turabian StyleJung, Jae-Hong, Daegun Kim, Kyung-Bae Lee, and Youngjin Lee. 2025. "Performance Evaluation of Large Language Model Chatbots for Radiation Therapy Education" Information 16, no. 7: 521. https://doi.org/10.3390/info16070521
APA StyleJung, J.-H., Kim, D., Lee, K.-B., & Lee, Y. (2025). Performance Evaluation of Large Language Model Chatbots for Radiation Therapy Education. Information, 16(7), 521. https://doi.org/10.3390/info16070521