1. Introduction
Many applications and use cases empowered by Large Language Models (LLMs) have recently been published [
1]. Multi-agent systems leveraging conversational LLMs are widely used for tasks that require creativity and analytical thinking, such as data analysis or code generation. In these systems, multiple agents are instantiated as needed, each with predefined tasks and specialized skill sets, as demonstrated in frameworks like AutoGen [
2]. This approach has proven effective for relatively simple creative tasks. However, when scaled to production-level use, these applications often suffer from inconsistency due to LLM hallucinations, i.e., generating responses beyond the model’s factual knowledge [
3]. As a result, confidence in deploying LLMs at scale is reduced.
To mitigate these issues, we propose a solution that uses a hybrid combination of rule-based and LLM-based generation techniques. We first generate an initial response from the LLM using a relevant prompt. This response is then passed to a second stage focused on verification and fact-checking. In this stage, we use a custom logic module to help a reviewer agent assess the factuality of the initial response. In addition, we developed a performance scoring function to evaluate factual consistency based on this logic.
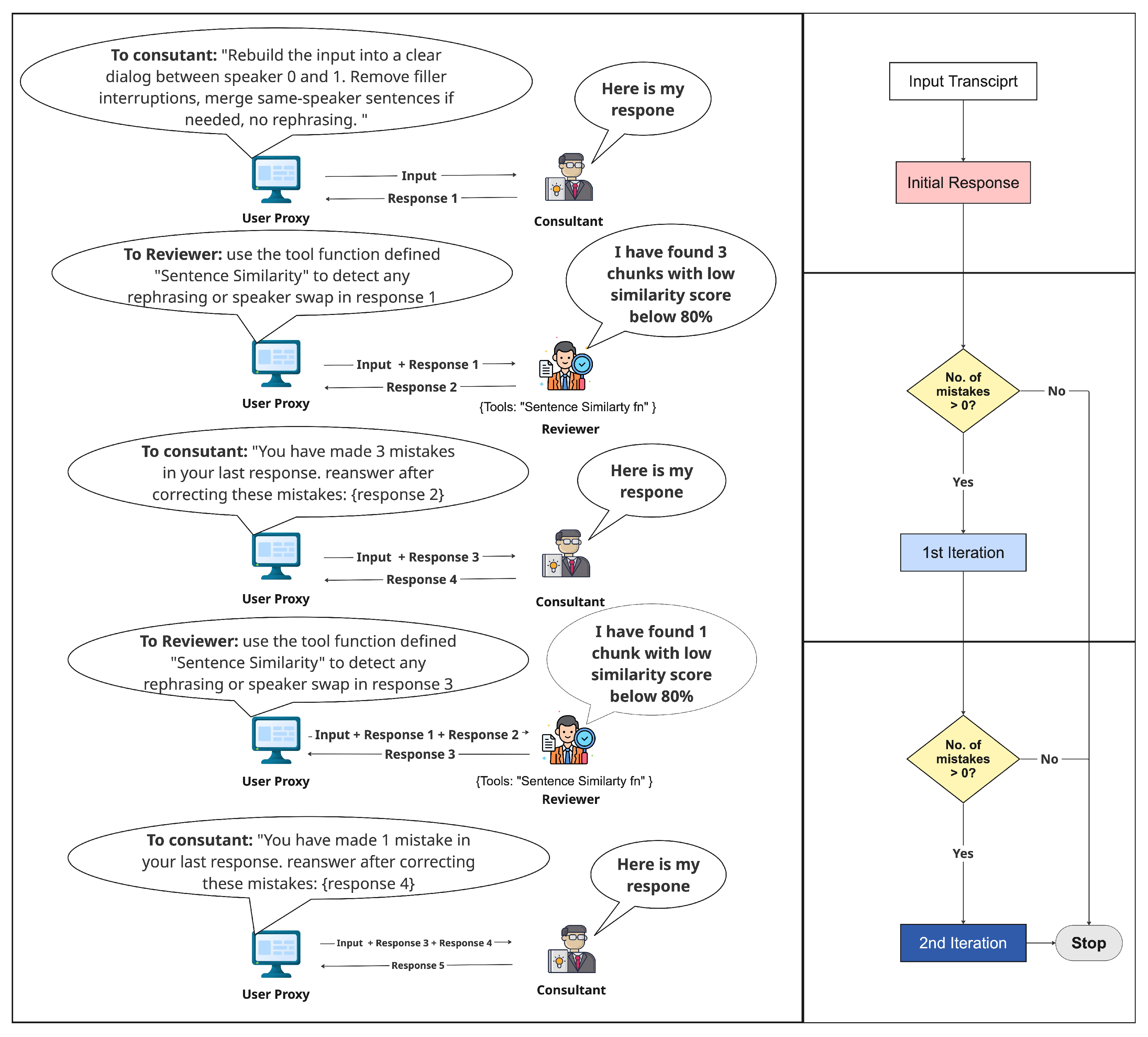
Figure 1 shows an overview of the proposed framework combining rule-based verification and LLM-based generation to improve factuality and coherence in noisy dialogue transcripts in call centers.
The proposed framework is general-purpose and was applied in a call center platform where call transcripts are often incoherent due to filler words and interruptions between agents and clients. Furthermore, in some instances, both speakers talk over each other, resulting in garbled content. The transcribed text is then input into an LLM, which is tasked with refining the conversation into a well-structured, punctuated dialogue free of filler words without rephrasing and while maintaining the original tone and wording of the speaker.
The LLM’s refined output is subsequently passed to another LLM agent, which is restricted to executing a predefined evaluation function and reporting its result only. More details about the evaluation function can be found in
Appendix A. In this framework, we define the similarity function to precisely compare the source and modified dialogue, detecting any rephrasing, or speaker swaps using a sequence-matching score. This function evaluates the initial LLM output, and if the similarity score falls below a set threshold, the system raises a flag for revision, or a concern is raised.
To refine the output, a controlled loop is initiated between the responsible LLM agent and the evaluator to tweak the response until it reaches a fixed number of iterations or a desired accuracy score within a specified tolerance. In our case, the stop criterion is either reaching zero mistakes in the consultant’s response or completing the second iteration, whichever comes first.
Figure 1 shows a process flowchart of the stop criteria used to control the consultant-reviewer iterations.
Then, a benchmark evaluation metric is calculated to evaluate the process performance over all processed transcripts. This evaluation is scalable and helps to detect any odd behavior of the LLM during deployment and take the necessary action. The evaluation matrix was primarily constructed using the similarity score between generated responses and reference answers. The mean similarity score was calculated for each model and iteration to provide an overall measure of average response quality. Alongside the mean, key descriptive statistics such as the standard deviation, minimum, 25th percentile, median (50th percentile), 75th percentile, and maximum similarity scores were computed to capture the distribution and variability of the model outputs. These metrics reveal not only the average quality but also the consistency and spread of the responses. Additionally, 95% confidence intervals (CIs) around the hallucination rates were calculated to quantify the uncertainty in these estimates, providing a statistical range within which the actual hallucination rate is expected to lie with 95% confidence. This combination of metrics enables a comprehensive and statistically robust assessment of model behavior across iterations. The contributions of this work include:
Design and implementation of a general hybrid framework that combines rule-based and LLM-based generation techniques. This framework is used for verifying and fact-checking initial LLM-generated responses and was applied to enhance the factuality and coherence of outputs in a call center transcript use case.
Proposal of a performance scoring function that assesses the factuality of LLM responses using custom-defined logic, supported by a controlled feedback loop between the generation and evaluation agents. This loop continues refining the responses until a set number of iterations is completed (two iterations in our case) or until the target accuracy threshold is achieved.
4. Experiment and Results
We applied our framework to 308 transcripts between speaker 0 (Call Center Agent) and speaker 1 (Client), each containing between 15 and 25 dialogue chunks.
We then evaluated the performance of the LLM consultant agent and benchmarked the similarity scores against a reference threshold of 80%.
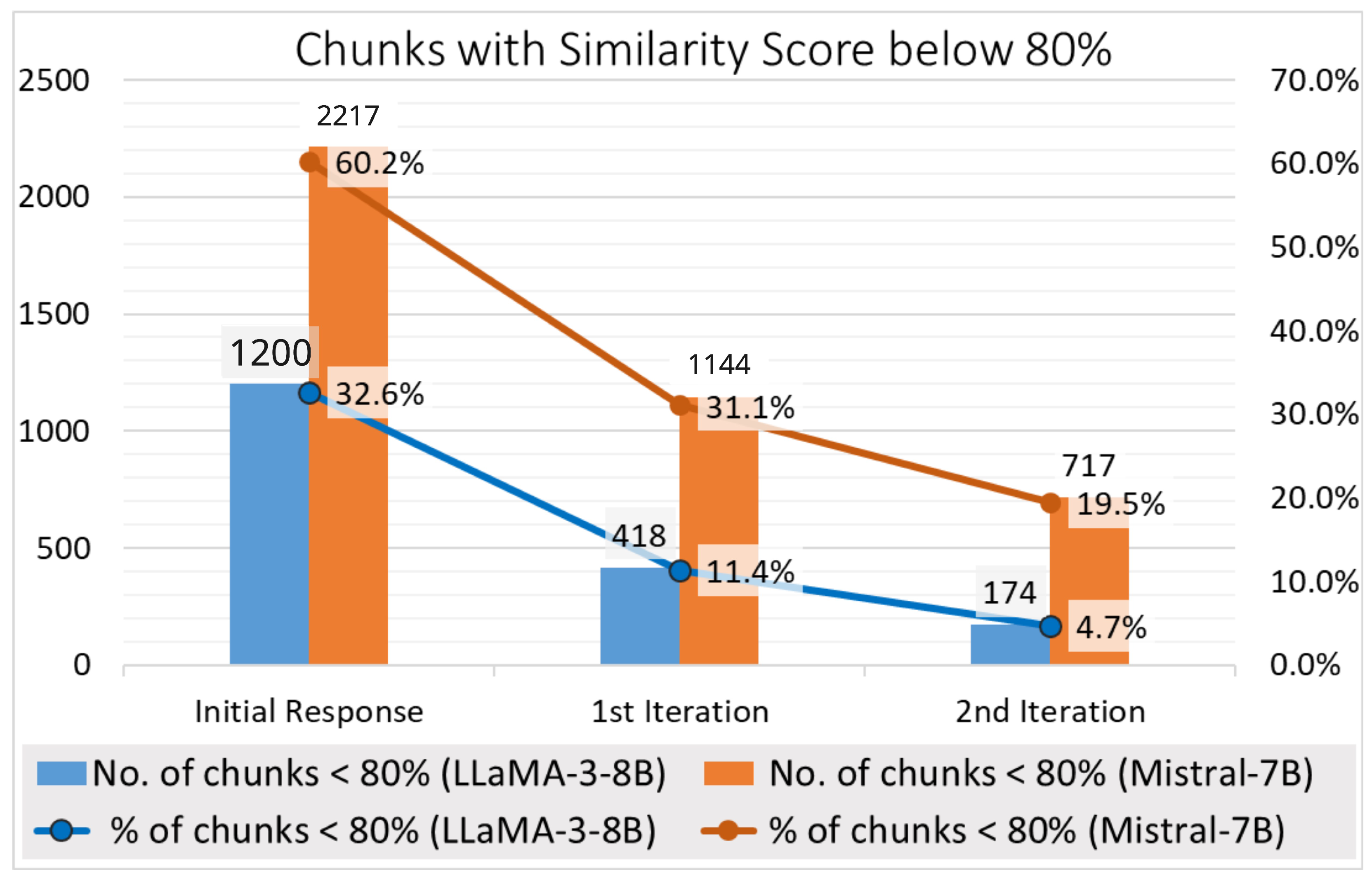
Of the 3680 total fragments across the 308 transcripts, 60.2% of Mistral-7B outputs and 32.6% of LLaMA-3-8B outputs fell below the 80% similarity threshold as shown in
Figure 5. The 95% confidence intervals indicate these differences are statistically robust (
Table 1). Overall, iterative refinement substantially improves factual accuracy, with LLaMA-3-8B demonstrating more effective reduction in hallucinations than Mistral-7B.
In the first iteration, we asked the same consultant agent to correct the mistakes in the initial response. The hallucination rate was reduced to 31.1% and 11.4% for Mistral-7B and LLaMA-3-8B, respectively. This rate was reduced to 19.5% and 4.7% in the last iteration with Mistral-7B and LLaMA-3-8B, respectively.
Table 2 shows the average similarity score (SS) for each model across different stages.
Despite the reduction in hallucination, LLMs may still produce minor hallucinations due to their reliance on learned patterns rather than factual grounding and limited internal knowledge. Prompt instructions are not always enforceable since the model lacks true understanding and instead predicts the most likely next token based on prior training data.
Table 3 displays the performance of the LLaMA-3-8B and Mistral-7B agents in terms of similarity scores across different iterations. As shown in the table, the number of hallucinating chunks with similarity scores below 80% was reduced from 1200 and 2217 to 174 and 717 for LLaMA-3-8B and Mistral-7B, respectively. The number of corrected chunks was 1,026 for LLaMA-3-8B and 1,500 for Mistral-7B, corresponding to reductions of 85.5% and 67.7% in hallucination rates after applying two-step iteration refinements.
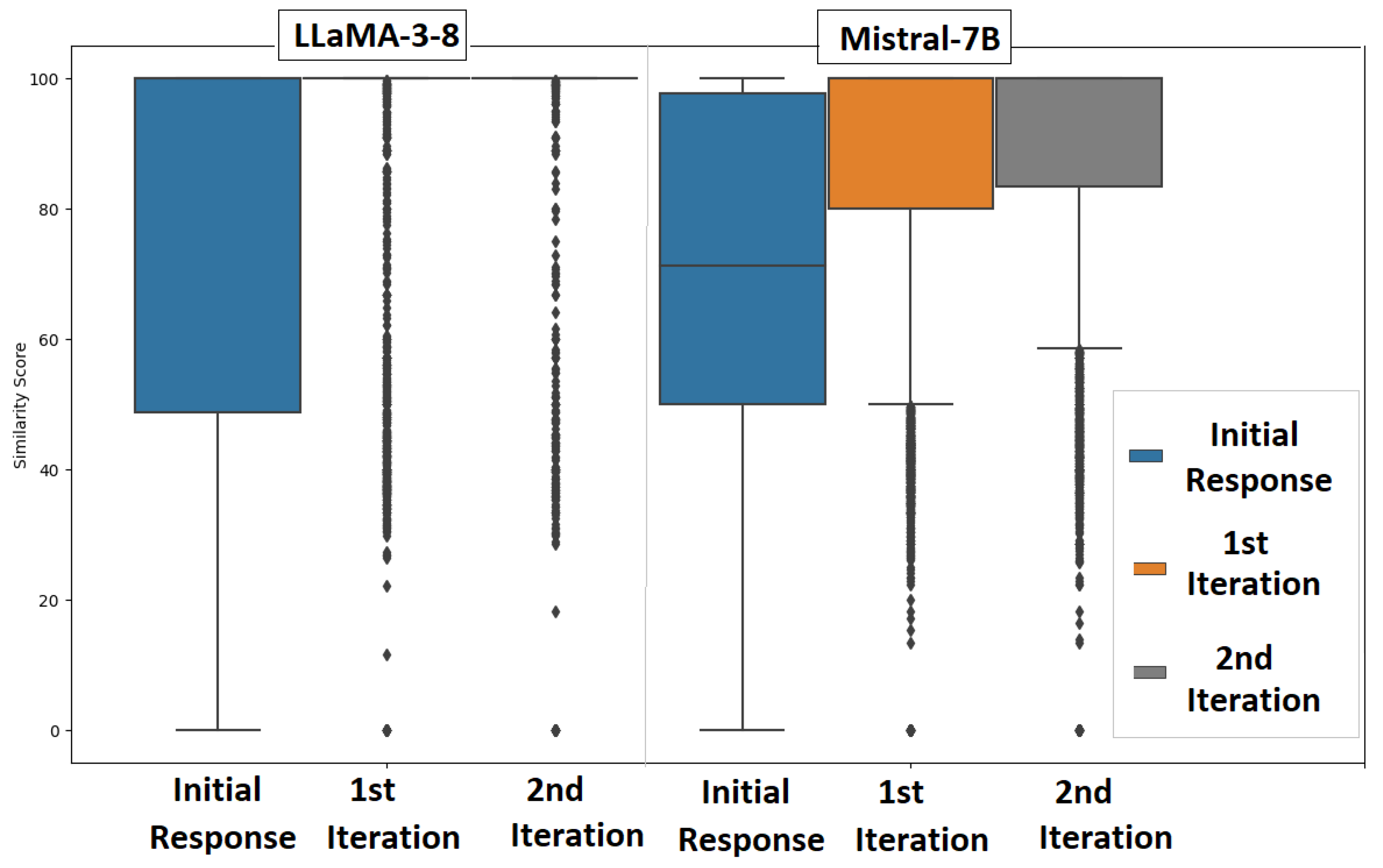
Figure 6 shows that observations reveal notable trends, including consistently high median scores for LLaMA-3-8B and Mistral-7B in the first and second iterations. The initial responses from Mistral and LLaMA exhibit greater variability and more outliers, indicating less consistent performance compared to their refined responses. In contrast, the first and second iterations show improved consistency, with reduced variability and fewer outliers.
Table 4 presents the descriptive statistics of SS produced by the two LLM models across different stages: initial response, first iteration, and second iteration. For both models, the central tendency (median) rapidly converges to 100% from the first iteration onward, indicating highly similar or near-identical outputs relative to reference answers. The inter-quartile ranges shrink with each iteration, particularly for Mistral-7B, suggesting increasing consistency in model behavior. While initial responses show more variability, especially in the lower quartiles, both models demonstrate a marked improvement in alignment and output similarity as iterative refinement progresses. The standard deviation decreases correspondingly, underscoring reduced variability in later responses.
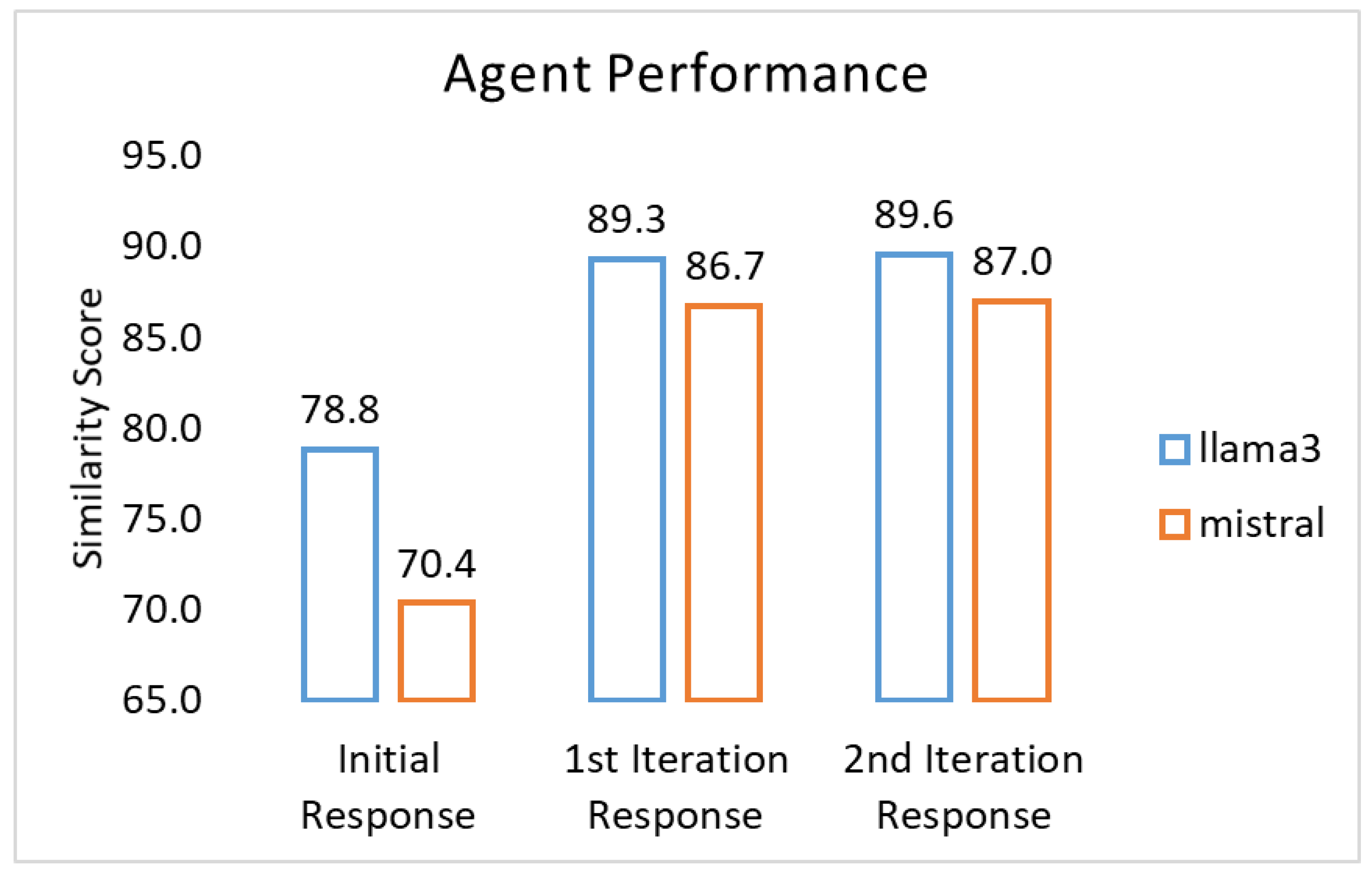
The initial response shows relatively low similarity scores, with LLaMA-3-8B scoring 78.84% and Mistral-7B scoring 70.35%. After the first iteration, both agents demonstrated significant improvement, with LLaMA-3-8B reaching 89.31% and Mistral-7B achieving 86.70%. The second iteration led to a slight additional improvement, with LLaMA-3-8B scoring 89.56% and Mistral-7B scoring 86.98% (
Figure 7). This trend indicates that our framework effectively improves the agents’ ability to generate more coherent and accurate responses.
Chunks are categorized into three main groups based on text length: (1) fewer than 50 words, (2) between 50 and 100 words, and (3) more than 100 words.
Table 5 shows the improvement in similarity score per chunk size category. The observed improvement appears to be independent of text length.
Figure 8 displays each model’s similarity score per chunk size category.
The progression from the Initial Response to subsequent iterations within the LLaMA and Mistral models demonstrates iterative improvements in performance, characterized by increased median similarity scores and reduced variability.
Based on these results, it is evident that our framework has a significant impact on the factual consistency of LLMs and the reduction in hallucinations. Moreover, the framework’s utility extends to a variety of scenarios. Additionally, the performance evaluation database facilitates the assessment of LLM agents across diverse use cases and datasets.
The framework was executed on a Linux-based machine equipped with an NVIDIA RTX 3090 GPU (24 GB VRAM) and an AMD Ryzen 9 5950X 16-core CPU (32 threads), completing the full dataset processing in approximately 52 min.
5. Discussion
While this work has made a significant contribution to improving the factual consistency of LLMs and reducing hallucinations, several promising avenues for future research remain. One such direction involves expanding the rule-based functions to incorporate a wider range of error detection and scoring algorithms, thereby enhancing the evaluation process. The evaluation function employed in our study is designed to detect hallucinations, which we define, within the context of our use case, as instances of speaker swaps or rephrasings. However, the notion of hallucination is inherently domain-dependent, and thus, rule-based evaluation functions should be adapted accordingly. For example, in code generation tasks, hallucinations may manifest as syntactically invalid outputs, which can be identified using executor LLMs or compilers. In machine translation, hallucinations may be assessed through deviations in grammatical correctness or fidelity to the source text. As a general principle, domain-specific rules grounded in expert knowledge can be formulated to measure the frequency with which generated outputs violate factual, structural, or functional constraints relevant to the target application.
In sentence restructure tasks, models with stronger language understanding and contextual reasoning generally yield more accurate and fluent outputs. LLaMA-3 8B demonstrates superior performance over Mistral-7B, as evidenced by its higher scores on benchmarks such as MMLU (68.4% vs. 60.1%) and HumanEval (62.2% vs. 36.6%), indicating better generalization and semantic control in generative tasks [
22,
23]. These differences are partly due to LLaMA-3’s larger parameter count and broader pretraining corpus, spanning 15 trillion tokens. While Mistral-7B is optimized for efficiency through Grouped Query Attention (GQA), its tradeoff is reflected in lower performance on tasks requiring nuanced paraphrasing. Therefore, LLaMA-3 8B is generally better suited for sentence restructuring where preservation of meaning and fluency is critical.
The proposed framework was executed on a Linux-based system equipped with an NVIDIA RTX 3090 GPU (24 GB VRAM) and an AMD Ryzen 9 5950X 16-core CPU (32 threads), completing the full dataset processing in approximately 52 min. To enhance computational efficiency, the system can be deployed on higher-performance hardware or optimized further by adjusting convergence parameters to reduce the number of correction iterations. However, such modifications may introduce a trade-off between processing speed and the effectiveness of hallucination mitigation.
Limitations
While the dataset offers valuable insights, it may suffer from limited diversity, primarily reflecting a specific market segment, customer base, or regional communication style. These limitations constrain the generalizability of models trained on the data to broader domains or geographic contexts. Although the transcripts are written in English, they exhibit considerable variation in dialects, accents, technical terminology, and informal speech patterns, introducing linguistic complexity that challenges robust model training. Additionally, the dataset may encode latent biases, such as the overrepresentation of certain customer demographics or service categories, leading to models that underperform for underrepresented groups. Structural biases may also exist, for example, a disproportionate focus on specific vehicle types, customer profiles, or support scenarios. These imbalances risk skewing model behavior and reducing performance in edge cases, such as interactions with first-time car owners or non-standard service requests.
This study is also limited to an open-domain dataset; other domains such as medical and legal remain unexplored. Furthermore, the current approach has only been tested on English-language conversations. Extending the evaluation to other languages will be constrained by the varying capabilities of LLMs in multilingual settings.
Future work could also benefit from the development of visualization dashboards and monitoring tools, which would offer deeper insights into model performance and aid in anomaly detection and tracking.
Author Contributions
Conceptualization, E.A.R. and G.K.; Methodology, A.M.D., E.A.R. and G.K.; Software, A.M.D.; Validation, A.M.D., E.A.R. and G.K.; Formal analysis, A.M.D.; Investigation, A.M.D., E.A.R. and G.K.; Resources, A.M.D.; Data curation, A.M.D.; Writing—original draft, A.M.D. and G.K.; Writing —review & editing, E.A.R. and G.K.; Visualization, A.M.D.; Supervision, E.A.R. and G.K.; Project administration, G.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used for the evaluation consists of real customer calls collected from a commercial call center in the automotive industry. The anonymized dataset supporting the findings of this study will be made available to ensure reproducibility, and the implementation framework is hosted in a private GitHub repository, accessible upon reasonable request and subject to approval.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Summary of Related Work
This appendix groups and compares the related work in terms of methodology, highlighting key differences in approaches, strengths, and limitations. Retrieval-augmented methods have been widely adopted to enhance the factual grounding of large language models (LLMs), particularly in open-domain and dialogue-based tasks. By integrating relevant external documents into the generation process, these systems reduce hallucinations by anchoring outputs in verifiable sources. For instance, models like MrRank and RAG-Prompter refine retrieval quality, while approaches such as WikiChat and Retrieval-Augmented Generation demonstrate the empirical benefits of grounding on open-domain knowledge like Wikipedia [
4,
5,
6,
25].
Table A1 summarizes recent retrieval-based grounding strategies and their contributions.
Self-reflection and prompt refinement techniques have emerged as effective internal correction mechanisms to mitigate hallucination. These methods allow models to introspect and revise their outputs, either through dedicated prompts or structured intervention. For example, Self-Reflection [
7] enables LLMs to critique and modify their own responses, while methods such as Chain-of-Verification and Tag Trapping [
13] enforce structured factual reasoning.
Table A2 highlights these strategies and their roles in improving factual consistency without external supervision.
Multi-agent verification frameworks introduce deliberation and disagreement to improve hallucination detection. These systems employ multiple agents that debate, verify, or challenge one another’s claims, mimicking human argumentation. AutoGen [
2] and ChatEval [
12] structure these interactions to filter hallucinated content, while Truth in Debate [
10] explicitly identifies falsehoods via contradiction. These techniques are described in
Table A3, showcasing how agent coordination improves factual grounding.
Contextually grounded prompting strategies provide source-tagged or structurally annotated inputs to guide LLMs toward accurate generation. These approaches improve transparency by labeling facts with their provenance or relevance. Tag Trapping [
13] uses annotated evidence to steer generations, while classifier-based methods like the one proposed by Bruno et al. [
19] assess whether the model adheres to grounded inputs.
Table A4 reviews these techniques and their application to hallucination mitigation.
Evaluating hallucinations requires robust benchmarks and metrics. Several datasets and frameworks have been proposed to quantify factual consistency in LLM outputs. Q² (2021) [
14] pioneered QA-based dialogue evaluation, while HaluEval (2023) [
15] and ANAH (2024) [
16] provide large-scale annotated resources across domains. Newer metrics like ChainPoll [
9] and summarization-based analyses [
17] further refine the hallucination detection landscape.
Table A5 presents a comparative overview of these evaluation tools.
Table A1.
Retrieval-augmented grounding.
| Method | Contribution |
|---|
| MrRank (2024) [25] | Proposes MrRank for enhancing retrieval in QA tasks, improving LLM grounding accuracy. |
| RAG-Prompter (2024) [5] | Introduces a RAG-based framework for improving LLM factual accuracy in domain-specific private knowledge bases. |
| WikiChat (2023) [6] | Uses few-shot grounding on Wikipedia to reduce hallucination in dialogue systems. |
| Retrieval-augmented Generation (2021) [4] | Demonstrates how retrieval augmentation reduces hallucinations in open-domain conversations. |
Table A2.
Self-reflection and prompt-based refinement.
| Method | Contribution |
|---|
| Self-Reflection (2023) [7] | Proposes self-reflection prompts to help LLMs identify and correct their own hallucinations. |
| Tag Trapping (2023) [13] | Introduces tagged context prompts to trap and minimize hallucination. |
Table A3.
Multi-agent debate/verification.
| Method | Contribution |
|---|
| AutoGen (2023) [2] | Introduces AutoGen, a framework for multi-agent collaboration among LLMs for enhanced factuality. |
| Let’s Discuss (2023) [11] | Uses divergent thinking in multi-agent debates to surface hallucinated content. |
| ChatEval (2023) [12] | Develops ChatEval, a multi-agent evaluator for hallucination detection in dialogues. |
| Truth in Debate (2024) [10] | Detects hallucination using a Markov chain-based multi-agent debate strategy. |
Table A4.
Contextual prompting (tagged sources).
| Method | Contribution |
|---|
| Tag Trapping (2023) [13] | Utilizes tagged context prompts to reduce hallucination by aligning source attribution. |
| Insights from LLM Research (2023) [19] | Suggests using context-aware classifiers and structured prompting to address hallucinations. |
Table A5.
Evaluation metrics and benchmarks.
| Method | Contribution |
|---|
| Q² (2021) [14] | Proposes Q2, a QA-based metric to evaluate factual consistency in dialogues. |
| HaluEval (2023) [15] | Introduces HaluEval, a benchmark for large-scale hallucination evaluation. |
| ANAH (2024) [16] | Proposes ANAH, an analytical framework for hallucination annotation. |
| Summarization Hallucination Analysis (2024) [17] | Analyzes hallucination trends in summarization, introducing circumstantial metrics. |
| ChainPoll (2023) [9] | Introduces ChainPoll, a high-efficacy hallucination detection method. |
References
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Wu, Q.; Bansal, G.; Zhang, J.; Wu, Y.; Li, B.; Zhu, E.; Jiang, L.; Zhang, X.; Zhang, S.; Liu, J.; et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. arXiv 2023, arXiv:2308.08155. [Google Scholar]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. arXiv 2023, arXiv:2311.05232. [Google Scholar] [CrossRef]
- Shuster, K.; Poff, S.; Chen, M.; Kiela, D.; Weston, J. Retrieval Augmentation Reduces Hallucination in Conversation. Facebook AI Res. 2021, 1. [Google Scholar] [CrossRef]
- Li, J.; Yuan, Y.; Zhang, Z. Enhancing LLM Factual Accuracy with RAG to Counter Hallucinations: A Case Study on Domain-Specific Queries in Private Knowledge-Bases. arXiv 2024, arXiv:2403.10446. [Google Scholar]
- Semnani, S.J.; Yao, V.Z.; Zhang, H.C.; Lam, M.S. WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia. arXiv 2023, arXiv:2305.14292. [Google Scholar]
- Ji, Z.; Yu, T.; Xu, Y.; Lee, N.; Ishii, E.; Fung, P. Towards Mitigating Hallucination in Large Language Models via Self-Reflection. arXiv 2023, arXiv:2310.06271. [Google Scholar]
- Varshney, N.; Raj, S.; Mishra, V.; Chatterjee, A.; Sarkar, R.; Saeidi, A.; Baral, C. Investigating and Addressing Hallucinations of LLMs in Tasks Involving Negation. arXiv 2024, arXiv:2406.05494. [Google Scholar]
- Friel, R.; Sanyal, A. ChainPoll: A high efficacy method for LLM hallucination detection. arXiv 2023, arXiv:2310.18344. [Google Scholar]
- Sun, X.; Li, J.; Zhong, Y.; Zhao, D.; Yan, R. Towards Detecting LLMs Hallucination via Markov Chain-based Multi-agent Debate Framework. arXiv 2024, arXiv:2406.03075. [Google Scholar]
- Liang, T.; He, Z.; Jiao, W.; Wang, X.; Wang, Y.; Wang, R.; Yang, Y.; Tu, Z.; Shi, S. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. arXiv 2023, arXiv:2305.19118. [Google Scholar]
- Chan, C.M.; Chen, W.; Su, Y.; Yu, J.; Liu, Z. CHATEVAL: Towards Better LLM-Based Evaluators Through Multi-Agent Debate. arXiv 2023, arXiv:2308.07201. [Google Scholar]
- Feldman, P.; Foulds, J.R.; Pan, S. Trapping LLM “Hallucinations” Using Tagged Context Prompts. arXiv 2023, arXiv:2306.06085. [Google Scholar]
- Honovich, O.; Choshen, L.; Aharoni, R.; Neeman, E.; Szpektor, I.; Abend, O. Q2: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering. arXiv 2021, arXiv:2104.08202. [Google Scholar]
- Li, J.; Cheng, X.; Zhao, W.X.; Nie, J.Y.; Wen, J.R. HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. arXiv 2023, arXiv:2305.11747. [Google Scholar]
- Ji, Z.; Gu, Y.; Zhang, W.; Lyu, C.; Lin, D.; Chen, K. ANAH: Analytical Annotation of Hallucinations in Large Language Models. arXiv 2024, arXiv:2405.20315. [Google Scholar]
- Ramprasad, S.; Ferracane, E.; Lipton, Z.C. Analyzing LLM Behavior in Dialogue Summarization: Unveiling Circumstantial Hallucination Trends. arXiv 2024, arXiv:2406.03487. [Google Scholar]
- Ahmad, M.; Yaramic, I.; Roy, T.D. Creating Trustworthy LLMs: Dealing with Hallucinations in Healthcare AI. Preprint 2023. [Google Scholar] [CrossRef]
- Bruno, A.; Mazzeo, P.L.; Chetouani, A.; Tliba, M.; Kerkouri, M.A. Insights into Classifying and Mitigating LLMs’ Hallucinations. arXiv 2023, arXiv:2311.08117. [Google Scholar]
- Deepgram. Available online: https://deepgram.com/learn/nova-2-speech-to-text-api (accessed on 12 May 2025).
- Mavroudis, V. LangChain. Preprint 2024. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar]
- Ilya Ilyankou, J.K. Comparison of Jaro-Winkler and Ratcliff/Obershelp algorithms in spell check. 2014, 1. Available online: https://ilyankou.wordpress.com/wp-content/uploads/2015/06/ib-extended-essay.pdf (accessed on 12 May 2025).
- Khamnuansin, D.; Chalothorn, T.; Chuangsuwanich, E. MrRank: Improving Question Answering Retrieval System through Multi-Result Ranking Model. arXiv 2024, arXiv:2406.05733. [Google Scholar]
Figure 1.
(Left) section: Overview of the proposed framework combining rule-based verification and LLM-based generation to improve factuality and coherence in noisy call center dialogue transcripts. (Right) section: Process flowchart of the stop criteria used to control the consultant-reviewer iterations.
Figure 2.
The three stages of data pre-processing and transformation from audio calls to the final dataset.
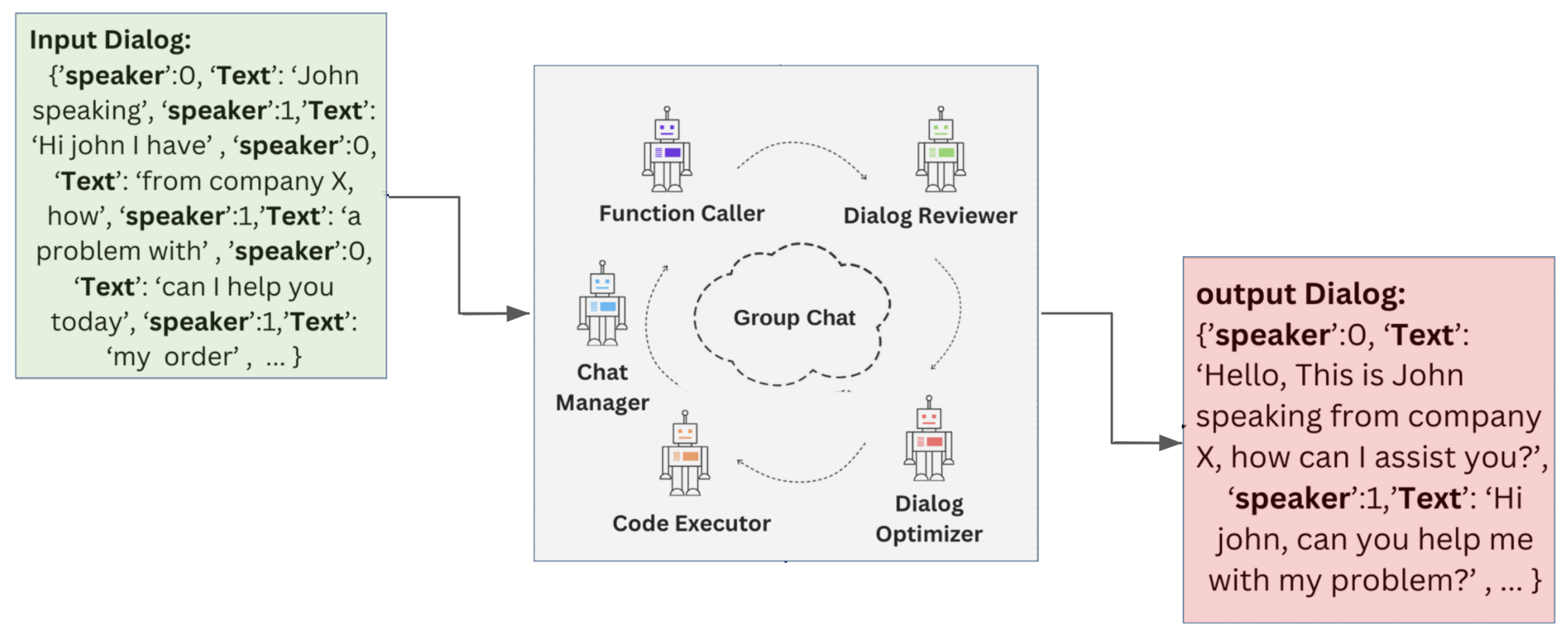
Figure 3.
Existing libraries for multi-agent conversation tasks lack control over agent transitions, often leading to divergent behaviors or off-topic discussions. Only minor tuning parameters are available to limit the maximum number of transitions.
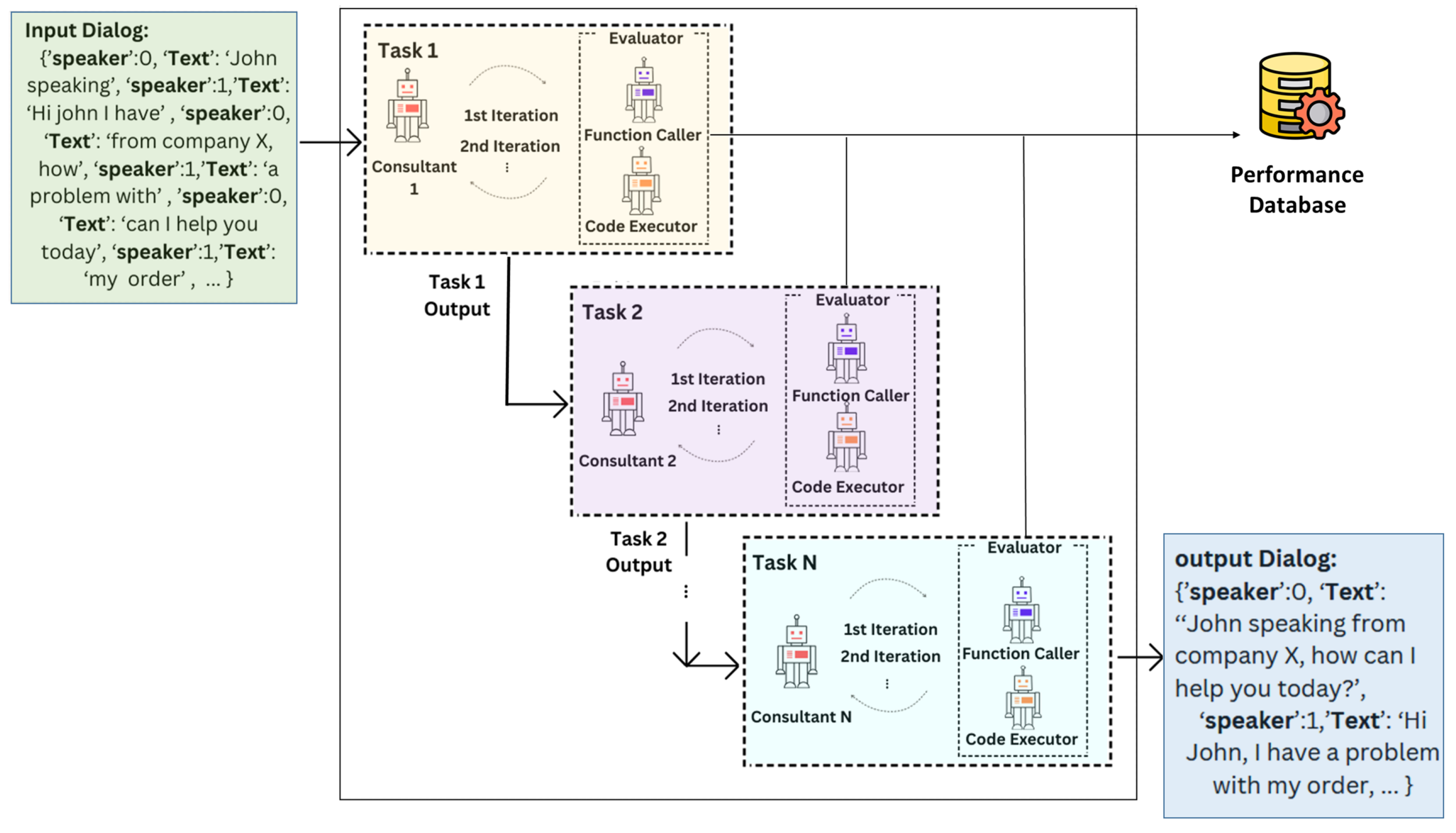
Figure 4.
The proposed framework simplifies complex tasks by breaking them into smaller, manageable sub-tasks, ensuring hallucination-free responses. The performance of LLM agents is monitored at every stage for each sub-task using a consultant-evaluator framework.
Figure 5.
Out of 3680 chunks in 308 transcripts, 60.2% and 32.6% had similarity scores below 80% for Mistral-7B and LLaMA-3-8B, respectively. After corrections, the hallucination rate dropped to 31.1% and 11.4% initially and further to 19.5% and 4.7% in the final iteration for Mistral-7B and LLaMA-3-8B, respectively.
Figure 6.
A boxplot shows consistently high median scores for LLaMA-3-8B and Mistral-7B in the 1st and 2nd iterations. Initial responses have greater variability, indicating inconsistency.
Figure 7.
Agents’ overall performance: similarity scores for initial response, 1st iteration, and 2nd iteration with LLaMA-3-8B and Mistral-7B.
Figure 8.
Performance of agents per chunk size: Similarity score enhancement with different chunk sizes for LLaMA-3-8B and Mistral-7B.
Table 1.
Hallucination rates and corresponding 95% confidence intervals for LLaMA-3-8B and Mistral-7B across initial response and subsequent refinement iterations.
| Iteration | Model | Halluc. Rate (%) | 95% CI Low (%) | 95% CI Up (%) |
|---|
| Initial Response | LLaMA-3-8B | 32.61 | 31.11 | 34.13 |
| Initial Response | Mistral-7B | 60.27 | 58.91 | 61.63 |
| 1st iteration | LLaMA-3-8B | 11.36 | 10.33 | 12.46 |
| 1st iteration | Mistral-7B | 31.09 | 29.60 | 32.60 |
| 2nd iteration | LLaMA-3-8B | 4.73 | 4.06 | 5.51 |
| 2nd iteration | Mistral-7B | 19.48 | 18.16 | 20.86 |
Table 2.
The average similarity score (SS) for each model across different stages.
| | LLaMA3-3-8B | Mistral-7B | SS (avg.) |
|---|
| Initial response | 78.84% | 70.35% | 73.92% |
| 1st iteration | 89.31% | 86.70% | 87.45% |
| 2nd iteration | 89.56% | 86.98% | 87.54% |
| SS (avg.) | 84.03% | 81.33% | 82.20% |
Table 3.
Number of chunks with similarity score below 80%.
| | LLaMA-3-8B | Mistral-7B | Total |
|---|
| Initial response | 1200 | 2217 | 3417 |
| 1st iteration | 418 | 1144 | 1562 |
| 2nd iteration | 174 | 717 | 891 |
Table 4.
Descriptive statistics of SS produced by the two LLM models across different stages.
| Model | Type | Std | Min | 25% | 50% | 75% | Max |
|---|
| LLaMA-3-8B | Initial response | 30.05 | 0.00 | 47.79 | 100.00 | 100.00 | 100.00 |
| 1st iteration | 24.07 | 0.00 | 98.31 | 100.00 | 100.00 | 100.00 |
| 2nd iteration | 25.13 | 0.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Mistral-7B | Initial response | 25.34 | 0.00 | 49.49 | 70.44 | 97.14 | 100.00 |
| 1st iteration | 24.27 | 0.00 | 72.42 | 100.00 | 100.00 | 100.00 |
| 2nd iteration | 24.87 | 0.00 | 74.61 | 100.00 | 100.00 | 100.00 |
Table 5.
Average similarity score per chunk size category. Long (more than 100 words), medium (50–100 words) and short (less than 50 words).
| Chunk Size | Model | Initial | 1st | 2nd | Avg. |
|---|
| | |
Response |
Iteration | Iteration | |
|---|
| Long | LLaMA-3-8B | 74.45 | 81.42 | 84.71 | 77.42 |
| Mistral-7B | 68.06 | 76.68 | 75.16 | 72.59 |
| Medium | LLaMA-3-8B | 77.20 | 86.06 | 86.30 | 80.88 |
| Mistral-7B | 67.37 | 82.45 | 82.71 | 76.56 |
| Short | LLaMA-3-8B | 81.65 | 91.98 | 92.06 | 87.61 |
| Mistral-7B | 74.07 | 90.53 | 90.69 | 86.07 |
| Avg. | | 73.92 | 87.45 | 87.54 | 82.20 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}