
Speech Emotion Recognition on MELD and RAVDESS Datasets Using CNN


Abstract
1. Introduction
2. Related Works
2.1. Classical and Traditional Approaches to Deep Learning
2.2. Modern Deep Learning Methodologies (2020–2024)
2.2.1. Transformer-Based Architectures
2.2.2. Self-Supervised Learning Models
2.2.3. Multimodal Speech Emotion Recognition
2.2.4. Lightweight and Embedded Systems
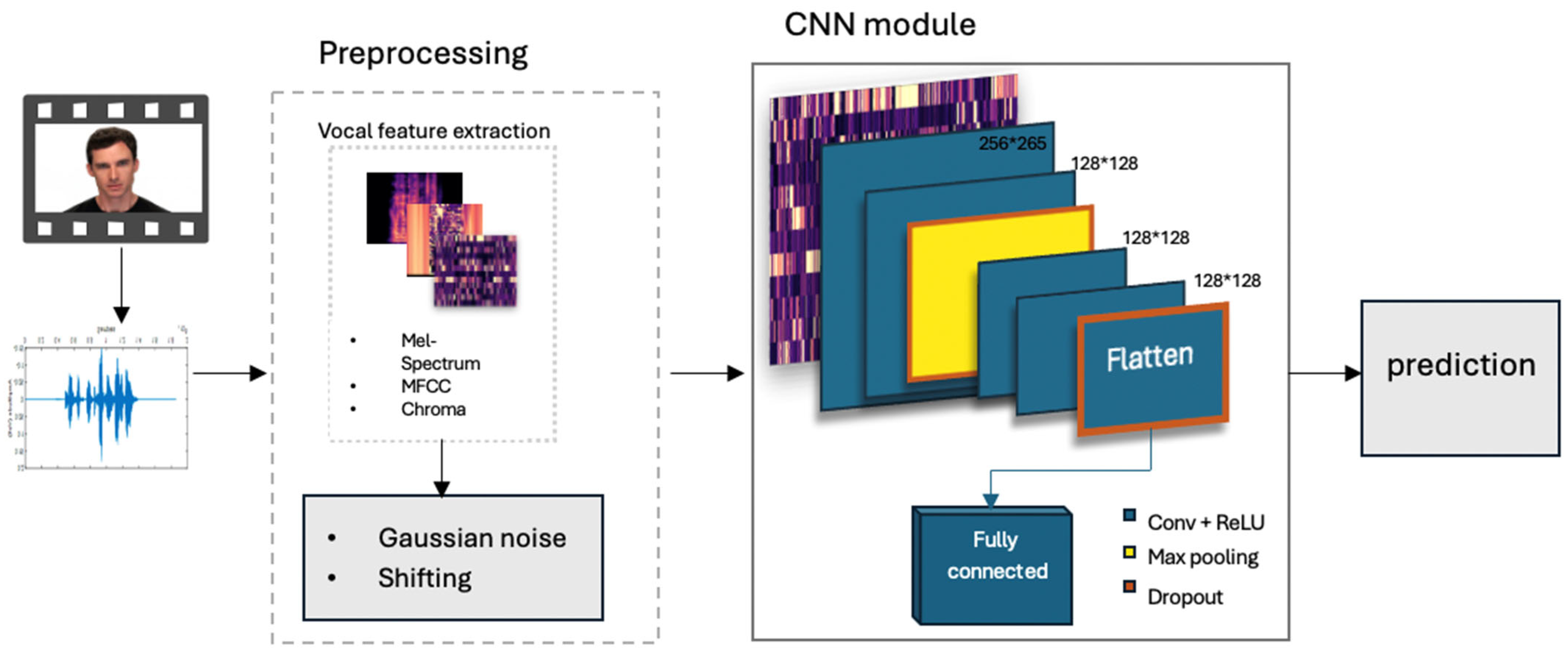
3. Methodology
3.1. Datasets
- MELD Dataset: This dataset consists of 13,000 utterances sourced from multi-party conversations in the television show Friends. Each utterance is categorised into one of seven emotional labels: neutral, sadness, surprise, anger, contempt, fear, and happiness. The dataset is publicly available at: “https://affective-meld.github.io/ (accessed on 16 July 2024)”.
- RAVDESS Dataset: This dataset contains 7356 audio–video recordings featuring actors portraying eight emotions: neutral, calm, happy, sad, angry, fearful, disgust, and surprised. However, since calmness is often acoustically indistinguishable from neutrality, we exclude it and focus on the remaining seven primary emotions for this study. The dataset is publicly available at: “https://zenodo.org/records/1188976” accessed on 29 October 2024.
3.2. Feature Extraction and Augmentation
- Mel-frequency Cepstral Coefficients (MFCCs):
- Captures short-term power spectrum features of audio signals.
- Simulates human auditory perception by mapping frequencies to the Mel scale, which aligns more closely with how humans perceive sound.
- Has shown strong performance.in recognising speech patterns and identifying emotions in audio.
- x[n]: Input audio signal in time domain;
- w[m-n]: Window function (e.g., Hamming, Hann) centered in time;
- m: Time shift, or frame index.;
- : angular frequency bin;
- : Complex exponential basis function (for Fourier transform);
- : The Time-frequency representation of the signal.
- t: Frame or time index.
- n: MFCC coefficient index (e.g., 1st, 2nd, …).
- K: Number of Mel filter banks.
- Power or energy of the signal at kth Mel filter for a frame.
- Logarithmic power spectrum (simulates human loudness perception).
- Cos [.. ]: DCT, which is used to decorrelate features.
- b.
- Mel-scaled spectrogram
- Converts audio signals into a time–frequency representation, providing a detailed analysis of sound over time.
- Delivers richer frequency resolution, effectively capturing the texture and nuances of the voice.
- c.
- Chroma Feature
- Extracts tonal and harmonic information from audio signals.
- Substantially contributes to detecting intonation and pitch variations, which are essential for capturing emotional expression.
- is the average value of z.
- is its standard deviation.
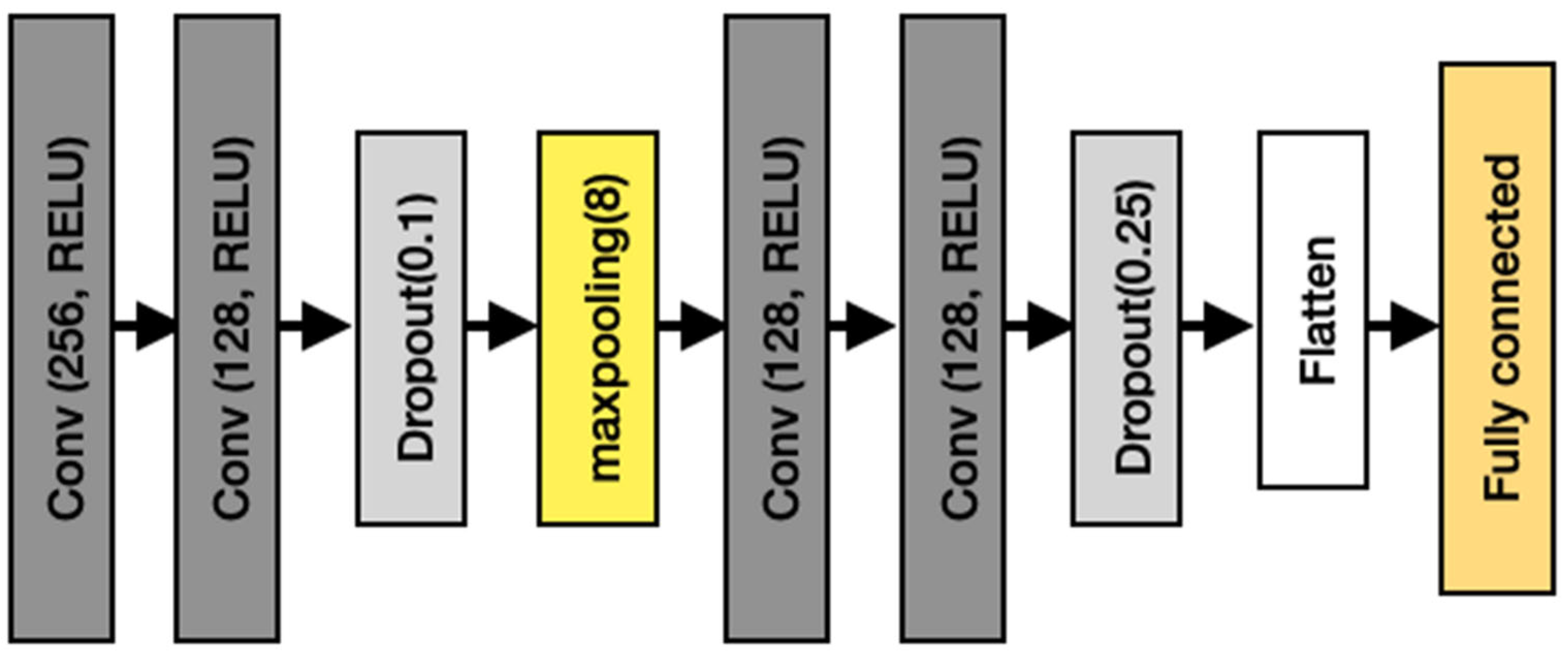
3.3. CNN Model
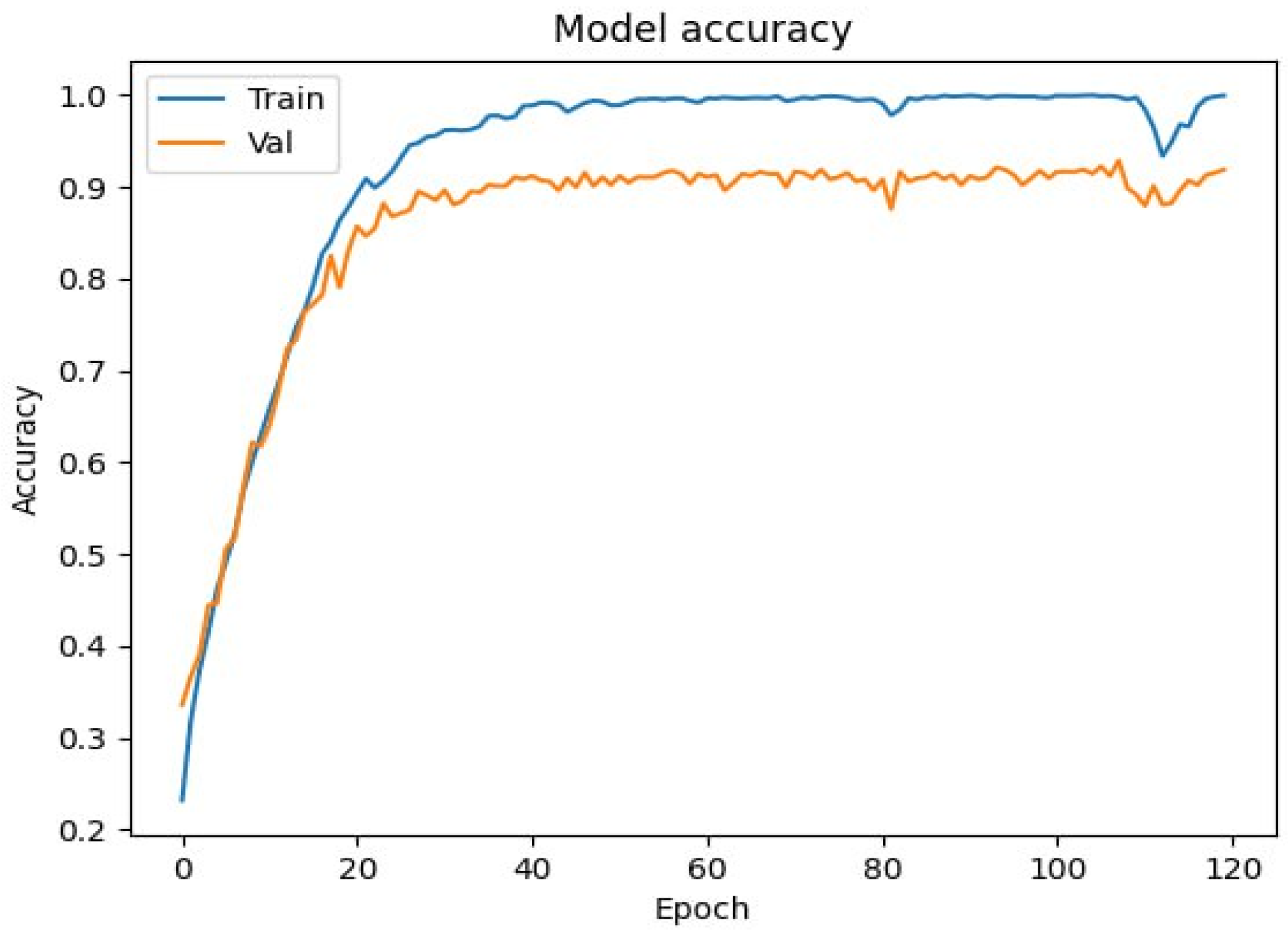
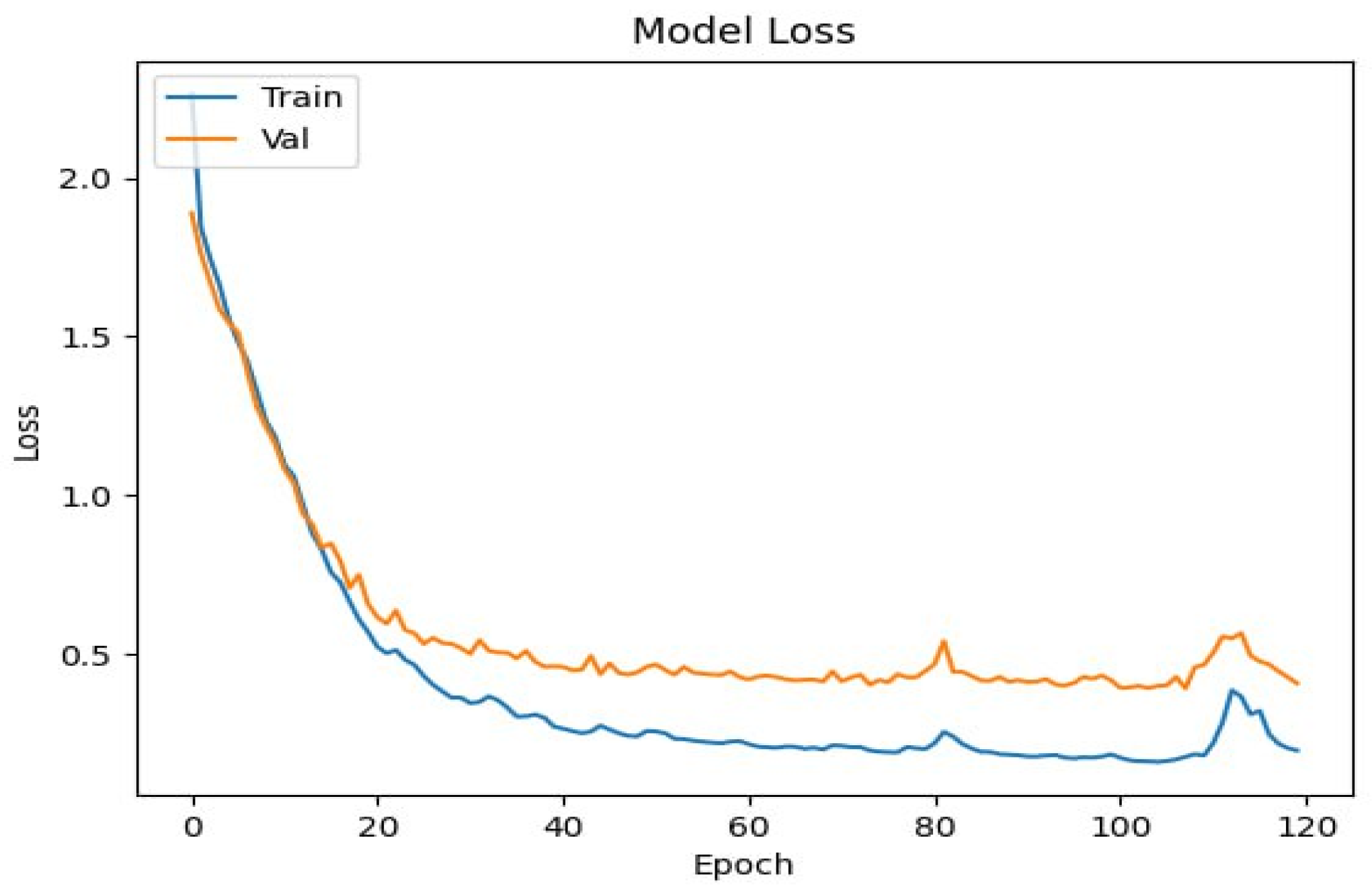
3.4. Training and Evaluation
4. Results and Discussion
4.1. Performance on RAVDESS Dataset
4.2. Performance on MELD Dataset
4.3. Ablation Study
- (1)
- Using MFCCs alone.
- (2)
- Combining MFCCs with Mel-spectrograms.
- (3)
- Integrating the full combination of MFCCs, Mel-spectrograms, and Chroma features.
4.4. Evaluation Metrics Overview
4.5. Comparative Analysis with State-of-the-Art Methods
- The effectiveness of directly modelling temporal dependencies using 1D convolution, which captures the sequential nature of speech more efficiently than 2D CNNs.
- The advantages of the feature fusion strategy, which integrates MFCCs, Mel-spectrograms, and Chroma features to provide a more comprehensive representation of emotional speech characteristics.
- The use of 1D convolutions, which effectively preserve the temporal dependencies present in speech signals.
- The integration of complementary features (MFCCs, Mel-spectrograms, and Chroma), resulting in a richer and more informative representation of emotional speech.
- The application of data augmentation techniques (e.g., Gaussian noise, time shifting), which improve the model’s robustness to speaker variability and varying recording conditions.
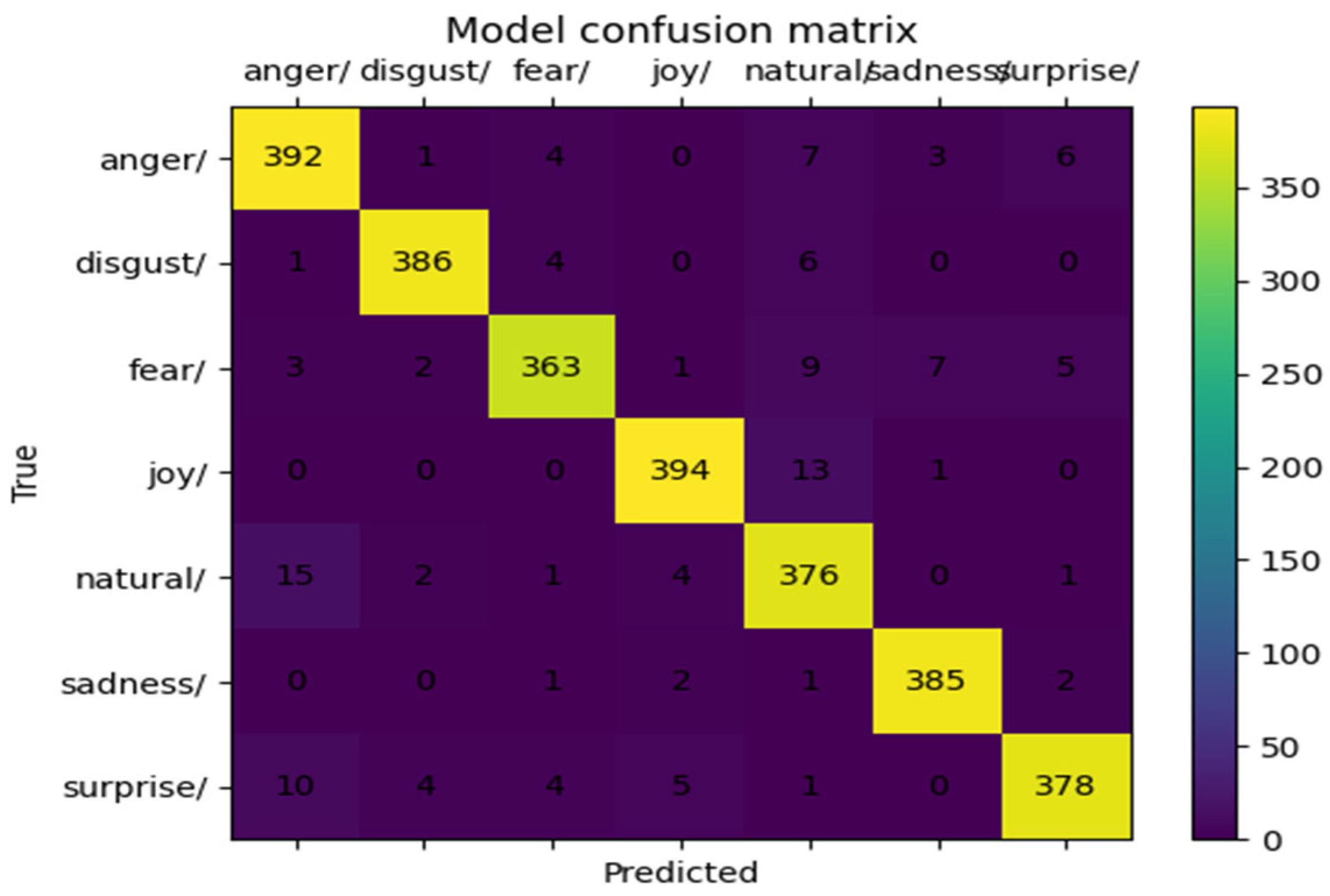
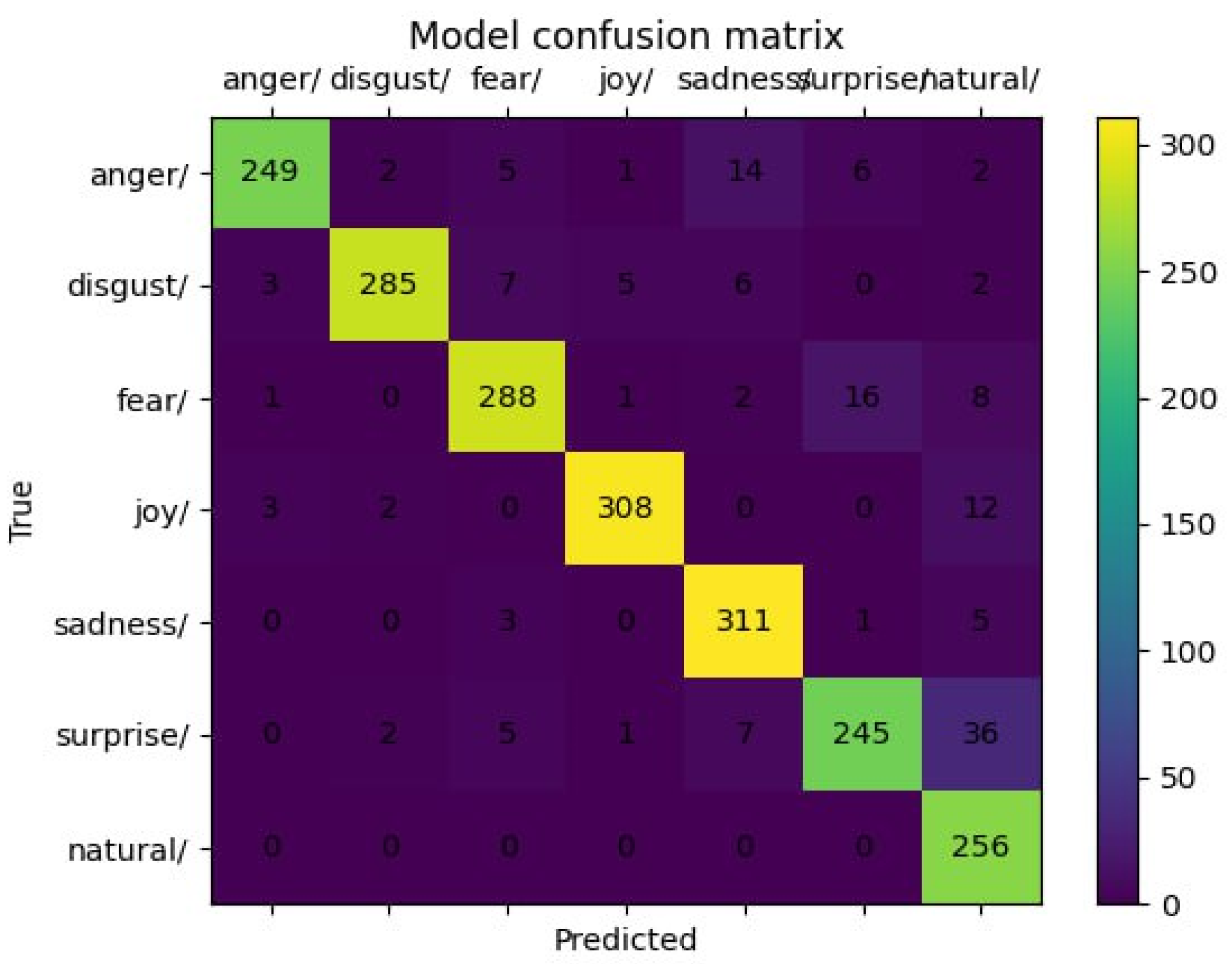
4.6. Confusion Matrix Analysis
4.6.1. MELD Dataset
4.6.2. RAVDESS Dataset
4.7. Model Efficiency
4.8. Limitations and Future Work
- Integrating attention mechanisms for enhanced context awareness.
- Taking advantage of multimodal information (i.e., integrating audio with transcript embeddings).
- Using domain adaptation methods to more effectively manage speaker and recording variation between data sets.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 116, 56–76. [Google Scholar] [CrossRef]
- AlHanai, T.; Ghassemi, M. Predicting latent narrative mood using audio and physiologic data. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, AAAI 2017, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar] [CrossRef]
- Eom, Y.; Bang, J. Speech emotion recognition based on 2D CNN and improved MFCC features. J. Inf. Commun. Converg. Eng. 2021, 19, 148–154. [Google Scholar]
- Bhavan, A.; Chauhan, P.; Hitkul; Shah, R.R. Bagged support vector machines for emotion recognition from speech. Knowl.-Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Tashev, I.J.; Wang, Z.-Q.; Godin, K. Speech emotion recognition based on Gaussian Mixture Models and Deep Neural Networks. In Proceedings of the 2017 Information Theory and Applications Workshop (ITA), La Jolla, CA, USA, 12–17 February 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Fahad, M.S.; Deepak, A.; Pradhan, G.; Yadav, J. DNN-HMM-Based Speaker-Adaptive Emotion Recognition Using MFCC and Epoch-Based Features. Circuits Syst. Signal Process. 2021, 40, 466–489. [Google Scholar] [CrossRef]
- Dal Rí, F.A.; Ciardi, F.C.; Conci, N. Speech Emotion Recognition and Deep Learning: An Extensive Validation Using Convolutional Neural Networks. IEEE Access 2023, 11, 116638–116649. [Google Scholar] [CrossRef]
- Li, D.; Liu, J.; Yang, Z.; Sun, L.; Wang, Z. Speech emotion recognition using recurrent neural networks with directional self-attention. Expert Syst. Appl. 2021, 173, 114683. [Google Scholar] [CrossRef]
- Hazmoune, S.; Bougamouza, F. Using transformers for multimodal emotion recognition: Taxonomies and state of the art review. Eng. Appl. Artif. Intell. 2024, 133, 108339. [Google Scholar] [CrossRef]
- Alarcão, S.M.; Fonseca, M.J. Emotions recognition using EEG signals: A survey. IEEE Trans. Affect. Comput. 2019, 10, 374–393. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, Z.; Shang, Z.; Zhang, P.; Yan, Y. LinearSpeech: Parallel Text-to-Speech with Linear Complexity. In Proceedings of the Interspeech 2021, ISCA, Brno, Czech Republic, 30 August–3 September 2021; pp. 4129–4133. [Google Scholar] [CrossRef]
- Tzirakis, P.; Zhang, J.; Schuller, B.W. End-to-End Speech Emotion Recognition Using Deep Neural Networks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5089–5093. [Google Scholar] [CrossRef]
- Abdelwahab, M.; Busso, C. Supervised domain adaptation for emotion recognition from speech. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5058–5062. [Google Scholar] [CrossRef]
- Özseven, T. Investigation of the effect of spectrogram images and different texture analysis methods on speech emotion recognition. Appl. Acoust. 2018, 142, 70–77. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, H.; Chen, G.; Wang, Q.; Zhao, Z.; Lu, X.; Wang, L. Multi-Level Knowledge Distillation for Speech Emotion Recognition in Noisy Conditions. In Proceedings of the Interspeech 2023, Dublin, Ireland, 20–24 August 2023; pp. 1893–1897. [Google Scholar] [CrossRef]
- Subasi, A.; Tuncer, T.; Dogan, S.; Tanko, D.; Sakoglu, U. EEG-based emotion recognition using tunable Q wavelet transform and rotation forest ensemble classifier. Biomed. Signal Process. Control. 2021, 68, 102648. [Google Scholar] [CrossRef]
- Gayathri, R.; Arun Kumar, B.; Inbanathan, S.; Karthick, S. Speech emotion recognition using CNN-LSTM. Int. J. Sci. Res. Eng. Manag. 2023, 7. [Google Scholar] [CrossRef]
- Wu, S.; Falk, T.H.; Chan, W.Y. Automatic speech emotion recognition using modulation spectral features. Speech Commun. 2011, 53, 768–785. [Google Scholar] [CrossRef]
- Lampropoulos, A.S.; Tsihrintzis, G.A. Evaluation of MPEG-7 descriptors for speech emotional recognition. In Proceedings of the 2012 8th International Conference on Intelligent Information Hiding and Multimedia Signal Processing, IIH-MSP 2012, Piraeus-Athens, Greece, 18–20 July 2012. [Google Scholar] [CrossRef]
- Wang, K.; An, N.; Li, B.N.; Zhang, Y.; Li, L. Speech emotion recognition using Fourier parameters. IEEE Trans. Affect. Comput. 2015, 6, 69–75. [Google Scholar] [CrossRef]
- Zeng, Y.; Mao, H.; Peng, D.; Yi, Z. Spectrogram based multi-task audio classification. Multimed. Tools Appl. 2019, 78, 3705–3722. [Google Scholar] [CrossRef]
- Popova, A.S.; Rassadin, A.G.; Ponomarenko, A.A. Emotion Recognition in Sound. In Advances in Neural Computation, Machine Learning, and Cognitive Research; Kryzhanovsky, B., Dunin-Barkowski, W., Redko, V., Eds.; Springer: Cham, Switzerland, 2018; pp. 117–124. [Google Scholar] [CrossRef]
- Tang, X.; Lin, Y.; Dang, T.; Zhang, Y.; Cheng, J. Speech Emotion Recognition Via CNN-Transformer and Multidimensional Attention Mechanism. Speech Commun. 2025, 171, 103242. [Google Scholar] [CrossRef]
- Dabbabi, K.; Mars, A. Self-supervised Learning for Speech Emotion Recognition Task Using Audio-visual Features and Distil Hubert Model on BAVED and RAVDESS Databases. J. Syst. Sci. Syst. Eng. 2024, 33, 576–606. [Google Scholar] [CrossRef]
- Pepino, L.; Riera, P.; Ferrer, L. Emotion recognition from speech using wav2vec 2.0 embeddings. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH 2021, Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar] [CrossRef]
- Chudasama, V.; Kar, P.; Gudmalwar, A.; Shah, N.; Wasnik, P.; Onoe, N. M2FNet: Multi-modal Fusion Network for Emotion Recognition in Conversation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Li, B.; Fei, H.; Liao, L.; Zhao, Y.; Teng, C.; Chua, T.-S.; Ji, D.; Li, F. Revisiting Disentanglement and Fusion on Modality and Context in Conversational Multimodal Emotion Recognition. In Proceedings of the MM 2023: The 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023. [Google Scholar] [CrossRef]
- Sadok, S.; Leglaive, S.; Seguier, R. A Vector Quantized Masked Autoencoder for Speech Emotion Recognition. In Proceedings of the ICASSPW 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing Workshops, Proceedings, Rhodes Island, Greece, 4–10 June 2023. [Google Scholar] [CrossRef]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A multimodal multi-party dataset for emotion recognition in conversations. In Proceedings of the ACL 2019—57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Russo, F.A. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in North American english. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef]
- Ho, N.-H.; Yang, H.-J.; Kim, S.-H.; Lee, G. Multimodal approach of speech emotion recognition using multi-level multi-head fusion attention-based recurrent neural network. IEEE Access 2020, 8, 61672–61686. [Google Scholar]
- Hu, D.; Bao, Y.; Wei, L.; Zhou, W.; Hu, S. Supervised adversarial contrastive learning for emotion recognition in conversations. arXiv 2023, arXiv:2306.01505. [Google Scholar]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient emotion recognition from speech using deep learning on spectrograms. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 1089–1093. [Google Scholar]
- Luna-Jiménez, C.; Kleinlein, R.; Griol, D.; Callejas, Z.; Montero, J.M.; Fernández-Martínez, F. A proposal for multimodal emotion recognition using aural transformers and action units on ravdess dataset. Appl. Sci. 2021, 12, 327. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Architecture | Dataset | Key Contribution |
|---|---|---|---|
| [15] [16] [17] [18] [19] [20] [22] [24] [25] [27] [28] [29] | Texture + Acoustic Fusion Hybrid ELM-DT SVM + TQWT 2D CNN + SVM MFCC + MSF + LDA MPEG 7 features GResNet Transformer + Self Attention DistilHuBERT M2FNet Graph- Attention Multimodal model VQ-MAE-S-12 | SAVEE, EMO-DB, eNTERFACE’05 CASIA RAVDESS, EMO-DB, SAVEE EMOVO EMO-DB Recorded Dataset EMO-DB RAVDESS RAVDESS, CERMA-D RAVDESS, BAVED MELD IEMOCAP RAVDESS | Improving image features 89% precision 90% Accuracy 88.3% precision 85% Accuracy 83.93% precision 65.97% Accuracy 82.4% (RAVDESS), 85.3% (CREMA-D) 90.79% (RAVDESS), 82.35% (BAVED) 91.2% accuracy 89.3% accuracy 84.1% accuracy for embedded systems |
| Feature Combination | Accuracy (RAVDESS) | Accuracy (MELD) |
|---|---|---|
| MFCC only | 85.0% | 87.1% |
| MFCC + Mel | 89.5% | 91.0% |
| MFCC + Mel + Chroma | 91.9% | 94.0% |
| Metric | RAVDESS (%) | MELD (%) |
|---|---|---|
| Accuracy | 91.9 | 94.0 |
| Precision | 90.5 | 93.2 |
| Recall | 91.1 | 93.8 |
| F1-Score | 90.8 | 93.5 |
| Study/Model | Year | Approach | Accuracy (%) |
|---|---|---|---|
| Ho et al. [32] | 2020 | RNN + Multi-level fusion Attention | 61.2 |
| Chudasama et al. [27] | 2022 | M2Fnet (Multimodal fusion (Text + Audio + visual)) | 66.7 |
| Hu et al. [33] | 2023 | SACL—LSTM | 68.28 |
| Li et al. [28] | 2023 | Attention-based Multi-modal | 68.28 |
| Ciardi et al. [8] | 2023 | 2D CNN with Spectrogram Inputs | 82.9 |
| Proposed Model | 2025 | 1D CNN + Feature Fusion | 94.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waleed, G.T.; Shaker, S.H. Speech Emotion Recognition on MELD and RAVDESS Datasets Using CNN. Information 2025, 16, 518. https://doi.org/10.3390/info16070518
Waleed GT, Shaker SH. Speech Emotion Recognition on MELD and RAVDESS Datasets Using CNN. Information. 2025; 16(7):518. https://doi.org/10.3390/info16070518
Chicago/Turabian StyleWaleed, Gheed T., and Shaimaa H. Shaker. 2025. "Speech Emotion Recognition on MELD and RAVDESS Datasets Using CNN" Information 16, no. 7: 518. https://doi.org/10.3390/info16070518
APA StyleWaleed, G. T., & Shaker, S. H. (2025). Speech Emotion Recognition on MELD and RAVDESS Datasets Using CNN. Information, 16(7), 518. https://doi.org/10.3390/info16070518